
The techniques for obtaining confidence intervals for estimates of relative risks, attributable risks and odds ratios are described. These can come either from an incidence study, where, for example, the frequency of a congenital malformation at birth is compared in two defined groups of mothers, or from a case-control study, where a group of patients with the disease of interest (the cases) is compared with another group of people without the disease (the controls).
The methods of obtaining confidence intervals for standardised disease ratios and rates in studies of incidence, prevalence, and mortality are described. Such rates and ratios are commonly calculated to enable appropriate comparisons to be made between study groups after adjustment for confounding factors like age and sex. The most frequently used standardised indices are the standardised incidence ratio (SIR) and the standardised mortality ratio (SMR).
Some of the methods given here are large sample approximations but will give reasonable estimates for small studies. Appropriate design principles for these types of study have to be adhered to, since confidence intervals convey only the effects of sampling variation on the precision of the estimated statistics. They cannot control for other errors such as biases due to the selection of inappropriate controls or in the methods of collecting the data.
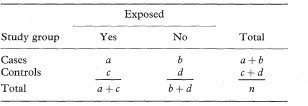
Suppose that the incidence or frequency of some outcome is assessed in two groups of individuals defined by the presence or absence of some characteristic. The data from such a study can be presented as in Table 7.1.
Table 7.1 Classification of outcome by group characteristic
The outcome probabilities in exposed and unexposed individuals are estimated from the study groups by A/(A + C) and B/(B + D) respectively. An estimate, R, of the relative risk (or risk ratio) from exposure is given by the ratio of these proportions, so that
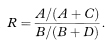
Confidence intervals for the population value of R can be constructed through a logarithmic transformation.1 The standard error of loge R is
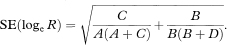
This can also be written as
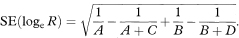
A 100(1 – α)% confidence interval for R is found by first calculating the two quantities
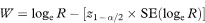
and
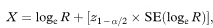
where Z1 – α/2 is the appropriate value from the standard Normal distribution for the 100(1 – α/2) percentile found in Table 18.1. The confidence interval for the population value of R is then given by exponentiating W and X as
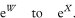
Table 7.2 Prevalence of Helicobacter pylori infection in preschool children according to mother’s history of ulcer2

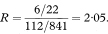
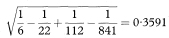
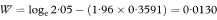
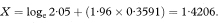
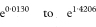
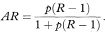

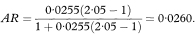
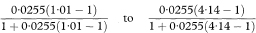
Suppose that groups of cases and controls are studied to assess exposure to a suspected causal factor. The data can be presented as in Table 7.3.
An approximate estimate of the relative risk for the disease associated with exposure to the factor can be obtained from a case-control study through the odds ratio,6 the relative risk itself not being directly estimable with this study design. The odds ratio (OR) is given as
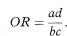
Table 7.3 Classification of exposure among cases and controls
A confidence interval for the population odds ratio can be constructed using several methods which vary in their ease and accuracy. The method described here (sometimes called the logit method) was devised by Woolf7 and is widely recommended as a satisfactory approximation. The exception to this is when any of the numbers a, b, c, or d is small, when a more accurate but complex procedure should be used if suitable computer facilities are available. Further discussion and comparison of methods can be found in Breslow and Day.8 The use of the following approach, however, should not in general lead to any misinterpretation of the results.
The logit method uses the Normal approximation to the distribution of the logarithm of the odds ratio (loge OR) in which the standard error is
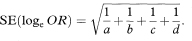
A 100(1 – α)% confidence interval for OR is found by first calculating the two quantities
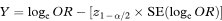
and
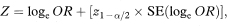
where z1 – α/2 is the appropriate value from the standard Normal distribution for the 100(1 – α/2) percentile (see Table 18.1). The confidence interval for the odds ratio in the population is then obtained by exponentiating Y and Z to give
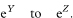
Table 7.4 ABO non-secretor state for 114 patients with spondyloarthropathies and 334 controls9

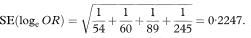
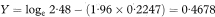
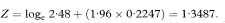
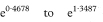
If there are more than two levels of exposure, one can be chosen as a baseline with which each of the others is compared. Odds ratios and their associated confidence intervals are then calculated for each comparison in the same way as shown previously for only two levels of exposure.
A combined estimate is sometimes required when independent estimates of the same odds ratio are available from each of K sets of data—for example, in a stratified analysis to control for confounding variables.
