Chapter 22
Exploring the Virtualization Environment
When something is virtualized, it no longer physically exists, but instead is simulated. In the information technology world, this simulation can apply to computer systems, which is accomplished through special software. Within the last few decades, virtualization has revolutionized the server room. By moving many systems or portions of systems to a virtualized environment, the amount of physical hardware housed in server rooms has been reduced, lowering the overall footprint required. In addition, these reductions have lowered the total amount of electricity needed by these rooms, which is not only better for the environment, but costs less. Server virtualization is a win-win on many levels.
Virtualization can now also be applied directly to software applications. Using special package management systems, apps are sandboxed along with all their needed dependencies. This allows an additional layer of security running on either a physical system or a virtualized one.
Hypervisors
Virtual machines (VMs) are simulated computer systems that appear and act as physical machines to their users. The process of creating these virtual machines is called virtualization.
Managing VMs
The primary software tool used to create and manage VMs is a hypervisor, which has been historically called either a virtual machine monitor or a virtual machine manager (VMM). Hypervisors come in two basic flavors: Type 1 and Type 2. However, you'll find that some hypervisor software doesn't neatly fit into either category.
The easier to understand is the Type 2 hypervisor, so we'll start there. A Type 2 hypervisor is a software application that operates between its created virtual machine (guest) and the physical system (host) on which the hypervisor is running. Figure 22.1 shows a diagrammed example of a Type 2 hypervisor.

FIGURE 22.1 Example of a Type 2 hypervisor
A Type 2 hypervisor acts as a typical software application in that it interacts with the host's operating system. However, its distinction lies in the fact that it provides one or more virtualized environments or virtual machines. These VMs each have their own operating system (guest OS) and can have various applications running on them. The host OS on the physical system is often completely different than the VM's guest OS.
There are several Type 2 hypervisors from which to choose. A few options that run on Linux include Oracle VirtualBox and VMware Workstation Player. Figure 22.2 shows Oracle VirtualBox with two Linux server systems installed.

FIGURE 22.2 Oracle VirtualBox Type 2 hypervisor
There are many considerations when setting up a virtualized environment. Some Type 2 hypervisors, such as Oracle VirtualBox, need a graphical user interface (GUI) on which to operate. Therefore, if you are managing a Linux system running a server distro that has no desktop capabilities, VirtualBox is not a good choice for your situation.
Also, when creating VMs with a Type 2 hypervisor, it is important to determine if you have enough resources, such as RAM, on your physical host machine. Keep in mind that you will need to accommodate the host OS and Type 2 hypervisor software, as well as the guest OS and applications on each VM.
A Type 1 hypervisor eliminates the need for the physical host's OS. This software runs directly on the physical system and therefore is sometimes called a bare-metal hypervisor. Figure 22.3 shows a diagrammed example of a Type 1 hypervisor.

FIGURE 22.3 Example of a Type 1 hypervisor
There are also several Type 1 hypervisors from which to choose. A few options include KVM, Xen, and Hyper-V. For Linux, KVM is built-in. KVM's kernel component has been included in the Linux kernel since v2.6.20.
An interesting feature with KVM and Hyper-V is that they can both be started while the host OS is running. These hypervisors then take over for the host OS and run as a Type 1 hypervisor. This is a case where the hypervisors don't neatly fit into the Type 1 category.
Creating a Virtual Machine
A virtual machine is made up of either one file or a series of files that resides on the host machine. Whether it is a single file or multiple files depends on the hypervisor used. The file (or files) contains configuration information, such as how much RAM is needed, as well as the VM's data, such as the guest OS and any installed application binaries.
There are many ways to create a virtual machine. When first starting out, most people will create a Linux virtual machine from the ground up; they set up the VM specifications within the hypervisor software of their choice and use an ISO file (live or otherwise) to install the guest operating system.
Lots of choices exist for creating VMs. Which methods you use depend on your organization's needs as well as the number of VMs you must deploy. Here are brief descriptions of some common options:
- Clone A clone is essentially a copy of another guest VM. Just like in science fiction, a VM clone is identical to its original. The files that make up the original VM are copied to a new filesystem location, and the VM is given a new name.
