This chapter examines the String class, which underlies C#’s string type. As all programmers know, string handling is a part of almost any program. For this reason, the String class defines an extensive set of methods, properties, and fields that give you detailed control of the construction and manipulation of strings. Closely related to string handling is the formatting of data into its human-readable form. Using the formatting subsystem, you can format the C# numeric types, date and time, and enumerations.
An overview of C#’s string handling was presented in Chapter 7, and that discussion is not repeated here. However, it is worthwhile to review how strings are implemented in C# before examining the String class.
In all computer languages, a string is a sequence of characters, but precisely how such a sequence is implemented varies from language to language. In some computer languages, such as C++, strings are arrays of characters, but this is not the case with C#. Instead, C# strings are objects of the built-in string data type. Thus, string is a reference type. Moreover, string is C#’s name for System.String, the standard .NET string type. Thus, a C# string has access to all of the methods, properties, fields, and operators defined by String.
Once a string has been created, the character sequence that comprises a string cannot be altered. This restriction allows C# to implement strings more efficiently. Though this restriction probably sounds like a serious drawback, it isn’t. When you need a string that is a variation on one that already exists, simply create a new string that contains the desired changes, and discard the original string if it is no longer needed. Since unused string objects are automatically garbage-collected, you don’t need to worry about what happens to the discarded strings. It must be made clear, however, that string reference variables may, of course, change the object to which they refer. It is just that the character sequence of a specific string object cannot be changed after it is created.
To create a string that can be changed, C# offers a class called StringBuilder, which is in the System.Text namespace. For most purposes, however, you will want to use string, not StringBuilder.
String is defined in the System namespace. It implements the IComparable, IComparable<string>, ICloneable, IConvertible, IEnumerable, IEnumerable<char>, and IEquatable<string> interfaces. String is a sealed class, which means that it cannot be inherited. String provides string-handling functionality for C#. It underlies C#’s built-in string type and is part of the .NET Framework. The next few sections examine String in detail.
The String class defines several constructors that allow you to construct a string in a variety of ways. To create a string from a character array, use one of these constructors:
public String(char[ ] value)
public String(char[ ] value, int startIndex, int length)
The first form constructs a string that contains the characters in value. The second form uses length characters from value, beginning at the index specified by startIndex.
You can create a string that contains a specific character repeated a number of times using this constructor:
public String(char c, int count)
Here, c specifies the character that will be repeated count times.
You can construct a string given a pointer to a character array using one of these constructors:
public String(char* value)
public String(char* value, int startIndex, int length)
The first form constructs a string that contains the characters pointed to by value. It is assumed that value points to a null-terminated array, which is used in its entirety. The second form uses length characters from the array pointed to by value, beginning at the index specified by startIndex. Because they use pointers, these constructors can be used only in unsafe code.
You can construct a string given a pointer to an array of bytes using one of these constructors:
public String(sbyte* value)
public String(sbyte* value, int startIndex, int length)
public String(sbyte* value, int startIndex, int length, Encoding enc)
The first form constructs a string that contains the bytes pointed to by value. It is assumed that value points to a null-terminated array, which is used in its entirety. The second form uses length characters from the array pointed to by value, beginning at the index specified by startIndex. The third form lets you specify how the bytes are encoded. The Encoding class is in the System.Text namespace. Because they use pointers, these constructors can be used only in unsafe code.
A string literal automatically creates a string object. For this reason, a string object is often initialized by assigning it a string literal, as shown here:
string str = “a new string”;
The String class defines one field, shown here:
public static readonly string Empty
Empty specifies an empty string, which is a string that contains no characters. This differs from a null String reference, which simply refers to no object.
There is one read-only indexer defined for String, which is shown here:
public char this[int index] { get; }
This indexer allows you to obtain the character at a specified index. Like arrays, the indexing for strings begins at zero. Since String objects are immutable, it makes sense that String supports a read-only indexer.
There is one read-only property:
public int Length { get; }
Length returns the number of characters in the string.
The String class overloads two operators: = = and !=. To test two strings for equality, use the = = operator. Normally, when the = = operator is applied to object references, it determines if both references refer to the same object. This differs for objects of type String. When the = = is applied to two String references, the contents of the strings, themselves, are compared for equality. The same is true for the != operator: the contents of the strings are compared. However, the other relational operators, such as < or >=, compare the references, just like they do for other types of objects. To determine if one string is greater than or less than another, use the Compare( ) or CompareTo( ) method defined by String.
As you will see, many string comparisons make use of cultural information. This is not the case with the = = and != operators. They simply compare the ordinal values of the characters within the strings. (In other words, they compare the binary values of the characters, unmodified by cultural norms.) Thus, these operators are case-sensitive and culture-insensitive.
The String class defines a large number of methods, and many of the methods have two or more overloaded forms. For this reason it is neither practical nor useful to list them all. Instead, several of the more commonly used methods will be presented, along with examples that illustrate them.
Perhaps the most frequently used string-handling operation is the comparison of one string to another. Before we examine any of the comparison methods, a key point needs to be made. String comparisons can be performed in two general ways by the .NET Framework. First, a comparison can reflect the customs and norms of a given culture, which is often the cultural setting in force when the program executes. This is the default behavior of some, but not all, of the comparison methods. Second, comparisons can be performed independently of cultural settings, using only the ordinal values of the characters that comprise the string. In general, string comparisons that are culture-sensitive use dictionary order (and linguistic features) to determine whether one string is greater than, equal to, or less than another. Ordinal string comparisons simply order strings based on the unmodified value of each character.
Choosing a comparison approach is an important decision. As a general rule (and with exceptions), if the strings are being compared for the purposes of displaying output to a user (such as showing a set of sorted strings in dictionary order), then a culture-sensitive comparison is often the right choice. However, if the strings contain fixed information that is not intended to be modified based on cultural differences, such as a filename, a keyword, a website URL, or a security-related value, then an ordinal comparison should usually be used. Of course, it is ultimately the specifics of your application that will dictate what approach is required.
NOTE Because of the differences between culture-sensitive comparisons and ordinal comparisons, and the implications of each, it is strongly suggested that you consult Microsoft’s currently recommended best practices in this regard. Choosing the wrong approach can, in some cases, make your program malfunction when it is used in an environment that differs from the development environment.
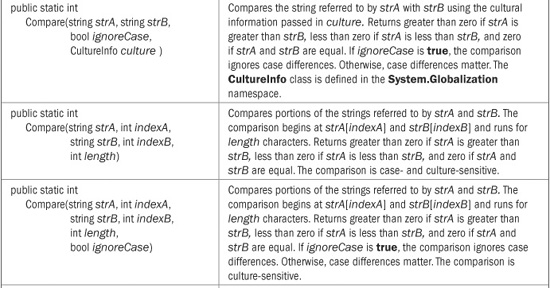
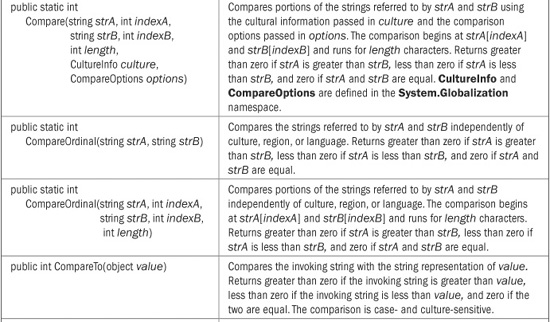
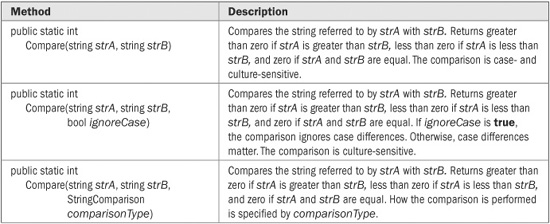
String provides a wide array of comparison methods. These are shown in Table 22-1. Of the comparison methods, the Compare( ) method is the most versatile. It can compare two strings in their entirety or in parts. It can use case-sensitive comparisons or ignore case. You can also specify how the comparison is performed by using a version that has a StringComparison parameter, or what cultural information governs the comparison using a version that has a CultureInfo parameter. The overloads of Compare( ) that do not include a StringComparison are case-sensitive and culture-sensitive. Overloads that don’t specify a CultureInfo parameter use the cultural information defined by the current execution environment. Although we won’t make use of the CultureInfo parameter in this chapter, the StringComparison parameter is of immediate importance.
