9 ARTIFICIAL NEURAL NETWORKS’ VIEW OF THE WORLD
THE MYSTIQUE OF ARTIFICIAL INTELLIGENCE
In 2016, a Bloomberg News reporter wrote that several startup companies had begun offering intelligent “chatbots” as personal assistants.1 One of these chatbots, named Amy Ingram, was marketed by her company as “a personal assistant who schedules meetings for you.” You simply needed to “cc” Amy to an email thread for her to do her magic. Users of the service liked Amy’s “humanlike tone” and “eloquent manners.” One user said she was “actually better than a human for this task.” Some men even asked her out on dates.2
Before we get into the details of how Amy worked, let’s go back in time a bit to see some trends in machine learning leading up to her debut. Beginning around 2006 and extending for the next decade, the ability of computers to recognize the contents of images and other media has improved dramatically because of a technology known as deep neural networks. These are like the networks we saw in the last chapter, but many layers deep. By some metrics, deep networks are now better than humans at recognizing objects in photographs, and they’ve become capable of artistic feats like rendering photographs as “paintings”—complete with brush strokes—and going the other way, creating photorealistic renderings of paintings. These breakthroughs have been the result of several factors, including more data, better hardware, better neural network architectures, and better ways to train these networks.
In the last chapter we learned to think about a neural network as a mapping that takes some input (pixels in an image) and produces some output (the value of performing joystick actions). Importantly—and consistent with the fact that neural networks can be the building blocks of automata—the mapping from inputs to outputs is fixed. There’s nothing magical or unpredictable about neural networks. Rather, they’re the exact opposite: perfectly predictable. Neural networks are just deterministic functions, compositions of the simple operations performed by their artificial neurons, which are just classifiers when we look at them closely enough.
We also learned that a network with just a single hidden layer can represent any function, from the network’s inputs to its outputs, to any degree of accuracy—provided that that hidden layer is big enough.3 Finding this function is just a matter of adjusting the weights of the network like knobs until it gives us the output we want, for whichever input we might give it. And as I mentioned in the last chapter, it’s possible to fit these weights automatically, by training the neural network with data.
At this point we might pause to ask ourselves whether these two facts are sufficient to say we understand neural networks well enough to move on to other topics. We know that it’s theoretically possible for a neural network with a single hidden layer to represent any function, and we know that it’s possible to train the network by feeding it enough data. Is this enough?
I’ll make the case below that the answer is an emphatic no. Knowing that it’s possible to train a neural network to recognize whatever we want still doesn’t shed light on important details, like what internal representation the neural network uses to understand the world, how a network could classify objects in photographs, and when a network won’t work well. Knowing these details is important for us if we hope to understand the capabilities and limitations of neural networks and the automata made out of them. Let’s turn briefly to a famous automaton for a more concrete lesson on why this is true.
THE AUTOMATON CHESS PLAYER, OR THE TURK
A mysterious mechanical device was built in the year 1770, a few decades after Vaucanson’s Flute Player. Like the Flute Player, this device was an automaton, and it looked and moved like a human. It sat at a desk, surrounded by the haze of two nearby candelabra. This device could perform an impressive—albeit mechanical—feat on the chessboard called the knight’s tour. Holding the chess piece with its gloved hand, which was attached to a wooden arm and torso, the device could move the knight from square to square with legal chess moves, visiting each square of the chessboard exactly once.
More impressively, this strange device could also play an expert game of chess, winning its games against the vast majority of human competitors.4
The public was even more enamored of the device than of the Flute Player; they came to know this one as the Automaton Chess Player, or sometimes, simply, as the Turk, given its headdress and the rest of its garb.5 The device’s owners took it around Europe and eventually to parts of the New World for public demonstrations, as growing crowds of spectators stared at it in awe, puzzling over its mechanical secrets. It even played legendary games against Napoleon and Benjamin Franklin in Paris.
But how did it work? Skeptics suspected that there was a child hidden inside, but the device’s owners invariably showed spectators its innards before they gave presentations. The spectators had seen clear through the Turk’s desk as the operator opened various drawers for them, one by one. They saw the mass of clock-like gears that powered the device. They even heard the whir of these gears, all devised by a mechanical genius who also had an inkling for building steam engines and devices to replicate human speech. When the operator lifted the robes of the human-like Turk to reveal its backside, the spectators saw that it was just wood and gears; the wooden figure was definitely not a person in a costume.6 And to make matters even more confusing, the original owner presented a small, coffin-like box that he claimed was necessary for the device to run properly, which he peered into from time to time. People wondered whether it was somehow magical.
Speculation abounded, as books with titles like Inanimate Reason were published to make sense of the phenomenon. Unlike Vaucanson, who shared his device’s workings with the French Academy of Sciences, the owners of the chess-playing automaton kept its workings a closely held secret.
The Turk was eventually destroyed in a fire some 84 years after it was built. Despite years of speculation, the secret of the automaton was never fully revealed during its lifetime. It had remained shrouded in mystery for two generations.