Hypervisors typically have easy methods for creating clones. However, before you start up a cloned VM, it is important to check the VM's settings. For example, some hypervisors do not issue a new network interface card (NIC) media access control (MAC) address when creating a VM clone. This could cause network issues should you have two running VMs that have identical NIC MAC addresses. The following is a brief list of items that may need to be modified for a Linux clone:
- Host name
- NIC MAC address
- NIC internet protocol (IP) address, if using a static IP
- Machine ID
- Any items employing a universally unique identifier (UUID)
- Configuration settings on the clone that employ any item in this list
There are some potentially interesting problems with cloning. For example, your system's machine ID is a unique hexadecimal 32-character identifier. The ID is stored in the
/etc/machine-idfile. D-Bus will use this ID if its own machine ID file,/var/lib/dbus/machine-id, does not exist. Typically on modern distributions, the D-Bus machine ID file will not exist or will be symbolically linked to the/etc/machine-idfile. Problems can ensue if you clone a machine and boot it so that the two machines share the same ID. These problems may include not being able to get an IP address if your network manager is configured to use the machine's ID instead of a NIC's MAC address for dynamic host control protocol (DHCP) services. To prevent this problem, after you clone a VM, you'll need to address the duplicate machine ID. Typically, you can do this on the clone by performing the following steps:- Delete the machine ID file:
rm /etc/machine-id. - Delete the D-Bus ID file:
rm /var/lib/dbus/machine-id. - Regenerate the ID:
dbus-uuidgen --ensure.
Keep in mind that a distribution may require additional steps, such as linking the
/var/lib/dbus/machine-idfile to/etc/machine-id. Be sure to look at your distro's documentation prior to changing a machine's identity. - Open Virtualization Format Another method employs the Open Virtualization Format (OVF). The OVF is a standard administered by the Distributed Management Task Force (DMTF) organization. This standard allows the hypervisor to export a VM's files into the OVF for use in other hypervisors. After you export the files, you can import them into any other hypervisor that honors the standard. It's like cloning a machine between two different hypervisor software applications. You'll need to change the appropriate settings on the new VMs, such as the hostname, if the VMs will be running on the same local network.
While the OVF file standard creates multiple files, some hypervisors recognize a single compressed archive file of OVF files, called an Open Virtualization Archive (OVA). This is useful if you need to transfer a VM's files across a network to a different host system.
- Template Outside of computing, a template is a pattern or mold that is used to guide the process of creating an item. In word processing, a template is often employed to provide formatting models, such as when creating a business letter.
In virtualization, a VM template is a master copy. It is similar to a VM clone, except you cannot boot it. Virtual machines are created using these templates as their base.
To create a template, you need a system image (sometimes called a VM image). This image contains the guest OS and any installed applications, as well as configuration and data files. The system image is created from a VM you have configured as your base system. You direct the hypervisor software to generate a template, which is often a file or set of files. Now, you can employ this system image to create several virtual machines based on that template.
Keep in mind that for a template-created VM, you may need to modify items prior to booting it. The same list covered in the previous “Clone” description applies here.
There are additional choices for creating virtual machines besides the ones listed here. For example, some companies offer software that will scan your current system and create a VM of it. The term used for these software offerings is physical-to-virtual (P2V).
Integrating via Linux Extensions
Before you jump into creating virtual machines, it's important to check that your Linux host system will support virtualization and the hypervisor product you have chosen. This support is accomplished via various extensions and modules.
A hardware extension is based within the system's CPU. It grants the hypervisor the ability to access the CPU directly, instead of going through the host OS, which improves performance.
First, you should determine whether your system's CPU has these hardware extensions available. You can research this via the /proc/cpuinfo file's flag information. Type in grep ^flags /proc/cpuinfo at the command line to view the various enabled features of your server's CPU. If enabled, you should see one of the following:
- For Intel CPUs:
vmx - For AMD CPUs:
svm
If you see the hypervisor flag (instead of vmx or svm), this means your Linux OS is not running on a physical machine, but a virtual one. You can check to see which hypervisor is being employed via the virt-what utility, which may or may not be installed on your Linux distro by default.
To use one of the required CPU extensions and support the chosen hypervisor software, the appropriate Linux modules must be loaded. You'll need to review your hypervisor's documentation to determine what modules are needed.
To check if a needed module is already loaded, use the lsmod command. An example is shown here, checking for support of the KVM hypervisor:
lsmod | grep -i kvm
If you find that the needed hypervisor modules are not loaded, employ the modprobe command to insert them. An example of loading up a needed KVM hypervisor module is shown here:
sudo modprobe kvm-amd
While your server may have everything it needs to run VMs, including the Linux extensions, if the virtualization is disabled in the startup firmware, it won't work. Check your system's firmware documentation and ensure that virtualization is enabled.
Containers
Containers are virtual entities, but they are different from virtual machines and serve distinct purposes. Whereas a VM provides an entire guest operating system, a container's focus is typically on a single app, application stack, or environment. A container gathers all the files necessary to run an application—the runtime files, library files, database files, and any operating system–specific files. The container becomes self-sufficient for the application to run, and everything the application needs is stored within the container.
