Back up data to a separate system.
Back up data to a separate system.There are so many enemies of your data. When it comes to disks, it’s not a question of whether your hard drives will fail, it’s a question of when. Beyond hard drive failure you find rm, dd, and a number of other Linux commands that are incredibly efficient at destroying your data. Just ask a good friend of mine who was trying to clean up his MP3 directory. A number of us were helping him perfect a find script that would delete all of the files in his MP3 directory that did not end in .mp3. Despite our warnings to test the script with echo first, he ran the full command: find . -type f ! -name '*.mp3' -exec rm -f {} \;. At first it appeared to be working, until he discovered he hadn’t run the command in his MP3 directory—he ran it in ~, his home directory. True, he had cleaned up his MP3 directory, along with the rest of his files. The bottom line is that the only real way to ensure that your data is safe is to back it up.
There are any number of ways to back up data under Ubuntu, and in this chapter I cover a graphical tool called BackupPC. I also discuss some commonsense backup tips and describe how to create a full image of a drive or partition. I include some special considerations for when you’re backing up a database. By the end of the chapter, if you haven’t set up a backup system yet, I hope you will be encouraged by how easy it is under Ubuntu.
There are a number of principles that should guide you when you set up your backup strategy. Most of these are common sense but bear repeating:
Back up data to a separate system.
That separate system might be a separate drive, a tape, or ideally a completely separate host. The point is not to back up data on a drive to the same drive. You really want your backups to be as far removed from the system as possible—even for my personal data at home I have a backup system in place to copy my most important files to a server out of state. That way, if my house burned down or serious file system corruption hit my server, my important data would still exist.
If you haven’t successfully restored from backup, you haven’t truly backed anything up. After you set up a backup system, you must make sure that you can restore from it. It’s a good practice to follow up with tests of your restore process periodically afterward. The worst time to find out a backup didn’t work is when you really need a file.
RAID is not a substitute for backups.
A common mistake among beginner administrators is to mistake RAID for backups. RAID provides you with redundancy for hard disks so that if a particular disk fails, your data still remains safe on the other disks. RAID does not protect you from a user deleting a file or, worse, complete file system corruption. In the case of a RAID mirror, if you write bad data to one drive, that bad data will simply be replicated to the second. On top of this, it’s not unheard of for a RAID controller to die and write bad data to the disks as it goes down. In any of these cases if you did not keep a backup that is separate from your RAID, your data would be gone.
Create full and incremental backup schedules.
The majority of files on a server tend to stay the same, particularly when you are talking about the core OS files. For this reason most administrators opt for a combination of full backups (a complete copy of every file) over a longer period of time, such as every week, and incremental backups (only files that have changed since the last backup) over a shorter period of time, usually daily. Since incremental backups generally involved fewer files, they take up less space and are faster to complete. Just keep in mind that if you restore multiple files, there’s a chance that some of the files aren’t included in the latest incremental backup. The safe approach is to restore from the full backup and then all subsequent incrementals if you aren’t sure every file made it into the last backup.
Decide how often to back up.
A common question one might ask is “How often should I back up?” The basic answer is “How much work can you afford to lose?” Many organizations can stand losing up to a day’s work, so they back up nightly. If you can afford to lose only a few hours of work, then you need to back your data up every few hours.
Archive your backups.
While it would be nice to save backups forever, the reality is that backups can consume an incredible amount of space. You may be able to keep only a month’s worth of backups on your system before you run out of space. Even if that is the case, consider archiving old backups to separate storage like a tape, a USB drive, or even DVDs that you label and store in a vault. Many organizations maintain a month’s worth of backups, and then archive off a full backup every month, every quarter, or every year. That way they have a snapshot of their data at that point so even if the backup server itself were to catch fire, there’s still a version of the data available.
An image is a complete bit-for-bit copy of a drive. Once you image a drive, its image should be indistinguishable from the original drive. One of the most guaranteed, if wasteful, methods for backing up a system is to take an image of its drives. Even if you don’t use drive imaging as your backup strategy, you will find a number of other circumstances where drive images come in handy, from cloning a system to file system recovery to forensics.
Warning
When imaging a drive, it’s important that the drive not be in use. If the drive changes while you image it, you will not be able to guarantee that the image is consistent, so be sure that any file systems on a drive are unmounted. The requirement that a drive you image not be in use is yet another reason why most people don’t use imaging as their primary backup strategy.
