us: user CPU time
us: user CPU timeTroubleshooting is a topic that is near and dear to me. While there are many other areas of system administration that I enjoy, I don’t think anything compares to the excitement of tracking down the root cause of an obscure problem. Good troubleshooting is a combination of Sherlock Holmes–style detective work, intuition, and a little luck. You might even argue that some people have a knack for troubleshooting while others struggle with it, but in my mind it’s something that all sysadmins get better at the more problems they run into.
While this chapter discusses troubleshooting, there are a number of common problems that can cause your Ubuntu system to not boot or to run in an incomplete state. I have moved all of these topics into their own chapter on rescue and recovery and have provided specific steps to fix common problems with the Ubuntu rescue CD. So if you are trying to solve a problem at the moment, check Chapter 12, Rescue and Recovery, first to see if I have already outlined a solution. If not, come back here to get the more general steps to isolate the cause of your problem and work out its solution.
In this chapter I discuss some aspects of my general philosophy on troubleshooting that could be applied to a wide range of problems. Then I cover a few common problems that you might run into and introduce some tools and techniques to help solve them. By the end of the chapter you should have a head start the next time a problem turns up. After all, in many organizations downtime is measured in dollars, not minutes, so there is a lot to be said for someone who can find a root cause quickly.
While there are specific steps you can take to address certain computer problems, most troubleshooting techniques rely on the same set of rules. Here I discuss some of these rules that will help make you a better troubleshooter.
When I’m faced with an unknown issue, I apply the same techniques as when I have to pick a number between 1 and 100. If you have ever played this game, you know that most people fall into one of two categories: the random guessers and the narrowers. The random guessers might start by choosing 15, then hear that the number is higher and pick 23, then hear it is still higher. Eventually they might either luck into the right number or pick so many numbers that only the right number remains. In either case they use far more guesses than they need to. Many people approach troubleshooting the same way: They choose solutions randomly until one happens to work. Such a person might eventually find the problem, but it takes way longer than it should.
In contrast to the random guessers, the narrowers strategically choose numbers that narrow the problem in half each time. Let’s say the number is 80, for instance; their guesses would go as follows: 50, 75, 88, 82, 78, 80. With each guess, the list of numbers that could contain the answer is reduced by half. When people like this troubleshoot a computer problem, their time is spent finding ways to divide the problem space in half as much as possible. As I go through specific problems in this chapter, you will see this methodology in practice.
What I mean here is that as you narrow down the possible causes of a problem, you will often end up with a few hypotheses that are equally likely. One hypothesis can be tested quickly but the other takes some time. For instance, if a machine can’t seem to communicate with the network, a quick test could be to see if the network cable is plugged in, while a longer test would involve more elaborate software tests on the host. If the quick test isolates the problem, you get the solution that much faster. If you still need to try the longer test, you aren’t out that much extra time.
Unless you absolutely prevent a problem from ever happening again, it’s likely that when a symptom that you’ve seen before pops up, it could have the same solution. Over the years you’ll find that you develop a common list of things you try first when you see a particular problem to rule out all of the common causes before you move on to more exotic hypotheses. Of course, you will have problems you’ve never seen before, too—that’s part of the fun of troubleshooting—but when you test some of your past solutions first, you will find you solve problems faster.
If you are part of a team that is troubleshooting a problem, you absolutely must have good communication among team members. That could be as simple as yelling across cubicle walls, or it could mean setting up a chat room. A common problem when a team works an issue is multiple members testing the same hypothesis. With good communication each person can tackle a different hypothesis and report the results. These results can then lead to new hypotheses that can be divided among the team members. One final note: Favor communication methods that allow multiple people to communicate at the same time. This means that often chat rooms work much better than phones for problem solving, since over the phone everyone has to wait for a turn to speak; in a chat room multiple people can communicate at once.
The more deeply you understand how a system works, the faster you can rule out causes of problems. Over the years I’ve noticed that when a problem occurs, people first tend to blame the technology they understand the least. At one point in my career, every time a network problem occurred, everyone immediately blamed DNS, even when it appeared obvious (at least to me) that not only was DNS functioning correctly, it never had actually been the cause of any of the problems. One day we decided to hold a lecture to explain how DNS worked and traced an ordinary DNS request from the client to every DNS server and back. Afterward everyone who attended the class stopped jumping to DNS as the first cause of network problems. There are core technologies with which every sysadmin deals on a daily basis, such as TCP/IP networking, DNS, Linux processes, programming, and memory management; it is crucial that you learn about these in as much depth as possible if you want to find a solution to a problem quickly.
Many organizations have as part of their standard practice a postmortem meeting after every production issue. A postmortem allows the team to document the troubleshooting steps they took to arrive at a root cause as well as what solution ultimately fixed the issue. Not only does this help make sure that there is no disagreement about what the root cause is, but when everyone is introduced to each troubleshooting step, it helps make all the team members better problem solvers going forward. When you document your problem-solving steps, you have a great guide you can go to the next time a similar problem crops up so it can be solved that much faster.
The Internet is an incredibly valuable resource when you troubleshoot a problem, especially if you are able to articulate it in search terms. After all, you are rarely the only person to face a particular problem, and in many cases other people have already come up with the solution. Be careful with your Internet research, though. Often your results are only as good as your understanding of the problem. I’ve seen many people go off on completely wrong paths to solve a problem because of a potential solution they found on the Internet. After all, a search for “Ubuntu server not on network” will turn up all sorts of completely different problems irrelevant to your issue.
