3
Big Data Handling, Storage and Solutions
3.1 Introduction
In this chapter we first look at the structure of data arising from and driving everyday business processes and then give an overview of the technical aspects of storing and accessing data. This is necessary background to understanding how these various types of data can be monetised, over and above their importance in the day‐to‐day running of the business.
Data is a fast‐moving field and new methods enable integration of different types of data into operational systems. New algorithms incorporated alongside analytical databases mean that rules can be developed to apply in operation. All these things mean that data, which is stored at considerable cost, is now utilised to give more than day‐to‐day running help; it now gives significant added value.
3.2 Big Data, Smart Data…
With social media and the ‘internet of things’ dominating our digital world, we are in the midst of an explosion of data. This is a valuable resource for companies and organisations. The ways in which they structure and utilise the data have totally changed. Previously, the datasets usually analysed were of manageable size, fixed and with consistent data types, but now we are more likely to encounter data that needs to be integrated from many different sources, is of different types and is preferably analysed in real time.
Data is everywhere, and everything and every action is represented by data. This is a result of the rise of social media, increasing connectivity and the fact that devices like smartphones and tablets enable us to have a real and a digital life in parallel. Big data emerges from the rapid growth of digital data produced by web sites, apps, devices, sensors, processes and other resources. Big data is characterised by coming from different sources in different data structures from an ever‐increasing number of users.
A report from the Gartner research and advisory company defined it as follows: big data is high‐volume, high‐velocity and/or high‐variety information assets that demand cost‐effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation (Figure 3.1).

Figure 3.1 Big data definition.
Source: TDWI Best Practices Report Q4 2011 – Big Data Analytics.
Only computerised information systems are considered here; other internal information systems, such as meeting notes, notices, hear‐say, post‐its and similar items are not considered.
Due to the ever‐growing amount of data (each decade growing by a factor of 1000) big data is a subject of great interest. The methods of big data analytics are vital in adding value to the business when generating, for example, forecasts and business simulations, and help to improve evidence‐based decision making. Not only is the amount and complexity of the data increasing but so is the desire for individuality. The degree of crosslinking between different company IT systems and the customer is growing exponentially. Each touchpoint (where the customer interacts with the business, such as making a purchase or responding to a promotion) produces its own data and the customer expects everything to be linked together for their benefit.
Familiar internet businesses generate vast amounts of data. For example, a foreign exchange desk produces around 100 terabytes of data every day. What is done with this data? It is used in real time to tune the system and determine exchange rates, but after the moment has passed, what happens? Time trends of aggregated data are displayed over a certain limited time range but not all of the data needs to be kept forever. In other industries, such as pipeline inspection, the signal transmitted by the pipeline inspection gauge (PIG) is subject to complicated compression routines that store data when the values change rather than at each millisecond. Cumulative data is useful for historical comparisons but the people involved in this activity are likely to be different to the operational staff. They will need different skills. The value added from sifting through past data depends on the strategic business issue. If there are challenges to be met or problems to be solved then the data will be useful. Otherwise it may never be looked at again.
Big data will be entered in and out of vast storage tanks for data in different parts of the world. The control over data in and out must be very complex. In any case, big data needs to be stored in such a way that it can be accessed and analysed with the greatest possible ease.
3.3 Big Data Solutions
In addition to the large amounts of data and the increasing complexity of the data structures, the need to make business decisions in real time is increasing as well. These developments mean that current IT systems are reaching their limits and must be extended in the future to encompass methods and systems from the big data analytics arena.
Companies faced with the need to analyse very large amounts of data come up against problems of performance, scalability and cost. Analytical databases are one solution to address these problems. They are more flexible in the way that information is made available and enable much faster analysis; up to 100 times faster than older technologies. User satisfaction is significantly increased by this faster and more flexible access to information. These new technologies enable profitable use of data that was previously stored at a cost but delivered little benefit.
Companies have traditionally held a large amount of data. Within the big data arena, we must distinguish between structured and poly‐structured data (often called unstructured data).
- Structured data includes transactional data, financial data, registration data and more; the characteristic is that it has a clear structure and is often organised in a relational database (as discussed below); usually around 20% of all corporate data is structured.
- Poly‐structured (or unstructured) data includes documents, complaints, contracts, protocols, e‐mails, pictures, podcasts, videos and others; this category makes up 80% of company data.
Nowadays other types of data affecting companies arises from the web (structured and poly‐structured data). Examples include social network posts. The internet of things provides even more, as the internet and real life converge. Mobile phones, smartphones and tablets are here to collect data, as are all kinds of other equipment: sensors, smart meters, fridges, heating systems, home entertainment systems and self‐driving cars, all producing a constant flow of data. All this is collected today under the term ‘big data’.
There are all kinds of data about consumption, behaviour and preferences, locations and movements, health and many other things. Analysis is therefore becoming increasingly important for companies in all industries. The use of analytics creates competitive advantages and avoids risks through a better and deeper knowledge of market and customers.
