By far, the hardest thing about learning a programming language is the fact that no element exists in isolation. Instead, the components of the language work together. This interrelatedness makes it difficult to discuss one aspect of C# without involving another. To help overcome this problem, this chapter provides a brief overview of several C# features, including the general form of a C# program, some basic control statements, and operators. It does not go into too many details, but rather concentrates on the general concepts common to any C# program. Most of the topics discussed here are examined in greater detail in the remaining chapters of Part I.
At the center of C# is object-oriented programming (OOP). The object-oriented methodology is inseparable from C#, and all C# programs are to at least some extent object oriented. Because of its importance to C#, it is useful to understand OOP’s basic principles before you write even a simple C# program.
OOP is a powerful way to approach the job of programming. Programming methodologies have changed dramatically since the invention of the computer, primarily to accommodate the increasing complexity of programs. For example, when computers were first invented, programming was done by toggling in the binary machine instructions using the computer’s front panel. As long as programs were just a few hundred instructions long, this approach worked. As programs grew, assembly language was invented so that a programmer could deal with larger, increasingly complex programs, using symbolic representations of the machine instructions. As programs continued to grow, high-level languages such as FORTRAN and COBOL were introduced that gave the programmer more tools with which to handle complexity. When these early languages began to reach their breaking point, structured programming languages, such as C, were invented.
At each milestone in the history of programming, techniques and tools were created to allow the programmer to deal with increasingly greater complexity. Each step of the way, the new approach took the best elements of the previous methods and moved forward. The same is true of object-oriented programming. Prior to OOP, many projects were nearing (or exceeding) the point where the structured approach no longer worked. A better way to handle complexity was needed, and object-oriented programming was the solution.
Object-oriented programming took the best ideas of structured programming and combined them with several new concepts. The result was a different and better way of organizing a program. In the most general sense, a program can be organized in one of two ways: around its code (what is happening) or around its data (what is being affected). Using only structured programming techniques, programs are typically organized around code. This approach can be thought of as “code acting on data.”
Object-oriented programs work the other way around. They are organized around data, with the key principle being “data controlling access to code.” In an object-oriented language, you define the data and the code that is permitted to act on that data. Thus, a data type defines precisely the operations that can be applied to that data.
To support the principles of object-oriented programming, all OOP languages, including C#, have three traits in common: encapsulation, polymorphism, and inheritance. Let’s examine each.
Encapsulation is a programming mechanism that binds together code and the data it manipulates, and that keeps both safe from outside interference and misuse. In an object-oriented language, code and data can be bound together in such a way that a self-contained black box is created. Within the box are all necessary data and code. When code and data are linked together in this fashion, an object is created. In other words, an object is the device that supports encapsulation.
Within an object, the code, data, or both may be private to that object or public. Private code or data is known to and accessible by only another part of the object. That is, private code or data cannot be accessed by a piece of the program that exists outside the object. When code or data is public, other parts of your program can access it even though it is defined within an object. Typically, the public parts of an object are used to provide a controlled interface to the private elements.
C#’s basic unit of encapsulation is the class. A class defines the form of an object. It specifies both the data and the code that will operate on that data. C# uses a class specification to construct objects. Objects are instances of a class. Thus, a class is essentially a set of plans that specify how to build an object.
Collectively, the code and data that constitute a class are called its members. The data defined by the class is referred to as fields. The terms member variables and instance variables also are used. The code that operates on that data is contained within function members, of which the most common is the method. Method is C#’s term for a subroutine. (Other function members include properties, events, and constructors.) Thus, the methods of a class contain code that acts on the fields defined by that class.
Polymorphism (from Greek, meaning “many forms”) is the quality that allows one interface to access a general class of actions. A simple example of polymorphism is found in the steering wheel of an automobile. The steering wheel (the interface) is the same no matter what type of actual steering mechanism is used. That is, the steering wheel works the same whether your car has manual steering, power steering, or rack-and-pinion steering. Thus, turning the steering wheel left causes the car to go left no matter what type of steering is used. The benefit of the uniform interface is, of course, that once you know how to operate the steering wheel, you can drive any type of car.
The same principle can also apply to programming. For example, consider a stack (which is a first-in, last-out list). You might have a program that requires three different types of stacks. One stack is used for integer values, one for floating-point values, and one for characters. In this case, the algorithm that implements each stack is the same, even though the data being stored differs. In a non-object-oriented language, you would be required to create three different sets of stack routines, with each set using different names. However, because of polymorphism, in C# you can create one general set of stack routines that works for all three specific situations. This way, once you know how to use one stack, you can use them all.
More generally, the concept of polymorphism is often expressed by the phrase “one interface, multiple methods.” This means that it is possible to design a generic interface to a group of related activities. Polymorphism helps reduce complexity by allowing the same interface to be used to specify a general class of action. It is the compiler’s job to select the specific action (that is, method) as it applies to each situation. You, the programmer, don’t need to do this selection manually. You need only remember and utilize the general interface.