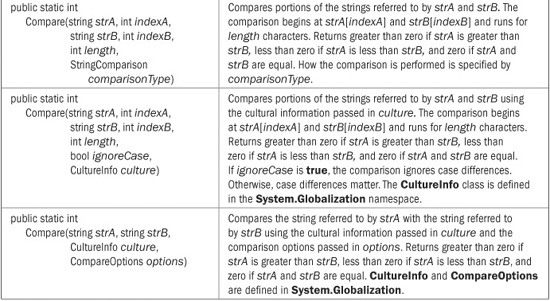
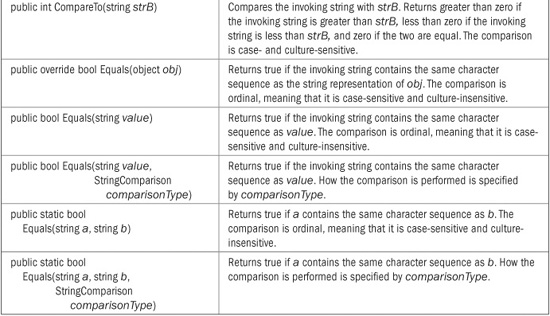
TABLE 22-1 The String Comparison Methods
StringComparison is an enumeration that defines the values shown in Table 22-2. Using these values, it is possible to craft a comparison that meets the specific needs of your application. Thus, the addition of the StringComparison parameter expands the capabilities of Compare( ) and other methods, such as Equals( ). It also lets you specify in an unambiguous way precisely what type of comparison you intend. Because of the differences between culture-sensitive and ordinal comparisons, it important to be as clear as possible in this regard. For this reason, the examples in this book will explicitly specify the StringComparison parameter in calls to methods that support such a parameter.
In all cases, Compare( ) returns less than zero when the first string is less than the second, greater than zero when the first string is greater than the second, and zero when the two strings compare as equal. Even though Compare( ) returns zero when it determines two strings are equal, it is usually better to use Equals( ) (or the = = operator) to determine equality. The reason is that Compare( ) determines equality based on sort order. When a culture-sensitive comparison is performed, two strings might compare as equal in terms of sort order, but not be equal otherwise. By default, Equals( ) determines equality based on the ordinal values of the characters and is culture-insensitive. Thus, by default, it compares two strings for absolute, character-by-character equality. Thus, it works like the = = operator.
Although Compare( ) is more versatile, when performing simple ordinal comparisons, the CompareOrdinal( ) method is a bit easier to use. Finally, notice that CompareTo( ) performs only a culture-sensitive comparison. At the time of this writing, there is no overload that lets you specify a different approach.
The following program demonstrates Compare( ), Equals( ), CompareOrdinal( ), and the = = and != operators. Notice that the first two comparisons clearly show the difference between culture-sensitive comparisons and ordinal comparisons in an English-language environment.
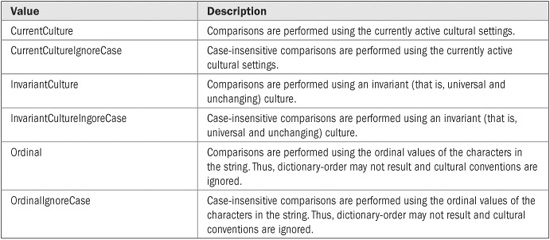
TABLE 22-2 The StringComparison Enumeration Values
// Demonstrate string comparisons.
using System;
class CompareDemo {
static void Main() {
string str1 = "alpha";
string str2 = "Alpha";
string str3 = "Beta";
string str4 = "alpha";
string str5 = "alpha, beta";
int result;
// First, demonstrate the differences between culture-sensitive
// and ordinal comparison.
result = String.Compare(str1, str2, StringComparison.CurrentCulture);
Console.Write("Using a culture-sensitive comparison: ");
if(result < 0)
Console.WriteLine(str1 + " is less than " + str2);
else if(result > 0)
Console.WriteLine(str1 + " is greater than " + str2);
else
Console.WriteLine(str1 + " equals " + str2);
result = String.Compare(str1, str2, StringComparison.Ordinal);
Console.Write("Using an ordinal comparison: ");
if(result < 0)
Console.WriteLine(str1 + " is less than " + str2);
else if(result > 0)
Console.WriteLine(str1 + " is greater than " + str2);
else
Console.WriteLine(str1 + " equals " + str4);
// Use the CompareOrdinal() method.
result = String.CompareOrdinal(str1, str2);
Console.Write("Using CompareOrdinal(): ");
if(result < 0)
Console.WriteLine(str1 + " is less than " + str2);
else if(result < 0)
Console.WriteLine(str1 + " is greater than " + str2);
else
Console.WriteLine(str1 + " equals " + str4);
Console.WriteLine();
// Use == to determine if two strings are equal.
// This comparison is ordinal.
if(str1 == str4) Console.WriteLine(str1 + " == " + str4);
// Use != on strings.
if(str1 != str3) Console.WriteLine(str1 + " != " + str3);
if(str1 != str2) Console.WriteLine(str1 + " != " + str2);
Console.WriteLine();
// Use Equals() to perform an ordinal, case-insensitive comparison.
if(String.Equals(str1, str2, StringComparison.OrdinalIgnoreCase))
Console.WriteLine("Using Equals() with OrdinalIgnoreCase, " +
str1 + " equals " + str2);
Console.WriteLine();
// Compare a portion of a string.
if(String.Compare(str2, 0, str5, 0, 3,
StringComparison.CurrentCulture) > 0) {
Console.WriteLine("Using the current culture, the first " +
"3 characters of " + str2 +
"\nare greater than the first " +
"3 characters of " + str5);
}
}
}
The output is shown here:
Using a culture-sensitive comparison: alpha is less than Alpha
Using an ordinal comparison: alpha is greater than Alpha
Using CompareOrdinal(): alpha is greater than Alpha
alpha == alpha
alpha != Beta
alpha != Alpha
Using Equals() with OrdinalIgnoreCase, alpha equals Alpha
Using the current culture, the first 3 characters of Alpha
are greater than the first 3 characters of alpha, beta
There are two ways to concatenate (join together) two or more strings. First, you can use the + operator, as demonstrated in Chapter 7. Second, you can use one of the various concatenation methods defined by String. Although using + is the easiest approach in many cases, the concatenation methods give you an alternative.
The method that performs concatenation is called Concat( ). One of its simplest forms is shown here:
public static string Concat(string str0, string str1)
This method returns a string that contains str1 concatenated to the end of str0. Another form of Concat( ), shown here, concatenates three strings:
public static string Concat(string str0, string str1, string str2)
In this version, a string that contains the concatenation of str0, str1, and str2 is returned. There is also a form that concatenates four strings:
public static string Concat(string str0, string str1, string str2, string str3)
This version returns the concatenation of all four strings.
The version of Concat( ) shown next concatenates an arbitrary number of strings:
public static string Concat(params string[ ] values)
Here, values refers to a variable number of arguments that are concatenated, and the result is returned. Because this version of Concat( ) can be used to concatenate any number of strings, including two, three, or four strings, you might wonder why the other forms just shown exist. The reason is efficiency; passing up to four arguments is more efficient than using a variable-length argument list.
The following program demonstrates the variable-length argument version of Concat( ):
// Demonstrate Concat().
using System;
class ConcatDemo {
static void Main() {
string result = String.Concat("This ", "is ", "a ",
"test ", "of ", "the ",
"String ", "class.");
Console.WriteLine("result: " + result);
}
}
The output is shown here:
result: This is a test of the String class.
