16 REAL-TIME AI AND STARCRAFT
Games are a helpful benchmark, but the goal is AI.
—Michael Bowling, professor at the University of Alberta1
BUILDING BETTER GAMING BOTS
Considering that the AI community has found a way to beat world champions at Go, and that Go was long considered to be one of the most difficult challenges for AI, what are the next big challenges we’re trying to tackle in the field? In this chapter, we’ll take a closer look at a concrete open problem that’s been receiving more and more attention: the problem of building a computer program—a bot, in the lingo of the community—that can play games like StarCraft as well as the best humans can. We’ll also look at which of the methods we’ve seen so far in this book can be useful in building StarCraft bots. Before going any further into the topic, I’ll warn you that we haven’t fully mastered the art of building these bots; so don’t expect to finish this chapter knowing how to do it.
StarCraft is among the most popular games in the history of computer gaming. Released in 1998, it sold over 10 million copies within a decade of its release.2 Of those copies, 4.5 million were sold in Korea alone, where the game is credited with starting the country’s gaming craze, and where the game is played competitively and watched by large audiences in professional sports stadiums.3 The top StarCraft players are idols; they receive gifts from adoring fans, and the very best ones receive lucrative contracts to play the game professionally. One of the world’s top players, a 28-year-old, received a three-year contract to play the game professionally for $690,000.4 Other players aren’t so fortunate. Another 28-year-old man became so engrossed in the game that he died of exhaustion after playing for 50 hours straight in a smoky internet café.5
STARCRAFT AND AI
StarCraft is a game of war set in the 26th century. Like chess, each player commands an army of different types of pieces, each of which has certain strengths and weaknesses. Some pieces, like pawns, are weak and can’t move very fast. Other pieces serve as tough, gnarly infantry, while yet other pieces can shoot projectiles or fly long distances (remember, StarCraft is played on a computer, not on a physical board). Unlike chess, StarCraft is a real-time strategy game. Instead of taking turns to move, players command individual units of their armies in real time across a large fighting area. Combat between army units is fast-paced and brutal, which gives an advantage to players who are quick with their fingers. Indeed, the top human StarCraft players routinely exceed five keyboard and mouse actions per second.6
Another feature that makes StarCraft interesting is that it requires each player to maintain a functioning economy. To develop their own army, players must construct and upgrade different types of buildings; and the order in which they do this matters. Different buildings allow them to create differently skilled pieces in their army or to create new buildings, so this is sometimes called the “technology tree”: the deeper into the tree players build, the stronger their pieces. But to construct and upgrade these buildings, the players must acquire resources from their environment (think: the equivalent of gold, wood, and oil in the 26th century). Obtaining the resources to build this economy often requires acquiring and protecting those resources by force. So a strong economy begets a strong army, and a strong army enables a strong economy.
To make the game even more interesting, a “fog of war” obscures most of the playing space in StarCraft. Players can see what’s happening on or near their pieces, but they can’t see far beyond their pieces on the world map. This means they must send out scouts or find other ways to learn about the world. So when players make decisions, they do so with uncertainty. Players must proactively think about when and how to gather intelligence throughout the game.
Let’s think back briefly to how we designed agents to play strategy games like chess and Go. In those games, the best agents searched through millions of game states and ran evaluation functions to find the states that were the most likely to lead to a successful outcome. The size of a game’s search tree—and an agent’s ability to search through it—depended on two factors: the branching factor at each level of the tree (how many moves the agent must choose from at a given time) and the depth of the tree (how many moves the agent might make in a game).
Go’s branching factor is about 250. StarCraft’s branching factor is much larger than this. At any given time, a player can choose to move any of one or more pieces, or she can upgrade or build new buildings. One conservative estimate of the game’s branching factor pins it at 1 followed by 50 zeros (it’s so high because players can move any subset of their pieces simultaneously).7 The length of a StarCraft game is also much longer than a game of Go: while a professional Go game lasts about 150 moves, StarCraft is a real-time game. The length of a typical 25-minute StarCraft game is about 36,000 moves.8 This means the search space for a typical StarCraft game is, very roughly, 101,799,640 times that of a typical Go game. To make things even more challenging, StarCraft players have imperfect information due to the fog of war; so traditional search methods as used in chess or Go won’t work for StarCraft.
In other words, StarCraft presents an awesome challenge for the field of artificial intelligence. Creating a bot that can play StarCraft well requires matching many qualities we believe define human intelligence, including the ability to make strategic decisions with limited information and the ability to react to unforeseen circumstances in real time. David Churchill, a professor of computer science at Memorial University of Newfoundland, called it the “pinnacle” of game AI research.
