20 Browsing Revisited
In chapter 15, we described how a web service answers a request. However, we made a simplifying assumption in that description: we assumed that the web service was built using only a single server to answer all requests. This structure is not how any widely used service (such as Google search) actually works, for two important reasons:
- 1. The number of requests coming from across the world is far larger than what any single computer could actually handle.
- 2. Even if we miraculously had a single machine that was fast enough, we would prefer to use multiple computers for fault tolerance.
We’d like to replace the single server we assumed previously with the effect of a single massive server that is unstoppable. Our ingredients are large collections of real (smaller) servers that fail independently. Those servers can be placed in different specialized facilities—the data centers that we have mentioned previously. Like different servers, we expect that different data centers fail independently.
We know that multiple servers will be required, but how do we organize them? There are three essential approaches:
- 1. Use multiple copies of functionally equivalent servers in a single location
- 2. Use multiple layers of functionally distinct servers in a single location
- 3. Replicate the resulting multicopy, multilayer collection of servers across multiple distinct geographic locations.
Spraying Requests
The first step is to be able to distribute requests across a collection of servers, where the servers are all equally able to provide the necessary service. This distribution is sometimes referred to as spraying the requests. A single “front-end” server sprays the traffic, acting as though it were the only server.
In figure 20.1, all of the clients issuing search requests are off to the left. We don’t see the clients, just some of their requests—labeled Req 1, Req 2, and Req 3. All of the clients interact with the front-end server, labeled as www.google.com in the diagram. That single server appears to provide all the service to them. Unknown to the clients, the front-end server actually maintains a list of real “back-end” servers. In the diagram, those servers are labeled as server1, server2, and server3. The front-end server sends every request it receives on to one of the back-end servers. The front-end server operates as a switching point sending traffic on, but never tries to do any meaningful work on a request.
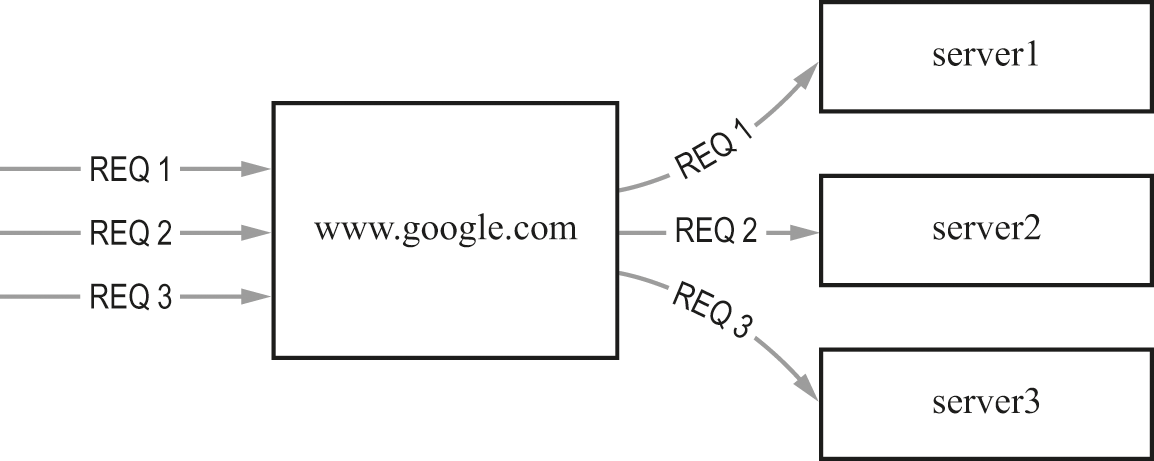
Spraying requests.
Because the front-end server is only touching the traffic long enough to redirect it, some other (back-end) server has to do all of the real work that’s required for any particular request. When a back-end server has a result, it sends that result to the client. The back-end server will usually send that information in a way that looks as though the front-end server produced it.
There are special-purpose systems for doing the front-end traffic-distribution tasks. Such a special-purpose system is called a content switch, load-balancer, or application delivery controller—those are all basically the same kind of thing, just going by different names. Sometimes such a special-purpose system includes special hardware; more often, it is simply a specialized piece of software running on an ordinary server.
