Throughout this book, we will explore Cascading and related open source projects in the context of brief programming examples. Familiarity with Java programming is required. We’ll show additional code in Clojure, Scala, SQL, and R. The sample apps are all available in source code repositories on GitHub. These sample apps are intended to run on a laptop (Linux, Unix, and Mac OS X, but not Windows) using Apache Hadoop in standalone mode. Each example is built so that it will run efficiently with a large data set on a large cluster, but setting new world records on Hadoop isn’t our agenda. Our intent here is to introduce a new way of thinking about how Enterprise apps get designed. We will show how to get started with Cascading and discuss best practices for Enterprise data workflows.
Cascading provides an open source API for writing Enterprise-scale apps on top of Apache Hadoop and other Big Data frameworks. In production use now for five years (as of 2013Q1), Cascading apps run at hundreds of different companies and in several verticals, which include finance, retail, health care, and transportation. Case studies have been published about large deployments at Williams-Sonoma, Twitter, Etsy, Airbnb, Square, The Climate Corporation, Nokia, Factual, uSwitch, Trulia, Yieldbot, and the Harvard School of Public Health. Typical use cases for Cascading include large extract/transform/load (ETL) jobs, reporting, web crawlers, anti-fraud classifiers, social recommender systems, retail pricing, climate analysis, geolocation, genomics, plus a variety of other kinds of machine learning and optimization problems.
Keep in mind that Apache Hadoop rarely if ever gets used in isolation. Generally speaking, apps that run on Hadoop must consume data from a variety of sources, and in turn they produce data that must be used in other frameworks. For example, a hypothetical social recommender shown in Figure 1 combines input data from customer profiles in a distributed database plus log files from a cluster of web servers, then moves its recommendations out to Memcached to be served through an API. Cascading encompasses the schema and dependencies for each of those components in a workflow—data sources for input, business logic in the application, the flows that define parallelism, rules for handling exceptions, data sinks for end uses, etc. The problem at hand is much more complex than simply a sequence of Hadoop job steps.
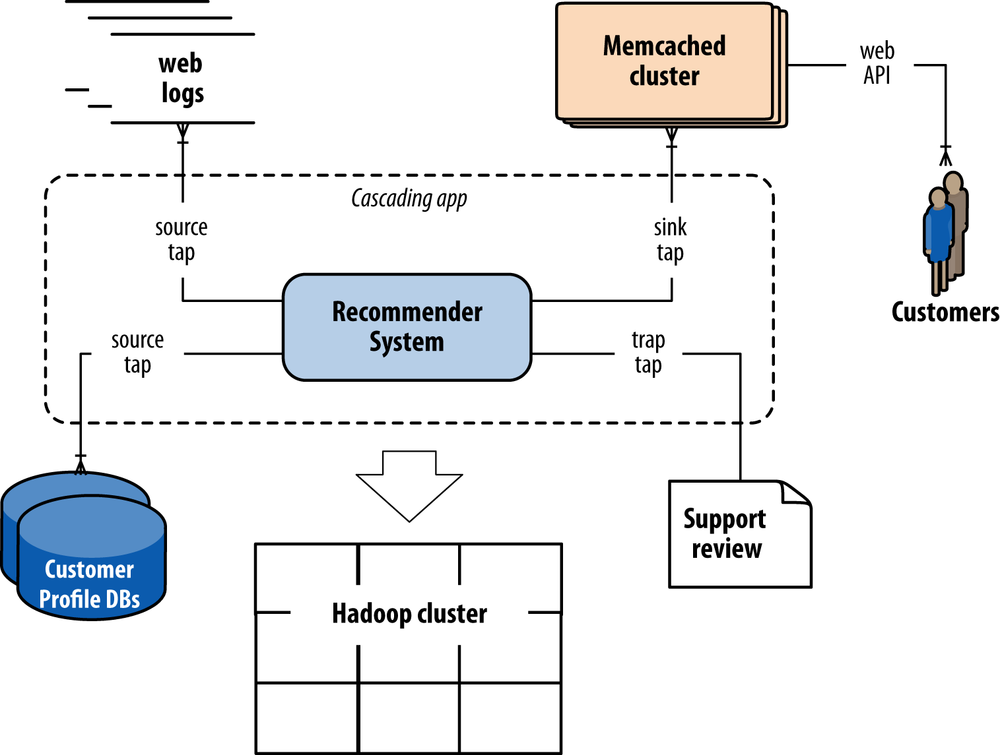
Moreover, while Cascading has been closely associated with Hadoop, it is not tightly coupled to it. Flow planners exist for other topologies beyond Hadoop, such as in-memory data grids for real-time workloads. That way a given app could compute some parts of a workflow in batch and some in real time, while representing a consistent “unit of work” for scheduling, accounting, monitoring, etc. The system integration of many different frameworks means that Cascading apps define comprehensive workflows.