David has been organizing competitions between StarCraft bots since he took it over from Ben Weber around 2010, so we have some idea of how far along we are in developing these bots. From what we’ve seen, we’re still a long way from cracking the StarCraft problem.9 As of 2017, if we were to provide letter grades to StarCraft bots, where professional players earn an A- to an A+, and where amateur players earn a C+ to B, StarCraft bots fall into the D to D+ range.10 But we have made some progress.
SIMPLIFYING THE GAME
The only way StarCraft bots can have even a remote chance at working is by decomposing the tasks they need to perform into manageable chunks. Some of the core ideas about what these chunks should be have come from careful analysis of how expert humans play the game.11 I’ve organized some of the recurring ideas in successful bots into an architecture shown in figure 16.1. You’ll probably recognize immediately that we’ve seen a very similar architecture when we looked at the self-driving cars at the beginning of this book and at neural networks that could play Atari games. The resemblance is partly due to the generality of the diagrams I’ve used (you could arguably put almost any agent into a diagram like this), but it’s worth reviewing how some StarCraft bots fit into this architecture.12

A sample StarCraft bot architecture, simplified.
At the far left of this architecture is the layer through which the agent interacts with the world. In self-driving cars, this layer contained sensors and controllers; and in the Atari agent, this layer interfaced with the Arcade Learning Environment. As of now, most StarCraft bots interact with their virtual world through an interface known as the BroodWar Application Programming Interface, a software library developed by a precocious young software developer named Adam Heinermann (BroodWar is an expansion pack—that is, a specific version—for StarCraft). For the StarCraft bot, this sensing and actuation layer offers a way for bots to interact with the game itself programmatically.
In the middle layer is a perception and world modeling layer that tracks military intelligence for the agent: it summarizes information the agent has gathered about the world, including information about opponents’ bases, units in the game, and the overall map. Different bots have varying levels of emphasis on this layer.
The “smart” behavior of the bot comes from the right-most part of the architecture, which we can separate into three levels. At the top level, these bots reason about strategy: which buildings should the bot build, which building upgrades should it perform, and when should it do these things? This strategic decision-making requires planning ahead for tens of minutes and has a direct, long-term impact on the game because the technology tree—that is, the buildings and their upgrades—directly affects the composition, strengths, and weaknesses of the bot’s army later in the game. This decision-making component also requires long-term planning to develop an economy that can support the tree. At a slightly lower level, the bot reasons about tactics, which involves planning ahead for about 30 seconds to a minute: where should the agent place its buildings? Where and when should it send its troops for battle? At the lowest of these three levels is a reactive layer, which requires planning and reaction time on the order of seconds. And feeding into these three layers is information about the world, via its intelligence layer.
Now, these three-layer architectures aren’t the formal three-layer architecture we saw in the self-driving cars that could navigate intersections; for example, the three layers in a StarCraft bot define levels of organization in a military command hierarchy or a set of buildings. As David Churchill, the computer science professor we met a moment ago, explains, “When a decision is made at the strategic level, an order is given to a tactical unit with only the information necessary to accomplish the tactical goal.”13 This is different from the formal three-layer architecture we saw in self-driving cars because there’s no explicit “sequencer,” or Monopoly board, layer.
PRAGMATIC STARCRAFT BOTS
What else has worked well in designing StarCraft-playing bots? Think back to the guiding principle we saw in the Pragmatic Theory team, the two guys without a clue who competed in the Netflix competition. Remember that Pragmatic Theory had exactly one goal: to win the competition. And so they aimed for quantity, combining hundreds of models and predictors, regardless of the how impractical it might be for Netflix to replicate their approach. They were pragmatic about achieving their goal.
Many of the creators of the top StarCraft bots have followed a similar philosophy, programming their bots with strategies that enable them to win the game, even if that means they aren’t building bots that we would consider intelligent. For example, some bots are programmed to follow simple “rush” strategies, which means that they build up a small army of weak fighting units (the only units they can create without a deep technology tree) and attack their opponent before she has had a chance to build up her defenses. These rush strategies are legitimate strategies, and expert human players use variants of them. But doing this requires the agent to follow a simple set of rules with utter disregard for any long-term strategy, and the bots that implement these strategies still fall far short of beating expert humans.
Churchill designed one of the more sophisticated and successful StarCraft-playing bots using a variety of tools from the field of AI. But even his bot, called UAlbertaBot, would sometimes lose to these “rush” bots. At one point, he studied his opponents’ bots’ strategies and adjusted UAlbertaBot to be more resistant to them. This worked for a little while, getting UAlbertaBot to the top in competitions, until more competitors popped up, with their own unique rush strategies; by that time, Churchill was too busy with being a professor to adjust his bot to handle these new strategies. (Most of his work on UAlbertaBot was while he was a graduate student at the University of Alberta.)
