Chapter 2
Storage Infrastructure
This chapter covers the following topics:
This chapter contains information related to Professional VMware vSphere 7.x (2V0-21.20) exam objectives 1.3, 1.3.1, 1.3.2, 1.3.3, 1.3.4, 1.3.5, 1.4, 1.6.5, 1.9, 1.9.1, 5.5, 7.4, 7.4.1, 7.4.2, and 7.4.3.
This chapter provides details on the storage infrastructure, both physical and virtual, involved in a vSphere 7.0 environment.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should study this entire chapter or move quickly to the “Exam Preparation Tasks” section. In any case, the authors recommend that you read the entire chapter at least once. Table 2-1 outlines the major headings in this chapter and the corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 2-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions Covered in This Section |
|---|---|
Storage Models and Datastore Types |
1, 2 |
vSAN Concepts |
3, 4 |
vSphere Storage Integration |
5, 6 |
Storage Multipathing and Failover |
7 |
Storage Policies |
8, 9 |
Storage DRS (SDRS) |
10 |
1. You need to configure a virtual machine to utilize N-Port ID Virtualization (NPIV). Which of the following are required? (Choose two.)
iSCSI
vVOLs
RDM
FCoE
vSAN
VMFS
2. You are preparing to implement vSphere with Kubernetes. Which type of virtual disk must you provide for storing logs, emptyDir volumes, and ConfigMaps?
Ephemeral
Container image
Persistent volume
Non-persistent volume
3. You are planning to implement a vSAN stretched cluster. Which of the following statements is true?
You should not enable DRS in automatic mode.
You should disable HA datastore heartbeats.
If you set PFFT to 0, you may be able to use SMP-FT.
If one of the fault domains is inaccessible, you cannot provision virtual machines.
4. You are planning to implement RAID 6 erasure coding for a virtual disk stored in a vSAN datastore. What percentage of the required capacity will be usable?
50%
67%
75%
100%
5. You are preparing to leverage VAAI in your vSphere environment. Which of the following primitives will not be available for your virtual machines stored in NFS datastores?
Atomic Test and Set
Full File Clone
Extended Statistics
Reserve Space
6. You are planning to implement vVols. Which of the following are logical I/O proxies?
Data-vVol instances
Storage providers
Storage containers
Protocol endpoints
7. You are explaining how vSphere interacts with storage systems. Which of the following steps may occur when VMware NMP receives an I/O request?
The PSP issues the I/O request on the appropriate physical path.
The SATP issues the I/O request on the appropriate physical path.
The PSP activates the inactive path.
The PSP calls the appropriate SATP.
8. In your vSphere environment where VASA is not implemented, you are planning to leverage storage policies associated with devices in your storage array. Which type of storage policies should you create?
VM storage policy for host-based data services
VM storage policy for vVols
VM storage policy for tag-based placement
vSAN storage policy
9. You are configuring storage policies for use with your vSAN cluster. Which of the following is not an available option?
Number of Replicas per Object
Number of Disk Stripes per Object
Primary Level of Failures to Tolerate
Secondary Level of Failures to Tolerate
10. You are testing Storage DRS (SDRS) in a scenario where the utilized space on one datastore is 82%, and it is 79% on another. You observe that SDRS does not make a migration recommendation. What might be the reason?
The Space Utilization Difference threshold is set too low.
The Space Utilization Difference threshold is set too high.
The Space Utilization Difference threshold is set to 78%.
The Space Utilization Difference threshold is set to 80%.
Foundation Topics
Storage Models and Datastore Types
This section explains how virtual machines access storage and describes the storage models and datastore types available in vSphere.
How Virtual Machines Access Storage
A virtual machine communicates with its virtual disk stored on a datastore by issuing SCSI commands. The SCSI commands are encapsulated into other forms, depending on the protocol that the ESXi host uses to connect to a storage device on which the datastore resides, as illustrated in Figure 2-1.
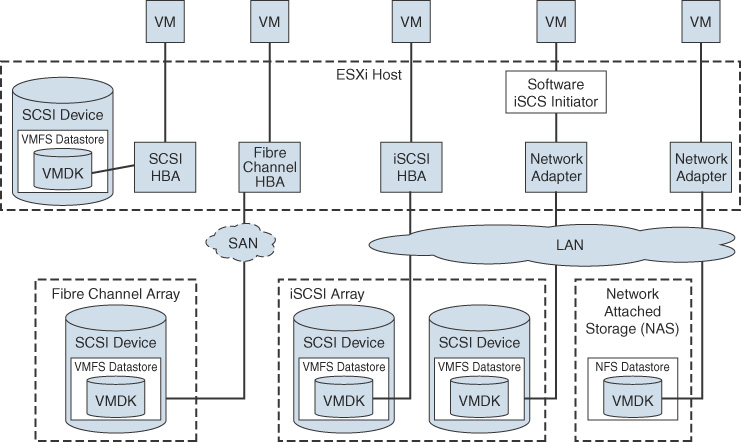
FIGURE 2-1 Virtual Machine Storage
Storage Virtualization: The Traditional Model
Storage virtualization refers to a logical abstraction of physical storage resources and capacities from virtual machines. ESXi provides host-level storage virtualization. In vSphere environments, a traditional model is built around the storage technologies and ESXi virtualization features discussed in the following sections.
Storage Devices (or LUNs)
In common ESXi vocabulary, the terms storage device and LUN are used interchangeably. Storage devices or LUNs are storage volumes that are presented to a host from a block storage system and are available to ESXi for formatting.
Virtual Disk
Virtual disks are sets of files that reside on a datastore that is deployed on physical storage. From the standpoint of the virtual machine, each virtual disk appears as if it were a SCSI drive connected to a SCSI controller. The physical storage is transparent to the virtual machine guest operating system and applications.
Local Storage
Local storage can be internal hard disks located inside an ESXi host and external storage systems connected to the host directly through protocols such as SAS or SATA. Local storage does not require a storage network to communicate with the host.
Fibre Channel
Fibre Channel (FC) is a storage protocol that a storage area network (SAN) uses to transfer data traffic from ESXi host servers to shared storage. It packages SCSI commands into FC frames. The ESXi host uses Fibre Channel host bus adapters (HBAs) to connect to the FC SAN, as illustrated in Figure 2-1. Unless you use directly connected Fibre Channel storage, you need Fibre Channel switches to route storage traffic. If a host contains FCoE (Fibre Channel over Ethernet) adapters, you can connect to shared Fibre Channel devices by using an Ethernet network.
iSCSI
Internet SCSI (iSCSI) is a SAN transport that can use Ethernet connections between ESXi hosts and storage systems. To connect to the storage systems, your hosts use hardware iSCSI adapters or software iSCSI initiators with standard network adapters.
With hardware iSCSI HBAs, the host connects to the storage through a hardware adapter that offloads the iSCSI and network processing. Hardware iSCSI adapters can be dependent and independent. With software iSCSI adapters, the host uses a software-based iSCSI initiator in the VMkernel and a standard network adapter to connect to storage. Both the iSCSI HBA and the software iSCSI initiator are illustrated in Figure 2-1.
FCoE
If an ESXi host contains FCoE adapters, it can connect to shared Fibre Channel devices by using an Ethernet network.
NAS/NFS
vSphere uses NFS to store virtual machine files on remote file servers accessed over a standard TCP/IP network. ESXi 7.0 uses Network File System (NFS) Version 3 and Version 4.1 to communicate with NAS/NFS servers, as illustrated in Figure 2-1. You can use NFS datastores to store and manage virtual machines in the same way that you use the VMFS datastores.
VMFS
The datastores that you deploy on block storage devices use the native vSphere Virtual Machine File System (VMFS) format. VMFS is a special high-performance file system format that is optimized for storing virtual machines.
Raw Device Mappings (RDMs)
A raw device mapping (RDM) is a mapping file that contains metadata that resides in a VMFS datastore and acts as a proxy for a physical storage device (LUN), allowing a virtual machine to access the storage device directly. It gives you some of the advantages of direct access to a physical device as well as some of the management advantages of VMFS-based virtual disks. The components involved with an RDM are illustrated in Figure 2-2.
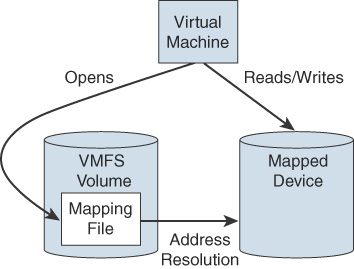
FIGURE 2-2 RDM Diagram
You can envision an RDM as a symbolic link from a VMFS volume to a storage device. The mapping makes the storage device appear as a file in a VMFS volume. The virtual machine configuration references the RDM, not the storage device. RDMs support two compatibility modes:
Virtual compatibility mode: The RDM acts much like a virtual disk file, enabling extra virtual disk features, such as the use of virtual machine snapshot and the use of disk modes (dependent, independent—persistent, and independent—nonpersistent).
Physical compatibility mode: The RDM offers direct access to the SCSI device, supporting applications that require lower-level control.
Virtual disk files are preferred over RDMs for manageability. You should only use RDMs when necessary. Use cases for RDMs include the following.
You plan to install in a virtual machine software that requires features inherent to the SAN, such as SAN management, storage-based snapshots, or storage-based replication. The RDM enables the virtual machine to have the required access to the storage device.
You plan to configure a Microsoft Custer Server (MSCS) clustering in a manner that spans physical hosts, such as virtual-to-virtual clusters and physical-to-virtual clusters. You should configure the data and quorum disks as RDMs rather than as virtual disk files.
Benefits of RDMs include the following:
User-friendly persistent names: Much as with naming a VMFS datastore, you can provide a friendly name to a mapped device rather than use its device name.
Dynamic name resolution: If physical changes (such as adapter hardware changes, path changes, or device relocation) occur, the RDM is updated automatically. The virtual machines do not need to be updated because they reference the RDM.
Distributed file locking: VMFS distributed locking is used to make it safe for two virtual machines on different servers to access the same LUN.
File permissions: Permissions are set on the mapping file to effectively apply permissions to the mapped file, much as they are applied to virtual disks.
File system operations: Most file system operations that are valid for an ordinary file can be applied to the mapping file and redirected to the mapped device.
Snapshots: Virtual machine snapshots can be applied to the mapped volume except when the RDM is used in physical compatibility mode.
vMotion: You can migrate the virtual machine with vMotion, as vCenter Server uses the RDM as a proxy, which enables the use of the same migration mechanism used for virtual disk files.
SAN management agents: RDM enables the use of SAN management agents (SCSI target-based software) inside a virtual machine. This requires hardware-specific SCSI commands as well as physical compatibility mode for the RDM.
N-Port ID Virtualization (NPIV): You can use NPIV technology, which allows a single Fibre Channel HBA port to register with the fabric by using multiple worldwide port names (WWPNs). This ability makes the HBA port appear as multiple virtual ports, each with its own ID and virtual port name. Virtual machines can claim each of these virtual ports and use them for all RDM traffic. NPIV requires the use of virtual machines with RDMs.
Note
To support vMotion involving RDMs, be sure to maintain consistent LUN IDs for RDMs across all participating ESXi hosts.
Note
To support vMotion for NPIV-enabled virtual machines, place the RDM files, virtual machine configuration file, and other virtual machines in the same datastore. You cannot perform Storage vMotion when NPIV is enabled.