The classic UNIX imaging tool is dd, and you will find it on just about any Linux system and definitely on any Ubuntu server. This straightforward and blunt tool in its most basic form reads an input file bit by bit and copies it to an output file bit by bit. If you had two drives of identical size, /dev/sda and /dev/sdb, here is the command to image sda to sdb:
$ sudo dd if=/dev/sda of=/dev/sdb
Of course, dd can use any file as its input and output file, so instead of imaging to another drive, you could image to a file. This is particularly handy for forensics, when you might have a number of file system images stored on a single large USB drive. Assuming you have mounted your USB drive at /media/disk1, here is how you could image /dev/sda to a file on that drive:
$ sudo dd if=/dev/sda of=/media/disk1/sda-image.img
To restore from this image, you would just reverse the two arguments. Here are the commands to restore the two previous examples:
$ sudo dd if=/dev/sdb of=/dev/sda
$ sudo dd if=/media/disk1/sda-image.img of=/dev/sda
You can also image individual partitions. This can be useful since you can easily mount the images loopback and read through them. First let’s image a partition on /dev/sda:
$ sudo dd if=/dev/sda1 of=/media/disk1/sda1-image.img
Now you can create a directory, /mnt/temp, and use the loop mount option to mount this image:
$ sudo mkdir /mnt/temp
$ sudo mount -o loop /media/disk1/sda1-image.img /mnt/temp
This is handy when you need to recover only a few files from an image. You can browse /mnt/temp like any other file system and copy individual files or entire directories from it. To copy this image back to the original drive, reverse the arguments once again:
$ sudo dd if=/media/disk1/sda1-image.img of=/dev/sda1
Another useful trick is imaging over the network. The fact is that with some servers you might not have a separate disk attached that can hold an image. One method might be to set up a remote NFS server with plenty of storage. Then you could mount the NFS share on the local system and create an image file that way. Of course, that requires that you have an NFS server set up. Another method is to pipe dd’s output to SSH. Since most servers will probably have SSH, you won’t have to set up anything special to create this image, and all of the data will be transferred over an encrypted channel.
To transfer /dev/sda from the local machine over the network to 10.1.1.5 and dump the image at /media/disk1/sda-image.img, you would type
$ sudo dd if=/dev/sda | ssh username@10.1.1.5 \
"cat > /media/disk1/sda-image.img"
To restore this image:
$ ssh username@10.1.1.5 "cat /media/disk1/sda-image.img" |
sudo dd of=/dev/sda
For the most part, backing up a system is as easy as making a copy of its files. On a database system, however, things aren’t quite so simple. A database often won’t commit changes to disk immediately, so if you simply make a copy of the database files, the database itself might be in an inconsistent state. When you restore it, you can’t necessarily guarantee that it is an uncorrupted copy.
The solution to this problem is to use tools included with the database to provide a consistent dump of the complete database to a file that you can back up. Next I describe how to use the tools provided for MySQL and PostgreSQL databases under Ubuntu.
The tool MySQL uses to create a backup of its database is called mysqldump. This tool dumps an entire database or databases to the screen. Most people then redirect the output to a file or pipe it to a tool like gzip to compress it first. For instance, if your user had a database called wordpress, here is how you would back it up:
$ mysqldump wordpress > wordpress_backup.sql
If you wanted to compress the database as it was dumped, you would put a pipe to gzip in the middle:
$ mysqldump wordpress | gzip > wordpress_backup.sql.gz
Now if you wanted to back up more than one database, there are two main ways to do it. The first way is to use the --databases argument followed by a space-separated list of databases to back up. The other method is to use the --all-databases argument, which backs up everything:
$ mysqldump --all-databases > all_databases_backup.sql
Of course, I assume you have set passwords for your database users so these commands won’t work for any of those users. This especially won’t work if you want to back up all databases, because at least some are owned by the root user. The solution is to use the -u and -p options to specify the user and password to use:
$ mysqldump --all-databases -u root -pinsecure >
all_databases_backup.sql
The preceding command would back up all of the databases as the root user using the password insecure. I list this example only to say that while this option works, it is insecure. The reason is that the full list of arguments, including the password, will be visible to all users on the system who run the ps command. A better method is to use -p without specifying a password:
$ mysqldump --all-databases -u root -p >
all_databases_backup.sql
When you specify -p without a password, mysqldump behaves like the mysql command and will prompt you to enter one. This provides good security, but of course it also means that you have to enter the password manually. Most people who back up their MySQL databases set up a cron job to do it at night. The way that MySQL recommends you solve this problem is to add the password to the client section in the ~/.my.cnf file for the user performing the backups. If you don’t already have a ~/.my.cnf file, create a new one and add the following text:
[client]
password=moresecure
Replace moresecure with the password your user will use to log in. Once you set up this file, you don’t need to specify the -p option anymore because mysqldump will pick up the password from this file. Of course, the downside here is that this password is in a plain-text file on the system, so you will want to set its permissions so that only your user can see it:
$ chmod 400 ~/.my.cnf
A backup isn’t much use if you can’t restore from it. To restore a backup on MySQL, use the mysql command-line tool and point it at your backup. For instance, to back up the test database to test_backup.sql, you would type
$ mysql test < test_backup.sql
If instead you were backing up a number of databases, just type
$ mysql < multiple_database_backup.sql
To restore all databases, you need to log in as the root user. Of course, you are a secure MySQL administrator and have set a root password, so you must use the -p option (unless you set up a .my.cnf file, in which case you can leave out -p):
$ mysql -u root -p < all_databases.sql
Since most people generally want to provide a MySQL backup at least once a day, here’s a quick and simple way to set up the cron job. First choose the location where you will store your backups. In this example I still store the backups in /root because I know only root can read that directory, but you will probably want to store them somewhere else with more space.