One of the ways we can tell that even the best StarCraft bots are still bad is because they still have major Achilles’ heels. This can sometimes lead to bizarre paper-rock-scissors cycles among some bots, as shown in figure 16.2. A few years ago, SkyNet Bot was generally very good compared to other bots, winning against AIUR Bot about 80 percent of the time. AIUR Bot was decent, and, like most other bots, it usually beat Xelnaga Bot. Xelnaga Bot used a “rush” strategy like the one we saw above: it attacked other players’ “pawn” pieces—the ones that can create buildings and collect resources. This strategy didn’t fare well against most bots, but it was also a unique weakness of SkyNet Bot, which meant that Xelnaga Bot could beat the otherwise good SkyNet Bot about 70 percent of the time!14 There’s no reason such cycles couldn’t happen among top Go or chess players; but its particular acuteness among the best StarCraft agents betrays their current weaknesses.
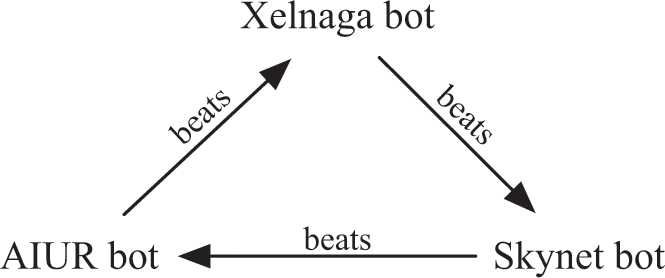
A paper-rock-scissors cycle among StarCraft bots from a 2011 competition. In the competition, Xelnaga usually won when it played against Skynet, Skynet usually won when it played against AIUR, and AIUR usually won when it played against Xelnaga.
If you’ve played these games before, you’ve almost surely played against a computer opponent, which means you’ve played against a bot. So you might be wondering: If it’s so difficult to create a bot to play a game like StarCraft, why was the computer so difficult to beat? Churchill disagrees that they’re difficult. “Because real-time strategy AI is so difficult to make intelligent,” he explained, “In-game bots often cheat in order to appear stronger than they really are.” The goal of the bots in the software you buy off the shelf is to offer an interesting and compelling experience for the human player, not to be objectively good.15 For example, in some cases, the computer is allowed to see the entire playing map, without the fog of war.16 The bots might send scouts around to make it look like they don’t have full visibility of the board, but this is only a trick, a form of misdirection similar to what the chess-playing Turk used, to look smarter than they actually are.17 Their strategies are equally simple: for example, on a given level, the computer might have a scripted—that is, a predefined—build tree with very simple rules to handle exceptions.
In fact, scripted build rules are common even in the “good” bots. When Churchill and his collaborators built UAlbertaBot, they built the skeleton first, filling in its different components—like the strategy, tactics, and reactive layers—with simple, scripted rules. The idea was to have a bot that could play StarCraft fully even if it couldn’t play well. Then, once the skeleton was in place, they could continue to improve the individual components, replacing their scripted “production module” with one that could search for an optimal order in which to develop their technology tree (they’ve exceeded humans at this), replacing their “combat commander” with a sophisticated combat simulation system, and so on.18 As StarCraft bots continue to improve, these individual modules will most likely improve rather than their overall architectures. Or will the architectures be vastly different as well?
OPENAI AND DOTA 2
Many StarCraft players are familiar with the game Defense of the Ancients 2, or, simply, DOTA 2. This is a capture-the-flag style game having many similarities with StarCraft. To master DOTA 2, the player must control a “hero” character who can move about the map, attack opponents, cast spells, and so on, with a goal of destroying their opponents’ “Ancient,” a building to be protected at all costs.
Professional DOTA 2 players compete annually for a $24 million prize pool. The total of past reward pools for DOTA 2 is $132 million, far beyond that of StarCraft (a “paltry” $7 million) and even StarCraft II ($25 million). Not surprisingly, the game is challenging: a bot designed to play DOTA 2, as with one designed to play StarCraft, must be capable of making sense of a world with an extraordinarily large search space.19
Elon Musk, whom we briefly met a few chapters ago, launched the research lab OpenAI to “build safe artificial intelligence and ensure that AI’s benefits are as widely and evenly distributed as possible.”20 In August 2017, OpenAI announced that they had created a bot that could beat some of the best DOTA 2 players in a limited, 1-vs-1 version of the game. How did they create a bot that could search through such a large space?
