The addition of exceptions to C++ changes things. Profoundly. Radically. Possibly uncomfortably. The use of raw, unadorned pointers, for example, becomes risky. Opportunities for resource leaks increase in number. It becomes more difficult to write constructors and destructors that behave the way we want them to. Special care must be taken to prevent program execution from abruptly halting. Executables and libraries typically increase in size and decrease in speed.
And these are just the things we know. There is much the C++ community does not know about writing programs using exceptions, including, for the most part, how to do it correctly. There is as yet no agreement on a body of techniques that, when applied routinely, leads to software that behaves predictably and reliably when exceptions are thrown. (For insight into some of the issues involved, see the article by Tom Cargill I refer to on page 287.)
We do know this much: programs that behave well in the presence of exceptions do so because they were designed to, not because they happen to. Exception-safe programs are not created by accident. The chances of a program behaving well in the presence of exceptions when it was not designed for exceptions are about the same as the chances of a program behaving well in the presence of multiple threads of control when it was not designed for multi-threaded execution: about zero.
That being the case, why use exceptions? Error codes have sufficed for C programmers ever since C was invented, so why mess with exceptions, especially if they're as problematic as I say? The answer is simple: exceptions cannot be ignored. If a function signals an exceptional condition by setting a status variable or returning an error code, there is no way to guarantee the function's caller will check the variable or examine the code. As a result, execution may continue long past the point where the condition was encountered. If the function signals the condition by throwing an exception, however, and that exception is not caught, program execution immediately ceases.
This is behavior that C programmers can approach only by using setjmp and longjmp. But longjmp exhibits a serious deficiency when used with C++: it fails to call destructors for local objects when it adjusts the stack. Most C++ programs depend on such destructors being called, so setjmp and longjmp make a poor substitute for true exceptions. If you need a way of signaling exceptional conditions that cannot be ignored, and if you must ensure that local destructors are called when searching the stack for code that can handle exceptional conditions, you need C++ exceptions. It's as simple as that.
Because we have much to learn about programming with exceptions, the Items that follow comprise an incomplete guide to writing exception-safe software. Nevertheless, they introduce important considerations for anyone using exceptions in C++. By heeding the guidance in the material below, you'll improve the correctness, robustness, and efficiency of the software you write, and you'll sidestep many problems that commonly arise when working with exceptions.
Say good-bye to pointers. Admit it: you never really liked them that much anyway.
Okay, you don't have to say good-bye to all pointers, but you do need to say sayonara to pointers that are used to manipulate local resources. Suppose, for example, you're writing software at the Shelter for Adorable Little Animals, an organization that finds homes for puppies and kittens. Each day the shelter creates a file containing information on the adoptions it arranged that day, and your job is to write a program to read these files and do the appropriate processing for each adoption.
A reasonable approach to this task is to define an abstract base class, ALA ("Adorable Little Animal"), plus concrete derived classes for puppies and kittens. A virtual function, processAdoption, handles the necessary species-specific processing:
class ALA {
public:
virtual void processAdoption() = 0;
...
};
class Puppy: public ALA {
public:
virtual void processAdoption();
...
};
class Kitten: public ALA {
public:
virtual void processAdoption();
...
};
You'll need a function that can read information from a file and produce either a Puppy object or a Kitten object, depending on the information in the file. This is a perfect job for a virtual constructor, a kind of function described in Item 25. For our purposes here, the function's declaration is all we need:
// read animal information from s, then return a pointer
// to a newly allocated object of the appropriate type
ALA * readALA(istream& s);
The heart of your program is likely to be a function that looks something like this:
void processAdoptions(istream& dataSource)
{
while (dataSource) { // while there's data
ALA *pa = readALA(dataSource); // get next animal
pa->processAdoption(); // process adoption
delete pa; // delete object that
} // readALA returned
}
This function loops through the information in dataSource, processing each entry as it goes. The only mildly tricky thing is the need to remember to delete pa at the end of each iteration. This is necessary because readALA creates a new heap object each time it's called. Without the call to delete, the loop would contain a resource leak.
Now consider what would happen if pa->processAdoption threw an exception. processAdoptions fails to catch exceptions, so the exception would propagate to processAdoptions's caller. In doing so, all statements in processAdoptions after the call to pa->processAdoption would be skipped, and that means pa would never be deleted. As a result, anytime pa->processAdoption throws an exception, processAdoptions contains a resource leak.
Plugging the leak is easy enough,
void processAdoptions(istream& dataSource)
{
while (dataSource) {
ALA *pa = readALA(dataSource);
try {
pa->processAdoption();
}
catch (...) { // catch all exceptions
delete pa; // avoid resource leak when an
// exception is thrown
throw; // propagate exception to caller
}
delete pa; // avoid resource leak when no
} // exception is thrown
}
but then you have to litter your code with try and catch blocks. More importantly, you are forced to duplicate cleanup code that is common to both normal and exceptional paths of control. In this case, the call to delete must be duplicated. Like all replicated code, this is annoying to write and difficult to maintain, but it also feels wrong. Regardless of whether we leave processAdoptions by a normal return or by throwing an exception, we need to delete pa, so why should we have to say that in more than one place?
We don't have to if we can somehow move the cleanup code that must always be executed into the destructor for an object local to processAdoptions. That's because local objects are always destroyed when leaving a function, regardless of how that function is exited. (The only exception to this rule is when you call longjmp, and this shortcoming of longjmp is the primary reason why C++ has support for exceptions in the first place.) Our real concern, then, is moving the delete from processAdoptions into a destructor for an object local to processAdoptions.
The solution is to replace the pointer pa with an object that acts like a pointer. That way, when the pointer-like object is (automatically) destroyed, we can have its destructor call delete. Objects that act like pointers, but do more, are called smart pointers, and, as Item 28 explains, you can make pointer-like objects very smart indeed. In this case, we don't need a particularly brainy pointer, we just need a pointer-like object that knows enough to delete what it points to when the pointer-like object goes out of scope.
It's not difficult to write a class for such objects, but we don't need to. The standard C++ library contains a class template called auto_ptr that does just what we want. Each auto_ptr class takes a pointer to a heap object in its constructor and deletes that object in its destructor. Boiled down to these essential functions, auto_ptr looks like this:
template<class T>
class auto_ptr {
public:
auto_ptr(T *p = 0): ptr(p) {} // save ptr to object
~auto_ptr() { delete ptr; } // delete ptr to object
private:
T *ptr; // raw ptr to object
};
The standard version of auto_ptr is much fancier, and this stripped-down implementation isn't suitable for real use† (we must add at least the copy constructor, assignment operator, and pointer-emulating functions discussed in Item 28), but the concept behind it should be clear: use auto_ptr objects instead of raw pointers, and you won't have to worry about heap objects not being deleted, not even when exceptions are thrown. (Because the auto_ptr destructor uses the single-object form of delete, auto_ptr is not suitable for use with pointers to arrays of objects. If you'd like an auto_ptr-like template for arrays, you'll have to write your own. In such cases, however, it's often a better design decision to use a vector instead of an array, anyway.)