The main thing to consider is how many backups you want to keep. If you have some sort of other backup system in place to back up all of your files, you may need to keep only one database backup file on the system, since older versions will be stored on your remote backup server. If you want to store, say, a week’s worth of backups, you can use a simple shell trick. The date command with no arguments can be used to output the current date, but you can add some arguments to it so that it outputs, for instance, only the current day of the week:
$ date +%A
Friday
When you run mysqldump, you can enclose that entire command in backticks, and the shell will replace that section of your script with the output of the command. So if you were to write
$ mysqldump -u root --all-databases >
/root/all_databases_backup-`date +%A`.sql
the shell would actually save the database to /root/all_databases_backup-Friday.sql. That means the next day it runs the command it will name it Saturday, and so on. After a week, the new backup will automatically overwrite the one from the previous week without your having to write in any extra shell logic. To make this command run every night, you just have to create a file as root called /etc/cron.daily/mysqlbackup containing the following script:
#!/bin/sh
mysqldump -u root --all-databases >
/root/all_databases_backup-`date +%A`.sql
Then you would type chmod a+x /etc/cron.daily/mysqlbackup so that the script is executable.
Finally, if you set up a root password for MySQL, you must create a /root/.my.cnf file with the password in it, as discussed earlier. Now every night when the cron.daily scripts run, this script will run as well. If you want to change how many backups you keep, it’s as easy as changing the date command within the backticks. If you want only one backup, you can just save to an ordinary file. If you want to keep a month’s worth of backups, for instance, just replace %A with %d, which lists the day of the month starting with 01.
PostgreSQL uses a backup mechanism similar to MySQL’s in that it provides a command-line dump tool called pg_dump that dumps one or more databases to the command line. In its simplest form it behaves a lot like the mysqldump command. To back up a database named test, created by your user, you could type
$ pg_dump test > test_backup.sql
The main database user for PostgreSQL is the postgres user, so you are more likely to do backups as that user:
$ sudo -u postgres pg_dump test > test_backup.sql
To back up all PostgreSQL databases, use the pg_dumpall command instead:
$ sudo -u postgres pg_dumpall > all_databases_backup.sql
Restoring PostgreSQL databases works much like MySQL except you use the psql tool. Here is how you would restore each of the backups I did previously:
$ psql test < test.sql
$ sudo -u postgres psql test < test.sql
$ sudo -u postgres psql < all_databases_backup.sql
The cron job to back up PostgreSQL is very similar to the one for MySQL, except in this case there’s no need to set up any /root/my.cnf files. You just need to create a new file called /etc/cron.daily/postgresqlbackup containing the following:
#!/bin/sh
/usr/bin/sudo -u postgres /usr/bin/pg_dumpall >
/root/all_databases_backup-`date +%A`.sql
Then you would make the script executable with chmod a+x /etc/cron.daily/postgresqlbackup. Now every night when the cron.daily scripts run, this script will run as well. Changing how many backups you keep is as easy as changing the date command within the backticks. If you wanted only one backup, you can just remove the backticks and everything between them. If you wanted to keep a month’s worth of backups, for instance, just replace %A with %d, which will output the day of the month starting with 01.
One of the simpler but still powerful backup programs for Ubuntu is called BackupPC. BackupPC is written in Perl and can make use of tar and rsync to back up Linux and UNIX hosts, and it can mount and back up SMB shares. Unlike many other backup programs, BackupPC does not necessarily back up a particular machine at the same time every day. This software was designed with networks of desktops that power off at the end of the day in mind, so as you add hosts, it probes them to see if they are up. If BackupPC is able to back them up during the evening backup window it will, but if it can’t, it will attempt to back up the host during the day.
A nice feature of BackupPC is that it not only compresses files it has backed up, it also scans through all of the files daily and, where it sees duplicates, creates a hard link. Since a lot of servers tend to have the same system files, this method means that you can squeeze a lot more data on a lot less disk. BackupPC is packaged for Ubuntu, so you can use your package manager to install it:
$ sudo apt-get install backuppc
BackupPC includes a Web-based interface you can use to manage backup jobs, view logs, and restore files, so it will include the Apache packages it needs if they aren’t already installed. During the install process you will be prompted to select a Web server for BackupPC. Unless you set up your own Web server ahead of time and know what you are doing, select apache2 here. BackupPC uses Apache htpasswd accounts to password-protect the page, and the installer creates a backuppc user and outputs a random password to the screen, so be sure to jot it down. If you forget to do that or forget the password later on, you can use the htpasswd command against the /etc/backuppc/htpasswd file.
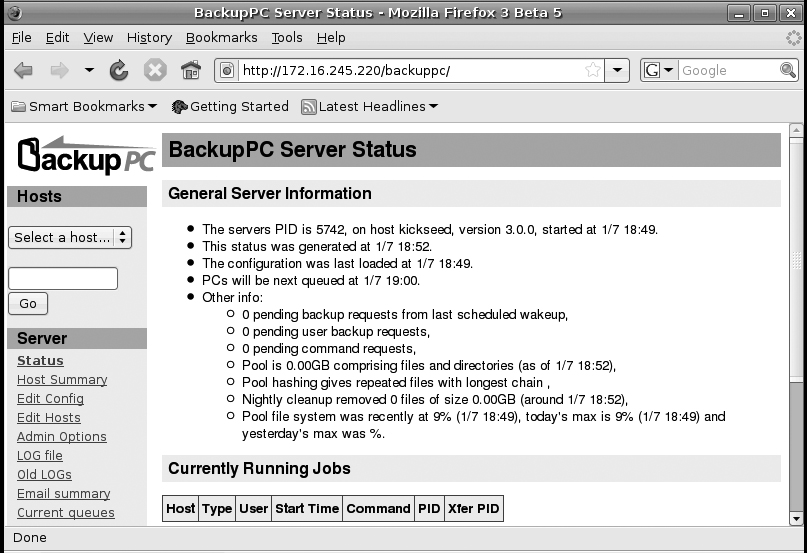
After the installer completes, open a Web browser and point it to the /backuppc directory on that host, so if your host was 10.1.1.7, you would point it to http://10.1.1.7/backuppc/. You will be prompted for login credentials, so use the login and password you were given during the install. Once you are logged in, you will see the default BackupPC admin page as shown in Figure 7-1.
