
 . Das Problem P wird auch unrestringiertes Optimierungsproblem
genannt. Allgemeiner werden manchmal auch Probleme mit offener zulässiger Menge M als unrestringiert bezeichnet. In der Tat lassen sich die im folgenden Abschn. 2.1 besprochenen Optimalitätsbedingungen ohne Weiteres auf diesen Fall übertragen, was wir aus Gründen der Übersichtlichkeit aber nicht explizit angeben werden. Abschn. 2.2 diskutiert ausführlich verschiedene numerische Lösungsverfahren für unrestringierte Optimierungsprobleme, die auf den zuvor hergeleiteten Optimalitätsbedingungen basieren.
. Das Problem P wird auch unrestringiertes Optimierungsproblem
genannt. Allgemeiner werden manchmal auch Probleme mit offener zulässiger Menge M als unrestringiert bezeichnet. In der Tat lassen sich die im folgenden Abschn. 2.1 besprochenen Optimalitätsbedingungen ohne Weiteres auf diesen Fall übertragen, was wir aus Gründen der Übersichtlichkeit aber nicht explizit angeben werden. Abschn. 2.2 diskutiert ausführlich verschiedene numerische Lösungsverfahren für unrestringierte Optimierungsprobleme, die auf den zuvor hergeleiteten Optimalitätsbedingungen basieren.2.1 Optimalitätsbedingungen
Zur Herleitung von ableitungsbasierten notwendigen bzw. hinreichenden Optimalitätsbedingungen führen wir in Abschn. 2.1.1 zunächst das ableitungsfreie Konzept der sogenannten Abstiegsrichtung für eine Funktion f an einer Stelle  ein. Für jede differenzierbare Funktion f lässt sich mit Hilfe der (mehrdimensionalen) ersten Ableitung von f an
ein. Für jede differenzierbare Funktion f lässt sich mit Hilfe der (mehrdimensionalen) ersten Ableitung von f an  eine hinreichende Bedingung dafür angeben, dass eine Richtung Abstiegsrichtung für f an
eine hinreichende Bedingung dafür angeben, dass eine Richtung Abstiegsrichtung für f an  ist, woraus wir in Abschn. 2.1.2 als zentrale notwendige Optimalitätsbedingung die Fermat’sche Regel herleiten werden.
ist, woraus wir in Abschn. 2.1.2 als zentrale notwendige Optimalitätsbedingung die Fermat’sche Regel herleiten werden.
Die dafür erforderliche Definition der mehrdimensionalen ersten Ableitung führt auf den Begriff des Gradienten der Funktion f an  , der selbst ein Vektor der Länge n ist. Die in Abschn. 2.1.3 diskutierten geometrischen Eigenschaften solcher Gradienten sind grundlegend für das Verständnis sowohl der Optimalitätsbedingungen als auch der numerischen Verfahren in Abschn. 2.2.
, der selbst ein Vektor der Länge n ist. Die in Abschn. 2.1.3 diskutierten geometrischen Eigenschaften solcher Gradienten sind grundlegend für das Verständnis sowohl der Optimalitätsbedingungen als auch der numerischen Verfahren in Abschn. 2.2.
Sofern f zweimal differenzierbar ist, lässt sich die obige hinreichende Bedingung für die Abstiegseigenschaft einer Richtung durch Informationen über die zweite Ableitung von f an  verfeinern, was eine stärkere notwendige Optimalitätsbedingung als die Fermat’sche Regel liefert, nämlich die in Abschn. 2.1.4 besprochene notwendige Optimalitätsbedingung zweiter Ordnung. Durch eine einfache Modifikation wird sich aus dieser Bedingung auch eine hinreichende Optimalitätsbedingung konstruieren lassen. Allerdings wird zwischen der notwendigen und der hinreichenden Optimalitätsbedingung zweiter Ordnung eine „Lücke“ klaffen. Wir diskutieren kurz, warum dies keine gravierenden Konsequenzen hat. Der abschließende Abschn. 2.1.5 reißt kurz an, wie die Optimalitätsbedingungen sich vereinfachen, wenn die Zielfunktion f zusätzlich konvex auf
verfeinern, was eine stärkere notwendige Optimalitätsbedingung als die Fermat’sche Regel liefert, nämlich die in Abschn. 2.1.4 besprochene notwendige Optimalitätsbedingung zweiter Ordnung. Durch eine einfache Modifikation wird sich aus dieser Bedingung auch eine hinreichende Optimalitätsbedingung konstruieren lassen. Allerdings wird zwischen der notwendigen und der hinreichenden Optimalitätsbedingung zweiter Ordnung eine „Lücke“ klaffen. Wir diskutieren kurz, warum dies keine gravierenden Konsequenzen hat. Der abschließende Abschn. 2.1.5 reißt kurz an, wie die Optimalitätsbedingungen sich vereinfachen, wenn die Zielfunktion f zusätzlich konvex auf  ist.
ist.
2.1.1 Abstiegsrichtungen
Um zu klären, welche notwendigen Bedingungen die Funktion f an einem Minimalpunkt erfüllen muss, geht man nach folgendem Ausschlussprinzip vor: Wenn man den Punkt  entlang einer Richtung
entlang einer Richtung  verlassen kann, während die Funktionswerte (zumindest zunächst) fallen, dann kommt
verlassen kann, während die Funktionswerte (zumindest zunächst) fallen, dann kommt  offensichtlich nicht als Minimalpunkt infrage. Die Punkte, die man beim Verlassen von
offensichtlich nicht als Minimalpunkt infrage. Die Punkte, die man beim Verlassen von  entlang d besucht, lassen sich per Punktrichtungsform einer Geraden explizit als
entlang d besucht, lassen sich per Punktrichtungsform einer Geraden explizit als  mit Skalaren t ≥ 0 adressieren.
mit Skalaren t ≥ 0 adressieren.
2.1.1 Definition (Abstiegsrichtung)
 und
und  . Ein Vektor
. Ein Vektor  heißt Abstiegsrichtung
für f in
heißt Abstiegsrichtung
für f in  , falls
, falls
2.1.2 Übung
Für  sei
sei  ein lokaler Minimalpunkt. Zeigen Sie, dass dann keine Abstiegsrichtung für f in
ein lokaler Minimalpunkt. Zeigen Sie, dass dann keine Abstiegsrichtung für f in  existiert.
existiert.
Im Folgenden werden wir die nur von der eindimensionalen Variable t abhängige Funktion  genauer untersuchen und geben ihr dazu eine eigene Bezeichnung.
genauer untersuchen und geben ihr dazu eine eigene Bezeichnung.
2.1.3 Definition (Eindimensionale Einschränkung)
 , ein Punkt
, ein Punkt  und ein Richtungsvektor
und ein Richtungsvektor  . Die Funktion
. Die Funktion
 in Richtung d verlaufende Gerade.
in Richtung d verlaufende Gerade. und die Richtung d definieren die Gerade
und die Richtung d definieren die Gerade  im zweidimensionalen Raum der Argumente, und φd beschreibt die Auswertung der Funktion f genau auf den Punkten dieser Geraden. Den Graphen gph φd von φd erhält man geometrisch also, indem man über der Geraden eine „senkrechte Ebene“ errichtet und diese mit dem Graphen gphf von f schneidet. Tatsächlich ist gph φd aber natürlich keine Teilmenge des
im zweidimensionalen Raum der Argumente, und φd beschreibt die Auswertung der Funktion f genau auf den Punkten dieser Geraden. Den Graphen gph φd von φd erhält man geometrisch also, indem man über der Geraden eine „senkrechte Ebene“ errichtet und diese mit dem Graphen gphf von f schneidet. Tatsächlich ist gph φd aber natürlich keine Teilmenge des  , wie es in Abb. 2.1 dargestellt ist, sondern Teilmenge des zweidimensionalen Raums, der mit der konstruierten „senkrechten Ebene“ übereinstimmt.
, wie es in Abb. 2.1 dargestellt ist, sondern Teilmenge des zweidimensionalen Raums, der mit der konstruierten „senkrechten Ebene“ übereinstimmt.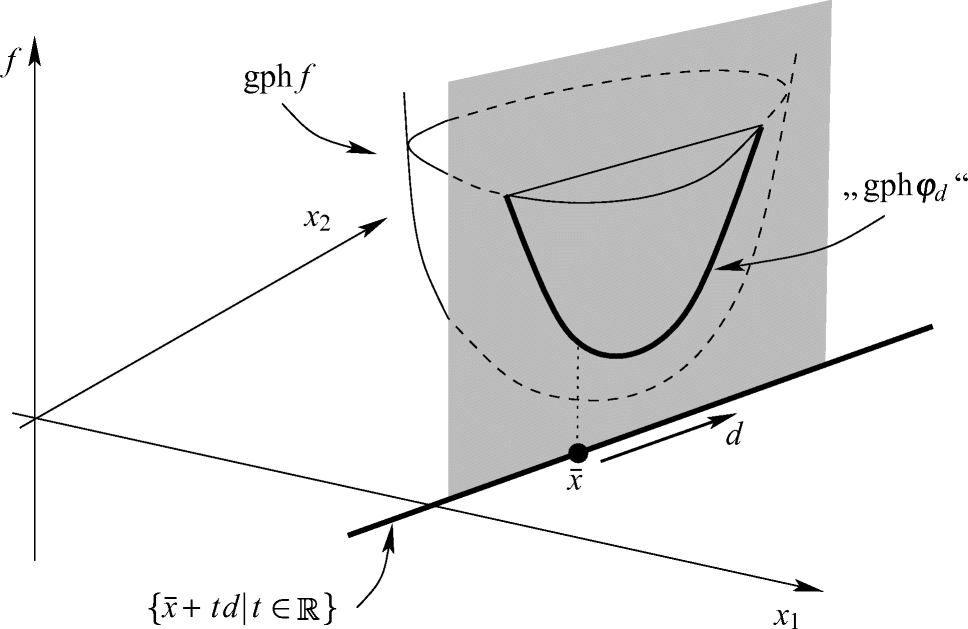
Eindimensionale Einschränkung
 für jede Richtung
für jede Richtung  . Daher ist d genau dann Abstiegsrichtung für f in
. Daher ist d genau dann Abstiegsrichtung für f in  , wenn
, wenn
2.1.2 Optimalitätsbedingung erster Ordnung
Im Folgenden werden wir eine Bedingung herleiten, die an jedem lokalen Minimalpunkt von f notwendigerweise erfüllt sein muss. Da sie Informationen aus ersten Ableitungen von f benutzt, spricht man von einer notwendigen Optimalitätsbedingung erster Ordnung. Um später (in Satz 3.3.21) eine Anwendung der folgenden Grundüberlegungen auch auf gewisse nichtglatte Probleme zuzulassen, führen wir sie unter einer sehr schwachen Voraussetzung an die Funktion f ein, nämlich ihrer einseitigen Richtungsdifferenzierbarkeit.
 ist. Als Verknüpfung von f mit der affin-linearen Funktion
ist. Als Verknüpfung von f mit der affin-linearen Funktion  ist dann auch die eindimensionale Einschränkung φd an
ist dann auch die eindimensionale Einschränkung φd an  differenzierbar. Ihre Ableitung
differenzierbar. Ihre Ableitung  gibt an, mit welcher Steigung die Funktionswerte von f sich ändern, wenn man
gibt an, mit welcher Steigung die Funktionswerte von f sich ändern, wenn man  in Richtung d verlässt. Diese Ableitung
in Richtung d verlässt. Diese Ableitung
 in Richtung d.
in Richtung d.Es erscheint plausibel, dass im Fall  die Funktionswerte von φd bei wachsendem t zunächst fallen, dass ein solches d also eine Abstiegsrichtung ist. Da negative Werte von t für dieses Argument aber gar keine Rolle spielen, benötigt man tatsächlich nicht die Richtungsableitung von f, sondern nur das folgende Konzept.
die Funktionswerte von φd bei wachsendem t zunächst fallen, dass ein solches d also eine Abstiegsrichtung ist. Da negative Werte von t für dieses Argument aber gar keine Rolle spielen, benötigt man tatsächlich nicht die Richtungsableitung von f, sondern nur das folgende Konzept.
2.1.4 Definition (Einseitige Richtungsableitung)
 heißt an
heißt an  in eine Richtung
in eine Richtung  einseitig richtungsdifferenzierbar
, wenn der Grenzwert
einseitig richtungsdifferenzierbar
, wenn der Grenzwert
 heißt dann einseitige Richtungsableitung
. Die Funktion f heißt an
heißt dann einseitige Richtungsableitung
. Die Funktion f heißt an  einseitig richtungsdifferenzierbar
, wenn f an
einseitig richtungsdifferenzierbar
, wenn f an  in jede Richtung
in jede Richtung  einseitig richtungsdifferenzierbar ist, und f heißt einseitig richtungsdifferenzierbar, wenn f an jedem
einseitig richtungsdifferenzierbar ist, und f heißt einseitig richtungsdifferenzierbar, wenn f an jedem  einseitig richtungsdifferenzierbar ist.
einseitig richtungsdifferenzierbar ist. in Richtung d besagt, dass für alle Folgen
in Richtung d besagt, dass für alle Folgen  mit
mit  der Grenzwert
der Grenzwert
 . Hingegen bedeutet die einseitige Richtungsdifferenzierbarkeit von f an
. Hingegen bedeutet die einseitige Richtungsdifferenzierbarkeit von f an  in Richtung d, dass nur für alle Folgen
in Richtung d, dass nur für alle Folgen  mit
mit  der Grenzwert
der Grenzwert
 .
.Offensichtlich ist jede an  in Richtung d richtungsdifferenzierbare Funktion f an
in Richtung d richtungsdifferenzierbare Funktion f an  in Richtung d auch einseitig richtungsdifferenzierbar mit
in Richtung d auch einseitig richtungsdifferenzierbar mit  . Damit ist insbesondere jede an
. Damit ist insbesondere jede an  differenzierbare Funktion f dort auch einseitig richtungsdifferenzierbar. Allerdings umfasst die Klasse der einseitig richtungsdifferenzierbaren Funktionen auch sehr viele nichtdifferenzierbare Funktionen, etwa alle auf
differenzierbare Funktion f dort auch einseitig richtungsdifferenzierbar. Allerdings umfasst die Klasse der einseitig richtungsdifferenzierbaren Funktionen auch sehr viele nichtdifferenzierbare Funktionen, etwa alle auf  konvexen Funktionen (Abschn. 2.1.5 und [34]) sowie Maxima endlich vieler glatter Funktionen (Übung 2.1.12). Als einfaches Beispiel ist
konvexen Funktionen (Abschn. 2.1.5 und [34]) sowie Maxima endlich vieler glatter Funktionen (Übung 2.1.12). Als einfaches Beispiel ist  an
an  weder differenzierbar noch richtungsdifferenzierbar, aber einseitig richtungsdifferenzierbar.
weder differenzierbar noch richtungsdifferenzierbar, aber einseitig richtungsdifferenzierbar.
2.1.5 Lemma
Die Funktion { sei an
sei an  in Richtung
in Richtung  einseitig richtungsdifferenzierbar mit
einseitig richtungsdifferenzierbar mit  . Dann ist d Abstiegsrichtung für f in
. Dann ist d Abstiegsrichtung für f in  .
.
Beweis.
 . Dann existiert kein
. Dann existiert kein  , so dass für alle
, so dass für alle  die Ungleichung
die Ungleichung  erfüllt ist. Insbesondere erfüllt für jedes
erfüllt ist. Insbesondere erfüllt für jedes  mindestens ein tk ∈ (0, 1/k) die Ungleichung
mindestens ein tk ∈ (0, 1/k) die Ungleichung  . Für jedes
. Für jedes  gilt dann wegen tk > 0 auch
gilt dann wegen tk > 0 auch
 in Richtung d liefert
in Richtung d liefert
 . Demnach ist die Annahme falsch und die Behauptung bewiesen.
. Demnach ist die Annahme falsch und die Behauptung bewiesen.Aus Übung 2.1.2 und Lemma 2.1.5 folgt sofort das nächste Resultat.
2.1.6 Lemma
Die Funktion  sei an einem lokalen Minimalpunkt
sei an einem lokalen Minimalpunkt  einseitig richtungsdifferenzierbar. Dann gilt
einseitig richtungsdifferenzierbar. Dann gilt  für jede Richtung
für jede Richtung  .
.
Lemma 2.1.5 und 2.1.6 motivieren die folgende Definitionen.
2.1.7 Definition (Abstiegsrichtung erster Ordnung)
Für eine am Punkt  in Richtung
in Richtung  einseitig richtungsdifferenzierbare Funktion
einseitig richtungsdifferenzierbare Funktion  heißt d Abstiegsrichtung erster Ordnung
, falls
heißt d Abstiegsrichtung erster Ordnung
, falls  gilt.
gilt.
2.1.8 Definition (Stationärer Punkt – unrestringierter Fall)
Die Funktion  sei an
sei an  einseitig richtungsdifferenzierbar. Dann heißt
einseitig richtungsdifferenzierbar. Dann heißt  stationärer Punkt von f, falls
stationärer Punkt von f, falls  für jede Richtung
für jede Richtung  gilt.
gilt.
In dieser Terminologie besagt Lemma 2.1.5, dass jede Abstiegsrichtung erster Ordnung tatsächlich eine Abstiegsrichtung im Sinne von Definition 2.1.1 ist. Die Definition der Stationarität eines Punkts aus Definition 2.1.8 lautet gerade, dass an ihm keine Abstiegsrichtung erster Ordnung existieren darf, und Lemma 2.1.6 sagt aus, dass jeder lokale Minimalpunkt einer dort einseitig richtungsdifferenzierbaren Funktion auch stationär ist.
 und kehren daher wieder zu einer in
und kehren daher wieder zu einer in  differenzierbaren Funktion f zurück. Wir betrachten als Richtungsvektor zunächst speziell den i-ten Einheitsvektor d = ei (setzen also di = 1 und dj = 0 für alle j ≠ i). Dann ist
differenzierbaren Funktion f zurück. Wir betrachten als Richtungsvektor zunächst speziell den i-ten Einheitsvektor d = ei (setzen also di = 1 und dj = 0 für alle j ≠ i). Dann ist  die partielle Ableitung
von f bezüglich der Variable xi , die man alternativ auch mit
die partielle Ableitung
von f bezüglich der Variable xi , die man alternativ auch mit  bezeichnet. Als erste Ableitung
einer partiell differenzierbaren Funktion
bezeichnet. Als erste Ableitung
einer partiell differenzierbaren Funktion  an
an  betrachtet man den Zeilenvektor
betrachtet man den Zeilenvektor
 . Der Spaltenvektor
. Der Spaltenvektor  wird als Gradient
von f an
wird als Gradient
von f an  bezeichnet. Im Hinblick auf spätere Konstruktionen halten wir fest, dass der Gradient
bezeichnet. Im Hinblick auf spätere Konstruktionen halten wir fest, dass der Gradient  zwar einerseits nur eine Liste von partiellen Ableitungsinformationen ist, andererseits aber genau wie
zwar einerseits nur eine Liste von partiellen Ableitungsinformationen ist, andererseits aber genau wie  als ein n-dimensionaler Vektor interpretiert werden darf.
als ein n-dimensionaler Vektor interpretiert werden darf. mit partiell differenzierbaren Komponenten
mit partiell differenzierbaren Komponenten  definiert man die erste Ableitung als
definiert man die erste Ableitung als
 . Gelegentlich werden wir auch für vektorwertige Funktionen f die Notation
. Gelegentlich werden wir auch für vektorwertige Funktionen f die Notation  benutzen.
benutzen.Eine wichtige Rechenregel für differenzierbare Funktionen ist die Kettenregel, deren Beweis man z. B. in [18] findet.
2.1.9 Satz (Kettenregel)
 differenzierbar an
differenzierbar an  und
und  differenzierbar an
differenzierbar an  . Dann ist
. Dann ist  differenzierbar an
differenzierbar an  mit
mit
Ein wesentlicher Grund dafür, die Jacobi-Matrix einer Funktion wie oben zu definieren, besteht darin, dass die Kettenregel dann völlig analog zum eindimensionalen Fall ( ) formuliert werden kann, obwohl das auftretende Produkt ein Matrixprodukt ist.
) formuliert werden kann, obwohl das auftretende Produkt ein Matrixprodukt ist.
 gilt k = m = 1 und
gilt k = m = 1 und  . Als Jacobi-Matrix von g erhält man
. Als Jacobi-Matrix von g erhält man

 mit dem Spaltenvektor d.
mit dem Spaltenvektor d. nennt man den so definierten Term
nennt man den so definierten Term


2.1.10 Lemma
Die Funktion  sei am Punkt
sei am Punkt  differenzierbar, und für die Richtung
differenzierbar, und für die Richtung  gelte
gelte  . Dann ist d Abstiegsrichtung für f in
. Dann ist d Abstiegsrichtung für f in  .
.
Für eine an  differenzierbare Funktion f ist d offensichtlich genau dann Abstiegsrichtung erster Ordnung im Sinne von Definition 2.1.7, wenn
differenzierbare Funktion f ist d offensichtlich genau dann Abstiegsrichtung erster Ordnung im Sinne von Definition 2.1.7, wenn  gilt.
gilt.
2.1.11 Bemerkung
 geometrisch zu interpretieren ist. Für zwei Vektoren
geometrisch zu interpretieren ist. Für zwei Vektoren  besitzt das Skalarprodukt
besitzt das Skalarprodukt  neben der algebraischen Definition zu
neben der algebraischen Definition zu  nämlich auch die Darstellung
nämlich auch die Darstellung
 den Winkel zwischen den beiden Vektoren a und b. Dieser lässt sich für n-dimensionale Vektoren a und b definieren, indem man ihn in der Ebene misst, die von a und b aufgespannt wird (also in der Menge
den Winkel zwischen den beiden Vektoren a und b. Dieser lässt sich für n-dimensionale Vektoren a und b definieren, indem man ihn in der Ebene misst, die von a und b aufgespannt wird (also in der Menge  ). Im Ausnahmefall, in dem die Vektoren a und b linear abhängig sind, spannen sie zwar keine Ebene auf, aber der Winkel zwischen a und b kann dann nur null (falls sie in die gleiche Richtung zeigen) oder π (falls sie in entgegengesetzte Richtungen zeigen) betragen. In diesen Fällen gilt
). Im Ausnahmefall, in dem die Vektoren a und b linear abhängig sind, spannen sie zwar keine Ebene auf, aber der Winkel zwischen a und b kann dann nur null (falls sie in die gleiche Richtung zeigen) oder π (falls sie in entgegengesetzte Richtungen zeigen) betragen. In diesen Fällen gilt  bzw.
bzw.  .
.Aus der Darstellung (2.1) erhalten wir die Bedingung  also genau dann, wenn
also genau dann, wenn  gilt, d. h. genau für
gilt, d. h. genau für  . Mit anderen Worten ist das Skalarprodukt der Vektoren a und b genau dann negativ, wenn sie einen stumpfen Winkel miteinander bilden. Analog ist das Skalarprodukt genau für einen spitzen Winkel bildende Vektoren positiv sowie genau für senkrecht zueinander stehende Vektoren null.
. Mit anderen Worten ist das Skalarprodukt der Vektoren a und b genau dann negativ, wenn sie einen stumpfen Winkel miteinander bilden. Analog ist das Skalarprodukt genau für einen spitzen Winkel bildende Vektoren positiv sowie genau für senkrecht zueinander stehende Vektoren null.
Insbesondere ist d genau dann eine Abstiegsrichtung erster Ordnung für f in  , wenn d einen stumpfen Winkel mit dem Gradienten
, wenn d einen stumpfen Winkel mit dem Gradienten  bildet. Wir werden später sehen, dass unter gewissen Zusatzvoraussetzungen auch Richtungen d Abstiegsrichtungen sein können, die senkrecht zum Vektor
bildet. Wir werden später sehen, dass unter gewissen Zusatzvoraussetzungen auch Richtungen d Abstiegsrichtungen sein können, die senkrecht zum Vektor  stehen.
stehen.
Auch für nur einseitig richtungsdifferenzierbare Funktionen lassen sich manchmal einfache Formeln für die einseitige Richtungsableitung angeben.
2.1.12 Übung
 , eine endliche Indexmenge K und an
, eine endliche Indexmenge K und an  differenzierbare Funktionen
differenzierbare Funktionen  , k ∈ K. Zeigen Sie, dass dann die Funktion
, k ∈ K. Zeigen Sie, dass dann die Funktion  an
an  einseitig richtungsdifferenzierbar ist und dass mit
einseitig richtungsdifferenzierbar ist und dass mit 