Using an auto_ptr object instead of a raw pointer, processAdoptions looks like this:
void processAdoptions(istream& dataSource)
{
while (dataSource) {
auto_ptr<ALA> pa(readALA(dataSource));
pa->processAdoption();
}
}
This version of processAdoptions differs from the original in only two ways. First, pa is declared to be an auto_ptr<ALA> object, not a raw ALA* pointer. Second, there is no delete statement at the end of the loop. That's it. Everything else is identical, because, except for destruction, auto_ptr objects act just like normal pointers. Easy, huh?
The idea behind auto_ptr — using an object to store a resource that needs to be automatically released and relying on that object's destructor to release it — applies to more than just pointer-based resources. Consider a function in a GUI application that needs to create a window to display some information:
// this function may leak resources if an exception
// is thrown
void displayInfo(const Information& info)
{
WINDOW_HANDLE w(createWindow());
display info in window corresponding to w;
destroyWindow(w);
}
Many window systems have C-like interfaces that use functions like createWindow and destroyWindow to acquire and release window resources. If an exception is thrown during the process of displaying info in w, the window for which w is a handle will be lost just as surely as any other dynamically allocated resource.
The solution is the same as it was before. Create a class whose constructor and destructor acquire and release the resource:
// class for acquiring and releasing a window handle
class WindowHandle {
public:
WindowHandle(WINDOW_HANDLE handle): w(handle) {}
~WindowHandle() { destroyWindow(w); }
operator WINDOW_HANDLE() { return w; } // see below
private:
WINDOW_HANDLE w;
// The following functions are declared private to prevent
// multiple copies of a WINDOW_HANDLE from being created.
// See Item 28 for a discussion of a more flexible approach.
WindowHandle(const WindowHandle&);
WindowHandle& operator=(const WindowHandle&);
};
This looks just like the auto_ptr template, except that assignment and copying are explicitly prohibited, and there is an implicit conversion operator that can be used to turn a WindowHandle into a WINDOW_HANDLE. This capability is essential to the practical application of a WindowHandle object, because it means you can use a WindowHandle just about anywhere you would normally use a raw WINDOW_HANDLE. (See Item 5, however, for why you should generally be leery of implicit type conversion operators.)
Given the WindowHandle class, we can rewrite displayInfo as follows:
// this function avoids leaking resources if an
// exception is thrown
void displayInfo(const Information& info)
{
WindowHandle w(createWindow());
display info in window corresponding to w;
}
Even if an exception is thrown within displayInfo, the window created by createWindow will always† be destroyed.
By adhering to the rule that resources should be encapsulated inside objects, you can usually avoid resource leaks in the presence of exceptions. But what happens if an exception is thrown while you're in the process of acquiring a resource, e.g., while you're in the constructor of a resource-acquiring class? What happens if an exception is thrown during the automatic destruction of such resources? Don't constructors and destructors call for special techniques? They do, and you can read about them in Items 10 and 11.
Imagine you're developing software for a multimedia address book. Such an address book might hold, in addition to the usual textual information of a person's name, address, and phone numbers, a picture of the person and the sound of their voice (possibly giving the proper pronunciation of their name).
To implement the book, you might come up with a design like this:
class Image { // for image data
public:
Image(const string& imageDataFileName);
...
};
class AudioClip { // for audio data
public:
AudioClip(const string& audioDataFileName);
...
};
class PhoneNumber { ... }; // for holding phone numbers
class BookEntry { // for each entry in the
public: // address book
BookEntry(const string& name,
const string& address = "",
const string& imageFileName = "",
const string& audioClipFileName = "");
~BookEntry();
// phone numbers are added via this function
void addPhoneNumber(const PhoneNumber& number);
...
private:
string theName; // person's name
string theAddress; // their address
list<PhoneNumber> thePhones; // their phone numbers
Image *theImage; // their image
AudioClip *theAudioClip; // an audio clip from them
};
Each BookEntry must have name data, so you require that as a constructor argument (see Item 4), but the other fields — the person's address and the names of files containing image and audio data — are optional. Note the use of the list class to hold the person's phone numbers. This is one of several container classes that are part of the standard C++ library (see Item 35).
A straightforward way to write the BookEntry constructor and destructor is as follows:
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
if (imageFileName != "") {
theImage = new Image(imageFileName);
}
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
}
BookEntry::~BookEntry()
{
delete theImage;
delete theAudioClip;
}
The constructor initializes the pointers theImage and theAudioClip to null, then makes them point to real objects if the corresponding arguments are non-empty strings. The destructor deletes both pointers, thus ensuring that a BookEntry object doesn't give rise to a resource leak. Because C++ guarantees it's safe to delete null pointers, BookEntry's destructor need not check to see if the pointers actually point to something before deleting them.
Everything looks fine here, and under normal conditions everything is fine, but under abnormal conditions — under exceptional conditions — things are not fine at all.
Consider what will happen if an exception is thrown during execution of this part of the BookEntry constructor:
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
An exception might arise because operator new (see Item 8) is unable to allocate enough memory for an AudioClip object. One might also arise because the AudioClip constructor itself throws an exception. Regardless of the cause of the exception, if one is thrown within the BookEntry constructor, it will be propagated to the site where the BookEntry object is being created.
Now, if an exception is thrown during creation of the object theAudioClip is supposed to point to (thus transferring control out of the BookEntry constructor), who deletes the object that theImage already points to? The obvious answer is that BookEntry's destructor does, but the obvious answer is wrong. BookEntry's destructor will never be called. Never.
C++ destroys only fully constructed objects, and an object isn't fully constructed until its constructor has run to completion. So if a BookEntry object b is created as a local object,
void testBookEntryClass()
{
BookEntry b("Addison-Wesley Publishing Company",
"One Jacob Way, Reading, MA 01867");
...
}
and an exception is thrown during construction of b, b's destructor will not be called. Furthermore, if you try to take matters into your own hands by allocating b on the heap and then calling delete if an exception is thrown,
void testBookEntryClass()
{
BookEntry *pb = 0;
try {
pb = new BookEntry("Addison-Wesley Publishing Company",
"One Jacob Way, Reading, MA 01867");
...
}
catch (...) { // catch all exceptions
delete pb; // delete pb when an
// exception is thrown
throw; // propagate exception to
} // caller
delete pb; // delete pb normally
}
you'll find that the Image object allocated inside BookEntry's constructor is still lost, because no assignment is made to pb unless the new operation succeeds. If BookEntry's constructor throws an exception, pb will be the null pointer, so deleting it in the catch block does nothing except make you feel better about yourself. Using the smart pointer class auto_ptr<BookEntry> (see Item 9) instead of a raw BookEntry* won't do you any good either, because the assignment to pb still won't be made unless the new operation succeeds.
