10.3Using the Text Search via SQL
As is the case with the majority of functions in SAP HANA, you can invoke the text search via SQL. To do this, you must use a SELECT statement with the keyword CONTAINS keyword, which enables you to call the manifold variants of the text search. The standard syntax is as follows:
FROM <table or view>
WHERE CONTAINS (<columns>,<search request>,<parameter>);
The following example provides an initial idea of how you can use the CONTAINS clause for a fuzzy search:
FUZZY(0.8));
Here, we run a search for airlines whose names are sufficiently similar to the search request, 'lusthansa'. Although the search request contains two errors (the search term starts with a lowercase letter and contains one incorrect letter), the system returns the expected data record, “Lufthansa.”
The following sections discuss the definition of similarity in detail. At this point, you should know that the FUZZY(0.8) parameter defines the threshold value, where a value between 0.7 and 0.8 is usually a good standard value to obtain results that are relatively similar to the search request. In addition to the threshold value, the FUZZY parameter provides many other setting options.
Apart from its use with the FUZZY parameter, you can use the CONTAINS statement in two other variants: EXACT and LINGUISTIC. In searches with the addition EXACT, the system searches for exact matches for the search request with entire words (based on the tokenization of the text in the database). EXACT also represents the default value if you don’t enter any parameter. In this case, you can also use wildcards such as '*' in the search request. In contrast to a LIKE in standard SQL, the CONTAINS clause allows you to perform searches across multiple columns. The following example shows an exact search for airlines whose names or web addresses contain “Airlines” or “Airways” or end with “.com”.
OR Airways OR *.com', EXACT)
This example is also useful for demonstrating the effects of a missing full text index. If no full text index exists for the carrname column, the names won’t be split into words (tokens); consequently, there will be no exact match between the search request 'Airlines' and an entry such as “United Airlines”.
If you run an additional analysis of the word stems via a text analysis (see Section 10.5), the LINGUISTIC parameter allows you to obtain additional results in which only the word stems must match.
[»]Limitations to the Text Search in SAP HANA SQL
As already mentioned, you can use SQL for text searches in SAP HANA. However, there are currently a couple limitations with regard to the supported combinations:
-
You can apply the CONTAINS clause only to text searches in tables of the column store.
-
You can’t apply the text search function to calculated attributes of a view.
This book focuses primarily on the subject of fuzzy searches because it’s difficult to implement an intuitively usable search function with the exact or linguistic search within an ABAP application. In both cases, fewer results are often found than in a classic ABAP input help.
10.3.1Fuzzy Search
The following section describes how you can use the fuzzy search function for a simple search run across one or several columns of a table or view. Section 10.3.2 and Section 10.3.3 will then provide details about the specific search variants that use additional semantic information about the data.
The examples used in this context involve the airline names (CARRNAME column in table SCARR) and the locations from the flight schedule (CITYFR and CITYTO columns in table SPFLI). For this purpose, a full text index is defined for each attribute using DDIC, as described in Section 10.2.
Searching across Multiple Columns
The CONTAINS statement allows you to specify multiple columns to be considered during the search run. The following example indicates a search in the flight schedule to “Tokio”:
'Tokio', fuzzy(0.8))
The result will contain all flights departing from and arriving in Tokyo, even though the spelling of the city’s name deviates slightly (in some languages, this is the common spelling of this city), as shown in Figure 10.6. Instead of the individual column names, you can also use an asterisk (*) to run the search across all columns that support a text search.
If you want to run the search across multiple columns in different tables that are linked through foreign key dependencies, you can either write an SQL join or use a view.
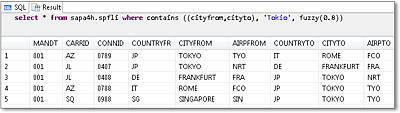
Figure 10.6Fuzzy Search across Multiple Columns
To include the airline name in addition to the departure and destination names in the flight schedule search, you can use a simple Core Data Services (CDS) view, DEMO_CDS_SCARR_SPFLI, as illustrated in Figure 10.7. The name of the appropriate database view is DEMO_CDS_JOIN.
