--suite precise
--suite preciseOne of the hottest trends in system administration today is virtualization. With virtualization you can create multiple instances of Ubuntu that all run on the same hardware. You can allocate parts of your server’s resources to each virtual machine. There are incredible amounts of processing power in a modern server, and with virtualization you can get much more out of the hardware you have. I even used virtual machines as a test lab for this book; it is much faster to set up a new Ubuntu server and try out a particular package when you can do so within a virtual machine rather than setting aside multiple hardware machines.
There are a number of different virtualization technologies available under Ubuntu Server, and in this chapter I cover two of the most popular, VMware Server and KVM. VMware Server is a free product produced by VMware, and KVM (Kernel-based Virtual Machine) is free software with support built into the Linux kernel.
KVM is the default virtualization technology supported by Ubuntu. This software takes advantage of virtualization support built into Intel and AMD processors and allows you to run a number of different distributions and operating systems as VMs (virtual machines) on a single host.
The one “gotcha” about KVM is that it doesn’t just take advantage of virtualization support in processors, it requires it. So before you do anything else, you should confirm that your processor has virtualization extensions. Run the following command on your host:
$ egrep '(vmx|svm)' /proc/cpuinfo
If you get some output, then your server has the necessary extensions and you can move on. If not, then you won’t be able to use KVM on this machine.
Once you have confirmed that your server will support KVM, you still will probably need to enable those extensions in your BIOS. Each BIOS is different, but reboot the machine and look for a section of the BIOS settings that includes processor settings or perhaps advanced settings and make sure that virtualization extensions are enabled.
Once the BIOS is all set, boot back into your server and install all of the packages you will need for KVM:
$ sudo apt-get install gemu-kvm libvirt-bin ubuntu-vm-builder
In addition to the KVM software and necessary libraries, this group of packages will also provide you with the virsh command-line tool you will need to manage your VMs. This will also install the ubuntu-vm-builder script, which makes spinning up new Ubuntu VMs incredibly easy.
Along with the root user you will probably want to set up at least one other user on the system who can directly manage VMs. To do this you simply need to add that user to the libvirtd group:
$ sudo adduser username libvirtd
Replace username with the name of your user. Note that you will have to log out and log back in for the group changes to take effect. Once you log back in, run the groups command and make sure that libvirtd is among your user’s list of groups. At this point you are ready to test whether KVM is functioning and your user can manage it, so run the following virsh command:
$ virsh -c qemu:///system list
Connecting to uri: qemu:///system
Id Name State
----------------------------------
You will use this virsh command a lot. In this case it outputs the list of all VMs currently running on this machine. We haven’t set up any yet, but the fact that we got valid output and not an error means that we are ready to proceed. If you got some sort of permissions error, it is likely because your user is not part of the libvirtd group.
There are two main ways you can set up networking for your VMs. The default networking setup provides a private network under 192.168.122.0/24. A DHCP server will hand out the rest of the IPs; alternatively, you can set up static IPs for your VM. The KVM host has the IP 192.168.122.1, and VMs then communicate with the outside world via that gateway using NAT (Network Address Translation). This works fine, especially for VMs on a desktop, but since we are talking about servers here, my assumption is that you want machines outside of the KVM host to be able to communicate with your VMs. While you could certainly set up some sort of iptables DNAT rules and forward traffic back in, that solution doesn’t scale very well. The real solution is to set up bridged networking so that your VMs appear to be on the same network as your host.
It is relatively simple to set up the br0 bridge interface on Ubuntu. Essentially you identify the interface over which you want to bridge traffic (probably eth0 or possibly bond0 if you set up bonding), transfer all of its configuration to br0 along with a few extra bridge options, and then change the original interface to manual mode. It makes more sense when you see the examples. For instance, if I had DHCP set up for eth0 and my old configuration in /etc/network/ interfaces looked like this:
auto eth0
iface eth0 inet dhcp
then my new configuration would look like this:
auto eth0
iface eth0 inet manual
auto br0
iface br0 inet dhcp
bridge_ports eth0
bridge_fd 9
bridge_hello 2
bridge_maxage 12
bridge_stp off
Note that I changed the inet mode for eth0 from dhcp to manual. If eth0 had a static IP configured, I would just transfer all that configuration to br0 instead, so it would go from this:
auto eth0
iface eth0 inet static
address 192.168.0.5
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
gateway 192.168.0.1
to this:
auto eth0
iface eth0 inet manual
auto br0
iface br0 inet static
address 192.168.0.5
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
gateway 192.168.0.1
bridge_ports eth0
bridge_fd 9
bridge_hello 2
bridge_maxage 12
bridge_stp off
Once I have set up /etc/network/interfaces to have the bridge, I then restart networking:
$ sudo /etc/init.d/networking restart
Now my ifconfig output should list my new bridged interface:
$ ifconfig
br0 Link encap:Ethernet HWaddr 00:17:42:1f:18:be
inet addr:192.168.0.5 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::217:42ff:fe1f:18be/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:17226 errors:0 dropped:0 overruns:0 frame:0
TX packets:13277 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:16519186 (16.5 MB) TX bytes:1455348 (1.4 MB)
Warning
Even though we are talking about servers with physical network connections here, I should bring up the fact that most wireless adapters don’t support bridging, so if you try to set this up on your laptop and bridge over your wireless interface, bridged mode won’t work.
Once the bridge interface is set up, the current KVM installation should be able to take advantage of it by default. Now you are ready to create your first VM.
Once KVM and your bridged network are set up, you are ready to create your first VM. Ubuntu has set up a tool called ubuntu-vm-builder (in newer releases renamed vmbuilder) that you can use to automate the process of creating a VM. With vmbuilder you can define the settings for a VM, including what Ubuntu release you want, and the tool will create the local virtual disk and perform the base install for you. It will even register the VM with the system so that it’s ready to go once it completes.
To streamline the process even further, Ubuntu has created a special Ubuntu installation known as JeOS (pronounced “juice”) for virtual machines. All of the nonessential kernel modules have been removed, and the OS in general is tuned for better performance as a VM. In the examples that follow I create VMs based on JeOS.
The vmbuilder script can create VMs for a number of different platforms, including KVM, so when you run the command, the first two options you pass it are the virtualization technology (hypervisor) to use and what type of OS (suite) it will install. Here’s the first segment of the command that we will build off of (but don’t hit Enter just yet):
$ sudo vmbuilder kvm ubuntu
There are different options you can choose from depending on which hypervisor and suite you choose, and you can pass the --help argument after each one to get a list of specific options:
$ sudo vmbuilder kvm ubuntu --help
The vmbuilder script creates a directory in your current directory and dumps the VM’s disk there, so if you have set aside a special place on the disk to store VM files, be sure to change to that directory first. Here’s a sample relatively basic vmbuilder command that creates an Ubuntu Precise VM called test1:
$ sudo vmbuilder kvm ubuntu --suite precise --flavour virtual
--arch i386 --hostname test1 --libvirt qemu:///system --
rootsize=2048 --swapsize=256 --user ubuntu --pass insecure
-d test1-kvm
2010-04-17 12:17:04,193 INFO : Calling hook: preflight_check
2010-04-17 12:17:04,196 INFO : Calling hook: set_defaults
2010-04-17 12:17:04,197 INFO : Calling hook: bootstrap
. . .
2009-02-27 16:52:31,480 INFO Cleaning up
After I run the command, the script will go out and retrieve all of the packages and files it needs and automatically build the VM for me. Now I describe each of the options I chose:
--suite precise
The --suite option chooses which Ubuntu version to install. I chose precise here but you could also choose dapper, feisty, gutsy, hardy, intrepid, jaunty, karmic, lucid, maverick, natty, oneiric, quantal, or raring
--flavour virtual
There are different kernel flavors available for Ubuntu. The virtual flavor chooses the JeOS kernel that’s optimized for VMs, but there are a number of different kernels from which you can choose, depending on which Ubuntu suite and architecture you choose.
--arch i386
This is the processor architecture to use for my VM. If I don’t specify this, it will default to the host architecture. Valid options are i386, amd64, and lpia.
--hostname test1
If you don’t specify a hostname, the VM will default to a hostname of ubuntu. This is fine until you decide you want to create more than one VM, at which point you will get an error that the domain ubuntu already exists. Use the --hostname option, so that not only can you specify the hostname within the OS, you can also specify the unique name that will be registered with KVM.
--libvirt qemu:///system
The --libvirt option will automatically add this VM to my local KVM instance.
--rootsize 2048 and --swapsize 256
For basic VMs you probably just want a single disk with a root and swap partition. In that case you can use --rootsize and --swapsize to specify the root and swap partition sizes in megabytes. There is also an --optsize option that will set up a separate /opt partition.
--user ubuntu and --pass insecure
You will want some sort of default user on the system so once it is built you can log in to it, unless your network uses LDAP or some other network authentication. The --user and --pass arguments let me specify the default user and password to use; otherwise both will default to ubuntu. You can also use the --name option to set the full name of the user.
