An exception is an error that occurs at runtime. Using C#’s exception-handling subsystem, you can, in a structured and controlled manner, handle runtime errors. A principal advantage of exception handling is that it automates much of the error-handling code that previously had to be entered “by hand” into any large program. For example, in a computer language without exception handling, error codes must be returned when a method fails, and these values must be checked manually each time the method is called. This approach is both tedious and error-prone. Exception handling streamlines error-handling by allowing your program to define a block of code, called an exception handler, that is executed automatically when an error occurs. It is not necessary to manually check the success or failure of each specific operation or method call. If an error occurs, it will be processed by the exception handler.
Exception handling is also important because C# defines standard exceptions for common program errors, such as divide-by-zero or index-out-of-range. To respond to these errors, your program must watch for and handle these exceptions. In the final analysis, to be a successful C# programmer means that you are fully capable of navigating C#’s exception-handling subsystem.
In C#, exceptions are represented by classes. All exception classes must be derived from the built-in exception class Exception, which is part of the System namespace. Thus, all exceptions are subclasses of Exception.
One very important subclass of Exception is SystemException. This is the exception class from which all exceptions generated by the C# runtime system (that is, the CLR) are derived. SystemException does not add anything to Exception. It simply defines the top of the standard exceptions hierarchy.
The.NET Framework defines several built-in exceptions that are derived from SystemException. For example, when a division-by-zero is attempted, a DivideByZeroException exception is generated. As you will see later in this chapter, you can create your own exception classes by deriving them from Exception.
C# exception handling is managed via four keywords: try, catch, throw, and finally. They form an interrelated subsystem in which the use of one implies the use of another. Throughout the course of this chapter, each keyword is examined in detail. However, it is useful at the outset to have a general understanding of the role each plays in exception handling. Briefly, here is how they work.
Program statements that you want to monitor for exceptions are contained within a try block. If an exception occurs within the try block, it is thrown. Your code can catch this exception using catch and handle it in some rational manner. System-generated exceptions are automatically thrown by the runtime system. To manually throw an exception, use the keyword throw. Any code that absolutely must be executed upon exiting from a try block is put in a finally block.
At the core of exception handling are try and catch. These keywords work together, and you can’t have a catch without a try. Here is the general form of the try/catch exception-handling blocks:
try {
// block of code to monitor for errors
}
catch (ExcepType1 exOb) {
// handler for ExcepType1
}
catch (ExcepType2 exOb) {
// handler for ExcepType2
}
.
.
.
Here, ExcepType is the type of exception that has occurred. When an exception is thrown, it is caught by its corresponding catch clause, which then processes the exception. As the general form shows, more than one catch clause can be associated with a try. The type of the exception determines which catch is executed. That is, if the exception type specified by a catch matches that of the exception, then that catch is executed (and all others are bypassed). When an exception is caught, the exception variable exOb will receive its value.
Actually, specifying exOb is optional. If the exception handler does not need access to the exception object (as is often the case), there is no need to specify exOb. The exception type alone is sufficient. For this reason, many of the examples in this chapter will not specify exOb.
Here is an important point: If no exception is thrown, then a try block ends normally, and all of its catch clauses are bypassed. Execution resumes with the first statement following the last catch. Thus, a catch is executed only if an exception is thrown.
Here is a simple example that illustrates how to watch for and catch an exception. As you know, it is an error to attempt to index an array beyond its boundaries. When this error occurs, the CLR throws an IndexOutOfRangeException, which is a standard exception defined by the.NET Framework. The following program purposely generates such an exception and then catches it:
// Demonstrate exception handling.
using System;
class ExcDemo1 {
static void Main() {
int[] nums = new int[4];
try {
Console.WriteLine("Before exception is generated.");
// Generate an index out-of-bounds exception.
for(int i=0; i <10; i++) {
nums[i] = i;
Console.WriteLine("nums[{0}]: {1}", i, nums[i]);
}
Console.WriteLine("this won't be displayed");
}
catch (IndexOutOfRangeException) {
// Catch the exception.
Console.WriteLine("Index out-of-bounds!");
}
Console.WriteLine("After catch block.");
}
}
This program displays the following output:
Before exception is generated.
nums[0]: 0
nums[1]: 1
nums[2]: 2
nums[3]: 3
Index out-of-bounds!
After catch block.
Notice that nums is an int array of four elements. However, the for loop tries to index nums from 0 to 9, which causes an IndexOutOfRangeException to occur when an index value of 4 is tried.