Analytics therefore also drives the use of innovative technologies for these petabytes and exabytes of data. Previously the market was dominated by relational databases, usually referred to as ‘data warehouses’. Now, due to the sheer volume and unstructured nature of the data, these relational database systems have reached their limits. New concepts are establishing themselves, including ‘analytical databases’ and ‘NoSQL data management systems’. These contain the innovative algorithms necessary for user access and storage management, and use innovative approaches such as column‐orientation and innovative hardware technology such as in‐memory processing (explained below).
As a result of this flood of data we need new technologies for analysis: the traditional relational database boundaries have to be overcome using new data management approaches. Relational data storage systems were appropriate for transaction processing and gave the necessary security and reliability guarantees; these still make up a major part of the analytical environment. There are various methods and technologies with which you can achieve the fast data reading now expected. Analytical databases are designed for fast reading, but you cannot optimise everything and, according to Brewers CAP theorem, faster reading systems necessarily compromise the safety and reliability of transaction processing.
One approach for handling a company’s unstructured data is to combine several methods and technologies to reach the individual best solution: the most frequently used methods are fracture orientation, compression, parallel processing, in‐memory processing and bundling of hardware and software. These approaches allow very large amounts of data to be analysed in real time. whereas earlier it required hours to days.
The rules derived from sophisticated analyses can also be applied directly within operational processes to allow immediate interaction with the system. So, in an operational sense, real‐time analytics allows immediate interaction with operational processes, such as customer interactions, production, logistics and so on, giving companies full ‘online’ control. The benefit of automating the analysis of operational data using these rules is shown by key performance indicators, such as faster throughput, fewer errors and better, more individualised processes.
In practice, two fundamentally different types of information systems have become established in the enterprise:
- operational systems supporting business processes
- analytical databases (analysis‐based information systems).
Both kinds of systems are dealing with big data issues, but the technological impact of big data on the systems is very different. The next sections deal with these two types of system.
3.4 Operational Systems supporting Business Processes
Information systems supporting operations, production and logistics are probably found in virtually all businesses to a varying extent. Automatic standardised operations such as sending out invoices, checking regulations, issuing order forms, cross‐checking warehouse status and giving automated orders achieve efficiencies. The use of operational systems is aimed initially at the rationalisation of standardised administrative processes, which are characterised by the accumulation of large amounts of data, resulting in the shortening of throughput times of processes. Operational information systems consist of the sum of all the individual systems necessary in the business.
One kind of operational information system is the traditional enterprise resource planning (ERP) systems, including financial accounting. The other kind of operational information systems are those that collect data from sensors, scanners, apps, devices, processes, websites and other data‐acquisition systems. Some of these constitute the so‐called internet of things (Figure 3.2). The concept arose in 1990s and was originally associated with electricity smart meters for large companies. Around 2010, the concept extended to the individual household level, when there was interest in saving money by using cheaper off‐peak electricity. The electricity companies were also interested in learning more about user demand and when peaks occurred. Since then the concept of an intelligent house has become common, with the incorporation of smart gadgets such as voice‐controlled security, lighting and heating and many other automated objects. The avalanche of data‐producing items has continued, for example equipment such as fitness sensors and connected cars. These gadgets can also feed into operational systems. For example, fitness and driving data can be used by the insurance industry to quantify their risks better and from the user/data supplier point of view, the benefit is more appropriate (lower) premium costs.

Figure 3.2 Internet of things timeline.
All these operational systems have been optimised to specific aspects of operational work, both in the way the data is processed and in the amount of data being stored. The databases may be implemented but their maintenance is not aligned with all the uses of the data, so there may be redundancy or duplication of effort. For example, amendments to addresses may be made for the benefit of one process but not be transferred to apply elsewhere. That, and the fact that such systems are often composed of very heterogeneous databases, increases the risk that inconsistencies may arise in the databases. The increasing need to make decisions in real time changes the operational environment dramatically. Similarly, the expectation that simulations and forecasts will be based on actual numbers means that real‐time analysis is needed. However, these expectations offer new opportunities for products and services shaped by the continuous flow of data.
The availability of big data, including the mass of unstructured data that is often held about interactions with customers, and the technologies to handle it have had an enormous impact on the development of all systems in the operational parts of businesses, forcing them to embrace new algorithms that enable the systems to make decisions themselves, without relying on human input and to act quickly and correctly.
This clearly leads to monetisation opportunities, because the data is helping to tune the business, helping managers find new ways to earn money from individual interactions. There are also opportunities for new sources of revenue. For example, a company can charge others for insights based on their enhanced understanding of the customer and processes, selling services, efficiency and enhanced convenience.
This section only gives a cursory look at operational systems and the impact of big data on them; much more detail can be found in the literature referenced in the bibliography. Further monetisation applications from operational systems are incorporated in the case studies below.
3.5 Analysis‐based Information Systems
Analysis‐based information systems are systems that are necessary to store data and make it ready for analysis. They also include the (user‐) tools, such as reporting, business intelligence, data mining, on‐line analytical processing (OLAP), with whose help one can gain benefit from the information stored. In terms of the architecture, the connected front‐end tools that help the user to access and analyse the datasets can be distinguished from the data‐storage components. The front‐end tools are thus not part of the data warehouse (for structured data) or big data solution (for structured and poly‐structured data) in the strict sense. Ideally, there should be independence between:
- the storage system and the various tools that have access to it
- the interfaces that can exchange data.