-d test1-kvm
By default, vmbuilder will install the VM’s root disk under the ubuntu-kvm directory in the user’s home directory. Of course, once you set up one VM, you won’t be able to reuse the same directory, so the -d option lets you specify the location of the destination directory.
Once the install completes, I will see that a new test1-kvm directory was created in my current directory and inside is the disk file for that VM:
$ ls test1-kvm/
run.sh tmpHHSJGz.qcow2
In addition, my new VM will be registered with KVM, and its XML file, which defines its settings, will be installed under /etc/libvirt/qemu/test1 .xml and look something like this:
<domain type='kvm'>
<name>test1</name>
<uuid>907a0091-e31f-e2b2-6181-dc2d1225ed65</uuid>
<memory>131072</memory>
<currentMemory>131072</currentMemory>
<vcpu>1</vcpu>
<os>
<type arch='i686' machine='pc-0.12'>hvm</type>
<boot dev='hd'/>
</os>
<features>
<acpi/>
</features>
<clock offset='utc'/>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>destroy</on_crash>
<devices>
<emulator>/usr/bin/kvm</emulator>
<disk type='file' device='disk'>
<source file='/home/ubuntu/vms/test1-kvm/tmpHHSJGz.qcow2'/>
<target dev='hda' bus='ide'/>
</disk>
<interface type='network'>
<mac address='52:54:00:c6:18:b7'/>
<source network='default'/>
<model type='virtio'/>
</interface>
<input type='mouse' bus='ps2'/>
<graphics type='vnc' port='-1' autoport='yes' listen='127.0.0.1'/>
<video>
<model type='cirrus' vram='9216' heads='1'/>
</video>
</devices>
</domain>
The example vmbuilder command I gave will certainly work, but the script supports a large number of additional options that might be useful for your VMs. For instance, in my example I list the --rootsize and --swapsize options to set the root and swap partitions in my VM’s disk. You might decide that you want a more complex partition layout than just a root and swap partition, in which case you can use the --part option. The --part option reads from a file you create that contains partition information and uses it when it sets up disks. The file has a very basic syntax. Each line contains a mount point followed by a partition size in megabytes. You can even set up multiple disks—just use --- on its own line to separate one disk from another.
For instance, let’s say I wanted to create two disks. The first disk would have a 100Mb /boot partition, a 2Gb / partition, and a 512Mb swap. The second disk would have a 5Gb /var partition. I could create a file called test1.partitions containing the following data:
/boot 100
root 2000
swap 512
---
/var 5000
Now when I run vm-builder I replace the --root 2000 --swap 256 lines in my command with --part /path/to/test1.partitions. The final command would look like this:
$ sudo vmbuilder kvm ubuntu --suite precise --flavour virtual
--arch i386 --hostname test1 --libvirt qemu:///system
--part /home/ubuntu/vminfo/test1.partitions --user ubuntu
--pass insecure -d test1-kvm
The vmbuilder script also has a number of handy preseed-like options for automating your install. Here are some options specifically aimed at package management:
--addpkg packagename and --removepkg packagename
The --addpkg and --removepkg commands will respectively add and remove a package you specify as an argument. You can add multiple --addpkg or --removepkg commands on the command line if you want to add or remove more than one package. Keep in mind that any packages that are interactive when they install (i.e., they ask you questions) won’t work here.
--mirror URL
Use the --mirror command followed by the URL for a specific Ubuntu mirror if you want to use something other than the default Ubuntu servers. This is handy if you have set up a local Ubuntu mirror, as the install will go much faster.
--components main, universe
If you want to add particular repositories to your Ubuntu VM such as universe or multiverse, for instance, use the --components argument followed by a comma-separated list of repositories.
--ppa PPA
If there is a particular PPA (Personal Package Archive) from ppa.launchpad.net that you want to add, just specify its name here.
By default VMs will be created using DHCP for their network information. You can optionally specify a static network setting on the command line. Here is a description of each network option along with a sample setting:
--domain example.org
This sets the default domain of the VM; otherwise it is set to the domain of the host.
--ip 192.168.0.100
Here you set the static IP address to assign the VM.
--mask 255.255.255.0
This value is set to the subnet mask.
--net 192.168.0.0
This value is set to the address for the network of the host.
Here you can specify the broadcast address.
--gw 192.168.0.1
If you don’t specify a gateway address with this option, the first address of your network will be chosen.
--dns 192.168.0.5
Like the gateway address, if you don’t specify an address here, it will use the first address on your network.
There are a number of options you can set with vmbuilder that can set up post-install scripts and other actions to help automate your install further. Here is a description of some of the main options you might use:
--ssh-key /root/.ssh/authorized_keys and --ssh-user-key /home/username/.ssh/authorized_keys
These options take the full path to your SSH authorized keys file for either the root user (--ssh-key) or a regular user (--ssh-user-key) and copy it to the host. You might set this up so that you can automatically ssh into a VM after it is installed and start without a password.
--copy filename
This option reads in a file you specify that contains a list of source and destination files, such as
/home/ubuntu/vmfiles/filename /etc/filename
It copies the file from the source file on the host to the destination file on the VM.
--execscript script
This argument runs a script you specify on the command line within the VM using chroot at the end of the install.
This option is like --execscript except it copies the script you specify into the VM and executes it the first time the VM boots.
--firstlogin script
The downside to most of the automated installer options is that they require that scripts be noninteractive. The --firstlogin option doesn’t have that limitation. It takes a script you specify and executes it the first time a user logs in to the VM. Since the first user who logs in will see the script, you have the option of making it interactive. You might also want to use this script to install any packages on your VM that have an interactive installer.
Once you have successfully created a VM with vmbuilder, you are ready to start your VM for the first time and manage it with virsh.
The virsh command is one of the main tools you will use to manage your VMs. The basic syntax for KVM is virsh -c qemu:///system followed by some sort of command. For instance, to list all of the running VMs, type
$ virsh -c qemu:///system list
Connecting to uri: qemu:///system
Id Name State
----------------------------------
Now that you have created a new VM, you can use the start command to start it:
$ virsh -c qemu:///system start test1
Connecting to uri: qemu:///system
Domain test1 started
$ virsh -c qemu:///system list
Connecting to uri: qemu:///system
Id Name State
----------------------------------
9 test1 running
Note that the start command is followed by the VM that you want to start. Similar commands to start are shutdown and destroy, which will shut down and pull the power from the VM, respectively. If you want the VM to start at boot time, use the autostart command:
$ virsh -c qemu:///system autostart test1
Connecting to uri: qemu:///system
Domain test1 marked as autostarted
If you want to remove the autostart option, add --disable to the command:
$ virsh -c qemu:///system autostart --disable test1
Connecting to uri: qemu:///system
Domain test1 unmarked as autostarted
KVM also supports snapshotting so you can save the current state of your VM and roll back to it later. To take a snapshot, use the save command followed by the VM and the file in which to save the state:
$ virsh -c qemu:///system save test1 test1-snapshot.state
Connecting to uri: qemu:///system
Domain test1 saved to test1-snapshot.state
Later you can use the restore command followed by the state file you saved previously to restore the VM to that state:
$ virsh -c qemu:///system restore test1-snapshot.state
Connecting to uri: qemu:///system
Domain restored from test1-snapshot.state
You can also suspend and resume VMs with the suspend and resume commands. Keep in mind that suspended VMs still do consume memory resources. Suspended VMs will show up in a list with the paused state:
$ virsh -c qemu:///system suspend test1
Connecting to uri: qemu:///system
Domain test1 suspended
$ virsh -c qemu:///system list
Connecting to uri: qemu:///system
Id Name State
----------------------------------
11 test2 running
12 test1 paused
$ virsh -c qemu:///system resume test1
Connecting to uri: qemu:///system
Domain test1 resumed
$ virsh -c qemu:///system list
Connecting to uri: qemu:///system
Id Name State
----------------------------------
11 test2 running
12 test1 running
One particularly nice feature of using VMs is that if a VM needs more RAM and your host has it available, you can make the change rather easily. First use the dominfo command to see the amount of RAM currently used by the VM. Once the VM is shut down, use the setmaxmem command to change the maximum RAM available to the VM and the setmem command to change the RAM the VM can currently use (the two can be different values, provided the maximum memory is larger). Once you restart the VM, it will come up with the new amount of RAM:
$ virsh -c qemu:///system dominfo test1
Connecting to uri: qemu:///system
Id: -
Name: test1
UUID: e1c9cbd2-a160-bef6-771d-18c762efa098
OS Type: hvm
State: shut off
CPU(s): 1
Max memory: 131072 kB
Used memory: 131072 kB
Autostart: disable
Security model: apparmor
Security DOI: 0
$ virsh -c qemu:///system setmaxmem test1 262144
Connecting to uri: qemu:///system
$ virsh -c qemu:///system dominfo test1
Connecting to uri: qemu:///system
Id: -
Name: test1
UUID: e1c9cbd2-a160-bef6-771d-18c762efa098
OS Type: hvm
State: shut off
CPU(s): 1
Max memory: 262144 kB
Used memory: 131072 kB
Autostart: disable
Security model: apparmor
Security DOI: 0
$ virsh -c qemu:///system setmem test1 262144
Connecting to uri: qemu:///system
$ virsh -c qemu:///system dominfo test1
Connecting to uri: qemu:///system
Id: -
Name: test1
UUID: e1c9cbd2-a160-bef6-771d-18c762efa098
OS Type: hvm
State: shut off
CPU(s): 1
Max memory: 262144 kB
Used memory: 262144 kB
Autostart: disable
Security model: apparmor
Security DOI: 0
There are a number of ways that you can get a console into a KVM VM. Some people simply set up ssh ahead of time and SSH into the machine, while others set up some sort of remote desktop with VNC. When you first get started, however, you might not have all of that infrastructure in place, so it’s nice to have some sort of tool to get a graphical console on your VM. The virt-manager utility makes this process simple.
