Saves a database ID field in an object to maintain identity between an in-memory object and a database row.
Relational databases tell one row from another by using key—in particular, the primary key. However, in-memory objects don’t need such a key, as the object system ensures the correct identity under the covers (or in C++’s case with raw memory locations). Reading data from a database is all very well, but in order to write data back you need to tie the database to the in-memory object system.
In essence, Identity Field is mind-numbingly simple. All you do is store the primary key of the relational database table in the object’s fields.
Although the basic notion of Identity Field is very simple, there are oodles of complicated issues that come up.
The first issue is what kind of key to choose in your database. Of course, this isn’t always a choice, since you’re often dealing with an existing database that already has its key structures in place. There’s a lot of discussion and material on this in the database community. Still, mapping to objects does add some concerns to your decision.
The first concern is whether to use meaningful or meaningless keys. A meaningful key is something like the U.S. Social Security number for identifying a person. A meaningless key is essentially a random number the database dreams up that’s never intended for human use. The danger with a meaningful key is that, while in theory they make good keys, in practice they don’t. To work at all, keys need to be unique; to work well, they need to be immutable. While assigned numbers are supposed to be unique and immutable, human error often makes them neither. If you mistype my SSN for my wife’s the resulting record is neither unique nor immutable (assuming you would like to fix the mistake.) The database should detect the uniqueness problem, but it can only do that after my record goes into the system, and of course that might not happen until after the mistake. As a result, meaningful keys should be distrusted. For small systems and/or very stable cases you may get away with it, but usually you should take a rare stand on the side of meaninglessness.
The next concern is simple versus compound keys. A simple key uses only one database field; a compound key uses more than one. The advantage of a compound key is that it’s often easier to use when one table makes sense in the context of another. A good example is orders and line items, where a good key for the line item is a compound of the order number and a sequence number makes a good key for a line item. While compound keys often make sense, there is a lot to be said for the sheer uniformity of simple keys. If you use simple keys everywhere, you can use the same code for all key manipulation. Compound keys require special handling in concrete classes. (With code generation this isn’t a problem). Compound keys also carry a bit of meaning, so be careful about the uniqueness and particularly the immutability rule with them.
You have to choose the type of the key. The most common operation you’ll do with a key is equality checking, so you want a type with a fast equality operation. The other important operation is getting the next key. Hence a long integer type is often the best bet. Strings can also work, but equality checking may be slower and incrementing strings is a bit more painful. Your DBA’s preferences may well decide the issue.
(Beware about using dates or times in keys. Not only are they meaningful, they also lead to problems with portability and consistency. Dates in particular are vulnerable to this because they are often stored to some fractional second precision, which can easily get out of sync and lead to identity problems.)
You can have keys that are unique to the table or unique database-wide. A table-unique key is unique across the table, which is what you need for a key in any case. A database-unique key is unique across every row in every table in the database. A table-unique key is usually fine, but a database-unique key is often easier to do and allows you to use a single Identity Map (195). Modern values being what they are, it’s pretty unlikely that you’ll run out of numbers for new keys. If you really insist, you can reclaim keys from deleted objects with a simple database script that compacts the key space—although running this script will require that you take the application offline. However, if you use 64-bit keys (and you might as well) you’re unlikely to need this.
Be wary of inheritance when you use table-unique keys. If you’re using Concrete Table Inheritance (293) or Class Table Inheritance (285), life is much easier with keys that are unique to the hierarchy rather than unique to each table. I still use the term “table-unique,” even if it should strictly be something like “inheritance graph unique.”
The size of your key may effect performance, particularly with indexes. This is dependent on your database system and/or how many rows you have, but it’s worth doing a crude check before you get fixed into your decision.
The simplest form of Identity Field is a field that matches the type of the key in the database. Thus, if you use a simple integral key, an integral field will work very nicely.
Compound keys are more problematic. The best bet with them is to make a key class. A generic key class can store a sequence of objects that act as the elements of the key. The key behavior for the key object (I have a quota of puns per book to fill) is equality. It’s also useful to get parts of the key when you’re mapping to the database.
If you use the same basic structure for all keys, you can do all of the key handling in a Layer Supertype (475). You can put default behavior that will work for most cases in the Layer Supertype (475) and extend it for the exceptional cases in the particular subtypes.
You can have either a single key class, which takes a generic list of key objects, or key class for each domain class with explicit fields for each part of the key. I usually prefer to be explicit, but in this case I’m not sure it buys very much. You end up with lots of small classes that don’t do anything interesting. The main benefit is that you can avoid errors caused by users putting the elements of the key in the wrong order, but that doesn’t seem to be a big problem in practice.
If you’re likely to import data between different database instances, you need to remember that you’ll get key collisions unless you come up with some scheme to separate the keys between different databases. You can solve this with some kind of key migration on the imports, but this can easily get very messy.
To create an object, you’ll need a key. This sounds like a simple matter, but it can often be quite a problem. You have three basic choices: get the database to auto-generate, use a GUID, or generate your own.
The auto-generate route should be the easiest. Each time you insert data for the database, the database generates a unique primary key without you having to do anything. It sounds too good to be true, and sadly it often is. Not all databases do this the same way. Many that do, handle it in such a way that causes problems for object-relational mapping.
The most common auto-generation method is declaring one auto-generated field, which, whenever you insert a row, is incremented to a new value. The problem with this scheme is that you can’t easily determine what value got generated as the key. If you want to insert an order and several line items, you need the key of the new order so you can put the value in the line item’s foreign key. Also, you need this key before the transaction commits so you can save everything within the transaction. Sadly, databases usually don’t give you this information, so you usually can’t use this kind of auto-generation on any table in which you need to insert connected objects.
An alternative approach to auto-generation is a database counter, which Oracle uses with its sequence. An Oracle sequence works by sending a select statement that references a sequence; the database then returns an SQL record set consisting of the next sequence value. You can set a sequence to increment by any integer, which allows you to get multiple keys at once. The sequence query is automatically carried out in a separate transaction, so that accessing the sequence won’t lock out other transactions inserting at the same time. A database counter like this is perfect for our needs, but it’s nonstandard and not available in all databases.
A GUID (Globally Unique IDentifier) is a number generated on one machine that’s guaranteed to be unique across all machines in space and time. Often platforms give you the API to generate a GUID. The algorithm is an interesting one involving ethernet card addresses, time of the day in nanoseconds, chip ID numbers, and probably the number of hairs on your left wrist. All that matters is that the resulting number is completely unique and thus a safe key. The only disadvantage to a GUID is that the resulting key string is big, and that can be an equally big problem. There are always times when someone needs to type in a key to a window or SQL expression, and long keys are hard both to type and to read. They may also lead to performance problems, particularly with indexes.
The last option is rolling your own. A simple staple for small systems is to use a table scan using the SQL max function to find the largest key in the table and then add one to use it. Sadly, this read-locks the entire table while you’re doing it, which means that it works fine if inserts are rare, but your performance will be toasted if you have inserts running concurrently with updates on the same table. You also have to ensure you have complete isolation between transactions; otherwise, you can end up with multiple transactions getting the same ID value.
A better approach is to use a separate key table. This table is typically one with two columns: name and next available value. If you use database-unique keys, you’ll have just one row in this table. If you use table-unique keys, you’ll have one row for each table in the database. To use the key table, all you need to do is read that one row and note the number, the increment, the number and write it back to the row. You can grab many keys at a time by adding a suitable number when you update the key table. This cuts down on expensive database calls and reduces contention on the key table.
If you use a key table, it’s a good idea to design it so that access to it is in a separate transaction from the one that updates the table you’re inserting into. Say I’m inserting an order into the orders table. To do this I’ll need to lock the orders row on the key table with a write lock (since I’m updating). That lock will last for the entire transaction that I’m in, locking out anyone else who wants a key. For table-unique keys, this means anyone inserting into the orders table; for database-unique keys it means anyone inserting anywhere.
By putting access to the key table in a separate transaction, you only lock the row for that, much shorter, transaction. The downside is that, if you roll back on your insert to the orders, the key you got from the key table is lost to everyone. Fortunately, numbers are cheap, so that’s not a big issue. Using a separate transaction also allows you to get the ID as soon as you create the in-memory object, which is often some before you open the transaction to commit the business transaction.
Using a key table affects the choice of database-unique or table-unique keys. If you use a table-unique key, you have to add a row to the key table every time you add a table to the database. This is more effort, but it reduces contention on the row. If you keep your key table accesses in a different transaction, contention is not so much of a problem, especially if you get multiple keys in a single call. But if you can’t arrange for the key table update to be in a separate transaction, you have a strong reason against database-unique keys.
It’s good to separate the code for getting a new key into its own class, as that makes it easier to build a Service Stub (504) for testing purposes.
Use Identity Field when there’s a mapping between objects in memory and rows in a database. This is usually when you use Domain Model (116) or Row Data Gateway (152). You don’t need this mapping if you’re using Transaction Script (110), Table Module (125), or Table Data Gateway (144).
For a small object with value semantics, such as a money or date range object that won’t have its own table, it’s better to use Embedded Value (268). For a complex graph of objects that doesn’t need to be queried within the relational database, Serialized LOB (272) is usually easier to write and gives faster performance.
One alternative to Identity Field is to extend Identity Map (195) to maintain the correspondence. This can be used for systems where you don’t want to store an Identity Field in the in-memory object. Identity Map (195) needs to look up both ways: give me a key for an object or an object for a key. I don’t see this very often because usually it’s easier to store the key in the object.
[Marinescu] discusses several techniques for generating keys.
The simplest form of Identity Field is a integral field in the database that maps to an integral field in an in-memory object.
class DomainObject...
public const long PLACEHOLDER_ID = -1;
public long Id = PLACEHOLDER_ID;
public Boolean isNew() {return Id == PLACEHOLDER_ID;}
An object that’s been created in memory but not saved to the database will not have a value for its key. For a .NET value object this is a problem since .NET values cannot be null. Hence, the placeholder value.
The key becomes important in two places: finding and inserting. For finding you need to form a query using a key in a where clause. In .NET you can load many rows into a data set and then select a particular one with a find operation.
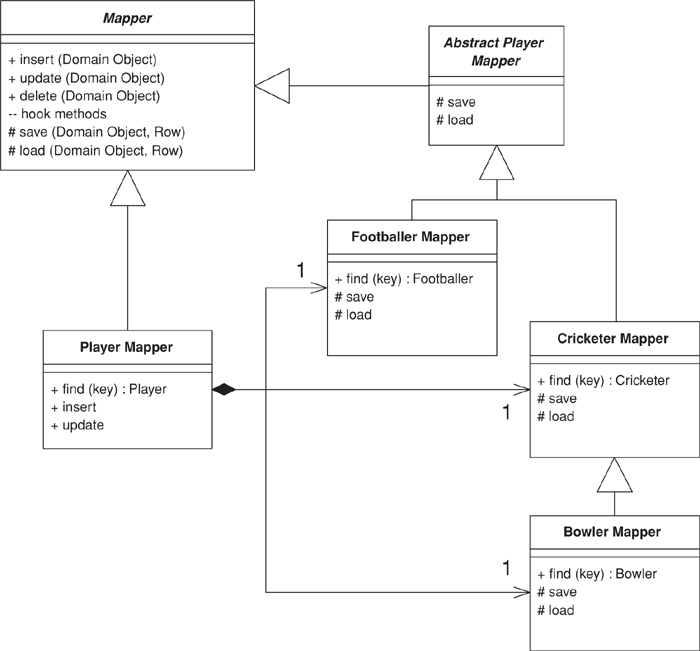
class CricketerMapper...
public Cricketer Find(long id) {
return (Cricketer) AbstractFind(id);
}
class Mapper...
protected DomainObject AbstractFind(long id) {
DataRow row = FindRow(id);
return (row == null) ? null : Find(row);
}
protected DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results[0];
}
public DomainObject Find (DataRow row) {
DomainObject result = CreateDomainObject();
Load(result, row);
return result;
}
abstract protected DomainObject CreateDomainObject();
Most of this behavior can live on the Layer Supertype (475), but you’ll often need to define the find on the concrete class just to encapsulate the downcast. Naturally, you can avoid this in a language that doesn’t use compile-time typing.
With a simple integral Identity Field the insertion behavior can also be held at the Layer Supertype (475).
class Mapper...
public virtual long Insert (DomainObject arg) {
DataRow row = table.NewRow();
arg.Id = GetNextID();
row["id"] = arg.Id;
Save (arg, row);
table.Rows.Add(row);
return arg.Id;
}
Essentially insertion involves creating the new row and using the next key for it. Once you have it you can save the in-memory object’s data to this new row.
If your database supports a database counter and you’re not worried about being dependent on database-specific SQL, you should use the counter. Even if you’re worried about being dependent on a database you should still consider it—as long as your key generation code is nicely encapsulated, you can always change it to a portable algorithm later. You could even have a strategy [Gang of Four] to use counters when you have them and roll your own when you don’t.
For the moment let’s assume that we have to do this the hard way. The first thing we need is a key table in the database.
CREATE TABLE keys (name varchar primary key, nextID int)
INSERT INTO keys VALUES ('orders', 1)
This table contains one row for each counter that’s in the database. In this case we’ve initialized the key to 1. If you’re preloading data in the database, you’ll need to set the counter to a suitable number. If you want database-unique keys, you’ll only need one row, if you want table-unique keys, you’ll need one row per table.
You can wrap all of your key generation code into its own class. That way it’s easier to use it more widely around one or more applications and it’s easier to put key reservation into its own transaction.
We construct a key generator with its own database connection, together with information on how many keys to take from the database at one time.
class KeyGenerator...
private Connection conn;
private String keyName;
private long nextId;
private long maxId;
private int incrementBy;
public KeyGenerator(Connection conn, String keyName, int incrementBy) {
this.conn = conn;
this.keyName = keyName;
this.incrementBy = incrementBy;
nextId = maxId = 0;
try {
conn.setAutoCommit(false);
} catch(SQLException exc) {
throw new ApplicationException("Unable to turn off autocommit", exc);
}
}
We need to ensure that no auto-commit is going on since we absolutely must have the select and update operating in one transaction.