OK, so those of us who have experience with Windows administration have learned over the years that when you have a weird problem, a reboot often fixes it. Resist this “technique” on your Ubuntu servers! I’ve had servers with uptimes measured in years because most problems found on a Linux machine can be solved without a reboot. The problem with rebooting a machine (besides ruining your uptime) is that if the problem does go away, you may never know what actually caused it. That means you can’t solve it for good and will ultimately see the problem again. As attractive as rebooting might be, keep it as your last resort.
While I would say that a majority of problems you will find on a server have some basis in networking, there is still a class of issues that involves only the localhost. What makes this tricky is that some local and networking problems often create the same set of symptoms, and in fact local problems can create network problems and vice versa. In this section I will cover problems that occur specifically on a host and leave issues that impact the network to the next section.
Probably one of the most common problems you will find on a host is that it is sluggish or completely unresponsive. Often this can be caused by network issues, but here I will discuss some local troubleshooting tools you can use to tell the difference between a loaded network and a loaded machine.
When a machine is sluggish, it is often because you have consumed all of a particular resource on the system. The main resources are CPU, RAM, disk I/O, and network (which I will leave to the next section). Overuse of any of these resources can cause a system to bog down to the point that often the only recourse is your last resort—a reboot. If you can log in to the system, however, there are a number of tools you can use to identify the cause.
System load average is probably the fundamental metric you start from when troubleshooting a sluggish system. One of the first commands I run when I’m troubleshooting a slow system is uptime:
$ uptime
13:35:03 up 103 days, 8 min, 5 users, load average: 2.03, 20.17, 15.09
The three numbers after the load average, 2.03, 20.17, and 15.09, represent the 1-, 5-, and 15-minute load averages on the machine, respectively. A system load average is equal to the average number of processes in a runnable or uninterruptible state. Runnable processes are either currently using the CPU or waiting to do so, and uninterruptible processes are waiting for I/O. A single-CPU system with a load average of 1 means the single CPU is under constant load. If that single-CPU system has a load average of 4, there is 4 times the load on the system that it can handle, so three out of four processes are waiting for resources. The load average reported on a system is not tweaked based on the number of CPUs you have, so if you have a two-CPU system with a load average of 1, one of your two CPUs is loaded at all times—i.e., you are 50% loaded. So a load of 1 on a single-CPU system is the same as a load of 4 on a four-CPU system in terms of the amount of available resources used.
The 1-, 5-, and 15-minute load averages describe the average amount of load over that respective period of time and are valuable when you try to determine the current state of a system. The 1-minute load average will give you a good sense of what is currently happening on a system, so in my previous example you can see that I most recently had a load of 2 over the last minute, but the load had spiked over the last 5 minutes to an average of 20. Over the last 15 minutes the load was an average of 15. This tells me that the machine had been under high load for at least 15 minutes and the load appeared to increase around 5 minutes ago, but it appears to have subsided. Let’s compare this with a completely different load average:
$ uptime
05:11:52 up 20 days, 55 min, 2 users, load average: 17.29, 0.12, 0.01
In this case both the 5- and 15-minute load averages are low, but the 1-minute load average is high, so I know that this spike in load is relatively recent. Often in this circumstance I will run uptime multiple times in a row (or use a tool like top, which I will discuss in a moment) to see whether the load is continuing to climb or is on its way back down.
A fair question to ask is what load average do you consider to be high. The short answer is “It depends on what is causing it.” Since the load describes the average number of active processes that are using resources, a spike in load could mean a few things. What is important to determine is whether the load is CPU-bound (processes waiting on CPU resources), RAM-bound (specifically, high RAM usage that has moved into swap), or I/O-bound (processes fighting for disk or network I/O).
For instance, if you run an application that generates a high number of simultaneous threads at different points, and all of those threads are launched at once, you might see your load spike to 20, 40, or higher as they all compete for system resources. As they complete, the load might come right back down. In my experience systems seem to be more responsive when under CPU-bound load than when under I/O-bound load. I’ve seen systems with loads in the hundreds that were CPU-bound, and I could run diagnostic tools on those systems with pretty good response times. On the other hand, I’ve seen systems with relatively low I/O-bound loads on which just logging in took a minute, since the disk I/O was completely saturated. A system that runs out of RAM resources often appears to have I/O-bound load, since once the system starts using swap storage on the disk, it can consume disk resources and cause a downward spiral as processes slow to a halt.
One of the first tools I turn to when I need to diagnose high load is top. I discussed the basics of how to use the top command in Chapter 2, so here I focus more on how to use its output to diagnose load. The basic steps are to examine the top output to identify what resources you are running out of (CPU, RAM, disk I/O). Once you have figured that out, you can try to identify what processes are consuming those resources the most. First let’s examine some standard top output from a system:
top - 14:08:25 up 38 days, 8:02, 1 user, load average: 1.70, 1.77, 1.68
Tasks: 107 total, 3 running, 104 sleeping, 0 stopped, 0 zombie
Cpu(s): 11.4%us, 29.6%sy, 0.0%ni, 58.3%id, .7%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1024176k total, 997408k used, 26768k free, 85520k buffers
Swap: 1004052k total, 4360k used, 999692k free, 286040k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9463 mysql 16 0 686m 111m 3328 S 53 5.5 569:17.64 mysqld
18749 nagios 16 0 140m 134m 1868 S 12 6.6 1345:01 nagios2db_status
24636 nagios 17 0 34660 10m 712 S 8 0.5 1195:15 nagios
22442 nagios 24 0 6048 2024 1452 S 8 0.1 0:00.04 check_time.pl
The first line of output is the same as you would see from the uptime command. As you can see in this case, the machine isn’t too heavily loaded for a four-CPU machine:
top - 14:08:25 up 38 days, 8:02, 1 user, load average: 1.70, 1.77, 1.68
top provides you with extra metrics beyond standard system load, though. For instance, the Cpu(s) line gives you information about what the CPUs are currently doing:
Cpu(s): 11.4%us, 29.6%sy, 0.0%ni, 58.3%id, 0.7%wa, 0.0%hi, 0.0%si, 0.0%st
These abbreviations may not mean much if you don’t know what they stand for, so I break down each of them next.