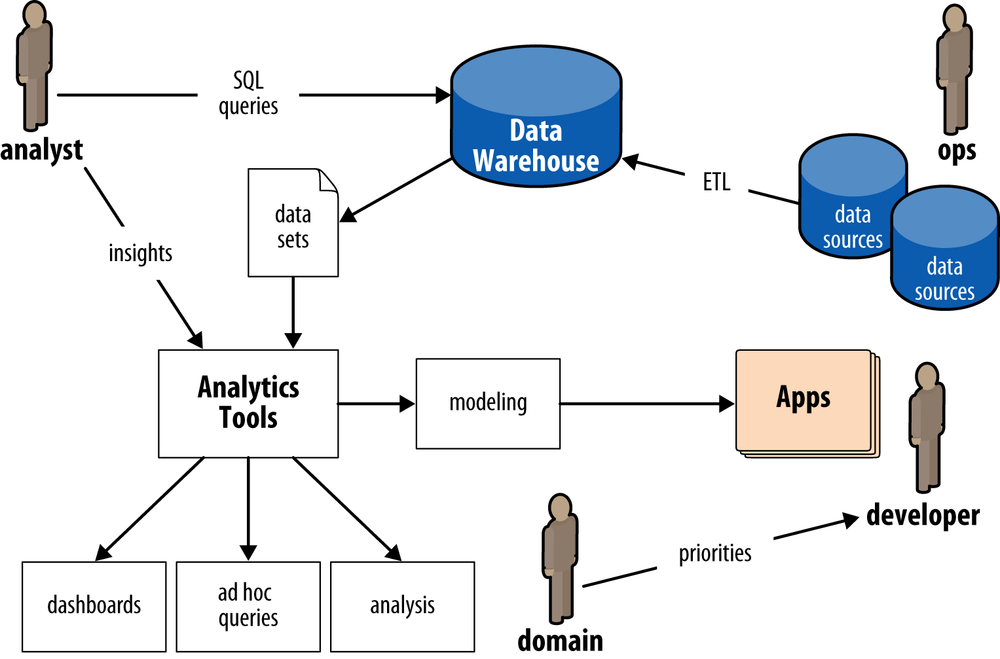
Circa early 2013, many Enterprise organizations are building out their Hadoop practices. There are several reasons, but for large firms the compelling reasons are mostly economic. Let’s consider a typical scenario for Enterprise data workflows prior to Hadoop, shown in Figure 2.
An analyst typically would make a SQL query in a data warehouse such as Oracle or Teradata to pull a data set. That data set might be used directly for a pivot tables in Excel for ad hoc queries, or as a data cube going into a business intelligence (BI) server such as Microstrategy for reporting. In turn, a stakeholder such as a product owner would consume that analysis via dashboards, spreadsheets, or presentations. Alternatively, an analyst might use the data in an analytics platform such as SAS for predictive modeling, which gets handed off to a developer for building an application. Ops runs the apps, manages the data warehouse (among other things), and oversees ETL jobs that load data from other sources. Note that in this diagram there are multiple components—data warehouse, BI server, analytics platform, ETL—which have relatively expensive licensing and require relatively expensive hardware. Generally these apps “scale up” by purchasing larger and more expensive licenses and hardware.