 gilt.
gilt.Wir können nun die zentrale Optimalitätsbedingung für unrestringierte glatte Optimierungsprobleme beweisen.
2.1.13 Satz (Notwendige Optimalitätsbedingung erster Ordnung – Fermat’sche Regel)
Die Funktion  sei differenzierbar an einem lokalen Minimalpunkt
sei differenzierbar an einem lokalen Minimalpunkt  . Dann gilt
. Dann gilt  .
.
Beweis.
 ein stationärer Punkt von f. Aufgrund der Darstellung der Richtungsableitung per Kettenregel gilt für jede Richtung
ein stationärer Punkt von f. Aufgrund der Darstellung der Richtungsableitung per Kettenregel gilt für jede Richtung  also
also
 , also
, also
 und (wegen der Definitheit der Norm)
und (wegen der Definitheit der Norm)  .
.Die Fermat’sche Regel wird als Optimalitätsbedingung erster Ordnung bezeichnet, da sie von ersten Ableitungen der Funktion f Gebrauch macht. Sie motiviert die folgende Definition.
2.1.14 Definition (Kritischer Punkt)
Die Funktion  sei an
sei an  differenzierbar. Dann heißt
differenzierbar. Dann heißt  kritischer Punkt
von f, wenn
kritischer Punkt
von f, wenn  gilt.
gilt.
In dieser Terminologie ist nach der Fermat’schen Regel jeder lokale Minimalpunkt einer differenzierbaren Funktion notwendigerweise kritischer Punkt.
2.1.15 Übung
Die Funktion  sei differenzierbar an einem Punkt
sei differenzierbar an einem Punkt  . Zeigen Sie, dass
. Zeigen Sie, dass  genau dann stationärer Punkt von f ist, wenn er kritischer Punkt von f ist.
genau dann stationärer Punkt von f ist, wenn er kritischer Punkt von f ist.
Übung 2.1.15 begründet, weshalb in der Literatur zur glatten unrestringierten Optimierung die Begriffe des stationären und des kritischen Punkts synonym gebraucht werden. Für nichtglatte oder restringierte glatte Probleme ist der Zusammenhang zwischen der durch das Fehlen einer Abstiegsrichtung erster Ordnung definierten Stationarität und einer algebraischen Optimalitätsbedingung (analog zur Kritikalität  ) allerdings weniger übersichtlich ([34] und Kap. 3). Die Begriffe der Stationarität und der Kritikalität werden in der Literatur aber nicht einheitlich gebraucht.
) allerdings weniger übersichtlich ([34] und Kap. 3). Die Begriffe der Stationarität und der Kritikalität werden in der Literatur aber nicht einheitlich gebraucht.
2.1.16 Beispiel
 von
von  rechnet man sofort
rechnet man sofort  nach. Für die beiden Funktionen
nach. Für die beiden Funktionen  und
und  ist
ist  allerdings ebenfalls kritischer Punkt, obwohl
allerdings ebenfalls kritischer Punkt, obwohl  kein lokaler Minimalpunkt ist. In der Tat liefert beispielsweise die Richtung
kein lokaler Minimalpunkt ist. In der Tat liefert beispielsweise die Richtung  für die eindimensionale Einschränkung beider Funktionen
für die eindimensionale Einschränkung beider Funktionen
 in diese Richtung verlassen kann, während die Funktionswerte fallen (damit ist d zwar Abstiegsrichtung, aber nicht Abstiegsrichtung erster Ordnung). Für f2 ist dies sogar in jeder beliebigen Richtung der Fall, da f2 an
in diese Richtung verlassen kann, während die Funktionswerte fallen (damit ist d zwar Abstiegsrichtung, aber nicht Abstiegsrichtung erster Ordnung). Für f2 ist dies sogar in jeder beliebigen Richtung der Fall, da f2 an  offensichtlich einen Maximalpunkt besitzt. Bei f3 wachsen hingegen in Richtung
offensichtlich einen Maximalpunkt besitzt. Bei f3 wachsen hingegen in Richtung  die Funktionswerte an. In diesem Fall spricht man von einem Sattelpunkt von f3.
die Funktionswerte an. In diesem Fall spricht man von einem Sattelpunkt von f3.2.1.17 Definition (Sattelpunkt)
Die Funktion  sei an
sei an  differenzierbar. Dann heißt
differenzierbar. Dann heißt  Sattelpunkt
von f, falls
Sattelpunkt
von f, falls  zwar kritischer Punkt von f, aber weder lokaler Minimal- noch lokaler Maximalpunkt ist.
zwar kritischer Punkt von f, aber weder lokaler Minimal- noch lokaler Maximalpunkt ist.
Beispiel 2.1.16 illustriert, dass die Fermat’sche Regel nur eine notwendige Optima- litätsbedingung ist. Sie besagt zwar, dass ein lokaler Minimalpunkt von f notwendigerweise kritischer Punkt ist, aber die Eigenschaft, ein kritischer Punkt zu sein, ist nicht hinreichend für Minimalität.
Damit ist klar, dass kritische Punkte lediglich Kandidaten für Minimalpunkte von f sind, aber auch beispielsweise Maximal- oder Sattelpunkten entsprechen können. Algorithmus 2.1 beschreibt ein auf dieser Beobachtung basierendes konzeptionelles Verfahren zur Minimierung mit Hilfe kritischer Punkte. Es nutzt die notwendige Optimalitätsbedingung, um unter allen zulässigen Punkten (also allen Punkten in  ) diejenigen „auszusieben“, die nicht als Kandidaten für Minimalpunkte infrage kommen. „Nur“ unter den restlichen Punkten muss dann noch ein Minimalpunkt gesucht werden.
) diejenigen „auszusieben“, die nicht als Kandidaten für Minimalpunkte infrage kommen. „Nur“ unter den restlichen Punkten muss dann noch ein Minimalpunkt gesucht werden.
Hier und im Folgenden nennen wir ein Optimierungsproblem P differenzierbar, wenn es durch differenzierbare Funktionen beschrieben wird. Im vorliegenden unrestringierten Fall betrifft dies natürlich nur die Differenzierbarkeit der Zielfunktion f.
Algorithmus 2.1: Konzeptioneller Algorithmus zur unrestringierten nichtlinearen Minimierung mit Informationen erster Ordnung
Input : Lösbares unrestringiertes differenzierbares Optimierungsproblem P
Output : Globaler Minimalpunkt  von f über
von f über 
1 begin
2 Bestimme alle kritischen Punkte von f, d. h. die Lösungsmenge K der Gleichung  .
.
3 Bestimme einen Minimalpunkt  von f in K.
von f in K.
4 end
Algorithmus 2.1 besitzt drei Nachteile, die seine Anwendung auf praktische Probleme behindern. Zunächst muss die Lösbarkeit des Problems P a priori bekannt sein, etwa durch Anwendung der Kriterien aus Abschn. 1.2. Beispielsweise besitzt die Funktion  genau die beiden kritischen Punkte x1 = −1 und x2 = 1, wobei x2 den kleineren Funktionswert besitzt und damit den Output von Algorithmus 2.1 bildet. Allerdings ist f auf
genau die beiden kritischen Punkte x1 = −1 und x2 = 1, wobei x2 den kleineren Funktionswert besitzt und damit den Output von Algorithmus 2.1 bildet. Allerdings ist f auf  nicht nach unten beschränkt und besitzt damit keinen globalen Minimalpunkt. Diese Unlösbarkeit kann von Algorithmus 2.1 nicht identifiziert werden.
nicht nach unten beschränkt und besitzt damit keinen globalen Minimalpunkt. Diese Unlösbarkeit kann von Algorithmus 2.1 nicht identifiziert werden.
Der zweite Nachteil von Algorithmus 2.1 besteht darin, dass er alle kritischen Punkte bestimmen muss. Bei einer nichtlinearen Kritische-Punkt-Gleichung ∇f(x) = 0 ist aber selten klar, wie alle Lösungen bestimmt werden können. Falls kritische Punkte übersehen werden, besteht die Gefahr, dass der Output von Algorithmus 2.1 kein globaler Minimalpunkt ist.
Als dritter Nachteil ist anzuführen, dass bei komplizierten Funktionen f schon die Berechnung eines einzigen kritischen Punkts sehr aufwendig sein kann.
Algorithmus 2.1 lässt sich demnach immerhin auf lösbare Optimierungsprobleme anwenden, deren kritische Punkte etwa durch Fallunterscheidung komplett und außerdem explizit berechenbar sind. Dies trifft leider oft nur auf niedrigdimensionale Probleme mit „übersichtlicher“ Zielfunktion zu.
2.1.18 Übung

 , 1 ≤ j ≤ m. Warum ist nicht garantiert, dass sich die Fermat’sche Regel auf jeden lokalen Minimalpunkt dieses Problems anwenden lässt?
, 1 ≤ j ≤ m. Warum ist nicht garantiert, dass sich die Fermat’sche Regel auf jeden lokalen Minimalpunkt dieses Problems anwenden lässt?
2.1.3 Geometrische Eigenschaften von Gradienten
 vollständig zu verstehen, bringen wir ihn mit der unteren Niveaumenge
vollständig zu verstehen, bringen wir ihn mit der unteren Niveaumenge
 gilt und im Vergleich zu
gilt und im Vergleich zu  „bessere“ Punkte x gerade solche sind, die die strikte Ungleichung
„bessere“ Punkte x gerade solche sind, die die strikte Ungleichung  erfüllen. Eine Abstiegsrichtung d für f in
erfüllen. Eine Abstiegsrichtung d für f in  sollte also in das „Innere“ von
sollte also in das „Innere“ von  zeigen. Abb. 2.2 illustriert, wie eine solche Menge für eine nichtlineare Funktion f aussehen kann, wobei zwei verschiedene Punkte x1 und x2 so gewählt sind, dass
zeigen. Abb. 2.2 illustriert, wie eine solche Menge für eine nichtlineare Funktion f aussehen kann, wobei zwei verschiedene Punkte x1 und x2 so gewählt sind, dass  gilt.
gilt.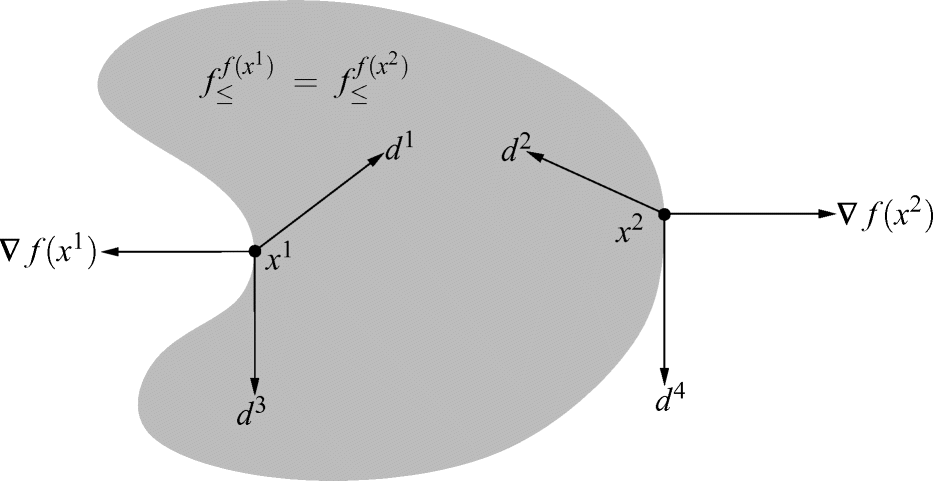
Gradienten und Abstiegsrichtungen
 mit
mit  eine Anstiegsrichtung erster Ordnung
ist. Da für einen nichtkritischen Punkt
eine Anstiegsrichtung erster Ordnung
ist. Da für einen nichtkritischen Punkt  die Gradientenrichtung
die Gradientenrichtung  die strikte Ungleichung
die strikte Ungleichung
 also eine Anstiegsrichtung erster Ordnung für f in
also eine Anstiegsrichtung erster Ordnung für f in  und zeigt damit sicherlich aus
und zeigt damit sicherlich aus  heraus.
heraus.In der Tat lässt sich sogar zeigen, dass  senkrecht auf dem Rand von
senkrecht auf dem Rand von  steht. Um dies korrekt zu begründen, muss man einen Tangentialkegel an die Menge
steht. Um dies korrekt zu begründen, muss man einen Tangentialkegel an die Menge  im Punkt
im Punkt  definieren, was wir auf Abschn. 3.1.2 verschieben, in dem Tangentialkegel an allgemeine Mengen eingeführt werden (Übung 3.2.9).
definieren, was wir auf Abschn. 3.1.2 verschieben, in dem Tangentialkegel an allgemeine Mengen eingeführt werden (Übung 3.2.9).
 linearisierte Menge
linearisierte Menge  , etwas mit der Linearisierung der Ungleichung zu tun hat, durch die die Menge definiert ist. In der Tat liegt für t > 0 und eine Richtung
, etwas mit der Linearisierung der Ungleichung zu tun hat, durch die die Menge definiert ist. In der Tat liegt für t > 0 und eine Richtung  der Punkt
der Punkt  in
in  , falls
, falls  gilt. Mit der eindimensionalen Einschränkung lässt sich dies auch als
gilt. Mit der eindimensionalen Einschränkung lässt sich dies auch als  schreiben. Eine Linearisierung dieser Ungleichung um
schreiben. Eine Linearisierung dieser Ungleichung um  , also die Taylor-Entwicklung erster Ordnung (s. auch Satz 2.1.19a) mit unterschlagenem Restglied, führt auf
, also die Taylor-Entwicklung erster Ordnung (s. auch Satz 2.1.19a) mit unterschlagenem Restglied, führt auf
 folgt. Mit den Ergebnissen aus Abschn. 3.2.2 werden wir in Übung 3.2.9 tatsächlich zeigen können, dass an einem nichtkritischen Punkt
folgt. Mit den Ergebnissen aus Abschn. 3.2.2 werden wir in Übung 3.2.9 tatsächlich zeigen können, dass an einem nichtkritischen Punkt  der Tangentialkegel an die Menge
der Tangentialkegel an die Menge  im Punkt
im Punkt  durch
durch
 , steht also senkrecht auf dem Gradienten
, steht also senkrecht auf dem Gradienten  . Folglich zeigt
. Folglich zeigt  nicht nur aus
nicht nur aus  heraus, sondern steht auch senkrecht zum Rand dieser Menge (bzw. ihres Tangentialkegels).
heraus, sondern steht auch senkrecht zum Rand dieser Menge (bzw. ihres Tangentialkegels).Abb. 2.2 illustriert dies für die Punkte x1 und x2. Da d1 und d2 stumpfe Winkel mit ∇f(x1) bzw. ∇f(x2) bilden, sind sie Abstiegsrichtungen erster Ordnung für f in x1 bzw. x2. Offensichtlich gerät man entlang dieser Richtungen auch (zunächst) ins Innere der Menge  . Der Vektor d3 steht senkrecht auf ∇f(x1), ist also keine Abstiegsrichtung erster Ordnung. Dass er dennoch als Abstiegsrichtung fungiert, ist der „nichtkonvexen Krümmung“ des Rands dieser Menge um x1 zu verdanken. Andererseits steht der Vektor d4 zwar ebenfalls senkrecht auf ∇f(x2), kommt als Abstiegsrichtung aber offensichtlich nicht infrage. Mit diesen beiden Effekten werden wir uns in Abschn. 2.1.4 genauer befassen.
. Der Vektor d3 steht senkrecht auf ∇f(x1), ist also keine Abstiegsrichtung erster Ordnung. Dass er dennoch als Abstiegsrichtung fungiert, ist der „nichtkonvexen Krümmung“ des Rands dieser Menge um x1 zu verdanken. Andererseits steht der Vektor d4 zwar ebenfalls senkrecht auf ∇f(x2), kommt als Abstiegsrichtung aber offensichtlich nicht infrage. Mit diesen beiden Effekten werden wir uns in Abschn. 2.1.4 genauer befassen.
Während wir bislang nur das Vorzeichen der Richtungsableitung  betrachtet haben, untersuchen wir abschließend noch, wie man den tatsächlichen An- oder Abstieg der Funktionswerte von
betrachtet haben, untersuchen wir abschließend noch, wie man den tatsächlichen An- oder Abstieg der Funktionswerte von  aus in Richtung d quantifizieren kann. Das Problem hierbei ist, dass zu jedem Vektor d ≠ 0 auch etwa der Vektor 2d in dieselbe Richtung zeigt, sich beim Austausch von d gegen 2d aber der Wert der Richtungsableitung verdoppelt. Um einen eindeutigen Wert der Richtungsableitung zu erhalten, liegt es nahe, nur solche Richtungen d zu betrachten, die die Länge eins besitzen, also
aus in Richtung d quantifizieren kann. Das Problem hierbei ist, dass zu jedem Vektor d ≠ 0 auch etwa der Vektor 2d in dieselbe Richtung zeigt, sich beim Austausch von d gegen 2d aber der Wert der Richtungsableitung verdoppelt. Um einen eindeutigen Wert der Richtungsableitung zu erhalten, liegt es nahe, nur solche Richtungen d zu betrachten, die die Länge eins besitzen, also  erfüllen. Dies entspricht der natürlichen Forderung, dass ein Schritt der Länge t von
erfüllen. Dies entspricht der natürlichen Forderung, dass ein Schritt der Länge t von  in Richtung d zu einem Punkt
in Richtung d zu einem Punkt  führt, der tatsächlich den Abstand t von
führt, der tatsächlich den Abstand t von  besitzt (denn mit
besitzt (denn mit  gilt
gilt  ).
).

 angenommen. Wegen
angenommen. Wegen  wird die kleinstmögliche Steigung
wird die kleinstmögliche Steigung  daher mit
daher mit
 mit
mit
 des Gradienten genau dem größtmöglichen Anstieg der Funktion f von
des Gradienten genau dem größtmöglichen Anstieg der Funktion f von  aus, und die Richtung des Gradienten zeigt in die zugehörige Richtung des steilsten Anstiegs.
aus, und die Richtung des Gradienten zeigt in die zugehörige Richtung des steilsten Anstiegs.Analog zeigt  in die Richtung des steilsten Abstiegs von f in
in die Richtung des steilsten Abstiegs von f in  . Dies wird in Abschn. 2.2 auf ein grundlegendes numerisches Verfahren führen. In der Tat arbeitet man numerisch allerdings nicht mit normierten Richtungsvektoren, da beispielsweise die Länge
. Dies wird in Abschn. 2.2 auf ein grundlegendes numerisches Verfahren führen. In der Tat arbeitet man numerisch allerdings nicht mit normierten Richtungsvektoren, da beispielsweise die Länge  der negativen Gradientenrichtung gerade in der Nähe der gesuchten kritischen Punkte nahe bei null liegt, und die Division
der negativen Gradientenrichtung gerade in der Nähe der gesuchten kritischen Punkte nahe bei null liegt, und die Division  dann numerisch instabil wäre.
dann numerisch instabil wäre.
2.1.4 Optimalitätsbedingungen zweiter Ordnung
Zur Herleitung der Fermat’schen Regel haben wir in Abschn. 2.1.2 ausgenutzt, dass an lokalen Minimalpunkten keine Abstiegsrichtungen erster Ordnung existieren können. Übung 2.1.2 schließt in lokalen Minimalpunkten allerdings jegliche Abstiegsrichtungen aus, und in Beispiel 2.1.16 sowie mit der Richtung d3 in Abb. 2.2 haben wir gesehen, dass es noch andere als Abstiegsrichtungen erster Ordnung gibt. Die im aktuellen Abschnitt hergeleiteten Optimalitätsbedingungen zweiter Ordnung basieren auf dem Konzept der Abstiegsrichtungen zweiter Ordnung.
Um es einzuführen, setzen wir f im Folgenden als mindestens zweimal differenzierbar am betrachteten Punkt  voraus. Dann ist auch die eindimensionale Einschränkung φd an
voraus. Dann ist auch die eindimensionale Einschränkung φd an  zweimal differenzierbar. Ihre zweite Ableitung
zweimal differenzierbar. Ihre zweite Ableitung  ist ein Maß für die Krümmung von φd in
ist ein Maß für die Krümmung von φd in  . Aus Abschn. 2.1.2 ist bekannt, dass φd im Fall
. Aus Abschn. 2.1.2 ist bekannt, dass φd im Fall  von
von  aus für wachsende Werte von t zunächst fällt und analog dass φd im Fall
aus für wachsende Werte von t zunächst fällt und analog dass φd im Fall  von
von  aus für wachsende Werte von t zunächst steigt. Im Grenzfall
aus für wachsende Werte von t zunächst steigt. Im Grenzfall  erscheint es plausibel, dass für
erscheint es plausibel, dass für  die Funktionswerte von φd bei wachsendem t zunächst fallen, dass ein solches d also eine Abstiegsrichtung ist. Um auch dies tatsächlich nachzuweisen, benötigen wir den aus der Analysis bekannten und beispielsweise in [16, 17, 28] bewiesenen Satz von Taylor in folgender Form, wobei der Begriff univariat
sich darauf bezieht, dass die betrachtete Funktion von einer nur eindimensionalen Variable abhängt.
die Funktionswerte von φd bei wachsendem t zunächst fallen, dass ein solches d also eine Abstiegsrichtung ist. Um auch dies tatsächlich nachzuweisen, benötigen wir den aus der Analysis bekannten und beispielsweise in [16, 17, 28] bewiesenen Satz von Taylor in folgender Form, wobei der Begriff univariat
sich darauf bezieht, dass die betrachtete Funktion von einer nur eindimensionalen Variable abhängt.
2.1.19 Satz (Entwicklungen erster und zweiter Ordnung per univariatem Satz von Taylor)
- a)Es sei
 differenzierbar an
differenzierbar an  . Dann gilt für alle
. Dann gilt für alle  wobei
wobei
 einen Ausdruck der Form
einen Ausdruck der Form  mit
mit  bezeichnet.
bezeichnet. - b)Es sei
 zweimal differenzierbar an
zweimal differenzierbar an  . Dann gilt für alle
. Dann gilt für alle  wobei
wobei
 einen Ausdruck der Form
einen Ausdruck der Form  mit
mit  bezeichnet.
bezeichnet.
2.1.20 Lemma
Für  , einen Punkt
, einen Punkt  und eine Richtung
und eine Richtung  seien
seien  und
und  . Dann ist d Abstiegsrichtung für f in
. Dann ist d Abstiegsrichtung für f in  .
.
Beweis.
 wieder ein tk ∈ (0, 1/k) mit
wieder ein tk ∈ (0, 1/k) mit
 liefert außerdem für jedes
liefert außerdem für jedes 

 und tk ≠ 0 erhalten wir insgesamt für jedes
und tk ≠ 0 erhalten wir insgesamt für jedes 

 . Im Grenzübergang gilt also
. Im Grenzübergang gilt also
 steht. Demnach ist d Abstiegsrichtung.
steht. Demnach ist d Abstiegsrichtung.2.1.21 Lemma
Für  sei
sei  ein lokaler Minimalpunkt. Dann gilt
ein lokaler Minimalpunkt. Dann gilt  , und jede Richtung
, und jede Richtung  erfüllt
erfüllt  .
.
Beweis.
Zunächst liefert Satz 2.1.13, dass  gilt und damit insbesondere auch
gilt und damit insbesondere auch  . Aus Übung 2.1.2 und Lemma 2.1.20 folgt daher die Behauptung.
. Aus Übung 2.1.2 und Lemma 2.1.20 folgt daher die Behauptung.
 , also für die Ableitung der bereits per Kettenregel berechneten ersten Ableitung
, also für die Ableitung der bereits per Kettenregel berechneten ersten Ableitung
 . Aus nochmaliger Anwendung der Kettenregel folgt
. Aus nochmaliger Anwendung der Kettenregel folgt

 treten jedenfalls partielle zweite Ableitungen von f auf. Um eine übersichtlichere Formel für
treten jedenfalls partielle zweite Ableitungen von f auf. Um eine übersichtlichere Formel für  zu finden, führen wir eine „n-dimensionale zweite Ableitung“
von f ein. Eine naheliegende Möglichkeit dafür ist es, die erste Ableitung der ersten Ableitung zu bilden, also die Jacobi-Matrix des Gradienten von f: Die (n, n)-Matrix
zu finden, führen wir eine „n-dimensionale zweite Ableitung“
von f ein. Eine naheliegende Möglichkeit dafür ist es, die erste Ableitung der ersten Ableitung zu bilden, also die Jacobi-Matrix des Gradienten von f: Die (n, n)-Matrix
 . Als zweite Ableitung sind in ihr Krümmungsinformationen von f an
. Als zweite Ableitung sind in ihr Krümmungsinformationen von f an  codiert.
codiert. gerade
gerade
 vorliegt. Damit können wir Lemma 2.1.20 umformulieren.
vorliegt. Damit können wir Lemma 2.1.20 umformulieren.2.1.22 Lemma
Für  , einen Punkt
, einen Punkt  und eine Richtung
und eine Richtung  seien
seien  und
und  . Dann ist d Abstiegsrichtung für f in
. Dann ist d Abstiegsrichtung für f in  .
.
Dies motiviert die folgende Definition.
2.1.23 Definition (Abstiegsrichtung zweiter Ordnung)
Zu  und
und  heißt jeder Richtungsvektor
heißt jeder Richtungsvektor  mit
mit  und
und  Abstiegsrichtung zweiter Ordnung
für f in
Abstiegsrichtung zweiter Ordnung
für f in  .
.
2.1.24 Beispiel
 ,
,  und
und  aus Beispiel 2.1.16 besitzen an
aus Beispiel 2.1.16 besitzen an  den Gradienten
den Gradienten  und die Hesse-Matrizen
und die Hesse-Matrizen
 folgt
folgt