us: user CPU time
This is the percentage of CPU time spent running users’ processes that aren’t niced (nicing a process allows you to change its priority in relation to other processes).
sy: system CPU time
This is the percentage of CPU time spent running the kernel and kernel processes.
ni: nice CPU time
If you have user processes that have been niced, this metric will tell you the percentage of CPU time spent running them.
id: CPU idle time
This is one of the metrics that you want to be high. It represents the percentage of CPU time that is spent idle. If you have a sluggish system but this number is high, you know the cause isn’t high CPU load.
wa: I/O wait
This number represents the percentage of CPU time that is spent waiting for I/O. It is a particularly valuable metric when you are tracking down the cause of a sluggish system, because if this value is low, you can pretty safely rule out disk or network I/O as the cause.
hi: hardware interrupts
This is the percentage of CPU time spent servicing hardware interrupts.
si: software interrupts
This is the percentage of CPU time spent servicing software interrupts.
st: steal time
If you are running virtual machines, this metric will tell you the percentage of CPU time that was stolen from you for other tasks.
In my previous example, you can see that the system is over 50% idle, which matches a load of 1.70 on a four-CPU system. When I diagnose a slow system, one of the first values I look at is I/O wait so I can rule out disk I/O. If I/O wait is low, then I can look at the idle percentage. If I/O wait is high, then the next step is to diagnose what is causing high disk I/O, which I cover shortly. If I/O wait and idle times are low, then you will likely see a high user time percentage, so you must diagnose what is causing high user time. If the I/O wait is low and the idle percentage is high, you then know any sluggishness is not because of CPU resources and will have to start troubleshooting elsewhere. This might mean looking for network problems, or in the case of a Web server looking at slow queries to MySQL, for instance.
A common and relatively simple problem to diagnose is high load due to a high percentage of user CPU time. This is common since the services on your server are likely to take the bulk of the system load and they are user processes. If you see high user CPU time but low I/O wait times, you simply need to identify which processes on the system are consuming the most CPU. By default, top will sort all of the processes by their CPU usage:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9463 mysql 16 0 686m 111m 3328 S 53 5.5 569:17.64 mysqld
18749 nagios 1 0 140m 134m 1868 S 12 6.6 1345:01 nagios2db_status
24636 nagios 17 0 34660 10m 712 S 8 0.5 1195:15 nagios
22442 nagios 24 0 6048 2024 1452 S 8 0.1 0:00.04 check_time.pl
In this example the mysqld process is consuming 53% of the CPU and the nagios2db_status process is consuming 12%. Note that this is the percentage of a single CPU, so if you have a four-CPU machine you could possibly see more than one process consuming 99% CPU.
The most common high-CPU-load situations you will see are all of the CPUs being consumed either by one or two processes or by a large number of processes. Either case is easy to identify since in the first case the top process or two will have a very high percentage of CPU and the rest will be relatively low. In that case, to solve the issue you could simply kill the process that is using the CPU (hit K and then type in the PID number for the process).
In the case of multiple processes, you might simply have a case of one system doing too many things. You might, for instance, have a large number of Apache processes running on a Web server along with some log parsing scripts that run from cron. All of these processes might be consuming more or less the same amount of CPU. The solution to problems like this can be trickier for the long term, as in the Web server example you do need all of those Apache processes to run, yet you might need the log parsing programs as well. In the short term you can kill (or possibly postpone) some processes until the load comes down, but in the long term you might need to consider increasing the resources on the machine or splitting some of the functions across more than one server.
The next two lines in the top output provide valuable information about RAM usage. Before diagnosing specific system problems, it’s important to be able to rule out memory issues.
Mem: 1024176k total, 997408k used, 26768k free, 85520k buffers
Swap: 1004052k total, 4360k used, 999692k free, 286040k cached
The first line tells me how much physical RAM is available, used, free, and buffered. The second line gives me similar information about swap usage, along with how much RAM is used by the Linux file cache. At first glance it might look as if the system is almost out of RAM since the system reports that only 26,768k is free. A number of beginner sysadmins are misled by the used and free lines in the output because of the Linux file cache. Once Linux loads a file into RAM, it doesn’t necessarily remove it from RAM when a program is done with it. If there is RAM available, Linux will cache the file in RAM so that if a program accesses the file again, it can do so much more quickly. If the system does need RAM for active processes, it won’t cache as many files.
To find out how much RAM is really being used by processes, you must subtract the file cache from the used RAM. In the preceding example, out of the 997,408k RAM that is used, 286,040k is being used by the Linux file cache, so that means that only 711,368k is actually being used.
In my example the system still has plenty of available memory and is barely using any swap at all. Even if you do see some swap being used, it is not necessarily an indicator of a problem. If a process becomes idle, Linux will often page its memory to swap to free up RAM for other processes. A good way to tell whether you are running out of RAM is to look at the file cache. If your actual used memory minus the file cache is high, and the swap usage is also high, you probably do have a memory problem.
