Chapter 4
Functions

Cippi uses functions to solve the challenge.
Software developers master complexity by dividing complex tasks into smaller units. After the small units are addressed, they put the smaller units together to master the complex task. A function is a typical unit and, therefore, the basic building block for a program. Functions are “the most critical part in most interfaces . . .” (C++ Core Guidelines about functions).
The C++ Core Guidelines have about forty rules for functions. They provide valuable information on the definition of functions, how you should pass the arguments (e.g., by copy or by reference), and what that means for the ownership semantics. They also state rules about the semantics of the return value and other functions such as lambdas. Let’s dive into them.
Function definitions
Presumably, the most important principle for good software is good names. This principle is often ignored and holds true in particular for functions.
Good names
The C++ Core Guidelines dedicate the first three rules to good names: “F.1: ‘Package’ meaningful operations as carefully named functions,” “F.2: A function should perform a single logical operation,” and “F.3: Keep functions short and simple.”
Let me start with a short anecdote. A few years ago, a software developer asked me, “How should I call my function?” I told him to give the function a name such as verbObject. In case of a member function, a verb may be fine because the function already operates on an object. The verb stands for the operation that is performed on the object. The software developer replied that this is not possible; the function must be called getTimeAndAddToPhonebook or just processData because the functions perform more than one job (single-responsibility principle). When you don’t find a meaningful name for your function (F.1), that’s a strong indication that your function does more than one logical operation (F.2) and that your function isn’t short and simple (F.3). A function is too long if it does not fit on a screen. A screen means roughly 60 lines by 140 characters, but your measure may differ. Now you should identify the operations of the function and package these operations into carefully named functions.
The guidelines present an example of a bad function:
void read_and_print() { // bad
int x;
std::cin >> x;
// check for errors
std::cout << x << '\n';
}
The function read_and_print is bad for many reasons. The function is tied to a specific input and output and cannot be used in a different context. Refactoring the function into two functions solves these issues and makes it easier to test and to maintain:
int read(std::istream& is) { // better
int x;
is >> x;
// check for errors
return x;
}
void print(std::ostream& os, int x) {
os << x << '\n';
}
If a function may have to be evaluated at compile-time, declare it constexpr |
A constexpr function is a function that has the potential to run at compile time. When you invoke a constexpr function within a constant expression, or you take the result of a constexpr with a constexpr variable, it runs at compile time. You can invoke a constexpr function with arguments that can be evaluated only at run time, too. constexpr functions are implicit inline.
The result of constexpr evaluated at compile time is stored in the ROM (read-only memory). Performance is, therefore, the first big benefit of a constexpr function. The second is that constexpr functions evaluated at compile time are const and, therefore, thread safe.
Finally, a result of the calculation is made available at run time as a constant in ROM.
// constexpr.cpp
constexpr auto gcd(int a, int b) {
while (b != 0) {
auto t = b;
b = a % b;
a = t;
}
return a;
}
int main() {
constexpr int i = gcd(11, 121); // (1)
int a = 11;
int b = 121;
int j = gcd(a, b); // (2)
}
Figure 4.1 shows the output of Compiler Explorer and depicts the assembly code generated by the compiler for this function. I used the Microsoft Visual Studio Compiler 19.22 without optimization.

Figure 4.1 Assembler instructions to the program constexpr.cpp
Based on the colors, you can see that (1) in the source code corresponds to line 35 in the assembler instructions and (2) in the source code corresponds to lines 38–41 in the assembler instructions. The call constexpr int i = gcd(11, 121); boils down to the value 11, but the call int j = gcd(a, b); results in a function call.
By declaring a function as noexcept, you reduce the number of alternative control paths; therefore, noexcept is a valuable hint to the optimizer. Even if your function can throw, noexcept often makes much sense. noexcept means in this case: I don’t care. The reason may be that you have no way to react to an exception. Therefore, the only way to deal with exceptions is to invoke std::terminate(). This noexcept declaration is also a piece of valuable information for the reader of your code.