Inheritance is the process by which one object can acquire the properties of another object. This is important because it supports the concept of hierarchical classification. If you think about it, most knowledge is made manageable by hierarchical (that is, top-down) classifications. For example, a Red Delicious apple is part of the classification apple, which in turn is part of the fruit class, which is under the larger class food. That is, the food class possesses certain qualities (edible, nutritious, and so on) which also, logically, apply to its subclass, fruit. In addition to these qualities, the fruit class has specific characteristics (juicy, sweet, and so on) that distinguish it from other food. The apple class defines those qualities specific to an apple (grows on trees, not tropical, and so on). A Red Delicious apple would, in turn, inherit all the qualities of all preceding classes and would define only those qualities that make it unique.
Without the use of hierarchies, each object would have to explicitly define all of its characteristics. Using inheritance, an object need only define those qualities that make it unique within its class. It can inherit its general attributes from its parent. Thus, the inheritance mechanism makes it possible for one object to be a specific instance of a more general case.
It is now time to look at an actual C# program. We will begin by compiling and running the short program shown next.
/*
This is a simple C# program.
Call this program Example.cs.
*/
using System;
class Example {
// A C# program begins with a call to Main().
static void Main() {
Console.WriteLine("A simple C# program.");
}
}
The primary development environment for C# is Microsoft’s Visual Studio. To compile all of the programs in this book, including those that use the new C# 4.0 features, you will need to use a version of Visual Studio 2010 (or later) that supports C#.
Using Visual Studio, there are two general approaches that you can take to creating, compiling, and running a C# program. First, you can use the Visual Studio IDE. Second, you can use the command-line compiler, csc.exe. Both methods are described here.
Although the Visual Studio IDE is what you will probably be using for your commercial projects, some readers will find the C# command-line compiler more convenient, especially for compiling and running the sample programs shown in this book. The reason is that you don’t have to create a project for the program. You can simply create the program and then compile it and run it—all from the command line. Therefore, if you know how to use the Command Prompt window and its command-line interface, using the command-line compiler will be faster and easier than using the IDE.
CAUTION If you are not familiar with the Command Prompt window, then it is probably better to use the Visual Studio IDE. Although the Command Prompt is not difficult to master, trying to learn both the Command Prompt and C# at the same time will be a challenging experience.
To create and run programs using the C# command-line compiler, follow these three steps:
1. Enter the program using a text editor.
2. Compile the program using csc.exe.
3. Run the program.
The source code for programs shown in this book is available at www.mhprofessional.com. However, if you want to enter the programs by hand, you are free to do so. In this case, you must enter the program into your computer using a text editor, such as Notepad. Remember, you must create text-only files, not formatted word-processor files, because the format information in a word processor file will confuse the C# compiler. When entering the program, call the file Example.cs.
To compile the program, execute the C# compiler, csc.exe, specifying the name of the source file on the command line, as shown here:
C:\>csc Example.cs
The csc compiler creates a file called Example.exe that contains the MSIL version of the program. Although MSIL is not executable code, it is still contained in an exe file. The Common Language Runtime automatically invokes the JIT compiler when you attempt to execute Example.exe. Be aware, however, that if you try to execute Example.exe (or any other exe file that contains MSIL) on a computer for which the .NET Framework is not installed, the program will not execute because the CLR will be missing.
NOTE Prior to running csc.exe you will need to open a Command Prompt window that is configured for Visual Studio. The easiest way to do this is to select Visual Studio Command Prompt under Visual Studio Tools in the Start menu. Alternatively, you can start an unconfigured Command Prompt window and then run the batch file vsvars32.bat, which is provided by Visual Studio.
To actually run the program, just type its name on the command line, as shown here:
C:\>Example
When the program is run, the following output is displayed:
A simple C# program.
Visual Studio is Microsoft’s integrated programming environment (IDE). It lets you edit, compile, run, and debug a C# program, all without leaving its well-thought-out environment. Visual Studio offers convenience and helps manage your programs. It is most effective for larger projects, but it can be used to great success with smaller programs, such as those that constitute the examples in this book.
The steps required to edit, compile, and run a C# program using the Visual Studio 2010 IDE are shown here. These steps assume the IDE provided by Visual Studio 2010 Professional. Slight differences may exist with other versions of Visual Studio.
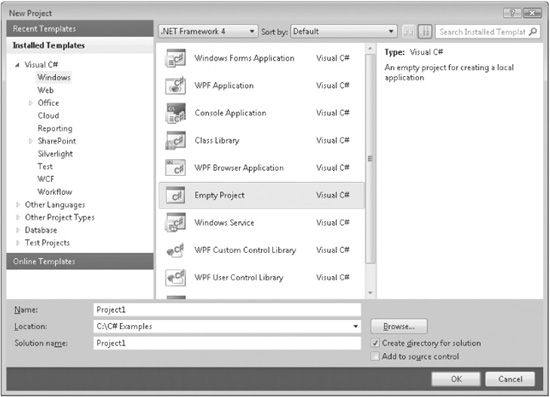
1. Create a new, empty C# project by selecting File | New | Project. Then, select Windows in the Installed Templates list. Next, select Empty Project:
Then, press OK to create the project.
