5 Background and Supporting Statistical Techniques
5.1 Introduction
Despite the mass of business data that can be used for monetisation, it is important to maintain a clear focus on the business issues; every piece of descriptive analytics should be of interest to someone in some part of the business and be clear enough to be easily understood. Before the value of any monetisation can be evaluated we need to understand where we are coming from and so we review the assessment of the baseline and the wider context of key performance indicators (KPIs). KPIs are chosen specifically to measure success in different industries. Examples include revenue per unit time or entity, market share, production rate and profit.
Business data is notorious for being in the wrong shape in terms of the layout of its rows and columns, and in poor shape in terms of its quality, and so we address these issues before introducing the basic statistical summaries and graphics that enable us to make sense of the mass of variables that are often encountered in real data. We can now address the real power of data analysis, which is working with the variation in data to understand patterns and look for relationships between measures and groups and start to generate ideas and plans for predictive analytics.
We consider ways to select features from alternative explanatory variables. Where the data are used for model building the effectiveness of the models depends on using training, testing and validation samples in a skilful way; sampling techniques and model tuning are also discussed.
5.2 Variables
5.2.1 Data
Data consists of a mass of variables. Numbers of customers, sales income, dates and locations are all quantities corresponding to specific variables. Variables can take different roles and have different relationships with each other. Before labelling variables as outcomes or predictors, it is important to consider how else the data can influence each other. Data analysis is all about making sense of this universe of information.
5.2.2 Confounding Variables
Confounding is a term used when one variable masks the effect of another. For example, a survey was carried out to explore the relationship between fluoridation of water and tooth decay. It was found that areas of high fluoridation had more tooth decay, which was unexpected. However, on closer examination it was found that the higher fluoridation area had an older population and the age variable had masked the underlying relationship. When the effect of age was allowed for, the benefit of fluoridation was clear: there was less tooth decay in the higher fluoride area. In this case age was a confounding variable for location.
Randomisation is a method of avoiding the effects of confounding. For example, if a new process is being compared to an old process, the different methods should be applied at random times in the week. Otherwise, if the new method might, say, always be tried out at the end of the week and the old method at the start of the week. Any apparent difference could be due to the different conditions at the start compared with the end of the week – different staffing, throughput or wear and tear – rather than the different processes. In this case time is the confounding variable for the different processes.
Confounding variables can mask a difference or falsely enhance it depending on which way they affect the outcome. Either way the effect is undesirable.
5.2.3 Moderating Variables
Some variables may have a moderating effect on other variables in that they change the relationships between the variables, as reflected in interactions. For example, the number of customers may be related to sales income in a different way depending on the day of the week. On weekdays, the sales income increases with the number of customers, but at the weekend, the sales income is much less affected by number of customers as many customers come to look but not to buy. In this case, the day of the week is a moderating variable, moderating the relationship between number of customers and sales income.
5.2.4 Mediating Variables
Sometimes variables have an apparent effect on an outcome but the effect is mainly due to a mediating variable. For example, family‐owned businesses may be more willing to undertake a voluntary audit of their accounts than other businesses. However, in a sample of businesses, when bank loans are considered in conjunction with family ownership, it is found that the apparent relationship between family‐ownership and voluntary audit nearly disappears. This suggests that it is really the issue of having a bank loan that affects the willingness to have an audit rather than family ownership. In this case having a bank loan is a mediating variable for family ownership.
The nature of the mediation should be assessed using business domain knowledge. Model choice and selection of variables are crucial issues in detecting mediation (and moderation) and should be guided by business considerations.
5.2.5 Instrumental Variables
Another important consideration is the use of instrumental variables. Multiple regression analysis assumes that the predictor variables are measured without any uncertainty and that the uncertainty in the outcome is unrelated to the predictors. Note that the uncertainty in the outcome is different to the value of the outcome.
Even if the uncertainty in the outcome is related to the predictors, the effect may not be very great. However, if this situation is thought to be a problem, one approach is to identify instrumental variables that relate to the predictor but not to the uncertainty in the outcome. For example, there may be feedback between the sales in one shop, shop A, and the sales in the shop next door, shop B. The outcome is the sales of shop A and the predictor is the sales of shop B. In this case an instrumental variable may be the number of reduced items on display in shop B. This is known to affect the sales of shop B but cannot directly affect the uncertainty of sales of shop A and can be used as a predictor for sales in shop A. The number of reduced items next door is an instrumental variable affecting the sales income of shop A. The relationship between the instrumental variable and the sales income of shop A can be explored using multiple regression. Suitable instrumental variables to give a meaningful analysis may be hard to find but are often apparent from the business scenario.
5.2.6 Business Considerations
The importance of thinking about the different types of variables and their different relationships is that when we come to statistical analysis it can help in the interpretation of the analytical results. It may also help in variable selection and the choice of features for inclusion in predictive models. There are other types of relationships to those described above and a thorough study of the subject quickly becomes quite philosophical and complex.
5.3 Key Performance Indicators
Bringing the discussion back to the business scenario, some variables are usefully identified as key performance indicators (KPIs). KPIs are used to assess the baseline situation, to measure success and to provide a way of evaluating change. Examples include basic bottom line values such as return on investment. This summarises the relationship between investment and profit and can be given as a percentage or as an absolute number. For example, an investment of €2000 is made by a company buying equipment and implementing it. Subsequent sales give a revenue of €5000. The profit is 5000 − 2000 = 3000 and the return on investment is the ratio of profit to investment, in this case 3000/2000 = 150%.
KPIs are chosen so as best to monitor the business and to summarise the performance in a small set of numbers. Typically, a relevant subset of KPIs are chosen by senior management for special attention. KPI definitions are often based on industry standards: companies may adapt the definitions to ensure they are appropriate and serve the function of giving a more exact and transparent indication of the business performance. They also provide a guideline for improvement as they help to compare current and past status. The KPIs chosen differ between businesses and also within business departments.
There are many KPIs in marketing, for example click through rates, response rates and cost per order. Sometimes the name of the KPI is the same but has a slightly different definition in different industries. For example, the definition of costs in the cost per customer (CPC) KPI may vary, so it can have different meanings in different environments or industries. The acronym itself can have slightly different meanings too. In marketing, CPC is cost per customer but in an online environment, especially in keyword advertising, it could mean cost per click. Agreed operational definitions are vital!
5.4 Taming the Data
Data generated within processes can be in a variety of forms. It is necessarily compressed and does not always appear in neat columns ready for analysis. Figure 5.1 shows structured data from a typical customer transaction process.
Data can be comma separated and have lots of NULL entries. NULL entries are not zero values but can arise for a number of reasons, such as where the data item is not available or was lost in transit or was not filled in.
There are several different types of missing information, as discussed above. One type is actually meaningful, for example, all the purchase categories will be blank in the situation where the person did not buy anything. This type of transaction can apply in any situation where the input reports on something that has happened, but nothing actually happened, for example where someone looks at a website but does not click on anything. Not doing something is also information and it is different to the situation in which they had no option to do something. In some cases the data really is missing; for example, no age or address is given. In this situation, the NULL can be replaced by imputing a suitable value. It is big mistake to accidentally take the NULL values as meaning zero or not applicable or any other intentional value without thinking carefully about what these mean.
If you have IT support they can help to prepare a dataset for you. But if you want or need to manipulate the data yourself, this section gives some hints on how to get started. The modern data scientist is often expected to have some competence in data handling and it can be unnerving if you have an aversion to raw data. Notwithstanding this, knowing how to manipulate data is empowering but it is always good to get expert help if necessary.
The headings all need to be documented, otherwise no sense can be made of the data. The dataset may have non‐English characters, and information in date structures and comment form. Decisions need to be made about how to handle these issues.
A good starting point is to look at a subset of manageable size, for example in an Excel spreadsheet. The filter options are helpful and can show the top and bottom few values, which can be useful for checking viability of the input.
Inserting an Excel pivot table will highlight some of these issues; for example, multiple spellings and wide ranging, sparsely filled gender options (say for ‘prefer not to say’, ‘transgender’, ‘missing’ and so on).
Arguably the first thing to do with a set of data is to plot it. However, the first attempts at plotting may be thwarted by features of the data.
Quantitative data may have extreme values, which upset the scaling and hide the detail contained in the majority of the dataset.
Qualitative data may have multiple versions, for example post codes and telephone numbers written with and without spaces. These need to be combined, edited or sorted in some way before a chart can be obtained.
There are many data formats available which can handle structured and unstructured data.
Depending on the analytical system being used, the data can be analysed directly or be converted to a suitable format. For example, Excel can handle data input in a wide range of formats, including XML, and can output data in different forms. Some data formats need special knowledge to handle them. New formats are appearing all the time and further details and pointers to places for web searches are given in the bibliography.
Statistical procedures usually require that certain conditions are fulfilled in the data. For example, there are often assumptions about normality, linearity or constant variance. In contrast, however, in data mining it is expected that these conditions may not be met. Data mining procedures are usually carried out with very large amounts of data (random sample sizes of 30,000 are quite common) and the non‐observance of the conditions does not matter too much.
5.5 Data Visualisation and Exploration of Data
The characteristics of data include:
data type
size and range
variation
shape of the distribution
datasets relate to each other.
The choice of which type of data visualisation will be most effective depends on whether the data is discrete, continuous, bounded, dependent on other variables or standalone.
5.5.1 Univariate Plots
Values of a single variable, such as customer age, can usefully be plotted in a histogram to show the main features. Nominal, ordinal, categorical and classification variables can be investigated by looking at the frequencies of each value and, depending on the type of the measurement, can be illustrated by plotting the data with histograms or bar charts.
