Chapter 10
Managing and Monitoring Clusters and Resources
This chapter covers the following topics:
This chapter contains information related to Professional VMware vSphere 7.x (2V0-21.20) exam objectives 1.6, 1.6.2, 1.6.3, 1.6.4, 1.6.4.1, 4.9, 5.1, 5.1.1, 5.2, 5.3, 7.5, and 7.12.
This chapter introduces vSphere 6.7, describes its major components, and identifies its requirements.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should study this entire chapter or move quickly to the “Exam Preparation Tasks” section. In any case, the authors recommend that you read the entire chapter at least once. Table 10-1 outlines the major headings in this chapter and the corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 10-1 “Do I Know This Already?” Section-to-Question Mapping
Foundation Topics Section |
Questions |
|---|---|
Creating and Configuring a vSphere Cluster |
1 |
Creating and Configuring a vSphere DRS Cluster |
2, 3 |
Creating and Configuring a vSphere HA Cluster |
4, 5 |
Monitoring and Managing vSphere Resources |
6–8 |
Events, Alarms, and Automated Actions |
9 |
Logging in vSphere |
10 |
1. In a cluster that you initially created using Quickstart and for which you chose the option Configure Network Settings Later, you now want to add a host. Which of the following is a true statement?
You cannot use Quickstart to add more hosts to the cluster.
You can use Quickstart to add hosts to the cluster and configure the host networking.
You can use Quickstart to add hosts to the cluster but must manually configure the host networking.
You can edit the cluster and change the Configure Networking Settings Later option.
2. You are creating a resource pool in a DRS cluster. Which of the following statements is not true?
When you create a child resource pool, the system applies admission control.
If you choose Scale Descendant’s Shares, child pools use scalable share.
The default CPU reservation is 0.
The default memory limit is 0.
3. You are configuring a vSphere HA cluster. Which of the following is not a valid setting for Define Host Failover Capacity?
Standby
Cluster Resource Percentage
Slot Policy (powered-on VMs)
Dedicated Failover Hosts
4. You want to configure VMCP in a vSphere cluster. Which of the following settings is valid?
In the vSphere HA settings, select Failures and Responses > Datastore with PDL and choose Power Off and Restart VMs–Conservative Restart Policy.
In the vSphere HA settings, select Failures and Responses > Datastore with PDL and choose Power Off and Restart VMs.
In the vSphere DRS settings, select Failures and Responses > Datastore with APD and choose Power Off and Restart VMs–Conservative Restart Policy.
In the vSphere DRS settings, select Failures and Responses > Datastore with APD and choose Power Off and Restart VMs–Aggressive Restart Policy.
5. You are configuring a vSphere HA cluster and want to configure proactive HA. Which of the following is not a requirement?
Host.Config.Quarantine and Host.Config.Maintenance privileges
A vendor-supplied vSphere Client plug-in
A VMware-supplied plug-in
vSphere DRS
6. You are experiencing poor performance for an application in a virtual machine. You learn from guest OS software and the vSphere client performance charts that the guest OS is paging. Which of the following is likely to fix the problem?
Increase the memory in the ESXi host.
Increase the memory size of the virtual machine.
Migrate the virtual machine to a host that has plenty of free memory.
Reserve all of the virtual machine’s memory.
7. You are configuring virtual disks for the virtual machines in your vSphere environment. Which provisioning type is the best choice when you care more about optimizing the space usage than about performance or availability risk?
Thin
Thick eager zeroed
Thick lazy zeroed
Sparse
8. You are using ESXTOP to analyze vSphere performance. Which of the following statistics is the best indicator of some resource contention?
%USED
%DRPTX
OVHD
READ/s
9. You are configuring alarms in your vSphere environment. Which of the following is not a valid event type?
Error
Warning
Information
Audit
10. You are examining vSphere logs. Which of the following logs contains data about the agent that manages and configures the ESXi host?
/var/log/vmkernel.log
/var/log/vpxa.log
/var/log/hostd.log
/var/log/vmksummary.log
Foundation Topics
Creating and Configuring a vSphere Cluster
By using the vSphere Client, you can create a vSphere cluster and use its Quickstart feature to configure the cluster. You can configure DRS, vSphere HA, and EVC on the cluster, as described in this chapter. You can also configure vSAN on the cluster, as described in Chapter 11, “Managing Storage.”
Creating a Cluster
To create a vSphere cluster that you plan to configure using Quickstart, you should ensure that the hosts have the same ESXi version and patch level. If you are adding hosts to the vCenter Server inventory, you need the credentials for the root user account for the hosts. You must have the Host.Inventory.Create Cluster privilege. To create a cluster that you manage with a single image, verify that you have a supported ESXi 7.0 or later image available in the vSphere Lifecycle Manager depot. You can use the following procedure to create the cluster:
Step 1. In the vSphere Client, right-click a data center in the inventory pane and select New Cluster.
Step 2. Enter a name for the cluster.
Step 3. Optionally, for each of the following services, slide the switch to the right to enable the service:
DRSv
Sphere HA
vSAN
If you enable DRS, you can optionally change its automation setting (default is Fully Automated using Threshold Level 3).
Step 4. Optionally, to create a cluster that you manage with a single image, select Manage All Hosts in the Cluster with a Single Image. and then do the following:
Select an ESXi version (image) from the drop-down menu.
Optionally, select options from the Vendor Addon and Vendor Addon Version drop-down menus.
Step 5. Click OK.
Configuring a Cluster with Quickstart
To modify an existing cluster, you can select the cluster in the inventory pane and click Configure > Configuration > Quickstart. On the Quickstart page are three cards: Cluster Basics, Add Hosts, and Configure Cluster. To change the name and the enabled cluster services, click Cluster Basics > Edit. To add a host to a cluster, you can use the following procedure:
Step 1. In the vSphere Client, select a cluster in the inventory pane and navigate to Configure > Configuration > Quickstart > Add Hosts > Add.
Step 2. Click New Hosts > Add and provide the name (or IP address) and credentials for each host that you want to add that is not already in the vCenter Server inventory.
Step 3. Optionally, select the Use the Same Credentials for All Hosts option.
Step 4. Click Existing Hosts > Add and select each host that you want to add that is already in the vCenter Server inventory.
Step 5. Click Next.
Step 6. On the Host Summary page, click Next.
Step 7. On the Ready to Complete page, click Finish.
Step 8. Monitor the progress under Recent Tasks, where you can see any errors.
Step 9. When the task is complete, you can view the number of hosts and the health on the Add Hosts card. Optionally, select Re-validate.
Step 10. Use the inventory pane to verify that the hosts are attached to the cluster and are in maintenance mode.
To configure cluster settings and host networking in a cluster, you can use the following procedure:
Step 1. In the vSphere Client, select a cluster in the inventory pane and navigate to Configure > Configuration > Quickstart.
Step 2. Optionally, if you want to configure the cluster manually, click Skip Quickstart, which is irreversible. Otherwise, continue with the following steps to use Quickstart to configure the cluster.
Step 3. Click Configure Cluster > Configure.
Step 4. On the Distributed Switches page, you can either select the irreversible option Configure Networking Settings Later or use the following steps to configure the cluster networking:
Specify the number of distributed switches to create (up to three).
Enter a unique name for each distributed switch. Alternatively, click Use Existing and select an existing compatible distributed switch and distributed port group.
To set up the vMotion network, select a distributed switch and assign a new port group to it.
In the Physical Adapters section, for each physical network adapter, assign a distributed switch name from the drop-down menu. Ensure that each new distributed switch is assigned to at least one physical adapter. For any existing distributed switch, to avoid an error, select the physical adapter that is currently mapped to the switch.
Click Next.
If you enabled the vSphere DRS feature during cluster creation, in the vMotion Traffic page that appears, provide the VLAN ID, protocol type, and IP configuration.
Step 5. Click Next.
Step 6. In the Advanced Options page, configure the following options:
If you enabled vSphere HA during cluster creation, use the options in the High Availability section to enable or disable host failure monitoring, virtual machine monitoring, and admission control. For admission control, you can specify the number of hosts for failover capacity.
If you enabled vSphere DRS during cluster creation, use the options in the Distributed Resource Scheduler section to set the automation level and migration threshold.
In the Host Options section, set the lockdown mode and enter an NTP server address.
Optionally, in the Enhanced vMotion Capability section, use the options to enable EVC and select a mode.
Step 7. Click Next.
Step 8. On the Ready to Complete page that appears, review the settings and click Finish.
You can extend a cluster by adding more hosts. If you initially selected the Skip Quickstart option, then you should add hosts manually. If you previously used Quickstart but selected Configure Networking Settings Later, you can add hosts by using Quickstart but must manually configure the host networking. To extend a cluster, you can use the following procedure:
Step 1. In the vSphere Client, right-click a configured cluster in the inventory pane and select Add Hosts.
Step 2. In the wizard, select hosts from the vCenter Server inventory and add new hosts (by providing names and credentials) to include in the cluster.
Step 3. On the Ready to Complete page, click Finish.
Step 5. On the Configure Hosts card of the Extend Cluster Guide page that appears, select Configure. If you previously used Quickstart to configure the host networking, the vMotion Traffic page appears. Provide the VLAN ID, protocol type, and IP configuration. Then a pop-up window appears, informing you that the configuration for the hosts that exist in the cluster is applied to the newly added hosts.
Step 6. Click Continue.
After successful validation, the Configure button in the Configure Hosts card becomes inactive, and the Re-validate button is available.
If you enable DRS, the default Automation Level setting is Fully Automated and the default Threshold setting is 3. If you enable HA, the default values are Host Monitoring and Admission Control Are Enabled and VM Monitoring Is Disabled. You can override the default values later in the workflow.