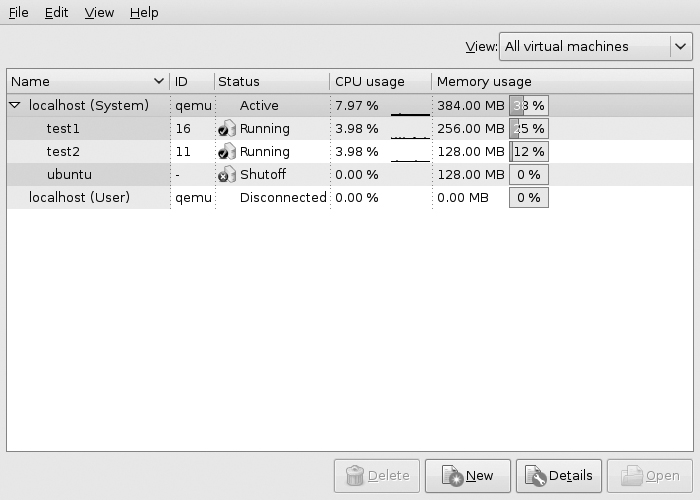
First, install the virt-manager packages with sudo apt-get install virt-manager. If your server has some sort of graphical desktop, you can run it from there. You will see a display of the potential local KVM instances to which you can connect. Double-click the localhost (System) entry and it will connect and expand to show you all of your available VMs, as shown in Figure 9-1. If any VMs are currently running, you will be able to see their current CPU and memory statistics.
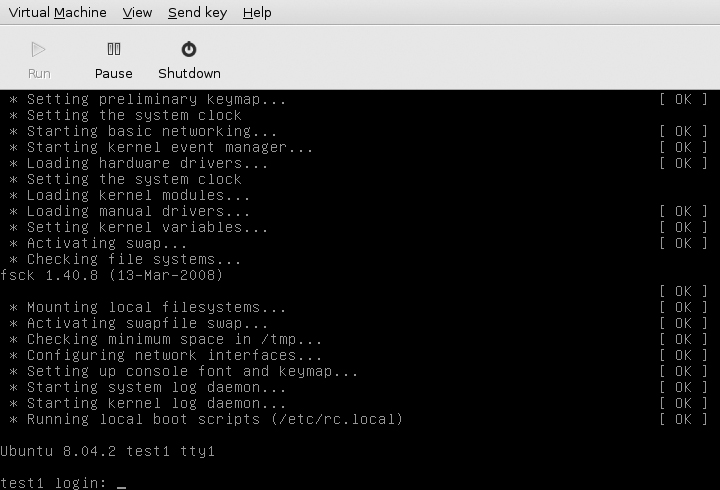
If you select a particular VM from the main screen and click the Open button, it will open up a graphical console into the machine as shown in Figure 9-2. From that window you can log in to your VM and run commands just as if you had a keyboard, mouse, and monitor connected to it. You can also power off, suspend, and take snapshots from within this interface.
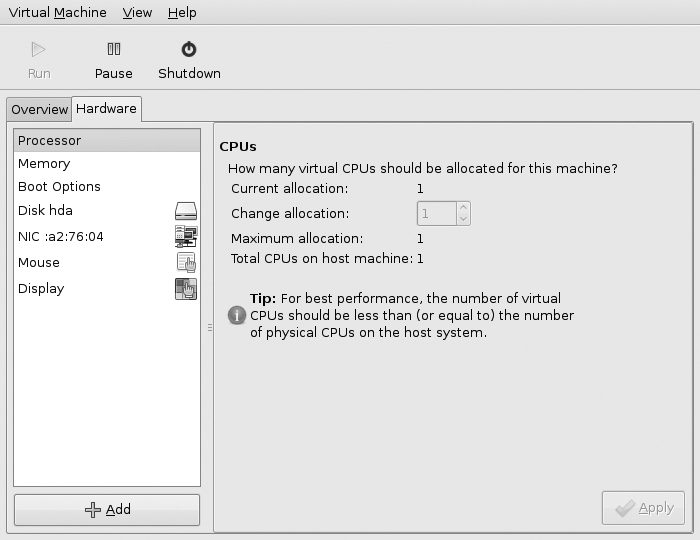
Back at the main menu you can also get more detailed information about a VM. Select the VM and then click Edit_Machine Details. From here not only can you see more detailed graphs of its current load, but if you click the Hardware tab (Figure 9-3), you can view, add, and remove hardware, although the host will need to be powered off, depending on what you want to change.
This tool isn’t limited to local KVM management as there’s a good chance that you don’t have a graphical environment on your server. You can also install the package to a desktop on your network and then connect to your KVM server via an SSH tunnel. Just make sure that you have SSH set up and then click File->Open Connection from the main Virtual Machine Manager window. Then select “Remote tunnel over SSH” in the Connection drop-down menu, make sure the hypervisor is set to QEMU, and then type in the hostname for your KVM server and click Connect.
Many people, when they think of cloud computing, particularly launching virtual machines in the cloud, they think of Amazon EC2. Amazon offers a number of different cloud services, but EC2 is the service that allows you to launch virtual machines that run on Amazon’s hardware. Amazon bills you for each hour the virtual machine is up with rates that vary depending on the resources the virtual machine uses. The rates start at $0.02 per hour for the smallest t1.micro instance. EC2 is an ideal environment for Ubuntu Server, and in this section I talk about how to use command-line tools that interface with EC2’s APIs to spawn and monitor your servers.
The first step is to register an account with Amazon to use EC2 by visiting https://aws.amazon.com/ec2/. Amazon currently runs a promotion that allows you a number of hours of free EC2 use provided you stick to the t1.micro instances. Because many of you might want to experiment with EC2 for free, my sample commands launch t1.micro instances by default.
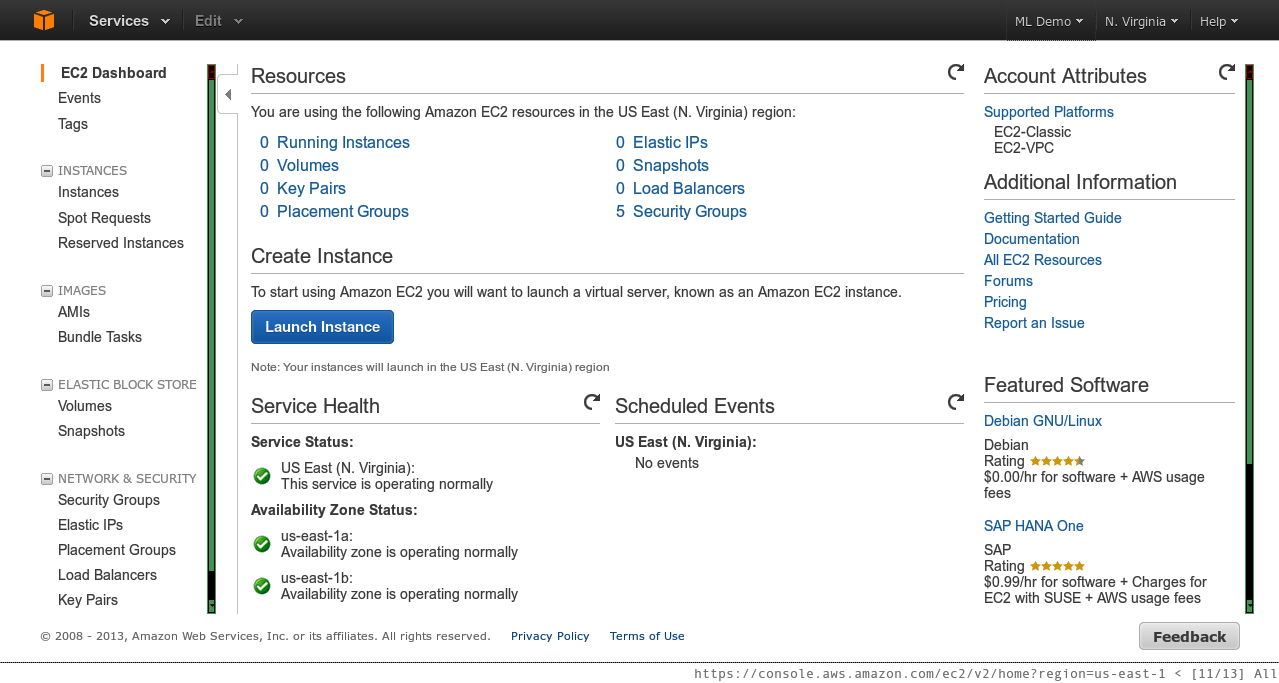
Once you register an account, you can log in and click on the drop-down menu either named My Account or named after the actual name of your account to visit the Amazon Web Services (AWS) Management Console, or the My Account page. The AWS Management console (Figure 9-4) provides a Web-based interface you can use to create new instances, change security group rules (firewall rules for your instances), add ssh key pairs, and otherwise manage EC2. Of course, in this section I’m going to try to avoid using the Web-based management console whenever possible and use command-line tools instead.