Software-Defined Storage Models
In addition to abstracting underlying storage capacities from VMs, as traditional storage models do, software-defined storage abstracts storage capabilities. With software-defined storage, a virtual machine becomes a unit of storage provisioning and can be managed through a flexible policy-based mechanism. Software-defined storage involves the vSphere technologies described in the following sections.
vSAN
vSAN is a layer of distributed software that runs natively on each hypervisor in a cluster. It aggregates local or direct-attached capacity, creating a single storage pool shared across all hosts in the vSAN cluster.
vVols
Virtual volumes are encapsulations of virtual machine files, virtual disks, and their derivatives that are stored natively inside a storage system. You do not provision virtual volumes directly. Instead, they are automatically created when you create, clone, or snapshot a virtual machine. Each virtual machine can be associated to one or more virtual volumes.
The Virtual Volumes (vVols) functionality changes the storage management paradigm from managing space inside datastores to managing abstract storage objects handled by storage arrays. With vVols, each virtual machine (rather than a datastore) is a unit of storage management. You can apply storage policies per virtual machine rather than per LUN or datastore.
Storage Policy Based Management
Storage Policy Based Management (SPBM) is a framework that provides a single control panel across various data services and storage solutions, including vSAN and vVols. Using storage policies, the framework aligns application demands of virtual machines with capabilities provided by storage entities.
I/O Filters
I/O filters are software components that can be installed on ESXi hosts and can offer additional data services to virtual machines. Depending on the implementation, the services might include replication, encryption, caching, and so on.
Datastore Types
In vSphere 7.0, you can use the datastore types described in the following sections.
VMFS Datastore
You can create VMFS datastores on Fibre Channel, iSCSI, FCoE, and local storage devices. ESXi 7.0 supports VMFS Versions 5 and 6 for reading and writing. ESXi 7.0 does not support VMFS Version 3. Table 2-2 compares the features and functionalities of VMFS Versions 5 and 6.
Table 2-2 Comparison of VMFS Version 5 and Version 6
VMFS Features and Functionalities |
Version 5 |
Version 6 |
|---|---|---|
Access for ESXi hosts Version 6.5 and later |
Yes |
Yes |
Access for ESXi hosts Version 6.0 and earlier |
Yes |
No |
Datastores per host |
512 |
512 |
512n storage devices |
Yes |
Yes (default) |
512e storage devices |
Yes (Not supported on local 512e devices.) |
Yes (default) |
4Kn storage devices |
No |
Yes |
Automatic space reclamation |
No |
Yes |
Manual space reclamation through the esxcli command. |
Yes |
Yes |
Space reclamation from guest OS |
Limited |
Yes |
GPT storage device partitioning |
Yes |
Yes |
MBR storage device partitioning |
Yes For a VMFS5 datastore that has been previously upgraded from VMFS3. |
No |
Storage devices greater than 2 TB for each VMFS extent |
Yes |
Yes |
Support for virtual machines with large-capacity virtual disks, or disks greater than 2 TB |
Yes |
Yes |
Support of small files (1 KB) |
Yes |
Yes |
Default use of ATS-only locking mechanisms on storage devices that support ATS |
Yes |
Yes |
Block size |
Standard 1 MB |
Standard 1 MB |
Default snapshots |
VMFSsparse for virtual disks smaller than 2 TB SEsparse for virtual disks larger than 2 TB |
SEsparse |
Virtual disk emulation type |
512n |
512n |
vMotion |
Yes |
Yes |
Storage vMotion across different datastore types |
Yes |
Yes |
High Availability and Fault Tolerance |
Yes |
Yes |
DRS and Storage DRS |
Yes |
Yes |
RDM |
Yes |
Yes |
When working with VMFS datastores in vSphere 7.0, consider the following:
Datastore extents: A spanned VMFS datastore must use only homogeneous storage devices—either 512n, 512e, or 4Kn. The spanned datastore cannot extend over devices of different formats.
Block size: The block size on a VMFS datastore defines the maximum file size and the amount of space a file occupies. VMFS Version 5 and Version 6 data-stores support a 1 MB block size.
Storage vMotion: Storage vMotion supports migration across VMFS, vSAN, and vVols datastores. vCenter Server performs compatibility checks to validate Storage vMotion across different types of datastores.
Storage DRS: VMFS Version 5 and Version 6 can coexist in the same datastore cluster. However, all datastores in the cluster must use homogeneous storage devices. Do not mix devices of different formats within the same datastore cluster.
Device Partition Formats: Any new VMFS Version 5 or Version 6 datastore uses the GUID Partition Table (GPT) to format the storage device, which means you can create datastores larger than 2 TB. If your VMFS Version 5 datastore has been previously upgraded from VMFS Version 3, it continues to use the Master Boot Record (MBR) partition format, which is characteristic for VMFS Version 3. Conversion to GPT happens only after you expand the datastore to a size larger than 2 TB.
NFS
You can create NFS datastores on NAS devices. ESXi 7.0 supports NFS Versions 3 and 4.1. To support both versions, ESXi 7.0 uses two different NFS clients. Table 2-3 compares the capabilities of NFS Versions 3 and 4.1.
Table 2-3 Comparison of NFS Version 3 and Version 4.1 Characteristics
NFS Characteristics |
Version 3 |
Version 4.1 |
|---|---|---|
Security mechanisms |
AUTH_SYS |
AUTH_SYS and Kerberos (krb5 and krb5i) |
Encryption algorithms with Kerberos |
N/A |
AES256-CTS-HMAC-SHA1-96 AES128-CTS-HMAC-SHA1-96 |
Multipathing |
Not supported |
Supported through the session trunking |
Locking mechanisms |
Propriety client-side locking |
Server-side locking |
Hardware acceleration |
Supported |
Supported |
Thick virtual disks |
Supported |
Supported |
IPv6 |
Supported |
Supported for AUTH_SYS and Kerberos |
ISO images presented as CD-ROMs to virtual machines |
Supported |
Supported |
Virtual machine snapshots |
Supported |
Supported |
Virtual machines with virtual disks greater than 2 TB |
Supported |
Supported |
Table 2-4 compares vSphere 7.0 features and related solutions supported by NFS Versions 3 and 4.1.
Table 2-4 Comparison of NFS Version 3 and Version 4.1 Support for vSphere Features and Solutions
NFS Features and Functionalities |
Version 3 |
Version 4.1 |
|---|---|---|
vMotion and Storage vMotion |
Yes |
Yes |
High Availability (HA) |
Yes |
Yes |
Fault Tolerance (FT) |
Yes |
Yes (Supports the new FT mechanism introduced in vSphere 6.0 that supports up to four vCPUs, not the legacy FT mechanism.) |
Distributed Resource Scheduler (DRS) |
Yes |
Yes |
Host Profiles |
Yes |
Yes |
Storage DRS |
Yes |
No |
Storage I/O Control |
Yes |
No |
Site Recovery Manager |
Yes |
No |
Virtual Volumes |
Yes |
Yes |
vSphere Replication |
Yes |
Yes |
vRealize Operations Manager |
Yes |
Yes |
When you upgrade ESXi from a version earlier than 6.5, existing NFS Version 4.1 datastores automatically begin supporting functionalities that were not available in the previous ESXi release, such as vVols and hardware acceleration. ESXi does not support automatic datastore conversions from NFS Version 3 to NFS Version 4.1. You can use Storage vMotion to migrate virtual machines from NFS Version 3 datastores to NFS Version 4.1 datastores. In some cases, storage vendors provide conversion methods from NFS Version 3 to Version 4.1. In some cases, you may be able to unmount an NFS Version 3 datastore from all hosts and remount it as NFS Version 4.1. The datastore can never be mounted using both protocols at the same time.
vVols Datastores
You can create a vVols datastore in an environment with a compliant storage system. A virtual volume, which is created and manipulated out of band by a vSphere APIs for Storage Awareness (VASA) provider, represents a storage container in vSphere. The VASA provider maps virtual disk objects and their derivatives, such as clones, snapshots, and replicas, directly to the virtual volumes on the storage system. ESXi hosts access virtual volumes through an intermediate point in the data path called the protocol endpoint. Protocol endpoints serve as gateways for I/O between ESXi hosts and the storage system, using Fibre Channel, FCoE, iSCSI, or NFS.
vSAN Datastores
You can create a vSAN datastore in a vSAN cluster. vSAN is a hyperconverged storage solution, which combines storage, compute, and virtualization into a single physical server or cluster. The following section describes the concepts, benefits, and terminology associated with vSAN.
Storage in vSphere with Kubernetes
To support the different types of storage objects in Kubernetes, vSphere with Kubernetes provides three types of virtual disks: ephemeral, container image, and persistent volume.
A vSphere pod requires ephemeral storage to store Kubernetes objects, such as logs, emptyDir volumes, and ConfigMaps. The ephemeral, or transient, storage exists if the vSphere pod exists.
The vSphere pod mounts images used by its containers as image virtual disks, enabling the container to use the software contained in the images. When the vSphere pod life cycle completes, the image virtual disks are detached from the vSphere pod. You can specify a datastore to use as the container image cache, such that subsequent pods can pull it from the cache rather than from the external container registry.
Some Kubernetes workloads require persistent storage to store the data independently of the pod. Persistent volume objects in vSphere with Kubernetes are backed by the First Class Disks on a datastore. A First Class Disk (FCD), which is also called an Improved Virtual Disk, is a named virtual disk that is not associated with a VM. To provide persistent storage, you can use the Workload Management feature in the vSphere Client to associate one or more storage policies with the appropriate namespace.
VMware NVMe
NVMe storage is a low-latency, low-CPU-usage, and high-performance alternative to SCSI storage. It is designed for use with faster storage media equipped with non-volatile memory, such as flash devices. NVMe storage can be directly attached to a host using a PCIe interface or indirectly through different fabric transport (NVMe-oF).
In a NVMe storage array, a namespace represents a storage volume. An NVMe namespace is analogous to a storage device (LUN) in other storage arrays. In the vSphere Client, an NVMe namespace appears in the list of storage devices. You can use a device to create a VMFS datastore.
Requirements for NVMe over PCIe
NVMe over PCIe requires the following:
Local NVMe storage devices
Compatible ESXi host
Hardware NVMe over PCIe adapter
Requirements for NVMe over RDMA (RoCE Version 2)
NVMe over RDMA requires the following:
NVMe storage array with NVMe over RDMA (RoCE Version 2) transport support
Compatible ESXi host
Ethernet switches supporting a lossless network
Network adapter that supports RDMA over Converged Ethernet (RoCE Version 2)
Software NVMe over RDMA adapter
NVMe controller
Requirements for NVMe over Fibre Channel
NVMe over Fibre Channel requires the following:
Fibre Channel storage array that supports NVMe
Compatible ESXi host
Hardware NVMe adapter (that is, a Fibre Channel HBA that supports NVMe)
NVMe controller
VMware High-Performance Plug-in (HPP)
VMware provides the High-Performance Plug-in (HPP) to improve the performance of NVMe devices on an ESXi host. HPP replaces NMP for high-speed devices, such as NVMe.
HPP is the default plug-in that claims NVMe-oF targets. In ESXi, the NVMe-oF targets are emulated and presented to users as SCSI targets. The HPP supports only active/active and implicit ALUA targets.