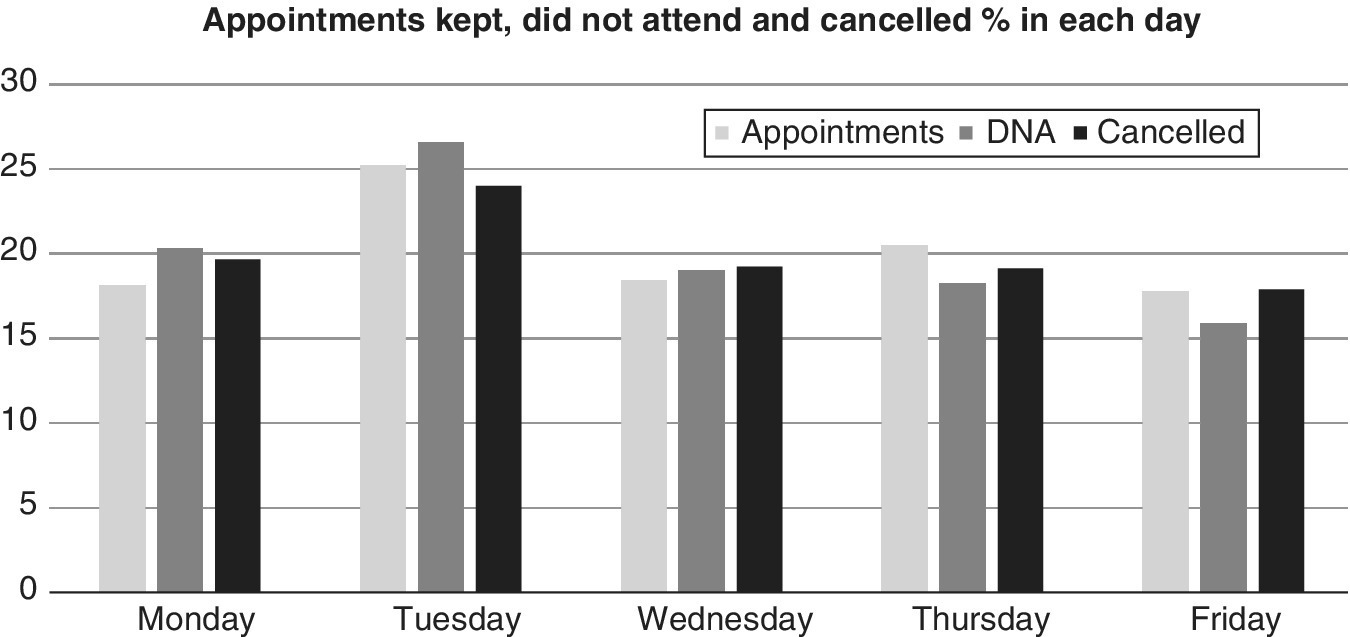
Besides looking at the observed frequencies, it is often useful to look at the proportional or relative frequencies. Bar charts can combine a lot of information. For example, Figure 5.2 shows attendance figures for appointments at a service provider. People cancelling or not turning up and wasting their appointment can be a big problem, causing extra administrative effort and lost expert time. The purpose of the bar chart was to illustrate how appointments, cancellations and ‘did not attends’ (DNAs) vary over the days of the week. The bar heights are the percentages of appointments kept, cancelled or missed, calculated over the days of the week. For each of the three categories, the sum of bar heights for the five days is therefore 100%. The bar chart contains a variety of information.
It can be seen that more appointments are kept on Tuesdays and there are more cancellations and DNAs on Tuesdays. On Thursdays and Fridays there are fewer cancellations and DNAs than expected from the percentage of patient appointments then. Care has to be taken with the interpretation of the chart because the bar heights represent percentages not numbers and there is no indication of the overall proportion of cancellations; just their distribution over the days of the week. The business impact of this bar chart is to suggest that DNAs may be due to work commitments, which are easier to avoid on Fridays, and so it may be sensible to offer an out‐of‐hours option for people who need to fit appointments around their work.
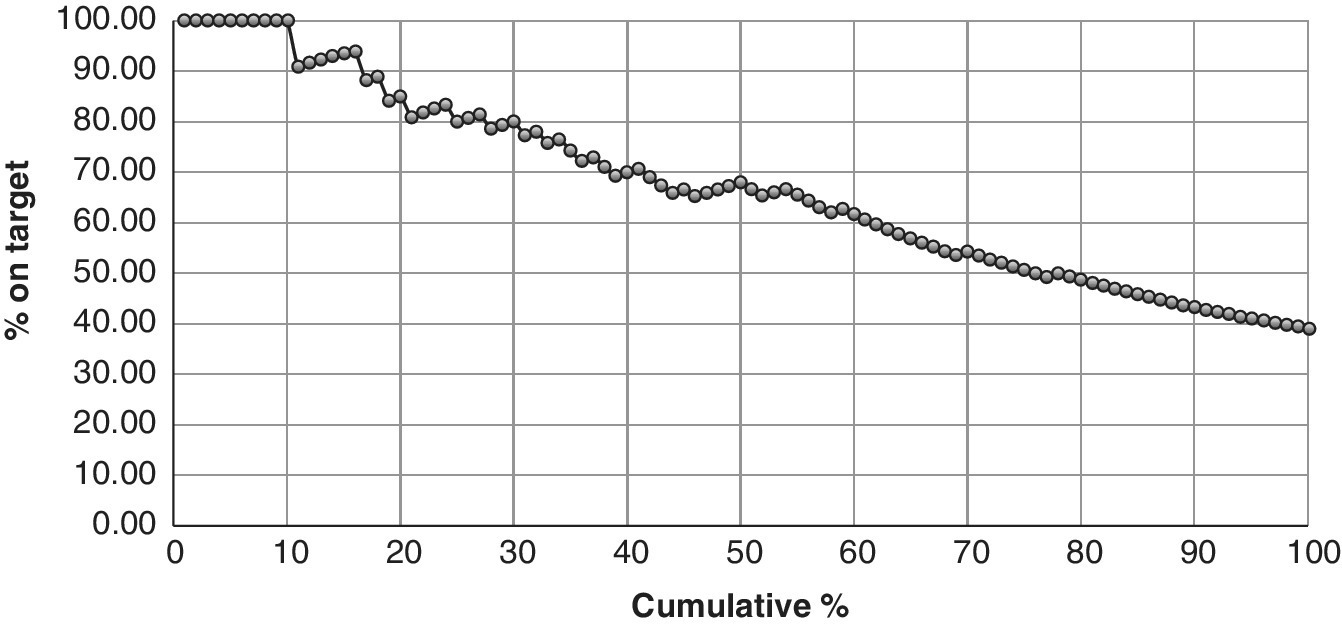
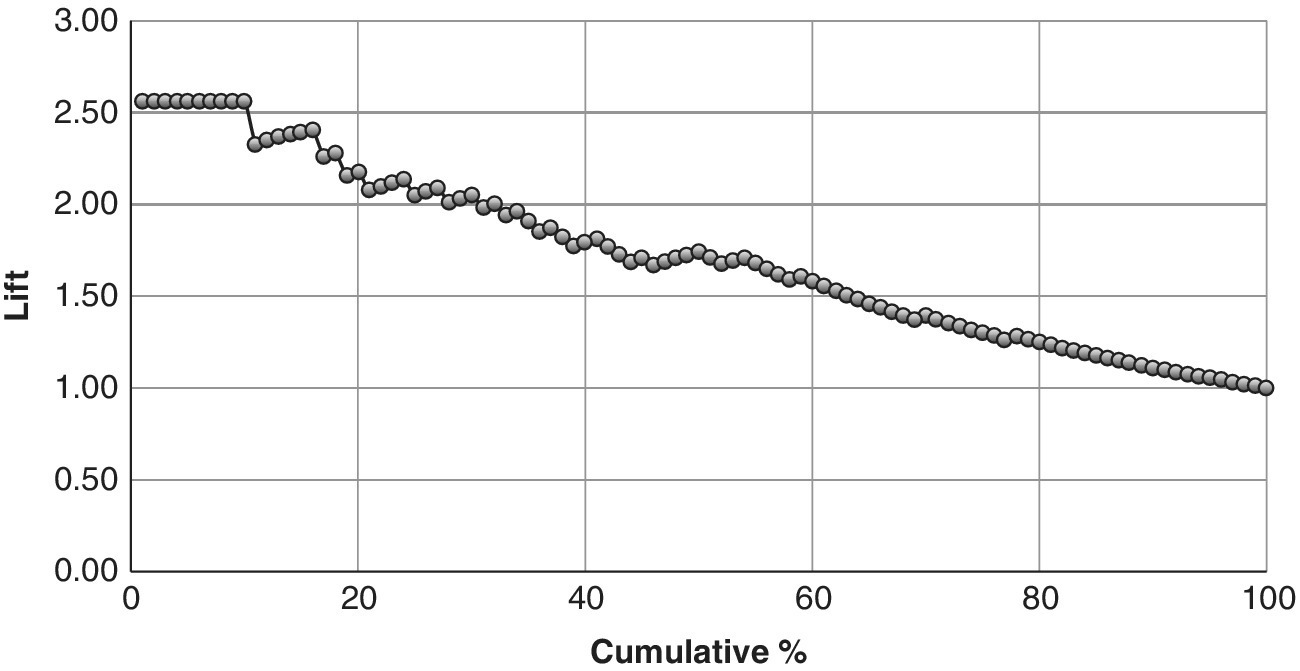
As well as looking at the frequency of different outcomes, it is sometimes informative to look at the cumulative counts. Traditionally, the vertical axis shows the cumulative sum of frequencies less than or equal to the value on the horizontal axis. In Figure 5.3, the left‐hand plot is the histogram of customers in nine different age groups. The right‐hand plot is the cumulative frequency for successive ages. Cumulative frequencies are also of interest to address particular questions, such as how the data builds up in the different categories. The accumulation can be emphasised by a superimposed line plot on the bar chart.
Cumulative frequencies are equally applicable to both ordinal and nominal variables. For example, we could say that a person likes to ride by train as well as using a car to reach a holiday destination. Stating that the cumulative frequency of these two modes of transport is 60% has an important meaning if it is contrasted against those using a plane and a car: it may reveal a hidden pattern relating to beneficial cost savings offered or savings in travel time or reduced effort required by the customer.
Seven quality improvement tools are cited in Total Quality Management standards. These tools were recommended by key figures in the quality improvement movement and miscellaneously include: bar charts, histograms, scatterplots, time‐series plots, flow charts, data collection forms, cause and effect diagrams, statistical process control charts and Pareto charts.
Pareto charts are named after the 19th century economist Vilfredo Pareto, who noted that 80% of the land was owned by 20% of people and that this ‘80/20 rule’ was a common occurrence in all walks of life. For example 80% of orders are for 20% of the product range, 80% of complaints are about 20% of issues or 80% of time is taken up by 20% of customers. Pareto charts are bar charts where the horizontal axis is such that the most frequent item appears first, on the left‐hand side, and the rest of the items occur in order of descending frequency. Typically there will be a large number of rare items and these are grouped together for the final bar on the right‐hand side. In addition, a cumulative frequency line is usually added; reading across at, say, 80% indicates which items need to be considered to cover 80% of cases.
Pareto charts are considered a most important management tool because they highlight the frequency of different types of occurrence and help to prioritise where to take action. They are often used to address problems or difficulties as in Figure 5.4, but can also be used in a positive sense as in Figure 9.2.
When the data represents one of a number of categories, it can be effectively plotted in a pie chart showing the proportions of occurrence of each category (see Figure 5.5). The proportions can be described or tabulated next to the chart. The chart gives a powerful visual summary and a good pointer to the important parts of the data.
There are many other types of univariate plot, such as the box plot, dot plot and incidence plot.
5.5.2 Scatterplots
Often it is the relationship between variables that is of most interest. Pairs of variables can be plotted on a scatterplot, with one variable on each axis. The pattern in the points indicates how the variables are related to each other.
If both variables are categorical or nominal then a scatterplot has a lot of coincident points. You can add jitter and use a scatterplot, or use a 3D scatterplot with the frequency as the third variable, or use a table instead.
It is sometimes useful to be shown a relationship between the points in a scatterplot. A straight line can be superimposed or a quadratic, cubic or higher polynomial. Sometimes it is preferable not to dictate the pattern in the points. In the general case, methods that smooth using summary estimates of nearest neighbours are useful. One such method is locally weighted scatterplot smoothing (LOESS or LOWESS). This helps pick out the pattern in the data based purely on the data, with no preconceived idea as to the form of any relationship. Such a line is based on localised solutions and does not result in an estimating equation.
