13 MINING THE BEST JEOPARDY! ANSWER
THE BASEMENT BASELINE
As David Ferrucci began plotting IBM’s path for taking on Jeopardy!, he wanted some evidence that the project wouldn’t be too hard. As Stephen Baker, the author of Final Jeopardy, observed, there was enough internal pushback that it could be politically risky to devote many person-years of effort if there was no chance that they could succeed.1 At the same time, he also became concerned about the possibility that it might be too easy to build a computer to play Jeopardy. What if IBM invested years of research in the project and spent millions on marketing, only to be shown up by a lone hacker working in his basement for a month? This could be a huge embarrassment—let alone a waste of time—for the company.2
Ferrucci and his team came up with a simple test that became known as the basement baseline. As most of his team spent a month converting their existing question-answering system to play Jeopardy, Ferrucci asked James Fan, who was the most enthusiastic member of the team about building a system to play the game, to spend that month working alone in his second-floor office, hacking together a system with whatever tools he could find. James Fan wouldn’t work at all with the rest of the team during this period, except to join them for lunch and meetings. Instead, he would have to come up with his own methods. This hacker baseline would then compete with the system the other researchers were converting in order to play Jeopardy. If James Fan’s system did better, then Ferrucci and his team needed to figure out how to address that.3 If they couldn’t demonstrate enough new ideas in this period, that would also be evidence that the problem was too hard.4
After a month of effort by the two teams—the regular research team and the team consisting of just James Fan—they found the basement baseline to be okay for a baseline—nearly as good as the converted system by some metrics—but it still couldn’t play Jeopardy anywhere close to how well a human could play Jeopardy. At the same time, James Fan had found some promising ideas during his effort.5 This was a relief, and the team now had some evidence that their problem had just the right amount of difficulty: it wasn’t so easy that they were likely to be embarrassed, and yet they had learned that they could improve on their current approaches by applying some good old-fashioned elbow grease and throwing some extra manpower at the problem.6
As we saw in the last chapter, however, they faced another problem: the system they had converted to play Jeopardy still fell far short of where it needed to be to beat a human player.7 Instead of trying to make their existing system work, they threw away their old assumptions and started from scratch. After months of experiments they converged on a system they named DeepQA.
Their DeepQA system began with the Question Analysis phase we saw in the last chapter. The goal of the Question Analysis phase was to pull the most salient information out of the clue, to find the people, places, and things mentioned in it; to find what type of answer the clue was looking for; and to carefully label these bits of information and package them up for later phases in the pipeline. The remaining phases in DeepQA, which we’ll cover in this chapter, would enable Watson to find the correct answer.
Watson didn’t find an answer to the question in the same way a human would have come up with an answer. A human might think about the question, decide on the single most appropriate source for the answer, and look the answer up in that source. If she doesn’t find the answer where she looked, she might look up the answer in the second-best source, or she might adjust her research path if she finds a promising lead along the way. Once the human researcher finds the answer—very possibly from a single source—she closes her books, puts them away, and answers the question confidently.
Watson, however, treated each question as a massive research project. Its process was a lot like searching for the perfect person to hire for a job opening. The first step involves creating a detailed job description; that was Watson’s Question Analysis phase, which we saw in the last chapter. Once Watson had finished putting the together the job description, it then collected résumés for hundreds of possible people from a myriad of sources, researched many of these candidates in detail by “interviewing” them, and then carefully weighed the pros and cons of each candidate to select the best one among them all.8 Let’s begin with the first of these steps in finding and evaluating candidates: the way Watson came up with a list of candidates, a phase Watson’s creators called its Candidate Generation phase.
CANDIDATE GENERATION
To fill your job vacancy, your first step at this stage would be to collect résumés of people who might be interested in the job. Your goal isn’t to select the right person; it’s just to put together a list of all people you should consider hiring. You would likely seek out these applicants in many places. You might list the job on a jobs search engine, you might reach out to some people in your professional network, and you might post the job opening on your company’s website. You might even put a listing in the local classified ads. After some time, you will have collected a nice stack of résumés for these candidates.
Watson used the same approach to create its list of candidate answers. Watson’s goal wasn’t to select the correct answer; it was just to collect possible candidates for it. But Watson’s problem was a bit trickier than the hiring problem: unlike a job opening—for which there might be more than one qualified applicant—clues in Jeopardy have exactly one correct answer. If the correct answer wasn’t part of Watson’s candidate list at the end of this stage, then Watson had no chance at answering the clue correctly. Watson therefore had a low bar to consider something as a candidate.
