In this chapter, we will examine application forensics. This includes files that require specific forensic techniques, web-based application forensics, e-mail forensics, and database forensics. Fortunately, all of these various application issues still depend on the basic forensics methodologies you have been learning throughout this book.
In previous chapters, we have discussed various file systems, and even briefly discussed file structure. In this section, we will be discussing files that are part of the operating systems. These include things like the Windows registry, index.dat, and related files.
The registry is a repository of everything in Windows. It has all the settings, files you have opened, desktop settings, network information, and more. It is built in a hierarchical structure, consisting of five hives. Given that the Windows registry contains so much information, it is clearly of interest in a forensic investigation. Microsoft describes the registry as follows:
A central hierarchical database used in the Microsoft Windows family of operating systems to store information necessary to configure the system for one or more users, applications, and hardware devices.
The registry contains information that Windows continually references during operation, such as profiles for each user, the applications installed on the computer, and the types of documents that each can create, property sheet settings for folders and application icons, what hardware exists on the system, and the ports that are being used.1
As you will see in this section, there is a great deal of forensic information one can gather from the registry. That is why it is important to have a good, thorough understanding of registry forensics. But first, how do you get to the registry? The usual path is through the tool regedit. In Windows 7 and Server 2008, you select Start and then Run and then type regedit. In Windows 8, you will have to go to the applications list and select All Apps and then find regedit. Most forensics tools provide a means for examining the registry as well.
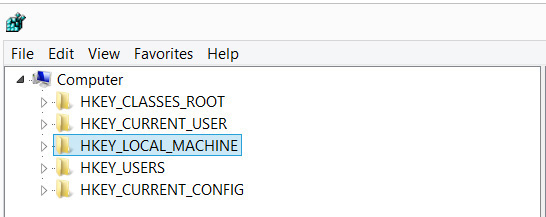
The registry is organized into five sections referred to as hives .Each of these sections contains specific information that can be useful to you. The five hives are described here:
• HKEY_CLASSES_ROOT (HKCR) This hive stores information about drag-and-drop rules, program shortcuts, the user interface, and related items.
• HKEY_CURRENT_USER (HKCU) This will be very important to any forensic investigation. It stores information about the currently logged-on user, including desktop settings, user folders, etc.
• HKEY_LOCAL_MACHINE (HKLM) This can also be important to a forensic investigation. It contains those settings common to the entire machine, regardless of the individual user.
• HKEY_USERS (HKU) This hive is critical to forensics investigations. It has profiles for all the users, including their settings.
• HKEY_CURRENT_CONFIG (HCU) This hive contains the current system configuration. This might also prove useful in your forensic examinations.
You can see the registry and these five hives in Figure 11-1.
Figure 11-1 The registry hives
All registry keys contain a value associated with them called LastWriteTime. This value indicates when this registry value was last changed. Rather than a standard date/time, this value is stored as a FILETIME structure. A FILETIME structure represents the number of 100 nanosecond intervals since January 1, 1601. Clearly, this is important forensically.
Let’s turn our attention to some specific registry entries that can be very useful forensically.
One of the first things most forensic analysts learn about the Windows registry is that they can find out what USB devices have been connected to the suspect machine. The registry key HKEY_LOCAL_MACHINE\System\ControlSet\Enum\UBSTOR lists USB devices that have been connected to the machine. A criminal often will move evidence to an external device and take it with them. This could indicate to you that there are devices you need to find and examine. This registry setting will tell you about the external drives that have been connected to this system. You can see this in Figure 11-2.

Figure 11-2 USB devices in the registry

NOTE Just before the UBSTOR key is a key named USB. You might suspect that would be the place to look, but you would be wrong. That key contains information about the actual USB bus within the machine.
This key is frequently used by malware to remain persistent on the target system. It shows those programs that are configured to start automatically when Windows starts—for example: HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run. You can see this in Figure 11-3.

Figure 11-3 Autostart
Obviously, you should expect to see legitimate programs in this registry key. However, if there is anything you cannot account for, this could indicate malware.
The key HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\ComDlg32\LastVisitedMRU will show recent sites that have been visited. The data is in hex format, but you can see the text translation when using regedit, and you will probably be able to make out the site visited just looking at regedit. You can see this registry key in Figure 11-4.
Figure 11-4 Last visited sites
Recent documents can be found at the following key: HKCU\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs. This can be quite forensically important, particularly in cases involving financial data or intellectual property. This key allows you to determine what documents have been accessed on that computer. You can see this key in Figure 11-5.

Figure 11-5 Recent documents
As you can see, it is first divided into document types. Then, once you select the type, you can see the recent documents of that type that have been accessed. In Figure 11-5, I selected docx as the type and then one specific document. You can see the document name in the image.
This is a very important registry key for any forensic examination. An intruder who breaks into a computer might install software on that computer for various purposes, such as recovering deleted files or creating a back door. He will then most likely delete the software he used. Or, an employee who is stealing data might install steganography software so he can hide the data. He will subsequently uninstall that software. This key lets you see all the software that has been uninstalled from this machine: HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall. You can see the key in Figure 11-6.

Figure 11-6 Uninstalled software
This key contains recent settings for the network adapter, such as system IP address and default gateway for the respective network adapters. Each GUID subkey refers to a network adapter. This will tell you all about every network adapter on the suspect machine: HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces\GUID. You can see this registry key in Figure 11-7.

Figure 11-7 Network adapters
Think, for just a moment, about connecting to a WiFi network. You probably had to enter some passphrase. But you did not have to enter that next time you connected to that WiFi network, did you? Obviously, that information is stored somewhere on the computer. But where? You guessed it—it is stored in the registry. When an individual connects to a wireless network, SSID (Service Set Identification) is logged as a preferred network connection. This information can be found in the registry in the HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Profiles\ key. You can see this in Figure 11-8.

