4 YIELDING AT INTERSECTIONS: THE BRAIN OF A SELF-DRIVING CAR
At this point the question naturally arises: Why do so many independently designed architectures turn out to have such a similar structure? Are three components necessary and/or sufficient, or is three just an aesthetically pleasing number or a coincidence?
—Erann Gatt1
THE URBAN CHALLENGE
Chris Urmson’s team spent the next two years preparing for the Urban Challenge. By this time Chris had become a professor at CMU. He was also the person in full charge of its racing team, now dubbed “Tartan Racing.” Not only had Chris’s team seen considerable turnover; it had also retired their Humvee, choosing instead a 2007 Chevrolet Tahoe they named “Boss.” Boss would incorporate the best of their previous design and much of what they had learned from the Stanford Racing Team the previous year.2
This challenge would be much more difficult than the previous ones. In the previous Grand Challenges, all the robot cars had driven solo, released one by one and monitored so they couldn’t interfere with one another. But the Urban Challenge was different. These self-driving cars would drive around an old military base with each other and with human drivers—a total of about 50 cars on the road at the same time—on city streets, at intersections, and in parking lots. And there would be no off-road driving allowed here: these cars could lose points or even be disqualified for disobeying California traffic laws.3
DARPA held several qualifying rounds before the November 2007 race. One called the Gauntlet required cars to carefully stay within their lanes while avoiding parked cars and other obstacles. Another qualifying round tested the cars’ higher-level thinking: they needed to stop at four-way intersections, wait, and proceed when it was their turn, and they needed to be capable of deciding when a route was blocked—and of finding an alternate route when it was.
Another qualification round, known as “Area A,” tested the cars’ ability to detect and avoid moving objects. This round required self-driving cars to drive in a loop, making left-hand turns in front of oncoming traffic, as shown in figure 4.1. Self-driving cars needed to follow the black arrows on the right half of the loop while professional human drivers drove around on the outside of the loop.
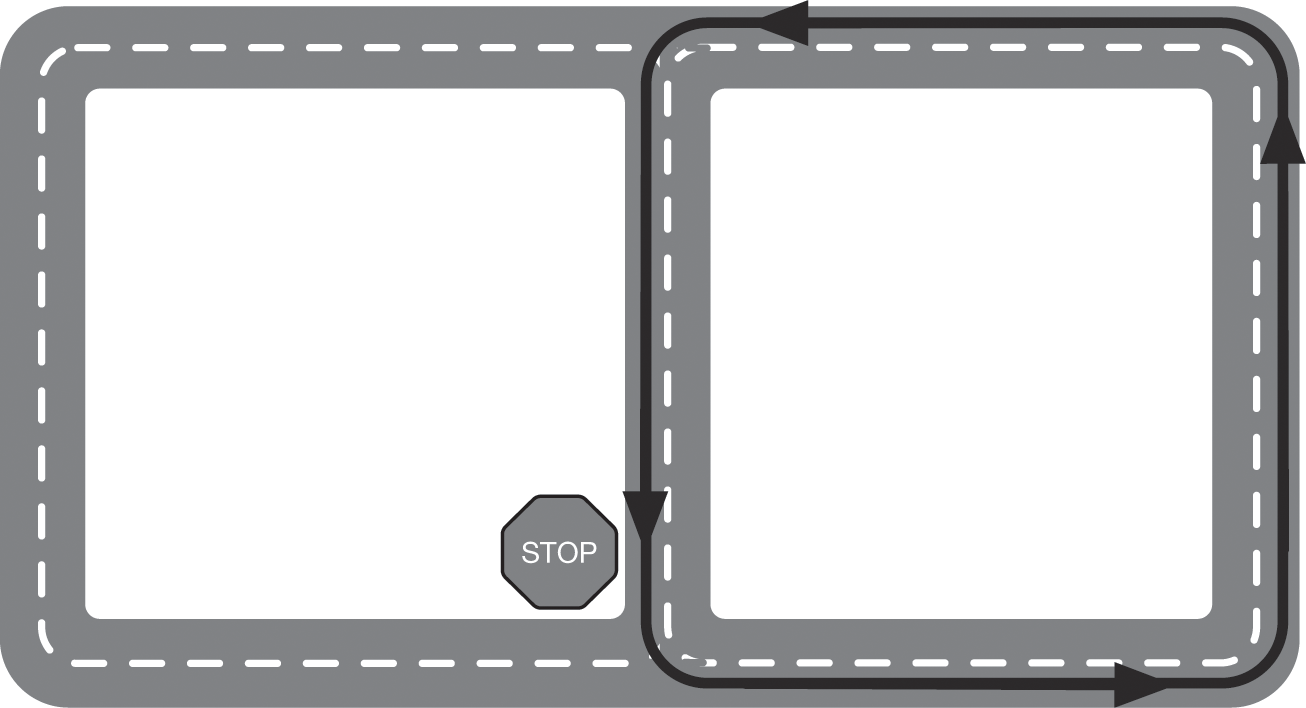
Area A in the DARPA Urban Challenge. Professional human drivers circled in the outer loop as self-driving cars circulated on the right half. The primary challenge here for autonomous cars was to merge into a lane of moving traffic at the stop sign. Self-driving cars were allowed to circulate as many times as they could within their time limit.
