Visual Perception and Bottom-Up Processing in Art
To appreciate what brain science can tell us about the beholder’s share—how we respond to a work of art—we need first to understand how our visual experiences are generated by the brain and how the sensory signals that are processed into bottom-up perceptions are modified by top-down influences and by the brain systems concerned with memory and emotion. We will first consider the bottom-up processes.
You are probably confident that you see the world as it is. You rely on your eyes to give you accurate information so that your actions are based on reality. While our eyes do provide information we need to act, they do not present our brain with a finished product. The brain actively extracts information about the three-dimensional organization of the world from the two-dimensional image on the retina. What is so wonderful—indeed, almost magical—about our brain is that we can perceive an object based on incomplete information, and we can perceive it as being the same under strikingly different conditions of lighting and context.
How does the brain do that? A guiding principle in its organization is that every mental process—perceptual, emotional, or motor—relies on distinct groups of specialized neural circuits located in an orderly, hierarchical arrangement in specific regions in the brain. However, while brain structures are separable conceptually at every level of organization, they are related to one another anatomically and functionally, and therefore cannot be separated physically.
The visual system is central to the beholder’s share. How is it organized? What levels of organization in the visual system come into play, for example, when we look at a face in a portrait?
In primates, and especially in humans, the cerebral cortex, the heavily wrinkled outer layer of the brain, is typically thought to be the most important region for higher cognition and consciousness. The cerebral cortex has four lobes: occipital, temporal, parietal, and frontal. The occipital lobe, located at the back of the brain, is where visual information from the eyes enters the brain; the temporal lobe is where visual information about faces is processed (
fig. 3.1).
Vision is the process of
discovering from images
what is present in the visual world and
where it is. This implies that the brain has two parallel processing streams, one that deals with what an image is about and one that deals with where it is located in the world. These two parallel processing streams in the cerebral cortex are the
what pathway and the
where pathway (
fig. 3.1). Both pathways start in the retina, the light-sensitive layer of cells at the back of the eye.
Visual information begins as reflected light. The wavelengths of light, such as those reflected by the face of a person or a portrait, are refracted by the cornea of the eye and projected onto the retina. The resulting retinal image is essentially a pattern of light that changes in intensity and wavelength over space and time (Albright 2015).
Retinal cells fall into two categories: rods and cones. Rods are exquisitely sensitive to the intensity of light and are used for black-and-white vision. Cones, in contrast, are less sensitive to light but carry information about color. Cones come in three types, each of which responds to different but overlapping wavelengths of light that represent all the colors in the visible spectrum. They are located predominantly in the center of the retina—an area called the fovea, where fine visual detail is registered best—whereas rods specialized for black-and-white vision are more prevalent on the periphery of the retina.
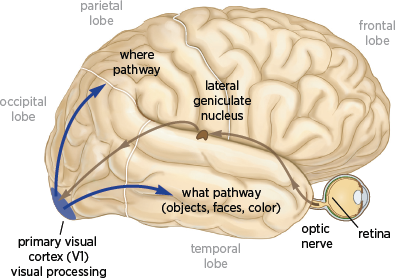
3.1 The visual system. Information flows from the retina to the lateral geniculate nucleus through the optic nerve. The lateral geniculate nucleus sends information to the primary visual cortex, which gives rise to two major pathways: the where pathway concerned with where an object or a person is located and the what pathway which is concerned with what an object is or who a person is.
The retina sends visual information to the lateral geniculate nucleus, a group of cells located in the thalamus, a structure deep within the brain that relays information to the primary visual cortex (also called the striate cortex, or area V1). The primary visual cortex is located in the occipital lobe at the back of the brain and is where visual information enters the brain (
fig. 3.1). According to Semir Zeki, a pioneer in the study of visual processing at University College London, “V1, in brief, acts much like a post office, distributing different signals to different destinations; it is but the first, though essential, stage in an elaborate machinery designed to extract the essential information from the visual world” (Zeki 1998).
The visual information that reaches the primary visual cortex is relatively simple and lightly processed information about what things are and where they are. It is difficult to imagine that information about what an object is can be divorced from where it is, yet that is exactly what happens next: the information leaves the primary visual cortex in two separate pathways.
The
what pathway runs from the primary visual cortex, area V1, to several regions near the bottom of the brain, including the unimaginatively named areas V2, V3, and V4, and on to the inferior temporal cortex, where face processing occurs. This information-processing stream, also known as the
inferior pathway because of its location in the brain, is concerned with the nature of objects or faces: their shape, color, identity, motion, and function (
fig. 3.1). The
what pathway is of particular interest in the context of portraiture. It not only carries information about form but also is the only visual pathway that leads directly to the hippocampus, the structure in the brain that is concerned with the explicit memory of people, places, and objects and that is recruited by the beholder’s brain for top-down processing.