There is a reason why C++ refuses to call destructors for objects that haven't been fully constructed, and it's not simply to make your life more difficult. It's because it would, in many cases, be a nonsensical thing — possibly a harmful thing — to do. If a destructor were invoked on an object that wasn't fully constructed, how would the destructor know what to do? The only way it could know would be if bits had been added to each object indicating how much of the constructor had been executed. Then the destructor could check the bits and (maybe) figure out what actions to take. Such bookkeeping would slow down constructors, and it would make each object larger, too. C++ avoids this overhead, but the price you pay is that partially constructed objects aren't automatically destroyed.
Because C++ won't clean up after objects that throw exceptions during construction, you must design your constructors so that they clean up after themselves. Often, this involves simply catching all possible exceptions, executing some cleanup code, then rethrowing the exception so it continues to propagate. This strategy can be incorporated into the BookEntry constructor like this:
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
try { // this try block is new
if (imageFileName != "") {
theImage = new Image(imageFileName);
}
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
}
catch (...) { // catch any exception
delete theImage; // perform necessary
delete theAudioClip; // cleanup actions
throw; // propagate the exception
}
}
There is no need to worry about BookEntry's non-pointer data members. Data members are automatically initialized before a class's constructor is called, so if a BookEntry constructor body begins executing, the object's theName, theAddress, and thePhones data members have already been fully constructed. As fully constructed objects, these data members will be automatically destroyed even if an exception arises in the BookEntry constructor†. Of course, if these objects' constructors call functions that might throw exceptions, those constructors have to worry about catching the exceptions and performing any necessary cleanup before allowing them to propagate.
You may have noticed that the statements in BookEntry's catch block are almost the same as those in BookEntry's destructor. Code duplication here is no more tolerable than it is anywhere else, so the best way to structure things is to move the common code into a private helper function and have both the constructor and the destructor call it:
class BookEntry {
public:
... // as before
private:
...
void cleanup(); // common cleanup statements
};
void BookEntry::cleanup()
{
delete theImage;
delete theAudioClip;
}
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
try {
... // as before
}
catch (...) {
cleanup(); // release resources
throw; // propagate exception
}
}
BookEntry::~BookEntry()
{
cleanup();
}
This is nice, but it doesn't put the topic to rest. Let us suppose we design our BookEntry class slightly differently so that theImage and theAudioClip are constant pointers:
class BookEntry {
public:
... // as above
private:
...
Image * const theImage; // pointers are now
AudioClip * const theAudioClip; // const
};
Such pointers must be initialized via the member initialization lists of BookEntry's constructors, because there is no other way to give const pointers a value. A common temptation is to initialize theImage and theAudioClip like this,
// an implementation that may leak resources if an
// exception is thrown
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
:theName(name), theAddress(address),
theImage(imageFileName != ""
? new Image(imageFileName)
: 0),
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
but this leads to the problem we originally wanted to eliminate: if an exception is thrown during initialization of theAudioClip, the object pointed to by theImage is never destroyed. Furthermore, we can't solve the problem by adding try and catch blocks to the constructor, because try and catch are statements, and member initialization lists allow only expressions. (That's why we had to use the ?: syntax instead of the if-then-else syntax in the initialization of theImage and theAudioClip.)
Nevertheless, the only way to perform cleanup chores before exceptions propagate out of a constructor is to catch those exceptions, so if we can't put try and catch in a member initialization list, we'll have to put them somewhere else. One possibility is inside private member functions that return pointers with which theImage and theAudioClip should be initialized:
class BookEntry {
public:
... // as above
private:
... // data members as above
Image * initImage(const string& imageFileName);
AudioClip * initAudioClip(const string&
audioClipFileName);
};
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
:theName(name), theAddress(address),
theImage(initImage(imageFileName)),
theAudioClip(initAudioClip(audioClipFileName))
{}
// theImage is initialized first, so there is no need to
// worry about a resource leak if this initialization
// fails. This function therefore handles no exceptions
Image * BookEntry::initImage(const string& imageFileName)
{
if (imageFileName != "") return new Image(imageFileName);
else return 0;
}
// theAudioClip is initialized second, so it must make
// sure theImage's resources are released if an exception
// is thrown during initialization of theAudioClip. That's
// why this function uses try...catch.
AudioClip * BookEntry::initAudioClip(const string&
audioClipFileName)
{
try {
if (audioClipFileName != "") {
return new AudioClip(audioClipFileName);
}
else return 0;
}
catch (...) {
delete theImage;
throw;
}
}
This is perfectly kosher, and it even solves the problem we've been laboring to overcome. The drawback is that code that conceptually belongs in a constructor is now dispersed across several functions, and that's a maintenance headache.
A better solution is to adopt the advice of Item 9 and treat the objects pointed to by theImage and theAudioClip as resources to be managed by local objects. This solution takes advantage of the facts that both theImage and theAudioClip are pointers to dynamically allocated objects and that those objects should be deleted when the pointers themselves go away. This is precisely the set of conditions for which the auto_ptr classes (see Item 9) were designed. We can therefore change the raw pointer types of theImage and theAudioClip to their auto_ptr equivalents:
class BookEntry {
public:
... // as above
private:
...
const auto_ptr<Image> theImage; // these are now
const auto_ptr<AudioClip> theAudioClip; // auto_ptr objects
};
Doing this makes BookEntry's constructor leak-safe in the presence of exceptions, and it lets us initialize theImage and theAudioClip using the member initialization list:
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(imageFileName != ""
? new Image(imageFileName)
: 0),
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
In this design, if an exception is thrown during initialization of theAudioClip, theImage is already a fully constructed object, so it will automatically be destroyed, just like theName, theAddress, and thePhones. Furthermore, because theImage and theAudioClip are now objects, they'll be destroyed automatically when the BookEntry object containing them is. Hence there's no need to manually delete what they point to. That simplifies BookEntry's destructor considerably:
BookEntry::~BookEntry()
{} // nothing to do!
This means you could eliminate BookEntry's destructor entirely.
It all adds up to this: if you replace pointer class members with their corresponding auto_ptr objects, you fortify your constructors against resource leaks in the presence of exceptions, you eliminate the need to manually deallocate resources in destructors, and you allow const member pointers to be handled in the same graceful fashion as non-const pointers.
Dealing with the possibility of exceptions during construction can be tricky, but auto_ptr (and auto_ptr-like classes) can eliminate most of the drudgery. Their use leaves behind code that's not only easy to understand, it's robust in the face of exceptions, too.
There are two situations in which a destructor is called. The first is when an object is destroyed under "normal" conditions, e.g., when it goes out of scope or is explicitly deleted. The second is when an object is destroyed by the exception-handling mechanism during the stackunwinding part of exception propagation.
