Why Are Pitchers So Unpredictable?
KEITH WOOLNER AND DAYN PERRY
In 1973, Tom Seaver worked 28 more innings than he did the previous season and lowered his ERA by almost a full run. His win total dropped by 2. In 1998, Roger Clemens won the AL Cy Young Award. The following year, he endured the worst season of his career. Also in 1998, Tom Glavine won the NL Cy Young on the strength of his 20 wins and 2.47 ERA. In 1999, Glavine won just 14 games as his ERA ballooned to 4.12. Again in 1998, Randy Johnson went 9-10 with a 4.33 ERA for Seattle. After a midseason trade to Houston, he went 10-1 with a 1.28 ERA the rest of the year.
These anecdotal facts all point to one statement that statistically inclined analysts and mainstream observers can agree upon: Pitching is hard to predict. Much harder, in fact, than hitting.
There are two reasons for this phenomenon. First, while the margin for error to be successful in pitching is small, the act of pitching is itself physically demanding and subject to degradation. Second, we use flawed statistics to measure pitching performance that make the pitcher responsible for factors beyond his own performance.
The Demands of Pitching
The act of pitching is an exercise in minutiae. Seemingly minor factors can drastically influence a pitcher’s performance: where he stands on the rubber, how high he holds his elbow, what he does with his glove hand during the delivery, how much he rotates his hips, the placement of his fingers on the ball, the action of his pivot foot, the placement of his landing foot, his follow-through, the stillness of his head during delivery. An intricate web of interrelated and overlapping actions must align for a pitcher to deliver a successful pitch.
But being able to deliver a variety of types of pitches with different velocities to any location around the plate is only part of the challenge. The pitcher has to do all those things over and over again, consistently and repeatedly. Furthermore, he must do all of it without giving cues to the hitter, injuring himself, or losing his ability to deceive. A breakdown in any part of the flow can lead to ineffectiveness and failure. Famed Yankees hurler Don Larsen met with success only after adopting a no-windup delivery. Future Hall-of-Famer Randy Johnson didn’t truly dominate opponents until Nolan Ryan helped him make some mechanical tweaks. Legendary Braves (now Orioles) pitching coach Leo Mazzone has rescued countless careers by making minor in-game adjustments and altering off-day throwing patterns.
Yet despite the razor-thin margins of error, the act of overhand pitching is itself an unnatural one. It is a destructive process, exacting a fierce toll on the shoulder and elbow. Rare is the hurler who has a career of significant length and doesn’t undergo at least one major surgical procedure. Even those injuries that don’t sideline the pitcher for an extended period of time or subject him to the surgeon’s knife can hinder his performance. Nagging cases of tendonitis or “tired arm syndrome” usually mean less effectiveness on the mound—though the time off gained may help the pitcher’s arm rest and recuperate in the process. Given the precision demanded by pitching, the ability of opposing hitters to crush weak pitches, and the risk of injury inherent in the physical act of throwing a baseball, it’s little wonder that it’s difficult to predict what the future holds for any given pitcher.
Won-Lost Record
Then there are the statistics we use to evaluate pitcher performance. The primary goal of a pitcher is to win games for his team. To many fans, then, the primary way to measure a starting pitcher’s success is his won-lost record. Any pitcher worth his salt should win more than he loses, and a 20-win season is the hallmark of excellence.
Except that there are two parts to winning a game: having your team score runs and preventing your opponent from doing so. In theory, pitchers can affect only half the equation by preventing runs. But since defense makes up a significant portion of run prevention, pitchers actually influence a fair bit less than half the equation. Pitchers in the National League may get a plate appearance or two toward scoring runs, but their general ineptitude at the plate means the burden lies mainly on their teammates; AL pitchers don’t even get to bat, thanks to the designated hitter rule.