If you do find you have a memory problem, the next step is to identify which processes are consuming RAM. top sorts processes by their CPU usage by default, so you will want to change this to sort by RAM usage instead. To do this, keep top open and hit the M key on your keyboard. This will cause top to sort all of the processes on the page by their RAM usage:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18749 nagios 16 0 140m 134m 1868 S 12 6.6 1345:01 nagios2db_status
9463 mysql 16 0 686m 111m 3328 S 53 5.5 569:17 mysqld
24636 nagios 17 0 34660 10m 712 S 8 0.5 1195:15 nagios
22442 nagios 24 0 6048 2024 1452 S 8 0.1 0:00.04 check_time.pl
Look at the %MEM column and see if the top processes are consuming a majority of the RAM. If you do find the processes that are causing high RAM usage, you can decide to kill them, or, depending on the program, you might need to perform specific troubleshooting to find out what is making that process use so much RAM.
Tip
top can actually sort its output by any of the columns. To change which column top sorts by, hit the F key to change to a screen where you can choose the sort column. After you hit a key that corresponds to a particular column (for instance, K for the CPU column), you can hit Enter to return to the main top screen.
The Linux kernel also has an out-of-memory (OOM) killer that can kick in if the system runs dangerously low on RAM. When a system is almost out of RAM, the OOM killer will start killing processes. In some cases this might be the process that is consuming all of the RAM, but this isn’t guaranteed. I’ve seen the OOM killer end up killing programs like sshd or other processes instead of the real culprit. In many cases the system is unstable enough after one of these events that you find you have to reboot it to ensure that all of the system processes are running. If the OOM killer does kick in, you will see lines like the following in your /var/log/syslog:
1228419127.32453_1704.hostname:2,S:Out of Memory: Killed process
21389 (java).
1228419127.32453_1710.hostname:2,S:Out of Memory: Killed process
21389 (java).
When I see high I/O wait, one of the first things I check is whether the machine is using a lot of swap. Since a hard drive is much slower than RAM, when a system runs out of RAM and starts using swap, the performance of almost any machine suffers. Anything that wants to access the disk has to compete with swap for disk I/O. So first diagnose whether you are out of memory and, if so, manage the problem there. If you do have plenty of RAM, you will need to figure out which program is consuming the most I/O.
It can sometimes be difficult to figure out exactly which process is using the I/O, but if you have multiple partitions on your system, you can narrow it down by figuring out which partition most of the I/O is on. To do this you will need the iostat program, which is provided by the sysstat Ubuntu package, so type
$ sudo apt-get install sysstat
Preferably you will have this program installed before you need to diagnose an issue. Once the program is installed, you can run iostat without any arguments to see an overall glimpse of your system:
$ sudo iostat
Linux 2.6.24-19-server (hostname) 01/31/2009
avg-cpu: %user %nice %system %iowait %steal %idle
5.73 0.07 2.03 0.53 0.00 91.64
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 9.82 417.96 27.53 30227262 1990625
sda1 6.55 219.10 7.12 15845129 515216
sda2 0.04 0.74 3.31 53506 239328
sda3 3.24 198.12 17.09 14328323 1236081
The first bit of output gives CPU information similar to what you would see in top. Below it are I/O stats on all of the disk devices on the system as well as their individual partitions. Here is what each of the columns represents:
tps
This lists the transfers per second to the device. “Transfers” is another way to say I/O requests sent to the device.
Blk_read/s
This is the number of blocks read from the device per second.
Blk_wrtn/s
This is the number of blocks written to the device per second.
Blk_read
In this column is the total number of blocks read from the device.
Blk_wrtn
In this column is the total number of blocks written to the device.
When you have a system under heavy I/O load, the first step is to look at each of the partitions and identify which partition is getting the heaviest I/O load. Say, for instance, that I have a database server and the database itself is stored on /dev/sda3. If I see that the bulk of the I/O is coming from there, I have a good clue that the database is likely consuming the I/O. Once you figure that out, the next step is to identify whether the I/O is mostly from reads or writes. Let’s say that I suspect that a backup job is causing the increase in I/O. Since the backup job is mostly concerned with reading files from the file system and writing them over the network to the backup server, I could possibly rule that out if I see that the bulk of the I/O is due to writes, not reads.
Note: Auto-Refresh iostat
You will probably have to run iostat more than one time to get an accurate sense of the current I/O on your system. If you specify a number on the command line as an argument, iostat will continue to run and give you new output after that many seconds. For instance, if I wanted to see iostat output every two seconds, I could type sudo iostat 2. Another useful argument to iostat if you have any NFS shares is -n. When you specify -n, iostat will give you I/O statistics about all of your NFS shares.
In addition to iostat, these days we have a much simpler tool available in Ubuntu called iotop. In effect it is a blend of top and iostat in that it shows you all of the running processes on the system sorted by their I/O statistics. The program isn’t installed by default but is provided by the iotop Ubuntu package, so type
$ sudo apt-get install iotop
Once the package is installed, you can run iotop as root and see output like the following:
$ sudo iotop
Total DISK READ: 189.52 K/s | Total DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO>
COMMAND
8169 be/4 root 189.52 K/s 0.00 B/s 0.00 % 0.00 %
rsync --server --se
4243 be/4 kyle 0.00 B/s 3.79 K/s 0.00 % 0.00 %
cli /usr/lib/gnome-
4244 be/4 kyle 0.00 B/s 3.79 K/s 0.00 % 0.00 %
cli /usr/lib/gnome-
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 %
init
In this case, I can see that there is an rsync process tying up my read I/O.