When we ask for a new key, the generator looks to see if it has one cached rather than go to the database.
class KeyGenerator...
public synchronized Long nextKey() {
if (nextId == maxId) {
reserveIds();
}
return new Long(nextId++);
}
If the generator hasn’t got one cached, it needs to go to the database.
class KeyGenerator...
private void reserveIds() {
PreparedStatement stmt = null;
ResultSet rs = null;
long newNextId;
try {
stmt = conn.prepareStatement("SELECT nextID FROM keys WHERE name = ? FOR UPDATE");
stmt.setString(1, keyName);
rs = stmt.executeQuery();
rs.next();
newNextId = rs.getLong(1);
}
catch (SQLException exc) {
throw new ApplicationException("Unable to generate ids", exc);
}
finally {
DB.cleanUp(stmt, rs);
}
long newMaxId = newNextId + incrementBy;
stmt = null;
try {
stmt = conn.prepareStatement("UPDATE keys SET nextID = ? WHERE name = ?");
stmt.setLong(1, newMaxId);
stmt.setString(2, keyName);
stmt.executeUpdate();
conn.commit();
nextId = newNextId;
maxId = newMaxId;
}
catch (SQLException exc) {
throw new ApplicationException("Unable to generate ids", exc);
}
finally {
DB.cleanUp(stmt);
}
}
In this case we use SELECT... FOR UPDATE to tell the database to hold a write lock on the key table. This is an Oracle-specific statement, so your mileage will vary if you’re using something else. If you can’t write-lock on the select, you run the risk of the transaction failing should another one get in there before you. In this case, however, you can pretty safely just rerun reserveIds until you get a pristine set of keys.
Using a simple integral key is a good, simple solution, but you often need other types or compound keys.
As soon as you need something else it’s worth putting together a key class. A key class needs to be able to store multiple elements of the key and to be able to tell if two keys are equal.
class Key...
private Object[] fields;
public boolean equals(Object obj) {
if (!(obj instanceof Key)) return false;
Key otherKey = (Key) obj;
if (this.fields.length != otherKey.fields.length) return false;
for (int i = 0; i < fields.length; i++)
if (!this.fields[i].equals(otherKey.fields[i])) return false;
return true;
}
The most elemental way to create a key is with an array parameter.
class Key...
public Key(Object[] fields) {
checkKeyNotNull(fields);
this.fields = fields;
}
private void checkKeyNotNull(Object[] fields) {
if (fields == null) throw new IllegalArgumentException("Cannot have a null key");
for (int i = 0; i < fields.length; i++)
if (fields[i] == null)
throw new IllegalArgumentException("Cannot have a null element of key");
}
If you find you commonly create keys with certain elements, you can add convenience constructors. The exact ones will depend on what kinds of keys your application has.
class Key...
public Key(long arg) {
this.fields = new Object[1];
this.fields[0] = new Long(arg);
}
public Key(Object field) {
if (field == null) throw new IllegalArgumentException("Cannot have a null key");
this.fields = new Object[1];
this.fields[0] = field;
}
public Key(Object arg1, Object arg2) {
this.fields = new Object[2];
this.fields[0] = arg1;
this.fields[1] = arg2;
checkKeyNotNull(fields);
}
Don’t be afraid to add these convenience methods. After all, convenience is important to everyone using the keys.
Similarly you can add accessor functions to get parts of keys. The application will need to do this for the mappings.
class Key...
public Object value(int i) {
return fields[i];
}
public Object value() {
checkSingleKey();
return fields[0];
}
private void checkSingleKey() {
if (fields.length > 1)
throw new IllegalStateException("Cannot take value on composite key");
}
public long longValue() {
checkSingleKey();
return longValue(0);
}
public long longValue(int i) {
if (!(fields[i] instanceof Long))
throw new IllegalStateException("Cannot take longValue on non long key");
return ((Long) fields[i]).longValue();
}
In this example we’ll map to an order and line item tables. The order table has a simple integral primary key, the line item table’s primary key is a compound of the order’s primary key and a sequence number.
CREATE TABLE orders (ID int primary key, customer varchar)
CREATE TABLE line_items (orderID int, seq int, amount int, product varchar,
primary key (orderID, seq))
The Layer Supertype (475) for domain objects needs to have a key field.
class DomainObjectWithKey...
private Key key;
protected DomainObjectWithKey(Key ID) {
this.key = ID;
}
protected DomainObjectWithKey() {
}
public Key getKey() {
return key;
}
public void setKey(Key key) {
this.key = key;
}
As with other examples in this book I’ve split the behavior into find (which gets to the right row in the database) and load (which loads data from that row into the domain object). Both responsibilities are affected by the use of a key object.
The primary difference between these and the other examples in this book (which use simple integral keys) is that we have to factor out certain pieces of behavior that are overridden by classes that have more complex keys. For this example I’m assuming that most tables use simple integral keys. However, some use something else, so I’ve made the default case the simple integral and have embedded the behavior for it the mapper Layer Supertype (475). The order class is one of those simple cases. Here’s the code for the find behavior:
class OrderMapper...
public Order find(Key key) {
return (Order) abstractFind(key);
}
public Order find(Long id) {
return find(new Key(id));
}
protected String findStatementString() {
return "SELECT id, customer from orders WHERE id = ?";
}
class AbstractMapper...
abstract protected String findStatementString();
protected Map loadedMap = new HashMap();
public DomainObjectWithKey abstractFind(Key key) {
DomainObjectWithKey result = (DomainObjectWithKey) loadedMap.get(key);
if (result != null) return result;
ResultSet rs = null;
PreparedStatement findStatement = null;
try {
findStatement = DB.prepare(findStatementString());
loadFindStatement(key, findStatement);
rs = findStatement.executeQuery();
rs.next();
if (rs.isAfterLast()) return null;
result = load(rs);
return result;
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {
DB.cleanUp(findStatement, rs);
}
}
// hook method for keys that aren't simple integral
protected void loadFindStatement(Key key, PreparedStatement finder) throws SQLException {
finder.setLong(1, key.longValue());
}
I’ve extracted out the building of the find statement, since that requires different parameters to be passed into the prepared statement. The line item is a compound key, so it needs to override that method.
class LineItemMapper...
public LineItem find(long orderID, long seq) {
Key key = new Key(new Long(orderID), new Long(seq));
return (LineItem) abstractFind(key);
}
public LineItem find(Key key) {
return (LineItem) abstractFind(key);
}
protected String findStatementString() {
return
"SELECT orderID, seq, amount, product " +
" FROM line_items " +
" WHERE (orderID = ?) AND (seq = ?)";
}
// hook methods overridden for the composite key
protected void loadFindStatement(Key key, PreparedStatement finder) throws SQLException {
finder.setLong(1, orderID(key));
finder.setLong(2, sequenceNumber(key));
}
//helpers to extract appropriate values from line item's key
private static long orderID(Key key) {
return key.longValue(0);
}
private static long sequenceNumber(Key key) {
return key.longValue(1);
}
As well as defining the interface for the find methods and providing an SQL string for the find statement, the subclass needs to override the hook method to allow two parameters to go into the SQL statement. I’ve also written two helper methods to extract the parts of the key information. This makes for clearer code than I would get by just putting explicit accessors with numeric indices from the key. Such literal indices are a bad smell.
The load behavior shows a similar structure—default behavior in the Layer Supertype (475) for simple integral keys, overridden for the more complex cases. In this case the order’s load behavior looks like this:
class AbstractMapper...
protected DomainObjectWithKey load(ResultSet rs) throws SQLException {
Key key = createKey(rs);
if (loadedMap.containsKey(key)) return (DomainObjectWithKey) loadedMap.get(key);
DomainObjectWithKey result = doLoad(key, rs);
loadedMap.put(key, result);
return result;
}
abstract protected DomainObjectWithKey doLoad(Key id, ResultSet rs) throws SQLException;
// hook method for keys that aren't simple integral
protected Key createKey(ResultSet rs) throws SQLException {
return new Key(rs.getLong(1));
}
class OrderMapper...
protected DomainObjectWithKey doLoad(Key key, ResultSet rs) throws SQLException {
String customer = rs.getString("customer");
Order result = new Order(key, customer);
MapperRegistry.lineItem().loadAllLineItemsFor(result);
return result;
}
The line item needs to override the hook to create a key based on two fields.
class LineItemMapper...
protected DomainObjectWithKey doLoad(Key key, ResultSet rs) throws SQLException {
Order theOrder = MapperRegistry.order().find(orderID(key));
return doLoad(key, rs, theOrder);
}
protected DomainObjectWithKey doLoad(Key key, ResultSet rs, Order order)
throws SQLException
{
LineItem result;
int amount = rs.getInt("amount");
String product = rs.getString("product");
result = new LineItem(key, amount, product);
order.addLineItem(result);//links to the order
return result;
}
//overrides the default case
protected Key createKey(ResultSet rs) throws SQLException {
Key key = new Key(new Long(rs.getLong("orderID")), new Long(rs.getLong("seq")));
return key;
}
The line item also has a separate load method for use when loading all the lines for the order.
class LineItemMapper...
public void loadAllLineItemsFor(Order arg) {
PreparedStatement stmt = null;
ResultSet rs = null;
try {
stmt = DB.prepare(findForOrderString);
stmt.setLong(1, arg.getKey().longValue());
rs = stmt.executeQuery();
while (rs.next())
load(rs, arg);
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt, rs);
}
}
private final static String findForOrderString =
"SELECT orderID, seq, amount, product " +
"FROM line_items " +
"WHERE orderID = ?";
protected DomainObjectWithKey load(ResultSet rs, Order order) throws SQLException {
Key key = createKey(rs);
if (loadedMap.containsKey(key)) return (DomainObjectWithKey) loadedMap.get(key);
DomainObjectWithKey result = doLoad(key, rs, order);
loadedMap.put(key, result);
return result;
}
You need the special handling because the order object isn’t put into the order’s Identity Map (195) until after it’s created. Creating an empty object and inserting it directly into the Identity Field would avoid the need for this (page 169).
Like reading, inserting has a default action for a simple integral key and the hooks to override this for more interesting keys. In the mapper supertype I’ve provided an operation to act as the interface, together with a template method to do the work of the insertion.
class AbstractMapper...
public Key insert(DomainObjectWithKey subject) {
try {
return performInsert(subject, findNextDatabaseKeyObject());
} catch (SQLException e) {
throw new ApplicationException(e);
}
}
protected Key performInsert(DomainObjectWithKey subject, Key key) throws SQLException {
subject.setKey(key);
PreparedStatement stmt = DB.prepare(insertStatementString());
insertKey(subject, stmt);
insertData(subject, stmt);
stmt.execute();
loadedMap.put(subject.getKey(), subject);
return subject.getKey();
}
abstract protected String insertStatementString();
class OrderMapper...
protected String insertStatementString() {
return "INSERT INTO orders VALUES(?,?)";
}
The data from the object goes into the insert statement through two methods that separate the data of the key from the basic data of the object. I do this because I can provide a default implementation for the key that will work for any class, like order, that uses the default simple integral key.
class AbstractMapper...
protected void insertKey(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
stmt.setLong(1, subject.getKey().longValue());
}
The rest of the data for the insert statement is dependent on the particular subclass, so this behavior is abstract on the superclass.
class AbstractMapper...
abstract protected void insertData(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException;
class OrderMapper...
protected void insertData(DomainObjectWithKey abstractSubject, PreparedStatement stmt) {
try {
Order subject = (Order) abstractSubject;
stmt.setString(2, subject.getCustomer());
} catch (SQLException e) {
throw new ApplicationException(e);
}
}
The line item overrides both of these methods. It pulls two values out for key.
class LineItemMapper...
protected String insertStatementString() {
return "INSERT INTO line_items VALUES (?, ?, ?, ?)";
}
protected void insertKey(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
stmt.setLong(1, orderID(subject.getKey()));
stmt.setLong(2, sequenceNumber(subject.getKey()));
}
It also provides its own implementation of the insert statement for the rest of the data.
class LineItemMapper...
protected void insertData(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
LineItem item = (LineItem) subject;
stmt.setInt(3, item.getAmount());
stmt.setString(4, item.getProduct());
}
Putting the data loading into the insert statement like this is only worthwhile if most classes use the same single field for the key. If there’s more variation for the key handling, then having just one command to insert the information is probably easier.
Coming up with the next database key is also something that I can separate into a default and an overridden case. For the default case I can use the key table scheme that I talked about earlier. But for the line item we run into a problem. The line item’s key uses the key of the order as part of its composite key. However, there’s no reference from the line item class to the order class, so it’s impossible to tell a line item to insert itself into the database without providing the correct order as well. This leads to the always messy approach of implementing the superclass method with an unsupported operation exception.
class LineItemMapper...
public Key insert(DomainObjectWithKey subject) {
throw new UnsupportedOperationException
("Must supply an order when inserting a line item");
}
public Key insert(LineItem item, Order order) {
try {
Key key = new Key(order.getKey().value(), getNextSequenceNumber(order));
return performInsert(item, key);
} catch (SQLException e) {
throw new ApplicationException(e);
}
}
Of course, we can avoid this by having a back link from the line item to the order, effectively making the association between the two bidirectional. I’ve chosen not to do it here to illustrate what to do when you don’t have that link.
By supplying the order, it’s easy to get the order’s part of the key. The next problem is to come up with a sequence number for the order line. To find that number, we need to find out what the next available sequence number is for an order, which we can do either with a max query in SQL or by looking at the line items on the order in memory. For this example I’ll do the latter.
class LineItemMapper...
private Long getNextSequenceNumber(Order order) {
loadAllLineItemsFor(order);
Iterator it = order.getItems().iterator();
LineItem candidate = (LineItem) it.next();
while (it.hasNext()) {
LineItem thisItem = (LineItem) it.next();
if (thisItem.getKey() == null) continue;
if (sequenceNumber(thisItem) > sequenceNumber(candidate)) candidate = thisItem;
}
return new Long(sequenceNumber(candidate) + 1);
}
private static long sequenceNumber(LineItem li) {
return sequenceNumber(li.getKey());
}
//comparator doesn't work well here due to unsaved null keys
protected String keyTableRow() {
throw new UnsupportedOperationException();
}
This algorithm would be much nicer if I used the Collections.max method, but since we may (and indeed will) have at least one null key, that method would fail.
After all of that, updates and deletes are mostly harmless. Again we have an abstract method for the assumed usual case and an override for the special cases.
