Web Services as the New Websites for Many Libraries
Anson Parker, V. P. Nagraj, and David Moody
ALOHA
As you peruse these pages, know this: they have been penned by absolutely average developers. We’re the grunts, followers of the Mack Truck Management Theory, and there are a lot of us out there.1 So this is about sustainable development—we’ve stood on enough shoulders to know that ours can support a little weight. We offer you this chapter, which describes some of the work that we’ve done and why we think it matters. As you read this, you might see just how easy it can be to create web services and what opportunities they can bring to life.
Sundar Pichai, head of Android at Google, announced that the 2013 Google IO conference would focus on helping developers “write better things”—a shift from previous conferences that touted new products for consumers.2 In the land of web development, this equates to creating web services: tools that allow other developers to gain access to our content stripped of all unnecessary layout and formatting. We’re still delivering the “product” our “consumers” expect (i.e., a standard website), but as we open the door for other developers to interface with our content, we open the door for our content to appear elsewhere, and for our site to (dare to dream) cease to exist.
As librarians, we choose to adopt unifying standards to increase the interoperability and fluidity of our data. We frequently do not create the data itself; we reference it, catalog it, and make it as accessible as possible. Moving toward web services from websites is a natural progression for libraries. Take the example of the doctor looking at a patient record: in an ideal world, that patient record would automatically query a database of literature and show relevant results on the patient record—no search needed. Making triggers like this possible is the long-term goal of a web service. The example that follows in this chapter will be much more modest; however, it should help to explain some of the underlying technology of web services.
One of the earliest web services to hit the net was RSS. (While there are many flavors of RSS—including ATOM, RSS 2.0, etc.—we’re going to discuss them all as RSS. For a more detailed breakdown of the similarities and differences, the Web offers many resources.3) Often dubbed “really simple syndication,” RSS is a data transmission tool with a fixed schema with only a few—under twenty—fields, of which title, description, and URL are required. While RSS 2.0 and ATOM have enabled developers to extend this fixed schema by adding namespaces, most RSS readers do not incorporate this flexibility. Ultimately RSS works well for transmitting basic content; however, when passing robust structured content, it may not suffice. More descriptive data formats such as JSON exist to fill in this gap. JSON allows developers to create objects of unlimited size that may be given both a type (e.g. number, string, array) and a value (see figure 6.1).
Using JSON as a standard format, we show how to use several frameworks to create web services for developers while maintaining an effective product for end users. In our discussion, we focus on two frameworks: Drupal and Solr. Both Drupal and Solr are open-source, community-driven tools with corporate sponsorship and hundreds of thousands of enterprise-level constituents.

FIGURE 6.1
JSON and Rendered Web Page
CHOOSING A WEB SERVICE STANDARD
Of the many technical religious wars, choosing a format for a web service is yet another. In many cases, this is a discussion to avoid, but in our use case we’re going to need to look at the distinctions between formats a bit.
RSS is a great tool; there are millions (billions?) of RSS feeds out there, and the number keeps growing. RSS has a fixed (albeit evolving) schema.4 A fixed schema in this case refers to the type of information that may be passed. For our example, let’s imagine there’s a new class being offered at the library that we want to feature as a calendar event (fig. 6.2).

FIGURE 6.2
A sample item from an RSS Feed
As a subset of XML, RSS adheres to familiar <object>data<object> markup. Here we have the required three fields (title, link, and description) as well as a publication date, a GUID, and a category. These values can be used to help filter content. All the tags in the RSS standard are fixed. This means you must call them exactly the same in all RSS feeds. So <title> must hold the title, <link> must have a link to the original content, and so forth.5
Now let’s look at a JSON feed for the same kind of content (fig. 6.3).
With a JSON feed we are now seeing dozens of terms matched to their content in a key:value pairing system. There is also a hierarchy to the notation, such that “location” now has the attributes “address” and “link” because it is a subset of the overall “events” key. The JSON format may be extended indefinitely, and there are no required fields as in RSS. The advantage of this is clear: with JSON you may describe your structured data to the degree you are willing to type. The cost of this descriptive capability is that the developer on the receiving end must address the various fields and hierarchies (see fig. 6.4).