Despite this conceptual separation, in practice there is often a close integration of technological tools with the data‐storage components. Specifically, analysis‐based information systems may consist of big data solutions, pure data warehouses and data marts, as well as analytical tools. Data warehouses and data marts are discussed in Sections 3.6 and 3.9 respectively.
The availability of big data, including the mass of unstructured data relating to customer interaction, and the technologies to handle it have had an enormous impact on the development of analysis‐based information systems belonging to knowledge‐retrieval parts of businesses, forcing them to develop better strategies and decisions and to find new rules and algorithms that will be used in the operational parts.
This clearly leads to monetisation opportunities, as these analytical methods help managers to perceive new market opportunities and think about new products and services. They enable money to be earned from the individual customer interactions. For example, the analysis may show correlations between time of day and type of contact and this insight may suggest a new way of doing business.
If you look more closely at analytical databases, then five potential benefits are apparent, as set out in the rest of this section.
3.5.1 Transparency
Once data has entered the analytical database it stays there and is available for further analysis and for re‐analysis checking. The use of analytics in networks provides a good example. In the telecommunications industry, one would like to analyse the call network or roaming behaviour of callers, for example to optimise traffic patterns. For this purpose it is necessary, amongst other things, to avoid possible unsafe paths, to reduce the number of network changes when roaming and to optimise roaming patterns in order to meet service‐level agreements. Similar tasks also arise for other enterprises that operate networks: in the transport, IT, or energy and water‐supply industries. To take advantage of this transparency benefit, however, any ‘silo mentality’ in the company has to be broken down. To be able to see the whole picture about a customer, market, network and so on, it has to be possible to collect data from specialist knowledge and to integrate it to build up the resources for analysis. In finance, it is still customary to keep data about financial markets, payment transactions and credit systems separately and to keep to departmental boundaries. This prevents building a coherent customer view and developing an understanding of the relationships and influences between financial markets. Transparency has the advantage of enabling astute error checking.
3.5.2 Using Control Measures to Learn
At the analysis speed that can be achieved by analytical databases, and with the new big data sources, such as data provided by mobile devices, we can find new ways to measure the effectiveness of activities and test hypotheses by means of controlled experiments. This allows us to check decisions and actions on the basis of facts and, where appropriate, make further adjustments. So, also cause–effect relationships can be distinguished from pure correlations. Large online retailers were some of the first to use such controlled experiments to increase the conversion rate of visitors to their websites. Certain functions and access to websites, offers, activities and so on were deliberately changed and the consequences measured accordingly. Thus it became possible to identify the factors that increased the conversion rates. Using location data from mobile phones on the internet allows for position mapping, and this concept can be transferred from web analysis to the real world. Now, for example, the effect of outdoor advertising can specifically be measured and optimised. This is made possible by analysis of the click‐through rates on the QR codes on advertising hoardings and signs on buses and cars. The process can be set up through big data analytics.
Cross‐media marketing can be set up in a campaign that targets different devices. For example, an offer might be sent to you on your mobile phone, inviting you to look at the advert that you are passing on a hoarding. As an extension, video recordings of customer movements combined with information about the customer interactions and order patterns that are hidden in transactional data can be used to control marketing activities. For example, an offer might be placed on an intelligent billboard outside a shop. The stream of customers entering the shop is captured on video, enabling a head count, and subsequent tracking of their movements through the shop. The consequent buying behaviour can be collected instantly and the offer on the billboard might be changed as a result. In another example, a customer would have been sent an offer (say for blue shirts). When they enter the shop (they have already allowed themselves to be recognised), the vendor records whether or not the customer takes up the offer and what else, if anything, they buy. This information is added to their customer profile and the vendor can immediately react and change the offer if necessary.
Changes in the product portfolio and placements as well as price changes can therefore be continuously and systematically reviewed and optimised. Cost savings follow, because reductions of the product range may be identified without risk of loss of market share, leading to an increase in the margin, and also through the sale of higher‐value products.
The cycle of learning can be applied in many other activities, including crowd control at airports. The cycle is: action – feedback – analytics – direct learning – reaction.
3.5.3 Personalisation in Real Time
Customer and market segmentation has a long tradition. Analytical databases bring completely new opportunities through real‐time personalisation of customer interactions. Commercially, we are already familiar with pioneering strategies in which products are offered on the basis of our actions and tailored to our profile. We are also used to having friendships proposed via our interactions with social networks. The benefits of such personalised customer interactions are also seen in other sectors, for example the insurance sector. Here insurance policies can be customised to the client and may be trimmed to their requirements. Databases serve continuously adapted profiles of customer risks, changes in the financial situation or even location data. Similarly, vehicles can be equipped with special transmitters enabling them immediately to be retrieved through tracking of their location in case of theft.
