
Though your in-laws may be one-dimensional, the world, in general, is not. Unfortunately, C++ hasn't yet caught on to that fact. At least, there's little evidence for it in the language's support for arrays. You can create two-dimensional, three-dimensional — heck, you can create n-dimensional — arrays in FORTRAN, in BASIC, even in COBOL (okay, FORTRAN only allows up to seven dimensions, but let's not quibble), but can you do it in C++? Only sometimes, and even then only sort of.
This much is legal:
int data[10][20]; // 2D array: 10 by 20
The corresponding construct using variables as dimension sizes, however, is not:
void processInput(int dim1, int dim2)
{
int data[dim1][dim2]; // error! array dimensions
... // must be known during
} // compilation
It's not even legal for a heap-based allocation:
int *data =
new int[dim1][dim2]; // error!
Multidimensional arrays are as useful in C++ as they are in any other language, so it's important to come up with a way to get decent support for them. The usual way is the standard one in C++: create a class to represent the objects we need but that are missing in the language proper. Hence we can define a class template for two-dimensional arrays:
template<class T>
class Array2D {
public:
Array2D(int dim1, int dim2);
...
};
Now we can define the arrays we want:
Array2D<int> data(10, 20); // fine
Array2D<float> *data =
new Array2D<float>(10, 20); // fine
void processInput(int dim1, int dim2)
{
Array2D<int> data(dim1, dim2); // fine
...
}
Using these array objects, however, isn't quite as straightforward. In keeping with the grand syntactic tradition of both C and C++, we'd like to be able to use brackets to index into our arrays,
cout << data[3][6];
but how do we declare the indexing operator in Array2D to let us do this?
Our first impulse might be to declare operator[][] functions, like this:
template<class T>
class Array2D {
public:
// declarations that won't compile
T& operator[][](int index1, int index2);
const T& operator[][](int index1, int index2) const;
...
};
We'd quickly learn to rein in such impulses, however, because there is no such thing as operator[][], and don't think your compilers will forget it. (For a complete list of operators, overloadable and otherwise, see Item 7.) We'll have to do something else.
If you can stomach the syntax, you might follow the lead of the many programming languages that use parentheses to index into arrays. To use parentheses, you just overload operator():
template<class T>
class Array2D {
public:
// declarations that will compile
T& operator()(int index1, int index2);
const T& operator()(int index1, int index2) const;
...
};
Clients then use arrays this way:
cout << data(3, 6);
This is easy to implement and easy to generalize to as many dimensions as you like. The drawback is that your Array2D objects don't look like built-in arrays any more. In fact, the above access to element (3, 6) of data looks, on the face of it, like a function call.
If you reject the thought of your arrays looking like FORTRAN refugees, you might turn again to the notion of using brackets as the indexing operator. Although there is no such thing as operator[][], it is nonetheless legal to write code that appears to use it:
int data[10][20];
...
cout << data[3][6]; // fine
What gives?
What gives is that the variable data is not really a two-dimensional array at all, it's a 10-element one-dimensional array. Each of those 10 elements is itself a 20-element array, so the expression data[3][6] really means (data[3])[6], i.e., the seventh element of the array that is the fourth element of data. In short, the value yielded by the first application of the brackets is another array, so the second application of the brackets gets an element from that secondary array.
We can play the same game with our Array2D class by overloading operator[] to return an object of a new class, Array1D. We can then overload operator[] again in Array1D to return an element in our original two-dimensional array:
template<class T>
class Array2D {
public:
class Array1D {
public:
T& operator[](int index);
const T& operator[](int index) const;
...
};
Array1D operator[](int index);
const Array1D operator[](int index) const;
...
};
The following then becomes legal:
Array2D<float> data(10, 20);
...
cout << data[3][6]; // fine
Here, data[3] yields an Array1D object and the operator[] invocation on that object yields the float in position (3, 6) of the original two-dimensional array.
Clients of the Array2D class need not be aware of the presence of the Array1D class. Objects of this latter class stand for one-dimensional array objects that, conceptually, do not exist for clients of Array2D. Such clients program as if they were using real, live, honest-to-Allah two-dimensional arrays. It is of no concern to Array2D clients that those objects must, in order to satisfy the vagaries of C++, be syntactically compatible with one-dimensional arrays of other one-dimensional arrays.
Each Array1D object stands for a one-dimensional array that is absent from the conceptual model used by clients of Array2D. Objects that stand for other objects are often called proxy objects, and the classes that give rise to proxy objects are often called proxy classes. In this example, Array1D is a proxy class. Its instances stand for one-dimensional arrays that, conceptually, do not exist. (The terminology for proxy objects and classes is far from universal; objects of such classes are also sometimes known as surrogates.)
operator[]The use of proxies to implement classes whose instances act like multidimensional arrays is common, but proxy classes are more flexible than that. Item 5, for example, shows how proxy classes can be employed to prevent single-argument constructors from being used to perform unwanted type conversions. Of the varied uses of proxy classes, however, the most heralded is that of helping distinguish reads from writes through operator[].
Consider a reference-counted string type that supports operator[]. Such a type is examined in detail in Item 29. If the concepts behind reference counting have slipped your mind, it would be a good idea to familiarize yourself with the material in that Item now.
A string type supporting operator[] allows clients to write code like this:
String s1, s2; // a string-like class; the
// use of proxies keeps this
// class from conforming to
// the standard string
... // interface
cout << s1[5]; // read s1
s2[5] = 'x'; // write s2
s1[3] = s2[8]; // write s1, read s2
Note that operator[] can be called in two different contexts: to read a character or to write a character. Reads are known as rvalue usages; writes are known as lvalue usages. (The terms come from the field of compilers, where an lvalue goes on the left-hand side of an assignment and an rvalue goes on the right-hand side.) In general, using an object as an lvalue means using it such that it might be modified, and using it as an rvalue means using it such that it cannot be modified.
We'd like to distinguish between lvalue and rvalue usage of operator[] because, especially for reference-counted data structures, reads can be much less expensive to implement than writes. As Item 29 explains, writes of reference-counted objects may involve copying an entire data structure, but reads never require more than the simple returning of a value. Unfortunately, inside operator[], there is no way to determine the context in which the function was called; it is not possible to distinguish lvalue usage from rvalue usage within operator[].
"But wait," you say, "we don't need to. We can overload operator[] on the basis of its constness, and that will allow us to distinguish reads from writes." In other words, you suggest we solve our problem this way:
class String {
public:
const char& operator[](int index) const; // for reads
char& operator[](int index); // for writes
...
};
Alas, this won't work. Compilers choose between const and non-const member functions by looking only at whether the object invoking a function is const. No consideration is given to the context in which a call is made. Hence:
String s1, s2;
...
cout << s1[5]; // calls non-const operator[],
// because s1 isn't const
s2[5] = 'x'; // also calls non-const
// operator[]: s2 isn't const
s1[3] = s2[8]; // both calls are to non-const
// operator[], because both s1
// and s2 are non-const objects
Overloading operator[], then, fails to distinguish reads from writes.