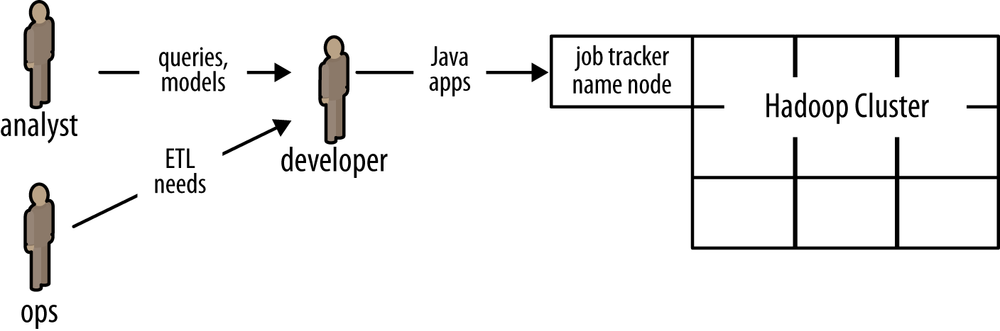
Circa late 1997 there was an inflection point, after which a handful of pioneering Internet companies such as Amazon and eBay began using “machine data”—that is to say, data gleaned from distributed logs that had mostly been ignored before—to build large-scale data apps based on clusters of “commodity” hardware. Prices for disk-based storage and commodity servers dropped considerably, while many uses for large clusters began to arise. Apache Hadoop derives from the MapReduce project at Google, which was part of this inflection point. More than a decade later, we see widespread adoption of Hadoop in Enterprise use cases. On one hand, generally these use cases “scale out” by running workloads in parallel on clusters of commodity hardware, leveraging mostly open source software. That mitigates the rising cost of licenses and proprietary hardware as data rates grow enormously. On the other hand, this practice imposes an interesting change in business process: notice how in Figure 3 the developers with Hadoop expertise become a new kind of bottleneck for analysts and operations.
Enterprise adoption of Apache Hadoop, driven by huge savings and opportunities for new kinds of large-scale data apps, has increased the need for experienced Hadoop programmers disproportionately. There’s been a big push to train current engineers and analysts and to recruit skilled talent. However, the skills required to write large Hadoop apps directly in Java are difficult to learn for most developers and far outside the norm of expectations for analysts. Consequently the approach of attempting to retrain current staff does not scale very well. Meanwhile, companies are finding that the process of hiring expert Hadoop programmers is somewhere in the range of difficult to impossible. That creates a dilemma for staffing, as Enterprise rushes to embrace Big Data and Apache Hadoop: SQL analysts are available and relatively less expensive than Hadoop experts.
An alternative approach is to use an abstraction layer on top of Hadoop—one that fits well with existing Java practices. Several leading IT publications have described Cascading in those terms, for example:
Management can really go out and build a team around folks that are already very experienced with Java. Switching over to this is really a very short exercise.
— Thor Olavsrud CIO magazine (2012)
Cascading recently added support for ANSI SQL through a library called Lingual. Another library called Pattern supports the Predictive Model Markup Language (PMML), which is used by most major analytics and BI platforms to export data mining models. Through these extensions, Cascading provides greater access to Hadoop resources for the more traditional analysts as well as Java developers. Meanwhile, other projects atop Cascading—such as Scalding (based on Scala) and Cascalog (based on Clojure)—are extending highly sophisticated software engineering practices to Big Data. For example, Cascalog provides features for test-driven development (TDD) of Enterprise data workflows.
It’s important to note that a tension exists between complexity and innovation, which is ultimately driven by scale. Closely related to that dynamic, a spectrum emerges about technologies that manage data, ranging from “conservatism” to “liberalism.”