Another common problem system administrators run into is a system that has run out of free disk space. If your monitoring is set up to catch such a thing, you might already know which file system is out of space, but if not, then you can use the df tool to check:
$ sudo df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 7.9G 541M 7.0G 8% /
varrun 189M 40K 189M 1% /var/run
varlock 189M 0 189M 0% /var/run
udev 189M 44K 189M 1% /dev
devshm 189M 0 189M 0% /dev/shm
/dev/sda3 20G 15G 5.9G 71% /home
The df command lets you know how much space is used by each file system, but after you know that, you still need to figure out what is consuming all of that disk space. The similarly named du command is invaluable for this purpose. This command with the right arguments can scan through a file system and report how much disk space is consumed by each directory. If you pipe it to a sort command, you can then easily see which directories consume the most disk space. What I like to do is save the results in /tmp (if there’s enough free space, that is) so I can refer to the output multiple times and not have to rerun du. I affectionately call this the “duck command”:
$ cd /
$ sudo du -ckx | sort -n > /tmp/duck-root
This command won’t output anything to the screen but instead creates a sorted list of what directories consume the most space and outputs the list to /tmp/duck-root. If I then use tail on that file, I can see the top ten directories that use space:
$ sudo tail /tmp/duck-root
67872 /lib/modules/2.6.24-19-server
67876 /lib/modules
69092 /var/cache/apt
69448 /var/cache
76924 /usr/share
82832 /lib
124164 /usr
404168 /
404168 total
In this case I can see that /usr takes up the most space, followed by /lib, /usr/share, and then /var/cache. Note that the output separates out /var/cache/apt and /var/cache so I can tell that /var/cache/apt is the subdirectory that consumes the most space under /var/cache. Of course, I might have to open the duck-root file with a tool like less or a text editor so I can see more than the last ten directories.
So what can you do with this output? In some cases the directory that takes up the most space can’t be touched (as with /usr), but often when the free space disappears quickly it is because of log files growing out of control. If you do see /var/log consuming a large percentage of your disk, you could then go to the directory and type sudo ls -lS to list all of the files sorted by their size. At that point you could truncate (basically erase the contents of) a particular file:
$ sudo sh -c "> /var/log/messages"
Alternatively, if one of the large files has already been rotated (it ends in something like .1 or .2), you could either gzip it if it isn’t already gzipped, or you could simply delete it if you don’t need the log anymore.
Note: Full / due to /tmp
I can’t count how many times I’ve been alerted about a full / file system (a dangerous situation that can often cause the system to freeze up) only to find out that it was caused by large files in /tmp. Specifically, these were large .swp files. When vim opens a file, it copies the entire contents into a .swp file. Certain versions of vim store this .swp file in /tmp, others in /var/tmp, and still others in ~/tmp. In any case, what had happened was that a particular user on the system decided to view an Apache log file that was gigabytes in size. When the user opened the file, it created a multigigabyte .swp file in /tmp and filled up the root file system. To solve the issue I had to locate and kill the offending vim process.
Another less common but tricky situation in which you might find yourself is the case of a file system that claims it is full, yet when you run df you see that there is more than enough space. If this ever happens to you, the first thing you should check is whether you have run out of inodes. When you format a file system, the mkfs tool decides at that point the maximum number of inodes to use as a function of the size of the partition. Each new file that is created on that file system gets its own unique inode, and once you run out of inodes, no new files can be created. Generally speaking, you never get close to that maximum; however, certain servers store millions of files on a particular file system, and in those cases you might hit the upper limit. The df -i command will give you information on your inode usage:
$ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda 520192 17539 502653 4% /
In this example my root partition has 520,192 total inodes but only 17,539 are used. That means I can create another 502,653 files on that file system. In the case where 100% of your inodes are used, there are only a few options at your disposal. Either you can try to identify a large number of files you can delete or move to another file system, possibly archive a group of files into a tar archive, or back up the files on your current file system, reformat it with more inodes, and copy the files back.
Most servers these days are attached to some sort of network and generally use the network to provide some sort of service. Many different problems can creep up on a network, so network troubleshooting skills become crucial for any system administrator. Linux provides a large set of network troubleshooting tools, and next I discuss a few common network problems along with how to use some of the tools available for Ubuntu to track down the root cause.
Probably the most common network troubleshooting scenario involves one server being unable to communicate with another server on the network. I use an example in which a server named ubuntu1 can’t access the Web service (port 80) on a second server named web1. There are any number of different problems that could cause this, so I run step by step through tests you can perform to isolate the cause of the problem. Normally when troubleshooting a problem like this, I might skip a few of these initial steps (such as checking link), since tests further down the line will also rule them out. For instance, if I test and confirm that DNS works, I’ve proven that my host can communicate on the local network. For this guide, though, I walk through each intermediary step to illustrate how you might test each level.
One quick test you can perform to narrow down the cause of your problem is to go to another host on the same network and try to access the server. In my example, I would find another server on the same network as ubuntu1, such as ubuntu2, and try to access web1. If ubuntu2 also can’t access web1, then I know the problem is more likely on web1, or on the network between ubuntu1 and ubuntu2, and web1. If ubuntu2 can access web1, then I know the problem is more likely on ubuntu1. To start, let’s assume that ubuntu2 can access web1, so we will focus our troubleshooting on ubuntu1.