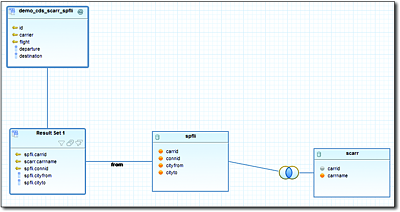
Figure 10.7CDS View as the Basis for a Fuzzy Search via Two Tables
In a view, the fuzzy search via SQL is carried out in the same manner as within a table. Thus, the result of the following SELECT statement contains all flights from or to Singapore, as well as all flights operated by Singapore Airlines:
Similarly, you can also use other view types such as attribute views.
Special Functions
Special scalar functions are available that enable you to retrieve additional information for individual data records in the result set. SAP HANA currently provides the score(), highlighted(), and snippets() functions, as described in the following sections.
The score() function provides information about the degree of similarity between the search result and the search request. This value ranges between 0 and 1, with higher values indicating a higher degree of similarity. Normally, the function is used for sorting the search results so that results with a higher degree of similarity are displayed at the top of the list:
fuzzy(0.8)) ORDER BY score() desc;
[ ! ]Difference between SCORE() and Threshold Values for Searches
The return value of the score() function doesn’t directly correspond to the threshold value in the fuzzy() statement. Consequently, it’s conceivable to obtain search results in which the value of the score() function is lower than the transferred threshold value.
In searches through longer texts, it’s particularly useful for users if the exact found location of a search request is highlighted in the text. For this purpose, SAP HANA SQL offers the highlighted() and snippets() functions. If the former is used, the system returns the entire text with the found location highlighted; if snippets() is used, only an extract of the text around the found location is returned. Note that there is no difference between the two with regard to shorter texts such as the airline names, for example.
When using these functions, you must specify the column as shown in the following example:
WHERE CONTAINS( carrname, 'airways', fuzzy(0.8))
ORDER BY score() desc;
The result contains the found location enclosed by markups that use the HTML tag <b>...</b> (see Figure 10.8). If you plan to implement your own type of search result display, you may want to replace these tags accordingly.
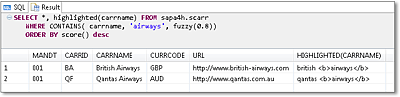
Figure 10.8Highlighting the Found Location Using the HIGHLIGHTED() Function
[»]Limitations of HIGHLIGHTED() and SNIPPETS()
The highlighted() and snippets() functions can only highlight hits within one column. If you run a search across multiple columns, you can query the value of individual attributes only. Thus, if no found location exists in a column, you won’t find any highlight in the value of the function. Moreover, you only get the first found location in a document and not all occurrences.
Other Parameterizations
The parameterization of the fuzzy search hasn’t yet been discussed in detail, and it’s beyond the scope of this book to describe all options and variants related to this topic. However, you should be familiar with some of these aspects, which are essential to using fuzzy search correctly. These involve, first and foremost, the similarCalculationMode and textSearch parameters. You must transfer these types of parameters by means of a character string in which you use commas to separate individual parameters, as shown in the following example:
CONTAINS(carrname, 'lusthansa',
fuzzy(0.8, 'similarCalculationMode=search'));
The similarCalculationMode parameter enables you to check how the fuzzy score (i.e., the degree of similarity) is calculated. In this context, you must distinguish between two scenarios. In a text comparison, the request and the text in the database as a whole should be similar; however, in a normal search run, it should be sufficient that the search request is part of the text. For this reason, you use the compare parameter value for text comparisons, and you use search for search runs. The following section describes how you can manually create a specific full text index and discusses the differences between the parameter values.
In addition, the textSearch parameter is important for the description of some of the more complex search options in the following sections; this parameter switches between separate technical implementations in SAP HANA. The details of this parameter and its use are described in Section 10.3.2.
10.3.2Synonyms and Noise Words
Lists of synonyms and stop words (also called noise words) represent an option to implement a more intelligent search. To do this, you must store the additional data in tables of a predefined structure, and the names of these configuration tables must be included in the search requests.