NMP is the default plug-in for local NVMe devices, but you can replace it with HPP. NMP cannot be used to claim the NVMe-oF targets. HPP should be used for NVMe-oF.
Table 2-5 describes vSphere 7.0 support for HPP.
Table 2-5 vSphere 7.0 HPP Support
HPP Support |
vSphere 7.0 |
|---|---|
Storage devices |
Local NVMe PCIe Shared NVMe-oF (active/active and implicit ALUA targets only) |
Multipathing |
Yes |
Second-level plug-ins |
No |
SCSI-3 persistent reservations |
No |
4Kn devices with software emulation |
No |
vSAN |
No |
Table 2-6 describes the path selection schemes (PSS) HPP uses when selecting physical paths for I/O requests.
Table 2-6 HPP Path Selection Schemes
PSS |
Description |
|---|---|
FIXED |
A designated preferred path is used for I/O requests. |
LB-RR (Load Balance—Round Robin) |
After transferring a specified number of bytes or I/Os on a current path, the scheme selects the path using the round robin algorithm. You can configure the IOPS and Bytes properties to indicate the criteria for path switching. (This is the default HPP scheme.) |
LB-IOPS (Load Balance—IOPS) |
After transferring a specified number of I/Os on a current path (1000 by default), the scheme selects an optimal path based on the least number of outstanding bytes. |
LB-BYTES (Load Balance—Bytes) |
After transferring a specified amount of data on a current path (10 MB by default), the scheme selects an optimal path based on the least number of outstanding I/Os. |
LB-Latency (Load Balance—Latency) |
The scheme selects an optimal path by considering the latency evaluation time and the sampling I/Os per path. |
HPP best practices include the following:
Use a vSphere version that supports HPP.
Use HPP for NVMe local and networked devices.
Do not use HPP with HDDs or any flash devices that cannot sustain 200,000 IOPS.
If you use NVMe with Fibre Channel devices, follow your vendor’s recommendations.
If you use NVMe-oF, do not mix transport types to access the same namespace.
When using NVMe-oF namespaces, make sure that active paths are presented to the host.
Configure VMs to use VMware Paravirtual controllers.
Set the latency sensitive threshold for virtual machines.
If a single VM drives a significant share of a device’s I/O workload, consider spreading the I/O across multiple virtual disks, attached to separate virtual controllers in the VM. Otherwise, you risk the I/O saturating a CPU core.
vSAN Concepts
vSAN virtualizes the local physical storage resources of ESXi hosts by turning them into pools of storage that can be used by virtual machines, based on their quality of service requirements. You can configure vSAN as a hybrid or an all-flash cluster. Hybrid clusters use flash devices for the cache layer and magnetic disks for the storage capacity layer. All-flash clusters use flash devices for both cache and capacity.
You can enable vSAN on existing host clusters as well as on new clusters. You can expand a datastore by adding to the cluster hosts with capacity devices or by adding local drives to the existing hosts in the cluster. vSAN works best when all ESXi hosts in the cluster are configured similarly, including similar or identical storage configurations. A consistent configuration enables vSAN to balance virtual machine storage components across all devices and hosts in the cluster. Hosts without any local devices can also participate and run their virtual machines on the vSAN datastore.
If a host contributes some of its local storage to a VSAN cluster, then it must contribute at least one device for cache. The drives contributed by a host form one or more disk groups. Each disk group contains a flash cache device and at least one capacity device. Each host can be configured to use multiple disk groups.
vSAN offers many features of a traditional SAN. Its main limitations are that each vSAN instance can support only one cluster. vSAN has the following benefits over traditional storage:
vSAN does not require a dedicated storage network, such as on a FC network or SAN.
With vSAN, you do not have to pre-allocate and preconfigure storage volumes (LUNs).
vSAN does not behave like traditional storage volumes based on LUNs or NFS shares. You do not have to apply standard storage protocols, such as FC, and you do not need to format the storage directly.
You can deploy, manage, and monitor vSAN by using the vSphere Client rather than other storage management tools.
A vSphere administrator, rather than a storage administrator, can manage a vSAN environment.
When deploying virtual machines, you can use automatically assigned storage policies with vSAN.
vSAN Characteristics
vSAN is like network-distributed RAID for local disks, transforming them into shared storage. vSAN uses copies of VM data, where one copy is local and another copy is on one of the other nodes in the cluster. The number of copies is configurable. Here are some of the features of vSAN:
Shared storage support: VMware features that require shared storage (that is, HA, vMotion, DRS) are available with vSAN.
On-disk format: Highly scalable snapshot and clone management are possible on a vSAN cluster.
All-flash and hybrid configurations: vSAN can be used on hosts with all-flash storage or with hybrid storage (that is, a combination of SSDs and traditional HDDs).
Fault domains: Fault domains can be configured to protect against rack or chassis failures, preventing all copies of VM disk data from residing on the same rack or chassis.
iSCSI target service: The vSAN datastore can be visible to and usable by ESXi hosts outside the cluster and by physical bare-metal systems.
Stretched cluster: vSAN supports stretching a cluster across physical geographic locations.
Support for Windows Server failover clusters (WSFCs): SCSI-3 Persistent Reservations (SCSI3-PR) is supported on virtual disks, which are required for shared disks and WSFCs. Microsoft SQL 2012 or later is supported on vSAN. The following limitations apply:
Maximum of 6 application nodes in each vSAN cluster
Maximum of 64 shared disks per ESXi host
vSAN health service: This service includes health checks for monitoring and troubleshooting purposes.
vSAN performance service: This service includes statistics for monitoring vSAN performance metrics. This can occur at the level of the cluster, ESXi host, disk group, disk, or VM.
Integration with vSphere storage features: Snapshots, linked clones, and vSphere Replication are all supported on vSAN datastores.
Virtual machine storage policies: Policies can be defined for VMs on vSAN. If no policies are defined, a default vSAN policy is applied.
Rapid provisioning: vSAN enables fast storage provisioning for VM creation and deployment from templates.
Deduplication and compression: Block-level deduplication and compression are available space-saving mechanisms on vSAN, and they can be configured at the cluster level and applied to each disk group.
Data at rest encryption: Data at rest encryption is encryption of data that is not in transit and on which no processes are being done (for example, deduplication or compression). If drives are removed, the data on those drives is encrypted.
SDK support: vSAN supports an extension (written in Java) of the VMware vSphere Management SDK. It has libraries, code examples, and documentation for assistance in automating and troubleshooting vSAN deployments.
vSAN Terminology
Be sure to know the following terminology for the Professional VMware vSphere 7.x (2V0-21.20) exam:
Disk group: A disk group is a group of local disks on an ESXi host contributing to the vSAN datastore. It must include one cache device and one capacity device. In a hybrid cluster, a flash disk is the cache device, and magnetic disks are used for capacity devices. In all-flash clusters, flash storage is used for both cache and capacity.
Consumed capacity: This is the amount of physical space used up by virtual machines at any point in time.
Object-based storage: Data is stored in vSAN by way of objects, which are flexible data containers. Objects are logical volumes with data and metadata spread among nodes in the cluster. Virtual disks are objects, as are snapshots. For object creation and placement, vSAN takes the following into account:
Virtual disk policy and requirements are verified.
The number of copies (replicas) is verified; the amount of flash read cache allocated for replicas, number of stripes for replica, and location are determined.
Policy compliance of virtual disks is ensured.
Mirrors and witnesses are placed on different hosts or fault domains.
vSAN datastores: Like other datastores, a vSAN datastore appears in the Storage Inventory view in vSphere. A vSAN cluster provides a single datastore for all the hosts in the cluster, even for hosts that do not contribute storage to vSAN. An ESXi host can mount VMFS and NFS datastores in addition to the vSAN datastore. Storage vMotion can be used to migrate VMs between datastore types.
Objects and components: vSAN includes the following objects and components:
VM home namespace: The VM home directory where all the VM files are stored
VMDK: Virtual disks for VMs
VM swap object: An object that allows memory to be swapped to disk during periods of contention and that is created at VM power on
Snapshot delta VMDKs: Change files created when a snapshot is taken of a VM
Memory object: An object created when a VM is snapshotted (and the VM’s memory is retained) or suspended
Virtual machine compliance status: Can be Compliant and Noncompliant, depending on whether each of the virtual machine’s objects meets the requirements of the assigned storage policy. The status is available on the Virtual Disks page on the Physical Disk Placement tab.
Component state: vSAN has two component states:
Degraded: vSAN detects a permanent failure of a component.
Absent: vSAN detects a temporary component failure.
Object state: vSAN has two object states:
Healthy: At least one RAID 1 mirror is available, or enough segments are available for RAID 5 or 6.
Unhealthy: No full mirror is available, or not enough segments are available for RAID 5 or 6.
Witness: This is a component consisting of only metadata. It is used as a tiebreaker. Witnesses consume about 2 MB of space for metadata on a vSAN datastore when on-disk format Version 1.0 is used and 4 MB when on-disk format Version 2.0 or later is used.
Storage Policy Based Management (SPBM): VM storage requirements are defined as a policy, and vSAN ensures that these policies are met when placing objects. If you do not apply a storage policy when creating or deploying VMs, the default vSAN policy is used, with Primary Level of Failures to Tolerate set to 1, a single stripe per object, and a thin provisioned disk.
Ruby vSphere Console (RVC): This is a command-line interface used for managing and troubleshooting vSAN. RVC provides a cluster-wide view and is included with a vCenter Server deployment.
VMware PowerCLI: vSAN cmdlets are included with PowerCLI to allow administration of vSAN.
vSAN Observer: This is a web-based utility, built on top of RVC, used for performance analysis and monitoring. It can display performance statistics on the capacity tier, disk group statistics, CPU load, memory consumption, and vSAN objects in-memory and their distribution across the cluster.
vSAN Ready Node: This preconfigured deployment is provided by VMware partners. It is a validated design using certified hardware.
User-defined vSAN cluster: This vSAN deployment makes use of hardware selected by you.
Note
The capacity disks contribute to the advertised datastore capacity. The flash cache devices are not included as capacity.
What Is New in vSAN 7.0
The following new features are available in vSAN 7.0:
vSphere Lifecycle Manager: vSphere Lifecycle Manager uses a desired-state model to enable simple, consistent lifecycle management for ESXi hosts, including drivers and firmware.
Integrated file services: The native vSAN File Services enables you to create and present NFS Version 4.1 and Version 3 file shares, effectively extending vSAN capabilities such as availability, security, storage efficiency, and operations management to files.
Native support for NVMe Hot-Plug: The Hot-Plug plug-in provides a consistent way of servicing NVMe devices and provides operational efficiency.
I/O redirect based on capacity imbalance with stretched clusters: This feature improves VM uptime by redirecting all virtual machine I/O from a capacity-strained site to the other site.
Skyline integration with vSphere Health and vSAN Health: Skyline Health for vSphere and vSAN are available, enabling native, in-product health monitoring and consistent, proactive analysis.
Removal of EZT for shared disk: vSAN 7.0 eliminates the prerequisite that shared virtual disks using the multi-writer flag must also use the eager zero thick format.
Support for vSAN memory as a metric in performance service: vSAN memory usage is now available in Performance Charts (vSphere Client) and through the API.
