C# is a language designed for the modern computing environment, of which the Internet is, obviously, an important part. A main design criteria for C# was, therefore, to include those features necessary for accessing the Internet. Although earlier languages, such as C and C++, could be used to access the Internet, support serverside operations, download files, and obtain resources, the process was not as streamlined as most programmers would like. C# remedies that situation. Using standard features of C# and the .NET Framework, it is easy to “Internet-enable” your applications and write other types of Internet-based code.
Networking support is contained in several namespaces defined by the .NET Framework. The primary namespace for networking is System.Net. It defines a large number of highlevel, easy-to-use classes that support the various types of operations common to the Internet. Several namespaces nested under System.Net are also provided. For example, low-level networking control through sockets is found in System.Net.Sockets. Mail support is found in System.Net.Mail. Support for secure network streams is found in System.Net.Security. Several other nested namespaces provide additional functionality. Another important networking-related namespace is System.Web. It (and its nested namespaces) supports ASP.NET-based network applications.
Although the .NET Framework offers great flexibility and many options for networking, for many applications, the functionality provided by System.Net is a best choice. It provides both convenience and ease-of-use. For this reason, System.Net is the namespace we will be using in this chapter.
System.Net is a large namespace that contains many members. It is far beyond the scope of this chapter to discuss them all or to discuss all aspects related to Internet programming. (In fact, an entire book is needed to fully cover networking in detail.) However, it is worthwhile to list the members of System.Net so you have an idea of what is available for your use.
The classes defined by System.Net are shown here:

System.Net defines the following interfaces:

It defines these enumerations:

System.Net also defines several delegates.
Although System.Net defines many members, only a few are needed to accomplish most common Internet programming tasks. At the core of networking are the abstract classes WebRequest and WebResponse. These classes are inherited by classes that support a specific network protocol. (A protocol defines the rules used to send information over a network.) For example, the derived classes that support the standard HTTP protocol are HttpWebRequest and HttpWebResponse.
Even though WebRequest and WebResponse are easy to use, for some tasks, you can employ an even simpler approach based on WebClient. For example, if you only need to upload or download a file, then WebClient is often the best way to accomplish it.
Fundamental to Internet programming is the Uniform Resource Identifier (URI). A URI describes the location of some resource on the network. A URI is also commonly called a URL, which is short for Uniform Resource Locator. Because Microsoft uses the term URI when describing the members of System.Net, this book will do so, too. You are no doubt familiar with URIs because you use one every time you enter an address into your Internet browser.
A URI has the following simplified general form:
Protocol:// HostName/FilePath? Query
Protocol specifies the protocol being used, such as HTTP. HostName identifies a specific server, such as mhprofessional.com or www.HerbSchildt.com. FilePath specifies the path to a specific file. If FilePath is not specified, the default page at the specified HostName is obtained. Finally, Query specifies information that will be sent to the server. Query is optional. In C#, URIs are encapsulated by the Uri class, which is examined later in this chapter.
The classes contained in System.Net support a request/response model of Internet interaction. In this approach, your program, which is the client, requests information from the server and then waits for the response. For example, as a request, your program might send to the server the URI of some website. The response that you will receive is the hypertext associated with that URI. This request/response approach is both convenient and simple to use because most of the details are handled for you.
The hierarchy of classes topped by WebRequest and WebResponse implement what Microsoft calls pluggable protocols. As most readers know, there are several different types of network communication protocols. The most common for Internet use is HyperText Transfer Protocol (HTTP). Another is File Transfer Protocol (FTP). When a URI is constructed, the prefix of the URI specifies the protocol. For example, http://www.HerbSchildt.com uses the prefix http, which specifies hypertext transfer protocol.
As mentioned earlier, WebRequest and WebResponse are abstract classes that define the general request/response operations that are common to all protocols. From them are derived concrete classes that implement specific protocols. Derived classes register themselves, using the static method RegisterPrefix( ), which is defined by WebRequest. When you create a WebRequest object, the protocol specified by the URI’s prefix will automatically be used, if it is available. The advantage of this “pluggable” approach is that most of your code remains the same no matter what type of protocol you are using.
The .NET runtime defines the HTTP, HTTPS, file, and FTP protocols. Thus, if you specify a URI that uses the HTTP prefix, you will automatically receive the HTTP-compatible class that supports it. If you specify a URI that uses the FTP prefix, you will automatically receive the FTP-compatible class that supports it.