That being the case, an exception may or may not be active when a destructor is invoked. Regrettably, there is no way to distinguish between these conditions from inside a destructor.† As a result, you must write your destructors under the conservative assumption that an exception is active, because if control leaves a destructor due to an exception while another exception is active, C++ calls the terminate function. That function does just what its name suggests: it terminates execution of your program. Furthermore, it terminates it immediately; not even local objects are destroyed.
As an example, consider a Session class for monitoring on-line computer sessions, i.e., things that happen from the time you log in through the time you log out. Each Session object notes the date and time of its creation and destruction:
class Session {
public:
Session();
~Session();
...
private:
static void logCreation(Session *objAddr);
static void logDestruction(Session *objAddr);
};
The functions logCreation and logDestruction are used to record object creations and destructions, respectively. We might therefore expect that we could code Session's destructor like this:
Session::~Session()
{
logDestruction(this);
}
This looks fine, but consider what would happen if logDestruction throws an exception. The exception would not be caught in Session's destructor, so it would be propagated to the caller of that destructor. But if the destructor was itself being called because some other exception had been thrown, the terminate function would automatically be invoked, and that would stop your program dead in its tracks.
In many cases, this is not what you'll want to have happen. It may be unfortunate that the Session object's destruction can't be logged, it might even be a major inconvenience, but is it really so horrific a prospect that the program can't continue running? If not, you'll have to prevent the exception thrown by logDestruction from propagating out of Session's destructor. The only way to do that is by using try and catch blocks. A naive attempt might look like this,
Session::~Session()
{
try {
logDestruction(this);
}
catch (...) {
cerr << "Unable to log destruction of Session object "
<< "at address "
<< this
<< ".\n";
}
}
but this is probably no safer than our original code. If one of the calls to operator<< in the catch block results in an exception being thrown, we're back where we started, with an exception leaving the Session destructor.
We could always put a try block inside the catch block, but that seems a bit extreme. Instead, we'll just forget about logging Session destructions if logDestruction throws an exception:
Session::~Session()
{
try {
logDestruction(this);
}
catch (...) {}
}
The catch block appears to do nothing, but appearances can be deceiving. That block prevents exceptions thrown from logDestruction from propagating beyond Session's destructor. That's all it needs to do. We can now rest easy knowing that if a Session object is destroyed as part of stack unwinding, terminate will not be called.
There is a second reason why it's bad practice to allow exceptions to propagate out of destructors. If an exception is thrown from a destructor and is not caught there, that destructor won't run to completion. (It will stop at the point where the exception is thrown.) If the destructor doesn't run to completion, it won't do everything it's supposed to do. For example, consider a modified version of the Session class where the creation of a session starts a database transaction and the termination of a session ends that transaction:
Session::Session() // to keep things simple,
{ // this ctor handles no
// exceptions
logCreation(this);
startTransaction(); // start DB transaction
}
Session::~Session()
{
logDestruction(this);
endTransaction(); // end DB transaction
}
Here, if logDestruction throws an exception, the transaction started in the Session constructor will never be ended. In this case, we might be able to reorder the function calls in Session's destructor to eliminate the problem, but if endTransaction might throw an exception, we've no choice but to revert to try and catch blocks.
We thus find ourselves with two good reasons for keeping exceptions from propagating out of destructors. First, it prevents terminate from being called during the stack-unwinding part of exception propagation. Second, it helps ensure that destructors always accomplish everything they are supposed to accomplish. Each argument is convincing in its own right, but together, the case is ironclad.
The syntax for declaring function parameters is almost the same as that for catch clauses:
class Widget { ... }; // some class; it makes no
// difference what it is
void f1(Widget w); // all these functions
void f2(Widget& w); // take parameters of
void f3(const Widget& w); // type Widget, Widget&, or
void f4(Widget *pw); // Widget*
void f5(const Widget *pw);
catch (Widget w) ... // all these catch clauses
catch (Widget& w) ... // catch exceptions of
catch (const Widget& w) ... // type Widget, Widget&, or
catch (Widget *pw) ... // Widget*
catch (const Widget *pw) ...
You might therefore assume that passing an exception from a throw site to a catch clause is basically the same as passing an argument from a function call site to the function's parameter. There are some similarities, to be sure, but there are significant differences, too.
Let us begin with a similarity. You can pass both function parameters and exceptions by value, by reference, or by pointer. What happens when you pass parameters and exceptions, however, is quite different. This difference grows out of the fact that when you call a function, control eventually returns to the call site (unless the function fails to return), but when you throw an exception, control does not return to the throw site.
Consider a function that both passes a Widget as a parameter and throws a Widget as an exception:
// function to read the value of a Widget from a stream
istream operator>>(istream& s, Widget& w);
void passAndThrowWidget()
{
Widget localWidget;
cin >> localWidget; // pass localWidget to operator>>
throw localWidget; // throw localWidget as an exception
}
When localWidget is passed to operator>>, no copying is performed. Instead, the reference w inside operator>> is bound to localWidget, and anything done to w is really done to localWidget. It's a different story when localWidget is thrown as an exception. Regardless of whether the exception is caught by value or by reference (it can't be caught by pointer — that would be a type mismatch), a copy of localWidget will be made, and it is the copy that is passed to the catch clause. This must be the case, because localWidget will go out of scope once control leaves passAndThrowWidget, and when localWidget goes out of scope, its destructor will be called. If localWidget itself were passed to a catch clause, the clause would receive a destructed Widget, an ex-Widget, a former Widget, the carcass of what once was but is no longer a Widget. That would not be useful, and that's why C++ specifies that an object thrown as an exception is copied.
This copying occurs even if the object being thrown is not in danger of being destroyed. For example, if passAndThrowWidget declares localWidget to be static,
void passAndThrowWidget()
{
static Widget localWidget; // this is now static; it
// will exist until the
// end of the program
cin >> localWidget; // this works as before
throw localWidget; // a copy of localWidget is
} // still made and thrown
a copy of localWidget would still be made when the exception was thrown. This means that even if the exception is caught by reference, it is not possible for the catch block to modify localWidget; it can only modify a copy of localWidget. This mandatory copying of exception objects† helps explain another difference between parameter passing and throwing an exception: the latter is typically much slower than the former (see Item 15).
When an object is copied for use as an exception, the copying is performed by the object's copy constructor. This copy constructor is the one in the class corresponding to the object's static type, not its dynamic type. For example, consider this slightly modified version of passAndThrowWidget:
class Widget { ... };
class SpecialWidget: public Widget { ... };
void passAndThrowWidget()
{
SpecialWidget localSpecialWidget;
...
Widget& rw = localSpecialWidget; // rw refers to a
// SpecialWidget
throw rw; // this throws an
// exception of type
} // Widget!