In Item 29, we resigned ourselves to this unsatisfactory state of affairs and made the conservative assumption that all calls to operator[] were for writes. This time we shall not give up so easily. It may be impossible to distinguish lvalue from rvalue usage inside operator[], but we still want to do it. We will therefore find a way. What fun is life if you allow yourself to be limited by the possible?
Our approach is based on the fact that though it may be impossible to tell whether operator[] is being invoked in an lvalue or an rvalue context from within operator[], we can still treat reads differently from writes if we delay our lvalue-versus-rvalue actions until we see how the result of operator[] is used. All we need is a way to postpone our decision on whether our object is being read or written until after operator[] has returned. (This is an example of lazy evaluation — see Item 17.)
A proxy class allows us to buy the time we need, because we can modify operator[] to return a proxy for a string character instead of a string character itself. We can then wait to see how the proxy is used. If it's read, we can belatedly treat the call to operator[] as a read. If it's written, we must treat the call to operator[] as a write.
We will see the code for this in a moment, but first it is important to understand the proxies we'll be using. There are only three things you can do with a proxy:
operator[] was invoked.operator[] was invoked.Here are the class definitions for a reference-counted String class using a proxy class to distinguish between lvalue and rvalue usages of operator[]:
class String { // reference-counted strings;
public: // see Item 29 for details
class CharProxy { // proxies for string chars
public:
CharProxy(String& str, int index); // creation
CharProxy& operator=(const CharProxy& rhs); // lvalue
CharProxy& operator=(char c); // uses
operator char() const; // rvalue
// use
private:
String& theString; // string this proxy pertains to
int charIndex; // char within that string
// this proxy stands for
};
// continuation of String class
const CharProxy
operator[](int index) const; // for const Strings
CharProxy operator[](int index); // for non-const Strings
...
friend class CharProxy;
private:
RCPtr<StringValue> value;
};
Other than the addition of the CharProxy class (which we'll examine below), the only difference between this String class and the final String class in Item 29 is that both operator[] functions now return CharProxy objects. Clients of String can generally ignore this, however, and program as if the operator[] functions returned characters (or references to characters — see Item 1) in the usual manner:
String s1, s2; // reference-counted strings
// using proxies
...
cout << s1[5]; // still legal, still works
s2[5] = 'x'; // also legal, also works
s1[3] = s2[8]; // of course it's legal,
// of course it works
What's interesting is not that this works. What's interesting is how it works.
Consider first this statement:
cout << s1[5];
The expression s1[5] yields a CharProxy object. No output operator is defined for such objects, so your compilers labor to find an implicit type conversion they can apply to make the call to operator<< succeed (see Item 5). They find one: the implicit conversion from CharProxy to char declared in the CharProxy class. They automatically invoke this conversion operator, and the result is that the string character represented by the CharProxy is printed. This is representative of the CharProxy-to-char conversion that takes place for all CharProxy objects used as rvalues.
Lvalue usage is handled differently. Look again at
s2[5] = 'x';
As before, the expression s2[5] yields a CharProxy object, but this time that object is the target of an assignment. Which assignment operator is invoked? The target of the assignment is a CharProxy, so the assignment operator that's called is in the CharProxy class. This is crucial, because inside a CharProxy assignment operator, we know that the CharProxy object being assigned to is being used as an lvalue. We therefore know that the string character for which the proxy stands is being used as an lvalue, and we must take whatever actions are necessary to implement lvalue access for that character.
Similarly, the statement
s1[3] = s2[8];
calls the assignment operator for two CharProxy objects, and inside that operator we know the object on the left is being used as an lvalue and the object on the right as an rvalue.
"Yeah, yeah, yeah," you grumble, "show me." Okay. Here's the code for String's operator[] functions:
const String::CharProxy String::operator[](int index) const
{
return CharProxy(const_cast<String&>(*this), index);
}
String::CharProxy String::operator[](int index)
{
return CharProxy(*this, index);
}
Each function just creates and returns a proxy for the requested character. No action is taken on the character itself: we defer such action until we know whether the access is for a read or a write.
Note that the const version of operator[] returns a const proxy. Because CharProxy::operator= isn't a const member function, such proxies can't be used as the target of assignments. Hence neither the proxy returned from the const version of operator[] nor the character for which it stands may be used as an lvalue. Conveniently enough, that's exactly the behavior we want for the const version of operator[].
Note also the use of a const_cast (see Item 2) on *this when creating the CharProxy object that the const operator[] returns. That's necessary to satisfy the constraints of the CharProxy constructor, which accepts only a non-const String. Casts are usually worrisome, but in this case the CharProxy object returned by operator[] is itself const, so there is no risk the String containing the character to which the proxy refers will be modified.
Each proxy returned by an operator[] function remembers which string it pertains to and, within that string, the index of the character it represents:
String::CharProxy::CharProxy(String& str, int index)
: theString(str), charIndex(index) {}
Conversion of a proxy to an rvalue is straightforward — we just return a copy of the character represented by the proxy:
String::CharProxy::operator char() const
{
return theString.value->data[charIndex];
}
If you've forgotten the relationship among a String object, its value member, and the data member it points to, you can refresh your memory by turning to Item 29. Because this function returns a character by value, and because C++ limits the use of such by-value returns to rvalue contexts only, this conversion function can be used only in places where an rvalue is legal.
We thus turn to implementation of CharProxy's assignment operators, which is where we must deal with the fact that a character represented by a proxy is being used as the target of an assignment, i.e., as an lvalue. We can implement CharProxy's conventional assignment operator as follows:
String::CharProxy&
String::CharProxy::operator=(const CharProxy& rhs)
{
// if the string is sharing a value with other String objects,
// break off a separate copy of the value for this string only
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
// now make the assignment: assign the value of the char
// represented by rhs to the char represented by *this
theString.value->data[charIndex] =
rhs.theString.value->data[rhs.charIndex];
return *this;
}
If you compare this with the implementation of the non-const String::operator[] in Item 29 on page 207, you'll see that they are strikingly similar. This is to be expected. In Item 29, we pessimistically assumed that all invocations of the non-const operator[] were writes, so we treated them as such. Here, we moved the code implementing a write into CharProxy's assignment operators, and that allows us to avoid paying for a write when the non-const operator[] is used only in an rvalue context. Note, by the way, that this function requires access to String's private data member value. That's why CharProxy is declared a friend in the earlier class definition for String.
The second CharProxy assignment operator is almost identical:
String::CharProxy& String::CharProxy::operator=(char c)
{
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
theString.value->data[charIndex] = c;
return *this;
}
As an accomplished software engineer, you would, of course, banish the code duplication present in these two assignment operators to a private CharProxy member function that both would call. Aren't you the modular one?
The use of a proxy class is a nice way to distinguish lvalue and rvalue usage of operator[], but the technique is not without its drawbacks. We'd like proxy objects to seamlessly replace the objects they stand for, but this ideal is difficult to achieve. That's because objects are used as lvalues in contexts other than just assignment, and using proxies in such contexts usually yields behavior different from using real objects.
Consider again the code fragment from Item 29 that motivated our decision to add a shareability flag to each StringValue object. If String::operator[] returns a CharProxy instead of a char&, that code will no longer compile:
String s1 = "Hello";
char *p = &s1[1]; // error!
