Silke Hamann
1 Introduction1
In this chapter, we will focus on changes in phonological systems across generations of speakers of the same language community. In contrast to phonetic changes, which have been dealt with in the previous chapter, phonological changes are not directly observable or measurable, because they involve a change in the mental representations of sounds. The present chapter will deal with the following questions:
(1) a How can we detect a phonological change?
b How can we distinguish it from a phonetic change?
c How does a phonological change emerge and how does it cease to exist?
d How can we formalise a phonological change (and why should we)?
e What modern techniques are used for its detection and description?
These questions will be tackled successively in the following sections, which will provide linguists with analytic tools to investigate and formally account for instances of phonological change. The focus is on recent or ongoing changes. On the way, we will encounter a number of research questions that haven’t been answered yet and might stimulate future research.
2 Detecting a phonological change
There are only indirect ways of discovering the phonemes and the phonological processes a speaker has learned and how they possibly differ from phonological systems and processes postulated by other speakers. The problem of investigating a possible phonological change (which equally holds for investigating possible morphemic or syntactic changes) is thus: How can we access the abstract knowledge of several generations of speakers?
The illustrations in the following subsections are mostly restricted to changes in segmental and suprasegmental (tonal) contrasts. Possible diachronic differences in a phonological process are mentioned in section 2.3.
2.1 New contrasts
The emergence of a new phonemic contrast is mostly a straightforward and easily detectable case of phonological change. The model example for a new contrast is the so-called phonemic split. A split usually occurs when the allophones of a single phoneme produced by speakers of an older generation are reanalysed as separate phonemes by the listeners/speakers of a younger generation. This reanalysis is accompanied by a loss of the contexts that conditioned the allophones. Such a split into two phonemes happened for instance in the development from Old to Modern English for the labiodental fricatives. The Old English phoneme /f/ had a voiced allophone [v] between voiced segments within the same word, see [li:f] ‘life’ and [li:vlic] ‘lively’. The (partial) loss of the conditioning environment led to a new phoneme contrast in Modern English, cf. /laIf/ – /laIv/ or /pɹu:f/ – /pɹu:v/. Loss of conditioning context and resulting (near) minimal pairs are clear diagnostics for the phonemic status of the new categories and thus for a phonological change. Phonemic splits are sometimes also called secondary splits (Hoenigswald 1965) and contrast with so-called primary splits (or conditioned mergers), where the conditioning context is not lost and the number of phonemes therefore does not change. Primary splits are discussed in section 2.3.
Another, less prototypical, case of an emerging phonemic contrast are loan phonemes, where segments that did not exist in the borrowing language have been integrated from a source language. An example is the emergence of the diphthong  in German from recent English loan words such as email, homepage, game (in contrast to earlier loans like spray /ʃpʁe:/, okay /o.ʹke:/, training /ʹtʁe:.nIŋ/). The status of such loan sounds as phonemes of a language is controversial because they are often only used by a part of the language community (namely those speakers that have continuous exposure or assign a high prestige to the source language), while the rest replaces the new structure with a similar sounding native phoneme or phoneme combination. This is the case for words with nasalised vowels that were borrowed from French into German and Dutch in the eighteenth and nineteenth century, such as parfum ‘perfume’, which has the nativised German forms /paʁʹfy:m/ and /paʁʹfœŋ/ alongside the loan form /paʁʹfœ̃/. In present-day Dutch, loan words with formerly nasalised vowels are all nativised by younger speakers. However, not all loan phonemes are unstable and disappear again from the phoneme system of the borrowing language. The borrowed long high vowel /i:/ in Dutch words such as analyse ‘analysis’ and team ‘team’ seems to be such a case. A reasonable account for such differences in the stability of borrowings was given by Jakobson (1931), who proposes that loan segments that consist of a combination of features already employed separately (though not in that combination) in the borrowing language are more easily integrated than other segments. Jakobson’s proposal, however, cannot account for the borrowing of click sounds from Khoisan into Bantu languages. For a better understanding of the role of loan segments in phonological change, further research on their possible phoneme statuses and their stability within the phonological systems is necessary.
in German from recent English loan words such as email, homepage, game (in contrast to earlier loans like spray /ʃpʁe:/, okay /o.ʹke:/, training /ʹtʁe:.nIŋ/). The status of such loan sounds as phonemes of a language is controversial because they are often only used by a part of the language community (namely those speakers that have continuous exposure or assign a high prestige to the source language), while the rest replaces the new structure with a similar sounding native phoneme or phoneme combination. This is the case for words with nasalised vowels that were borrowed from French into German and Dutch in the eighteenth and nineteenth century, such as parfum ‘perfume’, which has the nativised German forms /paʁʹfy:m/ and /paʁʹfœŋ/ alongside the loan form /paʁʹfœ̃/. In present-day Dutch, loan words with formerly nasalised vowels are all nativised by younger speakers. However, not all loan phonemes are unstable and disappear again from the phoneme system of the borrowing language. The borrowed long high vowel /i:/ in Dutch words such as analyse ‘analysis’ and team ‘team’ seems to be such a case. A reasonable account for such differences in the stability of borrowings was given by Jakobson (1931), who proposes that loan segments that consist of a combination of features already employed separately (though not in that combination) in the borrowing language are more easily integrated than other segments. Jakobson’s proposal, however, cannot account for the borrowing of click sounds from Khoisan into Bantu languages. For a better understanding of the role of loan segments in phonological change, further research on their possible phoneme statuses and their stability within the phonological systems is necessary.