Visibility of vSphere Replication objects: vSphere Replication objects are visible in vSAN capacity view.
Support for large-capacity drives: vSAN provides support for 32 TB physical capacity drives and up to 1 PB logical capacity when deduplication and compression are enabled.
Immediate repair after new witness is deployed: vSAN immediately invokes a repair object operation after a witness has been added during a replace witness operation.
vSphere with Kubernetes integration: Cloud Native Storage (CNS) is the default storage platform for vSphere with Kubernetes. This integration enables various stateful containerized workloads to be deployed on vSphere with Kubernetes Supervisor and Guest clusters on vSAN, VMFS, and NFS datastores.
File-based persistent volumes: Kubernetes developers can dynamically create shared (read/write/many) persistent volumes for applications. Multiple pods can share data. The native vSAN File Services is the foundation that enables this capability.
vVols support for modern applications: You can deploy modern Kubernetes applications to external storage arrays on vSphere using the CNS support added for vVols. vSphere now enables unified management for persistent volumes across vSAN, NFS, VMFS, and vVols.
vSAN VCG notification service: You can get notified through email about any changes to vSAN HCL components, such as vSAN ReadyNode, I/O controller, and drives (NVMe, SSD, HDD), and get notified through email about any changes.
Note
In vCenter Server 7.0.0a, vSAN File Services and vSphere Lifecycle Manager can be enabled simultaneously on the same vSAN cluster.
vSAN Deployment Options
When deploying vSAN, you have several options for the cluster topology, as described in the following sections.
Standard Cluster
A standard vSAN cluster, as illustrated in Figure 2-3, consists of a minimum of three hosts, typically residing at the same location and connected on the same Layer 2 network. 10 Gbps network connections are required for all-flash clusters and are recommended for hybrid configurations.
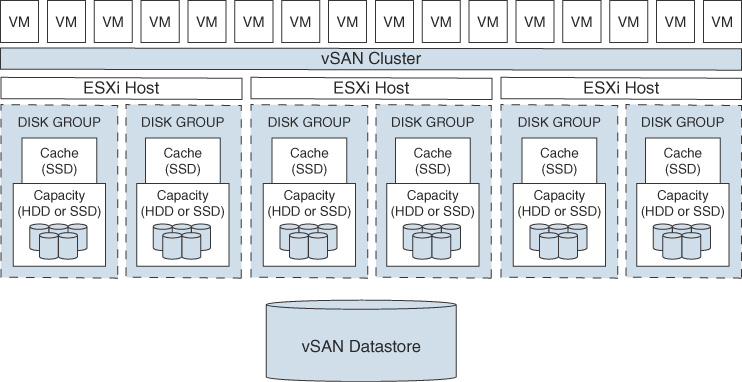
FIGURE 2-3 A Standard vSAN Cluster
Two-Host vSAN Cluster
The main use case for a two-host vSAN cluster is in a remote office/branch office environment, where workloads require high availability. A two-host vSAN cluster, as illustrated in Figure 2-4, consists of two hosts at the same location, connected to the same network switch or directly connected to one another. You can configure a two-host vSAN cluster that uses a third host as a witness, and the witness can be located separately from the remote office. Usually the witness resides at the main site, along with vCenter Server. For more details on the witness host, see the following section.
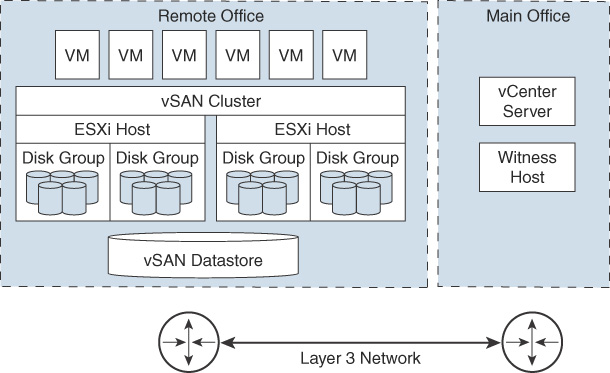
FIGURE 2-4 A Two-Node vSAN Cluster
Stretched Cluster
You can create a stretched vSAN cluster that spans two geographic sites and continues to function if a failure or scheduled maintenance occurs at one site. Stretched clusters, which are typically deployed in metropolitan or campus environments with short distances between sites, provide a higher level of availability and inter-site load balancing.
You can use stretched clusters for planned maintenance and disaster avoidance scenarios, with both data sites active. If either site fails, vSAN uses the storage on the other site, and vSphere HA can restart virtual machines on the remaining active site.
You should designate one site as the preferred site; it then becomes the only used site in the event that network connectivity is lost between the two sites. A vSAN stretched cluster can tolerate one link failure at a time without data becoming unavailable. During a site failure or loss of network connection, vSAN automatically switches to fully functional sites.
Note
A link failure is a loss of network connection between two sites or between one site and the witness host.
Each stretched cluster consists of two data sites and one witness host. The witness host resides at a third site and contains the witness components of virtual machine objects. It contains only metadata and does not participate in storage operations. Figure 2-5 shows an example of a stretched cluster, where the witness node resides at a third site, along with vCenter Server.
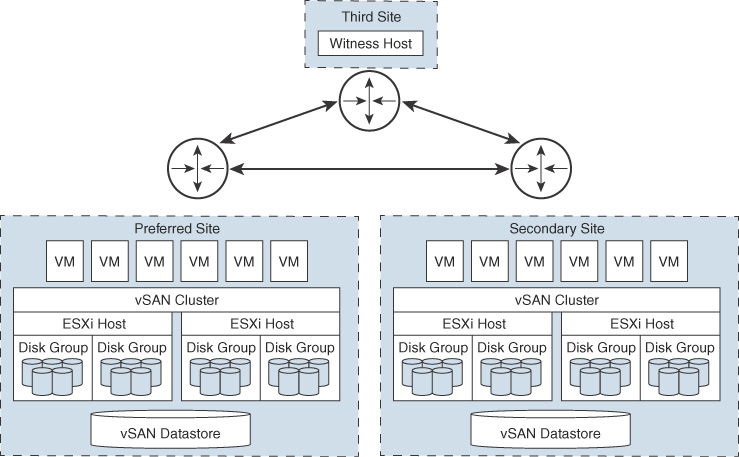
FIGURE 2-5 A Stretched vSAN Cluster
The witness host acts as a tiebreaker for decisions regarding availability of datastore components. The witness host typically forms a vSAN cluster with the preferred site but forms a cluster with secondary site if the preferred site becomes isolated. When the preferred site is online again, data is resynchronized.
A witness host has the following characteristics:
It can use low-bandwidth/high-latency links.
It cannot run VMs.
It can support only one vSAN stretched cluster.
It requires a VMkernel adapter enabled for vSAN traffic with connections to all hosts in the cluster. It can have only one VMkernel adapter dedicated to vSAN but can have another for management.
It must be a standalone host. It cannot be added to any other cluster or moved in inventory through vCenter Server.
It can be a physical ESXi host or a VM-based ESXi host.
Note
The witness virtual appliance is an ESXi host in a VM, packaged as an OVF or OVA, which is available in different options, depending on the size of the deployment.
Each site in a stretched cluster resides in a separate fault domain. Three default domains are used: the preferred site, the secondary site, and a witness host.
Beginning with vSAN Version 6.6, you can provide an extra level of local fault protection for objects in stretched clusters by using the following policy rules:
Primary Level of Failures to Tolerate (PFTT): This defines the number of site failures that a virtual machine object can tolerate. For a stretched cluster, only a value of 0 or 1 is supported.
Secondary Level of Failures to Tolerate (SFTT): This defines the number of additional host failures that the object can tolerate after the number of site failures (PFTT) is reached. For example, if PFTT = 1 and SFTT = 2, and one site is unavailable, then the cluster can tolerate two additional host failures. The default value is 0, and the maximum value is 3.
Data Locality: This enables you to restrict virtual machine objects to a selected site in the stretched cluster. The default value is None, but you can change it to Preferred or Secondary. Data Locality is available only if PFTT = 0.
Note
If you set SFTT for a stretched cluster, the Fault Tolerance Method rule applies to the SFTT. The failure tolerance method used for the PFTT is set to RAID 1.
Consider the following guidelines and best practices for stretched clusters:
DRS must be enabled on a stretched cluster.
You need to create two host groups, two virtual machines groups, and two VM-Host affinity rules to effectively control the placement of virtual machines between the preferred and secondary sites.
HA must be enabled on the cluster in a manner such that it respects the VM-Host affinity rules.
You need to disable HA datastore heartbeats.
On-disk format Version 2.0 or later is required.
You need to set Failures to Tolerate to 1.
Symmetric Multiprocessing Fault Tolerance (SMP-FT) is supported when PFFT is set to 0 and Data Locality is set to Preferred or Secondary. SMP-FT is not supported if PFFT is set to 1.
Using esxcli to add or remove hosts is not supported.
If one of the three fault domains (preferred site, secondary site, or witness host) is inaccessible, new VMs can still be provisioned, but they are noncompliant until the partitioned site rejoins the cluster. This implicit forced provisioning is performed only when two of the three fault domains are available.
If an entire site goes offline due to loss of power or network connection, you need to restart the site immediately. Bring all hosts online at approximately the same time to avoid resynchronizing a large amount of data across the sites.
If a host is permanently unavailable, you need to remove the host from the cluster before performing any reconfiguration tasks.
To deploy witnesses for multiple clusters, you should not clone a virtual machine that is already configured as a witness. Instead, you can first deploy a VM from OVF, then clone the VM, and then configure each clone as a witness host for a different cluster.
The stretched cluster network must meet the following requirements:
The management network requires connectivity across all three sites, using a Layer 2 stretched network or a Layer 3 network.
The vSAN network requires connectivity across all three sites, using a Layer 2 stretched network between the two data sites and a Layer 3 network between the data sites and the witness host.
The virtual machine network requires connectivity between the data sites but not the witness host. You can use a Layer 2 stretched network or Layer 3 network between the data sites. Virtual machines do not require a new IP address following failover to the other site.
The vMotion network requires connectivity between the data sites but not the witness host. You can use a Layer 2 stretched or a Layer 3 network between data sites.
vSAN Limitations
Limitations of vSAN include the following.
No support for hosts participating in multiple vSAN clusters
No support for vSphere DPM and storage I/O control
No support for SE sparse disks
No support for RDM, VMFS, diagnostic partition, and other device access features
vSAN Space Efficiency
You can use space efficiency techniques in vSAN to reduce the amount of space used for storing data. These techniques include the use of any or all of the following:
Thin provisioning: Consuming only the space on disk that is used (and not the total allocated virtual disk space)
Deduplication: Reducing duplicated data blocks by using SHA-1 hashes for data blocks
Compression: Compressing data using LZ4, which is a lightweight compression mechanism.
Erasure coding: Creating a strip of data blocks with a parity block (This is similar to parity with RAID configurations, except it spans ESXi hosts in the cluster instead of disks in the host.)
