11 NEURAL NETWORKS THAT CAN HEAR, SPEAK, AND REMEMBER
WHAT IT MEANS FOR A MACHINE TO “UNDERSTAND”
We’ve spent most of the past few chapters looking at how deep neural networks are able to recognize objects in images. I’ve focused on these networks largely because many of the machines in this book use vision in some form to perceive the world around them. But what if we wanted our machines to have other ways to interact with the world—to generate English sentences, or to understand human speech, for example? Would convolutional networks prove useful for this as well? Are there other neural network “primitives” that would be helpful? Popping up a level, does it even make sense to use neural networks for tasks like understanding speech?
The answer to all of these questions is yes, and in this chapter we’ll take a brief look at how to do these things. Before we get into these details, however, let me be clear about what I mean when I talk about computer programs that can “understand” human speech. We’re still a long way from having machines that can understand human language in the way a human does. However, we have figured out how to create computer programs that can turn a sound recording of a person speaking into a sequence of written words, a task commonly known as speech recognition. These algorithms do the same thing with a sound recording that AlexNet did with images: they classify the recording, tagging it with human-interpretable labels: words. And just as the algorithms to detect objects in images rival humans’ accuracy, our speech-recognition algorithms now rival humans’ ability to recognize speech.
DEEP SPEECH II
Imagine that you were given the task of designing a neural network that could transcribe human speech. Where would you begin? What would the input to the network look like, and what would its outputs be? How many layers would you use, and how would you connect these layers together? We can look at the speech-recognition system built by the web search giant Baidu to answer these questions. Baidu’s network rivals humans’ ability to transcribe speech; it could do this for the same reason Google’s network was able to rival humans at image classification: they started with lots of data. Baidu used 11,940 hours—over a full year of spoken English—to train one of their best speech networks. And just as the creators of AlexNet did with their ImageNet data, Baidu augmented their speech dataset by transforming samples from it: they stretched their recordings this way and that, changed the recordings’ frequencies, and added noise to them, so that they had many times the amount of data they started with.1 In each case they didn’t change what was being said; they just changed how it was being said. But having a lot of training data wasn’t enough on its own to build a network to accurately transcribe speech: they also needed to pick the right network architecture.
We want a neural network that can take a sound recording as its input and produce a sequence of letters—a written transcription of the recording—as its output. As the input to our speech network, we can use a spectrogram of the recording. A spectrogram summarizes a sound recording by describing the intensity of different frequencies in the recording over time. You can think of a spectrogram as a black-and-white image: the x-axis is time, the y-axis is frequency, and the darkness of each pixel is the intensity of a certain frequency at a certain time in the recording. The spectrogram for a high-frequency tone would consist of a single dark bar across the top of the spectrogram, while the spectrogram for a low-frequency tone would consist of a single bar across the bottom of the spectrogram. Several pulses of sound would appear in the image as dark blobs from left to right across a white background. And just as you can turn a sound recording into a spectrogram, you can also go the other way: from a spectrogram you can reconstruct the original recording. The fact that the spectrogram encodes the recording means that we can pass the spectrogram alone as an input to the neural network.
Now that we know that a sound recording can be turned into an image, we might ask ourselves whether the network should have some convolutional layers. The answer is yes, and that’s what Baidu’s network used: the first few layers of their network were indeed convolutional layers. But we’ll need more than just convolutional layers. We’ll need an explicit way for the neural network to deal with time.
RECURRENT NEURAL NETWORKS
The most common type of neural network that interacts with time-series data—or any sequential data, really—is the recurrent neural network, sometimes just called an RNN. An RNN is a neural network made up of identical “units” of neurons that feed into one another in a series, as in figure 11.1. Each of these units shares the same weights, just as convolutional filters share the same weights. The only difference is that convolutional filters that share the same weights don’t typically feed into one another. The very nature of RNNs, on the other hand, is that each RNN unit feeds its output directly into the next RNN unit, which, by definition, has identical weights as the last unit. And each RNN unit takes its input and transforms it in various ways before outputting it. This is the magic behind RNNs: the way they manipulate data and pass it to one another enables them to keep track of state.