As in the case for phonemic splits, loan segments can be detected through new (near) minimal pairs. In contrast to splits, which happen across generations, loan phonemes seem to come into being within one generation of speakers, an observation to which we will return in section 4.
2.2 Lost contrasts
While phoneme splits and the integration of loans add new phonemes to the inventory of a language, cases of phoneme merger involve the collapse of two phonemes into one category across generations of speakers. The resulting change in the phoneme inventory is similarly easy to observe. Where speakers of the older generation produce minimal pairs, speakers of the younger generation produce homophones. This is for instance the case in the Southern Standard British English merger of /uә/ and /o:/ in words like poor and pour to /o:/ (Wells 1982: 162–163). In the specific case of conditioned merger the number of phonemes does not change; we will come back to this case in section 2.3.
The term merger only applies if there is no indication that speakers retained a difference in their underlying phonological representation. Otherwise we deal with processes of neutralisation in the phonetics of underlyingly contrastive phonemes. This seems to be the case for the German voicing contrast of obstruents in syllable-final position, e.g.Rad [ʁa:t] ‘advice’ – Rat /ʁa:t/ ‘wheel’. Here, alternations in other morphological contexts, e.g. the genitive Rades [ʁa:.dәs], indicate that we have to assume an underlying form with a voiced obstruent:Rad /ʁa:d/ (see the discussion in Yu [2011] on the difference between neutralisation and merger).2
Interesting are so-called ‘near-mergers’ where speakers consistently differentiate in their production (as attested with acoustic measurements) but report that they cannot hear the difference between these forms (as attested in perception experiments). The very first example of a near-merger, from Labov, Yaeger and Steiner (1972), is the vowel contrast in the word pair source and sauce, which was thought to be pronounced the same in the vernacular of New York City. Contrary to these expectations, Labov et al. (1972) found a statistical difference between the acoustic realisations of the two vowels, though the speakers could not perceptually differentiate them. Based on their findings, Labov et al. suggest that such a sound change is happening when two sounds perceptually merge into one, but due to the consistent articulatory differentiation the phonemes stay separate, and their phonetic realisations move apart again in the following generations. In a later study, Labov et al. (1991: 45) observed considerable individual variation within the community that shows such near-merges.
Recent studies illustrate that perceptually ignoring a contrast seems to be at the will of the listener. Hay, Warren and Drager (2006) investigated the ongoing merger of /iә/ and /eә/ in New Zealand English and found that when listeners were presented with a photograph of a younger face, they were less accurate at identifying tokens of /iә/ and /eә/ than when they were presented with an older face. The listeners in this study thus seem to be able to ignore the category contrast when they assume they are listening to younger speakers who are known to show merger.
Phoneme loss, in which a phoneme disappears across generations, is another possible diachronic change that results in fewer phonemes. Examples of loss across all contexts are difficult to find, as closer inspection often shows that the assumedly lost phoneme merged with another, and the change thus belongs to the above-discussed merger, or cases are listed where only one allophone disappeared, which can be subsumed under the case of conditioned merger discussed in section 2.3 below. A clear example of phoneme loss occurred in Motu (an Austronesian language of Papua New Guinea), where the velar nasal /q/ disappeared (Crowley and Bowern 2010: 67).
While cases of real merger and loss are easily detectable (former minimal pairs become homophones across generations), cases of near-merger (with minimal pairs continuing across generations though not perceived as such by the younger generation) are difficult to deal with and are still a riddle for many phonologists and phoneticians: if there is a contrast in the underlying forms, why is it observable in production but not in perception? And why can listeners seemingly choose to ignore the contrast?
2.3 Changes with a stable number of contrasts
In the previous two sections we saw types of changes where a difference in the number of phonological contrasts between two stages of a language indicates a change in the phonological system: the number is either enlarged (by split or the integration of a loan phoneme) or reduced (by merger or loss). A change in the number of phonemes is not a diagnostic for the third type of phonological change we discuss now, where a phoneme contrast that used to be on a certain phonological dimension changes to be contrastive on another phonological dimension. Jakobson (1931) terms such processes Umphonologisierung, which has been translated into English as rephonologisation.
Conditioned mergers (also called primary splits, a specific case of phoneme split) are prototypical cases of such a rephonologisation, as they involve a change of a phonetic realisation of one phoneme in a specific context (an allophone) to a realisation that is identical to another phoneme. The following generation then interprets these two sounds as having the same underlying representation. As a result, the number of contrasts across the generations stays stable, but the distribution of the contrasts has slightly changed. An example of a conditioned merger in progress is the lowering of /eε/ to [æ] before /l/ by speakers of Australian English from Victoria (Cox and Palethorpe 2007: 246), resulting in the same pronunciation for hell and Hal.
Rephonologisation also applies to cases of phoneme combinations, e.g. consonant-vowel sequences, where a contrast in the consonant is lost but a new contrast on the adjacent vowel emerges. A classical example of rephonologisation is the emergence of tones from a former contrast in consonant voicing, as mentioned by Jakobson (1931: 262) for Chinese dialects and illustrated by Hyman (1976) for various Southeast-Asian languages. According to Hyman, several languages with a level tone contrast and contrastive voicing in stops ([pā] vs. [bā]) developed into languages with a contour tone contrast that lost the contrastive voicing ([pā] vs. [pá]). He explains that voiced plosives (but not voiceless ones) have an automatic effect of a slight lowering of the pitch at the beginning of the following vowel, which can be enlarged by a language to support the voicing contrast (cf. 2a) (a process Hyman calls ‘phonologisation’ though this choice of term is unfortunate because it implies a change in phonology). In a next step, the rising pitch in the vowel following the voiced plosive is then reinterpreted as phonemic (a rising tone), contrasting with a level tone (cf. 2b) (this process is called ‘phonologisation’ by Jakobson and ‘phonemicisation’ by Hyman). At the same time, the voiced plosive that initiated the pitch change is neutralised to a voiceless plosive (‘dephonologisation’ both in Jakobson’s and Hyman’s terminology). The simultaneous phonologisation and dephonologisation constitute a Jakobsonian rephonologisation (also termed trans-phonologisation; Hyman 1976).