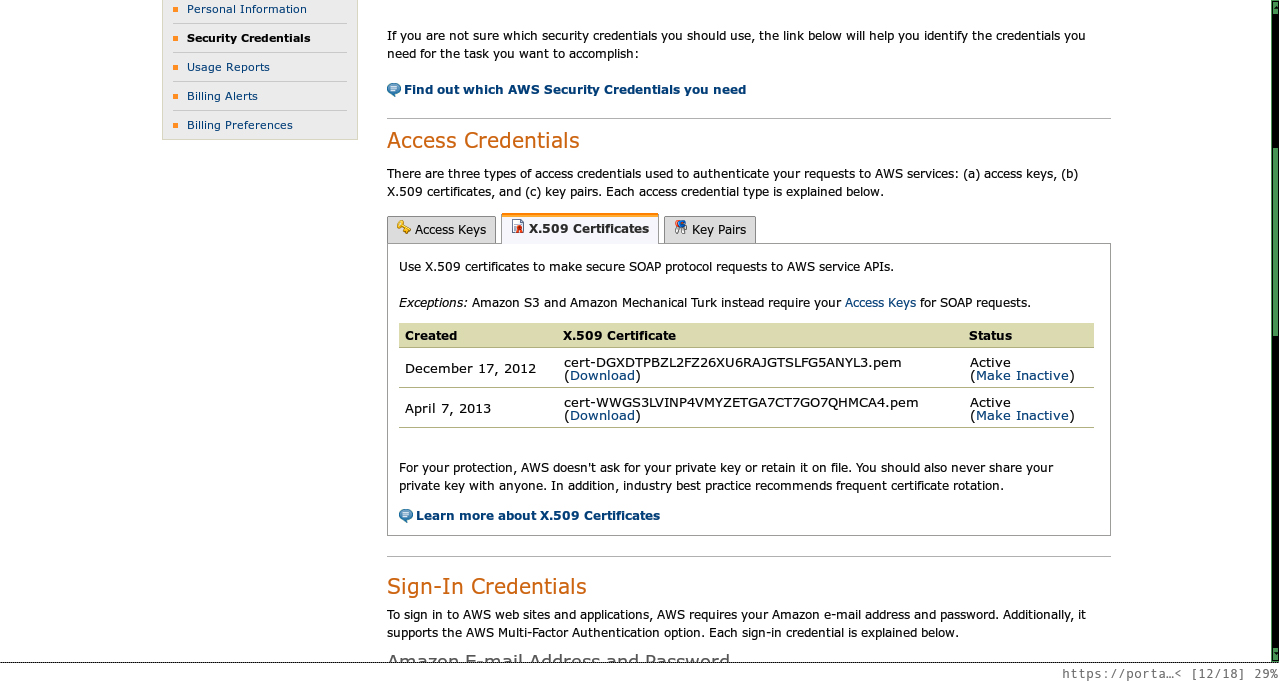
The My Account page gives you access to various account settings, but most importantly when you are getting started, it provides you the ability to create new sets of security credentials to work with the EC2 API. Once you are on the My Account page, select the Security Credentials link on the left side, scroll down to Access Credentials, and then select the X.509 Certificates tab where you can view and create new certificate pairs, as shown in Figure 9-5. An X.509 certificate consists of a private key and a public certificate file somewhat like public and private ssh key pairs. The public certificate is safe for public sharing, but the private key should be kept secret as you would a password or ssh private key. In fact, while this page lets you see a public certificate, you may download the corresponding private key only at the time you generate these certificates. If you lose the private key after that time, you’ll have to create a whole new certificate pair.
We do the bulk of our work with EC2 outside of the Web interface and with the command line. While there are a number of software libraries that have compatibility with the EC2 API, the ec2-api-tools package provides a simple command-line interface to all the major features of EC2. The first step is to install the ec2-api-tools package:
$ sudo apt-get install ec2-api-tools
While that software downloads and installs, if you don’t already have an X.509 certificate created, go to the AWS Security Credentials page, click on the X.509 Certificates tab, and create one. Remember to download at least the private key, as this will be your only opportunity, although you might as well also download the certificate file as well. You’ll need both of these files to configure the EC2 API tools.
The ec2-api-tools package installs a large number of different command-line tools that all start with “ec2,” so if you type ec2 and then press Tab twice, you will see a large number of commands. Of course, some of those commands are duplicates. For instance, the ec2-describe-regions command (which shows the currently available AWS regions) also goes by the alias ec2dre just to save on typing. You can use the -C and -K command-line arguments to pass along the path to the certificate and corresponding private key that we generated previously:
$ ec2-describe-regions -C ~/cert-WWGS3LVINP4VMYZETGA7CT7GO7QHMCA4.pem
-K ~/pk-WWGS3LVINP4VMYZETGA7CT7GO7QHMCA4.pem
REGION eu-west-1 ec2.eu-west-1.amazonaws.com
REGION sa-east-1 ec2.sa-east-1.amazonaws.com
REGION us-east-1 ec2.us-east-1.amazonaws.com
REGION ap-northeast-1 ec2.ap-northeast-1.amazonaws.com
REGION us-west-2 ec2.us-west-2.amazonaws.com
REGION us-west-1 ec2.us-west-1.amazonaws.com
REGION ap-southeast-1 ec2.ap-southeast-1.amazonaws.com
REGION ap-southeast-2 ec2.ap-southeast-2.amazonaws.com
In your case, you would change the preceding file names to match the name of your certificate and private key. Of course, that’s a lot of information to type every time, so these tools allow you to preset these values via environment variables. So create an ~/.ec2rc file containing the following settings:
export EC2_PRIVATE_KEY="~/pk-WWGS3LVINP4VMYZETGA7CT7GO7QHMCA4.pem"
export EC2_CERT="~/cert-WWGS3LVINP4VMYZETGA7CT7GO7QHMCA4.pem"
Now you can type source ~/.ec2rc and run the same command without the extra arguments, or you can even add the source line to your ~/.bashrc so these settings are loaded every time you start a new shell:
$ source ~/.ec2rc
$ ec2-describe-regions
REGION eu-west-1 ec2.eu-west-1.amazonaws.com
REGION sa-east-1 ec2.sa-east-1.amazonaws.com
REGION us-east-1 ec2.us-east-1.amazonaws.com
REGION ap-northeast-1 ec2.ap-northeast-1.amazonaws.com
REGION us-west-2 ec2.us-west-2.amazonaws.com
REGION us-west-1 ec2.us-west-1.amazonaws.com
REGION ap-southeast-1 ec2.ap-southeast-1.amazonaws.com
REGION ap-southeast-2 ec2.ap-southeast-2.amazonaws.com
The regions listed here correspond to data centers in different parts of the globe that you may create instances in. Each region has its own hourly costs for instances, and by default, commands use the us-east-1 region in Virginia, which also happens to have the lowest costs. You can observe this default setting by running the ec2-describe-availability-zones command, which lists the current availability zones in a region:
$ ec2-describe-availability-zones
AVAILABILITYZONE us-east-1a available us-east-1
AVAILABILITYZONE us-east-1b available us-east-1
AVAILABILITYZONE us-east-1c available us-east-1
As you can see, the us-east-1 region currently has three different availability zones. If you want to run commands in other regions, though, you can always specify a different region with the --region argument on any ec2-api-tools command:
$ ec2-describe-availability-zones --region us-west-2
AVAILABILITYZONE us-west-2a available us-west-2
AVAILABILITYZONE us-west-2b available us-west-2
AVAILABILITYZONE us-west-2c available us-west-2
In this case, I listed the availability zones for the us-west-2 region located in Oregon. So what’s the difference between a region and an availability zone? Every AWS region gets subdivided into availability zones. Each zone is guaranteed to be on different physical hardware, different power infrastructure, and different physical network. The idea is that no outage should ever affect more than one availability zone at a time, so if you distribute redundant servers so that they are on different availability zones, you should be safe from any outage Amazon might have.