The expression s1[1] returns a CharProxy, so the type of the expression on the right-hand side of the "=" is CharProxy*. There is no conversion from a CharProxy* to a char*, so the initialization of p fails to compile. In general, taking the address of a proxy yields a different type of pointer than does taking the address of a real object.
To eliminate this difficulty, you'll need to overload the address-of operators for the CharProxy class:
class String {
public:
class CharProxy {
public:
...
char * operator&();
const char * operator&() const;
...
};
...
};
These functions are easy to implement. The const function just returns a pointer to a const version of the character represented by the proxy:
const char * String::CharProxy::operator&() const
{
return &(theString.value->data[charIndex]);
}
The non-const function is a bit more work, because it returns a pointer to a character that may be modified. This is analogous to the behavior of the non-const version of String::operator[] in Item 29, and the implementation is equally analogous:
char * String::CharProxy::operator&()
{
// make sure the character to which this function returns
// a pointer isn't shared by any other String objects
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
// we don't know how long the pointer this function
// returns will be kept by clients, so the StringValue
// object can never be shared
theString.value->markUnshareable();
return &(theString.value->data[charIndex]);
}
Much of this code is common to other CharProxy member functions, so I know you'd encapsulate it in a private member function that all would call.
A second difference between chars and the CharProxys that stand for them becomes apparent if we have a template for reference-counted arrays that use proxy classes to distinguish lvalue and rvalue invocations of operator[]:
template<class T> // reference-counted array
class Array { // using proxies
public:
class Proxy {
public:
Proxy(Array<T>& array, int index);
Proxy& operator=(const T& rhs);
operator T() const;
...
};
const Proxy operator[](int index) const;
Proxy operator[](int index);
...
};
Consider how these arrays might be used:
Array<int> intArray;
...
intArray[5] = 22; // fine
intArray[5] += 5; // error!
++intArray[5]; // error!
As expected, use of operator[] as the target of a simple assignment succeeds, but use of operator[] on the left-hand side of a call to operator+= or operator++ fails. That's because operator[] returns a proxy, and there is no operator+= or operator++ for Proxy objects. A similar situation exists for other operators that require lvalues, including operator*=, operator<<=, operator--, etc. If you want these operators to work with operator[] functions that return proxies, you must define each of these functions for the Array<T>::Proxy class. That's a lot of work, and you probably don't want to do it. Unfortunately, you either do the work or you do without. Them's the breaks.
A related problem has to do with invoking member functions on real objects through proxies. To be blunt about it, you can't. For example, suppose we'd like to work with reference-counted arrays of rational numbers. We could define a class Rational and then use the Array template we just saw:
class Rational {
public:
Rational(int numerator = 0, int denominator = 1);
int numerator() const;
int denominator() const;
...
};
Array<Rational> array;
This is how we'd expect to be able to use such arrays, but, alas, we'd be disappointed:
cout << array[4].numerator(); // error!
int denom = array[22].denominator(); // error!
By now the difficulty is predictable; operator[] returns a proxy for a rational number, not an actual Rational object. But the numerator and denominator member functions exist only for Rationals, not their proxies. Hence the complaints by your compilers. To make proxies behave like the objects they stand for, you must overload each function applicable to the real objects so it applies to proxies, too.
Yet another situation in which proxies fail to replace real objects is when being passed to functions that take references to non-const objects:
void swap(char& a, char& b); // swaps the value of a and b
String s = "+C+"; // oops, should be "C++"
swap(s[0], s[1]); // this should fix the
// problem, but it won't
// compile
String::operator[] returns a CharProxy, but swap demands that its arguments be of type char&. A CharProxy may be implicitly converted into a char, but there is no conversion function to a char&. Furthermore, the char to which it may be converted can't be bound to swap's char& parameters, because that char is a temporary object (it's operator char's return value) and, as Item 19 explains, there are good reasons for refusing to bind temporary objects to non-const reference parameters.
A final way in which proxies fail to seamlessly replace real objects has to do with implicit type conversions. When a proxy object is implicitly converted into the real object it stands for, a user-defined conversion function is invoked. For instance, a CharProxy can be converted into the char it stands for by calling operator char. As Item 5 explains, compilers may use only one user-defined conversion function when converting a parameter at a call site into the type needed by the corresponding function parameter. As a result, it is possible for function calls that succeed when passed real objects to fail when passed proxies. For example, suppose we have a TVStation class and a function, watchTV:
class TVStation {
public:
TVStation(int channel);
...
};
void watchTV(const TVStation& station, float hoursToWatch);
Thanks to implicit type conversion from int to TVStation (see Item 5), we could then do this:
watchTV(10, 2.5); // watch channel 10 for
// 2.5 hours
Using the template for reference-counted arrays that use proxy classes to distinguish lvalue and rvalue invocations of operator[], however, we could not do this:
Array<int> intArray;
intArray[4] = 10;
watchTV(intArray[4], 2.5); // error! no conversion
// from Proxy<int> to
// TVStation
Given the problems that accompany implicit type conversions, it's hard to get too choked up about this. In fact, a better design for the TVStation class would declare its constructor explicit, in which case even the first call to watchTV would fail to compile. For all the details on implicit type conversions and how explicit affects them, see Item 5.
Proxy classes allow you to achieve some types of behavior that are otherwise difficult or impossible to implement. Multidimensional arrays are one example, lvalue/rvalue differentiation is a second, suppression of implicit conversions (see Item 5) is a third.
At the same time, proxy classes have disadvantages. As function return values, proxy objects are temporaries (see Item 19), so they must be created and destroyed. That's not free, though the cost may be more than recouped through their ability to distinguish write operations from read operations. The very existence of proxy classes increases the complexity of software systems that employ them, because additional classes make things harder to design, implement, understand, and maintain, not easier.
Finally, shifting from a class that works with real objects to a class that works with proxies often changes the semantics of the class, because proxy objects usually exhibit behavior that is subtly different from that of the real objects they represent. Sometimes this makes proxies a poor choice when designing a system, but in many cases there is little need for the operations that would make the presence of proxies apparent to clients. For instance, few clients will want to take the address of an Array1D object in the two-dimensional array example we saw at the beginning of this Item, and there isn't much chance that an ArraySize object (see Item 5) would be passed to a function expecting a different type. In many cases, proxies can stand in for real objects perfectly acceptably. When they can, it is often the case that nothing else will do.
Sometimes, to borrow a phrase from Jacqueline Susann, once is not enough. Suppose, for example, you're bucking for one of those high-profile, high-prestige, high-paying programming jobs at that famous software company in Redmond, Washington — by which of course I mean Nintendo. To bring yourself to the attention of Nintendo's management, you might decide to write a video game. Such a game might take place in outer space and involve space ships, space stations, and asteroids.
As the ships, stations, and asteroids whiz around in your artificial world, they naturally run the risk of colliding with one another. Let's assume the rules for such collisions are as follows:
This may sound like a dull game, but it suffices for our purpose here, which is to consider how to structure the C++ code that handles collisions between objects.