Although quite short, the preceding program illustrates several key points about exception handling. First, the code that you want to monitor for errors is contained within a try block. Second, when an exception occurs (in this case, because of the attempt to index nums beyond its bounds inside the for loop), the exception is thrown out of the try block and caught by the catch. At this point, control passes to the catch block, and the try block is terminated. That is, catch is not called. Rather, program execution is transferred to it. Thus, the WriteLine( ) statement following the out-of-bounds index will never execute. After the catch block executes, program control continues with the statements following the catch. Thus, it is the job of your exception handler to remedy the problem that caused the exception so program execution can continue normally.
Notice that no exception variable is specified in the catch clause. Instead, only the type of the exception (IndexOutOfRangeException in this case) is required. As mentioned, an exception variable is needed only when access to the exception object is required. In some cases, the value of the exception object can be used by the exception handler to obtain additional information about the error, but in many cases, it is sufficient to simply know that an exception occurred. Thus, it is not unusual for the catch variable to be absent in the exception handler, as is the case in the preceding program.
As explained, if no exception is thrown by a try block, no catch will be executed and program control resumes after the catch. To confirm this, in the preceding program, change the for loop from
for(int i=0; i < 10; i++) {
to
for(int i=0; i < nums.Length; i++) {
Now, the loop does not overrun nums’ boundary. Thus, no exception is generated, and the catch block is not executed.
It is important to understand that all code executed within a try block is monitored for exceptions. This includes exceptions that might be generated by a method called from within the try block. An exception thrown by a method called from within a try block can be caught by that try block, assuming, of course, that the method itself did not catch the exception.
For example, consider the following program. Main( ) establishes a try block from which the method GenException( ) is called. Inside GenException( ), an IndexOutOfRangeException is generated. This exception is not caught by GenException( ). However, since GenException( ) was called from within a try block in Main( ), the exception is caught by the catch statement associated with that try.
/* An exception can be generated by one
method and caught by another. */
using System;
class ExcTest {
// Generate an exception.
public static void GenException() {
int[] nums = new int[4];
Console.WriteLine("Before exception is generated.");
// Generate an index out-of-bounds exception.
for(int i=0; i < 10; i++) {
nums[i] = i;
Console.WriteLine("nums[{0}]: {1}", i, nums[i]);
}
Console.WriteLine("this won't be displayed");
}
}
class ExcDemo2 {
static void Main() {
try {
ExcTest.GenException();
}
catch (IndexOutOfRangeException) {
// Catch the exception.
Console.WriteLine("Index out-of-bounds!");
}
Console.WriteLine("After catch block.");
}
}
This program produces the following output, which is the same as that produced by the first version of the program shown earlier:
Before exception is generated.
nums[0]: 0
nums[1]: 1
nums[2]: 2
nums[3]: 3
Index out-of-bounds!
After catch block.
As explained, because GenException( ) is called from within a try block, the exception that it generates (and does not catch) is caught by the catch in Main( ). Understand, however, that if GenException( ) had caught the exception, then it never would have been passed back to Main( ).
Catching one of the standard exceptions, as the preceding program does, has a side benefit: It prevents abnormal program termination. When an exception is thrown, it must be caught by some piece of code, somewhere. In general, if your program does not catch an exception, it will be caught by the runtime system. The trouble is that the runtime system will report an error and terminate the program. For instance, in this example, the index out-of-bounds exception is not caught by the program:
// Let the C# runtime system handle the error.
using System;
class NotHandled {
static void Main() {
int[] nums = new int[4];
Console.WriteLine("Before exception is generated.");
// Generate an index out-of-bounds exception.
for(int i=0; i <10; i++) {
nums[i] = i;
Console.WriteLine("nums[{0}]: {1}", i, nums[i]);
}
}
}
When the array index error occurs, execution is halted and the following error message is displayed:
Unhandled Exception: System.IndexOutOfRangeException:
Index was outside the bounds of the array.
at NotHandled.Main()
Although such a message is useful while debugging, you would not want others to see it, to say the least! This is why it is important for your program to handle exceptions itself.
As mentioned earlier, the type of the exception must match the type specified in a catch. If it doesn’t, the exception won’t be caught. For example, the following program tries to catch an array boundary error with a catch for a DivideByZeroException (another built-in exception). When the array boundary is overrun, an IndexOutOfRangeException is generated, but it won’t be caught by the catch. This results in abnormal program termination.
// This won't work!
using System;
class ExcTypeMismatch {
static void Main() {
int[] nums = new int[4];
try {
Console.WriteLine("Before exception is generated.");
// Generate an index out-of-bounds exception.
for(int i=0; i <10; i++) {
nums[i] = i;
Console.WriteLine("nums[{0}]: {1}", i, nums[i]);
}
Console.WriteLine("this won't be displayed");
}
/* Can't catch an array boundary error with a
DivideByZeroException. */
catch (DivideByZeroException) {
// Catch the exception.