PERCEPTUAL ABSTRACTION
To understand how Boss maneuvered through these environments, let’s take a closer look at how Chris’s team developed the car’s brain. Like Stanley (the Stanford Racing Team’s car in the second Grand Challenge), they designated a layer in Boss’s brain to synthesize the data coming in from its eighteen sensors. They called this middle layer (shown in figure 4.2) the perception and world-modeling layer. Like Stanley’s perception layer, Boss’s perception layer didn’t do any complex reasoning because its sole purpose was to interpret the data coming from its sensors—its laser scanners, radar, camera, GPS, and accelerometers—and to generate higher-level models of the world from that data. The data abstractions generated by this layer would then be used by modules that reasoned at a higher level to perform more complex tasks.4

Boss’s architecture, simplified: the hardware, the perception (and world-modeling), and the reasoning (planning) modules, organized in increasing levels of reasoning abstraction from left to right. Its highest-level reasoning layer (planning, far right) was organized into its own three-layer architecture: the controller (route planner module), the sequencer (Monopoly board module), and the deliberator (motion planner module). The motion planner could have arguably been placed with the sequencer.
The perception and world-modeling layer performed some of the tasks we saw in earlier races: estimating where the edges of the road were, finding obstacles, and keeping track of where the car was, given its GPS data and its accelerometers. But for driving in urban environments, the perception layer needed to do more. Boss’s environment could change, as other cars came and went. So this layer represented static objects like trees and buildings with a grid on a map, filling in those grid cells or clearing them as sensors detected the presence or absence of objects. It also kept track of a road map provided by DARPA and a description of the missions to be completed, adjusting the map when it detected that paths on the map were blocked or unblocked.5
Boss’s perception and world-modeling layer also needed to detect and model the physics of moving objects. The module to detect moving objects had a rule that every observation made by its sensors should be associated with either a fixed or moving object in its object database. Boss calculated a quality measurement for that association; if the match between that measurement and an object was good, then that measurement would be incorporated into Boss’s model for that object, so that, in Boss’s mind, the object would move a little bit. But if Boss couldn’t find a high-quality match between the measurement and an existing object, then the module proposed the existence of a new object to explain that observation. Occasionally the proposal took a static object and converted it into a moving object. This might happen, for example, if Boss encountered a car that was parked but then began pulling out from its parking spot.
Once Boss detected a moving object, it could track the object with a traditional tracking algorithm. Boss used—yet again—a Kalman filter to track its moving objects.6 Boss also assumed that objects moved either like bikes—where they could move forward or backward and had an orientation—or like drifting points—where they could move in any direction but lacked an orientation; Boss based this decision on whichever model fit the data best. The assumptions for these models were then integrated directly into the Kalman filter: Kalman filters are very general, and they can be used to track not just objects’ positions, but also their velocities and accelerations.
Boss then imagined these objects as rectangles and other polygons moving around in its virtual world.7 Of course, Boss didn’t “see” them as part of a scene but rather as coordinates on a grid. As far as Boss was concerned, each rectangle should be given enough clearance, whether Boss was following the rectangle in a traffic lane or bearing toward it from the opposite lane.
THE RACE
After many months of testing and anticipation, the day of the Urban Challenge arrived. During the race, Boss and other cars would need to complete several “missions,” driving from one checkpoint on the base to another, all the while navigating through moving traffic along urban streets and amid other autonomous cars and human drivers. DARPA had provided a map of the compound to the competitors a couple of days before the race, and they provided mission descriptions to the teams just five minutes before the race. These missions required the cars to drive through the streets of the compound, park in parking lots, and navigate busy intersections fully autonomously.
DARPA officials wrote after the race that they had pared the applicant pool from eighty-nine to eleven for the final race by carefully reviewing the entrants’ applications and putting them through the qualifying rounds, which meant that the cars on the road during the final event had been carefully vetted.8 But this didn’t mean the human drivers were completely safe: the humans on the route—all of whom were professional drivers—drove with safety cages, race seats, and fire systems, and each autonomous car had a chase vehicle whose human drivers had a remote e-kill switch. The robot cars, while vetted, still had the very real potential to kill them.9
Fortunately, there were no major accidents on the day of the race. One car malfunctioned in a parking lot and tried to drive into an old building before DARPA officials hit its e-kill switch. There was also a low-speed collision between another couple of self-driving cars. By the middle of the morning, almost half of the contestants had been removed from the course.10
Yet several cars managed to finish the race successfully, including Boss. Within three years, self-driving cars had gone from being unable to drive more than eight miles in the desert to successfully maneuvering busy intersections while spending hours on the road. In addition to seeing with its perception and world-modeling layer, Boss and the other cars needed a way to reason about their environment. None of the cars we saw in the past two chapters could have come close to doing these things: So how did Boss do them?
BOSS’S HIGHER-LEVEL REASONING LAYER
Were improvements in hardware a factor? Hardware had been improving, of course, but in the three years since the first DARPA Grand Challenge there hadn’t been a notable revolution in the hardware of self-driving cars beyond what Moore’s law had predicted (Moore’s law predicted at the time that popular processors roughly doubled in performance doubled every 18 to 24 months). The real answer to this question—and the cause of hallucinations Boss would have during the race—lay in advances to these cars’ software architectures.