If you select an image for managing all the hosts in the cluster, you can later edit the image specification on the Updates tab. If you do not choose an image to manage hosts, you must manage the cluster by using baselines and baseline groups. You can switch from using baselines to using images later.
Starting with vSphere 7.0, you can use vSphere Lifecycle Manager to upgrade and update the hosts in a cluster. A vSphere Lifecycle Manager image is a combination of vSphere software, driver software, and firmware for specific host hardware. You can assign an image to a cluster used to control the software set to be installed on the hosts, including the ESXi version, additional VMware-provided software, and vendor software, such as firmware and drivers.
The image that you define during cluster creation is not immediately applied to the hosts. If you do not set up an image for a cluster, the cluster uses baselines and baseline groups. For more information about using images and baselines to manage hosts in clusters, see the Managing Host and Cluster Lifecycle documentation.
EVC Mode
As previously described, you can configure EVC by using Quickstart > Configure Cluster. You can also configure EVC directly in the cluster settings. You can set VMware EVC to Disable EVC, Enable EVC for AMD Hosts, or Enable EVC for Intel Hosts.
If you choose Enable EVC for AMD Hosts, you can set the mode to one of the options listed in Table 4-3 in Chapter 4, “Clusters and High Availability.”
If you choose Enable EVC for Intel Hosts, you can set the mode to one of the options listed in Table 4-2 in Chapter 4.
To view the EVC modes for all of a cluster’s virtual machines in the vSphere Client, you can select a cluster, navigate to its VMs tab, and select Show/Hide Columns > EVC Mode.
Creating and Configuring a vSphere DRS Cluster
This section describes how to create and configure a vSphere DRS cluster.
Creating a vSphere DRS Cluster
To create a vSphere DRS cluster, follow the procedure in the section “Creating a Cluster,” earlier in this chapter, and ensure that you choose to enable the DRS service. Use the information in the rest of this section to configure the DRS cluster.
Creating a Resource Pool
You can use the following procedure to create a child resource pool in a DRS cluster:
Step 1. In the vSphere Client, navigate to Hosts and Clusters, right-click a DRS cluster in the inventory, and select New Resource Pool.
Step 2. Provide a name for the resource pool.
Step 3. Optionally, select the Scale Descendant’s Shares checkbox to enable scalable shares. (Enabling this option causes any child resource pools to use scalable shares, which scale dynamically when virtual machines are added and removed.)
Step 4. Optionally, set CPU and Memory Shares to Low, Normal, High, or Custom. If you select custom, enter a numeric value.
Step 5. Optionally, set CPU and Memory Reservation to a numeric value (the default is 0) and a unit of measure (MB, GB, MHz, or GHz).
Step 6. Optionally, set CPU and Memory Limit to a numeric value (the default is Unlimited) and a unit of measure (MB, GB, MHz, or GHz).
Step 7. Optionally, set CPU and Memory Reservation Type to Expandable.
Step 8. Click OK.
Note
When you create a child resource pool, the vSphere Client prompts you for resource pool attribute information. The system uses admission control to ensure that you do not allocate resources that are not available. If you choose Scale Descendant’s Shares, each descendant pool will also use scalable shares. You cannot change this behavior for each child pool.
Configuring Advanced DRS Options
This section describes how to configure some advanced options for vSphere DRS.
Creating Affinity/Anti-Affinity Rules
Table 10-2 provides some common use cases for VM-to-VM affinity and anti-affinity rules.
Table 10-2 Use Cases for VM-to-VM Rules
Use Case |
Rule Details |
|---|---|
To improve application and communication performance for a multinode application. |
Use VM-to-VM affinity rules to ensure that sets of virtual machines that engage in significant data exchange reside on the same host, such that the data transfer occurs within the host system hardware and does not traverse the physical network infrastructure. |
To improve application availability for a multinode application |
Use VM-to-VM anti-affinity rules to ensure that sets of peer virtual machines reside on separate hosts, such that the failure of a single host does not result in the failure of all the peer application nodes. |
You can use the following procedure to create a VM-to-VM affinity or anti-affinity rule:
Step 1. Browse to the cluster in the vSphere Client.
Step 2. Navigate to Configure > VM/Host Rules and click Add.
Step 3. In the Create VM/Host Rule dialog box, type a name for the rule.
Step 4. From the Type drop-down menu, select either Keep Virtual Machines Together (affinity) or Separate Virtual Machines (anti-affinity).
Step 5. Click Add.
Step 6. Select at least two virtual machines to which the rule will apply and click OK.
Step 7. Click OK.
Configuring Predictive DRS
To configure predictive DRS, you can use the following procedure:
Step 1. In the vRealize Operations (vROps) GUI, select the appropriate vCenter Server adapter instance and choose Advanced Settings.
Step 2. Set Provide Data to vSphere Predictive DRS to True.
Step 3. In the vSphere Client, select the cluster in the inventory pane and navigate to Cluster > Services > vSphere DRS > Edit.
Step 4. Check the Predictive DRS checkbox.
Creating and Configuring a vSphere HA Cluster
This section describes how to create and configure a vSphere HA cluster.
Creating a vSphere HA Cluster
To create a vSphere HA cluster, follow the procedure in the section “Creating a Cluster,” earlier in this chapter, and ensure that you choose to enable the vSphere HA service. Use the information in the rest of this section to configure the vSphere HA cluster.
Configuring Advanced vSphere HA Options
You can use the following procedure to add vSphere HA advanced options, as described in Table 4-9:
Step 1. In the vSphere Client, select a vSphere HA cluster in the inventory pane and navigate to Configure > vSphere Availability > Edit > Advanced Options.
Step 2. Click Add.
Step 3. Enter the name of the advanced option and the value.
Step 4. Click OK.
Configuring vSphere HA Admission Control
To configure admission control for a vSphere HA cluster, you can use the following procedure:
Step 1. In the vSphere Client, select the vSphere HA cluster in the inventory pane and navigate to Configure > vSphere Availability > Edit.
Step 2. Click Admission Control and set Host Failures Cluster Tolerates to the maximum number of host failures you want the cluster to support.
Step 3. Select one of the following options for Define Host Failover Capacity By, as described in Table 4-8 in Chapter 4:
Cluster Resource Percentage
Slot Policy (powered-on VMs)
Dedicated failover hosts
Disabled (disables admission control)
Step 4. Optionally, set Performance Degradation VMs Tolerate to a percentage.
Step 5. Click OK.
Configuring VMCP
To configure Virtual Machine Component Protection (VMCP) in a vSphere HA cluster, you can use the following procedure:
Step 1. In the vSphere Client, select the cluster in the inventory pane and navigate to Configure > vSphere Availability > Edit.
Step 2. Select Failures and Responses > Datastore with PDL and choose one of the following:
Issue Events
Power Off and Restart VMs
Step 3. Select Failures and Responses > Datastore with APD and choose one of the following:
Issue Events
Power Off and Restart VMs–Conservative Restart Policy
Power Off and Restart VMs–Aggressive Restart Policy
Configuring Virtual Machine and Application Monitoring
You can use the following procedure to turn on and configure virtual machine and application monitoring in a vSphere HA cluster:
Step 1. In the vSphere Client, select the vSphere HA cluster in the inventory pane and navigate to Configure > vSphere Availability > Edit.
Step 2. Select Failures and Responses > VM Monitoring.
Step 3. Select VM Monitoring to turn on VMware Tools heartbeats.
Step 4. Select Application Monitoring to turn on application heartbeats.
Step 5. To set the heartbeat monitoring sensitivity, move the slider between Low and High or select Custom and provide a custom value.
Step 6. Click OK.
Configuring Proactive HA
To get started with implementing Proactive HA, you need to install a supported vendor-supplied vSphere Client plug-in and register the proactive HA provider. When you turn on proactive HA in a cluster, you can select from the list of providers for installed plug-ins that are monitoring every host in the cluster. You can use the following procedure to configure proactive HA in a cluster:
Step 1. Ensure that the following prerequisites are met:
vSphere HA and DRS are enabled.
To allow remediation actions, ensure that you have the Host.Config.Quarantine and Host.Config.Maintenance privileges.
Step 2. In the vSphere Client, select the cluster in the inventory pane and navigate to Configure > vSphere Availability > Edit.
Step 3. Select Turn on Proactive HA.
Step 4. Click Proactive HA Failures and Responses.
Step 5. Set Automation Level to Manual or Automated.
Step 6. Set Remediation to one of the following:
Quarantine Mode for All Failures
Quarantine Mode for Moderate and Maintenance Mode for Severe Failure (Mixed)
Maintenance Mode for All Failures
Configuring vSphere Fault Tolerance
Before enabling vSphere Fault Tolerance (FT) for a virtual machine, you must prepare the hosts and cluster by doing the following:
Step 1. Configure vSphere HA on the cluster.
Step 2. On each participating host, configure a vMotion port group, a VMkernel adapter enabled for vMotion, a Fault Tolerance logging network, and a VMkernel adapter enabled for FT Logging.
To turn on FT for a virtual machine, you can use the following procedure:
Step 1. In the vSphere Client, right-click the virtual machine in the inventory pane and select Fault Tolerance > Turn On Fault Tolerance.
Step 2. Click Yes.
Step 3. Select a datastore on which to place the secondary VM configuration files and click Next.
Step 4. Select a host on which to place the secondary VM and click Next.
Step 5. Review your selections and then click Finish.