 ist.
ist.2.1.25 Beispiel
In Beispiel 2.1.24 ist die Bedingung  aus Definition 2.1.23 erfüllt, weil schon
aus Definition 2.1.23 erfüllt, weil schon  gilt. Es gibt aber auch Abstiegsrichtungen zweiter Ordnung im Fall
gilt. Es gibt aber auch Abstiegsrichtungen zweiter Ordnung im Fall  , nämlich solche, die orthogonal zu
, nämlich solche, die orthogonal zu  stehen. Dies veranschaulicht etwa die Richtung d3 in Abb. 2.2. Die dortige Richtung d4 verdeutlicht andererseits, dass die bloße Orthogonalität natürlich nicht ausreicht. Die „nichtkonvexe Krümmung“ des Rands der Menge
stehen. Dies veranschaulicht etwa die Richtung d3 in Abb. 2.2. Die dortige Richtung d4 verdeutlicht andererseits, dass die bloße Orthogonalität natürlich nicht ausreicht. Die „nichtkonvexe Krümmung“ des Rands der Menge  an x1 entspricht gerade der Bedingung
an x1 entspricht gerade der Bedingung  , die d3 laut Definition 2.1.23 zu einer Abstiegsrichtung zweiter Ordnung macht. Dieser Zusammenhang wird noch klarer werden, wenn wir diese Bedingungen mit den Eigenwerten der Matrix
, die d3 laut Definition 2.1.23 zu einer Abstiegsrichtung zweiter Ordnung macht. Dieser Zusammenhang wird noch klarer werden, wenn wir diese Bedingungen mit den Eigenwerten der Matrix  in Verbindung gebracht haben.
in Verbindung gebracht haben.
Das folgende Beispiel belegt, dass nicht jede Abstiegsrichtung entweder von erster oder von zweiter Ordnung ist.
2.1.26 Beispiel
Für jede Abstiegsrichtung zweiter Ordnung d ist offenbar auch ihre „Gegenrichtung“ −d eine Abstiegsrichtung zweiter Ordnung. Daher ist beispielsweise d = −1 für die Funktion f(x) = x3 an  zwar eine Abstiegsrichtung, aber weder von erster noch von zweiter Ordnung.
zwar eine Abstiegsrichtung, aber weder von erster noch von zweiter Ordnung.
Die per Formel für  explizitere Formulierung von Lemma 2.1.21 besagt, dass an einem lokalen Minimalpunkt
explizitere Formulierung von Lemma 2.1.21 besagt, dass an einem lokalen Minimalpunkt  von f notwendigerweise
von f notwendigerweise  und
und  für alle
für alle  gilt. In der linearen Algebra wird letztere Bedingung an die Matrix
gilt. In der linearen Algebra wird letztere Bedingung an die Matrix  positive Semidefinitheit
genannt und kurz mit
positive Semidefinitheit
genannt und kurz mit  bezeichnet. Damit erhalten wir aus Lemma 2.1.21 folgendes Resultat.
bezeichnet. Damit erhalten wir aus Lemma 2.1.21 folgendes Resultat.
2.1.27 Satz (Notwendige Optimalitätsbedingung zweiter Ordnung)
Die Funktion  sei zweimal differenzierbar an einem lokalen Minimalpunkt
sei zweimal differenzierbar an einem lokalen Minimalpunkt  . Dann gilt
. Dann gilt  und
und  .
.
Um Satz 2.1.27 praktisch anwenden zu können, muss die Bedingung  überprüfbar sein. Nach Definition der positiven Semidefinitheit wären dazu aber unendlich viele Ungleichungen zu garantieren. Glücklicherweise stellt die lineare Algebra eine Charakterisierung von positiver Semidefinitheit zur Verfügung, sofern die Matrix
überprüfbar sein. Nach Definition der positiven Semidefinitheit wären dazu aber unendlich viele Ungleichungen zu garantieren. Glücklicherweise stellt die lineare Algebra eine Charakterisierung von positiver Semidefinitheit zur Verfügung, sofern die Matrix  symmetrisch ist (d. h., es gilt
symmetrisch ist (d. h., es gilt  ). Nach dem aus der Analysis bekannten Satz von Schwarz (z. B. [18]) ist Letzteres der Fall, wenn f nicht nur zweimal differenzierbar, sondern sogar zweimal stetig differenzierbar ist (kurz:
). Nach dem aus der Analysis bekannten Satz von Schwarz (z. B. [18]) ist Letzteres der Fall, wenn f nicht nur zweimal differenzierbar, sondern sogar zweimal stetig differenzierbar ist (kurz:  ).
).
Es sei daran erinnert, dass λ ein Eigenwert
zum Eigenvektor
v ≠ 0 von  ist, wenn
ist, wenn  gilt (eine Motivation dafür wird z. B. im Anhang von [24] gegeben). Obwohl Eigenwerte im Allgemeinen komplexe Zahlen sein können, wird in der linearen Algebra gezeigt (z. B. [8, 20]), dass Eigenwerte symmetrischer Matrizen stets reell sind. Insbesondere kann man dann ihre Vorzeichen betrachten. Eine symmetrische Matrix ist in der Tat genau dann positiv semidefinit, wenn ihre sämtlichen Eigenwerte nichtnegativ sind (z. B. [8, 20]). Demnach dürfen wir für jede C2-Funktion f die Bedingung
gilt (eine Motivation dafür wird z. B. im Anhang von [24] gegeben). Obwohl Eigenwerte im Allgemeinen komplexe Zahlen sein können, wird in der linearen Algebra gezeigt (z. B. [8, 20]), dass Eigenwerte symmetrischer Matrizen stets reell sind. Insbesondere kann man dann ihre Vorzeichen betrachten. Eine symmetrische Matrix ist in der Tat genau dann positiv semidefinit, wenn ihre sämtlichen Eigenwerte nichtnegativ sind (z. B. [8, 20]). Demnach dürfen wir für jede C2-Funktion f die Bedingung  verifizieren, indem wir die n Eigenwerte der Matrix
verifizieren, indem wir die n Eigenwerte der Matrix  berechnen und auf Nichtnegativität überprüfen.
berechnen und auf Nichtnegativität überprüfen.
2.1.28 Beispiel
Alle drei Funktionen f1, f2 und f3 aus Beispiel 2.1.24 sind zweimal stetig differenzierbar an  , so dass die positive Semidefinitheit ihrer Hesse-Matrizen mit Hilfe der Eigenwerte geprüft werden kann. Von den drei Hesse-Matrizen ist nur
, so dass die positive Semidefinitheit ihrer Hesse-Matrizen mit Hilfe der Eigenwerte geprüft werden kann. Von den drei Hesse-Matrizen ist nur  positiv semidefinit. Daher kann man mit Satz 2.1.27 ausschließen, dass f2 und f3 an
positiv semidefinit. Daher kann man mit Satz 2.1.27 ausschließen, dass f2 und f3 an  lokale Minimalpunkte besitzen.
lokale Minimalpunkte besitzen.
Beispiel 2.1.28 zeigt, dass Satz 2.1.27 die Kandidatenmenge für lokale Minimalpunkte gegenüber der Fermat’schen Regel stark reduzieren kann. Darauf basiert der konzeptionelle Algorithmus 2.2, der im Vergleich zu Algorithmus 2.1 das entsprechend „feinere Sieb“ zum Einsatz bringt. Die drei Hauptnachteile von Algorithmus 2.1, nämlich die fehlende Identifizierung der Unlösbarkeit des Optimierungsproblems, die Notwendigkeit, die Kandidatenmenge K komplett zu berechnen, sowie die Schwierigkeit, überhaupt kritische Punkte zu bestimmen, werden auch durch Algorithmus 2.2 nicht ausgeräumt. Sein Vorteil gegenüber Algorithmus 2.1 ist die üblicherweise erheblich kleinere Menge K.
Algorithmus 2.2: Konzeptioneller Algorithmus zur unrestringierten nichtlinearen Minimierung mit Informationen zweiter Ordnung
Input : Lösbares unrestringiertes zweimal stetig differenzierbares Optimierungsproblem P
Output : Globaler Minimalpunkt  von f über
von f über 
1 begin
2 Bestimme alle kritischen Punkte mit positiv semidefiniter Hesse-Matrix von f, d. h. die Lösungsmenge K der beiden Bedingungen  und
und  .
.
3 Bestimme einen Minimalpunkt  von f in K.
von f in K.
4 end
 gilt ∇f4(0) = 0, und die Hesse-Matrix
gilt ∇f4(0) = 0, und die Hesse-Matrix
 ist trotzdem kein lokaler Minimalpunkt von f. Dies führt auf die Frage nach einer hinreichenden Bedingung für lokale Minimalität.
ist trotzdem kein lokaler Minimalpunkt von f. Dies führt auf die Frage nach einer hinreichenden Bedingung für lokale Minimalität.Analog zu unseren bisherigen Betrachtungen ließe sich vermuten, dass f sicherlich dann einen lokalen Minimalpunkt an  besitzt, wenn für alle
besitzt, wenn für alle  die eindimensionale Einschränkung φd an
die eindimensionale Einschränkung φd an  einen lokalen Minimalpunkt besitzt. Die folgende Übung zeigt allerdings, dass diese Vermutung falsch ist.
einen lokalen Minimalpunkt besitzt. Die folgende Übung zeigt allerdings, dass diese Vermutung falsch ist.
2.1.29 Übung (Beispiel von Peano)
Zeigen Sie, dass die Funktion  zwar keinen lokalen Minimalpunkt bei
zwar keinen lokalen Minimalpunkt bei  besitzt, dass aber für jede Richtung
besitzt, dass aber für jede Richtung  die eindimensionale Einschränkung φd an
die eindimensionale Einschränkung φd an  einen lokalen Minimalpunkt aufweist.
einen lokalen Minimalpunkt aufweist.
Übung 2.1.29 illustriert einen Effekt, der für
univariate
Funktionen (also für n = 1) nicht auftreten kann: Der Funktionswert an  wird durch Funktionswerte an Punkten unterschritten, die nicht entlang einer Geraden durch
wird durch Funktionswerte an Punkten unterschritten, die nicht entlang einer Geraden durch  liegen, sondern entlang einer Parabel durch
liegen, sondern entlang einer Parabel durch  . In der Tat gilt in Übung 2.1.29 für die Richtung d, die an
. In der Tat gilt in Übung 2.1.29 für die Richtung d, die an  tangential zu dieser Parabel liegt,
tangential zu dieser Parabel liegt,  , während alle anderen Richtungen
, während alle anderen Richtungen  erfüllen.
erfüllen.
 durch Informationen zweiter Ordnung zu garantieren, sollte man also ausschließen, dass für eine Richtung d nur
durch Informationen zweiter Ordnung zu garantieren, sollte man also ausschließen, dass für eine Richtung d nur  gilt. Dies ist (neben der notwendigerweise aufzustellenden Bedingung
gilt. Dies ist (neben der notwendigerweise aufzustellenden Bedingung  ) gleichbedeutend mit der Forderung, jede Richtung d sei Anstiegsrichtung zweiter Ordnung, also
) gleichbedeutend mit der Forderung, jede Richtung d sei Anstiegsrichtung zweiter Ordnung, also
 bezeichnet wird, kurz
bezeichnet wird, kurz  . Falls die Hesse-Matrix wegen zweimaliger stetiger Differenzierbarkeit von f an
. Falls die Hesse-Matrix wegen zweimaliger stetiger Differenzierbarkeit von f an  symmetrisch ist, wird positive Definitheit dadurch charakterisiert, dass alle Eigenwerte von
symmetrisch ist, wird positive Definitheit dadurch charakterisiert, dass alle Eigenwerte von  strikt positiv sind (z. B. [8, 20]).
strikt positiv sind (z. B. [8, 20]).Der Beweis der resultierenden hinreichenden Optimalitätsbedingung zweiter Ordnung benutzt wieder den Satz von Taylor. Aus Übung 2.1.29 erschließt sich allerdings, dass univariate Versionen dieses Satzes, also Entwicklungen entlang von Geraden, nicht hilfreich sein werden.
Zum Glück lässt der Satz von Taylor sich auch im multivariaten Fall formulieren (ein Beweis wird z. B. in [16, 18] gegeben).
2.1.30 Satz (Entwicklungen erster und zweiter Ordnung per multivariatem Satz von Taylor)
- a)Es sei
 differenzierbar in
differenzierbar in  . Dann gilt für alle
. Dann gilt für alle  wobei
wobei
 einen Ausdruck der Form
einen Ausdruck der Form  mit
mit  bezeichnet.
bezeichnet. - b)Es sei
 zweimal differenzierbar in
zweimal differenzierbar in  . Dann gilt für alle
. Dann gilt für alle  wobei
wobei
 einen Ausdruck der Form
einen Ausdruck der Form  mit
mit  bezeichnet.
bezeichnet.

 bezeichnen und mit
bezeichnen und mit
 (wobei die Wahl der Norm
(wobei die Wahl der Norm  keine Rolle spielt).
keine Rolle spielt).2.1.31 Satz (Hinreichende Optimalitätsbedingung zweiter Ordnung)
Die Funktion  sei an
sei an  zweimal differenzierbar, und es gelte
zweimal differenzierbar, und es gelte  und
und  . Dann ist
. Dann ist  ein strikter lokaler Minimalpunkt von f.
ein strikter lokaler Minimalpunkt von f.
Beweis.
Der Beweis wird per Widerspruch geführt. Angenommen,  sei kein strikter lokaler Minimalpunkt von f. Falls
sei kein strikter lokaler Minimalpunkt von f. Falls  kein kritischer Punkt von f ist, liegt bereits ein Widerspruch vor, so dass wir im Folgenden
kein kritischer Punkt von f ist, liegt bereits ein Widerspruch vor, so dass wir im Folgenden  voraussetzen dürfen. Da
voraussetzen dürfen. Da  kein strikter lokaler Minimalpunkt ist, existiert per Definition 1.1.2 zu jeder Umgebung U von
kein strikter lokaler Minimalpunkt ist, existiert per Definition 1.1.2 zu jeder Umgebung U von  ein
ein  mit
mit  . Insbesondere existiert zu jeder Umgebung
. Insbesondere existiert zu jeder Umgebung  mit
mit  ein Punkt
ein Punkt  mit
mit  . Aus der speziellen Wahl der Umgebungen folgt außerdem
. Aus der speziellen Wahl der Umgebungen folgt außerdem  .
.
 eine Nullfolge positiver Zahlen, die Richtungen
eine Nullfolge positiver Zahlen, die Richtungen
 für alle
für alle  . Dass alle Richtungen dk normiert sind, bedeutet gerade, dass die Folge (dk) in der Einheitssphäre B = (0, 1) liegt. Da diese eine kompakte Menge ist, besitzt die Folge (dk) mindestens einen Häufungspunkt d ∈ B = (0, 1) (nach dem Satz von Bolzano-Weierstraß;
z. B. [18]). Nach Übergang zu einer entsprechenden Teilfolge erhalten wir die Existenz von Folgen (tk) und (dk) mit
. Dass alle Richtungen dk normiert sind, bedeutet gerade, dass die Folge (dk) in der Einheitssphäre B = (0, 1) liegt. Da diese eine kompakte Menge ist, besitzt die Folge (dk) mindestens einen Häufungspunkt d ∈ B = (0, 1) (nach dem Satz von Bolzano-Weierstraß;
z. B. [18]). Nach Übergang zu einer entsprechenden Teilfolge erhalten wir die Existenz von Folgen (tk) und (dk) mit  ,
,  ,
,  und
und
 . Satz 2.1.30b liefert nun für alle
. Satz 2.1.30b liefert nun für alle 

 folgt im Grenzübergang also
folgt im Grenzübergang also
 widerspricht dies aber der Voraussetzung
widerspricht dies aber der Voraussetzung  .
.2.1.32 Bemerkung
Die notwendigen Optimalitätsbedingungen erster und zweiter Ordnung lassen sich samt ihrer Beweise problemlos auf Funktionale auf Banach-Räumen  übertragen, also auf eine große Klasse unendlichdimensionaler Optimierungsprobleme. Die Verallgemeinerung hinreichender Bedingungen ist hingegen nur mit zusätzlichem Aufwand möglich. Hauptgrund hierfür ist, dass die Einheitssphäre in einem Banach-Raum nur in Spezialfällen kompakt ist (für Details s. z. B. [4, 19]).
übertragen, also auf eine große Klasse unendlichdimensionaler Optimierungsprobleme. Die Verallgemeinerung hinreichender Bedingungen ist hingegen nur mit zusätzlichem Aufwand möglich. Hauptgrund hierfür ist, dass die Einheitssphäre in einem Banach-Raum nur in Spezialfällen kompakt ist (für Details s. z. B. [4, 19]).
2.1.33 Übung

2.1.34 Bemerkung
Man kann sich fragen, warum es bei den Optimalitätsbedingungen zweiter Ordnung zwar eine notwendige und eine hinreichende Version gibt, bei den Bedingungen erster Ordnung aber nur die Fermat’sche Regel als notwendige Bedingung. Dazu sei daran erinnert, dass der Beweis der Fermat’schen Regel auf Lemma 2.1.6 für einseitig richtungsdifferenzierbare Funktionen basiert, also auf der Notwendigkeit von Stationarität für jeden lokalen Minimalpunkt. Im glatten Fall besagt dies, dass an einem lokalen Minimalpunkt  von f notwendigerweise die Ungleichungen
von f notwendigerweise die Ungleichungen  für alle
für alle  gelten.
gelten.
Würde man hier zur Konstruktion einer womöglich hinreichenden Optimalitätsbedingung erster Ordnung analog zu den Bedingungen zweiter Ordnung die nichtstrikte durch eine strikte Ungleichung ersetzen, erhielte man  für alle
für alle  . Diese Bedingung ist aber für keinen Vektor
. Diese Bedingung ist aber für keinen Vektor  erfüllbar und daher nutzlos.
erfüllbar und daher nutzlos.
Das Problem liegt dabei in der Glattheitsvoraussetzung an die Funktion f. Für lediglich einseitig richtungsdifferenzierbare Funktionen lässt sich sehr wohl zeigen, dass aus  für alle
für alle  die (strikte) lokale Minimalität von
die (strikte) lokale Minimalität von  für f folgt und dass diese Bedingung auch erfüllbar ist (z. B. für
für f folgt und dass diese Bedingung auch erfüllbar ist (z. B. für  und
und  ).
).
Für restringierte glatte Probleme werden wir in Korollar 3.2.68 wiederum eine hinreichende Optimalitätsbedingung erster Ordnung angeben können, weil (etwas lax formuliert) die dafür benötigte Nichtglattheit durch den Rand der zulässigen Menge bereitgestellt wird.
Da die hinreichende Bedingung aus Satz 2.1.31 etwas mehr liefert als gewünscht, nämlich sogar strikte lokale Minimalpunkte, kann man von ihr keine Charakterisierung lokaler Minimalität erwarten. Andererseits liefert diese hinreichende Bedingung auch keine Charakterisierung für strikte Minimalität, denn sie kann an strikten lokalen Minimalpunkten verletzt sein (z. B. für f(x) = x4 und  ).
).
Zwischen notwendigen und hinreichenden Optimalitätsbedingungen zweiter Ordnung klafft in diesem Sinne also eine Lücke. Die folgenden Ergebnisse zeigen allerdings, dass diese Lücke für „sehr viele“ Optimierungsprobleme keine Rolle spielt. Als Konsequenz daraus befassen wir uns weder mit Optimalitätsbedingungen noch mit Abstiegsrichtungen dritter und höherer Ordnung, obwohl sich diese mit Hilfe der entsprechenden Taylor-Entwicklungen durchaus angeben ließen. Für die folgende Definition sei daran erinnert, dass eine quadratische Matrix nichtsingulär heißt, wenn keiner ihrer Eigenwerte null ist.
2.1.35 Definition (Nichtdegenerierte kritische und Minimalpunkte)
Die Funktion  sei an
sei an  zweimal differenzierbar mit
zweimal differenzierbar mit  . Dann heißt
. Dann heißt 
- a)
nichtdegenerierter kritischer Punkt , falls
 nichtsingulär ist,
nichtsingulär ist, - b)
nichtdegenerierter lokaler Minimalpunkt , falls
 lokaler Minimalpunkt und nichtdegenerierter kritischer Punkt ist.
lokaler Minimalpunkt und nichtdegenerierter kritischer Punkt ist.
Beispielsweise ist der Sattelpunkt  von
von  ein nichtdegenerierter kritischer Punkt, während der Sattelpunkt
ein nichtdegenerierter kritischer Punkt, während der Sattelpunkt  ein degenerierter kritischer Punkt von
ein degenerierter kritischer Punkt von  ist.
ist.
Nichtdegenerierte lokale Minimalpunkte lassen sich durch Eigenschaften von Gradient und Hesse-Matrix charakterisieren.
2.1.36 Lemma
Der Punkt  ist genau dann nichtdegenerierter lokaler Minimalpunkt von f, wenn
ist genau dann nichtdegenerierter lokaler Minimalpunkt von f, wenn  und
und  gilt.
gilt.
Beweis.
Für einen lokalen Minimalpunkt  gilt nach Satz 2.1.27
gilt nach Satz 2.1.27  und
und  . Wenn
. Wenn  außerdem nichtdegenerierter kritischer Punkt ist, dann besitzt
außerdem nichtdegenerierter kritischer Punkt ist, dann besitzt  keinen verschwindenden Eigenwert, ist also positiv definit.
keinen verschwindenden Eigenwert, ist also positiv definit.
Es seien andererseits  und
und  . Dann ist
. Dann ist  nach Satz 2.1.31 ein lokaler Minimalpunkt. Da eine positiv definite Matrix nichtsingulär ist, ist dieser lokale Minimalpunkt auch nichtdegeneriert.
nach Satz 2.1.31 ein lokaler Minimalpunkt. Da eine positiv definite Matrix nichtsingulär ist, ist dieser lokale Minimalpunkt auch nichtdegeneriert.


 in einer passend gewählten Topologie auf dem Funktionenraum
in einer passend gewählten Topologie auf dem Funktionenraum  (die für die Definition einer Umgebung einer Funktion auch ihre ersten und zweiten Ableitungen berücksichtigt) eine offene Menge sein wird. Benutzt man dafür die starke Whitney-Topologie
(
(die für die Definition einer Umgebung einer Funktion auch ihre ersten und zweiten Ableitungen berücksichtigt) eine offene Menge sein wird. Benutzt man dafür die starke Whitney-Topologie
( -Topologie), dann gilt sogar das folgende Ergebnis, für dessen tiefliegenden Beweis wir auf [22] verweisen.
-Topologie), dann gilt sogar das folgende Ergebnis, für dessen tiefliegenden Beweis wir auf [22] verweisen.2.1.37 Satz
 ist
ist  -offen und -dicht in
-offen und -dicht in  .
.
Im Sinne von Satz 2.1.37 ist es also eine schwache Voraussetzung, die Nichtdegeneriertheit eines kritischen Punkts und insbesondere die Nichtdegeneriertheit eines lokalen Minimalpunkts zu fordern.
 auch nicht nur die Vorzeichen von Eigenwerten von
auch nicht nur die Vorzeichen von Eigenwerten von  wichtige Informationen enthalten, sondern auch deren tatsächlichen Werte. Dazu sei λ ein Eigenwert von
wichtige Informationen enthalten, sondern auch deren tatsächlichen Werte. Dazu sei λ ein Eigenwert von  , und d mit
, und d mit  sei ein zugehöriger Eigenvektor. Dann gilt
sei ein zugehöriger Eigenvektor. Dann gilt
 interpretieren kann.
interpretieren kann.Zudem ist für symmetrische (n, n)-Matrizen aus der linearen Algebra bekannt, dass die n Eigenvektoren der n Eigenwerte paarweise orthogonal zueinander gewählt werden können (z. B. [8, 20]). Dadurch lässt sich die lokale Struktur von f um einen nichtdegenerierten kritischen Punkt sehr genau beschreiben.
 von f mit
von f mit  gegeben, d. h.,
gegeben, d. h.,  besitzt (mindestens) einen negativen Eigenwert λ. Jeder zugehörige Eigenvektor d ist dann Abstiegsrichtung zweiter Ordnung, denn er erfüllt
besitzt (mindestens) einen negativen Eigenwert λ. Jeder zugehörige Eigenvektor d ist dann Abstiegsrichtung zweiter Ordnung, denn er erfüllt  und
und
2.1.38 Übung
Zeigen Sie, dass an einem nichtdegenerierten Sattelpunkt sowohl eine Abals auch eine Anstiegsrichtung zweiter Ordnung existieren.
2.1.5 Konvexe Optimierungsprobleme
Abschn. 2.1 hat mit Hilfe von ersten und zweiten Ableitungen einer Funktion Optimalitätsbedingungen für ihre lokalen Minimalpunkte angegeben. Da Ableitungen nur lokale Information über eine Funktion enthalten, kann man auch nicht mehr erwarten, sofern man nicht eine zusätzliche globale Eigenschaft der Funktion fordert. Eine solche ist die Konvexität. Da konvexe Optimierungsprobleme ausführlich in [33] behandelt werden, stellen wir im Folgenden nur einige wesentliche Resultate zusammen und verweisen für Beweise und weitergehende Überlegungen auf [33].
2.1.39 Definition (Konvexe Mengen und Funktionen)





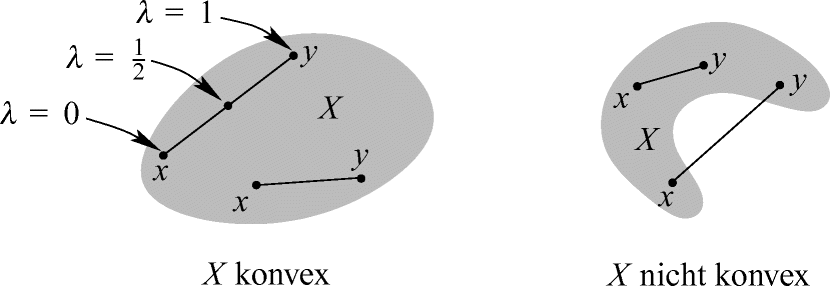
Konvexität von Mengen in 
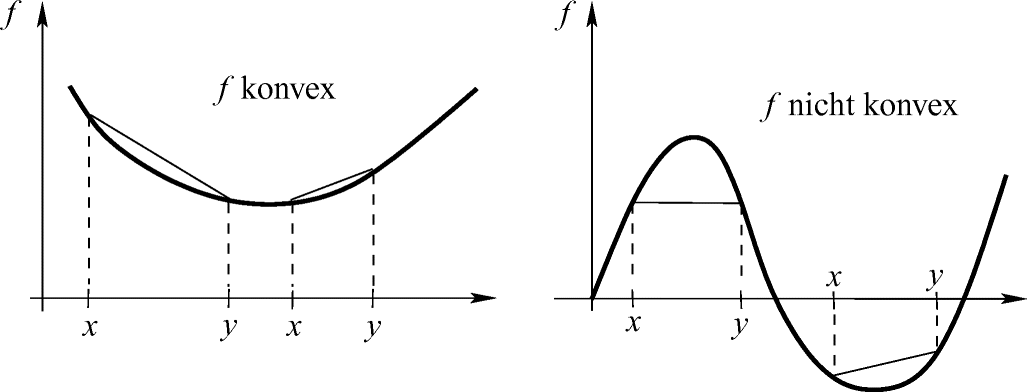
Konvexität von Funktionen auf 
 die Darstellung
die Darstellung
 und erhalten die (in y lineare) Funktion
und erhalten die (in y lineare) Funktion  als Approximation von f im Punkt x. Die angekündigte Charakterisierung von Konvexität stetig differenzierbarer Funktionen (kurz: f ∈ C1) lautet damit wie folgt.
als Approximation von f im Punkt x. Die angekündigte Charakterisierung von Konvexität stetig differenzierbarer Funktionen (kurz: f ∈ C1) lautet damit wie folgt.2.1.40 Satz ( -Charakterisierung von Konvexität)
-Charakterisierung von Konvexität)
 ist eine Funktion
ist eine Funktion  genau dann konvex, wenn
genau dann konvex, wenn
Der zentrale Satz für stetig differenzierbare konvexe unrestringierte Optimierungsprobleme ist die folgende weitreichende Verschärfung der Fermat’schen Regel.
2.1.41 Korollar
Die Funktion  sei konvex. Dann sind die kritischen Punkte von f genau die globalen Minimalpunkte von f.
sei konvex. Dann sind die kritischen Punkte von f genau die globalen Minimalpunkte von f.
Beweis.