The next function just crashes if it runs out of memory.
std::vector<std::string> collect(std::istream& is) noexcept {
std::vector<std::string> res;
for (std::string s; is >> s;) {
res.push_back(s);
}
return res;
}
The following types of functions should never throw: destructors (see the section Failing Destructor in Chapter 5), swap functions, move operations, and default constructors.
Pure functions are functions that always return the same result when given the same arguments. This property is also called referential transparency. Pure functions behave like infinite big lookup tables.
The function template square is a pure function:
template<class T>
auto square(T t) {
return t * t;
}
Conversely, impure functions are functions such as random() or time(), which can return a different result from call to call. To put it another way, functions that interact with state outside the function body are impure.
Pure functions have a few very interesting properties. You should, therefore, prefer pure functions, if possible.
Pure functions can
Be tested in isolation
Be verified or refactorized in isolation
Cache their result
Automatically be reordered or be executed on other threads
Pure functions are also often called mathematical functions. Functions in C++ are by default not pure such as in the pure functional programming language Haskell. Using pure functions is based on the discipline of the programmer. constexpr functions are pure when evaluated at compile time. Template metaprogramming is a pure functional language embedded in the imperative language C++.
Chapter 13, Templates and Generic Programming, gives a concise introduction to programming at compile time, including template metaprogramming.
Parameter passing: in and out
The C++ Core Guidelines have a few rules to express various ways to pass parameters in and out of functions.
The first rule presents the big picture. First, it provides an overview of the various ways to pass information in and out of a function (see Table 4.1).
Table 4.1 Normal parameter passing
Cheap to copy or impossible to copy |
Cheap to move or moderate cost to move or don’t know |
Expensive to move |
|
|---|---|---|---|
In |
|
|
|
In & retain “copy” |
|||
In/Out |
|
||
Out |
|
|
|
The table is very concise: The headings describe the characteristics of the data regarding the cost of copying and moving. The rows indicate the direction of parameter passing.
Kind of data
Cheap to copy or impossible to copy:
intorstd::unique_ptrCheap to move:
std::vector<T>orstd::stringModerate cost to move:
std::array<std::vector>orBigPOD(POD stands for Plain Old Data—that is, a class without constructors, destructors, and virtual member functions.)Don’t know: template
Expensive to move:
BigPOD[]orstd::array<BigPOD>
Direction of parameter passing
In: input parameter
In & retain “copy”: caller retains its copy
In/Out: parameter that is modified
Out: output parameter
A cheap operation is an operation with a few ints; moderate cost is about one thousand bytes without memory allocation.
These normal parameter passing rules should be your first choice. However, there are also advanced parameter passing rules (see Table 4.2). Essentially, the case with the “in & move from” semantics was added.
Table 4.2 Advanced parameter passing
Cheap to copy or impossible to copy |
Cheap to move or moderate cost to move or don’t know |
Expensive to move |
|
|---|---|---|---|
In |
|
|
|
In & retain “copy” |
|||
In & move from |
|
||
In/Out |
|
||
Out |
|
|
|
After the “in & move from” call, the argument is in the so-called moved-from state. Moved-from means that it is in a valid but not nearer specified state. Essentially, you have to initialize the moved-from object before using it again.
The remaining rules to parameter passing provide the necessary background information for these tables.
For “in” parameters, pass cheaply-copied types by value and others by reference to |
The rule is straightforward to follow. Input values should be copied by default if possible. When they cannot be cheaply copied, take them by const reference. The C++ Core Guidelines give a rule of thumb to the question, Which objects are cheap to copy or expensive to copy?
You should pass a parameter
parby value ifsizeof(par) < 3 * sizeof(void*).You should pass a parameter
parbyconstreference ifsizeof(par) > 3 * sizeof(void*).
void f1(const std::string& s); // OK: pass by reference to const;
// always cheap
void f2(std::string s); // bad: potentially expensive
void f3(int x); // OK: unbeatable
void f4(const int& x); // bad: overhead on access in f4()
For “forward” parameters, pass by |
This rule stands for a special input value. Sometimes you want to forward the parameter par. This means an lvalue is copied and an rvalue is moved. Therefore, the constness of an lvalue is ignored and the rvalueness of an rvalue is preserved.