Before we start a new instance, we need to do a few more things. First we need to generate an ssh key pair we can use to log in to instances we create. When you first create an instance, you can specify which key pair to use with it. and the ssh public key will automatically be copied to the instance as it boots. Since ssh is the primary way we will log in and access these servers, it’s a pretty important step. To create an ssh key pair, type ec2-add-keypair followed by the name you want to use for this key pair:
$ ec2-add-keypair default
KEYPAIR default 8c:48:69:73:bd:de:68:d2:61:83:d8:55:4b:1e:95:9b:7f:23:56:49
-----BEGIN RSA PRIVATE KEY-----
MIIEpAIBAAKCAQEAuLFXSzOk/ckgO81MeAQw/BLWjJE6CQSNFmnjpXbFkx6cov+F3ovQO3Dh/d5c
FcKJnQRxK5CQXsYwGprsUADUOofgb+6sXBfhxu8miPG2a8L5JQyewD7jhCyJ0/anA30fbJpyEZ42
V3LfDCPPhHmAxLktUmd8gT5WGF7RJtNzG7bqdVRMB33q8qLsTJFpSqGA24h89KZFhwE9nx5gX87E
lw7A6IGeQ3ijJndBWoNPPQXa0NDfeKhwr2Rt7CjhtBCoHf9lGa1Vo0SDBeaG9FOq7ZZJ8BmAoBJ/
+xGTFlFvz/f7SecvoI25ue3yPmOXPKZsX1zc8JzOUos0ClpWGng5xwIDAQABAoIBADSXm0n4zNTP
vvQIg+vxFZnSK3IfsKz8tMhbIs3tQlmgb+4iYRZ8LbGfdVr7RLGVkeY6a5eCNPon6W7KCtzFP6nj
I0/8YOxgiJRDaW+5lL6e6J9aNqJ7xgHPRPgs1mYx7Q7Z8/18VfEU7trgH6mTh819BaDfgx6yh4Wt
ClXKBI8xTIz1JnaZIMxgLUDwy1rDofH9P45B9dKTZZQqtfvNskv06PZytqKe9fQJmOnLmW/jGaOg
225oOPez+uqNMgAISDsDZOiRgmJBulYHAIPK3NwPZOxU64re3GcGOhFPW2fIt7xqRkpJqK3WRDvN
7sU20rybmRyFaFZ2NA45ZvGsNVECgYEA8c3Q3+nq4dVCKZBCi4tGRoA1Gi7pNB2vKWsrSx44VJWe
VlplehT8DkEtlsYxBCXjpQy363/rXVne4BSKm1PfGfEqno4P4wyXsdHBg6Wl/Za7aGVjF0K5ao5R
c94QwLtoEQszWmQ2iqexF97ZdeyiloQkOCrQnif1e9xrBvZ7FZMCgYEAw4ksg8u2b4K2CPt9v9JM
+q8t8VVsrly2Bil3GaqPW5kyA/SV8JWtRYnoEMHbdB0GXpt8eWZ1Jf2+JRYkXykZb58o5MecT0hK
Xuk6PZG9OVtn4rmvJJY+WBgvk76OlzkoyrTBybSCKXQyWCLgp1Gjpb4NhN0VSrK9TTryVqSlK30C
gYEAzDjPO/49ccUC30XG3kKf9PVdZCLQtUKI6QtpgkUgwFepZjds02IbzBJCZcA4L8+sZ37Ja24b
pDk+IrVWp397w1ZLb6R+SH4fNID61qw1+GqxF6fhvAiPvy46HwkjzxO4/gQeuC5BXnPo/0cpFQ7p
9wPd705B6gHHtHfiMPxF0l8CgYEAoXLBrpClMa1bYE9GpPufU90QshM2iUFDihLyo96QP7Fd+qYY
p2zuhFw5oJxv9o+Akt0PCa3vTE8WkMiXf3sP5Xok6cFm7o9h2Lv5upx7AMDYJfvrAOqMz3Ao2HSe
h35KkBRvbXv9fPzUFLG3jG98D32869cfnW23n+zr615GgoECgYAzOt0l53OJKySVAzeTMb3wdz31
e6Kg0i4MPk9tSrk0oXWjpu60grRNF1XWlH0t8m1EKvXjzxgnGILxfy0gxu3aoXivdeZDIcC40AlU
hJdLjv/Smii3ZuxzxBhbohrJ4EUS1UOIgRJmwAhouZtXktV07JhkpAwzya66bwwOXEpSKA==
-----END RSA PRIVATE KEY-----
The command outputs your private key to the screen, so select everything starting with -----BEGIN RSA PRIVATE KEY----- to the end of the output and paste it into a .pem file you can reference when you ssh into these machines. I recommend a file name such as ~/.ssh/ec2-default.pem. This file is a secret, so be sure to type chmod 600 ~/.ssh/ec2-default.pem, or whatever you decided to name the file. By the way, don’t worry about my pasting my private key into the book: I typed ec2-delete-keypair default to delete this key right after I created it. Make sure that your ~/.ssh directory has 700 permissions as well.
An Amazon Machine Image (AMI) is a prebuilt hard drive image that you select when you create an instance. This AMI hard drive image already has a basic OS install on it and in some cases might even have services already installed and ready to use. Each AMI has its own AMI ID that you can use to identify it, and each AMI is available only for a specific region. This is important to remember because if you want to create an Ubuntu server in two different regions, you’ll need to locate the specific AMI IDs for those regions. The AWS management interface allows you to browse through large numbers of community-provided images with different Linux distributions and different software installed. You can even create your own AMIs and upload them for use by your account, although for the purposes of this book I do not describe how to make custom AMIs because, personally, I prefer sticking with the default official Ubuntu AMIs provided by Canonical and then using a tool such as Puppet or Chef to take the base OS and modify it for my needs.
AMIs are categorized into two main instance types: instance-store and ebs. These categories have to do with how the instance’s data is stored on the physical server. An instance-store instance type stores its data directly on a local hard drive on a physical server. Although instance-store provides you with more speed, if you halt (not reboot) your server, the instance will disappear (be terminated) along with any data you had on it. Also, if the physical server crashes, your data will be lost. An ebs instance type stores its data on Amazon’s Elastic Block Storage (EBS), which means the data is stored over the network instead of on local storage and will persist in the event of a hardware failure. If you halt an ebs instance, it will not be terminated (deleted), and if the server that instance is on dies, you can restart it and your data will remain. While ebs instances cost a bit more (you do have to pay for the EBS service), if you are concerned about data loss, it is probably the instance type for you. On the other hand, if the instances you spawn in the EC2 are relatively disposable because they start, perform some sort of number crunching, then stop, you may want to save money with the instance-store instances.
Canonical provides an AMI finder page at https://cloud.ubuntu.com/ami/ that shows a grid with a large number of different AMIs split up for each zone (region), Ubuntu release, CPU architecture, and instance type (Figure 9-6). You can either scroll down until you see the specific instance you want or use the drop-down menus to narrow down each category to the one you want. Figure 9-6 shows an example of a narrowed-down list of just Ubuntu Precise ebs AMIs in the us-east-1 region. If I wanted to pick the amd64 AMI for that region, I would pick AMI ID ami-1ebb2077.
Now that we have selected an AMI ID, it’s time to create our first instance using the ec2-run-instances command (with the shortened alias ec2run):
$ ec2run ami-1ebb2077 -k default -t t1.micro -g default
RESERVATION r-f0186c8d 709488244382 default
INSTANCE i-788bed14 ami-1ebb2077 pending default 0 t1.micro
2013-04-07T21:56:20+0000 us-east-1c aki-88aa75e1
monitoring-disabled ebs paravirtual xen sg-aae1d4c2 default
The syntax for ec2run is relatively straightforward. First I specified which AMI I want to use. The -k argument specifies what key pair this instance will use. In my case, I pointed to the default key pair I had created earlier. The -t argument lets you choose the instance type. I picked t1.micro because it’s the smallest, cheapest instance type, but you might choose a m1.small, m1.medium, m1.large, or c1.large, among others, depending on how much money you have to spend and what resources you need. Finally the -g argument defines what security group this machine should be in. By default, all instances are part of the default security group, so this option was unnecessary, but I wanted to call it out because we discuss security groups shortly.