FIGURE 6.4
Sample Calendar Feeds
Working with the UVa Calendaring Systems
Our first practical application of a web-services approach stemmed from a need for event listings on our website. The Claude Moore Health Sciences Library is in a strange position—we exist as an appendage of the University of Virginia, but are more firmly tied to the UVa Health System. Both entities have distinct calendaring systems. Because the library aspires to facilitate collaboration across campus, we aimed to mingle the interests of both of these constituencies while populating calendar data. In doing so, we could also highlight classes, exhibits, and other events happening in the library. The goal was simple—exposure:
• Expose university-wide events to Health System stakeholders.
• Expose library events to a university-wide audience.
• Expose library events to Health System stakeholders.
• Expose augmented calendar data to developers.
The UVa calendar is built with Bedework, an open-source calendaring product (www.jasig.org/bedework). It conforms to current calendar standards and offers a clean and approachable interface for listing events. We decided to input library event listings directly into this system rather than merge objects later—we could push data in, and then dynamically pull it back to our site.
The ease of data entry is matched by the flexibility of data output. The calendar offers feeds in a variety of data formats: RSS, ICS (iCalendar), XML, or JSON. We chose JSON. This tool is highly configurable—we can facet event listings based on categories that are appropriate to our patrons. Our feed excludes listings that may be irrelevant but includes events that are not listed on the Health System calendar. Slavic Languages & Literatures? We probably don’t need that. Computer Science? Yeah, that might be relevant to Health System stakeholders, but wouldn’t be listed on the Health System calendar. Once we are done faceting, we pull library events (along with those corresponding to the categories we selected) into Drupal. All this data will be merged and indexed with event listings pulled from the Health System calendar.
Unlike the central UVa calendaring tool, the Health System calendar was built in Plone (http://plone.org). This presents some limitations, chiefly that the event listings are only available via RSS 1.0 feed. We discussed above why this isn’t ideal. In this case, we get fewer fields, which means less description and more work for us post-ingest. We can map and manipulate the data from the feed so that it can be indexed just as effectively as the main UVa event listings. With the Health System data in Drupal alongside the events from the central UVa feed, we can merge the content and display it on our site as a calendar. Once merged, we are able to index all the calendar items with Solr, which cleans up the data and makes events discoverable on our site via basic search.
Solr was introduced in 2004 as part of CNET’s search strategy.6 In 2006 it was open sourced, and today it is used by millions of people daily. Now it is one of the most widely used open-source search engines in the world, and has been implemented by enterprises such as Netflix, Zappos, and the United States government. Solr is capable of indexing many different kinds of objects—everything from websites to maps to solar systems. Solr’s facility in relating and recommending content makes it especially attractive for our calendar data. A patron searching for an event could discover other events, pages, or users that are related to that event. Solr has also been recognized for its nimble interaction with Drupal, our CMS of choice.
Faceting, ingesting, mapping, manipulating, indexing—all of this amounts to added value for the patrons who use our calendar. That value proliferates beyond the end user, and it does so because we provide web services. We make our data available as JSON and RSS for developers to improve and repurpose. Our content works for us, but one could imagine different use cases for the same data. We’ll leave that for the developers who have those use cases. But we’ll give them a hand along the way. Using Drupal, we can configure and adjust the output of our content with a high degree of granularity. Solr can also output results in a myriad of formats, including JSON, XML, RDF, Python (objects), PHP (objects), and Ruby (objects). We choose to provide data in both JSON and RSS format. We consider this redundancy an important feature; although we support JSON as a standard, we strive to make our data as usable as possible, and we understand that other calendaring tools may only support ingest of RSS content.
This is all described abstractly. What we’ll do next is walk you through each step, each setting, and each button that we push to make this happen.
The Workflow: A Step-by-Step JSON Walkthrough with Drupal and Solr
1. Someone enters a calendar event in Bedework, Plone, or where-have-you. Once the calendar entry is completed, Bedework allows XML, RSS, iCal, and JSON formats for exporting the content.
2. In Drupal parlance we must now create a “content type” to store this content locally. This container will serve for all our event content that we are harvesting. Content types serve as structured containers for data. As we ingest the calendar data that we entered elsewhere, Drupal will create individual nodes of the “Event” content type for each event. It’s worth noting that if for some reason a librarian wants to list an event only on our site and not on the main calendar site, that too is an option. The container exists, and content may be added manually or through feeds. See figure 6.5 for the result of a created content type.