There are also versions of the Concat( ) method that take object references, rather than string references. These obtain the string representation of the objects with which they are called and return a string containing the concatenation of those strings. (The string representations are obtained by calling ToString( ) on the objects.) These versions of Concat( ) are shown here:
public static string Concat(object arg0)
public static string Concat(object arg0, object arg1)
public static string Concat(object agr0, object arg1, object arg2)
public static string Concat(object arg0, object arg1, object arg2, object arg3)
public static string Concat(params object[ ] args)
The first method simply returns the string equivalent of arg0. The other methods return a string that contains the concatenation of their arguments. The object forms of Concat( ) are very convenient because they let you avoid having to manually obtain string representations prior to concatenation. To see how useful these methods can be, consider the following program:
// Demonstrate the object form of Concat().
using System;
class MyClass {
public static int Count = 0;
public MyClass() { Count++; }
}
class ConcatDemo {
static void Main() {
string result = String.Concat("The value is " + 19);
Console.WriteLine("result: " + result);
result = String.Concat("hello ", 88, " ", 20.0, " ",
false, " ", 23.45M);
Console.WriteLine("result: " + result);
MyClass mc = new MyClass();
result = String.Concat(mc, " current count is ",
MyClass.Count);
Console.WriteLine("result: " + result);
}
}
The output is shown here:
result: The value is 19
result: hello 88 20 False 23.45
result: MyClass current count is 1
In this example, Concat( ) concatenates the string representations of various types of data. For each argument, the ToString( ) method associated with that argument is called to obtain a string representation. Thus, in this call to concat( ):
string result = String.Concat("The value is " + 19);
Int32.ToString( ) is invoked to obtain the string representation of the integer value 19. Concat( ) then concatenates the strings and returns the result.
Also notice how an object of the user-defined class MyClass can be used in this call to Concat( ):
result = String.Concat(mc, " current count is ",
MyClass.Count);
In this case, the string representation of mc, which is of type MyClass, is returned. By default, this is simply its class name. However, if you override the ToString( ) method, then MyClass can return a different string. For example, try adding this version of ToString( ) to Myclass in the preceding program:
public override string ToString() {
return "An object of type MyClass";
}
When this version is used, the last line in the output will be
result: An object of type MyClass current count is 1
Version 4.0 of the .NET Framework adds two more forms of Concat( ), which are shown here:
public static string Concat<T>(IEnumerable<T> values)
public static string Concat(IEnumerable<string> values)
The first form returns a string that contains the concatenation of the string representation of the values in values, which can be any type of object that implements IEnumerable<T>. The second form concatenates the strings specified by values. (Understand, however, that if you are doing a large amount of string concatenations, then using a StringBuilder may be a better choice.)
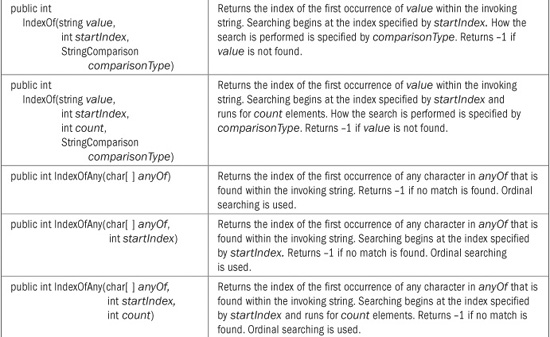
String offers many methods that allow you to search a string. For example, you can search for either a substring or a character. You can also search for the first or last occurrence of either. It is important to keep in mind that a search can be either culture-sensitive or ordinal.
To find the first occurrence of a string or a character, use the IndexOf( ) method. It defines several overloaded forms. Here is one that searches for the first occurrence of a character within a string:
public int IndexOf(char value)
This method returns the index of the first occurrence of the character value within the invoking string. It returns –1 if value is not found. The search to find the character ignores cultural settings. Thus, to find the first occurrence of a character, an ordinal search is used.
Here are two of forms of IndexOf( ) that let you search for the first occurrence of a string:
public int IndexOf(String value)
public int IndexOf(String value, StringComparison comparisonType)
The first form uses a culture-sensitive search to find the first occurrence of the string referred to by value. The second form lets you specify a StringComparison value that specifies how the search is conducted. Both return –1 if the item is not found.
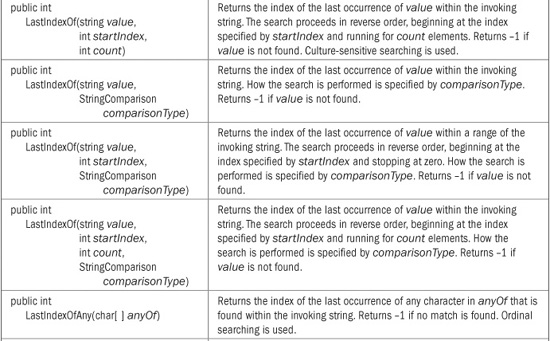
To search for the last occurrence of a character or a string, use the LastIndexOf( ) method. It also defines several overloaded forms. This one searches for the last occurrence of a character within the invoking string:
public int LastIndexOf(char value)
This method uses an ordinal search and returns the index of the last occurrence of the character value within the invoking string or – 1 if value is not found.
Here are two forms of LastIndexOf( ) that let you search for the last occurrence of a string:
public int LastIndexOf(string value)
public int LastIndexOf(string value, StringComparison comparisonType)
The first form uses a culture-sensitive search to find the first occurrence of the string referred to by value. The second form lets you specify a StringComparison value that specifies how the search is conducted. Both return –1 if the item is not found.
String offers two interesting supplemental search methods: IndexOfAny( ) and LastIndexOfAny( ). These search for the first or last character that matches any of a set of characters. Here are their simplest forms:
public int IndexOfAny(char[ ] anyOf)
public int LastIndexOfAny(char[ ] anyOf)
IndexOfAny( ) returns the index of the first occurrence of any character in anyOf that is found within the invoking string. LastIndexOfAny( ) returns the index of the last occurrence of any character in anyOf that is found within the invoking string. Both return –1 if no match is found. In both cases, an ordinal search is used.
When working with strings, it is often useful to know if a string begins with or ends with a given substring. To accomplish this task, use the StartsWith( ) and EndsWith( ) methods. Here are their two simplest forms:
public bool StartsWith(string value)
public bool EndsWith(string value)
StartsWith( ) returns true if the invoking string begins with the string passed in value.
EndsWith( ) returns true if the invoking string ends with the string passed in value. Both return false on failure. These use culture-sensitive searches. To specify how the searches are conducted, you can use a version of these methods that has a StringComparison parameter.
Here are examples:
public bool StartsWith(string value, StringComparison comparisonType)
public bool EndsWith(string value, StringComparison comparisonType)
They work like the previous versions, but let you explicitly specify how the search is conducted.
Here is a program that demonstrates several of the string search methods. For purposes of illustration, all use ordinal searching:
// Search strings.
using System;
class StringSearchDemo {
static void Main() {
string str = "C# has powerful string handling.";
int idx;
Console.WriteLine("str: " + str);
idx = str.IndexOf('h');
Console.WriteLine("Index of first 'h': " + idx);
idx = str.LastIndexOf('h');
Console.WriteLine("Index of last 'h': " + idx);
idx = str.IndexOf("ing", StringComparison.Ordinal);
Console.WriteLine("Index of first \"ing\": " + idx);
idx = str.LastIndexOf("ing", StringComparison.Ordinal);
Console.WriteLine("Index of last \"ing\": " + idx);
char[] chrs = { 'a', 'b', 'c' };
idx = str.IndexOfAny(chrs);
Console.WriteLine("Index of first 'a', 'b', or 'c': " + idx);
if(str.StartsWith("C# has", StringComparison.Ordinal))
Console.WriteLine("str begins with \"C# has\"");
if(str.EndsWith("ling.", StringComparison.Ordinal))
Console.WriteLine("str ends with \"ling.\"");
}
}
The output from the program is shown here:
str: C# has powerful string handling.
Index of first 'h': 3
Index of last 'h': 23
Index of first "ing": 19
Index of last "ing": 28
Index of first 'a', 'b', or 'c': 4
str begins with "C# has"
str ends with "ling."
A string search method that you will find useful in many circumstances is Contains( ). Its general form is shown here:
public bool Contains(string value)
It returns true if the invoking string contains the string specified by value, and false otherwise. It uses ordinal searching. This method is especially useful when all you need to know is if a specific substring exists within another string. Here is an example that demonstrates its use.
// Demonstrate Contains().
using System;
class ContainsDemo {
static void Main() {
string str = "C# combines power with performance.";
if(str.Contains("power"))
Console.WriteLine("The sequence power was found.");
if(str.Contains("pow"))
Console.WriteLine("The sequence pow was found.");
if(!str.Contains("powerful"))
Console.WriteLine("The sequence powerful was not found.");
}
}
The output is shown here:
The sequence power was found.