Here a Widget exception is thrown, even though rw refers to a SpecialWidget. That's because rw's static type is Widget, not SpecialWidget. That rw actually refers to a SpecialWidget is of no concern to your compilers; all they care about is rw's static type. This behavior may not be what you want, but it's consistent with all other cases in which C++ copies objects. Copying is always based on an object's static type (but see Item 25 for a technique that lets you make copies on the basis of an object's dynamic type).
The fact that exceptions are copies of other objects has an impact on how you propagate exceptions from a catch block. Consider these two catch blocks, which at first glance appear to do the same thing:
catch (Widget& w) // catch Widget exceptions
{
... // handle the exception
throw; // rethrow the exception so it
} // continues to propagate
catch (Widget& w) // catch Widget exceptions
{
... // handle the exception
throw w; // propagate a copy of the
} // caught exception
The only difference between these blocks is that the first one rethrows the current exception, while the second one throws a new copy of the current exception. Setting aside the performance cost of the additional copy operation, is there a difference between these approaches?
There is. The first block rethrows the current exception, regardless of its type. In particular, if the exception originally thrown was of type SpecialWidget, the first block would propagate a SpecialWidget exception, even though w's static type is Widget. This is because no copy is made when the exception is rethrown. The second catch block throws a new exception, which will always be of type Widget, because that's w's static type. In general, you'll want to use the
throw;
syntax to rethrow the current exception, because there's no chance that that will change the type of the exception being propagated. Furthermore, it's more efficient, because there's no need to generate a new exception object.
(Incidentally, the copy made for an exception is a temporary object. As Item 19 explains, this gives compilers the right to optimize it out of existence. I wouldn't expect your compilers to work that hard, however. Exceptions are supposed to be rare, so it makes little sense for compiler vendors to pour a lot of energy into their optimization.)
Let us examine the three kinds of catch clauses that could catch the Widget exception thrown by passAndThrowWidget. They are:
catch (Widget w) ... // catch exception by value
catch (Widget& w) ... // catch exception by
// reference
catch (const Widget& w) ... // catch exception by
// reference-to-const
Right away we notice another difference between parameter passing and exception propagation. A thrown object (which, as explained above, is always a temporary) may be caught by simple reference; it need not be caught by reference-to-const. Passing a temporary object to a non-const reference parameter is not allowed for function calls (see Item 19), but it is for exceptions.
Let us overlook this difference, however, and return to our examination of copying exception objects. We know that when we pass a function argument by value, we make a copy of the passed object, and we store that copy in a function parameter. The same thing happens when we pass an exception by value. Thus, when we declare a catch clause like this,
catch (Widget w) ... // catch by value
we expect to pay for the creation of two copies of the thrown object, one to create the temporary that all exceptions generate, the second to copy that temporary into w. Similarly, when we catch an exception by reference,
catch (Widget& w) ... // catch by reference
catch (const Widget& w) ... // also catch by reference
we still expect to pay for the creation of a copy of the exception: the copy that is the temporary. In contrast, when we pass function parameters by reference, no copying takes place. When throwing an exception, then, we expect to construct (and later destruct) one more copy of the thrown object than if we passed the same object to a function.
We have not yet discussed throwing exceptions by pointer, but throw by pointer is equivalent to pass by pointer. Either way, a copy of the pointer is passed. About all you need to remember is not to throw a pointer to a local object, because that local object will be destroyed when the exception leaves the local object's scope. The catch clause would then be initialized with a pointer to an object that had already been destroyed. This is the behavior the mandatory copying rule is designed to avoid.
The way in which objects are moved from call or throw sites to parameters or catch clauses is one way in which argument passing differs from exception propagation. A second difference lies in what constitutes a type match between caller or thrower and callee or catcher. Consider the sqrt function from the standard math library:
double sqrt(double); // from <cmath> or <math.h>
We can determine the square root of an integer like this:
int i;
double sqrtOfi = sqrt(i);
There is nothing surprising here. The language allows implicit conversion from int to double, so in the call to sqrt, i is silently converted to a double, and the result of sqrt corresponds to that double. (See Item 5 for a fuller discussion of implicit type conversions.) In general, such conversions are not applied when matching exceptions to catch clauses. In this code,
void f(int value)
{
try {
if (someFunction()) { // if someFunction() returns
throw value; // true, throw an int
}
...
}
catch (double d) { // handle exceptions of
... // type double here
}
...
}
the int exception thrown inside the try block will never be caught by the catch clause that takes a double. That clause catches only exceptions that are exactly of type double; no type conversions are applied. As a result, if the int exception is to be caught, it will have to be by some other (dynamically enclosing) catch clause taking an int or an int& (possibly modified by const or volatile).
Two kinds of conversions are applied when matching exceptions to catch clauses. The first is inheritance-based conversions. A catch clause for base class exceptions is allowed to handle exceptions of (publicly) derived class types, too. For example, consider the diagnostics portion of the hierarchy of exceptions defined by the standard C++ library:
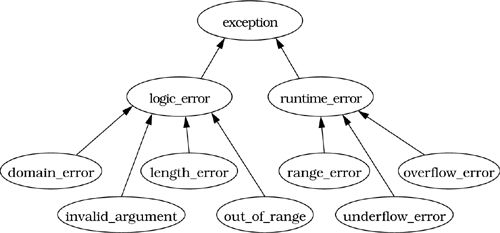
A catch clause for runtime_errors can catch exceptions of type range_error, underflow_error, and overflow_error, too, and a catch clause accepting an object of the root class exception can catch any kind of exception derived from this hierarchy.
This inheritance-based exception-conversion rule applies to values, references, and pointers in the usual fashion (though Item 13 explains why catching values or pointers is generally a bad idea):
catch (runtime_error) ... // can catch errors of type
catch (runtime_error&) ... // runtime_error,
catch (const runtime_error&) ... // range_error, or
// overflow_error
catch (runtime_error*) ... // can catch errors of type
catch (const runtime_error*) ... // runtime_error*,
// range_error*, or
// overflow_error*
The second type of allowed conversion is from a typed to an untyped pointer, so a catch clause taking a const void* pointer will catch an exception of any pointer type:
catch (const void*) ... // catches any exception
// that's a pointer
The final difference between passing a parameter and propagating an exception is that catch clauses are always tried in the order of their appearance. Hence, it is possible for an exception of a (publicly) derived class type to be handled by a catch clause for one of its base class types — even when a catch clause for the derived class is associated with the same try block! For example,
try {
...