NOTE The name of your project and its location may differ from that shown here.
2. Once the new project is created, the Visual Studio IDE will look like this:
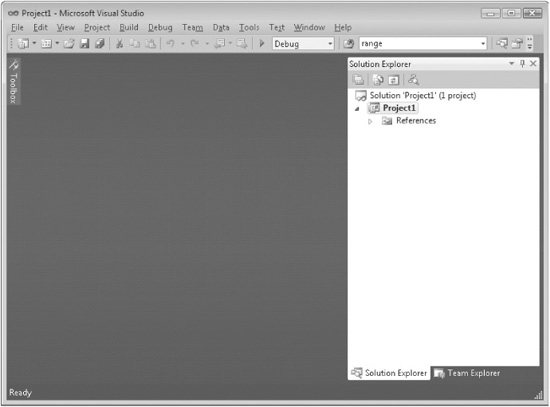
If for some reason you do not see the Solution Explorer window, activate it by selecting Solution Explorer from the View menu.
3. At this point, the project is empty and you will need to add a C# source file to it. Do this by right-clicking on the project’s name (which is Project1 in this example) in the Solution Explorer and then selecting Add. You will see the following:
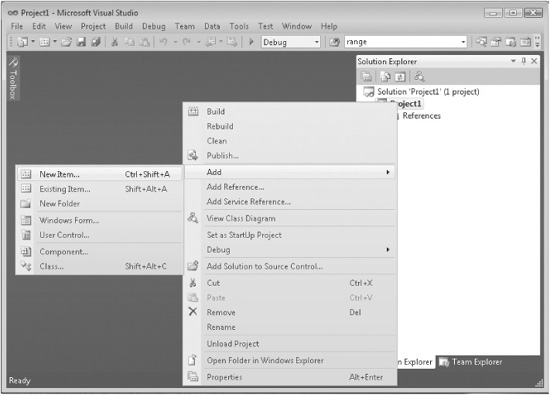
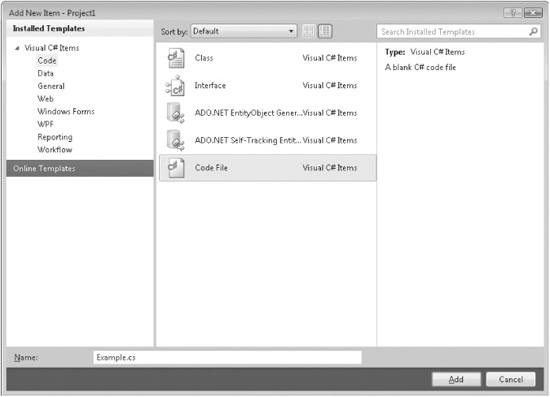
4. Next, select New Item. This causes the Add New Item dialog to be displayed. Select Code in the Installed Templates list. Next, select Code File and then change the name to Example.cs, as shown here:
5. Next, add the file to the project by pressing Add. Your screen will now look like this:
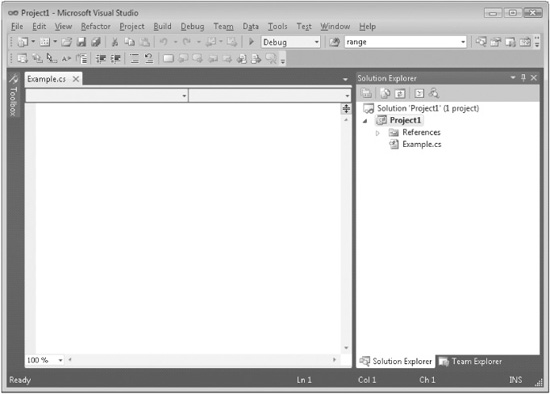
6. Next, type the example program into the Example.cs window. (You can download the source code to the programs in this book from www.mhprofessional.com so you won’t have to type in each example manually.) When done, your screen will look like this:
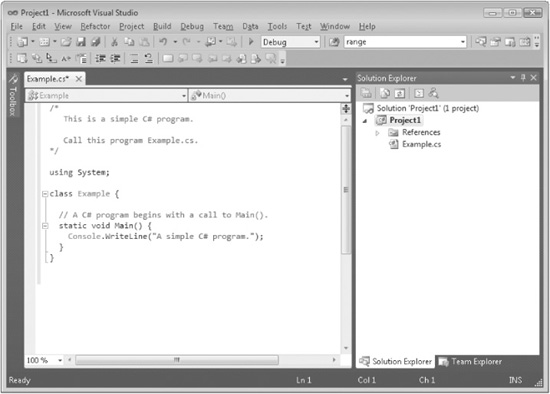
7. Compile the program by selecting Build Solution from the Build menu.
8. Run the program by selecting Start Without Debugging from the Debug menu. When you run the program, you will see the window shown here.