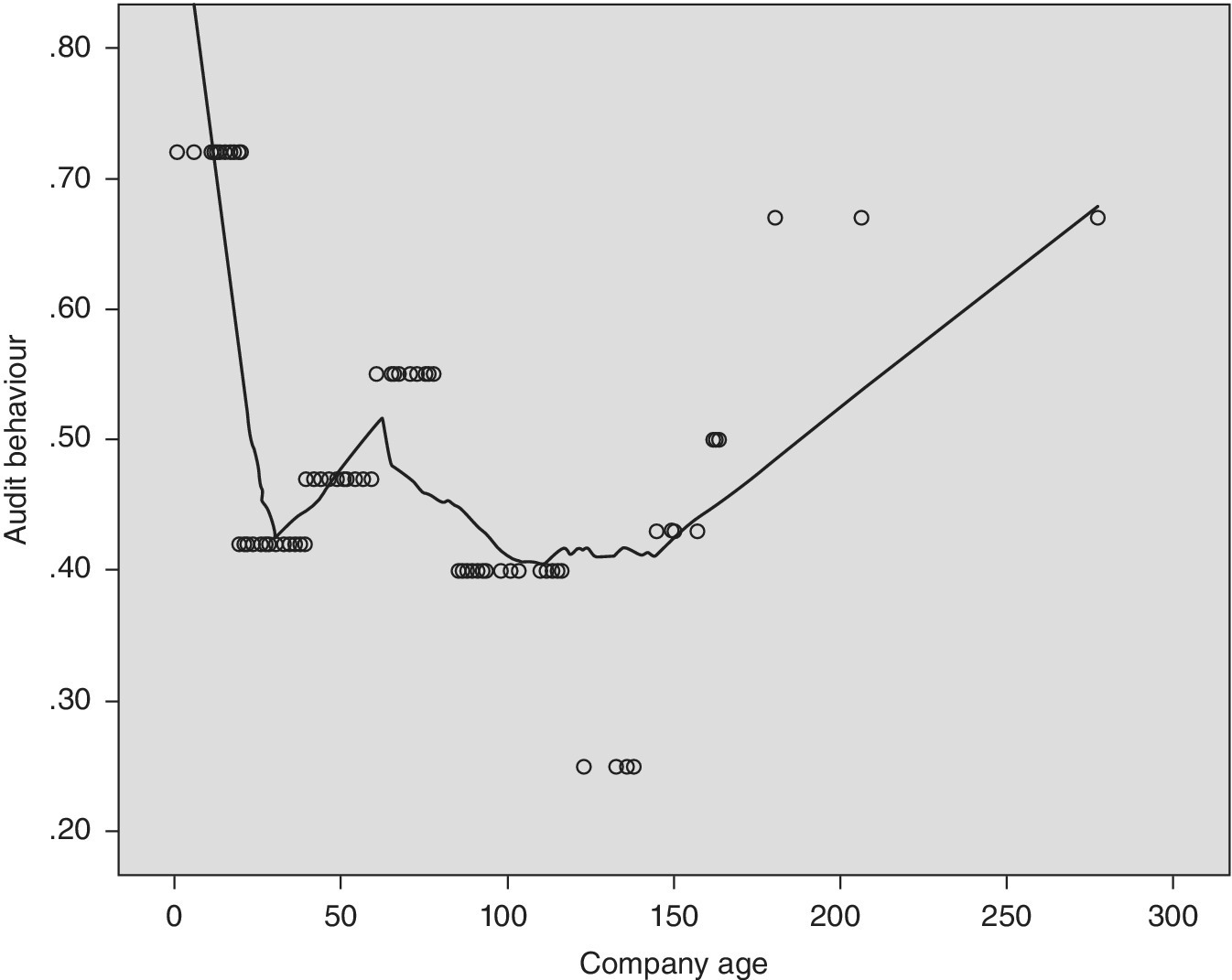
Figure 5.6 Scatterplot of company age and auditing behaviour with LOWESS line.
In Figure 5.6 the relationship between company age and auditing behaviour is clearly not polynomial and the LOWESS line helps to pick out the main features. The LOWESS line is based on a Gaussian kernel using a successive 50% of data points.
In many applications it is important to be able to estimate values between the measured points. Such interpolation can be carried out using kriging methods (see Section 5.5.7).
5.5.3 Multivariate Plots
Multivariate scatterplots, bubble plots, 3D surface plots, profile plots, parallel plots, contingency tables with frequencies on the z‐axis, ternary plots and radar plots are all ways of describing multivariate data and illustrating its salient features.
Figure 5.7 is a multivariate matrix of scatterplots and shows the distribution of the input variables in a designed experiment. It can be clearly seen that all input variables are well spread out over the design space.
Two‐way scatterplots can be expanded into a third dimension by adding different colours, using different symbols, or using the size of bubbles at each point to represent the third dimension. Bubble plots can also be animated to bring in a fourth dimension, such as time; the bubbles come and go as the time period of the data changes, giving a dynamic impression of the data.
A ternary diagram has three axes and can show the relative proportions of three variables. For example, we may be interested in the proportions of marketing expenditure on internet, face‐to‐face, and other activities by different companies. These proportions are constrained to add up to 100% and are referred to as compositional data. The ternary representation is favoured by people working with such data. The closer points are to a vertex, the higher the proportion of that variable.
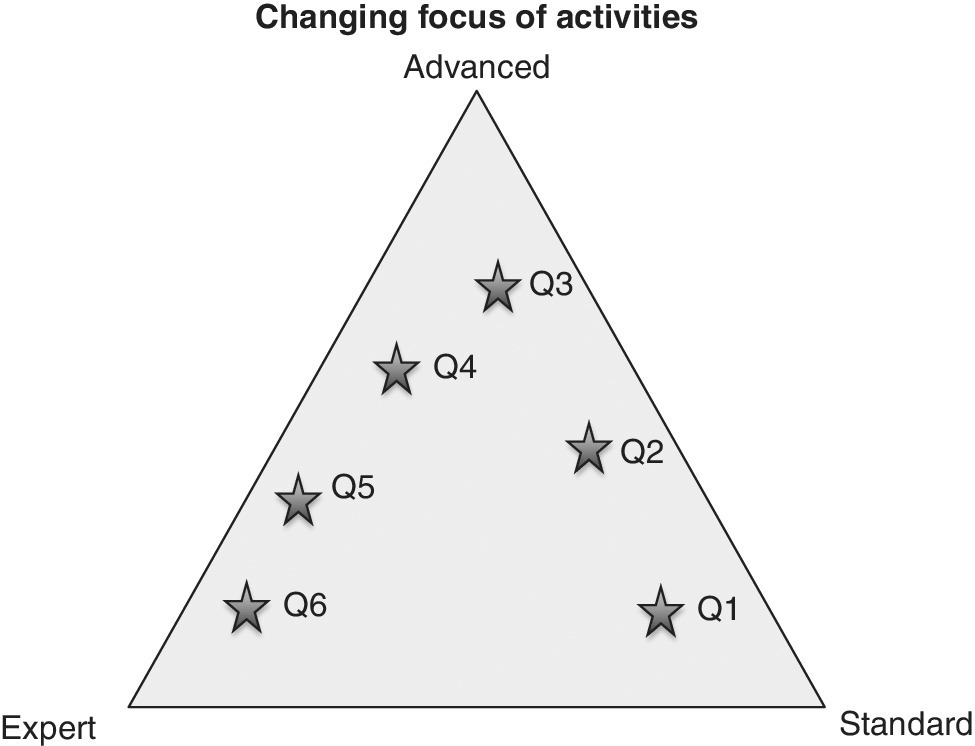
The ternary diagram in Figure 5.8 shows the performance of a service provider wanting to migrate from standard services, to more advanced services, to mostly providing expert services. In Quarter 1 the provider was occupied mostly with standard services but in Quarter 2 they had moved towards more advanced services. Finally, in Quarter 6 they had achieved their target. Ternary diagrams can be used to look at proportions for any subsets of three items, so they can be used to illustrate compositional data with any number of components.
Radar plots are a useful way of illustrating the changing values of a number of different variables on a number of different outcomes.
Figure 5.9 shows seven different indexes for five different performance types. The indexes are calculated from raw measurements collected directly from people grouped into five different fitness and activity levels and therefore having different types of performance. The plot immediately shows the key features of the comparison.
5.5.4 Concept Plots
Word clouds show the relationship of words to each other and indicate what concepts are associated with each other. An example is given in Figure 5.10.
Mind maps and social network maps also show how concepts are related to one another. A key feature is the freedom to have any scales and metrics. The plot doesn’t need to be rigid like a scatterplot and scales don’t matter. We can plot concepts like the number of connections people have in a social media network. This is totally different from traditional plots and reflects the unstructured, unfettered nature of modern analyses, including music and spatial and non‐parametric data (see Figure 5.11).
These plots can be purely descriptive but can also be used in a predictive sense. The concepts are added as they occur and the map can be dynamic.
5.5.5 Time‐series Plots
The second variable in a scatterplot may be time and then the plot shows the variable of interest as an ordered series of dots with time on the horizontal axis. If the time gap between data items is constant, for example weekly expenditure, then the interpretation is clear. Sometimes however, the time gap is variable, such as when there are occasional purchases of a product, and then the time axis can either:
correspond to the intermittent time giving uneven spaces between dots or
correspond to events in which case dots are equally spaced but represent different time gaps.
Time series are extremely important in business as they show trends, jumps, seasonality and other patterns. Statistical time‐series analysis usually requires a long series of equally time spaced data so that patterns can show up and a model can be built. Forecasting can only be effective if there are trends, seasonal patterns or strong time dependencies (called autocorrelation) on which to base the predictions, otherwise the future is just predicted as the mean value of the past.
Time‐series data are likely to be autocorrelated because subsequent values are related to preceding values. For example, the weather on one day is highly correlated with the weather the previous day. Time‐series data also often show trends – values steadily increasing or decreasing – or seasonality, for example contacts increasing in the morning and decreasing in the evening.
Real data is subject to systematic and natural variation. Ordered data such as time‐series can usefully be smoothed so that the noise is reduced and the underlying patterns are easier to see. Moving averages are a basic method of smoothing in which the mean value of a window of values (say a week’s worth of daily data) is plotted in place of the central value of the window (or in some cases as the end value of the window). A variation of the moving average is an exponentially weighted moving average where, instead of giving all values in the window equal importance (or weight) and using a simple arithmetic mean, more recent values are given a greater or lesser weight.
The longer the smoothing window, the smoother the plot is. Financial data analysts like to superimpose moving average plots calculated with different windows and interpret the cross‐over points. This field of so‐called ‘technical analysis’ recommends all manner of plots for stocks and shares and the skill is in using them to predict movements in the market that can be exploited.
5.5.6 Location Plots
It is impressive to show data superimposed on locations. For example, we can plot characteristics of customers and see how they relate to natural boundaries such as motorways and rivers. We can use their postcodes to find their precise location in terms of latitude and longitude. The conversion uses look‐up tables available from official statistics providers. We can explore a variety of customer features, such as their proximity to shops and services.