Let’s first consider the use of noise words. Names of airlines, for example, frequently contain the word “air,” which, compared to other words, presumably plays a minor role in search runs. For this reason, we want to include this term in the list of stop words. This doesn’t mean that the word will be completely ignored or even that the search will terminate, but merely that the system will attach less importance to the term.
The structure of the configuration table is shown in Table 10.2.
|
Column |
SQL Data Type |
Example |
|---|---|---|
|
stopword_id |
VARCHAR(32) |
“1“ |
|
list_id |
VARCHAR(32) |
“airline” |
|
language_code |
CHAR(2) |
|
|
term |
NVARCHAR(200) |
“Air” |
Table 10.2Structure of the Configuration for Stop Words
Here, the stopword_id field represents the unique key. The list_id column allows for storing multiple individual lists for different usage scenarios in the table. In addition, you can store words that are relevant only for specific languages (this value has been left empty in this example of airline names).
Figure 10.9 shows a table called ZA4H_BOOK_STOPW in the DDIC with a matching structure.
Now the sample data record from Table 10.2 is entered into this table. If you want to include the list of stop words in a fuzzy search, you must use the stopwordTable and stopwordListId parameters. The example in Listing 10.2 shows the search for the terms “air” and “united” and uses the previously generated stop word table.
OR united', fuzzy(0.8, 'textsearch=compare,
stopwordTable=ZA4H_BOOK_STOPW, stopwordListId=airline,
similarCalculationMode=search')) ORDER BY score();
Listing 10.2Fuzzy Search with Stop Word Table
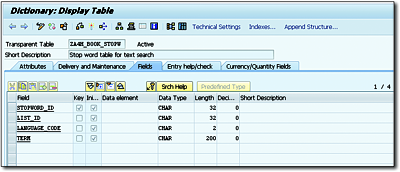
Figure 10.9Stop Word Table in DDIC
The textsearch=compare parameter is necessary if you want to use these search variants. The result contains the entry “United Airlines”, but not “Air Canada”, for example, because due to the stop word table, a lower degree of importance has been attached to the term “Air”.
This describes how you can use synonyms in your search requests. To do this, you must map those terms you want to treat as synonyms in a configuration table (term mapping). As is the case with stop words, you can store these terms based on individual languages and in multiple lists. In addition, you can store a weighting between 0 and 1 to indicate the extent to which the finding of a synonym is supposed to reduce the value of similarity. Table 10.3 shows the structure of the corresponding configuration table.
|
Column |
SQL Data Type |
Example |
|---|---|---|
|
mapping_id |
VARCHAR(32) |
“1“ |
|
list_id |
VARCHAR(32) |
“airline” |
|
language_code |
CHAR(2) |
|
|
term_1 |
NVARCHAR(255) |
“Airways” |
|
term_2 |
NVARCHAR(255) |
“Airlines” |
|
weight |
DECIMAL |
0.8 |
Table 10.3Structure of the Configuration for Synonyms
[»]Client-Dependent Stop Word and Synonym Lists
Although the table structures for stop words and synonyms don’t have any client column in SAP HANA, you can add such a table in ABAP tables and then simply put a view on the tables by taking this column from the projection list.
Similar to the previous example, we create an ABAP table ZA4H_BOOK_TMAP with the structure from Table 10.3 and enter the sample value from Table 10.3. The example in Listing 10.1 describes the search for the term, “United Airways”.
'united airways', fuzzy(0.8, 'textsearch=compare,
termMappingTable=ZA4H_BOOK_TMAP, termMappingListId=airline,
similarCalculationMode=search')) ORDER BY score();
Listing 10.3Fuzzy Search with List of Synonyms
The specification of the mapping table via the termMappingTable and termMappingListId parameters causes the fuzzy search to analyze the list of synonyms so that the result contains the expected entry, “United Airlines”.
In addition to terms with identical meaning (i.e., synonyms), you can use the mapping mechanism to include hypernyms and hyponyms; that is, more general or more concrete terms, which can be particularly useful with large, unstructured texts. This enables you, for example, to recognize the occurrence of the hypernym “airline” when searching for the term “Lufthansa” in a text. To achieve this, you have to choose a low value (e.g., 0.2) as the weight (WEIGHT).