Figure 11-8 Individual network adapter
This can be quite important forensically. It can verify that a suspect was connecting to a specific WiFi network and even when they connected.
If the user tells Internet Explorer (IE) to remember passwords, they are stored in the registry and you can retrieve them. The following key holds these values: HKCU\Software\Microsoft\Internet Explorer\IntelliForms\SPW. Note that in some versions of Windows, it will be \IntelliForms\Storage 1. You can see this key in Figure 11-9.

Figure 11-9 Stored passwords
Passwords are encrypted by the operating system. However, tools are available that can decrypt these values, such as Protected Storage PassView by NirSoft or Helix’s incident response tools.
We have discussed the Windows swap file in previous chapters. It is essentially a special file in the hard drive used to store data temporarily so it can be retrieved by RAM quickly. The Windows swap file used to end in a .swp extension, but since Windows XP, it is now pagefile.sys. It is typically found in the Windows root directory. The swap file is a binary file. Given that the swap file is used to augment RAM, it is often referred to as virtual memory. Since it is a physical file, you can analyze it as you would any other file.
This is an amazing file from the point of view of forensics. It stores pretty much everything the user does using Windows Explorer or Internet Explorer. That includes cookies, websites visited, and even any files opened. Even if the person erases his history, it is still possible to retrieve it if they were using Internet Explorer. Even if a file is on a USB device but was opened on the suspect machine, index.dat would contain a record of that file.
You can download a number of tools from the Internet that will allow you to retrieve and review the index.dat file. Here are a few:
• http://www.eusing.com/Window_Washer/Index_dat.htm
• http://www.acesoft.net/index.dat%20viewer/index.dat_viewer.htm
• http://download.cnet.com/Index-dat-Analyzer/3000-2144_4-10564321.html
You can see Window Washer in Figure 11-10.

Figure 11-10 Window Washer and index.dat
Of course, many of the more advanced forensic software suites will also analyze the index.dat file for you.
Many files in any operating system might contain data you can examine. For example, spool files, such as the print spool, can contain data. Print spools usually operate like a queue. That means the first data put in is the first data processed. Old data is not automatically flushed. It remains in the spool until that space is needed. In Windows, the print spool is found at %SystemRoot%\SYSTEM32\SPOOL\PRINTERS. This is a file like any other and can be analyzed using the file-carving techniques we discussed earlier in this book.
Temporary files can also contain valuable information. Windows will have a temporary directory where these are stored. This is usually found at %SystemRoot%\TEMP. Again, these are just files, like any other, and can be examined with any file-carving utility.

EXAM TIP The CCFP refers to these types of files as either traces or application debris. They are essentially the byproducts of other applications.
Obviously, memory is not a file per se; however, there is data in memory. Since memory is volatile, this is referred to as volatile memory analysis. Volatile memory analysis requires you to get a physical dump of the memory. This can be done with many forensic tools. Let’s take a look at one easy-to-use tool: RamCapture64 from Belkasoft (http://forensic.belkasoft.com/en/ram/download.asp). When you first launch the tool, it will prompt you for a location to put the output data. This is shown in Figure 11-11.

Figure 11-11 RamCapture output location
Then, just click the Capture button and the tool will do the rest. When the process is done, a .mem file will be generated, as seen in Figure 11-12.