Console.WriteLine("Index out-of-bounds!");
}
Console.WriteLine("After catch block.");
}
}
The output is shown here:
Before exception is generated.
nums[0]: 0
nums[1]: 1
nums[2]: 2
nums[3]: 3
Unhandled Exception: System.IndexOutOfRangeException:
Index was outside the bounds of the array.
at ExcTypeMismatch.Main()
As the output demonstrates, a catch for DivideByZeroException won’t catch an IndexOutOfRangeException.
One of the key benefits of exception handling is that it enables your program to respond to an error and then continue running. For example, consider the following example that divides the elements of one array by the elements of another. If a division-by-zero occurs, a DivideByZeroException is generated. In the program, this exception is handled by reporting the error and then continuing with execution. Thus, attempting to divide by zero does not cause an abrupt runtime error resulting in the termination of the program. Instead, it is handled gracefully, allowing program execution to continue.
// Handle error gracefully and continue.
using System;
class ExcDemo3 {
static void Main() {
int[] numer = { 4, 8, 16, 32, 64, 128 };
int[] denom = { 2, 0, 4, 4, 0, 8 };
for(int i=0; i <numer.Length; i++) {
try {
Console.WriteLine(numer[i] + " / " +
denom[i] + " is " +
numer[i]/denom[i]);
}
catch (DivideByZeroException) {
// Catch the exception.
Console.WriteLine("Can't divide by Zero!");
}
}
}
}
The output from the program is shown here:
4 / 2 is 2
Can't divide by Zero!
16 / 4 is 4
32 / 4 is 8
Can't divide by Zero!
128 / 8 is 16
This example makes another important point: Once an exception has been handled, it is removed from the system. Therefore, in the program, each pass through the loop enters the try block anew—any prior exceptions have been handled. This enables your program to handle repeated errors.
You can associate more than one catch clause with a try. In fact, it is common to do so. However, each catch must catch a different type of exception. For example, the program shown here catches both array boundary and divide-by-zero errors:
// Use multiple catch clauses.
using System;
class ExcDemo4 {
static void Main() {
// Here, numer is longer than denom.
int[] numer = { 4, 8, 16, 32, 64, 128, 256, 512 };
int[] denom = { 2, 0, 4, 4, 0, 8 };
for(int i=0; i <numer.Length; i++) {
try {
Console.WriteLine(numer[i] + " / " +
denom[i] + " is " +
numer[i]/denom[i]);
}
catch (DivideByZeroException) {
Console.WriteLine("Can't divide by Zero!");
}
catch (IndexOutOfRangeException) {
Console.WriteLine("No matching element found.");
}
}
}
}
This program produces the following output:
4 / 2 is 2
Can't divide by Zero!
16 / 4 is 4
32 / 4 is 8
Can't divide by Zero!
128 / 8 is 16
No matching element found.
No matching element found.
As the output confirms, each catch clause responds only to its own type of exception.
In general, catch clauses are checked in the order in which they occur in a program. Only the first matching clause is executed. All other catch blocks are ignored.
Occasionally, you might want to catch all exceptions, no matter the type. To do this, use a catch clause that specifies no exception type or variable. It has this general form:
catch {
// handle exceptions
}
This creates a “catch all” handler that ensures that all exceptions are caught by your program.
Here is an example of a “catch all” exception handler. Notice that it catches both the IndexOutOfRangeException and the DivideByZeroException generated by the program:
// Use the "catch all" catch.
using System;
class ExcDemo5 {
static void Main() {
// Here, numer is longer than denom.
int[] numer = { 4, 8, 16, 32, 64, 128, 256, 512 };
int[] denom = { 2, 0, 4, 4, 0, 8 };
for(int i=0; i <numer.Length; i++) {
try {
Console.WriteLine(numer[i] + " / " +
denom[i] + " is " +
numer[i]/denom[i]);
}
catch { // A "catch-all" catch.
Console.WriteLine("Some exception occurred.");
}
}
}
}
The output is shown here:
4 / 2 is 2
Some exception occurred.
16 / 4 is 4
32 / 4 is 8
Some exception occurred.
128 / 8 is 16
Some exception occurred.
Some exception occurred.
There is one point to remember about using a catch-all catch: It must be the last catch clause in the catch sequence.
NOTE In the vast majority of cases you should not use the “catch all” handler as a means of dealing with exceptions. It is normally better to deal individually with the exceptions that your code can generate. The inappropriate use of the “catch all” handler can lead to situations in which errors that would otherwise be noticed during testing are masked. It is also difficult to correctly handle all types of exceptions with a single handler. That said, a “catch all” handler might be appropriate in certain specialized circumstances, such as in a runtime code analysis tool.
