C# is Microsoft’s premier language for .NET development. It leverages time-tested features with cutting-edge innovations and provides a highly usable, efficient way to write programs for the modern enterprise computing environment. It is, by any measure, one of the most important languages of the twenty-first century.
The purpose of this chapter is to place C# into its historical context, including the forces that drove its creation, its design philosophy, and how it was influenced by other computer languages. This chapter also explains how C# relates to the .NET Framework. As you will see, C# and the .NET Framework work together to create a highly refined programming environment.
Computer languages do not exist in a void. Rather, they relate to one another, with each new language influenced in one form or another by the ones that came before. In a process akin to cross-pollination, features from one language are adapted by another, a new innovation is integrated into an existing context, or an older construct is removed. In this way, languages evolve and the art of programming advances. C# is no exception.
C# inherits a rich programming legacy. It is directly descended from two of the world’s most successful computer languages: C and C++. It is closely related to another: Java. Understanding the nature of these relationships is crucial to understanding C#. Thus, we begin our examination of C# by placing it in the historical context of these three languages.
The creation of C marks the beginning of the modern age of programming. C was invented by Dennis Ritchie in the 1970s on a DEC PDP-11 that used the UNIX operating system. While some earlier languages, most notably Pascal, had achieved significant success, it was C that established the paradigm that still charts the course of programming today.
C grew out of the structured programming revolution of the 1960s. Prior to structured programming, large programs were difficult to write because the program logic tended to degenerate into what is known as “spaghetti code,” a tangled mass of jumps, calls, and returns that is difficult to follow. Structured languages addressed this problem by adding well-defined control statements, subroutines with local variables, and other improvements. Through the use of structured techniques programs became better organized, more reliable, and easier to manage.
Although there were other structured languages at the time, C was the first to successfully combine power, elegance, and expressiveness. Its terse, yet easy-to-use syntax coupled with its philosophy that the programmer (not the language) was in charge quickly won many converts. It can be a bit hard to understand from today’s perspective, but C was a breath of fresh air that programmers had long awaited. As a result, C became the most widely used structured programming language of the 1980s.
However, even the venerable C language had its limits. One of the most troublesome was its inability to handle large programs. The C language hits a barrier once a project reaches a certain size, and after that point, C programs are difficult to understand and maintain. Precisely where this limit is reached depends upon the program, the programmer, and the tools at hand, but there is always a threshold beyond which a C program becomes unmanageable.
By the late 1970s, the size of many projects was near or at the limits of what structured programming methodologies and the C language could handle. To solve this problem, a new way to program began to emerge. This method is called object-oriented programming (OOP). Using OOP, a programmer could handle much larger programs. The trouble was that C, the most popular language at the time, did not support object-oriented programming. The desire for an object-oriented version of C ultimately led to the creation of C++.
C++ was invented by Bjarne Stroustrup beginning in 1979 at Bell Laboratories in Murray Hill, New Jersey. He initially called the new language “C with Classes.” However, in 1983 the name was changed to C++. C++ contains the entire C language. Thus, C is the foundation upon which C++ is built. Most of the additions that Stroustrup made to C were designed to support object-oriented programming. In essence, C++ is the object-oriented version of C. By building upon the foundation of C, Stroustrup provided a smooth migration path to OOP. Instead of having to learn an entirely new language, a C programmer needed to learn only a few new features before reaping the benefits of the object-oriented methodology.
C++ simmered in the background during much of the 1980s, undergoing extensive development. By the beginning of the 1990s, C++ was ready for mainstream use, and its popularity exploded. By the end of the decade, it had become the most widely used programming language. Today, C++ is still the preeminent language for the development of high-performance system code.
It is critical to understand that the invention of C++ was not an attempt to create an entirely new programming language. Instead, it was an enhancement to an already highly successful language. This approach to language development—beginning with an existing language and moving it forward—established a trend that continues today.