Figure 11-12 RamCapture file
This can be examined using one of the file-carving utilities discussed earlier in this book.
EXAM TIP In the case of virtual machines,VMware allows you to simply suspend the virtual machine and use the .vmem file as a memory image.
Unlike with traditional hard drive forensics, you don’t need to calculate a hash before data acquisition. Due to the volatile nature of running memory, the imaging process involves taking a snapshot of a “moving target.” Memory is constantly changing, so computing the hash would be difficult anyway.
To produce digital data from a live system as evidence in court, it is essential to justify the validity of the acquired memory data. One common approach is to acquire volatile memory data in a dump file for offline examination. A dump is a complete copy of every bit of memory or cache recorded in permanent storage or printed on paper. You can then analyze the dump electronically or manually in its static state.
Maintaining data consistency is a problem with live system forensics in which data is not acquired at a unified moment and is thus inconsistent. If a system is running, it is impossible to freeze the machine states in the course of data acquisition. Even the most efficient method introduces a time difference between the moment you acquire the first bit and the moment you acquire the last bit. For example, the program may execute function A at the beginning of the memory dump and execute function B at the end.
The data in the dump may correspond to different execution steps somewhere between function A and function B. Because you didn’t acquire the data at a unified moment, data inconsistency is inevitable in the memory dump.
We have been discussing live memory as if it were a single amorphous entity. In fact, there are actually two types of memory:
• Stack (S) Memory in the stack segment is allocated to local variables and parameters within each function. This memory is allocated based on the last-in, first-out (LIFO) principle. When the program is running, program variables use the memory allocated to the stack area again and again. This segment is the most dynamic area of the memory process. The data within this segment is discrepant and influenced by the program’s various function calls.
• Heap (H) Dynamic memory for a program comes from the heap segment. A process may use a memory allocator such as malloc (this is a C/C++ command to allocate memory) to request dynamic memory. When this happens, the address space of the process expands. The data in the heap area can exist between function calls. The memory allocator may reuse memory that has been released by the process. Therefore, heap data is less stable than the data in the data segment.
When a program is running, the code, data, and heap segments are usually placed in a single contiguous area. The stack segment is separated from the other segments. It expands within the memory-allocated space. Indeed, the memory comprises a number of processes of the operating system or the applications it is supporting. Memory can be viewed as a large array that contains many segments for different processes. In a live system, process memory grows and shrinks, depending on system usage and user activities.
EXAM TIP The CCFP won’t ask you details regarding types of memory, but for your forensic career, it is useful to know the difference between stack and heap.
By default, an object inherits permissions from its parent object, either at the time of creation or when it is copied or moved to its parent folder. The only exception to this rule occurs when you move an object to a different folder on the same volume. In this case, the original permissions are retained.2
• Same partition/drive:
• Copy/paste – Files/folders will inherit the rights of the folder they are being copied to.
• Cut/paste (move) – Files/folders will retain the original permissions (even if the files/folders have the “Include inheritable permissions…”/“ Allow inheritable permissions from parent to propagate to this object…” checked). This is because when the files/folders are on the same partition, they don’t actually move; rather, the “pointers to their locations” are updated.
• Different partition:
• Copy/paste OR cut/paste files/folders will inherit the rights of the folder they are being copied to.
EXAM TIP The CCFP will definitely ask you about file permissions, particularly when files are copied or moved.
A great many cybercrimes involve the World Wide Web. In this section, we will examine web forensics. We have already discussed IP addresses and protocols in previous chapters. In this chapter, we will discuss common web attacks and how to analyze them. In Chapter 8, we discussed some of these attacks. In this section, we will review what was discussed in Chapter 8, but add more detail and discuss some attacks not covered in Chapter 8. We will also be discussing how to forensically detect these attacks.
Before we delve deeper into web attacks, we should discuss how web applications are designed. It is often useful to take an historical approach to explaining this. When the Web was first invented, it consisted simply of HTML (Hypertext Markup Language) documents. This provided static, unchanging, and relatively simple web pages. Eventually, CGI (Common Gateway Interface) was created to allow the HTML page to initiate an application running on a server so the application could accomplish more robust tasks for the web page.
In the mid-1990s, a number of technologies emerged. JavaScript provided a scripting language for websites to enhance functionality. CSS (Cascading Style Sheets) provided a means to improve the layout and design of web pages. Eventually, robust programming languages that would run in a web browser emerged. These included Perl Scripts, Java, ASP (Active Server Pages), ASP.Net, and others. This allowed fully functioning and complex programs to be implemented on the Web. This advance led to the explosion of e-commerce, online banking, and other conveniences we take for granted today. However, it also led to the Web becoming the most popular target for hackers.
SQL injection is a very common web attack. It is based on inserting SQL (Structured Query Language) commands into text boxes, often the user name and password text fields on the login screen. To understand how SQL injection works, you have to first understand the basics of how a login screen is programmed and to understand SQL.
Obviously, a login screen requires the user enter a user name and password and that user name and password have to be validated. Mostly likely, they are validated by checking a database that has a table of users to see if the password matches that user. Relational databases are the most common sort of databases, and they all use SQL. Most of the common databases you are familiar with such as Oracle, Microsoft SQL, MySQL, PostGres, etc., are all relational databases. Modern websites use databases to store data, including login information.
SQL is relatively easy to understand—in fact, it looks a lot like English. There are commands like SELECT to get data, INSERT to put data in, and UPDATE to change data. In order to log in to a website, the web page has to query a database table to see if that user name and password are correct. The general structure of SQL is this:

or

Conditions:
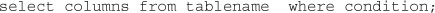
For example:
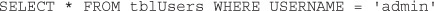
This statement retrieves all the columns or fields from a table named tblUsers where the user name is admin.
The problem arises because the website is not written in SQL. It is written in some programming language such as PHP, ASP.Net, etc. If you just place SQL statements directly in the web page code, an error will be generated. The SQL statements in the programming code for the website have to use quotation marks to separate the SQL code from the programming code. A typical SQL statement might look something like this:

If you enter user name “jdoe” and the password “password,” this code produces the SQL command:
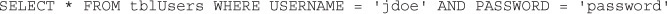
This is fairly easy to understand, even for nonprogrammers. And it is effective. If there is a match in the database, that means the user name and password match. If no records are returned from the database, that means there was no match, and this is not a valid login.
SQL injection is basically about subverting this process. The idea is to create a statement that will always be true. For example, you enter in ‘or ‘1’ = ‘1 into the user name and password boxes. This will cause the program to create this query:
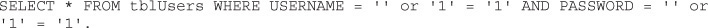
So you are telling the database and application to return all records where user name and password are blank or if 1 = 1. The fact is that 1 always equals 1, so this will work. Now if the programmer wrote the login code properly, this will not work. But in all too many cases, it does work. And then the intruder has logged into your web application and can do whatever any authorized user can do.
The example of SQL injection we just described is the most basic version of SQL injection. SQL injection can be much more advanced than this, and can do quite a bit more than this. In fact, SQL injection is only limited by your own knowledge of SQL. If you wish to delve further into this topic, I suggest the following resources:
• http://www.w3schools.com/sql/sql_injection.asp
• http://www.techkranti.com/2010/03/sql-injection-step-by-step-tutorial.html
• My own YouTube video on this topic: http://www.youtube.com/watch?v=HbjMqs_cN-A
So how do you detect SQL injection? The most important step is to check out the logs for the firewall, web server, and database to look for telltale SQL injection commands, such as ‘or ‘1’ = ‘1. This is only one possible SQL injection technique—there are many others. But there is also some good news about this crime for forensic investigations. The goal of this attack is to gain access to the target site and to get data. Therefore, this is very difficult to do if spoofing your IP address. In other words, if you see evidence of this attack in the logs, the source IP address is likely to be a real IP address. It could be a free WiFi hotspot at some public location, but it will likely be a real IP address, allowing you to at least partially track down the perpetrator.
NOTE This sort of attack is easily prevented by good programming practices. One technique is to simply filter whatever the user types in before processing it. Unfortunately, as late as the writing of this book, I routinely find websites still vulnerable to this attack when I conduct penetration tests/security audits.
This attack is closely related to SQL injection. It involves entering data other than what was intended, and it depends on the web programmer not filtering input. The perpetrator finds some area of a website that allows users to type in text that other users will see and then injects client-side script into those fields instead.
NOTE Before I describe this particular crime, I would point out that the major online retailers such as eBay and Amazon.com are not susceptible to this attack. They do filter user input.
To better understand this process, let’s look at a hypothetical scenario. Let’s assume ABC online book sales has a website. In addition to shopping, users can have accounts with credit cards stored, post reviews, etc. The attacker first sets up an alternative web page that looks as close to the real one as possible. Then the attacker goes to the real ABC online book sales website and finds a rather popular book. He goes to the review section, but instead of typing in a review, he types in this:

Now when users go to that book, this script will redirect them to the fake site, which looks a great deal like the real one. The attacker then can have the website tell the user that their session has timed out and to please log in again. That would allow the attacker to gather a lot of accounts and passwords. That is only one scenario, but it illustrates the attack.
The way to detect this forensically is two-fold. The most obvious is finding any script embedded in the web page. Another indication would be in the web server logs. Remember that earlier in this book when we discussed network forensics, we mentioned web server messages. The 300 series messages are redirect messages.
Many websites use what is called a cookie to store data. A cookie is basically a text file that has some information. One common thing they store is simply the user name and the fact that the user is currently logged in. For example, when you log in to a social media site, it might write a cookie that has your user name, the time of login, how long before your session expires, and the fact that you are logged in. It probably won’t store the actual password. Unfortunately, this still leads to possible attacks.
A few years ago, one intrepid attacker created a tool called Firesheep. It was an add-on for the Mozilla Firefox browser. What this tool did was sniff the WiFi network the attacker was connected to, listening for a cookie from Facebook. This cookie did not contain a password, but it did contain the user name and that they were logged in. Firesheep would then show that user’s profile in a window next to the Firefox browser. The attacker could, at will, simply click the profile in question and be logged on to Facebook as that user. This also worked for other social media sites like Twitter. You can see Firesheep in Figure 11-13. Accounts have been redacted and I used my own Facebook Fan Page image rather than an actual user’s.
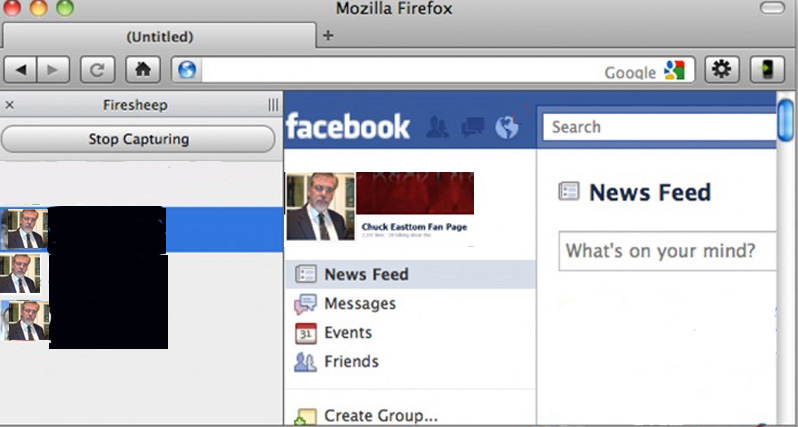
Figure 11-13 Firesheep
As far as computer crimes are concerned, hijacking someone’s social media page is certainly less serious than some other crimes. However, it is a crime, and as you can see, it is relatively easy to perpetrate. The immediate evidence of this crime is tampering with the social media page, often to post items that would be considered embarrassing to the actual owner of that social media page.
This technique is rather primitive. It is based on websites that don’t protect files. The attacker types in the complete URL to a specific file in order to download it directly, without even logging into the site. Fortunately, improvements in web programming are making this attack less common. However, if a site is vulnerable to this attack, it is easy to perform. It also may not leave any trace in any logs unless the web server is logging every single request.
When a web user takes advantage of a weakness with SQL by entering values they should not, it is known as a SQL injection attack. Similarly, when the user enters values that query XML (known as XPath) with values that take advantage of exploits, it is known as an XML injection attack . XPath works similarly to SQL, except that it does not have the same levels of access control, and taking advantage of weaknesses within can return entire documents.
E-mail forensics is a critical area to explore. A variety of crimes involve e-mail. Spam, cyber stalking, fraud, phishing—these are all e-mail–based cybercrimes. In this section, we will first examine how e-mail works and then look at how to forensically analyze it.
Before we can begin delving into e-mail forensics, we have to understand how e-mail works. The sender will first type an e-mail message using their preferred e-mail software (i.e., Outlook, Eudora, etc.). The e-mail is sent first to that sender’s e-mail server. Usually, that will be the company server or ISP server. That e-mail server will then send the e-mail to the recipient’s e-mail server. When the recipient logs on to their e-mail program, they can retrieve the e-mail from their server. You can see this in Figure 11-14.
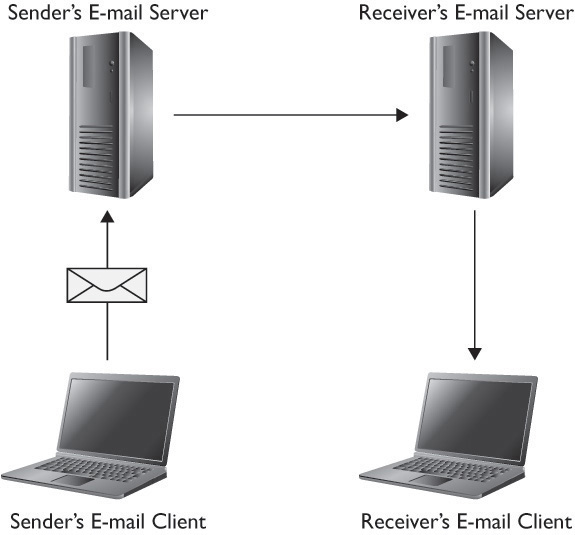
Figure 11-14 How e-mail works
This process is important forensically. E-mail evidence can be found at any of these locations. It could be on the sender’s computer, the sender’s e-mail server, the recipient’s e-mail server, or the recipient’s computer. When investigating crimes that have an e-mail component, it is important to check all four sources. Obviously, a subpoena may be needed to get e-mail records from an Internet service provider. It also is possible that they have purged their records; however, they may still have backups of the server that would have records.