Because HTTP is the most commonly used protocol, it is the only one discussed in this chapter. (The same techniques, however, will apply to all supported protocols.) The classes that support HTTP are HttpWebRequest and HttpWebResponse. These classes inherit WebRequest and WebResponse and add several members of their own, which apply to the HTTP protocol.
System.Net supports both synchronous and asynchronous communication. For many Internet uses, synchronous transactions are the best choice because they are easy to use. With synchronous communications, your program sends a request and then waits until the response is received. For some types of high-performance applications, asynchronous communication is better. Using the asynchronous approach, your program can continue processing while waiting for information to be transferred. However, asynchronous communications are more difficult to implement. Furthermore, not all programs benefit from an asynchronous approach. For example, often when information is needed from the Internet, there is nothing to do until the information is received. In cases like this, the potential gains from the asynchronous approach are not realized. Because synchronous Internet access is both easier to use and more universally applicable, it is the only type examined in this chapter.
Since WebRequest and WebResponse are at the heart of System.Net, they will be examined next.
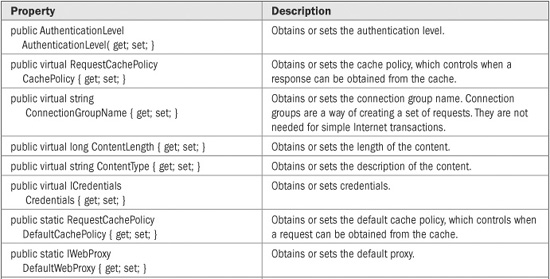
The WebRequest class manages a network request. It is abstract because it does not implement a specific protocol. It does, however, define those methods and properties common to all requests. The commonly used methods defined by WebRequest that support synchronous communications are shown in Table 26-1. The properties defined by WebRequest are shown in Table 26-2. The default values for the properties are determined by derived classes. WebRequest defines no public constructors.
To send a request to a URI, you must first create an object of a class derived from WebRequest that implements the desired protocol. This can be done by calling Create( ), which is a static method defined by WebRequest. Create( ) returns an object of a class that inherits WebRequest and implements a specific protocol.
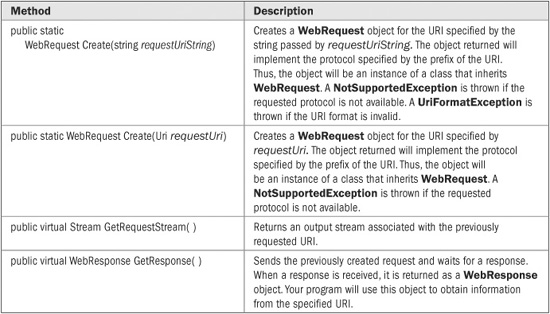
TABLE 26-1 Commonly Used Methods Defined by WebRequest that Support Synchronous Communications

TABLE 26-2 The Properties Defined by WebRequest
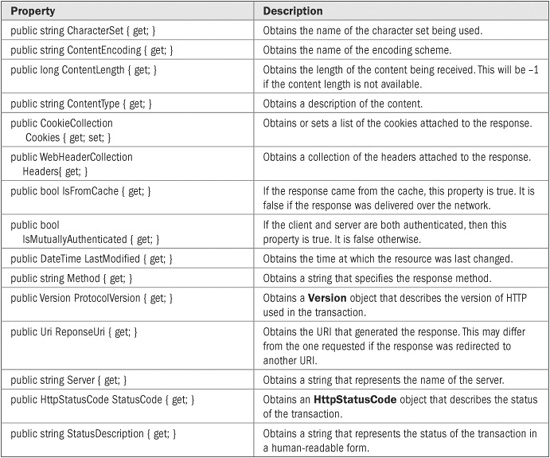
WebResponse encapsulates a response that is obtained as the result of a request. WebResponse is an abstract class. Inheriting classes create specific, concrete versions of it that support a protocol. A WebResponse object is normally obtained by calling the GetResponse( ) method defined by WebRequest. This object will be an instance of a concrete class derived from WebResponse that implements a specific protocol. The methods defined by WebResponse used in this chapter are shown in Table 26-3. The properties defined by WebResponse are shown in Table 26-4. The values of these properties are set based on each individual response. WebResponse defines no public constructors.

TABLE 26-3 Commonly Used Methods Defined by WebResponse Property Description
The classes HttpWebRequest and HttpWebResponse inherit the WebRequest and WebResponse classes and implement the HTTP protocol. In the process, both add several properties that give you detailed information about an HTTP transaction. Some of these properties are used later in this chapter. However, for simple Internet operations, you will not often need to use these extra capabilities.