The next major advance in programming languages is Java. Work on Java, which was originally called Oak, began in 1991 at Sun Microsystems. The main driving force behind Java’s design was James Gosling. Patrick Naughton, Chris Warth, Ed Frank, and Mike Sheridan also played a role.
Java is a structured, object-oriented language with a syntax and philosophy derived from C++. The innovative aspects of Java were driven not so much by advances in the art of programming (although some certainly were), but rather by changes in the computing environment. Prior to the mainstreaming of the Internet, most programs were written, compiled, and targeted for a specific CPU and a specific operating system. While it has always been true that programmers like to reuse their code, the ability to port a program easily from one environment to another took a backseat to more pressing problems. However, with the rise of the Internet, in which many different types of CPUs and operating systems are connected, the old problem of portability reemerged with a vengeance. To solve the problem of portability, a new language was needed, and this new language was Java.
Although the single most important aspect of Java (and the reason for its rapid acceptance) is its ability to create cross-platform, portable code, it is interesting to note that the original impetus for Java was not the Internet, but rather the need for a platform-independent language that could be used to create software for embedded controllers. In 1993, it became clear that the issues of cross-platform portability found when creating code for embedded controllers are also encountered when attempting to create code for the Internet. Remember: the Internet is a vast, distributed computing universe in which many different types of computers live. The same techniques that solved the portability problem on a small scale could be applied to the Internet on a large scale.
Java achieved portability by translating a program’s source code into an intermediate language called bytecode. This bytecode was then executed by the Java Virtual Machine (JVM). Therefore, a Java program could run in any environment for which a JVM was available. Also, since the JVM is relatively easy to implement, it was readily available for a large number of environments.
Java’s use of bytecode differed radically from both C and C++, which were nearly always compiled to executable machine code. Machine code is tied to a specific CPU and operating system. Thus, if you wanted to run a C/C++ program on a different system, it needed to be recompiled to machine code specifically for that environment. Therefore, to create a C/C++ program that would run in a variety of environments, several different executable versions of the program would be needed. Not only was this impractical, it was expensive. Java’s use of an intermediate language was an elegant, cost-effective solution. It is also a solution that C# would adapt for its own purposes.
As mentioned, Java is descended from C and C++. Its syntax is based on C, and its object model is evolved from C++. Although Java code is neither upwardly nor downwardly compatible with C or C++, its syntax is sufficiently similar that the large pool of existing C/C++ programmers could move to Java with very little effort. Furthermore, because Java built upon and improved an existing paradigm, Gosling, et al., were free to focus their attentions on the new and innovative features. Just as Stroustrup did not need to “reinvent the wheel” when creating C++, Gosling did not need to create an entirely new language when developing Java. Moreover, with the creation of Java, C and C++ became an accepted substrata upon which to base a new computer language.
While Java successfully addresses many of the issues surrounding portability in the Internet environment, there are still features that it lacks. One is cross-language interoperability, also called mixed-language programming. This is the ability for the code produced by one language to work easily with the code produced by another. Cross-language interoperability is needed for the creation of large, distributed software systems. It is also desirable for programming software components because the most valuable component is one that can be used by the widest variety of computer languages, in the greatest number of operating environments.
Another feature lacking in Java is full integration with the Windows platform. Although Java programs can be executed in a Windows environment (assuming that the Java Virtual Machine has been installed), Java and Windows are not closely coupled. Since Windows is the mostly widely used operating system in the world, lack of direct support for Windows is a drawback to Java.
To answer these and other needs, Microsoft developed C#. C# was created at Microsoft late in the 1990s and was part of Microsoft’s overall .NET strategy. It was first released in its alpha version in the middle of 2000. C#’s chief architect was Anders Hejlsberg. Hejlsberg is one of the world’s leading language experts, with several notable accomplishments to his credit. For example, in the 1980s he was the original author of the highly successful and influential Turbo Pascal, whose streamlined implementation set the standard for all future compilers.
