Thus far, we have looked at several examples of how to use Cascading. Now let’s step back a bit and take a look at some of the theory at its foundation.
The author of Cascading, Chris Wensel, was working at a large firm known well for many data products. Wensel was evaluating the Nutch project, which included Lucene and subsequently Hadoop—he was evaluating how to leverage these open source technologies for Big Data within an Enterprise environment. His takeaway was that it would be difficult to find enough Java developers who could write complex Enterprise apps directly in MapReduce.
An obvious response would have been to build some kind of abstraction layer atop Hadoop. Many different variations of this have been developed over the years, and that approach dates back to the many “fourth-generation languages” (4GL) starting in the 1970s. However, another takeaway Wensel had from the early days of Apache Hadoop use was that abstraction layers built by and for the early adopters typically would not pass the “bench test” for Enterprise. The operational complexity of large-scale apps and the need to leverage many existing software engineering practices would be difficult if not impossible to manage through a 4GL-styled abstraction layer.
A key insight into this problem was that MapReduce is based on the functional programming paradigm. In the original MapReduce paper by Jeffrey Dean and Sanjay Ghemawat at Google, the authors made clear that a functional programming model allowed for the following:
- Apps to be automatically parallelized on large clusters of commodity hardware
- Programmers who didn’t have experience with parallel/distributed processing to leverage large clusters
- Data frameworks “to use re-execution as the primary mechanism for fault tolerance"
The general pattern of parallelism achieved through a MapReduce framework traces back to what the AI community was doing in LISP in the 1970s and 1980s at MIT, Stanford, CMU, etc. Also, most of the nontrivial Hadoop apps are data pipelines—which are functional in essence.
The innovation of Cascading, in late 2007, was to introduce a Java API for functional programming with large-scale data workflows. As we’ve seen thus far, this approach allowed for a plumbing metaphor based on functional programming, which was very close to the use cases for Hadoop but abstracted a much higher level than writing MapReduce code directly. At the same time, this approach leveraged the JVM and Java-based tools without any need to create or support new languages. Programmers who had Java expertise could leverage the economics of Hadoop clusters yet still use their familiar tools.
In doing this, Cascading resolved many issues related to Hadoop use in Enterprise environments. Notably, it did the following:
- Eased the “staffing bottleneck,” because Java developers could work with familiar tools and processes
- Improved means for system integration, because Hadoop is rarely ever used in isolation, and the abstraction integrated other frameworks
- Reduced the operational complexity of large-scale apps by keeping apps defined as single JAR files
- Allowed for TDD and other software engineering practices at scale
A subtle point about the design of Cascading is that it created a foundation for building other abstraction layers in JVM-based functional programming languages. Codd had suggested the use of DSLs for manipulating the relational model as early as 1969. The proof is in the pudding, because Twitter, Etsy, eBay, The Climate Corporation, uSwitch, Nokia, LinkedIn, etc., have invested considerable engineering resources into developing and extending open source projects—Cascalog, Scalding, PyCascading, Cascading.JRuby, etc.—all based on functional programming. In turn they have built out their revenue apps, along with many other firms, based on those projects.
There are a few important theoretical aspects embodied by these data workflow abstractions based on Cascading. Those elements of theory can best be explained as layers in the process of structuring data:
- Pattern language
- Literate programming
- Separation of concerns
- Functional relational paradigm
Formally speaking, Cascading represents a pattern language. The notion of a pattern language is that the syntax of the language constrains what can be expressed to help ensure best practices. Stated in another way, a pattern language conveys expertise. For example, consider how a child builds a tower out of Lego blocks. The blocks snap together in predictable ways, allowing for complex structures that are reasonably sturdy. When the blocks are not snapped together properly, those structures tend to fall over. Lego blocks therefore provide a way of conveying expertise about building toy structures.
Use of pattern language came from architecture, based on work by Christopher Alexander on the “Oregon Experiment.” Kent Beck and Ward Cunningham subsequently used it to describe software design patterns, popularized by the “Gang of Four”—Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides—for object-oriented programming. Abstract Factory, Model-View-Controller (MVC), and Facade are examples of well-known software design patterns.
Cascading uses pattern language to ensure best practices specifically for robust, parallel data workflows at scale.
We see the pattern syntax enforced in several ways.
For example, flows must have at least one source and at least one tail sink defined.
For another example, aggregator functions such as Count must be used in an Every; in other words, that work gets performed in a reduce task.