SCSI UNMAP
SCSI UNMAP commands, which are supported in vSAN Version 6.7 Update 1 and later, enable you to reclaim storage space that is mapped to deleted vSAN objects. vSAN supports the SCSI UNMAP commands issued in a guest operating system to reclaim storage space. vSAN supports offline unmaps as well as inline unmaps. On Linux, offline unmaps are performed with the fstrim(8) command, and inline unmaps are performed when the mount -o discard command is used. On Windows, NTFS performs inline unmaps by default.
Deduplication and Compression
All-flash vSAN clusters support deduplication and compression. Deduplication removes redundant data blocks. Compression removes additional redundant data within each data block. Together, these techniques reduce the amount of space required to store data. As vSAN moves data from the cache tier to the capacity tier, it applies deduplication and then applies compression.
You can enable deduplication and compression as a cluster-wide setting, but they are applied on a disk group basis, and redundant data is reduced within each disk group.
When you enable or disable deduplication and compression, vSAN performs a rolling reformat of every disk group on every host, and this may take a long time. You should verify that enough physical capacity is available to place your data. You should also minimize how frequently these operations are performed.
Note
Deduplication and compression might not be effective for encrypted VMs.
The amount of storage reduction achieved through deduplication and compression depends on many factors, such as the type of data stored and the number of duplicate blocks. Larger disk groups tend to provide a higher deduplication ratio.
RAID 5 and RAID 6 Erasure Coding
In a vSAN cluster, you can use RAID 5 or RAID 6 erasure coding to protect against data loss while increasing storage efficiency compared with RAID 1 (mirroring). You can configure RAID 5 on all-flash clusters with four or more fault domains. You can configure RAID 5 or RAID 6 on all-flash clusters with six or more fault domains.
RAID 5 or RAID 6 erasure coding requires less storage space to protect your data than RAID 1 mirroring. For example, if you protect a VM by setting Primary Level of Failures to Tolerate (PFTT) to 1, RAID 1 requires twice the virtual disk size, and RAID 5 requires 1.33 times the virtual disk size. Table 2-7 compares RAID 1 with RAID 5/6 for a 100 GB virtual disk.
Table 2-7 RAID Configuration Comparison
RAID Configuration |
PFTT |
Data Size |
Required Capacity |
Usable Capacity |
|---|---|---|---|---|
RAID 1 (mirroring) |
1 |
100 GB |
200 GB |
50% |
RAID 5 or RAID 6 (erasure coding) with four fault domains |
1 |
100 GB |
133 GB |
75% |
RAID 1 (mirroring) |
2 |
100 GB |
300 GB |
33% |
RAID 5 or RAID 6 (erasure coding) with six fault domains |
2 |
100 GB |
150 GB |
67% |
RAID 1 (mirroring) |
3 |
100 GB |
400 GB |
25% |
RAID 5 or RAID 6 (erasure coding) with six fault domains |
3 |
N/A |
N/A |
N/A |
Before configuring RAID 5 or RAID 6 erasure coding in a vSAN cluster, you should consider the following:
All-flash disk groups are required.
On-disk format Version 3.0 or later is required.
A valid license supporting RAID 5/6 is required.
You can enable deduplication and compression on the vSAN cluster to achieve additional space savings.
PFTT must be set to less than 3.
vSAN Encryption
You can use data at rest encryption in a vSAN cluster, where all data is encrypted after all other processing, such as deduplication, is performed. All files are encrypted, so all virtual machines and their data are protected. Only administrators with encryption privileges can perform encryption and decryption tasks. Data at rest encryption protects data on storage devices in the event that a device is removed from the cluster.
vSAN encryption requires an external key management server (KMS), the vCenter Server system, and ESXi hosts. vCenter Server requests encryption keys from an external KMS. The KMS generates and stores the keys, and vCenter Server obtains the key IDs from the KMS and distributes them to the ESXi hosts. vCenter Server does not store the KMS keys but keeps a list of key IDs.
vSAN uses encryption keys in the following manner:
vCenter Server requests an AES-256 key encryption key (KEK) from the KMS.
vCenter Server stores only the ID of the KEK (not the key itself.)
The host encrypts disk data using the industry-standard AES-256 XTS mode.
Each disk has a unique, randomly generated data encryption key (DEK).
A host key is used to encrypt core dumps, not data. All hosts in the same cluster use the same host key.
When collecting support bundles, a random key is generated to re-encrypt the core dumps. You can specify a password to encrypt the random key.
Note
Each ESXi host uses the KEK to encrypt its DEKs and stores the encrypted DEKs on disk. The host does not store the KEK on disk. If a host reboots, it requests the KEK with the corresponding ID from the KMS. The host can then decrypt its DEKs as needed.
vSAN File Services
You can use vSAN File Services to provide vSAN-backed file shares that virtual machines can access as NFS Version 3 and NFS Version 4.1 file shares. It uses vSAN Distributed File System (vDFS), resilient file server endpoints, and a control plane, as illustrated in Figure 2-6. File shares are integrated into the existing vSAN Storage Policy Based Management and on a per-share basis. vSAN File Services creates a single vDFS for the cluster and places a file service virtual machine (FSVM) on each host. The FSVMs manage file shares and act as NFS file servers using IP addresses from a static IP address pool.
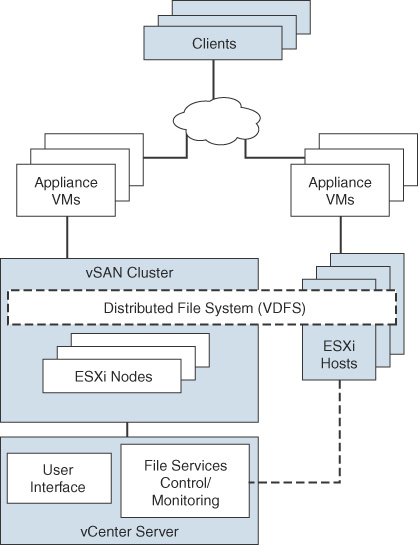
FIGURE 2-6 vSAN File Services Architecture
The vSAN File Services is not supported on a vSAN stretched cluster.
vSAN Requirements
Prior to deploying a vSAN cluster, you should address the requirements outlined in the following sections.
vSAN Planning and Sizing
When you plan the capacity for a vSAN datastore, you should consider the PFTT and the failure tolerance method, as illustrated previously in Table 2-7. For RAID 1, the required data store capacity can be calculated using the following formula:
Capacity = Expected Consumption Size × (PFTT +1)
For example, say that you plan to use RAID 1 for a 500 GB virtual disk that you expect to be completely filled. In this case, the required capacities are 1000 GB, 1500 GB, and 2000 GB for PFTT set to 1, 2, and 3, respectively.
Keep in mind the following guidelines for vSAN capacity sizing:
Plan for some extra overhead, as it may be required, depending on the on-disk format version. Version 1.0 adds approximately 1 GB overhead per capacity device. Versions 2.0 and 3.0 adds up to 2% overhead per capacity device. Version 3.0 adds 6.2% overhead for deduplication and compression checksums.
Keep at least 30% unused space to avoid vSAN rebalancing.
Plan for spare capacity to handle potential failure or replacement of capacity devices, disk groups, and hosts.
Reserve spare capacity to rebuild after a host failure or during maintenance. For example, with PFTT set to 1, at least four hosts should be placed in the cluster because at least three available hosts are required to rebuild components.
Provide enough spare capacity to make it possible to dynamically change a VM storage policy, which may require vSAN to create a new RAID tree layout for the object and temporarily consume extra space.
Plan for the space consumed by snapshots, which inherit the storage policy applied to the virtual disk.
Plan for space consumed by the VM home namespace, which includes the virtual machine’s swap file (in vSAN Version 6.7 and later).
When selecting devices to use for vSAN cache hardware (such as PCIe vs. SDD flash devices), in addition to cost, compatibility, performance, and capacity, you should consider write endurance.
When selecting storage controllers for use in a vSAN cluster, in addition to compatibility, you should favor adapters with higher queue depth to facilitate vSAN rebuilding operations. You should configure controllers for passthrough mode rather than RAID 0 mode to simplify configuration and maintenance. You should disable caching on the controller or set it to 100% read.
When sizing hosts, consider using at least 32 GB memory for full vSAN operations based on five disk groups per host and seven capacity devices per disk group.
Fault Domain Planning
If you span your vSAN cluster across multiple racks or blade server chassis, you can configure fault domains to protect against failure of a rack or chassis. A fault domain consists of one or more vSAN cluster member hosts sharing some physical characteristic, such as being in the same rack or chassis. For example, you can configure a fault domain to enable a vSAN cluster to tolerate the failure of an entire physical rack as well as the failure of a single host or other component (capacity devices, network link, or network switch) associated with the rack. When a virtual machine is configured with Primary Level of Failures to Tolerate set to 1 (PFTT=1), vSAN can tolerate a single failure of any kind and of any component in a fault domain, including the failure of an entire rack.
When you provision a new virtual machine, vSAN ensures that protection objects, such as replicas and witnesses, are placed in different fault domains. If you set a virtual machine’s storage policy to PFTT = n, vSAN requires a minimum of 2 × n + 1 fault domains in the cluster. A minimum of three fault domains are required to support PFTT = 1.
It is best to configure four or more fault domains in a cluster where PFTT=1 is used. A cluster with three fault domains has the same restrictions as a three-host cluster, such as the inability to again protect data after a failure and the inability to use the Full Data Migration Mode.
Say that you have a vSAN cluster where you plan to place four hosts per rack. In order to tolerate an entire rack failure, you need to create a fault domain for each rack. To support PFTT=1, you need to use a minimum of 12 hosts deployed to 3 racks. To support Full Data Migration Mode and the ability to again protect after a failure, deploy a minimum of 16 hosts to 4 racks. If you want Primary Level of Failures to Tolerate set to 2, you need to configure 5 fault domains in the cluster.
When working with fault domains, you should consider the following best practices:
At a minimum, configure three fault domains in a vSAN cluster. For best results, configure four or more fault domains.
Each host that is not directly added to a fault domain should reside in its own single-host fault domain.
You can add any number of hosts to a fault domain. Each fault domain must contain at least one host.
If you use fault domains, consider creating equal-sized fault domains (with the same number of same-sized hosts).
Hardware Requirements
You should examine the vSAN section of the VMware Compatibility Guide to verify that all the storage devices, drivers, and firmware versions are certified for the specific vSAN version you plan to use. Table 2-8 lists some of the vSAN storage device requirements.
Table 2-8 vSAN Storage Device Requirements
Component |
Requirements |
|---|---|
Cache |
One SAS or SATA SSD or PCIe flash device is required. For a hybrid disk group, the cache device must provide at least 10% of the anticipated storage consumed on the capacity devices in a disk group, excluding replicas. The flash devices used for vSAN cache must be dedicated. They cannot be used for vSphere Flash Cache or for VMFS. |
Capacity (virtual machine) storage |
For a hybrid disk group, at least one SAS or NL-SAS magnetic disk needs to be available. For an all-flash disk group, at least one SAS or SATA SSD or at least one PCIe flash device needs to be available. |
Storage controllers |
One SAS or SATA host bus adapter (HBA) or a RAID controller that is in passthrough mode or RAID 0 mode is required. If the same storage controller is backing both vSAN and non-vSAN disks, you should apply the following VMware recommendations to avoid issues:
|
The memory requirements for vSAN depend on the number of disk groups and devices that the ESXi hypervisor must manage. According to VMware Knowledge Base (KB) article 2113954, the following formula can be used to calculate vSAN memory consumption:
vSANFootprint = HOST_FOOTPRINT + NumDiskGroups × DiskGroupFootprint
where:
DiskGroupFootprint = DISKGROUP_FIXED_FOOTPRINT + DISKGROUP_SCALABLE_FOOTPRINT + CacheSize × CACHE_DISK_FOOTPRINT + NumCapacityDisks × CAPACITY_DISK_FOOTPRINT
The ESXi Installer creates a coredump partition on the boot device, whose default size is typically adequate. If ESXi host memory is 512 GB or less, you can boot the host from a USB, SD, or SATADOM device. When you boot a vSAN host from a USB device or SD card, the size of the boot device must be at least 4 GB. If ESXi host memory is more than 512 GB, consider the following guidelines:
You can boot the host from a SATADOM or disk device with a size of at least 16 GB. When you use a SATADOM device, use a single-level cell (SLC) device.