}
catch (logic_error& ex) { // this block will catch
... // all logic_error
} // exceptions, even those
// of derived types
catch (invalid_argument& ex) { // this block can never be
... // executed, because all
} // invalid_argument
// exceptions will be caught
// by the clause above
Contrast this behavior with what happens when you call a virtual function. When you call a virtual function, the function invoked is the one in the class closest to the dynamic type of the object invoking the function. You might say that virtual functions employ a "best fit" algorithm, while exception handling follows a "first fit" strategy. Compilers may warn you if a catch clause for a derived class comes after one for a base class (some issue an error, because such code used to be illegal in C++), but your best course of action is preemptive: never put a catch clause for a base class before a catch clause for a derived class. The code above, for example, should be reordered like this:
try {
...
}
catch (invalid_argument& ex) { // handle invalid_argument
... // exceptions here
}
catch (logic_error& ex) { // handle all other
... // logic_errors here
}
There are thus three primary ways in which passing an object to a function or using that object to invoke a virtual function differs from throwing the object as an exception. First, exception objects are always copied; when caught by value, they are copied twice. Objects passed to function parameters need not be copied at all. Second, objects thrown as exceptions are subject to fewer forms of type conversion than are objects passed to functions. Finally, catch clauses are examined in the order in which they appear in the source code, and the first one that can succeed is selected for execution. When an object is used to invoke a virtual function, the function selected is the one that provides the best match for the type of the object, even if it's not the first one listed in the source code.
When you write a catch clause, you must specify how exception objects are to be passed to that clause. You have three choices, just as when specifying how parameters should be passed to functions: by pointer, by value, or by reference.
Let us consider first catch by pointer. In theory, this should be the least inefficient way to implement the invariably slow process of moving an exception from throw site to catch clause (see Item 15). That's because throw by pointer is the only way of moving exception information without copying an object (see Item 12). For example:
class exception { ... }; // from the standard C++
// library exception
// hierarchy (see Item 12)
void someFunction()
{
static exception ex; // exception object
...
throw &ex; // throw a pointer to ex
...
}
void doSomething()
{
try {
someFunction(); // may throw an exception*
}
catch (exception *ex) { // catches the exception*;
... // no object is copied
}
}
This looks neat and tidy, but it's not quite as well-kept as it appears. For this to work, programmers must define exception objects in a way that guarantees the objects exist after control leaves the functions throwing pointers to them. Global and static objects work fine, but it's easy for programmers to forget the constraint. If they do, they typically end up writing code like this:
void someFunction()
{
exception ex; // local exception object;
// will be destroyed when
// this function's scope is
... // exited
throw &ex; // throw a pointer to an
... // object that's about to
} // be destroyed
This is worse than useless, because the catch clause handling this exception receives a pointer to an object that no longer exists.
An alternative is to throw a pointer to a new heap object:
void someFunction()
{
...
throw new exception; // throw a pointer to a new heap-
... // based object (and hope that
} // operator new -- see Item 8 --
// doesn't itself throw an
// exception!)
This avoids the I-just-caught-a-pointer-to-a-destroyed-object problem, but now authors of catch clauses confront a nasty question: should they delete the pointer they receive? If the exception object was allocated on the heap, they must, otherwise they suffer a resource leak. If the exception object wasn't allocated on the heap, they mustn't, otherwise they suffer undefined program behavior. What to do?
It's impossible to know. Some clients might pass the address of a global or static object, others might pass the address of an exception on the heap. Catch by pointer thus gives rise to the Hamlet conundrum: to delete or not to delete? It's a question with no good answer. You're best off ducking it.
Furthermore, catch-by-pointer runs contrary to the convention established by the language itself. The four standard exceptions — bad_alloc (thrown when operator new (see Item 8) can't satisfy a memory request), bad_cast (thrown when a dynamic_cast to a reference fails; see Item 2), bad_typeid (thrown when typeid is applied to a dereferenced null pointer), and bad_exception (available for unexpected exceptions; see Item 14) — are all objects, not pointers to objects, so you have to catch them by value or by reference, anyway.
Catch-by-value eliminates questions about exception deletion and works with the standard exception types. However, it requires that exception objects be copied twice each time they're thrown (see Item 12). It also gives rise to the specter of the slicing problem, whereby derived class exception objects caught as base class exceptions have their derivedness "sliced off." Such "sliced" objects are base class objects: they lack derived class data members, and when virtual functions are called on them, they resolve to virtual functions of the base class. (Exactly the same thing happens when an object is passed to a function by value.) For example, consider an application employing an exception class hierarchy that extends the standard one:
class exception { // as above, this is a
public: // standard exception class
virtual const char * what() const throw();
// returns a brief descrip.
... // of the exception (see
// Item 14 for info about
}; // the "throw()" at the
// end of the declaration)
class runtime_error: // also from the standard
public exception { ... }; // C++ exception hierarchy
class Validation_error: // this is a class added by
public runtime_error { // a client
public:
virtual const char * what() const throw();
// this is a redefinition
... // of the function declared
}; // in class exception above
void someFunction() // may throw a validation
{ // exception
...
if (a validation test fails) {
throw Validation_error();
}
...
}
void doSomething()
{
try {
someFunction(); // may throw a validation
} // exception
catch (exception ex) { // catches all exceptions
// in or derived from
// the standard hierarchy
cerr << ex.what(); // calls exception::what(),
... // never
} // Validation_error::what()
}
The version of what that is called is that of the base class, even though the thrown exception is of type Validation_error and Validation_error redefines that virtual function. This kind of slicing behavior is almost never what you want.
That leaves only catch-by-reference. Catch-by-reference suffers from none of the problems we have discussed. Unlike catch-by-pointer, the question of object deletion fails to arise, and there is no difficulty in catching the standard exception types. Unlike catch-by-value, there is no slicing problem, and exception objects are copied only once.
If we rewrite the last example using catch-by-reference, it looks like this:
void someFunction() // nothing changes in this
{ // function
...
if (a validation test fails) {
throw Validation_error();
}
...
}
void doSomething()
{
try {
someFunction(); // no change here
}
catch (exception& ex) { // here we catch by reference
// instead of by value
cerr << ex.what(); // now calls
// Validation_error::what(),
... // not exception::what()
}
}
There is no change at the throw site, and the only change in the catch clause is the addition of an ampersand. This tiny modification makes a big difference, however, because virtual functions in the catch block now work as we expect: functions in Validation_error are invoked if they redefine those in exception. Of course, if there is no need to modify the exception object in the handler, you'd catch not just by reference, but by reference to const.
What a happy confluence of events! If you catch by reference, you sidestep questions about object deletion that leave you damned if you do and damned if you don't; you avoid slicing exception objects; you retain the ability to catch standard exceptions; and you limit the number of times exception objects need to be copied. So what are you waiting for? Catch exceptions by reference!
There's no denying it: exception specifications have appeal. They make code easier to understand, because they explicitly state what exceptions a function may throw. But they're more than just fancy comments. Compilers are sometimes able to detect inconsistent exception specifications during compilation. Furthermore, if a function throws an exception not listed in its exception specification, that fault is detected at runtime, and the special function unexpected is automatically invoked. Both as a documentation aid and as an enforcement mechanism for constraints on exception usage, then, exception specifications seem attractive.