Instead of a hypervisor, a container is managed by a container engine. Figure 22.4 shows a diagrammed example of a container.
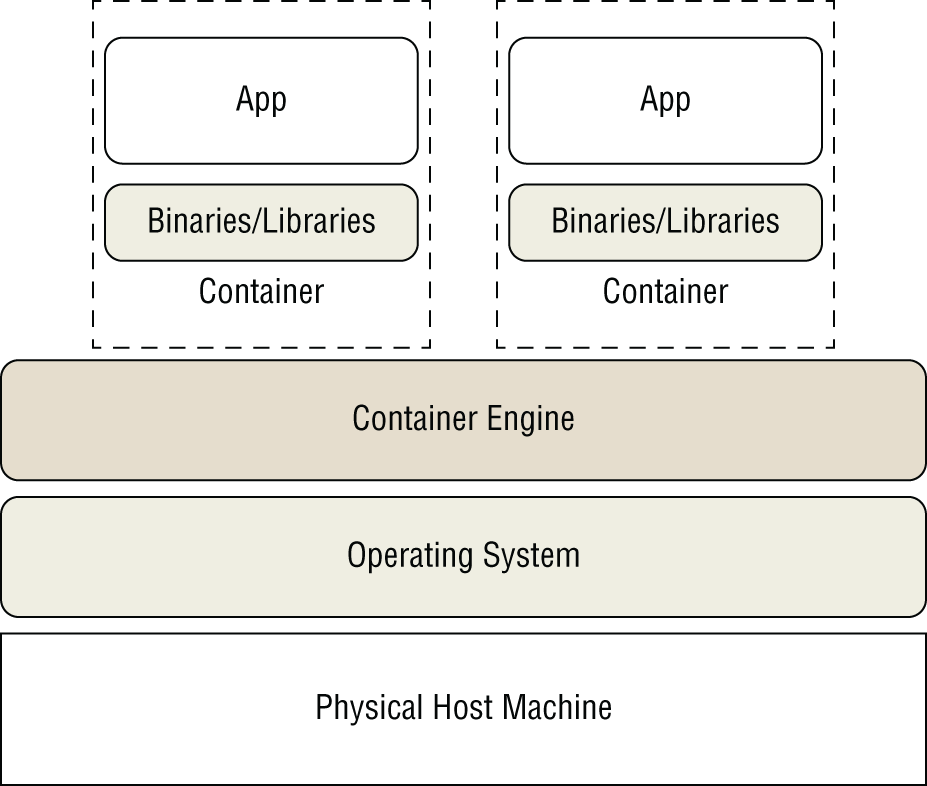
FIGURE 22.4 A container example
Notice in the figure that the physical machine's operating system is shared among the containers. However, each container has its own set of binaries and needed libraries to support its app, application stack, or environment.
Exploring Container Types
A container's focus depends on its purpose in life. Two container focal points are described here:
- Application Containers These containers focus on a single application, or an application stack, such as a web server. Application containers are heavily used in development and operations (DevOps). Software developers can modify their company's app in a newly created container. This same container, with the modified app, is then tested and eventually moved into production on the host machine. The old production container is destroyed. Using containers in this way eliminates production and development environment differences and provides little to no downtime for app users. Thus, containers are popular in continuous software deployment environments. The example in Figure 22.4 showed two application containers.
- Operating System Containers While containers are useful for developers, system admins can love them too. You can use a container that provides a fully functioning Linux OS space and is isolated from your host machine. Some in systems administration use containers to test their applications and needed libraries on various Linux distributions. Other system admins, prior to upgrading their host system distro, try out their environment on an upgraded Linux distribution. You can also employ VMs for these different evaluations, but containers provide a faster-to-deploy and more lightweight test area.
Keep in mind that virtualizing an application typically does not make it perform faster and should not be the primary motivation for moving it to a virtualized environment. Although containers allow you to quickly deploy applications, they will not cause an app to run more swiftly. Some hypervisors are termed efficient hypervisors, but that is only when there is a small performance difference between the physical environment and its virtualized self.
Looking at Container Software
Linux has been in the forefront of container development, making it a popular choice for developers. Two main container packages are commonly used in Linux, as described here:
- LXC The LXC package was developed as an open source standard for creating containers. Each container in LXC is a little more involved than just a standard lightweight application container, but not quite as heavy as a full virtual machine, placing it somewhere in the middle. LXC containers include their own bare-bones operating system that interfaces with the host system hardware directly, without requiring a host operating system. Because LXC containers include their own mini operating system, they are sometimes referred to as virtual machines although that term isn't quite correct as LXC containers still require a host operating system to operate.