The sequence pow was found.
The sequence powerful was not found.
As the output shows, Contains( ) searches for a matching sequence, not for whole words. Thus, both “pow” and “power” are found. However, because there are no sequences that match “powerful”, it is (correctly) not found.
Several of the search methods have additional forms that allow you to begin a search at a specified index or to specify a range to search within. All versions of the String search methods are shown in Table 22-3.
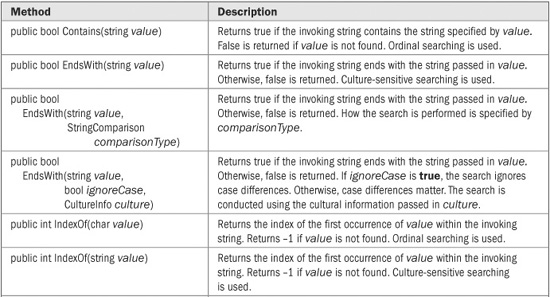
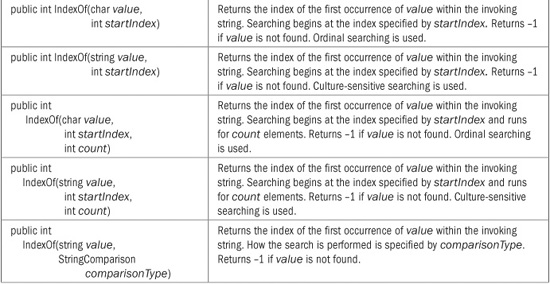
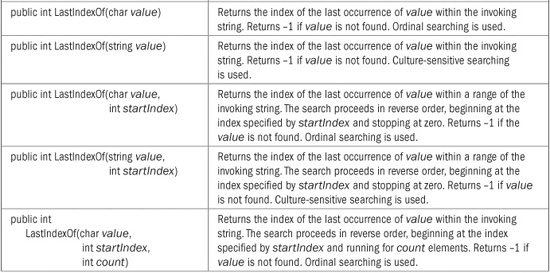
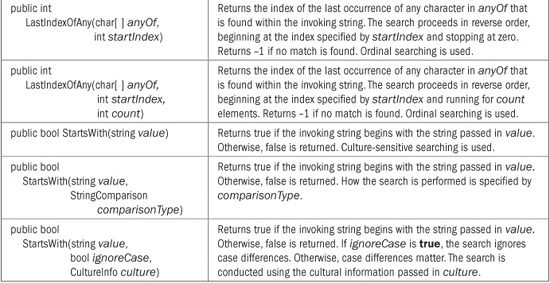
TABLE 22-3 The Search Methods Offered by String
Two fundamental string-handling operations are split and join. A split decomposes a string into its constituent parts. A join constructs a string from a set of parts. To split a string, String defines Split( ). To join a set of strings, String provides Join( ).
There are several versions of Split( ). Two commonly used forms, which have been available since C# 1.0, are shown here:
public string[ ] Split(params char[ ] separator)
public string[ ] Split(char[ ] separator, int count)
The first form splits the invoking string into pieces and returns an array containing the substrings. The characters that delimit each substring are passed in separator. If separator is null or refers to an empty string, then whitespace is used as the separator. In the second form, no more than count substrings will be returned.
There are several forms of the Join( ) method. Here are two that have been available since version 2.0 of the .NET Framework:
public static string Join(string separator, params string[ ] value)
public static string Join(string separator, string[ ] value, int startIndex, int count)
The first form returns a string that contains the concatenation of the strings in value. The second form returns a string that contains the concatenation of count strings in value, beginning at value[startIndex]. For both versions, each string is separated from the next by the string specified by separator.
The following program shows Split( ) and Join( ) in action:
// Split and join strings.
using System;
class SplitAndJoinDemo {
static void Main() {
string str = "One if by land, two if by sea.";
char[] seps = {' ', '.', ',' };
// Split the string into parts.
string[] parts = str.Split(seps);
Console.WriteLine("Pieces from split: ");
for(int i=0; i < parts.Length; i++)
Console.WriteLine(parts[i]);
// Now, join the parts.
string whole = String.Join(" | ", parts);
Console.WriteLine("Result of join: ");
Console.WriteLine(whole);
}
}
Here is the output:
Pieces from split:
One
if
by
land
two
if
by
sea
Result of join:
One | if | by | land | | two | if | by | sea |
There is one important thing to notice in this output: the empty string that occurs between “land” and “two”. This is caused by the fact that in the original string, the word “land” is followed by a comma and a space, as in “land, two”. However, both the comma and the space are specified as separators. Thus, when this string is split, the empty string that exists between the two separators (the comma and the space) is returned.
There are several additional forms of Split( ) that take a parameter of type StringSplitOptions. This parameter controls whether empty strings are part of the resulting split. Here are these forms of Split( ):
public string[ ] Split(char[ ] separator, StringSplitOptions options)
public string[ ] Split(string[ ] separator, StringSplitOptions options)
public string[ ] Split(char[ ] separator, int count, StringSplitOptions options)
public string[ ] Split(string[ ] separator, int count, StringSplitOptions options)
The first two forms split the invoking string into pieces and return an array containing the substrings. The characters that delimit each substring are passed in separator. If separator is null, then whitespace is used as the separator. In the third and fourth forms, no more than count substrings will be returned. For all versions, the value of options determines how to handle empty strings that result when two separators are adjacent to each other. The StringSplitOptions enumeration defines only two values: None and RemoveEmptyEntries. If options is None, then empty strings are included in the result (as the previous program showed). If options is RemoveEmptyEntries, empty strings are excluded from the result.
To understand the effects of removing empty entries, try replacing this line in the preceding program:
string[] parts = str.Split(seps);
with the following.
string[] parts = str.Split(seps, StringSplitOptions.RemoveEmptyEntries);
When you run the program, the output will be as shown next:
Pieces from split:
One
if
by
land
two
if
by
sea
Result of join:
One | if | by | land | two | if | by | sea
As you can see, the empty string that previously resulted because of the combination of the comma and space after “land” has been removed.
Splitting a string is an important string-manipulation procedure, because it is often used to obtain the individual tokens that comprise the string. For example, a database program might use Split( ) to decompose a query such as “show me all balances greater than 100” into its individual parts, such as “show” and “100”. In the process, the separators are removed. Thus, “show” (without any leading or trailing spaces) is obtained, not “show”. The following program illustrates this concept. It tokenizes strings containing binary mathematical operations, such as 10 + 5. It then performs the operation and displays the result.
// Tokenize strings.
using System;
class TokenizeDemo {
static void Main() {
string[] input = {
"100 + 19",
"100 / 3.3",
"-3 * 9",
"100 - 87"
};
char[] seps = {' '};
for(int i=0; i < input.Length; i++) {
// split string into parts
string[] parts = input[i].Split(seps);
Console.Write("Command: ");
for(int j=0; j < parts.Length; j++)
Console.Write(parts[j] + " ");
Console.Write(", Result: ");
double n = Double.Parse(parts[0]);
double n2 = Double.Parse(parts[2]);
switch(parts[1]) {
case "+":
Console.WriteLine(n + n2);
break;
case "-":
Console.WriteLine(n - n2);
break;
case "*":
Console.WriteLine(n * n2);
break;
case "/":
Console.WriteLine(n / n2);
break;
}
}
}
}
Command: 100 + 19, Result: 119
Command: 100 / 3.3, Result: 30.3030303030303
Command: -3 * 9, Result: -27
Command: 100 - 87, Result: 13
Beginning with .NET Framework 4.0, the following additional forms of Join( ) are also defined:
public static string Join(string separator, params object[ ] values)
public static string Join(string separator, IEnumerable<string>[ ] values)
public static string Join<T>(string separator, IEnumerable<T>[ ] values)
The first form returns a string that contains the concatenation of the string representation of the objects in values. The second form returns a string that contains the concatenation of the collection of strings referred to by values. The third form returns a string that contains the concatenation of the string representation of the collection of objects in values. In all cases, each string is separated from the next by separator.