At the core of Boss’s brain were three components with decreasing levels of “reasoning abstraction.” You can see this in the rightmost panel of the architecture in figure 4.2. At the top of this panel is the route planner module, which searched for a low-cost path from Boss’s current position to the next checkpoint on its mission. This was a lot like the module in Stanley that planned that vehicle’s smooth path at the beginning of the second Grand Challenge. Instead of planning a single path at the beginning of the race, Boss’s route planner planned its path continuously, re-estimating the best path from its current position to its destination again and again. To estimate the path, the route planner used a combination of time and risk in its cost function, trusting that the perception layer always presented it with an up-to-date map. So all it needed to do was plan its path and tell the component below it—located in the middle of the rightmost panel of figure 4.2—what it needed to do next.11
We’ll call this next lower layer of abstraction the Monopoly board layer, for reasons that will become clear very soon.12 This layer was arguably the most complex because it needed to keep track of what Boss was doing and what it needed to do next. It was implemented with something called a finite state machine.13
A finite state machine provides a way for a computer program to reason about the world by limiting the things it needs to worry about. It works a lot like the game Monopoly: you have a piece that can move around on a board, and at any given time, your piece can be in exactly one “state” (that is, position) on the board. This position determines what you’re allowed to do now and where you’re allowed to move next. If you land on Park Place when you’re playing Monopoly and nobody owns it, you’re allowed to buy it. If you wind up in jail, your options for getting out are to roll the dice and hope to get doubles, pay $50, or produce a get-out-of-jail-free card. The rules of the game—and the position of your playing piece on the board—simplify the world for you as a Monopoly player so you aren’t overwhelmed with possibilities. By implication, anything you’re not expressly allowed to do when you’re on a square, you’re not allowed to do at all. If you land on Park Place, you can’t buy Boardwalk or collect $200; you can’t do anything except buy Park Place (as long as no one else owns it and provided you want it).
Your current state (again, your position) on the Monopoly board also determines which set of moves you can make next: sometimes you can move forward up to 12 squares, depending on a dice roll, and buy a property, and sometimes you might go directly to jail. But you can’t jump to an arbitrary position on the board.
When Tartan Racing designed Boss, they created a variety of finite state machines for the Monopoly board module: one for each type of environment Boss might find itself in. As Boss drove along, its Monopoly board module moved a virtual Monopoly piece around its finite state machine in order to keep track of what the car was doing and what it needed to do to achieve its next goal.
Depending on Boss’s current situation, its Monopoly board used one of three finite state machines: one to drive down the road, keeping track of whether it needed to change lanes, for example; one to handle intersections; and one to maneuver itself into a specific position, such as a parking spot or the other side of a crowded intersection. Each of these finite state machines outlined a set of simple rules the module should follow to achieve its goal. Wherever it was, Boss’s Monopoly board module kept track of the world and its goals with its virtual piece on the board.
I show a simplification of Boss’s handle intersection finite state machine in figure 4.3.14 You can follow Boss’s line of reasoning about crossing an intersection in this state machine. When it was Boss’s turn to enter the intersection, Boss waited until the intersection was clear and would remain clear long enough for Boss to pass through it. It did this by using another, smaller finite state machine called a precedence estimator, which determined whether Boss had precedence to enter the intersection based on common driving etiquette. How did Boss know these rules about driving etiquette? A programmer simply encoded them into a set of states and transitions for the finite state machine, the same way Monopoly’s creator, Elizabeth Magie, originally created the rules to its precursor, the Landlord’s Game. This wasn’t just the case for the precedence estimator; humans encoded the rules for all of the state machines.