After it was destroyed, the son of the device’s final owner recognized that there was little reason to keep the secret, so he described the machine in a series of articles. The Turk was operated by an expert human chess player who was hidden inside the desk.7 It was nothing more than a giant puppet that used misdirection and some clever mechanics to trick viewers into thinking there was no human operator. The setup included magnets to transmit information through the chessboard to the hidden puppeteer and a sliding seat that enabled the chess player to move out of sight as the mechanic opened various drawers before the game. During the games, the puppeteer worked by candlelight within the dark confines of the desk. The smoke of his candle, in turn, was disguised by the haze of the candelabra. And the mysterious coffin-like box and clockwork served no useful purpose except to distract the audience. It was misdirection, a ruse to make it look as though the Turk was driven by other forces.
MISDIRECTION IN NEURAL NETWORKS
The Turk, with its “mysterious” mechanics, demonstrates that we should be unwilling to accept an answer such as “it works because it uses a neural network,” because that’s exactly the sort of thinking that allowed people to believe in the Turk. It leaves us open to getting caught up in some of the unfounded hype in AI, when that attention could be better focused on the more promising breakthroughs. Even worse, this careless thinking could leave us open to believing in hoaxes like the Turk—hoaxes that we still see every day. For example, Amy Ingram, the “artificially intelligent” chatbot I described at the beginning of this chapter, appeared to be such a hoax (although, if you looked at the fine print in her company’s advertising, you might conclude that humans could step in from time to time, and you might call it “rosy marketing” instead of a hoax). Several of the companies offering these bots were powered by humans working behind the scenes around the clock. Amy, for example, was powered by a variety of people, including, sometimes, a 24-year-old dude named Willie Calvin.8
One way to be sure we aren’t falling for hoaxes or for rosy marketing like this is to study these devices carefully, as we’ll do in the next few chapters, and to insist on a clear exposition from their creators about how they work. It’s unreasonable to expect everyone to understand these things in detail: people are busy, automata old and new are complicated, and the technology behind them continues to change rapidly. In those cases, however, we can still insist that these devices be scrutinized by scientific or engineering organizations, just as the French Academy of Sciences reviewed (and then accepted) the thesis that Vaucanson had presented to them. In the remaining cases—for example, when companies have a reasonable interest in protecting their intellectual property—you can hopefully be better prepared to make the judgment on your own.
For the reasons above, we’ll spend the rest of this chapter emphatically digging more deeply into some of the details behind how artificial neural networks—particularly deep neural networks—work; and we’ll start by creating a neural network that can recognize photos of dogs. Some of the details in the next few chapters will be involved, but they’ll pay dividends, as they will offer us a better understanding not just for what neural networks can do, but also for how and when they can do certain things.
RECOGNIZING OBJECTS IN IMAGES
Let’s imagine for the moment that you’ve already designed your neural network, and that you’re ready to train it to recognize photos of dogs. The process for training a neural network is, just like reinforcement learning, reminiscent of the process for training a pet with treats. First, we pick a picture that we want the network to understand. This “training example” is just a photo—a picture with a dog or a picture without a dog—that we want the network to remember. For the network to understand this training example, we first need to encode the example numerically. We do this by describing the picture with numbers to represent the color of each of its pixels: since we need three colors (red, green, and blue) per pixel, a picture with 300 × 200 is be represented with 300 × 200 × 3 = 180,000 numbers.
Once we’ve set the network’s input neurons to these numbers, we can “run” the network, letting the neurons propagate their information through the network. They will activate (or not) layer by layer until they produce an output at the end.
Remember from the last chapter that we can think about neurons in the network as little light bulbs that turn off or on, shining more brightly when their activation level is higher. Once the network has run, some of the little neurons in the network will be dark, while others will glow. Some might glow very brightly.
Generally we care most about how brightly the neurons at the output layer of the network are glowing, because those neurons represent what we’re trying to predict. Because we’re training the network to identify pictures of dogs, let’s assume that there’s exactly one neuron in the output layer; we’ll call this the “dog” neuron. If this neuron is brightly glowing, we’ll say that the network thinks that there was a dog in the picture, whereas if it’s dark, the network thinks there was not a dog. If it’s somewhere in-between, glowing but not bright, the network thinks there may be a dog but isn’t quite sure.
Once we’ve run the network to get a prediction of whether the training picture has a dog in it, we compare the brightness of the output neuron with the label of our training example, which tells us whether the photo actually had a dog or not. We would encode the label of this training example numerically: 1 if the picture has a dog in it and 0 if it doesn’t. So if the neuron at the end was glowing brightly and the label was 1, or if the neuron was dark and the label was 0, then the network was correct; otherwise, it was incorrect. We then create a new message describing how much error there was in the network’s prediction and propagate that message backward through the network, adjusting the weights between the neurons like little knobs so that the network will give a slightly better response the next time around. When the network is correct, or mostly correct, we will still send back a message and adjust the knobs, but we won’t adjust them by much.