Another benefit of pattern language in Cascading is that it promotes code reuse. Rather, it reduces the need for writing custom operations because much of the needed business process can be defined by combing existing components. In a larger context, this is related to the use of patterns in enterprise application integration (EAI).
The philosophy of literate programming was originated by Donald Knuth. A reasonable summary would be to say that instead of writing documentation about programs, write documents that embed programs. We see this practice quite directly in terms of the flow diagrams used in Cascading. A flow diagram is also a common expression of the business process in a Cascading app, even though different portions of that process may have been specified in Java, Clojure, Scala, Python, Ruby, ANSI SQL, PMML, etc. A flow diagram is the literal representation for the query that will run in parallel on a cluster.
Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.
— Literate Programming Donald Knuth (1992)
When a Cascading app runs, it creates a flow diagram that can optionally be written to a DOT file.
Flow diagrams provide intuitive, visual representations for apps, which are great for cross-team collaboration.
Several good examples exist, but one is the phenomenon of different developers troubleshooting a Cascading app together over the cascading-users email forum. Expert developers generally ask a novice to provide a flow diagram first, often before asking to see source code. For instance, a flow diagram for is provided in Figure 7-1.
Another good example is found in Scalding apps, which have a nearly 1:1 correspondence between function calls and the elements in their flow diagrams. This demonstrates excellent efficiency for language elision and literate representation. The benefit, in engineering terms, is that this property helps make the complex logic embodied in a Scalding app relatively simple to understand.

Based on the philosophy of literate programming, Cascading workflows emphasize the statement of business processes. This recalls a sense of business process management (BPM) for Enterprise apps. In other words, think of BPM/BPEL for Big Data as a means for workflow orchestration—in this case Cascading provides a kind of middleware. It creates a separation of concerns between the business process required for an app and its implementation details, such as Hadoop jobs, data serialization protocols, etc.
By virtue of the pattern language, the flow planners in Cascading have guarantees that they will be able to translate business processes into efficient, parallel code at scale. That is a kind of “one-two punch” in Cascading, leveraging computer science theory in different layers.
Cascalog developers describe the separation of concerns between business process and implementation (parallelization, etc.) as a principle: “specify what you require, not how it must be achieved.” That’s an important principle because in practice, quite arguably, developing Enterprise data workflows is an inherently complex matter. The frameworks for distributed systems such as Hadoop, HBase, Cassandra, Memcached, etc. introduce lots of complexity into the engineering process. Typical kinds of problems being solved, often leveraging machine learning algorithms to find a proverbial needle in a haystack within large data sets, also introduce significant complexity into apps.
The author of Cascalog, Nathan Marz, noted a general problem about Big Data frameworks: that the tools being used to solve a given problem can sometimes introduce more complexity than the problem itself. We call this phenomenon accidental complexity, and it represents an important anti-pattern in computer science.
A lot of people talk about how wonderfully expressive Clojure is. However, expressiveness is not the goal of Clojure. Clojure aims to minimize accidental complexity, and its expressiveness is a means to that end.
— Nathan Marz Twitter (2011)
There are limits to how much complexity people can understand at any given point, limits to how well we can understand the systems on which we rely. Some approaches to software design amplify that problem. For example, reading 50,000 lines of COBOL is not particularly simple. SQL and Java are notorious for encouraging the development of large, complicated apps. So it makes sense to prevent artifacts in our programming languages from making Enterprise data workflows even more complex.
Referring back to the original 1969 paper about the relational model, Edgar Codd focused on the process of structuring data as a mechanism for maintaining data integrity and consistency of state, while providing a separation of concerns regarding data storage and representation underneath. This description is quite apt for the workflow abstraction in Cascading. Codd’s first public paper about the relational model is archived in the ACM Digital Library.
More recently, in the highly influential 2006 paper “Out of the Tar Pit,” Ben Moseley and Peter Marks proposed functional relational programming (FRP) as a combination of three major programming paradigms: functional, relational, and logical. FRP is proposed as an alternative to object-oriented programming (OOP), with the intent to minimize the accidental complexity introduced into apps. For more information about FRP, see the following:
When it comes to accidental and essential complexity we firmly believe that the former exists and that the goal of software engineering must be both to eliminate as much of it as possible, and to assist with the latter.