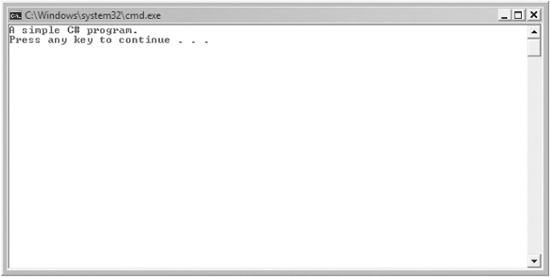
As the preceding instructions show, compiling short sample programs using the IDE involves a number of steps. However, you don’t need to create a new project for each example program in this book. Instead, you can use the same C# project. Just delete the current source file and add the new file. Then recompile and run. This approach greatly simplifies the process. Understand, however, that for real-world applications, each program will use its own project.
NOTE Although the preceding instructions are sufficient to compile and run the programs in this book, if you will be using the Visual Studio IDE for your main work environment, you should become familiar with all of its capabilities and features. It is a very powerful development environment that helps make large projects manageable. The IDE also provides a way of organizing the files and resources associated with a project. It is worth the time and effort that you spend to become proficient at running Visual Studio.
Although Example.cs is quite short, it includes several key features that are common to all C# programs. Let’s closely examine each part of the program, beginning with its name.
The name of a C# program is arbitrary. Unlike some computer languages (most notably, Java) in which the name of a program file is very important, this is not the case for C#. You were told to call the sample program Example.cs so that the instructions for compiling and running the program would apply, but as far as C# is concerned, you could have called the file by another name. For example, the preceding sample program could have been called Sample.cs, Test.cs, or even X.cs.
By convention, C# programs use the .cs file extension, and this is a convention that you should follow. Also, many programmers call a file by the name of the principal class defined within the file. This is why the filename Example.cs was chosen. Since the names of C# programs are arbitrary, names won’t be specified for most of the sample programs in this book. Just use names of your own choosing.
The program begins with the following lines:
/*
This is a simple C# program.
Call this program Example.cs.
*/
This is a comment. Like most other programming languages, C# lets you enter a remark into a program’s source file. The contents of a comment are ignored by the compiler. Instead, a comment describes or explains the operation of the program to anyone who is reading its source code. In this case, the comment describes the program and reminds you to call the source file Example.cs. Of course, in real applications, comments generally explain how some part of the program works or what a specific feature does.
C# supports three styles of comments. The one shown at the top of the program is called a multiline comment. This type of comment must begin with /* and end with */. Anything between these two comment symbols is ignored by the compiler. As the name suggests, a multiline comment can be several lines long.
The next line in the program is
using System;
This line indicates that the program is using the System namespace. In C#, a namespace defines a declarative region. Although we will examine namespaces in detail later in this book, a brief description is useful now. Through the use of namespaces, it is possible to keep one set of names separate from another. In essence, names declared in one namespace will not conflict with names declared in a different namespace. The namespace used by the program is System, which is the namespace reserved for items associated with the .NET Framework class library, which is the library used by C#. The using keyword simply states that the program is using the names in the given namespace. (As a point of interest, it is also possible to create your own namespaces, which is especially helpful for large projects.)
The next line of code in the program is shown here:
class Example {
This line uses the keyword class to declare that a new class is being defined. As mentioned, the class is C#’s basic unit of encapsulation. Example is the name of the class. The class definition begins with the opening curly brace ({) and ends with the closing curly brace (}). The elements between the two braces are members of the class. For the moment, don’t worry too much about the details of a class except to note that in C#, most program activity occurs within one.
The next line in the program is the single-line comment, shown here:
// A C# program begins with a call to Main().
This is the second type of comment supported by C#. A single-line comment begins with a // and ends at the end of the line. Although styles vary, it is not uncommon for programmers to use multiline comments for longer remarks and single-line comments for brief, line-byline descriptions. (The third type of comment supported by C# aids in the creation of documentation and is described in the Appendix.)
The next line of code is shown here:
static void Main() {
This line begins the Main() method. As mentioned earlier, in C#, a subroutine is called a method. As the comment preceding it suggests, this is the line at which the program will begin executing. All C# applications begin execution by calling Main(). The complete meaning of each part of this line cannot be given now, since it involves a detailed understanding of several other C# features. However, since many of the examples in this book will use this line of code, we will take a brief look at it here.
The line begins with the keyword static. A method that is modified by static can be called before an object of its class has been created. This is necessary because Main() is called at program startup. The keyword void indicates that Main() does not return a value. As you will see, methods can also return values. The empty parentheses that follow Main indicate that no information is passed to Main(). Although it is possible to pass information into Main(), none is passed in this example. The last character on the line is the {. This signals the start of Main()’s body. All of the code that comprises a method will occur between the method’s opening curly brace and its closing curly brace.
The next line of code is shown here. Notice that it occurs inside Main().
Console.WriteLine("A simple C# program.");
This line outputs the string “A simple C# program.” followed by a new line on the screen. Output is actually accomplished by the built-in method WriteLine(). In this case, WriteLine() displays the string that is passed to it. Information that is passed to a method is called an argument. In addition to strings, WriteLine() can be used to display other types of information. The line begins with Console, which is the name of a predefined class that supports console I/O. By connecting Console with WriteLine(), you are telling the compiler that WriteLine() is a member of the Console class. The fact that C# uses an object to define console output is further evidence of its object-oriented nature.