At first, the network will usually be incorrect. It will be guessing randomly. But over time, the network will become more and more accurate. After we’ve trained the network for a long time, we would also adjust its weights less and less, just as you would fine-tune the volume knob on a radio once you’re close to the volume you want.
In a nutshell, this is the way many standard neural networks are trained. This method, while simple, wasn’t discovered and well understood until the 1970s and the 1980s, even though neural networks had been around for decades before that.9 It should also go without saying that “we” aren’t doing much work here. The computer does all of the hard work for us, and we just need to feed the network as many training examples as we can find for it.10 If we were fitting a network to classify images, we would repeat this process with image after image,11 and we’d repeat the process until the network was no longer improving. As long as we have enough data and a big enough network, we could train the neural network to recognize just about anything we want it to recognize.
If you tried to train your neural network with a few pictures of your pet dog from around your house and a few pictures of your trip to Scotland, it wouldn’t work very well. More likely, the network would learn a simple rule, such as that the colors of the inside of your house are predictive of there being a dog in a photo, and the presence of lots of green in the image is predictive of there not being a dog in the photo. That’s because the operative phrase in the paragraph above, on which everything depends, was this one: as long as we have enough data and a big enough network.
OVERFITTING
One of the biggest challenges in fitting neural networks is that if the network is too flexible, or if we don’t have enough data to train the model, then we might learn a model that explains the training examples well but doesn’t generalize to other, unseen examples. We saw this same problem in chapter 6, about the Netflix Prize; this risk is called overfitting. What does overfitting look like in practice?
In figure 9.1a, I show a small sample of data. In this case, it’s just pairs of points, (input, output). Let’s say we want a model for these points that, given an input value, produces an estimate of the output value. This is exactly what you’re doing when you fit a neural network: you’re just fitting a model to predict some output values from the input values. And just below this, in figure 9.1b, is a model I’ve fit to these points. The model is the curvy line that goes through or near many of the points. From this model—the curvy line—you can see what it would predict for each input value, both for the inputs we had seen during training (the black dots) and for many values we hadn’t seen in training.

Plots to illustrate overfitting: (a) a sample of points (input, output) for which we hope to build a model; (b) a complex and overfit model of these points (the black curvy line); (c) a linear model of these points (the straight line); and (d) a complex but not overfit model of these points (the black, not-very-curvy line).
But there’s a problem with this model: although it matches the training data well, it’s unlikely to explain new data very well. It’s too complex. It makes too many assumptions about the data, so it’s got too many squiggles. Overfitting can become problematic because it might make assumptions about the data—assumptions like “lots of green in a photo means there isn’t a dog in it”—when it’s not justified in making these assumptions. We have no evidence yet that a much simpler model wouldn’t be better, or that we have enough data to fit the complex model. We would be remiss if we didn’t follow the principle of Occam’s razor, which states that we should favor the most simple model for our data absent compelling evidence for a more complex one. (A linguistics professor of mine once explained Occam’s razor succinctly as, “Keep it simple, stupid.”)
The two most common ways to avoid overfitting are either to use a simpler model—that is, a model with fewer knobs to tune (as I show in figure 9.1c) or to use more data with the complex model (figure 9.1d)—or some combination of these. As you can see, the model we find when there is a lot of data looks a lot more like a straight line, which confirms our hunch that we did indeed overfit the data with the first, curvy model.
Neural networks are especially prone to this problem of overfitting because they might have billions of connections between neurons—and, hence, billions of knobs to tune.12 If you don’t have lots of photos to train your network to find pictures of your dog, then you will very possibly overfit the neural network. Researchers typically address this with some combination of the solutions I mentioned above: by using a network that has fewer knobs to tune and by using as much data as possible. We’ll explore both of those now, starting with having lots of data.
IMAGENET
One popular source of photos to train neural networks is the web, but unfortunately most photos on the web don’t have explicit labels attached to them. It’s possible to use data like this to train neural networks; but in general, explicitly labeled pictures are better.