Updates work like this:
class AbstractMapper...
public void update(DomainObjectWithKey subject) {
PreparedStatement stmt = null;
try {
stmt = DB.prepare(updateStatementString());
loadUpdateStatement(subject, stmt);
stmt.execute();
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {
DB.cleanUp(stmt);
}
}
abstract protected String updateStatementString();
abstract protected void loadUpdateStatement(DomainObjectWithKey subject,
PreparedStatement stmt)
throws SQLException;
class OrderMapper...
protected void loadUpdateStatement(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
Order order = (Order) subject;
stmt.setString(1, order.getCustomer());
stmt.setLong(2, order.getKey().longValue());
}
protected String updateStatementString() {
return "UPDATE orders SET customer = ? WHERE id = ?";
}
class LineItemMapper...
protected String updateStatementString() {
return
"UPDATE line_items " +
" SET amount = ?, product = ? " +
" WHERE orderId = ? AND seq = ?";
}
protected void loadUpdateStatement(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
stmt.setLong(3, orderID(subject.getKey()));
stmt.setLong(4, sequenceNumber(subject.getKey()));
LineItem li = (LineItem) subject;
stmt.setInt(1, li.getAmount());
stmt.setString(2, li.getProduct());
}
Deletes work like this:
class AbstractMapper...
public void delete(DomainObjectWithKey subject) {
PreparedStatement stmt = null;
try {
stmt = DB.prepare(deleteStatementString());
loadDeleteStatement(subject, stmt);
stmt.execute();
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {
DB.cleanUp(stmt);
}
}
abstract protected String deleteStatementString();
protected void loadDeleteStatement(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
stmt.setLong(1, subject.getKey().longValue());
}
class OrderMapper...
protected String deleteStatementString() {
return "DELETE FROM orders WHERE id = ?";
}
class LineItemMapper...
protected String deleteStatementString() {
return "DELETE FROM line_items WHERE orderid = ? AND seq = ?";
}
protected void loadDeleteStatement(DomainObjectWithKey subject, PreparedStatement stmt)
throws SQLException
{
stmt.setLong(1, orderID(subject.getKey()));
stmt.setLong(2, sequenceNumber(subject.getKey()));
}
Maps an association between objects to a foreign key reference between tables.


Objects can refer to each other directly by object references. Even the simplest object-oriented system will contain a bevy of objects connected to each other in all sorts of interesting ways. To save these objects to a database, it’s vital to save these references. However, since the data in them is specific to the specific instance of the running program, you can’t just save raw data values. Further complicating things is the fact that objects can easily hold collections of references to other objects. Such a structure violates the first normal form of relational databases.
A Foreign Key Mapping maps an object reference to a foreign key in the database.
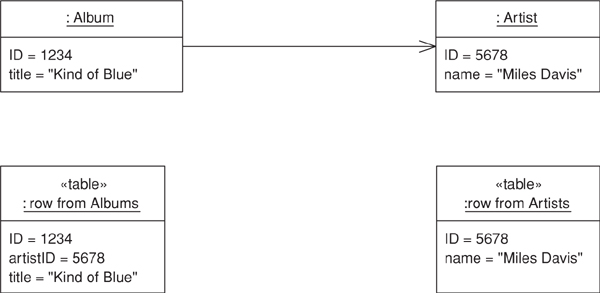
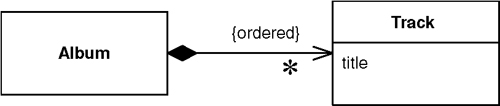
The obvious key to this problem is Identity Field (216). Each object contains the database key from the appropriate database table. If two objects are linked together with an association, this association can be replaced by a foreign key in the database. Put simply, when you save an album to the database, you save the ID of the artist that the album is linked to in the album record, as in Figure 12.1.
Figure 12.1. Mapping a collection to a foreign key.
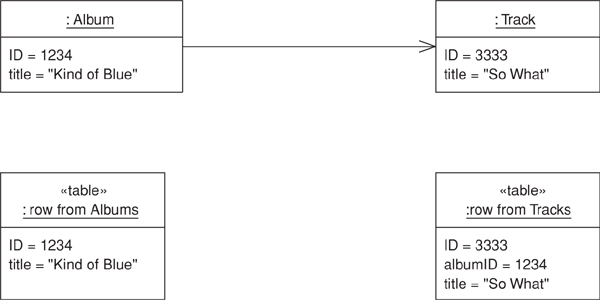
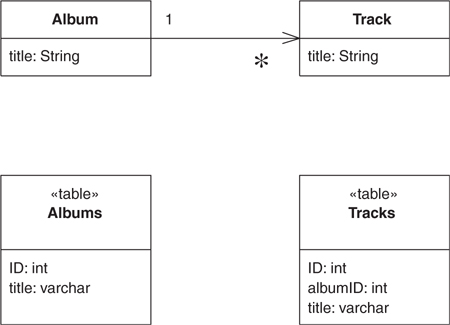
That’s the simple case. A more complicated case turns up when you have a collection of objects. You can’t save a collection in the database, so you have to reverse the direction of the reference. Thus, if you have a collection of tracks in the album, you put the foreign key of the album in the track record, as in Figures 12.2 and 12.3. The complication occurs when you have an update. Updating implies that tracks can be added to and removed from the collection within an album. How can you tell what alterations to put in the database? Essentially you have three options: (1) delete and insert, (2) add a back pointer, and (3) diff the collection.
Figure 12.2. Mapping a collection to a foreign key.
Figure 12.3. Classes and tables for a multivalued reference.
With delete and insert you delete all the tracks in the database that link to the album, and then insert all the ones currently on the album. At first glance this sounds pretty appalling, especially if you haven’t changed any tracks. But the logic is easy to implement and as such it works pretty well compared to the alternatives. The drawback is that you can only do this if tracks are Dependent Mappings (262), which means they must be owned by the album and can’t be referred to outside it.
Adding a back pointer puts a link from the track back to the album, effectively making the association bidirectional. This changes the object model, but now you can handle the update using the simple technique for single-valued fields on the other side.
If neither of those appeals, you can do a diff. There are two possibilities here: diff with the current state of the database or diff with what you read the first time. Diffing with the database involves rereading the collection back from the database and then comparing the collection you read with the collection in the album. Anything in the database that isn’t in the album was clearly removed; anything in the album that isn’t on the disk is clearly a new item to be added. Then look at the logic of the application to decide what to do with each item.
Diffing with what you read in the first place means that you have to keep what you read. This is better as it avoids another database read. You may also need to diff with the database if you’re using Optimistic Offline Lock (416).
In the general case anything that’s added to the collection needs to be checked first to see if it’s a new object. You can do this by seeing if it has a key; if it doesn’t, one needs to be added to the database. This step is made a lot easier with Unit of Work (184) because that way any new object will be automatically inserted first. In either case you then find the linked row in the database and update its foreign key to point to the current album.
For removal you have to know whether the track was moved to another album, has no album, or has been deleted altogether. If it’s been moved to another album it should be updated when you update that other album. If it has no album, you need to null the foreign key. If the track was deleted, then it should be deleted when things get deleted. Handling deletes is much easier if the back link is mandatory, as it is here, where every track must be on an album. That way you don’t have to worry about detecting items removed from the collection since they will be updated when you process the album they’ve been added to.
If the link is immutable, meaning that you can’t change a track’s album, then adding always means insertion and removing always means deletion. This makes things simpler still.
One thing to watch out for is cycles in your links. Say you need to load an order, which has a link to a customer (which you load). The customer has a set of payments (which you load), and each payment has orders that it’s paying for, which might include the original order you’re trying to load. Therefore, you load the order (now go back to the beginning of this paragraph.)
To avoid getting lost in cycles you have two choices that boil down to how you create your objects. Usually it’s a good idea for a creation method to include data that will give you a fully formed object. If you do that, you’ll need to place Lazy Load (200) at appropriate points to break the cycles. If you miss one, you’ll get a stack overflow, but if you’re testing is good enough you can manage that burden.
The other choice is to create empty objects and immediately put them in an Identity Map (195). That way, when you cycle back around, the object is already loaded and you’ll end the cycle. The objects you create aren’t fully formed, but they should be by the end of the load procedure. This avoids having to make special case decisions about the use of Lazy Load (200) just to do a correct load.
A Foreign Key Mapping can be used for almost all associations between classes. The most common case where it isn’t possible is with many-to-many associations. Foreign keys are single values, and first normal form means that you can’t store multiple foreign keys in a single field. Instead you need to use Association Table Mapping (248).
If you have a collection field with no back pointer, you should consider whether the many side should be a Dependent Mapping (262). If so, it can simplify your handling of the collection.
If the related object is a Value Object (486) then you should use Embedded Value (268).
This is the simplest case, where an album has a single reference to an artist.
class Artist...
private String name;
public Artist(Long ID, String name) {
super(ID);
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
class Album...
private String title;
private Artist artist;
public Album(Long ID, String title, Artist artist) {
super(ID);
this.title = title;
this.artist = artist;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Artist getArtist() {
return artist;
}
public void setArtist(Artist artist) {
this.artist = artist;
}
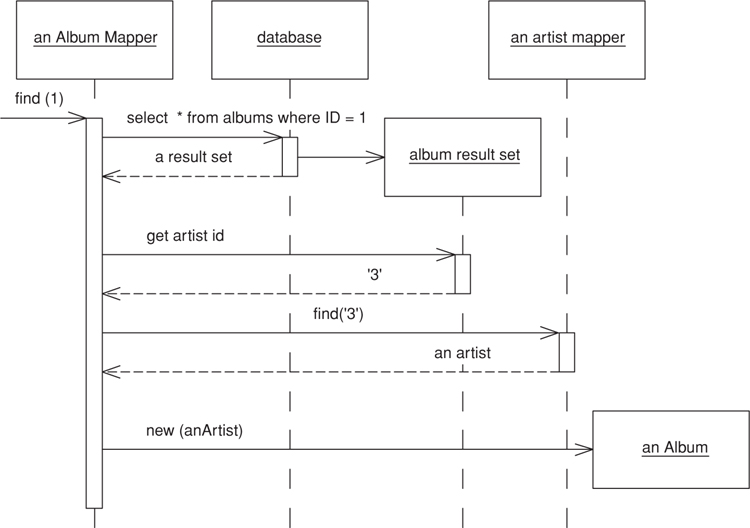
Figure 12.4 shows how you can load an album. When an album mapper is told to load a particular album it queries the database and pulls back the result set for it. It then queries the result set for each foreign key field and finds that object. Now it can create the album with the appropriate found objects. If the artist object was already in memory it would be fetched from the cache; otherwise, it would be loaded from the database in the same way.
Figure 12.4. Sequence for loading a single-valued field.
The find operation uses abstract behavior to manipulate an Identity Map (195).
class AlbumMapper...
public Album find(Long id) {
return (Album) abstractFind(id);
}
protected String findStatement() {
return "SELECT ID, title, artistID FROM albums WHERE ID = ?";
}
class AbstractMapper...
abstract protected String findStatement();
protected DomainObject abstractFind(Long id) {
DomainObject result = (DomainObject) loadedMap.get(id);
if (result != null) return result;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
stmt = DB.prepare(findStatement());
stmt.setLong(1, id.longValue());
rs = stmt.executeQuery();
rs.next();
result = load(rs);
return result;
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {cleanUp(stmt, rs);}
}
private Map loadedMap = new HashMap();
The find operation calls a load operation to actually load the data into the album.
class AbstractMapper...
protected DomainObject load(ResultSet rs) throws SQLException {
Long id = new Long(rs.getLong(1));
if (loadedMap.containsKey(id)) return (DomainObject) loadedMap.get(id);
DomainObject result = doLoad(id, rs);
doRegister(id, result);
return result;
}
protected void doRegister(Long id, DomainObject result) {
Assert.isFalse(loadedMap.containsKey(id));
loadedMap.put(id, result);
}
abstract protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException;
class AlbumMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
String title = rs.getString(2);
long artistID = rs.getLong(3);
Artist artist = MapperRegistry.artist().find(artistID);
Album result = new Album(id, title, artist);
return result;
}
To update an album the foreign key value is taken from the linked artist object.
class AbstractMapper...
abstract public void update(DomainObject arg);
class AlbumMapper...
public void update(DomainObject arg) {
PreparedStatement statement = null;
try {
statement = DB.prepare(
"UPDATE albums SET title = ?, artistID = ? WHERE id = ?");
statement.setLong(3, arg.getID().longValue());
Album album = (Album) arg;
statement.setString(1, album.getTitle());
statement.setLong(2, album.getArtist().getID().longValue());
statement.execute();
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {
cleanUp(statement);
}
}
While it’s conceptually clean to issue one query per table, it’s often inefficient since SQL consists of remote calls and remote calls are slow. Therefore, it’s often worth finding ways to gather information from multiple tables in a single query. I can modify the above example to use a single query to get both the album and the artist information with a single SQL call. The first alteration is that of the SQL for the find statement.
class AlbumMapper...
public Album find(Long id) {
return (Album) abstractFind(id);
}
protected String findStatement() {
return "SELECT a.ID, a.title, a.artistID, r.name " +
" from albums a, artists r " +
" WHERE ID = ? and a.artistID = r.ID";
}
I then use a different load method that loads both the album and the artist information together.
class AlbumMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
String title = rs.getString(2);
long artistID = rs.getLong(3);
ArtistMapper artistMapper = MapperRegistry.artist();
Artist artist;
if (artistMapper.isLoaded(artistID))
artist = artistMapper.find(artistID);
else
artist = loadArtist(artistID, rs);
Album result = new Album(id, title, artist);
return result;
}
private Artist loadArtist(long id, ResultSet rs) throws SQLException {
String name = rs.getString(4);
Artist result = new Artist(new Long(id), name);
MapperRegistry.artist().register(result.getID(), result);
return result;
}
There’s tension surrounding where to put the method that maps the SQL result into the artist object. On the one hand it’s better to put it in the artist’s mapper since that’s the class that usually loads the artist. On the other hand, the load method is closely coupled to the SQL and thus should stay with the SQL query. In this case I’ve voted for the latter.
The case for a collection of references occurs when you have a field that constitutes a collection. Here I’ll use an example of teams and players where we’ll assume that we can’t make player a Dependent Mapping (262) (Figure 12.5).
class Team...
public String Name;
public IList Players {
get {return ArrayList.ReadOnly(playersData);}
set {playersData = new ArrayList(value);}
}
public void AddPlayer(Player arg) {
playersData.Add(arg);
}
private IList playersData = new ArrayList();
Figure 12.5. A team with multiple players.
In the database this will be handled with the player record having a foreign key to the team (Figure 12.6).
class TeamMapper...
public Team Find(long id) {
return (Team) AbstractFind(id);
}
class AbstractMapper...
protected DomainObject AbstractFind(long id) {
Assert.True (id != DomainObject.PLACEHOLDER_ID);
DataRow row = FindRow(id);
return (row == null) ? null : Load(row);
}
protected DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results[0];
}
protected DataTable table {
get {return dsh.Data.Tables[TableName];}
}
public DataSetHolder dsh;
abstract protected String TableName {get;}
class TeamMapper...
protected override String TableName {
get {return "Teams";}
}
Figure 12.6. Database structure for a team with multiple players.