The location maps can be coloured in a meaningful way. The shading in Figure 5.12 shows house prices. The maps can be interactive, so that when the user points at an area additional information such as flood plains or local school exam success appears.
It is straightforward to access geographical information and combine the maps with other information. A detailed example is given in Section 6.4.4. A neat example created by a tourism company enabled the tourist to hear local folk songs by clicking on different regions of a map. In this way they can plan their musical tour of the countryside.
There are many variants on informative maps. For example, we can show a density index superimposed for different cities, as in Figure 5.13. The density index is important because it shows activity standardised by a measure such as population or number of eligible purchasers so that different areas can be realistically compared.
The nature of big data is to fill all the space of possible values. In other words, there are likely to be instances of all possible combinations of variables. This is the opposite situation to the sparse nature of planned experimental data. In this case it may be necessary to estimate intermediate values, a process referred to as ‘interpolation’.
Where appropriate, missing values can be filled by linear interpolation between neighbouring values. This simple approach is not always the best solution. The kriging method of interpolation was first developed to deduce the most likely distribution of gold from samples from a few boreholes. The methodology is invaluable in interpolating between the measured points of a designed experiment, particularly where each experimental run is very expensive and so there are very few design points.
In kriging the interpolated points are determined by predicting the value of a function at the point from a weighted mean of the known values of the function in the neighbourhood of the point.
5.6 Basic Statistics
5.6.1 Introduction
This section gives a brief background to statistical analysis of data. Predictive models depend on finding variables with reliable relationships to each other. Statistical analysis aims to give an objective justification for the decisions made when modelling. Data analysis is inextricably tied up with the idea of uncertainty. Decisions are based on behaviour of people, systems and products, and rather than being fixed these are underpinned by probability. Different outcomes occur with different probabilities, and these are described by probability distributions. From theoretical or observed distributions, models aim to make predictions and estimates. Some of the more common statistical tests are described because they are used in the monetisation of data. This is followed by an overview of correlation and statistical process control, which is a business improvement method giving a practical approach to sustaining the gains from monetisation.
5.6.2 Probability
Everything in life is uncertain except paying tax! The uncertainty can be expressed as a probability (p) where a p value of 1 is a certainty and 0 is an impossibility. Likelihood is the converse of uncertainty. P values between 0 and 1 represent differing degrees of uncertainty (or likelihood). Probability theory underlies all human decisions and also all aspects of statistical analysis.
We can distinguish between probabilities that can be calculated or estimated from past or current experience from those that cannot be calculated. We can calculate the probability of throwing a 10 with two six‐sided dice as a fraction: the number of ways to get 10 divided by the total number of possible outcomes. (The answer is 3/36 = 1/12, assuming the dice are unbiased). We can estimate the probability that it will rain tomorrow from a knowledge of similar weather patterns or complex weather simulation models. Then there is the case where we cannot calculate the probability because we have no basis for our inputs. An example is the probability of a disruptive new development occurring this year, for example the jump from using a candle for light to using an electric light bulb.
Probability depends on assumptions and underlying conditions. Conditional probability expresses the likelihood of something happening on the condition that some other event has happened. For example, the probability of catching your bus is high, but the probability of catching your bus if you leave home too late is low. Conditional probabilities feature in Bayesian approaches to analysing data. Bayesian networks show conditional probabilities between items and have been found to be very helpful in understanding complex interrelationships in crime, finance and health.
5.6.3 Distributions
Histograms and bar charts illustrate how probability is distributed over the possible values of a variable. If the distribution follows a mathematically defined distribution then this can be used to model the data and make predictions, estimates and decisions. Here we consider some common distributions.
Measurements such as the IQ of employees are likely to have a symmetrical, bell‐shaped distribution referred to as the ‘normal’ distribution. Most employees have an average IQ, some have higher and some have lower. Company age is likely to have a positively skewed distribution; all values are positive, many companies are young and a few are very old. This may be modelled by a Weibull distribution. Rounding errors of different sizes are likely to occur equally often, giving a flat histogram and a distribution referred to as the ‘uniform’. These are examples of continuous or scale data distributions because the data can take values at any level of precision.
The number of customers buying a product in a specific period of time is not a continuous variable as it can only take whole numbers. It is a discrete variable. A bar chart, for example of the number of customers buying each week, is likely to be positively skewed; all the values have to be positive or zero, most time periods have average numbers buying but some have exceptionally large numbers. This situation may follow a Poisson distribution. If the number buying is larger than about 20, then the distribution tends to be more or less symmetrical and can be approximated by the normal distribution. The number of people in a focus group who complain may vary from 0 to all of them, depending on the underlying probability of dissatisfaction. This situation may follow a binomial distribution, although if the focus group size is larger than about 20 and the probability of complaining is such that the number of people complaining is greater than about 5, then the distribution can be approximated by the normal distribution.
The approximation of distributions by the normal distribution when the sample size is large is explained by the central limit theorem. It also applies to the distribution of mean values from distributions that are skewed or discrete.
There are situations where no standard model fits the data. For example, the risk scores for a set of maintenance jobs may occur in clumps. In this case, if there are enough data, the empirical distribution can be used to estimate values such as the cutoff risk score, which includes 95% of the maintenance jobs.
5.6.4 Population Statistics
Business data typically contain variety in terms of customers, dates, products, suppliers and so on. It is often useful to give an overall summary, especially at the start of a data analysis. If we want to summarise the age of our customers, the mean or median value is a good choice. The median is the 50th percentile, so called because 50% of the data have values less than the median:
The mean is the sum of all values divided by the number of items
The median is the middle value when items are placed in order.
If we want to comment on company suppliers then the mode – the most common supplier – would be useful to know.
These summaries only give a measure of magnitude, for example ‘mean customer age is 45 years’. It makes a difference to our interpretation of the age of customers whether all customers were exactly 45 years old or whether half were 30 and half were 60 years old. The range of the data is the difference between the maximum value and the minimum value. The range can be adversely affected by outliers and does not indicate where most of the values lie. The inter‐quartile range is between the 25th and 75th percentiles and indicates where the central 50% of values lie.
If the data are assumed to have a normal distribution then a 95% tolerance interval is expected to include 95% of the values in the population. The 95% tolerance interval is from the mean minus 1.96 standard deviations to the mean plus 1.96 standard deviations. Standard deviation (sd) summarises the variation in a continuous or scale variable and is expressed in the same units as the data itself. For example, the mean age is 45 years and the standard deviation is 5 years.
The 95% tolerance interval is approximately from (mean – 2 × sd) to (mean + 2 × sd). In this case the 95% tolerance interval is from 35 to 55 years.
If the data have a distribution other than the normal then the tolerance interval needs to be calculated in a way appropriate to that distribution. If the data do not follow any standard distribution, then empirical limits can be found from the 2.5 percentile and 97.5 percentile, a range which contains 95% of values.
It is considered to be a natural rule of thumb that an interval from the mean minus three standard deviations to the mean plus three standard deviations contains nearly all the data values. This is a useful guideline as it gives an objective way to decide what limits to set in order to incorporate the vast majority of the population.
5.6.5 Variability and Uncertainty in Samples
Most statistical analysis is carried out on samples from a population rather than on the whole population. Samples are subject to sampling variation, and summaries such as the mean value will be different for different samples. The true underlying mean is not known for sure but the sample mean gives an unbiased estimate of it. If the data are assumed to have a normal distribution, we can calculate a 95% confidence interval for the true value. This confidence interval is subtly different from the tolerance interval discussed above. The correct interpretation is that the probability that the true population mean is contained within the 95% confidence interval is 0.95. The confidence interval depends on the sample size: the bigger the sample, the tighter the confidence interval. The 95% confidence interval is from the mean minus 1.96 standard errors to the mean plus 1.96 standard errors, where the standard error (se) is equal to the standard deviation divided by the square root of the sample size: se = sd/√n.
When dealing with samples, nothing is absolutely certain, but statistical analysis provides objective and reliable guesses. All data is subject to random variation. To be convinced of the random nature of data, imagine a bag full of equal quantities of red and green counters. If you reach in and take a sample of counters and then count how many are red and how many are green, you would be amazed to find equal quantities of each colour, particularly if you repeated the exercise several times. The underlying influences that affect which counters you grab are too subtle, diverse and plentiful to be analysed and quantified. They all contribute to random variation. The sources of random variation in business data include the multiple influences that affect the timing of an action, the many different ways that people react to marketing and sales promotions and their capricious choice of purchases. These small, transient causes of variation form the background random variation affecting the sales.
Statistical analysis accepts random variation and focuses attention on finding systematic or identifiable causes of variation. One obvious cause of grabbing more red counters than green would be if red counters were heavier or sticky and clumped together or if there were actually more red counters than green in the bag. Statistical testing can help distinguish systematic effects from random variation and can thus give evidence to believe that things differ from what was originally assumed.
Confidence intervals are calculated whenever population values are estimated from sample values. If the data have a distribution other than the normal distribution, the confidence intervals need to be calculated in a way appropriate to the different distribution. If the data do not follow any standard distribution, then the confidence intervals are calculated using bootstrap methods.
Bootstrap methods are so called from the phrase ‘pulling oneself up by one’s bootstraps’. In other words, getting something for nothing without adding anything extra. In statistics, bootstrap samples are selected by taking successive random samples from the same data and using the variation in bootstrap sample summary statistics as a proxy for the true variation.
5.6.6 Basis of Statistical Tests
One way to make sense of reality is via the positivist paradigm, which says reality exists and we can find out about it by measuring it. We construct hypotheses, gather data and test whether the data supports the hypotheses. In business, there are many different things to hypothesise about and these can be expressed in questions such as:
Does age affect purchasing behaviour?
Is the effect of age on purchasing decisions independent of the person’s occupation?
Is our sample representative of the population?
Are sales quantities dependent on marketing expenditure?
Are distance travelled to an event and age of attendee dependent on each other or are they independent variables?
The basis of statistical tests is that a null hypothesis is stated and a corresponding alternative hypothesis is specified; then a test statistic is calculated. The size of the test statistic is compared to standard tables and on that basis it is decided whether the null hypothesis should be rejected in favour of the alternative hypothesis or whether the null hypothesis should be accepted. Null hypothesis is denoted as H0 and the alternative hypothesis is written as H1.
For example:
H0: The variables are independent of each other
H1: The variables are not independent of each other.
The aim of the testing is usually to reject the null hypothesis: this is usually the more useful or interesting outcome. There are two possible outcomes for a hypothesis test: accept or reject the null hypothesis. There are also two possibilities for the underlying truth of the situation. Recall that the hypothesis test is carried out on a sample of data with a view to determining the truth about the population. There are therefore, four possible situations that can result from a hypothesis test. These four situations are shown in Table 5.2.
The probability of rejecting the null hypothesis, although it is actually true, is called the type 1 error, and is often denoted α (alpha). The probability of accepting the null hypothesis, although it is actually wrong, is called the type 2 error, and is denoted β (beta). As the aim of the hypothesis test is usually to reject the null hypothesis when it is false – when it should be rejected – this probability is also called the power of the test. The more powerful the test the better, because it implies a significant result is likely to be achieved if the evidence supports it. One reason for a low‐power test is that there is not enough data, for example because the sample size is too small. With small samples, patterns in the data that we want to detect may be lost amongst the random noise of the data and the test cannot pick up their significance. Small samples, however, are less of a problem in business data, which is more likely to be ‘big data’.