You also can use a combination of stop words and synonyms in a search request; in that case, the system calculates the synonymous variants first, followed by the stop words.
10.3.3Searching across Date Fields and Address Data
Finally, this section describes some of the more comprehensive options we introduced in Section 10.1.2 so that you can get an idea of how to use them. This section focuses on fuzzy searches in date fields as well as on the search for ZIP codes. Unfortunately, both options can’t be used directly from within ABAP because they require specific data types and column definitions. These kinds of native developments in the database require additional design concepts.
For this reason, we will manually create a table for our scenarioin a separate database schema. This table will store customer addresses as well as the date and time of the last booking from within the ABAP tables where native SAP HANA types were used. We’ll then run a fuzzy search across this data in which the semantic characteristics of dates and ZIP codes will be used.
For the sake of convenience, the scenario is implemented here exclusively via the SQL console in SAP HANA Studio. Of course, you can also execute these native SQL statements from within an ABAP program through the ADBC interface.
The table is created via SQL, as shown in Listing 10.4. Here, you must replace <schema> with your own database schema.
mandt NVARCHAR(3) DEFAULT '000' NOT NULL ,
id NVARCHAR(8) DEFAULT '00000000' NOT NULL ,
name NVARCHAR(25) DEFAULT '' NOT NULL ,
city NVARCHAR(25) DEFAULT '' NOT NULL ,
postcode NVARCHAR(10) FUZZY SEARCH MODE 'postcode',
lastbooking DATE
);
Listing 10.4Creating a Table with Customer Addresses and Booking Dates via SQL
For the date, we use the native data type DATE, and specify a fuzzy search mode for the ZIP code. Both these settings can’t be used in the same manner for a DDIC table.
After that, the table is populated based on the data from tables SCUSTOM and SBOOK using the SQL statement in Listing 10.5.
SELECT c.mandt, c.id, c.name, c.city, c.postcode,
to_date( MIN ( b.order_date ) ) as lastbooking
FROM sbook as b INNER JOIN scustom as c
ON b.mandt = c.mandt and b.customid = c.id
GROUP BY c.mandt, c.id, c.name, c.city, c.postcode;
Listing 10.5Populating the Database Table with Data
In a fuzzy search for a date field, the degree of similarity is impacted by the time difference between the date values and by typical typing errors in date entries. You don’t need to create a full text index for this kind of fuzzy search because a fragmentation into tokens (words) isn’t needed here.
In Listing 10.6, we search for customers whose last booking was carried out on or around November 13, 2015. The maxDateDistance=3 parameter specifies the maximum difference in days. In addition, the system also returns results that contain an incorrect number, for example, or in which the day and month have been exchanged.
WHERE CONTAINS(lastbooking, '2015-11-13',
FUZZY(0.9, 'maxDateDistance=3'))
ORDER BY score() DESC;
Listing 10.6Fuzzy Search for a Date
As described in Section 10.1.2, in the fuzzy search for a ZIP code, the degree of similarity is determined through the geographical proximity, which is indicated by the internal structure of the ZIP codes. Listing 10.7 searches for codes close to ‘69190’.
WHERE CONTAINS( postcode, '69190', fuzzy(0.7))
ORDER BY score() desc;
Listing 10.7Fuzzy Search for ZIP Codes
Figure 10.10 shows the result of a combined search for customers close to Walldorf, Germany (ZIP code 69190), whose last booking was carried out on or around January 31, 2016.
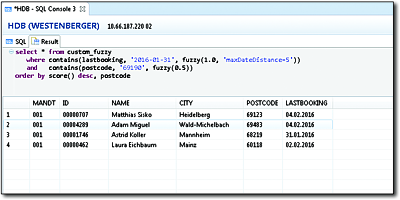
Figure 10.10Fuzzy Search for a Date and ZIP Code
In addition to ZIP codes, you can also run fuzzy searches for house numbers containing specific characteristics such as number ranges (e.g., “8–10”) or letters (“8a”).