The ec2run command outputs a lot of information about the instance, including what availability zone it is in (us-east-1c), its current state (pending), and most importantly, its instance ID (i-788bed14). The instance ID is important because it’s the unique ID that distinguishes this instance from any other instance I may create. By default, I can get information about all of my instances with the ec2-describe-instances command (with the shortened alias ec2din):
$ ec2din
RESERVATION r-f0186c8d 709488244382 default
INSTANCE i-788bed14 ami-1ebb2077 ec2-50-19-174-100
.compute-1.amazonaws.com ip-10-245-29-169.ec2.internal
running default 0 t1.micro 2013-04-07T21:56:20+0000
us-east-1c aki-88aa75e1 monitoring-disabled 50.19.174.100
10.245.29.169 ebs paravirtual xen sg-aae1d4c2 default
BLOCKDEVICE /dev/sda1 vol-2ae8eb6c 2013-04-07T21:56:24.000Z
RESERVATION r-1c047061 709488244382 default
INSTANCE i-a4a90acf ami-1ebb2077 ec2-54-235-26-33
.compute-1.amazonaws.com ip-10-117-33-240.ec2.internal
running default 0 t1.micro 2013-04-07T22:00:11+0000
us-east-1c aki-88aa75e1 monitoring-disabled 54.235.26.33
10.117.33.240 ebs paravirtual xen sg-aae1d4c2 default
BLOCKDEVICE /dev/sda1 vol-aef3f0e8 2013-04-07T22:00:15.000Z
RESERVATION r-ae0571d3 709488244382 default
INSTANCE i-a4dbfdc8 ami-1ebb2077 ec2-23-20-150-126
.compute-1.amazonaws.com ip-10-112-53-44.ec2.internal
running default 0 t1.micro 2013-04-07T22:01:21+0000
us-east-1c aki-88aa75e1 monitoring-disabled 23.20.150.126
10.112.53.44 ebs paravirtual xen sg-aae1d4c2 default
BLOCKDEVICE /dev/sda1 vol-cff1f289 2013-04-07T22:01:26.000Z
There is a lot of information in this output, because by default, it lists information about all instances. I can specify a particular instance ID, though, to see information about only the instance I just created:
$ ec2din i-788bed14
RESERVATION r-f0186c8d 709488244382 default
INSTANCE i-788bed14 ami-1ebb2077 ec2-50-19-174-100
.compute-1.amazonaws.com ip-10-245-29-169.ec2.internal
running default 0 t1.micro 2013-04-07T21:56:20+0000
us-east-1c aki-88aa75e1 monitoring-disabled 50.19.174.100
10.245.29.169 ebs paravirtual xen sg-aae1d4c2 default
BLOCKDEVICE /dev/sda1 vol-2ae8eb6c 2013-04-07T21:56:24.000Z
The output is different from when I launched the instance because there’s now more information to report. For instance, the state of the instance has changed from pending to running. Also, I can now see both the external and internal IPs for the instance (50.19.174.100 and 10.245.29.169 respectively). The external IP is potentially accessible from the outside world, depending on what security groups the instance is a part of and what firewall rules those groups have in place.
Since your EC2 instances share physical hardware and network resources with other AWS customers, your instances could potentially be exposed to other customers were it not for security groups. Security groups allow you to define a set of firewall rules to control what ports and protocols are accessible for members of that group. By default you have only one security group, called “default,” and it is configured to allow members of that group to access TCP, UDP, and ICMP packets only from other members of the group. You can see security group settings with the ec2-describe-group command:
$ ec2-describe-group
GROUP sg-aae1d4c2 709488244382 default default group
PERMISSION 709488244382 default ALLOWS icmp -1 -1
FROM USER 709488244382 NAME default ID sg-aae1d4c2 ingress
PERMISSION 709488244382 default ALLOWS tcp 0 65535
FROM USER 709488244382 NAME default ID sg-aae1d4c2 ingress
PERMISSION 709488244382 default ALLOWS udp 0 65535
FROM USER 709488244382 NAME default ID sg-aae1d4c2 ingress
What these security group settings mean is that even though I have an ssh key ready on my instance and ssh is running, by default I wouldn’t be allowed to ssh into the instance from the outside. If I do want to ssh to my instance, I need to add a rule to this security group using the ec2-authorize command:
$ ec2-authorize default -P tcp -p 22
GROUP default
PERMISSION default ALLOWS tcp 22 22
FROM CIDR 0.0.0.0/0 ingress
This is a very permissive command in that it allows any external IP access to TCP port 22. If I wanted to be more restrictive, I could use the -s argument to specify a particular IP subnet to allow access. For instance, if I wanted to allow everyone on the 205.192.8.x subnet to access ssh I could type
$ ec2-authorize default -P tcp -p 22 -s 205.192.8.1/24
Then I could use the ec2-revoke command to get rid of my more permissive rule:
$ ec2-revoke default -P tcp -p 22
In either case, the downside to this rule is that it applies to every member of the default security group. If I wanted a custom firewall rule that applied to only one instance, I would have to create the group ahead of time; then when I create the instance, I would need to remember to add that group to the instance. Unfortunately, you cannot add an instance to a group after it has been created, so you’ll want to think about any firewall rules you want to add to a host before you create it.
Here’s how you might create a special security group just for ssh access and then create a new instance that is a member of it:
$ ec2-create-group ssh -d "SSH Access"
GROUP sg-621dea09 ssh SSH Access
$ ec2-authorize ssh -P tcp -p 22
GROUP ssh
PERMISSION ssh ALLOWS tcp 22 22
FROM CIDR 0.0.0.0/0 ingress
$ ec2run ami-1ebb2077 -k default -t t1.micro -g default -g ssh
RESERVATION r-4655213b 709488244382 default,ssh
INSTANCE i-7a0d4b1f ami-1ebb2077 pending
default 0 t1.micro 2013-04-07T22:40:14+0000 us-east-1c
aki-88aa75e1 monitoring-disabled ebs paravirtual
xen sg-aae1d4c2, sg-621dea09 default
Note that on the line that starts with RESERVATION, my security groups are set as default,ssh.
$ ec2din i-7a0d4b1f
RESERVATION r-4655213b 709488244382 default,ssh
INSTANCE i-7a0d4b1f ami-1ebb2077 ec2-67-202-50-22
.compute-1.amazonaws.com ip-10-243-115-104.ec2.internal
running default 0 t1.micro 2013-04-07T22:40:14+0000
us-east-1c aki-88aa75e1 monitoring-disabled 67.202.50.22
10.243.115.104 ebs paravirtual xen sg-aae1d4c2,
sg-621dea09 default
BLOCKDEVICE /dev/sda1 vol-5ab1b21c 2013-04-07T22:40:16.000Z
In this case the external IP is 67.202.50.22, so I can ssh as normal, except that I must use the -i argument to point to the ssh key I generated previously:
$ ssh -i ~/.ssh/ec2-default.pem ubuntu@67.202.50.22
The authenticity of host '67.202.50.22 (67.202.50.22)' can't be
established.
ECDSA key fingerprint is
be:d3:8f:10:91:22:1c:32:8e:b5:c2:c3:bd:59:3c:6b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '67.202.50.22' (ECDSA) to the list of
known hosts.
Welcome to Ubuntu 12.04.2 LTS (GNU/Linux 3.2.0-39-virtual x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Mon Apr 8 00:45:27 UTC 2013
System load: 0.0 Processes: 57
Usage of /: 10.9% of 7.87GB Users logged in: 0
Memory usage: 6%
IP address for eth0: 10.243.115.104
Swap usage: 0%
Graph this data and manage this system at
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Use Juju to deploy your cloud instances and workloads:
https://juju.ubuntu.com/#cloud-precise
0 packages can be updated.
0 updates are security updates.
The programs included with the Ubuntu system are free
software; the exact distribution terms for each program are
described in the individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
To run a command as administrator (user "root"), use
"sudo <command>".
See "man sudo_root" for details.
ubuntu@ip-10-243-115-104:~$
There are a few things to note about the default Canonical Ubuntu AMI. First, the default user is set to ubuntu, and that user can sudo to root without a password being set. Second, the hostname is set to ip, followed by its internal IP address separated by dashes (in this case, ip-10.243-115-104). The host itself knows only about its internal IP address, so you must access the API (such as with ec2din) to find out the external IP address. Finally, unless you are using Amazon’s VPC service, all instances get their IP addresses dynamically from DHCP, so you can’t necessarily assume your IP will always remain the same if the instance stops and starts again. Now that the machine is up, from this point I could add other users or add my own ssh public key to the ubuntu user’s ~/.ssh/authorized_keys file to make my ssh command a bit simpler.
Apart from those differences, for the most part this machine will act much like any other virtual machine running Ubuntu. I can follow the steps in Chapter 5 to install and configure various services on this instance. Just as with other VMs; the only difference is that if I want any ports exposed to the outside, I must make changes to the appropriate security group.
Of course, instances cost money, so there comes a point when you are finished with an instance and want to shut it down. Now if you just want to stop the instance so it isn’t costing you money, but you want the ability to start it later (and it was an ebs instance type), you could just type:
$ ec2stop i-7a0d4b1f
INSTANCE i-7a0d4b1f running stopping
To start the instance back up, you would use ec2start:
$ ec2start i-7a0d4b1f
INSTANCE i-7a0d4b1f stopped pending
If you want to completely terminate the instance so that it is no longer available at all, you would type
$ ec2kill i-7a0d4b1f
INSTANCE i-7a0d4b1f running shutting-down
Note that since stopping an instance that is backed by instance-store instead of EBS will also terminate it, you can run either ec2kill or ec2stop for those instances. In either case, it may take up to an hour after you have killed an instance for it to be removed from the output of ec2din:
$ ec2din i-7a0d4b1f
RESERVATION r-4655213b 709488244382 default,ssh
INSTANCE i-7a0d4b1f ami-1ebb2077 terminated default 0
t1.micro 2013-04-08T00:56:27+0000 us-east-1c aki-88aa75e1
monitoring-disabled ebs paravirtual xen
sg-aae1d4c2, sg-621dea09 default
Note that the instance state has changed from running to terminated.