One try block can be nested within another. An exception generated within the inner try block that is not caught by a catch associated with that try is propagated to the outer try block. For example, here the IndexOutOfRangeException is not caught by the inner try block, but by the outer try:
// Use a nested try block.
using System;
class NestTrys {
static void Main() {
// Here, numer is longer than denom.
int[] numer = { 4, 8, 16, 32, 64, 128, 256, 512 };
int[] denom = { 2, 0, 4, 4, 0, 8 };
try { // outer try
for(int i=0; i < numer.Length; i++) {
try { // nested try
Console.WriteLine(numer[i] + " / " +
denom[i] + " is " +
numer[i]/denom[i]);
}
catch (DivideByZeroException) {
Console.WriteLine("Can't divide by Zero!");
}
}
}
catch (IndexOutOfRangeException) {
Console.WriteLine("No matching element found.");
Console.WriteLine("Fatal error -- program terminated.");
}
}
}
The output from the program is shown here:
4 / 2 is 2
Can't divide by Zero!
16 / 4 is 4
32 / 4 is 8
Can't divide by Zero!
128 / 8 is 16
No matching element found.
Fatal error -- program terminated.
In this example, an exception that can be handled by the inner try—in this case a divide-by-zero error—allows the program to continue. However, an array boundary error is caught by the outer try, which causes the program to terminate.
Although certainly not the only reason for nested try statements, the preceding program makes an important point that can be generalized. Often, nested try blocks are used to allow different categories of errors to be handled in different ways. Some types of errors are catastrophic and cannot be fixed. Some are minor and can be handled immediately. Many programmers use an outer try block to catch the most severe errors, allowing inner try blocks to handle less serious ones. You can also use an outer try block as a “catch all” block for those errors that are not handled by the inner block.
The preceding examples have been catching exceptions generated automatically by the runtime system. However, it is possible to throw an exception manually by using the throw statement. Its general form is shown here:
throw exceptOb;
The exceptOb must be an object of an exception class derived from Exception.
Here is an example that illustrates the throw statement by manually throwing a DivideByZeroException:
// Manually throw an exception.
using System;
class ThrowDemo {
static void Main() {
try {
Console.WriteLine("Before throw.");
throw new DivideByZeroException();
}
catch (DivideByZeroException) {
Console.WriteLine("Exception caught.");
}
Console.WriteLine("After try/catch statement.");
}
}
The output from the program is shown here:
Before throw.
Exception caught.
After try/catch statement.
Notice how the DivideByZeroException was created using new in the throw statement. Remember, throw throws an object. Thus, you must create an object for it to throw. That is, you can’t just throw a type. In this case, the default constructor is used to create a DivideByZeroException object, but other constructors are available for exceptions.
Most often, exceptions that you throw will be instances of exception classes that you created. As you will see later in this chapter, creating your own exception classes allows you to handle errors in your code as part of your program’s overall exception-handling strategy.
An exception caught by one catch can be rethrown so that it can be caught by an outer catch. The most likely reason for rethrowing an exception is to allow multiple handlers access to the exception. For example, perhaps one exception handler manages one aspect of an exception, and a second handler copes with another aspect. To rethrow an exception, you simply specify throw, without specifying an expression. That is, you use this form of throw:
throw ;
Remember, when you rethrow an exception, it will not be recaught by the same catch clause. Instead, it will propagate to an outer catch.
The following program illustrates rethrowing an exception. In this case, it rethrows an IndexOutOfRangeException.
// Rethrow an exception.
using System;
class Rethrow {
public static void GenException() {
// Here, numer is longer than denom.
int[] numer = { 4, 8, 16, 32, 64, 128, 256, 512 };
int[] denom = { 2, 0, 4, 4, 0, 8 };
for(int i=0; i <numer.Length; i++) {
try {
Console.WriteLine(numer[i] + " / " +
denom[i] + " is " +
numer[i]/denom[i]);
}
catch (DivideByZeroException) {
Console.WriteLine("Can't divide by Zero!");
}
catch (IndexOutOfRangeException) {
Console.WriteLine("No matching element found.");
throw; // rethrow the exception
}
}
}
}
class RethrowDemo {
static void Main() {
try {
Rethrow.GenException();
}
catch(IndexOutOfRangeException) {
// recatch exception
Console.WriteLine("Fatal error -- " + "program terminated.");
}
}
}
In this program, divide-by-zero errors are handled locally, by GenException( ), but an array boundary error is rethrown. In this case, the IndexOutOfRangeException is handled by Main( ).
Sometimes you will want to define a block of code that will execute when a try/catch block is left. For example, an exception might cause an error that terminates the current method, causing its premature return. However, that method may have opened a file or a network connection that needs to be closed. Such types of circumstances are common in programming, and C# provides a convenient way to handle them: finally.
To specify a block of code to execute when a try/catch block is exited, include a finally block at the end of a try/catch sequence. The general form of a try/catch that includes finally is shown here:
try {
// block of code to monitor for errors
}
catch (ExcepType1 exOb) {
// handler for ExcepType1
}
catch (ExcepType2 exOb) {
// handler for ExcepType2
}
.