Sometimes you will want to remove leading and trailing spaces from a string. This type of operation, called trimming, is often needed by command processors. For example, a database might recognize the word “print”. However, a user might enter this command with one or more leading or trailing spaces. Any such spaces must be removed before the string can be recognized by the database. Conversely, sometimes you will want to pad a string with spaces so that it meets some minimal length. For example, if you are preparing formatted output, you might need to ensure that each line is a certain length in order to maintain an alignment. Fortunately, C# includes methods that make these types of operations easy.
To trim a string, use one of these Trim( ) methods:
public string Trim( )
public string Trim(params char[ ] trimChars)
The first form removes leading and trailing whitespace from the invoking string. The second form removes leading and trailing occurrences of the characters specified by trimChars. In both cases, the resulting string is returned.
You can pad a string by adding characters to either the left or the right side of the string. To pad a string on the left, use one of the methods shown here:
public string PadLeft(int totalWidth)
public string PadLeft(int totalWidth, char paddingChar)
The first form adds spaces on the left as needed to the invoking string so that its total length equals totalWidth. The second form adds the character specified by paddingChar as needed to the invoking string so that its total length equals totalWidth. In both cases, the resulting string is returned. If totalWidth is less than the length of the invoking string, a copy of the invoking string is returned unaltered.
To pad a string to the right, use one of these methods:
public string PadRight(int totalWidth)
public string PadRight(int totalWidth, char paddingChar)
The first form adds spaces on the right as needed to the invoking string so that its total length equals totalWidth. The second form adds the characters specified by paddingChar as needed to the invoking string so that its total length equals totalWidth. In both cases, the resulting string is returned. If totalWidth is less than the length of the invoking string, a copy of the invoking string is returned unaltered.
The following program demonstrates trimming and padding:
// Trimming and padding.
using System;
class TrimPadDemo {
static void Main() {
string str = "test";
Console.WriteLine("Original string: " + str);
// Pad on left with spaces.
str = str.PadLeft(10);
Console.WriteLine("|" + str + "|");
// Pad on right with spaces.
str = str.PadRight(20);
Console.WriteLine("|" + str + "|");
// Trim spaces.
str = str.Trim();
Console.WriteLine("|" + str + "|");
// Pad on left with #s.
str = str.PadLeft(10, '#');
Console.WriteLine("|" + str + "|");
// Pad on right with #s.
str = str.PadRight(20, '#');
Console.WriteLine("|" + str + "|");
// Trim #s.
str = str.Trim('#');
Console.WriteLine("|" + str + "|");
}
}
The output is shown here:
Original string: test
| test|
| test |
|test|
|######test|
|######test##########|
|test|
You can insert a string into another using the Insert( ) method, shown here:
public string Insert(int startIndex, string value)
Here, the string referred to by value is inserted into the invoking string at the index specified by startIndex. The resulting string is returned.
You can remove a portion of a string using Remove( ), shown next:
public string Remove(int startIndex)
public string Remove(int startIndex, int count)
The first form begins at the index specified by startIndex and removes all remaining characters in the string. The second form begins at startIndex and removes count number of characters. In both cases, the resulting string is returned.
You can replace a portion of a string by using Replace( ). It has these forms:
public string Replace(char oldChar, char newChar)
public string Replace(string oldValue, string newValue)
The first form replaces all occurrences of oldChar in the invoking string with newChar. The second form replaces all occurrences of the string referred to by oldValue in the invoking string with the string referred to by newValue. In both cases, the resulting string is returned.
Here is an example that demonstrates Insert( ), Remove( ), and Replace( ):
// Inserting, replacing, and removing.
using System;
class InsRepRevDemo {
static void Main() {
string str = "This test";
Console.WriteLine("Original string: " + str);
// Insert
str = str.Insert(5, "is a ");
Console.WriteLine(str);
// Replace string
str = str.Replace("is", "was");
Console.WriteLine(str);
// Replace characters
str = str.Replace('a', 'X');
Console.WriteLine(str);
// Remove
str = str.Remove(4, 5);
Console.WriteLine(str);
}
}
Original string: This test
This is a test
Thwas was a test
ThwXs wXs X test
ThwX X test
String offers two convenient methods that enable you to change the case of letters within a string. These are called ToUpper( ) and ToLower( ). Here are their simplest forms:
public string ToLower( )
public string ToUpper( )
ToLower( ) lowercases all letters within the invoking string. ToUpper( ) uppercases all letters within the invoking string. The resulting string is returned. For both, the transformation is culture-sensitive. There are also versions of these methods that allow you to specify cultural settings that determine how the methods perform their conversions. These are shown here:
public string ToLower(CultureInfo culture)
public string ToUpper(CultureInfo culture)
Using these forms lets you avoid ambiguity in your source code about what rules you want to follow when changing case, and these are the forms recommended for use.
Also available are the methods ToUpperInvariant( ) and ToLowerInvariant( ), shown here:
public string ToUpperInvariant( )
public string ToLowerInvariant( )
These work like ToUpper( ) and ToLower( ) except that they use the invariant culture to perform the transformations to upper- or lowercase.
You can obtain a portion of a string by using the Substring( ) method. It has these two forms:
public string Substring(int startIndex)
public string Substring(int startIndex, int length)
In the first form, the substring begins at the index specified by startIndex and runs to the end of the invoking string. In the second form, the substring begins at startIndex and runs for length characters. In each case, the substring is returned.
The following program demonstrates the Substring( ) method:
// Use Substring().
using System;
class SubstringDemo {
static void Main() {
string str = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
Console.WriteLine("str: " + str);
Console.Write("str.Substring(15): ");
string substr = str.Substring(15);
Console.WriteLine(substr);
Console.Write("str.Substring(0, 15): ");
substr = str.Substring(0, 15);
Console.WriteLine(substr);
}
}
The following output is produced:
str: ABCDEFGHIJKLMNOPQRSTUVWXYZ
str.Substring(15): PQRSTUVWXYZ
str.Substring(0, 15): ABCDEFGHIJKLMNO
As mentioned earlier, String implements IEnumerable<T>. This means that beginning with C# 3.0, a String object can call the extension methods defined by Enumerable and Queryable, which are both in the System.Linq namespace. These extension methods primarily provide support for LINQ, but some can also be used for other purposes, such as certain types of string handling. See Chapter 19 for a discussion of extension methods.
When a human-readable form of a built-in type, such as int or double, is needed, a string representation must be created. Although C# automatically supplies a default format for this representation, it is also possible to specify a format of your own choosing. For example, as you saw in Part I, it is possible to output numeric data using a dollars and cents format. A number of methods format data, including Console.WriteLine( ), String.Format( ), and the ToString( ) method defined for the numeric structure types. The same approach to formatting is used by all three; once you have learned to format data for one, you can apply it to the others.
Formatting is governed by two components: format specifiers and format providers. The form that the string representation of a value will take is controlled through the use of a format specifier. Thus, it is the format specifier that dictates how the human-readable form of the data will look. For example, to output a numeric value using scientific notation, you will use the E format specifier.
In many cases, the precise format of a value will be affected by the culture and language in which the program is running. For example, in the United States, money is represented in dollars. In Europe, money is represented in euros. To handle the cultural and language differences, C# uses format providers. A format provider defines the way that a format specifier will be interpreted. A format provider is created by implementing the IFormatProvider interface, which defines the GetFormat( ) method. Format providers are predefined for the built-in numeric types and many other types in the .NET Framework. In general, you can format data without having to worry about specifying a format provider, and format providers are not examined further in this book.
To format data, include a format specifier in a call to a method that supports formatting. The use of format specifiers was introduced in Chapter 3, but is worthwhile reviewing here. The discussion that follows uses Console.WriteLine( ), but the same basic approach applies to other methods that support formatting.
To format data using WriteLine( ), use the version of WriteLine( ) shown here:
WriteLine(“format string”, arg0, arg1, ..., argN);
In this version, the arguments to WriteLine( ) are separated by commas and not + signs. The format string contains two items: regular, printing characters that are displayed as-is, and format items (also called format commands).
Format items take this general form:
{argnum, width: fmt}
Here, argnum specifies the number of the argument (starting from zero) to display. The minimum width of the field is specified by width, and the format specifier is represented by a string in fmt. Both width and fmt are optional. Thus, in its simplest form, a format item simply indicates which argument to display. For example, {0} indicates arg0, {1} specifies arg1, and so on.