The data set holder is a class that holds onto the data set in use, together with the adapters needed to update it to the database.
class DataSetHolder...
public DataSet Data = new DataSet();
private Hashtable DataAdapters = new Hashtable();
For this example, we’ll assume that it has already been populated by some appropriate queries.
The find method calls a load to actually load the data into the new object.
class AbstractMapper...
protected DomainObject Load (DataRow row) {
long id = (int) row ["id"];
if (identityMap[id] != null) return (DomainObject) identityMap[id];
else {
DomainObject result = CreateDomainObject();
result.Id = id;
identityMap.Add(result.Id, result);
doLoad(result,row);
return result;
}
}
abstract protected DomainObject CreateDomainObject();
private IDictionary identityMap = new Hashtable();
abstract protected void doLoad (DomainObject obj, DataRow row);
class TeamMapper...
protected override void doLoad (DomainObject obj, DataRow row) {
Team team = (Team) obj;
team.Name = (String) row["name"];
team.Players = MapperRegistry.Player.FindForTeam(team.Id);
}
To bring in the players, I execute a specialized finder on the player mapper.
class PlayerMapper...
public IList FindForTeam(long id) {
String filter = String.Format("teamID = {0}", id);
DataRow[] rows = table.Select(filter);
IList result = new ArrayList();
foreach (DataRow row in rows) {
result.Add(Load (row));
}
return result;
}
To update, the team saves its own data and delegates the player mapper to save the data into the player table.
class AbstractMapper...
public virtual void Update (DomainObject arg) {
Save (arg, FindRow(arg.Id));
}
abstract protected void Save (DomainObject arg, DataRow row);
class TeamMapper...
protected override void Save (DomainObject obj, DataRow row){
Team team = (Team) obj;
row["name"] = team.Name;
savePlayers(team);
}
private void savePlayers(Team team){
foreach (Player p in team.Players) {
MapperRegistry.Player.LinkTeam(p, team.Id);
}
}
class PlayerMapper...
public void LinkTeam (Player player, long teamID) {
DataRow row = FindRow(player.Id);
row["teamID"] = teamID;
}
The update code is made much simpler by the fact that the association from player to team is mandatory. If we move a player from one team to another, as long as we update both team, we don’t have to do a complicated diff to sort the players out. I’ll leave that case as an exercise for the reader.
Saves an association as a table with foreign keys to the tables that are linked by the association.


Objects can handle multivalued fields quite easily by using collections as field values. Relational databases don’t have this feature and are constrained to single-valued fields only. When you’re mapping a one-to-many association you can handle this using Foreign Key Mapping (236), essentially using a foreign key for the single-valued end of the association. But a many-to-many association can’t do this because there is no single-valued end to hold the foreign key.
The answer is the classic resolution that’s been used by relational data people for decades: create an extra table to record the relationship. Then use Association Table Mapping to map the multivalued field to this link table.
The basic idea behind Association Table Mapping is using a link table to store the association. This table has only the foreign key IDs for the two tables that are linked together, it has one row for each pair of associated objects.
The link table has no corresponding in-memory object. As a result it has no ID. Its primary key is the compound of the two primary keys of the tables that are associated.
In simple terms, to load data from the link table you perform two queries. Consider loading the skills for an employee. In this case, at least conceptually, you do queries in two stages. The first stage queries the skillsEmployees table to find all the rows that link to the employee you want. The second stage finds the skill object for the related ID for each row in the link table.
If all the information is already in memory, this scheme works fine. If it isn’t, this scheme can be horribly expensive in queries, since you do a query for each skill that’s in the link table. You can avoid this cost by joining the skills table to the link table, which allows you to get all the data in a single query, albeit at the cost of making the mapping a bit more complicated.
Updating the link data involves many of the issues in updating a many-valued field. Fortunately, the matter is made much easier since you can in many ways treat the link table like a Dependent Mapping (262). No other table should refer to the link table, so you can freely create and destroy links as you need them.
The canonical case for Association Table Mapping is a many-to-many association, since there are really no any alternatives for that situation.
Association Table Mapping can also be used for any other form of association. However, because it’s more complex than Foreign Key Mapping (236) and involves an extra join, it’s not usually the right choice. Even so, in a couple of cases Association Table Mapping is appropriate for a simpler association; both involve databases where you have less control over the schema. Sometimes you may need to link two existing tables, but you aren’t able to add columns to those tables. In this case you can make a new table and use Association Table Mapping. Other times an existing schema uses an associative table, even when it isn’t really necessary. In this case it’s often easier to use Association Table Mapping than to simplify the database schema.
In a relational database design you may often have association tables that also carry information about the relationship. An example is a person/company associative table that also contains information about a person’s employment with the company. In this case the person/company table really corresponds to a true domain object.
Here’s a simple example using the sketch’s model. We have an employee class with a collection of skills, each of which can appear for more than one employee.
class Employee...
public IList Skills {
get {return ArrayList.ReadOnly(skillsData);}
set {skillsData = new ArrayList(value);}
}
public void AddSkill (Skill arg) {
skillsData.Add(arg);
}
public void RemoveSkill (Skill arg) {
skillsData.Remove(arg);
}
private IList skillsData = new ArrayList();
To load an employee from the database, we need to pull in the skills using an employee mapper. Each employee mapper class has a find method that creates an employee object. All mappers are subclasses of the abstract mapper class that pulls together common services for the mappers.
class EmployeeMapper...
public Employee Find(long id) {
return (Employee) AbstractFind(id);
}
class AbstractMapper...
protected DomainObject AbstractFind(long id) {
Assert.True (id != DomainObject.PLACEHOLDER_ID);
DataRow row = FindRow(id);
return (row == null) ? null : Load(row);
}
protected DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results[0];
}
protected DataTable table {
get {return dsh.Data.Tables[TableName];}
}
public DataSetHolder dsh;
abstract protected String TableName {get;}
class EmployeeMapper...
protected override String TableName {
get {return "Employees";}
}
The data set holder is a simple object that contains an ADO.NET data set and the relevant adapters to save it to the database.
class DataSetHolder...
public DataSet Data = new DataSet();
private Hashtable DataAdapters = new Hashtable();
To make this example simple—indeed, simplistic—we’ll assume that the data set has already been loaded with all the data we need.
The find method calls load methods to load data for the employee.
class AbstractMapper...
protected DomainObject Load (DataRow row) {
long id = (int) row ["id"];
if (identityMap[id] != null) return (DomainObject) identityMap[id];
else {
DomainObject result = CreateDomainObject();
result.Id = id;
identityMap.Add(result.Id, result);
doLoad(result,row);
return result;
}
}
abstract protected DomainObject CreateDomainObject();
private IDictionary identityMap = new Hashtable();
abstract protected void doLoad (DomainObject obj, DataRow row);
class EmployeeMapper...
protected override void doLoad (DomainObject obj, DataRow row) {
Employee emp = (Employee) obj;
emp.Name = (String) row["name"];
loadSkills(emp);
}
Loading the skills is sufficiently awkward to demand a separate method to do the work.
class EmployeeMapper...
private IList loadSkills (Employee emp) {
DataRow[] rows = skillLinkRows(emp);
IList result = new ArrayList();
foreach (DataRow row in rows) {
long skillID = (int)row["skillID"];
emp.AddSkill(MapperRegistry.Skill.Find(skillID));
}
return result;
}
private DataRow[] skillLinkRows(Employee emp) {
String filter = String.Format("employeeID = {0}", emp.Id);
return skillLinkTable.Select(filter);
}
private DataTable skillLinkTable {
get {return dsh.Data.Tables["skillEmployees"];}
}
To handle changes in skills information we use an update method on the abstract mapper.
class AbstractMapper...
public virtual void Update (DomainObject arg) {
Save (arg, FindRow(arg.Id));
}
abstract protected void Save (DomainObject arg, DataRow row);
The update method calls a save method in the subclass.
class EmployeeMapper...
protected override void Save (DomainObject obj, DataRow row) {
Employee emp = (Employee) obj;
row["name"] = emp.Name;
saveSkills(emp);
}
Again, I’ve made a separate method for saving the skills.
class EmployeeMapper...
private void saveSkills(Employee emp) {
deleteSkills(emp);
foreach (Skill s in emp.Skills) {
DataRow row = skillLinkTable.NewRow();
row["employeeID"] = emp.Id;
row["skillID"] = s.Id;
skillLinkTable.Rows.Add(row);
}
}
private void deleteSkills(Employee emp) {
DataRow[] skillRows = skillLinkRows(emp);
foreach (DataRow r in skillRows) r.Delete();
}
The logic here does the simple thing of deleting all existing link table rows and creating new ones. This saves me having to figure out which ones have been added and deleted.
One of the nice things about ADO.NET is that it allows me to discuss the basics of an object-relational mapping without getting into the sticky details of minimizing queries. With other relational mapping schemes you’re closer to the SQL and have to take much of that into account.
When you’re going directly to the database it’s important to minimize the queries. For my first version of this I’ll pull back the employee and all her skills in two queries. This is easy to follow but not quite optimal, so bear with me.
Here’s the DDL for the tables:
create table employees (ID int primary key, firstname varchar, lastname varchar)
create table skills (ID int primary key, name varchar)
create table employeeSkills (employeeID int, skillID int, primary key (employeeID, skillID))
To load a single Employee I’ll follow a similar approach to what I’ve done before. The employee mapper defines a simple wrapper for an abstract find method on the Layer Supertype (475).
class EmployeeMapper...
public Employee find(long key) {
return find (new Long (key));
}
public Employee find (Long key) {
return (Employee) abstractFind(key);
}
protected String findStatement() {
return
"SELECT " + COLUMN_LIST +
" FROM employees" +
" WHERE ID = ?";
}
public static final String COLUMN_LIST = " ID, lastname, firstname ";
class AbstractMapper...
protected DomainObject abstractFind(Long id) {
DomainObject result = (DomainObject) loadedMap.get(id);
if (result != null) return result;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
stmt = DB.prepare(findStatement());
stmt.setLong(1, id.longValue());
rs = stmt.executeQuery();
rs.next();
result = load(rs);
return result;
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt, rs);
}
}
abstract protected String findStatement();
protected Map loadedMap = new HashMap();
The find methods then call load methods. An abstract load method handles the ID loading while the actual data for the employee is loaded on the employee’s mapper.
class AbstractMapper...
protected DomainObject load(ResultSet rs) throws SQLException {
Long id = new Long(rs.getLong(1));
return load(id, rs);
}
public DomainObject load(Long id, ResultSet rs) throws SQLException {
if (hasLoaded(id)) return (DomainObject) loadedMap.get(id);
DomainObject result = doLoad(id, rs);
loadedMap.put(id, result);
return result;
}
abstract protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException;
class EmployeeMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
Employee result = new Employee(id);
result.setFirstName(rs.getString("firstname"));
result.setLastName(rs.getString("lastname"));
result.setSkills(loadSkills(id));
return result;
}
The employee needs to issue another query to load the skills, but it can easily load all the skills in a single query. To do this it calls the skill mapper to load in the data for a particular skill.
class EmployeeMapper...
protected List loadSkills(Long employeeID) {
PreparedStatement stmt = null;
ResultSet rs = null;
try {
List result = new ArrayList();
stmt = DB.prepare(findSkillsStatement);
stmt.setObject(1, employeeID);
rs = stmt.executeQuery();
while (rs.next()) {
Long skillId = new Long (rs.getLong(1));
result.add((Skill) MapperRegistry.skill().loadRow(skillId, rs));
}
return result;
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt, rs);
}
}
private static final String findSkillsStatement =
"SELECT skill.ID, " + SkillMapper.COLUMN_LIST +
" FROM skills skill, employeeSkills es " +
" WHERE es.employeeID = ? AND skill.ID = es.skillID";
class SkillMapper...
public static final String COLUMN_LIST = " skill.name skillName ";
class AbstractMapper...
protected DomainObject loadRow (Long id, ResultSet rs) throws SQLException {
return load (id, rs);
}
class SkillMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
Skill result = new Skill (id);
result.setName(rs.getString("skillName"));
return result;
}
The abstract mapper can also help find employees.
class EmployeeMapper...
public List findAll() {
return findAll(findAllStatement);
}
private static final String findAllStatement =
"SELECT " + COLUMN_LIST +
" FROM employees employee" +
" ORDER BY employee.lastname";
class AbstractMapper...
protected List findAll(String sql) {
PreparedStatement stmt = null;
ResultSet rs = null;
try {
List result = new ArrayList();
stmt = DB.prepare(sql);
rs = stmt.executeQuery();
while (rs.next())
result.add(load(rs));
return result;
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt, rs);
}
}
All of this works quite well and is pretty simple to follow. Still, there’s a problem in the number of queries, and that is that each employee takes two SQL queries to load. Although we can load the basic employee data for many employees in a single query, we still need one query per employee to load the skills. Thus, loading a hundred employees takes 101 queries.
It’s possible to bring back many employees, with their skills, in a single query. This is a good example of multitable query optimization, which is certainly more awkward. For that reason do this when you need to, rather than every time. It’s better to put more energy into speeding up your slow queries than into many queries that are less important.
The first case we’ll look at is a simple one where we pull back all the skills for an employee in the same query that holds the basic data. To do this I’ll use a more complex SQL statement that joins across all three tables.
class EmployeeMapper...
protected String findStatement() {
return
"SELECT" + COLUMN_LIST +
" FROM employees employee, skills skill, employeeSkills es" +
" WHERE employee.ID = es.employeeID AND skill.ID = es.skillID AND employee.ID = ?";
}
public static final String COLUMN_LIST =
" employee.ID, employee.lastname, employee.firstname, " +
" es.skillID, es.employeeID, skill.ID skillID, " +
SkillMapper.COLUMN_LIST;
The abstractFind and load methods on the superclass are the same as in the previous example, so I won’t repeat them here. The employee mapper loads its data differently to take advantage of the multiple data rows.
class EmployeeMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
Employee result = (Employee) loadRow(id, rs);
loadSkillData(result, rs);
while (rs.next()){
Assert.isTrue(rowIsForSameEmployee(id, rs));
loadSkillData(result, rs);
}
return result;
}
protected DomainObject loadRow(Long id, ResultSet rs) throws SQLException {
Employee result = new Employee(id);
result.setFirstName(rs.getString("firstname"));
result.setLastName(rs.getString("lastname"));
return result;
}
private boolean rowIsForSameEmployee(Long id, ResultSet rs) throws SQLException {
return id.equals(new Long(rs.getLong(1)));
}
private void loadSkillData(Employee person, ResultSet rs) throws SQLException {
Long skillID = new Long(rs.getLong("skillID"));
person.addSkill ((Skill)MapperRegistry.skill().loadRow(skillID, rs));
}
In this case the load method for the employee mapper actually runs through the rest of the result set to load in all the data.