Internet access centers around WebRequest and WebResponse. Before we examine the process in detail, it will be useful to see an example that illustrates the request/response approach to Internet access. After you see these classes in action, it is easier to understand why they are organized as they are.

TABLE 26-4 The Properties Defined by WebResponse
The following program performs a simple, yet very common, Internet operation. It obtains the hypertext contained at a specific website. In this case, the content of McGraw-Hill.com is obtained, but you can substitute any other website. The program displays the hypertext on the screen in chunks of 400 characters, so you can see what is being received before it scrolls off the screen.
// Access a website.
using System;
using System.Net;
using System.IO;
class NetDemo {
static void Main() {
int ch;
// First, create a WebRequest to a URI.
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create("http://www.McGraw-Hill.com");
// Next, send that request and return the response.
HttpWebResponse resp = (HttpWebResponse)
req.GetResponse();
// From the response, obtain an input stream.
Stream istrm = resp.GetResponseStream();
/* Now, read and display the html present at
the specified URI. So you can see what is
being displayed, the data is shown
400 characters at a time. After each 400
characters are displayed, you must press
ENTER to get the next 400. */
for(int i=1; ; i++) {
ch = istrm.ReadByte();
if(ch == -1) break;
Console.Write((char) ch);
if((i%400)==0) {
Console.Write("\nPress Enter.");
Console.ReadLine();
}
}
// Close the Response. This also closes istrm.
resp.Close();
}
}
The first part of the output is shown here. (Of course, over time this content will differ from that shown here.)
<html>
<head>
<title>Home - The McGraw-Hill Companies</title>
<meta name="keywords" content="McGraw-Hill Companies,McGraw-Hill, McGraw Hill,
Aviation Week, BusinessWeek, Standard and Poor’s, Standard and Poor’s,CTB/McGraw-
Hill,Glencoe/McGraw-Hill,The Grow Network/McGraw-Hill,Macmillan/McGraw-Hill,
McGraw-Hill Contemporary,McGraw-Hill Digital Learning,McGraw-Hill Professional
Development,SRA/McGraw
Press Enter.
-Hill,Wright Group/McGraw-Hill,McGraw-Hill Higher Education,McGraw-Hill/Irwin,
McGraw-Hill/Primis Custom Publishing,McGraw-Hill/Ryerson,Tata/McGraw-Hill,
McGraw-Hill Interamericana,Open University Press, Healthcare Information Group,
Platts, McGraw-Hill Construction, Information & Media Services" />
<meta name="description" content="The McGraw-Hill Companies Corporate Website." />
<meta http-equiv
Press Enter.
This is part of the hypertext associated with the McGraw-Hill.com website. Because the program simply displays the content character-by-character, it is not formatted as it would be by a browser; it is displayed in its raw form.
Let’s examine this program line-by-line. First, notice the System.Net namespace is used. As explained, this is the namespace that contains the networking classes. Also notice that System.IO is included. This namespace is needed because the information from the website is read using a Stream object.
The program begins by creating a WebRequest object that contains the desired URI. Notice that the Create( ) method, rather than a constructor, is used for this purpose. Create( ) is a static member of WebRequest. Even though WebRequest is an abstract class, it is still possible to call a static method of that class. Create( ) returns a WebRequest object that has the proper protocol “plugged in,” based on the protocol prefix of the URI. In this case, the protocol is HTTP. Thus, Create( ) returns an HttpWebRequest object. Of course, its return value must still be cast to HttpWebRequest when it is assigned to the HttpWebRequest reference called req. At this point, the request has been created, but not yet sent to the specified URI.
To send the request, the program calls GetResponse( ) on the WebRequest object. After the request has been sent, GetResponse( ) waits for a response. Once a response has been received, GetResponse( ) returns a WebResponse object that encapsulates the response. This object is assigned to resp. Since, in this case, the response uses the HTTP protocol, the result is cast to HttpWebResponse. Among other things, the response contains a stream that can be used to read data from the URI.
Next, an input stream is obtained by calling GetResponseStream( ) on resp. This is a standard Stream object, having all of the attributes and features of any other input stream. A reference to the stream is assigned to istrm. Using istrm, the data at the specified URI can be read in the same way that a file is read.
Next, the program reads the data from McGraw-Hill.com and displays it on the screen. Because there is a lot of information, the display pauses every 400 characters and waits for you to press ENTER. This way the first part of the information won’t simply scroll off the screen. Notice that the characters are read using ReadByte( ). Recall that this method returns the next byte from the input stream as an int, which must be cast to char. It returns –1 when the end of the stream has been reached.