We begin by noting that ships, stations, and asteroids share some common features. If nothing else, they're all in motion, so they all have a velocity that describes that motion. Given this commonality, it is natural to define a base class from which they all inherit. In practice, such a class is almost invariably an abstract base class, and, if you heed the warning I give in Item 33, base classes are always abstract. The hierarchy might therefore look like this:
class GameObject { ... };
class SpaceShip: public GameObject { ... };
class SpaceStation: public GameObject { ... };
class Asteroid: public GameObject { ... };
Now, suppose you're deep in the bowels of your program, writing the code to check for and handle object collisions. You might come up with a function that looks something like this:
void checkForCollision(GameObject& object1,
GameObject& object2)
{
if (theyJustCollided(object1, object2)) {
processCollision(object1, object2);
}
else {
...
}
}
This is where the programming challenge becomes apparent. When you call processCollision, you know that object1 and object2 just collided, and you know that what happens in that collision depends on what object1 really is and what object2 really is, but you don't know what kinds of objects they really are; all you know is that they're both GameObjects. If the collision processing depended only on the dynamic type of object1, you could make processCollision virtual in GameObject and call object1.processCollision(object2). You could do the same thing with object2 if the details of the collision depended only on its dynamic type. What happens in the collision, however, depends on both their dynamic types. A function call that's virtual on only one object, you see, is not enough.
What you need is a kind of function whose behavior is somehow virtual on the types of more than one object. C++ offers no such function. Nevertheless, you still have to implement the behavior required above. The question, then, is how you are going to do it.
One possibility is to scrap the use of C++ and choose another programming language. You could turn to CLOS, for example, the Common Lisp Object System. CLOS supports what is possibly the most general object-oriented function-invocation mechanism one can imagine: multi-methods. A multi-method is a function that's virtual on as many parameters as you'd like, and CLOS goes even further by giving you substantial control over how calls to overloaded multi-methods are resolved.
Let us assume, however, that you must implement your game in C++ — that you must come up with your own way of implementing what is commonly referred to as double-dispatching. (The name comes from the object-oriented programming community, where what C++ programmers know as a virtual function call is termed a "message dispatch." A call that's virtual on two parameters is implemented through a "double dispatch." The generalization of this — a function acting virtual on several parameters — is called multiple dispatch.) There are several approaches you might consider. None is without its disadvantages, but that shouldn't surprise you. C++ offers no direct support for double-dispatching, so you must yourself do the work compilers do when they implement virtual functions (see Item 24). If that were easy to do, we'd probably all be doing it ourselves and simply programming in C. We aren't and we don't, so fasten your seat belts, it's going to be a bumpy ride.
Virtual functions implement a single dispatch; that's half of what we need; and compilers do virtual functions for us, so we begin by declaring a virtual function collide in GameObject. This function is overridden in the derived classes in the usual manner:
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);
...
};
Here I'm showing only the derived class SpaceShip, but SpaceStation and Asteroid are handled in exactly the same manner.
The most common approach to double-dispatching returns us to the unforgiving world of virtual function emulation via chains of if-then-elses. In this harsh world, we first discover the real type of otherObject, then we test it against all the possibilities:
// if we collide with an object of unknown type, we
// throw an exception of this type:
class CollisionWithUnknownObject {
public:
CollisionWithUnknownObject(GameObject& whatWeHit);
...
};
void SpaceShip::collide(GameObject& otherObject)
{
const type_info& objectType = typeid(otherObject);
if (objectType == typeid(SpaceShip)) {
SpaceShip& ss = static_cast<SpaceShip&>(otherObject);
process a SpaceShip-SpaceShip collision;
}
else if (objectType == typeid(SpaceStation)) {
SpaceStation& ss =
static_cast<SpaceStation&>(otherObject);
process a SpaceShip-SpaceStation collision;
}
else if (objectType == typeid(Asteroid)) {
Asteroid& a = static_cast<Asteroid&>(otherObject);
process a SpaceShip-Asteroid collision;
}
else {
throw CollisionWithUnknownObject(otherObject);
}
}
Notice how we need to determine the type of only one of the objects involved in the collision. The other object is *this, and its type is determined by the virtual function mechanism. We're inside a SpaceShip member function, so *this must be a SpaceShip object. Thus we only have to figure out the real type of otherObject.
There's nothing complicated about this code. It's easy to write. It's even easy to make work. That's one of the reasons RTTI is worrisome: it looks harmless. The true danger in this code is hinted at only by the final else clause and the exception that's thrown there.
We've pretty much bidden adios to encapsulation, because each collide function must be aware of each of its sibling classes, i.e., those classes that inherit from GameObject. In particular, if a new type of object — a new class — is added to the game, we must update each RTTI-based if-then-else chain in the program that might encounter the new object type. If we forget even a single one, the program will have a bug, and the bug will not be obvious. Furthermore, compilers are in no position to help us detect such an oversight, because they have no idea what we're doing.
This kind of type-based programming has a long history in C, and one of the things we know about it is that it yields programs that are essentially unmaintainable. Enhancement of such programs eventually becomes unthinkable. This is the primary reason why virtual functions were invented in the first place: to shift the burden of generating and maintaining type-based function calls from programmers to compilers. When we employ RTTI to implement double-dispatching, we are harking back to the bad old days.
The techniques of the bad old days led to errors in C, and they'll lead to errors in C++, too. In recognition of our human frailty, we've included a final else clause in the collide function, a clause where control winds up if we hit an object we don't know about. Such a situation is, in principle, impossible, but where were our principles when we decided to use RTTI? There are various ways to handle such unanticipated interactions, but none is very satisfying. In this case, we've chosen to throw an exception, but it's not clear how our callers can hope to handle the error any better than we can, since we've just run into something we didn't know existed.
There is a way to minimize the risks inherent in an RTTI approach to implementing double-dispatching, but before we look at that, it's convenient to see how to attack the problem using nothing but virtual functions. That strategy begins with the same basic structure as the RTTI approach. The collide function is declared virtual in GameObject and is redefined in each derived class. In addition, collide is overloaded in each class, one overloading for each derived class in the hierarchy:
class SpaceShip; // forward declarations
class SpaceStation;
class Asteroid;
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
virtual void collide(SpaceShip& otherObject) = 0;
virtual void collide(SpaceStation& otherObject) = 0;
virtual void collide(Asteroid& otherobject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);
virtual void collide(SpaceShip& otherObject);
virtual void collide(SpaceStation& otherObject);
virtual void collide(Asteroid& otherobject);
...
};
The basic idea is to implement double-dispatching as two single dispatches, i.e., as two separate virtual function calls: the first determines the dynamic type of the first object, the second determines that of the second object. As before, the first virtual call is to the collide function taking a GameObject& parameter. That function's implementation now becomes startlingly simple:
void SpaceShip::collide(GameObject& otherObject)
{
otherObject.collide(*this);
}
At first glance, this appears to be nothing more than a recursive call to collide with the order of the parameters reversed, i.e., with otherObject becoming the object calling the member function and *this becoming the function's parameter. Glance again, however, because this is not a recursive call. As you know, compilers figure out which of a set of functions to call on the basis of the static types of the arguments passed to the function. In this case, four different collide functions could be called, but the one chosen is based on the static type of *this. What is that static type? Being inside a member function of the class SpaceShip, *this must be of type SpaceShip. The call is therefore to the collide function taking a SpaceShip&, not the collide function taking a GameObject&.