As with any other backup server, BackupPC needs a lot of storage. All of the backups are ultimately stored under /var/lib/backuppc, so if you have a separate disk (or set of disks in a RAID) for BackupPC, this is a good place to mount it. Let’s assume you have a second SCSI partition at /dev/sdb1 that you want to use for BackupPC. First move the old directory out of the way, mount the new drive, and copy over the current /var/lib/backuppc files. BackupPC must be stopped while you do this so that it doesn’t write to that directory while you’re changing it:
$ sudo service backuppc stop
$ sudo mv /var/lib/backuppc /var/lib/backuppc.orig
$ sudo mkdir /var/lib/backuppc
$ sudo chown backuppc:backuppc /var/lib/backuppc
$ sudo mount /dev/sdb1 /var/lib/backuppc
$ sudo rsync -av /var/lib/backuppc.orig/ /var/lib/backuppc/
$ sudo service backuppc start
Finally don’t forget to add the new /dev/sdb1 mount point into /etc/fstab so it will mount automatically the next time the system boots.
Of course, the default Web interface isn’t very useful until you add a host. BackupPC’s default behavior is defined in /etc/backuppc/config.pl, its core configuration file. If you are unfamiliar with Perl, this file may seem a bit daunting at first as all of the options are configured in Perl data structures. I walk you through adding an Ubuntu host that you will back up with rsync, and as you will see, once you get the core configuration file set, it is relatively simple to add hosts.
The config.pl file defines the default settings for all hosts BackupPC backs up, such as how often to back up, what directories to back up, whether to use smb, rsync, or tar to back up, and even what arguments to pass to those commands. What you want to do is generate a config.pl that works for the majority of your hosts and then create host-specific configuration files when a host needs special options. Any host-specific configuration goes into a .pl file under /etc/backuppc/ named after the host. So if you had a host named web1 and wanted to change some settings just for it, you would copy those specific options from /etc/backuppc/config.pl to /etc/ backuppc/web1.pl. Any options you set in web1.pl will override anything in config.pl when web1 is being backed up.
In this example I assume a network mostly made up of other Ubuntu servers and use rsync for the backup. This is all-important because by default BackupPC logs in over SSH as root. On a network of Ubuntu servers this wouldn’t work, because root is disabled by default, so we need to change some settings.
There are two different ways to edit the BackupPC configuration. The first (and easier) is through the Web interface; with the second you just open /etc/backuppc/config.pl with a text editor and locate and tweak settings directly.
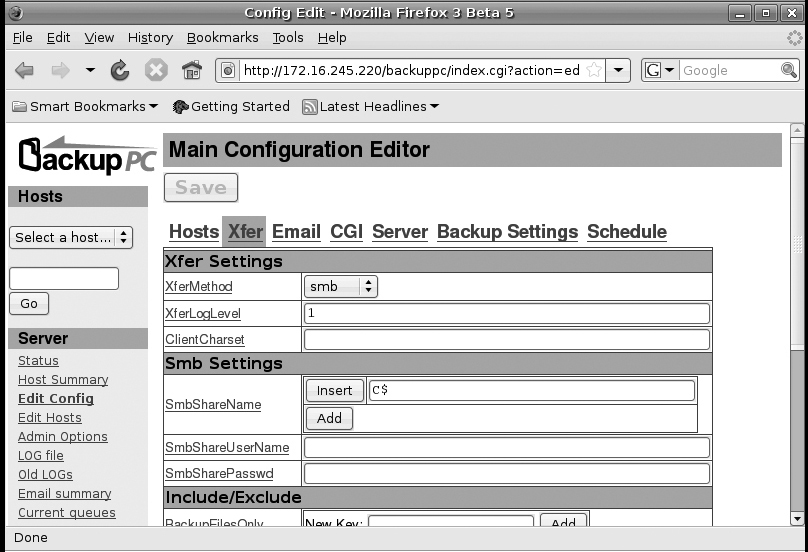
You can actually change all of the options you need directly from the Web interface. From the BackupPC home page click the Edit Config link in the left pane and then click the Xfer link along the top of the right pane. You will then see a configuration screen like the one in Figure 7-2. On the XferMethod drop-down menu change from smb to rsync. Then scroll down until you see the RsyncClientCmd and RsyncClientRestoreCmd options. Change both of them from
$sshPath -q -x -l root $host $rsyncPath $argList+
to
$sshPath -q -x -l backuppc $host sudo $rsyncPath $argList+
Then scroll back up to the top of the page and click the Save button. Once you are done with all of your changes, click the Admin Options link in the left sidebar and then click Reload so BackupPC can read your new settings.