The where pathway runs from the primary visual cortex to areas near the top of the brain. This pathway, also known as the superior pathway, is concerned with the processing of motion, depth, and spatial information to determine where an object is in the external world.
The separation between the two pathways is not absolute, because we often need to combine information about where and what an object is. For that reason, the pathways can exchange information along their courses. But the separation is quite pronounced, and it is something that cannot happen in the physical world or in a simple photograph: an object is what it is and where it is at the same time. As we shall see, art is often quite successful in exploiting the fact that seemingly inseparable information is in fact separated in our brain.
Together with the
where pathway, the
what pathway performs three types of visual processing.
Low-level processing occurs in the retina and is concerned with detecting an image.
Intermediate-level processing begins in the primary visual cortex. A visual scene comprises thousands of line segments and surfaces. Intermediate-level vision discerns which surfaces and boundaries belong to specific objects and which are part of the background. Together, low- and intermediate-level visual processing identify the areas of an image that are related to particular objects and the background area that is not. Intermediate-level processing is also concerned with contour integration, a grouping operation designed to combine features into distinct objects. These two types of visual processing are critical for the bottom-up processing of the beholder’s share.
High-level visual processing integrates information from a variety of regions in the brain to make sense of what we have seen. Once this information has reached the highest level of the what pathway, top-down processing occurs: the brain uses cognitive processes such as attention, learning, and memory—everything we have seen and understood before—to interpret the information. In the case of a portrait, this leads to conscious perception of the face and recognition of the person who is depicted (see Albright 2013; Gilbert 2013b). Information in the where pathway is processed in much the same way. Thus the what and where pathways of our visual system also function as a parallel-processing perceptual system.
The existence of two visual pathways in our brain poses a binding problem for neural integration. How does the brain combine the pieces of information about a particular object provided by these parallel processing streams? Anne Treisman has found that binding requires focused attention on an object (Treisman 1986). Her studies suggest that visual perception involves two processes in addition to what and where. First comes a preattentive process, which is concerned only with detection of the object. In this bottom-up process the beholder rapidly scans an object’s global features—such as its shape and texture—and focuses on distinctions between figure and ground by encoding all the useful elementary properties of the image simultaneously: its color, size, and orientation. This is followed by an attentive process, a top-down searchlight of attention that allows higher centers in the brain to infer that since these several features occupy one location, they must be bound together (Treisman 1986; Wurtz and Kandel 2000).
Thus, once information from the
what pathway reaches the higher regions of the brain, it is reappraised. This top-down reappraisal operates on four principles: it disregards details that are perceived as behaviorally irrelevant in a given context; it searches for constancy; it attempts to abstract the essential, constant features of objects, people, and landscapes; and, particularly important, it compares the present image to images encountered in the past. These biological findings confirm Kris and Gombrich’s inference that visual perception is not a simple window on the world, but truly a creation of the brain.
The visual system’s segregation of function becomes obvious in cases of brain damage. Damage to any given area of the visual system produces very specific effects. For example, damage to the inferior medial temporal lobe compromises our ability to recognize faces, a condition known as face blindness, or prosopagnosia. This condition was first discovered in 1946 by the neurologist Joachim Bodamer (1947). People with damage in the front of the inferior temporal cortex can recognize a face as a face but cannot tell whose face it is. People with damage to the back of the inferior temporal cortex cannot see a face at all. In Oliver Sacks’s famous story “The Man Who Mistook His Wife for a Hat,” a man with face blindness tried to pick up his wife’s head and put it on his head because he mistook her head for his hat (Sacks 1985). A modest degree of face blindness is not rare; about 10 percent of people are born with it.
Bodamer’s discovery was important because, as Charles Darwin first emphasized, face recognition is essential for our functioning as social beings. In The Expression of Emotions in Man and Animals (1872), Darwin argues that we are biological creatures who have evolved from simpler animal ancestors. Evolution is driven by sexual selection, and therefore sex is central to human behavior. A key to sexual attraction—indeed, to all social interaction—is facial expression. We recognize each other and even ourselves through our faces.
3.2 a. Multiple areas of the nonhuman primate brain respond to faces. b. Rembrandt’s self-portrait. c. Rembrandt’s self-portrait from a simple line drawing.
Being social animals, we need to communicate not only our ideas and plans but also our emotions, and we do that through our faces. We convey emotions in large part through a limited number of facial expressions. Thus, you can attract another person by smiling seductively, or you can keep that person away by looking foreboding.
Since all faces have the same number of features—one nose, two eyes, and one mouth—the sensory and motor aspects of emotional signals communicated by the face must be universal, independent of culture. Darwin argued that both the ability to form facial expressions and the ability to read the facial expressions of others are innate, not learned. Years later, experiments in cognitive psychology showed that face recognition begins in infancy.