Pitchers need run-scoring help from their teammates to win games. But there are wide differences between the amounts of run support that pitchers receive, even on the same team. For example, Jeremy Bonderman and Nate Robertson were teammates on the 2005 Tigers. Bonderman threw 189 innings in 29 starts, posting an ERA of 4.57, while Robertson threw 196.7 innings in 32 starts, with a slightly better ERA of 4.48. But their run-support levels were vastly different. Bonderman received an average of 5.67 runs of support, while Robertson suffered through just 3.66 runs of support per 9 innings. The result? Bonderman posted a winning record of 14-13, while Robertson was 9 games below .500 at 7-16.
Furthermore, starting pitchers don’t throw complete games as they did one hundred years ago. It’s rare for a pitcher to finish even 20 percent of his games. Other pitchers from the bullpen will finish what he starts, and his team’s chance to win or lose a game often rides on the fortunes of those relievers. Relievers can preserve a lead the starter gave them or blow the opportunity to close out the win. They can rescue a pitcher who leaves with runners on base in a tight game, or allow those runs to score, hanging the loss on the now-departed starter. A reliever can also come in with his team trailing and hang in there long enough for the bats to rally, bailing out the starter from a deserved loss. With the outcome of the game and the eventual awarding of wins and losses so dependent on factors other than the pitcher’s own performance, won-lost record and winning percentage cannot act as credible measures of pitcher performance.
Earned Run Average
Baseball long ago recognized the problem of relying solely on won-lost record, though the traditionalists still refer to it more than they should. To eliminate some of the confounding effects of the pitcher’s supporting offense, earned run average was created to measure a pitcher’s own run-prevention abilities in isolation. This was an improvement. A good pitcher on a bad-hitting team might have a terrible W-L record while still sporting a low ERA. Among the most famous examples of this occurred in 1987, when Nolan Ryan led the NL with a 2.76 ERA yet was credited with just an 8-16 W-L record.
Tracking ERA lessens the problem of teammate reliance but does not eliminate it. True, the impact of a pitcher’s offense is eliminated, but there is still a dependency on the bullpen, as a pitcher can leave the game with runners on base. If the next reliever does a good job and strands those runners, the starting pitcher escapes with no further damage to his ERA. But if the reliever allows them to score, all the resulting runs from those inherited runners are charged to the previous pitcher, even though he’s not entirely to blame.
Treating all runs the same has its problems too—within a game all runs are not created equal. Giving up an eleventh run is not as damaging as giving up a fourth run, because once you’ve given up 10 you’ve already probably lost the game. Yet ERA treats all runs equally. One bad outing out of ten can have disproportionate effects on a pitcher’s ERA, even if he pitched brilliantly the other nine times out. A pitcher who throws nine 7 IP, 2 R games and one 3 IP, 10 R game will have a winning percentage implied by his ERA (based on the Pythagorean formula) of about .574, about 20 points lower than an average team’s actual expected winning percentage of .594. The negative effect of the one blown game is overstated in his ERA and taints his overall record.
Support Neutral Statistics
To address the “runs are not created equal” problem, Baseball Prospectus created the Support Neutral family of statistics. Unlike position players, starting pitchers participate in few games but are involved in almost every defensive play of those games for as deep into the game as they go. A pitcher’s performance is a continuous chain of batters faced, with the results of one plate appearance directly setting up the circumstances of the next one. The pitcher is more responsible for the game situation than anyone else on the field at the time; the allocation of credit or blame should reflect that fact. But at the same time, no matter how well or poorly he performs in this game, the pitcher can create at most one win or one loss. Were he to allow 20 runs to score, his ERA would skyrocket, yet only one loss would be recorded in the standings.
The Support Neutral statistics are designed to address both this one-game reality and the fact that offensive and bullpen run support vary widely and are outside a pitcher’s immediate control. The most elementary member of this family is the Support-Neutral Win (SNW): Given how many innings the pitcher threw, the number of runs scored before he was removed, and any runners still on base when he was removed, what is the probability that an average-hitting team with an average bullpen would win the game? The Support-Neutral name comes from the fact that we are removing, or neutralizing, the variability of having different levels of run support and bullpen support. An average-hitting team might win games where the starter went 7 innings and allowed no runs 85 percent of the time and thus would be worth 0.85 SNW. A Support-Neutral Loss (SNL) is the reverse—the chance of an average team losing given that effort by the starting pitching. That 7 IP, 0 R start would be worth 0.15 SNL. Over the course of a season, a pitcher’s Support-Neutral Won-Lost (SNWL) record is simply the sum of SNW and SNL in each start. This gives a truer indication of how well a pitcher performed, without the distortions of offensive and bullpen support. The deeper into a game a pitcher goes and the fewer runs he allows, the greater portion of a SNW he will earn.