C# is directly related to C, C++, and Java. This is not by accident. These are three of the most widely used—and most widely liked—programming languages in the world. Furthermore, at the time of C#’s creation, nearly all professional programmers knew C, C++, and/or Java. By building C# upon a solid, well-understood foundation, C# offered an easy migration path from these languages. Since it was neither necessary nor desirable for Hejlsberg to “reinvent the wheel,” he was free to focus on specific improvements and innovations.
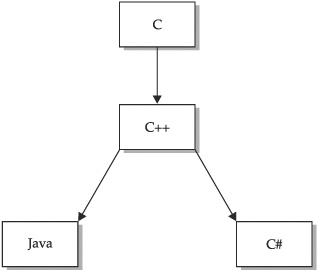
The family tree for C# is shown in Figure 1-1. The grandfather of C# is C. From C, C# derives its syntax, many of its keywords, and its operators. C# builds upon and improves the object model defined by C++. If you know C or C++, then you will feel at home with C#.
C# and Java have a bit more complicated relationship. As explained, Java is also descended from C and C++. It too shares the C/C++ syntax and object model. Like Java, C# is designed to produce portable code. However, C# is not descended from Java. Instead, C# and Java are more like cousins, sharing a common ancestry, but differing in many important ways. The good news, though, is that if you know Java, then many C# concepts will be familiar. Conversely, if in the future you need to learn Java, then many of the things you learn about C# will carry over.
C# contains many innovative features that we will examine at length throughout the course of this book, but some of its most important relate to its built-in support for software components. In fact, C# has been characterized as being a component-oriented language because it contains integral support for the writing of software components. For example, C# includes features that directly support the constituents of components, such as properties, methods, and events. However, C#’s ability to work in a secure, mixed-language environment is perhaps its most important component-oriented feature.
Since its original 1.0 release, C# has been evolving at a rapid pace. Not long after C# 1.0, Microsoft released version 1.1. It contained many minor tweaks but added no major features. However, the situation was much different with the release of C# 2.0.
C# 2.0 was a watershed event in the lifecycle of C# because it added many new features, such as generics, partial types, and anonymous methods, that fundamentally expanded the scope, power, and range of the language. Version 2.0 firmly put C# at the forefront of computer language development. It also demonstrated Microsoft’s long-term commitment to the language.
The next major release of C# was 3.0. Because of the many new features added by C# 2.0, one might have expected the development of C# to slow a bit, just to let programmers catch up, but this was not the case. With the release of C# 3.0, Microsoft once again put C# on the cutting edge of language design, this time adding a set of innovative features that redefined the programming landscape. These include lambda expressions, language-integrated query (LINQ), extension methods, and implicitly typed variables, among others. Although all of the new 3.0 features were important, the two that had the most high-profile impact on the language were LINQ and lambda expressions. They added a completely new dimension to C# and further emphasized its lead in the ongoing evolution of computer languages.
The current release is C# 4.0, and that is the version of C# described by this book. C# 4.0 builds on the strong foundation established by the previous three major releases, adding several new features. Perhaps the most important are named and optional arguments. Named arguments let you link an argument with a parameter by name. Optional arguments give you a way to specify a default argument for a parameter. Another important new feature is the dynamic type, which is used to declare objects that are type-checked at runtime, rather than compile time. Covariance and contravariance support is also provided for type parameters, which are supported by new uses of the in and out keywords. For those programmers using the Office Automation APIs (and COM in general), access has been simplified. (Office Automation and COM are outside the scope of this book). In general, the new 4.0 features further streamline coding and improve the usability of C#.
There is another major feature that relates directly to C# 4.0 programming, but which is provided by the .NET Framework 4.0. This is support for parallel programming through two major new features. The first is the Task Parallel Library (TPL) and the second is Parallel LINQ (PLINQ). Both of these dramatically enhance and simplify the process of creating programs that use concurrency. Both also make it easier to create multithreaded code that automatically scales to utilize the number of processors available in the computer. Put directly, multicore computers are becoming commonplace, and the ability to parallelize your code to take advantage of them is an increasingly important part of nearly every C# programmer’s job description. Because of the significant impact the TPL and PLINQ are having on programming, both are covered in this book.