Finally, the response is closed by calling Close( ) on resp. Closing the response stream automatically closes the input stream, too. It is important to close the response between each request. If you don’t, it is possible to exhaust the network resources and prevent the next connection.
Before leaving this example, one other important point needs to be made: It was not actually necessary to use an HttpWebRequest or HttpWebResponse object to display the hypertext received from the server. Because the preceding program did not use any HTTP specific features, the standard methods defined by WebRequest and WebResponse were sufficient to handle this task. Thus, the calls to Create( ) and GetResponse( ) could have been written like this:
// First, create a WebRequest to a URI.
WebRequest req = WebRequest.Create("http://www.McGraw-Hill.com");
// Next, send that request and return the response.
WebResponse resp = req.GetResponse();
In cases in which you don’t need to employ a cast to a specific type of protocol implementation, it is better to use WebRequest and WebResponse because it allows protocols to be changed with no impact on your code. However, since all of the examples in this chapter will be using HTTP, and a few will be using HTTP-specific features, the programs will use HttpWebRequest and HttpWebResponse.
Although the program in the preceding section is correct, it is not resilient. Even the simplest network error will cause it to end abruptly. Although this isn’t a problem for the example programs shown in this chapter, it is something that must be avoided in real-world applications. To handle network exceptions that the program might generate, you must monitor calls to Create( ), GetResponse( ), and GetResponseStream( ). It is important to understand that the exceptions that can be generated depend upon the protocol being used. The following discussion describes several of the exceptions possible when using HTTP.
The Create( ) method defined by WebRequest that is used in this chapter can generate four exceptions. If the protocol specified by the URI prefix is not supported, then NotSupportedException is thrown. If the URI format is invalid, UriFormatException is thrown. If the user does not have the proper authorization, a System.Security.SecurityException will be thrown. Create( ) can also throw an ArgumentNullException if it is called with a null reference, but this is not an error generated by networking.
A number of errors can occur when obtaining an HTTP response by calling GetResponse( ). These are represented by the following exceptions: InvalidOperationException, ProtocolViolationException, NotSupportedException, and WebException. Of these, the one of most interest is WebException.
WebException has two properties that relate to network errors: Response and Status. You can obtain a reference to the WebResponse object inside an exception handler through the Response property. For the HTTP protocol, this object describes the error. It is defined like this:
public WebResponse Response { get; }
When an error occurs, you can use the Status property of WebException to find out what went wrong. It is defined like this:
public WebExceptionStatus Status {get; }
WebExceptionStatus is an enumeration that contains the following values:

Once the cause of the error has been determined, your program can take appropriate action.
For the HTTP protocol, the GetResponseStream( ) method of WebResponse can throw a ProtocolViolationException, which, in general, means that some error occurred relative to the specified protocol. As it relates to GetResponseStream( ), it means that no valid response stream is available. An ObjectDisposedException will be thrown if the response has already been disposed. Of course, an IOException could occur while reading the stream, depending on how input is accomplished.
The following program adds handlers for network exceptions to the example shown earlier:
// Handle network exceptions.
using System;
using System.Net;
using System.IO;
class NetExcDemo {
static void Main() {
int ch;
try {
// First, create a WebRequest to a URI.
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create("http://www.McGraw-Hill.com");
// Next, send that request and return the response.
HttpWebResponse resp = (HttpWebResponse)
req.GetResponse();
// From the response, obtain an input stream.
Stream istrm = resp.GetResponseStream();
/* Now, read and display the html present at
the specified URI. So you can see what is
being displayed, the data is shown
400 characters at a time. After each 400
characters are displayed, you must press
ENTER to get the next 400. */
for(int i=1; ; i++) {
ch = istrm.ReadByte();
if(ch == -1) break;
Console.Write((char) ch);
if((i%400)==0) {
Console.Write("\nPress Enter.");
Console.ReadLine();
}
}
// Close the Response. This also closes istrm.
resp.Close();
} catch(WebException exc) {
Console.WriteLine("Network Error: " + exc.Message +
"\nStatus code: " + exc.Status);
} catch(ProtocolViolationException exc) {
Console.WriteLine("Protocol Error: " + exc.Message);
} catch(UriFormatException exc) {
Console.WriteLine("URI Format Error: " + exc.Message);
} catch(NotSupportedException exc) {
Console.WriteLine("Unknown Protocol: " + exc.Message);
} catch(IOException exc) {
Console.WriteLine("I/O Error: " + exc.Message);
} catch(System.Security.SecurityException exc) {
Console.WriteLine("Security Exception: " + exc.Message);
} catch(InvalidOperationException exc) {
Console.WriteLine("Invalid Operation: " + exc.Message);
}
}
}
Now the network-based exceptions that the networking methods might generate have been caught. For example, if you change the call to Create( ) as shown here,
WebRequest.Create("http://www.McGraw-Hill.com/moonrocket");
and then recompile and run the program, you will see this output:
Network Error: The remote server returned an error: (404) Not Found.