FIGURE 6.5
Calendar Item Data Entry Screen
3. Because we’ve already added our content to the main university calendar, we want to avoid double data entry. We’ll use the Feeds module to help us in this process. Feeds is a tool in Drupal that is designed to harvest content in many formats: XML, JSON, RSS, CSV, and even direct SQL harvesting (provided you have credentials to the given database).7 Feeds then auto-populates the content type based on field mappings that you establish.
4. Because RSS has a fixed schema, importing RSS feeds is a very straightforward process (see figure 6.6).

FIGURE 6.6
Setting up an RSS Feed
5. Creating a mapping with JSON requires two steps (see figures 6.7 and 6.8). In this example we declare the main context as “$.bwEventList.events.*” (with the asterisk here used as a wildcard to include all the content within the context), and after that we parse the rest of the JSON feed using the key values with periods used to go deeper in the hierarchy. For expedience we defined our context-two levels into the JSON document. bwEventList is the top level of our document, and under that is the events key. We might just as easily have specified the context as $.* and then defined each mapping, such as bwEventList.events.events.location.address, for instance. But by defining the context-two layers deep at the top, we’ve saved ourselves a few keystrokes.
6. Now that we’ve pulled our RSS and JSON feeds into Drupal, we’re about halfway there. We’ve enjoyed two other sites’ web services, and now it’s time for us to create our own web service. While creating web services we’ll also give our patrons something to see. The patron perspective for our calendar data may be presented a number of ways. Views is a popular way to display content in Drupal (see figure 6.9 for an example). Much like feeds, there are many ways to extend Views (http://drupal.org/project/views).

FIGURE 6.7
Initial JSON Mapping Screen
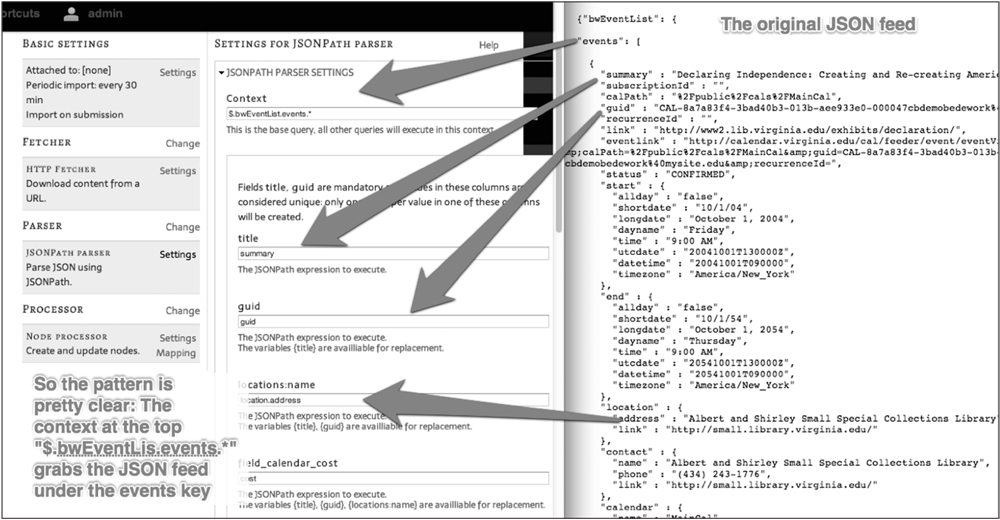
FIGURE 6.8
JSON Mapping Screen after Declaring the Mappings
7. The first view we create will be a tabled page of all our events listed sorted by date. Because the Bedework calendar has a JSON output, we are able—without any manual labor—to extract start and end dates.