.
.
finally {
// finally code
}
The finally block will be executed whenever execution leaves a try/catch block, no matter what conditions cause it. That is, whether the try block ends normally, or because of an exception, the last code executed is that defined by finally. The finally block is also executed if any code within the try block or any of its catch blocks returns from the method.
Here is an example of finally:
// Use finally.
using System;
class UseFinally {
public static void GenException(int what) {
int t;
int[] nums = new int[2];
Console.WriteLine("Receiving " + what);
try {
switch(what) {
case 0:
t = 10 / what; // generate div-by-zero error
break;
case 1:
nums[4] = 4; // generate array index error
break;
case 2:
return; // return from try block
}
}
catch (DivideByZeroException) {
Console.WriteLine("Can't divide by Zero!");
return; // return from catch
}
catch (IndexOutOfRangeException) {
Console.WriteLine("No matching element found.");
}
finally {
Console.WriteLine("Leaving try.");
}
}
}
class FinallyDemo {
static void Main() {
for(int i=0; i < 3; i++) {
UseFinally.GenException(i);
Console.WriteLine();
}
}
}
Here is the output produced by the program:
Receiving 0
Can't divide by Zero!
Leaving try.
Receiving 1
No matching element found.
Leaving try.
Receiving 2
Leaving try.
As the output shows, no matter how the try block is exited, the finally block is executed.
One other point: Syntactically, when a finally block follows a try block, no catch clauses are technically required. Thus, you can have a try followed by a finally with no catch clauses. In this case, the finally block is executed when the try exits, but no exceptions are handled.
Up to this point, we have been catching exceptions, but we haven’t been doing anything with the exception object itself. As explained earlier, a catch clause allows you to specify an exception type and a variable. The variable receives a reference to the exception object. Since all exceptions are derived from Exception, all exceptions support the members defined by Exception. Here we will examine several of its most useful members and constructors, and put the exception variable to use.
Exception defines several properties. Three of the most interesting are Message, StackTrace, and TargetSite. All are read-only. Message contains a string that describes the nature of the error. StackTrace contains a string that contains the stack of calls that lead to the exception. TargetSite obtains an object that specifies the method that generated the exception.
Exception also defines several methods. One that you will often use is ToString( ), which returns a string that describes the exception. ToString( ) is automatically called when an exception is displayed via WriteLine( ), for example.
The following program demonstrates these properties and this method:
// Using Exception members.
using System;
class ExcTest {
public static void GenException() {
int[] nums = new int[4];
Console.WriteLine("Before exception is generated.");
// Generate an index out-of-bounds exception.
for(int i=0; i < 10; i++) {
nums[i] = i;
Console.WriteLine("nums[{0}]: {1}", i, nums[i]);
}
Console.WriteLine("this won't be displayed");
}
}
class UseExcept {
static void Main() {
try {
ExcTest.GenException();
}
catch (IndexOutOfRangeException exc) {
Console.WriteLine("Standard message is: ");
Console.WriteLine(exc); // calls ToString()
Console.WriteLine("Stack trace: " + exc.StackTrace);
Console.WriteLine("Message: " + exc.Message);
Console.WriteLine("TargetSite: " + exc.TargetSite);
}
Console.WriteLine("After catch block.");
}
}
The output from this program is shown here:
Before exception is generated.
nums[0]: 0
nums[1]: 1
nums[2]: 2
nums[3]: 3
Standard message is:
System.IndexOutOfRangeException: Index was outside the bounds of the array.
at ExcTest.GenException()
at UseExcept.Main()
Stack trace: at ExcTest.GenException()
at UseExcept.Main()
Message: Index was outside the bounds of the array.
TargetSite: Void GenException()
After catch block.
Exception defines the following four constructors:
public Exception( )
public Exception(string message)
public Exception(string message, Exception innerException)
protected Exception(System.Runtime.Serialization.SerializationInfo info,
System.Runtime.Serialization.StreamingContext context)
The first is the default constructor. The second specifies the string associated with the Message property associated with the exception. The third specifies what is called an inner exception. It is used when one exception gives rise to another. In this case, innerException specifies the first exception, which will be null if no inner exception exists. (The inner exception, if it exists, can be obtained from the InnerException property defined by Exception.) The last constructor handles exceptions that occur remotely and require deserialization.
One other point: In the fourth Exception constructor shown above, notice that the types SerializationInfo and StreamingContext are contained in the System.Runtime.Serialization namespace.