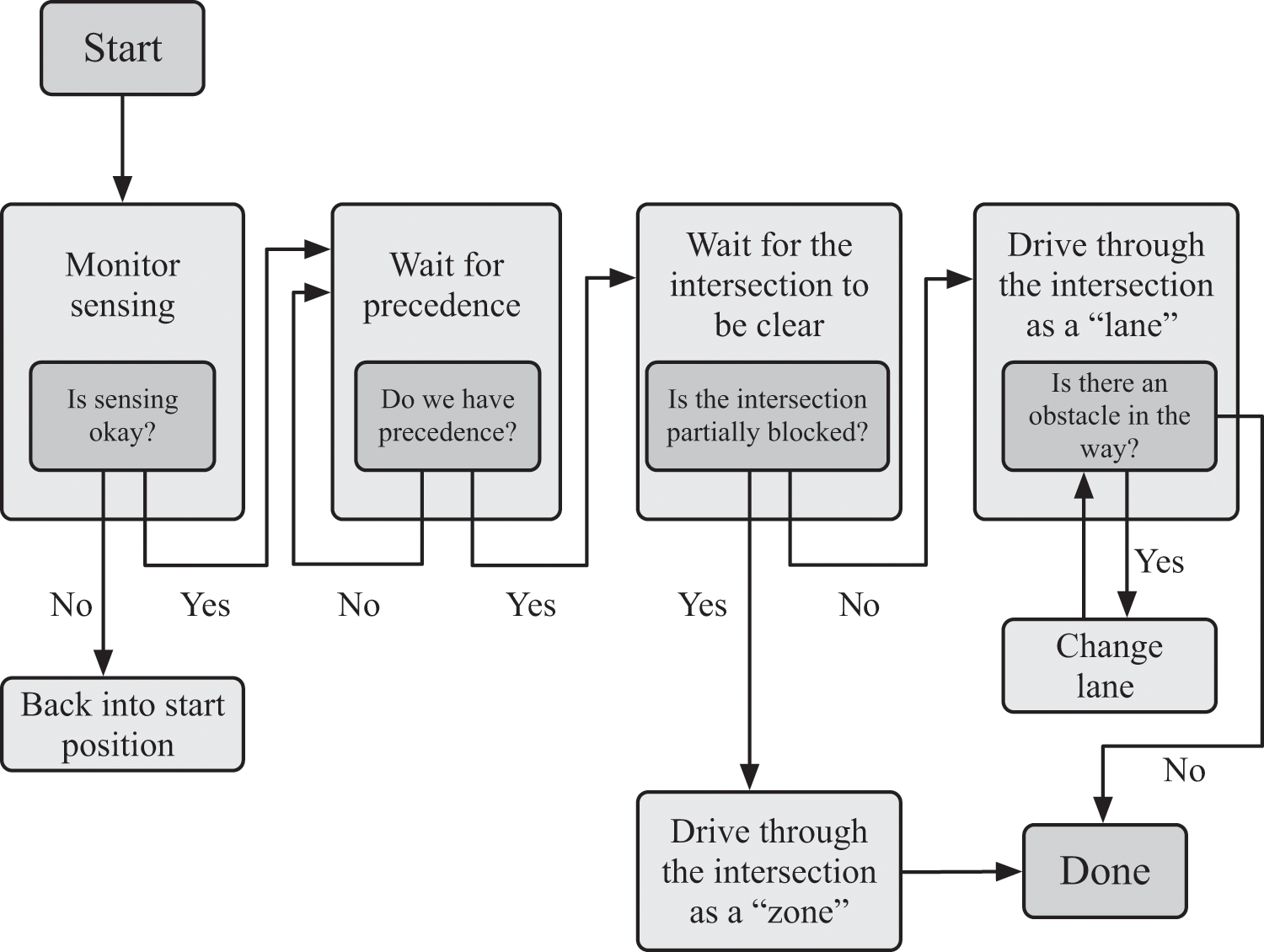
The handle intersection finite state machine. The Monopoly board module steps through the diagram, from “start” to “done.” The state machine waits for precedence and then attempts to enter the intersection. If the intersection is partially blocked, it is handled as a “zone,” which is a complex area like a parking lot, instead of being handled as a “lane”; otherwise the state machine creates a “virtual lane” through the intersection and drives in that lane. This is a simplified version of the state machine described in Urmson et al. (see note 7).
The Monopoly board performed much of the “human” reasoning you might associate with driving, but Boss didn’t need to be smart to use its Monopoly board module. A human playing Monopoly may make careful, deliberate calculations about which actions to take. But the Monopoly board module didn’t actually play monopoly, and it didn’t have any concept of success or winning, so it didn’t make any careful, strategic decisions about what it should do or where it should go next. It was more like the rulebook for Monopoly. At each state, the Monopoly board module simply followed a set of dead-simple rules, and then it moved to the next state based on the results of another simple test. Boss did perform careful, deliberative planning, but that happened in its route planner—the module we saw a few pages ago, which searched for paths.
The functional responsibility of the Monopoly board module, then, was to take its assignment from the route planner, keep track of how far along it was in completing that assignment, and to delegate actions in the meantime to the next lower level—the motion planner—until its assignment was complete.
The responsibility of the motion planner, the module represented in the bottom-right of figure 4.2, was to find and execute a trajectory for the car that would bring it safely from its current position toward a goal state assigned by the Monopoly board. For example, the Monopoly board might order the motion planner to perform one of these actions:
- Plan and execute a way to park in that empty spot over there (giving the motion planner a position).
- Continue driving straight in this lane.
- Switch to the left lane.
- Drive through this intersection.
Once the Monopoly board gave the motion planner an order, the motion planner would find a path from its current position to its goal position. The motion planner was a bit like the route planner in this respect, except that the motion planner’s goal was to plan out actions on a much shorter timescale. While the route planner planned movement at the scale of minutes and miles, the motion planner planned movement at the scale of seconds and feet: at its largest, it might have planned in areas up to about a third of a mile, or a half kilometer.15
The Monopoly board assumed that the motion planner would try to achieve its goal safely, although the motion planner was allowed to tell the Monopoly board that it had failed—for example, because the parking spot turned out to be occupied by a motorcycle that it hadn’t seen until it tried to park—in which case the Monopoly board would find a contingency plan.16
Another difference between the route planner and the motion planner was that the route planner only needed to account for the car’s position on a map when searching for a path, while the motion planner needed to search for a path while keeping track of the car’s position, velocity, and orientation, all while making sure that Boss didn’t violate any laws of physics. Cars can only move in the direction their wheels are pointing: they don’t slide sideways unless something’s going wrong, and the motion planner needed to account for this (roboticists would call this the car’s kinematic constraints). The motion planner also made sure the car didn’t accelerate, turn, or stop too quickly: it shouldn’t brake or accelerate aggressively, and it shouldn’t turn so quickly that it flips over. The Red Team’s Humvee had flipped during testing, a mistake that devastated its sensors just weeks before the first Grand Challenge, as “a quarter million dollars’ worth of electronics was crushed in an instant.”17 The Humvee’s sensors were never the same again, and this likely had at least some impact on its performance during that race.