Status code: ProtocolError
Since the McGraw-Hill.com website does not have a directory called “moonrocket,” this URI is not found, as the output confirms.
To keep the examples short and uncluttered, most of the programs in this chapter will not contain full exception handling. However, your real-world applications must.
In Table 26-1, notice that WebRequest.Create( ) has two different versions. One accepts the URI as a string. This is the version used by the preceding programs. The other takes the URI as an instance of the Uri class, which is defined in the System namespace. The Uri class encapsulates a URI. Using Uri, you can construct a URI that can be passed to Create( ). You can also dissect a Uri, obtaining its parts. Although you don’t need to use Uri for many simple Internet operations, you may find it valuable in more sophisticated situations.
Uri defines several constructors. Two commonly used ones are shown here:
public Uri(string uriString)
public Uri(Uri baseUri, string relativeUri)
The first form constructs a Uri given a URI in string form. The second constructs a Uri by adding a relative URI specified by relativeUri to an absolute base URI specified by baseUri. An absolute URI defines a complete URI. A relative URI defines only the path.
Uri defines many fields, properties, and methods that help you manage URIs or that giveyou access to the various parts of a URI. Of particular interest are the properties shown here:

These properties are useful for breaking a URI into its constituent parts. The following program demonstrates their use:
// Use Uri.
using System;
using System.Net;
class UriDemo {
static void Main() {
Uri sample = new Uri("http://HerbSchildt.com/somefile.txt?SomeQuery");
Console.WriteLine("Host: " + sample.Host);
Console.WriteLine("Port: " + sample.Port);
Console.WriteLine("Scheme: " + sample.Scheme);
Console.WriteLine("Local Path: " + sample.LocalPath);
Console.WriteLine("Query: " + sample.Query);
Console.WriteLine("Path and query: " + sample.PathAndQuery);
}
}
The output is shown here:
Host: HerbSchildt.com
Port: 80
Scheme: http
Local Path: /somefile.txt
Query: ?SomeQuery
Path and query: /somefile.txt?SomeQuery
When using HttpWebResponse, you have access to information other than the content of the specified resource. This information includes such things as the time the resource was last modified and the name of the server, and is available through various properties associated with the response. These properties, which include the six defined by WebResponse, are shown in Table 26-5. The following sections illustrate how to use representative samples.
You can access the header information associated with an HTTP response through the Headers property defined by HttpWebResponse. It is shown here:
public WebHeaderCollection Headers{ get; }
An HTTP header consists of pairs of names and values represented as strings. Each name/value pair is stored in a WebHeaderCollection. This specialized collection stores key/valuepairs and can be used like any other collection. (See Chapter 25.) A string array of the names can be obtained from the AllKeys property. You can obtain the values associated with aname by calling the GetValues( ) method. It returns an array of strings that contains the values associated with the header passed as an argument. GetValues( ) is over loaded toaccept a numeric index or the name of the header.
TABLE 26-5 The Properties Defined by HttpWebResponse
The following program displays headers associated with McGraw-Hill.com:
// Examine the headers.
using System;
using System.Net;
class HeaderDemo {
static void Main() {
// Create a WebRequest to a URI.
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create("http://www.McGraw-Hill.com");
// Send that request and return the response.
HttpWebResponse resp = (HttpWebResponse)
req.GetResponse();
// Obtain a list of the names.
string[] names = resp.Headers.AllKeys;
// Display the header name/value pairs.
Console.WriteLine("{0,-20}{1}\n", "Name", "Value");
foreach(string n in names) {
Console.Write("{0,-20}", n);
foreach(string v in resp.Headers.GetValues(n))
Console.WriteLine(v);
}
// Close the Response.
resp.Close();
}
}
Here is the output that was produced. (Remember, all header information is subject tochange, so the precise output that you see may differ.)