Support-Neutral Value Added (SNVA) measures how far a pitcher performed above an average (.500) pitcher. In our 1-game 0.85 SNW example, his SNVA is 0.85 – 0.50 = 0.35 SNVA. There are further extensions for comparing pitchers not to average but to replacement level and for adjusting probabilities based on how strong the opposing hitters were. The most comprehensive statistic in the Support-Neutral family is Support-Neutral Lineup-adjusted Value Added Above Replacement (SNLVAR). In 2005 Roger Clemens led the majors with a 9.4 SNLVAR, meaning he pitched well enough to add 9.4 wins to an average team above what a fringe, replacement-level pitcher would have done against the same batters (see Chapter 5-1 for more on replacement level).
ERA Redux
Let’s return to earned run average and another of the goals behind it. ERA attempts to isolate the effect of the fielders behind a pitcher from his own performance, as runs are charged to the pitcher only if they are “earned”—that is, if they did not score due to the result of a fielder’s error. Although noble in intent, the concept of earned versus unearned runs is faulty. Error rates have fallen dramatically over the decades, and fielding percentages are at or near all-time highs. The defensive differences among fielders in the modern game are more the result of range and positioning than whether they are error-prone. A fly ball that Andruw Jones effortlessly glides over to catch will fall into the gap for an easy double if Bernie Williams is patrolling center field. Errors and fielding percentage do not adequately capture the differences in the quality of fielders behind a pitcher. Thus, using errors to differentiate between runs that are the pitcher’s fault and those that are the fielders’ fault is unsound.
Run Average
Run Average (RA) is often used instead of ERA to eliminate the misleading distinction between earned runs and unearned runs. This seems like a step backward, not even attempting to separate pitcher performance from fielder performance. However, if we recognize that what is being measured is really the performance of the whole defense (pitching plus fielding), then it makes more sense. Run prevention is run prevention, and it doesn’t matter whether a run is earned or unearned for determining wins and losses. As we will see, there are better ways of separating pitcher and fielder performance than using an incomplete and skewed method such as ERA.
Both ERA and RA have a problem related to the clustering of batting events. More runs score when hits and walks are clustered together than if they are scattered evenly throughout a game. This is because, except for a home run, the offense needs a sequence of batting successes to bring a run across the plate. Two pitchers with the same hit, extra-base, and walk totals allowed can end up with different numbers of runs, based on how those hits and walk happen to be distributed. But that’s mostly random, as pitchers don’t exhibit significant control over when they give up hits and walks.
Peripheral ERA
To overcome the clustering problem, we can use a pitcher’s “peripherals”—the basic rates at which he gives up hits, walks, strikeouts, and home runs—to put together an “expected” ERA or RA. This is called Peripheral ERA (PERA). (ERA is traditionally used instead of RA in the name, though the concept is equally applicable to either version.) PERA essentially adjusts the clustering in a pitcher’s record to that of an average pitcher. A pitcher who gave up unusually large numbers of runs given his peripherals will see that high clustering reduced, while a pitcher who happened to scatter his hits and walks will see the effect of a more typical amount of clustering in his PERA.
PERA synthesizes a pitcher’s peripheral rates into something recognizable and interpretable to the average fan—the ERA he deserved. PERA, which uses just hit rate, walk rate, home-run rate, and strikeout rate, is a better predictor of ERA in the following season than ERA is. It is a truer reflection of how the pitcher performed. In computing PERA, one of the peripherals is the rate of hits given up. But other than home runs, hits result from balls batted into the field of play. Fielding these batted balls almost always involves other fielders, and thus the defensive performances of a pitcher’s teammates are reflected in his hit rate too. We touched on this subject earlier in dismissing the concept of an earned run because it does not properly account for the influence of teammates’ defensive range. Even a pitcher’s peripheral rates, specifically hit rate, are not a sufficiently pure indication of a pitcher’s performance.