FIGURE 6.10
Views Settings to Configure JSON Output
8. Views Data Source (http://drupal.org/project/views_datasource) is a helper module for Views that will allow you to output content in JSON, XML, and so on. Now that we’ve ingested all of this content, we can spit out the aggregated Health System and UVa calendars as either RSS or JSON feeds and be done with it (see figures 6.10 and 6.11). We’ve now gone full circle—from JSON and RSS, to human viewable display, and back out as JSON and RSS for other complete strangers to devour and regurgitate as their own web services.

FIGURE 6.11
Sample JSON Output
Indexing in Solr: What If We Could Do More?
Indexing content with SOLR is a technical and meticulous process (see figure 6.12). The ApacheSolr module in Drupal (http://drupal.org/project/apachesolr) takes care of most of the complexity for us. To index content with this tool, go to administration “Configuration” > “ApacheSolr Search” > “Default Index” tab. Here you can easily check the content types like the events we created earlier in the chapter to add to your Solr index, as in figure 6.13. Much as we have done with our Views, we are aiming to create both patron and developer tools.
For the Patron
For the patron we need do little more than turn on the Solr and Drupal. The defaults work off the shelf with little need to adjust anything. Search results are displayed with facets if desired, and the net result looks a lot like figure 6.14.


FIGURE 6.13
Configuring Solr in Drupal

For the Developers
Now that we’ve got the 99 percent of our users taken care of, it’s time to make work lighter for the developer community. Solr provides search results in many formats, including JSON. This data may be used by our development team or exposed to any developer. Retrieving the JSON data is easy. Because Solr searches are made and retrieved through a simple URL or REST (representational state transfer) request, you can simply add a “wt=JSON” parameter to your Solr search REST URL to give you the output in JSON format. Your search URL will look something like this:
After receiving the JSON data in your REST response, you can now use it in your applications however you want.
One consideration for exposing your Solr data is for client-side application work. It is worth mentioning that Solr can help you get around the JSON cross-domain browser security issues by also exposing the data is a slightly modified JSON format, JSONP. This means that, for instance, if Virginia.edu wants to pull services from Yale.edu, it’s entirely possible.8
To obtain the JSONP format, simply add “json.wrf=callback” to your REST URL. It will now look something like
By using the JSONP format your new application will not throw the errors associated with using content generated from a domain other than the destination URL.
MEASURING SUCCESS
We do a pretty good job keeping tabs on how our library’s website is being used. Google Analytics gives us all kinds of metrics—we know (roughly) who is using what when, where, and how. But in the world we’re advocating, websites take a backseat to web services. We’re offering our data by various means in various formats to be reused by various entities for various purposes. How do we keep track? A standard tool like Google Analytics won’t cut it off the shelf. How do we measure success in this paradigm?
It’s a serious question, and we don’t have a final answer. We’re experimenting with some resources that are beginning to help us track usage. One of these tools is Piwik; it does a good job of monitoring activity. Because it’s run on the server, it is able to track all URLs from the Apache logs, rather than working (as Google Analytics does) by inserting a tracking code on every page. This means that the views that are being used to create JSON feeds are quantifiable. Another tool we can use to measure the implementation of our web services is the Apache Solr Stats module (https://drupal.org/project/apachesolr_stats), with the results as seen in figure 6.15. Solr also provides statistics from its administrative panel, which has become much more robust as of the 4.x release. While these tools certainly give us a better sense of how developers may be using our tools, we are still looking for better ways to monitor.