3.5.4 Process Control and Fully Automated Analytical Databases
Analytical databases can expand the use of analytics for process control and automation. So, for example, sensor data can be used in production lines for auto‐regulation of production processes. Thus cost savings can be achieved through optimal use of materials and by avoiding human intervention, while at the same time throughput can be increased. Proactive maintenance is another area of application. Machines can be monitored continuously by sensors, so that irregularities are detected immediately and can be corrected in time before damage occurs or production stops. Other examples come from the consumer goods industry. Drinks or ice cream manufacturers benefit from the daily weather forecasts enabling them to adjust their demand planning processes to the current weather. The data about temperature, rainfall and sunshine hours are crucial. This knowledge allows for process improvement through optimisation, and although this improvement may only represent a few percent points, that can mean a lot of money.
3.5.5 Innovative Information‐driven Business Models
By using analytical databases, information becomes available that formerly could not be evaluated, since the benefits of doing so did not justify the cost. That is different now, and so new, innovative business models are possible on the basis of this new information. Let us look at an example of the information on market prices, which is publicly available in the era of the internet and e‐commerce in general. This allows users of the internet and other dealers to monitor prices and to react to price changes. But it also allows the customer to obtain information on prices, helping them to obtain the best price for a desired product. Some vendors specialise in this process of consolidation, aggregation and analysis of pricing data; their own business models are based on selling this knowledge. This applies not only in retail, but also in healthcare, where treatment costs are made transparent by such information providers.
As with the coverage of operational systems in Section 3.4, this section only gives a brief look at analytical systems and the impact of big data; much more detail can be found in the literature referenced in the bibliography. Further monetisation successes using analytical systems data are incorporated in the case studies in Chapter 10.
3.6 Structured Data – Data Warehouses
A data warehouse is a collection of data gathered for the specific purpose of analysis. The data warehouse is very different to all other information systems in a company, as the relevant data is quality‐checked and then possibly processed within the data warehouse. Information systems typically do not allow an overview, whereas data warehouses are designed with this in mind.
Unlike in other operational systems, the mapping of historical data, data history and external data has a large role in the data warehouse. The term ‘data warehouse’ is now generally understood to mean something that serves as an enterprise‐wide database about a whole range of applications, which supports analytical tasks for specialists and executives. The data warehouse is operated separately from the operational information systems and filled from internal databases and external sources of data. The data warehouse is a logical centralised resource.
A data warehouse is generally understood to be topic‐oriented rather than being a concrete database system product, with separate company‐specific applications; it combines decision‐related data. In other words, whereas other databases are specific to particular software, a data warehouse depends completely on the ideas that the company wants to explore. It cannot be built up mechanically by software alone.
The contents of a data warehouse can be characterised as having four main features, which reveal the significant differences to other operational data:
- topic orientation
- logical integration and homogenisation
- presence of a reference period
- low volatility.
These topics are dealt with below.
3.6.1 Topic Orientation
In contrast to operational systems, which are oriented towards specific organisational units, remits and work processes, the contents of the data warehouse are oriented towards matters that affect the decisions made by the company in specific topic areas. Typical topics include the customer, the products, payments and advertising or sales campaigns. Besides affecting the content of the data warehouse, this topic‐orientation also has great influence on the logical data model used. For example, in operational systems the customer as such does not appear; rather it is the product and invoice numbers that mainly feature and which are followed up in subsequent processes. The data may often be stored in totally different places: accounting systems, logistics and delivery systems and stock control systems. By contrast, the data warehouse will be customer‐oriented and if you follow the customer number it is easy to find all the information associated with a particular customer regardless of in which system the data is stored.
3.6.2 Logical Integration and Homogenisation
A data warehouse traditionally consists of common data structures based on the ideas of relational databases. However, unstructured no‐SQL (SQL stands for structured query language) databases are also being seen, arriving alongside the development of big data. The truly great quantity of data coming from log files and social networks necessitates a different architecture and way of storing data. The aim of both data warehouses and big data architecture is an enterprise‐wide integration of all relevant data into a consistent set in a continuous system model. This goal also implies the cross‐functional use of the data.
3.6.3 Reference Period
Information for decision support should be provided in a timely fashion. However, it is relatively unimportant for data processing to take place at a particular time in operational systems: it is much more important to be able to incorporate the different periods of time without problems in the ensuing analysis. In an operational system, the time factor has only a descriptive role but in the data warehouse it is an important structural component. The special feature of the data warehouse is the fact that historical data is retained, even, for example, data which has been archived in the operational system for a long time or might have been destroyed in a company reorganisation.
3.6.4 Low Volatility
Data that was once stored in a data warehouse should not change, although there may be amendments to the data warehouse as a whole. For example, where there are errors in the data due to a faulty charging process, the action is to insert new records to describe the new charging process rather than overwrite the old records. This is in clear contrast to operational systems. As an example, a product might be purchased, but later the purchase is cancelled. In the operational system the record with the order would be overwritten by the reversal record or be deleted. In the data warehouse, there would be two records: one with the order and one with the cancellation. Both records would be included in the data warehouse to enable understanding of the action of the customer and also to allow different analyses to be carried out. In the operational system there would be no extra external data or information available to explain the entry or deleted records, since the failed purchase is no longer relevant.
3.6.5 Using the Data Warehouse
In summary, we can say that the data warehouse is a central storage database, with the aforementioned four characteristics, centralising all relevant data in the enterprise. Generally, therefore, a data warehouse is characterised by the way it was formed and the specific architecture that generated it. The way the data warehouse was formed depends on how the regular operational data is integrated with other data. The data warehouse functions independently from the operational system; its main roles are to support decision making and for analytical purposes.