What is it about faces that makes them special? Even very powerful computers have great difficulty recognizing faces, yet a child of two or three years can readily learn to distinguish up to two thousand different faces. Moreover, we can readily recognize Rembrandt’s self-portrait from a simple line drawing (
figs. 3.2b and
c): the slight exaggeration in the drawing actually helps with recognition. These observations raise another question: What is it about our brain that enables us to recognize faces so easily?
Our brain devotes more computational power, more bottom-up processing, to faces than to any other object. Charles Gross at Princeton, and later Margaret Livingstone, Doris Tsao, and Winrich Freiwald at Harvard, carried Bodamer’s findings several important steps further and in so doing made a number of important discoveries about the brain’s machinery for analyzing faces (Tsao et al. 2008; Freiwald et al. 2009; Freiwald and Tsao 2010). Using a combination of brain imaging and electrical recording of signals from individual cells, these scientists found six small structures in the temporal lobe of macaque monkeys that light up in response to a face (
fig. 3.2a). The scientists called these structures
face patches. They found a similar, although smaller, set of face patches in the human brain.
When the scientists recorded electrical signals from cells in the face patches, they found that different patches respond to different aspects of the face: head-on view, side view, and so on. The cells are also sensitive to changes in a face’s position, size, and direction of gaze, as well as to the shape of the various parts of the face. Moreover, face patches are interconnected and serve as a processing stream for information about the face.
Figure 3.3 shows a cell in a monkey’s face patch responding to various images. Not surprisingly, the cell fires very nicely when the monkey is shown a picture of another monkey (a). The cell fires even more dramatically in response to a cartoon face (b). This finding indicates that monkeys, like people, respond more powerfully to cartoons than to real objects because the features in a cartoon are exaggerated. Such exaggerated responses are mediated by the built-in machinery of bottom-up processing. The association of a particular face with a particular person or the recollection of a face seen before is added to this bottom-up processing by top-down processing, whose mechanisms we will consider further in
chapter 8.
3.3 Holistic face detection. Top: Recording site and location of a face cell. Bottom (a–h): the height of the bars indicates the firing rate of action potentials and thus the strength of face recognition in response to various types of facial stimuli.
The cells in a monkey’s
face patch respond to the total form, or
Gestalt, of the face, not to isolated features: a face has to be complete in order to elicit a response. When the monkey is shown two eyes in a circle (c), there is no response. A mouth and no eyes (d) elicits no response. Two eyes and a mouth—a nose is not necessary—inside a square (e), also no response. If the monkey is shown only a circle (f), there is no response. The cell responds only to two eyes and a mouth inside a circle (g). If the circle and the mouth are only outlined (h), there is no longer a response. In addition, if the monkey is shown an inverted face, it does not respond.
Computer models of vision suggest that some facial features are defined by contrast (Sinha 2002). For example, the eyes tend to be darker than the forehead, regardless of lighting conditions. Moreover, computer models suggest that such contrast-defined features signal the brain that a face is present. To test these ideas, Ohayon, Freiwald, and Tsao (Ohayon et al. 2012). presented monkeys with a series of artificial faces, each of whose features was assigned a unique luminous value ranging from dark to bright. They then recorded the activity of individual cells in the monkeys’ middle face patches in response to the artificial faces and found that the cells do respond to contrasts between facial features. Moreover, most of the cells are tuned to contrasts between specific pairs of features, the most common being those in which the nose is brighter than one of the eyes.
These preferences agree with those predicted by the computer model of vision. But since results in both the monkey and computer studies are based on artificial faces, the obvious question is whether they extend to real faces.
To answer that question, Ohayon and his colleagues studied the response of the cells to images of a large variety of real faces. They found that responses increased with the number of contrast-defined features. Specifically, the cells did not respond to real faces containing only four contrast-defined features, although they did recognize them as faces. But they responded well to faces containing eight or more contrast-defined features.
Tsao, Freiwald, and their colleagues had found earlier (Tsao et al. 2008) that cells in these face patches respond selectively to the shape of some facial features, such as noses and eyes. Ohayon’s findings now showed that the preference for a particular facial feature depends on its luminance relative to other parts of the face. This may be one of the reasons that makeup is effective in highlighting women’s facial features. Importantly, most of the cells in the middle face patches respond both to contrast and to the shape of facial features. This fact leads us to an important conclusion: contrast is useful for face detection, and shape is useful for face recognition.
These studies have shed new light on the nature of the templates our brain uses to detect faces. Behavioral studies suggest further that there is a powerful link between the brain’s face detection machinery and the areas that control attention, which may explain why faces and portraits grab our attention so powerfully. Moreover, this explains why our response to Schoenberg’s figurative self-portrait (
fig. 5.10) is so different from our response to his more abstract versions (
figs. 5.11–
5.13). The figurative version gives a lot of detail to activate our face cells, whereas the abstract versions do not activate the face cells, leaving more to our imagination.