Consider that technology start-ups rarely follow a straight path from initial concept to success. Instead they tend to pivot through different approaches and priorities before finding market traction. The book Lean Startup by Eric Ries (Crown Business) articulates the process in detail. Flexibility is key to avoiding disaster; one of the biggest liabilities a start-up faces is that it cannot change rapidly enough to pivot toward potential success—or that it will run out of money before doing so. Many start-ups choose to use Ruby on Rails, Node.js, Python, or PHP because of the flexibility those scripting languages allow.
On one hand, technology start-ups tend to crave complexity; they want and need the problems associated with having many millions of customers. Providing services so mainstream and vital that regulatory concerns come into play is typically a nice problem to have. Most start-ups will never reach that stage of business or that level of complexity in their apps; however, many will try to innovate their way toward it. A start-up typically wants no impediments—that is where the “liberalism” aspects come in. In many ways, Facebook exemplifies this approach; the company emerged through intense customer experimentation, and it retains that aspect of a start-up even after enormous growth.
On the other hand, you probably don’t want your bank to run customer experiments on your checking account, not anytime soon. Enterprise differs from start-ups because of the complexities of large, existing business units. Keeping a business running smoothly is a complex problem, especially in the context of aggressive competition and rapidly changing markets. Generally there are large liabilities for mishandling data: regulatory and compliance issues, bad publicity, loss of revenue streams, potential litigation, stock market reactions, etc. Enterprise firms typically want no surprises, and predictability is key to avoiding disaster. That is where the “conservatism” aspects come in.
Enterprise organizations must live with complexity 24/7, but they crave innovation. Your bank, your airline, your hospital, the power plant on the other side of town—those have risk profiles based on “conservatism.” Computing environments in Enterprise IT typically use Java virtual machine (JVM) languages such as Java, Scala, Clojure, etc. In some cases scripting languages are banned entirely. Recognize that this argument is not about political views; rather, it’s about how to approach complexity. The risk profile for a business vertical tends to have a lot of influence on its best practices.
Trade-offs among programming languages and abstractions used in Big Data exist along these fault lines of flexibility versus predictability. In the “liberalism” camp, Apache Hive and Pig have become popular abstractions on top of Apache Hadoop. Early adopters of MapReduce programming tended to focus on ad hoc queries and proof-of-concept apps. They placed great emphasis on programming flexibility. Needing to explore a large unstructured data set through ad hoc queries was a much more common priority than, say, defining an Enterprise data workflow for a mission-critical app. In environments where scripting languages (Ruby, Python, PHP, Perl, etc.) run in production, scripting tools such as Hive and Pig have been popular Hadoop abstractions. They provide lots of flexibility and work well for performing ad hoc queries at scale.
Relatively speaking, circa 2013, it is not difficult to load a few terabytes of unstructured data into an Apache Hadoop cluster and then run SQL-like queries in Hive. Difficulties emerge when you must make frequent updates to the data, or schedule mission-critical apps, or run many apps simultaneously. Also, as workflows integrate Hive apps with other frameworks outside of Hadoop, those apps gain additional complexity: parts of the business logic are declared in SQL, while other parts are represented in another programming language and paradigm. Developing and debugging complex workflows becomes expensive for Enterprise organizations, because each issue may require hours or even days before its context can be reproduced within a test environment.
A fundamental issue is that the difficulty of operating at scale is not so much a matter of bigness in data; rather, it’s a matter of managing complexity within the data. For companies that are just starting to embrace Big Data, the software development lifecycle (SDLC) itself becomes the hard problem to solve. That difficulty is compounded by the fact that hiring and training programmers to write MapReduce code directly is already a bitter pill for most companies.
Table 1 shows a pattern of migration, from the typical “legacy” toolsets used for large-scale batch workflows—such as J2EE and SQL—into the adoption of Apache Hadoop and related frameworks for Big Data.