All is simple when we’re loading the data for a single employee. However, the real benefit of this multitable query appears when we want to load lots of employees. Getting the reading right can be tricky, particularly when we don’t want to force the result set to be grouped by employees. At this point it’s handy to introduce a helper class to go through the result set by focusing on the associative table itself, loading up the employees and skills as it goes along.
I’ll begin with the SQL and the call to the special loader class.
class EmployeeMapper...
public List findAll() {
return findAll(findAllStatement);
}
private static final String findAllStatement =
"SELECT " + COLUMN_LIST +
" FROM employees employee, skills skill, employeeSkills es" +
" WHERE employee.ID = es.employeeID AND skill.ID = es.skillID" +
" ORDER BY employee.lastname";
protected List findAll(String sql) {
AssociationTableLoader loader = new AssociationTableLoader(this, new SkillAdder());
return loader.run(findAllStatement);
}
class AssociationTableLoader...
private AbstractMapper sourceMapper;
private Adder targetAdder;
public AssociationTableLoader(AbstractMapper primaryMapper, Adder targetAdder) {
this.sourceMapper = primaryMapper;
this.targetAdder = targetAdder;
}
Don’t worry about the skillAdder—that will become a bit clearer later. For the moment notice that we construct the loader with a reference to the mapper and then tell it to perform a load with a suitable query. This is the typical structure of a method object. A method object [Beck Patterns] is a way of turning a complicated method into an object on its own. The great advantage of this is that it allows you to put values in fields instead of passing them around in parameters. The usual way of using a method object is to create it, fire it up, and then let it die once its duty is done.
The load behavior comes in three steps.
class AssociationTableLoader...
protected List run(String sql) {
loadData(sql);
addAllNewObjectsToIdentityMap();
return formResult();
}
The loadData method forms the SQL call, executes it, and loops through the result set. Since this is a method object, I’ve put the result set in a field so I don’t have to pass it around.
class AssociationTableLoader...
private ResultSet rs = null;
private void loadData(String sql) {
PreparedStatement stmt = null;
try {
stmt = DB.prepare(sql);
rs = stmt.executeQuery();
while (rs.next())
loadRow();
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt, rs);
}
}
The loadRow method loads the data from a single row in the result set. It’s a bit complicated.
class AssociationTableLoader...
private List resultIds = new ArrayList();
private Map inProgress = new HashMap();
private void loadRow() throws SQLException {
Long ID = new Long(rs.getLong(1));
if (!resultIds.contains(ID)) resultIds.add(ID);
if (!sourceMapper.hasLoaded(ID)) {
if (!inProgress.keySet().contains(ID))
inProgress.put(ID, sourceMapper.loadRow(ID, rs));
targetAdder.add((DomainObject) inProgress.get(ID), rs);
}
}
class AbstractMapper...
boolean hasLoaded(Long id) {
return loadedMap.containsKey(id);
}
The loader preserves any order there is in the result set, so the output list of employees will be in the same order in which it first appeared. So I keep a list of IDs in the order I see them. Once I’ve got the ID I look to see if it’s already fully loaded in the mapper—usually from a previous query. If it not I load what data I have and keep it in an in-progress list. I need such a list since several rows will combine to gather all the data from the employee and I may not hit those rows consecutively.
The trickiest part to this code is ensuring that I can add the skill I’m loading to the employees’ list of skills, but still keep the loader generic so it doesn’t depend on employees and skills. To achieve this I need to dig deep into my bag of tricks to find an inner interface—the Adder.
class AssociationTableLoader...
public static interface Adder {
void add(DomainObject host, ResultSet rs) throws SQLException ;
}
The original caller has to supply an implementation for the interface to bind it to the particular needs of the employee and skill.
class EmployeeMapper...
private static class SkillAdder implements AssociationTableLoader.Adder {
public void add(DomainObject host, ResultSet rs) throws SQLException {
Employee emp = (Employee) host;
Long skillId = new Long (rs.getLong("skillId"));
emp.addSkill((Skill) MapperRegistry.skill().loadRow(skillId, rs));
}
}
This is the kind of thing that comes more naturally to languages that have function pointers or closures, but at least the class and interface get the job done. (They don’t have to be inner in this case, but it helps bring out their narrow scope.)
You may have noticed that I have a load and a loadRow method defined on the superclass and the implementation of the loadRow is to call load. I did this because there are times when you want to be sure that a load action will not move the result set forward. The load does whatever it needs to do to load an object, but loadRow guarantees to load data from a row without altering the position of the cursor. Most of the time these two are the same thing, but in the case of this employee mapper they’re different.
Now all the data is in from the result set. I have two collections: a list of all the employee IDs that were in the result set in the order of first appearance and a list of new objects that haven’t yet made an appearance in the employee mapper’s Identity Map (195).
The next step is to put all the new objects into the Identity Map (195).
class AssociationTableLoader...
private void addAllNewObjectsToIdentityMap() {
for (Iterator it = inProgress.values().iterator(); it.hasNext();)
sourceMapper.putAsLoaded((DomainObject)it.next());
}
class AbstractMapper...
void putAsLoaded (DomainObject obj) {
loadedMap.put (obj.getID(), obj);
}
The final step is to assemble the result list by looking up the IDs from the mapper.
class AssociationTableLoader...
private List formResult() {
List result = new ArrayList();
for (Iterator it = resultIds.iterator(); it.hasNext();) {
Long id = (Long)it.next();
result.add(sourceMapper.lookUp(id));
}
return result;
}
class AbstractMapper...
protected DomainObject lookUp (Long id) {
return (DomainObject) loadedMap.get(id);
}
Such code is more complex than the average loading code, but this kind of thing can help cut down the number of queries. Since it’s complicated, this is something to be used sparingly when you have laggardly bits of database interaction. However, it’s an example of how Data Mapper (165) can provide good queries without the domain layer being aware of the complexity involved.
Has one class perform the database mapping for a child class.
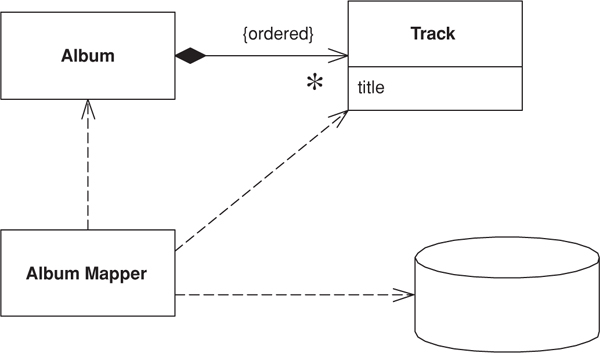
Some objects naturally appear in the context of other objects. Tracks on an album may be loaded or saved whenever the underlying album is loaded or saved. If they aren’t referenced to by any other table in the database, you can simplify the mapping procedure by having the album mapper perform the mapping for the tracks as well—treating this mapping as a dependent mapping.
The basic idea behind Dependent Mapping is that one class (the dependent) relies upon some other class (the owner) for its database persistence. Each dependent can have only one owner and must have one owner.
This manifests itself in terms of the classes that do the mapping. For Active Record (160) and Row Data Gateway (152), the dependent class won’t contain any database mapping code; its mapping code sits in the owner. With Data Mapper (165) there’s no mapper for the dependent, the mapping code sits in the mapper for the owner. In a Table Data Gateway (144) there will typically be no dependent class at all, all the handling of the dependent is done in the owner.
In most cases every time you load an owner, you load the dependents too. If the dependents are expensive to load and infrequently used, you can use a Lazy Load (200) to avoid loading the dependents until you need them.
An important property of a dependent is that it doesn’t have an Identity Field (216) and therefore isn’t stored in a Identity Map (195). It therefore cannot be loaded by a find method that looks up an ID. Indeed, there’s no finder for a dependent since all finds are done with the owner.
A dependent may itself be the owner of another dependent. In this case the owner of the first dependent is also responsible for the persistence of the second dependent. You can have a whole hierarchy of dependents controlled by a single primary owner.
It’s usually easier for the primary key on the database to be a composite key that includes the owner’s primary key. No other table should have a foreign key into the dependent’s table, unless that object has the same owner. As a result, no in-memory object other than the owner or its dependents should have a reference to a dependent. Strictly speaking, you can relax that rule providing that the reference isn’t persisted to the database, but having a nonpersistent reference is itself a good source of confusion.
In a UML model, it’s appropriate to use composition to show the relationship between an owner and its dependents.
Since the writing and saving of dependents is left to the owner, and there are no outside references, updates to the dependents can be handled through deletion and insertion. Thus, if you want to update the collection of dependents you can safely delete all rows that link to the owner and then reinsert all the dependents. This saves you from having to do an analysis of objects added or removed from the owner’s collection.
Dependents are in many ways like Value Objects (486), although they often don’t need the full mechanics that you use in making something a Value Object (486) (such as overriding equals). The main difference is that there’s nothing special about them from a purely in-memory point of view. The dependent nature of the objects is only really due to the database mapping behavior.
Using Dependent Mapping complicates tracking whether the owner has changed. Any change to a dependent needs to mark the owner as changed so that the owner will write the changes out to the database. You can simplify this considerably by making the dependent immutable, so that any change to it needs to be done by removing it and adding a new one. This can make the in-memory model harder to work with, but it does simplify the database mapping. While in theory the in-memory and database mapping should be independent when you’re using Data Mapper (165), in practice you have to make the occasional compromise.
You use Dependent Mapping when you have an object that’s only referred to by one other object, which usually occurs when one object has a collection of dependents. Dependent Mapping is a good way of dealing with the awkward situation where the owner has a collection of references to its dependents but there’s no back pointer. Providing that the many objects don’t need their own identity, using Dependent Mapping makes it easier to manage their persistence.
For Dependent Mapping to work there are a number of preconditions.
• A dependent must have exactly one owner.
• There must be no references from any object other than the owner to the dependent.
There is a school of OO design that uses the notion of entity objects and dependent objects when designing a Domain Model (116). I tend to think of Dependent Mapping as a technique to simplify database mapping rather than as a fundamental OO design medium. In particular, I avoid large graphs of dependents. The problem with them is that it’s impossible to refer to a dependent from outside the graph, which often leads to complex lookup schemes based around the root owner.
I don’t recommend Dependent Mapping if you’re using Unit of Work (184). The delete and reinsert strategy doesn’t help at all if you have a Unit of Work (184) keeping track of things. It can also lead to problems since the Unit of Work (184) isn’t controlling the dependents. Mike Rettig told me about an application where a Unit of Work (184) would keep track of rows inserted for testing and then delete them all when done. Because it didn’t track dependents, orphan rows appeared and caused failures in the test runs.
In this domain model (Figure 12.7) an album holds a collection of tracks. This uselessly simple application doesn’t need anything else to refer to a track, so it’s an obvious candidate for Dependent Mapping. (Indeed, anyone would think the example is deliberately constructed for the pattern.)
Figure 12.7. An album with tracks that can be handled using Dependent Mapping.
This track just has a title. I’ve defined it as an immutable class.
class Track...
private final String title;
public Track(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
The tracks are held in the album class.
class Album...
private List tracks = new ArrayList();
public void addTrack(Track arg) {
tracks.add(arg);
}
public void removeTrack(Track arg) {
tracks.remove(arg);
};
public void removeTrack(int i) {
tracks.remove(i);
}
public Track[] getTracks() {
return (Track[]) tracks.toArray(new Track[tracks.size()]);
}
The album mapper class handles all the SQL for tracks and thus defines the SQL statements that access the tracks table.
class AlbumMapper...
protected String findStatement() {
return
"SELECT ID, a.title, t.title as trackTitle" +
" FROM albums a, tracks t" +
" WHERE a.ID = ? AND t.albumID = a.ID" +
" ORDER BY t.seq";
}
The tracks are loaded into the album whenever the album is loaded.
class AlbumMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
String title = rs.getString(2);
Album result = new Album(id, title);
loadTracks(result, rs);
return result;
}
public void loadTracks(Album arg, ResultSet rs) throws SQLException {
arg.addTrack(newTrack(rs));
while (rs.next()) {
arg.addTrack(newTrack(rs));
}
}
private Track newTrack(ResultSet rs) throws SQLException {
String title = rs.getString(3);
Track newTrack = new Track (title);
return newTrack;
}
For clarity I’ve done the track load in a separate query. For performance, you might want to consider loading them in the same query along the lines of the example on page 243.
When the album is updated all the tracks are deleted and reinserted.
class AlbumMapper...
public void update(DomainObject arg) {
PreparedStatement updateStatement = null;
try {
updateStatement = DB.prepare("UPDATE albums SET title = ? WHERE id = ?");
updateStatement.setLong(2, arg.getID().longValue());
Album album = (Album) arg;
updateStatement.setString(1, album.getTitle());
updateStatement.execute();
updateTracks(album);
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(updateStatement);
}
}
public void updateTracks(Album arg) throws SQLException {
PreparedStatement deleteTracksStatement = null;
try {
deleteTracksStatement = DB.prepare("DELETE from tracks WHERE albumID = ?");
deleteTracksStatement.setLong(1, arg.getID().longValue());
deleteTracksStatement.execute();
for (int i = 0; i < arg.getTracks().length; i++) {
Track track = arg.getTracks()[i];
insertTrack(track, i + 1, arg);
}
} finally {DB.cleanUp(deleteTracksStatement);
}
}
public void insertTrack(Track track, int seq, Album album) throws SQLException {
PreparedStatement insertTracksStatement = null;
try {
insertTracksStatement =
DB.prepare("INSERT INTO tracks (seq, albumID, title) VALUES (?, ?, ?)");
insertTracksStatement.setInt(1, seq);
insertTracksStatement.setLong(2, album.getID().longValue());
insertTracksStatement.setString(3, track.getTitle());
insertTracksStatement.execute();
} finally {DB.cleanUp(insertTracksStatement);
}
}
Maps an object into several fields of another object’s table.

Many small objects make sense in an OO system that don’t make sense as tables in a database. Examples include currency-aware money objects and date ranges. Although the default thinking is to save an object as a table, no sane person would want a table of money values.
An Embedded Value maps the values of an object to fields in the record of the object’s owner. In the sketch we have an employment object with links to a date range object and a money object. In the resulting table the fields in those objects map to fields in the employment table rather than make new records themselves.
This exercise is actually quite simple. When the owning object (employment) is loaded or saved, the dependent objects (date range and money) are loaded and saved at the same time. The dependent classes won’t have their own persistence methods since all persistence is done by the owner. You can think of Embedded Value as a special case of Dependent Mapping (262), where the value is a single dependent object.