The path-finding algorithm for Boss’s motion planner was a bit more complicated than its algorithm for route planning because it needed to keep track of Boss’s position, velocity, and orientation (we can call these three things together its “state”). The motion planner couldn’t search for a path in a simple grid because a grid alone can’t keep track of all of these things. In parking lots, the motion planner searched for a best path from its current state to its goal state by searching for ways to combine very small path segments to make one large path, where each path segment ensured that Boss’s velocity and position followed the laws of physics. For example, if the beginning of one path segment indicates that Boss would be at its current position, facing forward, and moving at five feet per second with no acceleration, then the end of that path segment needs to be consistent with the beginning: it must assert that Boss is five feet ahead of its current position, facing forward, moving at five feet per second.18 I show an example of this process in the four diagrams of figure 4.4. This planning could take time, so Boss used a second motion planner to plan its subsequent path simultaneously so it didn’t need to pause between motions.
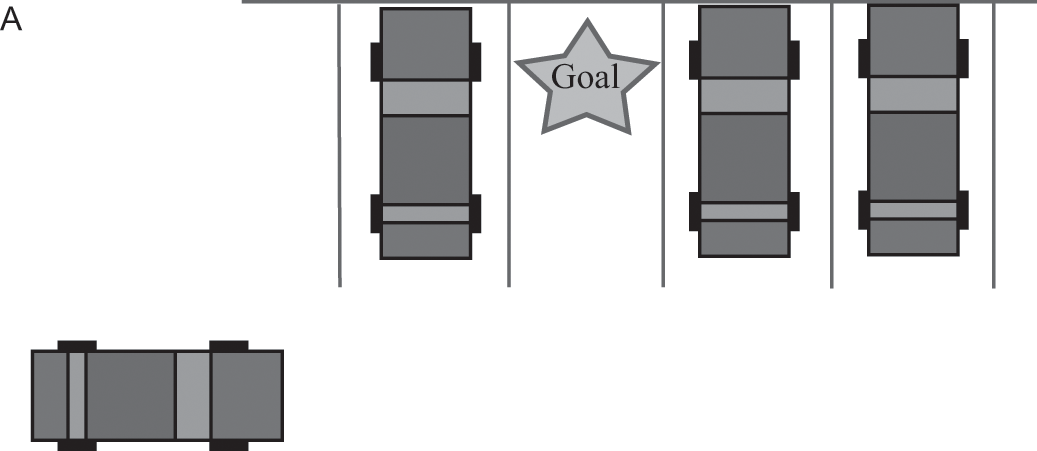
The motion planner of a self-driving car has been instructed by the Monopoly board to park in the designated parking spot.
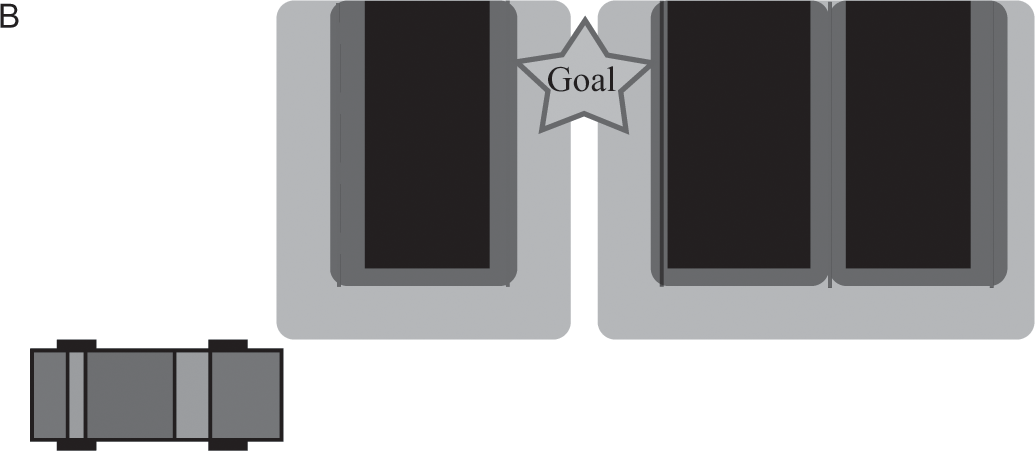
The car has an internal map represented as a grid in which obstacles fill up cells in that grid. The motion planner also uses a cost function when picking its path (shaded gray). The cost function incorporates the distance to obstacles (in this case, other cars).

The motion planner searches for a path to its goal. The path will comprise many small path segments that encode velocity, position, and orientation. Unlike this picture, the search is performed from the end state to the start state.