While the Web interface provides an easy way to configure BackupPC, some people prefer doing it all through the command line. If you are one of those people, open the /etc/backuppc/config.pl file in your preferred text editor and then search for the line that matches this one:
$Conf{XferMethod} = 'smb';
This option defines the default method BackupPC uses to transfer files. SMB might work well for a network of Windows machines, but since we have Ubuntu hosts, we change this to rsync:
$Conf{XferMethod} = 'rsync';
Next, we need to set BackupPC so that it logs in to each machine as a regular user and then uses sudo to become root. We create a backuppc user on each host along with a secure sudo role so that BackupPC can log in and back up the machine. First locate the following line:
$Conf{RsyncClientCmd} = '$sshPath -q -x -l root $host $rsyncPath
$argList+';
This defines what command BackupPC uses when it backs up with rsync. Change it to
$Conf{RsyncClientCmd} = '$sshPath -q -x -l backuppc $host sudo
$rsyncPath $argList+';
We need to do the same thing for the command BackupPC uses when it restores to a host, so find the line that matches
$Conf{RsyncClientRestoreCmd} = '$sshPath -q -x -l root $host
$rsyncPath $argList+';
and change that along the same lines as the previous option:
$Conf{RsyncClientRestoreCmd} = '$sshPath -q -x -l backuppc $host
sudo $rsyncPath $argList+';
By default, BackupPC backs up the entire root file system along with all mounted file systems. I’m leaving this setting alone for now because I do want to back up all of the files on the host, but I discuss how to change it later in the chapter.
Now that you have changed the config.pl option, you are ready to set up BackupPC so that it can log in and back up your client. In this example we call our client web1, so where you see web1 listed in the example, replace it with your client’s hostname.
Since BackupPC needs to be able to log in to hosts without interaction, you must set up passwordless SSH keys for the backuppc user. On the BackupPC server type
$ sudo -u backuppc ssh-keygen -t rsa
Hit Enter at each of the prompts to accept the defaults. The public and private keys will be stored at /var/lib/backuppc/.ssh/.
Now log in to your client and create a backuppc user (hit Enter when prompted for the name and room number and other information about the user) and create a .ssh directory for the same user:
$ sudo adduser backuppc --disabled-password
$ sudo mkdir /home/backuppc/.ssh
$ sudo chown backuppc /home/backuppc/.ssh
Tip
If your client does not yet have an SSH server running, then run sudo apt-get install openssh-server.
Now you need to copy the contents of the /var/lib/backuppc/.ssh/id_ rsa.pub file from your BackupPC server to the /home/backuppc/.ssh/authorized_keys file. One way to do this is to log in to both machines on separate terminals, open both files, and then use your mouse to copy and paste between them. Another method is to use scp on the server to copy the file to the /tmp directory on the client and then log in to the client and copy it from there.
On the server:
$ sudo scp /var/lib/backuppc/.ssh/id_rsa.pub user@web1:/tmp/
Replace user@web1 with the username and hostname on the client. Then on the client:
$ sudo sh -c "cat /tmp/id_rsa.pub >>
/home/backuppc/.ssh/authorized_keys"
Now you should be able to go to the BackupPC server and log in to the client as the backuppc user without a password:
$ sudo -u backuppc ssh web1
Now we need to configure sudo on the client machine so that the backuppc user can run rsync as root without a password. To do this, run sudo visudo on the client and add the following line to the /etc/sudoers file:
backuppc ALL=(root) NOPASSWD:/usr/bin/rsync
Now that BackupPC can log in to the client and run rsync as root, we are ready to add it to the list of hosts BackupPC backs up. All of the hosts are defined in /etc/backuppc/hosts, and you can add hosts either by editing the file directly or via the Web interface.
To add a host in the Web interface, click Edit Config in the left sidebar and then click the Hosts link on the top of the right pane. Click the Add button to add a new host, and once you are finished, click the Save button. Finally, click Admin Options in the left sidebar and then the Reload button so BackupPC will reload the changes.
To add a host via the command line, open /etc/backuppc/ hosts in a text editor and add the following line at the bottom:
web1 0 backuppc
Change web1 to the hostname of the server you want to back up. The 0 tells BackupPC that this host has a static IP address, and the backuppc at the end sets what user can manage this host on the Web interface. I just used a single space in this example, but you can separate the columns with multiple spaces so everything lines up and looks nicer. If you wanted other users to also be able to back up and restore this host from the Web interface, you could add a fourth column to this line and list those users separated by commas. So if I had two users, allan and jorge, that I wanted to be able to manage web1, the line would read
web1 0 backuppc allan,jorge
Once you save the changes to /etc/backuppc/hosts, tell BackupPC to reload its configuration with sudo service backuppc reload or sudo /etc/init.d/backuppc reload.