Unlike operational systems, a data warehouse has ‘read access’ to large amounts of data in complex structures. Particular attention is paid to the changing information needs. Therefore it is necessary to design the structures so that complex queries that involve large amounts of data, as well as extensive aggregation and joining operations, can be managed. This typical form of a data warehouse makes using it significantly different to using operational systems. In the data warehouse, utilisation is subject to significant fluctuations, with pronounced peaks, which are directly related to the queries being made. In contrast, the utilisation of an operational system is close to constant and stays at a uniformly high level (see Figure 3.3).

Figure 3.3 Example data structure.
The construction of a data warehouse helps some companies solve the massive resource conflict between the execution of daily business and the implementation of the complex analyses needed to support decision‐making. To implement a data warehouse we need to consider three different forms of organisation:
- central database warehouse
- distributed database warehouse
- virtual database warehouse.
The most common form of implementation is the central database warehouse; this is where the management of all datasets for the various front‐end applications are on a single system. Distributed data warehouses are when different departments might run their own data warehouses, each optimised for their needs. In some parts of the literature these are also called ‘data marts’. There is confusion in the literature, because some people call them data warehouses; there is some inconsistency of the terms used. When we speak about data warehouses we mean storage of detailed data and when we speak about a data mart we mean more or less prepared data for special uses, say data aggregated to control marketing campaigns or prepared for data mining.
A virtual data warehouse is sometimes created for reporting and involves creating views of the original data in the legacy system or the original data sources. Everything done in the central data warehouse through so‐called ‘extraction, transforming and loading’ processes is implemented in the view but not carried out on the real data.
3.6.6 The Three Components of a Data Warehouse
A data warehouse can be seen as a database system with three components: the database management system (DBMS), the database (DB) and the database communications interface (DBCS). The DBMS contains metadata on loading, error detection, constraints and validation. The DB is the storage for the data. The DBCS gives the possibility of analysing the data using, for example, SQL or other suitable languages.
3.6.6.1 Database Management System
The DBMS in the data warehouse is mainly for managing the analysis‐oriented databases. It provides the functionality for data definition and manipulation. Therefore, the database management system in a data warehouse has different requirements to that of an operational system.
3.6.6.2 Database
Integrity and consistency in DB datasets for analysis are evaluated differently to those for operational systems. Data security and availability are different too. This is because the data in a data warehouse is made up of copies of operational datasets, with the addition of any changes made in the operational system and any additional information extracted from the data. For example, the operational data may store salutation only (Mr, Mrs, Ms, Miss, Master), but in the data warehouse marital status and gender could be determined from the salutation. If the salutation changes from Mrs to Ms, then the operational data just records the new value, but the warehouse records the old and the new as well as the time it changed, as well as any consequent information like marital status.
Hence the effort involved in ensuring integrity, consistency, security and availability is greater in the data warehouse than in the operational system. For this reason, only the administrator or defined processes can change the data in a data warehouse, whereas any of the human operators can add to the data in an operational system or change it, e.g. by adding new addresses.
Data is more business orientated in a data warehouse. This can lead to critical and strategic information showing up earlier. There is a greater demand to think about the issue of security and the consequent roles of data because the data is now immediately useful, say to competitors.
Storage and access must be optimised to give the user a short response time for complex queries and analysis, but this must not lead to a loss of flexibility in the analysis.
3.6.6.3 Database Communication Systems
Database communication systems play a prominent role in analysis‐oriented information systems, because without them the use of the data stored in the data warehouse is very difficult. At the same time, front‐end tools and their internal data management systems put very different demands on the interfaces.
An indispensable part of the analysis‐oriented information system and particularly of the data warehouse is detailed meta databases. Unlike in the operational system, where their role is less important, meta databases are particularly suitable for the users of data warehouses because the metadata is essential to perform analysis on the data effectively.
One can see that one of the critical success factors for an analytically‐oriented information system is a well maintained meta database complete with the relevant business terms.
3.7 Poly‐structured (Unstructured) Data – NoSQL Technologies
NoSQL data management systems are now widely discussed in the context of big data. They focus on the attitude and processing of poly‐structured data, thus complementing the traditional relational data models, which were designed primarily for structured data. This means in effect that the relational algebra has no unique claim as a ‘single’ data management model.
Just as different methods of analytical databases are not new, NoSQL approaches have been around for a long time, but are now gaining new attention in big data applications. NoSQL data management systems can be classified as shown in Figure 3.4.