It is worth noting the difference between statistical and practical significance. A small sample with a pattern of practical significance may not give a statistically significant test result. If sample sizes are massive then even a very slight pattern will be detected as statistically significant even though it is of no practical significance. For example, small differences in buying propensity may not be worth detecting if the costs of selling are high or the population is changing fast.
Significance tests result in a statistic and a corresponding p value, which is the probability of obtaining such a value for the statistic if the null hypothesis is true. The p value is compared to significance borders as shown in Table 5.3.
Tending towards significance (10% significance level)
<= 0.05
Significant (5% significance level)
<= 0.01
Very significant (1% significance level)
<= 0.001
Very highly significant (0.1% significance level)
Real observed data, especially business data, tends to be very noisy. In an exploratory analysis, it may make sense to accept significance borders of 15% or 20% and still include the variable as possibly important. One such case is in decision trees, which determine the variables for the branches. It often makes sense to raise the significance border to ensure that variables that are only slightly significant are still considered. This is because although the variable is not directly related, it may be important in an interrelated way through an interaction with another variable.
5.6.7 Measures of Dependence
5.6.7.1 Summary of tests
Data mining for insight is all about looking for patterns in data and, in particular, for dependencies and relationships between variables. There is a wide range of statistical tests available and the variety corresponds to the different types of data that may be encountered.
Table 5.4 shows examples of some of the most common statistical tests that might be applied to a set of business sales data:
Is daily value of sales equal to company standard?
Continuous vs fixed standard
t‐test (one sample)
Is value of sales dependent on whether discount is offered?
Continuous vs nominal (binary)
t‐test (two sample)
Is the value of sales affected by staff training?
Continuous vs nominal (binary)
t‐test (paired sample)
Is loyalty dependent on gender?
Discrete vs nominal (binary)
t‐test (two sample) if loyalty has a wide range of possible values, say 0–30 or a percentage score so it can be treated like a continuous variable
Is loyalty dependent on gender?
Discrete vs nominal (binary)
Mann–Whitney test if loyalty has a limited range of possible values, say 0–10 and cannot be treated as a continuous variable
Is value of sales dependent on type of customer service?
Continuous vs nominal (categorical)
ANOVA for two or more groups
Is loyalty dependent on type of customer service?
Discrete vs nominal (categorical)
ANOVA if loyalty has a wide range of possible values, say 0–30 or a percentage, so that it can be treated as a continuous variable
Is loyalty dependent on type of customer service?
Discrete vs nominal (categorical)
Kruskal–Wallis (nonparametric ANOVA) if loyalty has a limited range of possible values, say 0–10 and cannot be treated as a continuous variable
Is value of sales dependent on time spent on training?
Continuous vs continuous
Regression modelling
Is value of sales dependent on time spent on training and gender?
Continuous vs continuous and nominal
ANCOVA or regression with indicator variables
Is value of sales related to time spent on training?
Continuous vs continuous
Pearson correlation coefficient
Is age related to loyalty?
Continuous vs ordinal
Spearman rank order correlation coefficient
Is age group related to loyalty?
Ordinal vs ordinal
Spearman rank order correlation coefficient if one or both variables have a reasonably wide range of categories, say 0–30 or a percentage so that it can be treated as a continuous variable
Is age group related to loyalty?
Ordinal vs ordinal
Kendall’s tau if limited range of categories, say 0–4
Is loyalty related to location?
Ordinal vs nominal
Chi‐square test
Is purchase related to location?
Nominal vs nominal
Chi‐square test
ANOVA is analysis of variance; ANCOVA is analysis of covariance.
These tests can be carried out in statistical software and details of suitable textbooks can be found in the bibliography.
5.6.7.2 Correlations
Correlations evaluate the relationship between two variables when the variables have at least an ordinal level of measurement. For variables with nominal scale, no correlations can be calculated and contingency table analysis is appropriate. The correlation coefficient can take values between −1 and 1. If the value lies near to 1 or − 1, one can assume that a strong linear relationship (positive or negative) exists. If the value lies close to 0, it can be assumed that no linear correlation exists.
Correlation analysis should always be accompanied by a scatterplot of the two variables, because they may be related in a non‐linear way, in which case the correlation coefficient will be near to zero even though a relationship exists. An example of a non‐linear relationship is age and time spent shopping because the time may be larger for teenagers and older (retired) people but less for those busy working in middle age. Because of the non‐linear relationship between age and time spent shopping, the correlation coefficient may be near zero even though there is clearly a relationship between these two variables. Independent variables have no relationship with each other; they have zero correlation. Dependent variables, however, can also have zero correlation, so zero correlation does not indicate independence.
Correlations are essentially a pairwise evaluation. If both variables are correlated with an underlying third variable then the correlation will be high even though the correlation may not logically make sense. This is the case of so‐called ‘spurious correlation’, where the number of birds is related to the number of births, not because the birds bring the babies but because numbers of both birds and babies are increasing/decreasing with time. Partial correlation coefficients, however, can be constructed to evaluate the relationship between two variables allowing for one or more other variables. Because of the way most correlation coefficients are calculated, they ignore information about the mean values. Correlation adds more information than whether or not the variables are linearly related as it shows both the strength and the direction of the relationship.
5.6.7.3 Compositional data
An issue arises when the correlation is being investigated between data that are actually proportions of a whole entity. This sort of data is referred to as compositional data and is common in the pharmaceutical sector where proportions in recipes are adjusted to give desirable properties of the final product. It also appears in some business activities. Proportions are different to other numbers because they are constrained to sum to one. Constrained data occur whenever percentages are allocated in some process, for example the proportion of marketing expenditure used in TV, web and email campaigns. If more is given to one component, then less is given to another. Similarly, if we are comparing proportions of job types making up a workload then the proportion is constrained to one; if one part of the company has a higher proportion of one type of job then it must have a lower proportion of another. The effect of this constraint on the correlation coefficients between components is that the sum of pairwise correlations is always negative.
5.6.7.4 Chi‐square test
The relationship between nominal and ordinal variables can be observed by cross tabulation and combined bar charts. The strength of relationship between the variables can be analysed statistically using a chi‐square test. The variables are entered into a contingency table (see Table 5.5) and a chi‐square test of association between the variables indicates whether the variables are independent or not.
The chi‐square test compares the observed frequencies in the contingency table with those expected under the null hypothesis. A null hypothesis of no association between two categorical variables implies that expected values are equal to row total × column total/grand total. The chi‐square test statistic is then the sum of {(observed – expected frequencies for each cell)2/expected frequency}.
For a 2 x 2 contingency table, the critical value for a 5% significance level of the chi‐square test statistic is 3.84, so if the chi‐square statistic is greater than 3.84, the null hypothesis is rejected and the association is considered to be statistically significant.
Note that using the chi‐square test is not recommended when the expected cell frequency is low; a rule of thumb is that the test only has a sensible result if more than 80% of the cells in the contingency table have expected frequency of at least 5. If necessary, categories must be combined in one or both variables to avoid cells with small frequencies.
A non‐significant result implies that the variables are independent. If the variables represent a target and an input variable, a non‐significant result implies that the input variable does not influence the target. A significant result implies that the input variable and target are not independent and that the input variable can discriminate between different levels of the target. It can then be useful in predicting different levels of the target variable.
If the variables are ordinal rather than binary, the contingency table may show up non‐linear relationships where some levels of the input variable lead to higher levels of the target variable. This is very useful and adds more than a dependence analysis. Contingency table analysis can be extended to interval (continuous) variables as well if they are first categorised.
The linear‐by‐linear chi‐square test assesses whether there is a linear pattern to the frequencies. For example, for a subset of customers, the region in which they live and whether they purchased in the last year or not may be known. There may be an increasing likelihood of purchase depending on some characteristic of the region in which they live, for example its distance from a major retailer or its socio‐economic make‐up, and this can be evaluated using the linear‐by‐linear chi‐square test.
The chi‐square test is also used as a goodness‐of‐fit test and an extension of it referred to as the M test (discussed in Section 6.4.2) is used to check for sample representativeness. Large sample sizes make even small associations show up as statistically significant and so in data mining it is not uncommon to find many large chi‐square test results.
5.6.8 Statistical Process Control
Businesses determine the key performance indicators (KPIs) that they wish to follow. In addition, business analytics may uncover other measures that merit observation. Statistical process control (SPC) is a way to monitor the KPIs and also to improve the processes generating them.
SPC methodology was originally developed in the manufacturing sector and is now well established in process industries, and the healthcare and service sectors. SPC involves calculating control limits or thresholds that indicate the expected range of data. The control limits are calculated from representative past time‐series data. New points are added to the control chart and actions are indicated whenever points occur outside of the control limits. Plotting key metrics in an SPC chart indicates when there are significant changes and also shows when the business is performing as normal.
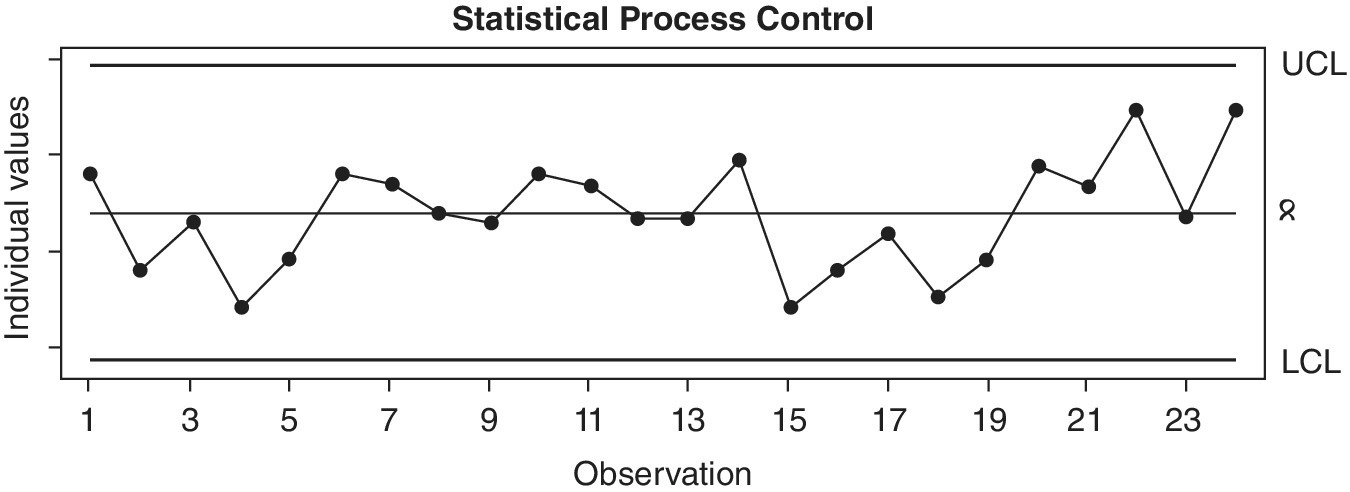
Figure 5.14 gives an example from the shipping industry. The individual values plotted are the variation in fuel consumption for a fixed journey after allowing for weather and tide conditions.