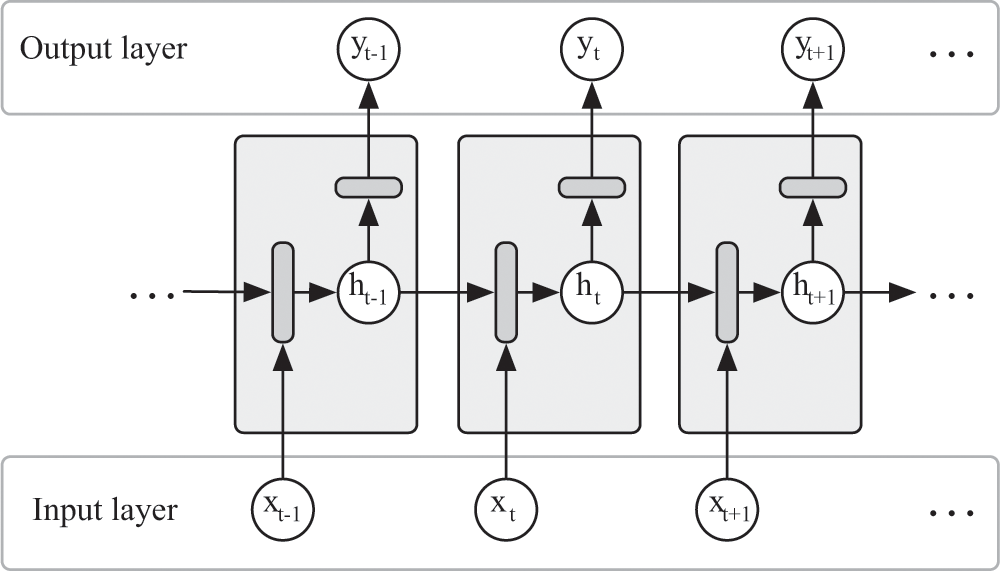
Recurrent neural network (RNN) units unfolded in time. Each unit has a state variable h that transitions from unit to unit. The transition is determined by the input x and the state of the previous unit. Each unit also produces an output y to share information about the state with the rest of the network. The dark boxes represent transformations—typically encoded by other neurons in the network—that may take place within the unit.
Let’s briefly think back to what it was about self-driving cars that enabled them to exhibit complex behavior. Their ability to make sense of the world—that is, their ability to perceive—was certainly critical. But cars like Boss that drove through urban environments needed some way to make intelligent decisions as they encountered complex situations. In the middle of Boss’s reasoning layer was a finite state machine (its Monopoly board), which kept track of how far along it was in carrying out its mission. As Boss made progress on its mission, it moved a virtual piece around on its Monopoly board to keep track of its state: where it is now, where it can go next, and how it should decide where to go next.
RNNs provide the same service for the neural network that the Monopoly board played for Boss. Each recurrent unit looks at its current state, does (or doesn’t do) something with that state, and sometimes changes the state based on what it perceives in the world. You can think of the RNN’s role as the piece-mover for the Monopoly board.
There are a few differences from Boss’s Monopoly board, of course. Boss’s finite-state machine had, not surprisingly, a finite number of states. The state of an RNN is often encoded with a vector of floating-point numbers, so the concept of a state in an RNN is more fluid: it’s a point in a high-dimensional space, and its position in that space defines the semantics of the state. Another difference is that the finite-state machine in a self-driving car like Boss was handcrafted by humans, with simple rules that Boss would follow to transition from state to state.
The states and transitions in an RNN, on the other hand, are based on rules encoded into its neurons’ weights; and these weights are learned from data. That said, each RNN unit is still very simple: it doesn’t do much more than keep track of, and update, this state. It’s just a state updater. To enable the network to do something interesting with the state, the RNN unit will typically output messages about the state to other parts of the network. For our speech network, these units output their messages deeper into the network. As you can imagine, with enough data, a chain of recurrent units in a speech network will learn states that are useful for summarizing frequency spectrograms of recorded human speech. They’ll learn that certain sounds are common and which sounds tend to follow other sounds.
Now that we have RNNs, we can use them in different places in the speech network. Just as we can build RNNs that point forward in time, we can also build RNNs that point backward in time, so that they learn states and transitions that will summarize spectrograms in a different way. We can also stack sequences of RNNs on top of one another—not end-to-end in the time dimension, but placed on top of one another so that they’re aligned in the time dimension, as in figure 11.2. Stacking RNNs this way helps for the same reason it helps to have multiple convolutional layers: as we go deeper, each RNN layer will summarize the previous layer by finding the most salient trends in it, building up higher and higher levels of abstraction to reason about the input to the network. Once we’ve stacked several layers of RNNs on top of one other, and stacked those on top of some convolutional layers, we can add a fully connected layer on top.