This is one of those patterns where the doing of it is very straightforward, but knowing when to use it a little more complicated.
The simplest cases for Embedded Value are the clear, simple Value Objects (486) like money and date range. Since Value Objects (486) don’t have identity, you can create and destroy them easily without worrying about such things as Identity Maps (195) to keep them all in sync. Indeed, all Value Objects (486) should be persisted as Embedded Value, since you would never want a table for them there.
The grey area is in whether it’s worth storing reference objects, such as an order and a shipping object, using Embedded Value. The principal question here is whether the shipping data has any relevance outside the context of the order. One issue is the loading and saving. If you only load the shipping data into memory when you load the order, that’s an argument for saving both in the same table. Another question is whether you’ll want to access the shipping data separately though SQL. This can be important if you’re reporting through SQL and don’t have a separate database for reporting.
If you’re mapping to an existing schema, you can use Embedded Value when a table contains data that you split into more than one object in memory. This may occur because you want a separate object to factor out some behavior in the object model, but it’s all still one entity in the database. In this case you have to be careful that any change to the dependent marks the owner as dirty—which isn’t an issue with Value Objects (486) that are replaced in the owner.
In most cases you’ll only use Embedded Value on a reference object when the association between them is single valued at both ends (a one-to-one association). Occasionally you may use it if there are multiple candidate dependents and their number is small and fixed. Then you’ll have numbered fields for each value. This is messy table design, and horrible to query in SQL, but it may have performance benefits. If this is the case, however, Serialized LOB (272) is usually the better choice.
Since so much of the logic for deciding when to use Embedded Value is the same as for Serialized LOB (272), there’s the obvious matter of choosing between the two. The great advantage of Embedded Value is that it allows SQL queries to be made against the values in the dependent object. Although using XML as the serialization, together with XML-based query add-ons to SQL, may alter that in the future, at the moment you really need Embedded Value if you want to use dependent values in a query. This may be important for separate reporting mechanisms on the database
Embedded Value can only be used for fairly simple dependents. A solitary dependent, or a few separated dependents, works well. Serialized LOB (272) works with more complex structures, including potentially large object subgraphs.
Embedded Value has been called a couple of different names in its history. TOPLink refers to it as aggregate mapping. Visual Age refers to it as composer.
This is the classic example of a value object mapped with Embedded Value. We’ll begin with a simple product offering class with the following fields.
class ProductOffering...
private Product product;
private Money baseCost;
private Integer ID;
In these fields the ID is an Identity Field (216) and the product is a regular record mapping. We’ll map the base cost using Embedded Value. We’ll do the overall mapping with Active Record (160) to keep things simple.
Since we’re using Active Record (160) we need save and load routines. These simple routines are in the product offering class because it’s the owner. The money class has no persistence behavior at all. Here’s the load method.
class ProductOffering...
public static ProductOffering load(ResultSet rs) {
try {
Integer id = (Integer) rs.getObject("ID");
BigDecimal baseCostAmount = rs.getBigDecimal("base_cost_amount");
Currency baseCostCurrency = Registry.getCurrency(rs.getString("base_cost_currency"));
Money baseCost = new Money(baseCostAmount, baseCostCurrency);
Integer productID = (Integer) rs.getObject("product");
Product product = Product.find((Integer) rs.getObject("product"));
return new ProductOffering(id, product, baseCost);
} catch (SQLException e) {
throw new ApplicationException(e);
}
}
Here’s the update behavior. Again it’s a simple variation on the updates.
class ProductOffering...
public void update() {
PreparedStatement stmt = null;
try {
stmt = DB.prepare(updateStatementString);
stmt.setBigDecimal(1, baseCost.amount());
stmt.setString(2, baseCost.currency().code());
stmt.setInt(3, ID.intValue());
stmt.execute();
} catch (Exception e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(stmt);}
}
private String updateStatementString =
"UPDATE product_offerings" +
" SET base_cost_amount = ?, base_cost_currency = ? " +
" WHERE id = ?";
Saves a graph of objects by serializing them into a single large object (LOB), which it stores in a database field.
Object models often contain complicated graphs of small objects. Much of the information in these structures isn’t in the objects but in the links between them. Consider storing the organization hierarchy for all your customers. An object model quite naturally shows the composition pattern to represent organizational hierarchies, and you can easily add methods that allow you to get ancestors, siblings, descendents, and other common relationships.
Not so easy is putting all this into a relational schema. The basic schema is simple—an organization table with a parent foreign key, however, its manipulation of the schema requires many joins, which are both slow and awkward.
Objects don’t have to be persisted as table rows related to each other. Another form of persistence is serialization, where a whole graph of objects is written out as a single large object (LOB) in a table this Serialized LOB then becomes a form of memento [Gang of Four].
There are two ways you can do the serialization: as a binary (BLOB) or as textual characters (CLOB). The BLOB is often the simplest to create since many platforms include the ability to automatically serialize an object graph. Saving the graph is a simple matter of applying the serialization in a buffer and saving that buffer in the relevant field.
The advantages of the BLOB are that it’s simple to program (if your platform supports it) and that it uses the minimum of space. The disadvantages are that your database must support a binary data type for it and that you can’t reconstruct the graph without the object, so the field is utterly impenetrable to casual viewing. The most serious problem, however, is versioning. If you change the department class, you may not be able to read all its previous serializations; since data can live in the database for a long time, this is no small thing.
The alternative is a CLOB. In this case you serialize the department graph into a text string that carries all the information you need. The text string can be read easily by a human viewing the row, which helps in casual browsing of the database. However the text approach will usually need more space, and you may need to create your own parser for the textual format you use. It’s also likely to be slower than a binary serialization.
Many of the disadvantages of CLOBs can be overcome with XML. XML parsers are commonly available, so you don’t have to write your own. Furthermore, XML is a widely supported standard so you can take advantage of tools as they become available to do further manipulations. The disadvantage that XML doesn’t help with is the matter of space. Indeed, it makes the space issue much worse because its a very verbose format. One way to deal with that is to use a zipped XML format as your BLOB—you lose the direct human readability, but it’s an option if space is a real issue.
When you use Serialized LOB beware of identity problems. Say you want to use Serialized LOB for the customer details on an order. For this don’t put the customer LOB in the order table; otherwise, the customer data will be copied on every order, which makes updates a problem. (This is actually a good thing, however, if you want to store a snapshot of the customer data as it was at the placing of the order—it avoids temporal relationships.) If you want your customer data to be updated for each order in the classical relational sense, you need to put the LOB in a customer table so many orders can link to it. There’s nothing wrong with a table that just has an ID and a single LOB field for its data.
In general, be careful of duplicating data when using this pattern. Often it’s not a whole Serialized LOB that gets duplicated but part of one that overlaps with another one. The thing to do is to pay careful attention to the data that’s stored in the Serialized LOB and be sure that it can’t be reached from anywhere but a single object that acts as the owner of the Serialized LOB.
Serialized LOB isn’t considered as often as it might be. XML makes it much more attractive since it yields a easy-to-implement textual approach. Its main disadvantage is that you can’t query the structure using SQL. SQL extensions appear to get at XML data within a field, but that’s still not the same (or portable).
This pattern works best when you can chop out a piece of the object model and use it to represent the LOB. Think of a LOB as a way to take a bunch of objects that aren’t likely to be queried from any SQL route outside the application. This graph can then be hooked into the SQL schema.
Serialized LOB works poorly when you have objects outside the LOB reference objects buried in it. To handle this you have to come up with some form of referencing scheme that can support references to objects inside a LOB—it’s by no means impossible, but it’s awkward, awkward enough usually not to be worth doing. Again XML, or rather XPath, reduces this awkwardness somewhat.
If you’re using a separate database for reporting and all other SQL goes against that database, you can transform the LOB into a suitable table structure. The fact that a reporting database is usually denormalized means that structures suitable for Serialized LOB are often also suitable for a separate reporting database.
For this example we’ll take the notion of customers and departments from the sketch and show how you might serialize all the departments into an XML CLOB. As I write this, Java’s XML handling is somewhat primitive and volatile, so the code may look different when you get to it (I’m also using an early version of JDOM).
The object model of the sketch turns into the following class structures:
class Customer...
private String name;
private List departments = new ArrayList();
class Department...
private String name;
private List subsidiaries = new ArrayList();
The database for this has only one table.
create table customers (ID int primary key, name varchar, departments varchar)
We’ll treat the customer as an Active Record (160) and illustrate writing the data with the insert behavior.
class Customer...
public Long insert() {
PreparedStatement insertStatement = null;
try {
insertStatement = DB.prepare(insertStatementString);
setID(findNextDatabaseId());
insertStatement.setInt(1, getID().intValue());
insertStatement.setString(2, name);
insertStatement.setString(3, XmlStringer.write(departmentsToXmlElement()));
insertStatement.execute();
Registry.addCustomer(this);
return getID();
} catch (SQLException e) {
throw new ApplicationException(e);
} finally {DB.cleanUp(insertStatement);
}
}
public Element departmentsToXmlElement() {
Element root = new Element("departmentList");
Iterator i = departments.iterator();
while (i.hasNext()) {
Department dep = (Department) i.next();
root.addContent(dep.toXmlElement());
}
return root;
}
class Department...
Element toXmlElement() {
Element root = new Element("department");
root.setAttribute("name", name);
Iterator i = subsidiaries.iterator();
while (i.hasNext()) {
Department dep = (Department) i.next();
root.addContent(dep.toXmlElement());
}
return root;
}
The customer has a method for serializing its departments field into a single XML DOM. Each department has a method for serializing itself (and its subsidiaries recursively) into a DOM as well. The insert method then takes the DOM of the departments, converts it into a string (via a utility class) and puts it in the database. We aren’t particularly concerned with the structure of the string. It’s human readable, but we aren’t going to look at it on a regular basis.
<?xml version="1.0" encoding="UTF-8"?>
<departmentList>
<department name="US">
<department name="New England">
<department name="Boston" />
<department name="Vermont" />
</department>
<department name="California" />
<department name="Mid-West" />
</department>
<department name="Europe" />
</departmentList>
Reading back is a fairly simple reversal of this process.
class Customer...
public static Customer load(ResultSet rs) throws SQLException {
Long id = new Long(rs.getLong("id"));
Customer result = (Customer) Registry.getCustomer(id);
if (result != null) return result;
String name = rs.getString("name");
String departmentLob = rs.getString("departments");
result = new Customer(name);
result.readDepartments(XmlStringer.read(departmentLob));
return result;
}
void readDepartments(Element source) {
List result = new ArrayList();
Iterator it = source.getChildren("department").iterator();
while (it.hasNext())
addDepartment(Department.readXml((Element) it.next()));
}
class Department...
static Department readXml(Element source) {
String name = source.getAttributeValue("name");
Department result = new Department(name);
Iterator it = source.getChildren("department").iterator();
while (it.hasNext())
result.addSubsidiary(readXml((Element) it.next()));
return result;
}
The load code is obviously a mirror image of the insert code. The department knows how to create itself (and its subsidiaries) from an XML element, and the customer knows how to take an XML element and create the list of departments from it. The load method uses a utility class to turn the string from the database into a utility element.
An obvious danger here is that someone may try to edit the XML by hand in the database and mess up the XML, making it unreadable by the load routine. More sophisticated tools that would support adding a DTD or XML schema to a field as validation will obviously help with that.
Represents an inheritance hierarchy of classes as a single table that has columns for all the fields of the various classes.
Relational databases don’t support inheritance, so when mapping from objects to databases we have to consider how to represent our nice inheritance structures in relational tables. When mapping to a relational database, we try to minimize the joins that can quickly mount up when processing an inheritance structure in multiple tables. Single Table Inheritance maps all fields of all classes of an inheritance structure into a single table.
In this inheritance mapping scheme we have one table that contains all the data for all the classes in the inheritance hierarchy. Each class stores the data that’s relevant to it in one table row. Any columns in the database that aren’t relevant are left empty. The basic mapping behavior follows the general scheme of Inheritance Mappers (302).
When loading an object into memory you need to know which class to instantiate. For this you have a field in the table that indicates which class should be used. This can be the name of the class or a code field. A code field needs to be interpreted by some code to map it to the relevant class. This code needs to be extended when a class is added to the hierarchy. If you embed the class name in the table you can just use it directly to instantiate an instance. The class name, however, will take up more space and may be less easy to process by those using the database table structure directly. As well it may more closely couple the class structure to the database schema.
In loading data you read the code first to figure out which subclass to instantiate. On saving the data the code needs be written out by the superclass in the hierarchy.
Single Table Inheritance is one of the options for mapping the fields in an inheritance hierarchy to a relational database. The alternatives are Class Table Inheritance (285) and Concrete Table Inheritance (293).
These are the strengths of Single Table Inheritance:
• There’s only a single table to worry about on the database.
• There are no joins in retrieving data.
• Any refactoring that pushes fields up or down the hierarchy doesn’t require you to change the database.
The weaknesses of Single Table Inheritance are
• Fields are sometimes relevant and sometimes not, which can be confusing to people using the tables directly.
• Columns used only by some subclasses lead to wasted space in the database. How much this is actually a problem depends on the specific data characteristics and how well the database compresses empty columns. Oracle, for example, is very efficient in trimming wasted space, particularly if you keep your optional columns to the right side of the database table. Each database has its own tricks for this.
• The single table may end up being too large, with many indexes and frequent locking, which may hurt performance. You can avoid this by having separate index tables that either list keys of rows that have a certain property or that copy a subset of fields relevant to an index.
• You only have a single namespace for fields, so you have to be sure that you don’t use the same name for different fields. Compound names with the name of the class as a prefix or suffix help here.
Remember that you don’t need to use one form of inheritance mapping for your whole hierarchy. It’s perfectly fine to map half a dozen similar classes in a single table, as long as you use Concrete Table Inheritance (293) for any classes that have a lot of specific data.
Like the other inheritance examples, I’ve based this one on Inheritance Mappers (302), using the classes in Figure 12.8. Each mapper needs to be linked to a data table in an ADO.NET data set. This link can be made generically in the mapper superclass. The gateway’s data property is a data set that can be loaded by a query.