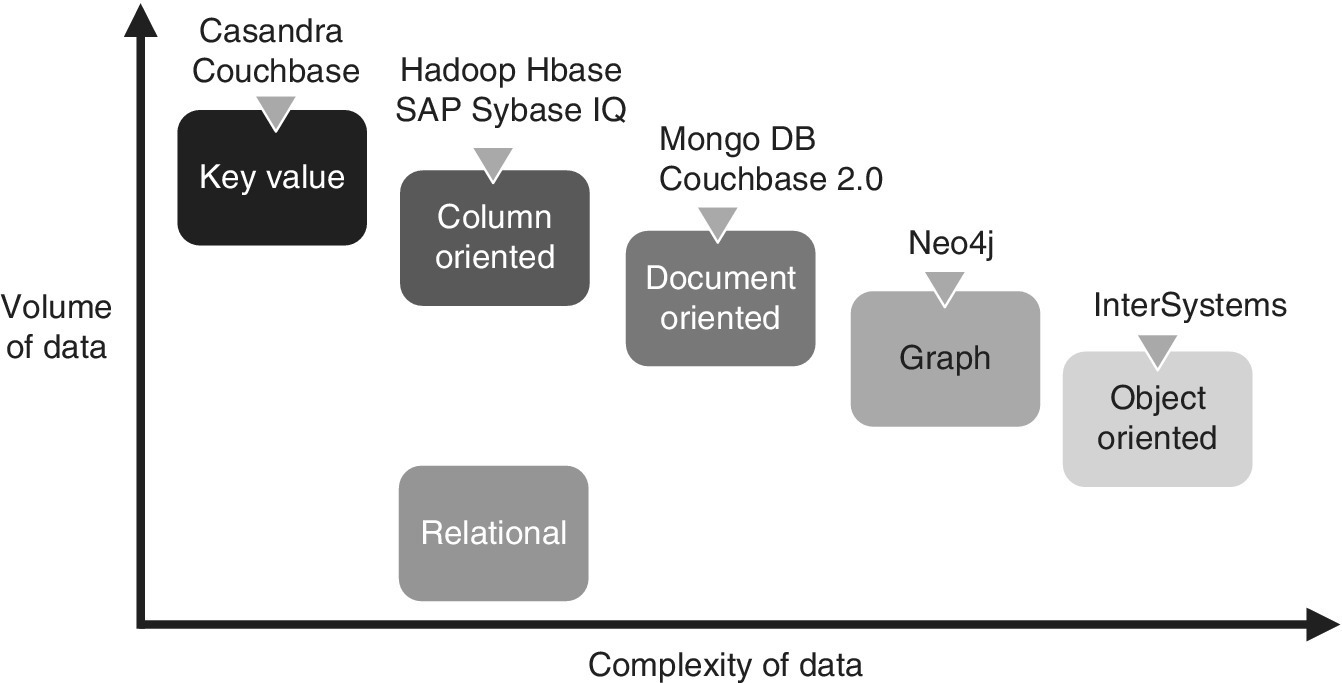
Figure 3.4 NoSQL management systems.
- Object‐oriented databases In the 90s, object‐oriented databases already offered an alternative to the relational model. They had a basic approach, which can be found in all modern NoSQL data management systems. They are schematic free and rely on alternative techniques to determine how data is stored. Protocols other than SQL are used for the communication between the application and data storage systems. Similar to analytical databases, the architecture of many NoSQL databases is optimised for scalability: The processing and management of large datasets is done via distributed clusters of standard systems.
- Graph databases Graph databases (or entity‐relationship databases) date back to developments in computer‐aided software engineering (CASE) in the late 1980s. Graph databases represent data as nodes or entities. Instead of traditional records, the nodes are linked by user‐defined relationships and this information is stored as properties (attributes). Graph databases have particular advantages when as in (social) networks, the relationships between the data are the central feature of interest and are the focus of analyses based on matching and comparing networks.
- Document‐oriented databases Document‐oriented databases store ‘texts’ of any length as poly‐structured information and allow you to find them based on document content. The stored documents do not contain the same fields. XML (Extensible Markup Language) databases are document‐oriented databases with semi‐structured data.
- Column‐oriented databases Column‐oriented databases belong to the class of analytical databases, which shows that analytical and NoSQL databases are not mutually exclusive. These are just analytical database systems, still based on the relational model.
- Key‐value databases Here, interest focuses on the key to a value, which can be any string in its simplest form. Key‐value databases are also not new. They featured in the Unix world, as traditional embedded databases such as dbm, gdbm and Berkley DB. Key‐value databases work either as an in‐memory system or in an on‐disk version. They are particularly suitable for quick searches.
Hadoop is going to set a standard for the future in big data storage and management. This is an Apache Software Foundation open‐source development project. It works as a data operating system and consists of three components:
- the storage layer, HDFS (Hadoop Distributed File System)
- a programming environment for parallel processing of queries
- a function library.
HBase is a scalable, analytical data management system for managing very large amounts of data within a Hadoop cluster. HBase is an open‐source implementation. The storage layer, HDFS, stores data in 64 MB blocks, which support parallel processing and are excellently suited for dealing with large amounts of data. The disadvantage is that such processing is naturally batch‐oriented and is therefore not suitable for transaction processing or real‐time analysis. HDFS has a built‐in redundancy. It is designed to run on hundreds or thousands of inexpensive servers, some of which one can assume will repeatedly fail. Therefore, in the Hadoop default, each data block is stored three times. New data will always be appended, and never inserted (‘no insert’). This increases the speed of storing and reading data, and also increases the reliability of the systems.