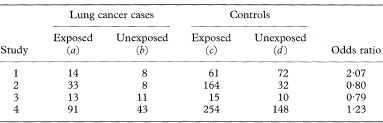
One approach is to use the logit method to give a pooled estimate of the odds ratio (ORlogit) and then derive a confidence interval for the odds ratio in a similar way to that for a single 2 × 2 table. The logit combined estimate (ORlogit) is defined by
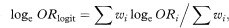
where ORi = aidi/bici is the odds ratio in the ith table, ai, bi, ci, and di are the frequencies in the ith 2 × 2 table, ni = ai + bi + ci + di, the summation ∑ is over i = 1 to K for the K tables and wi is defined as
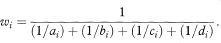
The standard error of loge (ORlogit) is given by
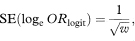
where w = ∑wi.
A 100(1 – α)% confidence interval for ORlogit can then be found by calculating
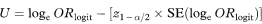
and
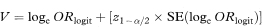
where z1 – α/2 is the appropriate value from the standard Normal distribution for the 100(1 – α/2) percentile (see Table 18.1).
The confidence interval for the population value of ORlogit is given by exponentiating U and V as
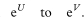
It is important to mention that, before combining independent estimates, there should be some reassurance that the separate odds ratios do not vary markedly, apart from sampling error.6,8 Hence, a test for homogeneity of the odds ratio over the strata is recommended. Further discussion of homogeneity tests, methods for the calculation of 95% confidence intervals and a worked example are given in Breslow and Day.8 The logit method is unsuitable if any of the numbers ai, bi, ci or di is small. This will happen, for example, with increasing stratification, and in such cases a more complex exact method is available.8
An alternative approach which gives a consistent estimate of the common odds ratio with large numbers of small strata is to use the Mantel–Haenszel pooled estimate of the odds ratio (ORM – H) which is given by
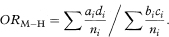
A method of calculating confidence intervals for this estimate is described in Armitage and Berry.6 It is more complex, however, than the previous approach which extends the single case-control technique shown earlier. For samples of reasonable size both methods will usually give similar values for the combined odds ratio and confidence interval.
The scope of a stratified analysis for case-control studies can be extended using a logistic regression model.8 This also enables the joint effects of two or more factors on disease risk to be assessed (see chapter 8).
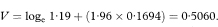
Table 7.5 Exposure to passive smoking among female lung cancer cases and controls in four studies10
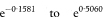
If each of n cases of a disease is matched to one control to form n pairs and each individual’s exposure to a suspected causal factor is recorded the data can be presented as in Table 7.6. For this type of study an approximate estimate (in fact the Mantel–Haenszel estimate) of the relative risk of the disease associated with exposure is again given by the odds ratio which is now calculated as
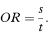
An exact 100(1 – α)% confidence interval for the population value of OR is found by first determining a confidence interval for s (the number of case-control pairs with only the case exposed).6 Conditional on the sum of the numbers of “discordant” pairs (s + t) the number s can be considered as a Binomial variable with sample size s + t and proportion s/(s + t).
The 100(1 – α)% confidence interval for the population value of the Binomial proportion can be obtained from tables based on the Binomial distribution (for example, Lentner11). If this confidence interval is denoted by AL to AU the 100(1 – α)% confidence interval for the population value of OR is then given by
Table 7.6 Classification of matched case-control pairs by exposure
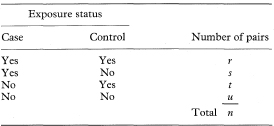
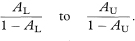
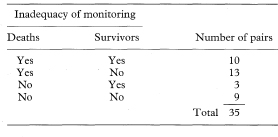
Table 7.7 Inadequacy of monitoring in hospital of deaths and survivors among 35 matched pairs of asthma patients12
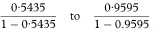
Sometimes each case is matched with more than one control. The odds ratio is then given by the Mantel–Haenszel estimate as
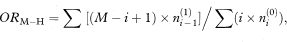
where M is the number of matched controls for each case, 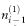 is the number of matched sets in which the case and i – 1 of the matched controls are exposed, ni(0) is the number of sets in which the case is unexposed and i of the matched controls are exposed, and the summation is from i = 1 to M.
is the number of matched sets in which the case and i – 1 of the matched controls are exposed, ni(0) is the number of sets in which the case is unexposed and i of the matched controls are exposed, and the summation is from i = 1 to M.