All the collide functions are virtual, so the call inside SpaceShip::collide resolves to the implementation of collide corresponding to the real type of otherObject. Inside that implementation of collide, the real types of both objects are known, because the left-hand object is *this (and therefore has as its type the class implementing the member function) and the right-hand object's real type is SpaceShip, the same as the declared type of the parameter.
All this may be clearer when you see the implementations of the other collide functions in SpaceShip:
void SpaceShip::collide(SpaceShip& otherObject)
{
process a SpaceShip-SpaceShip collision;
}
void SpaceShip::collide(SpaceStation& otherObject)
{
process a SpaceShip-SpaceStation collision;
}
void SpaceShip::collide(Asteroid& otherObject)
{
process a SpaceShip-Asteroid collision;
}
As you can see, there's no muss, no fuss, no RTTI, no need to throw exceptions for unexpected object types. There can be no unexpected object types — that's the whole point of using virtual functions. In fact, were it not for its fatal flaw, this would be the perfect solution to the double-dispatching problem.
The flaw is one it shares with the RTTI approach we saw earlier: each class must know about its siblings. As new classes are added, the code must be updated. However, the way in which the code must be updated is different in this case. True, there are no if-then-elses to modify, but there is something that is often worse: each class definition must be amended to include a new virtual function. If, for example, you decide to add a new class Satellite (inheriting from GameObject) to your game, you'd have to add a new collide function to each of the existing classes in the program.
Modifying existing classes is something you are frequently in no position to do. If, instead of writing the entire video game yourself, you started with an off-the-shelf class library comprising a video game application framework, you might not have write access to the GameObject class or the framework classes derived from it. In that case, adding new member functions, virtual or otherwise, is not an option. Alternatively, you may have physical access to the classes requiring modification, but you may not have practical access. For example, suppose you were hired by Nintendo and were put to work on programs using a library containing GameObject and other useful classes. Surely you wouldn't be the only one using that library, and Nintendo would probably be less than thrilled about recompiling every application using that library each time you decided to add a new type of object to your program. In practice, libraries in wide use are modified only rarely, because the cost of recompiling everything using those libraries is too great.
The long and short of it is if you need to implement double-dispatching in your program, your best recourse is to modify your design to eliminate the need. Failing that, the virtual function approach is safer than the RTTI strategy, but it constrains the extensibility of your system to match that of your ability to edit header files. The RTTI approach, on the other hand, makes no recompilation demands, but, if implemented as shown above, it generally leads to software that is unmaintainable. You pays your money and you takes your chances.
There is a way to improve those chances. You may recall from Item 24 that compilers typically implement virtual functions by creating an array of function pointers (the vtbl) and then indexing into that array when a virtual function is called. Using a vtbl eliminates the need for compilers to perform chains of if-then-else-like computations, and it allows compilers to generate the same code at all virtual function call sites: determine the correct vtbl index, then call the function pointed to at that position in the vtbl.
There is no reason you can't do this yourself. If you do, you not only make your RTTI-based code more efficient (indexing into an array and following a function pointer is almost always more efficient than running through a series of if-then-else tests, and it generates less code, too), you also isolate the use of RTTI to a single location: the place where your array of function pointers is initialized. I should mention that the meek may inherit the earth, but the meek of heart may wish to take a few deep breaths before reading what follows.
We begin by making some modifications to the functions in the GameObject hierarchy:
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);
virtual void hitSpaceShip(SpaceShip& otherObject);
virtual void hitSpaceStation(SpaceStation& otherObject);
virtual void hitAsteroid(Asteroid& otherobject);
...
};
void SpaceShip::hitSpaceShip(SpaceShip& otherObject)
{
process a SpaceShip-SpaceShip collision;
}
void SpaceShip::hitSpaceStation(SpaceStation& otherObject)
{
process a SpaceShip-SpaceStation collision;
}
void SpaceShip::hitAsteroid(Asteroid& otherObject)
{
process a SpaceShip-Asteroid collision;
}
Like the RTTI-based hierarchy we started out with, the GameObject class contains only one function for processing collisions, the one that performs the first of the two necessary dispatches. Like the virtual-function-based hierarchy we saw later, each kind of interaction is encapsulated in a separate function, though in this case the functions have different names instead of sharing the name collide. There is a reason for this abandonment of overloading, and we shall see it soon. For the time being, note that the design above contains everything we need except an implementation for SpaceShip::collide; that's where the various hit functions will be invoked. As before, once we successfully implement the SpaceShip class, the SpaceStation and Asteroid classes will follow suit.
Inside SpaceShip::collide, we need a way to map the dynamic type of the parameter otherObject to a member function pointer that points to the appropriate collision-handling function. An easy way to do this is to create an associative array that, given a class name, yields the appropriate member function pointer. It's possible to implement collide using such an associative array directly, but it's a bit easier to understand what's going on if we add an intervening function, lookup, that takes a GameObject and returns the appropriate member function pointer. That is, you pass lookup a GameObject, and it returns a pointer to the member function to call when you collide with something of that GameObject's type.
Here's the declaration of lookup:
class SpaceShip: public GameObject {
private:
typedef void (SpaceShip::*HitFunctionPtr)(GameObject&);
static HitFunctionPtr lookup(const GameObject& whatWeHit);
...
};
The syntax of function pointers is never very pretty, and for member function pointers it's worse than usual, so we've typedefed HitFunctionPtr to be shorthand for a pointer to a member function of SpaceShip that takes a GameObject& and returns nothing.
Once we've got lookup, implementation of collide becomes the proverbial piece of cake:
void SpaceShip::collide(GameObject& otherObject)
{
HitFunctionPtr hfp =
lookup(otherObject); // find the function to call
if (hfp) { // if a function was found
(this->*hfp)(otherObject); // call it
}
else {
throw CollisionWithUnknownObject(otherObject);
}
}
Provided we've kept the contents of our associative array in sync with the class hierarchy under GameObject, lookup must always find a valid function pointer for the object we pass it. People are people, however, and mistakes have been known to creep into even the most carefully crafted software systems. That's why we still check to make sure a valid pointer was returned from lookup, and that's why we still throw an exception if the impossible occurs and the lookup fails.
All that remains now is the implementation of lookup. Given an associative array that maps from object types to member function pointers, the lookup itself is easy, but creating, initializing, and destroying the associative array is an interesting problem of its own.
Such an array should be created and initialized before it's used, and it should be destroyed when it's no longer needed. We could use new and delete to create and destroy the array manually, but that would be error-prone: how could we guarantee the array wasn't used before we got around to initializing it? A better solution is to have compilers automate the process, and we can do that by making the associative array static in lookup. That way it will be created and initialized the first time lookup is called, and it will be automatically destroyed sometime after main is exited.
Furthermore, we can use the map template from the Standard Template Library (see Item 35) as the associative array, because that's what a map is:
class SpaceShip: public GameObject {
private:
typedef void (SpaceShip::*HitFunctionPtr)(GameObject&);
typedef map<string, HitFunctionPtr> HitMap;
...
};
SpaceShip::HitFunctionPtr
SpaceShip::lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap;
...