Das Problem der globalen Minimierung stetig differenzierbarer konvexer Funktionen ist also äquivalent zu einem Nullstellenproblem, nämlich zur Lösung der Gleichung ∇f(x) = 0.
Obwohl notwendige oder hinreichende Optimalitätsbedingungen zweiter Ordnung im konvexen Fall offenbar überflüssig sind, spielen Hesse-Matrizen dennoch eine wichtige Rolle, nämlich um ein einfaches Kriterium zum Nachweis der Konvexität zweimal stetig differenzierbarer Funktionen anzugeben.
2.1.42 Satz ( -Charakterisierung von Konvexität)
-Charakterisierung von Konvexität)
 ist genau dann konvex, wenn
ist genau dann konvex, wenn
Zum Abschluss dieses Abschnitts betrachten wir für  einen nichtdegenerierten lokalen Minimalpunkt
einen nichtdegenerierten lokalen Minimalpunkt  von f, d. h., an ihm gelte
von f, d. h., an ihm gelte  . Wegen der Stetigkeit von D2f und der stetigen Abhängigkeit der Eigenwerte symmetrischer Matrizen von den Matrixeinträgen [36] gilt auch D2f(x) ≻ 0 für die x aus einer ganzen Umgebung von
. Wegen der Stetigkeit von D2f und der stetigen Abhängigkeit der Eigenwerte symmetrischer Matrizen von den Matrixeinträgen [36] gilt auch D2f(x) ≻ 0 für die x aus einer ganzen Umgebung von  . Nach Satz 2.1.42 ist f also lokal um den nichtdegenerierten lokalen Minimalpunkt
. Nach Satz 2.1.42 ist f also lokal um den nichtdegenerierten lokalen Minimalpunkt  konvex.
konvex.
2.1.43 Übung
 mit
mit  und
und  . Zeigen Sie, dass q eine auf
. Zeigen Sie, dass q eine auf  konvexe Funktion ist und dass ihr eindeutiger Minimalpunkt
konvexe Funktion ist und dass ihr eindeutiger Minimalpunkt

Angemerkt sei, dass die Funktion q aus Übung 2.1.43 nach [33] sogar gleichmäßig konvex ist.
2.1.44 Übung

2.2 Numerische Verfahren
In diesem Abschnitt entwickeln wir numerische Verfahren zur Minimierung einer glatten Funktion  , wobei der vage Begriff „glatt“ bedeuten wird, dass die jeweils benötigten Stetigkeits- und Differenzierbarkeitsvoraussetzungen stets erfüllt sind. Alle vorgestellten Verfahren gehen von einem vom Benutzer bereitgestellten Startpunkt x0 aus und erzeugen daraus iterativ eine Folge (xk), deren Häufungspunkte zumindest kritische Punkte von f sind, also Nullstellen des Gradienten ∇f. Wir werden sehen, dass diese Folge unter gewissen Voraussetzungen sogar konvergiert, und dass ihr Grenzpunkt üblicherweise ein lokaler Minimalpunkt von f sein wird. Nicht erwarten kann man, so numerisch einen globalen Minimalpunkt von f zu finden, sofern nicht zusätzliche globale Informationen über f vorliegen. Für Verfahren der globalen Optimierung verweisen wir stattdessen auf [33].
, wobei der vage Begriff „glatt“ bedeuten wird, dass die jeweils benötigten Stetigkeits- und Differenzierbarkeitsvoraussetzungen stets erfüllt sind. Alle vorgestellten Verfahren gehen von einem vom Benutzer bereitgestellten Startpunkt x0 aus und erzeugen daraus iterativ eine Folge (xk), deren Häufungspunkte zumindest kritische Punkte von f sind, also Nullstellen des Gradienten ∇f. Wir werden sehen, dass diese Folge unter gewissen Voraussetzungen sogar konvergiert, und dass ihr Grenzpunkt üblicherweise ein lokaler Minimalpunkt von f sein wird. Nicht erwarten kann man, so numerisch einen globalen Minimalpunkt von f zu finden, sofern nicht zusätzliche globale Informationen über f vorliegen. Für Verfahren der globalen Optimierung verweisen wir stattdessen auf [33].
Abschn. 2.2.1 wird zunächst als sehr allgemeinen Rahmen ein sogenanntes Abstiegsverfahren einführen, ohne es bereits explizit auszugestalten. Trotzdem wird es möglich sein, hinreichende Bedingungen für das Terminieren dieses Verfahrens zu formulieren, die wir später für die explizit angegebenen Verfahren überprüfen können. Die neuen Iterierten werden dabei durch eine Kombination von Suchrichtungsvektoren und Schrittweiten entlang dieser Suchrichtungen generiert, und die genannten hinreichenden Bedingungen sind die sogenannte Gradientenbezogenheit der Suchrichtungsfolge sowie die Effizienz der Schrittweitenfolge. Abschn. 2.2.2 stellt drei Möglichkeiten zur Bestimmung effizienter Schrittweitenfolgen vor, die danach in den konkreten Abstiegsverfahren zum Einsatz kommen können.
In Abschn. 2.2.3 untersuchen wir die naheliegendste Wahl zur Konstruktion gradientenbezogener Suchrichtungsfolgen, was auf das Gradientenverfahren führt. Es erweist sich in der Praxis allerdings als sehr langsam, was wir zunächst durch die Einführung verschiedener Konvergenzgeschwindigkeiten quantifizieren. Mit der geometrischen Einsicht, dass der Hauptgrund für die Langsamkeit des Gradientenverfahrens in der mangelnden Verwertung von Krümmungsinformation der Zielfunktion liegt, modifizieren wir es in Abschn. 2.2.4 zur Klasse der Variable-Metrik-Verfahren.
Ein wichtiger Vertreter dieser Verfahrensklasse ist das in Abschn. 2.2.5 besprochene Newton-Verfahren. Obwohl seine quadratische Konvergenzgeschwindigkeit sehr hoch ist, besitzt es den entscheidenden Nachteil, unter oft nur sehr unrealistischen Voraussetzungen ein Abstiegsverfahren zu sein. Wir modifizieren unseren Ansatz daher weiter und geben in Abschn. 2.2.6 zunächst sehr allgemeine Voraussetzungen an, unter denen Variable-Metrik-Verfahren wenigstens superlinear konvergieren, bevor Abschn. 2.2.7 darauf basierend die Quasi-Newton-Verfahren einführt.
Dass die Quasi-Newton-Verfahren auf Krümmungsinformation aus Approximationen der Hesse-Matrix der Zielfunktion angewiesen sind, kann bei hochdimensionalen Optimierungsproblemen zu Speicherplatzproblemen führen. Daher versuchen wir, das Gradientenverfahren auch durch matrixfreie Verfahren zu verbessern. Überraschenderweise lässt sich durch eine geschickte Kombination von Gradienteninformationen so viel Krümmungsinformation gewinnen, dass tatsächlich solche Verfahren existieren. Dies sind die auf dem in Abschn. 2.2.8 erklärten Konzept der konjugierten Richtungen basierenden und in Abschn. 2.2.9 eingeführten Konjugierte-Gradienten-Verfahren.
Abschn. 2.2.10 widmet sich abschließend den Trust-Region-Verfahren, die im Gegensatz zu den anderen besprochenen Abstiegsverfahren nicht zuerst eine Suchrichtung und dann eine Schrittweite, sondern erst einen Suchradius und dann die Richtung zur neuen Iterierten bestimmen.
2.2.1 Abstiegsverfahren
Neben der Stetigkeit der Zielfunktion f werden wir im gesamten Abschn. 2.2 fordern, dass die untere Niveaumenge  zum Startpunkt
zum Startpunkt  beschränkt ist. Falls diese Voraussetzung verletzt sein sollte, sind die vorgestellten Konvergenzbeweise nicht durchführbar, und die betrachteten Verfahren können dann nur als Heuristiken angesehen werden. Nach Lemma 1.2.26 ist die Voraussetzung aber zum Beispiel für jeden beliebigen Startpunkt x0 erfüllt, wenn f auf
beschränkt ist. Falls diese Voraussetzung verletzt sein sollte, sind die vorgestellten Konvergenzbeweise nicht durchführbar, und die betrachteten Verfahren können dann nur als Heuristiken angesehen werden. Nach Lemma 1.2.26 ist die Voraussetzung aber zum Beispiel für jeden beliebigen Startpunkt x0 erfüllt, wenn f auf  koerziv ist.
koerziv ist.
Als ersten Grund für die Einführung dieser Voraussetzung stellen wir fest, dass für beschränktes  eine stetige Funktion f nach Korollar 1.2.17 einen globalen Minimalpunkt besitzt und dass dann insbesondere die Gleichung ∇f(x) = 0 überhaupt lösbar ist.
eine stetige Funktion f nach Korollar 1.2.17 einen globalen Minimalpunkt besitzt und dass dann insbesondere die Gleichung ∇f(x) = 0 überhaupt lösbar ist.
2.2.1 Bemerkung
Für beschränktes  ist die Funktion f also nach unten beschränkt. In der Literatur wird für Konvergenzbeweise manchmal auch nur diese schwächere Voraussetzung benutzt. Allerdings wird die dadurch später getroffene Voraussetzung der Lipschitz-Stetigkeit des Gradienten ∇f auf
ist die Funktion f also nach unten beschränkt. In der Literatur wird für Konvergenzbeweise manchmal auch nur diese schwächere Voraussetzung benutzt. Allerdings wird die dadurch später getroffene Voraussetzung der Lipschitz-Stetigkeit des Gradienten ∇f auf  in vielen Anwendungen zu einer starken oder sogar unerfüllbaren Voraussetzung (s. dazu Bemerkung 2.2.11).
in vielen Anwendungen zu einer starken oder sogar unerfüllbaren Voraussetzung (s. dazu Bemerkung 2.2.11).

 nicht notwendig invertierbar sein muss (und eventuell schwer auszuwerten) und dass das Newton-Verfahren auch gegen lokale Maximalpunkte und Sattelpunkte konvergieren kann.
nicht notwendig invertierbar sein muss (und eventuell schwer auszuwerten) und dass das Newton-Verfahren auch gegen lokale Maximalpunkte und Sattelpunkte konvergieren kann.
Ein allgemeines Abstiegsverfahren ist in Algorithmus 2.3 formuliert. In seinem Input sowie nachfolgend sprechen wir etwas lax von einem „C1-Optimierungsproblem P“, wenn die definierenden Funktionen von P stetig differenzierbar sind.
Aus theoretischer Sicht würde häufig sogar nur die Differenzierbarkeit genügen. In Anwendungen sind differenzierbare Funktionen aber typischerweise auch stetig differenzierbar, so dass diese Voraussetzung üblich ist und keine entscheidende Einschränkung darstellt.
Algorithmus 2.3: Allgemeines Abstiegsverfahren
Input : C1-Optimierungsproblem P
Output : Approximation  eines kritischen Punkts von f (falls das Verfahren terminiert; Korollar 2.2.10)
eines kritischen Punkts von f (falls das Verfahren terminiert; Korollar 2.2.10)
1 begin
2 Wähle einen Startpunkt x0, eine Toleranz  und setze
und setze  .
.
3 While  do
do
4 Wähle  mit
mit  .
.
5 Ersetze k durch  .
.
6 end
7 Setze  .
.
8 end
Verschiedene Abstiegsverfahren unterscheiden sich durch die Wahl von xk + 1 in Zeile 4 von Algorithmus 2.3. Im Folgenden werden wir zunächst unabhängig von der speziellen Ausgestaltung der Zeile 4 schwache Bedingungen an die Wahl von xk + 1 herleiten, die garantieren, dass Algorithmus 2.3 tatsächlich nach endlich vielen Schritten terminiert.
Für den Fall, in dem diese schwachen Bedingungen verletzt sind, versieht man Algorithmus 2.3 häufig noch mit einer „Notbremse“, nämlich mit dem zusätzlichen Abbruchkriterium  mit einer hohen Iterationszahl
mit einer hohen Iterationszahl  (wie etwa
(wie etwa  ). Vom Output
). Vom Output  kann man dann natürlich nicht erwarten, einen kritischen Punkt von f zu approximieren, aber immerhin erfüllt er die Ungleichung
kann man dann natürlich nicht erwarten, einen kritischen Punkt von f zu approximieren, aber immerhin erfüllt er die Ungleichung  . Zur Übersichtlichkeit werden wir im Folgenden auf die explizite Betrachtung der „Notbremse“ verzichten.
. Zur Übersichtlichkeit werden wir im Folgenden auf die explizite Betrachtung der „Notbremse“ verzichten.
2.2.2 Bemerkung
In der Praxis ist man manchmal schon damit zufrieden, irgendeinen Punkt  mit besserem Zielfunktionswert als x0 zu finden, also mit
mit besserem Zielfunktionswert als x0 zu finden, also mit  . Dafür genügen offenbar endlich viele Schritte jedes Abstiegsverfahrens (wie auch bei Verbesserungsheuristiken [24]), ohne dass das Abbruchkriterium in Zeile 3 erfüllt zu sein braucht. Die Implementierung der oben beschriebenen „Notbremse“ liefert bei jedem Abstiegsverfahren garantiert einen solchen Output
. Dafür genügen offenbar endlich viele Schritte jedes Abstiegsverfahrens (wie auch bei Verbesserungsheuristiken [24]), ohne dass das Abbruchkriterium in Zeile 3 erfüllt zu sein braucht. Die Implementierung der oben beschriebenen „Notbremse“ liefert bei jedem Abstiegsverfahren garantiert einen solchen Output  .
.
In Zeile 3 des allgemeinen Abstiegsverfahrens 2.3 testet man als Abbruchkriterium  mit einer Toleranz ɛ > 0, da man nicht erwarten kann, numerisch einen kritischen Punkt exakt zu bestimmen (eine While-Schleife zur Bedingung
mit einer Toleranz ɛ > 0, da man nicht erwarten kann, numerisch einen kritischen Punkt exakt zu bestimmen (eine While-Schleife zur Bedingung  würde in den meisten Fällen also nie abbrechen). Der generierte Output
würde in den meisten Fällen also nie abbrechen). Der generierte Output  mit
mit  ist dann natürlich nur die Approximation eines kritischen Punkts.
ist dann natürlich nur die Approximation eines kritischen Punkts.
Um zu garantieren, dass Algorithmus 2.3 nach endlich vielen Iterationen terminiert, muss man nachweisen können, dass unabhängig von der Wahl von ɛ ein  mit
mit  existiert. Dies ist sicher dann gewährleistet, wenn die Folge (∇f(xk)) gegen den Nullvektor konvergiert. Es genügt aber beispielsweise auch, dass diese Folge den Nullvektor lediglich als Häufungspunkt besitzt. Da andererseits für vorgegebenes ɛ > 0 im Fall der Terminierung von Algorithmus 2.3 gar keine unendliche Folge erzeugt werden würde, werden wir für die folgenden Konvergenzuntersuchungen künstlich ɛ = 0 setzen und von den erhaltenen Resultaten auf die endliche Terminierung im Fall ɛ > 0 schließen.
existiert. Dies ist sicher dann gewährleistet, wenn die Folge (∇f(xk)) gegen den Nullvektor konvergiert. Es genügt aber beispielsweise auch, dass diese Folge den Nullvektor lediglich als Häufungspunkt besitzt. Da andererseits für vorgegebenes ɛ > 0 im Fall der Terminierung von Algorithmus 2.3 gar keine unendliche Folge erzeugt werden würde, werden wir für die folgenden Konvergenzuntersuchungen künstlich ɛ = 0 setzen und von den erhaltenen Resultaten auf die endliche Terminierung im Fall ɛ > 0 schließen.
Zunächst untersuchen wir, ob die Iterierten xk selbst sowie ihre Funktionswerte konvergieren.
2.2.3 Lemma
Für beschränktes  bricht die von Algorithmus 2.3 mit ɛ = 0 erzeugte Folge (xk) entweder nach endlich vielen Schritten mit einem kritischen Punkt ab, oder sie besitzt mindestens einen Häufungspunkt in
bricht die von Algorithmus 2.3 mit ɛ = 0 erzeugte Folge (xk) entweder nach endlich vielen Schritten mit einem kritischen Punkt ab, oder sie besitzt mindestens einen Häufungspunkt in  , und die Folge der Funktionswerte (f(xk)) ist konvergent.
, und die Folge der Funktionswerte (f(xk)) ist konvergent.
Beweis.
Aufgrund der Abstiegseigenschaft in Zeile 4 liegen alle Iterierten xk in der Menge  . Diese ist als beschränkt vorausgesetzt und nach Übung 1.2.10 außerdem abgeschlossen, insgesamt also kompakt. Nach dem Satz von Bolzano-Weierstraß
(z. B. [18]) besitzt die Folge (xk) also mindestens einen Häufungspunkt in
. Diese ist als beschränkt vorausgesetzt und nach Übung 1.2.10 außerdem abgeschlossen, insgesamt also kompakt. Nach dem Satz von Bolzano-Weierstraß
(z. B. [18]) besitzt die Folge (xk) also mindestens einen Häufungspunkt in  . Außerdem ist die Folge (f(xk)) monoton fallend und durch den globalen Minimalwert von f nach unten beschränkt, also konvergent.
. Außerdem ist die Folge (f(xk)) monoton fallend und durch den globalen Minimalwert von f nach unten beschränkt, also konvergent.
Die folgende Übung zeigt, dass aus Lemma 2.2.3 noch nicht folgt, dass ein Häufungspunkt der Iterierten xk existiert, der auch kritischer Punkt von f ist.
2.2.4 Übung
Betrachten Sie die Funktion f(x) = x2, den Startpunkt x0 = 3 sowie die Iterierten  ,
,  . Zeigen Sie, dass die Iterierten die Abstiegsbedingung aus Zeile 4 von Algorithmus 2.3 erfüllen, dass sie zwei Häufungspunkte besitzen, dass aber keiner davon kritischer Punkt von f ist.
. Zeigen Sie, dass die Iterierten die Abstiegsbedingung aus Zeile 4 von Algorithmus 2.3 erfüllen, dass sie zwei Häufungspunkte besitzen, dass aber keiner davon kritischer Punkt von f ist.

 ansetzen darf, denn durch passende Wahlen von tk und dk lässt sich jede neue Iterierte xk + 1 in dieser Form realisieren. Eine einfache Möglichkeit dafür wäre es,
ansetzen darf, denn durch passende Wahlen von tk und dk lässt sich jede neue Iterierte xk + 1 in dieser Form realisieren. Eine einfache Möglichkeit dafür wäre es,  und tk = 1 zu setzen; nachfolgend werden wir dk und tk aber geschickter wählen.
und tk = 1 zu setzen; nachfolgend werden wir dk und tk aber geschickter wählen.Die Wahl der neuen Iterierten xk + 1 wird durch den Ansatz (2.2) in zwei separate Operationen aufgeteilt, nämlich die Bestimmung einer Suchrichtung dk und die einer Schrittweite tk. Die klassischen Optimierungsverfahren, auf die wir uns zunächst konzentrieren werden, bestimmen erst eine Suchrichtung dk und dann eine Schrittweite tk. Man spricht daher auch von Suchrichtungsverfahren mit Schrittweitensteuerung. Die Grundidee der moderneren Trust-Region-Verfahren, die wir in Abschn. 2.2.10 besprechen werden, besteht darin, erst einen Suchradius tk und dann eine Abstiegsrichtung dk zu berechnen.
Wir beginnen mit Suchrichtungsverfahren. Im Folgenden sei dk eine Abstiegsrichtung erster Ordnung für f in xk, es gelte also  . Wir suchen nach schwachen Bedingungen an die Wahl von tk und dk, die
. Wir suchen nach schwachen Bedingungen an die Wahl von tk und dk, die  garantieren, also
garantieren, also  für jeden Häufungspunkt
für jeden Häufungspunkt  der Folge (xk).
der Folge (xk).
 gegen null. Nach dem Satz von Taylor (Satz 2.1.30) stimmt der tatsächliche Abstieg
gegen null. Nach dem Satz von Taylor (Satz 2.1.30) stimmt der tatsächliche Abstieg  ungefähr mit dem „Abstieg erster Ordnung“
ungefähr mit dem „Abstieg erster Ordnung“  überein, woraus wir durch geeignete Voraussetzungen die Konvergenz der ∇f(xk) gegen null schließen können. Zunächst fordern wir, dass der tatsächliche Abstieg eine Unterschranke an den Abstieg erster Ordnung liefert, dass die Werte von f also hinreichend schnell fallen:
überein, woraus wir durch geeignete Voraussetzungen die Konvergenz der ∇f(xk) gegen null schließen können. Zunächst fordern wir, dass der tatsächliche Abstieg eine Unterschranke an den Abstieg erster Ordnung liefert, dass die Werte von f also hinreichend schnell fallen:
 und
und  liefert das Sandwich-Theorem
liefert das Sandwich-Theorem
 gilt, müssen wir Bedingungen an die Folgen (tk) und (dk) aufstellen, die ausschließen, dass der Grenzwert in (2.4) aus anderen Gründen null wird.
gilt, müssen wir Bedingungen an die Folgen (tk) und (dk) aufstellen, die ausschließen, dass der Grenzwert in (2.4) aus anderen Gründen null wird. schließen zu können, darf jedenfalls (tk) nicht zu schnell gegen null konvergieren, muss also genügend groß bleiben. Wir fordern daher
schließen zu können, darf jedenfalls (tk) nicht zu schnell gegen null konvergieren, muss also genügend groß bleiben. Wir fordern daher
 für einen Moment zurückstellen. Wegen
für einen Moment zurückstellen. Wegen

2.2.5 Definition (Effiziente Schrittweiten)

Das folgende Ergebnis beweist man wie oben mit dem Sandwich-Theorem.
2.2.6 Satz
Die Menge  sei beschränkt, (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung, und (tk) sei eine effiziente Schrittweitenfolge. Dann gilt (2.6).
sei beschränkt, (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung, und (tk) sei eine effiziente Schrittweitenfolge. Dann gilt (2.6).
Nun benötigen wir noch eine Bedingung an die Folge (dk), die  garantiert. Dazu stellen wir fest, dass (2.6) zwar unter der gewünschten Bedingung
garantiert. Dazu stellen wir fest, dass (2.6) zwar unter der gewünschten Bedingung  gilt (weil alle Vektoren
gilt (weil alle Vektoren  die Länge eins besitzen und damit eine beschränkte Folge bilden), dass (2.6) aber auch dadurch erfüllt sein kann, dass nicht die Längen der Vektoren ∇f(xk) gegen null gehen, sondern ihre Richtungen im Grenzüber- gang senkrecht zu einem Grenzpunkt der Folge
die Länge eins besitzen und damit eine beschränkte Folge bilden), dass (2.6) aber auch dadurch erfüllt sein kann, dass nicht die Längen der Vektoren ∇f(xk) gegen null gehen, sondern ihre Richtungen im Grenzüber- gang senkrecht zu einem Grenzpunkt der Folge  stehen. In diesem Sinne müssen wir also ausschließen, dass die Vektoren ∇f(xk) und
stehen. In diesem Sinne müssen wir also ausschließen, dass die Vektoren ∇f(xk) und  „asymptotisch senkrecht“ aufeinander stehen. Ohne die Division von dk durch
„asymptotisch senkrecht“ aufeinander stehen. Ohne die Division von dk durch  würde man dann insbesondere den Fall dk→0 ausschließen, was aber bereits für die Wahl
würde man dann insbesondere den Fall dk→0 ausschließen, was aber bereits für die Wahl  wegen des gewünschten Verhaltens der Folge (∇f(xk)) sinnlos wäre.
wegen des gewünschten Verhaltens der Folge (∇f(xk)) sinnlos wäre.
 dürfen also nicht gegen einen rechten Winkel konvergieren. Äquivalent können wir fordern, dass die negativen Werte
dürfen also nicht gegen einen rechten Winkel konvergieren. Äquivalent können wir fordern, dass die negativen Werte  nicht gegen null konvergieren. Dazu setzen wir die Existenz einer Konstante c > 0 voraus, so dass alle
nicht gegen null konvergieren. Dazu setzen wir die Existenz einer Konstante c > 0 voraus, so dass alle  die Ungleichung
die Ungleichung

 durchmultipliziert haben, um den Fall
durchmultipliziert haben, um den Fall  abzufangen. Dies rechtfertigt die folgende Definition.
abzufangen. Dies rechtfertigt die folgende Definition.2.2.7 Definition (Gradientenbezogene Suchrichtungen)

2.2.8 Übung
Zeigen Sie, dass die Folge der Suchrichtungen  ,
,  , gradientenbezogen ist.
, gradientenbezogen ist.
Wir können nun das folgende zentrale Ergebnis zum allgemeinen Abstiegsverfahren zeigen.
2.2.9 Satz
Die Menge  sei beschränkt, und in Zeile 4 von Algorithmus 2.3 sei
sei beschränkt, und in Zeile 4 von Algorithmus 2.3 sei  mit einer gradientenbezogenen Suchrichtungsfolge (dk) und einer effizienten Schrittweitenfolge (tk) gewählt. Für ɛ = 0 stoppt dann das Verfahren entweder nach endlich vielen Schritten mit einem kritischen Punkt, oder die Folge (xk) besitzt einen Häufungspunkt, und für jeden solchen Punkt
mit einer gradientenbezogenen Suchrichtungsfolge (dk) und einer effizienten Schrittweitenfolge (tk) gewählt. Für ɛ = 0 stoppt dann das Verfahren entweder nach endlich vielen Schritten mit einem kritischen Punkt, oder die Folge (xk) besitzt einen Häufungspunkt, und für jeden solchen Punkt  gilt
gilt  .
.
Beweis.
Aus Lemma 2.2.3 wissen wir, dass das Verfahren entweder nach endlich vielen Schritten mit einem kritischen Punkt abbricht oder die Folge (xk) einen Häufungspunkt in  besitzt. Es bezeichne
besitzt. Es bezeichne  einen beliebigen solchen Häufungspunkt. Satz 2.2.6, die Definition der Gradientenbezogenheit sowie das Sandwich-Theorem liefern nun die Behauptung.
einen beliebigen solchen Häufungspunkt. Satz 2.2.6, die Definition der Gradientenbezogenheit sowie das Sandwich-Theorem liefern nun die Behauptung.
Dass Algorithmus 2.3 nach endlichen vielen Schritten mit einer exakten Lösung abbricht, ist natürlich kaum zu erwarten, wird in Satz 2.2.9 aber als Alternative angeführt, damit man andernfalls über Häufungspunkte einer „echten“ Folge sprechen kann.
Für den Fall, dass in  nur ein einziger kritischer Punkt
nur ein einziger kritischer Punkt  liegt, muss dieser der globale Minimalpunkt von f sein, und jeder Häufungspunkt der Folge (xk) aus Satz 2.2.9 stimmt mit
liegt, muss dieser der globale Minimalpunkt von f sein, und jeder Häufungspunkt der Folge (xk) aus Satz 2.2.9 stimmt mit  überein. Dies bedeutet, dass dann sogar
überein. Dies bedeutet, dass dann sogar  gilt.
gilt.
2.2.10 Korollar
Die Menge  sei beschränkt, und in Zeile 4 von Algorithmus 2.3 sei
sei beschränkt, und in Zeile 4 von Algorithmus 2.3 sei  mit einer gradientenbezogenen Suchrichtungsfolge (dk) und einer effizienten Schrittweitenfolge (tk) gewählt. Dann terminiert das Verfahren für jedes ɛ > 0 nach endlich vielen Schritten.
mit einer gradientenbezogenen Suchrichtungsfolge (dk) und einer effizienten Schrittweitenfolge (tk) gewählt. Dann terminiert das Verfahren für jedes ɛ > 0 nach endlich vielen Schritten.
2.2.2 Schrittweitensteuerung
Während die Existenz einer gradientenbezogenen Suchrichtungsfolge nach Übung 2.2.8 klar ist, müssen wir uns noch mit der Konstruktion effizienter Schrittweiten befassen. Ob solche existieren, ist zunächst nicht klar, da die Bedingungen (2.3) und (2.5) grob gesagt gleichzeitig Ober- und Unterschranken an tk fordern und damit vielleicht nicht simultan erfüllbar sind. Im Folgenden sei der Index  der besseren Übersichtlichkeit halber fest und unterschlagen, d. h., wir setzen x = xk, t = tk und d = dk.
der besseren Übersichtlichkeit halber fest und unterschlagen, d. h., wir setzen x = xk, t = tk und d = dk.
In der Tat werden wir die Effizienz von drei beliebten Schrittweitenstrategien nachweisen, nämlich der Wahl exakter Schrittweiten te, gewisser konstanter Schrittweiten tc sowie der Armijo-Schrittweiten ta. Allgemein bezeichnet man die Wahl geeigneter Schrittweiten auch als Schrittweitensteuerung (line search).
 benötigen. Dazu sei daran erinnert, dass eine Funktion
benötigen. Dazu sei daran erinnert, dass eine Funktion  Lipschitz-stetig auf
Lipschitz-stetig auf  (bezüglich der euklidischen Norm) heißt, falls
(bezüglich der euklidischen Norm) heißt, falls
 zum Beispiel für jede C2-Funktion f Lipschitz-stetig auf
zum Beispiel für jede C2-Funktion f Lipschitz-stetig auf  . Dieses Wissen schließt leider nicht automatisch die Kenntnis der Größe der Konstante L ein, was uns später bei der Wahl konstanter Schrittweiten tc ein Problem bereiten wird.
. Dieses Wissen schließt leider nicht automatisch die Kenntnis der Größe der Konstante L ein, was uns später bei der Wahl konstanter Schrittweiten tc ein Problem bereiten wird.2.2.11 Bemerkung
Für beschränkte (und daher kompakte) Mengen  ist die Voraussetzung der Lipschitz-Stetigkeit von ∇f auf
ist die Voraussetzung der Lipschitz-Stetigkeit von ∇f auf  also eine schwache Voraussetzung. Dies wäre nicht der Fall, wenn wir anstelle der Beschränktheit von
also eine schwache Voraussetzung. Dies wäre nicht der Fall, wenn wir anstelle der Beschränktheit von  z. B. nur gefordert hätten, dass f auf
z. B. nur gefordert hätten, dass f auf  nach unten beschränkt ist (vgl. dazu Bemerkung 2.2.1).
nach unten beschränkt ist (vgl. dazu Bemerkung 2.2.1).
Beweistechnisch werden wir im folgenden Lemma die Lipschitz-Stetigkeit von ∇f auf einer konvexen Menge ausnutzen müssen, was bei der Menge  aber nicht notwendigerweise gegeben ist. Daher werden wir sie sogar auf der konvexen Hülle
aber nicht notwendigerweise gegeben ist. Daher werden wir sie sogar auf der konvexen Hülle
 von
von  fordern, also auf der kleinsten konvexen Obermenge von
fordern, also auf der kleinsten konvexen Obermenge von  .
.
2.2.12 Bemerkung
Bei beschränktem (und daher kompaktem)  ist die Menge
ist die Menge  ebenfalls kompakt, so dass die Forderung der Lipschitz-Stetigkeit von ∇f auch auf
ebenfalls kompakt, so dass die Forderung der Lipschitz-Stetigkeit von ∇f auch auf  eine schwache Voraussetzung ist.
eine schwache Voraussetzung ist.
Das folgende Ergebnis besagt, dass man bei Lipschitz-stetigem Gradienten den Fehlerterm  aus der multivariaten Taylor-Entwicklung erster Ordnung (Satz 2.1.30a) betraglich durch einen quadratischen Term nach oben abschätzen kann.
aus der multivariaten Taylor-Entwicklung erster Ordnung (Satz 2.1.30a) betraglich durch einen quadratischen Term nach oben abschätzen kann.
2.2.13 Lemma
 sei f differenzierbar mit Lipschitz-stetigem Gradienten ∇f und zugehöriger Lipschitz-Konstante L > 0. Dann gilt
sei f differenzierbar mit Lipschitz-stetigem Gradienten ∇f und zugehöriger Lipschitz-Konstante L > 0. Dann gilt
Beweis.
 und x aus D folgt wegen der Konvexität von D für alle t ∈ [0, 1]
und x aus D folgt wegen der Konvexität von D für alle t ∈ [0, 1]
 mit t ∈ [0, 1] ausnutzen können. Wir fassen den Punkt x als den für t = 1 auftretenden Endpunkt der Strecke
mit t ∈ [0, 1] ausnutzen können. Wir fassen den Punkt x als den für t = 1 auftretenden Endpunkt der Strecke![$$
[\bar x,x]\ =\ \{\bar x + t(x-\bar x)|\ t\in[0,1]\}
$$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_Equcb.png)