- Docker The Docker package was developed by Docker Incorporated and released as an open source project. Docker is extremely lightweight, allowing several containers to run on the same host Linux system. Docker uses a separate daemon that runs on the host Linux system that manages the installed Docker images. The daemon listens for requests from the individual containers as well as from a Docker command-line interface that allows you to control the container environment.
Because containers are still relatively new in the computing world, container packages are often confused with Linux orchestration packages. We cover the orchestration topic next.
Organizing Containers
Orchestration refers to the organization of a process that is balanced, coordinated, and achieves consistency in the results. Orchestration of containers requires various orchestration engines (also called orchestration systems). These orchestration packages help you to manage the numerous containers you typically end up managing on your Linux systems.
No one orchestration system can do it all. The best combination is a set of general and specialized orchestration tools. We cover just a few here.
EMBRACING KUBERNETES
Originally designed and used by Google, Kubernetes is an open source orchestration system that is considered by many to be the de facto standard. Not only is Kubernetes popular and free, it also is highly scalable, fault tolerant, and easy to learn.
In some documentation, you will see the word k8s in reference to Kubernetes. The 8 replaces the “ubernete” portion of the Kubernetes name.
This system contains years of Google's orchestration experience, and because it is open source, additional community-desired features have been added. This is one reason so many companies have adopted its use for container orchestration.
Each Kubernetes managed service or application has the following primary components:
- Cluster service: Uses a markup language file to deploy and manage app pods
- Pod: Contains one or more running app containers
- Worker: Pod host system that uses a kubelet (agent) to communicate with cluster services
- YAML file: Contains a particular app container's automated configuration management and desired state settings
This distributed component configuration allows high scalability and great flexibility. It also works well for continuous software delivery desired by companies employing those development models.
INSPECTING DOCKER SWARM
Docker, the popular app container management utility, created its own orchestration system, called Docker Swarm (also called Swarm). A group of Docker containers is referred to as a cluster, which appears to a user as a single container. To orchestrate a Docker cluster, you can employ Swarm.
With the Swarm system, you can monitor the cluster's health and return the cluster to the desired state should a container within the cluster fail. You can also deploy additional Docker containers if the desired app performance is not currently being met. Swarm is typically faster than Kubernetes when it comes to deploying additional containers.
While not as popular as the Kubernetes orchestration system, Docker Swarm has its place. It is often used by those who are new to orchestration and already familiar with Docker tools.
SURVEYING MESOS
Mesos (also called Apache Mesos) is not a container orchestration system. Instead, Apache Mesos, created at the University of California, Berkeley, is a distributed systems kernel. It is similar to the Linux kernel, except it operates at a higher construct level. One of its features is the ability to create containers. The bottom line is that Apache Mesos combined with another product, Marathon, does provide a type of container orchestration system framework. You could loosely compare Mesos with Marathon to Docker with Swarm.
Mesos with Marathon provides high availability and health monitoring integration and can support both Mesos and Docker containers. This orchestration framework has a solid history for large container deployment environments.
If you desire to find out more about Mesos with Marathon, don't use search engine terms like Mesos orchestration. Instead, go straight to the source at https://mesosphere.github.io/marathon/.
A whole or partial Linux server is not the only thing you can virtualize nowadays. Software packaging is also getting in on this movement. We cover that topic next.
Software Packaging
Software packaging has some troublesome issues. As an example, there are several packages and libraries needed (called dependencies) to make PostgreSQL (covered in Chapter 21, “Managing Database Servers”) fully functional. So when you install the postgresql using apt or the postgresql-server package using dnf, the needed dependencies are installed too. If a dependency is not available or the wrong version of it is installed, your database may not function correctly or securely. In addition, when the database server is set up and run, it is not fully isolated from the other software and services on the system.
At some point in time, software package developers (sometimes called publishers) realized that system administrators and app developers were having all the fun with containers. It became apparent that software could be delivered and implemented on Linux systems in their own container-like environment. As a result, package developers began exploring this brave new world of software distribution.
Using a container-like package system resolves many of the problems in our PostgreSQL example. A compressed software package holds all the needed dependencies, and each is the correct version. These packages are installed and run in a protected sandbox, making them unable to adversely affect other software and services on the system. This includes newer versions of the software package itself, so you could run two versions of PostgreSQL on the same system!
In this section, we take a look at two container-like package formats, more appropriately called universal package systems. One is Snap, and the other is Flatpak.
Looking at Ubuntu Snap
Canonical (keepers of the Ubuntu distribution) introduced a new package system around 2015. However, it was released to the world in a limited form—focused on only cloud-based applications and available only on the Ubuntu distribution.