Enter Li Fei-Fei. Fei-Fei is an energetic and intensely focused machine learning and computer vision professor at Stanford University (who has recently joined Google to lead its cloud AI efforts). Fei-Fei became famous in part for her work on producing large, well-labeled collections of images that can be used for training computers to understand images—and for evaluating their ability to do so. She began this work as she was developing an algorithm in her research. To train and evaluate that algorithm, she and her colleagues collected images by flipping through the pages of a dictionary, finding entries with illustrations. Once she and her colleagues found 101 different entries that could serve as object categories, they looked for as many images as possible from each category with Google Image Search. The result was a collection of about nine thousand images that researchers could use to train and evaluate their own algorithms.13
Recognizing how useful this data was, Fei-Fei and her students embarked on a more ambitious project over the next decade: ImageNet. She and her colleagues again collected images for a variety of categories using Google Image Search, adjusting their queries and issuing the queries in different languages to get a broader variety of images.14 After doing this, she and her research teams had millions of images, but some didn’t match the expected category very well. For example, if I search for “kayak” on Google Image Search, one of the results is the logo for the travel website Kayak.com, when what I probably want is the thing I’d use to travel down a river. To filter out these images, Fei-Fei and her team turned to Amazon Mechanical Turk.15
Amazon Mechanical Turk is a relatively recent milestone in the history of automata. It’s a website provided by Amazon.com that allows any user to dispatch small, simple tasks to a “computer” that performs these tasks. The user must provide simple instructions to the website describing how these tasks should be accomplished and then pay a small fee for each task. Fei-Fei and her team gave the Amazon Mechanical Turk precise instructions asking the computer in effect to “tell us whether this image contains a kayak” or “tell us whether this image contains a Siamese cat.”16 Once tasks like this have been uploaded to Amazon.com, the website’s computers then process the tasks as instructed.
Amazon Mechanical Turk takes its name because, like the chess-playing Turk, its “computers” aren’t actually automata: they’re people, often just sitting at home on their own personal computers. The website “abstracts away” the people behind the service, making it feel as if these tasks are being performed automatically by a computer. (The website doesn’t keep it a secret that humans perform these tasks, and you can still interact in limited ways with the users who have worked on your tasks.)
The result of Fei-Fei’s effort—downloading images from Google Image Search and cleaning up their tags with Amazon Mechanical Turk—is that ImageNet grew to over 14 million high-resolution images, labeled with over 22,000 categories.17 Compared to other benchmark datasets at the time, ImageNet provided an order of magnitude more labeled images. While other datasets might have a category for cat or dog, ImageNet also had fine-grained labels for some categories. Among the 120 different labels it had for dogs, for example, were Dalmatian, Keeshond, and Miniature Schnauzer.18
In 2010, Fei-Fei organized a competition with 1.4 million images from 1,000 categories in this dataset: the ImageNet Large-Scale Visual Recognition Challenge. One part of the competition required researchers’ algorithms to identify which of the objects across the 1,000 categories were in an image; these categories ranged broadly, from great white shark to hen to hourglass.19
The first two years of the competition saw measured improvement, as the error rate dropped from 28 percent in 2010 to 26 percent in 2011. Like the second year of the Netflix Prize, researchers in the field of computer vision had picked all of the low-hanging fruit over the years. Each year the field eked out small gains by adding more and more handcrafted features. But a paradigm shift happened in 2012, when an inelegant and underdog submission became the undisputed winner of the ImageNet Challenge. The submission was a deep neural network, and it came in with an error rate of 16 percent, far below the previous year’s rate of 26 percent.20
CONVOLUTIONAL NEURAL NETWORKS