Notice that the WriteLine() statement ends with a semicolon, as does the using System statement earlier in the program. In general, statements in C# end with a semicolon. The exception to this rule are blocks, which begin with a { and end with a }. This is why those lines in the program don’t end with a semicolon. Blocks provide a mechanism for grouping statements and are discussed later in this chapter.
The first } in the program ends Main(), and the last } ends the Example class definition.
One last point: C# is case-sensitive. Forgetting this can cause serious problems. For example, if you accidentally type main instead of Main, or writeline instead of WriteLine, the preceding program will be incorrect. Furthermore, although the C# compiler will compile classes that do not contain a Main() method, it has no way to execute them. So, had you mistyped Main, you would see an error message that states that Example.exe does not have an entry point defined.
If you are new to programming, it is important to learn how to interpret and respond to errors that may occur when you try to compile a program. Most compilation errors are caused by typing mistakes. As all programmers soon find out, accidentally typing something incorrectly is quite easy. Fortunately, if you type something wrong, the compiler will report a syntax error message when it tries to compile your program. This message gives you the line number at which the error is found and a description of the error itself.
Although the syntax errors reported by the compiler are, obviously, helpful, they sometimes can also be misleading. The C# compiler attempts to make sense out of your source code no matter what you have written. For this reason, the error that is reported may not always reflect the actual cause of the problem. In the preceding program, for example, an accidental omission of the opening curly brace after the Main() method generates the following sequence of errors when compiled by the csc command-line compiler. (Similar errors are generated when compiling using the IDE.)
Example.CS(12,21): error CS1002: ; expected
Example.CS(13,22): error CS1519: Invalid token '(' in class, struct, or
interface member declaration
Example.CS(15,1): error CS1022: Type or namespace definition, or
end-of-file expected
Clearly, the first error message is completely wrong, because what is missing is not a semicolon, but a curly brace. The second two messages are equally confusing.
The point of this discussion is that when your program contains a syntax error, don’t necessarily take the compiler’s messages at face value. They may be misleading. You may need to “second guess” an error message in order to find the problem. Also, look at the last few lines of code immediately preceding the one in which the error was reported. Sometimes an error will not be reported until several lines after the point at which the error really occurred.
Although all of the programs in this book will use it, the line
using System;
at the start of the first example program is not technically needed. It is, however, a valuable convenience. The reason it’s not necessary is that in C# you can always fully qualify a name with the namespace to which it belongs. For example, the line
Console.WriteLine("A simple C# program.");
can be rewritten as
System.Console.WriteLine("A simple C# program.");
Thus, the first example could be recoded as shown here:
// This version does not include "using System;".
class Example {
// A C# program begins with a call to Main().
static void Main() {
// Here, Console.WriteLine is fully qualified.
System.Console.WriteLine("A simple C# program.");
}
}
Since it is quite tedious to always specify the System namespace whenever a member of that namespace is used, most C# programmers include using System at the top of their programs, as will all of the programs in this book. It is important to understand, however, that you can explicitly qualify a name with its namespace if needed.
Perhaps no other construct is as important to a programming language as the variable. A variable is a named memory location that can be assigned a value. It is called a variable because its value can be changed during the execution of a program. In other words, the content of a variable is changeable, not fixed.
The following program creates two variables called x and y.
// This program demonstrates variables.
using System;
class Example2 {
static void Main() {
int x; // this declares a variable
int y; // this declares another variable
x = 100; // this assigns 100 to x
Console.WriteLine("x contains " + x);
y = x / 2;
Console.Write("y contains x / 2: ");
Console.WriteLine(y);
}
}
When you run this program, you will see the following output:
x contains 100
y contains x / 2: 50
This program introduces several new concepts. First, the statement
int x; // this declares a variable
declares a variable called x of type integer. In C#, all variables must be declared before they are used. Further, the kind of values that the variable can hold must also be specified. This is called the type of the variable. In this case, x can hold integer values. These are whole numbers. In C#, to declare a variable to be of type integer, precede its name with the keyword int. Thus, the preceding statement declares a variable called x of type int.
The next line declares a second variable called y.
int y; // this declares another variable
Notice that it uses the same format as the first except that the name of the variable is different.
In general, to declare a variable, you will use a statement like this:
type var-name;
Here, type specifies the type of variable being declared, and var-name is the name of the variable. In addition to int, C# supports several other data types.
The following line of code assigns x the value 100:
x = 100; // this assigns 100 to x
In C#, the assignment operator is the single equal sign. It copies the value on its right side into the variable on its left.
The next line of code outputs the value of x preceded by the string “x contains”.
Console.WriteLine("x contains " + x);
In this statement, the plus sign causes the value of x to be displayed after the string that precedes it. This approach can be generalized. Using the + operator, you can chain together as many items as you want within a single WriteLine() statement.