To be concrete, let’s look at the clue about the 2008 Olympics we saw in the last chapter, to see how Watson would find candidates for it. Here’s that clue again:
Milorad Čavić almost upset this man’s perfect 2008 Olympics, losing to him by one hundredth of a second.
During the Question Analysis phase described in the last chapter, Watson would have found out several things about the clue: in figure 12.3, we saw that Watson would have identified the proper nouns “Milorad Čavić” and “2008 Olympics” in the clue, that it would have found the focus, this man, and that it would have found the answer type, man. With this information about its clue, Watson could start to seek out candidate answers.
Watson looked all over the place for its candidate answers, including in news articles and encyclopedia articles. Some of its candidates came from its structured data sources, which were mostly tables with different types of relations (remember, relations were connections between people, places, and things). As a rough rule of thumb, you can assume that the relations Watson knew about were the contents of those “info-boxes” you can find on the margin of some Wikipedia pages.9 For example, in 2010, the info-boxes on the Wikipedia pages about Milorad Čavić and the 2008 Olympics included the facts that Čavić’s nationality is Serbian and that the 2008 Olympics took place in Beijing. So Watson would add “Serbian” and “Beijing” to its list of candidate answers, along with some of the other arguments to relations it found about these two. You can see some candidates I found for this clue from these relations in table 13.1.
Candidate answers for the clue “Milorad Čavić almost upset this man’s perfect 2008 Olympics, losing to him by one hundredth of a second”
|
Source of candidates |
Candidate answer |
|
Relations from Wikipedia info-boxes (DBPedia) related to “Milorad Čavić” and “2008 Olympics” |
Serbian (Čavić’s nationality) |
|
Candidates from Wikipedia: the titles of articles in the search results, articles that redirect to these articles, text of hyperlinks between articles, and titles of the pages linked from these results |
Grobari (title) |
As I mentioned in the last chapter, databases of relations only worked for a small fraction of clues. This clue was no exception: although Watson wouldn’t have known this yet, none of the candidates we found from these structured databases provided the correct answer. But that’s okay. Remember: Watson didn’t need to select the correct answer at this stage in the pipeline. It just needed to make sure the correct answer was somewhere in its list. That’s why Watson looked in many more places.
SEARCHING FOR ANSWERS
Watson continued its search for candidate answers in its vast unstructured data stores, collections of documents like encyclopedia and newspaper articles, Wikipedia articles, literary works, dictionaries, and thesauri. But how could Watson find answers from these massive collections within just a few seconds? Watson did it in the same way you find answers in large collections of text documents: with a search engine.10
Since Watson wasn’t allowed to access the internet during the competition, it couldn’t simply use a web search engine like Google. Therefore Watson’s researchers collected all of Watson’s documents and loaded them into their own custom search engines before unplugging Watson from the internet. These search engines then ran as part of Watson in IBM’s datacenter during the game.11 From the perspective of Watson, these search engines worked a lot like a web search engine works for you: you enter a search query and get back a list of search results.12
To use these search engines, Watson just needed to come up with search queries. To make these search queries, it used the words or phrases from the clue that it found during its Question Analysis phase to be important, and it included the answer type (president, vegetable, sense organ, duo) in the query. If it found a relation in the clue, like the actor-in relation, it gave any arguments to that relation in the clue more weight. When you search for an answer on Google, you probably sometimes take a moment to think about which terms to include in your search query. Watson didn’t think at all about how it crafted its queries: it just filled in blanks in simple templates created by its developers with the information it found during its Question Analysis phase.
After Watson sent these queries to its search engines, it created more candidate answers from the results. Sometimes this was as simple as adding the titles of the search results as candidate answers.13 Other times Watson used more nuanced tricks.