It is also important to keep in mind that the content of e-mail can be very important even in noncomputer crime cases. Given how common e-mail communications are, it should no surprise to you to find that criminals often communicate via e-mail. Some crimes, like cyber stalking, usually include an e-mail element. Other crimes, such as drug trafficking and terrorism, can utilize e-mail communication. In financial crimes, such as insider trading, as well as in civil litigation, e-mail is often a critical piece of evidence. Keep in mind that the sender and perhaps even the recipient may have deleted the e-mail, but it could still reside on an e-mail server or in the backup media for that server.
Earlier in this book, we introduced you to basic e-mail protocols. Before we go deeper into e-mail forensics, it is necessary to refresh your memory on this topic. The first e-mail protocol we will look at is Simple Mail Transfer Protocol (SMTP) that is used to send e-mail. This typically operates on port 25. There is also secure SMTP that is encrypted with either SSL or TLS, and that protocol operates on port 465. For many years, Post Office Protocol version 3 (POP3) was the only means for retrieving e-mail. However, in recent years, there has been an improvement on POP3. That improvement is IMAP. Internet Message Access Protocol operates on port 143. One advantage of IMAP over POP3 is that it allows the client to download only the headers to the machine and then the user can choose which messages to fully download. This is particularly useful for smartphones.
The process of spoofing e-mail involves making an e-mail message appear to come from someone or somewhere other than the real sender or location. The e-mail sender uses a software tool that is readily available on the Internet to cut out his or her IP address and replace it with someone else’s address. However, the first machine to receive the spoofed message records the sending machine’s real IP address. Thus, the header contains both the faked ID and the real IP address (unless, of course, the perpetrator is clever enough to have also spoofed their IP address).
Many websites will let someone send an e-mail and choose any “from” address they want. Here are just a few:
• http://sendanonymousemail.net/
• http://theanonymousemail.com/
Even though e-mail can be spoofed, it is still important to forensically examine it. In many cases, including cyber stalking, civil litigation, etc., it is less common to find spoofed e-mails.
One of the first things to learn about is the headers. The header for an e-mail message tells you a great deal about the e-mail. The standard for e-mail format, including headers, is RFC 2822. It is important that all e-mail use the same format. That is why you can send an e-mail from Outlook on a Windows 8 PC and the recipient can read it from their Hotmail account on an Android phone (that runs Linux for an operating system!). All e-mail programs use the same format, regardless of what operating system they run on.
Make sure that any e-mail you offer as evidence includes the message, any attachments, and the full e-mail header. The header keeps a record of the message’s journey as it travels through the communications network. As the message is routed through one or more mail servers, each server adds its own information to the message header. Each device in a network has an IP address that identifies the device and provides a location address. A forensic investigator may be able to identify the IP addresses from a message header and use this information to determine who sent the message.
Obviously, the content of the e-mail itself could be evidence of a crime. In the case of child pornography sent via e-mail, cyber stalking, or in civil cases where the e-mail has incriminating messages, the message itself (along with attachments) can be compelling evidence. But it is important to also examine the message header.
Consider the specifications for the e-mail format given in RFC 2822:
NOTE RFCs are “request for comments,” and they are the standards for various network protocols established by the Internet Engineering Task Force (IETF).
• The message header must include at least the following fields:
• From : The e-mail address, and optionally, the name of the sender.
• Date : The local time and date the message was written.
• The message header should include at least the following fields:
• Message-ID : Also an automatically generated field.
• In-Reply-To : Message-ID of the message that this is a reply to. Used to link related messages together.
RFC 3864 describes message header field names. Common header fields for e-mail include:
• To : The e-mail address.
• Subject : A brief summary of the topic of the message.
• Cc : Carbon copy; send a copy to secondary recipients.