The typical use case for forwarding parameters is a factory function that creates an arbitrary object by invoking its constructor. You do not know if the arguments are rvalues nor do you know how many arguments the constructor needs.
// forwarding.cpp
#include <string>
#include <utility>
template <typename T, typename ... T1> // (1)
T create(T1&& ... t1) {
return T(std::forward<T1>(t1)...);
}
struct MyType {
MyType(int, double, bool) {}
};
int main() {
// lvalue
int five=5;
int myFive= create<int>(five);
// rvalues
int myFive2= create<int>(5);
// no arguments
int myZero= create<int>();
// three arguments; (lvalue, rvalue, rvalue)
MyType myType = create<MyType>(myZero, 5.5, true);
}
The three dots (ellipsis) in the function create (1) denote a parameter pack. We call a template using a parameter pack a variadic template.
The combination of forwarding together with variadic templates is the typical creation pattern in C++. Here is a possible implementation of std::make_unique<T>.
template<typename T, typename... Args>
std::unique_ptr<T> make_unique(Args&&... args) {
return std::unique_ptr<T>(new T(std::forward<Args>(args)...));
}
std::make_unique<T> creates a std::unique_ptr for T
The rule communicates its intention to the caller: This function modifies its argument.
std::vector<int> myVec{1, 2, 3, 4, 5};
void modifyVector(std::vector<int>& vec) {
vec.push_back(6);
vec.insert(vec.end(), {7, 8, 9, 10});
}
For “out” output values, prefer return values to output parameters |
The rule is straightforward. Just return the value, but don’t use a const value because it has no added value and interferes with move semantics. Maybe you think that copying a value is an expensive operation. Yes and no. Yes, you are right, but no, the compiler applies RVO (Return Value Optimization) or NRVO (Named Return Value Optimization). RVO means that the compiler is allowed to remove unnecessary copy operations. What was a possible optimization step becomes in C++17 a guarantee.
MyType func() {
return MyType{}; // no copy with C++17
}
MyType myType = func(); // no copy with C++17
Two unnecessary copy operations can happen in these few lines, the first in the return call and the second in the function call. With C++17, no copy operation takes place. If the return value has a name, we call it NRVO. Maybe you guessed that.
MyType func() {
MyType myValue;
return myValue; // one copy allowed
}
MyType myType = func(); // no copy with C++17
The subtle difference is that the compiler can still copy the value myValue in the return statement according to C++17. But no copy will take place in the function call.
Often, a function has to return more than one value. Here, the rule F.21 kicks in.
To return multiple “out” values, prefer returning a struct or tuple |
When you insert a value into a std::set, overloads of the member function insert return a std::pair of an iterator to the inserted element and a bool set to true if the insertion was successful. std::tie with C++11 or structured binding with C++17 are two elegant ways to bind both values to a variable.
// returnPair.cpp; C++17
#include <iostream>
#include <set>
#include <tuple>
int main() {
std::cout << '\n';
std::set<int> mySet;
std::set<int>::iterator iter;
bool inserted = false;
std::tie(iter, inserted) = mySet.insert(2011); // (1)
if (inserted) std::cout << "2011 was inserted successfully\n";
auto [iter2, inserted2] = mySet.insert(2017); // (2)
if (inserted2) std::cout << "2017 was inserted successfully\n";
std::cout << '\n';
}
Line (1) uses std::tie to unpack the return value of insert into iter and inserted. Line (2) uses structured binding to unpack the return value of insert into iter2 and inserted2. std::tie needs, in contrast to structured binding, a predeclared variable. See Figure 4.2.