MOVING FORWARD
We know that the scope of our use case might obscure the bigger picture. Our implementation of web services is admittedly humble. We’re talking about calendar data—so what? To really discuss the implications of this approach, we have to take a few steps back and look at the broader environment of what is happening in academic libraries.
Today users of information systems have choices, and libraries are desperately trying to stay relevant. One approach to advocating library services is to embed librarians in domain-specific contexts. The embedded librarian has become a familiar role in academic libraries.9 In this paradigm, the library goes to the patron rather than the other way around. A web-services approach mirrors this shift by taking resources straight to the dashboards of third-party software.
But if we are embedding our data in other systems, then why should users come to the library website at all? Our answer: maybe they shouldn’t. We have to be realistic about how our patrons look for information. If we are so conceited as to believe that our website should be the only space for our resources, then we close ourselves off from a whole group of users and a whole suite of services we could provide. By increasing access points for library data, we increase the access points for library services.
Let’s go back to the example of the doctor looking at the patient record: this is a physician who may not have the time or inclination to seek out library services. But if we make our collections data available to the EMR (electronic medical record) software, then he can still benefit from relevant resources he serendipitously discovers. These have been described and curated by librarians, who also serve as a point of contact for training and instruction. At no point has he navigated to the library website—we have to be okay with that.
So will the library of the future even have a website? It isn’t likely we’ll shutter our doors or our website any time soon. But as developers move to adopt techniques that integrate their data with other systems, library websites may be more austere than they are today. Accepting this outcome is the biggest challenge to implementing a web-services approach. As we’ve shown, technical frameworks such as Drupal and Solr can help developers efficiently create robust, scalable web services. And while tools exist to monitor nontraditional metrics of web-services implementations, politically justifying this shift can be a tall order. So it might be a few years before the dashboards our patrons use are tightly integrated with the resources available in our institution—but when the political dust settles, we’ll be ready.
ACKNOWLEDGEMENT
We would like to send a special thanks to Vincent Massaro of Yale University for getting us started with the Feeds JSON Calendar work.
1. “Knowledge Hoarders & the Mack Truck Theory,” accessed March 13, 2014, http://askthemanager.com/2008/07/knowledge-hoarders-the-mack-truck-theory/.
2. Steven Levy, “New Android Boss Finally Reveals Plans for World’s Most Popular Mobile OS,” Wired, May 13, 2013, www.wired.com/business/2013/05/exclusive-sundar-pichai-reveals-his-plans-for-android/.
3. See Fred Oiveira’s “RSS vs. Atom, You Know, ‘For Dummies,’” http://blog.webreakstuff.com/2005/07/rss-vs-atom-you-know-for-dummies/, and Ben Joan’s “Difference between RSS and ATOM,” www.differencebetween.net/technology/difference-between-rss-and-atom/.
4. Dave Winer, “RSS 2.0 at Harvard Law,” the Berkman Center for Internet & Society at Harvard Law School, July 15, 2003, http://cyber.law.harvard.edu/rss/rss.html.
5. RSS 2.0 and ATOM formats are extensible; however, they require the user to add namespaces to the RSS feed. While this is not necessarily difficult, it requires the developer to delve in to namespaces to find their desired extension. Also worth noting: the average feed reader is going to ignore most of this information, so for the developer, JSON becomes an attractive solution.
6. Wikipedia, sv. “Apache Solr,” accessed March 13, 2014, http://en.wikipedia.org/wiki/Apache_Solr.
7. Relevant Drupal modules include Feeds XPath Parser (https://drupal.org/project/feeds_xpathparser), Feeds JSONPath Parser (https://drupal.org/project/feeds_jsonpath_parser), and Feeds SQL (https://drupal.org/project/feeds_sql).
8. If you have this need, the following two resources will help you understand this slight but necessary data variation: Wikipedia’s article on JSONP (http://en.wikipedia.org/wiki/JSONP) and skipperkongen’s article “SOLR with JSONP with JQUERY” (http://skipperkongen.dk/2011/01/11/solr-with-jsonp-with-jquery/).
9. K. Brady and M. Kraft, “Embedded & Clinical Librarianship: Administrative Support for Vital New Roles,” Journal of Library Administration 52, no. 8 (November 2012), 716–730.