The paradigm-shifting 2012 network became known as AlexNet, named after the first author on the paper that made it famous. AlexNet worked better than its competitors for several reasons, two of which I mentioned above: it had been trained on a huge amount of data, and it was built in such a way that it didn’t have too many weights to tune. The researchers had architected the network so that the number and locations of its knobs made efficient use of their data. (In fact, AlexNet wouldn’t be called efficient or accurate by our “modern” standards of just six years later, but I’ll come back to this point shortly.)
Let’s return to our goal of building a neural network that can detect pictures of dogs and use the ideas from AlexNet. AlexNet was, like the Atari-playing network, a convolutional neural network using a sequence of convolutional layers followed by a sequence of fully connected layers (five of the former and three of the latter as shown in figure 9.2).21
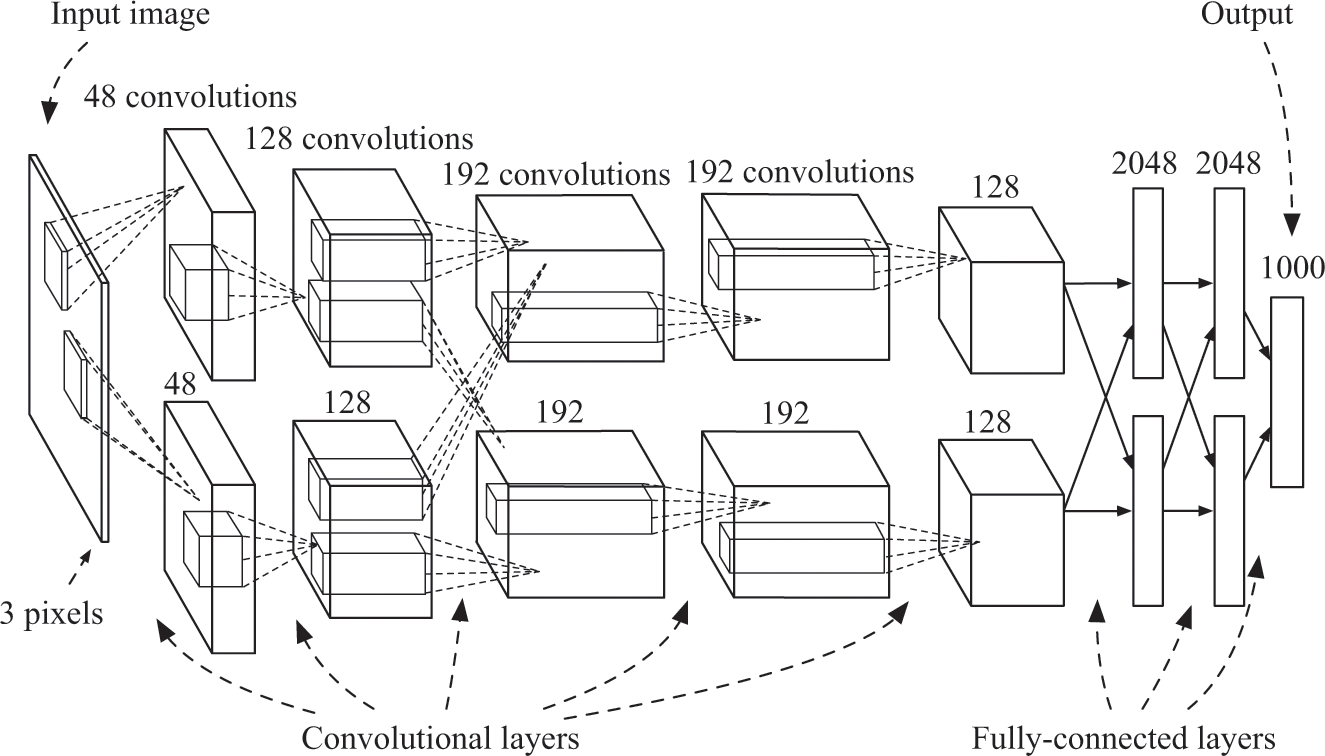
The architecture of AlexNet, the artificial network that won the 2012 ImageNet Challenge, set the stage for further improvements in image classification. AlexNet had five convolutional layers followed by three fully connected layers. Much of the network was trained on two different processors, so that some layers didn’t process any inputs from the convolutional layers handled by the other processor. The input layer represented the red-green-blue values of an image, while the output layer had 1,000 neurons corresponding to each of the categories predicted by the network. Image adapted with permission from Russakovsky et al., “ImageNet Large Scale Visual Recognition Challenge.”
This pattern—convolutional layers followed by fully connected layers—turns out to be very common in networks used for image recognition. What’s so special about this architecture that makes it successful across a range of applications?
Remember from the last chapter that convolutional layers transform the image by finding objects in it. Each convolutional layer has a set of filters that look for distinct patterns in the image (or images) in the previous layer. The convolutional layer slides each filter over patches of neurons in the previous layer. You can imagine this as looking for different items on a beach with a bunch of magical “thing detectors.” The “thing detectors” are the filters. One filter might look for beautiful shells on the beach, while another might look for wristwatches left behind by beachgoers. The output of the convolutional layer is a collection of maps of the beach, one for each filter. If the shell filter doesn’t find a shell in any patch of the image that matches its pattern, then the map for that filter will be dark everywhere; otherwise it will have a bright spot wherever it found a shell; the same applies to the watch detector. As we saw in the last chapter, a neuron in the output layer of the convolution will be very bright if there is a strong match for the filter at that position of the input to the convolution.
In the last chapter I discussed filters for aliens and paddles. But that was a bit idealistic and unrealistic for the filters in the first convolutional layer for a network that recognizes natural images (and, probably, for one that plays Atari games as well). It’s unlikely that any single filter of a convolutional layer would recognize complex objects like this, in part because the filters in the first layer are usually fairly small. In AlexNet, for example, the filters in the first layer looked for patterns in 11 × 11 patches of pixels.
If these filters can’t recognize aliens and spaceships from pixels, how can they identify pictures of dogs, let alone dogs of different breeds? Remember that AlexNet has five layers of convolutions. It’s not until the final layers that the network is able to recognize complex objects like dogs and spaceships. Before we can understand how they do that, let’s look back at the first layer. AlexNet used about a hundred filters in its first layer, which meant that it had a hundred magical “thing detectors.”
I show a set of filters from a convolutional neural network just like AlexNet in figure 9.3a. Each square in this image shows a patch of pixels that will brightly light up one of the filters in the first convolutional layer. Although you can’t see it in these black-and-white images, these filters also matched different colors; some tended to match blue and white, while others matched yellow and red, and so on. A lot of researchers interpret these filters as “edge detectors” because they match edges or other simple patterns in the input image. These patches of pixels may not look very meaningful, but they become meaningful when combined with other edge detectors by layers deeper in the network. In other words, they’re the building blocks used by the layers further downstream in the network. And this is where the magic of convolutional neural networks really starts.