Table 1. Migration of batch toolsets
| Workflow | Legacy | Manage complexity | Early adopter | |
|---|---|---|---|---|
Pipelines | J2EE | Cascading | Pig | |
Queries | SQL | Lingual (ANSI SQL) | Hive | |
Predictive models | SAS | Pattern (PMML) | Mahout |
As more Enterprise organizations move to use Apache Hadoop for their apps, typical Hadoop workloads shift from early adopter needs toward mission-critical operations. Typical risk profiles are shifting toward “conservatism” in programming environments. Cascading provides a popular solution for defining and managing Enterprise data workflows. It provides predictability and accountability for the physical plan of a workflow and mitigates difficulties in handling exceptions, troubleshooting bugs, optimizing code, testing at scale, etc.
Also keep in mind the issue of how the needs for a start-up business evolve over time. For the firms working on the “liberalism” end of this spectrum, as they grow there is often a need to migrate into toolsets that are more toward the “conservatism” end. A large code base that has been originally written based on using Pig or Hive can be considerably difficult to migrate. Alternatively, writing that same functionality in a framework such as Cascalog would provide flexibility for the early phase of the start-up, while mitigating complexity as the business grows.
In the mid-2000s, Chris Wensel was a system architect at an Enterprise firm known for its data products, working on a custom search engine for case law. He had been working with open source code from the Nutch project, which gave him early hands-on experience with popular spin-offs from Nutch: Lucene and Hadoop. On one hand, Wensel recognized that Hadoop had great potential for indexing large sets of documents, which was core business at his company. On the other hand, Wensel could foresee that coding in Hadoop’s MapReduce API directly would be difficult for many programmers to learn and would not likely scale for widespread adoption.
Moreover, the requirements for Enterprise firms to adopt Hadoop—or for any programming abstraction atop Hadoop—would be on the “conservatism” end of the spectrum. For example, indexing case law involves large, complex ETL workflows, with substantial liability if incorrect data gets propagated through the workflow and downstream to users. Those apps must be solid, data provenance must be auditable, workflow responses to failure modes must be deterministic, etc. In this case, Ops would not allow solutions based on scripting languages.
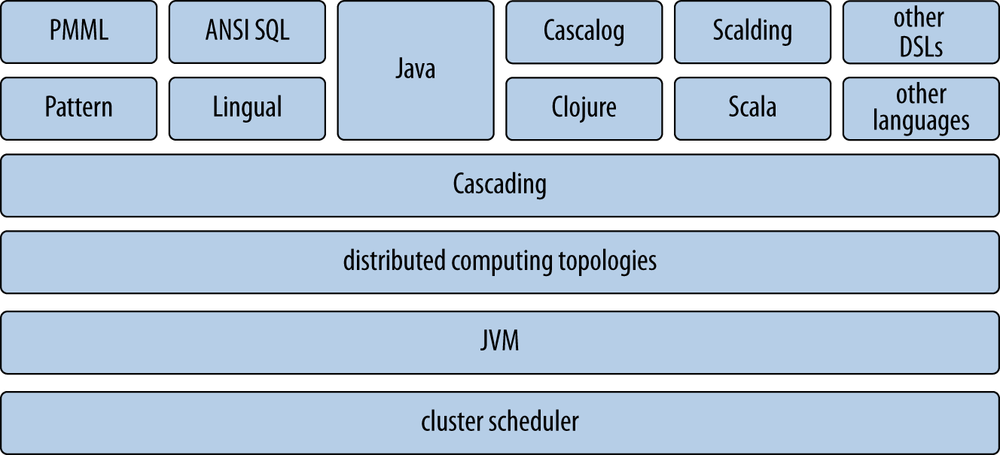
Late in 2007, Wensel began to write Cascading as an open source application framework for Java developers to develop robust apps on Hadoop, quickly and easily. From the beginning, the project was intended to provide a set of abstractions in terms of database primitives and the analogy of “plumbing.” Cascading addresses complexity while embodying the “conservatism” of Enterprise IT best practices. The abstraction is effective on several levels: capturing business logic, implementing complex algorithms, specifying system dependencies, projecting capacity needs, etc. In addition to the Java API, support for several other languages has been built atop Cascading, as shown in Figure 4.