| (2) |
|
phonology |
phonetics |
|
a |
/pā/ – /bā/ |
[pā] – [bá] |
|
b |
/pā/ – /bá/ |
[pā] – [bá] |
|
|
/pā/ – /pá/ |
[pā] – [pá] |
A process like the one in (2b) is easily detectable since a former contrasting phonological feature ([±voice] for the plosives in this example) has lost its contrastiveness and a new phonological contrast ([H] versus [LH]) emerged instead.
More difficult and controversial are cases where a phonetic change (a change in the acoustics and articulation of a sound class) occurs without any obvious consequences for the phonological system of the language. The fronting of the vowel /u:/ (as in goose) in Southern Standard British English seems to be such a case. The younger generations pronounce /u:/ as the fronted vowel [ʉ:] (Harrington, Kleber and Reubold 2008), but their number of phonemes has not changed. Nevertheless, Harrington et al. (2008: 2833) speak of “a difference of phonological category between the two [generations]” with older listeners having an ‘/u:/’ where younger listeners have an ‘/ʉ:/’ (ibid.). How can we decide whether the younger listeners indeed have a different phonological category than the older or whether the change is purely phonetic? To answer this question, we have to look at the function of the two sounds in their respective systems, i.e. compare the phonological behaviour of the sounds across generations. The optional process of homorganic glide insertion in British English provides evidence on the phonological behaviour of the fronted back vowel (Uffmann 2010). Via this process, a glide is inserted at a morpheme boundary after a high vowel. The quality of the glide is determined by the tongue position of the preceding vowel, with a front glide [j] after the front vowel /i:/ and a back glide [w] after the back vowel /u:/, see the examples in (3a) and (3b), respectively.
| (3) |
a |
see [j] it |
b |
do [w] it |
|
|
be [j] on |
|
Sue [w] on |
In phonological feature theories, homorganic glide insertion can be formalised as a spreading of a place feature (e.g., [±back]) from the vowel onto the following glide. Interestingly, the insertion of [w] in Southern Standard British English is irrespective of the phonetic realisation of the preceding /u:/ because the younger generation, which realises this vowels as fronted [ʉ:], still inserts the back glide [w] (Uffmann 2010). This can be seen as evidence that the underlying representation for the vowel has not changed across generations (e.g., [+back]), while its phonetic realisation did.3 A phonetic sound change, i.e. a gradual shift along a phonetic dimension without any consequences for the phonology (or morphology), is known as a Neogrammarian change in the field of diachronic phonology. This type of change holds for all realisations of the changing segment in a given environment, irrespective of (lexical) context.
The examples in this section illustrate that the phonetic label (in the form of an IPA symbol) assigned to a sound should not be confused with its abstract phonological representation. The phonetic form (and the label) can change in a purely phonetic shift without a resulting change in the phonological representation. To establish whether a phonetically measurable shift also includes a change in the phonological system, we have to look at the phonological behaviour of the changed segment(s).
3 The life cycle of a phonological change
The change from voicing to tone contrast in (2) above shows that phonological changes often start out as phonetic variation: according to Hyman (1976), some languages choose to enlarge the intrinsic tone-lowering quality of voiced obstruents, which can then be picked up (by a later generation) as a phonological quality associated with the following vowel.
Many (if not all) phonological changes start out as changes in the phonetic realisation, only. It seems as if a shift in the phonetic characteristics of a sound can trigger a different interpretation of the sound’s function by a following generation. However, it is impossible to predict which phonetic changes exactly result in a phonological change, just as it is impossible to predict which variation in the phonetics exactly results in a phonetic change (in Hyman’s example, why some languages choose to enlarge the intrinsic tone lowering while others don’t).
There are, nevertheless, certain biases observable in both types of changes that let us account for changes that have occurred (see also Labov [2010] chapter 5 for an overview of possible initiating factors of change). Phonetic changes often are in the direction of articulatory simplifications (lenitions, assimilations) or show a directionality of perceptual (mis-) interpretation (Ohala 1981). In phonology, we can observe a bias towards structural simplicity, i.e. the preference for acquiring simple, non-changing mappings between underlying and surface forms and as few phonological processes as possible. An example for the structural bias in action is the word-final postnasal [g]-loss in Late Modern English described by Garrett and Blevins (2009) and Bermudez-Otero and Trousdale (2012: 698), where the underlying /g/ was only visible at the surface when a vowel-initial word followed (e.g., /siqg it/ [siŋgit] but /siŋg/ [siŋ])4. Bermudez-Otero and Trousdale argue that the fact that prevocalic instances with [g] occurred far less often than preconsonantal instances without [g] led the following generation to postulate underlying word forms without /g/ (e.g. /sɪŋ/), based on what they heard most frequently. This example illustrates that frequency of alternating forms is an important bias in the postulation of underlying forms, and thus in phonological changes.