Over time, this package format, called Snap, became so popular that it was made available to other major Linux distributions, including Red Hat. Snap is now used not only for cloud-based applications, but also for desktop, server, and Internet of Things (IoT) apps.
EXPLORING THE SNAP PACKAGE SYSTEM
The Snap package system consists of many different components in its framework. The following parts are important for system administrators:
- Snap Packages Software packages in the Snap format are called snaps and focus on a single software application. For example, you could install the Multipass orchestration snap on your system. The snaps download as a single self-contained compressed package file that holds all the binaries and dependencies needed for the app to work.
Snaps are distribution independent. In other words, they don't require any modification for their apps to run on a different Linux distribution than the one for which they were originally packaged. This simplifies application version testing for the system administrator and package building for the package managers. However, keep in mind not all Linux distributions support Snap.
A popular aspect of snaps concerns heightened security. When you run an app installed from a snap package, it operates in a sandbox. This way, it is isolated from other data and applications on a Linux system, including other running snaps.
- Snap Channels A common problem with managing system applications is maintaining an older version of the app. There could be additional products or hardware that need to be upgraded prior to the installation of the latest and greatest software version. Sometimes your customers may refuse to sanction an application upgrade. Whatever the reason, a snap channel can help.
Snap channels are snap delivery pathways. Your snap package is updated using a set channel, though you can switch channels if desired. What's even nicer is that you can have two different snaps, each updating from a separate channel. This is a wonderful feature for testing the latest and greatest app modifications.
The channels are named to indicate items such as app stability, using the following format:
track/risk/branchA
trackis typically set tolatestfor normal production updates, orinsiderfor app developers, withlatestbeing the default. Ariskisstable,candidate,beta, oredge, withstablebeing the least risky all the way toedgebeing the most daring for those who like to use software on the bleeding edge. Be aware that some snaps usealphain place ofedgefor the risk level. Abranchis a temporary channel naming for quick fixes and is generally closed after 30 days of no updates.The snaps on your system are updated continuously. You can pause the updates, but only for a certain period of time, such as a few days. Also, a snap channel may close if the publisher no longer believes the channel fits the snap package.
- The Snap Daemon One of the primary duties of the snap daemon,
snapd, is checking the snaps' channels for app updates. This is typically done multiple times per day.Potentially confusing is that
snapdis also the package name for the Snap package management framework. - The
snapCommand The gateway to managing snaps is thesnapcommand. Using this command-line interface, you can install and remove snaps. You can also view snaps that are available to install and get detailed information concerning them, such as their current snap channels and publishers. Thesnapcommand even allows you to manage the entire Snap framework after it is installed, which is handy. - The Snap Store You can think of the snap store as a type of package repository. What's a little different about it is that it's a central location where publishers can share their snaps, and system administrators can view what's available.
The snap store is a GUI-based app. So if you want to view what's available using this method, you'll need to install it on your Linux desktop and not any GUI-less servers. However, you don't have to use the snap store to see all the available snaps. The
snapcommand also allows you to list information concerning snaps available for installation, so you're covered on those servers without a GUI.Be aware that there is a web-based store with an identical name. However, it is for the Snapchat messaging app, and not snap packages.
While snaps sound wonderful, there are a few potential disadvantages to consider. For one, you cannot stop a snap update on a channel. You can only delay it. When your snap is updated, you receive more than just a few changes to the software. Instead, you'll receive an entirely new snap package, some of which are rather large.
Finally, while a publisher may be an entire team of people, typically it's just one individual. Often with a software package maintained by a distribution, many eyes have viewed the code for flaws before it hits the repository. However, there have been cases where even a team of people have missed large security holes in an application's code. You need to be aware of these problems, in case any of them cause snaps to not fit well into your organization's requirements.
INSTALLING THE SNAP FRAMEWORK
On modern Ubuntu distributions, the Snap package management framework comes pre-installed. The package name for Snap is snapd, which is a little confusing, since it's the same name as the Snap daemon. Here's a snipped example of checking the package's status on Ubuntu, using the dpkg -s command:
$ dpkg -s snapdPackage: snapdStatus: install ok installed[…]
On other distributions, you'll have to install the Snap framework. On CentOS, you'll also need to install the epel repository, as snapd isn't available in the standard repos. This is shown snipped using the root account here:
# dnf install epel-release[…]Is this ok [y/N]: yDownloading Packages:[…]Installed:epel-release-8-8.el8.noarchComplete!## dnf install snapd[…]Install 3 PackagesUpgrade 2 PackagesTotal download size: 39 MIs this ok [y/N]: y[…]Importing GPG key […]:Userid : "Fedora EPEL […]"Fingerprint: […]From : […]Is this ok [y/N]: yKey imported successfullyRunning transaction checkTransaction check succeeded.Running transaction test[…]Installed:snap-confine-2.49-2.el8.x86_64snapd-2.49-2.el8.x86_64snapd-selinux-2.49-2.el8.noarchComplete!#
Once you've installed snapd on your system, be sure to enable it at system boot and start it, using super user privileges and the systemctl command as follows:
# systemctl enable snapd# systemctl start snapd
USING BASIC COMMANDS
The snap command has many subcommands. You can see all of them by typing in snap --help at the command line, but Table 22.1 describes the basic ones you'll use when getting started with snaps.