Before FT is turned on for a virtual machine, FT performs several validation steps related to the FT requirements listed in Chapter 4. The virtual machine datastores and memory are replicated as FT is turned on. This may take several minutes, during which the virtual machine status does not appear as protected. When the replication completes and the state of the secondary VM is synchronized with that of the primary VM, the status changes to Protected.
To test FT failover for a virtual machine, right-click the virtual machine and select Fault Tolerance > Test Failover. Likewise, you can select Fault Tolerance > Test Restart Secondary to restart the Secondary VM.
Monitoring and Managing vSphere Resources
You can use the vSphere client performance charts to view compute, storage, and network resource usage for virtual machines, hosts, and clusters. For a more granular look from the host perspective, you can use the ESXTOP utility. You can use vCenter Server alarms to bring attention to conditions and events that may call for human intervention, such as low resource availability on a cluster, host, or data-store. To bring multi-vCenter Server monitoring, predictive analysis, and intelligent operations to an environment, you can consider integrating vRealize Operations (vROps).
Metrics
Performance metrics are organized into logical groups based on the object or object device, as shown in Table 10-3.
Table 10-3 Metrics
Metric Group |
Description |
|---|---|
Cluster Services |
Performance metrics on vSphere host clusters. |
CPU |
CPU utilization metrics for hosts, virtual machines, resource pools, or compute resources. |
Datastore |
Datastore utilization metrics. |
Disk |
Disk utilization metrics for hosts, virtual machines, or datastores. |
Memory |
Memory utilization metrics for hosts, virtual machines, resource pools, or compute resources. |
Network |
Network utilization metrics for physical NICs, virtual NICs, and other network devices. |
Power |
Energy and power utilization metrics for hosts. |
Storage Adapter |
Data traffic metrics for host bus adapters (HBAs). |
Storage Path |
Data traffic metrics for paths. |
System |
Overall system availability metrics, such as the system heartbeat and uptime. These counters are available directly from hosts and from vCenter Server. |
Virtual Disk |
Disk utilization and disk performance metrics for virtual machines. |
Virtual Flash |
Virtual flash metrics. |
Virtual Machine Operations |
Virtual machine power and provisioning operations metrics in a cluster or data center. |
vSphere Replication |
Virtual machine replication metrics. |
Disk metrics include I/O performance, such as latency and read/write speeds, and utilization metrics for storage as a finite resource.
The value obtained for memory utilization is one of the following:
For virtual machines, memory refers to the guest physical memory, which is the virtual memory the hypervisor presents to the guest as physical memory.
For hosts, memory refers to the machine memory, which is the physical memory in the host system.
vSphere Client Performance Charts
The vSphere client performance charts enable you to view performance metrics in different types of charts, depending on the selected object and metric type, as described in Table 10-4.
Table 10-4 Performance Chart Types
Chart Type |
Description |
Example |
|---|---|---|
Line chart |
Displays metrics for a single inventory object, where data for each metric is represented by a separate line. |
For example, Aa network chart for a host can contain one line showing the number of packets received and another line showing the number of packets transmitted. |
Bar chart |
Displays metrics for objects, where each bar represents metrics for an object. |
A bar chart can display metrics for datastores, where each datastore is represented as a bar. Each bar displays metrics based on the file type, such as virtual disk or snapshot. |
Pie chart |
Displays metrics for a single object, where each slice represents a category or child object. |
A datastore pie chart can display the amount of storage space occupied by each virtual machine or by each file type. |
Stacked Chart |
Displays metrics for child objects. |
A host’s stacked CPU usage chart displays metrics for the 10 virtual machines on the host that are consuming the most CPU. The Other amount displays the total CPU usage of the remaining virtual machines. |
Overview and advanced performance charts are available for data center, cluster, host, resource pool, vApp, and virtual machine objects. Overview performance charts are also available for datastores and datastore clusters. Performance charts are not available for network objects. Charts are organized into views, which you can use to see related data together on one screen. You can specify the time range or data collection interval. Advanced charts contain more information than overview charts. You can print, configure, and export advanced charts (PNG, JPEG, or CSV formats).
Overview Performance Charts
You can use the vSphere Client to examine the overview performance charts for data centers, clusters, datastores (and datastore clusters), hosts, resource pools, vApps, and virtual machines.
To view a performance chart, you can use the following procedure:
Step 1. In the vSphere Client, select an appropriate object in the inventory pane and navigate to Monitor > Performance.
Step 2. Select a view.
Step 3. Select a predefined or custom time range.
Table 10-5 lists the available performance chart views by object type.
Table 10-5 Views by Object Type
Object Type |
View List Items |
|---|---|
Data center |
Clusters: Thumbnail CPU and memory charts for each cluster and stacked charts for total data center CPU and memory. Storage: Space utilization charts for each datastore by file type. |
Datastore and datastore cluster |
Space: Space utilization charts by datastore, by file type, and by virtual machine. Performance: Disk performance (latency, throughput, and queuing) charts for the datastore (or datastore cluster, when Storage DRS is enabled) by virtual machine, by virtual disk, and by file type. |
Cluster |
Home: CPU and memory charts for the cluster. Resource pools and virtual machines: Thumbnail charts for resource pools and virtual machines and stacked charts for total cluster CPU and memory usage. Hosts: Thumbnail charts for each host and stacked charts for total cluster CPU, memory, disk usage, and network usage. |
Host |
Home: CPU, memory, disk, and network charts for the host. Virtual machines: Thumbnail charts for virtual machines, and stacked charts for total CPU usage and total host memory usage. |
Resource Pool |
Home: CPU and memory charts for the resource pool. Resource pools and virtual machines: Thumbnail charts for resource pools and virtual machines and stacked charts for total resource CPU and memory usage. |
vApps |
Home: CPU and memory charts for the resource pool. Resource pools and virtual machines: Thumbnail charts for resource pools and virtual machines and stacked charts for total vApp CPU and memory usage. |
Virtual Machine |
Storage: Space utilization charts for the virtual machine by file type and by datastore. Fault tolerance: CPU and memory charts that display metrics for the fault-tolerant primary and secondary virtual machines. Home: CPU, memory, network, and host thumbnail charts and disk performance charts for the virtual machine. |
Note
When Storage I/O Control is disabled, the values for the Storage I/O Normalized Latency metrics are zeros.
Advanced Performance Charts
For more granularity, you can use advanced performance charts or create your own custom charts. Advanced performance charts are especially useful when overview performance charts do not provide sufficient data for troubleshooting a specific issue. Advanced performance charts include the following features:
Customizable: You can change and save chart settings.
More information: You can include data counters that are not supported in other performance charts. You can hover over a data point to see details at that point.
Exportable: You can save an image to a file or spreadsheet. You can export the data to a spreadsheet.
Figure 10-1 shows an example of an advanced performance chart that includes memory metrics for a virtual machine.
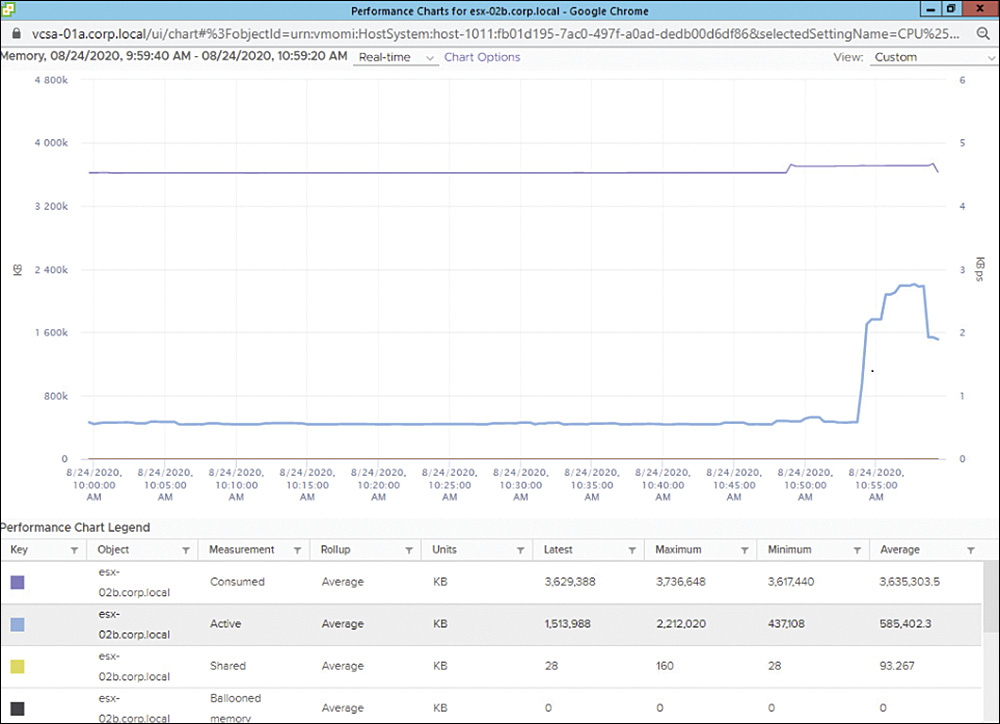
FIGURE 10-1 Sample Advanced Performance Chart
You can use the following procedure to access an advanced performance chart:
Step 1. In the vSphere Client, select an appropriate object in the inventory pane and navigate to Monitor > Performance.
Step 2. Click Advanced.
Step 3. Optionally, select an appropriate view from View drop-down list.
Step 4. Optionally, click the Popup Chart icon to open the chart in a separate window.
Step 5. Click Chart Options.
Step 6. Under Chart Metrics, select an appropriate metric group.
Step 7. Select a timespan. If you choose Custom Interval, then select one of the following:
Last: Specify the number of hours, days, weeks, or months.