As is often the case, however, beauty is only skin deep. The default behavior for unexpected is to call terminate, and the default behavior for terminate is to call abort, so the default behavior for a program with a violated exception specification is to halt. Local variables in active stack frames are not destroyed, because abort shuts down program execution without performing such cleanup. A violated exception specification is therefore a cataclysmic thing, something that should almost never happen.
Unfortunately, it's easy to write functions that make this terrible thing occur. Compilers only partially check exception usage for consistency with exception specifications. What they do not check for — what the language standard prohibits them from rejecting (though they may issue a warning) — is a call to a function that might violate the exception specification of the function making the call.
Consider a declaration for a function f1 that has no exception specification. Such a function may throw any kind of exception:
extern void f1(); // might throw anything
Now consider a function f2 that claims, through its exception specification, it will throw only exceptions of type int:
void f2() throw(int);
It is perfectly legal C++ for f2 to call f1, even though f1 might throw an exception that would violate f2's exception specification:
void f2() throw(int)
{
...
f1(); // legal even though f1 might throw
// something besides an int
...
}
This kind of flexibility is essential if new code with exception specifications is to be integrated with older code lacking such specifications.
Because your compilers are content to let you call functions whose exception specifications are inconsistent with those of the routine containing the calls, and because such calls might result in your program's execution being terminated, it's important to write your software in such a way that these kinds of inconsistencies are minimized. A good way to start is to avoid putting exception specifications on templates that take type arguments. Consider this template, which certainly looks as if it couldn't throw any exceptions:
// a poorly designed template wrt exception specifications
template<class T>
bool operator==(const T& lhs, const T& rhs) throw()
{
return &lhs == &rhs;
}
This template defines an operator== function for all types. For any pair of objects of the same type, it returns true if the objects have the same address, otherwise it returns false.
This template contains an exception specification stating that the functions generated from the template will throw no exceptions. But that's not necessarily true, because it's possible that operator& (the address-of operator) has been overloaded for some types. If it has, operator& may throw an exception when called from inside operator==. If it does, our exception specification is violated, and off to unexpected we go.
This is a specific example of a more general problem, namely, that there is no way to know anything about the exceptions thrown by a template's type parameters. We can almost never provide a meaningful exception specification for a template, because templates almost invariably use their type parameter in some way. The conclusion? Templates and exception specifications don't mix.
A second technique you can use to avoid calls to unexpected is to omit exception specifications on functions making calls to functions that themselves lack exception specifications. This is simple common sense, but there is one case that is easy to forget. That's when allowing users to register callback functions:
// Function pointer type for a window system callback
// when a window system event occurs
typedef void (*CallBackPtr)(int eventXLocation,
int eventYLocation,
void *dataToPassBack);
// Window system class for holding onto callback
// functions registered by window system clients
class CallBack {
public:
CallBack(CallBackPtr fPtr, void *dataToPassBack)
: func(fPtr), data(dataToPassBack) {}
void makeCallBack(int eventXLocation,
int eventYLocation) const throw();
private:
CallBackPtr func; // function to call when
// callback is made
void *data; // data to pass to callback
}; // function
// To implement the callback, we call the registered func-
// tion with event's coordinates and the registered data
void CallBack::makeCallBack(int eventXLocation,
int eventYLocation) const throw()
{
func(eventXLocation, eventYLocation, data);
}
Here the call to func in makeCallBack runs the risk of a violated exception specification, because there is no way of knowing what exceptions func might throw.
This problem can be eliminated by tightening the exception specification in the CallBackPtr typedef:†
typedef void (*CallBackPtr)(int eventXLocation,
int eventYLocation,
void *dataToPassBack) throw();
Given this typedef, it is now an error to register a callback function that fails to guarantee it throws nothing:
// a callback function without an exception specification
void callBackFcn1(int eventXLocation, int eventYLocation,
void *dataToPassBack);
void *callBackData;
...
CallBack c1(callBackFcn1, callBackData);
// error! callBackFcn1
// might throw an exception
// a callback function with an exception specification
void callBackFcn2(int eventXLocation,
int eventYLocation,
void *dataToPassBack) throw();
CallBack c2(callBackFcn2, callBackData);
// okay, callBackFcn2 has a
// conforming ex. spec.
This checking of exception specifications when passing function pointers is a relatively recent addition to the language, so don't be surprised if your compilers don't yet support it. If they don't, it's up to you to ensure you don't make this kind of mistake.
A third technique you can use to avoid calls to unexpected is to handle exceptions "the system" may throw. Of these exceptions, the most common is bad_alloc, which is thrown by operator new and operator new[] when a memory allocation fails (see Item 8). If you use the new operator (again, see Item 8) in any function, you must be prepared for the possibility that the function will encounter a bad_alloc exception.
Now, an ounce of prevention may be better than a pound of cure, but sometimes prevention is hard and cure is easy. That is, sometimes it's easier to cope with unexpected exceptions directly than to prevent them from arising in the first place. If, for example, you're writing software that uses exception specifications rigorously, but you're forced to call functions in libraries that don't use exception specifications, it's impractical to prevent unexpected exceptions from arising, because that would require changing the code in the libraries.
If preventing unexpected exceptions isn't practical, you can exploit the fact that C++ allows you to replace unexpected exceptions with exceptions of a different type. For example, suppose you'd like all unexpected exceptions to be replaced by UnexpectedException objects. You can set it up like this,
class UnexpectedException {}; // all unexpected exception
// objects will be replaced
// by objects of this type
void convertUnexpected() // function to call if
{ // an unexpected exception
throw UnexpectedException(); // is thrown
}
and make it happen by replacing the default unexpected function with convertUnexpected:
set_unexpected(convertUnexpected);
Once you've done this, any unexpected exception results in convertUnexpected being called. The unexpected exception is then replaced by a new exception of type UnexpectedException. Provided the exception specification that was violated includes UnexpectedException, exception propagation will then continue as if the exception specification had always been satisfied. (If the exception specification does not include UnexpectedException, terminate will be called, just as if you had never replaced unexpected.)
Another way to translate unexpected exceptions into a well known type is to rely on the fact that if the unexpected function's replacement rethrows the current exception, that exception will be replaced by a new exception of the standard type bad_exception. Here's how you'd arrange for that to happen:
void convertUnexpected() // function to call if
{ // an unexpected exception
throw; // is thrown; just rethrow
} // the current exception
set_unexpected(convertUnexpected);
// install convertUnexpected
// as the unexpected
// replacement
If you do this and you include bad_exception (or its base class, the standard class exception) in all your exception specifications, you'll never have to worry about your program halting if an unexpected exception is encountered. Instead, any wayward exception will be replaced by a bad_exception, and that exception will be propagated in the stead of the original one.