Phonologists sometimes describe sound changes as passing through a ‘life cycle’ (see e.g. Kiparsky 1995 and Bermúdez-Otero 2007). We saw above how a phonetic change can turn into a phonological one, i.e. how a phonological change can come into being. But how can it ‘die’? Given the definition of merger in section 2.2 above, it is impossible that a phoneme that disappeared through merger turns up again a generation later unless we are dealing with near-mergers, where the following generation has an indication in the phonetic form that there are systematic differences between the two sound classes. The impossibility to undo mergers through linguistic means has been formalised by Labov (1994: 311) as Garde’s principle. A new phoneme that emerged through split can disappear again in the next generation, as, for example, the case of nasal vowels as loan phonemes of Dutch in section 2.1 showed. Besides such cases of simple undoing of phonological changes, phonological changes can also cease to be active by turning into morphologically conditioned processes or become fully lexicalised over time.
The Bantu language Jita shows a phonological alternation that is morphologically conditioned, namely the process of /r/-spirantisation, which occurs only if certain morphemes with initial /i/ or /j/ (as the causative and agentive suffix) are added to a stem that ends in a rhotic tap, compare (4a) to (b). Other morphemes (as the applicative and perfective suffix) also starting with /i/ or /j/ do not cause spirantisation of the preceding rhotic, see (4c) (Downing 2007).
| (4) |
a |
[oku-saɾ-a] |
base infinitive of stem |
/saɾ/ |
‘to go mad’ |
|
b |
[omu-sas-i] |
agentive |
|
|
|
c |
[oku-saɾ-iɾ-a] |
applicative |
|
|
Learners of Jita thus have to store whether a morpheme causes the phonological process of spirantisation or not in their mental lexicon. Interestingly, this process seems to have been a regular phonological one in Proto-Bantu, which has been reconstructed as a seven-vowel system with two high front vowels, /i/ and /ɪ/, where only the former caused spirantisation (Schadeberg 1995; Downing 2007). This regularity was obscured in numerous Bantu languages by a merger of the two high front vowels and the fact that some instances of the merged vowel changed to the glide /j/. In general, avoiding sequences of rhotics plus high front vocoids (/i/ and /j/) seems typologically rather common. Hall and Hamann (2010) provide examples from several unrelated languages exhibiting this avoidance and argue that it is an articulatorily-motivated restriction as these sequences involve a change in tongue body from a retracted position (to allow tongue tip raising or velar constriction) to a fronted and raised position (for the high front vocoids). In German, a restriction on /ij/ is phonologically active, as it blocks the process of glide formation (turning /i/ into [j] in fast speech) from occurring after a rhotic, see e.g.Piano ‘piano’ [pi. ʹa:.no] ~ [ʹpja:.no] but Triade ‘triad’ [tʁi. ʹa:.də], *[ʹtʁja:.də] (ibid.). We can see from these examples that the same type of phonetically motivated process can be at different levels in its life cycle in different languages (phonological in German and morphological in Jita) or at different diachronic stages of the same language (phonological in Proto-Bantu and morphological in modern-day Jita).
The full life cycle of a sound change is summarised in (5) (cf. Bermúdez-Otero 2007).
(5) phonetic process > phonological process > morphophonological process
4 Phonological changes and grammar models
This section deals with the question phrased in (1d): How can we formalise a phonological change and why should we? Let us start with the second part of this question. Formalising the knowledge we need to have as speakers and listeners to be able to exhibit certain linguistic behaviour is the topic of theoretical linguistics in general. Formalising is thus a way of making our assumptions about linguistic knowledge explicit, and it provides us with testable predictions. Such formalisation has to start with an exact description of the phenomenon under investigation. With respect to phonological changes, this means a description of what changed across the generations. Formalisations in diachronic phonology often involve nothing more than formal statements of the changes that occurred, as in the form of feature-changing rules in Generative Phonology. The ongoing conditional merger of /ɛ/-lowering in Australian English of speakers from Victoria (cf. section 2.3) can be stated in such a way, cf. (6) (where]σ stands for a syllable boundary and (C) for optional consonants).
(6) /ɛ/ → /æ/ / __ [+lateral] (C) ]σ
Formal statements of changes as in (6) are useful because they enable us to compare the sounds or classes of sounds that changed and the contexts of such changes, and can for instance be the basis of typological studies on diachronic changes (as the study on rj- avoidances by Hall and Hamann [2010]). However, such descriptions do not provide an account of the mental knowledge that speakers/listeners of different generations of the changing language have.
Early Generative Phonology considered sound changes as the addition of a new rule like the one in (6) to the grammar of a speaker (e.g. King 1969). The next generation of speakers was then assumed to construct a grammar that provided the same output but with simpler or less rules and different underlying representations (recall the discussion on structural bias in section 3). While the idea that a diachronic phonological change involves the construction of a different grammar by the learning child is still widely accepted (even in phonetically-oriented accounts that invoke misperception as cause of change, see Ohala [1981]), the assumption that phonological changes start off as the addition of a rule as in (6) to the mental grammar of speakers is more problematic. The statement in (6) transforms one phoneme into another, which is not describing a phonological process but rather a lexical restructuring that might take place from one generation to another. A rule as in (6) might be added to the phonological grammar of an adult speaker of the older generation as an (optional) allophonic rule, and in that case should have the allophone [æ] as output. This still raises the question why a speaker should add such a rule, how this can lead to a different grammar in the learning child, and how we can formalise these two factors in our linguistic model of phonological change.