Defense-Independent Pitching Statistics
So how can you separate pitching from fielding? For batted balls that stay on the field, the entire event flows from the ball leaving the pitcher’s hand, coming off the hitter’s bat, and landing in a fielder’s glove. It’s an interconnected series of acts that takes place in mere seconds, without the break in the action that separates one inning, one plate appearance, or even one pitch from another. For years, teasing out the relationship between how pitchers and fielders interact seemed impossible until a radical theory proposed by Voros McCracken took the baseball analysis world by storm in the early 2000s.
McCracken demonstrated that what happens to a ball that the hitter puts into play has little to do with the pitcher who threw it. Measuring how often a ball in play went for a hit, a statistic dubbed batting average on balls in play (BABIP), can show how well the pitcher and fielders performed as a unit at their primary defensive responsibility: turning batted balls into outs. By comparing pitchers who were teammates—and thus were working with the same defense from year to year—it was possible to estimate how much of an effect the pitcher has on BABIP and how much of BABIP was the fielder’s responsibility.
The results were shocking. There seemed to be no relationship between the quality of a pitcher and his BABIP. The best pitchers in the league were almost as likely to have a high BABIP as the worst. For example, in 2005, perennial Cy Young candidate Roy Oswalt had a .310 BABIP. Lowly Devil Ray Doug Waechter had a .308. Gopher-ball generator Eric Milton posted a .317, front-line starter John Lackey a .328. The mediocre Scott Elarton had a .274 BABIP, while budding star Jake Peavy had a .281.
Furthermore, these were not mere one-year flukes. Good and bad pitchers appeared scattered through the list of BABIP leaders and laggards season after season. Also, there was no consistency in a pitcher ranking high or low over time. The same pitcher might top the list one year and be near the bottom the next. The same pitchers would see their BABIP bounce up and down to a frightening degree. The inevitable conclusion McCracken reached was that pitchers had a surprisingly small influence on whether batted balls in play became hits or outs—so small, in fact, that it could be virtually ignored as a first approximation. If the ball stayed in play, what happened to it was almost entirely the purview of the fielders, not the pitcher. And while team fielding was relatively consistent across entire seasons, the defensive support given to individual pitchers on a team varied widely and randomly, leading to the chaotic BABIP results for pitchers.
To say this result was counterintuitive or hard to believe is an understatement. A ball hit off Pedro Martinez was virtually no different from one hit off Jose Lima (excluding ones hit over the fences)? After McCracken presented his results in a variety of forums, including the Baseball Prospectus Web site, his conclusions were scrutinized thoroughly and were largely confirmed. Unfortunately, the popularized version of what he found was that “pitchers have no effect on balls in play.” Though that’s a succinct way to put it, it’s not quite correct—the statement needlessly sparked a controversy in the baseball press when highlighted in Michael Lewis’s book Moneyball. Distortions and sensationalism aside, the essence of the results—that pitchers have a very small influence on BABIP and that such an influence is dwarfed by variations in defensive support from year to year—proved to be true and is now well accepted in the analysis community. BABIP can now be found even on mainstream sports Web sites such as ESPN’s.
From this research, a new pitching measurement arose. Defense-independent pitching statistics (DIPS) are a further attempt to eliminate the fielder’s effect on the pitcher’s performance. By removing all the outcomes that routinely involve another fielder, non-strikeout outs, and non-home-run hits, we are left with just strikeouts, walks (and hit by pitches), and home runs. Much like Peripheral ERA, DIPS ERA estimates what a pitcher’s ERA should have been with an average defense behind him given only his strikeout, walk, and home-run rates. But DIPS ERA is “purer” than PERA, as it eliminates the randomness of BABIP from its evaluation. (See Chapter 3-1 for more on DIPS.)