One trick made clever use of Wikipedia articles. During his month of hacking on the basement baseline, James Fan discovered that Wikipedia could be exceptionally useful in generating candidate answers.14 After researching Wikipedia a bit more, the team working on Candidate Generation discovered that an astounding 95 percent of Jeopardy answers were also the title of some Wikipedia article.15
Armed with this information, the team made Wikipedia a cornerstone in Watson’s Candidate Generation phase. Any time Watson found a Wikipedia passage in its search results for a clue, it went through a checklist to generate candidate answers from that passage. First, it added the Wikipedia page title for the passage to its list of candidate answers. It also looked more closely at the passage matching the search query to find more candidates: it created candidate answers from the text of any hyperlinks (called anchor text) in the passage, as well as from the titles of any Wikipedia pages linked from those passages and the titles of any Wikipedia pages that redirected to those links.16
Watson’s researchers also built up a list of all Wikipedia article titles so they could look for these phrases elsewhere, whether they appeared in documents from other sources—where they could become candidate answers—or in the clue itself during Watson’s Question Analysis phase.17 This is how Watson could know, for example, that “2008 Olympics” is a proper noun in its clue: there’s also a Wikipedia article titled “2008 Olympics.”
Let’s look back at that clue about the 2008 Olympics to see what candidates we could get out of these Wikipedia tricks. I created a search query for the clue similar to what Watson would have come up with, and I entered it into Google, restricting the search to just give results from Wikipedia.org.18 Remember, Watson couldn’t use Google since it was cut off from the internet, but its custom search engines served roughly the same role, and Wikipedia was one of the sources Watson’s researchers programmed into Watson’s search engines. If we go through these search results and follow the checklist Watson followed for Wikipedia—adding the text from article titles, the text of web links, and so on—then we’ll come up with a lot more candidate answers, such as: Rafael Muñoz, Pieter van den Hoogenband, Swimming at the 2012 Summer Olympics, and Michael Phelps. I show these and more in the bottom half of table 13.1.
These candidates are already starting to look a lot better! This is in part because now at least some of them match the clue’s answer type, which was man. But remember: Watson didn’t know these answers were more promising. In fact, when I was collecting these answer candidates to write this chapter, I found the correct answer, with strong evidence to support the answer. But even though Watson would have come across this evidence when it was generating candidates, it didn’t check whether it found the correct answer until later on. It just continued its search, looking through more and more sources, to compile its large list of candidates.
LIGHTWEIGHT FILTER
By the time Watson had finished compiling its list, it typically had several hundred candidates, and it needed to perform a deeper analysis of each of them to figure out which one was correct. Watson would need to devote considerable effort to researching each candidate—enough effort to prevent researching them all—so it narrowed its list down to a smaller set with a “lightweight filter.”
You would do the same thing in your search for someone to fill the job opening. Once you had a stack of résumés for your job posting, your next step would be to perform a “deeper analysis” of your job applicants—that is, you would invite some of them onsite for interviews. If you’re hiring to fill a single role and you have a few hundred applications, however, you don’t have enough time to interview all of these applicants onsite. You would instead apply a lightweight filter to narrow down the résumés—for example, by eliminating those candidates lacking a college degree or experience most relevant to your job—before inviting that smaller set of candidates for an onsite interview. Out of necessity—you have a lot of résumés to review—this filter would be simple.
Watson’s lightweight filter was also very simple: it might test whether the candidate answer matched the answer type—president, city, or man, for example.19 For the clue about the 2008 Olympics, the answer type was man, so we could assume that Watson narrowed down its candidate list for this clue to those that match the names of people. Any candidates that passed the lightweight filter moved on to the Evidence Retrieval phase, so that Watson could spend more time collecting information about each candidate.20
EVIDENCE RETRIEVAL
This Evidence Retrieval phase was akin to doing onsite interviews. Whereas you might interview only a few candidates, Watson carefully researched about 100 of its candidate answers.21 To do this, Watson again turned to its databases and search engines.
If you were interviewing a job candidate onsite, you probably wouldn’t get to know the job candidate by going through the job description bullet by bullet. You would ask the candidate questions tailored to the individual’s background as well as to the specifics of the job opening, hoping to find unique ways the candidate is a good fit for the job. Watson did the same thing when it researched its candidate answers. It formulated questions—search queries—specific to both the answer candidate and the clue. Again, it turned to its structured and unstructured data sources to do this research.
Watson created its search queries by combining important words and phrases from the clue with the candidate answer, treating the candidate answer as a required phrase. Here’s how that might look for the 2008 Olympics clue, if we were to formulate it as a Google search query:
+“Rafael Muñoz” Milorad Čavić upset 2008 Olympics losing hundredth second
Watson then issued queries like this to its search engines, as in figure 13.1, so it could collect evidence tailored to both the candidate and the clue.