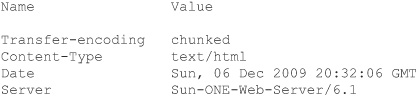
You can gain access to the cookies associated with an HTTP response through the Cookies property defined by HttpWebResponse. Cookies contain information that is stored by a browser. They consist of name/value pairs, and they facilitate certain types of web access. The Cookies property is defined like this:
public CookieCollection Cookies { get; set; }
CookieCollection implements ICollection and IEnumerable and can be used like any other collection. (See Chapter 25.) It has an indexer that allows a cookie to be obtained by specifying its index or its name.
CookieCollection stores objects of type Cookie. Cookie defines several properties that give you access to the various pieces of information associated with a cookie. The two that we will use here are Name and Value, which are defined like this:
public string Name { get; set; }
public string Value { get; set; }
The name of the cookie is contained in Name, and its value is found in Value.
To obtain a list of the cookies associated with a response, you must supply a cookie container with the request. For this purpose, HttpWebRequest defines the property CookieContainer, shown here:
public CookieContainer CookieContainer { get; set; }
CookieContainer provides various fields, properties, and methods that let you store cookies. By default, this property is null. To use cookies, you must set it equal to an instance of the CookieContainer class. For many applications, you won’t need to work with the CookieContainer property directly. Instead, you will use the CookieCollection obtained from the response. CookieContainer simply provides the underlying storage mechanism for the cookies.
The following program displays the names and values of the cookies associated with the URI specified on the command line. Remember, not all websites use cookies, so you might have to try a few until you find one that does.
/* Examine Cookies.
To see what cookies a website uses,
specify its name on the command line.
For example, if you call this program
CookieDemo, then
CookieDemo http://msn.com
displays the cookies associated with msn.com.
*/
using System;
using System.Net;
class CookieDemo {
static void Main(string[] args) {
if(args.Length != 1) {
Console.WriteLine("Usage: CookieDemo <uri>");
return ;
}
// Create a WebRequest to the specified URI.
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create(args[0]);
// Get an empty cookie container.
req.CookieContainer = new CookieContainer();
// Send the request and return the response.
HttpWebResponse resp = (HttpWebResponse)
req.GetResponse();
// Display the cookies.
Console.WriteLine("Number of cookies: " +
resp.Cookies.Count);
Console.WriteLine("{0,-20}{1}", "Name", "Value");
for(int i=0; i < resp.Cookies.Count; i++)
Console.WriteLine("{0, -20}{1}",
resp.Cookies[i].Name,
resp.Cookies[i].Value);
// Close the Response.
resp.Close();
}
}
Sometimes you will want to know when a resource was last updated. This is easy to find out when using HttpWebResponse because it defines the LastModified property. It is shown here:
public DateTime LastModified { get; }
LastModified obtains the time that the content of the resource was last modified.
The following program displays the time and date at which the URI entered on the command-line site was last updated:
/* Use LastModified.
To see the date on which a website was
last modified, enter its URI on the command
line. For example, if you call this program
LastModifiedDemo, then to see the date of last
modification for HerbSchildt.com enter
LastModifiedDemo http://www.HerbSchildt.com
*/
using System;
using System.Net;
class LastModifiedDemo {
static void Main(string[] args) {
if(args.Length != 1) {
Console.WriteLine("Usage: LastModifiedDemo <uri>");
return ;
}
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create(args[0]);
HttpWebResponse resp = (HttpWebResponse)
req.GetResponse();
Console.WriteLine("Last modified: " + resp.LastModified);
resp.Close();
}
}
To show how easy WebRequest and WebReponse make Internet programming, a skeletal web crawler called MiniCrawler will be developed. A web crawler is a program that moves from link to link to link. Search engines use web crawlers to catalog content. MiniCrawler is, of course, far less sophisticated than those used by search engines. It starts at the URI that you specify and then reads the content at that address, looking for a link. If a link is found, it then asks if you want to go to that link, search for another link on the existing page, or quit. Although this scheme is quite simple, it does provide an interesting example of accessing the Internet using C#.
MiniCrawler has several limitations. First, only absolute links that are specified using the href="http hypertext command are found. Relative links are not used. Second, there is no way to go back to an earlier link. Third, it displays only the links and no surrounding content. Despite these limitations, the skeleton is fully functional, and you will have no trouble enhancing MiniCrawler to perform other tasks. In fact, adding features to MiniCrawler is a good way to learn more about the networking classes and networking in general.
Here is the entire code for MiniCrawler:
/* MiniCrawler: A skeletal Web crawler.