The next line of code assigns y the value of x divided by 2:
y = x / 2;
This line divides the value in x by 2 and then stores that result in y. Thus, after the line executes, y will contain the value 50. The value of x will be unchanged. Like most other computer languages, C# supports a full range of arithmetic operators, including those shown here:
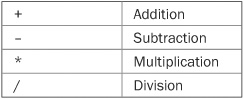
Here are the next two lines in the program:
Console.Write("y contains x / 2:");
Console.WriteLine(y);
Two new things are occurring here. First, the built-in method Write() is used to display the string “y contains x / 2:”. This string is not followed by a new line. This means that when the next output is generated, it will start on the same line. The Write() method is just like WriteLine(), except that it does not output a new line after each call. Second, in the call to WriteLine(), notice that y is used by itself. Both Write() and WriteLine() can be used to output values of any of C#’s built-in types.
One more point about declaring variables before we move on: It is possible to declare two or more variables using the same declaration statement. Just separate their names by commas. For example, x and y could have been declared like this:
int x, y; // both declared using one statement
NOTE C# includes a feature called an implicitly typed variable. Implicitly typed variables are variables whose type is automatically determined by the compiler. Implicitly typed variables are discussed in Chapter 3.
In the preceding program, a variable of type int was used. However, an int variable can hold only whole numbers. It cannot be used when a fractional component is required. For example, an int variable can hold the value 18, but not the value 18.3. Fortunately, int is only one of several data types defined by C#. To allow numbers with fractional components, C# defines two floating-point types: float and double, which represent single- and double-precision values, respectively. Of the two, double is the most commonly used.
To declare a variable of type double, use a statement similar to that shown here:
double result;
Here, result is the name of the variable, which is of type double. Because result has a floating-point type, it can hold values such as 122.23, 0.034, or –19.0.
To better understand the difference between int and double, try the following program:
/*
This program illustrates the differences
between int and double.
*/
using System;
class Example3 {
static void Main() {
int ivar; // this declares an int variable
double dvar; // this declares a floating-point variable
ivar = 100; // assign ivar the value 100
dvar = 100.0; // assign dvar the value 100.0
Console.WriteLine("Original value of ivar: " + ivar);
Console.WriteLine("Original value of dvar: " + dvar);
Console.WriteLine(); // print a blank line
// Now, divide both by 3.
ivar = ivar / 3;
dvar = dvar / 3.0;
Console.WriteLine("ivar after division: " + ivar);
Console.WriteLine("dvar after division: " + dvar);
}
}
The output from this program is shown here:
Original value of ivar: 100
Original value of dvar: 100
ivar after division: 33
dvar after division: 33.3333333333333
As you can see, when ivar (an int variable) is divided by 3, a whole-number division is performed, and the outcome is 33—the fractional component is lost. However, when dvar (a double variable) is divided by 3, the fractional component is preserved.
As the program shows, when you want to specify a floating-point value in a program, you must include a decimal point. If you don’t, it will be interpreted as an integer. For example, in C#, the value 100 is an integer, but the value 100.0 is a floating-point value.
There is one other new thing to notice in the program. To print a blank line, simply call WriteLine() without any arguments.
The floating-point data types are often used when working with real-world quantities where fractional components are commonly needed. For example, this program computes the area of a circle. It uses the value 3.1416 for pi.
// Compute the area of a circle.
using System;
class Circle {
static void Main() {
double radius;
double area;
radius = 10.0;
area = radius * radius * 3.1416;
Console.WriteLine("Area is " + area);
}
}
The output from the program is shown here:
Area is 314.16
Clearly, the computation of a circle’s area could not be achieved satisfactorily without the use of floating-point data.
Inside a method, execution proceeds from one statement to the next, top to bottom. It is possible to alter this flow through the use of the various program control statements supported by C#. Although we will look closely at control statements later, two are briefly introduced here because we will be using them to write sample programs.
You can selectively execute part of a program through the use of C#’s conditional statement: the if. The if statement works in C# much like the IF statement in any other language. For example, it is syntactically identical to the if statements in C, C++, and Java. Its simplest form is shown here:
if(condition) statement;
Here, condition is a Boolean (that is, true or false) expression. If condition is true, then the statement is executed. If condition is false, then the statement is bypassed. Here is an example:
if(10 < 11) Console.WriteLine("10 is less than 11");
In this case, since 10 is less than 11, the conditional expression is true, and WriteLine() will execute. However, consider the following:
if(10 < 9) Console.WriteLine("this won’t be displayed");
In this case, 10 is not less than 9. Thus, the call to WriteLine() will not take place.