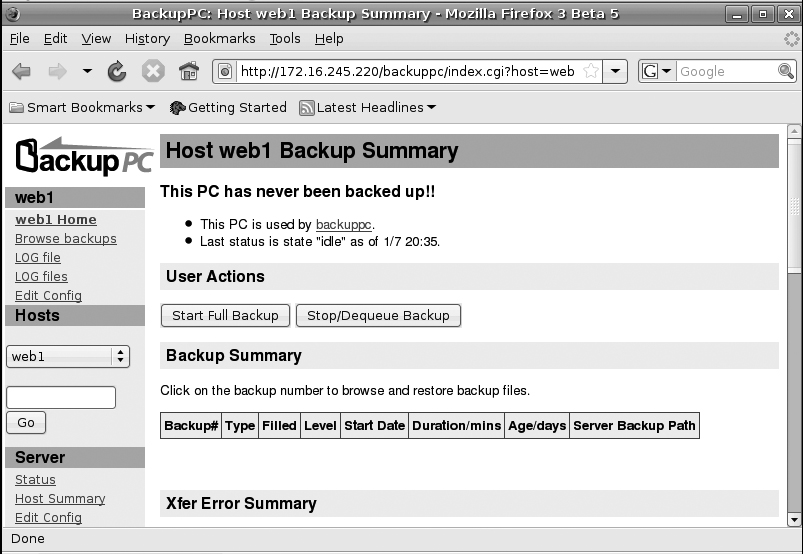
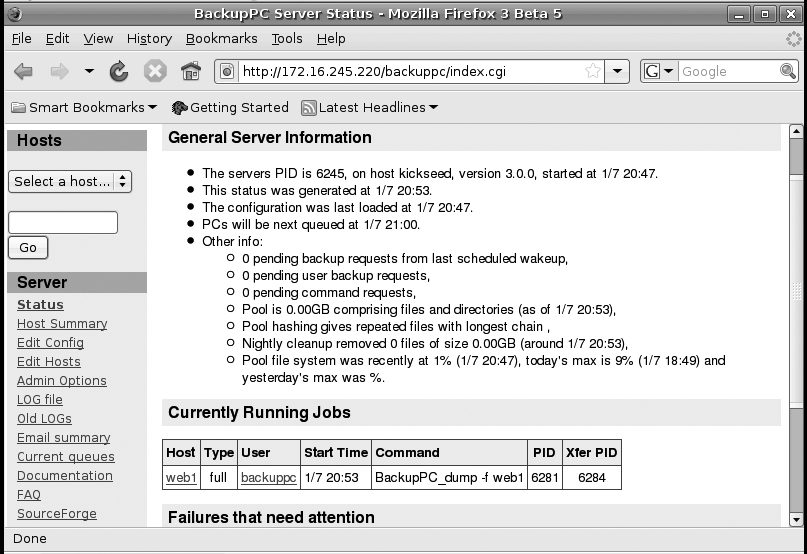
Once the BackupPC program reloads its configuration, go back to the BackupPC Web interface and reload the page. You should be able to see your host in the “Select a host...” drop-down menu on the left side of the page. Select that option and you will see the default host page as shown in Figure 7-3. To test that everything is set up correctly, click Start Full Backup to initiate the first backup for the host. Then you can click Status in the left sidebar to go to the main status page and see that your backup job has started. It should look something like Figure 7-4. To stop a job for a particular host, go to that host’s page and then click the Stop/Dequeue Backup button.
While most of the default rsync options should be fine for the average user, there are a few extra options you might want to enable depending on your environment.
If your host is relatively new, it should have a version of rsync greater than or equal to 2.6.3 (if you aren’t sure what version you have, type rsync --version). If so, you can take advantage of the --checksum-seed option, which can cache rsync’s checksums and overall speed up the rsync process. To do this you need to add that option to the RsyncArgs and RsyncRestoreArgs option in your BackupPC configuration.
To add this setting from the Web, click Web Config in the sidebar, then the Xfer link. Then scroll down to the RsyncArgs option where you can see each individual option on its own line. At the end of these options is an Add button. Click that and add --checksum-seed=32761. Then scroll down and add the same option to the RsyncRestoreArgs section.
To make the same change on the command line, open /etc/backuppc/config .pl in a text editor and find the line that starts with $Conf{RsyncArgs}. Each rsync option is on its own line, but if you are still using the config.pl that came with the package, you will see this option commented out:
#'--checksum-seed=32761',
Just remove the # from the beginning of that option. If you don’t see the commented-out option, just add a line below the last RsyncArgs option that reads
'--checksum-seed=32761',
Then move down to the RsyncRestoreArgs section (generally it’s the next option) and do the same thing for this option.
By default, BackupPC traverses all of the file systems on the host and backs up absolutely everything. There are circumstances when you might not want that to be the default behavior, especially in a cluster when you can easily replace the main system files by rebuilding the host. In these circumstances what you want to do instead is tell rsync to stick to one file system at a time, and then specify which mount points BackupPC should back up.
The first step is relatively simple because this option goes in the same place as the --checksum-seed option. Follow the steps I described earlier to add the --checksum-seed option to RsyncArgs and RsyncRestoreArgs, in either the Web interface or the command line. This time, though, the option you add is
--one-file-system
Once you set that option, you must define each file system that BackupPC will back up. In this example, let’s assume that you have /home and /var on separate partitions and want to back up only them. The option you will change is called RsyncShareName. In the Web interface return to the Xfer configuration screen you used to add --one-file-system to RsyncArgs. Above that section you will see the section named RsyncShareName. Each share is on its own line, as with RsyncArgs. First you change the first option from / to /home. Then you click the Add button and add a new share named /var.
To change the same option on the command line, open config.pl, find the line that looks like
$Conf{RsyncShareName} = '/';
and change that to
$Conf{RsyncShareName} = ['/home', '/var'];
You might find that you typically want to back up all of the files on the host apart from a few different directories. For instance, in the preceding example, you might want to back up /home and /var, but perhaps you want to skip /var/spool/mail and /var/tmp. To do this you go back to the Xfer configuration screen on the Web interface and scroll down to the BackupFilesExclude option. Then you type in /var/tmp under the New Key field and click Add. Once the screen refreshes, you can scroll down and add /var/spool/mail the same way.