The multistage processing stream for faces has turned out to represent a general principle of vision. Colors and shapes are also represented in multistage processing patches and are also located in the inferior temporal lobe, as we shall see in
chapter 10.
The central nervous system comprises the brain and the spinal cord. It can best be understood as containing several clearly defined structural levels of organization, as outlined by Patricia Churchland and Terrence Sejnowski (1988). These levels are based on the spatial scale at which an anatomical organization can be identified (
fig. 3.4). Thus, at the highest level is the central nervous system, while at the lowest is the individual molecule.
In terms of the new science of mind, the highest level is the brain, an astonishingly complex computational organ that constructs our perception of the external world, fixes our attention, and controls our actions. The next level comprises the various systems of the brain: the sensory systems such as vision, hearing, and touch and the motor systems for movement. The next level is maps, such as the representation of the visual receptors of the retina on the primary visual cortex. The level below maps is that of the networks, such as the reflex movements of the eyes when a novel stimulus appears at the edge of our visual field. Below that is the level of neurons, then synapses, and finally the molecules.
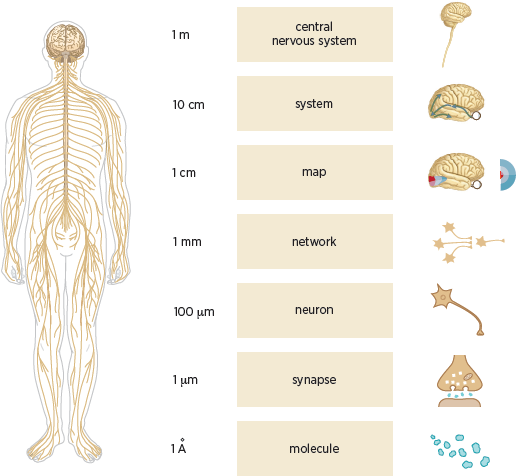
3.4 The nervous system has many levels of structural organization ranging from the central nervous system to molecules, and the spatial scale at which the corresponding anatomical organizations can be identified varies over many orders of magnitude. Left: Drawing of the human brain, the spinal cord, and the peripheral nerves. Right: Schematic diagrams illustrating (from top to bottom) the central nervous system; an individual brain system (vision); a map of the visual field as relayed via the retina and represented in the primary visual cortex; a small network of neurons; a single neuron; a chemical synapse; and molecules. Relatively less is known about the properties of networks compared with the detailed knowledge we have of synapses and the general organization of pathways in the sensory and motor systems.
Modern brain science has revealed that several regions of the brain thought to be specialized for processing visual information are also activated by touch (Lacey and Sathian 2012). One particularly important region that responds to both the sight and the feel of an object is located in the lateral occipital cortex (
fig. 3.5). The texture of an object activates cells in a neighboring region of the brain, the medial occipital cortex, regardless of whether the object is perceived by the eye or by the hand (Sathian et al. 2011). This relationship is thought to explain, in part, why we can easily identify and distinguish between the different materials of an object—skin, cloth, wood, or metal—and can often do so at a glance (Hiramatsu et al. 2011).
In exploring further how our brain creates the external world, imaging studies have revealed that the brain’s coding of visual information about materials changes gradually in the course of viewing an object. When we first look at a painting or any other object, our brain processes only visual information. Shortly thereafter, additional information processed by other senses is thought to come into play, resulting in a multisensory representation of the object in higher regions of the brain. Combining visual information with information from other senses enables us to categorize different materials (Hiramatsu et al. 2011). In fact, the perception of texture, which is central to both Willem de Kooning’s and Jackson Pollock’s paintings, is intimately tied to visual discrimination and to associations in these higher regions of the brain (Sathian et al. 2011), which have robust and efficient mechanisms for processing textured images. Combining information from several senses is critical to the brain’s experience of art.

3.5 Areas involved in the early stages of visual processing (V1), in visual-tactile interactions (lateral occipital cortex) and in emotional response to a visual object or person (amygdala, hypothalamus, and dopaminergic pathways).
In addition to their interaction with each other, vision and touch, both alone and in combination, are capable of recruiting the emotional systems of the brain. These consist of the amygdala, which orchestrates emotions, both positive and negative; the hypothalamus, which executes and makes us feel emotion; and the dopaminergic modulatory system, which enhances the appreciation of emotion (see
fig. 3.5). We will explore these systems further in
chapter 10.
Modern abstract art was predicated on the liberation of line and the liberation of color. We have seen here how lines and forms are processed in the brain. Equally important for abstract art is the processing of color, which makes an impact on the beholder not only because of its importance in helping us discern the spatial details of form (see, for example,
fig. 10.1) but also because of color’s extraordinary ability, whether alone or in combination with line and form, to elicit strong emotional responses. We will explore emotional responses to color further in
chapters 8 and
10.