Patterns of pixels that activate filters in various layers of AlexNet in convolutional layers 1 (a), 2 (b), 3 (c), and 4 (d). These filters search for patterns of light and dark (they also search for certain colors, which you can’t see in this picture). Images used with permission from Yosinski et al., “Understanding Neural Networks Through Deep Visualization.”
AlexNet’s remaining four convolutional layers each have a few hundred more filters.22 Each successive convolutional layer uses filters from its preceding layer as building blocks to compose them into more complex patterns. The second convolutional layer doesn’t think in terms of pixels; it thinks in terms of filters from the first layer—that is, in terms of edges—and it builds up patterns of these edges to search for. You can see some of these patterns in figure 9.3b. Each square in this figure represents which pixels in the input image would brightly light up a filter in the output of the second layer. These patterns are still not full objects, but it’s clear that they’re starting to become more interesting: some of them look a bit like fur (which is useful for recognizing dogs), while some of them look like curvy segments (which is useful for recognizing snakes, lips, or other curvy objects).
As we continue to move deeper into the network, the compositions captured by the convolutional filters continue to become more and more complex. You can see the filters for the third and fourth convolutional layers in figure 9.3c and figure 9.3d. As before, each square represents a patch of pixels that would highly activate some filter in that layer. Here you can begin to make out coherent parts of objects: some patches appear to be animals’ eyes, while others appear to be larger patches of fur. Others yet appear to be larger parts of animals. One even looks a bit like a face! This increasing abstraction continues as we go deeper into the convolutional layers in AlexNet.
Once we’ve moved past the fifth convolutional layer, we find three fully connected layers. The output of the network had a thousand different neurons, corresponding to each of the categories in the ImageNet Challenge. AlexNet was trained so that, when presented with an image containing one of these categories, the corresponding output neuron should light up. If presented with an image of a shark, then the shark neuron should light up. If presented with an image of an hourglass, the hourglass neuron should light up. Otherwise these neurons should stay dark.
You can see a sample of image patches that would light up some of the neurons in the final, output layer of this network in the four images shown in figure 9.4. Not surprisingly, image patches that light up the neuron for one of these categories tend to match our intuition: the image patch that lights up the great white shark neuron appears to have great white sharks in it, and the image patch that lights up the hourglass neuron appears to have an hourglass in it. Amazingly, the objects in these images didn’t come from any single picture: these image patches were generated from the network itself, to reflect precisely what each neuron “looks” for.
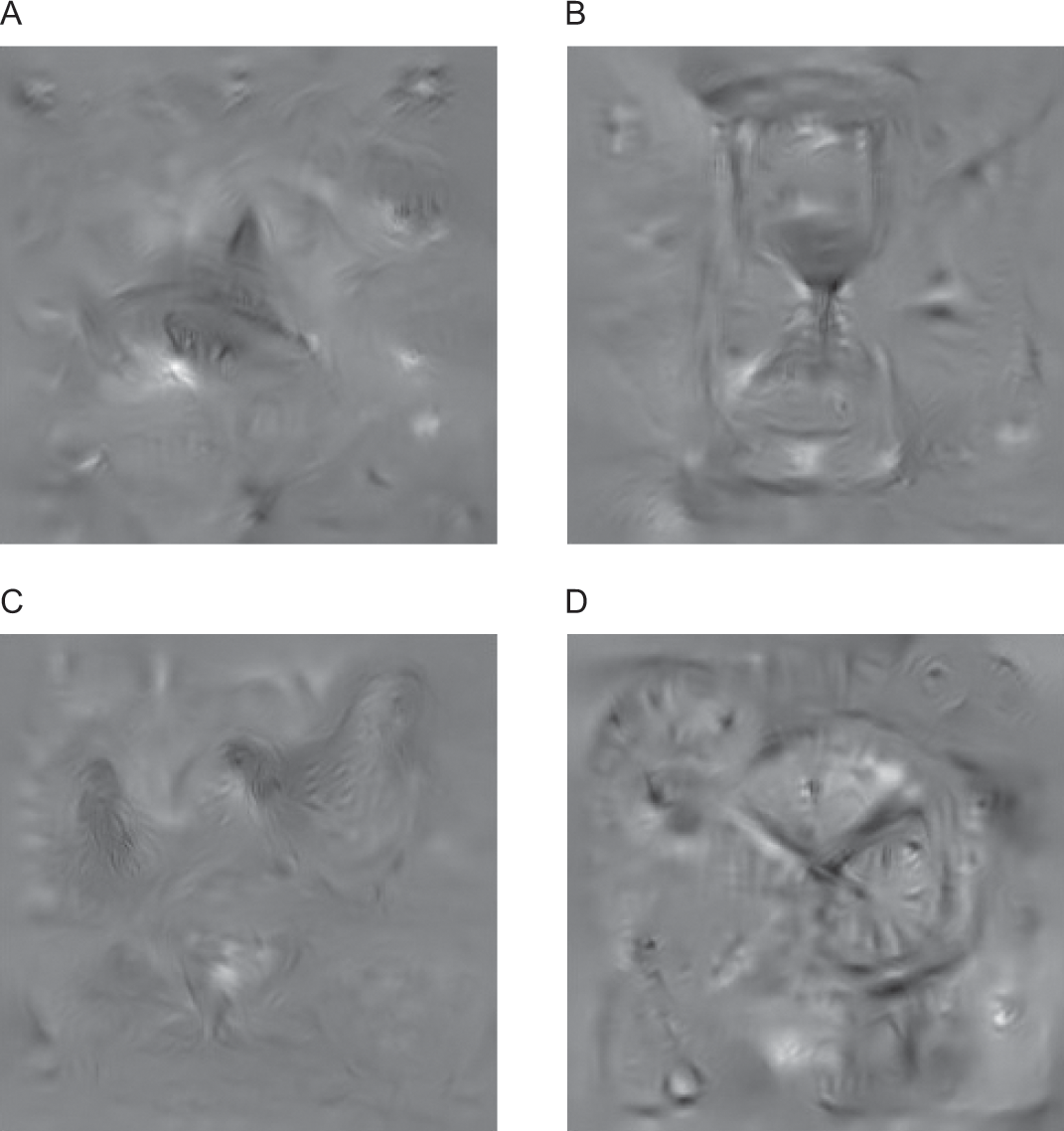
Image patches that activate the neurons in the output layer of our network. Neurons correspond to categories in the ImageNet Challenge (A: great white shark; B: hourglass; C: hen; D: wall clock). Images used with permission from Yosinski et al., “Understanding Neural Networks Through Deep Visualization.”
The images in the ImageNet Challenge were biased toward animals, with 120 different categories for domestic dogs alone, out of its 1,000 total categories. This means that, to create our network to recognize your pet dog, we can probably just use the AlexNet network with only a small modification: we just remove (or ignore) all output neurons except for the ones that best match your dog. But in general, we might want to keep the other output neurons, since it can be helpful to know whether the image matches other things, such as a different type of dog or even a cat.