• Bcc : Blind carbon copy; addresses added to the SMTP delivery list that are not shown to other recipients.
• Content-Type : Information about how the message is to be displayed, usually a MIME type.
• Precedence : Commonly with values “bulk,” “junk,” or “list”; used to indicate that automated “vacation” or “out of office” responses should not be returned for this mail, e.g., to prevent vacation notices from being sent to all other subscribers of a mailing list.
• Received : Tracking information generated by mail servers that have previously handled a message, but in reverse order (last handler first).
• References : Message-ID of the message that this is a reply to.
• Reply-To : Address that should be used to reply to the message.
• Sender : Address of the actual sender acting on behalf of the author listed in the From header.
The headers are to be read chronologically from bottom to top—the oldest are at the bottom. Every new server on the way adds its own message. One of the first issues is to see who sent the e-mail. Following is the header information from an e-mail I sent to myself from one e-mail address I have to another for testing purposes. I have bolded important items.
X-Apparently-To: chuck@chuckeasttom.com via 98.138.83.191; Tue, 22 Apr 2014 16:59:18 +0000
Received-SPF: none (domain of cec-security.com does not designate permitted sender hosts)
X-YMailISG:HnqC9kgWLDurJ7R3t2xKTOhqmJuptmbl1HkGtHSTNu8dS4M2 xMKy4SogkFof.zujJKGroSdCwC0.LFH.rc17CxJb63OYRkuNQ6ta6bq.bEyd v.RryfHe_1hU04UU72BFufYJErl3.QimX4CNkGll14ty4kr2y1LRIUtEm8mf BdtspKAQc.hk75UDi0wsbQtwBZa_T.fpQ5cyh4.GaK07lxFjpWOoTTnBGui_yD6GTlz6eiDfAzAgx0tlhq0k48_bwZFZ6JsixZe6UUtRJyXE2u5.Z5QFfZ18r2hxQqIonP1owUr0rK8WMcBHxHLRaXbpm.Bf1.o3Szsrd2epjLLmpv_ULeKz yIjibV7zj9TFOlHr.67lQ5sJLavMqec.pki2oaZQBn1ULP27O7EgOsFN6ziM jwgXNFY3Vvufj6mYWfzexU7b_8.BZo4fEj2cO1753a4HBMpKrDFMiZxfUphn
e68YjMgmPmXQlDKPKCvMMa3XRKYnaYsBqc0GDyQKKJ7GHQAxssCeIu4OZdS
9tRQOgY8JLHdtsX92wUD6kF4dG6ZfTvZc1eej50xNVWYZZxc17G6ZiA5O62luf4dd7VlAUstwF.AXsFyA7kNTOtTKVAdSPZxMJAEuF.qZfUWUrkPoENBe4gG 50NQ1v4yXkkqVn7w4Jx2ZRkIa6pgJ3jVyvvBgssS6jIEZeOw9.ef1juige6C ikofU6EM3d7FF141Sx6CpRaCbX5IrD7rlYzdXkPmiFUgje914L_kchQSa9QXJcBeM4cj6JqUf6QIgA6MBuSpX_eqkOFWNYHVJmsaszRbqeZftVvhjPoO_uE8 5s7XU41AZJ8J7xxUZv4DZUhqlVCPm2w4SOSpV5U49AbXSGQlDIjrIw.bxbso GAXGqDuvAsa_F_rnsZOsxPBQKB2zQ8Pc1fSqhNnC6XbiWWuYD4AsSwe08_UJ
IrpYCjW7oZ2J6NT3nFsKyMW3IOjKXJ.4I6._jpVoJa54TOs6.MrPAWLBWVzl KA0rE9hxg7f2J8uXBJgDA5HKslV0JfmUF9oujCmMHdDQ9gM_NydiVsDKoxmg MkHrN4j5CnMOFZllM4mcr2ivKlw521Hn.sbYoNprDng508eTNVFl.75Q774b YD46b.llTJfsEslkRGzasm09sCWA12Z8WlSxVx1SJzGi7WbZ5PefsU1PsFcM 6Wdj.hL.gHvYBNXFP6oh39ABEkTP39hf86cy8VWp_Q2yWmz.z5WSfSd6jFyR gQLH4W0KlygKRet.njaffo0qoYYayDa.pX43OGucAeOIfPFGn.Iv5cioLSM2 73sWC06iSYEZnz0UgfdYkwHRb_d_ctEti3f2Akkxs81TG.HIj3OlACvd68I8 nhdCpdBWxs7msndHtk5ViyTBu5SfpgI2SBRBxcshMIo0jINl6c2KAYM-X-Originating-IP: [173.201.192.105]
Authentication-Results: mta1010.biz.mail.gq1.yahoo.com from=cec-security.com; domainkeys=neutral (no sig); from=cec-security.com; dkim=neutral (no sig) Received: from 127.0.0.1 (EHLO p3plsmtpa06-04.prod.phx3.secureserver.net) (173.201.192.105)
by mta1010.biz.mail.gq1.yahoo.com with SMTP; Tue, 22 Apr 2014 16:59:17 +0000
Received: from cecmain ([173.64.206.194])
by p3plsmtpa06-04.prod.phx3.secureserver.net with
id t4zF1n00X4CB0Ed014zG7A; Tue, 22 Apr 2014 09:59:17 -0700
From: “Chuck Easttom” <ceasttom@cec-security.com>
To: “Chuck Easttom” <chuck@chuckeasttom.com>
Subject: Test Message
Date: Tue, 22 Apr 2014 11:59:15 -0500
Message-ID: <00a001cf5e4c$31fc56a0$95f503e0$@cec-security.com>
MIME-Version: 1.0
Content-Type: multipart/mixed;
boundary=“----=_NextPart_000_00A1_01CF5E22.492C6920”
X-Mailer: Microsoft Outlook 15.0
Content-Language: en-us
Thread-Index: Ac9eTC6Yocf6q6bIQPe+s7XJm2yRVg==
X-MS-TNEF-Correlator:
0000000042B94DC204F2AC4A836F291A4ABFD7EDC4E32200
The Received from line shows the e-mail server used to send the e-mail. The second line shows the IP address of the user who sent the e-mail using this server. The actual From field can be forged, so you want to look at the Received from field. Date shows the date and time the message was composed. X-Mailer tells you the e-mail client the sender used.
Return path and Reply to are the same, and this is where replies will be sent. Seeing any mismatches between Received from, From, Return path, and Reply is an indication this e-mail might be spoofed. It is also usually a good idea to trace any IP addresses. For example, an e-mail that purports to be from your local bank in Tampa, Florida, but that actually comes from an IP address in China is likely to be spoofed.
The simplest method that works in Outlook 2010 and Outlook 2013 is to first select a message and open it, as shown in Figure 11-15.