}
Here, collisionMap is our associative array. It maps the name of a class (as a string object) to a SpaceShip member function pointer. Because map<string, HitFunctionPtr> is quite a mouthful, we use a typedef to make it easier to swallow. (For fun, try writing the declaration of collisionMap without using the HitMap and HitFunctionPtr typedefs. Most people will want to do this only once.)
Given collisionMap, the implementation of lookup is rather anticlimactic. That's because searching for something is an operation directly supported by the map class, and the one member function we can always (portably) call on the result of a typeid invocation is name (which, predictably†, yields the name of the object's dynamic type). To implement lookup, then, we just find the entry in collisionMap corresponding to the dynamic type of lookup's argument.
The code for lookup is straightforward, but if you're not familiar with the Standard Template Library (again, see Item 35), it may not seem that way. Don't worry. The comments in the function explain what's going on.
SpaceShip::HitFunctionPtr
SpaceShip::lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap; // we'll see how to
// initialize this below
// look up the collision-processing function for the type
// of whatWeHit. The value returned is a pointer-like
// object called an "iterator" (see Item 35).
HitMap::iterator mapEntry=
collisionMap.find(typeid(whatWeHit).name());
// mapEntry == collisionMap.end() if the lookup failed;
// this is standard map behavior. Again, see Item 35.
if (mapEntry == collisionMap.end()) return 0;
// If we get here, the search succeeded. mapEntry
// points to a complete map entry, which is a
// (string, HitFunctionPtr) pair. We want only the
// second part of the pair, so that's what we return.
return (*mapEntry).second;
}
The final statement in the function returns (*mapEntry).second instead of the more conventional mapEntry->second in order to satisfy the vagaries of the STL. For details, see page 96.
Which brings us to the initialization of collisionMap. We'd like to say something like this,
// An incorrect implementation
SpaceShip::HitFunctionPtr
SpaceShip::lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap;
collisionMap["SpaceShip"] = &hitSpaceShip;
collisionMap["SpaceStation"] = &hitSpaceStation;
collisionMap["Asteroid"] = &hitAsteroid;
...
}
but this inserts the member function pointers into collisionMap each time lookup is called, and that's needlessly inefficient. In addition, this won't compile, but that's a secondary problem we'll address shortly.
What we need now is a way to put the member function pointers into collisionMap only once — when collisionMap is created. That's easy enough to accomplish; we just write a private static member function called initializeCollisionMap to create and initialize our map, then we initialize collisionMap with initializeCollisionMap's return value:
class SpaceShip: public GameObject {
private:
static HitMap initializeCollisionMap();
...
};
SpaceShip::HitFunctionPtr
SpaceShip::lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap = initializeCollisionMap();
...
}
But this means we may have to pay the cost of copying the map object returned from initializeCollisionMap into collisionMap (see Items 19 and 20). We'd prefer not to do that. We wouldn't have to pay if initializeCollisionMap returned a pointer, but then we'd have to worry about making sure the map object the pointer pointed to was destroyed at an appropriate time.
Fortunately, there's a way for us to have it all. We can turn collisionMap into a smart pointer (see Item 28) that automatically deletes what it points to when the pointer itself is destroyed. In fact, the standard C++ library contains a template, auto_ptr, for just such a smart pointer (see Item 9). By making collisionMap a static auto_ptr in lookup, we can have initializeCollisionMap return a pointer to an initialized map object, yet never have to worry about a resource leak; the map to which collisionMap points will be automatically destroyed when collisionMap is. Thus:
class SpaceShip: public GameObject {
private:
static HitMap * initializeCollisionMap();
...
};
SpaceShip::HitFunctionPtr
SpaceShip::lookup(const GameObject& whatWeHit)
{
static auto_ptr<HitMap>
collisionMap(initializeCollisionMap());
...
}
The clearest way to implement initializeCollisionMap would seem to be this,
SpaceShip::HitMap * SpaceShip::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)["SpaceShip"] = &hitSpaceShip;
(*phm)["SpaceStation"] = &hitSpaceStation;
(*phm)["Asteroid"] = &hitAsteroid;
return phm;
}
but as I noted earlier, this won't compile. That's because a HitMap is declared to hold pointers to member functions that all take the same type of argument, namely GameObject. But hitSpaceShip takes a SpaceShip, hitSpaceStation takes a SpaceStation, and, hitAsteroid takes an Asteroid. Even though SpaceShip, SpaceStation, and Asteroid can all be implicitly converted to GameObject, there is no such conversion for pointers to functions taking these argument types.
To placate your compilers, you might be tempted to employ reinterpret_casts (see Item 2), which are generally the casts of choice when converting between function pointer types:
// A bad idea...
SpaceShip::HitMap * SpaceShip::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)["SpaceShip"] =
reinterpret_cast<HitFunctionPtr>(&hitSpaceShip);
(*phm)["SpaceStation"] =
reinterpret_cast<HitFunctionPtr>(&hitSpaceStation);
(*phm)["Asteroid"] =
reinterpret_cast<HitFunctionPtr>(&hitAsteroid);
return phm;
}
This will compile, but it's a bad idea. It entails doing something you should never do: lying to your compilers. Telling them that hitSpaceShip, hitSpaceStation, and hitAsteroid are functions expecting a GameObject argument is simply not true. hitSpaceShip expects a SpaceShip, hitSpaceStation expects a SpaceStation, and hitAsteroid expects an Asteroid. The casts say otherwise. The casts lie.
More than morality is on the line here. Compilers don't like to be lied to, and they often find a way to exact revenge when they discover they've been deceived. In this case, they're likely to get back at you by generating bad code for functions you call through *phm in cases where GameObject's derived classes employ multiple inheritance or have virtual base classes. In other words, if SpaceStation, SpaceShip, or Asteroid had other base classes (in addition to GameObject), you'd probably find that your calls to collision-processing functions in collide would behave quite rudely.
Consider again the A-B-C-D inheritance hierarchy and the possible object layout for a D object that is described in Item 24:
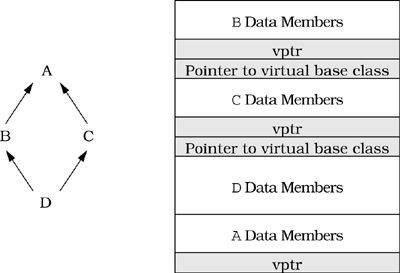
Each of the four class parts in a D object has a different address. This is important, because even though pointers and references behave differently (see Item 1), compilers typically implement references by using pointers in the generated code. Thus, pass-by-reference is typically implemented by passing a pointer to an object. When an object with multiple base classes (such as a D object) is passed by reference, it is crucial that compilers pass the correct address — the one corresponding to the declared type of the parameter in the function being called.
But what if you've lied to your compilers and told them your function expects a GameObject when it really expects a SpaceShip or a SpaceStation? Then they'll pass the wrong address when you call the function, and the resulting runtime carnage will probably be gruesome. It will also be very difficult to determine the cause of the problem. There are good reasons why casting is discouraged. This is one of them.
Okay, so casting is out. Fine. But the type mismatch between the function pointers a HitMap is willing to contain and the pointers to the hitSpaceShip, hitSpaceStation, and hitAsteroid functions remains. There is only one way to resolve the conflict: change the types of the functions so they all take GameObject arguments:
class GameObject { // this is unchanged
public:
virtual void collide(GameObject& otherObject) = 0;
...