The architecture for Deep Speech 2, Baidu’s speech-recognition system. The network is trained using written transcriptions of recordings of human speech and a concept known as connectionist temporal classification, which searches for an alignment between the label and the fully connected layers. This image is adapted from Amodei et al., “Deep Speech 2” (cited in note 1).
So a speech network takes a spectrogram as input, and processes it with a network that looks a lot like AlexNet, except that there are some RNN layers sandwiched between the convolutional layers and the fully connected layers to enable the network to model the transition between different sounds. At this point, we just need a way to predict the transcription from the output layer of the network.
The output layer of the network is a grid of neurons that represent time in one direction and letters of the English alphabet (plus gaps between these letters) in another direction. When run, the network produces a prediction of how likely each letter is to occur at any given moment during the transcription. This prediction is encoded in the output values: it’s higher if the letter (at a given moment) is more likely to occur and lower if that letter is less likely to occur. But this leads to a challenge in predicting the transcription from the recorded sequence: we need to align the neurons in the output layer with the actual transcription. If we do the simplest thing, and take the most-likely letter at any given moment, then we will end up with many repeating letters, like this:
wwwhhhaattt iissss tthhe wwweeeaatthheerrrr lllikke iiinnn bboostinn rrrightt nnowww
One way to resolve this—at least for the task of predicting a sequence of letters—is to simply take the string of the most likely character at each moment in time, and then to remove duplicates.2 This will often lead to a plausible, if slightly incorrect, transcription, like this one:
what is the weather like in bostin right now3
Note that the word “Boston” has clearly been misspelled but is phonetically correct. Sometimes the transcription is mostly phonetic but looks more like gibberish, as in this transcription:
arther n tickets for the game4
That should have been transcribed as: “Are there any tickets for the game?”
We can fix these transcriptions by using statistics about sequences of English words. To get an intuition for how this can help, see which of the following two phrases sounds more natural. Is it this one?:
People he about spilled thing the fun secret most of the the was blender
Or this one?:
He spilled the secret of the blender was the most fun thing about people
These phrases have the exact same words, and both of them are semantically meaningless, but you’d probably agree that the second one just sounds more natural. If you look more closely at that phrase and pick any three consecutive words in it, those words flow like you might find them in a normal sentence. This isn’t the case for the first sequence of words. Baidu’s researchers used this same idea, keeping track of which word collections, up to five words long, sound the most natural, based on how frequently they appeared in English text.5 As you can imagine, using statistics about sequences of words like this can drastically narrow down the set of likely transcriptions. As another exercise, see whether you can predict the following word in this sequence:
rain fell from the _____.
Clearly this phrase ends with a word like sky or clouds. So, even if the recording objectively sounded more like “rain fell from this guy,” Baidu’s speech-recognition system would use language statistics to pick a transcription more like “rain fell from the sky.”
Baidu’s speech system then used a search algorithm to find this best-matching sequence of letters, given both the output layer of the speech network and the statistics about sequences of words it had from elsewhere. This search algorithm was a lot like the path-search algorithm Boss used to park in a parking lot, except that instead of finding a way to combine small path segments, the speech system searched for a sequence of letters; and instead of using factors like time and risk in its cost function, the speech system tried to maximize the likelihood of different letters and words in its transcription, given both the predictions from its network and the statistics of these words from its five-word language model.
GENERATING CAPTIONS FOR IMAGES
Although speech-recognition systems like the one above can accurately transcribe sound recordings, they don’t understand the content of the audio recording. We’re still far from having networks that can understand language, but researchers have found ways to use RNNs to make it look they can understand language. One recent breakthrough is networks that can create natural-sounding phrases to describe the content of images.
What’s so spectacular about these image-captioning algorithms is that everything—from understanding the image to generating a sequence of words to describe the image—is done by neural networks (with the exception of another search algorithm, which we’ll see in a moment). To put these algorithms into context, let’s take a quick look at some of their predecessors, which filled in templates with the names of objects the algorithm detected in the image. The output of these algorithms was like the typical “baby talk” you might expect from a computer program:
There are one cow and one sky. The golden cow is by the blue sky.6
Here’s another example:
This is a photograph of one sky, one road and one bus. The blue sky is above the gray road. The gray road is near the shiny bus. The shiny bus is near the blue sky.7
Although these algorithms do explain the scene, they’re also awkward: it is true that the shiny bus is near the blue sky in the photograph, but it’s semantically weird to say that the bus is near the sky. Yet this is what we’ve grown to expect from computers. You expect that your image-manipulation software can perform low-level image operations on an image, like adjust color balance and blurring pixels, but not more complicated things. And we don’t expect computers to use language in a complicated way either.