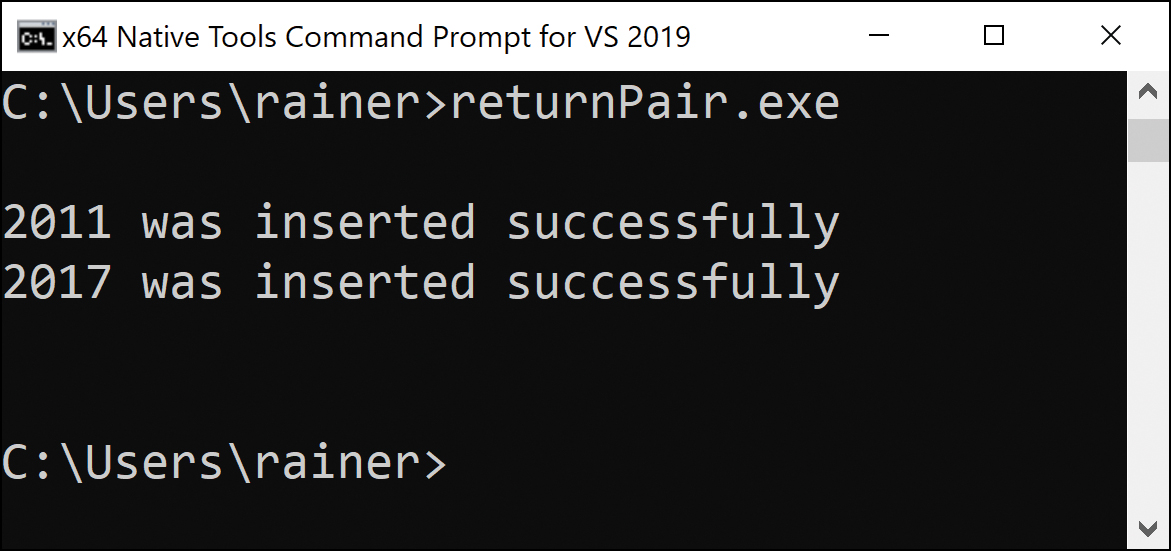
Figure 4.2 Returning a std::pair
Parameter passing: ownership semantics
The last section was about the flow of parameters: which parameters are input, input/output, or output values. But there is more to arguments than the direction of the flow. Passing parameters is about ownership semantics. This section presents five typical ways to pass parameters: by copy, by pointer, by reference, by std::unique_ptr, or by std::shared_ptr. Only the rules to smart pointers are inside this section. The rule to pass by copy is part of the previous section Parameter Passing: In and Out, and the rules to pointers and references are part of Chapter 3, Interfaces.
Table 4.3 provides the first overview.
Table 4.3 Ownership semantics of parameter passing
Example |
Ownership |
Rule |
|---|---|---|
|
|
|
|
|
|
|
|
I.11 and F.7 |
|
|
|
|
|
Here are more details:
func(value): The function
funchas its own copy of thevalueand is its owner.funcautomatically releases the resource.func(pointer*):
funchas borrowed the resource and is, therefore, not authorized to delete the resource.funchas to check before each usage that the pointer is not a null pointer.func(reference&):
funchas borrowed the resource. In contrast to the pointer, the reference always has a valid value.func(std::unique_ptr):
funcis the new owner of the resource. The caller of thefunchas explicitly transferred the ownership of the resource to the callee.funcautomatically releases the resource.func(std::shared_ptr):
funcis an additional owner of the resource.funcextends the lifetime of the resource. At the end offunc,funcends its ownership of the resource. This end causes the release of the resource iffuncwas the last owner.
Here are five variants of ownership semantics in practice.