WHY “DEEP” NETWORKS?
What is it about deep neural networks—and AlexNet in particular—that enabled them to work so well in the ImageNet Challenges? Did the networks’ architectures help? For example, did these networks need to be so deep? As we already know, neural networks with just a single hidden layer should be capable of representing arbitrarily complex functions, so it should be possible, at least in theory, for a network with just a single hidden layer to beat the ImageNet Challenge.
The problem with a single hidden layer is that we have no guarantee that the hidden layer won’t need to become extraordinarily large to represent the function we want. If the hidden layer becomes too large—that is, too wide—then we would need to learn too many weights, and we’re likely to overfit without an extraordinarily large amount of data. On the other hand, there’s theoretical evidence that suggests that by going deeper instead of wider, we can represent complex functions much more efficiently—that is, with far fewer neurons, and therefore with far fewer weights to learn.23
What is it about going deeper instead of wider that makes a network more efficient? If you’ve ever used a Nintendo Wii, there’s a good chance that you’ve created a Mii. A Mii is a cartoon character that represents you, as a player. It’s your avatar for certain Nintendo Wii games. To create your Mii, you select eyes, nose, skin color, hair, and a variety of other facial and body features to make a character that looks like yourself. For each characteristic, you have a handful of options—we’ll say about 5 to 10—from which to select. While the end result is often more cartoonish than photorealistic, it can still bear a striking (and humorous) resemblance to you, or to anyone else for whom you make a character. By using just a handful of building blocks—the eyes, nose, hair, mouth, and other features shared as building blocks for all Mii characters—you can create a wide variety of Mii characters that can faithfully represent just about anyone you might imagine.
Now let’s think back to the benefit that convolutional layers provide. Neural net researchers have suggested that convolutional layers are powerful because they use a distributed representation to process an image. They let you reuse components among different neurons. If your neural network can recognize 120 different breeds of dogs, the first few layers can focus on recognizing the very basic characteristics we might use to describe dogs: the different types of fur they might have, different types of ears, and different patterns of coloration. Then the deeper layers can focus on combining these different “primitives” in various ways. Just as you can construct a Mii using a variety of well-defined and reusable facial and body features, higher-level convolutional layers can construct objects—like dogs—from the features found in earlier convolutional layers. And this can repeat at each level, giving an exponential increase in the things that can be represented with each layer. As you can imagine, in some layer beyond where the network can recognize dogs and people, you might have neurons that can explain entire scenes. You might have, for example, a neuron that recognizes recreational parks (by leveraging neurons earlier in the network that recognize dogs, people, and playground equipment); or you might have a neuron that recognizes urban environments (cars, streets, and commercial storefronts). In the next chapter we’ll actually look at neural networks that can generate captions for scenes like this. The creators of AlexNet saw this benefit to using multiple layers empirically as well. If they removed any convolutional layer, then their network’s performance degraded.24 The ImageNet Challenge contestants also noticed this in the years following AlexNet: as they continued to build deeper and deeper networks, their performance on the challenge continued to improve.