From: Specify beginning and ending times.
Step 8. Under Target Objects, select the appropriate inventory objects. (Optionally, use the All or None buttons.)
Step 9. Select an appropriate chart type.
Step 10. Under Counters, select the data counters to display in the chart. (Optionally, use the All or None buttons.)
Step 11. Optionally, click Save Options As and save your settings as a custom chart.
Note
Pop-up charts are useful for maximizing the available real estate for a chart and for comparing two separate charts side by side.
Note
For the stacked graph type, you can use only one measurement unit. In addition, per-virtual-machine stacked graphs are available only for hosts. You can click on a counter’s description name to display details, such as whether the selected metric can be stacked for each virtual machine.
After you create a custom chart, the chart is added to the View drop-down list. You can then use the chart in the same manner that you would any prebuilt view.
You can use the following procedure to delete a custom chart:
Step 1. In the vSphere Client, select an appropriate object in the inventory pane and navigate to Monitor > Performance.
Step 2. Select Advanced > Chart Options.
Step 3. Select the chart and click Delete Options.
You can use the following procedure to save data from an advanced performance chart to a file either in a graphic format or in a comma-separated values (CSV) format:
Step 1. In the vSphere Client, select an object in the inventory pane and navigate to Monitor > Performance.
Step 2. Click Advanced.
Step 3. Optionally, select a view or change chart options until you are satisfied with the chart.
Step 4. Click the Export icon.
Step 5. Select one of the following options:
To PNG: Exports a bitmap image to PNG format.
To JPEG: Exports a bitmap image to JPEG format.
To CSV: Exports text data to CSV format.
To SVG: Exports a vector image to SVG format.
Step 6. Provide a filename and location.
Step 7. Click Save.
Troubleshooting and Optimizing Performance
Table 10-6 provides the likely causes and potential solutions for some sample symptoms, based on vSphere performance metrics.
Table 10-6 CPU Performance Analysis
Symptoms |
Likely Causes |
Potential Solutions |
|---|---|---|
Host: CPU usage is consistently high. Virtual machine: CPU usage is above 90%. CPU ready is above 20%. Application performance is poor. |
The host has insufficient CPU resources to meet the demand. Too many virtual CPUs are running on the host. Storage or network operations are placing the CPU in a wait state. The guest OS generates too much load for the CPU. |
Add the host to a DRS cluster. Increase the number of hosts in the DRS cluster. Migrate one or more virtual machines to other hosts. Upgrade the physical CPUs of the host. Upgrade ESXi to the latest version. Enable CPU-saving features such as TCP segmentation offload, large memory pages, and jumbo frames. Increase the amount of memory allocated to the virtual machines, which may improve cached I/O and reduce CPU utilization. Reduce the number of virtual CPUs assigned to virtual machines. Ensure that VMware Tools is installed. Compare the CPU usage of troubled virtual machines with that of other virtual machines on the host or in the resource pool. (Hint: Use a stacked graph.) Increase the CPU limit, shares, or reservation on the troubled virtual machine. |
Host: Memory usage is consistently 94% or higher. Free memory is 6% or less. Virtual machine: Swapping is occurring. (Memory usage may be high or low.) |
The host has insufficient memory resources to meet the demand. |
Ensure that VMware Tools is installed and that the balloon driver is enabled for all virtual machines. Reduce the memory size on oversized virtual machines. |
|
|
Reduce the memory reservation of virtual machines where it is set higher than needed. Add the host to a DRS cluster. Increase the number of hosts in the DRS cluster. Migrate one or more virtual machines to other hosts. Add physical memory to the host. |
Virtual machine: Memory usage is high. Guest OS: Memory usage is high. Paging is occurring. |
The guest OS is not provided sufficient memory by the virtual machine. |
Increase the memory size of the virtual machine. |
Virtual machine: CPU ready is low. Guest OS: CPU utilization is high. |
The guest OS is not provided sufficient CPU resources by the virtual machine. |
Increase the number of CPUs for the virtual machine. Migrate the virtual machine to a host with faster CPUs. |
Datastore: Space utilization is high. |
Snapshot files are consuming a lot of datastore space. Some virtual machines are provisioned with more storage space than required. The datastore has insufficient storage space to meet the demand. |
Delete or consolidate virtual machine snapshots. Convert some virtual disks to thin provisioned. Migrate one or more virtual machines (or virtual disks) to other datastores. Add the datastore to a Storage DRS datastore cluster. Add datastores with available space to the datastore cluster. Add more storage space to the datastore. |
Disk: Device latency is greater than 15 ms. |
Problems are occurring with the storage array. |
Migrate the virtual machines to datastores backed by other storage arrays. |
Disk: VMkernel latency is greater than 4 ms. Queue latency is greater than zero. |
The maximum throughput of a storage device is not sufficient to meet the demand of the current workload. |
Migrate the virtual machines to datastores backed by storage devices (LUNs) with more spindles. Balance virtual machines and their disk I/O across the available physical resources. Use Storage DRS I/O balancing. Add more disks (spindles) to the storage device backing the datastore. Configure the queue depth and cache settings on the RAID controllers. Adjust the Disk.SchedNumReqOutstanding parameter. Configure multipathing. Increase the memory size of the virtual machine to eliminate any guest OS paging. Increase the guest OS caching of disk I/O. Ensure that no virtual machine swapping or ballooning is occurring. Defragment guest file systems. Use eager zeroed thick provisioned virtual disks. |
Network: The number of packets dropped is greater than zero. Latency is high. The transfer rate is low. |
The maximum throughput of a physical network adapter is not sufficient to meet the demand of the current workload. Virtual machine network resource shares are too few. Network packet size is too large, which results in high network latency. Use the VMware AppSpeed performance monitoring application or a third-party application to check network latency. Network packet size is too small, which increases the demand for the CPU resources needed for processing each packet. Host CPU, or possibly virtual machine CPU, resources are not enough to handle the load. |
Install VMware Tools on each virtual machine and configure the guest OS to use the best-performing network adapter driver (such as vmxnet3). Migrate virtual machines to other hosts or to other physical network adapters. Verify that all NICs are running in full duplex mode. Implement TCP Segmentation Offload (TSO) and jumbo frames. Assign additional physical adapters as uplinks for the associated port groups. Replace physical network adapters with high-bandwidth adapters. Place sets of virtual machines that communicate with each other regularly on the same ESXi host. |
Performance charts are empty. |
Some metrics are not available for pre-ESXi 5.0 hosts. Data is deleted when you remove objects to vCenter Server or remove them. Performance chart data for inventory objects that were moved to a new site by VMware vCenter Site Recovery Manager is deleted from the old site and not copied to the new site. Performance charts data is deleted when you use VMware vMotion across vCenter Server instances. Real-time statistics are not available for disconnected hosts or powered-off virtual machines. |
Upgrade hosts to a later version of ESXi. Allow time for data collection on objects that were recently added, migrated, or recovered to the vCenter Server. Power on all hosts and allow time for real-time statistics to collect. Allow time for the required roll-ups for non-real-time statistics. |
|
Non-real-time statistics are rolled up at specific intervals. For example, 1-day statistics might not be available for 30 minutes after the current time, depending on when the sample period began. The 1-day statistics are rolled up to create one data point every 30 minutes. If a delay occurs in the roll-up operation, the 1-week statistics might not be available for 1 hour after the current time. It takes 30 minutes for the 1-week collection interval, plus 30 minutes for the 1-day collection interval. The 1-week statistics are rolled up to create one data point every two hours. If a delay occurs in the roll-up operations, the 1-month statistics might not be available for 3 hours. It takes 2 hours for the 1-month collection interval, plus 1 hour for the 1-week collection interval. The 1-month statistics are rolled up to create one data point every day. If a delay occurs in the roll-up operations, the statistics might not be available for 1 day and 3 hours. It takes 1 day for the past year collection interval, plus 3 hours for the past month collection interval. During this time, the charts are empty. |
|
Monitoring and Managing Cluster Resources
On a Summary tab for a vSphere DRS cluster, you can see the Capacity, Used, and Free metrics for CPU, Memory, and Storage resources in the upper-right corner, as shown in Figure 10-2.
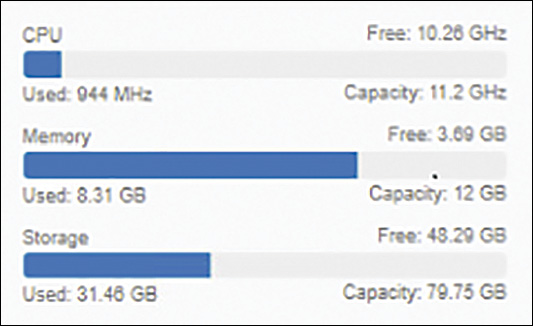
FIGURE 10-2 DRS Cluster Resource Usage
To examine the CPU and memory usage more closely, you can navigate to Monitor > vSphere DRS and select CPU Utilization or Memory Utilization. Each of these pages shows a bar graph, where each bar represents the total resource (CPU or memory) usage of a specific host and each bar is split into sections representing the resource usage of individual virtual machines. Likewise, you can select Monitor > vSphere DRS > Network Utilization to examine the network utilization of each host in the cluster.
The Summary tab shows the vSphere DRS score, the number of DRS recommendations, and the number of DRS faults, as shown in Figure 10-3.