Figure 12.8. The generic class diagram of Inheritance Mappers (302).
class Mapper...
protected DataTable table {
get {return Gateway.Data.Tables[TableName];}
}
protected Gateway Gateway;
abstract protected String TableName {get;}
Since there is only one table, this can be defined by the abstract player mapper.
class AbstractPlayerMapper...
protected override String TableName {
get {return "Players";}
}
Each class needs a type code to help the mapper code figure out what kind of player it’s dealing with. The type code is defined on the superclass and implemented in the subclasses.
class AbstractPlayerMapper...
abstract public String TypeCode {get;}
class CricketerMapper...
public const String TYPE_CODE = "C";
public override String TypeCode {
get {return TYPE_CODE;}
}
The player mapper has fields for each of the three concrete mapper classes.
class PlayerMapper...
private BowlerMapper bmapper;
private CricketerMapper cmapper;
private FootballerMapper fmapper;
public PlayerMapper (Gateway gateway) : base (gateway) {
bmapper = new BowlerMapper(Gateway);
cmapper = new CricketerMapper(Gateway);
fmapper = new FootballerMapper(Gateway);
}
Each concrete mapper class has a find method to get an object from the data.
class CricketerMapper...
public Cricketer Find(long id) {
return (Cricketer) AbstractFind(id);
}
This calls generic behavior to find an object.
class Mapper...
protected DomainObject AbstractFind(long id) {
DataRow row = FindRow(id);
return (row == null) ? null : Find(row);
}
protected DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results[0];
}
public DomainObject Find (DataRow row) {
DomainObject result = CreateDomainObject();
Load(result, row);
return result;
}
abstract protected DomainObject CreateDomainObject();
class CricketerMapper...
protected override DomainObject CreateDomainObject() {
return new Cricketer();
}
I load the data into the new object with a series of load methods, one on each class in the hierarchy.
class CricketerMapper...
protected override void Load(DomainObject obj, DataRow row) {
base.Load(obj,row);
Cricketer cricketer = (Cricketer) obj;
cricketer.battingAverage = (double)row["battingAverage"];
}
class AbstractPlayerMapper...
protected override void Load(DomainObject obj, DataRow row) {
base.Load(obj, row);
Player player = (Player) obj;
player.name = (String)row["name"];
}
class Mapper...
protected virtual void Load(DomainObject obj, DataRow row) {
obj.Id = (int) row ["id"];
}
I can also load a player through the player mapper. It needs to read the data and use the type code to determine which concrete mapper to use.
class PlayerMapper...
public Player Find (long key) {
DataRow row = FindRow(key);
if (row == null) return null;
else {
String typecode = (String) row["type"];
switch (typecode){
case BowlerMapper.TYPE_CODE:
return (Player) bmapper.Find(row);
case CricketerMapper.TYPE_CODE:
return (Player) cmapper.Find(row);
case FootballerMapper.TYPE_CODE:
return (Player) fmapper.Find(row);
default:
throw new Exception("unknown type");
}
}
}
The basic operation for updating is the same for all objects, so I can define the operation on the mapper superclass.
class Mapper...
public virtual void Update (DomainObject arg) {
Save (arg, FindRow(arg.Id));
}
The save method is similar to the load method—each class defines it to save the data it contains.
class CricketerMapper...
protected override void Save(DomainObject obj, DataRow row) {
base.Save(obj, row);
Cricketer cricketer = (Cricketer) obj;
row["battingAverage"] = cricketer.battingAverage;
}
class AbstractPlayerMapper...
protected override void Save(DomainObject obj, DataRow row) {
Player player = (Player) obj;
row["name"] = player.name;
row["type"] = TypeCode;
}
The player mapper forwards to the appropriate concrete mapper.
class PlayerMapper...
public override void Update (DomainObject obj) {
MapperFor(obj).Update(obj);
}
private Mapper MapperFor(DomainObject obj) {
if (obj is Footballer)
return fmapper;
if (obj is Bowler)
return bmapper;
if (obj is Cricketer)
return cmapper;
throw new Exception("No mapper available");
}
Insertions are similar to updates; the only real difference is that a new row needs to be made in the table before saving.
class Mapper...
public virtual long Insert (DomainObject arg) {
DataRow row = table.NewRow();
arg.Id = GetNextID();
row["id"] = arg.Id;
Save (arg, row);
table.Rows.Add(row);
return arg.Id;
}
class PlayerMapper...
public override long Insert (DomainObject obj) {
return MapperFor(obj).Insert(obj);
}
Deletes are pretty simple. They’re defined at the abstract mapper level or in the player wrapper.
class Mapper...
public virtual void Delete(DomainObject obj) {
DataRow row = FindRow(obj.Id);
row.Delete();
}
class PlayerMapper...
public override void Delete (DomainObject obj) {
MapperFor(obj).Delete(obj);
}
Represents an inheritance hierarchy of classes with one table for each class.
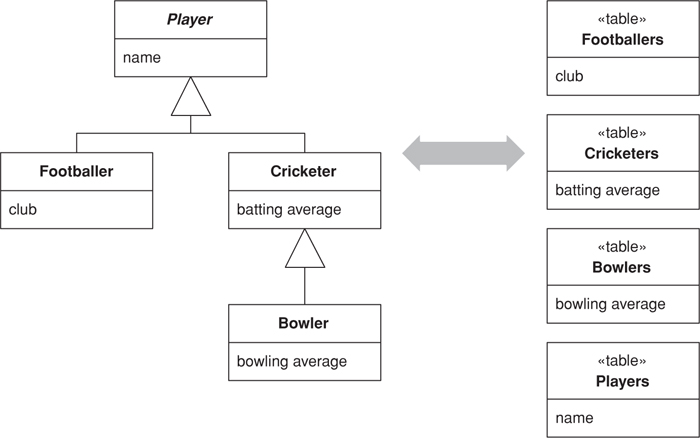
A very visible aspect of the object-relational mismatch is the fact that relational databases don’t support inheritance. You want database structures that map clearly to the objects and allow links anywhere in the inheritance structure. Class Table Inheritance supports this by using one database table per class in the inheritance structure.
The straightforward thing about Class Table Inheritance is that it has one table per class in the domain model. The fields in the domain class map directly to fields in the corresponding tables. As with the other inheritance mappings the fundamental approach of Inheritance Mappers (302) applies.
One issue is how to link the corresponding rows of the database tables. A possible solution is to use a common primary key value so that, say, the row of key 101 in the footballers table and the row of key 101 in the players table correspond to the same domain object. Since the superclass table has a row for each row in the other tables, the primary keys are going to be unique across the tables if you use this scheme. An alternative is to let each table have its own primary keys and use foreign keys into the superclass table to tie the rows together.
The biggest implementation issue with Class Table Inheritance is how to bring the data back from multiple tables in an efficient manner. Obviously, making a call for each table isn’t good since you have multiple calls to the database. You can avoid this by doing a join across the various component tables; however, joins for more than three or four tables tend to be slow because of the way databases do their optimizations.
On top of this is the problem that in any given query you often don’t know exactly which tables to join. If you’re looking for a footballer, you know to use the footballer table, but if you’re looking for a group of players, which tables do you use? To join effectively when some tables have no data, you’ll need to do an outer join, which is nonstandard and often slow. The alternative is to read the root table first and then use a code to figure out what tables to read next, but this involves multiple queries.
Class Table Inheritance, Single Table Inheritance (278) and Concrete Table Inheritance (293) are the three alternatives to consider for inheritance mapping.
The strengths of Class Table Inheritance are
• All columns are relevant for every row so tables are easier to understand and don’t waste space.
• The relationship between the domain model and the database is very straightforward.
The weaknesses of Class Table Inheritance are
• You need to touch multiple tables to load an object, which means a join or multiple queries and sewing in memory.
• Any refactoring of fields up or down the hierarchy causes database changes.
• The supertype tables may become a bottleneck because they have to be accessed frequently.
• The high normalization may make it hard to understand for ad hoc queries.
You don’t have to choose just one inheritance mapping pattern for one class hierarchy. You can use Class Table Inheritance for the classes at the top of the hierarchy and a bunch of Concrete Table Inheritance (293) for those lower down.
A number of IBM texts refer to this pattern as Root-Leaf Mapping [Brown et al.].
Here’s an implementation for the sketch. Again I’ll follow the familiar (if perhaps a little tedious) theme of players and the like, using Inheritance Mappers (302) (Figure 12.9).
Figure 12.9. The generic class diagram of Inheritance Mappers (302).
Each class needs to define the table that holds its data and a type code for it.
class AbstractPlayerMapper...
abstract public String TypeCode {get;}
protected static String TABLENAME = "Players";
class FootballerMapper...
public override String TypeCode {
get {return "F";}
}
protected new static String TABLENAME = "Footballers";
Unlike the other inheritance examples, this one doesn’t have a overridden table name because we have to have the table name for this class even when the instance is an instance of the subclass.
If you’ve been reading the other mappings, you know the first step is the find method on the concrete mappers.
class FootballerMapper...
public Footballer Find(long id) {
return (Footballer) AbstractFind (id, TABLENAME);
}
The abstract find method looks for a row matching the key and, if successful, creates a domain object and calls the load method on it.
class Mapper...
public DomainObject AbstractFind(long id, String tablename) {
DataRow row = FindRow (id, tableFor(tablename));
if (row == null) return null;
else {
DomainObject result = CreateDomainObject();
result.Id = id;
Load(result);
return result;
}
}
protected DataTable tableFor(String name) {
return Gateway.Data.Tables[name];
}
protected DataRow FindRow(long id, DataTable table) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
return (results.Length == 0) ? null : results[0];
}
protected DataRow FindRow (long id, String tablename) {
return FindRow(id, tableFor(tablename));
}
protected abstract DomainObject CreateDomainObject();
class FootballerMapper...
protected override DomainObject CreateDomainObject(){
return new Footballer();
}
There’s one load method for each class which loads the data defined by that class.
class FootballerMapper...
protected override void Load(DomainObject obj) {
base.Load(obj);
DataRow row = FindRow (obj.Id, tableFor(TABLENAME));
Footballer footballer = (Footballer) obj;
footballer.club = (String)row["club"];
}
class AbstractPlayerMapper...
protected override void Load(DomainObject obj) {
DataRow row = FindRow (obj.Id, tableFor(TABLENAME));
Player player = (Player) obj;
player.name = (String)row["name"];
}
As with the other sample code, but more noticeably in this case, I’m relying on the fact that the ADO.NET data set has brought the data from the database and cached it into memory. This allows me to make several accesses to the table-based data structure without a high performance cost. If you’re going directly to the database, you’ll need to reduce that load. For this example you might do this by creating a join across all the tables and manipulating it.
The player mapper determines which kind of player it has to find and then delegates the correct concrete mapper.
class PlayerMapper...
public Player Find (long key) {
DataRow row = FindRow(key, tableFor(TABLENAME));
if (row == null) return null;
else {
String typecode = (String) row["type"];
if (typecode == bmapper.TypeCode)
return bmapper.Find(key);
if (typecode == cmapper.TypeCode)
return cmapper.Find(key);
if (typecode == fmapper.TypeCode)
return fmapper.Find(key);
throw new Exception("unknown type");
}
}
protected static String TABLENAME = "Players";
The update method appears on the mapper superclass
class Mapper...
public virtual void Update (DomainObject arg) {
Save (arg);
}
It’s implemented through a series of save methods, one for each class in the hierarchy.
class FootballerMapper...
protected override void Save(DomainObject obj) {
base.Save(obj);
DataRow row = FindRow (obj.Id, tableFor(TABLENAME));
Footballer footballer = (Footballer) obj;
row["club"] = footballer.club;
}
class AbstractPlayerMapper...
protected override void Save(DomainObject obj) {
DataRow row = FindRow (obj.Id, tableFor(TABLENAME));
Player player = (Player) obj;
row["name"] = player.name;
row["type"] = TypeCode;
}
The player mapper’s update method overrides the general method to forward to the correct concrete mapper.
class PlayerMapper...
public override void Update (DomainObject obj) {
MapperFor(obj).Update(obj);
}
private Mapper MapperFor(DomainObject obj) {
if (obj is Footballer)
return fmapper;
if (obj is Bowler)
return bmapper;
if (obj is Cricketer)
return cmapper;
throw new Exception("No mapper available");
}
The method for inserting an object is declared on the mapper superclass. It has two stages: creating new database rows and then using the save methods to update these blank rows with the necessary data.
class Mapper...
public virtual long Insert (DomainObject obj) {
obj.Id = GetNextID();
AddRow(obj);
Save(obj);
return obj.Id;
}
Each class inserts a row into its table.
class FootballerMapper...
protected override void AddRow (DomainObject obj) {
base.AddRow(obj);
InsertRow (obj, tableFor(TABLENAME));
}
class AbstractPlayerMapper...
protected override void AddRow (DomainObject obj) {
InsertRow (obj, tableFor(TABLENAME));
}
class Mapper...
abstract protected void AddRow (DomainObject obj);
protected virtual void InsertRow (DomainObject arg, DataTable table) {
DataRow row = table.NewRow();
row["id"] = arg.Id;
table.Rows.Add(row);
}
The player mapper delegates to the appropriate concrete mapper.
class PlayerMapper...
public override long Insert (DomainObject obj) {
return MapperFor(obj).Insert(obj);
}
To delete an object, each class deletes a row from the corresponding table in the database.
class FootballerMapper...
public override void Delete(DomainObject obj) {
base.Delete(obj);
DataRow row = FindRow(obj.Id, TABLENAME);
row.Delete();
}
class AbstractPlayerMapper...
public override void Delete(DomainObject obj) {
DataRow row = FindRow(obj.Id, tableFor(TABLENAME));
row.Delete();
}
class Mapper...
public abstract void Delete(DomainObject obj);
The player mapper again wimps out of all the hard work and just delegates to the concrete mapper.
class PlayerMapper...
override public void Delete(DomainObject obj) {
MapperFor(obj).Delete(obj);
}
Represents an inheritance hierarchy of classes with one table per concrete class in the hierarchy.
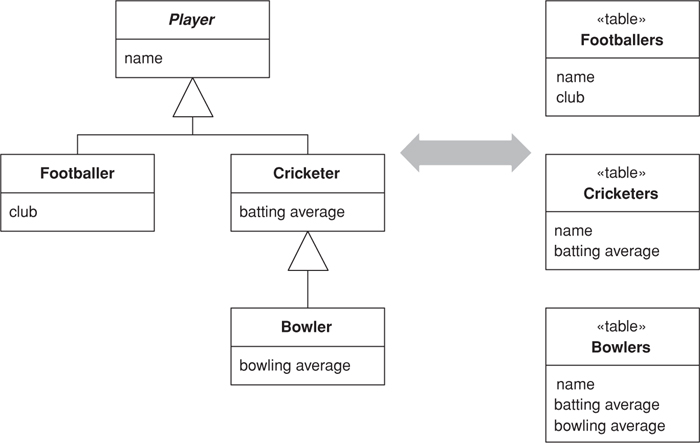
As any object purist will tell you, relational databases don’t support inheritance—a fact that complicates object-relational mapping. Thinking of tables from an object instance point of view, a sensible route is to take each object in memory and map it to a single database row. This implies Concrete Table Inheritance, where there’s a table for each concrete class in the inheritance hierarchy.