TABLE 22.1: Basic snap Subcommands
| SUBCOMMAND | DESCRIPTION |
|---|---|
find query
|
Searches the snap store for snaps containing query in their description |
info snaps-name
|
Displays detailed information concerning the snaps-name snap package |
install snaps-name
|
Installs the snaps-name snap package, if you use super user privileges when issuing a command |
list |
Displays a list of installed snaps along with their version and revision number, channel, publisher, and any notes |
remove snaps-name
|
Uninstalls the snaps-name snap package, if you use super user privileges when issuing a command |
On Ubuntu, you'll have a few pre-installed snaps that you can view using the snap list command, as shown here:
$ snap listName Version Rev Tracking Publisher Notescore18 20210309 1997 latest/stable canonical✓ baselxd 4.0.5 19647 4.0/stable/… canonical✓ -snapd 2.49.2 11588 latest/stable canonical✓ snapd$
If your distribution doesn't have any pre-installed snaps, you'll receive the following message when you attempt the list subcommand:
$ snap listNo snaps are installed yet. Try 'snap install hello-world'.$
One nice feature about using the snap find command to search through the snap store for snaps is that the query you use can be the snap package's name, the publisher's name, or some subset of information in the description. In Figure 22.5, we issued the command snap find canonical | less to take our time in viewing all the snaps available from the canonical publisher in the less pager.

FIGURE 22.5 Using the snap find command
To get more detailed information on a particular snap package than the find subcommand provides, use snap info as shown here:
$ snap info cvescanname: cvescansummary: Security/CVE vulnerability monitoring for Ubuntupublisher: Canonical✓store-url: https://snapcraft.io/cvescan[…]channels:latest/stable: 2.5.0 2020-09-01 (281) 43MB -latest/candidate: ↑latest/beta: ↑latest/edge: ↑$
Though many of the snap basic commands work without any special privileges, you will need super user privileges to install and remove snaps. We decided to install the cvescan snap on Ubuntu as shown snipped here:
$ sudo snap install cvescan[sudo] password for sysadmin:Download snap "cvescan" (281) from channel "stable" […][…]Setup snap "cvescan" (281) security profilescvescan 2.5.0 from Canonical✓ installed$$ which cvescan/snap/bin/cvescan$
Once you have a snap package installed, you run the app just as you would normally, as shown here for the cvescan software:
$ cvescan -p critical✅ Ubuntu vulnerability datbase successfully downloaded!✅ Scan complete!Summary------------------------------------ ------------------Ubuntu Release focalInstalled Packages 620CVE Priority critical or higherUnique Packages Fixable by Patching 0Unique CVEs Fixable by Patching 0Vulnerabilities Fixable by Patching 0Fixes Available by `apt-get upgrade` 0------------------------------------ ------------------$
Removing snaps is just as easy as installing them. Just use the required super user privileges and the snap remove snap-name command. We don't want to remove our cvescan snap package just yet because there is further exploration we'd like to do with it.
VIEWING THE SNAP DIRECTORIES
An interesting activity to do once you've installed a snap package and tried it out is to view where its files are located, as we've done here using the find command:
$ sudo find / -name cvescan/snap/bin/cvescan/snap/cvescan/snap/cvescan/281/bin/cvescan/snap/cvescan/281/lib/python3.6/site-packages/cvescan/home/sysadmin/snap/cvescan/var/snap/cvescan$
When installing snaps, you'll find that their file locations are slightly different than traditional packages:
- Binaries are stored in the
/snap/bin/directory. - Any needed libraries and configuration files are located within the
/snap/snap-name/directory tree. - User data associated with the snap application is a
snapsubdirectory of the user's$HOMEdirectory. - Variable data typically stored in the
/var/directory for nonsnap apps is stored in the/var/snap/snap-name/directory for snaps.