MapReduce (MR) is based on the column‐oriented big table implementations of the Google File System. It is a programming environment for parallel queries, and is extremely fast. MR processes large amounts of data. The programming within MR can be done in languages such as Java, C++, Perl, Python, Ruby, or R. MR program libraries can not only support HDFS, but also other file and database systems. In some analytical database systems, MR programs and in‐database analytic functions are supported, and these can be used in SQL statements. MapReduce is, however, only used in batch, not in real‐time processing, and therefore it is not interactive.
In addition, there are HLQL (high level query languages) like Hive and Pig. Hive is a data warehouse software project, and is a development from Facebook. Hive is related to the HLQL to which SQL belongs. Since there are not yet many resources for programming environments that can handle Hadoop and MapReduce, HLQLs are very welcome: they allow developers to use an SQL‐like syntax. Another HLQL is Pig, a procedural language. Using Pig, parallel versions of complex analyses are easier than when using MapReduce and are more understandable and practicable. Moreover, unlike MapReduce, Pig also offers automated optimisation of complex arithmetic operations. Pig is also open source and can be supplemented with customisable functionality.
For managing Hadoop applications, there are supporting projects such as Chukwa, which is a flexible and powerful tool‐kit for displaying, monitoring and analysing results in order to make the best use of the collected data. Even with all these new big data technologies it is still worth thinking about data marts and how they aggregate the data under specific views and in accordance with domain knowledge. This is the topic of Section 3.9.
3.8 Data Structures and Latency
Analysis is ultimately classified by reference to the different data structures and latency (or timing) requirements. Figure 3.5 visualises this classification in the two dimensions of complexity of data structures and processing method (batch/offline or real‐time/online). The term ‘Real time’ can have different meanings: either low‐latency access to data already stored or processing and querying of data streams with zero latency.
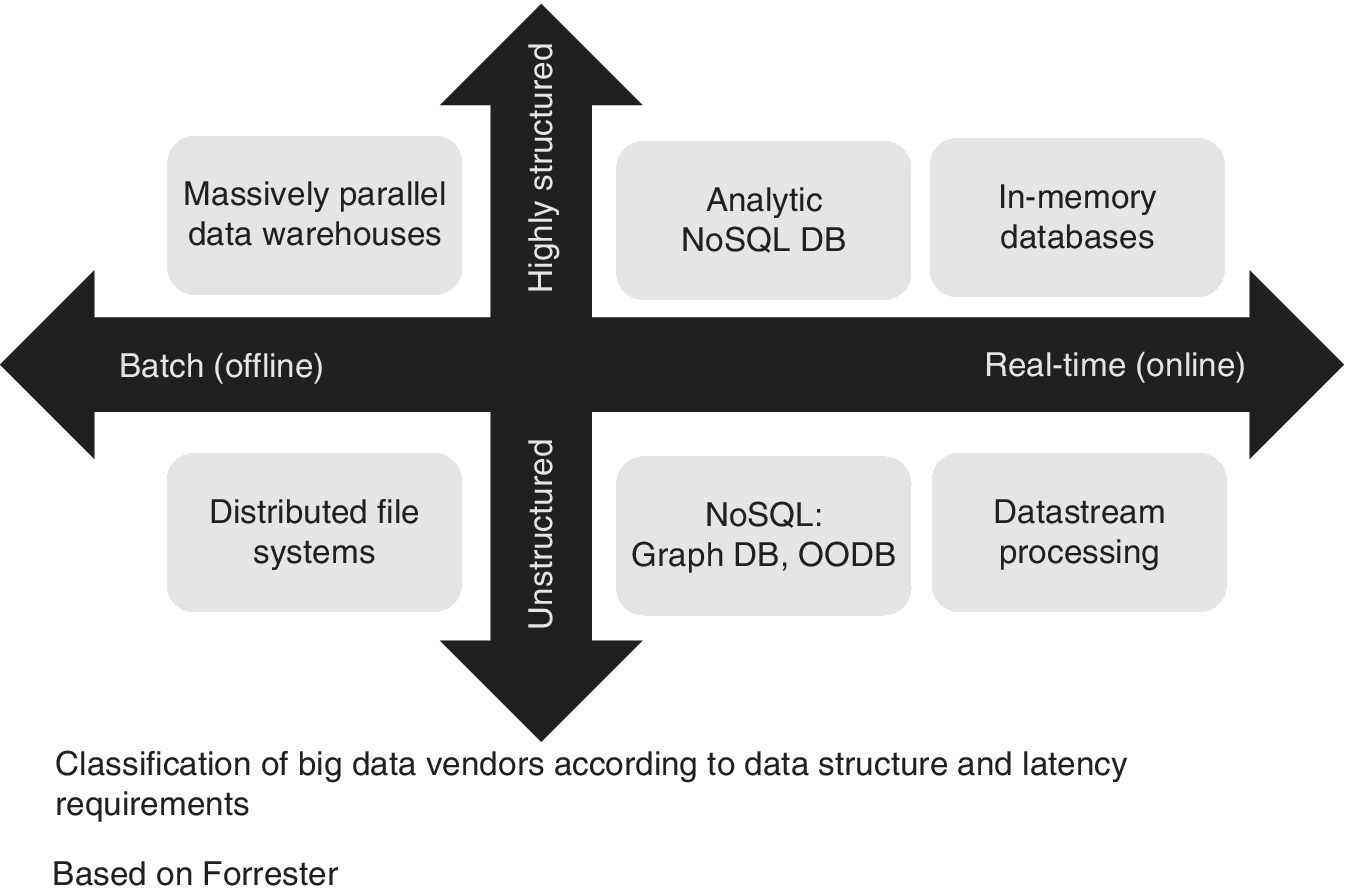
Figure 3.5 Big data structure and latency.