The evidence retrieval phase of Watson. Watson first filtered its answer candidates using a lightweight filter and then collected reams of evidence for each of its remaining candidates from its databases and search engines.
In doing its research, Watson collected a pile of evidence to support each of its candidates; most of this evidence was just pieces of text from its search results. For the candidate answer “Rafael Muñoz,” the Wikipedia search results aren’t too promising: the first result, a page about swimming in the 2008 Olympics, only references Rafael Muñoz in a table with one of his swim times. (As an aside, it turns out that evidence for the correct answer—which is not Rafael Muñoz—is actually elsewhere on this page, but again, Watson would have had no idea about this, because it was following prescriptive rules, and none of these rules told it to look at that part of the page.) The other search results for the query about “Rafael Muñoz” are similarly useless.
Of course, Watson didn’t stop after researching its first candidate. It carefully researched all of the candidates that passed through its lightweight filter. Let’s try this Evidence Retrieval exercise with a different candidate answer: Pieter van den Hoogenband. The search results for this query are a bit better, though they’re still not great. One result is the Wikipedia page about Hoogenband, which contains the following passage:
He returned to the Olympic Games in 2008 in Beijing and finished fifth in the 100 m freestyle.
That sentence has matches for 2008, Olympics, and 100 (which is like hundredth), but otherwise is not a good match. The remaining results for this candidate are also underwhelming. Let’s try one final candidate: Michael Phelps. The very first search result, a Wikipedia page about swimming in the 2008 Olympics, contains this passage:
U.S. swimmer Michael Phelps set a new Olympic record of 50.58 to defend his title in the event, edging out Serbia’s Milorad Čavić (50.59) by one hundredth of a second (0.01).22
Ah-ha! That looks much more promising. A similar passage appears in another search result, the Wikipedia page about Michael Phelps:
On August 16, Phelps won his seventh gold medal of the Games in the men's 100-meter butterfly, setting an Olympic record for the event with a time of 50.58 seconds and edging out his nearest competitor Čavić, by one hundredth (0.01) of a second.23
Again, the candidate “Michael Phelps” looks very promising. If we can trust Watson’s ability to evaluate the evidence for its candidates later in the pipeline, this approach for the Evidence Retrieval phase seems promising.
Wikipedia wasn’t the only source Watson used in its Evidence Retrieval stage; as I mentioned above, Watson used a variety of sources, including dictionaries, thesauri, encyclopedias, newswire archives, and tables of relations, like alive-until and capital-city-of. Watson’s creators made sure Watson’s queries to different sources were appropriately customized. Watson created queries for each relevant source given what it had learned about the clue from the Question Analysis phase and given the candidate answer it was researching, sometimes using information from the clue’s parse tree. Then it stored the results of the search to use later.
When we found the passage suggesting that “Michael Phelps” was the correct answer to the clue, we were satisfied that we had the answer and knew we could stop looking. But Watson wouldn’t have stopped its research like a human would have done, because it didn’t try to understand the evidence it was collecting yet. It didn’t start to judge its candidates until its next phase, when it would score the evidence. As far as Watson was concerned at this point, the supporting evidence for Michael Phelps was no stronger than the evidence for Pieter van den Hoogenband; the evidence for each candidate was simply pieces of text sitting somewhere in its computer memory, similar to notes taken by the people who interviewed the job candidate. Instead, Watson simply continued its research, collecting passage after passage of evidence to support its remaining candidates. When Watson was finally done interviewing candidates, it was ready for perhaps the most interesting bit: scoring each of these candidates.
SCORING
After collecting supporting evidence for each of its candidates, Watson passed the results to a collection of scoring algorithms. Just as Watson used a variety of rules to analyze its question, its Scoring phase used a variety of rules to analyze the evidence for each candidate answer.
These scorers did most of the work you’d probably consider “interesting” in Watson: they estimated how closely each piece of evidence about each candidate answer matched the clue.
This phase would be akin to creating a giant spreadsheet to evaluate the evidence for each job candidate. To evaluate each piece of evidence for a candidate, you might use several different criteria: whether the evidence demonstrates good communication, job-related experience, culture fit, or on-their-toes critical thinking ability. Your goal in this Scoring phase is not to evaluate the candidates themselves: your goal is to evaluate only the candidates’ responses to the questions you asked, to try to stay objective. This means you might need to separately score many pieces of evidence for each candidate. You’d then distill the spreadsheet’s results into a final decision in a later stage, just as Watson waited until a later stage to weigh its own scores for each piece of evidence.