When you spawn many instances in the cloud, you may not want to have to log in to each of them and manually set them up. Instead you will probably want to set up some sort of post-install script that is run when the instance first starts. This sort of script may install some packages and configure the server completely, or it may just install a configuration management tool such as Puppet or Chef. In any case, the ec2run script allows you to specify a file that gets copied to the remote server and run as root when the server starts up.
To demonstrate how this works, suppose I want to use my instance as a cheap remote shell server for IRC and other basic tasks. I create a simple bash script that installs the screen and irssi packages and touches a file named /home/ubuntu/script_has_run just to indicate the script did the work. First I create the script named userdata in my local home directory:
#!/bin/bash
apt-get update
apt-get -y install screen irssi
touch /home/ubuntu/script_has_run
Now I use ec2run to launch the instance and point it to this script:
$ ec2run ami-1ebb2077 -k default -t t1.micro -g default -g ssh
-f userdata
RESERVATION r-9e1265e3 709488244382 default,ssh
INSTANCE i-d1a0b7b1 ami-1ebb2077 pending default 0
t1.micro 2013-04-08T01:10:49+0000 us-east-1c aki-88aa75e1
monitoring-disabled ebs paravirtual xen
sg-aae1d4c2, sg-621dea09 default
Once I give the instance a minute or two to start up, I can ssh in and see whether my script ran:
$ ssh -i ~/.ssh/ec2-default.pem ubuntu@23.22.89.82
. . .
ubuntu@ip-10-202-163-26:~$ ls
script_has_run
ubuntu@ip-10-202-163-26:~$ dpkg
--get-selections | egrep "irssi|screen"
irssi install
screen install
You can customize the userdata script to put just about any post-install script you might think up. My only recommendation is to try to avoid storing any secret information such as passwords or private keys in the userdata script because even though the script is executed by root, the contents of the script are accessible by any regular user on this server with an API call for the life of the machine.
Creating new EC2 instances from the command line isn’t too difficult, but as you get going you might find your post-install userdata scripts keep getting more and more involved. If you are looking for even better levels of server automation on EC2, you might be interested in new software from Canonical called Juju.
The idea behind Juju is that when an administrator sets up services in the cloud, the individual servers are often less important than the service itself. For instance, an administrator may say, “I want WordPress backed by a MySQL database,” or “I want a Jenkins server,” but in the cloud you may not necessarily care which particular m1.large instance hosts WordPress as long as it has the resources it needs. With Juju you just specify what services you want to exist in the cloud and how the services are related to each other, and Juju pulls down pre-existing scripts written by people in the Juju community to install and configure those services according to best practices.
It’s a bit easier to understand what Juju does when you see it operate, so let’s get it installed and configured. While Juju does have a package in Ubuntu 12.04, Juju is a relatively new and fast-moving project, so the official recommendation is to install Juju from its PPA. To do so, install the python-software-properties package to pull in the add-apt-repository command, then use that program to add the appropriate repository, then update the list of available packages, and finally install the juju package itself:
$ sudo apt-get install python-software-properties
$ sudo add-apt-repository ppa:juju/pkgs
You are about to add the following PPA to your system:
More info: https://launchpad.net/~juju/+archive/pkgs
Press [ENTER] to continue or ctrl-c to cancel adding it
gpg: keyring `/tmp/tmpbTfwwc/secring.gpg' created
gpg: keyring `/tmp/tmpbTfwwc/pubring.gpg' created
gpg: requesting key C8068B11 from hkp server keyserver.ubuntu.com
gpg: /tmp/tmpbTfwwc/trustdb.gpg: trustdb created
gpg: key C8068B11: public key "Launchpad Ensemble PPA" imported
gpg: Total number processed: 1
gpg: imported: 1 (RSA: 1)
OK
$ sudo apt-get update
$ sudo apt-get install juju
The account you run Juju commands from will need an ssh key pair to communicate with the remote Juju management server in the cloud, so if you haven’t already generated an ssh key pair, do so now:
$ ssh-keygen -t rsa -b 2048
Now that you have an ssh key pair, run juju bootstrap. The command will error out because there is no configured environment for it to bootstrap, but as a result it will dump out a sample ~/.juju/environments.yaml file you can use to start your configuration:
$ juju bootstrap
error: No environments configured. Please edit:
/home/krankin/.juju/environments.yaml
$ cat ~/.juju/environments.yaml
environments:
sample:
type: ec2
control-bucket: juju-e1d1c9fa72f0402487aba4c4e9692fe2
admin-secret: 2b1ecbb8775e42a29b24f2da9efebfb3
default-series: precise
ssl-hostname-verification: true
This default ~/.juju/environments.yaml file won’t have all of the configuration you need to properly bootstrap a Juju environment. Visit your Amazon AWS My Account page, click on the Security Credentials link on the left-hand side of the page, and then scroll down until you can see the Access Credentials section with the Access Keys tab selected as in Figure 9-7. If you don’t have an access key pair created yet, create one now. The Access Key ID and Secret Access Key can be thought of like a username and password you can use to access AWS APIs, so in particular treat the Secret Access Key as a true secret (don’t worry, I deleted this key pair after I used it for this demo).
Now that you have an access key pair, you can add them to you environments.yaml file with the access-key and secret-key configuration variables. The resulting sample ~/.juju/environments.yaml file ends up looking like this:
environments:
sample:
type: ec2
control-bucket: juju-e1d1c9fa72f0402487aba4c4e9692fe2
admin-secret: 2b1ecbb8775e42a29b24f2da9efebfb3
default-series: precise
ssl-hostname-verification: true
access-key: AKIAIZEHLG2HMSF5YDFA
secret-key: QXsX05loL8CVivDR11ordAWj8lUjz9ZHGE86TYSF
Now that your configuration file is ready, you can type juju bootstrap to use this config. The juju bootstrap command actually launches a new server in your EC2 cloud environment and configures it to orchestrate any further juju commands you might run. It also keeps track of what servers you are managing with Juju and how they are related to each other.
$ juju bootstrap
2013-04-07 11:30:30,289 INFO Bootstrapping environment 'sample'
(origin: distro type: ec2)...
2013-04-07 11:30:36,704 INFO 'bootstrap' command finished
successfully
The juju bootstrap command finishes quickly, but it may take a few minutes for the server to complete its configuration. You can keep track of Juju’s progress when spawning services with the juju status command:
$ juju status
2013-04-07 11:33:13,616 INFO Connecting to environment...
2013-04-07 11:34:49,259 INFO Connected to environment.
machines:
0:
agent-state: running
dns-name: ec2-23-20-194-49.compute-1.amazonaws.com
instance-id: i-31566851
instance-state: running
services: {}
2013-04-07 11:34:50,287 INFO 'status' command finished
successfully
In this example, you can see that a single Juju machine is running. If the command takes a long time to complete when you first run it, it’s probably because the Juju server itself isn’t finished with its configuration.
Once the bootstrap process has completed, you are ready to spawn a new service. Let’s say you want to spawn a WordPress blog that’s backed by a MySQL server. Traditionally, you might do this by spawning a few servers in the cloud, and then sshing into the machines to install and configure the various packages. In fact, the “WordPress, a Sample LAMP Environment” section in Chapter 5 is dedicated to documenting that procedure. In Juju it’s a bit simpler:
$ juju deploy wordpress
2013-04-07 11:35:44,569 INFO Searching for charm
cs:precise/wordpress in charm store
2013-04-07 11:35:53,892 INFO Connecting to environment...
2013-04-07 11:35:58,221 INFO Connected to environment.
2013-04-07 11:36:03,906 INFO Charm deployed as service:
'wordpress'
2013-04-07 11:36:03,914 INFO 'deploy' command finished
successfully
$ juju deploy mysql
2013-04-07 11:36:23,446 INFO Searching for charm
cs:precise/mysql in charm store
2013-04-07 11:36:25,862 INFO Connecting to environment...
2013-04-07 11:36:28,929 INFO Connected to environment.
2013-04-07 11:36:33,188 INFO Charm deployed as service:
'mysql'
2013-04-07 11:36:33,191 INFO 'deploy' command finished
successfully
$ juju add-relation wordpress mysql
2013-04-07 11:36:40,264 INFO Connecting to environment...
2013-04-07 11:36:43,302 INFO Connected to environment.
2013-04-07 11:36:44,581 INFO Added mysql relation to all
service units.