Let us look at the four quadrants of Figure 3.5 in more detail:
- Batch and highly‐structured Solutions are based on massively parallel architectures and highly scalable, virtual infrastructure. Such an approach significantly reduces storage costs and greatly improves the processing efficiency of traditional data warehouses.
- Real‐time and highly‐structured Solutions focus on analytical real‐time processing and data mining for predictive analytics. If it is ‘only’ fast analysis that is required (‘analysis in real time’) then analytic NoSQL data management systems are well suited. But when it comes to ‘real‐time analytics’, in‐memory databases are the solution, as they manage the analysis and the data together in main memory rather than on disk. You also gain speed by drastically reducing the input/output times when accessing the data and provide a better assessable performance than disk‐based databases.
- Batch and unstructured This is the way that most big data analysis is carried out. The solution here is to have a powerful software framework. This framework contains management applications, processing engines for very large data volumes and a file system.
- Real‐time and unstructured The need to get analytic results in real time is becoming more and more relevant and the increasing use of sensor data pushes this even more, especially if the prediction of the outcome of the next event is the relevant goal. One technology for treating real‐time analytics is called event‐stream processing and is used to manage multiple event streams and get meaningful insights.
3.9 Data Marts
The term ‘data mart’ is widely used and describes a different concept to a data warehouse. However, both data warehouses and data marts are building blocks that serve to store data in the context of analysis‐oriented information systems.
A data mart is defined as a specific collection of data, in which only the needs of a specific view and use are mapped. For example, a data mart could be constructed for customer‐based predictive analyses, such as the prediction of those customers with the highest probability to buy next.
Data is often arranged in very different ways. A data mart on the one hand is seen as a subset of the data warehouse, in which a portion of the dataset is duplicated. On the other hand, it can be an entity in its own right. If there is duplication of data in the data mart, this is justified by the size and structure of the data warehouse. The data warehouse contains very large datasets that are based on ‘relational’ database systems and are thus organised in relation to usage; they are not necessarily structures that are fully adequate for addressing specific problems. Especially when interactive access to the datasets is desirable, the representation of data in the data warehouse and the response times may not be very good. Constructing a data mart solves this problem; function‐ or area‐specific extracts from the data warehouse database are collected and stored in duplicate in a data mart.
Data mart storage can be realised with the same technology and a data model can be used that corresponds to a proper subset of the data warehouse, so that the data mart can be easily maintained. Alternatively, it also seems appropriate for the data mart, with its manageable data volume (in contrast to the relational‐based data warehouse), to use a multidimensional database system in order to exploit the potentially better modelling and querying capabilities of this technology. In particular, the necessary transformation of data into the new model can be carried out. However, because the care of such data marts is expensive, it is sensible to consider the advantages and disadvantages of heterogeneous data models. Note that the term ‘models’ here is used in the sense of computer science and refers to the data structure, including aspects such as which data item is the primary key, and which is the secondary one, and so on.
The users receive the data mart, which has been tailored to their information needs and includes a sub‐section of the enterprise‐wide database. With careful delineation of these data mart excerpts, requests for essential parts of the data mart compare favourably, in terms of speed of access, to direct access to the data warehouse. Basically, data marts can be close to the form of data storage (relational and multidimensional) in the data warehouse but, unlike the data warehouse, which is created only once, the data mart is regularly updated as a whole or in part.
3.9.1 Regularly Filled Data Marts
Data marts that need to be updated regularly, are often needed for reporting and on‐line analytical processing (OLAP) or for data mining aggregated data that is continuously available. Such data mart tables and files are typically compressed, but at different levels, say sales figures for the current year. Depending on the definition of this information, it should be available daily, weekly or monthly. The shorter the update period, the more important it is that the process of updating is fully automated, or that the refill is carried out according to fixed rules and within defined procedures. With a daily loading cycle, updates take place during the night, after data from operational systems have accumulated in the data warehouse, giving the most current information available.
3.9.2 Comparison of Data Marts and Data Warehouses
Many companies offer data marts to provide users with pre‐aggregated information. The data warehouse database is stored there, with the current and historical data from all divisions in the different stages of compression in the core of the analysis‐oriented information system. There is a recognisable conflict from the user perspective: in a data mart, data is aggregated for the analysis of major interest, but there is little scope to analyse detailed individual values or to respond to new data requirements to link them.
Data warehouses do not give rise to this dilemma. While data marts may be deployed to contain aggregated and possibly transformed data, in the data warehouse the data is stored at the finest possible granularity. For the data warehouse, the relational storage of data as a quasi‐state has emerged over the years, while data marts, depending on the application, will create both relational and multidimensional data.