Watson used many scorers to evaluate its evidence, but each scorer tended to be fairly simple. One scorer, for example, measured the number of overlapping words between the clue and the supporting passage. It weighted each word with an approach called IDF, which gives rare words more weight, as a proxy for how much “information” the word conveys. The intuition behind this approach is that rare words convey more information precisely because they are rare: if the clue and the passage share a rare word, such as “Čavić” or “scorpion,” then this should carry more weight than if they share a frequent word, like “almost” or “one.”24 The candidate answer “Michael Phelps” would have been scored well by this metric, because many supporting passages for the candidate Michael Phelps shared rare words, like “Čavić,” with the clue. The passages supporting the other candidates wouldn’t have fared so well for this scorer.
The glaring weakness of this word-overlap scorer is that it completely ignores the order of words in the supporting passage. For example, take this clue:
He famously became the President of China in June of 2003.
The word-overlap scorer would score the following passage highly even though it suggests the wrong answer:
President George W. Bush famously praised China in June of 2003.
Clearly this scorer would give the wrong passage too much weight, simply because it has many overlapping words.
So Watson also had some scorers that could address this shortcoming. One of them attempted to align the words in the clue and the passage sequentially, finding an alignment between the two with a search algorithm. Once aligned, matching words caused the score to be higher, while mismatching or missing words caused the score to be lower. As before, the alignment scorer gave more weight to rare words, preferring alignments that matched on rare words over those that matched on common words.
One scorer the IBM researchers added was a gender scorer; it was evident that Watson needed this scorer after Watson saw this clue during testing:
This first lady was born Thelma Catherine Ryan, on March 16, 1912, in Nevada.25
Watson’s answer, before it had the gender scorer, was “Richard Nixon.” (The correct answer was Nixon’s wife, Thelma Catherine “Pat” Nixon.)
Watson also used parse trees in its scorers. One scorer was like the word-overlap scorer, but instead of measuring word overlap, it counted how often pairs of words that were connected to each other in the clue’s parse tree were also connected to each other in the supporting passage’s parse tree.26 Another scorer tried to directly align the parse tree for the clue with the parse tree for the passage; if the resulting two parse trees, when aligned, matched the focus to the candidate answer, then this provided strong support for the candidate.
Some scorers checked whether dates from the clue and supporting passages agreed; others checked for geographic agreement between the clue and the passage. The list of scorers used by Watson went on and on; Watson had over a hundred scorers in all. As with the models for the Netflix Prize, any time someone in the team behind Watson found a shortcoming in the way Watson scored its answers, she could turn her intuition into a mathematical function, encode it as a scorer, test whether it improved Watson, and, if so, add it to Watson.
By the time Watson had finally finished scoring its candidates, it still hadn’t formed an opinion about which candidate was best, although it was much closer. At this point it had lists of numerical scores for each bit of evidence for its candidates. Watson would finally form an opinion about its candidate answers in its final stage: the Aggregation and Ranking phase.
AGGREGATION AND RANKING
You might think that for Watson to select its top candidate, it could just score its answers with a simple classifier—just as we did for the children’s cookbook, or just as an artificial neuron does with its inputs. But things weren’t so simple for Watson. Watson did eventually use a classifier, but it needed to transform its spreadsheet of scored evidence into the right format first. Remember that when we created the spreadsheet to evaluate bits of evidence for each candidate, we might have had lots of pieces of evidence for some—and therefore lots of scores for these candidates—while we might have had little or no evidence for others—and therefore few scores for those candidates. The list of candidates was unwieldy in other ways too: there could be duplicate answers among them, and so on.
In short, this spreadsheet wasn’t in the right form yet to feed into a classifier, because the things Watson was classifying—answer candidates—were heterogeneous. Weighted-average classifiers expect each item you’re classifying to have the same set of features. Using a classifier on these candidates would be like trying to fit a square peg into a round hole. It just doesn’t work. To resolve this mess, Watson used a sequence of seven separate transformations, each with its own classifier, before producing a final answer.27 You can see a sketch of this in figure 13.2.