There are strict rules governing the calculation of the position of the control limits and on when a warning or an action signal should be given. The power of SPC is in preventing panic or overreaction when natural fluctuations in performance within the control limits are observed. Correspondingly, SPC charts clearly show when something special has happened, for example when fuel consumption is exceptionally high or exceptionally low. SPC charts can be constructed for individual values and for the moving range of values. A moving range chart would show when the process is jumping around more than expected.
SPC charts can be used to monitor performance and also to improve it by identifying disruptive causes of variation. Whenever there is an action signal, a set investigation procedure is activated. For example, an increase in fuel consumption may imply a need for maintenance. In a fashion business, if the SPC chart for the proportion of male customers indicates a significant decrease, this may suggest the company needs to make changes, for example to the décor or the ambience.
Although there are many international standards relating to different types of SPC, the positioning of the control limits needs to be fine‐tuned to individual business needs. If control limits are too close together it will lead to more ‘false alarms’, when points exceed control limits because of natural variation rather than an underlying special cause, but if the control limits are too wide then important signals may be missed.
If the KPIs are affected by the season, the control limits need to be adjusted to allow for seasonal effects. Note that seasonality effects are notoriously difficult to fix, because, say, winter can start or end earlier or later than expected, and market or weather conditions can vary in the extent of their influence.
Control charts need to be reviewed at suitable periods, say quarterly for daily charts. As we gather more data at different times of year we can determine if it is appropriate to recalculate the position of the control limits.
SPC charts can be used to monitor the gains from data analytics. The precision of predictions can be plotted to ensure that the prediction models continue to work well.
5.7 Feature Selection and Reduction of Variables
5.7.1 Introduction
Feature selection helps maintain focus on the most important variables. Databases typically have many variables, for example describing the circumstances of a transaction and the nature of the purchaser. There may also be many additional variables, such as new seasonally adjusted values or variables representing changes since last transaction. An important step before analysing such data is to focus on the key variables by selecting the most influential. Feature selection is sometimes mistakenly thought of as data cleaning, but it is more than that and requires technically clean data as input. Clean data has missing values and duplications resolved. Duplications can be variants on names and addresses, for example, but can also arise in other ways. An example would be finding that 30% of a sample of employees started their engagement with the company on the same date. This anomaly becomes clear when it is realised that actually this date is just when a new computer or system was released.
In some cases, feature selection will identify variables that will not be immediately discarded but will be noted as candidates for likely removal when a sample is further analysed. In addition, some variables may be very closely correlated with each other. If one such variable is missing or unreliable, then another can be used as a proxy for that variable. Feature selection methods can be used to identify variables that may be used as proxies or be kept in reserve.
Whereas in traditional statistics, it is often preferable to have a model based on a smaller number of highly influential variables, in practical data mining it is often preferable to retain a larger number of variables in the model so that smaller groups of items can be differentiated. For example, a predictive model may be constructed to identify potential customers; if the variables we have included in the model as predictors have values shared by large groups of customers, then the expected target values will be the same for large ‘clumps’ of customers. If the aim is to pick out the top 10% of potential customers then the model will not be able to distinguish these. An extreme example is a decision tree that shows age as an important feature; if customers are only categorised according to whether they are ‘old’ or ‘young’, we still have the problem of identifying the best subset of the large number of young customers for our marketing activity.
Nevertheless, it is often desirable to reduce the number of variables to make the data mining less cumbersome.
5.7.2 Feature Selection using Domain Knowledge
An effective way to reduce the number of variables is to consider what we know about the dataset and check if any of the variables are likely to be constant throughout the data. We can use a histogram or bar chart for this. It is important to consider whether a variable that has the same values throughout can add to the analysis or whether constant‐valued variables need to be removed. The variable may not always be constant and in a different training sample it may have varying values.
Another way that constant variables can arise is when the content of the variable is highly dependent on ad‐hoc management decisions, for example when management specify that the price will be fixed or the amount of product produced will be fixed. There could be dependencies on other variables, for example if a specific product is only produced in a specific plant. In this case, if the analysis is carried out just for this product, the plant variable will have a constant value.
Sometimes one variable is a constant multiple of another. For example, the ratio of gross to net may just be the tax rate. In this case logic tells us that both variables are related in the same way to the target and therefore only one of them is needed and the other can be discarded for this analysis.
A variable may be available in the training set, but domain knowledge may tell us that it will not be available in the future, so it too would need to be excluded from the model.
5.7.3 Feature Selection using the Chi Square Test
A quick way to prune out the least important variables is to carry out chi‐square tests individually on all variables. Each variable in turn is classified into two groups and presented in a two‐way contingency table with the binary target variable; the variables with the highest chi‐square test values will be selected. The cutoff value for the p value corresponding to the calculated chi‐square statistic depends on whether there is a lot of good data. The probability border p < 0.001 could be used for good data, or p = 0.05 for poor data. As the chi‐square statistic has one degree of freedom, with good data this corresponds to having a chi‐square value greater than 10. Otherwise, with poor data, a lower cutoff of about 4 could be used. Note that the chi‐square test of association does not take account of order in the variables and the cutoff value depends on the number of rows and columns in the contingency table. If there are more than two categories and order is important, the linear‐by‐linear chi‐square test can be used to pick out the more influential variables.
5.7.4 Decision Trees
Decision trees are important as an analytical modelling procedure (see 6.2.5), but can also be used in a feature selection mode to identify likely variables for inclusion in the modelling procedure. Decision trees are a practical way of sifting through data and finding relationships and patterns. The decision tree method finds interactions as well as identifying important variables.
The basic idea behind the method is to search through all the possible explanatory variables and find the one which best differentiates between the values of the target variable. There are no fundamental restrictions on the types of data involved and any of the variables can be allocated as the target. For example, an employee satisfaction survey for older workers asked many questions motivated by defined hypotheses. The result is a mass of data. Human resources personnel may be interested in which factors best discriminate between people who have high job satisfaction and those who do not. The job satisfaction scores have been scaled so that overall they have a mean value of zero. The decision tree analysis in Figure 5.15 shows that being able to have discussions with their employer is the most important discriminator: those who can do so have a mean job satisfaction of +0.741 whereas those who are less able to do so have a mean job satisfaction of −1.282. The highest job satisfaction value is 1.468, for those people in node 4 with the characteristics of working in an environment where elderly employees are accepted and who are able to have discussions with their employer.
Figure 5.15 Decision tree analysis for older workers.
Decision tree analysis can be used with any data type as the target. There are many variants of the method, and different approaches as to how the tree is formed. Decision tree analysis will always produce a result, even if there are only weak relationships between the target and input variables. If it is likely that the relationships are weak and it is uncertain which is the best model to use, there are ways of combining models and tuning the predictions. These are discussed in Section 5.9.8. Clearly the variables that appear in the tree are likely to be important in further modelling.
5.7.5 Principal Components
Principal components analysis (PCA) can be used to reduce a set of variables to a smaller number of components by identifying the common sources of variation in the data. PCA is most effective when there is strong correlation between some of the variables within the data, so that there is effectively some redundancy in the variables: instead of needing all p variables to describe the cases, we only need a subset of k component variables.
An example where PCA is effective is where there are several variables related to a general theme, such as size of expenditure or enthusiasm for innovation. In these scenarios PCA will pick out a component which describes the wealth of the person or the overall appetite for innovation. The new component variable will be a weighted mean of all the expenditure variables, or all the variables relating to enthusiasm. Having created a component which describes overall wealth, subsequent principal components will pick out other aspects of the varied expenditure between people, for example a contrast between those who spend money on sport and leisure and those who spend money on consumer items. A further component may identify a key pattern in the data such as the contrast in expenditure between single and married people. The high‐dimensional dataset can be represented by a smaller number of component variables that contain most of the rich character of the data.
Using principal components in place of variables has the advantage of reducing the number of variables but introduces a further level of complexity in that the principal components (PCs) are a combination of all of the input variables and have to be clearly interpreted. Binary variables often end up with a principal component to themselves because they are good discriminators and explain a lot of the variation in the items.
Although typically only a few principal components are needed to represent the original variables, all the original variables contribute to the principal components and so they have to be present and have non‐missing values. Also, the analysis necessarily assumes that the same principal component equations as obtained from a historical dataset are appropriate for current and future data as used in the deployment phase.
Good descriptions of PCA are included in many statistics text books including those in the bibliography. PCA is also available in most statistical software packages.
5.8 Sampling
5.8.1 Motivation
Although the whole dataset needs to be cleaned and prepared for analysis, it is not necessary to use the whole dataset for the analysis. Analysing large quantities of data is not a problem with modern computer power, but nevertheless there are other reasons for preferring to focus on a sample of the data rather than the whole population. It is better to use samples of data to construct statistical models because they can then be tested and validated on other samples, giving a more robust methodology.
5.8.2 Methods
Random samples can be obtained by giving each item an equal chance of being selected. However, this may not be the best rationale. The items of interest may be quite rare within the dataset. For example, only a small proportion of customers will purchase at any one time and these are usually the people of most interest. A random sample may contain no purchasers, and then it will not be possible to use the sample to construct models predicting who will make a purchase.
We need to understand the structure of the data to obtain a sample that will be useful for constructing models to make sensible predictions. There may be several targets and they may have varying chances of occurring. We may find, for example, data such as that in Table 5.6.
Rather than take a random sample, it is wiser to take random samples within specified strata. This is called a stratified random sample and is should give an acceptable mix of target and non‐target items.
Stratified random samples often contain the same proportions as in the whole dataset, but where the target data is known to be more variable (less homogeneous) than the non‐target group, the proportions may be chosen so that more of the variable stratum is chosen than of the less variable stratum. If there are very few in the target group, then the sample will consist of all of them. To make the sample size comparable to that of the non‐target group, it may be necessary to augment this group by taking random re‐samples from within the sparse group so that we are effectively adding to the sample by sampling with replacement.
5.8.3 Sample Sizes
Determining the appropriate sample size is a major obsession of many business researchers because it is often difficult to acquire enough data for a respectable statistical analysis. However, in data mining we have a different issue. The population size of data may be enormous and 10 million cases are not uncommon. Indeed big data is becoming more mainstream in data mining analysis, and so the size of datasets is increasing all the time. It is not problematic to select a large sample, but even in data mining the sample quality remains an issue. The sample should be representative of the population, at least as regards key variables.
One of the main constraints is that for some statistical analyses the sample size must exceed the number of variables used in the models. After transformation, classification and binning, there can be thousands of variables and 7–8000 is not uncommon. When there is enough data, sample sizes bigger than 10,000 are not uncommon in data mining.
The sample size depends on the original size of the dataset. For example, if the population is 10 million or more, then a sample of 10,000 is not enough, as it may not faithfully represent the features of the data and may not have examples of all the various combinations of the variables. If a particular combination of variables is not present in the sample used to build a statistical model, the model cannot be tested on a sample that does include that particular combination. The issue has to be resolved by increasing the sample size or reducing the variables and variable levels that are included in the model.