A confidence interval for the population value of ORM – H can be derived by one of the methods in Breslow and Day.8 These authors also explain the calculation of a confidence interval for the odds ratio estimated from a study with a variable number of matched controls for each case.8
If x is the observed number of individuals with the outcome (or disease) of interest, and Py the number of person-years at risk, the incidence rate is given by IR = x/Py.
The 100(1 – α)% confidence interval for the population value of IR can be calculated by first assuming x to have a Poisson distribution, and finding its related confidence interval.3 Table 18.3 gives 90%, 95% and 99% confidence intervals for x in the range 0 to 100. It also indicates how to obtain approximate confidence intervals for x taking values greater than 100. Denote this confidence interval by xL to xU. Assuming Py is a constant with no sampling variation, the 100(1 – α)% confidence interval for IR is given by
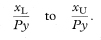
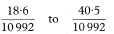
If O is the observed number of incident cases (or deaths) in a study group and E the expected number based on, for example, the age-specific disease incidence (or mortality) rates in a reference or standard population the standardised incidence ratio (SIR) or standardised mortality ratio (SMR) is O/E. This is usually called the indirect method of standardisation because the specific rates of a standard population are used in the calculation rather than the rates of the study population. The expected number is calculated as
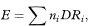
where ni is the number of individuals in age group i of the study group, DRi is the death rate in age group i of the reference population, and ∑ denotes summation over all age groups.
The 100(1 – α)% confidence interval for the population value of O/E can be found by first regarding O as a Poisson variable and finding its related confidence interval14 (see Table 18.3). Denote this confidence interval by OL to OU.
The 100(1 – α)% confidence interval for the population value of O/E is then given by
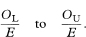
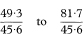
Sometimes the standardised incidence ratio (or standardised mortality ratio) is multiplied by 100 and then the same must be done to the figures describing the confidence interval.
Let O1 and O2 be the observed numbers of cases (deaths) in two study groups and E1 and E2 the two expected numbers. It is sometimes appropriate to calculate the ratio of the two standardised incidence ratios (standardised mortality ratios) O1/E1 and O2/E2 and find a confidence interval for this ratio. Although there are known limitations to this procedure if the age-specific incidence ratios within each group to the standard are not similar, these are not serious in usual applications.14 Again O1 and O2 can be regarded as Poisson variables and a confidence interval for the ratio O1/O2 is obtained as described by Ederer and Mantel.16 The procedure recognises that conditional on the total of O1 + O2 the number O1 can be considered as a Binomial variable with sample size O1 + O2 and proportion O1/(O1 + O2). The 100(1 – α)% confidence interval for the population value of the Binomial proportion can be obtained from tables based on the Binomial distribution (for example, Lentner11). Denote this confidence interval by AL to AU. The 100(1 – α)% confidence interval for the population value of O1/O2 can now be found as
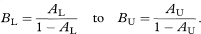
The 100(1 – α)% confidence interval for the population value of the ratio of the two standardised incidence ratios (standardised mortality ratios) is then given by
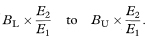
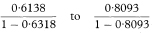
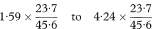
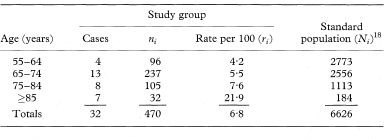
If a rate rather than a ratio is required the standardised rate (SR) in a study group is given by
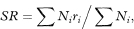
where Ni is the number of individuals in age group i of the reference population, ri is the disease rate in age group i of the study group, and ∑ indicates summation over all age groups. This is usually known as the direct method of standardisation because the specific rates of the population being studied are used directly. If ni is the number of individuals in age group i of the study group the standard error of SR can be estimated as
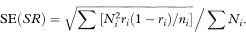
This can be approximated by
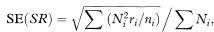
assuming that the rates ri are small.6
The 100(1 – α)% confidence interval for the population value of SR is then given by
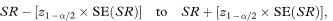
where Z1 – α/2 is the appropriate value from the Normal distribution for the 100(1 – α/2) percentile (see Table 18.1).
Note that if the rates ri are given as rates per 10m (for example, m = 3 gives a rate per 1000), rather than as proportions, then the standardised rate (SR) is also a rate per 10m and SE(SR) as given above needs to be multiplied by 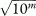 .
.