Many of the submissions to the ImageNet Challenge after 2012 followed AlexNet’s lead and used deep neural networks. Although AlexNet won by a commanding lead in 2012, a number of other teams beat AlexNet in 2013, when all of the top teams used deep learning. In a research field otherwise used to eking out small gains each year, the error rate plummeted over the next few years, as researchers continued to improve their new favorite toy. In 2014, Google produced a network that by some metrics exceeded the accuracy of humans.
In 2018, as I write this book, the field of research is still extraordinarily active and fruitful, as researchers are discovering new ways to connect layers to one another. The top-performing networks in the ImageNet Challenge now have an error rate of 2.3 percent, a small fraction of AlexNet’s 16 percent error rate.25 As Dave Patterson, a computer architecture researcher at Google Brain and former professor at UC Berkeley, noted, it’s shocking even to pioneers in the field that these methods in deep learning are working so well.
Noticing that network depth can be helpful, contestants in the ImageNet Challenge have made their networks deeper and deeper, to seemingly absurd levels. One 22-layer network designed by Google, for example, was called the Inception Network, a reference to the 2010 movie Inception and the internet meme, “We need to go deeper.”26 But adding more layers increases the number of parameters we need to tune; so how did Google’s researchers manage to go so deep without overfitting? One way was by recognizing that the neurons in its convolutional layers might be too simple (they are, after all, just weighted-average classifiers). So they replaced them with miniature networks that could find more complicated patterns. Critically, however, they did this in such a way that they used fewer parameters per layer (for example: two 3 × 3 filters and one 1 × 1 filter, and three weights to combine them, require 22 parameters altogether, while a single, “dumb” 5 × 5 filter has 25 parameters). Depths like that of the Inception Network are no longer considered extreme; it’s not uncommon now for a network to be 10 to 20 layers deep, with billions of weights to tune. Some networks have gone thousands of layers deep.27
Researchers have discovered ways to improve networks besides depth. They’ve discovered, for example, that networks can perform better when information is allowed to “bypass” certain layers, something made possible by adding connections between nonadjacent convolutional layers. They’ve also found ways for neurons to reinforce one another within a layer, a process called excitation. This is useful when, for example, one part of a convolutional layer recognizes cat fur: that should be a signal to other parts of the layer to be on the lookout for related items, like cat eyes and cat tongues.
DATA BOTTLENECKS
AlexNet’s network architecture was important, but another factor in its success was the sheer scale of the data its researchers used to train it. They used 1.2 million images from the competition to train their network, but, observing that “object identity is invariant to changes in the intensity and color of the illumination,” they augmented their training data by flipping their images horizontally, translating them, and adjusting their color balance.28 As a result, they ended up with 2,000 times the amount of training data they started with, or about 2 billion images with which to train their network. If they hadn’t augmented their training data like this, they would have needed to use a much smaller—and less expressive—network.29
With so many images for training, their bottleneck wasn’t how many images they could feed into their network, but rather how fast they could feed them in. As the creators of AlexNet observed:
In the end, the network’s size is limited mainly by the amount of memory available on current [processors] and by the amount of training time that we are willing to tolerate. Our network takes between five and six days to train. … All of our experiments suggest that our results can be improved simply by waiting for faster [processors] and bigger datasets to become available.30
Conveniently, the hardware most suited to train these networks has continued to improve since then. Training neural networks involves performing many matrix operations. Computer games must perform exactly the same types of operations to render high-quality graphics, and graphics cards have been optimized over the past few decades to support these operations. Deep learning researchers have begun using these cards because they can speed up the time it takes to train a network by a factor of anywhere from 10 to 50. The market for computer graphics cards that perform these operations had become large and competitive even before deep learning depended on them, which had forced the cards to become affordable, until demand for the cards picked back up in the past few years.31 NVidia, one of the primary manufacturers of these cards, has been printing them like newspapers and selling them like hotcakes; the company has also begun producing even more specialized hardware for self-driving cars. These facts have not been lost on its investors, who are willing to pay $242 for a precious share of its stock in 2018 when they only paid $20 per share 2015. Google has meanwhile introduced specialized chips that appear to improve upon the speeds of the graphics chips by a similar order of magnitude.32
So far we’ve focused on the high-level details of how neural networks allow computers to perceive the contents of images. We’ve looked at the way their layers are organized and the way they’re trained, and at how improvements at this high level have pushed the boundaries of what’s possible with computer perception. But as researchers have been figuring out useful ways to architect these networks at a macroscopic level, they’ve also been looking at ways to improve these networks at the microscopic level—that is, at the level of individual neurons. Changing the way neurons in a network light up, given their inputs, can have surprising effects on these networks’ ability to retain the information we use to train them. We’ll take a closer look at why this is the case in the next chapter.