Component Pitching Rates
Of course DIPS ERA itself is a synthesis of more fundamental components: strikeout rate, walk rate, and home-run rate. In terms of outcomes over which the pitcher has the most influence, these three rates can be considered the basis of pitcher performance. It’s the clearest look at the pitcher and the events in the game he can control, without the distorting effects of his fielders, offensive support, and clustering of hits.
Actually, we’re not quite done yet—there’s another slight improvement we can make. There are some external factors involved with a pitcher’s home-run rate too. Pitchers seem to be able to influence whether the ball is hit on the ground or in the air. But how far the ball is hit, or whether it lands in play versus going over the wall, depends a lot on other factors. Prevailing weather conditions and winds, the configuration of the park, the power of the batter at the plate, and other events make home-run rate more variable from year to year than simply looking at a pitcher’s overall groundball and flyball tendencies. This aspect differs from the statistics we’ve looked at up to now in that it doesn’t reflect an actual game outcome—outs, hits, walks, runs, and wins—but rather a flavor or type associated with some of those events. A groundball single is not different from a flyball single. A run is worth the same whether it scores on a sacrifice fly or on a groundout to second. But in terms of understanding how well a pitcher has performed, it’s a useful distinction to make, so we’ll substitute groundball percentage in place of home-run rate.
These three component statistics—strikeout rate, walk rate, and groundball percentage—reflect important abilities that are fundamental to a pitcher’s job: the ability to find the strike zone, to make hitters miss the ball, and to keep the balls that batters don’t miss on the ground. At this level, none of these are dependent on the offensive or defensive performance of his teammates—the pitcher bears these responsibilities. They are also the most reliable and consistent pitching statistics from year to year. In fact, these component statistics are as reliable as batting statistics.
Reliability of Pitching Statistics
Traditional measures of pitching performance don’t provide an accurate picture. A pitcher can deliver the same quality of performance in one year as he did in a previous season, but if he’s had worse defenders playing behind him, didn’t get offensive run support, or just plain got unlucky on the timing of giving up hits, those traditional numbers aren’t going to look the same. You have to look deeper to see that the pitcher hasn’t changed. Instead, his environment has.
Another way to illustrate the point is to look at the year-to-year stability of the different pitching statistics. More specifically, we can look at the correlation between the value of a statistic in one year and the value of the same statistic in the following year. Correlations range from –1 to +1. The closer the value is to +1, the more stable and predictable the stat is from year-to-year. Correlations near zero indicate that there is no consistency from year-to-year. Correlations near –1 indicate that the values flip-flop—high value in the first year strongly suggests a low value in the second year. Table 2-1.1 looks at every pitcher from 1972 to 2004 who faced at least 500 batters in consecutive seasons and computes the correlation from year-to-year in various pitching statistics that we’ve examined in this chapter.
TABLE 2-1.1 Year-to-Year Correlation in Pitching Statistics
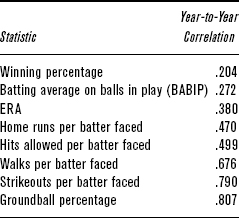
Measures such as walks, strikeouts, and groundball percentage that reflect skills attributable to the pitcher show up as highly correlated and thus consistent and sustainable from year to year. On the other hand, measures that have a lot of other factors that affect them, such as winning percentage and BABIP, have very low correlations. The highest correlations on the list are comparable to the predictability we see in batting statistics such as on-base percentage (OBP) and slugging average (SLG), which measure a batter’s performance independent of his teammates.
Pitchers are unpredictable in that they’re more likely to get injured or fatigued than any other player on the diamond. But when it comes to measuring a pitcher’s performance by the numbers, only flawed, context-dependent measures such as wins and ERA make them unpredictable. Use the right measures, and pitching performance becomes much less enigmatic. At Baseball Prospectus, we use a variety of statistics such as Support-Neutral Value Added, Peripheral ERA, and component pitching rates that progressively peel away the layers of the onion to inform our analyses, improve our predictions, and understand how pitchers are truly performing. By using better tools, you can gain a better understanding of a pitcher’s value—and a better shot at predicting what he’ll do in the future.