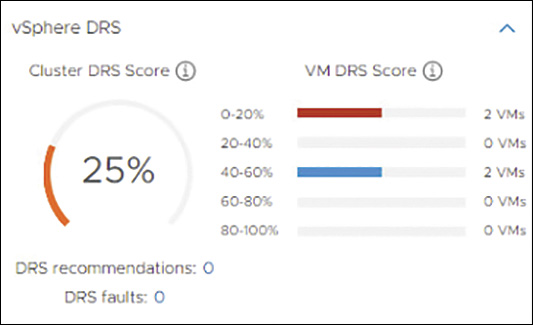
FIGURE 10-3 Sample DRS Score
If DRS is in manual mode, you can click on the number of DRS recommendations on the summary tab, which is a link that takes you to the DRS Recommendations page. On the DRS Recommendations page, you can view the current recommendations, select those that you want to apply, and click the Apply Recommendations button. Each recommendation includes a description, such as which virtual machine to migrate to which host, and a reason, such as balance average memory loads.
Optionally, you can click the Run DRS Now button to make DRS perform its analysis and potentially generate new recommendations.
Monitoring and Managing Resource Pool Resources
To view resource pool configuration details, you can select a DRS cluster in the inventory pane and navigate to Hosts > Resource Pools. On that page, you can see all the resource pools that are direct children of the cluster. For each pool, you see the CPU and memory resource settings, including Reservation, Limit, Shares Setting (such as Low or Custom), Shares Value (numeric share value), and Allocation Type (Expandable or non-Expandable). You can click on the name of a resource pool, which is a link to the pool’s Summary page, which shows the current capacity, usage, and free compute resources for the resource pool. The summary page also shows the number of virtual machines, powered-on virtual machines, child resource pools, and vApps in the pool.
For more detail, you can navigate to Monitor > Utilization or to Monitor > Resource Allocation and select CPU, Memory, or Storage. For both CPU and memory resources, the Utilization page shows the resource configuration and the consumed, active, and worst-case allocation. The Utilization page also shows a breakdown of guest memory, including the Active Guest Memory, Swapped, Compressed, and Ballooned metrics.
You can use overview and advanced performance charts with resource pools. When you see undesired behavior, you can edit the settings for an existing resource pool to change the pool’s CPU and memory shares, reservations, and limits. For example, consider a scenario where you configure two resource pools in a cluster with 100 GHz CPU capacity. In a pool with 40 virtual machines, you set CPU Shares to High. In another pool, which has 8 virtual machines, you set CPU Shares to Normal. You see in the performance charts that the virtual machines in the pool with the 40 virtual machines have greater CPU Ready values than the virtual machines in the other pool. You realize that although you used higher CPU shares for the first pool, the virtual machines are experiencing more CPU contention than are virtual machines in the second pool. To correct this, you could take one of the following actions:
Increase the CPU shares on the first pool by using a custom value.
Change the CPU shares on the second pool to Low.
Set an appropriate CPU reservation on the first pool.
Set an appropriate CPU limit on the second pool.
Change the configuration to use scalable shares.
Monitoring and Managing Host Resources and Health
You can use the vSphere Client to monitor the state of host hardware components, such as CPUs, memory, fans, temperature, voltage, power, network, battery, storage, cable (interconnect), software components, watchdog, and PCI devices. To view the host hardware health status with the vSphere Client, you can use the following procedure:
Step 1. In the vSphere Client, select host in the inventory pane and navigate to Monitor > Hardware Health.
Step 2. Select the type of information to view:
Sensors
Storage Sensors
Alerts and Warnings
System Event Log
The host health monitoring tool presents data gathered using Systems Management Architecture for Server Hardware (SMASH) profiles. The information displayed depends on the sensors available on the server hardware.
Note
You can also set alarms to trigger when the host health status changes.
If you participate in the Customer Experience Improvement Program (CEIP), you can configure Skyline Health to perform online health checks. If CEIP is not enabled, the Internet connectivity check is unavailable. You can use the following procedure to configure Skyline Health:
Step 1. In the vSphere client, select a vCenter Server or a host in the inventory pane and navigate to Monitor > Skyline Health.
Step 2. Expand the Online Health Connectivity category and select one of the following options:
CEIP: Verifies whether CEIP is enabled for the vCenter Server.
Online Health Connectivity (Internet check): Verifies vCenter Server to vmware.com connectivity via HTTPS/443.
Advisor: Provides additional features, such as automatic support log bundle transfer with Log Assist. (Advisor is included in Production and Premier Support contracts.)
Audit CEIP Collected Data: Allows you to view data collected and sent for CEIP.
Number of Online Health Checks Performed Successfully: Indicates, as it says, how many checks have been performed successfully.
Step 3. Expand the following categories and examine the related health warnings:
Compute Health Checks
Network Health Checks
Security Health Check
Storage Health Checks
General Health Checks
Step 4. Click Retest to run the health checks immediately.
Step 5. Optionally, if issues are discovered, click the Ask VMware button to request a knowledge base article that describes how to resolve the issue.
Monitoring and Managing Virtual Machine Resources
Table 10-7 lists and describes some of the key metrics for monitoring virtual machines.
Table 10-7 Virtual Machine Metrics
Metric |
Unit |
Description |
|---|---|---|
CPU Usage |
% |
Indicates the CPU workload for the virtual machine. |
ms |
Indicates the amount of time a virtual CPU is ready to work (that is, has a workload and is ready to be scheduled) but is waiting to be scheduled on hardware. High CPU Ready Time is a sign of CPU contention. |
|
Memory Consumed |
KB |
Indicates the amount of physical memory currently backing the virtual machine. |
Memory Active |
KB |
Indicates the amount of consumed memory that is actively being read or written by the guest OS. |
Memory Swap In Rate |
Kbps |
Indicates the amount of memory read from the virtual machine’s swap file over time. |
Disk Usage |
Kbps |
Indicates the disk throughput. |
Virtual Disk Read Latency |
ms |
Indicates the average amount of time for a read operation to complete. |
Network Usage |
Kbps |
Indicates the amount of data transmitted and received over time. |
Network Transmit Packets Dropped |
number |
Indicates the number of packets transmitted to the network that were dropped. |
Shares, Limits, and Reservations
You can set the CPU and memory shares, reservation, and limit on a virtual machine by using the following procedure:
Step 1. In the vSphere Client, right-click your virtual machine in the inventory and select Edit Settings.
Step 2. Edit the Shares, Reservation, and Limit values under CPU Resources.
Step 3. Set the Shares, Reservation, and Limit values under Memory Resources.
Step 4. Click OK.
The relative priority represented by each share changes whenever additional sibling virtual machines are powered on or powered off. Likewise, each share’s relative priority changes whenever the shares on siblings are increased or decreased. This affects all virtual machines in the same resource pool.
For example, consider the following scenario:
All virtual machines have the same number of vCPUs.
Two virtual machines are run in a resource pool with CPU Limit set to 8 GHz.
The virtual machines are CPU bound (that is, they are demanding more CPU resources than they are receiving).
The virtual machines’ CPU shares are set to Normal.
You should expect each virtual machine’s performance chart to show CPU Utilization as 4 GHz.
When you power on a third CPU-bound sibling virtual machine with CPU Shares value set to High, you should expect to see that the new virtual machine uses 4 GHz and the first two machines drop to 2 GHz each.
To understand the impact of shares, consider another scenario, where a set of sibling virtual machines are frequently CPU bound and are using all the resources in their parent resource pool. During these periods of CPU contention in the resource pool, you see significantly high CPU Ready Time values on each of the virtual machines. You are only concerned about improving the performance of one specific virtual machine, so you increase its CPU Shares value. The CPU’s Ready Time setting for that machine should decrease during periods of CPU contention, and the CPU Ready Time settings of its siblings should rise.
To guarantee that a specific amount of resources are always available to a running virtual machine, even when the physical server is heavily loaded, you can set its CPU or memory reservation. The vCenter Server or ESXi host allows you to power on a virtual machine only if there are enough unreserved resources to satisfy the virtual machine’s reservation. Likewise, your attempts to increase the reservation on a running virtual machine (or a resource pool) succeed only if there are enough unreserved resources to satisfy the request. In the previous scenario, if you want to ensure that a virtual machine always has access to at least 1 GHz, regardless of the number or resource settings of siblings, you should set its CPU reservation to 1 GHz.
Note
The default CPU and memory reservation for a virtual machine is zero, meaning that its guest OS is not guaranteed any specific amount of either resource. Instead, with default settings, shares would be applied during periods of compute resource contention.
You can set limits for CPU, memory, and storage I/O for a virtual machine to establish an upper bound (maximum) amount of resources that can be allocated to the virtual machine. The host never allocates more than the limit, even when there are unused resources on the system. By default, the limits are set to Unlimited, which means the virtual machine’s configured memory becomes its effective limit. Using limits has both benefits and drawbacks:
Benefits: If you are concerned that the performance of a virtual machine may deteriorate as you add virtual machines to the cluster, you could set limits on the virtual machine to simulate having fewer available resources and measure its performance.
Drawbacks: You might be wasting idle resources because the system prevents virtual machines from exceeding the limits that you set, even when the system is underutilized and idle resources are available.
Note
If you want to reduce the risk that a virtual machine may consume excessive resources and impact the performance of other virtual machines, you can consider setting low shares on the virtual machine. Low shares decrease the virtual machine’s access to the resource during periods of resource contention but also do not prevent the virtual machine from using idle resources.
Admission Control
When you power on a virtual machine, the system checks the amount of available unreserved CPU and memory resources. The system determines whether it can guarantee the reservation for the virtual machine. This process is called admission control. If enough unreserved CPU and memory are available (or if there is no reservation), the virtual machine is powered on. Otherwise, an “Insufficient Resources” warning appears.
Note
Each virtual machine, including those with no user-specified memory reservation, may have some reservation for its memory overhead. The memory overhead reservation is considered by admission control.