Table 7.8 Paget’s disease of bone in British male migrants to Australia by age group17
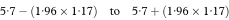
Many of the methods described here and others are also given with examples by Rothman and Greenland.19 Several alternative methods of constructing confidence intervals for standardised rates and ratios have been developed.20–23 Further discussion of confidence limits for the relative risk can be found in Bailey.24 In particular, a method based on likelihood scores is evaluated by Gart and Nam25 (see also chapter 10). A useful review of approximate confidence intervals for relative risks and odds ratios is given by Sato.26
1 Katz D, Baptista J, Azen SP, Pike MC. Obtaining confidence intervals for the risk ratio in cohort studies. Biometrics 1978;34:469–74.
2 Brenner H, Rothenbacher D, Bode G, Adler G. Parental history of gastric or duodenal ulcer and prevalence of Helicobacter pylori infection in preschool children: population based study. BMJ 1998;316:665.
3 Daly LE. Confidence limits made easy: interval estimation using a substitution method. Am J Epidemiol 1998;147:783–90.
4 Greenland S. Re: “Confidence limits made easy: Interval estimation using a substitution method”. Am J Epidemiol 1999;149:884.
5 Walter SD. The estimation and interpretation of attributable risk in health research. Biometrics 1976;32:829–49.
6 Armitage P, Berry G. Statistical methods in medical research. 3rd edn. Oxford: Blackwell, 1994: 438, 509, 512, 514.
7 Woolf B. On estimating the relationship between blood group and disease. Ann Hum Genet 1955;19:251–3.
8 Breslow NE, Day NE. Statistical methods in cancer research. Volume 1—The analysis of case-control studies. Lyon: International Agency for Research on Cancer, 1980: 124–146, 169–182, 192–246.
9 Shinebaum R, Blackwell CC, Forster PJG, Hurst NP, Weir DM, Nuki G. Nonsecretion of ABO blood group antigens as a host susceptibility factor in the spondyloarthropathies. BMJ 1987;294:208–10.
10 Wald NJ, Nanchahal K, Thompson SG, Cuckle HS. Does breathing other people’s tobacco smoke cause lung cancer? BMJ 1986;293:1217–22.
11 Lentner C, ed. Geigy scientific tables. Volume 2. 8th edn. Basle: Ciba-Geigy, 1982:89–102.
12 Eason J, Markowe HLJ. Controlled investigation of deaths from asthma in hospitals in the North East Thames region. BMJ 1987;294:1255–8.
13 Nunn AJ, Mulder DW, Kamali A, Ruberantwari A, Kengeya-Kayondo J-F, Whitworth J. Mortality associated with HIV-1 infection over five years in a rural Ugandan population: cohort study. BMJ 1997;315:767–71.
14 Breslow NE, Day NE. Statistical methods in cancer research. Volume 2—The design and analysis of cohort studies. Oxford: Oxford University Press, 1988: 69, 93.
15 Roman E, Beral V, Carpenter L, et al. Childhood leukaemia in the West Berkshire and the Basingstoke and North Hampshire District Health Authorities in relation to nuclear establishments in the vicinity. BMJ 1987;294:597–602.
16 Ederer F, Mantel N. Confidence limits on the ratio of two Poisson variables. Am J Epidemiol 1974;100:165–7.
17 Gardner MJ, Guyer PB, Barker DJP. Radiological prevalence of Paget’s disease of bone in British migrants to Australia. BMJ 1978;i:1655–7.
18 Barker DJP, Clough PWL, Guyer PB, Gardner MJ. Paget’s disease of bone in 14 British towns. BMJ 1977;i:1181–3.
19 Rothman KJ, Greenland S. Modern epidemiology. 2nd edn. Philadelphia: Lippincott-Raven, 1998; chapters 14–16.
20 Ulm K. A simple method to calculate the confidence interval of a standardized mortality ratio (SMR). Am J Epidemiol 1990;131:373–5.
21 Sahai H, Khurshid A. Confidence intervals for the mean of a Poisson distribution: a review. Biom J 1993;7:857–67.
22 Fay MP, Feuer EJ. Confidence intervals for directly standardized rates: a method based on the gamma distribution. Statist Med 1997;16:791–801.
23 Kulkarni PM, Tripathi RC, Michalek JE. Maximum (max) and mid-p confidence intervals and p values for the standardized mortality and incidence ratios. Am J Epidemiol 1998;147:83–6.
24 Bailey BJR. Confidence limits to the risk ratio. Biometrics 1987;43:201–5.
25 Gart JJ, Nam J. Approximate interval estimation of the ratio of binomial parameters: A review and corrections for skewness. Biometrics 1988;44:323–38.
26 Sato T. Confidence intervals for effect parameters common in cancer epidemiology. Environ Health Perspect 1990;87:95–101.