1 // ownershipSemantic.cpp
2
3 #include <iostream>
4 #include <memory>
5 #include <utility>
6
7 class MyInt {
8 public:
9 explicit MyInt(int val): myInt(val) {}
10 ~MyInt() noexcept {
11 std::cout << myInt << '\n';
12 }
13 private:
14 int myInt;
15 };
16
17 void funcCopy(MyInt myInt) {}
18 void funcPtr(MyInt* myInt) {}
19 void funcRef(MyInt& myInt) {}
20 void funcUniqPtr(std::unique_ptr<MyInt> myInt) {}
21 void funcSharedPtr(std::shared_ptr<MyInt> myInt) {}
22
23 int main() {
24
25 std::cout << '\n';
26
27 std::cout << "=== Begin" << '\n';
28
29 MyInt myInt{1998};
30 MyInt* myIntPtr = &myInt;
31 MyInt& myIntRef = myInt;
32 auto uniqPtr = std::make_unique<MyInt>(2011);
33 auto sharedPtr = std::make_shared<MyInt>(2014);
34
35 funcCopy(myInt);
36 funcPtr(myIntPtr);
37 funcRef(myIntRef);
38 funcUniqPtr(std::move(uniqPtr));
39 funcSharedPtr(sharedPtr);
40
41 std::cout << "==== End" << '\n';
42
43 std::cout << '\n';
44
45 }
The type MyInt displays in its destructor (lines 10–12) the value of myInt (line 14). The five functions in the lines 17–21 implement each of the ownership semantics. The lines 29–33 have the corresponding values. See Figure 4.3.

Figure 4.3 The five ownership semantics
The screenshot shows that two destructors are called before and two destructors are called at the end of the main function. The destructors of the copied myInt (line 35) and the moved uniquePtr (line 38) are called before the end of main. In both cases, funcCopy or funcUniqPtr becomes the owner of the resource. The lifetime of the functions ends before the lifetime of main. This end of the lifetime does not hold for the original myInt (line 29) and the sharedPtr (line 33). Their lifetime ends with main, and therefore, the destructor is called at the end of the main function.
Value return semantics
The seven rules in this section are in accordance with the previously mentioned rule “F.20: For ‘out’ output values, prefer return values to output parameters.” The rules of this section are, in particular, about special use cases and don’ts.
When to return a pointer (T*) or an lvalue reference (T&)
As we know from the last section (Parameter Passing: Ownership Semantics), a pointer or a reference should never transfer ownership.
A pointer should indicate only a position. This is exactly what the function find does.
Node* find(Node* t, const string& s) {
if (!t || t->name == s) return t;
if ((auto p = find(t->left, s))) return p;
if ((auto p = find(t->right, s))) return p;
return nullptr;
}
The pointer indicates that the Node is holding the position of s.
Return a |
When return no object is not an option, using a reference instead of a pointer comes into play.
Sometimes you want to chain operations without unnecessary copying and destruction of temporaries. Typical use cases are input and output streams or assignment operators (“F.47: Return T& from assignment operators”). What is the subtle difference between returning by T& or returning by T in the following code snippet?
A& operator = (const A& rhs) { ... };
A operator = (const A& rhs) { ... };
A = a1, a2, a3;
a1 = a2 = a3;
The copy assignment operator returning a copy (A) triggers the creation of two additional temporary objects of type A.
A reference to a local
Returning a reference (pointer) to a local is undefined behavior.
Undefined behavior essentially means this: Don’t make any assumptions about your program. Fix undefined behavior. The program lambdaFunctionCapture.cpp returns a reference to a local.
// lambdaFunctionCapture.cpp
#include <functional>
#include <iostream>
#include <string>
auto makeLambda() {
const std::string val = "on stack created";
return [&val]{return val;}; // (2)
}
int main() {
auto bad = makeLambda(); // (1)
std::cout << bad(); // (3)
}
The main function calls the function makeLambda() (1). The function returns a lambda expression, which has a reference to the local variable val (2).
The call bad() (3) causes the undefined behavior because the lambda expression uses a reference to the local val. As local, its lifetime ends with the scope of makeLambda().
Executing the program gives unpredictable results. Sometimes I get the entire string, sometimes a part of the string, or sometimes just the value 0. As an example, here are two runs of the program.
In the first run, arbitrary characters are displayed until the string terminating symbol (\0) ends it (see Figure 4.4).

Figure 4.4 Displaying arbitrary characters
In the second run, the program causes a core dump (see Figure 4.5).

Figure 4.5 Causing a core dump
and
Both rules are very rigorous.