};
class SpaceShip: public GameObject {
public:
virtual void collide(GameObject& otherObject);
// these functions now all take a GameObject parameter
virtual void hitSpaceShip(GameObject& spaceShip);
virtual void hitSpaceStation(GameObject& spaceStation);
virtual void hitAsteroid(GameObject& asteroid);
...
};
Our solution to the double-dispatching problem that was based on virtual functions overloaded the function name collide. Now we are in a position to understand why we didn't follow suit here — why we decided to use an associative array of member function pointers instead. All the hit functions take the same parameter type, so we must give them different names.
Now we can write initializeCollisionMap the way we always wanted to:
SpaceShip::HitMap * SpaceShip::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)["SpaceShip"] = &hitSpaceShip;
(*phm)["SpaceStation"] = &hitSpaceStation;
(*phm)["Asteroid"] = &hitAsteroid;
return phm;
}
Regrettably, our hit functions now get a general GameObject parameter instead of the derived class parameters they expect. To bring reality into accord with expectation, we must resort to a dynamic_cast (see Item 2) at the top of each function:
void SpaceShip::hitSpaceShip(GameObject& spaceShip)
{
SpaceShip& otherShip=
dynamic_cast<SpaceShip&>(spaceShip);
process a SpaceShip-SpaceShip collision;
}
void SpaceShip::hitSpaceStation(GameObject& spaceStation)
{
SpaceStation& station=
dynamic_cast<SpaceStation&>(spaceStation);
process a SpaceShip-SpaceStation collision;
}
void SpaceShip::hitAsteroid(GameObject& asteroid)
{
Asteroid& theAsteroid =
dynamic_cast<Asteroid&>(asteroid);
process a SpaceShip-Asteroid collision;
}
Each of the dynamic_casts will throw a bad_cast exception if the cast fails. They should never fail, of course, because the hit functions should never be called with incorrect parameter types. Still, we're better off safe than sorry.
We now know how to build a vtbl-like associative array that lets us implement the second half of a double-dispatch, and we know how to encapsulate the details of the associative array inside a lookup function. Because this array contains pointers to member functions, however, we still have to modify class definitions if a new type of GameObject is added to the game, and that means everybody has to recompile, even people who don't care about the new type of object. For example, if Satellite were added to our game, we'd have to augment the SpaceShip class with a declaration of a function to handle collisions between satellites and spaceships. All SpaceShip clients would then have to recompile, even if they couldn't care less about the existence of satellites. This is the problem that led us to reject the implementation of double-dispatching based purely on virtual functions, and that solution was a lot less work than the one we've just seen.
The recompilation problem would go away if our associative array contained pointers to non-member functions. Furthermore, switching to non-member collision-processing functions would let us address a design question we have so far ignored, namely, in which class should collisions between objects of different types be handled? With the implementation we just developed, if object 1 and object 2 collide and object 1 happens to be the left-hand argument to processCollision, the collision will be handled inside the class for object 1. If object 2 happens to be the left-hand argument to processCollision, however, the collision will be handled inside the class for object 2. Does this make sense? Wouldn't it be better to design things so that collisions between objects of types A and B are handled by neither A nor B but instead in some neutral location outside both classes?
If we move the collision-processing functions out of our classes, we can give clients header files that contain class definitions without any hit or collide functions. We can then structure our implementation file for processCollision as follows:
#include "SpaceShip.h"
#include "SpaceStation.h"
#include "Asteroid.h"
namespace { // unnamed namespace -- see below
// primary collision-processing functions
void shipAsteroid(GameObject& spaceShip,
GameObject& asteroid);
void shipStation(GameObject& spaceShip,
GameObject& spaceStation);
void asteroidStation(GameObject& asteroid,
GameObject& spaceStation);
...
// secondary collision-processing functions that just
// implement symmetry: swap the parameters and call a
// primary function
void asteroidShip(GameObject& asteroid,
GameObject& spaceShip)
{ shipAsteroid(spaceShip, asteroid); }
void stationShip(GameObject& spaceStation,
GameObject& spaceShip)
{ shipStation(spaceShip, spaceStation); }
void stationAsteroid(GameObject& spaceStation,
GameObject& asteroid)
{ asteroidStation(asteroid, spaceStation); }
...
// see below for a description of these types/functions
typedef void (*HitFunctionPtr)(GameObject&, GameObject&);
typedef map< pair<string,string>, HitFunctionPtr > HitMap;
pair<string,string> makeStringPair(const char *s1,
const char *s2);
HitMap * initializeCollisionMap();
HitFunctionPtr lookup(const string& class1,
const string& class2);
} // end namespace
void processCollision(GameObject& object1,
GameObject& object2)
{
HitFunctionPtr phf = lookup(typeid(object1).name(),
typeid(object2).name());
if (phf) phf(object1, object2);
else throw UnknownCollision(object1, object2);
}
Note the use of the unnamed namespace to contain the functions used to implement processCollision. Everything in such an unnamed namespace is private to the current translation unit (essentially the current file) — it's just like the functions were declared static at file scope. With the advent of namespaces, however, statics at file scope have been deprecated, so you should accustom yourself to using unnamed namespaces as soon as your compilers support them.
Conceptually, this implementation is the same as the one that used member functions, but there are some minor differences. First, HitFunctionPtr is now a typedef for a pointer to a non-member function. Second, the exception class CollisionWithUnknownObject has been renamed UnknownCollision and modified to take two objects instead of one. Finally, lookup must now take two type names and perform both parts of the double-dispatch. This means our collision map must now hold three pieces of information: two types names and a HitFunctionPtr.
As fate would have it, the standard map class is defined to hold only two pieces of information. We can finesse that problem by using the standard pair template, which lets us bundle the two type names together as a single object. initializeCollisionMap, along with its makeStringPair helper function, then looks like this:
// we use this function to create pair<string,string>
// objects from two char* literals. It's used in
// initializeCollisionMap below. Note how this function
// enables the return value optimization (see Item 20).
namespace { // unnamed namespace again -- see below
pair<string,string> makeStringPair(const char *s1,
const char *s2)
{ return pair<string,string>(s1, s2); }
} // end namespace
namespace { // still the unnamed namespace -- see below
HitMap * initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)[makeStringPair("SpaceShip","Asteroid")] =
&shipAsteroid;
(*phm)[makeStringPair("SpaceShip", "SpaceStation")] =
&shipStation;
...
return phm;
}
} // end namespace
lookup must also be modified to work with the pair<string, string> objects that now comprise the first component of the collision map:
namespace { // I explain this below -- trust me
HitFunctionPtr lookup(const string& class1,
const string& class2)
{
static auto_ptr<HitMap>
collisionMap(initializeCollisionMap());
// see below for a description of make_pair
HitMap::iterator mapEntry=
collisionMap->find(make_pair(class1, class2));
if (mapEntry == collisionMap->end()) return 0;
return (*mapEntry).second;
}
} // end namespace
This is almost exactly what we had before. The only real difference is the use of the make_pair function in this statement:
HitMap::iterator mapEntry=
collisionMap->find(make_pair(class1, class2));
make_pair is just a convenience function (template) in the standard library (see Item 35) that saves us the trouble of specifying the types when constructing a pair object. We could just as well have written the statement like this:
HitMap::iterator mapEntry=
collisionMap->find(pair<string,string>(class1, class2));
This calls for more typing, however, and specifying the types for the pair is redundant (they're the same as the types of class1 and class2), so the make_pair form is more commonly used.