If you are using vSAN 6.5 or later, you must resize the coredump partition on ESXi hosts to boot from USB/SD devices.
Consider using at least 32 GB memory per host for full vSAN operations based on five disk groups per host and seven capacity devices per disk group. Plan for 10% CPU overhead for vSAN.
Cluster Requirements
You should verify that a host cluster contains a minimum of three hosts that contribute capacity to the cluster. A two-host vSAN cluster consists of two data hosts and an external witness host. It is important to ensure that each host that resides in a vSAN cluster does not participate in other clusters.
Software Requirements
For full vSAN capabilities, the participating hosts must be version 6.7 Update 3 or later. vSAN 6.7.3 and later software supports all on-disk formats.
Network Requirements
You should ensure that the network infrastructure and configuration support vSAN as described in Table 2-9.
Table 2-9 vSAN Networking Requirements
Component |
Requirement |
|---|---|
Host bandwidth |
For hybrid configuration, each host requires 1 Gbps (dedicated). For all-flash configuration, each host requires 10 Gbps (dedicated or shared). |
Host network |
Each vSAN cluster member host cluster (even those that do not contribute capacity) must have a vSAN-enabled VMkernel network adapter connected to a Layer 2 or Layer 3 network. |
IP version |
vSAN supports IPv4 and IPv6. |
Network latency |
Maximum round trip time (RTT) between all the member hosts in a standard vSAN clusters is 1 ms. Maximum RTT between the two main sites in a stretched vSAN cluster is 5 ms. Maximum RTT between each main site and the witness host in a stretched cluster is 200 ms. |
License Requirements
You should ensure that you have a valid vSAN license that supports your required features. If you do not need advanced or enterprise features, a standard license is sufficient. An advanced (or enterprise) license is required for advanced features such as RAID 5/6 erasure coding, deduplication, and compression. An enterprise license is required for enterprise features such as encryption and stretched clusters.
The capacity of the license must cover the total number of CPUs in the cluster.
Other vSAN Considerations
The following sections outline some other considerations that are important in planning a vSAN deployment.
vSAN Network Best Practices
Consider the following networking best practices concerning vSAN:
For hybrid configurations, use dedicated network adapters (at least 1 Gbps). For best performance, use dedicated or shared 10 Gbps adapters.
For all-flash configurations, use a dedicated or shared 10 GbE physical network adapter.
Provision one additional physical NIC as a failover NIC.
If you use a shared 10 GbE network adapter, place the vSAN traffic on a distributed switch with Network I/O Control (NIOC) configured.
Boot Devices and vSAN
You can boot ESXi from a local VMFS on a disk that is not associated with vSAN.
You can boot a vSAN host from a USB/SD device, but you must use a high-quality 4 GB or larger USB or SD flash drive. If the ESXi host memory is larger than 512 GB, for vSAN 6.5 or later, you must resize the coredump partition on ESXi hosts to boot from USB/SD devices.
You can boot a vSAN host from a SATADOM device, but you must use a 16 GB or larger single-level cell (SLC) device.
Persistent Logging in a vSAN Cluster
When you boot ESXi from a USB or SD device, log information and stack traces are lost on host reboot because the scratch partition is on a RAM drive. You should consider using persistent storage other than vSAN for logs, stack traces, and memory dumps. You could use VMFS or NFS or you could configure the ESXi Dump Collector and vSphere Syslog Collector to send system logs to vCenter Server.
vSAN Policies
Storage policies are used in vSAN to define storage requirements for virtual machines. These policies determine how to provision and allocate storage objects within the datastore to guarantee the required level of service. You should assign at least one storage policy to each virtual machine in a vSAN datastore. Otherwise, vSAN assigns a default policy with Primary Level of Failures to Tolerate set to 1, a single disk stripe per object, and a thin-provisioned virtual disks.
Storage policies, including those specific to vSAN, are covered later in this chapter.
vSphere Storage Integration
In a vSphere 7.0 environment, you have several options for integrating with supported storage solutions, including Virtual Volumes (vVols), vSphere APIs for Storage Awareness (VASA), and vSphere APIs for Array Integration (VAAI).
VASA
Storage vendors or VMware can make use of VASA. Storage providers (VASA providers) are software components that integrate with vSphere to provide information about the physical storage capabilities. Storage providers are utilized by either ESXi hosts or vCenter to gather information about the storage configuration and status and display it to administrators in the vSphere Client. There are several types of storage providers:
Persistent storage providers: These storage providers manage storage arrays and handle abstraction of the physical storage. vVols and vSAN use persistent storage providers.
Data storage providers: This type of provider is used for host-based caching, compression, and encryption.
Built-in storage providers: These storage providers are offered by VMware and usually do not require registration. Examples of these are vSAN and I/O filters included in ESXi installations.
Third-party storage providers: If a third party is offering a storage provider, it must be registered.
The information that storage providers offer may include the following:
Storage data services and capabilities (which are referenced when defining a storage policy)
Storage status, including alarms and events
Storage DRS information
Unless the storage provider is VMware, the vendor must provide the policy. There are other requirements related to implementing storage providers as well:
Contact your storage vendor for information about deploying the storage provider and ensure that it is deployed correctly.
Ensure that the storage provider is compatible by verifying it with the VMware Compatibility Guide.
Do not install the VASA provider on the same system as vCenter.
Upgrade storage providers to new versions to make use of new functionalities.
Unregister and reregister a storage provider when upgrading.
Storage providers must be registered in the vSphere Client to be able to establish a connection between vCenter and the storage provider. VASA is essential when working with vVols, vSAN, vSphere APIs for I/O Filtering (VAIO), and storage VM policies.
Note
If vSAN is being used, service providers are registered automatically and cannot be manually registered.
VAAI
VAAI, also known as hardware acceleration or hardware offload APIs, enable ESXi hosts to be able to communicate with storage arrays. They use functions called storage primitives, which allow offloading of storage operations to the storage array itself. The goal is to reduce overhead and increase performance. This allows storage to be responsible for cloning operations and zeroing out disk files. Without VAAI hardware offloading, the VMkernel Data Mover service is used to copy data from the source datastore to the destination datastore, incurring physical network latencies and increasing overhead. The VMkernel always attempts to offload to the storage array by way of VAAI, but if the offload fails, it employs its Data Mover service.
Storage primitives were introduced in vSphere 4.1 and applied to Fibre Channel, iSCSI, and FCoE storage only. vSphere 5.0 added primitives for NAS storage and vSphere thin provisioning. The storage primitives discussed in the following sections are available in vSphere 7.0.
VAAI Block Primitives
The following are the VAAI primitives for block storage:
Atomic Test and Set (ATS): Replaces the use of SCSI reservations on VMFS datastores when updating metadata. With SCSI reservations, only one process can establish a lock on the LUN at a time, leading to contention and SCSI reservation errors. Metadata updates occur whenever a thin-provisioned disk grows, a VM is provisioned, or a vSphere administrator manually grows a virtual disk. With ATS, a lock is placed on a sector of the VMFS datastore when updating metadata. ATS allows larger datastores to be used without running into such contention issues. On storage arrays that do not support VAAI, SCSI reservations are still used.
ATS Only Flag: Can be set on VMFS datastores that were created as VMFS Version 5 but cannot be enabled on VMFS Version 5 datastores that were upgraded from VMFS Version 3. The ATS Only Flag primitive forces ATS to be used as opposed to SCSI reservations for all metadata updates and operations. Manually enabling the ATS only flag is done via vmkfstools, using the following syntax:
vmkfstools –configATSOnly 1 [storage path]
XCOPY (Extended Copy): Allows the VMkernel to offload cloning or Storage vMotion migrations to the storage array, avoiding use of the VMkernel Data Mover service.
Write Same (Zero): Used with eager zeroed thick-provisioned virtual disks, allowing the storage device to write the zeros for the disk. This reduces overhead on the ESXi host in terms of CPU time, DMA buffers, and use of the device queue. Write same is used whenever you clone a virtual machine with eager zeroed thick-provisioned disks, whenever a thin-provisioned disk expands, or when lazy zeroed thick disks need to be zeroed out (at first write).
VAAI NAS Primitives
The following are the VAAI primitives for NAS:
Full File Clone: Works the same way as XCOPY but applies to NAS devices as opposed to block storage devices.
Fast File Clone/Native Snapshot Support: Allows snapshot creation to be offloaded to the storage device for use in linked clones used in VMware Horizon View or in vCloud Director, which leverage reading from replica disks and writing to delta disks.
Extended Statistics: Allows an ESXi host to have insight into space utilization on a NAS device. For example, when a NAS device is using thin provisioning without the Extended Statistics primitive, the ESXi host lacks visibility into the actual storage usage, leading you to run out of space.
Reserve Space: Allows thick provisioning of virtual disks on NAS datastores. Prior to this primitive, only thin provisioning could be used on NAS storage devices.
VAAI Thin Provisioning Primitives
If you are using thin provisioning, and VMs are deleted or migrated off a datastore, the array may not be informed that blocks are no longer in use. Multiple primitives, including the following, were added in vSphere 5.0 to add better support for thin provisioning:
Thin Provisioning Stun: Prior to vSphere 5.0, if a thin-provisioned datastore reached 100% space utilization, all VMs on that datastore were paused. After the release of vSphere 5.0, only the VMs requiring extra space are paused, and other VMs are not affected.
Thin Provisioning Space Threshold Warning: When a VM is migrated to a different datastore or is deleted, the SCSI UNMAP command is used for the ESXi host to tell the storage array that space can be reclaimed.
Virtual Volumes (vVols)
With vVols, you have a storage operational module that is similar to vSAN, and you can leverage SAN and NAS arrays. As with vSAN, with vVols you can leverage SPBM, which allows you to streamline storage operations. The VASA provider communicates with vCenter Server to report the underlying characteristics of the storage container. You can leverage these characteristics as you create and apply storage policies to virtual machines to optimize the placement and enable the underlying services (such as caching or replication).
The main use case for vVols is to simplify the operational model for virtual machines and their storage. With vVols, the operational model changes from managing space inside datastores to managing abstract storage objects handled by storage arrays.
The major components in vVols are vVols device, protocol endpoints, storage container, VASA provider, and array. These components are illustrated in Figure 2-7.