C# defines a full complement of relational operators that can be used in a conditional expression. They are shown here:
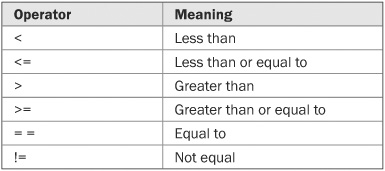
Here is a program that illustrates the if statement:
// Demonstrate the if.
using System;
class IfDemo {
static void Main() {
int a, b, c;
a = 2;
b = 3;
if(a < b) Console.WriteLine("a is less than b");
// This won't display anything.
if(a == b) Console.WriteLine("you won't see this");
Console.WriteLine();
c = a - b; // c contains -1
Console.WriteLine("c contains -1");
if(c >= 0) Console.WriteLine("c is non-negative");
if(c < 0) Console.WriteLine("c is negative");
Console.WriteLine();
c = b - a; // c now contains 1
Console.WriteLine("c contains 1");
if(c >= 0) Console.WriteLine("c is non-negative");
if(c < 0) Console.WriteLine("c is negative");
}
}
The output generated by this program is shown here:
a is less than b
c contains -1
c is negative
c contains 1
c is non-negative
Notice one other thing in this program. The line
int a, b, c;
declares three variables, a, b, and c, by use of a comma-separated list. As mentioned earlier, when you need two or more variables of the same type, they can be declared in one statement. Just separate the variable names with commas.
You can repeatedly execute a sequence of code by creating a loop. C# supplies a powerful assortment of loop constructs. The one we will look at here is the for loop. Like the if statement, the C# for loop is similar to its counterpart in C, C++, and Java. The simplest form of the for loop is shown here:
for(initialization; condition; iteration) statement;
In its most common form, the initialization portion of the loop sets a loop control variable to an initial value. The condition is a Boolean expression that tests the loop control variable. If the outcome of that test is true, the for loop continues to iterate. If it is false, the loop terminates. The iteration expression determines how the loop control variable is changed each time the loop iterates. Here is a short program that illustrates the for loop:
// Demonstrate the for loop.
using System;
class ForDemo {
static void Main() {
int count;
for(count = 0; count < 5; count = count+1)
Console.WriteLine("This is count: " + count);
Console.WriteLine("Done!");
}
}
The output generated by the program is shown here:
This is count: 0
This is count: 1
This is count: 2
This is count: 3
This is count: 4
Done!
In this example, count is the loop control variable. It is set to zero in the initialization portion of the for. At the start of each iteration (including the first one), the conditional test count < 5 is performed. If the outcome of this test is true, the WriteLine() statement is executed. Next, the iteration portion of the loop is executed, which adds 1 to count. This process continues until count reaches 5. At this point, the conditional test becomes false, causing the loop to terminate. Execution picks up at the bottom of the loop.
As a point of interest, in professionally written C# programs you will almost never see the iteration portion of the loop written as shown in the preceding program. That is, you will seldom see statements like this:
count = count + 1;
The reason is that C# includes a special increment operator that performs this operation. The increment operator is ++ (that is, two consecutive plus signs). The increment operator increases its operand by one. By use of the increment operator, the preceding statement can be written like this:
count++;
Thus, the for in the preceding program will usually be written like this:
for(count = 0; count < 5; count++)
You might want to try this. As you will see, the loop still runs exactly the same as it did before.
C# also provides a decrement operator, which is specified as – –. This operator decreases its operand by one.
Another key element of C# is the code block. A code block is a grouping of statements. This is done by enclosing the statements between opening and closing curly braces. Once a block of code has been created, it becomes a logical unit that can be used any place a single statement can. For example, a block can be a target for if and for statements. Consider this if statement:
if(w < h) {
v = w * h;
w = 0;
}
Here, if w is less than h, then both statements inside the block will be executed. Thus, the two statements inside the block form a logical unit, and one statement cannot execute without the other also executing. The key point here is that whenever you need to logically link two or more statements, you do so by creating a block. Code blocks allow many algorithms to be implemented with greater clarity and efficiency.
Here is a program that uses a code block to prevent a division by zero:
// Demonstrate a block of code.
using System;
class BlockDemo {
static void Main() {
int i, j, d;
i = 5;
j = 10;
// The target of this if is a block.
if(i != 0) {
Console.WriteLine("i does not equal zero");
d = j / i;
Console.WriteLine("j / i is " + d);
}
}
}
The output generated by this program is shown here:
i does not equal zero
j / i is 2
In this case, the target of the if statement is a block of code and not just a single statement. If the condition controlling the if is true (as it is in this case), the three statements inside the block will be executed. Try setting i to zero and observe the result.
Here is another example. It uses a code block to compute the sum and the product of the numbers from 1 to 10.
// Compute the sum and product of the numbers from 1 to 10.
using System;
class ProdSum {
static void Main() {
int prod;
int sum;
int i;
sum = 0;
prod = 1;
for(i=1; i <= 10; i++) {
sum = sum + i;
prod = prod * i;
}
Console.WriteLine("Sum is " + sum);
Console.WriteLine("Product is " + prod);
}
}
The output is shown here:
Sum is 55
Product is 3628800
Here, the block enables one loop to compute both the sum and the product. Without the use of the block, two separate for loops would have been required.
One last point: Code blocks do not introduce any runtime inefficiencies. In other words, the { and } do not consume any extra time during the execution of a program. In fact, because of their ability to simplify (and clarify) the coding of certain algorithms, the use of code blocks generally results in increased speed and efficiency.