Before we look further at the above-mentioned questions, let us take into consideration what other factors have to be included in our model. It was illustrated in sections 2 and 3 that a phonetic change is not the same as a phonological change, and that the former does not imply the latter. For a distinction between both types of changes, we need to postulate that speakers have separate phonetic and phonological representations, which reside in their respective grammar components. Our model therefore has to include both a phonetic and a phonological module. Some phonological theories assume that the interface between these two modules is universal, meaning that a phonological feature has the same phonetic interpretation in all languages that employ this feature (see e.g. Hale and Kissock 2007). In such approaches, a change in the phonetics as in the example of Southern Standard British /u/-fronting has to be accompanied by a change in the phonological representation (e.g. from [+back] to [-back]) in order to keep the universal phonetic implementation intact.5 Alternative approaches, which we will follow here, assume that the connections between the phonetic and the phonological representations are language-specific and learned, see e.g. Keating (1988), which allows for a principle distinction between phonetic and phonological changes. Note that non-symbolic theories like Exemplar Theory (e.g. Bybee 2001), which consider abstract underlying phonological representations redundant and assume that category labels are sufficient to derive abstractions across all stored exemplars, run also into problems accounting for the difference between purely phonetic changes and changes in the phonology.
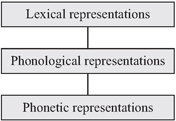
In addition to a phonetic and a phonological module, we will have to include a lexical module to account for formerly phonological changes that moved on to being lexicalised restrictions. This gives us a grammar model with three independent modules, depicted in Figure 10.1, as proposed by Bermudez-Otero (2007, in press) for the formalisation of the complete life cycle of change.
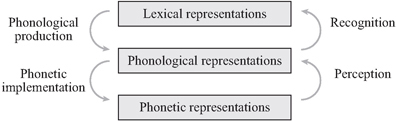
The mapping between the three modules in Figure 10.1 can be formalised in terms of rules, constraints or connections. According to Bermudez-Otero (2007, in press), such a modular theory is feed-forward, i.e. moving from the lexical representation via phonological representations to generate phonetic representations at the bottom. It models the speaker in the process of phonological production and phonetic implementation; see the left side of Figure 10.2 for the two processing steps. This is the traditional assumption within phonological theory, which neglects the reverse process of comprehension (on the right side of Figure 10.2) that involves the construction of a lexical representation via phonological representations (speech recognition) on the basis of an auditory phonetic representation (speech perception; see the overview in Boersma and Hamann [2009] for phonological models that include the comprehension process).
Figure 10.1 A modular theory for the formalisation of sound changes
Figure 10.2 The processing-directions for the formalisation of sound changes
Many phonetic and phonological studies have shown the important role of the (adult or child) listener in sound change (see e.g. Hyman 1976: 40; Ohala 1981; Hamann 2009). Especially children, who acquire the language by perceiving and analysing the parents’ acoustic output, are often considered responsible for phonological changes (see Stanford, this volume). We therefore need to include the process of speech comprehension in an exhaustive model of sound change. While at first glance it seems impossible to formalise, for example, the notion of misperception as used by Ohala (1981), a closer look shows it is helpful and even necessary to have a formalisation of the mapping between auditory and phonological representations that can account for perceptual similarities between segments and thus for often occurring changes. A formalisation of the perception process, furthermore, can show that in some cases a perceptually caused change might be better described as a best-fitting interpretation of the input data rather than a misperception (see Hamann [2009] for an illustration).
The inclusion of both processing directions is necessary but still not sufficient for a complete model of phonological change. Ideally, we also have to provide a model of how the connections between the representations and the representations themselves are acquired, i.e. an explicit formalisation of the learning process. At present, only few theories allow a formalisation of the acquisition of the connections (e.g., Boersma 2011), and the learning of representations is still problematic for symbolic theories of phonology (as they have to deal with the question of how and when a symbolic representation emerges).
Furthermore, several studies have shown that adults keep updating their phonetic realisations, see for instance the famous study of the Christmas broadcasts of the Queen of England and the subtle change in her acoustic vowel space over the years (Harrington, Palethorpe and Watson 2000). Such continuous adjustments need to be included in the formalisation. It is less clear whether phonological representations and processes are also updated throughout our lives. In section 2.1 on loan segments this seemed plausible, and the assumption of early Generative Phonology of sound change as a rule addition in adult life point in the same direction, though further studies are needed to test this hypothesis. If it turns out that the phonological representations are updated throughout the lives of the speakers/listeners, this finding will have to be incorporated into a model that accounts for phonological change.
In addition to the linguistic considerations mentioned above, there are social factors that come into play. While younger children model their grammar based on the input provided by the principle caregivers, children from at least the age of eight years onwards seem to focus on their peer group and people of other social relevance as models for their language (see e.g. Kerswill and Williams 2005; Stanford, this volume). A sociolinguistically valid model of sound change has to incorporate such a shift in the ranking of the input data.
Needless to say that at present there exists no formalisation of a linguistic model of sound change that includes all of the above-mentioned factors. section 5.2 below provides information on the simulation of some of the aspects mentioned here. When formalizing phonological changes we thus have to be aware of the restrictions of the model we chose to employ and have to make these restrictions explicit.
5 New techniques
The classical approach in historical phonology to gain information on the phonology of past stages of a language is the Comparative Method of reconstruction; for further information on this the reader is referred to Weiss (this volume) and Hale (this volume). In the following, we will look at the possibilities of measuring recent and ongoing phonological changes (section 5.1) and at simulating changes with the help of computer models (section 5.2).
5.1 Experimental methods
In the last 50 years, numerous studies were performed that tested possible phonetic motivations of typologically common sound changes by means of acoustic measurements or perceptual experiments (see for instance the classical study by Ohala [1981]). These studies contribute to our understanding of the biases that can lead to phonetic changes (recall the discussion in section 3.1), but are usually not concerned with the function of the changing segments in the languages of investigation and thus do not provide us with information on possible phonological changes.