Note
When the vSphere Distributed Power Management (DPM) feature is enabled and some hosts are in standby mode, their unreserved resources are considered available for admission control. If a virtual machine cannot be powered on without these resources, vSphere DPM makes a recommendation to power on one or more standby hosts.
VMware Tools and Microsoft Windows Perfmon
When VMware Tools is installed, VMware provides performance counters that enable you to view data within a Windows guest OS by using the Microsoft Windows Perfmon utility. VMware provides virtual machine–specific performance counter libraries for the Windows Perfmon utility, which enables administrators to accurately examine virtual machine usage data and guest OS usage data within the same pane of glass.
For a Windows virtual machine where VMware Tools is installed, you can use the following procedure to examine Vmware-specific statistics in the Windows Perfmon utility:
Step 1. Log on to Windows and click Start > Run.
Step 2. Enter Perfmon and press Enter.
Step 3. In the Performance dialog box, click Add.
Step 4. In the Add Counters dialog box, select Use Local Computer Counters.
Step 5. Select a performance object whose name begins with VM (that is, a virtual machine performance object).
Step 6. Select the counters that you want to display for that object.
Step 7. If the performance object has multiple instances, select the instances you want to display.
Step 8. Click Add.
Step 9. Examine the data for the selected performance object.
Step 10. Click Close.
Latency Sensitivity
If you have a latency-sensitive application, such as voice over IP (VOIP) or a media player application, you can edit the virtual machine’s settings and set VM Options > Advanced >Latency Sensitivity to High. With this setting, you should ensure that all the virtual machine’s configured CPU and memory are reserved. With this setting, the system effectively gives exclusive physical CPU access to each virtual CPU. If the virtual machine is in a DRS cluster, DRS automatically creates a VM-Host soft affinity rule.
The Impact of Virtual Machine Configurations
The specific settings you make for a virtual machine can impact its performance, as summarized in Table 10-8.
Table 10-8 The Impact of Virtual Machine Configurations
Configuration |
Impact |
|---|---|
Compute oversize/undersize |
An oversized compute size for a virtual machine may result in wasted resources. With an undersized compute size, the virtual machine may experience poor performance. |
Virtual disk oversize/undersize |
An oversized virtual disk may result in wasted resources. With an undersized virtual disk, the virtual machine may experience denial of service. |
VMDK provisioning types |
If a virtual disk is thin provisioned, then you may be maximizing the use of your storage space while decreasing the virtual machine’s performance and increasing its risk of denial of service. |
Resource reservations |
If a resource is reserved, you may be improving and guaranteeing the guest OS performance while reducing the density of virtual machines on the resource. |
Independent disks |
If a virtual disk is set to independent mode, then you are prevented from taking snapshots of it. If it is set to Independent–Nonpersistent, all changes are discarded when you power off or reset the virtual machine. |
Guest OS type |
The choice for the guest OS type during virtual machine creation directly impacts the type of virtual devices that are used in the virtual machine. |
VMware Tools version |
The VMware Tools version impacts the set of device drivers it provides to the guest OS. |
Permissions |
The permissions set on a virtual machine impacts who can use (power on, open a console), who can modify (change virtual hardware settings), and who can manage (set permissions, migrate) the virtual machine. |
Other Virtual Machine Resource Management Features
You can configure virtual machines to support SRIOV, VGPU, RDMA, and DirectPath I/O passthrough, as discussed in Chapter 14, “Managing Virtual Machines.”
ESXTOP
ESXTOP is a utility that provides a detailed real-time look at resource usage from the ESXi Shell. You can run ESXTOP in Interactive, Batch, or Replay mode. You must have root user privileges. RESXTOP is a similar tool that can be installed and run from a Linux server and connected to ESXi hosts.
By default, when you issue the command esxtop, the utility opens in interactive mode to show the CPU panel, where statistics for each virtual machine and other groups are displayed in separate rows. To see just virtual machines statistics, you can press Shift+V. Each column provides CPU statistics, such as %USED, %WAIT, %RDY, %CSTP, and %SWPWT. To see statistics for the multiple worlds (processes) that comprise a virtual machine, you can press the E key and enter the virtual machine’s ID. Figure 10-4 shows an example of an ESXTOP CPU panel, displaying virtual machine statistics with one virtual machine (GID 33791) expanded.
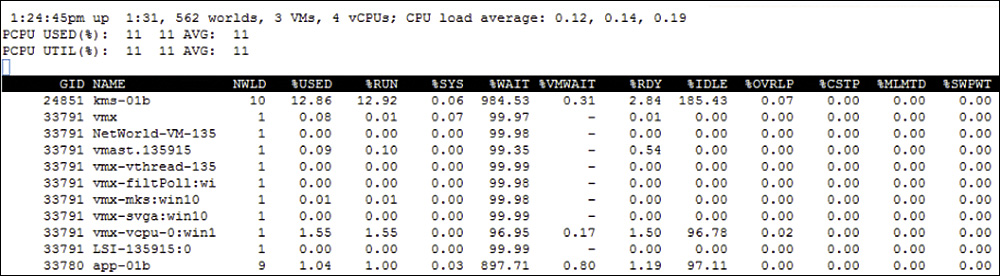
FIGURE 10-4 Sample ESXTOP CPU Panel
You can change the view from the CPU panel to other panels by using keystrokes. For example, you can press M Key for the memory panel, V Key for the virtual machine storage panel, or N Key for the network panel. Table 10-9 describes some of the key statistics available for each panel.
Table 10-9 Key ESXTOP Panels and Metrics
Panel |
Statistic |
Description |
|---|---|---|
CPU |
%USED |
Percentage of physical CPU core cycles used by the virtual machine. |
CPU |
%RUN |
Percentage of total time scheduled for the virtual machine without accounting for hyperthreading, system time, co-stopping, and waiting: %RUN = 100% – %RDY – %CSTP – %WAIT |
CPU |
%RDY |
Percentage of time the virtual machine was ready to run but was not provided CPU resources on which to execute. Indicator of CPU contention on the host. |
CPU |
%WAIT |
Percentage of time the virtual machine spent in the blocked or busy wait state, including idle time. %WAIT includes %SWPWT. |
CPU |
%CSTP |
Percentage of time a virtual machine spends in a ready, co-deschedule state. A high value indicates that the virtual machine’s multiple CPUs are in contention. |
CPU |
%SWPWT |
Percentage of time a virtual machine spends waiting for the host to swap memory. |
Memory |
MEMSZ |
Amount of physical memory allocated to a virtual machine: MEMSZ = GRANT + MCTLSZ + SWCUR + “Never Touched” |
Memory |
GRANT |
Amount of guest physical memory mapped to a virtual machine |
Memory |
CNSM |
Amount of the memory consumed by the virtual machine: CNSM = GRANT – Shared Memory |
Memory |
SWCUR |
Amount of memory swapped by the virtual machine. |
Memory |
SWR/s |
Rate at which the host swaps in memory from disk for the virtual machine. |
Memory |
OVHD |
Amount of memory used for virtual machine overhead, which is memory charged to the virtual machine that is not used by the guest OS. |
Virtual Machine Storage |
READS/s |
Number of read commands issued per second. |
Virtual Machine Storage |
WRITES/s |
Number of write commands issued per second. |
Virtual Machine Storage |
MBREAD/s |
Megabytes read per second. |
Virtual Machine Storage |
LAT/rd |
Average latency (in milliseconds) per read. |
Network |
PKRRX/s |
Number of packets received per second. |
Network |
MbTX/s |
Megabits transmitted per second. |
Network |
%DRPTX |
Percentage of transmit packets dropped. Indicates that the physical network adapter cannot meet the demand, perhaps due to load from other virtual machines. |
Network |
%DRPRX |
Percentage of receive packets dropped. Indicates that insufficient CPU resources are available for network processing. |
Note
The Network panel contains a row for each NIC in a virtual machine rather than a row for each virtual machine. The E and Shift+V keystrokes are not applicable to the Network panel.
You can use the -b argument to run ESXTOP in batch mode, in which you collect statistics in a CSV file. You can later manipulate this file with other tools, such as Microsoft Perfmon or Excel. For example, you can use the following command to collect statistics in a file named mydata.csv:
esxtop -b > mydata.csv
You can use ESXTOP in Replay mode, where it uses pre-collected data rather than real-time data. To collect the data, you should run vm-support in Snapshot mode, specifying the data collection interval and duration (in seconds), as shown in the following example:
vm-support -S -d 3600 -I 5
After collecting the data, you must unpack and decompress the resulting tar file. Then you can run ESXTOP in Replay mode, providing the path to the data file, as shown here:
esxtop -R vm-support_dir_path
VIMTOP
VIMTOP is a tool you can run in vCenter Server Appliance to see resource usage for the services that are running. It is like ESXTOP but displays services, such as vCenter Server, Certificate Manager, vPostgres, and ESXi Agent Manager, rather than virtual machines and ESXi worlds (processes). You can use VIMTOP to identify which service is using the most compute, disk, or network resources whenever vCenter Server is running poorly.
vCenter Server Appliance Management Interface (VAMI)
In the vCenter Server Appliance Management Interface (VAMI), you select Monitor to view the resource usage of the vCenter Server. To see compute usage graphs, select Monitor > CPU and Memory. To see the usage of each storage partition, select Monitor > Disks. To use a graph where you can select and view specific network metrics, select Monitor > Network.
You can navigate to Monitor > Database to view database utilization of alarms, events, tasks, and statistics. You can also view the overall space utilization of the database and database log.