Figure 11-15 Outlook message
Then, with the message open, select File and then Properties, as shown in Figure 11-16.

Figure 11-16 Outlook message properties
Then you will see the headers, shown in Figure 11-17.

Figure 11-17 Outlook headers
If you are working with Yahoo! e-mail, first open the message. Then select Actions and then Full Headers, as shown in Figure 11-18.
Figure 11-18 Yahoo! headers
Then you can examine the header information.
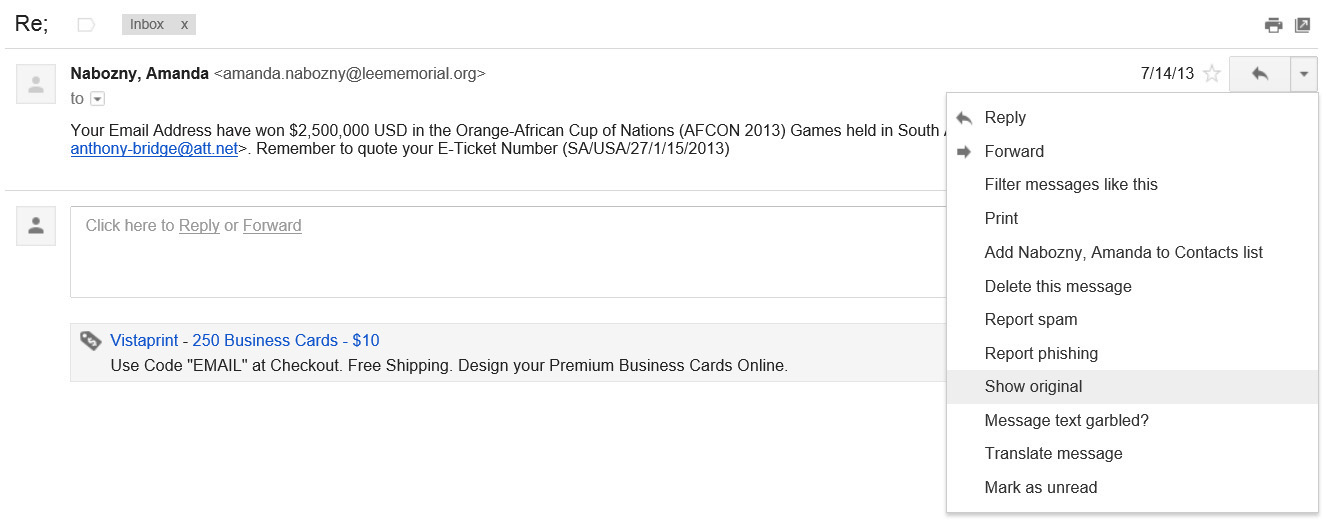
Viewing e-mail headers in Gmail is fairly simple and not that different from Yahoo! mail. You first open the message. Then, on the right, click the drop-down list, and select Show Original. This will give you the full headers, as shown in Figure 11-19.
Figure 11-19 Gmail headers
E-mail clients store the e-mail on the local machine. That means there is a file somewhere on your computer that has your entire mailbox. That includes all subfolders, calendars, etc. The file extension will depend on the e-mail client you are using. Here is a list of the most common e-mail client file extensions:
• .pst (Outlook)
• .ost (Offline Outlook Storage)
• .mbx or .dbx (Outlook Express)
• .mbx (Eudora)
• .emi (common to several e-mail clients)
If a person has multiple e-mails set up with an e-mail client, each e-mail will have its own file. For example, if you use Outlook and have jdoe@xyz.com and jdoe@abc.com, each will have a separate file. It is also possible for someone who wishes to hide e-mail communication to have a separate e-mail file that they leave detached from their client. So it is a good idea to scan the suspect drive(s) for any e-mail files. Most major forensics suites such as EnCase and FTK will examine e-mail and search for key terms.
E-mail tracing involves examining e-mail header information to look for clues about where a message has been. This will be one of your more frequent responsibilities as a forensic investigator. You will often use audits or paper trails of e-mail traffic as evidence in court. One of the first steps is to trace where the e-mail came from. You will get the necessary IP addresses from the headers, but then you have to trace it to its origin. You can do this with a simple tracert command (traceroute in Linux and Unix). You can tracert either IP addresses or domain names, as shown in Figure 11-20.

Figure 11-20 Using tracert to examine e-mail
You can also use the Whois tools described in Chapter 8 to track down who an IP address or domain name is registered to.
At some point, you need to check the e-mail server. Both the sender and the recipient could have deleted relevant e-mails, but there is a good chance a copy is still on the e-mail server. When you examine an e-mail server, be aware that a variety of e-mail server programs could be in use. Microsoft Exchange is a common server. Lotus Notes and Novell Groupwise are also popular e-mail server products.
The file formats associated with the most widely used e-mail server software are listed here:
• Exchange Server (.edb)
• Exchange Public Folders (pub.edb)
• Exchange Private Folders (priv.edb)
• Streaming Data (priv.stm)
• Lotus Notes (.nsf)
• GroupWise (.db)
• GroupWise Post Office Database (wphost.db)
• GroupWise User databases (userxxx.db)
• Linux E-Mail Server Logs/var/log/mail.*
Obviously, tools like Forensic Toolkit and EnCase will allow you to add these files to a case and to work with them. You can also manually examine these files provided you have access to the relevant software (i.e., Exchange, Lotus Notes, etc.).
Databases are often the focus of computer crime. This is because many crimes, like fraud and identity theft, center on information. Therefore, it is logical for the database to be a target. This means that database forensics is also important.
We have already discussed relational databases earlier in this chapter and their reliance on SQL. Here we will provide just a little bit more information. Relational databases are constructed of columns or fields that are ordered by tables that, in turn, are organized into databases. For example, you might have a table that has student data. It would have columns such as last name, first name, city, state, etc. Then you might have another table with class information. It would have columns such as class name, description, prerequisites, etc. These tables would be linked via key columns. You can see this in Figure 11-21.