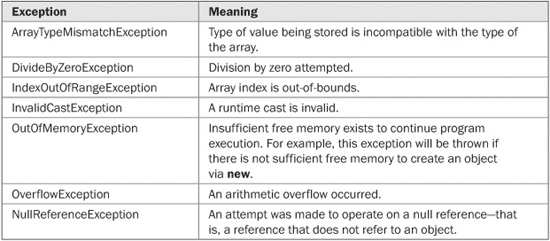
The System namespace defines several standard, built-in exceptions. All are derived (either directly or indirectly) from SystemException since they are generated by the CLR when runtime errors occur. Several of the more commonly used standard exceptions are shown in Table 13-1.
TABLE 13-1 Commonly Used Exceptions Defined Within the System Namespace
Most of the exceptions in Table 13-1 are self-explanatory, with the possible exception of NullReferenceException. This exception is thrown when there is an attempt to use a null reference as if it referred to an object—for example, if you attempt to call a method on a null reference. A null reference is a reference that does not point to any object. One way to create a null reference is to explicitly assign it the value null by using the keyword null. Null references can also occur in other ways that are less obvious. Here is a program that demonstrates the NullReferenceException:
// Use the NullReferenceException.
using System;
class X {
int x;
public X(int a) {
x = a;
}
public int Add(X o) {
return x + o.x;
}
}
// Demonstrate NullReferenceException.
class NREDemo {
static void Main() {
X p = new X(10);
X q = null; // q is explicitly assigned null
int val;
try {
val = p.Add(q); // this will lead to an exception
} catch (NullReferenceException) {
Console.WriteLine("NullReferenceException!");
Console.WriteLine("fixing...\n");
// Now, fix it.
q = new X(9);
val = p.Add(q);
}
Console.WriteLine("val is {0}", val);
}
}
The output from the program is shown here:
NullReferenceException!
fixing...
val is 19
The program creates a class called X that defines a member called x and the Add( ) method, which adds the invoking object’s x to the x in the object passed as a parameter. In Main( ), two X objects are created. The first, p, is initialized. The second, q, is not. Instead, it is explicitly assigned null. Then p.Add( ) is called with q as an argument. Because q does not refer to any object, a NullReferenceException is generated when the attempt is made to obtain the value of q.x.
Although C#’s built-in exceptions handle most common errors, C#’s exception-handling mechanism is not limited to these errors. In fact, part of the power of C#’s approach to exceptions is its ability to handle exception types that you create. You can use custom exceptions to handle errors in your own code. Creating an exception is easy. Just define a class derived from Exception. Your derived classes don’t need to actually implement anything—it is their existence in the type system that allows you to use them as exceptions.
NOTE In the past, custom exceptions were derived from ApplicationException since this is the hierarchy that was originally reserved for application-related exceptions. However, Microsoft no longer recommends this. Instead, at the time of this writing, Microsoft recommends deriving custom exceptions from Exception. For this reason, this approach is used here.
The exception classes that you create will automatically have the properties and methods defined by Exception available to them. Of course, you can override one or more of these members in exception classes that you create.
When creating your own exception class, you will generally want your class to support all of the constructors defined by Exception. For simple custom exception classes, this is easy to do because you can simply pass along the constructor’s arguments to the corresponding Exception constructor via base. Of course, technically, you need to provide only those constructors actually used by your program.
Here is an example that makes use of a custom exception type. At the end of Chapter 10 an array class called RangeArray was developed. As you may recall, RangeArray supports single-dimensional int arrays in which the starting and ending index is specified by the user. For example, an array that ranges from –5 to 27 is perfectly legal for a RangeArray. In Chapter 10, if an index was out of range, a special error variable defined by RangeArray was set. This meant that the error variable had to be checked after each operation by the code that used RangeArray. Of course, such an approach is error-prone and clumsy. A far better design is to have RangeArray throw a custom exception when a range error occurs. This is precisely what the following version of RangeArray does:
// Use a custom Exception for RangeArray errors.
using System;
// Create a RangeArray exception.
class RangeArrayException : Exception {
/* Implement all of the Exception constructors. Notice that
the constructors simply execute the base class constructor.
Because RangeArrayException adds nothing to Exception,
there is no need for any further actions. */
public RangeArrayException() : base() { }
public RangeArrayException(string message) : base(message) { }
public RangeArrayException(string message, Exception innerException) :
base(message, innerException) { }
protected RangeArrayException(
System.Runtime.Serialization.SerializationInfo info,
System.Runtime.Serialization.StreamingContext context) :
base(info, context) { }
// Override ToString for RangeArrayException.
public override string ToString() {
return Message;
}
}
// An improved version of RangeArray.
class RangeArray {
// Private data.
int[] a; // reference to underlying array
int lowerBound; // smallest index
int upperBound; // largest index
// An auto-implemented, read-only Length property.
public int Length { get; private set; }
// Construct array given its size.