Recall that for each app, snaps are a single self-contained compressed package file that holds all the binaries and dependencies needed for the application to work. One difference between snaps and other package files is that snaps are never unpacked. They also stay in a compressed format, living in the /var/lib/snapd/ directory, as shown here:
$ ls -Fw 50 /var/lib/snapd/snaps/core18_1988.snap lxd_19647.snapcore18_1997.snap partial/cvescan_281.snap snapd_11402.snaplxd_19188.snap snapd_11588.snap$
The snap package files have a .snap file extension. Notice that the cvescan snap package name has a number in it. This is the revision number, which we can see using the snap list command:
$ snap list cvescanName Version Rev Tracking Publisher Notescvescan 2.5.0 281 latest/stable canonical✓ -
Using the snap list command, you can also see what channel the cvescan app is set to update. In this case, it's using the latest/stable snap channel.
Snap is still relatively new to the package management world. Now that you have some basic concepts, you can start exploring more with snaps.
Looking at Flatpak
Flatpak is a package format similar to Snap. Software packages are called flatpaks, focused on a single software application, and are a single self-contained compressed package file that holds all the binaries and dependencies needed for the app to work. Flatpak packages are distribution independent, earning Flatpak the same designation as Snap, a universal package system.
When you run an app installed from a flatpak package, it operates in a sandbox. Thus, it is isolated from other data and applications on a Linux system, including other running flatpaks. This provides increased security of the apps and the host system.
Though the concept of Flatpak has been around longer than Snap, this universal package system is only now starting to gain ground. Currently, flatpaks are available only for desktop applications on Linux, not server applications. However, it's still important for you to know the general concepts around Flatpak, since all things tend to evolve to greater heights in Linux.
EXPLORING THE FLATPAK PACKAGE SYSTEM
Flatpak has some terms and structures that are unique to it. The following are some of those items you should know:
- Application Sandboxes Each app installed from a flatpak runs in a sandboxed environment. Within that environment are all the application's binaries, and some or all of the needed libraries. The application can access only items in the sandbox or items through portals to which clear access has been given. However, the apps cannot directly access other running programs. Application sandboxes also include a runtime.
- Runtimes Think of these structures as container engines that run on a host's operating system. Each flatpak app sandbox operates with a runtime environment. These environments include all the needed libraries that are not bundled into the app itself.
- Portals Flatpak apps running in a sandbox can access items outside the sandbox, such as files. This is done through portals. Only those items to which clear access has been given through sandbox permissions are accessible.
An interesting feature of Flatpak is the ability to install flatpaks without using elevated privileges. In other words, your users can install their own flatpaks and runtimes without involving you and your ability to use super user privileges in the process. That can be a benefit to some Linux environments, while a security nightmare for those organizations that need to restrict apps installed and used on their systems.
INSTALLING THE FLATPAK FRAMEWORK
On modern Red Hat–based server distributions, the Flatpak package management framework does not necessarily come pre-installed. You can quickly check to see if your system has the Flatpak universal package system by looking for the flatpak command with which, as shown here on a CentOS server distribution:
$ which flatpak/usr/bin/which: no flatpak in (/home/sysadmin/.local/bin:/home/sysadmin/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/var/lib/snapd/snap/bin)$
The package name for Flatpak is flatpak, which keeps things simple. Here's a snipped example of installing the Flatpak package framework on a CentOS server distro using the root account:
$ su -Password:[root@localhost ~]# dnf install flatpakLast metadata expiration check:[…].Dependencies resolved.[…]Install 29 PackagesTotal download size: 6.7 MInstalled size: 25 MIs this ok [y/N]: yDownloading Packages:[…]Running transaction checkTransaction check succeeded.Running transaction testTransaction test succeeded.Running transaction[…]Complete![root@localhost ~]# which flatpak/usr/bin/flatpak[root@localhost ~]#
If you'd like to install the Flatpak framework on Ubuntu, you'll need to use super user privileges, update the apt repository information, and install the flatpak package with these commands:
$ sudo apt update$ sudo apt install flatpak
There is no service to enable or start. So you're ready to start using Flatpak once the package installation is completed.
USING BASIC COMMANDS
Once installed, the flatpak command is available, and the next step is to add a Flatpak remote repository. A repository is a location on the Internet that contains various flatpak packages to choose from. There are several repositories, but the most popular one is flathub. Adding this particular repository is shown here:
[root@localhost ~]# flatpak remote-add flathub \> https://flathub.org/repo/flathub.flatpakrepo[root@localhost ~]#[root@localhost ~]# flatpak remotesName Optionsflathub system[root@localhost ~]#
Now that there is a Flatpak remote repository, you can start installing flatpak apps. Table 22.2 shows a few basic subcommands you can use with flatpak to install and manage your flatpaks.