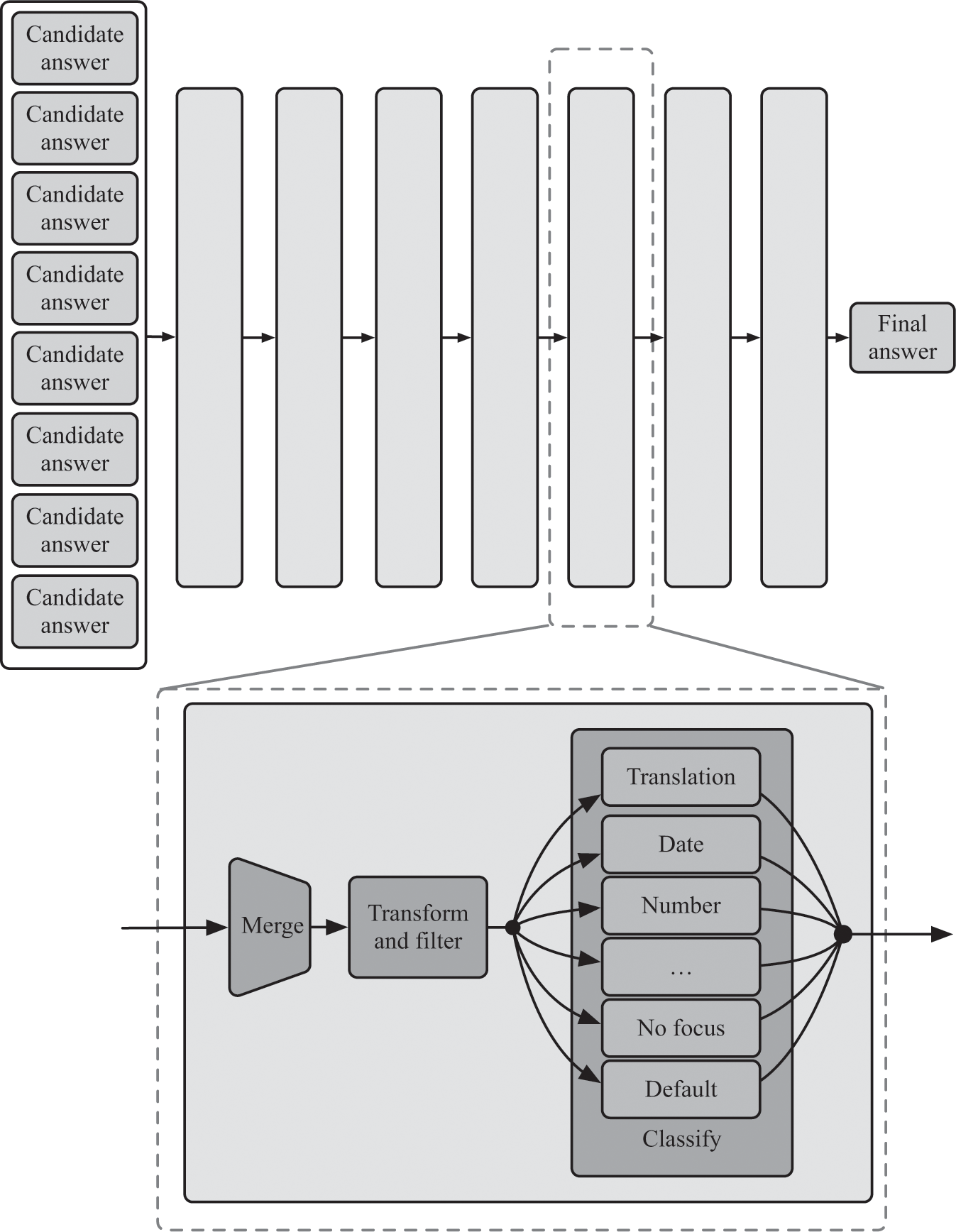
The Merging and Ranking phase in the DeepQA framework on which Watson ran. This phase consisted of seven operations, each of which had a merge step, a transform and filter step, and a linear classifier step, which used different classifiers for different types of questions. Each of the seven operations was unique in that their merge, transform, and classify steps differed (some transformations even skipped one or more of these steps), but the framework provided the capability for each step within each transformation.