Whatever device or software is used, the effect is still similar: the back-end servers are presented as though they constitute a larger, more-powerful, more-fault-tolerant single server. The resulting virtual server is more capable than any of the individual servers can be. When we previously saw virtual memory and virtual machines (chapter 12), the “magic” came from the raw speed of the step-taking machinery. That speed made it possible to rearrange limited resources fast enough so that they looked unlimited, or at least much larger than they really were. In some ways the mechanisms involved in a virtual server are the reverse. Instead of a limited resource trying to look larger, we now have a large collection of servers trying to look like a single server.
Let’s pause to consider what’s solved and unsolved so far. This arrangement lets us build a “team” of multiple servers, where each one is able to take the place of another. We can now expect to handle many more requests than any single server could, by spraying the requests across multiple servers. However, we are still vulnerable to the failure of a single back-end server once it’s started working on one of those requests. The server might simply not give an answer; or it might fail in a way that has a bad effect on other requests. For example, the server might fail while holding a lock on some shared data (recall locks from chapter 10). Or the server might fail after only doing a part of some set of changes, which would leave shared data inconsistent. So spraying the traffic across servers isn’t enough; we also need some way of making sure that an activity that fails “in the middle” of something complicated doesn’t leave behind a mess.
Fortunately, there are such mechanisms in the form of transactions. Transactions are a powerful approach to build all-or-nothing changes to data. If a failure occurs partway through a set of changes, the transaction mechanism has recorded enough information so that the changes can be undone or redone to get back to a consistent state. Transactions are a fascinating subject in their own right, but the crucial summary for a nonspecialist is that they provide the right kind of selective reversibility or time travel; they allow for complex partial changes to be automatically canceled out if there’s a failure.
What if we aren’t concerned about a partial failure muddling the data, but a complete failure of the front-end server? As described so far, we’ve increased the capacity of the system but we’re still vulnerable to a failure in that one component. It seems like we want to have multiple front-end servers, but we’ll have to do something different to distribute traffic across them: it clearly won’t improve anything to just put another front-end server in place to spray requests across multiple front-end servers. We’ll solve this problem later in the chapter. First we’ll take up another way of increasing the capacity of those multiple servers.
Tiers
We know that we want to build a web service that is more powerful in terms of capacity and resilience than what we can do with a single server. Grouping multiple servers to look like a single server was the first step, but there are additional techniques we can apply to build large services.
We can think about dividing the service into stages, as in figure 20.2.

Three tiers between user and stored data.
We’ve divided a typical application into three different kinds of activities. On the left is the work required for interacting with web clients: maintaining the conversations with clients, and translating between the vocabulary of the web and the data structures of the application. In the middle is the work of determining what to do with a particular request. That work might be pretty straightforward, or it might require a lot of computation. On the right is the work of interacting with various kinds of stored data. For typical applications, this “three-tier” framework works well—although it’s not always the right choice.
To really take advantage of a multitiered structure, we don’t just think about a logical division of the application as we did above. Instead, we actually use multiple servers to implement each separate tier. Within a tier, all of the servers are able to provide the same function; so within a tier, it doesn’t matter which of the servers we use. As a result, the number of servers in a tier can be adjusted to match the demands of that tier, independent of what may be required in other tiers.
The next diagram replaces the simple three-tier structure from a logical view of three stages to a physical view of tiered servers, with multiple servers per tier.
In figure 20.3, all three tiers consist of multiple servers, but the tiers are not the same size. The boxes in each column represent servers in a tier. In this particular example, the web tier has the most servers, and the application tier has the least. This is just an example—there is no particular rule that governs their relative sizes. The number of servers in a tier is determined by the workload of that tier.