During execution, when a format item is encountered in the format string, the corresponding argument, as specified by argnum, is substituted and displayed. Thus, it is the position of a format item within the format string that determines where its matching data will be displayed. It is the argument number that determines which argument will be formatted.
If fmt is present, then the data is displayed using the specified format. Otherwise, the default format is used. If width is present, then output is padded with spaces to ensure that the minimum field width is attained. If width is positive, output is right-justified. If width is negative, output is left-justified.
The remainder of this chapter examines formatting and format specifiers in detail.
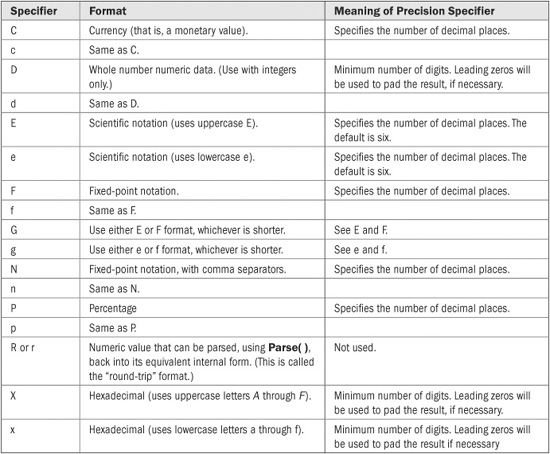
There are several format specifiers defined for numeric data. They are shown in Table 22-4. Each format specifier can include an optional precision specifier. For example, to specify that a value be represented as a fixed-point value with two decimal places, use F2.
As explained, the precise effect of certain format specifiers depends upon the cultural settings. For example, the currency specifier, C, automatically displays a value in the monetary format of the selected culture. For most users, the default cultural information matches their locale and language. Thus, the same format specifier can be used without concern about the cultural context in which the program is executed.
TABLE 22-4 The Numeric Format Specifiers
Here is a program that demonstrates several of the numeric format specifiers:
// Demonstrate various format specifiers.
using System;
class FormatDemo {
static void Main() {
double v = 17688.65849;
double v2 = 0.15;
int x = 21;
Console.WriteLine("{0:F2}", v);
Console.WriteLine("{0:N5}", v);
Console.WriteLine("{0:e}", v);
Console.WriteLine("{0:r}", v);
Console.WriteLine("{0:p}", v2);
Console.WriteLine("{0:X}", x);
Console.WriteLine("{0:D12}", x);
Console.WriteLine("{0:C}", 189.99);
}
}
The output is shown here:
17688.66
17,688.65849
1.768866e+004
17688.65849
15.00 %
15
000000000021
$189.99
Notice the effect of the precision specifier in several of the formats.
It is important to understand that the argument associated with a format item is determined by the argument number, not the argument’s position in the argument list. This means the same argument can be output more than once within the same call to WriteLine( ). It also means that arguments can be displayed in a sequence different than they are specified in the argument list. For example, consider the following program:
using System;
class FormatDemo2 {
static void Main() {
// Format the same argument three different ways:
Console.WriteLine("{0:F2} {0:F3} {0:e}", 10.12345);
// Display arguments in non-sequential order.
Console.WriteLine("{2:d} {0:d} {1:d}", 1, 2, 3);
}
}
The output is shown here:
10.12 10.123 1.012345e+001
3 1 2
In the first WriteLine( ) statement, the same argument, 10.12345, is formatted three different ways. This is possible because each format specifier refers to the first (and only) argument. In the second WriteLine( ) statement, the three arguments are displayed in nonsequential order. Remember, there is no rule that format specifiers must use the arguments in sequence. Any format specifier can refer to any argument.
Although embedding format commands into WriteLine( ) is a convenient way to format output, sometimes you will want to create a string that contains the formatted data, but not immediately display that string. Doing so lets you format data in advance, allowing you to output it later, to the device of your choosing. This is especially useful in a GUI environment, such as Windows, in which console-based I/O is rarely used, or for preparing output for a web page.
In general, there are two ways to obtain the formatted string representation of a value. One way is to use String.Format( ). The other is to pass a format specifier to the ToString( ) method of the built-in numeric types. Each approach is examined here.
You can obtain a formatted value by calling one of the Format( ) methods defined by String. They are shown in Table 22-5. Format( ) works much like WriteLine( ), except that it returns a formatted string rather than outputting it to the console.
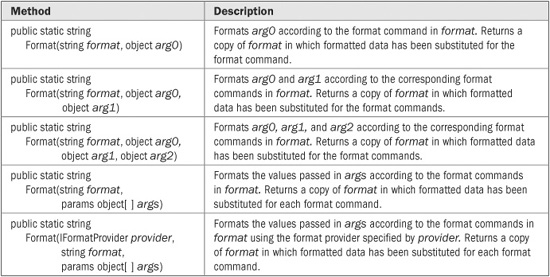
TABLE 22-5 The Format( ) Methods
Here is the previous format demonstration program rewritten to use String.Format( ). It produces the same output as the earlier version.
// Use String.Format() to format a value.
using System;
class FormatDemo {
static void Main() {
double v = 17688.65849;
double v2 = 0.15;
int x = 21;
string str = String.Format("{0:F2}", v);
Console.WriteLine(str);
str = String.Format("{0:N5}", v);
Console.WriteLine(str);
str = String.Format("{0:e}", v);
Console.WriteLine(str);
str = String.Format("{0:r}", v);
Console.WriteLine(str);
str = String.Format("{0:p}", v2);
Console.WriteLine(str);
str = String.Format("{0:X}", x);
Console.WriteLine(str);
str = String.Format("{0:D12}", x);
Console.WriteLine(str);
str = String.Format("{0:C}", 189.99);
Console.WriteLine(str);
}
}
Like WriteLine( ), String.Format( ) lets you embed regular text along with format specifiers, and you can use more than one format item and value. For example, consider this program, which displays the running sum and product of the numbers 1 through 10:
// A closer look at Format().
using System;
class FormatDemo2 {
static void Main() {
int i;
int sum = 0;
int prod = 1;
string str;
// Display the running sum and product for the
// numbers 1 through 10.
for(i=1; i <= 10; i++) {
sum += i;
prod *= i;
str = String.Format("Sum:{0,3:D} Product:{1,8:D}",
sum, prod);
Console.WriteLine(str);
}
}
}
The output is shown here:
Sum: 1 Product: 1
Sum: 3 Product: 2
Sum: 6 Product: 6
Sum: 10 Product: 24
Sum: 15 Product: 120
Sum: 21 Product: 720
Sum: 28 Product: 5040
Sum: 36 Product: 40320
Sum: 45 Product: 362880
Sum: 55 Product: 3628800
In the program, pay close attention to this statement:
str = String.Format("Sum:{0,3:D} Product:{1,8:D}",
sum, prod);
This call to Format( ) contains two format items, one for sum and one for prod. Notice that the argument numbers are specified just as they are when using WriteLine( ). Also, notice that regular text, such as “Sum:” is included. This text is passed through and becomes part of the output string.
For all of the built-in numeric structure types, such as Int32 or Double, you can use ToString( ) to obtain a formatted string representation of the value. To do so, you will use this general form of ToString( ):
ToString(“format string”)
It returns the string representation of the invoking object as specified by the format specifier passed in format string. For example, the following program creates a monetary representation of the value 188.99 through the use of the C format specifier:
string str = 189.99.ToString("C");
Notice how the format specifier is passed directly to ToString( ). Unlike embedded format commands used by WriteLine( ) or Format( ), which supply an argument-number and fieldwidth component, ToString( ) requires only the format specifier, itself.
Here is a rewrite of the previous format program that uses ToString( ) to obtain formatted strings. It produces the same output as the earlier versions.