Acoustic measurements (e.g. of the formant frequencies of vowels) such as the large-scale study by Labov et al. (1972) on the dialectal variation in vowel realisations are necessary to map phonetic changes in acoustic space, which gives us indications of possible phonological changes, but they cannot tap into the phonological knowledge of the speakers. Even a total overlap of two segments in the acoustic space could be due to a synchronic process of neutralisation rather than a diachronic merger of phonemes (recall the discussion in section 2.2).
Perceptual experiments, on the other hand, can test the existence of underlying phonemes through the effect of categorical perception. As listeners we use the phonemic categories of our native language (L1) to categorise incoming language input. If we hear two sounds that are acoustically different but both possible realisations of one L1 phoneme, we tend to perceive them as being the same, while two sounds that show the same acoustic distance as the first pair but are realisations of two different L1 phonemes are perceived as different sounds. Categorical perception can be tested with two types of experiments. In an identification task (also called categorisation test), listeners have to indicate to which category the heard stimulus belongs. Stimuli are from an acoustic continuum that spans the realisations of the categories investigated (e.g., the /u/ - /i/ continuum in a study on a possible merger of high vowels). Answer categories are usually a closed set, and can be orthographic representations of the phonemes or picture representations of words containing the phonemes. The results of an identification experiment are identification curves, and the crossover points of these curves yield the category boundaries.
In the other type of perceptual experiment, which is called a discrimination task, participants are presented with two sounds at a time and have to indicate whether the two are the same or different. Stimuli are again from an acoustic continuum, with a fixed acoustic distance between the two stimuli presented as pairs. Only those stimuli pairs that cross category boundaries yield the answer ‘different’, and the discrimination curve resulting from this type of experiment shows peaks at category boundary locations. In discrimination tasks, the time between stimuli (the so-called inter-stimulus interval) has to be long enough so listeners cannot rely on their short-term memory of the acoustics of the first stimulus.
The two types of experiments on categorical perception provide us with information on the number of underlying categories and are therefore useful tools in the detection of phonological mergers or splits. Both involve behavioural tasks and an active decision on the part of the participant, which can be influenced by non-linguistic factors such as attention and expectations. To avoid such influences, one can use methods that measure unconscious responses to speech stimuli. In the eye-tracking paradigm, for instance, participants automatically react to auditory stimuli by looking at a screen with several simultaneously presented pictures or words. The eye movements of the participants as response to the stimuli are measured and analysed. Koops, Gentry and Pantos (2008) use the eye-tracking paradigm in their study of a near-merger. Another possibility is to record event-related electrical responses of the brain by electroence-phalography (EEG). A negative activity occurs, for instance, when participants passively listen to a sequence of tokens of a phoneme and suddenly hear a token of another phoneme (the so-called oddball paradigm). Such negative activities indicate two different underlying representations, and therefore can be used in testing cases of phoneme merger or split. Further recently-developed non-behavioural methods involve, for example, the use of magnetoencephalography (MEG) to measure magnetic fields generated by neural activity of the brain or the use of functional magnetic resonance imaging (fMRI) to detect changes in blood flow caused by brain activity.
All the above-mentioned methods are able to discover differences in the number of underlying phonemes between groups of speakers. To glean information on the existence or productivity of phonological processes across generations of speakers (such as the process of glide insertion in British English), simple production experiments can be employed, including nonsense words as in the wug test (Berko 1958).
5.2 Computer simulations of change
Computer simulations are useful tools to test hypotheses on the acquisition of phonological systems. The types of changes we can observe in such simulations can be tested against real occurrences of sound changes and provide insight into the accuracy of the underlying assumptions. Usually, however, computer simulations proceed the other way around, i.e. they start with existing data on changes and try to model the data as closely as possible, sometimes irrespective of whether the simulation is realistic in mimicking the knowledge of a speaker/listener or not.
Many simulations in the literature involve the modelling of changes in a multi-dimensional phonetic space. De Boer (2000), for instance, simulates the emergence of vowel inventories in a phonetic space that is defined by the first formant (that reflects the tongue height) and the second formant (reflecting the tongue position during the articulation of the vowel), where categories are prototypical values in this two-dimensional space. Agents interact in this simulation by trying to imitate each other’s output. De Boer’s model allows the collapse of categories and the emergence of new categories, though the determining factors for this to happen are the proximity of two categories in the phonetic space (for a collapse) and random additions of new categories (for a new emergence). The simulation by de Boer does not include the function of the phonetic categories in the linguistic system, i.e. their phonological behaviour, and thus does not seem able to account for phonological changes.
Another example of modelling a change in phonetic space is the simulation by Kirby (2011) of a near-neutralised voicing contrast in alveolar plosives (based on word-final data from Dutch), which employs four phonetic dimensions. With the use of a statistical learning algorithm, the model learner constructs the number of categories that best matches the received input. As in de Boer’s case, the simulation by Kirby thus involves unsupervised learning. The input data is drawn from one of four agents (based on real speaker behaviour from Dutch), and the number of phonetic dimensions that is available varies between one and four. Kirby’s simulation provides us with valuable information on the likelihood that a phonetic near-merger can still be undone by a following generation given the distributions in the input data. But as in de Boer’s case, this simulation does not include any phonological considerations.