If you want to change this on the command line instead, you search through the file until you see a line that looks like this:
$Conf{BackupFilesExclude} = undef;
By default no files are excluded. To add the two directories you change that option to
$Conf{BackupFilesExclude} = ['/var/tmp', '/var/spool/mail'];
As with any configuration changes, once you have changed everything, don’t forget to save and then reload BackupPC so the changes take effect.
While you can set up a default BackupPC config that works for most of your hosts, you will likely run into a few machines that need something slightly different from the default. With BackupPC it’s particularly easy to branch off from the default config and customize options. For instance, you might want to apply the --one-file-system option or exclude directories only on one host.
Basically, to add custom options for a particular host, copy those options from the /etc/backuppc/config.pl file into /etc/backuppc/hostname.pl, where hostname is the name of the host you want to change. So if, for instance, you wanted to back up only /home and /var on your BackupPC host and not traverse file systems on the host called web1, you would copy the entire RsyncArgs and RsyncRestoreArgs in a file named /etc/backuppc/web1.pl along with the RsyncShareName option. The result would look something like this:
$Conf{RsyncShareName} = ['/home', '/var'];
$Conf{RsyncArgs} = [
#
# Do not edit these!
#
'--numeric-ids',
'--perms',
'--owner',
'--group',
'-D',
'--links',
'--hard-links',
'--times',
'--block-size=2048',
'--recursive',
# my custom options
'--one-file-system',
];
$Conf{RsyncRestoreArgs} = [
#
# Do not edit these!
#
'--numeric-ids',
'--perms',
'--owner',
'--group',
'-D',
'--links',
'--hard-links',
'--times',
'--block-size=2048',
'--recursive',
# my custom options
'--one-file-system',
];
By default, BackupPC takes one full backup per week and in between takes an incremental backup of every host. BackupPC keeps one full backup and six incremental backups before it deletes anything. Finally, BackupPC will not start up new jobs for hosts that are always on the network between 7:00 a.m. and 7:30 p.m. during the week. These defaults are not suitable for everyone. For instance, you might be required to keep a month’s worth of full backups, or everyone might be out of the office by 6:00 p.m. so you can start backups then. All of these options are easy to change in the BackupPC Web interface.
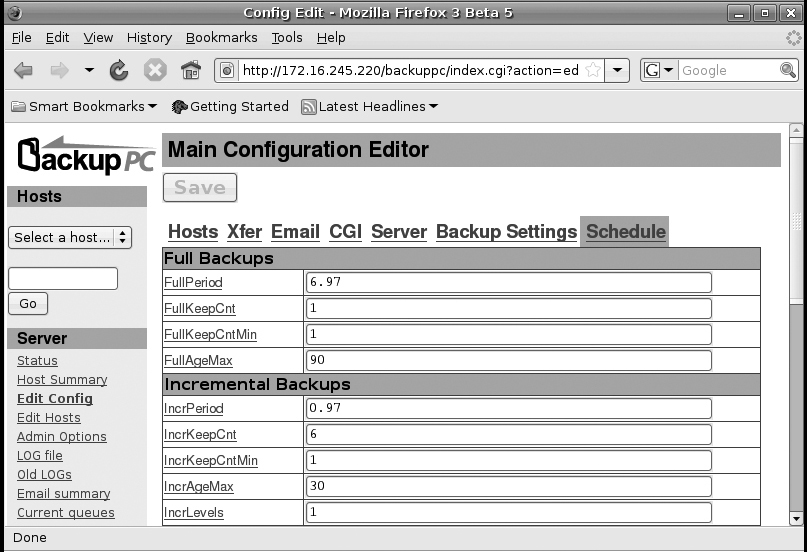
To start, click the Edit Config link in the left sidebar and then click the Schedule link on the top right-hand side of the screen. You will see a schedule-editing screen as shown in Figure 7-5. The first set of options lets you schedule your full backups. Each of the options is hyperlinked to a manual page so you can read about what they change.
The FullPeriod option defines how much time should pass (in days) before a new full backup should be scheduled. This option is always set slightly below a full number. In the case of the default, 6.97, a full backup will be scheduled every seven days. The FullKeepCnt and FullKeepCntMin options configure how many full backups to keep and the minimum number to keep, respectively, and FullAgeMax defines the maximum number of days before an old full backup is deleted. Incremental backups can save backup resources as they back up only what has changed since the last full backup. They take most of the same options as the full backups, and by default they are run every day and the last six are saved.
The Blackouts section of this page lets you define BackupPC’s blackout period. The blackout period is the range of time during which BackupPC will not attempt to back up hosts that are always on the network. This way, if you have desktops that might be powered off in the evening, BackupPC will back them up during the day, but for servers that are always on, BackupPC knows it can wait until the evening when they are presumably under less load. When you add a new host to BackupPC, it will try to ping it periodically to determine whether it is always on the network. If it is, BackupPC will back it up only during the blackout period. The hourBegin option defines what hour or fraction of an hour the blackout period begins, and the hourEnd option sets when it ends. The weekDays option sets which days of the week the blackout period is in effect. By default the blackout period is between 7:00 a.m. and 7:30 p.m. Monday through Friday.