A candidate path to the goal.
For driving down the road, Boss’s motion planner also used a search algorithm that was more like Stanley’s steering algorithm. First, it generated a set of possible trajectories for the car. These began at the car’s current position and speed and ended farther down the road but varied in lateral offset and curvature. Then the motion planner scored these paths based on factors like their smoothness, how close they were to the center of the road, and how close they were to obstacles.19 Boss then ran this motion planner constantly, continuously searching for the best path from its current state. This meant that it would continuously adjust its path, gracefully correcting its little errors as they occurred.
GETTING PAST TRAFFIC JAMS
The three layers of high-level reasoning in the rightmost panel of figure 4.2—Boss’s route planner, its Monopoly board, and its motion planner—enabled Boss to travel through the old military base on the day of the race. However, none of the systems I’ve described so far would have saved Boss when it started to hallucinate during the race.
Boss had demonstrated in the qualifying rounds that it was among the best prepared of the contestants. But during the Urban Challenge, as it was racing down the road to complete one of its missions, it found the lane in front of it blocked by another car. Boss slowed, came to a stop, and waited. It made a couple of attempts to move forward, but there was no way through: the road was completely blocked by traffic.20 So Boss waited, the seconds ticking by on the race timer.
The problem was, this traffic jam didn’t exist. There was nothing in front of Boss at all; what it thought was a blocked lane was just a hallucination. And this wasn’t the first time Boss had imagined things on the day of the race.21
Boss’s hallucination was caused by a problem in one of its perception algorithms. When it saw a car in front of it, and that car moved away, it didn’t always clear its estimate of the car’s location, so it would occasionally think there was still something there. It’s possible that improved perception algorithms would have prevented this specific hallucination, but Chris and his team were experienced enough in building complex software to know that all software has bugs. Fortunately they had the foresight to make Boss robust to problems like this.
This problem Boss faced was similar to the problem the Humvee faced in the first Grand Challenge, when it got stuck behind a rock. Chris’s team fixed this in the second race by programming the Humvee to simply back up 10 meters if it was stuck, clear its estimate of obstacles, and try again. But that was a short-term hack: it was a brittle solution—a Band-Aid—and by no means robust, and it might not work at a crowded intersection. Chris’s team needed a system that could handle bugs or unexpected situations, and they needed a system that would never give up. Tartan Racing formalized this idea in Boss by adding a more general “error recovery” system to the Monopoly board layer; it had three key principles, reminiscent of Isaac Asimov’s three robot laws:22
- Until the error is resolved, the car should be willing to take greater and greater risks, and its attempts to recover should not repeat.
- The recovery behavior should be appropriate to the driving context. For example, Boss should have different recovery behavior in traffic lanes than in parking lots.
- The error recovery should be kept as simple as possible to reduce the likelihood of introducing more software bugs or undesirable behaviors.
As a last-ditch effort, if Boss didn’t move more than a meter within five minutes, its error-recovery system simply selected a random nearby goal position in an algorithm called wiggle. The idea was that Boss should be able to dislodge itself from whatever predicament it had found itself in, and then it could clear its memory and try again.23
When Boss faced the (imagined) blocked lane during the Urban Challenge, five levels of error recovery kicked in. First, it tried to get to a spot a little past the traffic jam; second, it tried to get to a spot farther past the jam; third, it tried to get to a spot even farther past the traffic jam; fourth, it backed up and tried to get to a spot past the jam again. Finally, it assumed the road in front of it was completely blocked and made a U-turn. When it assumed the road was completely blocked, it actually marked the road as impassable in the route map in its perception and world-modeling layer, causing the route planner to find an alternative path.24
Boss hallucinated twice during the race, and the result was that the car drove an extra two miles that day, a minor inconvenience for a race that took about four hours. Despite these inconveniences, Boss went on to finish the race 19 minutes ahead of Stanford’s car.25 A redundant error-handling system—in which higher-level planning could resolve problems with lower-level planning or perception—was one of the most important parts of Boss’s architecture, handing Chris and his team the prize he had focused on for so long.
THREE-LAYER ARCHITECTURES
What enabled Boss—and Stanley from chapter 3—to work so spectacularly? As we saw, it had a lot to do with their reasoning architectures. One key design principle in both Boss and Stanley was their organization into hardware, perception, and planning (reasoning) layers, the three layers from left to right in figure 4.2. As we’ve seen, the perception layer enabled the reasoning components on the right side of the figure to focus on higher-level tasks. They weren’t burdened with the challenge of dealing with low-level sensor data, because that was the responsibility of the perception modules. The perception modules, in turn, were largely implemented with machine learning models that turned raw sensor data into actionable information, but they didn’t focus on any high-level planning or decision-making. As we saw in the last chapter, each perception module had one job to do, which meant that each module could do its job quickly.
But Boss demonstrated some other, more important qualities of a self-driving car: the ability to carry out complex behaviors such as driving miles in an urban environment, parking in parking spots, and interacting with other moving cars, while still gracefully reacting to unanticipated situations.