One of these transformations merged duplicate answers. In our Olympics example, the candidate answer Phelps is the same as Michael Phelps, and Bolt is the same as Usain Bolt. Sometimes Watson had a more-specific version of an answer and a less-specific version of the answer, such as a generic “sword” and “Excalibur,” the name of a legendary sword. In each of these cases, Watson merged these duplicate answers into a single answer, combining their supporting evidence in the process.28
Another problem Watson faced was that it might have a different number of scores from each scorer across different candidate answers. So another of these seven transformations combined these scores in whichever way made sense for the scorer. Watson averaged the results of some scorers for each candidate, while for other scorers Watson took the highest value the scorer produced across all of the candidate’s supporting evidence.29 Yet other phases in Watson’s ranking pipeline transformed the scores by scaling them or filling in missing feature values.30
Finally, a single classifier that’s good at separating the best candidates from the worst candidates might be bad at differentiating between the very best candidates. So one transformation in Watson’s pipeline used a classifier to filter out the very worst candidates, another selected the top five candidates, and then one more selected the best of those five.31
These transformations ultimately manipulated Watson’s candidates until they were in a form that was conducive to applying a simple classifier, which was the final stage in the pipeline. The transformations took the square peg and shaved off its corners so that it could fit through the round hole, so that Watson could eventually feed it into that classifier.
The fascinating thing about these seven layers in Watson’s final Merging and Ranking phase was that each layer had the same architecture. That doesn’t mean that they did the same thing; as we just saw, each layer performed a different operation for Watson. But the way Watson plumbed data through each layer was identical. Each layer was composed of three basic elements: an evidence merging step, a processing step that performed whatever operation was unique to that layer—like manipulating features or filtering out candidates—and then a classification step to rescore candidates for the next phase. In some ways, these seven layers were similar to a seven-layer neural network; you can even think of this as a custom-built neural network on steroids, where the operations at the neuron level were more expressive than simple neurons, a bit like Google’s Inception network.32 The first two steps of each layer performed nonlinear transformations to the candidates, and then the third step—the classification step—was a simple linear classifier followed by the S-curve we saw in the last chapter. And the result of these transformations was a list of Watson’s final answers, each with a confidence score. Watson’s selected answer was the candidate from this list with the highest score.
TUNING WATSON
Watson was an absolutely massive system. In its complexity, it was also slow and difficult to tune. In an early version of Watson, which ran on a single CPU, Watson took two hours to answer a single question.33 Fortunately Watson was also designed so that many of its stages could be run in parallel. For example, instead of researching the individual candidates separately in succession, Watson researched them all at once by farming its work out to many different CPUs. By making Watson parallel and distributing its work across about 2,880 processors, Ferrucci’s team drove down Watson’s answer time until it was consistently less than five seconds—and fast enough to beat Rutter and Jennings.
But how did Ferrucci and his team reason about such a complicated system? Watson was a huge software project that required the coordination of a large team of researchers—about 25 researchers working over a four-year period.34 Changes couldn’t be made in isolation. If a researcher improved her part of the system, her change might cause unanticipated problems elsewhere. To design and tune a complex machine like Watson, Ferrucci and his team used experimentation and end-to-end metrics extensively. They carefully measured every change they made, and they performed “marginal” analyses of Watson to measure how well Watson performed if they added or removed a single scorer; or how well Watson performed if they included only a single scorer. And all throughout, they kept careful track of where Watson was in the Winners Cloud, the scatterplot that we saw in the last chapter, which summarized how accurate human Jeopardy champions were when they answered questions at different levels of confidence.
DEEPQA REVISITED
What was so special about Watson that enabled it to beat its human competitors at Jeopardy, when no other system up to that time could come anywhere close? Watson differed from its predecessors mostly in its sheer scale and in its use of DeepQA. Up to now, I’ve talked about Watson and DeepQA as if they were the same thing; but they were technically somewhat different. DeepQA is a data-processing engine, and Watson—at least Watson the Jeopardy-playing program I’ve talked about in the past two chapters—was built on top of DeepQA. DeepQA was a more general-purpose engine that could be used for other purposes, and IBM had experimented with it in applications as diverse as medicine and gaming. Ferrucci and his team found that, when they adapted DeepQA to one of the question-answering competitions they had worked on before Jeopardy, it performed better than the system they’d built specifically for that competition.35 Meanwhile, the converse wasn’t true: when they tried to adapt the older, competition-specific system to play Jeopardy in that first month of work, it failed miserably.
DeepQA has nothing to do with the deep learning. The “Deep” in DeepQA refers to deep natural language processing or deep question answering, phrases IBM used to contrast it with simpler approaches to natural language processing, like the methods used in its individual scorers. Its strength came in its blending of these shallow methods, one of its core design principles, just as the best models from the Netflix Prize were blends of simpler models.36
WAS WATSON INTELLIGENT?