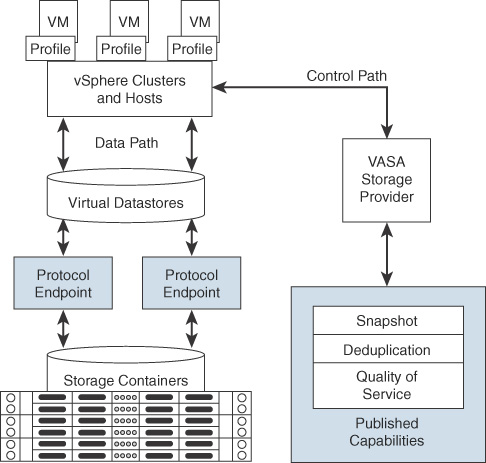
FIGURE 2-7 vVols Architecture
These are the main characteristics of vVols:
It has no file system.
ESXi manages the array through VASA.
Arrays are logically partitioned into containers, called storage containers.
vVols objects are encapsulations of VM files, and disks are stored natively on the storage containers.
Storage containers are pools of raw storage or aggregations of storage capabilities that a storage device can provide to vVols.
I/O from an ESXi host to a storage array is addressed through an access point called a protocol endpoint (PE).
PEs are logical I/O proxies, used for communication for vVols and the virtual disk files. These endpoints are used to establish data paths on demand, by binding the ESXi hosts with the PEs.
Bind requests must be sent from ESXi hosts or vCenter Server before a virtual volume can be used.
Data services, such as snapshot, replication, and encryption, are offloaded to the array.
Virtual volumes are managed through the SPBM framework. VM storage policies are required for VMs to use virtual volumes.
There are five types of virtual volumes:
Config-vVol: Metadata
Data-vVol: VMDKs
Mem-vVol: Snapshots
Swap-vVol: Swap files
Other-vVol: Vendor solution specific
Limitations of vVols include the following:
You cannot use vVols with a standalone ESXi host.
vVols does not support RDMs.
A vVols storage container cannot span different physical arrays.
Host profiles that contain virtual datastores are vCenter Server specific. A profile created by one vCenter Server instance cannot be applied by another vCenter Server instance.
Storage Multipathing and Failover
vSphere provides multipathing and failover as described in this section.
Multipathing Overview
Multipathing is used for performance and failover. ESXi hosts can balance the storage workload across multiple paths for improved performance. In the event of a path, adapter, or storage processor failure, the ESXi host fails over to an alternate path.
During path failover, virtual machine I/O can be delayed for a maximum of 60 seconds. Active/passive type arrays can experience longer delays than active/active arrays. vSphere supports several types of failover:
Fibre Channel failover: For multipathing, hosts should have at least two HBAs in addition to redundant Fibre Channel switches (the switch fabric) and redundant storage processors. If a host has two HBAs, attached to two Fibre Channel switches, connected to two storage processors, then the datastores attached to the SAN can withstand the loss of any single storage processor, Fibre Channel switch, or HBA.
Host-based failover with iSCSI: As with Fibre Channel failover, with host-based failover with iSCSI, hosts should have at least two hardware iSCSI initiators or two NIC ports used with the software iSCSI initiator. This is in addition to at least two physical switches and at least two storage processors.
Array-based failover with iSCSI: On some storage systems, the storage device abstracts the physical ports from the ESXi hosts, and the ESXi hosts see only a single virtual port. The storage system uses this abstraction for load balancing and path failover. If the physical port where the ESXi host is attached should be disconnected, the ESXi host automatically attempts to reconnect to the virtual port, and the storage device redirects it to an available port.
Path failover and virtual machines: When a path failover occurs, disk I/O could pause for 30 to 60 seconds. During this time, viewing storage in the vSphere client or virtual machines may appear stalled until the I/O fails over to the new path. In some cases, Windows VMs could fail if the failover is taking too long. VMware recommends increasing the disk timeout inside the guest OS registry to 60 seconds at least to prevent this.
Pluggable Storage Architecture (PSA)
PSA was introduced in vSphere 4 as a way for storage vendors to provide their own multipathing policies, which users can install on ESXi hosts. PSA is based on a modular framework that can make use of third-party multipathing plug-ins (MPPs) or the VMware-provided Native Multipathing Plug-in (NMP), as illustrated in Figure 2-8.
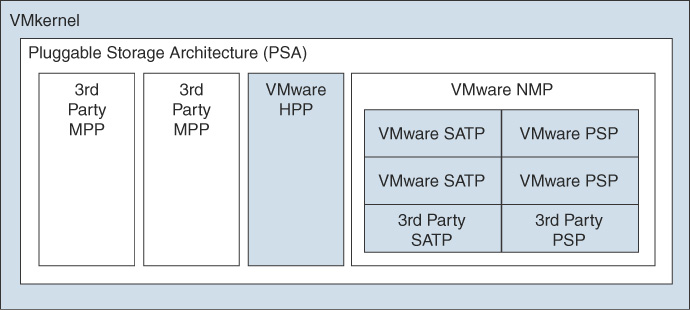
FIGURE 2-8 Pluggable Storage Architecture
VMware provides generic native multipathing modules, called VMware NMP and VMware HPP. In addition, the PSA offers a collection of VMkernel APIs that third-party developers can use. Software developers can create their own load-balancing and failover modules for a particular storage array. These third-party MPPs can be installed on the ESXi host and run in addition to the VMware native modules or as their replacement. When installed, the third-party MPPs can replace the behavior of the native modules and can take control of the path failover and the load-balancing operations for the specified storage devices.
VMware NMP
VMware NMP supports all storage arrays listed on the VMware storage HCL and provides a default path selection algorithm based on the array type. It associates a set of physical paths with a specific storage device (LUN). NMP uses submodules, called Storage Array Type Plug-ins (SATPs) and Path Selection Plug-ins (PSPs).
NMP performs the following operations.
Manages physical path claiming and unclaiming
Registers and unregisters logical devices
Maps physical paths with logical devices
Supports path failure detection and remediation
Processes I/O requests to logical devices:
Selects an optimal physical path
Performs actions necessary to handle path failures and I/O command retries
Supports management tasks, such as resetting logical devices
Storage Array Type Plug-ins (SATPs)
SATPs are submodules of the VMware NMP and are responsible for array-specific operations. The SATP handles path failover for a device. ESXi offers an SATP for every type of array that VMware supports. ESXi also provides default SATPs that support non-specific active/active, active/passive, ALUA, and local devices.
Each SATP performs the array-specific operations required to detect path state and to activate an inactive path. This allows the NMP module to work with multiple storage arrays without being aware of the storage device specifics.
NMP determines which SATP to use for a specific storage device and maps the SATP with the storage device’s physical paths. The SATP implements the following tasks:
Monitors the health of each physical path
Reports changes in the state of each physical path
Performs array-specific actions necessary for storage failover (For example, for active/passive devices, it activates passive paths.)
Table 2-10 provides details on the native SATP modules.
Table 2-10 SATP Module Details
SATP Module |
Description |
|---|---|
VMW_SATP_LOCAL |
SATP for local direct-attached devices. Supports VMW_PSP_MRU and VMW_PSP_FIXED but not VMW_PSP_RR. |
VMW_SATP_DEFAULT_AA |
Generic SATP for active/active arrays. |
VMW_SATP_DEFAULT_AP |
Generic SATP for active/passive arrays. |
VMW_SATP_ALUA |
SATP for ALUA-compliant arrays. |
Note
You do not need to obtain or download any SATPs. ESXi automatically installs an appropriate SATP for any array you use. Beginning with vSphere 6.5 Update 2, VMW_SATP_LOCAL provides multipathing support for the local devices, except the devices in 4K native format. You are no longer required to use other SATPs to claim multiple paths to the local devices.
Path Selection Plug-ins (PSPs)
VMware PSPs are submodules of NMP. PSPs handle path selection for I/O requests for associated storage devices. NMP assigns a default PSP for each logical device based on the device type. You can override the default PSP.
Each PSP enables and enforces a corresponding path selection policy. Table 2-11 provides details on the native path selection policies.
Table 2-11 VMware Path Selection Policies
PSP Module |
Policy |
Description |
|---|---|---|
VMW_PSP_MRU |
Most Recently Used (VMware) |
Initially, MRU selects the first discovered working path. If the path fails, MRU selects an alternative path and does not revert to the original path when that path becomes available. MRU is default for most active/passive storage devices. |
VMW_PSP_FIXED |
Fixed (VMware) |
FIXED uses the designated preferred path if it is working. If the preferred path fails, FIXED selects an alternative available path but reverts to the preferred path when it becomes available again. FIXED is the default policy for most active/active storage devices. |
VMW_PSP_RR |
Round Robin (VMware) |
RR uses an automatic path selection algorithm to rotate through the configured paths. RR sends an I/O set down the first path, sends the next I/O set down the next path, and continues sending the next I/O set down the next path until all paths are used; then the pattern repeats, beginning with the first path. Effectively, this allows all the I/O from a specific host to use the aggregated bandwidth of multiple paths to a specific storage device. Both active/active and active/passive arrays use RR. With active/passive arrays, RR uses active paths. With active/active arrays, RR uses available paths. The latency mechanism that is activated for the policy by default makes it more adaptive. To achieve better load-balancing results, the mechanism dynamically selects an optimal path by considering the I/O bandwidth and latency for the path. RR is the default policy for many arrays. |
PSA Summary
To summarize, the PSA performs the following tasks:
Loads and unloads multipathing plug-ins
Hides virtual machine specifics from a particular plug-in
Routes I/O requests for a specific logical device to the MPP managing that device
Handles I/O queueing to the logical devices
Implements logical device bandwidth sharing between virtual machines
Handles I/O queueing to the physical storage HBAs
Handles physical path discovery and removal
Provides logical device and physical path I/O statistics
The following process occurs when VMware NMP receives an I/O request for one of its managed storage devices:
Step 1. The NMP calls the appropriate PSP.
Step 2. The PSP selects an appropriate physical path.
Step 3. The NMP issues the I/O request on the selected path.
Step 4. If the I/O operation is successful, the NMP reports its completion.
Step 5. If the I/O operation reports an error, the NMP calls the appropriate SATP.
Step 6. The SATP interprets the errors and, when appropriate, activates the inactive paths.
Step 7. The PSP selects a new path for the I/O.
When coordinating the VMware native modules and any installed third-party MPPs, the PSA performs the following tasks:
Loads and unloads MPPs
Hides virtual machine specifics from MPPs
Routes I/O requests for a specific logical device to the appropriate MPP
Handles I/O queuing to the logical devices
Shares logical device bandwidth between virtual machines
Handles I/O queuing to the physical storage HBAs
Storage Policies
Storage policies can be used to define which datastores to use when placing virtual machines disk. The following storage policies can be created:
VM storage policies for host-based data services: These policies are rules for services that are offered by the ESXi hosts, such as encryption.
VM storage policies for vVols: These policies allow you to set rules for VMs that apply to vVols datastores. This can include storage devices that are replicated for disaster recovery purposes or have specific performance characteristics.
VM storage policies for tag-based placement: You can create custom policies for VMs and custom tags for storage devices. This is helpful for storage arrays that do not support VASA and whose storage characteristics are not visible to the vSphere client. For example, you could create a tag named Gold and use it to identify your best-performing storage.