While one of the self-driving cars from Alphabet, Google’s parent company, was driving around Mountain View, California, it came upon a rather singular situation. Chris Urmson explained the scene during his TED2015 talk, gesturing to a video of the scene as he spoke:
This is a woman in an electric wheelchair chasing a duck in circles on the road. Now it turns out, there is nowhere in the DMV [driving] handbook that tells you how to deal with that. But our vehicles were able to encounter that, slow down, and drive safely.26
If all unexpected contingencies occurred as infrequently as you encounter a woman in an electric wheelchair chasing a duck in the middle of the street, it might not be a problem for self-driving cars. But the curse of these rare contingencies is that, taken together, they happen frequently, and they’re always a bit different. They could be caused by missing signs in construction zones, chain-installation blockades on snowy mountain roads, or even police guiding traffic through intersections. Each situation will have its own particular quirks, and a self-driving car must be able to handle all of them. What was it about Boss that enabled it to handle these situations?
We can answer this question by looking at the second important decision Chris’s team made in designing Boss: the organization of its higher-level-reasoning components into three layers of increasing abstraction, represented by the three boxes shown in the rightmost panel of figure 4.2. This way of organizing an agent is sometimes called a three-layer architecture in the field of robotics, and it enabled self-driving cars like Stanley and Boss to react quickly in real-time environments. To emphasize, when I refer to a three-layer architecture, I’m talking specifically about the three boxes on the right of figure 4.2, not the left-to-right organization of Boss’s brain.
The top layer in a three-layer architecture performs deliberative behaviors, which typically involves slow, careful planning. In the case of Boss, this slow, deliberative step was precisely its route planner, which searched for paths through the city environment. This is where Boss planned its highest-level goals—possibly its most “intelligent” behavior. Formulating these goals was possible because this planning layer didn’t need to worry about perception (the perception layer handled that) and because it didn’t need to worry about unanticipated contingencies (the Monopoly board handled that). The route planner just needed to plan missions and paths.
The bottom layer of a three-layer architecture is called the controller. In the case of Boss, the controller layer was its motion planner and its steering and speed controllers.27 This layer performed relatively low-level actions, such as “park in that spot over there.” The motion planner was tied to the actuators, which directly controlled the steering wheel, brake, and gas pedals. This layer also included the three-rule controllers we saw in the first chapter. Traditionally the controller layer doesn’t do anything very smart: its purpose is to perform simple actions and react to simple sensor readings. A typical reaction to the environment might be to increase motor torque or apply brakes to bring the car’s speed to the target speed.
In between the deliberator and the control layer is the sequencer. The goal of the sequencer is to carry out assignments from the top-level, deliberative layer by giving the controller below it a sequence of commands. Boss’s sequencer was its Monopoly board. The sequencer can’t just give the controller a fixed sequence of commands, because the state of the world may change before the full sequence is carried out. To see how things could go wrong in a robot that couldn’t respond to a changing world, imagine that I’ve designed a robot butler to serve you a glass of wine. This robot might carry a bottle of wine out of the kitchen, roll over to you, and reach out its robot hand with the bottle to pour you some wine. You might helpfully lift your glass from the table toward the robot to make it easier for the robot. But the robot butler had been planning to pour the wine directly into the glass on the table, and thus would have ignored your gesture, pouring a glass worth of wine directly onto the table.
This wouldn’t be acceptable for a robot butler, let alone a self-driving car. A real-time AI system needs to react to changes in the environment. For Boss, a finite state machine was its way of keeping track of which actions the controller had successfully completed and which it should try next. If the world changes before the controller is able to carry out its job, then the sequencer can come up with a contingency plan and send updated instructions to the controller.
Erann Gat was a researcher at Cal Tech’s Jet Propulsion Lab when he and several other research teams simultaneously discovered this three-layer architecture—the deliberator, sequencer, and controller—while they were designing robots. He summarized the role of the sequencer based on their shared research:
The fundamental design principle underlying the sequencer is the notion of cognizant failure. A cognizant failure is a failure which the system can detect somehow. Rather than design algorithms which never fail, we instead use algorithms which (almost) never fail to detect a failure.28
Why bother designing algorithms that could sometimes fail instead of designing ones that never fail? Gat continues:
First, it is much easier to design navigation algorithms which fail cognizantly than ones which never fail. Second, if a failure is detected then corrective action can be taken to recover from that failure. Thus, algorithms with high failure rates can be combined into an algorithm whose overall failure rate is quite low provided that the failures are cognizant failures.29
The three-layer architecture may seem obvious now that you’re reading about it, but it wasn’t so obvious at first. To understand why, it’s worth looking at some versions that preceded three-layer architectures. As Erann Gat recalled, one such architecture was sense-plan-act, which was widely used in robots until 1985.30 This architecture lives up to its name: the robot senses the world around it, plans its next step, and executes that step. Information flows in a single direction, from sensors to the planner to the controller. The shortcoming of this architecture, of course, is that it is not reactive. If your robot butler used the sense-plan-act architecture, I would advise you to ask it to serve clear fluids only.