T&&
You should not use a T&& as a return type. Here is a small example to demonstrate the issue.
// returnRvalueReference.cpp
int&& returnRvalueReference() {
return int{};
}
int main() {
auto myInt = returnRvalueReference();
}
When compiled, the GCCcompiler complains immediately about a reference to a temporary (see Figure 4.6). To be precise, the lifetime of the temporary ends with the end of the full expression auto myInt = returnRvalueReference();.

Figure 4.6 Returning a reference to a temporary
std::move(local)
Thanks to copy elision with RVO and NRVO, using return std::move(local) is not an optimization but a pessimization. Pessimization means that your program may become slower.
According to the C++ standard, there are two variations of the main function:
int main() { ... }
int main(int argc, char** argv) { ... }
The second version is equivalent to int main(int argc, char* argv[]) { ... }.
The main function does not need a return statement. If control reaches the end of the main function without encountering a return statement, the effect is that of executing return 0;. return 0 stands for the successful execution of the program.
Other functions
The rules in this section advise on when to use lambdas and compare va_arg with fold expressions.
Lambdas
Use a lambda when a function won’t do (to capture local variables, or to write a local function) |
This rule states the use case for lambdas. This immediately raises the question, When do you have to use a lambda or a function? Here are two obvious reasons.
If your callable has to capture local variables or is declared in a local scope, you have to use a lambda function.
If your callable should support overloading, use a function.
Now I want to present my crucial arguments for lambdas that are often ignored.
Expressiveness
“Explicit is better than implicit.” This meta-rule from Python (PEP 20—The Zen of Python) also applies to C++. It means that your code should explicitly express its intent (see rule “P.1: Express ideas directly in code”). Of course, this holds true in particular for lambdas.
std::vector<std::string> myStrVec = {"523345", "4336893456", "7234",
"564", "199", "433", "2435345"};
std::sort(myStrVec.begin(), myStrVec.end(),
[](const std::string& f, const std::string& s) {
return f.size() < s.size();
}
);
Compare this lambda with the function lessLength, which is subsequently used.
std::vector<std::string> myStrVec = {"523345", "4336893456", "7234",
"564", "199", "433", "2435345"};
bool lessLength(const std::string& f, const std::string& s) {
return f.size() < s.size();
}
std::sort(myStrVec.begin(), myStrVec.end(), lessLength);
Both the lambda and the function provide the same order predicate for the sort algorithm. Imagine that your coworker named the function foo. This means you have no idea what the function is supposed to do. As a consequence, you have to document the function.
// sorts the vector ascending, based on the length of its strings std::sort(myStrVec.begin(), myStrVec.end(), foo);
Further, you have to hope that your coworker did it right. If you don’t trust them, you have to analyze the implementation. Maybe that’s not possible because you have the declaration of the function. With a lambda, your coworker cannot fool you. The code is the truth. Let me put it more provocatively: Your code should be so expressive that it does not require documentation.
Prefer capturing by reference in lambdas that will be used locally, including passed to algorithms |
and
Both rules are strongly related, and they boil down to the following observation: A lambda should operate only on valid data. When the lambda captures the data by copy, the data is by definition valid. When the lambda captures data by reference, the lifetime of the data must outlive the lifetime of the lambda. The previous example with a reference to a local showed different results of a lambda referring to invalid data.
Sometimes the issue is not so easy to catch.
int main() {
std::string str{"C++11"};
std::thread thr([&str]{ std::cout << str << '\n'; });
thr.detach();
}
Okay, I hear you say, “That is easy.” The lambda expression used in the created thread thr captures the variable str by reference. Afterward, thr is detached from the lifetime of its creator, which is the main thread. Therefore, there is no guarantee that the created thread thr uses a valid string str because the lifetime of str is bound to the lifetime of the main thread. Here is a straightforward way to fix the issue. Capture str by copy:
int main() {
std::string str{"C++11"};
std::thread thr([str]{ std::cout << str << '\n'; });
thr.detach();
}
Problem solved? No! The crucial question is, Who is the owner of std::cout? std::cout’s lifetime is bound to the lifetime of the process. This means that the thread thr may be gone before std::cout prints C++11 onscreen. The way to fix this problem is to join the thread thr. In this case, the creator waits until the created is done, and therefore, capturing by reference is also fine.