Exakte Schrittweiten
 sei eine Abstiegsrichtung erster Ordnung d für f in x gegeben. Wegen
sei eine Abstiegsrichtung erster Ordnung d für f in x gegeben. Wegen  gilt
gilt  für kleine positive t. Für beschränktes
für kleine positive t. Für beschränktes  besitzt φd nach dem Satz von Weierstraß
sogar globale Minimalpunkte te > 0, die exakte Schrittweiten
genannt werden. Per Definition der eindimensionalen Einschränkung φd erfüllen sie
besitzt φd nach dem Satz von Weierstraß
sogar globale Minimalpunkte te > 0, die exakte Schrittweiten
genannt werden. Per Definition der eindimensionalen Einschränkung φd erfüllen sie

Eine exakte Schrittweite zu berechnen, um den größtmöglichen Abstieg von x aus entlang d zu erzielen, ist im Allgemeinen sehr aufwendig, so dass wir dieses Konzept meist nur für theoretische Zwecke benutzen werden und später stattdessen zu inexakten Schrittweiten übergehen werden. Bei spezieller Struktur von f lassen sich aber exakte Schrittweiten manchmal leicht berechnen, wie zum Beispiel die folgende Übung zeigt.
2.2.14 Übung
 mit
mit  und
und  , die nach Übung 1.2.24 koerziv und nach Übung 2.1.43 konvex ist. Zeigen Sie, dass für jedes
, die nach Übung 1.2.24 koerziv und nach Übung 2.1.43 konvex ist. Zeigen Sie, dass für jedes  und jede Abstiegsrichtung erster Ordnung d für q in x die exakte Schrittweite eindeutig zu
und jede Abstiegsrichtung erster Ordnung d für q in x die exakte Schrittweite eindeutig zu
2.2.15 Satz
Die Menge  sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf
sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf  , und (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung. Dann ist jede Folge von exakten Schrittweiten
, und (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung. Dann ist jede Folge von exakten Schrittweiten  effizient.
effizient.
Beweis.
 sei wieder fest und unterschlagen. Da man von x0 aus nur Abstiege ausgeführt hat, liegen sowohl x als auch x + ted in der Menge
sei wieder fest und unterschlagen. Da man von x0 aus nur Abstiege ausgeführt hat, liegen sowohl x als auch x + ted in der Menge  . Es sei L > 0 eine nach Voraussetzung existierende Lipschitz-Konstante von ∇f auf
. Es sei L > 0 eine nach Voraussetzung existierende Lipschitz-Konstante von ∇f auf  . Aus der Cauchy-Schwarz-Ungleichung folgt dann zunächst
. Aus der Cauchy-Schwarz-Ungleichung folgt dann zunächst
 , also
, also
 liegt der Punkt x + td für alle t ∈ (0, te) in
liegt der Punkt x + td für alle t ∈ (0, te) in  . Lemma 2.2.13 liefert daher für diese t
. Lemma 2.2.13 liefert daher für diese t


 unabhängigen Konstante c = (2L)−1 die Behauptung folgt.
unabhängigen Konstante c = (2L)−1 die Behauptung folgt.Damit ist neben der Existenz gradientenbezogener Suchrichtungen auch die Existenz effizienter Schrittweiten gezeigt, weshalb insbesondere Satz 2.2.9 nicht trivialerweise gilt (weil er nicht „von der leeren Menge handelt“).
Konstante Schrittweiten
Falls die Funktion f keine besondere Struktur aufweist (wie etwa in Übung 2.2.14), lohnt sich üblicherweise der Aufwand nicht, in jedem Iterationsschritt eine exakte Schrittweite  zu berechnen. Da man weniger an Minimalpunkten der Hilfsfunktionen
zu berechnen. Da man weniger an Minimalpunkten der Hilfsfunktionen  interessiert ist als an denen von f, benutzt man dann lieber inexakte
Schrittweiten, die ebenfalls effizient, aber erheblich leichter zu berechnen sind.
interessiert ist als an denen von f, benutzt man dann lieber inexakte
Schrittweiten, die ebenfalls effizient, aber erheblich leichter zu berechnen sind.
 die im Beweis von Satz 2.2.15 aufgetretenen und leicht berechenbaren Hilfsgrößen
die im Beweis von Satz 2.2.15 aufgetretenen und leicht berechenbaren Hilfsgrößen
 gezeigt. Im speziellen Fall
gezeigt. Im speziellen Fall  gilt sogar
gilt sogar
Leider lässt sich diese Wahl algorithmisch nur umsetzen, wenn eine Lipschitz-Konstante L > 0 von ∇f auf  explizit bekannt ist. Mit gewissem Aufwand und unter Einsatz der Intervallarithmetik [33] lassen sich Lipschitz-Konstanten in der Tat häufig ermitteln. Während allerdings nur kleinstmögliche Lipschitz-Konstanten das Verhalten von ∇f gut beschreiben, muss man sich dann oft mit groben Überschätzungen von L zufrieden geben. Die entsprechenden Schrittweiten
explizit bekannt ist. Mit gewissem Aufwand und unter Einsatz der Intervallarithmetik [33] lassen sich Lipschitz-Konstanten in der Tat häufig ermitteln. Während allerdings nur kleinstmögliche Lipschitz-Konstanten das Verhalten von ∇f gut beschreiben, muss man sich dann oft mit groben Überschätzungen von L zufrieden geben. Die entsprechenden Schrittweiten  können dadurch sehr klein werden, so dass die Iteration langsamer als nötig voranschreitet.
können dadurch sehr klein werden, so dass die Iteration langsamer als nötig voranschreitet.
Es sei betont, dass eine explizite Kenntnis von L im Effizienzbeweis für die exakten Schrittweiten in Satz 2.2.15 nicht erforderlich war.
Armijo-Schrittweiten
 seien d eine Abstiegsrichtung erster Ordnung und σ ∈ (0, 1). Dann existiert ein
seien d eine Abstiegsrichtung erster Ordnung und σ ∈ (0, 1). Dann existiert ein  , so dass für alle
, so dass für alle  die Werte φd(t) unter der „nach oben gedrehten Tangente“
die Werte φd(t) unter der „nach oben gedrehten Tangente“  liegen, so dass also
liegen, so dass also
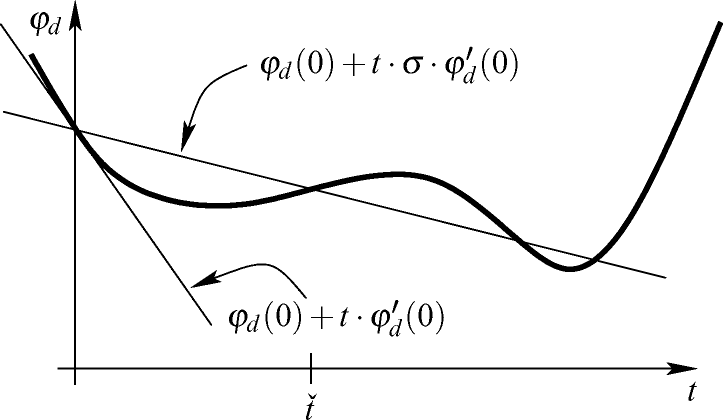
Armijo-Regel
Offensichtlich erfüllt jedes solche t die Bedingung (2.3) mit c1 = σ. Wie kann man unter diesen Schrittweiten aber ein ta > 0 so wählen, dass außerdem (2.5) erfüllt ist? Dies realisiert die in Algorithmus 2.4 angegebene Armijo-Regel mit einer Backtracking Line Search genannten Idee.
Algorithmus 2.4: Armijo-Regel
Input : C1-Funktion f und  mit
mit 
Output : Armijo-Schrittweite ta
1 begin
2 Wähle  sowie
sowie  (alle unabhängig von x und d).
(alle unabhängig von x und d).
3 Wähle eine Startschrittweite  und setze
und setze  .
.
4 While  do
do
5 Setze  .
.
6 Ersetze ℓ durch  .
.
7 end
8 Setze  .
.
9 end
2.2.16 Satz
Die Menge  sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf
sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf  , und (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung. Dann ist die Folge der Armijo-Schrittweiten
, und (dk) sei eine Folge von Abstiegsrichtungen erster Ordnung. Dann ist die Folge der Armijo-Schrittweiten  aus Algorithmus 2.4 (mit unabhängig von k gewählten Parametern σ, ρ und γ) wohldefiniert und effizient.
aus Algorithmus 2.4 (mit unabhängig von k gewählten Parametern σ, ρ und γ) wohldefiniert und effizient.
Beweis.
Der Index  sei wieder fest und unterschlagen. Wegen ρ ∈ (0, 1) gilt in Algorithmus 2.4
sei wieder fest und unterschlagen. Wegen ρ ∈ (0, 1) gilt in Algorithmus 2.4  , also existiert ein
, also existiert ein  mit
mit  (Abb. 2.5). Die Abbruchbedingung in Zeile 4 von Algorithmus 2.4 ist folglich nach endlich vielen Schritten erfüllt, und die Folge der Armijo-Schrittweiten ist damit wohldefiniert.
(Abb. 2.5). Die Abbruchbedingung in Zeile 4 von Algorithmus 2.4 ist folglich nach endlich vielen Schritten erfüllt, und die Folge der Armijo-Schrittweiten ist damit wohldefiniert.
 abbricht, so gilt (2.5) mit c2 = γ. Im Folgenden sei also
abbricht, so gilt (2.5) mit c2 = γ. Im Folgenden sei also  mit
mit  . Da
. Da  das Abbruchkriterium noch nicht erfüllt hatte, gilt
das Abbruchkriterium noch nicht erfüllt hatte, gilt
 einzusetzen, unterscheiden wir nun zwei Fälle, wobei
einzusetzen, unterscheiden wir nun zwei Fälle, wobei ![$[x,x + t^{\ell-1}d]$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq626.png) die Strecke
die Strecke ![$\{\,x + td|\,t\in[0,t^{\ell-1}]\,\}$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq627.png) bezeichne.
bezeichne.Fall 1: ![$\ [x,x + t^{\ell-1}d]\,\subseteq\,\textrm{conv}(f_\le^{f(x^0)})$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq628.png)

 folgt daraus
folgt daraus


Fall 2: ![$\ [x,x + t^{\ell-1}d]\,\not\subseteq\,\textrm{conv}(f_\le^{f(x^0)})$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq630.png)
![$[x,x + t^{\ell-1}d]$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq631.png) garantiert. Mit einer exakten Schrittweite te liegen allerdings sowohl x als auch x + ted in
garantiert. Mit einer exakten Schrittweite te liegen allerdings sowohl x als auch x + ted in  und demnach die Strecke [x, x + ted] in
und demnach die Strecke [x, x + ted] in  . Die Voraussetzung des zweiten Falls impliziert daher
. Die Voraussetzung des zweiten Falls impliziert daher  . Mit der Schrittweite
. Mit der Schrittweite  aus dem Beweis zu Satz 2.2.15 folgt
aus dem Beweis zu Satz 2.2.15 folgt

Angemerkt sei, dass die konkrete Größe der Lipschitz-Konstante L auch für diesen Effizienzbeweis irrelevant war.
In der Praxis haben sich Werte σ ∈ [0.01, 0.2] und ρ = 0.5 bewährt. Statt t0 in Algorithmus 2.4 per γ zu bestimmen, wird häufig t0 : = 1 gesetzt. Die folgende Übung zeigt, dass Algorithmus 2.4 dann aber nicht notwendigerweise terminiert.
2.2.17 Übung
Zeigen Sie für die Funktion  , den Startpunkt x0 = −3, die Richtungen
, den Startpunkt x0 = −3, die Richtungen  sowie
sowie  , dass der durch die Wahl t0 : = 1 modifizierte Algorithmus 2.4 nicht zu einer effizienten Schrittweitenfolge führt.
, dass der durch die Wahl t0 : = 1 modifizierte Algorithmus 2.4 nicht zu einer effizienten Schrittweitenfolge führt.
Man sollte t0 also so initialisieren, wie in Algorithmus 2.4 angegeben, wobei sich die Wahl γ = 10−4 bewährt hat. Es ist außerdem nicht schwer zu sehen, dass sich die Armijo-Regel auch für nur einseitig richtungsdifferenzierbare Funktionen einsetzen lässt, indem man das Skalarprodukt  durch
durch  ersetzt. Davon werden wir in Abschn. 3.3.6 Gebrauch machen.
ersetzt. Davon werden wir in Abschn. 3.3.6 Gebrauch machen.
2.2.3 Gradientenverfahren
Nach dieser Vorarbeit können wir mit Algorithmus 2.5 ein implementierbares numerisches Minimierungsverfahren angeben, nämlich das Gradientenverfahren . Es ist auch unter der Bezeichnung Cauchy-Verfahren bekannt, und ferner aufgrund seiner geometrischen Grundidee (Abschn. 2.1.3) als Verfahren des steilsten Abstiegs .
Algorithmus 2.5: Gradientenverfahren
Input : C1-Optimierungsproblem P
Output : Approximation  eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.18)
eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.18)
1 begin
2 Wähle einen Startpunkt x0, eine Toleranz  und setze
und setze  .
.
3 While  do
do
4 Setze  .
.
5 Bestimme eine Schrittweite tk.
6 Setze  .
.
7 Ersetze k durch 
6 end
9 Setze  .
.
10 end
2.2.18 Satz
Die Menge  sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf
sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf  , und in Zeile 5 seien exakte Schrittweiten
, und in Zeile 5 seien exakte Schrittweiten  oder Armijo-Schrittweiten
oder Armijo-Schrittweiten  gewählt. Dann terminiert Algorithmus 2.5 für jedes ɛ > 0 nach endlich vielen Schritten. Falls eine Lipschitz-Konstante L > 0 zur Lipschitz-Stetigkeit von ∇f auf
gewählt. Dann terminiert Algorithmus 2.5 für jedes ɛ > 0 nach endlich vielen Schritten. Falls eine Lipschitz-Konstante L > 0 zur Lipschitz-Stetigkeit von ∇f auf  bekannt ist, dann gilt dieses Ergebnis auch für die dann berechenbaren konstanten Schrittweiten
bekannt ist, dann gilt dieses Ergebnis auch für die dann berechenbaren konstanten Schrittweiten  ,
,  .
.


2.2.19 Übung
Gegeben sei die quadratische Funktion  mit
mit  und
und  . Zeigen Sie, dass der Gradient ∇q auf ganz
. Zeigen Sie, dass der Gradient ∇q auf ganz  Lipschitz-stetig mit
Lipschitz-stetig mit  ist.
ist.
2.2.20 Beispiel
Für die Funktion  mit
mit  und
und  erzeugt das Gradientenverfahren eine sogar gegen den globalen Minimalpunkt von q konvergente Folge von Iterierten (xk), wenn entweder exakte, konstante oder Armijo-Schrittweiten gewählt werden.
erzeugt das Gradientenverfahren eine sogar gegen den globalen Minimalpunkt von q konvergente Folge von Iterierten (xk), wenn entweder exakte, konstante oder Armijo-Schrittweiten gewählt werden.
In der Tat ist q nach Übung 1.2.24 koerziv, weshalb zu jedem  die untere Niveaumenge
die untere Niveaumenge  beschränkt ist. Ferner ist ∇q nach Übung 2.2.19 sogar auf ganz
beschränkt ist. Ferner ist ∇q nach Übung 2.2.19 sogar auf ganz  Lipschitz-stetig mit
Lipschitz-stetig mit  . Die erwähnten Schrittweitenwahlen sind demnach effizient, so dass nach Satz 2.2.9 jeder Häufungspunkt der vom Gradientenverfahren für q erzeugten Iterierten xk ein kritischer Punkt von q ist. Übung 2.1.43 zeigt außerdem, dass der einzige kritische Punkt
. Die erwähnten Schrittweitenwahlen sind demnach effizient, so dass nach Satz 2.2.9 jeder Häufungspunkt der vom Gradientenverfahren für q erzeugten Iterierten xk ein kritischer Punkt von q ist. Übung 2.1.43 zeigt außerdem, dass der einzige kritische Punkt  von q mit dem eindeutigen globalen Minimalpunkt übereinstimmt. Damit konvergiert die Folge der Iterierten (xk), und ihr Grenzpunkt ist globaler Minimalpunkt von q.
von q mit dem eindeutigen globalen Minimalpunkt übereinstimmt. Damit konvergiert die Folge der Iterierten (xk), und ihr Grenzpunkt ist globaler Minimalpunkt von q.


Wegen der expliziten Kenntnis der Lipschitz-Konstante  ist schließlich auch die Wahl der konstanten Schrittweite
ist schließlich auch die Wahl der konstanten Schrittweite  möglich. Mit der Berechnung der Spektralnorm
möglich. Mit der Berechnung der Spektralnorm  einer symmetrischen und positiv definiten Matrix A als größtem Eigenwert
einer symmetrischen und positiv definiten Matrix A als größtem Eigenwert  von A werden wir uns in Bemerkung 2.2.38 befassen.
von A werden wir uns in Bemerkung 2.2.38 befassen.
Aufgrund der Konvergenzresultate sowie wegen seiner einfachen Implementierbarkeit wird das Gradientenverfahren in der Praxis gerne benutzt. Allerdings hat die Strategie, in jedem Schritt lokal den steilsten Abstieg zu wählen (eine Greedy-Strategie), den Nachteil, dass das Verfahren häufig sehr langsam konvergiert. Man kann daher oft nur grobe Toleranzen ɛ > 0 vorgeben, wenn das Verfahren nach einer vertretbaren Zeit terminieren soll.
 in deren gemeinsamem Zentrum besitzen, dann zeigt −∇f(xk) typischerweise nicht in die Richtung von
in deren gemeinsamem Zentrum besitzen, dann zeigt −∇f(xk) typischerweise nicht in die Richtung von  . Die Iterierten springen dadurch entlang einer Zickzacklinie, weshalb man in Anlehnung an die englischsprachige Literatur auch vom Zigzagging-Effekt
spricht.
. Die Iterierten springen dadurch entlang einer Zickzacklinie, weshalb man in Anlehnung an die englischsprachige Literatur auch vom Zigzagging-Effekt
spricht.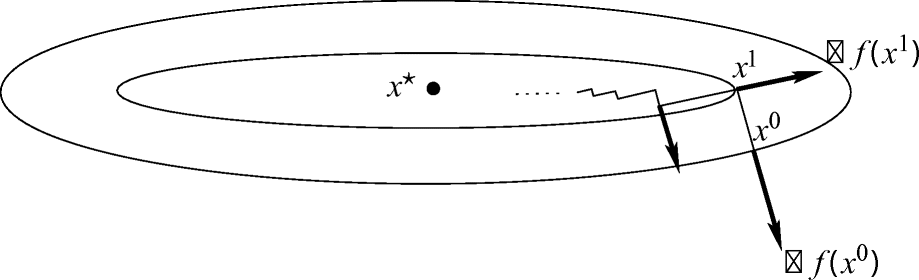
Zigzagging-Effekt
Um bessere Verfahren zu konstruieren, benötigen wir zunächst eine Klassifikation von Konvergenzgeschwindigkeiten.
2.2.21 Definition (Konvergenzgeschwindigkeiten)
Es sei (xk) eine konvergente Folge mit Grenzpunkt  . Sie heißt
. Sie heißt
- a)linear konvergent , falls

- b)superlinear konvergent , falls

- c)quadratisch konvergent , falls

Es ist nicht schwer zu sehen, dass quadratische Konvergenz superlineare Konvergenz impliziert und dass Letztere lineare Konvergenz nach sich zieht. Während superlineare Konvergenz „schnell“ und quadratische Konvergenz „sehr schnell“ sind, kann lineare Konvergenz bei einer Konstante c ≈ 1 sehr langsam sein.
Wir weisen darauf hin, dass die Punkte xk in Definition 2.2.21 nicht notwendigerweise Iterierte eines Abstiegsverfahrens zu sein brauchen. Insbesondere kann man für ein Abstiegsverfahren auch die Konvergenzgeschwindigkeit der Funktionswerte f(xk) gegen einen Grenzwert  messen.
messen.
In der Tat zeigt der folgende Satz, dass das Gradientenverfahren schon für sehr angenehme Funktionen nur linear konvergente Funktionswerte der Iterierten besitzt, und zwar mit einer Konstante c, die sehr nahe bei eins liegen kann.
Konkret betrachten wir die konvex-quadratische Funktion  mit
mit  sowie
sowie  und bezeichnen den größten und den kleinsten Eigenwert der Matrix A mit
und bezeichnen den größten und den kleinsten Eigenwert der Matrix A mit  bzw.
bzw.  . Nach Beispiel 2.2.20 konvergieren die Iterierten des Gradientenverfahrens mit exakten Schrittweiten gegen den globalen Minimalpunkt
. Nach Beispiel 2.2.20 konvergieren die Iterierten des Gradientenverfahrens mit exakten Schrittweiten gegen den globalen Minimalpunkt  von q, und die Stetigkeit von q impliziert die Konvergenz der Funktionswerte q(xk) gegen
von q, und die Stetigkeit von q impliziert die Konvergenz der Funktionswerte q(xk) gegen  . Wir betrachten nun die Konvergenzgeschwindigkeit dieser Funktionswerte.
. Wir betrachten nun die Konvergenzgeschwindigkeit dieser Funktionswerte.
Dazu benötigen wir folgendes Ergebnis, das zum Beispiel in [16] bewiesen wird.
2.2.22 Lemma (Kantorowitsch-Ungleichung)
 mit maximalem und minimalem Eigenwert
mit maximalem und minimalem Eigenwert  bzw.
bzw.  . Dann gilt für jedes
. Dann gilt für jedes 

2.2.23 Satz
 mit
mit  und
und  werde das Gradientenverfahren mit exakten Schrittweiten und ɛ = 0 angewendet. Dann gilt für alle
werde das Gradientenverfahren mit exakten Schrittweiten und ɛ = 0 angewendet. Dann gilt für alle 