Figure 11-21 How relational databases work
There are several widely used, well-known relational databases that you are likely to encounter in your forensic career. Each are briefly described here:
• Microsoft SQL Server This is Microsoft’s database server for medium to large-scale databases. It is a full-featured relational database that is widely used.
• Oracle Oracle and Microsoft SQL Server are the two most widely used commercial relational database systems. They both have a robust and complex structure.
• Microsoft Access This system is meant for small databases, no more than 2 gigabytes in size. It lacks some of the more advanced features found in Microsoft SQL Server.
• MySQL This is a popular open-source database management system. It is very popular in the web development community. In fact, one will often see jobs for a LAMP developer, LAMP being an acronym for Linux, Apache, MySQL, and PHP. So when investigating web crimes, you are likely to see MySQL.
• PostGres This is another popular open-source database management system, especially Linux/Unix users.
Another type of database is the NoSQL database. The book Getting Started with NoSQL (Packt Publishing, 2013) describes NoSQL as follows: “In computing, NoSQL (mostly interpreted as ‘not only SQL’) is a broad class of database management systems identified by its non-adherence to the widely used relational database management system model; that is, NoSQL databases are not primarily built on tables, and as a result, generally do not use SQL for data manipulation.”3 MongoDB is a common implementation of the NoSQL database.4
A hierarchical database is one in which the data is linked from parent to child data.5 Forensically, this does not significantly change the analysis. Hierarchical structures were widely used in the first mainframe database management systems, but have been mostly supplanted by relational databases.
There are also object-oriented databases. These databases are built using the same principles applied in object-oriented programming. This entails child objects inheriting properties or data from parent objects and then modifying or adding to those properties or data. This method has been around for many years, but has not gained wide use. The relational database model is the most widely used.
Databases often are stored on their own servers, so you should start with the same examinations you would do for any server. That means looking at logs, checking for malware, restoring deleted files, etc. However, some items are unique to databases.
One of the best places to seek forensic evidence regarding a database is the transaction log. Most modern database systems are set up to log every transaction that occurs. That means every insert, delete, update, select, etc. These transaction logs will provide a very good picture of what has occurred with that database. In any forensic examination involving databases, reviewing the transaction log is a must.
It is also important to look at user accounts in the database. It is possible to add a new user via advanced SQL injection techniques. If you find any user accounts that cannot be accounted for, this might indicate an intrusion.
Database backups are also an important source of forensic evidence. Databases are usually backed up quite frequently. This is to allow the system to be restored to operation should there be a database crash. Fortunately for forensic analysts, this also provides a means to potentially find data that may have been deleted from the current running database system.
NOTE Databases are often the ultimate target for financially motivated cybercrimes. Being at least basically proficient in a few of the most widely used database management systems is definitely recommended for any forensic analyst.
It is not uncommon to uncover a database that has damaged data. This can occur because data has been deleted or because the database has become corrupted.
Record carving is a process to recover deleted records from a database. This occurs not just in traditional relational database systems, but also in smaller systems like the SQLite used in some smartphones. In some cases, the records are carved from a disk image in an attempt to restore data. The process is similar to file carving. Record carving requires specialized tools—wdsCarve is one such tool.
One can also reference transaction logs to attempt to recover missing data. For example, Microsoft SQL Server has the main database file (.mdf file) and a log file (.ldf). By reviewing the transactions that brought the database to its current state, it might be possible to reconstruct damaged or missing data. Continuing with Microsoft SQL Server as an example database management system, you can see multiple fields in the log. The transaction ID and the operation are the two most important. The first identifies the transaction, and the second tells you what was done (update, delete, insert, etc.). The SANS institute publishes a paper that provides a walk-through of recovering an SQL database.6
A number of crimes can be perpetrated via databases, e-mail, files, etc. Each of these has its own specific forensic challenges and techniques. It is important that you have a working knowledge of these various forensic issues. Web attacks such as SQL injection are quite common, and you will likely encounter these during your career.
1. Firesheep is an example of:
A. SQL injection
B. Cookie manipulation
C. Forceful browsing
D. XML injection
2. What is the most common type of database management system?
A. SQL Server
B. Object oriented
C. NoSQL
D. Relational
3. Which of the following protocols encrypts outgoing e-mail?
A. SMTPS
B. POP3
C. IMAP
D. POP4
4. If you copy a file between two folders on different partitions, what permissions will the file have after being copied?
A. The source folder
B. Neither folder
C. The destination folder
D. The source partition
5. Which of the following is the extension of a local Microsoft Outlook e-mail file?
A. MDB
B. MFT
C. PST
D. XML
1. B. Firesheep works by manipulating cookies, specifically copying them.
2. D. Relational databases are the most common.
3. A. The last S in SMTPS is for “secure,” and it is SMTP encrypted with either SSL or TLS.
4. C. When copying or moving between partitions, the file always inherits the properties of the destination folder.
5. C. Microsoft Outlook stores mailboxes locally in .pst files.
1. Microsoft Computer Dictionary.
2. http://support.microsoft.com/kb/310316.
3. Getting Started with NoSQL by Gaurav Vaish.
5. http://codex.cs.yale.edu/avi/db-book/db6/appendices-dir/e.pdf.
6. https://www.sans.org/reading-room/whitepapers/application/forensic-analysis-sql-server-2005-database-server-1906.