The first troubleshooting steps to perform are on the client. You first want to verify that your client’s connection to the network is healthy. To do this you can use the ethtool program (installed via the ethtool package) to verify that your link is up (the Ethernet device is physically connected to the network), so if your Ethernet device was at eth0:
$ sudo ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 100Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pg
Wake-on: d
Current message level: 0x000000ff (255)
Link detected: yes
Here on the final line you can see that Link detected is set to yes so ubuntu1 is physically connected to the network. If this were set to no you would need to physically inspect ubuntu1’s network connection and make sure it is connected. Since it is physically connected, I can move on.
Note: Slow Network Speeds
ethtool has uses beyond simply checking for link. It can also be used to diagnose and correct duplex issues. When a Linux server connects to a network, typically it autonegotiates with the network to see what speeds it can use and whether the network supports full duplex. The Speed and Duplex lines in the example ethtool output illustrate what a 100Mb/s, full duplex network should report. If you notice slow network speeds on a host, its speed and duplex settings are a good place to look. Run ethtool as in the preceding example, and if you notice Duplex set to Half, then run:
$ sudo ethtool -s eth0 autoneg off duplex full
Replace eth0 with your Ethernet device.
Once you have established that you are physically connected to the network, the next step is to confirm that the network interface is configured correctly on your host. The best way to check this is to run the ifconfig command with your interface as an argument, so to test eth0’s settings I would run
$ sudo ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:17:42:1f:18:be
inet addr:10.1.1.7 Bcast:10.1.1.255 Mask:255.255.255.0
inet6 addr: fe80::217:42ff:fe1f:18be/64 Scope:Link
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:11 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:229 (229.0 B) TX bytes:2178 (2.1 KB)
Interrupt:10
Probably the most important line in this output is the second line, which tells us our host has an IP address (10.1.1.7) and subnet mask (255.255.255.0) configured. Now whether these are the right settings for this host is something you will need to confirm. If the interface is not configured, try running sudo ifup eth0 and then run ifconfig again to see if the interface comes up. If the settings are wrong or the interface won’t come up, inspect /etc/network/interfaces. There you can correct any errors in the network settings. Now if the host gets its IP through DHCP, you will need to move your troubleshooting to the DHCP host to find out why you aren’t getting a lease.
Once you see that the interface is up, the next step is to see if a default gateway has been set and whether you can access it. The route command will display your current routing table, including your default gateway:
$ sudo route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.1.1.0 * 255.255.255.0 U 0 0 0 eth0
default 10.1.1.1 0.0.0.0 UG 100 0 0 eth0
The line you are interested in is the last line that starts with default. Here you can see that my host has a gateway of 10.1.1.1. Note that I used the -n option with route so it wouldn’t try to resolve any of these IP addresses into hostnames. For one thing, the command runs more quickly, but more important, I don’t want to cloud my troubleshooting with any potential DNS errors. Now if you don’t see a default gateway configured here, and the host you want to reach is on a different subnet (say, web1, which is on 10.1.2.5), that is the likely cause of your problem. Either be sure to set the gateway in /etc/network/interfaces, or if you get your IP via DHCP, be sure it is set correctly on the DHCP server and then reset your interface with sudo service networking restart.
Once you have identified the gateway, use the ping command to confirm that you can communicate with the gateway:
$ ping -c 5 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=3.13 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=1.43 ms
64 bytes from 10.1.1.1: icmp_seq=3 ttl=64 time=1.79 ms
64 bytes from 10.1.1.1: icmp_seq=5 ttl=64 time=1.50 ms
--- 10.1.1.1 ping statistics ---
5 packets transmitted, 4 received, 20% packet loss, time 4020ms
rtt min/avg/max/mdev = 1.436/1.966/3.132/0.686 ms
As you can see, I was able to successfully ping the gateway, which means that I can at least communicate with the 10.1.1.0 network. If you couldn’t ping the gateway, it could mean a few things. It could mean that your gateway is blocking ICMP packets. If so, tell your network administrator that blocking ICMP is an annoying practice with negligible security benefits and then try to ping another Linux host on the same subnet. If ICMP isn’t being blocked, then it’s possible that the switch port on your host is set to the wrong VLAN, so you will need to further inspect the switch to which it is connected.
Once you have confirmed that you can speak to the gateway, the next thing to test is whether DNS functions. The nslookup and dig tools both can be used to troubleshoot DNS issues, but since I need to perform only basic testing at this point, I just use nslookup to see if I can resolve web1 into an IP:
$ nslookup web1
Server: 10.1.1.3
Address: 10.1.1.3#53
Name: web1.example.net
Address: 10.1.2.5
In this example DNS is working. The web1 host expands into web1 .example.net and resolves to the address 10.1.2.5. Of course, make sure that this IP matches the IP that web1 is supposed to have! In this case DNS works, so we can move on to the next section; however, there are also a number of ways DNS could fail.
This is the most obvious error message you might get from nslookup when name servers can’t be reached:
$ nslookup web1
;; connection timed out; no servers could be reached
If you see this error, it could mean either you have no name servers configured for your host, or they are inaccessible. In either case you will need to inspect /etc/resolv.conf and see if any name servers are configured there. If you don’t see any IP addresses configured there, you will need to add a name server to the file. Otherwise, if you see something like
search example.net
nameserver 10.1.1.3
you now need to start troubleshooting your connection with your name server, starting off with ping. If you can’t ping the name server and its IP address is in the same subnet (in this case 10.1.1.3 is within my subnet), the name server itself could be completely down. If you can’t ping the name server and its IP address is in a different subnet, then skip ahead to the Can I Route to the Remote Host? section, only apply those troubleshooting steps to the name server’s IP. If you can ping the name server but it isn’t responding, skip ahead to the Is the Remote Port Open? section.