TABLE 22.2: Basic flatpak Subcommands
| SUBCOMMAND | DESCRIPTION |
|---|---|
info name
|
Displays detailed information concerning the name flatpak package or runtime |
install name
|
Installs the name flatpak package or runtime |
list |
Displays a list of installed flatpaks and/or runtimes |
uninstall name
|
Removes the name flatpak package or runtime |
update name
|
Updates the installed name flatpak package |
search query
|
Searches the added flatpak repository(ies) for flatpaks containing query in their description |
Once you have a flatpak name that you'd like to install, just use super user privileges, if desired, and use flatpak install flatpak-name to complete the task. An example of installing the gedit flatpak on CentOS using the root account is shown snipped here:
[root@localhost ~]# flatpak install geditLooking for matches…Found similar ref(s) for 'gedit' in remote 'flathub'[…]Use this remote? [Y/n]: YFound ref 'app/org.gnome.gedit/[…]in remote 'flathub'[…]Use this ref? [Y/n]: YRequired runtime for org.gnome.gedit/x86_64/stable (runtime/org.gnome.Platform/x86_64/40) found in remote flathubDo you want to install it? [Y/n]: nerror: The application org.gnome.gedit/x86_64/stable requires the runtime org.gnome.Platform/x86_64/40 which is not installed[root@localhost ~]#
Notice that this installation was not successful. Because we answered n to installing the gnome runtime, the gedit flatpak would not install. For a flatpak installation to complete successfully, you'll have to install any required runtimes.
Because these universal package systems are fairly new to the Linux environment, it is wise to determine exactly what your company needs in package management. Then, before installing either the Snap or Flatpak software framework on your system, do some research and determine if the current state of these software systems meets your particular organization's app management and security needs.
The Bottom Line
- Understand basic hypervisor components. Hypervisors are used to create and manage VMs and are generally categorized as Type 1, Type 2, or hybrid. There are pros and cons associated with each category. For example, when creating a VM using a Type 2 hypervisor, host machine resources need auditing to determine if the VM's requirements can be met. While a Type 1 hypervisor eliminates the need for the physical host's OS, it still can consume significant resources to run VMs. Creating a VM using hypervisor software is done using many different methods, such as P2V, cloning, using templates, or employing OVF files.
- Master It You need to create and deploy several VMs that contain the same brand new application and need the same environment. After reviewing the various options, which method would you choose to create these VMs and why?
- Generate a container with a Bash shell. Containers each have their own set of binaries and needed libraries to support their app, application stack, or environment, but they share the physical host's operating system. Starting and stopping containers, instead of performing software upgrades within them, is one reason why they are so popular for development and operations (DevOps). Docker is one such container engine that is extremely popular. It uses a daemon on the Linux system to listen for requests from the individual containers as well as from a Docker command-line interface that allows you to control the container environment.
- Master It Imagine you are a system administrator for an Ubuntu Linux system, and the development team is considering Docker containers to use in their production of applications. To let them try this environment, you need to install Docker to create and manage containers. Your Ubuntu system is specifically a server distro, so you want to manage the containers from the command line. What steps can you take to quickly install the Docker engine and generate a test CentOS container with access to the Bash shell for the software developers to try?
- Manage the Snap universal package system. The Snap universal package system employs the snap command to install and manage snap packages. The
snapddaemon updates these packages on a regular basis through the appropriate Snap channel. When run, snaps operate in an isolated sandbox, protecting other data and applications on a Linux system, including other running snaps.- Master It You have recently visited the snap store and found a wonderful snap application that will assist in your orchestration management of containers, Multipass. After installing it and running it through several tests, you decide to use it in your production environment. However, you'd like to also keep up-to-date with the new developments in this special snap package. Besides reading about up-and-coming Multipass features, how can you stay informed using a snap package?
- Install the Flatpak framework. Software packages, flatpaks, in the Flatpak universal package system focus on a single software application and are a single self-contained compressed package file that holds all the binaries and dependencies needed for the app to work. Though Flatpak is similar to Snap, flatpaks are currently available only for Desktop applications on Linux systems.
- Master It You are a system administrator for a CentOS Desktop Linux system used by developers for creating the company's main software product. The developers are interested in a different text editor that will allow them to efficiently operate as they update the company's software app. Because there is a consideration to move development from the current Linux distro to another one that also uses Flatpak, you decide to install this text editor's flatpak package that is available in
flathub. What steps should you take to get this framework and text editor installed for the developers on this current system?
- Master It You are a system administrator for a CentOS Desktop Linux system used by developers for creating the company's main software product. The developers are interested in a different text editor that will allow them to efficiently operate as they update the company's software app. Because there is a consideration to move development from the current Linux distro to another one that also uses Flatpak, you decide to install this text editor's flatpak package that is available in