To demonstrate how you would change these options, I define a different backup policy that might be used in an organization. In this organization we want weekly full backups and daily incremental backups, but we want to save the full backups up to a month before discarding them. We also want to keep the last two weeks of incremental backups. Finally, everyone in the office leaves by 6:00 p.m., so we want to start backups then. To make these changes I need to change only the following values:
FullKeepCnt = 4
IncrKeepCnt = 12
hourEnd = 18
Backing up files is all well and good, but it isn’t too useful unless you can restore them. One of the best features of BackupPC in my opinion is its easy-to-use Web-based restore. If you set up additional Web accounts for backuppc (use htpasswd -c /etc/backuppc/htpasswd username), you can add those accounts to specific hosts in the /etc/backuppc/hosts.conf (or on the Web interface) and those users can log in to BackupPC and restore their own files.
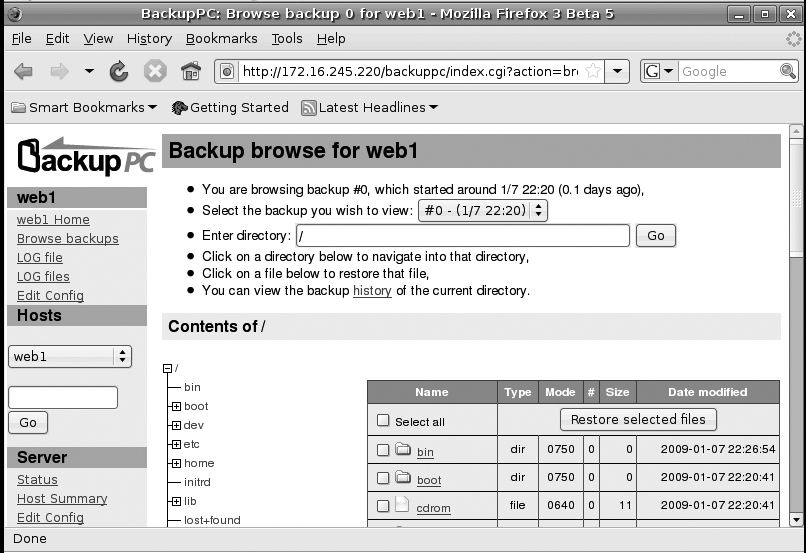
To restore a file or directories for a host, first go to the host’s home page on BackupPC (select the host in the drop-down menu in the left sidebar). On the host’s main page you will see a list of completed backups in a table that lists whether the backup was full or incremental, when the backup started, how long it took, and where those files are stored on the file system. Click the hyperlinked backup number at the beginning of a particular row to restore from that backup. You will then see the entire directory structure of your host on the page with checkboxes next to files and directories (see Figure 7-6). The interface is like that of most file managers, and you can click on an individual directory to expand it. Once you have selected all of the files you wish to restore, click the “Restore selected files” button at the top or bottom of the page.
BackupPC provides you with three different restore options:
Direct restore
In a direct restore, BackupPC restores the files or directories directly to a host. You can actually choose which host to restore to, as BackupPC lets you choose any host it has configured. By default BackupPC restores to the share and directory below the share that the files originally came from, so if you want to overwrite or replace what is currently there, you can just click the Start Restore button. You can even completely overwrite the entire / directory on the remote host with the full backup if you need to. Instead of restoring the files to their original directory, you could also restore to a different directory if you wanted to compare the two files.
Download zip archive
This option is very useful when you back up Windows desktops and allow your users to restore their own files. Instead of restoring a file directly to a host, you can instead generate a .zip file that contains all of your restored files and directories and download it to your current computer.
Download tar archive
This and the zip archive option are essentially the same, except in this case you get a tar archive instead, which is more useful for Linux desktops.
The following list details the common directories and files BackupPC uses, including where it stores configuration files and where it logs.
/etc/backuppc
This directory contains all of the configuration files for BackupPC, including its Apache config and any host-specific configuration files.
/etc/backuppc/config.pl
All of the default BackupPC options are set in the config.pl file. The version of config.pl that comes with the package by default is full of documentation that explains each option and gives examples. Any host-specific configuration goes into a separate file named after the host and ending in .pl.
/etc/backuppc/hosts
All of the hosts that BackupPC will back up are defined here.
/etc/backuppc/htpasswd
Web users along with their passwords are set in this file by default. This is a standard Apache password file, so you can use the htpasswd command to make changes (type man htpasswd for details on how to use the program).
/etc/backuppc/apache.conf
This file defines all of the virtual host settings for the BackupPC Web administration page. BackupPC creates a symlink from /etc/apache2/conf.d/backuppc.conf to this file, although these days it would fit better under /etc/apache2/sites-available.
Here is BackupPC’s init script. BackupPC starts the service by default once it is installed and automatically starts at boot time.
/var/lib/backuppc
This directory contains all of the files that BackupPC backs up, so you should consider putting this directory on a separate large mount point or at least make sure it has plenty of free space.
/var/lib/backuppc/log
All of the logs for each backup can be found under this directory. You can also access the logs from the Web interface.
/var/lib/backuppc/pc
Each host has its own directory here that contains its latest set of files. BackupPC pools together identical files from multiple hosts with hard links, but if you have removed a host from BackupPC and want to delete its files as well, delete the host’s directory under here first.