Some models that have been employed to simulate phonetic change can theoretically also deal with phonological changes, e.g. Wedel (2011) and Boersma and Hamann (2008), as they allow additional levels of abstraction. The simulation in Boersma and Hamann employs supervised learning, as the mapping between phonetic values and an abstract category is acquired with the help of a lexicon, which requires that both the abstract categories and the lexicon are given. This is not a realistic assumption for the early stage of acquisition, though it approaches the natural acquisition in older infants that have started building a lexicon. A further drawback of their model is that the number of categories is fixed and therefore cannot predict phoneme mergers and phoneme splits (though phonetic mergers and splits are possible).
We saw in this subsection that the discussed simulations employed different linguistic models and focused on different aspects of change. A computer simulation that includes both phonetic and phonological changes by modelling the acquisition of phonetic and phonological categories and where the speakers/listeners interact with several other agents does not exist yet.
6 Historical context
This chapter started off following the Structuralist tradition in focusing on the phonological contrasts within a language and how the function of these contrasts can change across generations (section 2). We moved on to ideas of the Generative tradition in employing a modular view of the grammar to describe the life cycle of a sound change (section 3), and in considering the child as innovator of phonological change, who restructures the underlying representation to yield a maximally simple grammar (section 4). We touched upon the Variationist tradition and Labov’s work in discussing near-mergers (section 2.2), factors playing a role in the life cycle of change (section 3) and acoustic analyses of large groups of speakers (section 5.1). The last section (section 5.2) was concerned with experimental methods and computer simulations of sound change, and can be placed in the tradition of Laboratory Phonology, with its focus on empirical studies to support theoretical assumptions. This chapter thus provided a short history of the development of diachronic phonology as a scientific field. The different approaches where not explicitly named when their contributions were described, in order to focus on their contributions to the field of diachronic phonology, and not to draw the attention to the possible contrasts between these paradigms. Hopefully it became clear how valuable all of these contributions are for a complete description of phonological changes.
Notes
1 I am grateful to Claire Bowern and Joseph Salmons for their comments and suggestions.
2 A number of experimental studies found phonetically distinct realisations of the neutralised and underlying voiceless obstruents in German. Kharlamov (2012) gives an overview of these studies and argues that their results are artefacts of the experimental conditions.
3 The phonological difference between /i:/ and fronted /u:/ could also be a different specification for the feature [± round]. Furthermore, it is interesting to note that /u: /-fronting does not occur before tautomorphemic /l/, resulting in minimal pairs such as [ɹu: lə] ‘measuring device’ vs. [ɹʉ: lə] ‘monarch’ (Uffmann 2010); we are thus dealing with a possible case of conditioned merger.
4 At this stage, an alternative lexical representation of the velar nasal as /ng/ could also be assumed, as, for example, by Borowsky (1989), together with processes of nasal assimilation and g-deletion. However, at a later stage of English, this analysis would run into problems because of the unpredictability of g-deletion.
5 Underspecification of the feature [back] is another possibility; see Uffmann (2010).
Further reading
Bermúdez-Otero, Ricardo. in press. Amphichronic explanation and the life cycle of phonological processes. In Patrick Honeybone and Joe Salmons (eds) The Oxford handbook of historical phonology. Oxford: Oxford University Press.
Hualde, José Ignacio. 2011. Sound change. In Marc van Oostendorp, Marc, Colin J. Ewen, Elizabeth V. Hume and Keren Rice (eds) The Blackwell companion to phonology. Oxford: Blackwell, 2214–2214.
Jakobson, Roman. 1931. Prinzipien der historischen Phonologie. Travaux du Cercle Linguistique de Prague 4: 247–247. [English translation: 1971. Principles of historical phonology. In Philip Baldi and Ronald N. Werth (eds) Readings in Historical Phonology. Philadelphia: PSUP , 103–120].
Yu, Alan C. L. 2011. Mergers and neutralization. In van Oostendorp et al. (eds), 1892–1892.
References
Berko, Jean. 1958. The child’s learning of English morphology. Word 14: 150–150.
Bermudez-Otero, Ricardo. (2007). Diachronic phonology. In Paul de Lacy (ed.) The Cambridge handbook of phonology. Cambridge: Cambridge University Press, 497–497.
——in press. Amphichronic explanation and the life cycle of phonological processes. In Patrick Honeybone and Joe Salmons (eds) The Oxford handbook of historical phonology. Oxford: Oxford University Press.
Bermudez-Otero, Ricardo and Graeme Trousdale. 2012. Cycles and continua: on unidirectionality and gradualness in language change. In Terttu Nevalainen and Elizabeth Closs Traugott (eds) The Oxford handbook of the history of English. New York: Oxford University Press, 691–720.
Boer, Bart de. 2000. Self-organization in vowel systems. Journal of Phonetics 28: 441–465.
Boersma, Paul. 2011. A programme for bidirectional phonology and phonetics and their acquisition and evolution. In Anton Benz and Jason Mattausch (eds) Bidirectional optimality theory. Amsterdam: John Benjamins, 33–72.
Boersma, Paul and Silke Hamann. 2008. The evolution of auditory dispersion in bidirectional constraint grammars. Phonology 25(2): 217–270.
—— 2009. Introduction: models of phonology in perception. In Boersma and Hamann (eds), 1–24.
—— (eds). 2009. Phonology in perception. Berlin: Mouton de Gruyter.
Borowsky, Toni. 1989. Structure preservation and the syllable coda in English. Natural Language and Linguistic Theory 7: 145–166.
Bybee, Joan. 2001. Phonology and language use. Cambridge: Cambridge University Press.
Cox, Felicity and Sallyanne Palethorpe. 2007. Illustrations of the IPA: Australian English. Journal of the International Phonetic Association 37: 341–350.