The answer, as a researcher from OpenAI explained, is that they didn’t. OpenAI used a combination of the tools we’ve seen in this chapter and the chapters about neural networks, but their architecture didn’t use a search algorithm like Monte Carlo Tree Search.21
To play DOTA 2, a small team of researchers at OpenAI created a neural network that was like two of the networks we saw earlier in this book. At a first cut, it was a bit like the Atari-playing network. Remember that the Atari-playing agent evaluated its network over and over, selecting whichever action the network indicated would lead to the highest time-adjusted stream of rewards (i.e., chocolate). At each time step, the input to the Atari network was a vector summarizing which pixels were on the screen for the past four screenshots, while the output represented its expected future reward for taking each action. The DOTA 2 architecture, which you can see in figure 16.3, was similar, in that its output neurons determined which actions the agent should take. Also like the Atari network, the input to the DOTA 2 network was a list of features that encoded the current state of the game. Like the backgammon-playing neural network and AlphaGo, their neural network improved by playing games against itself.22
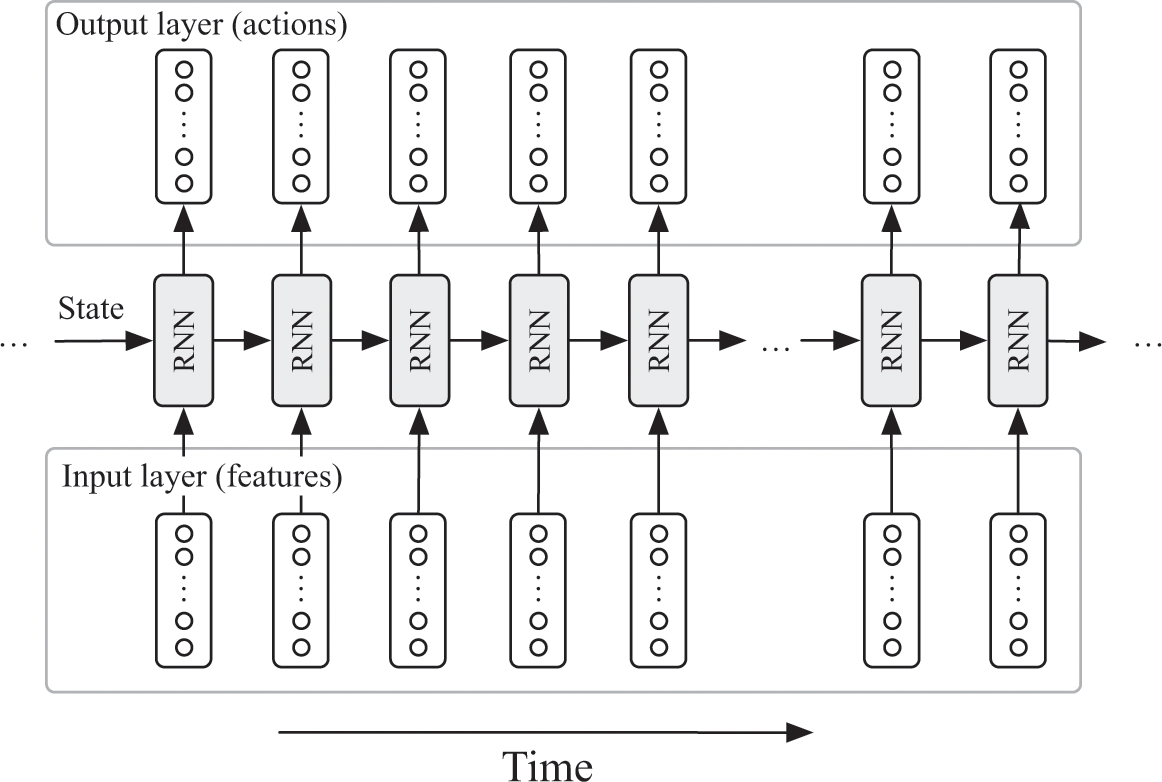
An architecture of the bot that beat some top human players at DOTA 2. At each epoch, the agent runs a neural network that takes in a feature vector summarizing the current world and outputs variables that determine the action the agent will select. The agent also keeps track of state, which it passes from epoch to epoch. This state serves as a sort of “memory” for the agent.