Formally speaking, Cascading represents a pattern language for the business process management of Enterprise data workflows. Pattern languages provide structured methods for solving large, complex design problems—where the syntax of the language promotes use of best practices. For example, the “plumbing” metaphor of pipes and operators in Cascading helps indicate which algorithms should be used at particular points, which architectural trade-offs are appropriate, where frameworks need to be integrated, etc.
One benefit of this approach is that many potential problems can get caught at compile time or at the flow planner stage. Cascading follows the principle of “Plan far ahead.” Due to the functional constraints imposed by Cascading, flow planners generally detect errors long before an app begins to consume expensive resources on a large cluster. Or in another sense, long before an app begins to propagate the wrong results downstream.
Also in late 2007, Yahoo! Research moved the Pig project to the Apache Incubator. Pig and Cascading are interesting to contrast, because newcomers to Hadoop technologies often compare the two. Pig represents a data manipulation language (DML), which provides a query algebra atop Hadoop. It is not an API for a JVM language, nor does it specify a pattern language. Another important distinction is that Pig attempts to perform optimizations on a logical plan, whereas Cascading uses a physical plan only. The former is great for early adopter use cases, ad hoc queries, and less complex applications. The latter is great for Enterprise data workflows, where IT places a big premium on “no surprises.”
In the five years since 2007, there have been two major releases of Cascading and hundreds of Enterprise deployments. Programming with the Cascading API can be done in a variety of JVM-based languages: Java, Scala, Clojure, Python (Jython), and Ruby (JRuby). Of these, Scala and Clojure have become the most popular for large deployments.
Several other open source projects, such as DSLs, taps, libraries, etc., have been written based on Cascading sponsored by Twitter, Etsy, eBay, Climate, Square, etc.—such as Scalding and Cascalog—which help integrate with a variety of different frameworks.
Most of the code samples in this book draw from the GitHub repository for Cascading:
We also show code based on these third-party GitHub repositories:
Note
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the world’s leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of product mixes and pricing programs for organizations, government agencies, and individuals. Subscribers have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like O’Reilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and dozens more. For more information about Safari Books Online, please visit us online.
Please address comments and questions concerning this book to the publisher:
| O’Reilly Media, Inc. |
| 1005 Gravenstein Highway North |
| Sebastopol, CA 95472 |
| 800-998-9938 (in the United States or Canada) |
| 707-829-0515 (international or local) |
| 707-829-0104 (fax) |
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://oreil.ly/enterprise-data-workflows.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Many thanks go to Courtney Nash and Mike Loukides at O’Reilly; to Chris Wensel, author of Cascading, and other colleagues: Joe Posner, Gary Nakamura, Bill Wathen, Chris Nardi, Lisa Henderson, Arvind Jain, and Anthony Bull; to Chris Severs at eBay, and Dean Wampler for help with Scalding; to Girish Kathalagiri at AgilOne, and Vijay Srinivas Agneeswaran at Impetus for contributions to Pattern; to Serguey Boldyrev at Nokia, Stuart Evans at CMU, Julian Hyde at Optiq, Costin Leau at ElasticSearch, Viswa Sharma at TCS, Boris Chen, Donna Kidwell, and Jason Levitt for many suggestions and excellent feedback; to Hans Dockter at Gradleware for help with Gradle build scripts; to other contributors on the “Impatient” series of code examples: Ken Krugler, Paul Lam, Stephane Landelle, Sujit Pal, Dmitry Ryaboy, Chris Severs, Branky Shao, and Matt Winkler; and to friends who provided invaluable help as technical reviewers for the early drafts: Paul Baclace, Bahman Bahmani, Manish Bhatt, Allen Day, Thomas Lockney, Joe Posner, Alex Robbins, Amit Sharma, Roy Seto, Branky Shao, Marcio Silva, James Todd, and Bill Worzel.