public RangeArray(int low, int high) {
high++;
if(high < = low) {
throw new RangeArrayException("Low index not less than high.");
}
a = new int[high - low];
Length = high - low;
lowerBound = low;
upperBound = --high;
}
// This is the indexer for RangeArray.
public int this[int index] {
// This is the get accessor.
get {
if(ok(index)) {
return a[index - lowerBound];
} else {
throw new RangeArrayException("Range Error.");
}
}
// This is the set accessor.
set {
if(ok(index)) {
a[index - lowerBound] = value;
}
else throw new RangeArrayException("Range Error.");
}
}
// Return true if index is within bounds.
private bool ok(int index) {
if(index >= lowerBound & index < = upperBound) return true;
return false;
}
}
// Demonstrate the index-range array.
class RangeArrayDemo {
static void Main() {
try {
RangeArray ra = new RangeArray(-5, 5);
RangeArray ra2 = new RangeArray(1, 10);
// Demonstrate ra.
Console.WriteLine("Length of ra: " + ra.Length);
for(int i = -5; i < = 5; i++)
ra[i] = i;
Console.Write("Contents of ra: ");
for(int i = -5; i < = 5; i++)
Console.Write(ra[i] + " ");
Console.WriteLine("\n");
// Demonstrate ra2.
Console.WriteLine("Length of ra2: " + ra2.Length);
for(int i = 1; i < = 10; i++)
ra2[i] = i;
Console.Write("Contents of ra2: ");
for(int i = 1; i < = 10; i++)
Console.Write(ra2[i] + " ");
Console.WriteLine("\n");
} catch (RangeArrayException exc) {
Console.WriteLine(exc);
}
// Now, demonstrate some errors.
Console.WriteLine("Now generate some range errors.");
// Use an invalid constructor.
try {
RangeArray ra3 = new RangeArray(100, -10); // Error
} catch (RangeArrayException exc) {
Console.WriteLine(exc);
}
// Use an invalid index.
try {
RangeArray ra3 = new RangeArray(-2, 2);
for(int i = -2; i < = 2; i++)
ra3[i] = i;
Console.Write("Contents of ra3: ");
for(int i = -2; i < = 10; i++) // generate range error
Console.Write(ra3[i] + " ");
} catch (RangeArrayException exc) {
Console.WriteLine(exc);
}
}
}
The output from the program is shown here:
Length of ra: 11
Contents of ra: -5 -4 -3 -2 -1 0 1 2 3 4 5
Length of ra2: 10
Contents of ra2: 1 2 3 4 5 6 7 8 9 10
Now generate some range errors.
Low index not less than high.
Contents of ra3: -2 -1 0 1 2 Range Error.
When a range error occurs, RangeArray throws an object of type RangeArrayException. Notice there are three places in RangeArray that this might occur: in the get indexer accessor, in the set indexer accessor, and by the RangeArray constructor. To catch these exceptions implies that RangeArray objects must be constructed and accessed from within a try block, as the program illustrates. By using an exception to report errors, RangeArray now acts like one of C#’s built-in types and can be fully integrated into a program’s exception-handling mechanism.
Notice that none of the RangeArrayException constructors provide any statements in their body. Instead, they simply pass their arguments along to Exception via base. As explained, in cases in which your exception class does not add any functionality, you can simply let the Exception constructors handle the process. There is no requirement that your derived class add anything to what is inherited from Exception.
Before moving on, you might want to experiment with this program a bit. For example, try commenting-out the override of ToString( ) and observe the results. Also, try creating an exception using the default constructor, and observe what C# generates as its default message.
You need to be careful how you order catch clauses when trying to catch exception types that involve base and derived classes, because a catch for a base class will also match any of its derived classes. For example, because the base class of all exceptions is Exception, catching Exception catches all possible exceptions. Of course, using catch without an exception type provides a cleaner way to catch all exceptions, as described earlier. However, the issue of catching derived class exceptions is very important in other contexts, especially when you create exceptions of your own.
If you want to catch exceptions of both a base class type and a derived class type, put the derived class first in the catch sequence. This is necessary because a base class catch will also catch all derived classes. Fortunately, this rule is self-enforcing because putting the base class first causes a compile-time error.
The following program creates two exception classes called ExceptA and ExceptB. ExceptA is derived from Exception. ExceptB is derived from ExceptA. The program then throws an exception of each type. For brevity, the custom exceptions supply only one constructor (which takes a string that describes the exception). But remember, in commercial code, your custom exception classes will normally provide all four of the constructors defined by Exception.