Beweis.
 fest gewählt. Zur Übersichtlichkeit unterschlagen wir im Folgenden den Index k und setzen
fest gewählt. Zur Übersichtlichkeit unterschlagen wir im Folgenden den Index k und setzen  . Da
. Da  globaler Minimalwert von q ist, sind die Beträge in der behaupteten Ungleichung überflüssig. Wegen
globaler Minimalwert von q ist, sind die Beträge in der behaupteten Ungleichung überflüssig. Wegen  und
und





 dazu im Vergleich zu
dazu im Vergleich zu  sehr klein werden muss, schlägt sich geometrisch in „sehr lang gezogenen“ Niveaumengen von q nieder, wie sie bereits als Höhenlinien in Abb. 2.6 illustriert wurden.
sehr klein werden muss, schlägt sich geometrisch in „sehr lang gezogenen“ Niveaumengen von q nieder, wie sie bereits als Höhenlinien in Abb. 2.6 illustriert wurden.2.2.24 Bemerkung (Ellipsodiale Niveaumengen und Eigenwerte)

 mit
mit  und
und  .
. das Minimalniveau von q, und den zugehörigen Minimalpunkt
das Minimalniveau von q, und den zugehörigen Minimalpunkt  können wir als Mittelpunkt jedes Ellipsoids
können wir als Mittelpunkt jedes Ellipsoids  mit
mit  auffassen. Für jedes solche α kann man von diesem Mittelpunkt
auffassen. Für jedes solche α kann man von diesem Mittelpunkt  aus in eine beliebige vorgegebene Richtung
aus in eine beliebige vorgegebene Richtung  „laufen“ und wird sicher die Niveaumenge
„laufen“ und wird sicher die Niveaumenge  treffen. Allerdings wird die Größe der entsprechenden Schrittweite t > 0 mit
treffen. Allerdings wird die Größe der entsprechenden Schrittweite t > 0 mit  im Allgemeinen von der Richtung d abhängen. In Formeln ausgedrückt ist dies die Frage nach dem zu d gehörigen t > 0 mit
im Allgemeinen von der Richtung d abhängen. In Formeln ausgedrückt ist dies die Frage nach dem zu d gehörigen t > 0 mit


 getroffen wird. Für Eigenwerte nahe bei null ist der Weg also sehr weit, während er für große Eigenwerte kurz ist. Die Länge eines solchen Wegs wird auch als Länge der durch v bestimmten Halbachse
des zugehörigen Ellipsoids bezeichnet.
getroffen wird. Für Eigenwerte nahe bei null ist der Weg also sehr weit, während er für große Eigenwerte kurz ist. Die Länge eines solchen Wegs wird auch als Länge der durch v bestimmten Halbachse
des zugehörigen Ellipsoids bezeichnet.Dies erklärt letztendlich, dass einer großen Diskrepanz zwischen  und
und  eine große Diskrepanz zwischen längster und kürzester Halbachse jedes Ellipsoids entspricht, das eine Niveaumenge von q bildet, dass also die Niveaumengen von q geometrisch „sehr lang gezogen“ sind.
eine große Diskrepanz zwischen längster und kürzester Halbachse jedes Ellipsoids entspricht, das eine Niveaumenge von q bildet, dass also die Niveaumengen von q geometrisch „sehr lang gezogen“ sind.
2.2.25 Übung
Berechnen Sie für eine Matrix  die Längen der Halbachsen des Ellipsoids
die Längen der Halbachsen des Ellipsoids  .
.
2.2.26 Übung
Zu einer Matrix  mit maximalem und minimalem Eigenwert
mit maximalem und minimalem Eigenwert  bzw.
bzw.  heißt
heißt  Konditionszahl
von A. Bei einer Konditionszahl nahe bei eins spricht man von einer gut konditionierten Matrix. Drücken Sie den Linearitätsfaktor des Gradientenverfahrens aus Satz 2.2.23 mit Hilfe der Konditionszahl aus. Wie wirkt sich demnach die Güte der Kondition von A auf die Geschwindigkeit des Verfahrens aus?
Konditionszahl
von A. Bei einer Konditionszahl nahe bei eins spricht man von einer gut konditionierten Matrix. Drücken Sie den Linearitätsfaktor des Gradientenverfahrens aus Satz 2.2.23 mit Hilfe der Konditionszahl aus. Wie wirkt sich demnach die Güte der Kondition von A auf die Geschwindigkeit des Verfahrens aus?
2.2.4 Variable-Metrik-Verfahren
Satz 2.2.23 zur langsamen Konvergenz des Gradientenverfahrens und seine geometrische Interpretation (Abb. 2.6) legen die Idee nahe, die Abstiegsrichtung  durch eine Richtung zu ersetzen, die Krümmungsinformation über f berücksichtigt. Dies lässt sich wie folgt bewerkstelligen.
durch eine Richtung zu ersetzen, die Krümmungsinformation über f berücksichtigt. Dies lässt sich wie folgt bewerkstelligen.
Nach Satz 2.2.23 minimiert das Gradientenverfahren (mit exakten Schrittweiten) eine konvex-quadratische Funktion  in einem einzigen Schritt, wenn der kleinste und größte Eigenwert
in einem einzigen Schritt, wenn der kleinste und größte Eigenwert  bzw.
bzw.  von A übereinstimmen. Dann stimmen natürlich auch alle Eigenwerte von A miteinander überein, so dass q sphärenförmige Niveaumengen besitzt.
von A übereinstimmen. Dann stimmen natürlich auch alle Eigenwerte von A miteinander überein, so dass q sphärenförmige Niveaumengen besitzt.
Die geometrische Hauptidee der folgenden Verfahren ist es, bei der Minimierung einer (nicht notwendigerweise konvex-quadratischen) C1-Funktion f an jeder Iterierten xk ein jeweils neues Koordinatensystem so einzuführen, dass f um xk in den neuen Koordinaten möglichst sphärenförmige Niveaumengen besitzt. In den neuen Koordinaten ist folglich ein Abstieg in die negative Gradientenrichtung sinnvoll. Wenn die Koordinatentransformation linear ist, werden wir eine einfache Darstellung dieser Suchrichtung in den originalen Koordinaten herleiten können, so dass der explizite Gebrauch der Koordinatentransformation danach nicht mehr nötig ist.
 , wobei wir vernachlässigen, dass der Punkt, an dem die Suchrichtung berechnet werden soll, eine Iterierte ist, und ihn stattdessen mit
, wobei wir vernachlässigen, dass der Punkt, an dem die Suchrichtung berechnet werden soll, eine Iterierte ist, und ihn stattdessen mit  bezeichnen. Links sind ellipsenförmige Niveaulinien von q dargestellt, für die das Gradientenverfahren von
bezeichnen. Links sind ellipsenförmige Niveaulinien von q dargestellt, für die das Gradientenverfahren von  aus zu langsamer Konvergenz führen würde. Ein sowohl von der Orientierung als auch von der Skalierung her zu den Niveaulinien „passenderes“ Koordinatensystem ist gestrichelt eingezeichnet, und die neuen Koordinaten sind mit y1 und y2 anstelle von x1 und x2 bezeichnet. (Man könnte zusätzlich als Ursprung des neuen Koordinatensystems den gemeinsamen Mittelpunkt der Ellipsen wählen, was sich aber später als unnötig erweisen würde.)
aus zu langsamer Konvergenz führen würde. Ein sowohl von der Orientierung als auch von der Skalierung her zu den Niveaulinien „passenderes“ Koordinatensystem ist gestrichelt eingezeichnet, und die neuen Koordinaten sind mit y1 und y2 anstelle von x1 und x2 bezeichnet. (Man könnte zusätzlich als Ursprung des neuen Koordinatensystems den gemeinsamen Mittelpunkt der Ellipsen wählen, was sich aber später als unnötig erweisen würde.)
Koordinatentransformation in der Variable-Metrik-Idee
![$$
b^1\ =\ \begin{pmatrix}\,\,\,\frac12\\[2pt]-\frac12\end{pmatrix}\quad\text{und}\quad b^2\ =\ \begin{pmatrix}1\\1\end{pmatrix}
$$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_Equdo.png)
 seine Koordinaten y1 und y2 bezüglich des neuen Koordinatensystems bestimmen, denn diese erfüllen das lineare Gleichungssystem
seine Koordinaten y1 und y2 bezüglich des neuen Koordinatensystems bestimmen, denn diese erfüllen das lineare Gleichungssystem
 . Beispielsweise erfüllen die neuen Koordinaten y1 und y2 des Punkts
. Beispielsweise erfüllen die neuen Koordinaten y1 und y2 des Punkts  das System
das System
 folgt. In der Tat muss man zur Bestimmung neuer Koordinaten nicht notwendigerweise Gleichungssysteme lösen. Da die Vektoren b1 und b2 eine Basis des
folgt. In der Tat muss man zur Bestimmung neuer Koordinaten nicht notwendigerweise Gleichungssysteme lösen. Da die Vektoren b1 und b2 eine Basis des  bilden, ist die Matrix B invertierbar, und die Vorschrift y = B−1x liefert zu jedem
bilden, ist die Matrix B invertierbar, und die Vorschrift y = B−1x liefert zu jedem  explizit die neuen Koordinaten y.
explizit die neuen Koordinaten y.Die Abbildung  ist die gesuchte lineare Koordinatentransformation. Sie transformiert die Geometrie der linken Seite aus Abb. 2.7 in die der rechten Seite.
ist die gesuchte lineare Koordinatentransformation. Sie transformiert die Geometrie der linken Seite aus Abb. 2.7 in die der rechten Seite.
 , an dem wir eine dem negativen Gradienten von q überlegene Abstiegsrichtung suchen, auf den Punkt
, an dem wir eine dem negativen Gradienten von q überlegene Abstiegsrichtung suchen, auf den Punkt  abgebildet. In den neuen Koordinaten y sind die Höhenlinien von q kreisförmig, so dass von
abgebildet. In den neuen Koordinaten y sind die Höhenlinien von q kreisförmig, so dass von  aus die negative Gradientenrichtung zum Minimalpunkt zeigt. Entscheidend dabei ist, wie die „Funktion q in neuen Koordinaten“ explizit lautet, von der hier die Höhenlinien betrachtet werden und deren Gradient berechnet werden soll. Wegen
aus die negative Gradientenrichtung zum Minimalpunkt zeigt. Entscheidend dabei ist, wie die „Funktion q in neuen Koordinaten“ explizit lautet, von der hier die Höhenlinien betrachtet werden und deren Gradient berechnet werden soll. Wegen
 diese gesuchte Darstellung von q in neuen Koordinaten, und
diese gesuchte Darstellung von q in neuen Koordinaten, und  ist die gesuchte Gradientenrichtung in
ist die gesuchte Gradientenrichtung in  .
. realisiert wird. Um den resultierenden Vektor
realisiert wird. Um den resultierenden Vektor  in originalen Koordinaten darzustellen, benutzen wir die Kettenregel und erhalten für jedes
in originalen Koordinaten darzustellen, benutzen wir die Kettenregel und erhalten für jedes 
![$$
D\widetilde q(y)\ =\ D[q(B(y))]\ =\ Dq(By)B\ =\ Dq(x)B,
$$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_Equds.png)
 und
und
Für den allgemeinen Fall n ≥ 1 und ohne grafische Veranschaulichung ist an dieser Stelle leider noch unklar, wie die Matrix B konstruiert werden soll. Auch im Allgemeinen existiert aber stets ein rechtwinkliges Koordinatensystem, das zur Lage der ellipsodialen Niveaumengen von q „passend ausgerichtet“ ist. Seine Achsen entsprechen gerade den Hauptachsen dieser Ellipsoide, also den durch die Eigenvektoren  von A gegebenen Richtungen (da A symmetrisch ist, existieren in der Tat genau n verschiedene und paarweise senkrecht zueinander stehende Eigenvektoren von A). Wie in Abb. 2.7 verzichten wir allerdings darauf, den Mittelpunkt der Ellipsoide (also den Minimalpunkt von q) mit dem Koordinatenursprung des neuen Koordinatensystems zu identifizieren.
von A gegebenen Richtungen (da A symmetrisch ist, existieren in der Tat genau n verschiedene und paarweise senkrecht zueinander stehende Eigenvektoren von A). Wie in Abb. 2.7 verzichten wir allerdings darauf, den Mittelpunkt der Ellipsoide (also den Minimalpunkt von q) mit dem Koordinatenursprung des neuen Koordinatensystems zu identifizieren.
 , i = 1, … , n, mit passend gewählten Faktoren
, i = 1, … , n, mit passend gewählten Faktoren  besitzen. Die neuen Koordinaten
besitzen. Die neuen Koordinaten  eines Punkts
eines Punkts  erfüllen dann jedenfalls das System
erfüllen dann jedenfalls das System
 eingeführt haben. Mit der Diagonalmatrix
eingeführt haben. Mit der Diagonalmatrix
 die Darstellung B = VC ablesen. In neuen Koordinaten lautet die Funktion q also
die Darstellung B = VC ablesen. In neuen Koordinaten lautet die Funktion q also  mit B = VC.
mit B = VC. zu berechnen, mit denen
zu berechnen, mit denen  sphärenförmige Niveaumengen besitzt, sorgen wir dafür, dass die Hesse-Matrix von
sphärenförmige Niveaumengen besitzt, sorgen wir dafür, dass die Hesse-Matrix von  identische Eigenwerte besitzt. Diese Matrix lesen wir aus
identische Eigenwerte besitzt. Diese Matrix lesen wir aus

 auftretende Matrix
auftretende Matrix  mit der Diagonalmatrix
mit der Diagonalmatrix
 für alle i = 1, … , n sowie andererseits
für alle i = 1, … , n sowie andererseits  für alle i ≠ j. Daher gilt
für alle i ≠ j. Daher gilt

 etwa für die Wahlen
etwa für die Wahlen  , i = 1, … , n, sphärenförmige Niveaumengen besitzt. Mit den Definitionen
, i = 1, … , n, sphärenförmige Niveaumengen besitzt. Mit den Definitionen
 lässt sich dieser Zusammenhang auch kurz als
lässt sich dieser Zusammenhang auch kurz als  schreiben, so dass die gesuchte Matrix
schreiben, so dass die gesuchte Matrix
 in originale Koordinaten erhalten wir wie oben den Vektor
in originale Koordinaten erhalten wir wie oben den Vektor  , wobei die Matrix
, wobei die Matrix  jetzt wie folgt geschrieben werden kann:
jetzt wie folgt geschrieben werden kann:
 zu
zu

 lautet demnach
lautet demnach  .
.Für eine nicht notwendigerweise konvex-quadratische Funktion  ist abschließend noch zu klären, wie man an einer Stelle
ist abschließend noch zu klären, wie man an einer Stelle  ein Koordinatensystem einführen kann, in dem f möglichst sphärenförmige Niveaumengen besitzt. Beschränkt man sich darauf, approximativ eine Konstruktion wie bei konvex-quadratischen Funktionen zu benutzen, motiviert dies die folgende Definition.
ein Koordinatensystem einführen kann, in dem f möglichst sphärenförmige Niveaumengen besitzt. Beschränkt man sich darauf, approximativ eine Konstruktion wie bei konvex-quadratischen Funktionen zu benutzen, motiviert dies die folgende Definition.
2.2.27 Definition (Gradient bezüglich einer positiv definiten Matrix)
 und eine (n, n)-Matrix
und eine (n, n)-Matrix  heißt
heißt
 ist diese Suchrichtung an einem nichtkritischen Punkt x jedenfalls eine Abstiegsrichtung erster Ordnung, denn da mit A auch A−1 positiv definit ist, gilt
ist diese Suchrichtung an einem nichtkritischen Punkt x jedenfalls eine Abstiegsrichtung erster Ordnung, denn da mit A auch A−1 positiv definit ist, gilt
Um den Begriff „variable Metrik“ zu motivieren, stellen wir zunächst fest, dass jede Matrix  auch ein Skalarprodukt und eine Norm definiert.
auch ein Skalarprodukt und eine Norm definiert.
2.2.28 Übung
Zeigen Sie, dass für jedes  die Funktion
die Funktion  ein Skalarprodukt auf
ein Skalarprodukt auf  ist.
ist.
2.2.29 Übung
 und das von A induzierte Skalarprodukt
und das von A induzierte Skalarprodukt  die Funktion
die Funktion
 ist.
ist.Das von A induzierte Skalarprodukt und die von A induzierte Norm erlauben es, weitere Einblicke zu gewinnen.
2.2.30 Übung


Wegen Übung 2.2.30 macht Satz 2.2.23 auch eine Aussage über die Konvergenzgeschwindigkeit der Iterierten (und nicht nur ihrer Funktionswerte) des Gradientenverfahrens, sofern man die passende Norm wählt. Da aber die quadrierten Abstände der Iterierten zum Grenzpunkt linear konvergieren, erhält man daraus eine sogar noch langsamere als lineare (nämlich eine sog. sublineare) Konvergenz der Iterierten selbst.
2.2.31 Übung

2.2.32 Übung
 induzierte Skalarprodukt
induzierte Skalarprodukt  und die induzierte Norm
und die induzierte Norm  die Cauchy-Schwarz-Ungleichung:
die Cauchy-Schwarz-Ungleichung:
Da die Niveaumengen  mit c > 0 Ellipsoide sind, werden die Abstände um
mit c > 0 Ellipsoide sind, werden die Abstände um  in der Norm
in der Norm  unterschiedlich gewichtet. Das folgende Lemma zeigt, dass bezüglich dieser neuen Abstände der Vektor ∇Af(x) eine „Richtung steilsten Abstiegs“ ist.
unterschiedlich gewichtet. Das folgende Lemma zeigt, dass bezüglich dieser neuen Abstände der Vektor ∇Af(x) eine „Richtung steilsten Abstiegs“ ist.
2.2.33 Lemma


 .
.Beweis.
 die Cauchy-Schwarz-Ungleichung, also für alle d mit
die Cauchy-Schwarz-Ungleichung, also für alle d mit 

Bekanntlich lässt sich mit Hilfe jeder Norm  auf
auf  auch eine Metrik
auf
auch eine Metrik
auf  einführen, indem der Abstand zweier Punkte x und y zu
einführen, indem der Abstand zweier Punkte x und y zu  definiert wird. Diese Metrik werden wir nicht explizit benutzen, sie erklärt aber die benutzte Terminologie: Verfahren, die in jeder Iteration eine neue Matrix
definiert wird. Diese Metrik werden wir nicht explizit benutzen, sie erklärt aber die benutzte Terminologie: Verfahren, die in jeder Iteration eine neue Matrix  wählen und damit die Suchrichtung
wählen und damit die Suchrichtung  definieren, heißen Variable-Metrik-Verfahren. Algorithmus 2.6 setzt diese Idee um.
definieren, heißen Variable-Metrik-Verfahren. Algorithmus 2.6 setzt diese Idee um.
In Zeile 2 von Algorithmus 2.6 wählt man häufig A0 = E, also als erste Suchrichtung die Gradientenrichtung  . In Zeile 3 wäre ein konsistenteres Abbruchkriterium eigentlich
. In Zeile 3 wäre ein konsistenteres Abbruchkriterium eigentlich  , aber wegen
, aber wegen
Algorithmus 2.6: Variable-Metrik-Verfahren
Input : C1-Optimierungsproblem P
Output : Approximation  eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.37)
eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.37)
1 begin
2 Wähle einen Startpunkt x0, eine Matrix  , eine Toleranz
, eine Toleranz  und setze
und setze  .
.
3 While  do
do
4 Setze  .
.
5 Bestimme eine Schrittweite tk.
6 Setze  .
.
7 Wähle  .
.
8 Ersetze k durch  .
.
9 end
10 Setze  .
.
11 end

 und
und  (d. h., es gibt Konstanten
(d. h., es gibt Konstanten  , so dass alle
, so dass alle  die Abschätzungen
die Abschätzungen  erfüllen) kann man ebensogut das angegebene und weniger aufwendigere Kriterium testen. In Zeile 4 berechnet man die Suchrichtung dk numerisch nicht durch die eine Matrixinversion enthaltende Definition
erfüllen) kann man ebensogut das angegebene und weniger aufwendigere Kriterium testen. In Zeile 4 berechnet man die Suchrichtung dk numerisch nicht durch die eine Matrixinversion enthaltende Definition  , sondern weniger aufwendig als Lösung des linearen Gleichungssystems
, sondern weniger aufwendig als Lösung des linearen Gleichungssystems  .
.Möchte man die Konvergenz von Variable-Metrik-Verfahren im Sinne von Satz 2.2.9 garantieren, benötigt man neben der Effizienz der Schrittweiten auch die Gradientenbezogenheit der Suchrichtungen. Diese muss man noch fordern.
2.2.34 Definition (Gleichmäßig positiv definite und beschränkte Matrizen)


2.2.35 Übung
Die Folge (Ak) sei gleichmäßig positiv definit und beschränkt mit Konstanten c1 und c2 . Zeigen Sie, dass dann die Folge  gleichmäßig positiv definit und beschränkt mit Konstanten 1/c2 und 1/c1 ist. Zeigen Sie außerdem, dass die Folge
gleichmäßig positiv definit und beschränkt mit Konstanten 1/c2 und 1/c1 ist. Zeigen Sie außerdem, dass die Folge  der größten Eigenwerte von
der größten Eigenwerte von  durch 1/c1 nach oben beschränkt ist.
durch 1/c1 nach oben beschränkt ist.
2.2.36 Satz
Die Folge (Ak) sei gleichmäßig positiv definit und beschränkt. Dann ist die Folge (dk) mit  ,
,  , gradientenbezogen.
, gradientenbezogen.
Beweis.
 . Im Fall ∇f(xk) = 0 ist nichts zu zeigen, daher sei im Folgenden ∇f(xk) ≠ 0. Nach Übung 2.2.35 gilt zunächst
. Im Fall ∇f(xk) = 0 ist nichts zu zeigen, daher sei im Folgenden ∇f(xk) ≠ 0. Nach Übung 2.2.35 gilt zunächst

 für eine symmetrische positiv definite Matrix A benutzt haben (Bemerkung 2.2.38). Da der Zähler des ersten Bruchs bei der folgenden Abschätzung negativ ist, folgt für alle
für eine symmetrische positiv definite Matrix A benutzt haben (Bemerkung 2.2.38). Da der Zähler des ersten Bruchs bei der folgenden Abschätzung negativ ist, folgt für alle 

2.2.37 Satz
Die Menge  sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf
sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf  , die Folge (Ak) sei gleichmäßig positiv definit und beschränkt, und in Zeile 5 seien exakte Schrittweiten
, die Folge (Ak) sei gleichmäßig positiv definit und beschränkt, und in Zeile 5 seien exakte Schrittweiten  oder Armijo-Schrittweiten
oder Armijo-Schrittweiten  gewählt. Dann terminiert Algorithmus 2.5 für jedes ɛ > 0 nach endlich vielen Schritten.
gewählt. Dann terminiert Algorithmus 2.5 für jedes ɛ > 0 nach endlich vielen Schritten.
2.2.38 Bemerkung (Spektralnorm und Eigenwerte)


 den größten Eigenwert der positiv semidefiniten Matrix
den größten Eigenwert der positiv semidefiniten Matrix  bezeichnet (Beispiel 3.2.45). Dass die Menge der Eigenwerte einer Matrix auch als Spektrum von A bezeichnet wird, erklärt die Terminologie für
bezeichnet (Beispiel 3.2.45). Dass die Menge der Eigenwerte einer Matrix auch als Spektrum von A bezeichnet wird, erklärt die Terminologie für  .
. die Eigenwerte von
die Eigenwerte von  gerade die quadrierten Eigenwerte von A sind, folgt dann
gerade die quadrierten Eigenwerte von A sind, folgt dann
 .
. bei Matrizen A von vollem Spaltenrang zumindest motivieren. Dann ist die Matrix
bei Matrizen A von vollem Spaltenrang zumindest motivieren. Dann ist die Matrix  nämlich sogar positiv definit, und wir können mit Hilfe der Matrix Λ der Eigenwerte von
nämlich sogar positiv definit, und wir können mit Hilfe der Matrix Λ der Eigenwerte von  sowie der Matrix V der zugehörigen Eigenvektoren die Matrix
sowie der Matrix V der zugehörigen Eigenvektoren die Matrix
 mit
mit  führt dann zu
führt dann zu



was dem behaupteten Wert von  entspricht und wobei wir benutzt haben, dass die Eigenwerte der positiv definiten Matrix
entspricht und wobei wir benutzt haben, dass die Eigenwerte der positiv definiten Matrix  genau die Kehrwerte der Eigenwerte von
genau die Kehrwerte der Eigenwerte von  sind. Zumindest für n = 2 und n = 3 ist zwar geometrisch einsichtig, dass die größte Verzerrung eines Ellipsoids in der Tat entlang der längsten Halbachse auftritt, dies ist allerdings noch kein Beweis, sondern nur eine Motivation. Der Beweis wird wie erwähnt in Beispiel 3.2.45 geführt.
sind. Zumindest für n = 2 und n = 3 ist zwar geometrisch einsichtig, dass die größte Verzerrung eines Ellipsoids in der Tat entlang der längsten Halbachse auftritt, dies ist allerdings noch kein Beweis, sondern nur eine Motivation. Der Beweis wird wie erwähnt in Beispiel 3.2.45 geführt.
2.2.5 Newton-Verfahren mit und ohne Dämpfung
Wählt man in Algorithmus 2.6 für  in jedem Schritt
in jedem Schritt  , so erhält man das bereits zu Beginn von Abschn. 2.2.1 kurz erwähnte Newton-Verfahren, sofern die Matrizen
, so erhält man das bereits zu Beginn von Abschn. 2.2.1 kurz erwähnte Newton-Verfahren, sofern die Matrizen  positiv definit sind. Allerdings werden die Newton-Schritte durch den Faktor tk, der üblicherweise im Intervall (0, 1) liegt, „gedämpft“. Man spricht dann vom gedämpften Newton-Verfahren
. Wir haben bereits angeführt, dass das Newton-Verfahren nur für x0 hinreichend nahe bei einer Lösung
positiv definit sind. Allerdings werden die Newton-Schritte durch den Faktor tk, der üblicherweise im Intervall (0, 1) liegt, „gedämpft“. Man spricht dann vom gedämpften Newton-Verfahren
. Wir haben bereits angeführt, dass das Newton-Verfahren nur für x0 hinreichend nahe bei einer Lösung  wohldefiniert und schnell ist. Etwas genauer gilt Folgendes.
wohldefiniert und schnell ist. Etwas genauer gilt Folgendes.
 nichtdegenerierter lokaler Minimalpunkt von f, dann gilt aus den bereits am Ende von Abschn. 2.1.5 aufgeführten Stetigkeitsgründen D2f(x) ≻ 0 für alle x aus einer Umgebung von
nichtdegenerierter lokaler Minimalpunkt von f, dann gilt aus den bereits am Ende von Abschn. 2.1.5 aufgeführten Stetigkeitsgründen D2f(x) ≻ 0 für alle x aus einer Umgebung von  . Für x0 aus dieser Umgebung kann man also
. Für x0 aus dieser Umgebung kann man also  setzen und erhält ein wohldefiniertes Abstiegsverfahren. Ferner sind die Suchrichtungen
setzen und erhält ein wohldefiniertes Abstiegsverfahren. Ferner sind die Suchrichtungen  gradientenbezogen, falls f um
gradientenbezogen, falls f um  gleichmäßig konvex ist, d. h. falls für eine Umgebung U von
gleichmäßig konvex ist, d. h. falls für eine Umgebung U von 

 resultiert dabei aus der Stetigkeit von D2f. Die Nichtdegeneriertheit des lokalen Minimalpunkts
resultiert dabei aus der Stetigkeit von D2f. Die Nichtdegeneriertheit des lokalen Minimalpunkts  gilt bei gleichmäßig konvexem f automatisch.
gilt bei gleichmäßig konvexem f automatisch.Die Dämpfung des Newton-Verfahrens hat den Vorteil, dass der Konvergenzradius (also der mögliche Abstand von x0 zu  ) etwas größer wird. Andererseits ist zunächst nicht klar, ob die Dämpfung nicht auch die lokale Konvergenz verlangsamt. Das ungedämpfte Newton-Verfahren
konvergiert unter schwachen Voraussetzungen jedenfalls quadratisch.
) etwas größer wird. Andererseits ist zunächst nicht klar, ob die Dämpfung nicht auch die lokale Konvergenz verlangsamt. Das ungedämpfte Newton-Verfahren
konvergiert unter schwachen Voraussetzungen jedenfalls quadratisch.
2.2.39 Satz (Quadratische Konvergenz des Newton-Verfahrens)

 , und D2f sei Lipschitz-stetig auf einer konvexen Umgebung von
, und D2f sei Lipschitz-stetig auf einer konvexen Umgebung von  . Dann konvergiert die Folge (xk) quadratisch gegen
. Dann konvergiert die Folge (xk) quadratisch gegen  .
.Beweis.

 in (2.10) sowie der quadratischen Abschätzung des dabei entstehenden Fehlerterms mit Hilfe von Lemma 2.2.13. Da wir im Rahmen dieses Lehrbuchs nur Taylor-Entwicklungen von reellwertigen (und nicht von vektorwertigen) Funktionen betrachtet haben, gehen wir wie folgt vor: Für jedes i ∈ {1, … , n} erfüllt der Fehlerterm
in (2.10) sowie der quadratischen Abschätzung des dabei entstehenden Fehlerterms mit Hilfe von Lemma 2.2.13. Da wir im Rahmen dieses Lehrbuchs nur Taylor-Entwicklungen von reellwertigen (und nicht von vektorwertigen) Funktionen betrachtet haben, gehen wir wie folgt vor: Für jedes i ∈ {1, … , n} erfüllt der Fehlerterm