What followed sense-plan-act, Erann Gat observed, was a profusion of subsumption architectures. These look like sense-plan-act, with the flow of information from the environment to the planner to the controller; but they differ because their modules can react to the environment by “overriding” actions from lower layers. Robots designed with the subsumption architecture could zip around the research lab more impressively than their sense-plan-act predecessors, but roboticists found that their architectures grew complex very quickly. The connections between layers became confusing, and the modules interacted in unpredictable ways. A small change to the low-level layers might require a redesign of the whole system. Design of these systems became a mess. The three-layer architecture, on the other hand, enables robots to react quickly while still providing a clean separation between the different parts of the architecture so we can still reason about it.31
The motion planner in Boss, rather complicated for a controller, is almost a three-layer architecture by itself, without a sequencer. This complexity suggests another possibility: What if we nest three-layer architectures, with one serving as another one’s controller? We might even imagine that cities will one day use AI to improve traffic congestion. At the top level of planning, some module might search for optimal traffic flows to decrease congestion during rush hour, telling individual self-driving cars in the controller which routes they can’t take. The cities’ sequencers might react to accidents and other contingencies.
Self-driving cars, treated by the city as controllers, might themselves be implemented with three-layer architectures; and given the constraints imposed by the city’s sequencer, along with their own goals, would then plan their missions accordingly.
CLASSIFYING THE OBJECTS SEEN BY SELF-DRIVING CARS
Machine learning’s role in self-driving cars has received a lot of attention, to the extent that many people confound the algorithms that perform perception with those that perform high-level planning. This is probably in part because Alphabet’s self-driving cars were on the road and picking up media attention around the time other major breakthroughs in machine learning (many also by Alphabet companies like Google) were being reported in the news. Although clever machine learning algorithms can exist in the top-level planning layer of self-driving cars, much of the high-level reasoning layer comes from ideas that have been around in AI for decades—ideas like search algorithms and finite state machines—that wouldn’t traditionally be considered machine learning (remember, machine learning deals primarily with teaching machines using data, while AI doesn’t necessarily need data). Instead, much of the machine learning used in self-driving cars lies comfortably within their perception and world-modeling layer.
One of the important perception tasks of a self-driving car is classifying objects seen by its sensors into categories. Boss didn’t attempt to classify objects into fine categories; its urban environment was artificial, so the only moving objects in its environment were cars. In the wild, self-driving cars encounter many different types of objects, so they must classify these objects into different categories to react appropriately. By understanding whether an object is a car, a bicycle, a pedestrian, or a woman in an electric wheelchair chasing a duck, the car can better model it and predict its path.
How could a self-driving car categorize the objects it sees with its sensors? A certain class of machine vision algorithms showed significant advances in the years surrounding 2012. This class of algorithms, from a field known as deep learning, enable computers to classify the content of photographs as accurately as many humans. These algorithms advanced rapidly in the ensuing few years, to the extent that custom hardware was developed by companies like NVidia for express use in self-driving cars’ vision systems. Later in this book we’ll take a closer look at how these algorithms work.
SELF-DRIVING CARS ARE COMPLICATED SYSTEMS
There are a lot of important aspects to building self-driving cars that we haven’t covered yet. Let’s take a brief look at a few of these now.
Among other things, a huge amount of software must be written for a self-driving car. Writing this software requires a huge amount of human investment. The winning teams were large, on the scale of roughly 40 to 60 people, including researchers, engineers, and undergraduate students. Such large-scale efforts require careful management between people and parties to ensure that contributors are happy and productive. But even happy, productive workers can write bugs.
As we saw, one way to handle bugs was via graceful error-recovery systems. The successful teams in the Grand Challenges also put a lot of effort into testing and simulation. One Wired magazine reporter saw Chris Urmson bring up a visualization that resembled a “mountainous Tron landscape.” It was detailed enough to run simulations of how a self-driving car could handle the road, right down to its tires and shocks.32 These teams, especially in later years, developed simulation environments that would allow them to replay past drives so they could improve their learning algorithms and exception handling.33 This topic alone is enough to fill an entire book, but we have other topics to digest.
THE TRAJECTORY OF SELF-DRIVING CARS
After nearly a decade of winter for self-driving cars in the 1990s, DARPA’s Grand Challenges had helped to reignite the field. Despite the advances made during those races, it would be years before these cars could drive without humans on public roads due to both technical and legal challenges.34 A decade after the Urban Challenge, the ability to handle unexpected situations remained among the biggest problems these cars continue to face. Uber was still struggling with this problem as of 2017. Their experimental self-driving cars, which have humans behind the wheel at all times, could only drive about 0.8 miles on average before a disengagement—that is, before a human needed to intervene.35 Waymo, Alphabet’s self-driving car company, which has logged a great deal more miles on the road than Uber, logged just 0.2 disengagements per 1,000 miles at the time.36 And beyond this, the teams behind these cars must build and maintain highly detailed maps.37
Many of the rivals in the DARPA Grand Challenges ended up working together to build self-driving cars in the years following the races. Sebastian Thrun, leading Alphabet’s self-driving car project, eventually hired Chris Urmson and Andrew Levandowski, a creator of the self-balancing motorcycle, along with other leaders in the field. Chris himself eventually became Alphabet’s self-driving car project lead in 2013.38 The project—possible because of a field kick-started by a well-organized DARPA competition in 2004—would log over 1.2 million miles on the road by the time he left in 2016.39