Although C# is a computer language that can be studied on its own, it has a special relationship to its runtime environment, the .NET Framework. The reason for this is twofold. First, C# was initially designed by Microsoft to create code for the .NET Framework. Second, the libraries used by C# are the ones defined by the .NET Framework. Thus, even though it is theoretically possible to separate C# the language from the .NET environment, the two are closely linked. Because of this, it is important to have a general understanding of the .NET Framework and why it is important to C#.
The .NET Framework defines an environment that supports the development and execution of highly distributed, component-based applications. It enables differing computer languages to work together and provides for security, program portability, and a common programming model for the Windows platform. As it relates to C#, the .NET Framework defines two very important entities. The first is the Common Language Runtime (CLR). This is the system that manages the execution of your program. Along with other benefits, the Common Language Runtime is the part of the .NET Framework that enables programs to be portable, supports mixed-language programming, and provides for secure execution.
The second entity is the .NET class library. This library gives your program access to the runtime environment. For example, if you want to perform I/O, such as displaying something on the screen, you will use the .NET class library to do it. If you are new to programming, then the term class may be new. Although it is explained in detail later in this book, for now a brief definition will suffice: a class is an object-oriented construct that helps organize programs. As long as your program restricts itself to the features defined by the .NET class library, your programs can run anywhere that the .NET runtime system is supported. Since C# automatically uses the .NET Framework class library, C# programs are automatically portable to all .NET environments.
The Common Language Runtime manages the execution of .NET code. Here is how it works: When you compile a C# program, the output of the compiler is not executable code. Instead, it is a file that contains a special type of pseudocode called Microsoft Intermediate Language (MSIL). MSIL defines a set of portable instructions that are independent of any specific CPU. In essence, MSIL defines a portable assembly language. One other point: although MSIL is similar in concept to Java’s bytecode, the two are not the same.
It is the job of the CLR to translate the intermediate code into executable code when a program is run. Thus, any program compiled to MSIL can be run in any environment for which the CLR is implemented. This is part of how the .NET Framework achieves portability.
Microsoft Intermediate Language is turned into executable code using a JIT compiler. “JIT” stands for “Just-In-Time.” The process works like this: When a .NET program is executed, the CLR activates the JIT compiler. The JIT compiler converts MSIL into native code on demand as each part of your program is needed. Thus, your C# program actually executes as native code even though it is initially compiled into MSIL. This means that your program runs nearly as fast as it would if it had been compiled to native code in the first place, but it gains the portability benefits of MSIL. Also, during compilation, code verification takes place to ensure type safety (unless a security policy has been established that avoids this step).
In addition to MSIL, one other thing is output when you compile a C# program: metadata. Metadata describes the data used by your program and enables your code to interact easily with other code. The metadata is contained in the same file as the MSIL.
In general, when you write a C# program, you are creating what is called managed code. Managed code is executed under the control of the Common Language Runtime, as just described. Because it is running under the control of the CLR, managed code is subject to certain constraints—and derives several benefits. The constraints are easily described and met: the compiler must produce an MSIL file targeted for the CLR (which C# does) and use the .NET class library (which C# does). The benefits of managed code are many, including modern memory management, the ability to mix languages, better security, support for version control, and a clean way for software components to interact.
The opposite of managed code is unmanaged code. Unmanaged code does not execute under the Common Language Runtime. Thus, Windows programs prior to the creation of the .NET Framework use unmanaged code. It is possible for managed code and unmanaged code to work together, so the fact that C# generates managed code does not restrict its ability to operate in conjunction with preexisting programs.
Although all managed code gains the benefits provided by the CLR, if your code will be used by other programs written in different languages, then, for maximum usability, it should adhere to the Common Language Specification (CLS). The CLS describes a set of features that different .NET-compatible languages have in common. CLS compliance is especially important when creating software components that will be used by other languages. The CLS includes a subset of the Common Type System (CTS). The CTS defines the rules concerning data types. Of course, C# supports both the CLS and the CTS.