int main() {
std::string str{"C++11"};
std::thread thr([&str]{ std::cout << str << '\n'; });
thr.join();
}
Where there is a choice, prefer default arguments over overloading |
If you need to invoke a function with a different number of arguments, prefer default arguments over overloading if possible. Therefore, you follow the DRY principle (don’t repeat yourself).
void print(const string& s, format f = {});
The equivalent functionality with overloading requires two functions:
void print(const string& s); // use default format void print(const string& s, format f);
The title of this rule is too short. Use variadic templates instead of va_arg arguments when your function should accept an arbitrary number of arguments.
Variadic functions are functions such as std::printf that can take an arbitrary number of arguments. The issue is that you have to assume that the correct types were passed. Of course, this assumption is very error prone and relies on the discipline of the programmer.
To understand the implicit danger of variadic functions, here is a small example.
// vararg.cpp
#include <iostream>
#include <cstdarg>
int sum(int num, ... ) {
int sum = 0;
va_list argPointer;
va_start(argPointer, num );
for( int i = 0; i < num; i++ )
sum += va_arg(argPointer, int );
va_end(argPointer);
return sum;
}
int main() {
std::cout << "sum(1, 5): " << sum(1, 5) << '\n';
std::cout << "sum(3, 1, 2, 3): " << sum(3, 1, 2, 3) << '\n';
std::cout << "sum(3, 1, 2, 3, 4): "
<< sum(3, 1, 2, 3, 4) << '\n'; // (1)
std::cout << "sum(3, 1, 2, 3.5): "
<< sum(3, 1, 2, 3.5) << '\n'; // (2)
}
sum is a variadic function. Its first argument is the number of arguments that should be summed up. The following background information about va_arg macros helps with understanding the code.
va_list: holds the necessary information for the following macros
va_start: enables access to the variadic function arguments
va_arg: accesses the next variadic function argument
va_end: ends the access of the variadic function arguments
For more information, read cppreference.com about variadic functions.
In (1) and (2), I had a bad day. First, the number of the arguments num is wrong; second, I provided a double instead of an int. The output shows both issues. The last element in (1) is missing, and the double is interpreted as int (2). See Figure 4.7.

Figure 4.7 Summation with va_arg
These issues can be easily overcome with fold expressions in C++17. In contrast to va_args, fold expressions automatically deduce the number and the type of their arguments.
// foldExpressions.cpp
#include <iostream>
template<class ... Args>
auto sum(Args ... args) {
return (... + args);
}
int main() {
std::cout << "sum(5): " << sum(5) << '\n';
std::cout << "sum(1, 2, 3): " << sum(1, 2, 3) << '\n';
std::cout << "sum(1, 2, 3, 4): " << sum(1, 2, 3, 4) << '\n';
std::cout << "sum(1, 2, 3.5): " << sum(1, 2, 3.5) << '\n';
}
The function sum may look scary to you. It requires at least one argument and uses C++11 variadic templates. These are templates that can accept an arbitrary number of arguments. The arbitrary number is held by a so-called parameter pack denoted by an ellipsis (. . .). Additionally, with C++17, you can directly reduce a parameter pack with a binary operator. This addition, based on variadic templates, is called fold expressions. In the case of the sum function, the binary + operator (...+ args) is applied. If you want to know more about fold expressions in C++17, details are at https://www.modernescpp.com/index.php/fold-expressions.
The output of the program is as expected (see Figure 4.8).

Figure 4.8 Summation with fold expressions
Related rules
An additional rule to lambdas is in Chapter 8, Expressions and Statements: “ES.28: Use lambdas for complex initialization, especially of const variables.”
I skipped the C++20 feature std::span in this chapter and provided basic information on std::span in Chapter 7, Resource Management.