Because makeStringPair, initializeCollisionMap, and lookup were declared inside an unnamed namespace, each must be implemented within the same namespace. That's why the implementations of the functions above are in the unnamed namespace (for the same translation unit as their declarations): so the linker will correctly associate their definitions (i.e., their implementations) with their earlier declarations.
We have finally achieved our goals. If new subclasses of GameObject are added to our hierarchy, existing classes need not recompile (unless they wish to use the new classes). We have no tangle of RTTI-based switch or if-then-else conditionals to maintain. The addition of new classes to the hierarchy requires only well-defined and localized changes to our system: the addition of one or more map insertions in initializeCollisionMap and the declarations of the new collision-processing functions in the unnamed namespace associated with the implementation of processCollision. It may have been a lot of work to get here, but at least the trip was worthwhile. Yes? Yes?
Maybe.
There is one final problem we must confront. (If, at this point, you are wondering if there will always be one final problem to confront, you have truly come to appreciate the difficulty of designing an implementation mechanism for virtual functions.) Everything we've done will work fine as long as we never need to allow inheritance-based type conversions when calling collision-processing functions. But suppose we develop a game in which we must sometimes distinguish between commercial space ships and military space ships. We could modify our hierarchy as follows, where we've heeded the guidance of Item 33 and made the concrete classes CommercialShip and MilitaryShip inherit from the newly abstract class SpaceShip:
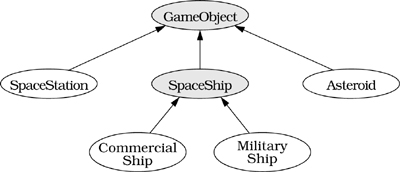
Suppose commercial and military ships behave identically when they collide with something. Then we'd expect to be able to use the same collision-processing functions we had before CommercialShip and MilitaryShip were added. In particular, if a MilitaryShip object and an Asteroid collided, we'd expect
void shipAsteroid(GameObject& spaceShip,
GameObject& asteroid);
to be called. It would not be. Instead, an UnknownCollision exception would be thrown. That's because lookup would be asked to find a function corresponding to the type names "MilitaryShip" and "Asteroid," and no such function would be found in collisionMap. Even though a MilitaryShip can be treated like a SpaceShip, lookup has no way of knowing that.
Furthermore, there is no easy way of telling it. If you need to implement double-dispatching and you need to support inheritance-based parameter conversions such as these, your only practical recourse is to fall back on the double-virtual-function-call mechanism we examined earlier. That implies you'll also have to put up with everybody recompiling when you add to your inheritance hierarchy, but that's just the way life is sometimes.
That's really all there is to say about double-dispatching, but it would be unpleasant to end the discussion on such a downbeat note, and unpleasantness is, well, unpleasant. Instead, let's conclude by outlining an alternative approach to initializing collisionMap.
As things stand now, our design is entirely static. Once we've registered a function for processing collisions between two types of objects, that's it; we're stuck with that function forever. What if we'd like to add, remove, or change collision-processing functions as the game proceeds? There's no way to do it.
But there can be. We can turn the concept of a map for storing collision-processing functions into a class that offers member functions allowing us to modify the contents of the map dynamically. For example:
class CollisionMap {
public:
typedef void (*HitFunctionPtr)(GameObject&, GameObject&);
void addEntry(const string& type1,
const string& type2,
HitFunctionPtr collisionFunction,
bool symmetric = true); // see below
void removeEntry(const string& type1,
const string& type2);
HitFunctionPtr lookup(const string& type1,
const string& type2);
// this function returns a reference to the one and only
// map -- see Item 26
static CollisionMap& theCollisionMap();
private:
// these functions are private to prevent the creation
// of multiple maps -- see Item 26
CollisionMap();
CollisionMap(const CollisionMap&);
};
This class lets us add entries to the map, remove them from it, and look up the collision-processing function associated with a particular pair of type names. It also uses the techniques of Item 26 to limit the number of CollisionMap objects to one, because there is only one map in our system. (More complex games with multiple maps are easy to imagine.) Finally, it allows us to simplify the addition of symmetric collisions to the map (i.e., collisions in which the effect of an object of type T1 hitting an object of type T2 is the same as that of an object of type T2 hitting an object of type T1) by automatically adding the implied map entry when addEntry is called with the optional parameter symmetric set to true.
With the CollisionMap class, each client wishing to add an entry to the map does so directly:
void shipAsteroid(GameObject& spaceShip,
GameObject& asteroid);
CollisionMap::theCollisionMap().addEntry("SpaceShip",
"Asteroid",
&shipAsteroid);
void shipStation(GameObject& spaceShip,
GameObject& spaceStation);
CollisionMap::theCollisionMap().addEntry("SpaceShip",
"SpaceStation",
&shipStation);
void asteroidStation(GameObject& asteroid,
GameObject& spaceStation);
CollisionMap::theCollisionMap().addEntry("Asteroid",
"SpaceStation",
&asteroidStation);
...
Care must be taken to ensure that these map entries are added to the map before any collisions occur that would call the associated functions. One way to do this would be to have constructors in GameObject subclasses check to make sure the appropriate mappings had been added each time an object was created. Such an approach would exact a small performance penalty at runtime. An alternative would be to create a RegisterCollisionFunction class:
class RegisterCollisionFunction {
public:
RegisterCollisionFunction(
const string& type1,
const string& type2,
CollisionMap::HitFunctionPtr collisionFunction,
bool symmetric = true)
{
CollisionMap::theCollisionMap().addEntry(type1, type2,
collisionFunction,
symmetric);
}
};
Clients could then use global objects of this type to automatically register the functions they need:
RegisterCollisionFunction cf1("SpaceShip", "Asteroid",
&shipAsteroid);
RegisterCollisionFunction cf2("SpaceShip", "SpaceStation",
&shipStation);
RegisterCollisionFunction cf3("Asteroid", "SpaceStation",
&asteroidStation);
...
int main(int argc, char * argv[])
{
...
}
Because these objects are created before main is invoked, the functions their constructors register are also added to the map before main is called. If, later, a new derived class is added
class Satellite: public GameObject { ... };
and one or more new collision-processing functions are written,
void satelliteShip(GameObject& satellite,
GameObject& spaceShip);
void satelliteAsteroid(GameObject& satellite,
GameObject& asteroid);
these new functions can be similarly added to the map without disturbing existing code:
RegisterCollisionFunction cf4("Satellite", "SpaceShip",
&satelliteShip);
RegisterCollisionFunction cf5("Satellite", "Asteroid",
&satelliteAsteroid);
This doesn't change the fact that there's no perfect way to implement multiple dispatch, but it does make it easy to provide data for a map-based implementation if we decide such an approach is the best match for our needs.