On the other hand, the neural network approach to generating captions can create descriptions such as the following:
A group of people shopping at an outdoor market
A group of people sitting in a boat in the water
and
A giraffe standing in a forest with trees in the background8
The neural networks to generate captions like these use a series of transformations to convert the photograph into a series of words. In the first of these transformations, they use a convolutional neural network to process the image. This is a lot like the way AlexNet processes an image, except that instead of predicting whether different objects were in the image, the network “encodes” the image into a large vector of numbers that provide a succinct description of the scene for the rest of the network. Once the algorithm has this vector summary of the image, the rest of the network—which consists of a sequence of RNN units—generates its caption. The units, as before, are linked by their states, and each unit in the chain outputs a single word of the caption, as in figure 11.3.9
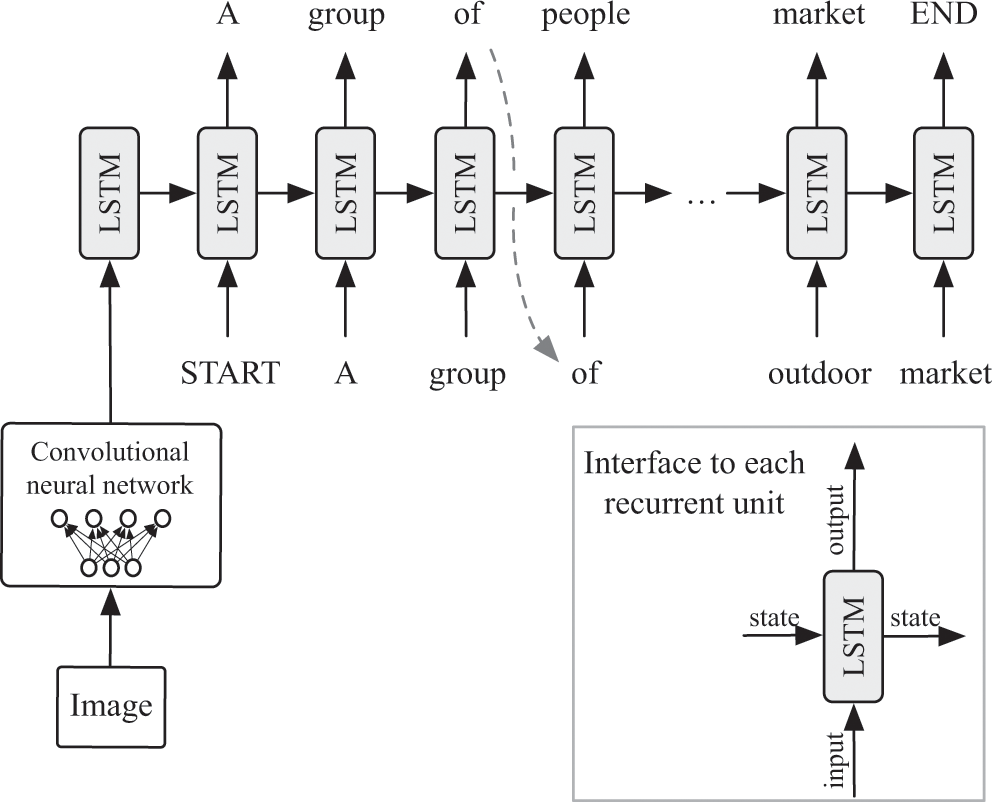
An image-captioning neural network. The state for each RNN unit summarizes how much of the caption has been generated. The output of each unit is a probability distribution over words; and the input to each unit is the previously generated word. The input to the first unit is the output of a convolutional neural network. This image is adapted from Vinyals et al., “Show and Tell.”
How could such a simple network generate coherent English captions? Remember the key feature of recurrent units: they enable a neural network to keep track of state. As we move further along in the chain, the state can change to keep track of what’s been said and what hasn’t been said. As each unit inspects its current state and outputs a new word, it updates its internal state so the next recurrent unit can do its job. And to help each unit update its state, the input to each recurrent unit is the word output by the previous recurrent unit.