Was Watson’s ability to answer Jeopardy questions an indication that it was truly intelligent? The answer is the same as for the other machines in this book: not really—at least if we’re going to compare it with human intelligence. To understand why, let’s think back to how Watson found the correct answer when it was presented with a clue. Watson’s first step was to tease apart the clue with a variety of rules created by humans. It created a sentence diagram and used its handcrafted rules to pull out and label key bits of information that it would use to answer the clue. Watson then used these bits of information to search for the correct answer with search engines. It created a list of candidates with the result, filtered these candidates down, and searched for more evidence to support each candidate. After this it scored the evidence it had collected, and then finally it selected the best candidate with its series of transformations and classifiers.
At no point in this pipeline, however, did Watson actually understand what the clue was asking. It simply followed a deterministic sequence of steps, inspecting the question and scoring the supporting evidence with human-engineered rules and weights it had learned from data.
We can gain more insight into Watson’s limitations by looking at where it went wrong during its live games. We already saw a case where Watson embarrassed itself by guessing that Richard Nixon was a first lady of the United States before it had a gender scorer. These problems could occur any time Watson lacked the correct scorer or filter. A related problem caused Watson to sometimes offer offensive answers.
As Stephen Baker noted in Final Jeopardy, Watson and some human competitors were asked during a practice session for a four-letter word in the category Just Say No. Although Watson wasn’t confident enough about its answer to buzz in, its top choice, which was displayed on the screen for all to see, was “What is Fuck?” (Fortunately, a Jeopardy executive and his colleagues in the room found this funny rather than offensive.) This wasn’t an isolated mishap: the team found that five percent of Watson’s answers might be considered embarrassing even if they weren’t outright offensive. Ferrucci put together a team to ensure Watson wouldn’t say anything stupid during its live game (this team became known as the “Stupid Team”), while another team built a profanity filter with the potential to “censor” Watson during its live game.37
Watson was also limited by the ways it interacted with the world. For example, during one of its live games, Watson came upon a category in which it could answer clues very accurately. Watson’s creators had cleverly programmed it to favor such categories when it had control of the board. Unfortunately for Watson, the clues from this category were also very short, which meant that any time Watson selected a clue from this category, its human competitors could answer more quickly than Watson, taking points for the answer and taking control of the board away from Watson.38 In another case, Watson buzzed in after Ken Jennings answered a question incorrectly. Watson’s answer was incorrect too, but it wasn’t an unreasonable incorrect answer. The problem was that Watson gave the same incorrect answer Jennings had just given!
Most information about DeepQA has come from IBM itself, which has a financial incentive—and a skilled marketing team—to promote Watson as truly “intelligent.”39 In one of its white papers, for example, IBM described Watson’s scorers as “reasoning algorithms,” which is a bit of a stretch, when some of these scorers only do things like count up the number of overlapping words. IBM has marketed Watson to be a generically intelligent solution for a wide variety of problems.
However great Watson was at Jeopardy, the original version was still engineered for that one very specific task. Just as Pragmatic Theory focused on winning the Netflix Prize above all else, the team behind Watson focused on building a system that could play Jeopardy. And so Watson—at least the original version of Watson—couldn’t do anything else, without first being retooled. And indeed, IBM has marketed Watson for a variety of other applications. Some of these other systems are likely to have been implemented so differently from the original Watson that it’s difficult to judge their performance on those other applications. In fact, the Watson brand has sometimes received disappointing reviews beyond Jeopardy.
That said, when Watson made its initial splash, IBM published about how it worked, and this research has been accepted into the mainstream natural language processing community. No doubt that Watson’s ability to play Jeopardy is widely seen as a truly respectable engineering achievement, and IBM set the bar considerably higher in building it.40
During a game of Jeopardy, players like Watson must make many types of decisions during the game that have nothing to do with understanding natural language. These decisions involve higher-level strategy, such as when to buzz in, whether to buzz in, how much to wager, and which clue to select next. In addition to their clue scorer, the team behind Watson carefully crafted algorithms for Watson to make these strategic decisions.
These algorithms were based on models Watson had of its human opponents’ behavior. We could spend an entire chapter on this topic, outlining how Watson simulated its games far into the future to make its decisions. But instead of focusing on Watson for another chapter, let’s instead look in the next chapter at the more general question of how smart machines can play games of strategy.