5.8.4 Sample Quality and Stability
Models built from a sample of data need to be applicable to the whole population. Even in a stratified random sample, where the proportions of the target variables may not be representative of the population, we still require the input variables to be representative. In this section, we consider how to check the sample is representative. If it is not, the sample size may need to be increased and/or the range of variables and levels of variables may need to be restricted.
The tests should be carried out using just some of the variables, choosing those that are well filled with few real missing values; in other words, any kind of variable for which every case has a meaningful value. Examples from commercial data would be lifetime revenue or time since last purchase. The test variables should be relevant and important, as well as being fundamental and of primary concern in the dataset, so that if they are comparable you can be reasonably confident that the samples are comparable.
The sample characteristics can be checked against the population characteristics by comparing their summary statistics. A one sample t‐test compares the means of the sample and the population; this test needs to be non‐significant. We can also compare sample and population variances using an F‐test. If the data are ordinal and there are a reasonable number of categories then we can use a non‐parametric test, such as the Mann–Whitney.
If the data are categorical with no specific order, for example the location of the item, then we can plot a composite bar chart comparing proportions in the sample and population. The population provides the expected numbers in each location for a sample of any sample size. A chi‐square test can be used to compare the numbers in each category of the sample with the numbers expected if the sample has the same pattern as the population. If the chi‐square test is significant then it implies that the sample does not have the same pattern as the population. Whether the overall chi‐square test is significant or not, the individual contributions to the chi‐square can usually be tested to identify the main causes of any discrepancy between sample and population using the M‐test. This is discussed in Section 6.2.4.
If any of the checks and tests are found to be significant and imply discrepancies between the sample and population, then a simple solution is to take another sample and try again.
In addition to providing reassurance that the sample is representative and that a statistical model built from the sample has a good chance of being useful for the population, examining the sample is helpful in understanding the dataset. Statistically sound sampling should provide us with representative samples. Multiple samples will be stable in the sense that there are no surprises; they are placeholders for the important and relevant real events and patterns in the whole population.
5.9 Statistical Methods for Proving Model Quality and Generalisability and Tuning Models
5.9.1 Introduction
The importance of business evaluation has been stressed throughout the book. It should be constantly checked to see that the models make sense, are valid and applicable in the general business scenario, and are worth the effort required to produce them.
Data mining is used to explain the relationships between variables and also to produce models that can predict outcomes for each person or case. The closer the predictions are to the observed outcomes, the better the model and the more useful it will be. The way the checking process works is as follows. Two or three of the most promising models are selected from the contending models, using business domain knowledge as well as statistical knowledge. The models are then assessed for their applicability to the whole population. We consider these three areas in detail:
business evaluation
statistical evaluation
application to the full historic population to check for abnormalities and unexpected consequences.
The range of methods and models to be considered depends on business preference, and this is related to the software and personnel available. Some businesses prefer to stick with well‐established methods available in software with which they are familiar; not all businesses are willing to embrace new methods. We distinguish between methods, model types and specific models. Methods is a general term including descriptive analytics, visualisation, data mining and statistical modelling. Model types include linear models, discriminant analysis and Bayesian networks. Specific models are those based on specific factors and variables, with coefficients determined from the data on which the model is built.
Business evaluation involves ensuring that models are not only of good quality but also reflect all aspects of business knowledge adequately. The models should be based on measurable, reliable factors and covariates and have sufficient discrimination to be useful. Clearly a model based on unreliable or hard‐to‐measure variables will be less useful than one based on reliable and readily available variables. Models are valuable if they predict similar results to those observed and if they give reliable forecasts. In practical data mining, it is important to make sure the models are useful, and according to the type of problem being addressed, it can make sense to prefer models based on a large number of variables. This is different to the usual statistical practice of preferring models with as few variables as possible. However, when using forecast models it can make sense to obtain a very detailed ranking of the customers. This requires that each group of customers identified contains a reasonably small number of customers. This satisfactory situation is more likely to be obtained if the model contains many variables. This will contribute to the segmentation of the customers by the model. Even if the practice of including many variables in the model and using this more granulated model to identify suitable customers seems rash, it is no worse than taking a random sample from the large number of customers identified as suitable by a model with fewer variables and hence less granulation. It is important to be able to select a sample if business issues mean that we can only handle a limited number of cases.
The business evaluation should consider whether the model has longevity; in other words, whether the population is stable. New ideas and scenarios are emerging all the time and the model will not be able to predict new situations reliably if there are underlying changes. For example, if the model predicts the likelihood of sales of red and blue vehicles and then a green vehicle is introduced, the model has no way of dealing with this scenario, other than giving a prediction of average sales based on the current colours. This issue is akin to extrapolating beyond the range of data in a simple correlation plot or trend chart. It is preferable to include some data with the new colours even if this is a small proportion of the total dataset. If this is not possible, one solution is to look for the underlying traits of the different colours and use this as a means of making a prediction for the new colour. For example, blue could be the fashionable colour of the previous year and green of the new year, so sales of green cars are likely to be closer to those of blue cars than to other coloured cars.
The statistical evaluation of the model must be carried out using established statistical methodologies. This is considered further in the later sections of this chapter. It is not sufficient to assess the validity of a model by the results when applied to the data from which the model was built because the model is tuned to that data and the predicted values tend to give an overoptimistic picture. There are two aspects to validation. As part of statistical evaluation, we need to check that the model type is suitable, regardless of which subset of data is used to build the model. The other aspect of validation is to check whether a model generated on one set of data can be successfully used on another completely separate set of data. This is the requirement that the model is valid for future use. Methods such as ‘leaving‐one‐out’ and k‐fold validation are considered in Section 5.9.7.
The models can be predictive models or rule‐based models and they will have been created using training data subsets extracted from the full historic dataset. The chosen models need to be checked against the full population (as well as test and validation samples) to make sure that they function correctly with all the variants of the input data variables. This provides a further opportunity to assess the modelling and is the final and very important stage of proving the quality and generalisability of the models.
The statistical evaluation and application success of the two or three chosen models can then be compared. On this basis, one or more final models can be chosen to be used in practice.
5.9.2 Assessment of Model Quality for Scale Targets
Predictive models aim to pick out the features that explain variation in the target variable. The extent to which the model achieves this objective can be assessed in a number of ways. If the target variable is a scale or continuous variable, such as expenditure, then an important check on the model is to examine the discrepancies between the observed target values and those predicted by the model. These discrepancies are called ‘residuals’ and they give important information about the fit of the model and can be used to diagnose possible problem areas. Information about most of these problem areas can be obtained from a visual exploration of the residuals.
After fitting a model, it is necessary to examine various diagnostic plots of the residuals to look for patterns:
Histograms In some business contexts we expect the residuals to have an approximately normal distribution and so the histogram should be symmetrical with a single peak around zero. But in any case, a histogram shows if the fit is poor anywhere and gives an overall impression of how close the predicted and actual values are.
Plots of residualsin case order We want the model to fit early and later cases equally well and, if this is the situation, the residuals will vary randomly when plotted in case order, with no trend or cycle.
Scatterplots of residuals against either predicted values or explanatoryvariables We want the model to fit equally well for large and small predicted values; also we want the model to include all important aspects of the explanatory variables. In these cases, scatterplots will show no trend or other pattern.
If any patterns are evident in the diagnostic plots it implies that the model can be improved, either by transforming one or more of the variables or by adding additional explanatory variables.
As more variables are added to a model, the fit generally improves. The fit is often summarised in a statement of the percentage variation explained. However, the improved fit has to be balanced against overfitting the model to the learning dataset. The problem with overfitting is that the model will not fit as well to test and validation samples and in subsequent uses on new data. In smaller samples, overfitting is avoided by checking that the coefficients of factors and covariates are statistically significant. In data mining, because of the large sample sizes, statistical significance occurs quite often. Tuning a statistical model can be assisted by choosing a model with an optimum information criterion, for example choosing the model with the minimum Akaike information criterion. Overfitting may sometimes be preferable, however, as discussed above, to ensure that the model is useful, on the grounds that making decisions based on vague statistical evidence may be better than guesswork.
As the model improves, assuming that it is not overfitted, the increasing precision of predictions can be used as a means of demonstrating the value of the model. Statistical modelling aims to add value to decision making. Without analysis, one can only predict that the value of a scale target variable is likely to lie somewhere between the extremes already observed, with some values within the range being more likely than others. But once predictive analytics has been carried out, then predictions using the model can be more precise; that is they can be made with more certainty. Exactly how much more precise the predictions are and hence the improvement made by putting effort into finding a statistical model is naturally of great interest and can be used to inform decisions on how much time and resources to put into statistical analysis.
5.9.3 Assessment of Model Quality for Categorical Targets
Models for predicting categorical outcomes include logistic regression models and decision trees. In the former, the result for each case is a probability of being in each category. In the decision tree analysis, the outcome is the prediction of taking a particular categorical value.
The fit of the model is assessed by examining how well the dependent variable can be predicted by the independent variables and whether the model needs to be more complex, for example by including interactions, to represent the data better.
The predicted and observed outcomes can be illustrated in a matrix, referred to as an error or confusion matrix, so called because it shows if and where the model has confused the predictions. The predicted values can come from application of a model built on a learning dataset and applied to a test or validation dataset or from cross‐validation. For example, the target could be whether a customer buys a product from a store or not as shown in Table 5.7.
In our experience, one should be very suspicious of a model that fits too well because real data is very noisy. An exceptionally good fit should be examined further. For example, it may be that one or more of the input variables separates the target variable cleanly into its various options in the period. An example would be where the input variable is purchases of a specific type of product, like leather trousers, and the target variable is to spend or not spend over a certain monetary value. A good fit could arise because leather trousers tend to be sold at very expensive, flagship establishments where customers often spend large amounts of money.
The input and target variables should be well separated in time. Although the timescale of variables is normally clear, there can be mix‐ups if input and target variables are not time‐stamped. If the input occurs before the target then the model can appear to fit over‐well. For example, if a woman has bought an oversize garment (last week) and this is an input variable used to model the target of buying oversize (also last week) then the model will appear to be very good. In fact it is not telling us anything. Alternatively, if the input variable has actually occurred after the target variable, the model may appear to be poor, even though if the timing were compatible it would be a very good model. This can happen if third‐party data are used but are not time‐stamped. For example, one input variable could be a flag for a certain behaviour, such as a house being redecorated or having new double‐glazed windows installed. This data may be provided by a third party, but without a time stamp. If the target variable is house prices and the house price was measured before the new windows were installed then the model will not be very accurate.
If a model appears to fit too well, an easy method to identify the relevant input variable is to calculate correlations or to construct a contingency table for the target and the input variable. If nearly all the frequencies are on the diagonal this implies a high correlation and a possible cause for the good fit. Note that if the model is being used for explanation or description, an over‐good fit is not a problem and is in fact an interesting finding. However, if the model is being used for prediction it is unlikely to work on new data.
When dealing with company data, sample sizes are typically so big that goodness‐of‐fit tests, such as the chi‐square test, will be significant, implying that the fit is poor. This happens because the large sample size makes the tests very sensitive to any association. A goodness‐of‐fit test for a large data model may therefore be too strict in a practical sense. Other ways of testing and validating the models include lift and gains charts and receiver operator characteristic (ROC) curves. These also have the advantage of presenting the situation in a more business‐relevant way and are considered in Sections 5.9.4 and 5.9.6 respectively.