Storage Policy Based Management (SPBM)
You can define a required policy for a VM, such as requiring it to reside on fast storage. You can then use VASA or define storage tags manually. Then a VM can only be placed on a storage device matching the requirements.
Virtual Disk Types
When creating a virtual disk, you need to determine how you are going to allocate space to that virtual disk. The way space is allocated to a virtual disk is through writing zeros; this process is typically referred to as zeroing out the file. For example, if you wanted to create a 20 GB virtual disk and allocate all of the space up front, a VMDK file is created, and 20 GB worth of zeros are written to that file. You can determine when the zeros get written:
Eager zeroed thick: The disk space for the virtual disk files is allocated and erased (zeroed out) at the time of creation. If the storage device supports VAAI, this operation can be offloaded to the storage array. Otherwise, the VMkernel writes the zeros, and this process could be slow. This method is the slowest for virtual disk creation, but it is the best for guest performance.
Lazy zeroed thick: The disk space for the virtual disk files is allocated at the time of creation but not zeroed. Each block is zeroed, on demand at runtime, prior to being presented to the guest OS for the first time. This increases the time required for disk format operations and software installations in the guest OS.
Thin provisioned: The disk space for the virtual disk files is not allocated or zeroed at the time of creation. The space is allocated and zeroed on demand. This method is the fastest for virtual disk creation but the worst for guest performance.
vSAN-Specific Storage Policies
vSAN storage policies define how VM objects are placed and allocated on vSAN to meet performance and redundancy requirements. Table 2-12 describes the vSAN storage policies.
Table 2-12 vSAN Storage Policies
Policy |
Description |
|---|---|
Primary Level of Failures to Tolerate (PFTT) |
This policy defines how many host and device failures a VM object can withstand. For n failures tolerated, data is stored in n+1 location. (This includes parity copies with RAID 5 or 6.) If no storage policy is selected at the time of provisioning a VM, this policy is assigned by default. Where fault domains are used, 2n+1 fault domains, each with hosts adding to the capacity, are required. If an ESXi host isn’t in a fault domain, it is considered to be in a single-host fault domain. The default setting for this policy is 1, and the maximum is 3. |
Secondary Level of Failures to Tolerate (SFTT) |
In stretched clusters, this policy defines how many additional host failures can be tolerated after a site failure’s PFTT has been reached. If PFTT = 1, SFTT = 2, and one site is inaccessible, two more host failures can be tolerated. The default setting for this policy is 1, and the maximum is 3. |
Data Locality |
If PFTT=0, this option is available. The options for this policy are None, Preferred, and Secondary. This allows objects to be limited to one site or one host in stretched clusters. The default setting for this policy is None. |
Failure Tolerance Method |
This policy defines whether the data replication mechanism is optimized for performance or capacity. If RAID-1 (Mirroring)—Performance is selected, there will be more space consumed in the object placement but better performance for accessing the space. If RAID-5/6 (Erasure Coding)—Capacity is selected, there will be less disk utilization, but performance will be reduced. |
Number of Disk Stripes per Object |
This policy determines the number of capacity devices where each VM object replica is striped. Setting this above 1 can improve performance but consumes more resources. The default setting for this policy is 1, and the maximum is 12. |
Flash Read Cache Reservation |
This policy defines the amount of flash capacity that is reserved for read caching of VM objects. This is defined as a percentage of the size of the VMDK. This is supported only in hybrid vSAN clusters. The default setting for this policy is 0%, and the maximum is 100%. |
Force Provisioning |
If set to yes, this policy forces provisioning of objects, even when policies cannot be met. The default setting for this policy is no. |
Object Space Reservation |
This policy defines the percentage of VMDK objects that must be thick provisioned on deployment. The options are as follows:
|
Disable Object Checksum |
A checksum is used end-to-end in validating the integrity of the data to ensure that data copies are the same as the original. In the event of a mismatch, incorrect data is overwritten. If this policy is set to yes, a checksum is not calculated. The default setting for this policy is no. |
IOPS Limit for Object |
This policy sets a limit for IOPS of an object. If set to 0, there is no limit. |
Storage DRS (SDRS)
You can use vSphere Storage DRS (SDRS) to manage the storage resources of a datastore cluster. A datastore cluster is a collection of datastores with shared resources and a shared management interface. SDRS provides a number of capabilities for a datastore cluster, as discussed in the following sections.
Initial Placement and Ongoing Balancing
SDRS provides recommendations for initial virtual machine placement and ongoing balancing operations in a datastore cluster. Optionally, SDRS can automatically perform the recommended placements and balancing operations. Initial placements occur when the virtual machine is being created or cloned, when a virtual machine disk is being migrated to another datastore cluster, and when you add a disk to an existing virtual machine. SDRS makes initial placement recommendations (or automatically performs the placement) based on space constraints and SDRS settings (such as space and I/O thresholds).
Space Utilization Load Balancing
You can set a threshold for space usage to avoid filling a datastore to its full capacity. When space usage on a datastore exceeds the threshold, SDRS generates recommendations or automatically performs Storage vMotion migrations to balance space usage across the datastore cluster.
I/O Latency Load Balancing
You can set an I/O latency threshold to avoid bottlenecks. When I/O latency on a datastore exceeds the threshold, SDRS generates recommendations or automatically performs Storage vMotion migrations to balance I/O across the datastore cluster.
SDRS is invoked at the configured frequency (every eight hours by default) or when one or more datastores in a datastore cluster exceeds the user-configurable space utilization thresholds. When Storage DRS is invoked, it checks each datastore’s space utilization and I/O latency values against the threshold. For I/O latency, Storage DRS uses the 90th percentile I/O latency measured over the course of a day to compare against the threshold.
SDRS Automation Level
Table 2-13 describes the available SDRS automation levels.
Table 2-13 SDRS Automation Levels
Option |
Description |
|---|---|
No Automation (manual mode) |
Placement and migration recommendations are displayed but do not run until you manually apply the recommendation. |
Partially Automated |
Placement recommendations run automatically, and migration recommendations are displayed but do not run until you manually apply the recommendation. |
Fully Automated |
Placement and migration recommendations run automatically. |
SDRS Thresholds and Behavior
You can control the behavior of SDRS by specifying thresholds. You can use the following standard thresholds to set the aggressiveness level for SDRS:
Space Utilization: SDRS generates recommendations or performs migrations when the percentage of space utilization on the datastore is greater than the threshold you set in the vSphere Client.
I/O Latency: SDRS generates recommendations or performs migrations when the 90th percentile I/O latency measured over a day for the datastore is greater than the threshold.
Space Utilization Difference: SDRS can use this threshold to ensure that there is some minimum difference between the space utilization of the source and the destination prior to making a recommendation. For example, if the space used on datastore A is 82% and on datastore B is 79%, the difference is 3. If the threshold is 5, Storage DRS does not make migration recommendations from datastore A to datastore B.
I/O Load Balancing Invocation Interval: After this interval, SDRS runs to balance I/O load.
I/O Imbalance Threshold: Lowering this value makes I/O load balancing less aggressive. Storage DRS computes an I/O fairness metric between 0 and 1, with 1 being the fairest distribution. I/O load balancing runs only if the computed metric is less than 1 – (I/O Imbalance Threshold / 100).
SDRS Recommendations
For datastore clusters, where SDRS automation is set to No Automation (manual mode), SDRS makes as many recommendations as necessary to enforce SDRS rules, balance the space, and balance the I/O resources of the datastore cluster. Each recommendation includes the virtual machine name, the virtual disk name, the data-store cluster name, the source datastore, the destination datastore, and a reason for the recommendation.
SDRS makes mandatory recommendations when the datastore is out of space, when anti-affinity or affinity rules are being violated, or when the datastore is entering maintenance mode. SDRS makes optional recommendations when a datastore is close to running out of space or when adjustments should be made for space and I/O load balancing.
SDRS considers moving powered-on and powered-off virtual machines for space balancing. Storage DRS considers moving powered-off virtual machines with snapshots for space balancing.
Anti-affinity Rules
To ensure that a set of virtual machines are stored on separate datastores, you can create anti-affinity rules for the virtual machines. Alternatively, you can use an affinity rule to place a group of virtual machines on the same datastore.
By default, all virtual disks belonging to the same virtual machine are placed on the same datastore. If you want to separate the virtual disks of a specific virtual machine on separate datastores, you can do so with an anti-affinity rule.
Datastore Cluster Requirements
Datastore clusters can contain a mix of datastores having different sizes, I/O capacities, and storage array backing. However, the following types of datastores cannot coexist in a datastore cluster:
NFS and VMFS datastores cannot be combined in the same datastore cluster.
Replicated datastores cannot be combined with non-replicated datastores in the same SDRS-enabled datastore cluster.
All hosts attached to the datastores in a datastore cluster must be ESXi 5.0 and later. If datastores in the datastore cluster are connected to ESX/ESXi 4.x and earlier hosts, SDRS does not run.
Datastores shared across multiple data centers cannot be included in a data-store cluster.
As a best practice, all datastores in a datastore cluster should have identical hardware acceleration (enabled or disabled) settings.
NIOC, SIOC, and SDRS
In vSphere, you can use Network I/O Control (NIOC), Storage I/O Control (SIOC), and SDRS to manage I/O. These features are often confused by people in the VMware community. Table 2-14 provides a brief description of each feature along with the chapter in this book where you can find more detail.
Table 2-14 Comparing NIOC, SIOC, and SDRS
Feature |
Description |
Chapter |
|---|---|---|
NIOC |
Allows you to allocate network bandwidth to business-critical applications and to resolve situations where several types of traffic compete for common resources. |
|
SIOC |
Allows you to control the amount of storage I/O that is allocated to virtual machines during periods of I/O congestion by implementing shares and limits. |
|
SDRS |
Allows you to control and balance the use of storage space and I/O resources across the datastores in a datastore cluster. |
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have some choices for exam preparation: the exercises here, Chapter 15, “Final Preparation,” and the exam simulation questions on the companion website.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 2-15 lists these key topics and the page number on which each is found.
Complete Tables and Lists from Memory
Print a copy of Appendix B, “Memory Tables” (found on the companion website), or at least the section for this chapter, and complete the tables and lists from memory. Appendix C, “Memory Tables Answer Key” (also on the companion website), includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
Review Questions
1. You are deploying datastores in a vSphere environment and want to use the latest VMFS version that supports ESXi 6.5 and ESXi 7.0. Which version should you use?
VMFS Version 3
VMFS Version 4
VMFS Version 5
VMFS Version 6
2. You are preparing to manage and troubleshoot a vSAN environment. Which of the following is a command-line interface that provides a cluster-wide view and is included with the vCenter Server deployment?
VMware PowerCLI
vSAN Observer
Ruby vSphere Console
esxcli
3. You want to integrate vSphere with your storage system. Which of the following provides software components that integrate with vSphere to provide information about the physical storage capabilities?
VASA
VAAI
SATP
NMP
4. Which of the following is the default path selection policy for most active/passive storage devices?
VMW_PSP_MRU
VMW_PSP_FIXED
VMW_PSP_RR
VMW_PSP_AP
5. You are deploying virtual machines in a vSphere environment. Which virtual disk configuration provides the best performance for the guest OS?
Thin provisioned
Thick eager zeroed
Thick lazy zeroed
Thin eager zeroed