— Moseley and Marks “Out of the Tar Pit” (2006)
Moseley and Marks attempted to categorize the different kinds of complexity encountered in software engineering, and analyzed the dimensions of state, code volume, and explicit (imperative) concern with the flow of control through a system. They noted that “complexity breeds complexity” in the absence of language-enforced guarantees—in other words, it creates positive feedback loops in software practice. They pointed out that complexity that derives from state is one of the biggest hurdles for making code testable. Their paper also considered the origins of the relational model, going back to Codd:
In FRP all essential state takes the form of relations, and the essential logic is expressed using relational algebra extended with (pure) user-defined functions.
— Moseley and Marks “Out of the Tar Pit” (2006)
In other words, if we can cut out the unnecessary state represented in an app and focus on the essential state (relations) we can eliminate much of the accidental complexity. Cascading embodies much of that philosophy, putting FRP into the practice of building Enterprise data workflows. Cascading and FRP have several important aspects of computer science theory in common:
Moseley and Marks also point toward a management approach indicated by FRP. For example, an organization could focus one team on minimizing the accidental aspects of a system. Other teams could then focus on the essential aspects, providing the infrastructure and the requirements for interfacing with other systems. Roughly speaking, that corresponds respectively to the roles of developer, data scientist, ops, etc.; however, the objectives of those teams become clarified through FRP. It also fits well with what is shown in Figure 6-3 for cross-team functional integration based on Cascading.
In summary, there are several theoretical aspects of the workflow abstraction. These get leveraged in Cascading and the DSLs to help minimize the complexity of the engineering process, and the complexity of understanding systems.
Generally speaking, in terms of Enterprise data workflows, there are two avenues to the party—scale versus complexity—a contrast that is seen quite starkly in use case analysis of Cascading deployments.
On one hand, there are Enterprise firms where people must contend with complexity at scale all day, every day. Incumbents in the Enterprise space make very large investments in their back office infrastructure and practices—generally using Java, ANSI SQL, SAS, etc., and have a large staff trained in those systems and processes. While the incumbents typically face considerable challenges in trying to be innovative, they are faced with multiple priorities for migrating workflows onto Apache Hadoop. One priority is based on economics: scaling out a machine learning app on a Hadoop cluster implies much less in licensing costs than running the app in SAS. Another priority is risk management: being able to scale efficiently and rapidly, when the business requires it. Meanwhile, a big part of the challenge is to leverage existing staff and integrate infrastructure without disrupting established processes. The workflow abstraction in Cascading addresses those issues directly.
On the other hand, start-ups crave complexity and must scale to become viable. Start-ups are generally good at innovation and light on existing process. They tend to leverage sophisticated engineering practices—e.g., Cascalog and Scalding—so that they can have a relatively lean staff while positioning to compete against the Enterprise incumbents and disrupt their market share. Cascading provides the foundation for DSLs in functional programming languages that help power those ventures.
There is a transition curve plotted along the dimensions of scale, complexity, and innovation. One perspective of this is shown in Figure 7-2.
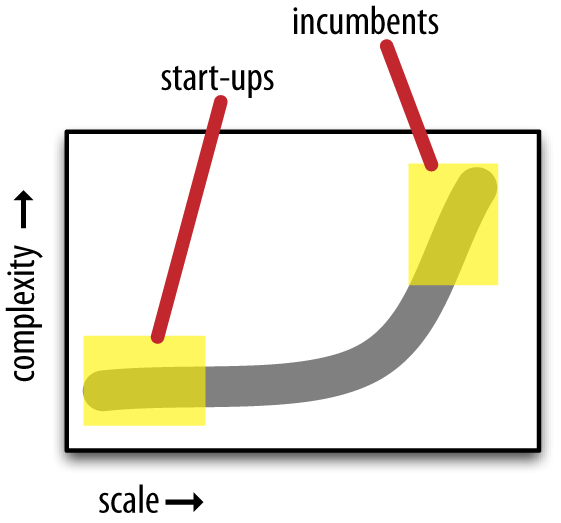
Both the Enterprise incumbents and the start-ups are connected on that curve for any given Big Data project. Ultimately, when they succeed, they tend to meet in the middle. Dijkstra foresaw this relationship quite clearly:
Computing’s core challenge is how not to make a mess of it. If people object that any science has to meet that challenge, we should give a double rebuttal. Firstly, machines are so fast and storage capacities are so huge that we face orders of magnitude more room for confusion, the propagation and diffusion of which are easily inadvertently mechanized. Secondly, because we are dealing with artefacts, all unmastered complexity is of our own making; there is no one else to blame and so we had better learn how not to introduce the complexity in the first place.[3]
— Edsger Dijkstra The next fifty years