5.9.4 Lift and gains charts
The quality and usefulness of a model can be demonstrated graphically as well as in tables like the confusion matrix. In business applications, it is important to show the value added in taking the time and effort to carry out statistical modelling. The lift and gains charts discussed below can be used to show the benefits of using the model and also to compare competing models. They are appropriate for scale or categorical targets.
To construct the charts, the cases are first sorted in order of their predicted outcome. This could be a value such as predicted customer satisfaction, or a probability of achieving a particular target category. A simplified example of data is shown in Table 5.8. The observed values are employees’ life satisfaction ratings on a scale of −5 to +5, where positive is better, and the predicted values are predicted life satisfaction ratings from a model based on job satisfaction, health, ability to handle stress and other factors. The ‘On target’ column takes the value 1 if observed scores are on target, that is they have positive or zero values. Otherwise, the ‘On target’ column takes the value 0. The ‘Lift’ column is calculated by comparing the percentage on target in column 6 and the overall percentage of people on target, which in this example is 39 people out of 100 who have positive observed life satisfaction. The gains chart is constructed to demonstrate the performance of the prediction of positive life satisfaction score, referred to as being on target.
The gains chart can be plotted with increasing cumulative percentage from column 5 along the horizontal axis and percentage on target from column 6 on the vertical axis, as shown in Figure 5.16.
A less jagged gains chart is obtained if the cases are grouped, for example if points are plotted for deciles of population. The group response is then the percentage of people in that group who are on target. In this case, the first 10% on the horizontal axis represent the group with the highest expected life satisfaction. If the model is good, then the observed percentage response should be high for the group with the highest predicted response. The percentage response will then decrease from left to right as the predicted responses decrease.
The gains chart shows how the model performs. However, the data can also be rearranged and plotted to show the value of the model. In a lift chart, the data is ordered as before but the vertical axis now shows the improvement in response over that in the general or sample population. In the example above, the percentage of people with positive life satisfaction is 39%, which is the last row of the gains table. The observed response in the top 10% of employees is 100%; the gains chart shows 100% but the lift chart shows 100%/39% which is equal to 2.56. The lift chart therefore demonstrates that the model has lifted the response in that group by a factor of 2.56, as shown in Figure 5.17.
In this example, the vertical axis of the lift chart starts at 1. Gains and lift charts can also be plotted non‐cumulatively, so that each group is evaluated separately. The vertical axis then starts at zero. In this example, non‐cumulative charts would be generated from Table 5.9. The lift chart vertical axis is calculated by dividing column 2 by 39%, the percentage of people with positive life satisfaction.
Lift and gains charts can be used to compare models. Usually we are interested in particular parts of the charts rather than the whole picture. For example, we might want a model that is good at predicting the top 25% customers, who can be offered a bonus or some other special treatment. In this case, we are not so concerned about the right‐hand side of the graph with the lesser potential customers, although if we are anxious to prevent churn these customers may be more important.
If the lift chart line fluctuates too much around the percentage response of interest then the model needs to be further refined, or an additional model is needed to address this particular business issue.
The charts show that using the model improves prediction quality. If the response is revenue then the charts show that you can target those expected to give high revenue and ignore those who are unlikely to spend. Looking at the population in this way, the modelling enables management to calculate advertisement costs before embarking on a marketing campaign. With an estimate of the buying rate and revenue they can predict the cost per order and decide whether this cost fits within the business strategy and hence decide whether to go ahead or not with a campaign. If it is decided to go ahead with the campaign, the predictive model can help to determine how many people to contact because the groups on the charts clearly show where there are cutoffs in added value.
Lift and gains charts can be used with any type of target variable, although they are more commonly used with a binary target. If the target variable is a scale variable such as expenditure, then the customers would be ordered by expected expenditure. The gains chart would show the observed expenditure on the vertical axis corresponding to the predicted expenditure on the horizontal axis. The lift chart would show the observed expenditure as a percentage of average expenditure. The charts are both focused on a scenario where either ‘largest is best’ or ‘smallest is best’. If the interest lies in accurate prediction, for example of time spent shopping, and the length of time is not an issue, then the charts would need to be drawn and interpreted in a different way.
5.9.5 Confusion Matrix, Sensitivity and Specificity
The success of a model can be summarised by comparison of observed and predicted scores in a confusion matrix. An example was given in Table 5.7. Because of the way the information is going to be utilised, the entries in the matrix are customarily summarised in terms of sensitivity and specificity.
The sensitivity of the model is summarised as the true positive rate, which in Table 5.7 is the number of people correctly predicted to buy divided by the total number who buy, which is equal to 1600/1700 = 94%. This can also be thought of as the probability of detection.
The false positive rate in Table 5.7 is the number of people incorrectly predicted to buy divided by the total number of people who do not buy, which is 2,300/28,300. The false positive rate can also be thought of as the probability of a false alarm. The specificity of the model is one minus the false positive rate: 26,000/28,300 = 92%. There are costs associated with misclassification in either direction. A false alarm may be more costly than poor detection. In the example, both the sensitivity and specificity of this model analysis are good.
If the model behind the confusion matrix produces a probability for buying, then the sensitivity and specificity are dependent on the threshold set for deciding whether a person has a high or low probability of buying. If sensitivity and/or specificity are poor then it may be feasible to consider changing the threshold.
5.9.6 ROC Curves
Statistical models are used to make decisions. People who score high in a predictive model may be treated differently to those who score lower. The threshold at which to cutoff between the two groups is an important issue. What is a suitable discrimination threshold? If the threshold is set too low then we risk including too many poor prospects, but if it is set too high, we could miss people who could become good customers. Threshold analytics is based on experience and data analytics. The receiver operator characteristic (ROC) curve is a useful tool that illustrates the performance of a model as the threshold value is changed. It can help to determine the threshold and also compare the performance of models.
In the ROC curve, the true positive rate is plotted against the false positive rate. The curve shows how we can select a different threshold to achieve the sensitivity and specificity that we require. True positive (sensitivity) is a beneficial outcome and false positive (1 − specificity) is usually a costly outcome. Note that the curve passes through (0, 0) when the threshold for being positive is 1, so that nothing counts as positive, and (1, 1) when the threshold for being positive is zero, so everything counts as positive. The ROC curve for a poor model would be an approximately straight line connecting these two points, implying prediction at random. In contrast, a good model extends to the left‐hand side (see Figure 5.18).
Figure 5.18 ROC curve development during predictive modelling.
The ROC curve can be used with any model, including those that produce a predicted probability of a particular outcome. The sensitivity and specificity, however, are based on binary classification. The development of ROC curves for three or more categories or for a scale target is still the subject of research.
Confusion matrices and ROC curves can be used to compare the results of applying models to a test or validation sample. A slight difference may be acceptable, but it is undesirable to have a model with a big difference between results when the model is applied to the training and validation samples.
ROC curves can also be used to help select the best models, as a good model will give points above the diagonal line, thus representing good classification results (better than random). The choice of model is usually carried out independently from cost considerations but ROC analysis can also be used to compare models with similar costs and this leads to sound decision making.
5.9.7 Methods of Validation
The aim of the modelling is to provide a means of predicting future outcomes. As part of the validation of the model for this purpose, models are tested on test samples of data which are separate from the training/learning data to check that they work more generally. If a model is built from a training sample and is then applied to the training sample itself, the predicted values tend to give an optimistic picture of the model. Instead, testing should involve inputting a test sample of data into the models derived from the training sample to seeing how good the predicted outcomes are. The models can be run again on one or more validation samples. The results of the validation are presented as part of the evidence of the validity of the modelling process and may include a statement of the percent variation explained, or a confusion matrix.
If there is not much data (although this is unlikely in data mining), so that obtaining separate learning and test datasets is not feasible, then the model can be tested using cross‐validation. In ‘leaving one out’ validation, successive models are built, leaving out just one or more cases each time. The omitted cases are predicted by the model. The process is repeated until all cases have been predicted. When larger quantities of data are left out, the validation is referred to as k‐fold validation. For example, if 90% of the data is used to build the model and the model is then applied to the remaining 10% then the validation is referred to as 10‐fold validation. Again, the process is repeated until all cases have been predicted. The whole cross‐validation is typically repeated several times. The performance of the model is assessed from the combined results, for example the mean prediction error.
The successive models built leaving out some data will not necessarily be identical to each other. Cross‐validation therefore provides a test of the model type as well as of the specific model. Cross‐validation should be used in addition to learning and testing even when there is a lot of data.
Once statistical validity of the model type has been assessed using cross‐validation and a specific model built on a training set of data has been shown to work well on test and validation samples, it is then applied to all the data to check for abnormalities and unexpected consequences. Some people recommend rebuilding the model using all the data. This is thought to avoid the model fitting too closely to the data in the learning set. However, experience suggests that it is better to use the model generated from the learning data as this has been thoroughly tested and may also be more robust.
Business data changes all the time. For example, a new product mix or business focus by competitors may have a knock‐on effect on the business and change the data being collected. Where possible, make sure the population is as all‐encompassing as possible, including different time periods. This should lead to more robust models and less likelihood of having to rebuild them.
5.9.8 Methods for Tuning the Predictions
In practice, it may be that a model is poor quality and does not reflect all aspects of business knowledge adequately. In this case, we may generate additional models from different samples used as learning sets. After testing and checking these models, they may all be found to be useful to a certain extent but their usefulness is enhanced if the predictions are combined. So, having evaluated the predictions the analyst may choose to combine them in a weighted mean to give a final result. Deciding how and when to do this is the skill of the experienced practitioner.
There are many interesting ways of helping to strengthen models and improve confidence in them. If the relationships in a dataset are weak, different decision trees will be produced depending on which subset of data is used. It can be helpful to produce a random forest of decision trees and combine the characteristics of the trees into a more stable and trustworthy model. The technical details of this process can be found in the bibliography and in the help files of statistical software packages. A brief summary is given here.
Random trees are used to create a random forest to help build up a picture of which variables are the most persistently reliable in predicting the outcome. A random tree is generated on a random sample of the data in the same manner as decision trees. The difference is that for each split only a random subset of variables is available as the candidate to be the splitting variable. This technique helps to improve the accuracy of the classification of each sample member. The random forest has the effect of reducing the amount of noise modelled and helps determine the important (signal) variables.
The term ‘bagging’ is a contraction of ‘bootstrap aggregating’. The technique improves the classification by combining classifications of successive randomly generated training sets (bootstrap samples). Random forests add an additional layer of randomness to bagging by only making a random subset of variables available for each split.
Boosting addresses the issue of some sample members being poorly classified. It does this by increasing the importance of these cases in the data analysis. This can be done by bootstrap sampling of the weak cases so that there are more of them and they have more influence in the derivation of the decision tree.
In applications, the random forest gives a more robust decision on which outcome is most applicable to each member case, for example whether the member is a buyer or a non‐buyer. The final classification is the category with the most votes. If the output variable is continuous, an average is calculated.