
Never let something important become urgent.
—Eliyahu Goldratt
2.6

PREVENTING NEGLIGENCE

Small Town, USA, 2015
 CTO Frank sighs heavily over his third Mountain Dew of the morning. It’s the second time this week that the database server has hit maximum capacity utilization. The team can’t get their heads above water long enough to perform seriously delinquent maintenance.
CTO Frank sighs heavily over his third Mountain Dew of the morning. It’s the second time this week that the database server has hit maximum capacity utilization. The team can’t get their heads above water long enough to perform seriously delinquent maintenance.
Like an old broken chair, it’s easy to cast aside an aging request when a new request arrives in the backlog. But as we’ve discussed previously, the cost of starting new things before finishing old things is high. When too much work is in process, bad stuff happens: context switching increases, bottlenecks develop, dependencies rise, windows of opportunity close, and holidays arrive. And because things are delayed, people want to pile on more things—you know, “Let’s add this other fix while the hood is up.” This all causes work to take longer than it should and delays the delivery of business value.
An IT Operations team at one company I worked with had a workflow where the last step before Done was Validate. There was no good process at the time to provide timely feedback, so work items just sat, waiting to be validated after they were delivered. The norm was to assume that all was okay if no one complained. While work sat idle in Validate, people pulled more work out of the backlog into “Implement.” The Validate queue grew and grew until it had close to 100 work items. Many of the items delivered were indeed okay, but some were not, and those customers were unhappy.
When those downstream, internal customers mentioned that the work hadn’t been delivered as expected, the IT Operations people took a long time to respond because they were already working on the next task. As the time grew between customer feedback and Operation’s response, those customers became very unhappy and eventually gave up trying to communicate with Operations. They complained among themselves and to other departments. “Ops never responds,” they said. “They’re like a big black hole—hell will freeze over before they do anything,” they groused. “What a worthless team.” The Operations team’s reputation slid down the drain.
The board in Figure 27 represents the IT Operations workflow. I show this board image in my workshop and ask folks, “Where is work stuck here?” It doesn’t take more than a second before people respond with, “The Validate queue!”
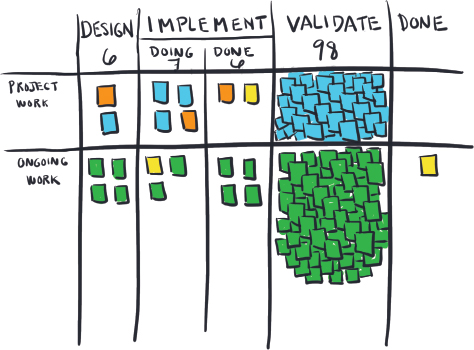
Figure 27. The Validate Pit
This is the power of the unified language of kanban boards—the message is communicated instantaneously. Because the bottleneck lies in Validate, we must tackle the Validate queue first.
Here’s the experiment we did: We set a timeframe to close the items sitting in the Validate queue. All items (called tickets by this group) that had not been updated in fourteen days or more would be closed. We asked a few key people what they thought, and we began to socialize the idea among the IT Operations and Development teams. No one really seemed too concerned by our proposal, so we prepared boilerplate comments to add to all the tickets sitting in Validate and communicated our plan across the Development and Operations teams. We told people that we were going to close the tickets on a set day and that they should let us know if they had any issue with it. That day, we closed 104 tickets, and only two people responded to say they still wanted to keep the ticket open. It felt so good to get all those tickets closed.
You may be thinking that the validate function was worthless if all those tickets could just be closed like that. Many of the tickets closed that day were ancient and already obsolete. Remember, other teams had given up on the Operations team and found other means to get the job done. But we didn’t stop there.
The next part of the experiment included gradually reducing the number of days a ticket could sit idle (getting stale) in Validate. We gave the teams thirty days to adjust to idle tickets being automatically closed and then squeezed the timeframe from fourteen days to ten days for the next month. Teams adjusted and started validating tickets sooner. Unlike before, when the tickets were stale and all but forgotten, it was relatively easy for them to complete the validation because the work was still fresh in their minds.
This is one of the major problems with neglected work and an important reason why we should avoid it. Once the work has sat untouched for weeks or even months, we forget the details, and it takes a long time to dive back in. Thief Neglected Work loves it when work sits around so long that you no long remember what was happening. Smack Thief Neglected Work upside the head by keeping work clipping along at a smooth pace.
Of course, continuous improvement is always the goal, and thirty days later, we cut the timeframe from ten days to seven days. Thirty days after that, we went from seven days to five days. Why didn’t we just start out with five days? Because five days never would have flown in the beginning. The change would have been too abrupt. Two weeks is, relatively speaking, a long time—it’s not threatening to anyone. The gradual change allowed people to adjust and adapt. Because the Validate queue usually empties every five days now (sometimes things take longer, but now people update the ticket with comments keeping it active), the cycle time of the tickets has decreased dramatically. Work flows through the system quickly, and problems in Validate surface right away. With the Validate pit improved, we moved on to the next bottleneck.
Multitasking is an effective way to get less done. It’s an effective way to give negligence free reign. When you try to do too many things at one time, you won’t do any of them great, and sometimes you won’t finish them at all. Neglected work is another term for partially completed work. Consider a partially completed bridge. It is already expensive, but it provides zero value until it’s finished.
Thief Neglected Work steals time from you when important work becomes urgent. Good time-management means spending time on important things and not just urgent things. Make time to work on fire prevention so that you can reduce the amount of time you spend putting out fires.
Revenue-protecting work is a major target of Thief Neglected Work. Because the business is often unaware of what’s involved in keeping a system secure, reliable, and functioning, revenue-generating work is considered a higher priority than intangible maintenance and sustainment work. In many companies, short-term revenue-generating work is top-of-mind for business people, but the long-term health of the platform system is rarely contemplated. As a result, revenue protection work takes a backseat until something blows up, such as a distributed denial-of-service attack or a corrupt finance database that brings down credit card fulfillment.
It’s not intentional—people just tend to focus on doing their job and assume their coworkers will do the same and that everything will be fine. Humans are like that. We tend to avoid the annual doctor’s exam until something is really wrong.
Call Out Neglected Work
Here’s a way to make neglected work obvious. Flag work items that haven’t moved or been updated within a certain number of days. In Figure 28 there are two flagged items, one for nine days and one for thirteen days, respectively.