It is also possible that you will get the following error for your nslookup command:
$ nslookup web1
Server: 10.1.1.3
Address: 10.1.1.3#53
** server can't find web1: NXDOMAIN
Here you see that the server did respond, since it gave a response server can't find web1. This could mean two different things. One, it could mean that web1’s domain name is not in your DNS search path. This is set in /etc/resolv.conf in the line that begins with search. A good way to test this is to perform the same nslookup command, only use the fully qualified domain name (in this case web1.example.net). If it does resolve, then either always use the fully qualified domain name, or if you want to be able to use just the hostname, add the domain name to the search path in /etc/resolv.conf.
If even the fully qualified domain name doesn’t resolve, then the problem is on the name server. The complete method to troubleshoot all DNS issues is a bit beyond the scope of this chapter, but here are some basic pointers. If the name server is supposed to have that record, then that zone’s configuration needs to be examined. If it is a recursive name server, then you will have to test whether recursion is not working on the name server by looking up some other domain. If you can look up other domains, then you must check whether the problem is on the remote name server that does contain the zones.
After you have ruled out DNS issues and see that web1 is resolved into its IP 10.1.2.5, you must test whether you can route to the remote host. Assuming ICMP is enabled on your network, one quick test might be to ping web1. If you can ping the host, you know your packets are being routed there and you can move to the next section, Is the Remote Port Open? If you can’t ping web1, try to identify another host on that network and see if you can ping it. If you can, then it’s possible web1 is down or blocking your requests, so move to the next section.
If you can’t ping any hosts on the network, packets aren’t being routed correctly. One of the best tools to test routing issues is traceroute. Once you provide traceroute a host, it will test each hop between you and the host. For example, a successful traceroute between ubuntu1 and web1 would look like the following:
$ traceroute 10.1.2.5
traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets
1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms
2 web1 (10.1.2.5) 8.039 ms 8.348 ms 8.643 ms
Here you can see that packets go from ubuntu1 to its gateway (10.1.1.1), and then the next hop is web1. This means it’s likely that 10.1.1.1 is the gateway for both subnets. On your network you might see a slightly different output if there are more routers between you and your host. If you can’t ping web1, your output would look more like the following:
$ traceroute 10.1.2.5
traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets
1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms
2 * * *
3 * * *
Once you start seeing asterisks in your output, you know that the problem is on your gateway. You will need to go to that router and investigate why it can’t route packets between the two networks. If instead you see something more like
$ traceroute 10.1.2.5
traceroute to 10.1.2.5 (10.1.2.5), 30 hops max, 40 byte packets
1 10.1.1.1 (10.1.1.1) 5.432 ms 5.206 ms 5.472 ms
1 10.1.1.1 (10.1.1.1) 3006.477 ms !H 3006.779 ms !H 3007.072 ms
then you know that the ping timed out at the gateway, so the host is likely down or inaccessible even from the same subnet. At this point if I hadn’t tried to access web1 from a machine on the same subnet as web1, I would try pings and other tests now.
Tip
If you have one of those annoying networks that block ICMP, don’t worry, you can still troubleshoot routing issues. You will just need to install the tcptraceroute package (sudo apt-get install tcptraceroute), then run the same commands as for traceroute, only substitute tcptraceroute for traceroute.
So you can route to the machine but you still can’t access the Web server on port 80. The next test is to see whether the port is even open. There are a number of different ways to do this. For one, you could try telnet:
$ telnet 10.1.2.5 80
Trying 10.1.2.5...
telnet: Unable to connect to remote host: Connection refused
If you see Connection refused, then either the port is down (likely Apache isn’t running on the remote host or isn’t listening on that port) or the fire-wall is blocking your access. If telnet can connect, then, well, you don’t have a networking problem at all. If the Web service isn’t working the way you suspected, you need to investigate your Apache configuration on web1. Instead of telnet, I prefer to use nmap to test ports because it can often detect firewalls for me. If nmap isn’t installed, run sudo apt-get install nmap to install it. To test web1 I would type the following:
$ nmap -p 80 10.1.2.5
Starting Nmap 4.62 ( http://nmap.org ) at 2009-02-05 18:49 PST
Interesting ports on web1 (10.1.2.5):
PORT STATE SERVICE
80/tcp filtered http
Aha! nmap is smart enough that it can often tell the difference between a closed port that is truly closed and a closed port behind a firewall. Now normally when a port is actually down, nmap will report it as closed. Here it reported it as filtered. What this tells me is that there is some firewall in the way that is dropping my packets to the floor. This means I need to investigate any firewall rules on my gateway (10.1.1.1) and on web1 itself to see if port 80 is being blocked.
At this point we have either been able to narrow the problem down to a network issue or we believe the problem is on the host itself. If we think the problem is on the host itself, there are a few things we can do to test whether port 80 is available.