But there were some important differences between these networks. First, many of the DOTA 2 network’s input features were hand-crafted by humans, encoding things like the currently controlled piece’s position on the map and details on the map. Second—and much more importantly—the DOTA 2 network had a memory.23
Remember that the Atari network couldn’t play certain games, such as Montezuma’s Revenge, very well. Montezuma’s Revenge required its agent to do two things: explore a very large environment and remember what it had done recently. But the Atari network had no memory, so even if it had a lot of experience, it would have still performed poorly at the game. How could we endow an agent with a memory?
We saw a hint at a memory unit for neural networks in chapter 11, when we looked at networks that could generate captions for images. Remember that these networks could keep track of which words they had uttered so far because they were recurrent neural networks, or RNNs. The units in RNNs are connected to one another in a series: the output-state of one recurrent unit feeds as an input-state into the next recurrent unit in the series. Each unit in the network inspects its state and any other inputs, produces some output value, updates the state, and then sends that state to the next unit in the sequence.
The DOTA 2 network used this same idea. Like the Atari-playing network, the DOTA 2 network was running constantly, in a loop, taking in its input features and producing some output values. But it was also an RNN: one of its outputs was the state, which it passed on to the next unit in the network to use. As the network was run, it “remembered” things using this state vector.24
The DOTA 2 bot was far from perfect. First, having a memory alone wouldn’t solve all of its problems; Atari agents that have been endowed with memories still can’t beat Montezuma’s Revenge. After its win, OpenAI hosted a session for other players to beat up their DOTA 2 bot, and these players found some glaring Achilles’ heels in the program, just as humans had already seen with StarCraft-playing bots. But the network’s ability to defeat several of the top players in the world still moved us one step closer to creating bots that can play competitively against humans at the standard, 5-vs-5 version of DOTA 2—and bringing us ideas in the meantime that will also be useful in designing successful StarCraft bots.25
THE FUTURE OF STARCRAFT BOTS
To see one possible direction of where StarCraft is headed in the future, let’s return to a character we’ve seen sporadically throughout this book: Demis Hassabis, the founder of DeepMind. Although Demis was late to join the StarCraft bot community, he became interested in the game some time before he founded DeepMind. When Demis discovered that one of his colleagues was a competitive StarCraft player, he became fascinated by this colleague’s ability to consistently win the game. As another colleague recalled:
Demis wanted to beat this guy. He would lock himself in a room with the guy night after night. He’d handicap him, by getting the guy to play without a mouse or one-handed so he could analyze exactly what he was doing to be brilliant. It was a bit like going into the boxing ring and getting beaten up, and then returning every night. It showed his incredible will to win.26
More recently, Demis turned some of DeepMind’s efforts toward building a bot to play StarCraft competitively. DeepMind and Blizzard, the company behind StarCraft, announced a collaboration to develop and release an official interface for bots to play StarCraft II, as well as an environment for developers to create their own “curricula” for bots to learn in more structured ways.27
One of the curious things about DeepMind’s decision to pivot toward StarCraft is that researchers at the University of Alberta had been looking at this problem for a decade beforehand. Remember: David Churchill studied there while performing pioneering research in StarCraft bot design. This fact in isolation might not be very interesting; but what is interesting is the profound impact the University of Alberta has had on the field of artificial intelligence overall, and on DeepMind’s efforts in particular. As we saw in chapter 7, researchers at the University of Alberta developed the Arcade Learning Environment, which provided DeepMind with a way for its Atari-playing agent to interact with the world. Several key researchers from DeepMind’s team that developed AlphaGo cut their teeth on computer Go at the university. And the University of Alberta has several of the world’s leading experts on a variety of topics in artificial intelligence, including Richard Sutton, who has been described as the “Godfather of Reinforcement Learning.” One of Sutton’s contributions to the field was the very algorithm that the Atari-playing agent used to learn from its actions—the algorithm it used for off-policy learning.
If we could solve StarCraft, does that mean we can solve intelligence? Quite simply, no. There are many parts of human intelligence not addressed by StarCraft, including the ability of humans to make sense of, and draw conclusions from, entirely new and unstructured environments.
As several famous AI researchers wrote in one of the first papers about computer chess, “If one could devise a successful chess machine, one would seem to have penetrated to the core of human endeavor.”28 Now that it’s been a couple of decades since we’ve devised a successful chess machine, it’s not clear that we’re any closer to the “core of human endeavor” than we were before we beat Garry Kasparov, although now we at least know how to design a system that can play an excellent game of chess. The same rough assessment applies to computer Go and StarCraft. Creating a bot that can play StarCraft competitively may to turn out to be a similarly impressive but narrow result. The tools and architectures we pick up along the way, however—the new search algorithms, new perception algorithms, and new reinforcement-learning algorithms—will be the more important accomplishments.