I’ll confess to having had some difficulty naming this pattern. Most people think of it as leaf oriented since you usually have one table per leaf class in a hierarchy. Following that logic, I could call this pattern leaf table inheritance, and the term “leaf” is often used for this pattern. Strictly, however, a concrete class that isn’t a leaf usually gets a table as well, so I decided to go with the more correct, if less intuitive term.
Concrete Table Inheritance uses one database table for each concrete class in the hierarchy. Each table contains columns for the concrete class and all its ancestors, so any fields in a superclass are duplicated across the tables of the subclasses. As with all of these inheritance schemes the basic behavior uses Inheritance Mappers (302).
You need to pay attention to the keys with this pattern. Punningly, the key thing is to ensure that keys are unique not just to a table but to all the tables from a hierarchy. A classic example of where you need this is if you have a collection of players and you’re using Identity Field (216) with table-wide keys. If keys can be duplicated between the tables that map the concrete classes, you’ll get multiple rows for a particular key value. Thus, you need a key allocation system that keeps track of key usage across tables; also, you can’t rely on the database’s primary key uniqueness mechanism.
This becomes particularly awkward if you’re hooking up to databases used by other systems. In many of these cases you can’t guarantee key uniqueness across tables. In this situation you either avoid using superclass fields or use a compound key that involves a table identifier.
You can get around some of this by not having fields that are typed to the superclass, but obviously that compromises the object model. As alternative is to have accessors for the supertype in the interface but to use several private fields for each concrete type in the implementation. The interface then combines values from the private fields. If the public interface is a single value, it picks whichever of the private values aren’t null. If the public interface is a collection value, it replies with the union of values from the implementation fields.
For compound keys you can use a special key object as your ID field for Identity Field (216). This key uses both the primary key of the table and the table name to determine uniqueness.
Related to this are problems with referential integrity in the database. Consider an object model like Figure 12.10. To implement referential integrity you need a link table that contains foreign key columns for the charity function and for the player. The problem is that there’s no table for the player, so you can’t put together a referential integrity constraint for the foreign key field that takes either footballers or cricketers. Your choice is to ignore referential integrity or use multiple link tables, one for each of the actual tables in the database. On top of this you have problems if you can’t guarantee key uniqueness.
Figure 12.10. A model that causes referential integrity problems for Concrete Table Inheritance.
If you’re searching for players with a select statement, you need to look at all tables to see which ones contain the appropriate value. This means using multiple queries or using an outer join, both of which are bad for performance. You don’t suffer the performance hit when you know the class you need, but you do have to use the concrete class to improve performance.
This pattern is often referred to as along the lines of leaf table inheritance. Some people prefer a variation where you have one table per leaf class instead of one table per concrete class. If you don’t have any concrete superclasses in the hierarchy, this ends up as the same thing. Even if you do have concrete superclasses the difference is pretty minor.
When figuring out how to map inheritance, Concrete Table Inheritance, Class Table Inheritance (285), and Single Table Inheritance (278) are the alternatives.
The strengths of Concrete Table Inheritance are:
• Each table is self-contained and has no irrelevant fields. As a result it makes good sense when used by other applications that aren’t using the objects.
• There are no joins to do when reading the data from the concrete mappers.
• Each table is accessed only when that class is accessed, which can spread the access load.
The weaknesses of Concrete Table Inheritance are:
• Primary keys can be difficult to handle.
• You can’t enforce database relationships to abstract classes.
• If the fields on the domain classes are pushed up or down the hierarchy, you have to alter the table definitions. You don’t have to do as much alteration as with Class Table Inheritance (285), but you can’t ignore this as you can with Single Table Inheritance (278).
• If a superclass field changes, you need to change each table that has this field because the superclass fields are duplicated across the tables.
• A find on the superclass forces you to check all the tables, which leads to multiple database accesses (or a weird join).
Remember that the trio of inheritance patterns can coexist in a single hierarchy. So you might use Concrete Table Inheritance for one or two subclasses and Single Table Inheritance (278) for the rest.
Here I’ll show you an implementation for the sketch. As with all inheritance examples in this chapter, I’m using the basic design of classes from Inheritance Mappers (302), shown in Figure 12.11.
Figure 12.11. The generic class diagram of Inheritance Mappers (302).
Each mapper is linked to the database table that’s the source of the data. In ADO.NET a data set holds the data table.
class Mapper...
public Gateway Gateway;
private IDictionary identityMap = new Hashtable();
public Mapper (Gateway gateway) {
this.Gateway = gateway;
}
private DataTable table {
get {return Gateway.Data.Tables[TableName];}
}
abstract public String TableName {get;}
The gateway class holds the data set within its data property. The data can be loaded up by supplying suitable queries.
class Gateway...
public DataSet Data = new DataSet();
Each concrete mapper needs to define the name of the table that holds its data.
class CricketerMapper...
public override String TableName {
get {return "Cricketers";}
}
The player mapper has fields for each concrete mapper.
class PlayerMapper...
private BowlerMapper bmapper;
private CricketerMapper cmapper;
private FootballerMapper fmapper;
public PlayerMapper (Gateway gateway) : base (gateway) {
bmapper = new BowlerMapper(Gateway);
cmapper = new CricketerMapper(Gateway);
fmapper = new FootballerMapper(Gateway);
}
Each concrete mapper class has a find method that returns an object given a key value.
class CricketerMapper...
public Cricketer Find(long id) {
return (Cricketer) AbstractFind(id);
}
The abstract behavior on the superclass finds the right database row for the ID, creates a new domain object of the correct type, and uses the load method to load it up (I’ll describe the load in a moment).
class Mapper...
public DomainObject AbstractFind(long id) {
DataRow row = FindRow(id);
if (row == null) return null;
else {
DomainObject result = CreateDomainObject();
Load(result, row);
return result;
}
}
private DataRow FindRow(long id) {
String filter = String.Format("id = {0}", id);
DataRow[] results = table.Select(filter);
if (results.Length == 0) return null;
else return results[0];
}
protected abstract DomainObject CreateDomainObject();
class CricketerMapper...
protected override DomainObject CreateDomainObject(){
return new Cricketer();
}
The actual loading of data from the database is done by the load method, or rather by several load methods: one each for the mapper class and for all its superclasses.
class CricketerMapper...
protected override void Load(DomainObject obj, DataRow row) {
base.Load(obj,row);
Cricketer cricketer = (Cricketer) obj;
cricketer.battingAverage = (double)row["battingAverage"];
}
class AbstractPlayerMapper...
protected override void Load(DomainObject obj, DataRow row) {
base.Load(obj, row);
Player player = (Player) obj;
player.name = (String)row["name"];
class Mapper...
protected virtual void Load(DomainObject obj, DataRow row) {
obj.Id = (int) row ["id"];
}
This is the logic for finding an object using a mapper for a concrete class. You can also use a mapper for the superclass: the player mapper, which it needs to find an object from whatever table it’s living in. Since all the data is already in memory in the data set, I can do this like so:
class PlayerMapper...
public Player Find (long key) {
Player result;
result = fmapper.Find(key);
if (result != null) return result;
result = bmapper.Find(key);
if (result != null) return result;
result = cmapper.Find(key);
if (result != null) return result;
return null;
}
Remember, this is reasonable only because the data is already in memory. If you need to go to the database three times (or more for more subclasses) this will be slow. It may help to do a join across all the concrete tables, which will allow you to access the data in one database call. However, large joins are often slow in their own right, so you’ll need to do some benchmarks with your own application to find out what works and what doesn’t. Also, this will be an outer join, and as well as slowing the syntax it’s nonportable and often cryptic.
The update method can be defined on the mapper superclass.
class Mapper...
public virtual void Update (DomainObject arg) {
Save (arg, FindRow(arg.Id));
}
Similar to loading, we use a sequence of save methods for each mapper class.
class CricketerMapper...
protected override void Save(DomainObject obj, DataRow row) {
base.Save(obj, row);
Cricketer cricketer = (Cricketer) obj;
row["battingAverage"] = cricketer.battingAverage;
}
class AbstractPlayerMapper...
protected override void Save(DomainObject obj, DataRow row) {
Player player = (Player) obj;
row["name"] = player.name;
}
The player mapper needs to find the correct concrete mapper to use and then delegate the update call.
class PlayerMapper...
public override void Update (DomainObject obj) {
MapperFor(obj).Update(obj);
}
private Mapper MapperFor(DomainObject obj) {
if (obj is Footballer)
return fmapper;
if (obj is Bowler)
return bmapper;
if (obj is Cricketer)
return cmapper;
throw new Exception("No mapper available");
}
Insertion is a variation on updating. The extra behavior is creating the new row, which can be done on the superclass.
class Mapper...
public virtual long Insert (DomainObject arg) {
DataRow row = table.NewRow();
arg.Id = GetNextID();
row["id"] = arg.Id;
Save (arg, row);
table.Rows.Add(row);
return arg.Id;
}
Again, the player class delegates to the appropriate mapper.
class PlayerMapper...
public override long Insert (DomainObject obj) {
return MapperFor(obj).Insert(obj);
}
Deletion is very straightforward. As before, we have a method defined on the superclass:
class Mapper...
public virtual void Delete(DomainObject obj) {
DataRow row = FindRow(obj.Id);
row.Delete();
}
and a delegating method on the player mapper.
class PlayerMapper...
public override void Delete (DomainObject obj) {
MapperFor(obj).Delete(obj);
}
A structure to organize database mappers that handle inheritance hierarchies.
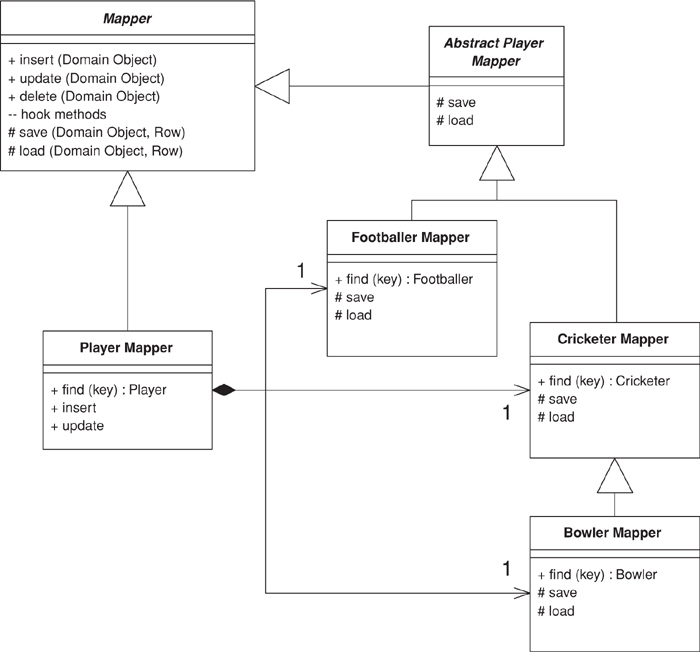
When you map from an object-oriented inheritance hierarchy in memory to a relational database you have to minimize the amount of code needed to save and load the data to the database. You also want to provide both abstract and concrete mapping behavior that allows you to save or load a superclass or a subclass.
Although the details of this behavior vary with your inheritance mapping scheme (Single Table Inheritance (278), Class Table Inheritance (285), and Concrete Table Inheritance (293)) the general structure works the same for all of them.
You can organize the mappers with a hierarchy so that each domain class has a mapper that saves and loads the data for that domain class. This way you have one point where you can change the mapping. This approach works well for concrete mappers that know how to map the concrete objects in the hierarchy. There are times, however, where you also need mappers for the abstract classes. These can be implemented with mappers that are actually outside of the basic hierarchy but delegate to the appropriate concrete mappers.
To best explain how this works, I’ll start with the concrete mappers. In the sketch the concrete mappers are the mappers for footballer, cricketer, and bowler. Their basic behavior includes the find, insert, update, and delete operations.
The find methods are declared on the concrete subclasses because they will return a concrete class. Thus, the find method on BowlerMapper should return a bowler, not an abstract class. Common OO languages can’t let you change the declared return type of a method, so it’s not possible to inherit the find operation and still declare a specific return type. You can, of course, return an abstract type, but that forces the user of the class to downcast—which is best to avoid. (A language with dynamic typing doesn’t have this problem.)
The basic behavior of the find method is to find the appropriate row in the database, instantiate an object of the correct type (a decision that’s made by the subclass), and then load the object with data from the database. The load method is implemented by each mapper in the hierarchy which loads the behavior for its corresponding domain object. This means that the bowler mapper’s load method loads the data specific to the bowler class and calls the superclass method to load the data specific to the cricketer, which calls its superclass method, and so on.
The insert and update methods operate in a similar way using a save method. Here you can define the interface on the superclass—indeed, on a Layer Supertype (475). The insert method creates a new row and then saves the data from the domain object using the save hook methods. The update method just saves the data, also using the save hook methods. These methods operate similarly to the load hook methods, with each class storing its specific data and calling the superclass save method.
This scheme makes it easy to write the appropriate mappers to save the information needed for a particular part of the hierarchy. The next step is to support loading and saving an abstract class—in this example, a player. While a first thought is to put appropriate methods on the superclass mapper, that actually gets awkward. While concrete mapper classes can just use the abstract mapper’s insert and update methods, the player mapper’s insert and update need to override these to call a concrete mapper instead. The result is one of those combinations of generalization and composition that twist your brain cells into a knot.
I prefer to separate the mappers into two classes. The abstract player mapper is responsible for loading and saving the specific player data to the database. This is an abstract class whose behavior is just used only by the concrete mapper objects. A separate player mapper class is used for the interface for operations at the player level. The player mapper provides a find method and overrides the insert and update methods. For all of these its responsibility is to figure out which concrete mapper should handle the task and delegate to it.
Although a broad scheme like this makes sense for each type of inheritance mapping, the details do vary. Therefore, it’s not possible to show a code example for this case. You can find good examples in each of the inheritance mapping pattern sections: Single Table Inheritance (278), Class Table Inheritance (285), and Concrete Table Inheritance (293).
This general scheme makes sense for any inheritance-based database mapping. The alternatives involve such things as duplicating superclass mapping code among the concrete mappers and folding the player’s interface into the abstract player mapper class. The former is a heinous crime, and the latter is possible but leads to a player mapper class that’s messy and confusing. On the whole, then, its hard to think of a good alternative to this pattern.