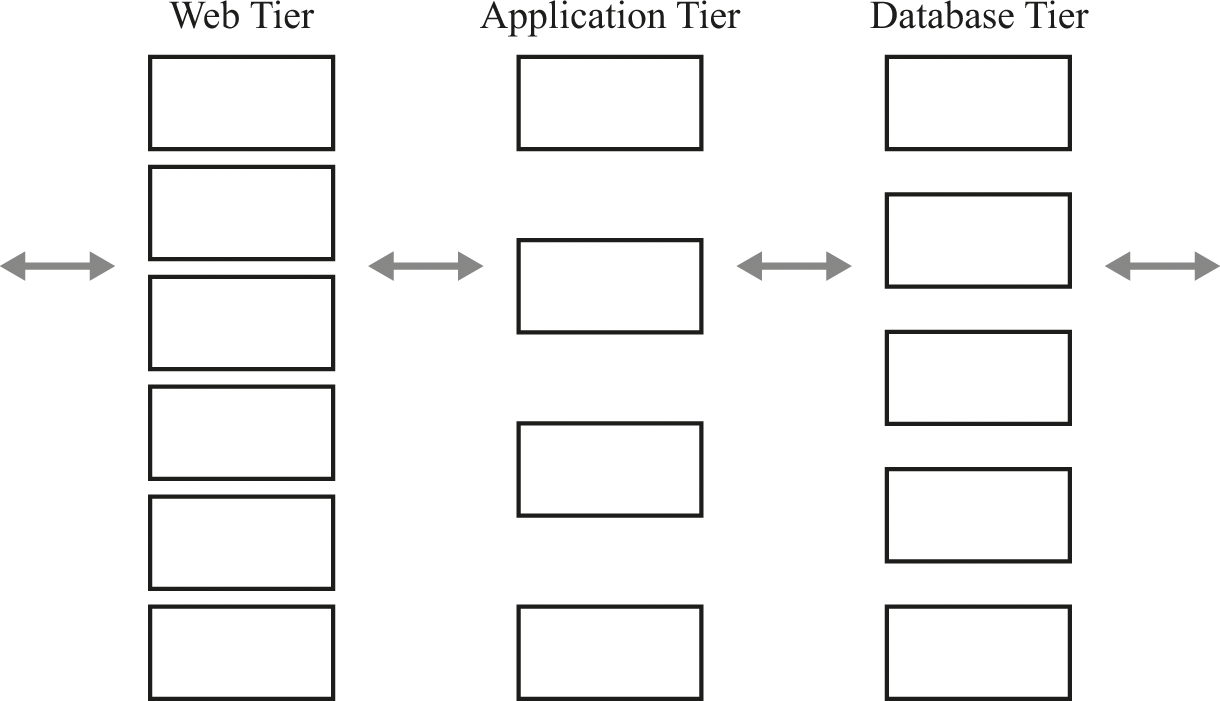
Each tier may have a different numbers of servers.
This diagram still uses the same simple arrows that we showed previously connecting the three logical stages. However, a more accurate diagram would be more complicated, with many more arrows. Traffic within each tier may be balanced independently of any other tier’s actions. If we consider the path of a single request through the servers (figure 20.4), it’s entirely possible that the request would be handled by a server in a quite different place in each tier.

A single request may have a complex path.
As shown by the dashed arrows in figure 20.4, the server shown at the top of the web tier handles the request, then passes it to the server at the bottom of the application tier, which then passes it to the server in the middle of the database tier.
Geographic Distribution
We first saw how we could spray traffic across servers, then we saw how we could divide processing into stages using tiers. Those were two approaches that spread the work across multiple machines. Spreading the work lets us build high-capacity, high-resilience multiserver systems.
There is a third ingredient we can add to the mix: we can divide up these servers geographically, rather than having them all in one area. Even if we are only concerned with fault-tolerance, it’s often useful to have some servers in one data center and some other similar servers in a different data center. We know from our previous musings on separation (chapter 13) that we don’t want to have distance just for the sake of distance. But some geographic distance can help the system to tolerate a local natural disaster like an earthquake or hurricane. To gain resilience from geographic diversity, there are two requirements. First, the two data centers must have enough independence that one can continue functioning even if there’s some kind of catastrophic failure in the other one. Second, the servers in each data center have to be able to provide similar services even if the other data center is unavailable.
Is resilience the only reason for dispersing servers geographically? No, there are at least two additional reasons: regulations and speed.
Let’s first consider regulations. Sometimes there is a legal requirement to keep certain kinds of information in one country and other kinds of information in a different country: for example, information about German customers might have to be stored in Germany, while information about French customers might have to be stored in France. So some geographic spreading of servers is driven primarily by reasons of law and regulatory compliance.
Next, let’s consider speed. The spreading of servers across geography is sometimes prompted by performance requirements. As we mentioned in chapter 13, light is not actually very speedy for certain kinds of interaction across long distances. If an application has demanding performance requirements and its users are spread out across the world, it becomes important to spread servers out as well—not so that they fail separately, or are in particular countries, but so they are closer to those users.