Crowley, Terry and Claire Bowern. 2010. An introduction to historical linguistics. Oxford: Oxford University Press.
Downing, Laura. 2007. Explaining the role of the morphological continuum in Bantu spirantisation. Africana Linguistica 13: 53–78.
Garrett, Andrew and Juliette Blevins. 2009. Analogical morphophonology. In Kristin Hanson and Sharon Inkelas (eds). The nature of the word: essays in honor of Paul Kiparsky. Cambridge, Mass.: MIT Press, 527–545.
Hale, Mark and Madelyn Kissock. 2007. The phonetics-phonology interface and the acquisition of perseverant underspecification. In Gillian Ramchand and Charles Reiss (eds) The Oxford handbook of linguistic interfaces. Oxford: Oxford University Press, 81–102.
Hall, T. A. and Silke Hamann. 2010. On the cross-linguistic avoidance of rhotic plus high front vocoid sequences. Lingua 120: 1821–1844.
Hamann, Silke. 2009. The learner of a perception grammar as a source of sound change. In Boersma and Hamann (eds), 109–147.
Harrington, Jonathan, Sallyanne Palethorpe and Catherine Watson. 2000. Monophthongal vowel changes in Received Pronunciation: an acoustic analysis of the Queen’s Christmas broadcasts. Journal of the International Phonetic Association 30(1/2): 63–78.
Harrington, Jonathan, Felicitas Kleber and Ulrich Reubold. 2008. Compensation for coarticulation, /u/- fronting, and sound change in standard southern British: an acoustic and perceptual study. Journal of the Acoustical Society of America, 123(5): 2825–2835.
Hay, Jennifer, Paul Warren and Katie Drager. 2006. Factors influencing speech perception in the context of a merger-in-progress. Journal of Phonetics 34: 458–484.
Hoenigswald, Henry M. 1965. Language change and linguistic reconstruction. Chicago: University of Chicago Press.
Hualde, José Ignacio. 2011. Sound change. In van Oostendorp et al. (eds), 2214–2235.
Hyman, Larry M. 1976. Phonologization. In Alphonse G. Juilland (ed.) Linguistic studies offered to Joseph Greenberg. Saratoga: Anma Libri, 407–418.
Jakobson, Roman. 1931. Prinzipien der historischen Phonologie. Travaux du Cercle Linguistique de Prague 4: 247–267. [English translation: 1971. Principles of historical phonology. In Philip Baldi and Ronald N. Werth (eds)Readings in historical phonology. Philadelphia: PSUP, 103–120].
Keating, P. A. 1988. The phonology-phonetics interface. In Frederick Newmeyer (ed.) Linguistics: the Cambridge survey. Volume 1: Linguistic theory: foundations. Cambridge: Cambridge University Press, 281–302.
Kerswill, Paul and Ann Williams. 2005. New towns and koineization: linguistic and social correlates. Linguistics 43(5): 1023–1048.
Kharlamov, Viktor. 2012. Incomplete neutralization and task effects in experimentally-elicited speech. PhD dissertation. University of Ottawa.
King, Robert D. 1969. Historical linguistics and generative grammar. Englewood Cliffs, NJ: Prentice-Hall.
Kiparsky, Paul. 1995. The phonological basis of sound change. In John A. Goldsmith (ed.) The handbook of phonological theory. Oxford: Blackwell, 640–670.
Kirby, James P. 2011. Modelling the acquisition of covert contrast. In Wai-Sum Lee and Eric Zee (eds) Proceedings of the XVII International Congress of Phonetic Sciences, 1090–1093. [Available at: www.icphs2011.hk/ICPHS_CongressProceedings.htm; accessed 14 November 2013].
Koops, Christian, Elizabeth Gentry and Andrew Pantos. 2008. The effect of perceived speaker age on the perception of PIN and PEN vowels in Houston, Texas. University of Pennsylvania Working Papers in Linguistics 14: 93–101.
Labov, William. 1994. Principles of linguistic change. Volume 1: Internal factors. Malden, MA: Blackwell.
—— 2010. Principles of linguistic change. Volume 3: Cognitive and cultural factors. Malden, MA: Wiley-Blackwell.
Labov, William, Mark Karen and Corey Miller. 1991. Near-mergers and the suspension of phonemic contrast. Language Variation and Change 3: 33–74.
Labov, William, Malcah Yaeger and Richard Steiner. 1972. A quantitative study of sound change in progress. Philadelphia: U.S. Regional Survey.
Ohala, John J. 1981. The listener as a source of sound change. In Carrie S. Masek, Robert A. Hendrick and Mary Frances Miller (eds) Proceedings of the Chicago Linguistics Society17:Papers from the Parasession on Language and Behaviour. Chicago: University of Chicago, 178–203.
Schadeberg, Thilo C. 1995. Spirantization and the 7-to-5 vowel merger in Bantu. Belgian Journal of Linguistics 9: 73–84.
Uffmann, Christian. 2010. The non-trivialness of segmental representations. Paper presented at the Old World Conference on Phonology (OCP) 7, Nice.
van Oostendorp, Marc, Colin J. Ewen, Elizabeth V. Hume and Keren Rice (eds). 2011. The Blackwell companion to phonology. Oxford: Blackwell.
Wedel, Andrew. 2011. Self-organization in phonology. In van Oostendorp et al. (eds), 130–147.
Wells, John C. 1982. Accents of English. Cambridge: Cambridge University Press.
Yu, Alan C. L. 2011. Mergers and neutralization. In van Oostendorp et al. (eds), 1892–1918.