 Lipschitz-stetig mit Konstante L > 0 auf der konvexen Umgebung D von
Lipschitz-stetig mit Konstante L > 0 auf der konvexen Umgebung D von  , auf der auch die Lipschitz-Stetigkeit von D2f mit Konstante L > 0 vorausgesetzt ist, also die Bedingung
, auf der auch die Lipschitz-Stetigkeit von D2f mit Konstante L > 0 vorausgesetzt ist, also die Bedingung
 und
und  für alle x, y ∈ D
für alle x, y ∈ D
 liegen die Iterierten xk in D, so dass Lemma 2.2.13 für den Fehlerterm dann sogar
liegen die Iterierten xk in D, so dass Lemma 2.2.13 für den Fehlerterm dann sogar

 aus Stetigkeitsgründen auf einer Umgebung von
aus Stetigkeitsgründen auf einer Umgebung von  durch eine Konstante c > 0 beschränkt ist:
durch eine Konstante c > 0 beschränkt ist:
2.2.40 Bemerkung
Die Voraussetzungen von Satz 2.2.39 lassen sich noch erheblich abschwächen. Erstens gilt die Aussage für jeden nichtdegenerierten kritischen Punkt  , also nicht nur für lokale Minimalpunkte. Zweitens werden wir in Satz 2.2.48 sehen, dass die Konvergenz der Folge (xk) bereits impliziert, dass der Grenzpunkt
, also nicht nur für lokale Minimalpunkte. Zweitens werden wir in Satz 2.2.48 sehen, dass die Konvergenz der Folge (xk) bereits impliziert, dass der Grenzpunkt  ein nichtdegenerierter kritischer Punkt ist.
ein nichtdegenerierter kritischer Punkt ist.
Die Konvergenzgeschwindigkeit überträgt sich aus Satz 2.2.39 natürlich auf das gedämpfte Newton-Verfahren, falls man mit einem  für alle k ≥ k0 nur tk = 1 wählt. Die folgende Übung gibt eine natürliche Bedingung dafür an.
für alle k ≥ k0 nur tk = 1 wählt. Die folgende Übung gibt eine natürliche Bedingung dafür an.
2.2.41 Übung
Für  liege x in einer genügend kleinen Umgebung eines nichtdegenerierten lokalen Minimalpunkts, und die Suchrichtung d werde mit dem gedämpften Newton-Verfahren per Armijo-Regel mit t0 = 1 und
liege x in einer genügend kleinen Umgebung eines nichtdegenerierten lokalen Minimalpunkts, und die Suchrichtung d werde mit dem gedämpften Newton-Verfahren per Armijo-Regel mit t0 = 1 und  bestimmt. Zeigen Sie, dass dann
bestimmt. Zeigen Sie, dass dann  gilt und dass die Armijo-Regel die Schrittweite ta = 1 wählt.
gilt und dass die Armijo-Regel die Schrittweite ta = 1 wählt.
2.2.42 Übung
Zeigen Sie, dass das ungedämpfte Newton-Verfahren für die Funktion  mit
mit  und
und  von jedem Startpunkt
von jedem Startpunkt  aus nach einem Schritt den globalen Minimalpunkt von q liefert.
aus nach einem Schritt den globalen Minimalpunkt von q liefert.
2.2.43 Übung
 sei eine Iterierte xk mit
sei eine Iterierte xk mit  gegeben. Zeigen Sie, dass dann die vom Newton-Verfahren erzeugte Suchrichtung dk der eindeutige lokale Minimalpunkt der konvex-quadratischen Funktion
gegeben. Zeigen Sie, dass dann die vom Newton-Verfahren erzeugte Suchrichtung dk der eindeutige lokale Minimalpunkt der konvex-quadratischen Funktion
Die Grundidee des Newton-Verfahrens, die Nullstellensuche von ∇f iterativ durch die Bestimmung von Nullstellen linearer Approximationen an ∇f zu ersetzen, lässt sich laut Übung 2.2.43 also auch so interpretieren, dass das Newton-Verfahren zur Minimierung von f in jeder Iteration den Minimalpunkt einer quadratischen Approximation an f berechnet. Auf diese Interpretation werden wir später bei der Betrachtung von CG-, Trust-Region- und SQP-Verfahren zurückkommen.
 mit einer glatten Funktion
mit einer glatten Funktion . Falls r linear ist, spricht man von einem linearen Kleinste-Quadrate-Problem (z. B. [24, 25]). Da sich f dann leicht als konvex-quadratisch identifizieren lässt (Übung 2.1.44), ist dieser Fall numerisch sehr effizient behandelbar [25]. Für nichtlineare Kleinste-Quadrate-Probleme berechnet man per Ketten- und Produktregel die Hesse-Matrix
. Falls r linear ist, spricht man von einem linearen Kleinste-Quadrate-Problem (z. B. [24, 25]). Da sich f dann leicht als konvex-quadratisch identifizieren lässt (Übung 2.1.44), ist dieser Fall numerisch sehr effizient behandelbar [25]. Für nichtlineare Kleinste-Quadrate-Probleme berechnet man per Ketten- und Produktregel die Hesse-Matrix
 zu wählen, sondern
zu wählen, sondern  . Dass die restlichen Summanden in der Darstellung von
. Dass die restlichen Summanden in der Darstellung von  eine untergeordnete Rolle spielen, kann zum einen daran liegen, dass für m ≥ n üblicherweise ein Punkt
eine untergeordnete Rolle spielen, kann zum einen daran liegen, dass für m ≥ n üblicherweise ein Punkt  mit
mit  approximiert wird, so dass die Werte
approximiert wird, so dass die Werte  fast verschwinden, oder zum anderen daran, dass die Krümmungen der Funktionen rj an
fast verschwinden, oder zum anderen daran, dass die Krümmungen der Funktionen rj an  vernachlässigbar sind, so dass sich die Matrizen
vernachlässigbar sind, so dass sich die Matrizen  in der Nähe der Nullmatrix aufhalten.
in der Nähe der Nullmatrix aufhalten.Obwohl zum Aufstellen von Ak im Gauß-Newton-Verfahren also nur Ableitungsinformationen erster Ordnung (die Matrix Dr(xk)) erforderlich sind, lässt sich unter bestimmten Zusatzvoraussetzungen sogar quadratische Konvergenz zeigen [25]. Zusätzlich sind die Suchrichtungen dk im Gauß-Newton-Verfahren im Gegensatz zum allgemeinen Newton-Verfahren garantiert Abstiegsrichtungen (erster Ordnung), so dass eine Schrittweitensteuerung etwa per Armijo-Regel möglich ist.
Sollte die Jacobi-Matrix Dr(xk) nicht den vollen Rang besitzen oder zumindest schlecht konditioniert sein, so lässt das Gauß-Newton-Verfahren sich durch die Wahl  mit gewissen σk > 0 und der Einheitsmatrix E passender Dimension stabilisieren, was auf das Levenberg-Marquardt-Verfahren
führt. Eine alternative Formulierung dieses Verfahrens kann als Vorläufer der in Abschn. 2.2.10 vorgestellten Trust-Region-Verfahren aufgefasst werden (für Einzelheiten s. [25]).
mit gewissen σk > 0 und der Einheitsmatrix E passender Dimension stabilisieren, was auf das Levenberg-Marquardt-Verfahren
führt. Eine alternative Formulierung dieses Verfahrens kann als Vorläufer der in Abschn. 2.2.10 vorgestellten Trust-Region-Verfahren aufgefasst werden (für Einzelheiten s. [25]).
2.2.44 Übung
Zeigen Sie für Kleinste-Quadrate-Probleme die Darstellung der Hesse-Matrix D2f(x) aus (2.11).
2.2.6 Superlineare Konvergenz
Falls im Newton-Verfahren x0 zu weit von einem nichtdegenerierten Minimalpunkt entfernt liegt, ist  nicht notwendigerweise positiv definit und die Newton-Richtung
nicht notwendigerweise positiv definit und die Newton-Richtung  entweder nicht definiert oder nicht notwendigerweise eine Abstiegsrichtung. Man versucht daher, das Newton-Verfahren zu globalisieren
, d. h. Konvergenz im Sinne von Satz 2.2.9 gegen einen lokalen Minimalpunkt von jedem Startpunkt
entweder nicht definiert oder nicht notwendigerweise eine Abstiegsrichtung. Man versucht daher, das Newton-Verfahren zu globalisieren
, d. h. Konvergenz im Sinne von Satz 2.2.9 gegen einen lokalen Minimalpunkt von jedem Startpunkt  aus zu erzwingen (was nicht zu verwechseln ist mit der Konvergenz gegen einen globalen Minimalpunkt; für solche Verfahren s. [33]).
aus zu erzwingen (was nicht zu verwechseln ist mit der Konvergenz gegen einen globalen Minimalpunkt; für solche Verfahren s. [33]).

Dann gilt  , und bei Konvergenz gegen einen nichtdegenerierten lokalen Minimalpunkt kann man σk = 0 für alle hinreichend großen k wählen (d. h., das Verfahren startet als Gradientenverfahren und geht nach endlich vielen Schritten in das gedämpfte Newton-Verfahren über). Unter geeigneten Voraussetzungen kann man superlineare Konvergenz des Verfahrens zeigen (z. B. Satz 2.2.48). Ein Nachteil des Verfahrens besteht darin, dass die Bestimmung von σk sehr aufwendig sein kann: Man halbiert oder verdoppelt z. B. σk so lange, bis ein Test auf positive Definitheit von
, und bei Konvergenz gegen einen nichtdegenerierten lokalen Minimalpunkt kann man σk = 0 für alle hinreichend großen k wählen (d. h., das Verfahren startet als Gradientenverfahren und geht nach endlich vielen Schritten in das gedämpfte Newton-Verfahren über). Unter geeigneten Voraussetzungen kann man superlineare Konvergenz des Verfahrens zeigen (z. B. Satz 2.2.48). Ein Nachteil des Verfahrens besteht darin, dass die Bestimmung von σk sehr aufwendig sein kann: Man halbiert oder verdoppelt z. B. σk so lange, bis ein Test auf positive Definitheit von  erfolgreich ist. Das Verfahren wird in dieser Form daher in der Praxis nicht verwendet.
erfolgreich ist. Das Verfahren wird in dieser Form daher in der Praxis nicht verwendet.
2.2.45 Übung
Es seien A eine symmetrische (n, n)-Matrix und E die (n, n)-Einheitsmatrix. Zeigen Sie, dass für alle hinreichend großen  die Matrix A + σE positiv definit ist.
die Matrix A + σE positiv definit ist.
Im Folgenden werden wir Verfahren kennenlernen, die nicht nach endlich vielen Schritten, sondern nur asymptotisch in das gedämpfte Newton-Verfahren übergehen. Für diese lässt sich immerhin noch superlineare Konvergenz zeigen. Der entsprechende Konvergenzsatz erfordert einige Vorbereitungen.
Zunächst besitzt die Folge der Iterierten (xk) nach Satz 2.2.9 einen Häufungspunkt, und jeder solche Häufungspunkt ist kritisch, sofern die Menge  beschränkt ist und gradientenbezogene Suchrichtungen sowie effiziente Schrittweiten benutzt werden. Die Gradientenbezogenheit der Suchrichtungen wird durch Satz 2.2.36 für gleichmäßig positiv definite und beschränkte (Ak) garantiert. Dass die Folge (xk) tatsächlich konvergiert, können wir mit den Mitteln dieses Lehrbuchs nur in einfachen Fällen zeigen (z. B. falls f einen eindeutigen kritischen Punkt besitzt), werden es für die nachfolgenden Untersuchungen der Konvergenzgeschwindigkeit aber voraussetzen.
beschränkt ist und gradientenbezogene Suchrichtungen sowie effiziente Schrittweiten benutzt werden. Die Gradientenbezogenheit der Suchrichtungen wird durch Satz 2.2.36 für gleichmäßig positiv definite und beschränkte (Ak) garantiert. Dass die Folge (xk) tatsächlich konvergiert, können wir mit den Mitteln dieses Lehrbuchs nur in einfachen Fällen zeigen (z. B. falls f einen eindeutigen kritischen Punkt besitzt), werden es für die nachfolgenden Untersuchungen der Konvergenzgeschwindigkeit aber voraussetzen.


 konvergenten Folge (xk) (Definition 2.2.21b) zu
konvergenten Folge (xk) (Definition 2.2.21b) zu
2.2.46 Lemma
Die Folge (xk) sei nach der Vorschrift (2.12) gebildet und gegen  konvergent. Ferner seien die Folgen
konvergent. Ferner seien die Folgen  und
und  beschränkt. Dann gilt:
beschränkt. Dann gilt:
- a)

- b)

Beweis.

 gilt
gilt




 und
und  beschränkt sind und
beschränkt sind und
2.2.47 Lemma
Für zwei (n, n)-Matrizen A und B sei  . Dann gilt:
. Dann gilt:
- a)
A und B sind nichtsingulär.
- b)
 .
. - c)
 .
.
Beweis.
Wegen  sind die Eigenwerte von E − AB betraglich echt kleiner als eins (Beispiel 3.2.45). Damit kann die Matrix AB nicht den Eigenwert null besitzen, ist also nichtsingulär. Folglich sind auch A und B nichtsingulär, und Aussage a ist gezeigt.
sind die Eigenwerte von E − AB betraglich echt kleiner als eins (Beispiel 3.2.45). Damit kann die Matrix AB nicht den Eigenwert null besitzen, ist also nichtsingulär. Folglich sind auch A und B nichtsingulär, und Aussage a ist gezeigt.

 . Dann gilt mit u : = C−1z und
. Dann gilt mit u : = C−1z und 




2.2.48 Satz
Die Folge (xk) sei nach der Vorschrift (2.12) gebildet und gegen  konvergent. Ferner sei
konvergent. Ferner sei  . Dann gelten die folgenden Aussagen:
. Dann gelten die folgenden Aussagen:
- a)
 ist nichtsingulär.
ist nichtsingulär. - b)
 .
. - c)
(xk) konvergiert mindestens linear gegen
 .
. - d)
Es gilt L = 0 genau im Fall von
 , und in diesem Fall konvergiert (xk) superlinear gegen
, und in diesem Fall konvergiert (xk) superlinear gegen  .
.
Beweis.
 existiert ein
existiert ein  , so dass für alle k ≥ k0
, so dass für alle k ≥ k0
 nichtsingulär, was Aussage a beweist, und außerdem ist für k ≥ k0 auch Hk nichtsingulär. Aus Lemma 2.2.47b und c folgt nun die Beschränktheit der Folgen
nichtsingulär, was Aussage a beweist, und außerdem ist für k ≥ k0 auch Hk nichtsingulär. Aus Lemma 2.2.47b und c folgt nun die Beschränktheit der Folgen  und
und  , so dass Lemma 2.2.46a Aussage b liefert. Nach Lemma 2.2.46b haben wir ferner
, so dass Lemma 2.2.46a Aussage b liefert. Nach Lemma 2.2.46b haben wir ferner
 gilt
gilt




 und
und  . Das zu Beginn dieses Kapitels vorgeschlagene Verfahren erreicht dies mit hohem Aufwand bereits nach endlich vielen Schritten, ist in diesem Sinne also nicht effizient.
. Das zu Beginn dieses Kapitels vorgeschlagene Verfahren erreicht dies mit hohem Aufwand bereits nach endlich vielen Schritten, ist in diesem Sinne also nicht effizient.2.2.7 Quasi-Newton-Verfahren
 ? Ein möglicher Ansatz dazu besteht darin, zunächst das Sekantenverfahren
zur Nullstellensuche einer Funktion von
? Ein möglicher Ansatz dazu besteht darin, zunächst das Sekantenverfahren
zur Nullstellensuche einer Funktion von  nach
nach  zu betrachten. Im Hinblick auf Optimierungsverfahren sei dies die Funktion
zu betrachten. Im Hinblick auf Optimierungsverfahren sei dies die Funktion  für eine zu minimierende Funktion
für eine zu minimierende Funktion  . Das Sekantenverfahren unterscheidet sich vom Newton-Verfahren dadurch, dass die linearen Approximationen an
. Das Sekantenverfahren unterscheidet sich vom Newton-Verfahren dadurch, dass die linearen Approximationen an  , deren Nullstellen berechnet werden, nicht durch Tangenten an
, deren Nullstellen berechnet werden, nicht durch Tangenten an  , sondern durch Sekanten gegeben sind. In der Tat approximiert man die Tangente an
, sondern durch Sekanten gegeben sind. In der Tat approximiert man die Tangente an  in einem Iterationspunkt xk + 1 mit der Sekante an den Funktionsgraphen durch die beiden Punkte
in einem Iterationspunkt xk + 1 mit der Sekante an den Funktionsgraphen durch die beiden Punkte  und
und  (Abb. 2.8).
(Abb. 2.8).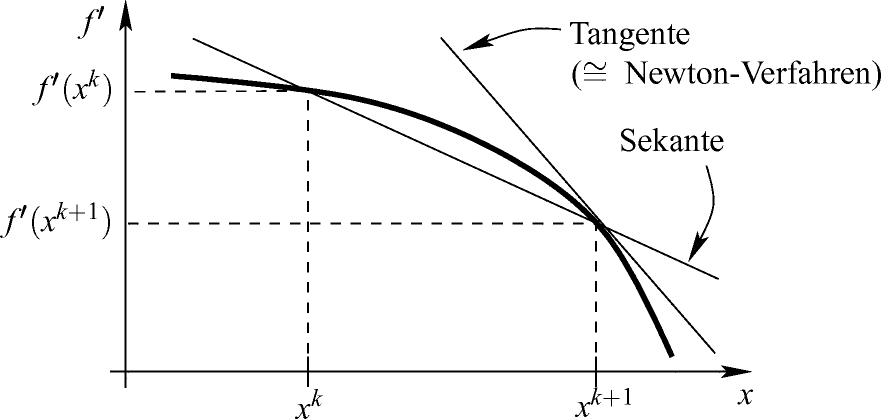
Grundidee des Sekantenverfahrens

 zu approximieren, also die Eigenschaft
zu approximieren, also die Eigenschaft  . In Analogie dazu bezeichnet man für n ≥ 1 die Gleichung
. In Analogie dazu bezeichnet man für n ≥ 1 die Gleichung

 und Vektoren uk,
und Vektoren uk,  , die so gewählt sind, dass Ak + 1 die Sekantengleichung (2.13) erfüllt.
, die so gewählt sind, dass Ak + 1 die Sekantengleichung (2.13) erfüllt.Die auftretenden Matrizen sind dabei von der Bauart  mit zwei Spaltenvektoren a und b. Eine solche Matrix besitzt stets höchstens den Rang eins und heißt dyadisches Produkt
der Vektoren a und b. In unserer Anwendung gilt zusätzlich b = a, so dass das dyadische Produkt auch eine symmetrische Matrix ist.
mit zwei Spaltenvektoren a und b. Eine solche Matrix besitzt stets höchstens den Rang eins und heißt dyadisches Produkt
der Vektoren a und b. In unserer Anwendung gilt zusätzlich b = a, so dass das dyadische Produkt auch eine symmetrische Matrix ist.


 fest und unterschlagen. Dann folgt
fest und unterschlagen. Dann folgt



 explizit angeben zu können. Wegen der einfachen Struktur des Rang-2-Updates ist dies hier in der Tat möglich, und zwar mit Hilfe der Sherman-Morrison-Woodbury-Formel
.
explizit angeben zu können. Wegen der einfachen Struktur des Rang-2-Updates ist dies hier in der Tat möglich, und zwar mit Hilfe der Sherman-Morrison-Woodbury-Formel
.2.2.49 Übung (Sherman-Morrison-Woodbury-Formel)
- a)
Zeigen Sie für eine nichtsinguläre (n, n)-Matrix A und Vektoren
 , dass
, dass  genau dann nichtsingulär ist, wenn
genau dann nichtsingulär ist, wenn  nicht verschwindet.
nicht verschwindet. - b)Beweisen Sie die Sherman-Morrison-Woodbury-Formel für eine (n, n)-Matrix A und Vektoren
 , wobei A und
, wobei A und  nichtsingulär seien:
nichtsingulär seien:





 .
.
 . Die Einführung eines zusätzlichen Parameters
. Die Einführung eines zusätzlichen Parameters  liefert die Updates der Broyden-Familie
liefert die Updates der Broyden-Familie

 und
und  . Für die Wahl
. Für die Wahl

Zur Division durch die Zahlen  und
und  in den Update-Formeln lässt sich Folgendes anmerken. In Lemma 2.2.51 werden wir zeigen, dass für θ ≥ 0 mit B0 auch alle iterierten Matrizen Bk positiv definit sind, sofern
in den Update-Formeln lässt sich Folgendes anmerken. In Lemma 2.2.51 werden wir zeigen, dass für θ ≥ 0 mit B0 auch alle iterierten Matrizen Bk positiv definit sind, sofern  positiv ist. Insbesondere gilt dann yk ≠ 0 und
positiv ist. Insbesondere gilt dann yk ≠ 0 und  .
.
 stets positiv ist. Zumindest für konvex-quadratische Funktionen
stets positiv ist. Zumindest für konvex-quadratische Funktionen  mit
mit  haben wir
haben wir

 auch dann positiv, wenn man exakte Schrittweiten
auch dann positiv, wenn man exakte Schrittweiten  wählt.
wählt.2.2.50 Übung

 die Ungleichung
die Ungleichung
Die Anwendung der Armijo-Regel mit Backtracking Line Search garantiert ebenfalls die Positivität von  [25].
[25].
Offenbar „erben“ die Matrizen  für alle
für alle  Symmetrie von B. Mit einer symmetrischen Matrix B0 sind also alle iterierten Matrizen Bk ebenfalls symmetrisch. Für die Vererbung von positiver Definitheit gilt folgendes Ergebnis.
Symmetrie von B. Mit einer symmetrischen Matrix B0 sind also alle iterierten Matrizen Bk ebenfalls symmetrisch. Für die Vererbung von positiver Definitheit gilt folgendes Ergebnis.
2.2.51 Lemma
Es sei θ ≥ 0 beliebig. Dann gilt unter den Bedingungen B ≻ 0 und  auch
auch  .
.
Beweis.


 nichtnegativ.
nichtnegativ. tatsächlich positiv ist. Dies ist im Fall
tatsächlich positiv ist. Dies ist im Fall

Angemerkt sei, dass die Voraussetzung θ ≥ 0 aus Lemma 2.2.51 zwar für den SR1-Update nicht garantiert ist, er in der Praxis aber dennoch häufig gute Ergebnisse liefert.
 ,
,  , so berechnet man für beliebiges
, so berechnet man für beliebiges  leicht die Suchrichtung
leicht die Suchrichtung
 identisch. Weil man aber entlang dieser Richtung exakt eindimensional minimiert, liefern alle Verfahren der Broyden-Familie identische Lösungsfolgen (xk).
identisch. Weil man aber entlang dieser Richtung exakt eindimensional minimiert, liefern alle Verfahren der Broyden-Familie identische Lösungsfolgen (xk).Dieses überraschende Ergebnis wird dadurch relativiert, dass man in der Praxis meist nicht exakt, sondern inexakt eindimensional minimiert, etwa per Armijo-Schrittweitensteuerung mit Backtracking Line Search. Bei inexakter Schrittweitenwahl können sich die Lösungsfolgen in der Tat ganz erheblich unterscheiden. Während zum Beispiel das DFP-Update dazu tendiert, schlecht konditionierte Matrizen Bk zu erzeugen, verhält sich das BFGS-Update für Probleme mittlerer Größe numerisch oft sehr robust. Hierbei bedeutet „mittlere Größe“, dass der Platzbedarf zur Speicherung der Matrizen Bk nicht zu hoch wird (etwa in Bezug auf die Größe des Arbeitsspeichers).
Leider lässt sich nicht zeigen, dass die Matrizen Bk stets gegen  streben, wie es zur Anwendung von Satz 2.2.48 zur superlinearen Konvergenz wünschenswert wäre. Mit einer recht technischen Verallgemeinerung von Satz 2.2.48 lässt sich für
streben, wie es zur Anwendung von Satz 2.2.48 zur superlinearen Konvergenz wünschenswert wäre. Mit einer recht technischen Verallgemeinerung von Satz 2.2.48 lässt sich für  trotzdem die superlineare Konvergenz der BFGS- und DFP-Verfahren nachweisen, falls
trotzdem die superlineare Konvergenz der BFGS- und DFP-Verfahren nachweisen, falls  und
und  wenigstens entlang der Suchrichtungen dk asymptotisch gleich sind (für Einzelheiten s. [25])
wenigstens entlang der Suchrichtungen dk asymptotisch gleich sind (für Einzelheiten s. [25])
2.2.8 Konjugierte Richtungen
Für viele Anwendungsprobleme ist die Anzahl der Variablen so hoch, dass sich zwar Vektoren der Länge n wie xk und dk noch gut abspeichern lassen, die Speicherung der n(n + 1)/2 Einträge von Matrizen wie Bk aber zu einem Platzproblem führt. Um auch für solch hochdimensionale Probleme effizientere Verfahren als das Gradientenverfahren herzuleiten, befassen wir uns in diesem Abschnitt mit der besonderen Rolle, die Orthogonalität bezüglich eines Skalarprodukts  spielt.
spielt.
2.2.52 Definition (Konjugiertheit bezüglich einer positiv definiten Matrix)
Es sei A eine (n, n)-Matrix mit  . Zwei Vektoren
. Zwei Vektoren  heißen konjugiert bezüglich A
, falls
heißen konjugiert bezüglich A
, falls  gilt.
gilt.

 und Abstiegsrichtungen erster Ordnung dk für die konvex-quadratische Funktion
und Abstiegsrichtungen erster Ordnung dk für die konvex-quadratische Funktion
 und
und  . Als erstes Ergebnis wird sich herausstellen, dass bezüglich A konjugierte Suchrichtungen viel schneller zur Identifikation eines globalen Minimalpunkts führen als etwa die negativen Gradientenrichtungen von q.
. Als erstes Ergebnis wird sich herausstellen, dass bezüglich A konjugierte Suchrichtungen viel schneller zur Identifikation eines globalen Minimalpunkts führen als etwa die negativen Gradientenrichtungen von q.2.2.53 Übung
Für  seien
seien  paarweise konjugiert bezüglich A und sämtlich ungleich null. Zeigen Sie:
paarweise konjugiert bezüglich A und sämtlich ungleich null. Zeigen Sie:
- a)
Die Vektoren
 sind linear unabhängig. Insbesondere gilt k < n.
sind linear unabhängig. Insbesondere gilt k < n. - b)Für k = n − 1 gilt

2.2.54 Lemma
 seien
seien  paarweise konjugiert bezüglich A. Dann gilt
paarweise konjugiert bezüglich A. Dann gilt
Beweis.
 resultiert die Behauptung aus (2.7), denn die exakte Schrittweite
resultiert die Behauptung aus (2.7), denn die exakte Schrittweite  erfüllt
erfüllt
 gilt
gilt

 und der Konjugiertheit der Vektoren
und der Konjugiertheit der Vektoren  zu
zu 

2.2.55 Satz
Die Vektoren  seien paarweise konjugiert bezüglich A und sämtlich ungleich null. Dann ist xn der globale Minimalpunkt von q.
seien paarweise konjugiert bezüglich A und sämtlich ungleich null. Dann ist xn der globale Minimalpunkt von q.
Beweis.