In C#, the semicolon signals the end of a statement. That is, each individual statement must end with a semicolon.
As you know, a block is a set of logically connected statements that are surrounded by opening and closing braces. A block is not terminated with a semicolon. Since a block is a group of statements, it makes sense that a block is not terminated by a semicolon; instead, the end of the block is indicated by the closing brace.
C# does not recognize the end of the line as the end of a statement—only a semicolon terminates a statement. For this reason, it does not matter where on a line you put a statement. For example, to C#,
x = y;
y = y + 1;
Console.WriteLine(x + " " + y);
is the same as
x = y; y = y + 1; Console.WriteLine(x + " " + y);
Furthermore, the individual elements of a statement can also be put on separate lines. For example, the following is perfectly acceptable:
Console.WriteLine("This is a long line of output" +
x + y + z +
"more output");
Breaking long lines in this fashion is often used to make programs more readable. It can also help prevent excessively long lines from wrapping.
You may have noticed in the previous examples that certain statements were indented. C# is a free-form language, meaning that it does not matter where you place statements relative to each other on a line. However, over the years, a common and accepted indentation style has developed that allows for very readable programs. This book follows that style, and it is recommended that you do so as well. Using this style, you indent one level after each opening brace and move back out one level after each closing brace. There are certain statements that encourage some additional indenting; these will be covered later.
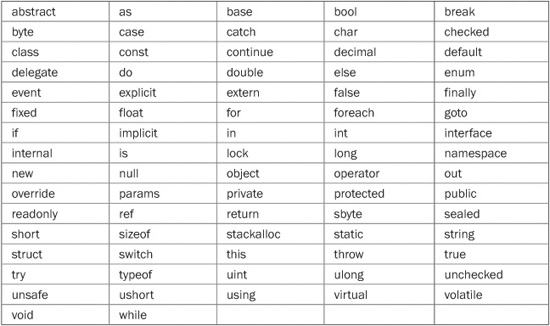
At its foundation, a computer language is defined by its keywords because they determine the features built into the language. C# defines two general types of keywords: reserved and contextual. The reserved keywords cannot be used as names for variables, classes, or methods. They can be used only as keywords. This is why they are called reserved. The terms reserved words or reserved identifiers are also sometimes used. There are currently 77 reserved keywords defined by version 4.0 of the C# language. They are shown in Table 2-1.
C# 4.0 defines 18 contextual keywords that have a special meaning in certain contexts. In those contexts, they act as keywords. Outside those contexts, they can be used as names for other program elements, such as variable names. Thus, they are not technically reserved. As a general rule, however, you should consider the contextual keywords reserved and avoid using them for any other purpose. Using a contextual keyword as a name for some other program element can be confusing and is considered bad practice by many programmers. The contextual keywords are shown in Table 2-2.
TABLE 2-1 The C# Reserved Keywords

TABLE 2-2 The C# Contextual Keywords
In C#, an identifier is a name assigned to a method, a variable, or any other user-defined item. Identifiers can be one or more characters long. Identifiers may start with any letter of the alphabet or an underscore. Next may be a letter, a digit, or an underscore. The underscore can be used to enhance the readability of a variable name, as in line_count. However, identifers containing two consecutive underscores, such as max_ _value, are reserved for use by the compiler. Uppercase and lowercase are different; that is, to C#, myvar and MyVar are separate names. Here are some examples of acceptable identifiers: Remember, you can’t start an identifier with a digit. Thus, 12x is invalid, for example. Good programming practice dictates that you choose identifiers that reflect the meaning or usage of the items being named.

Although you cannot use any of the reserved C# keywords as identifiers, C# does allow you to precede a keyword with an @, allowing it to be a legal identifier. For example, @for is a valid identifier. In this case, the identifier is actually for and the @ is ignored. Here is a program that illustrates the use of an @ identifier:
// Demonstrate an @ identifier.
using System;
class IdTest {
static void Main() {
int @if; // use if as an identifier
for(@if = 0; @if < 10; @if++)
Console.WriteLine("@if is " + @if);
}
}
The output shown here proves the @if is properly interpreted as an identifier:
@if is 0
@if is 1
@if is 2
@if is 3
@if is 4
@if is 5
@if is 6
@if is 7
@if is 8
@if is 9
Frankly, using @-qualified keywords for identifiers is not recommended, except for special purposes. Also, the @ can precede any identifier, but this is considered bad practice.
The sample programs shown in this chapter make use of two built-in methods: WriteLine() and Write(). As mentioned, these methods are members of the Console class, which is part of the System namespace, which is defined by the .NET Framework’s class library. As explained earlier in this chapter, the C# environment relies on the .NET Framework class library to provide support for such things as I/O, string handling, networking, and GUIs. Thus, the C# environment as a totality is a combination of the C# language itself, plus the .NET standard classes. As you will see, the class library provides much of the functionality that is part of any C# program. Indeed, part of becoming a C# programmer is learning to use these standard classes. Throughout Part I, various elements of the .NET library classes and methods are described. Part II examines portions of the .NET library in detail.