Usage:
To start crawling, specify a starting
URI on the command line. For example,
to start at McGraw-Hill.com use this
command line:
MiniCrawler http://McGraw-Hill.com
*/
using System;
using System.Net;
using System.IO;
class MiniCrawler {
// Find a link in a content string.
static string FindLink(string htmlstr,
ref int startloc) {
int i;
int start, end;
string uri = null;
i = htmlstr.IndexOf("href=\"http", startloc,
StringComparison.OrdinalIgnoreCase);
if(i != -1) {
start = htmlstr.IndexOf('"', i) + 1;
end = htmlstr.IndexOf('"', start);
uri = htmlstr.Substring(start, end-start);
startloc = end;
}
return uri;
}
static void Main(string[] args) {
string link = null;
string str;
string answer;
int curloc; // holds current location in response
if(args.Length != 1) {
Console.WriteLine("Usage: MiniCrawler <uri>");
return ;
}
string uristr = args[0]; // holds current URI
HttpWebResponse resp = null;
try {
do {
Console.WriteLine("Linking to " + uristr);
// Create a WebRequest to the specified URI.
HttpWebRequest req = (HttpWebRequest)
WebRequest.Create(uristr);
uristr = null; // disallow further use of this URI
// Send that request and return the response.
resp = (HttpWebResponse) req.GetResponse();
// From the response, obtain an input stream.
Stream istrm = resp.GetResponseStream();
// Wrap the input stream in a StreamReader.
StreamReader rdr = new StreamReader(istrm);
// Read in the entire page.
str = rdr.ReadToEnd();
curloc = 0;
do {
// Find the next URI to link to.
link = FindLink(str, ref curloc);
if(link != null) {
Console.WriteLine("Link found: " + link);
Console.Write("Link, More, Quit?");
answer = Console.ReadLine();
if(string.Equals(answer, "L",
StringComparison.OrdinalIgnoreCase)) {
uristr = string.Copy(link);
break;
} else if(string.Equals(answer, "Q",
StringComparison.OrdinalIgnoreCase)) {
break;
} else if(string.Equals(answer, "M",
StringComparison.OrdinalIgnoreCase)) {
Console.WriteLine("Searching for another link.");
}
} else {
Console.WriteLine("No link found.");
break;
}
} while(link.Length > 0);
// Close the Response.
if(resp != null) resp.Close();
} while(uristr != null);
} catch(WebException exc) {
Console.WriteLine("Network Error: " + exc.Message +
"\nStatus code: " + exc.Status);
} catch(ProtocolViolationException exc) {
Console.WriteLine("Protocol Error: " + exc.Message);
} catch(UriFormatException exc) {
Console.WriteLine("URI Format Error: " + exc.Message);
} catch(NotSupportedException exc) {
Console.WriteLine("Unknown Protocol: " + exc.Message);
} catch(IOException exc) {
Console.WriteLine("I/O Error: " + exc.Message);
} finally {
if(resp != null) resp.Close();
}
Console.WriteLine("Terminating MiniCrawler.");
}
}
Here is a short sample session that begins crawling at McGraw-Hill.com. (Remember, the precise output will vary over time as content changes.)
Linking to http://mcgraw-hill.com
Link found: http://sti.mcgraw-hill.com:9000/cgi-bin/query?mss=search&pg=aq
Link, More, Quit? M
Searching for another link.
Link found: http://investor.mcgraw-hill.com/phoenix.zhtml?c=96562&p=irol-irhome
Link, More, Quit? L
Linking to http://investor.mcgraw-hill.com/phoenix.zhtml?c=96562&p=irol-irhome
Link found:
http://www.mcgraw-hill.com/index.html
Link, More, Quit? L
Linking to http://www.mcgraw-hill.com/index.html
Link found: http://sti.mcgraw-hill.com:9000/cgi-bin/query?mss=search&pg=aq
Link, More, Quit? Q
Terminating MiniCrawler.
Let’s take a close look at how MiniCrawler works. The URI at which MiniCrawler begins is specified on the command line. In Main( ), this URI is stored in the string called uristr. A request is created to this URI and then uristr is set to null, which indicates that this URI has already been used. Next, the request is sent and the response is obtained. The content is then read by wrapping the stream returned by GetResponseStream( ) inside a StreamReader and then calling ReadToEnd( ), which returns the entire contents of the stream as a string.