Satz 2.2.55 besagt, dass ein Abstiegsverfahren für die konvex-quadratische Funktion q bei exakter Schrittweitensteuerung und paarweise konjugierten Suchrichtungen nach höchstens n Schritten den globalen Minimalpunkt von q findet („höchstens“, weil ein xk mit k < n zufällig schon ein Minimalpunkt sein kann). Da für ein Abstiegsverfahren wegen  stets
stets  gilt, kann insbesondere keiner der Vektoren dk verschwinden.
gilt, kann insbesondere keiner der Vektoren dk verschwinden.
Im nächsten Schritt suchen wir nach Möglichkeiten, konjugierte Suchrichtungen explizit zu erzeugen. Der folgende Satz besagt, dass man konjugierte Richtungen zum Beispiel aus den Quasi-Newton-Verfahren der Broyden-Familie erhält.
2.2.56 Satz
Für θ ≥ 0 werde Algorithmus 2.6 mit  und
und  auf
auf  mit
mit  angewendet, und für ein
angewendet, und für ein  seien die Iterierten
seien die Iterierten  paarweise verschieden. Dann sind die Richtungen
paarweise verschieden. Dann sind die Richtungen  paarweise konjugiert bezüglich A und sämtlich von null verschieden.
paarweise konjugiert bezüglich A und sämtlich von null verschieden.
Beweis.







Die Verfahren der Broyden-Familie mit θ ≥ 0 sind nach Lemma 2.2.51 Abstiegsverfahren. Solange ein solches Verfahren nicht abbricht, erzeugt es paarweise verschiedene Iterierte, so dass die Voraussetzung des Satzes für den Beginn jeder vom Verfahren generierten Folge (xk) erfüllt ist. Wegen (2.16) sind daher alle Richtungen  von null verschieden.
von null verschieden.



 sieht man diese Behauptung folgendermaßen: Wegen
sieht man diese Behauptung folgendermaßen: Wegen  und (2.16) kann
und (2.16) kann  nicht verschwinden. Damit gilt
nicht verschwinden. Damit gilt
 gerade mit der Sekantengleichung (2.19) überein.
gerade mit der Sekantengleichung (2.19) überein.Die verbleibenden Fälle behandeln wir per vollständiger Induktion über k. Für k = 1 ist die Hilfsbehauptung nur für  zu zeigen, was wegen
zu zeigen, was wegen  aber gerade geschehen ist. Die Hilfsbehauptung gelte nun für ein
aber gerade geschehen ist. Die Hilfsbehauptung gelte nun für ein  und soll für k + 1 bewiesen werden. Wir müssen also die Eigenschaften (2.21) bis (2.23) mit k + 1 anstelle von k für alle
und soll für k + 1 bewiesen werden. Wir müssen also die Eigenschaften (2.21) bis (2.23) mit k + 1 anstelle von k für alle  zeigen. Um die zu zeigenden Eigenschaften von denen aus der Induktionsvoraussetzung unterscheiden zu können, werden wir sie ab jetzt mit (2.21)
zeigen. Um die zu zeigenden Eigenschaften von denen aus der Induktionsvoraussetzung unterscheiden zu können, werden wir sie ab jetzt mit (2.21) bis (2.23)
bis (2.23) bzw. (2.21)k bis (2.23)k adressieren.
bzw. (2.21)k bis (2.23)k adressieren.










Bei Wahl exakter Schrittweiten minimieren die Quasi-Newton-Verfahren der Broyden-Familie konvex-quadratische Funktionen also in höchstens n Schritten. Für eine beliebige C2-Funktion f lässt sich das dahingehend interpretieren, dass sie die lokale quadratische Approximation an f in n Schritten minimieren, im Hinblick auf Übung 2.2.43 also einen Schritt des Newton-Verfahrens simulieren. Unter geeigneten Voraussetzungen und mit Neustarts nach jeweils n Schritten konvergieren sie daher „n-Schritt-quadratisch“ (für Details s. [25]).
2.2.9 Konjugierte-Gradienten-Verfahren
Wie bereits angemerkt möchte man bei hochdimensionalen Problemen vermeiden, Matrizen wie die Bk in den Quasi-Newton-Verfahren abzuspeichern. Man sucht daher nach matrixfreien Möglichkeiten, konjugierte Richtungen zu erzeugen. Verfahren, die iterativ konjugierte Richtungen erzeugen, nennt man Konjugierte-Gradienten-Verfahren oder kurz CG-Verfahren (CG = conjugate gradients).

 sowie
sowie  und bilden die Folge (xk) mit exakten Schrittweiten. Gesucht sind Möglichkeiten, konjugierte Suchrichtungen (dk) zu erzeugen.
und bilden die Folge (xk) mit exakten Schrittweiten. Gesucht sind Möglichkeiten, konjugierte Suchrichtungen (dk) zu erzeugen. zu
zu

2.2.57 Lemma
 paarweise konjugiert bezüglich A und
paarweise konjugiert bezüglich A und  schon generiert mit
schon generiert mit  für
für  . Dann ist dk genau dann konjugiert zu einem
. Dann ist dk genau dann konjugiert zu einem  mit
mit  , wenn
, wenn
Beweis.

 die Behauptung.
die Behauptung.2.2.58 Satz



Beweis.



Algorithmus 2.7: CG-Verfahren von Fletcher-Reeves
Input : C1-Optimierungsproblem P
Output : Approximation  eines kritischen Punkts von f (falls das Verfahren terminiert [25, Th. 5.7])
eines kritischen Punkts von f (falls das Verfahren terminiert [25, Th. 5.7])
1 begin
2 Wähle einen Startpunkt x0, eine Toleranz  und setze
und setze  sowie
sowie  .
.
3 While  do
do
4 Setze  .
.
5 Setze  .
.
6 Ersetze k durch  .
.
7 end
8 Setze  .
.
9 end
Satz 2.2.58 motiviert den Algorithmus 2.7, da er für  mit
mit  nach höchstens n Schritten den globalen Minimalpunkt liefert. Man benutzt dieses Verfahren zum Beispiel zur Lösung hochdimensionaler linearer Gleichungssysteme Ax = b durch den Kleinste-Quadrate-Ansatz
, also per Minimierung von
nach höchstens n Schritten den globalen Minimalpunkt liefert. Man benutzt dieses Verfahren zum Beispiel zur Lösung hochdimensionaler linearer Gleichungssysteme Ax = b durch den Kleinste-Quadrate-Ansatz
, also per Minimierung von  mit dem Residuum r(x) = Ax − b.
mit dem Residuum r(x) = Ax − b.
Wegen Rundungsfehlern (vor allem aufgrund der Division durch  ) bricht das Verfahren aber selten tatsächlich nach n Schritten ab, so dass auch seine Konvergenzgeschwindigkeit untersucht wurde. Es stellt sich heraus, dass sie von der Wurzel der Konditionszahl (also dem Quotienten aus größtem und kleinstem Eigenwert) der Matrix
) bricht das Verfahren aber selten tatsächlich nach n Schritten ab, so dass auch seine Konvergenzgeschwindigkeit untersucht wurde. Es stellt sich heraus, dass sie von der Wurzel der Konditionszahl (also dem Quotienten aus größtem und kleinstem Eigenwert) der Matrix  abhängt. Es bietet sich daher an, das Gleichungssystem Ax = b zunächst so äquivalent umzuformen, dass diese Konditionszahl sinkt. Dies ist als Präkonditionierung
bekannt. Für eine kurze Einführung dazu sei auf [16] verwiesen.
abhängt. Es bietet sich daher an, das Gleichungssystem Ax = b zunächst so äquivalent umzuformen, dass diese Konditionszahl sinkt. Dies ist als Präkonditionierung
bekannt. Für eine kurze Einführung dazu sei auf [16] verwiesen.
2.2.59 Bemerkung
Der Kleinste-Quadrate-Ansatz per CG-Verfahren zur Lösung linearer Gleichungssysteme Ax = b lässt sich auch auf überbestimmte
Gleichungssysteme anwenden, die keine Lösung besitzen. Man gibt sich dann mit dem x zufrieden, das  minimiert, auch wenn der Optimalwert nicht null lautet.
minimiert, auch wenn der Optimalwert nicht null lautet.
Für unterbestimmte
Gleichungssysteme besteht andererseits die Möglichkeit, unter allen Lösungen von Ax = b eine spezielle auszuwählen. Oft wählt man dazu das „kleinste“ x in dem Sinne, dass  über dem Lösungsraum minimiert wird. Dies führt allerdings auf ein restringiertes Optimierungsproblem (Kap. 3).
über dem Lösungsraum minimiert wird. Dies führt allerdings auf ein restringiertes Optimierungsproblem (Kap. 3).
Entscheidend für die Einsetzbarkeit von Algorithmus 2.7 ist, dass für f = q nirgends explizit die Matrix A eingeht, aber trotzdem bezüglich A konjugierte Suchrichtungen erzeugt werden. Man kann das Verfahren also auch für beliebige C1-Funktionen formulieren, wobei in Zeile 4 die exakte Schrittweite  im Allgemeinen durch eine inexakte wie die Armijo-Schrittweite
im Allgemeinen durch eine inexakte wie die Armijo-Schrittweite  ersetzt werden muss. Unter geeigneten Voraussetzungen erhält man wieder, dass n CG-Schritte einen Newton-Schritt simulieren, also „n-Schritt-quadratische Konvergenz“. Dazu empfiehlt sich nach je n Schritten ein „Neustart“, indem man
ersetzt werden muss. Unter geeigneten Voraussetzungen erhält man wieder, dass n CG-Schritte einen Newton-Schritt simulieren, also „n-Schritt-quadratische Konvergenz“. Dazu empfiehlt sich nach je n Schritten ein „Neustart“, indem man  für
für  setzt.
setzt.

 durch diese Ausdrücke andere Verfahren erhält, nämlich die CG-Verfahren von Hestenes-Stiefel bzw. von Polak-Ribière (für Details s. [25]).
durch diese Ausdrücke andere Verfahren erhält, nämlich die CG-Verfahren von Hestenes-Stiefel bzw. von Polak-Ribière (für Details s. [25]).2.2.10 Trust-Region-Verfahren
Im Gegensatz zu klassischen Suchrichtungsverfahren wählen Trust-Region-Verfahren erst den Suchradius t und dann die Suchrichtung d (formal gilt also d = d(t) anstatt t = t(d)). Dazu benutzt man in Iteration k des allgemeinen Abstiegsverfahrens aus Algorithmus 2.3 wie folgt ein quadratisches Modell für f.


 ,
,  und einer symmetrischen Matrix Ak (zum Beispiel, aber nicht notwendigerweise,
und einer symmetrischen Matrix Ak (zum Beispiel, aber nicht notwendigerweise,  ) nennt man die Funktion
) nennt man die Funktion
 und
und  sowie aus der Tatsache, dass mk die Funktion f im Allgemeinen nur für d aus einer hinreichend kleinen Umgebung des Nullpunkts „gut“ beschreibt.
sowie aus der Tatsache, dass mk die Funktion f im Allgemeinen nur für d aus einer hinreichend kleinen Umgebung des Nullpunkts „gut“ beschreibt. mit einem hinreichend kleinen Suchradius tk. Falls das Verhalten von mk auf
mit einem hinreichend kleinen Suchradius tk. Falls das Verhalten von mk auf  „gut“ ist, nennt man
„gut“ ist, nennt man  eine „vertrauenswürdige Umgebung“, also eine Trust Region
. Um hierbei den Begriff „gut“ zu quantifizieren, bestimmt man einen optimalen Punkt dk des Trust-Region-Hilfsproblems
eine „vertrauenswürdige Umgebung“, also eine Trust Region
. Um hierbei den Begriff „gut“ zu quantifizieren, bestimmt man einen optimalen Punkt dk des Trust-Region-Hilfsproblems


 stets positiv ist, und zwar selbst dann, wenn die Matrix Ak nicht positiv definit ist. In der Tat würde die Ungleichung
stets positiv ist, und zwar selbst dann, wenn die Matrix Ak nicht positiv definit ist. In der Tat würde die Ungleichung  wegen der Zulässigkeit von d = 0 für TRk die Identität von mk(0) und
wegen der Zulässigkeit von d = 0 für TRk die Identität von mk(0) und  implizieren, so dass neben dk auch d = 0 Minimalpunkt von TRk wäre. Da die Restriktion von TRk an d = 0 nicht aktiv ist, würde daraus
implizieren, so dass neben dk auch d = 0 Minimalpunkt von TRk wäre. Da die Restriktion von TRk an d = 0 nicht aktiv ist, würde daraus  folgen, im Widerspruch dazu, dass das allgemeine Abstiegsverfahren 2.3 in diesem Fall bereits terminiert hätte.
folgen, im Widerspruch dazu, dass das allgemeine Abstiegsverfahren 2.3 in diesem Fall bereits terminiert hätte.Ein Wert rk < 0 impliziert daher  , d. h.,
, d. h.,  würde einen Anstieg im Zielfunktionswert liefern. Folglich ist die Trust Region zu groß, und ihr Radius tk muss verkleinert werden.
würde einen Anstieg im Zielfunktionswert liefern. Folglich ist die Trust Region zu groß, und ihr Radius tk muss verkleinert werden.
Liegt andererseits rk nahe bei eins, dann beschreibt das lokale Modell die Funktion f sehr gut; man setzt  und vergrößert in der nächsten Iteration probeweise den Trust-Region-Radius tk.
und vergrößert in der nächsten Iteration probeweise den Trust-Region-Radius tk.
Details zu diesem Vorgehen, vor allem zur Annahme von Schritten und zur Veränderung von tk bei anderen Werten von rk, gibt Algorithmus 2.8. Insbesondere für rk ≥ 1/4 wird tk dort nicht verkleinert, und der Schritt wird angenommen, für rk < 0 wird tk verkleinert, und der Schritt wird abgelehnt, und für rk ∈ [0, 1/4) wird tk verkleinert, und der Schritt wird dann abgelehnt, wenn rk ≤ η gilt.
Algorithmus 2.8: Trust-Region-Verfahren
Input : C1-Optimierungsproblem P
Output : Approximation  eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.63)
eines kritischen Punkts von f (falls das Verfahren terminiert; Satz 2.2.63)
1 begin
2 Wähle einen Startpunkt x0, eine Matrix  , eine Toleranz
, eine Toleranz  , einen Maximalradius
, einen Maximalradius  , einen Startradius
, einen Startradius  , einen Parameter
, einen Parameter  und setze
und setze  .
.
3 While  do
do
4 Berechne einen (inexakten) Optimalpunkt dk von TRk und setze

5 If  then
then
6 Setze  .
.
7 else
8 If then
then
9 Setze  .
.
10 else
11 Setze  .
.
12 end
13 end
14 If  thend
thend
15 Setze  .
.
16 else
17 Setze  .
.
18 end
19 Wähle  .
.
20 Ersetze k durch  .
.
21 end
22 Setze  .
.
23 end
 eines Trust-Region-Verfahrens im Vergleich zu einer neuen Iterierten eines Suchrichtungsverfahrens
eines Trust-Region-Verfahrens im Vergleich zu einer neuen Iterierten eines Suchrichtungsverfahrens  mit gleicher Schrittweite. Zumindest in diesem Beispiel führt der Trust-Region-Schritt näher an den Minimalpunkt von f als der Suchrichtungsschritt.
mit gleicher Schrittweite. Zumindest in diesem Beispiel führt der Trust-Region-Schritt näher an den Minimalpunkt von f als der Suchrichtungsschritt.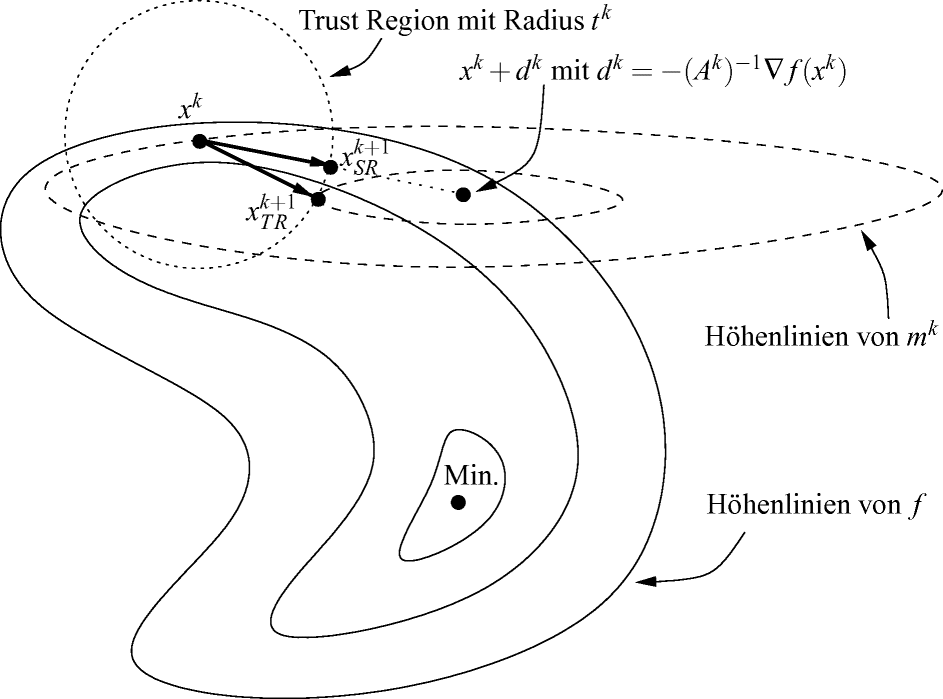
Schritte von Suchrichtungs- und Trust-Region-Verfahren
Je nach Wahl der Matrizen Ak + 1 in Zeile 19 von Algorithmus 2.8 spricht man von Trust-Region-Newton-Verfahren, Trust-Region-BFGS-Verfahren usw. Ein entscheidender Vorteil von Trust-Region-Verfahren gegenüber Variable-Metrik-Verfahren besteht allerdings darin, dass die Matrizen Ak nicht positiv definit zu sein brauchen.


Wir betrachten daher wieder den Fall einer symmetrischen Matrix Ak ≠ 0. Das Problem TRk zu lösen, kann schwer sein, insbesondere für eine indefinite Matrix Ak. Analog zur inexakten eindimensionalen Minimierung bei Suchrichtungsverfahren genügt allerdings auch hier eine inexakte Lösung von TRk, um globale Konvergenz zu gewährleisten.




Fall 1: 

 auf s ∈ [0, 1] streng monoton fällt, ihren Minimalpunkt also in
auf s ∈ [0, 1] streng monoton fällt, ihren Minimalpunkt also in  besitzt.
besitzt.Fall 2: 
 konvex-quadratisch, und Minimalpunkt ist entweder ihr Scheitelpunkt
konvex-quadratisch, und Minimalpunkt ist entweder ihr Scheitelpunkt
 , je nachdem, welcher Wert kleiner ist.
, je nachdem, welcher Wert kleiner ist.

 .
.2.2.60 Definition (Cauchy-Punkt)
Der Punkt  heißt Cauchy-Punkt
zu xk und tk.
heißt Cauchy-Punkt
zu xk und tk.
2.2.61 Übung
 die Ungleichung
die Ungleichung
2.2.62 Bemerkung
Die exakte Lösung  von TRk erfüllt wegen der Zulässigkeit von
von TRk erfüllt wegen der Zulässigkeit von  für TRk die Ungleichung
für TRk die Ungleichung  und damit nach Übung 2.2.61 ebenfalls (2.24) mit c = 1/2.
und damit nach Übung 2.2.61 ebenfalls (2.24) mit c = 1/2.
Wir können nun einen Satz zur globalen Konvergenz formulieren [25, Th. 4.5 und 4.6].
2.2.63 Satz
Die Menge  sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf
sei beschränkt, die Funktion ∇f sei Lipschitz-stetig auf  , die Folge
, die Folge  sei beschränkt, und die Folge (dk) der inexakten Lösungen von TRk erfülle (2.24) mit c > 0. Dann gilt in Algorithmus 2.8:
sei beschränkt, und die Folge (dk) der inexakten Lösungen von TRk erfülle (2.24) mit c > 0. Dann gilt in Algorithmus 2.8:
- a)
Für η = 0 ist
 (d. h., (xk) besitzt einen Häufungspunkt
(d. h., (xk) besitzt einen Häufungspunkt  mit
mit  ).
). - b)
Für η ∈ (0, 1/4) ist
 (d. h., alle Häufungspunkte von (xk) sind kritisch).
(d. h., alle Häufungspunkte von (xk) sind kritisch).
Nach Übung 2.2.61, Bemerkung 2.2.62 und Satz 2.2.63 liefern sowohl die inexakten Lösungen  als auch die exakten Lösungen
als auch die exakten Lösungen  von TRk globale Konvergenz. Während die exakte Lösung
von TRk globale Konvergenz. Während die exakte Lösung  wie erwähnt schwer berechenbar sein kann, ist das Ausweichen auf die inexakte Lösung
wie erwähnt schwer berechenbar sein kann, ist das Ausweichen auf die inexakte Lösung  selten ratsam, da die Matrix Ak lediglich die Länge von
selten ratsam, da die Matrix Ak lediglich die Länge von  beeinflusst und man so im Wesentlichen nach wie vor das Gradientenverfahren erhält.
beeinflusst und man so im Wesentlichen nach wie vor das Gradientenverfahren erhält.
Wir betrachten daher noch zwei in der Praxis gebräuchliche inexakte Approximationen für einen Optimalpunkt dk von TRk, für die ebenfalls  und damit (2.24) mit c = 1/2 gilt (für Details zu Konvergenzaussagen s. [25]). Die erste Möglichkeit besitzt als einschränkende Voraussetzung die positive Definitheit der Matrizen Ak, die zweite hingegen nicht.
und damit (2.24) mit c = 1/2 gilt (für Details zu Konvergenzaussagen s. [25]). Die erste Möglichkeit besitzt als einschränkende Voraussetzung die positive Definitheit der Matrizen Ak, die zweite hingegen nicht.
Dogleg-Methode
 fest und unterschlagen sowie A positiv definit. Wir fragen zunächst danach, wie die exakten Lösungen de(t) von TR sich bei variierendem t ≥ 0 verhalten. Per Definition löst de(t) das Problem
fest und unterschlagen sowie A positiv definit. Wir fragen zunächst danach, wie die exakten Lösungen de(t) von TR sich bei variierendem t ≥ 0 verhalten. Per Definition löst de(t) das Problem
 gegenüber
gegenüber  vernachlässigbar, so dass de(t) dann ungefähr mit der Lösung von
vernachlässigbar, so dass de(t) dann ungefähr mit der Lösung von
 , übereinstimmt. Ist t andererseits hinreichend groß, so erfüllt der unrestringierte Minimalpunkt von
, übereinstimmt. Ist t andererseits hinreichend groß, so erfüllt der unrestringierte Minimalpunkt von  , nämlich
, nämlich
 von TR. Für wachsende t ≥ 0 beschreiben die Punkte x + de(t) also typischerweise eine Kurve von x nach x + dA, wie sie in Abb. 2.10 dargestellt ist.
von TR. Für wachsende t ≥ 0 beschreiben die Punkte x + de(t) also typischerweise eine Kurve von x nach x + dA, wie sie in Abb. 2.10 dargestellt ist.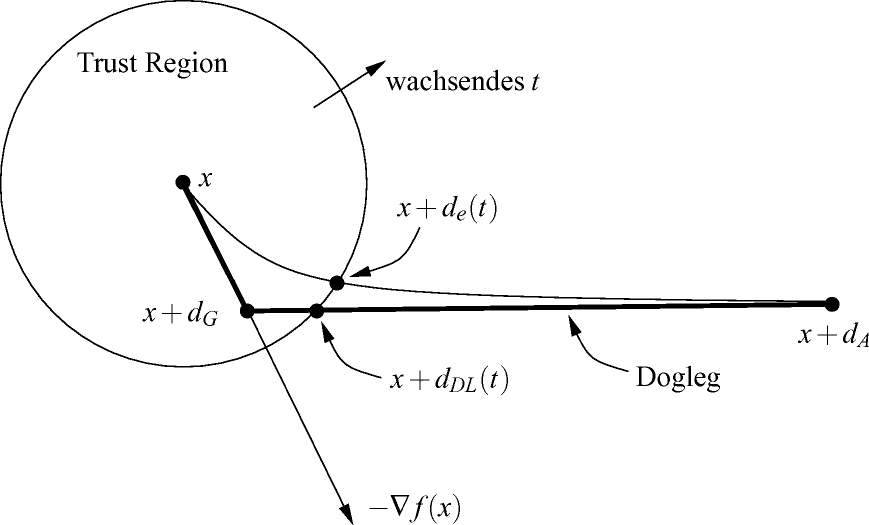
Approximation der Kurve  per Dogleg
per Dogleg

![$\{\,x + \widetilde d(s)|\ s\in[0,2]\,\}$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_IEq1127.png) mit
mit
2.2.64 Übung
Zeigen Sie für  :
:
- a)
 ist monoton wachsend in s.
ist monoton wachsend in s. - b)
 ist monoton fallend in s.
ist monoton fallend in s.
 den Rand der Trust Region gar nicht und sonst in genau einem Punkt. Dieser ist aus
den Rand der Trust Region gar nicht und sonst in genau einem Punkt. Dieser ist aus![$$
\begin{array}{ll}
\|s\cdot d_G\|_2\ =\ t\,, & \text{falls }\ t<\|d_G\|_2\\[1ex]
\|d_G + (s-1)(d_A-d_G)\|_2\ =\ t\,, & \text{sonst}
\end{array}
$$](../images/439970_1_De_2_Chapter/439970_1_De_2_Chapter_TeX_Equiz.png)
 gerade dA ist und im Fall
gerade dA ist und im Fall  der obige Schnittpunkt des Polygonzugs mit dem Rand der Trust Region. Die jeweilige Lösung ist die von der Dogleg-Methode gewählte inexakte Lösung dDL(t) für TR, mit der die neue Iterierte x + dDL(t) generiert wird.
der obige Schnittpunkt des Polygonzugs mit dem Rand der Trust Region. Die jeweilige Lösung ist die von der Dogleg-Methode gewählte inexakte Lösung dDL(t) für TR, mit der die neue Iterierte x + dDL(t) generiert wird.Minimierung auf einem zweidimensionalen Teilraum

Ein Hauptvorteil dieses Ansatzes besteht darin, dass er sich im Gegensatz zur Dogleg-Methode sinnvoll auf indefinite Matrizen A erweitern lässt. Für Details sei auf [25] verwiesen.