// Use ToString() to format values.
using System;
class ToStringDemo {
static void Main() {
double v = 17688.65849;
double v2 = 0.15;
int x = 21;
string str = v.ToString("F2");
Console.WriteLine(str);
str = v.ToString("N5");
Console.WriteLine(str);
str = v.ToString("e");
Console.WriteLine(str);
str = v.ToString("r");
Console.WriteLine(str);
str = v2.ToString("p");
Console.WriteLine(str);
str = x.ToString("X");
Console.WriteLine(str);
str = x.ToString("D12");
Console.WriteLine(str);
str = 189.99.ToString("C");
Console.WriteLine(str);
}
}
Although the predefined numeric format specifiers are quite useful, C# gives you the ability to define your own, custom format using a feature sometimes called picture format. The term picture format comes from the fact that you create a custom format by specifying an example (that is, a picture) of how you want the output to look. This approach was mentioned briefly in Part I. Here it is examined in detail.
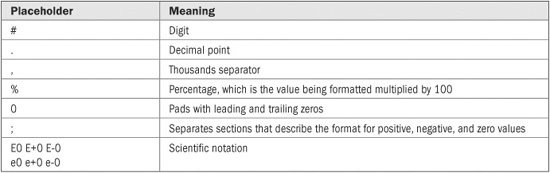
When you create a custom format, you specify that format by creating an example (or picture) of what you want the data to look like. To do this, you use the characters shown in Table 22-6 as placeholders. Each is examined in turn.
TABLE 22-6 Custom Format Placeholder Characters
The period specifies where the decimal point will be located.
The # placeholder specifies a digit position. The # can occur on the left or right side of the decimal point, or by itself. When one or more #s occur on the right side of the decimal point, they specify the number of decimal digits to display. The value is rounded if necessary. When the # occurs to the left of the decimal point, it specifies the digit positions for the whole-number part of the value. Leading zeros will be added if necessary. If the whole-number portion of the value has more digits than there are #s, the entire whole-number portion will be displayed. In no cases will the whole-number portion of a value be truncated. If there is no decimal point, then the # causes the value to be rounded to its integer value. A zero value that is not significant, such as a trailing zero, will not be displayed. This causes a somewhat odd quirk, however, because a format such as #.## displays nothing at all if the value being formatted is zero. To output a zero value, use the 0 placeholder described next.
The 0 placeholder causes a leading or trailing 0 to be added to ensure that a minimum number of digits will be present. It can be used on both the right and left side of the decimal point. For example,
Console.WriteLine("{0:00##.#00}", 21.3);
displays this output:
0021.300
Values containing more digits will be displayed in full on the left side of the decimal point and rounded on the right side.
You can insert commas into large numbers by specifying a pattern that embeds a comma within a sequence of #s. For example, this:
Console.WriteLine("{0:#,###.#}", 3421.3);
displays
3,421.3.
It is not necessary to specify each comma for each position. Specifying one comma causes it to be inserted into the value every third digit from the left. For example,
Console.WriteLine("{0:#,###.#}", 8763421.3);
produces this output:
8,763,421.3.
Commas have a second meaning. When they occur on the immediate left of the decimal point, they act as a scaling factor. Each comma causes the value to be divided by 1,000. For example,
Console.WriteLine("Value in thousands: {0:#,###,.#}", 8763421.3);
produces this output:
Value in thousands: 8,763.4
As the output shows, the value is scaled in terms of thousands.
In addition to the placeholders, a custom format specifier can contain other characters. Any other characters are simply passed through, appearing in the formatted string exactly as they appear in the format specifier. For example, this WriteLine( ) statement:
Console.WriteLine("Fuel efficiency is {0:##.# mpg}", 21.3);
produces this output:
Fuel efficiency is 21.3 mpg
You can also use the escape sequences, such as \t or \n, if necessary.
The E and e placeholders cause a value to be displayed in scientific notation. At least one 0, but possibly more, must follow the E or e. The 0s indicate the number of decimal digits that will be displayed. The decimal component will be rounded to fit the format. Using an uppercase E causes an uppercase E to be displayed; using a lowercase e causes a lowercase e to be displayed. To ensure that a sign character precedes the exponent, use the E+ or e+ forms. To display a sign character for negative values only, use E, e, E–, or e–.
The “;” is a separator that enables you to specify different formats for positive, negative, and zero values. Here is the general form of a custom format specifier that uses the “;”:
positive-fmt;negative-fmt;zero-fmt
Here is an example:
Console.WriteLine("{0:#.##;(#.##);0.00}", num);
If num is positive, the value is displayed with two decimal places. If num is negative, the value is displayed with two decimal places and is between a set of parentheses. If num is zero, the string 0.00 is displayed. When using the separators, you don’t need to supply all parts. If you just want to specify how positive and negative values will look, omit the zero format. (In this case, zero is formatted as a positive value.) Alternatively, you can omit the negative format. In this case, the positive format and the zero format will be separated by two semicolons. This causes the positive format to also be used for negative values.
The following program demonstrates just a few of the many possible custom formats that you can create:
// Using custom formats.
using System;
class PictureFormatDemo {
static void Main() {
double num = 64354.2345;
Console.WriteLine("Default format: " + num);
// Display with 2 decimal places.
Console.WriteLine("Value with two decimal places: " +
"{0:#.##}", num);
// Display with commas and 2 decimal places.
Console.WriteLine("Add commas: {0:#,###.##}", num);
// Display using scientific notation.
Console.WriteLine("Use scientific notation: " +
"{0:#.###e+00}", num);
// Scale the value by 1000.
Console.WriteLine("Value in 1,000s: " +
"{0:#0,}", num);
/* Display positive, negative, and zero
values differently. */
Console.WriteLine("Display positive, negative, " +
"and zero values differently.");
Console.WriteLine("{0:#.#;(#.##);0.00}", num);
num = -num;
Console.WriteLine("{0:#.##;(#.##);0.00}", num);
num = 0.0;
Console.WriteLine("{0:#.##;(#.##);0.00}", num);
// Display a percentage.
num = 0.17;
Console.WriteLine("Display a percentage: {0:#%}", num);
}
}
The output is shown here:
Default format: 64354.2345
Value with two decimal places: 64354.23
Add commas: 64,354.23
Use scientific notation: 6.435e+04
Value in 1,000s: 64
Display positive, negative, and zero values differently.
64354.2
(64354.23)
0.00
Display a percentage: 17%
In addition to formatting numeric values, another data type to which formatting is often applied is DateTime. DateTime is a structure that represents date and time. Date and time values can be displayed in a variety of ways. Here are just a few examples:
06/05/2005
Friday, January 1, 2010
12:59:00
12:59:00 PM
Also, the date and time representations can vary from country to country. For these reasons, the .NET Framework provides an extensive formatting subsystem for time and date values.
Date and time formatting is handled through format specifiers. The format specifiers for date and time are shown in Table 22-7. Because the specific date and time representation may vary from country to country and by language, the precise representation generated will be influenced by the cultural settings.
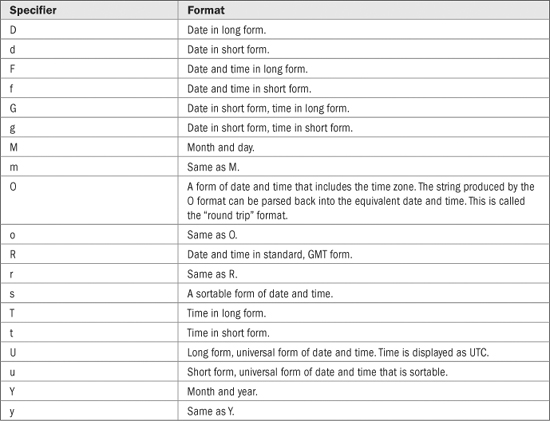
TABLE 22-7 The Date and Time Format Specifiers
Here is a program that demonstrates the date and time format specifiers:
// Format time and date information.