Events, Alarms, and Automated Actions
A configurable events and alarms subsystem exists in vSphere that tracks events throughout vSphere and stores the data in log files and in the vCenter Server database. It enables you to specify the conditions under which alarms are triggered. Alarms can change state from normal (green) to warning (yellow) to alert (red), depending on changing conditions. Triggered alarms can automatically launch alarm actions.
Events
Events are simply recorded incidents, such as user actions or system actions, that occurred involving a host or any object managed by vCenter Server. The following are a few examples:
A license key expires.
A virtual machine is migrated.
A virtual machine is powered on.
A host connection is lost.
Event data includes details such as who generated it, when it occurred, and what type of event it was. Table 10-10 describes the types of events
Table 10-10 Event Types
Event Type |
Description |
|---|---|
Audit |
Provides data concerning events that are tracked because that data is crucial for the security framework. The data includes action details, such as who did it, when it occurred, and the IP address of the user. |
Information |
Indicates that the operation completed successfully. |
Warning |
Indicates a potential risk to the system that needs to be addressed. This event does not terminate the process or operation. |
Alert |
Indicates that a fatal problem has occurred in the system and terminates the process or operation. |
Viewing Events in the vSphere Client
You can use the following procedure to view events in the vSphere Client:
Step 1. In the vSphere Client, select an object in the inventory pane and navigate to Monitor > Events.
Step 2. Select an event to see its details.
Step 3. Use the column headings to sort the events, show columns, hide columns, and filter the events.
Viewing the System Event Log
To view system events that are recorded in the vCenter Server database, you can use the following procedure:
Step 1. Log on to the vSphere Client as a user with the Global.Diagnostics privilege.
Step 2. Select the vCenter Server in the inventory pane.
Step 3. Navigate to Monitor > Hardware Health.
Step 4. Click System Event Log.
Step 5. Optionally, click Export.
Streaming Events to a Remote Syslog Server
You can enable remote streaming, such that the vCenter Server streams newly generated events to a remote syslog server. In the syslog server, the events have the following format:
<syslog-prefix> : Event [eventId] [partInfo] [createdTime] [eventType] [severity] [user] [target] [chainId] [desc]
Messages that are longer than 1024 characters are split into multiple syslog messages.
Note
In an environment with no more than 30 hosts, you can configure hosts to send log files to a vCenter Server rather than store them to a local disk. This option is intended for smaller environments with stateless ESXi hosts. For all other cases, VMware recommends that you use a dedicated log server.
As an alternative to streaming events, you can forward events. When you forward events, the events are sent to a remote server rather than recorded.
You can use the following procedure to forward vCenter Server logs to a remote syslog server:
Step 1. Log on to VAMI as root.
Step 2. Select Syslog.
Step 3. In the Forwarding Configuration section, click Configure.
Step 4. In the Create Forwarding Configuration pane, enter the server address of the destination host. The maximum number of supported destination hosts is three.
Step 5. Select a protocol (TLS, TCP, RELP, or UDP) to use.
Step 6. Provide a port number.
Step 7. Optionally, add more destination servers.
Step 8. Click Save.
Step 9. Optionally, click Send Test Message.
You can configure the writing of events to the vCenter Server streaming facility. Streaming events is disabled by default. You can use the following procedure to stream events to a remote syslog server:
Step 1. In the vSphere Client, select the vCenter Server in the inventory pane and navigate to Configure > Settings > Advanced Settings.
Step 2. Click Edit.
Step 3. Enable the vpxd.event.syslog option.
Alarms
An alarm is a notification that is activated in response to an event, a set of conditions, or the state of an inventory object. Table 10-11 describes the elements that are used in an alarm definition
Table 10-11 Alarm Definition Elements
Element |
Description |
|---|---|
Name |
A name (label) that is used to identify the alarm |
Description |
Text that is useful for understanding the purpose of the alarm |
Targets |
The type of object that is monitored by the alarm |
Alarm Rules |
A set of rules that define the alarm’s triggers, severity, and actions |
Last Modified |
The date of the most recent change to the alarm definition |
For example, you might want to monitor the memory usage of all virtual machines in a specific vSphere cluster. In the vSphere Client, you can select the cluster in the inventory, create an alarm for the cluster, set the alarm’s Targets value to virtual machine, and configure rules with triggers based on memory usage.
Note
You can enable, disable, and modify alarms only from the object at which the alarm is defined. For example, if you define a virtual machine memory alarm on a cluster, you cannot change the alarm at the individual virtual machine level.
Viewing and Acknowledging Triggered Alarms
To view triggered alarm, you can use the following procedure:
Step 1. In the vSphere Client, select an object in the inventory pane and navigate to Monitor > Issues and Alarms.
Step 2. Click Triggered Alarms.
Step 3. Optionally, select an alarm and click Acknowledge.
You can acknowledge an alarm to let other users know that you are taking ownership of the issue and to prevent the alarm from sending more email messages. The alarm, however, is still visible in the system.
Note
After you acknowledge an alarm in the vSphere Client, its alarm actions are discontinued. Alarms are not cleared or reset when acknowledged.
To clear an alarm (that is, reset its state to normal), you need the Alarm.Set Alarm Status privilege. You can select a triggered alarm and choose Reset to Green.
Creating Alarm Definitions
To create or configure an alarm, you must use a user account with the Alarms.Create Alarm or Alarms.Modify Alarm privilege. To create an alarm, you can use the following procedure:
Step 1. In the vSphere client, select an object in the inventory pane and navigate to Configure > More > Alarm Definitions.
Step 2. Click Add.
Step 3. Provide the name, description, target type, and target.
Step 4. Click Next.
Step 5. Create an alarm rule by specifying the following:
Conditions: Trigger, Arguments, Operator, Threshold
Severity: Warning or Critical
Actions: Send Email Notifications, Send SNMP Traps, Run Script
Step 6. Optionally click Add Another Rule, Duplicate Rule, or Remove Rule.
Step 7. Click Next.
Step 8. Specify alarm reset rules by enabling the Reset the Alarm to Green option and providing details, such as arguments, operators, and actions.
Step 9. Click Next.
Step 10. Click Enable this Alarm.
Alarm Actions
Alarm actions are operations that are automatically triggered by alarms. Table 10-12 provides details on available alarm actions.
Table 10-12 Alarm Actions
Action |
Details |
|---|---|
Send Email Notification |
Indicates the recipient email address. Requires that you first configure the mail settings for your vCenter Server. You must set the primary receiver URL to the DNS name or IP address of your SNMP receiver. You should set the receiver port to an appropriate value between 1 and 65535 and set the community string to an appropriate community identifier. |
Send SNMP Traps |
Requires that you first configure the SNMP Receivers settings for your vCenter Server. You must set Mail.Server to the DNS name or IP address of your SMTP gateway. You must set Mail.Sender to the email address of the sender. |
Run Scripts |
Provides the full pathname of the command or script, formatted into a single string. The execution occurs on the vCenter Server Appliance. |
Advanced Actions |
Only applicable to alarms that target virtual machines and hosts. Examples of host actions include Enter Maintenance Mode and Exit Maintenance Mode. Examples of virtual machine actions include Migrate VM and Reboot Guest on VM. |
Advanced Use Cases for Alarms
You can create custom alerts with notifications for many purposes, such as the following:
Something has failed or disconnected (such as host connection failure or VASA provider disconnected).
Something is not performing well (such as excessive CPU ready time, memory swapping, disk latency, or packets dropped).
Health is poor (such as vSAN health, key management server health, vCenter HA cluster health).
Logging in vSphere
It is important that you understand logging in vSphere components and related products and that you be prepared to implement logging.
ESXi Logs
Table 10-13 provides details on most of the ESXi log files, including the location and purpose of each of them. You should become familiar with each of them and learn which logs are useful for various troubleshooting scenarios. For example, when troubleshooting virtual machine issues, the only directly useful logs are vmkernel, vmkwarning, hostd, and the specific virtual machine’s log files. When troubleshooting issues related to the connection between an ESXi host and the vCenter Server, the vpxa log is most useful.
Table 10-13 ESXi Log Files
Component |
Location |
Description |
|---|---|---|
VMkernel |
/var/log/vmkernel.log |
Data related to virtual machines and ESXi |
VMkernel warnings |
/var/log/vmkwarning.log |
Data related to virtual machines |
VMkernel summary |
/var/log/vmksummary.log |
Data related to uptime and availability statistics for ESXi |
ESXi host agent |
/var/log/hostd.log |
Data related to the agent that manages and configures the ESXi host and its virtual machines |
vCenter agent |
/var/log/vpxa.log |
Data related to the agent that communicates with vCenter Server |
ESXi Shell |
/var/log/shell.log |
Data related to each command typed into the ESXi Shell as well as shell events |
Authentication |
/var/log/auth.log |
Data related to event authentication for the local system |
System messages |
/var/log/syslog.log |
General log messages that can be used for troubleshooting |
Virtual machines |
vmware.log located in the same folder as the virtual machine configuration file. |
Data related to virtual machine power events, system failure information, tool status and activity, time sync, virtual hardware changes, vMotion migrations, machine clones, and more |
Trusted infrastructure agent |
/var/run/log/kmxa.log |
Data related to the client service on the ESXi trusted host |
Key provider service |
/var/run/log/kmxd.log |
Data related to the vSphere Trust Authority key provider service |
Attestation service |
/var/run/log/attestd.log |
Data related to the vSphere Trust Authority attestation service |
ESX token service |
/var/run/log/esxtokend.log |
Data related to the vSphere Trust Authority ESXi token service |
ESX API forwarder |
/var/run/log/esxapiadapter.log |
Data related to the vSphere Trust Authority API forwarder |
Quick Boot |
/var/log/loadESX.log |
Data related to restarting an ESXi host through Quick Boot |
You can use the ESXi host client to examine the logs on a specific ESXi host by navigating to Monitor > Logs and selecting a specific log file. You can scroll through the log and search for specific text. You can select a log, click Actions, and choose Open in New Window or Generate a Support Bundle.