Using the content, the program then searches for a link. It does this by calling FindLink( ), which is a static method also defined by MiniCrawler. FindLink( ) is called with the content string and the starting location at which to begin searching. The parameters that receive these values are htmlstr and startloc, respectively. Notice that startloc is a ref parameter. FindLink( ) looks for a substring that matches href="http, which indicates a link. If a match is found, the URI is copied to uri, and the value of startloc is updated to the end of the link. Because startloc is a ref parameter, this causes its corresponding argument to be updated in Main( ), enabling the next search to begin where the previous one left off. Finally, uri is returned. Since uri was initialized to null, if no match is found, a null reference is returned, which indicates failure.
Back in Main( ), if the link returned by FindLink( ) is not null, the link is displayed, and the user is asked what to do. The user can go to that link by pressing L, search the existing content for another link by pressing M, or quit the program by pressing Q. If the user presses L, the link is followed and the content of the link is obtained. The new content is then searched for a link. This process continues until all potential links are exhausted.
You might find it interesting to increase the power of MiniCrawler. For example, you might try adding the ability to follow relative links. (This is not hard to do.) You might try completely automating the crawler by having it go to each link that it finds without user interaction. That is, starting at an initial page, have it go to the first link it finds. Then, in the new page, have it go to the first link and so on. Once a dead-end is reached, have it backtrack one level, find the next link, and then resume linking. To accomplish this scheme, you will need to use a stack to hold the URIs and the current location of the search within a URI. One way to do this is to use a Stack collection. As an extra challenge, try creating treelike output that displays the links.
Before concluding this chapter, a brief discussion of WebClient is warranted. As mentioned near the start of this chapter, if your application only needs to upload or download data to or from the Internet, then you can use WebClient instead of WebRequest and WebResponse. The advantage to WebClient is that it handles many of the details for you.
WebClient defines one constructor, shown here:
public WebClient( )
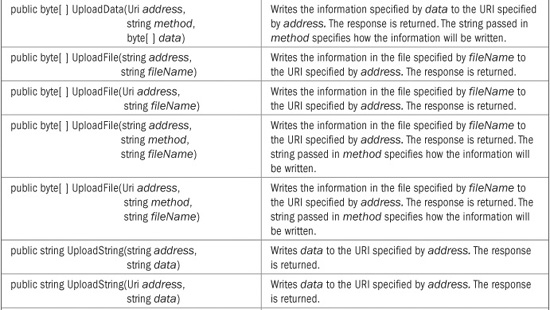
WebClient defines the properties shown in Table 26-6. WebClient defines a large number of methods that support both synchronous and asynchronous communication. Because asynchronous communication is beyond the scope of this chapter, only those methods that support synchronous requests are shown in Table 26-7. All methods throw a WebException if an error occurs during transmission.
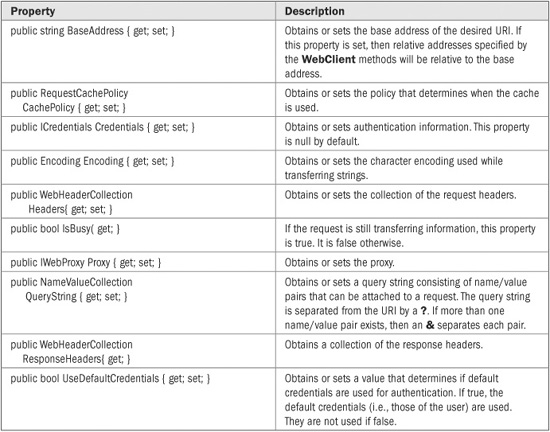
TABLE26-6 The Properties Defined by WebClient


TABLE 26-7 The Synchronous Methods Defined by WebClient
The following program demonstrates how to use WebClient to download data into a file:
// Use WebClient to download information into a file.
using System;
using System.Net;
using System.IO;
class WebClientDemo {
static void Main() {
WebClient user = new WebClient();
string uri = "http://www.McGraw-Hill.com";
string fname = "data.txt";
try {
Console.WriteLine("Downloading data from " +
uri + " to " + fname);
user.DownloadFile(uri, fname);
} catch (WebException exc) {
Console.WriteLine(exc);
}
user.Dispose();
Console.WriteLine("Download complete.");
}
}
This program downloads the information at McGrawHill.com and puts it into a file called data.txt. Notice how few lines of code are involved. By changing the string specified by uri, you can download information from any URI, including specific files.
Although WebRequest and WebResponse give you greater control and access to more information, WebClient is all that many applications will need. It is particularly useful when all you need to do is download information from the Web. For example, you might use WebClient to allow an application to obtain documentation updates.