By now you understand that exception specifications can be a lot of trouble. Compilers perform only partial checks for their consistent usage, they're problematic in templates, they're easy to violate inadvertently, and, by default, they lead to abrupt program termination when they're violated. Exception specifications have another drawback, too, and that's that they result in unexpected being invoked even when a higher-level caller is prepared to cope with the exception that's arisen. For example, consider this code, which is taken almost verbatim from Item 11:
class Session { // for modeling online
public: // sessions
~Session();
...
private:
static void logDestruction(Session *objAddr) throw();
};
Session::~Session()
{
try {
logDestruction(this);
}
catch (...) {}
}
The Session destructor calls logDestruction to record the fact that a Session object is being destroyed, but it explicitly catches any exceptions that might be thrown by logDestruction. However, logDestruction comes with an exception specification asserting that it throws no exceptions. Now, suppose some function called by logDestruction throws an exception that logDestruction fails to catch. This isn't supposed to happen, but as we've seen, it isn't difficult to write code that leads to the violation of exception specifications. When this unanticipated exception propagates through logDestruction, unexpected will be called, and, by default, that will result in termination of the program. This is correct behavior, to be sure, but is it the behavior the author of Session's destructor wanted? That author took pains to handle all possible exceptions, so it seems almost unfair to halt the program without giving Session's destructor's catch block a chance to work. If logDestruction had no exception specification, this I'm-willing-to-catch-it-if-you'll-just-give-me-a-chance scenario would never arise. (One way to prevent it is to replace unexpected as described above.)
It's important to keep a balanced view of exception specifications. They provide excellent documentation on the kinds of exceptions a function is expected to throw, and for situations in which violating an exception specification is so dire as to justify immediate program termination, they offer that behavior by default. At the same time, they are only partly checked by compilers and they are easy to violate inadvertently. Furthermore, they can prevent high-level exception handlers from dealing with unexpected exceptions, even when they know how to. That being the case, exception specifications are a tool to be applied judiciously. Before adding them to your functions, consider whether the behavior they impart to your software is really the behavior you want.
To handle exceptions at runtime, programs must do a fair amount of bookkeeping. At each point during execution, they must be able to identify the objects that require destruction if an exception is thrown; they must make note of each entry to and exit from a try block; and for each try block, they must keep track of the associated catch clauses and the types of exceptions those clauses can handle. This bookkeeping is not free. Nor are the runtime comparisons necessary to ensure that exception specifications are satisfied. Nor is the work expended to destroy the appropriate objects and find the correct catch clause when an exception is thrown. No, exception handling has costs, and you pay at least some of them even if you never use the keywords try, throw, or catch.
Let us begin with the things you pay for even if you never use any exception-handling features. You pay for the space used by the data structures needed to keep track of which objects are fully constructed (see Item 10), and you pay for the time needed to keep these data structures up to date. These costs are typically quite modest. Nevertheless, programs compiled without support for exceptions are typically both faster and smaller than their counterparts compiled with support for exceptions.
In theory, you don't have a choice about these costs: exceptions are part of C++, compilers have to support them, and that's that. You can't even expect compiler vendors to eliminate the costs if you use no exception-handling features, because programs are typically composed of multiple independently generated object files, and just because one object file doesn't do anything with exceptions doesn't mean others don't. Furthermore, even if none of the object files linked to form an executable use exceptions, what about the libraries they're linked with? If any part of a program uses exceptions, the rest of the program must support them, too. Otherwise it may not be possible to provide correct exception-handling behavior at runtime.
That's the theory. In practice, most vendors who support exception handling allow you to control whether support for exceptions is included in the code they generate. If you know that no part of your program uses try, throw, or catch, and you also know that no library with which you'll link uses try, throw, or catch, you might as well compile without exception-handling support and save yourself the size and speed penalty you'd otherwise probably be assessed for a feature you're not using. As time goes on and libraries employing exceptions become more common, this strategy will become less tenable, but given the current state of C++ software development, compiling without support for exceptions is a reasonable performance optimization if you have already decided not to use exceptions. It may also be an attractive optimization for libraries that eschew exceptions, provided they can guarantee that exceptions thrown from client code never propagate into the library. This is a difficult guarantee to make, as it precludes client redefinitions of library-declared virtual functions; it also rules out client-defined callback functions.
A second cost of exception-handling arises from try blocks, and you pay it whenever you use one, i.e., whenever you decide you want to be able to catch exceptions. Different compilers implement try blocks in different ways, so the cost varies from compiler to compiler. As a rough estimate, expect your overall code size to increase by 5-10% and your runtime to go up by a similar amount if you use try blocks. This assumes no exceptions are thrown; what we're discussing here is just the cost of having try blocks in your programs. To minimize this cost, you should avoid unnecessary try blocks.
Compilers tend to generate code for exception specifications much as they do for try blocks, so an exception specification generally incurs about the same cost as a try block. Excuse me? You say you thought exception specifications were just specifications, you didn't think they generated code? Well, now you have something new to think about.
Which brings us to the heart of the matter, the cost of throwing an exception. In truth, this shouldn't be much of a concern, because exceptions should be rare. After all, they indicate the occurrence of events that are exceptional. The 80-20 rule (see Item 16) tells us that such events should almost never have much impact on a program's overall performance. Nevertheless, I know you're curious about just how big a hit you'll take if you throw an exception, and the answer is it's probably a big one. Compared to a normal function return, returning from a function by throwing an exception may be as much as three orders of magnitude slower. That's quite a hit. But you'll take it only if you throw an exception, and that should be almost never. If, however, you've been thinking of using exceptions to indicate relatively common conditions like the completion of a data structure traversal or the termination of a loop, now would be an excellent time to think again.
But wait. How can I know this stuff? If support for exceptions is a relatively recent addition to most compilers (it is), and if different compilers implement their support in different ways (they do), how can I say that a program's size will generally grow by about 5-10%, its speed will decrease by a similar amount, and it may run orders of magnitude slower if lots of exceptions are thrown? The answer is frightening: a little rumor and a handful of benchmarks (see Item 23). The fact is that most people — including most compiler vendors — have little experience with exceptions, so though we know there are costs associated with them, it is difficult to predict those costs accurately.
The prudent course of action is to be aware of the costs described in this item, but not to take the numbers very seriously. Whatever the cost of exception handling, you don't want to pay any more than you have to. To minimize your exception-related costs, compile without support for exceptions when that is feasible; limit your use of try blocks and exception specifications to those locations where you honestly need them; and throw exceptions only under conditions that are truly exceptional. If you still have performance problems, profile your software (see Item 16) to determine if exception support is a contributing factor. If it is, consider switching to different compilers, ones that provide more efficient implementations of C++'s exception-handling features.