Likewise, you can use the ESXi Direct Console User Interface (DCUI) to view system logs. In the DCUI, after you click View System Logs and select the log you want, you can use the Enter key (or Spacebar) to scroll through the log messages and press the forward slash (/) key to begin a search.
If you have the Global.Diagnostics privilege, you can also use the vSphere Client to export a host’s system logs by following these steps:
Step 1. In the vSphere Client, right-click an ESXi host in the inventory pane.
Step 2. Click Export System Logs.
Step 3. Select the appropriate objects.
Step 4. Optionally, click Gather Performance Data.
Step 5. Optionally, provide a password for encrypted coredumps.
Step 6. Click Export Logs.
Step 7. Monitor the status of the Downloading Log Bundles task in the Recent Tasks pane.
When you finish this process, the file is located in the default location. On a Windows desktop, the location is the Downloads folder, and the filename begins with VMware-vCenter-support.
Note
In step 3, you can select or deselect entire categories, such as System, Virtual Machines, and Storage. You can also select or deselect specific objects within each category, such as logs and coredumps.
You can collect ESXi log files by using the /usr/bin/vm-support command, which generates a file named using the following format:
esx-date-unique-xnumber.tgz
vCenter Server Logs
The main logs in a vCenter Server appliance are located in /var/log/vmware. The most important logs are in the vpxd subdirectory. Some other sibling subdirectories include vsan-health, vsphere-ui, and vpostgres.
Uploading System Logs to VMware
To export system logs from the vCenter Server and all its hosts, you can use the procedure outlined in the section “ESXi Logs” but begin by selecting the vCenter Server instead of a specific host. In the wizard, you can select which hosts to include, and you can optionally select Include vCenter Serer and vSphere UI Client Logs.
You can export a vCenter Server instance’s support bundle by using the URL shown on the DCUI home screen (https://FQDN:443/appliance/support-bundle).
Alternatively, you can run the vc-support.sh script in the vCenter Server appliance Bash Shell to collect the support bundle.
You can directly upload a log package to an open VMware service request by using the following procedure:
Step 1. In the vSphere Client, navigate to Administration > Support.
Step 2. Click Upload File to Service Request.
Step 3. Provide a service request ID.
Step 4. Click Choose File, select the appropriate log bundle, and click OK.
Log Levels
The default log level setting is Info; this is where errors, warnings, and informational level are logged. You can change the log level to lower levels, such as Verbose, which is useful for troubleshooting and debugging but is not recommended for normal use in production environments. You can use the vSphere Client to change the logging level by selecting the vCenter Server, selecting Configure > Settings > General > Edit, and setting the logging settings to the appropriate level, as described in Table 10-14.
Table 10-14 vCenter Server Logging Options
Logging Option |
Description |
|---|---|
None (Disable Logging) |
No vCenter Server logging occurs. |
Error (Errors Only) |
The vCenter Server collects only error entries in its log files. |
Warning (Warning and Errors) |
The vCenter Server collects warning and error entries in its log files. |
Info (Normal Logging) |
The vCenter Server collects information, warning, and error entries in its log files. |
Verbose (Verbose) |
The vCenter Server collects verbose, information, warning, and error entries in its log files. |
Trivia (Extended Verbose) |
The vCenter Server collects trivia, verbose, information, warning, and error entries in its log files. |
Although setting the logging level to Verbose or Trivia may be beneficial for troubleshooting, doing so for long durations may cause noticeable vCenter Server performance degradation. VMware recommends that you use these levels in rare cases, such as while actively troubleshooting, and that you reset the logging level immediately afterward. Changes to the logging level are saved in the vCenter Server configuration file /etc/vmware-vpx/vpxd.cfg. You can make additional changes to logging behavior by editing the advanced settings of a vCenter Server. For example, you can use the vSphere Client to edit the following settings, which impact log size, retention, rotation, and compression:
config.log.level
config.log.maxFileNum
config.log.maxFileSize
config.log.compressOnRoll
Note
By default, vCenter Server vpxd log files are rolled up and compressed into .gz files. You can turn off compression for vpxd log files by adding the log.compressOnRoll key with the value false to the vCenter Server advanced settings.
Configuring Syslog on ESXi Hosts
You can use the following procedure to configure the syslog service for a host:
Step 1. In the vSphere Client, select a host in the inventory pane and navigate to Configure > System > Advanced System Settings.
Step 2. Click Edit.
Step 3. Filter for syslog.
Step 4. To set up logging globally for the following options, select the appropriate option and enter the appropriate value:
Syslog.global.defaultRotate: Maximum number of logs to keep when rotating logs.
Syslog.global.defaultSize: Size of log (in KB) before triggering a log rotation.
Syslog.global.LogDir: Directory in a VMFS or NFS datastore to store logs specified in the format [datastore] /path. For example, to store logs in the /vmfs/volumes/VMFS-01/systemlogs folder, specify [VMFS-01] /systemlogs.
Syslog.global.logDirUnique: A subdirectory for the host at the specified path, which is useful when multiple hosts use the same shared datastore for logging.
Syslog.global.LogHost: Remote syslog host and port to which messages are forwarded. For example, to forward to a server named syslogsvr-1 using port 1514, specify ssl://syslogsvr-1:1514.
Step 5. Optionally, select specific log names and change the number of rotations and log size for just that specific log.
Step 6. Click OK.
You can control how log files are maintained for virtual machines. A new log file is created each time you power on or resume a virtual machine or whenever the file size exceeds the vmx.log.rotateSize value, unless the value is 0 (default). VMware recommends saving 10-log files, each one limited to no less than 2 MB. If you need logs for a longer time span, you can set vmx.log.keepOld to 20.
You can use the following procedure to change the number of log files for a single virtual machine:
Step 1. In the vSphere Client, right-click a host or a virtual machine in the inventory pane and click Edit Settings.
Step 2. Select VM Options > Advanced.
Step 3. Click Edit Configuration.
Step 4. Add or edit the vmx.log.keepOld parameter, set to the appropriate number.
Step 5. Click OK.
Note
To set the vmx.log.keepOld value for all virtual machines on a specific host, edit the /etc/vmware/config file and add or edit a line like the following:
vmx.log.keepOld = "10"
You can modify the /etc/vmware/logfilters file on a host to change its logging behavior. In this file you can add an entry specifying the following options:
Add numLogs to specify the maximum number of log entries before the specified log messages are filtered and ignored. Use 0 to filter and ignore all the specified log messages.
Add Ident to specify one or more system components to apply the filter.
Add logRegexp to specify a case-sensitive phrase to filter the log messages by their content.
Add the following line to the /etc/vmsyslog.conf file: enable_logfilters = true.
Run the command esxcli system syslog reload.
vRealize Log Insight (vRLI)
To collect and analyze vSphere data using vRLI, after you deploy vRLI, follow these steps:
Step 1. In the vRLI web interface, navigate to the Administration tab.
Step 2. Click Integration > vSphere.
Step 3. Provide the hostname and credentials to connect to a vCenter Server.
Step 4. Click Test Connection.
Step 5. If you use an untrusted SSL certificate, click Accept in the dialog.
Step 6. Click Save.
Step 7. Use the vRLI web interface to configure the data collection from vCenter.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have some choices for exam preparation: the exercises here, Chapter 15, “Final Preparation,” and the exam simulation questions on the companion website.
Review All the Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 10-15 lists these key topics and the page number on which each is found.
Table 10-15 Key Topics for Chapter 10
Key Topic Element |
Description |
Page Number |
|---|---|---|
List |
Add a host using Quickstart |
|
Use cases for VM-to-VM rules |
||
List |
Configuring vSphere HA admission control |
|
Section |
Configuring proactive HA |
|
Section |
Performance graph overview |
|
List |
Configuring Skyline Health |
|
Section |
The impact of virtual machine configuration |
Complete Tables and Lists from Memory
Print a copy of Appendix B, “Memory Tables” (found on the companion website), or at least the section for this chapter, and complete the tables and lists from memory. Appendix C, “Memory Tables Answer Key” (also on the companion website), includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
Review Questions
1. You are creating a resource pool in a vSphere DRS cluster. Which of the following is a default setting?
The Memory Limit is disabled.
CPU Shares is 0.
Memory Reservation is 0.
The CPU Reservation is normal.
2. You want to configure predictive DRS in your vSphere cluster. Which of the following is a requirement?
Set DRS to Fully Automated.
In the cluster, set Provide Data to vSphere Predictive DRS to True.
In the vRealize Operations, set Provide Data to vSphere Predictive DRS to True.
In the vRealize Automation, set Provide Data to vSphere Predictive DRS to True.
3. You are configuring a vSphere HA cluster and do not want it to automatically reserve resources for failure. What setting should you use?
Set Cluster Resource Percentage to 0.
Set Cluster Resource Percentage to 100.
Set Define Host Failover Capacity to Dedicated Host Failures.
Set Define Host Failover Capacity to Disabled.
4. You want to use a command-line tool that shows real-time CPU statistics for the services running in the vCenter Server. Which should you choose?
VIMTOP
ESXTOP
Performance charts
vCenter Server Management Interface
5. You are examining vSphere logs. Which of the following logs is in the same folder as the virtual machine configuration file?
vpxa.log
vmksummary.log
auth.log
vmware.log