2013-04-07 11:36:44,583 INFO 'add_relation' command finished
successfully
So what’s happening here? The juju deploy commands each spawn an individual server on EC2 of the type you specify. When you tell it to deploy WordPress, it creates a server labeled wordpress, and then looks for a Juju charm for the WordPress service. A charm is essentially a set of scripts that automatically install and configure a service according to agreed-upon best practices. The juju deploy mysql command that performs the same steps, only this time it pulls down the MySQL charm instead. Now if you ran only those first two commands, you would have a standalone WordPress server with no database and a standalone MySQL database hosting no data. What ties the two together is the final command, juju add-relation wordpress mysql. That command tells Juju that the wordpress and mysql servers previously deployed are related, and Juju is intelligent enough to know that the way these two services relate to each other is that the server labeled mysql should be configured to host the database for the WordPress front-end. Juju will then configure those two services so WordPress knows how to use the MySQL server, and the MySQL server has a WordPress database added to it.
If you run a juju status command while these servers are spinning up, you get a status that shows things aren’t yet ready:
$ juju status
2013-04-07 11:36:47,492 INFO Connecting to environment...
2013-04-07 11:36:50,636 INFO Connected to environment.
machines:
0:
agent-state: running
dns-name: ec2-23-20-194-49.compute-1.amazonaws.com
instance-id: i-31566851
instance-state: running
1:
agent-state: not-started
dns-name: ec2-50-17-54-6.compute-1.amazonaws.com
instance-id: i-9643dff8
instance-state: running
2:
agent-state: not-started
dns-name: ec2-54-234-234-68.compute-1.amazonaws.com
instance-id: i-af5668cf
instance-state: pending
services:
mysql:
charm: cs:precise/mysql-16
relations:
db:
- wordpress
units:
mysql/0:
agent-state: pending
machine: 2
public-address: null
wordpress:
charm: cs:precise/wordpress-11
relations:
db:
- mysql
loadbalancer:
- wordpress
units:
wordpress/0:
agent-state: pending
machine: 1
public-address: null
2013-04-07 11:36:56,082 INFO 'status' command finished
successfully
At this point, you wait until the output of a status command shows the WordPress service as started instead of pending:
$ juju status
2013-04-07 11:47:54,880 INFO Connecting to environment...
2013-04-07 11:47:58,123 INFO Connected to environment.
machines:
0:
agent-state: running
dns-name: ec2-23-20-194-49.compute-1.amazonaws.com
instance-id: i-31566851
instance-state: running
1:
agent-state: running
dns-name: ec2-50-17-54-6.compute-1.amazonaws.com
instance-id: i-9643dff8
instance-state: running
2:
agent-state: running
dns-name: ec2-54-234-234-68.compute-1.amazonaws.com
instance-id: i-af5668cf
instance-state: running
services:
mysql:
charm: cs:precise/mysql-16
relations:
db:
- wordpress
units:
mysql/0:
agent-state: started
machine: 2
public-address: ec2-54-234-234-68.compute-1.amazonaws.com
wordpress:
charm: cs:precise/wordpress-11
exposed: false
relations:
db:
- mysql
loadbalancer:
- wordpress
units:
wordpress/0:
agent-state: started
machine: 1
public-address: ec2-50-17-54-6.compute-1.amazonaws.com
2013-04-07 11:48:02,952 INFO 'status' command finished
successfully
Once the services are ready, you run one final command so that the instance is available from the outside:
$ juju expose wordpress
2013-04-07 11:56:38,080 INFO Connecting to environment...
2013-04-07 11:56:41,587 INFO Connected to environment.
2013-04-07 11:56:41,885 INFO Service 'wordpress' was exposed.
2013-04-07 11:56:41,895 INFO 'expose' command finished
successfully
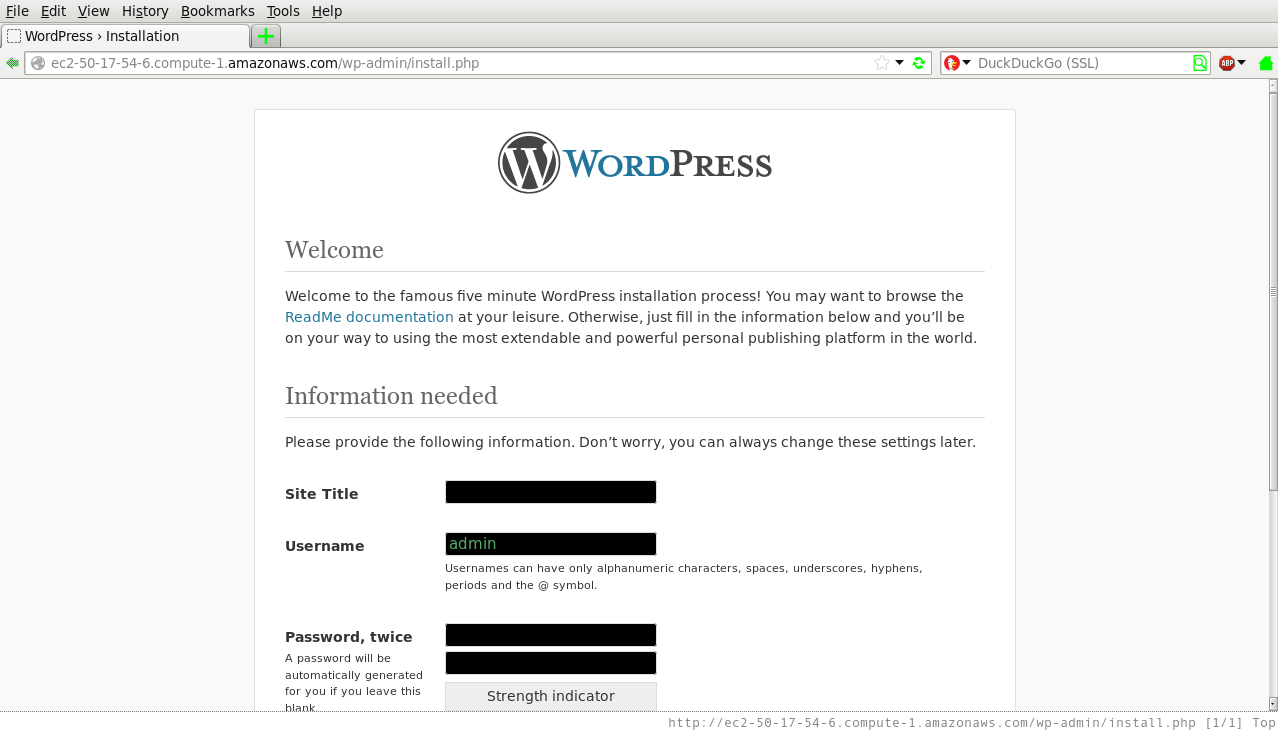
The expose command modifies security groups set in place for this service so that you can access the appropriate ports from the outside. Once the command is run, you can put the public address of the WordPress service from a juju status output (ec2-50-17-54-6.compute-1.amazonaws.com) into a browser and see the standard WordPress configuration screen, as in Figure 9-8.
If you aren’t yet ready to expose this WordPress instance to the outside world, you can undo the preceding command with juju unexpose:
$ juju unexpose wordpress
2013-04-07 12:05:59,025 INFO Connecting to environment...
2013-04-07 12:06:02,668 INFO Connected to environment.
2013-04-07 12:06:02,988 INFO Service 'wordpress' was unexposed.
2013-04-07 12:06:02,993 INFO 'unexpose' command finished
successfully
While all of these commands are certainly useful, part of what makes Juju useful in the cloud is how simple it makes it to scale your service. Let’s say your wordpress instance is now taking a fair amount of traffic, and you decide to add an extra instance of it for fault tolerance. To do so, just type juju add-unit wordpress, and it spawns an extra instance of wordpress for that service. What’s more, since it already knows about the relation between wordpress and mysql services, it automatically configures this new wordpress service to use that mysql service.
Once you are done with a particular service, it is relatively simple to destroy with Juju:
$ juju destroy-service mysql
2013-04-07 12:06:18,080 INFO Connecting to environment...
2013-04-07 12:06:22,109 INFO Connected to environment.
2013-04-07 12:06:25,136 INFO Service 'mysql' destroyed.
2013-04-07 12:06:25,139 INFO 'destroy_service' command finished
successfully
If instead you want to remove the entire Juju environment, including all of the services it’s managing, you use the juju destroy-environment command:
$ juju destroy-environment
WARNING: this command will destroy the 'sample' environment
(type: ec2). This includes all machines, services, data, and
other resources. Continue [y/N] y
2013-04-07 12:06:52,476 INFO Destroying environment 'sample'
(type: ec2)...
2013-04-07 12:06:56,200 INFO 'destroy_environment' command
finished successfully
While these examples show you how to get started, there are a lot more charms available for Juju, and more are being developed all of the time. On top of that, it’s relatively simple to create your own custom Juju charms if you need a service that isn’t already represented. For more information on advanced Juju use, charms, and other Juju resources, visit https://juju.ubuntu.com.