Figure 28. Expose Neglected Work
Then you can make aging work visible. Query all your WIP (so, not the backlog and not the done or archive work) in your system that hasn’t been touched for thirty days. If that produces too many items to see at one time on the screen without scrolling, bump up the search criteria to sixty, ninety, or 120 days. I’ve seen teams with WIP over 300 days, so don’t feel bad if you’ve got a few like that too.
To deal with those archaic items, schedule a ten-minute meeting (yes, just ten-minutes) every day directly following stand-up with the creator and the current assignee of the work.
Here’s some language for you to use:
Subject: Work Item # nnnnn (enter title of item here).
Invitees: The creator of the work item and the current assignee of the work item.
Location: Dominica’s desk (or video chat if remote).
Description: This work item is now famous. It’s the oldest WIP in the system.
Can we please take 10 minutes directly after stand-up tomorrow to see what it would take to close it?
Many thanks!
Dominica
These meetings should help you determine which projects are worth saving, which can be quickly wrapped up, and which are zombie projects that need to be purged. Remember, zombie projects are low-value projects that nevertheless consume time, energy, and money. Killing them helps reduce neglected work and allows you to deliver more important projects faster and with fewer interruptions.
Even though neglected work is not a priority, it still consumes some mental budget. Like that reminder on the fridge to schedule your annual physical, Thief Neglected Work stalks you every so often, distracting you just long enough to divert your attention away from what you should be focusing on. Here’s what you need to do to get Thief Neglected Work off your back in three steps:
- Acknowledge the neglected work sitting on your board that’s not moving and the impact it has on other work.
- To create space to finish the most important work, lower WIP to a discussion on priorities. Something has to give. Either give work the attention it needs, kill it, or move it back to the backlog.
- Ruthlessly protect your time using some of the techniques mentioned in Section 2.4 and stop starting new work before finishing old work. As author Arne Roock says in his book Stop Starting, start finishing!
EXERCISE

Create an Aging Report
PURPOSE: To improve the flow of value by making stale work visible. An aging report shows WIP that is stale.
 Time: 40 to 60 minutes
Time: 40 to 60 minutes
MATERIALS
- Large whiteboard or large paper or wall space
- Sticky notes
- Markers
- Computer (and, of course, a pizza)
INSTRUCTIONS: Query your work-tracking tool to find high-priority, yet partially completed work that has not moved
or been updated in thirty days. If thirty days results in a huge list, then increase to sixty or ninety days. Randomly select seven to eleven of those high priority items. Statistically, seven to eleven is sufficient—as long as it’s truly a random sample set.
For each of the seven to eleven items, note the following:
- The number of days the item has been stale (not been updated or moved or made any progress).
- The average cycle time for cards of a similar work item type.
- How many days the item has been in progress in comparison to other similar items.
Now, write down what happens if this item continues to be delayed for another week. Consider lowering your WIP limit and reprioritizing your WIP based on what might happen if the work is delayed. Identify the utmost valuable work currently on your board and separate out the lower value items. If possible, do an improvement blitz to push through the one highest priority item to get it delivered. Improve flow by making work visible. Remember the goal is to improve flow by making important, stale work visible.
KEY TAKEAWAYS

- Important work that is delayed becomes urgent, unplanned work.
- Visualize delays.
- Call out neglected work and purge low-value projects.