In figure 20.5, we show a variety of requests from around the world interacting with a service that is delivered from a single site in California. It’s worth noting both the length of the arrows and the density of lines near that data center.

Serving global clients from a single site.
In contrast, figure 20.6 takes the exact same traffic but now sends it to three data centers—there is still one in California, but now there is also one in London and another in China. Many of the longest lines have become much shorter, which probably translates into better performance for the users issuing those requests. And now the global service is less vulnerable to a catastrophe that affects the California data center.

Serving global clients from multiple sites.
This geographic distribution typically arises from cunning use of DNS, which we previously examined in chapter 15. Nothing about DNS requires that every client looking up a name be given the exact same answer. So it’s possible to arrange for clients in different parts of the world to be sent to different servers. In addition, that same trick solves the problem that we saw earlier in this chapter, where we had multiple back-end servers but also wanted to have multiple front-end servers. In a single data center we are not concerned with geographic distribution, but we can still use DNS to spread traffic. We might think that if we can spread traffic using DNS, why did we bother with introducing those front-end servers earlier in the chapter? It turns out that cunning use of DNS is quite a bit weaker than a front-end server in terms of the level of traffic control possible. So we’d choose DNS for that purpose only when we can’t do something better.
Some specialists have built their own networks of servers for reaching widespread clients. The networks they have built, and sometimes the companies that run them, are called content distribution networks or CDNs. The business of a CDN is effectively renting out some or all of its servers in “slices” for different applications. If you could benefit from having your application on lots of different servers, but it doesn’t make economic sense for you to set up and run all those servers yourself, you are a good candidate for a CDN.
To summarize: building a large-scale version of a web service like Google search may include geographic distribution of servers. A part of that geographic spread is to improve fault-tolerance, but there may also be reasons connected to law and to system performance.
Cloud Computing and Big Data
All of these server-side structuring tricks are effectively invisible to the browser. From the client’s point of view, all of this complexity is hidden. The client’s activity is unchanged from what we described previously: the client (still) simply converts URLs to entities and displays them. The server side may be organized using geographic distribution, multiple physical servers to implement a logical server, and/or the layering of servers in tiers—but the client doesn’t need or want to know about that structure.
Since the client is unaffected by the structure of the implementation, there is a tremendous opportunity for adjusting the scale of a multiserver system. If there’s high demand, more servers can be added: more capacity but a higher cost. If there’s low demand, some of the servers can be taken away: lower cost but a lower capacity. When we take advantage of this kind of flexibility, we can apply the term cloud computing. Where we previously had a network cloud that let us wave our hands about how messages traveled from one endpoint to another, now even some endpoints are being pulled into the cloud and turned into computing services rather than identifiable machines. In cloud computing, the supply of computing and storage is treated as a metered utility, like electricity or gas. With such a metered model, you use more or less as you need it, and you are effectively renting the underlying machinery rather than owning it.
You and your household likely neither know nor care how your electricity is generated. Likewise, the typical cloud computing user is largely indifferent to the exact physical implementation of the computing being performed. Instead, the cloud computing user supplies one or more virtual machines to perform the computation, along with identifying the computing and storage to be used. The cloud computing supplier responds to these demands by allocating or deallocating servers and storage to be used by the virtual machine(s).
Cloud computing is interesting in its own right as a way of building flexible large-scale services. In addition, the cloud computing approach is a crucial ingredient for most uses of big data techniques. In those big data approaches, large collections of computing power are briefly brought to bear on large collections of data to produce useful insights in ways that were not previously feasible. The key change that enables big data is more economic than technological: cloud computing allows for the short-term rental of large collections of computing resources.
A roughly similar situation arises when considering cars and transportation. If we own a single car, we can effectively lend it to a different friend on each of a dozen different days; but if all dozen friends are coming on the same day, perhaps to attend a special event, our single car is not very useful. It’s more powerful to be able to rent a dozen different cars for a single day in the case where all dozen friends are coming to town simultaneously. Entertaining all dozen friends simultaneously might be very appealing, and would be impossible if we were limited to what we could do with a single car.
In a similar fashion, it can be useful to apply a large collection of computing simultaneously to get a result quickly. The cost may be the same as applying a smaller amount of computing for a long time to get the result. The appeal of big data techniques largely center on this rearrangement enabled by cloud computing: it’s possible to get results much faster for roughly the same cost.