You probably won’t be surprised to hear that we can improve the way this network generates captions by attaching a search algorithm to the top of the network, just as Baidu did for its speech recognition system. Technically the output layer of the neural network has one neuron for each word for each time step; its output values can be combined to predict how likely each word is to appear as the next word in the sequence. From the examples I showed a few pages ago, you can probably guess that the first word is likely to be “A” no matter what is in the image. If there is a cat in the image, then it’s not unlikely that the next word will be “cat,” and so on.
Instead of running the model once and selecting the most likely word each time we have a choice, the search algorithm runs the model many times to generate many sequences of words. Each time it needs to select a word, it selects a word that’s likely under the model, but the search algorithm searches in a narrow beam among the most promising candidate captions: in some iterations it might select “furry” instead of “cat,” and so on. Once the algorithm has run the model many times to generate many possible phrases, it evaluates each of them according to a cost function that measures how likely each sequence of words was according to the network, to find the best caption among many.10
LONG SHORT-TERM MEMORY
Because RNNs have units that feed into one another, we can think of them as deep networks when unfolded in time.11 For a long time RNNs couldn’t be built too deep because the messages that we need to send through a chain of these units during training tended to decay as they passed through the chain. The deeper into the chain of recurrent units you went, the more they tended to forget. One way the research community has gotten around this is by using “control” neurons that modify the way the unit interprets and modifies its state, as in figure 11.4.12 You can think of these control neurons as special wires that change the way the unit behaves. These control wires work like the “set” button on a digital clock that allows you to set the time. If you hold down the set button, the clock will enter a special mode, so that when you press the other buttons, you can modify the time. When you’re done, you can return the clock to its normal mode, which is to just increment the time, second by second.13 When the control wires are set on these RNNs, their state can be updated just like that clock; otherwise they transform the state based on their normal rules. These special units, used in Google’s image-captioning network among other places, are called Long Short-Term Memory units, or LSTMs (see figure 11.4).

Long Short-Term Memory (LSTM) units in a recurrent neural network. This particular LSTM is the one used by Google for its image caption generator. As with a general RNN, the state can shift with each subsequent unit based on what is observed in the network. LSTMs like this one use “gates” to modify the input, the output, and the state for each unit, typically with just a multiplication. Adapted from Vinyals et al., “Show and Tell” (cited in note 8).
ADVERSARIAL DATA
Although these algorithms are getting automata a bit closer to understanding natural human language, they are still very primitive, in the sense that they can break down easily, especially if you give them inputs intended to trick them. For example, we saw in the last chapter that it’s possible to create optical illusions that can trick neural networks into thinking they’re seeing something that’s not actually there. It would be similarly easy to trip up the caption-generating network by passing such an image to it. Researchers in the field of machine learning would call inputs like this—that is, data intended to trick a machine-learned model—adversarial inputs.
This idea of “tricking” neural networks with adversarial inputs is important because by understanding what sorts of images can trick these networks, we can also learn how to make them more robust. Some very recent and promising work in the field of deep learning embraces this idea to train networks that can generate realistic images.14 One part of the system tries as hard as possible to generate images that look like the images that come from some category you care about—such as pictures of cats’ faces—while another part of the system tries its best to figure out whether the generated image is from that category. Both sides of these generative adversarial networks (GANS) continue to improve until the generative part of the system is extremely good at creating realistic data. It’s a game of cat-and-mouse, an adversarial arms race, where each side does its best to compete against the other side.
It may not seem immediately obvious why GANS are useful: why should we care about two networks that compete with each other? These networks are useful when we want to create data for some purpose: we might want a network that can generate a natural-looking picture of a horse, a bird, or a person, for example. It’s possible to train one of these networks with pictures of horses and zebras, for example, to create a “generative network” that can convert photos of horses into convincing (but fake) photos of zebras; and we can train a network to produce photorealistic scenes from Van Gogh paintings.15 And as I mentioned above, these networks can be used to generate non-image data, like sounds or realistic English sentences.
On that note, let’s get back to the difficulties in building a program that can understand human language. The programs that we’ve discussed so far are still far from understanding human language. They can generate short sentences to describe images, but when you look closely enough at these algorithms, you’ll quickly recognize their limitations.
In the first chapter of this book I mentioned IBM’s Watson, which beat champions Ken Jennings and Brad Rutter in the American game show Jeopardy!. If we’re still far from designing machines that can understand natural human language, you might wonder, how could Watson have performed so well at a game that seems to require a contestant to understand of the nuances of the English language? There was certainly some clever engineering in the project, but as we’ll see in chapter 12, Watson wasn’t engineered to understand the questions. Watson was engineered to answer them.