One of the first things I would do on web1 is test whether port 80 is listening. The netstat -lnp command will list all ports that are listening along with the process that has the port open. I could just run that and parse through the output for anything that is listening on port 80, or I could use grep to show me only things listening on port 80:
$ sudo netstat -lnp | grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 919/apache
The first column tells you what protocol the port is using. The second and third columns are the receive and send queues (both set to 0 here). The column you want to pay attention to is the fourth column, as it lists the local address on which the host is listening. Here the 0.0.0.0:80 tells us that the host is listening on all of its IPs for port 80 traffic. If Apache were listening only on web1’s Ethernet address, I would see 10.1.2.5:80 here. The final column will tell you which process has the port open. Here I can see that Apache is running and listening. If you do not see this in your netstat output, you need to start your Apache server.
If the process is running and listening on port 80, it’s possible that web1 has some sort of firewall in place. Use the ufw command to list all of your firewall rules. If your firewall is disabled, your output would look like this:
$ sudo ufw status
Status: inactive
If your firewall is enabled but has no rules, it might look like this:
$ sudo ufw status
Status: inactive
It’s possible, though, that your firewall is set to deny all packets by default even if it doesn’t list any rules. A good way to test whether a firewall is in the way is to simply disable ufw temporarily if it is enabled and see if you can connect:
$ sudo ufw disable
On the other hand, if you had a firewall rule that blocked port 80, it might look like this:
$ sudo ufw status
Status: inactive
To Action From
-- ------ ----
80:tcp DENY Anywhere
Clearly in the latter case I would need to modify my firewall rules to allow port 80 traffic from my host. To find out more about firewall rules, review the Firewalls section of Chapter 6, Security.
For the most part you will probably spend your time troubleshooting host or network issues. After all, hardware is usually pretty obvious when it fails. A hard drive will completely crash; a CPU will likely take the entire system down. There are, however, a few circumstances when hardware doesn’t completely fail and as a result causes random strange behavior. Here I describe how to test a few hardware components for errors.
When a network card starts to fail, it can be rather unnerving as you will try all sorts of network troubleshooting steps to no real avail. Often when a network card or some other network component to which your host is connected starts to fail, you can see it in packet errors on your system. The ifconfig command we used for network troubleshooting before can also tell you about TX (transmit) or RX (receive) errors for a card. Here’s an example from a healthy card:
$ sudo ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:17:42:1f:18:be
inet addr:10.1.1.7 Bcast:10.1.1.255 Mask:255.255.255.0
inet6 addr: fe80::217:42ff:fe1f:18be/64 Scope:Link
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:11 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:229 (229.0 B) TX bytes:2178 (2.1 KB)
Interrupt:10
The lines you are most interested in are
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:11 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
These lines will tell you about any errors on the device. If you start to see lots of errors here, then it’s worth troubleshooting your physical network components. It’s possible a network card, cable, or switch port is going bad.
Of all of the hardware on your system, your hard drives are the components most likely to fail. Most hard drives these days support SMART, a system that can predict when a hard drive failure is imminent. To test your drives, first install the smartmontools package (sudo apt-get install smartmontools). Next, to test a particular drive’s health, pass the smartctl tool the -H option along with the device to scan. Here’s an example from a healthy drive:
$ sudo smartctl -H /dev/sda
smartctl version 5.37 [i686-pc-linux-gnu] Copyright (C) 2002-6 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
SMART Health Status: OK
This can be useful when a particular drive is suspect, but generally speaking, it would be nice to constantly monitor your drives’ health and report to you. The smartmontools package is already set up for this purpose. All you need to do is open the /etc/default/smartmontools file in a text editor and uncomment the line that says
#start_smartd=yes
so that it looks like
start_smartd=yes
Then the next time the system reboots, smartd will launch automatically. Any errors will be e-mailed to the root user on the system. If you want to manually start the service, you can type sudo service smartmontools start or sudo /etc/init.d/smartmontools start.
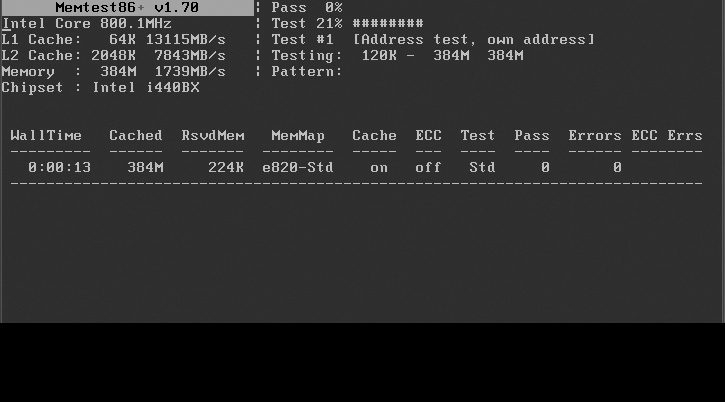
Some of the most irritating types of errors to troubleshoot are those caused by bad RAM. Often errors in RAM cause random mayhem on your machine with programs crashing for no good reason, or even random kernel panics. Ubuntu ships with an easy-to-use RAM testing tool called Memtest86+ that is not only installed by default, it’s ready as a boot option. At boot time, hit the Esc key to see the full boot menu. One of the options in the GRUB menu is Memtest86+. Select that option and Memtest86+ will immediately launch and start scanning your RAM, as shown in Figure 11-1.
Memtest86+ runs through a number of exhaustive tests that can identify different types of RAM errors. On the top right-hand side you can see which test is currently being run along with its progress, and in the Pass field you can see how far along you are with the complete test. A thorough memory test can take hours to run, and I know some administrators with questionable RAM who let the test run overnight or over multiple days if necessary to get more than one complete test through. If Memtest86+ does find any errors, they will be reported in the results output at the bottom of the screen.