// Derived exceptions must appear before base class exceptions.
using System;
// Create an exception.
class ExceptA : Exception {
public ExceptA(string message) : base(message) { }
public override string ToString() {
return Message;
}
}
// Create an exception derived from ExceptA.
class ExceptB : ExceptA {
public ExceptB(string message) : base(message) { }
public override string ToString() {
return Message;
}
}
class OrderMatters {
static void Main() {
for(int x = 0; x <3; x++) {
try {
if(x==0) throw new ExceptA("Caught an ExceptA exception");
else if(x==1) throw new ExceptB("Caught an ExceptB exception");
else throw new Exception();
}
catch (ExceptB exc) {
Console.WriteLine(exc);
}
catch (ExceptA exc) {
Console.WriteLine(exc);
}
catch (Exception exc) {
Console.WriteLine(exc);
}
}
}
}
The output from the program is shown here:
Caught an ExceptA exception
Caught an ExceptB exception
System.Exception: Exception of type 'System.Exception' was thrown.
at OrderMatters.Main()
Notice the type and order of the catch clauses. This is the only order in which they can occur. Since ExceptB is derived from ExceptA, the catch for ExceptB must be before the one for ExceptA. Similarly, the catch for Exception (which is the base class for all exceptions) must appear last. To prove this point for yourself, try rearranging the catch clauses. Doing so will result in a compile-time error.
One good use of a base class catch clause is to catch an entire category of exceptions. For example, imagine you are creating a set of exceptions for some device. If you derive all of the exceptions from a common base class, then applications that don’t need to know precisely what problem occurred could simply catch the base class exception, avoiding the unnecessary duplication of code.
A special feature in C# relates to the generation of overflow exceptions in arithmetic computations. As you know, it is possible for some types of arithmetic computations to produce a result that exceeds the range of the data type involved in the computation. When this occurs, the result is said to overflow. For example, consider the following sequence:
byte a, b, result;
a = 127;
b = 127;
result = (byte)(a * b);
Here, the product of a and b exceeds the range of a byte value. Thus, the result overflows the type of the result.
C# allows you to specify whether your code will raise an exception when overflow occurs by using the keywords checked and unchecked. To specify that an expression be checked for overflow, use checked. To specify that overflow be ignored, use unchecked. In this case, the result is truncated to fit into the target type of the expression.
The checked keyword has these two general forms. One checks a specific expression and is called the operator form of checked. The other checks a block of statements and is called the statement form.
checked (expr)
checked {
// statements to be checked
}
Here, expr is the expression being checked. If a checked expression overflows, then an OverflowException is thrown.
The unchecked keyword also has two general forms. The first is the operator form, which ignores overflow for a specific expression. The second ignores overflow for a block of statements.
unchecked (expr)
unchecked {
// statements for which overflow is ignored
}
Here, expr is the expression that is not being checked for overflow. If an unchecked expression overflows, then truncation will occur.
Here is a program that demonstrates both checked and unchecked:
// Using checked and unchecked.
using System;
class CheckedDemo {
static void Main() {
byte a, b;
byte result;
a = 127;
b = 127;
try {
result = unchecked((byte)(a * b));
Console.WriteLine("Unchecked result: " + result);
result = checked((byte)(a * b)); // this causes exception
Console.WriteLine("Checked result: " + result); // won't execute
}
catch (OverflowException exc) {
Console.WriteLine(exc);
}
}
}
The output from the program is shown here:
Unchecked result: 1
System.OverflowException: Arithmetic operation resulted in an overflow.
at CheckedDemo.Main()
As is evident, the unchecked expression resulted in a truncation. The checked expression caused an exception.
The preceding program demonstrated the use of checked and unchecked for a single expression. The following program shows how to check and uncheck a block of statements.
// Using checked and unchecked with statement blocks.
using System;
class CheckedBlocks {
static void Main() {
byte a, b;
byte result;
a = 127;
b = 127;
try {
unchecked {
a = 127;
b = 127;
result = unchecked((byte)(a * b));
Console.WriteLine("Unchecked result: " + result);
a = 125;
b = 5;
result = unchecked((byte)(a * b));
Console.WriteLine("Unchecked result: " + result);
}
checked {
a = 2;
b = 7;
result = checked((byte)(a * b)); // this is OK
Console.WriteLine("Checked result: " + result);
a = 127;
b = 127;
result = checked((byte)(a * b)); // this causes exception
Console.WriteLine("Checked result: " + result); // won't execute
}
}
catch (OverflowException exc) {
Console.WriteLine(exc);
}
}
}
The output from the program is shown here:
Unchecked result: 1
Unchecked result: 113
Checked result: 14
System.OverflowException: Arithmetic operation resulted in an overflow.
at CheckedBlocks.Main()
As you can see, the unchecked block results in the overflow being truncated. When overflow occurred in the checked block, an exception was raised.
One reason that you may need to use checked or unchecked is that the default checked/unchecked status of overflow is determined by the setting of a compiler option and the execution environment, itself. Thus, for some types of programs, it is best to specify the overflow check status explicitly.