using System;
class TimeAndDateFormatDemo {
static void Main() {
DateTime dt = DateTime.Now; // obtain current time
Console.WriteLine("d format: {0:d}", dt);
Console.WriteLine("D format: {0:D}", dt);
Console.WriteLine("t format: {0:t}", dt);
Console.WriteLine("T format: {0:T}", dt);
Console.WriteLine("f format: {0:f}", dt);
Console.WriteLine("F format: {0:F}", dt);
Console.WriteLine("g format: {0:g}", dt);
Console.WriteLine("G format: {0:G}", dt);
Console.WriteLine("m format: {0:m}", dt);
Console.WriteLine("M format: {0:M}", dt);
Console.WriteLine("o format: {0:o}", dt);
Console.WriteLine("O format: {0:O}", dt);
Console.WriteLine("r format: {0:r}", dt);
Console.WriteLine("R format: {0:R}", dt);
Console.WriteLine("s format: {0:s}", dt);
Console.WriteLine("u format: {0:u}", dt);
Console.WriteLine("U format: {0:U}", dt);
Console.WriteLine("y format: {0:y}", dt);
Console.WriteLine("Y format: {0:Y}", dt);
}
}
Sample output is shown here:
d format: 2/11/2010
D format: Thursday, February 11, 2010
t format: 11:21 AM
T format: 11:21:23 AM
f format: Thursday, February 11, 2010 11:21 AM
F format: Thursday, February 11, 2010 11:21:23 AM
g format: 2/11/2010 11:21 AM
G format: 2/11/2010 11:21:23 AM
m format: February 11
M format: February 11
o format: 2010-02-11T11:21:23.3768153-06:00
O format: 2010-02-11T11:21:23.3768153-06:00
r format: Thu, 11 Feb 2010 11:21:23 GMT
R format: Thu, 11 Feb 2010 11:21:23 GMT
s format: 2010-02-11T11:21:23
u format: 2010-02-11 11:21:23Z
U format: Thursday, February 11, 2010 5:21:23 PM
y format: February, 2010
Y format: February, 2010
The next program creates a very simple clock. The time is updated once every second. At the top of each hour, the computer’s bell is sounded. It uses the ToString( ) method of DateTime to obtain the formatted time prior to outputting it. If the top of the hour has been reached, then the alert character (\a) is appended to the formatted time, thus ringing the bell.
// A simple clock.
using System;
class SimpleClock {
static void Main() {
string t;
int seconds;
DateTime dt = DateTime.Now;
seconds = dt.Second;
for(;;) {
dt = DateTime.Now;
// update time if seconds change
if(seconds != dt.Second) {
seconds = dt.Second;
t = dt.ToString("T");
if(dt.Minute==0 && dt.Second==0)
t = t + "\a"; // ring bell at top of hour
Console.WriteLine(t);
}
}
}
}
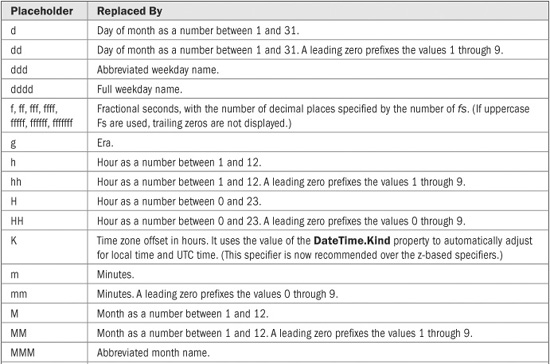
Although the standard date and time format specifiers will apply to the vast majority of situations, you can create your own, custom formats. The process is similar to creating custom formats for the numeric types, as described earlier. In essence, you simply create an example (picture) of what you want the date and time information to look like. To create a custom date and time format, you will use one or more of the placeholders shown in Table 22-8.
If you examine Table 22-8, you will see that the placeholders d, f, g, m, M, s, and t are the same as the date and time format specifiers shown in Table 22-7. In general, if one of these characters is used by itself, it is interpreted as a format specifier. Otherwise, it is assumed to be a placeholder. If you want to use one of these characters by itself, but have it interpreted as a placeholder, then precede the character with a %.
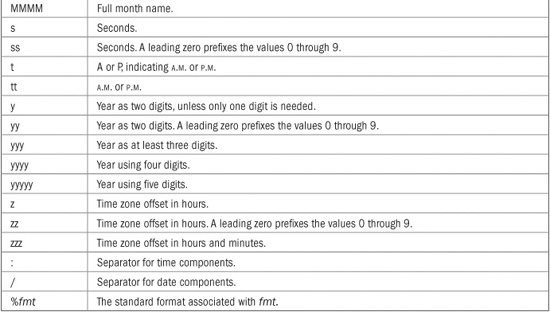
TABLE 22-8 The Custom Date and Time Placeholder Characters
The following program demonstrates several custom time and date formats:
// Format time and date information.
using System;
class CustomTimeAndDateFormatsDemo {
static void Main() {
DateTime dt = DateTime.Now;
Console.WriteLine("Time is {0:hh:mm tt}", dt);
Console.WriteLine("24 hour time is {0:HH:mm}", dt);
Console.WriteLine("Date is {0:ddd MMM dd, yyyy}", dt);
Console.WriteLine("Era: {0:gg}", dt);
Console.WriteLine("Time with seconds: " +
"{0:HH:mm:ss tt}", dt);
Console.WriteLine("Use m for day of month: {0:m}", dt);
Console.WriteLine("Use m for minutes: {0:%m}", dt);
}
}
The output is shown here:
Time is 11:19 AM
24 hour time is 11:19
Date is Thu Feb 11, 2010
Era: A.D.
Time with seconds: 11:19:40 AM
Use m for day of month: February 11
Use m for minutes: 19
Beginning with .NET Framework 4.0, you can also format objects of type TimeSpan. TimeSpan is a structure that represents a span of time. A TimeSpan object can be obtained in various ways, one of which is by subtracting one DateTime object from another. Although it is not common to format a TimeSpan value, it warrants a brief mention.
By default, TimeSpan supports three standard format specifiers: c, g, and G. These correspond to an invariant form, a culture-sensitive short form, and a culture-sensitive long form, which always includes days. TimeSpan also supports custom format specifiers. These are shown in Table 22-9. In general, if one of these characters is used by itself, precede the character with a %.
TABLE 22-9 The Custom TimeSpan Placeholder Characters
The following program demonstrates the formatting of TimeSpan objects by displaying the approximate amount of time it takes a for loop to display 1,000 integers:
// Format a TimeSpan.
using System;
class TimeSpanDemo {
static void Main() {
DateTime start = DateTime.Now;
// Output the numbers 1 through 1000.
for(int i = 1; i <= 1000; i++) {
Console.Write(i + " ");
if((i % 10) == 0) Console.WriteLine();
}
Console.WriteLine();
DateTime end = DateTime.Now;
TimeSpan span = end - start;
Console.WriteLine("Run time: {0:c}", span);
Console.WriteLine("Run time: {0:g}", span);
Console.WriteLine("Run time: {0:G}", span);
Console.WriteLine("Run time: 0.{0:fff} seconds", span);
}
}
. . .
981 982 983 984 985 986 987 988 989 990
991 992 993 994 995 996 997 998 999 1000
Run time: 00:00:00.0140000
Run time: 0:00:00.014
Run time: 0:00:00:00.0140000
Run time: 0.014 seconds
C# allows you to format the values defined by an enumeration. In general, enumeration values can be displayed using their name or their value. The enumeration format specifiers are shown in Table 22-10. Pay special attention to the G and F formats. Enumerations that will be used to represent bit-fields can be preceded by the Flags attribute. Typically, bitfields hold values that represent individual bits and are arranged in powers of two. If the Flags attribute is present, then the G specifier will display the names of all of the values that comprise the value, assuming the value is valid. The F specifier will display the names of all of the values that comprise the value if the value can be constructed by ORing together two or more fields defined by the enumeration.

TABLE 22-10 The Enumeration Format Specifiers
The following program demonstrates the enumeration specifiers:
// Format an enumeration.
using System;
class EnumFmtDemo {
enum Direction { North, South, East, West }
[Flags] enum Status { Ready=0x1, OffLine=0x2,
Waiting=0x4, TransmitOK=0x8,
RecieveOK=0x10, OnLine=0x20 }
static void Main() {
Direction d = Direction.West;
Console.WriteLine("{0:G}", d);
Console.WriteLine("{0:F}", d);
Console.WriteLine("{0:D}", d);
Console.WriteLine("{0:X}", d);
Statuss = Status.Ready | Status.TransmitOK;
Console.WriteLine("{0:G}", s);
Console.WriteLine("{0:F}", s);
Console.WriteLine("{0:D}", s);
Console.WriteLine("{0:X}", s);
}
}
The output is shown here:
West
West
3
00000003
Ready, TransmitOK
Ready, TransmitOK
9
00000009