CHAPTER 1
The Development of Big Data
1.1 The Concept of Big Data
Gartner defines big data as a massive, high growth rate, and diversified information asset that requires new processing mode to have stronger decision-making power, insight and discovery ability, and process optimisation ability (Ward & Barker, 2013).
McKinsey’s definition: big data refers to the data collection that cannot be collected, stored, managed, and analysed by traditional database software tools within a certain period.
Modern society is an information-based and digital society. With the rapid development of the Internet, Internet of Things, and cloud computing technology, data is flooding the whole world, which makes data become a new resource. People must make rational, efficient, and full use of it. The number of data is increasing exponentially, and the structure of data is becoming increasingly complex, which makes ‘big data’ have different deep connotations from ordinary ‘data’.
The volume of data in such fields as astronomy, high-energy physics, biology, computer simulation, Internet applications, and e-commerce has shown a rapid growth trend. According to the United States Internet Data Center (IDC), data on the Internet grows by more than 50% per year, doubling every two years, and more than 90% of the world’s data has been generated in recent years. Data does not simply refer to the information that people publish on the Internet; the world’s industrial equipment, cars, meters with countless sensors, measuring and transmitting information about position, movement, vibration, temperature, humidity, and even changes in the air quality at any time, also generated a huge amount of data.
Dr. Jim Gray, a famous database expert, author of transaction processing, and Turing Award winner, summed up that in the history of human scientific research, there have been three paradigms, namely, Empirical, Theoretical, and Computational. Today, with the increasing amount of data and the complexity of data structure, these three paradigms can no longer meet the needs of scientific research in new fields, so Dr. Jim Gray proposed the fourth paradigm, a new data research method, namely Data Exploration, to guide and update scientific research in different fields.
The size of data is not the only indicator to judge big data. The characteristics of big data can be summarised in 4Vs, which are volume, velocity, variety, and value.
1.1.1 Large Amount of Data
As we enter the information society, data grows naturally, and its production is not transferred according to human will. From 1986 to 2010, the amount of global data has increased 100 times. In the future, the growth rate of data will be faster. We are living in an era of ‘data explosion’. Today, only 25% of the world’s devices are connected to the Internet, and about 80% of Internet devices are computers and mobile phones. In the near future, more users will become Internet users, and various devices such as automobiles, televisions, household appliances, and manufacturing equipment will also be connected to the Internet. With the rapid development of Web 2.0 and mobile Internet, people can publish all kinds of information, including blogs, microblogs, WeChat, and so on, anytime, anywhere, and at will. In the future, with the promotion and popularisation of the Internet of Things, all kinds of sensors and cameras will be everywhere in our work and life. These devices automatically generate a large amount of data every moment.
1.1.2 Variety of Data Types
Big data comes from many sources, with new data being generated continuously from scientific research, enterprise applications, and web applications. Biological big data, transportation big data, medical big data, telecom big data, electric power big data, financial big data, etc. are showing a ‘blowout’ growth, involving a huge number, which has jumped from the TB level to PB level.
The data types of big data are rich, including structured data and unstructured data. The former accounts for about 10%, mainly refer to the data stored in the relational database; the latter accounts for about 90% with various types, mainly including email, audio, video, WeChat, microblog, location information, link information, mobile phone call information, and network log.
Such a wide variety of heterogeneous data brings new challenges and opportunities to data processing and analysis technology.
1.1.3 Fast Processing Speed
In the era of big data, the speed of data generation is very fast. In Web 2.0 applications, Sina can generate 20,000 microblogs, Twitter can generate 100,000 tweets, Apple can download 47,000 applications, Taobao can sell 60,000 products, Renren can generate 300,000 visits, and Baidu can generate 1,000,000 tweets in 1 minute. Facebook generates 6 million page views for 900,000 search queries. The famous Large Hadron Collider (LHC) generates about 600 million collisions per second, generating about 700 MB of data per second, with thousands of computers analysing these collisions.
Many applications in the era of big data need to provide real-time analysis results based on rapidly generated data to guide production and a life practice. As a result, the speed of data processing and analysis is usually in the order of seconds, which is fundamentally different from traditional data mining techniques, which do not require real-time analysis results.
1.1.4 Low-Value Density
As beautiful as it may look, big data has a much lower value density than what is already available in traditional relational databases. In the era of big data, much of the valuable information is scattered throughout the mass of data. In the case of an accident, only a small piece of video recording of the event will be valuable. However, in order to get the valuable video in case of theft, we have to invest a lot of money to buy surveillance equipment, network equipment, storage devices, and consume a lot of power and storage space to save the continuous monitoring data from the cameras.
1.2 The Past and Present of Big Data
At the symposium of the 11th International Joint Conference on Artificial Intelligence held in Detroit, Michigan, USA in 1989, the concept of ‘Knowledge Discovery (KDD) in Database’ was put forward for the first time. In 1995, the first International Conference on Knowledge Discovery and Data Mining was held. With the increase of participants, the KDD International Conference was developed into an annual meeting. The fourth International Conference on Knowledge Discovery and Data Mining was held in New York in 1998, where not only academic discussions were held but also more than 30 software companies demonstrated their products. For example, Intelligent Miner, developed by IBM, is used to provide a solution for data mining. SPSS Co., Ltd. developed data mining software Clementine based on decision tree. Darwin data mining suite is developed by Oracle, Enterprise of SAS and Mine set of SGI, and so on.
In the academic community, nature launched a special issue of ‘big data’ as early as 2008, which focuses on the research of big data from the aspects of Internet technology, supercomputing, and other aspects.
Economic interests have become the main driving force, and multinational giants such as IBM, Oracle, Microsoft, Google, Amazon, Facebook, Teradata, EMC, HP, and other multinational giants have become more competitive due to the development of big data technology. In 2009 alone, Google contributed $54 billion to the U.S. economy through big data business; since 2005, IBM has invested $16 billion in more than 30 big data-related acquisitions, making the performance stable and promoting rapid growth. In 2012, the share price of IBM broke the $200 mark, tripled in three years; eBay accurately calculated the return of each keyword in advertising through data mining. Since 2007, advertising expenses have decreased by 99%, while the percentage of top sellers in total sales has increased to 32%; in 2011, Facebook made public, for the first time, a new data processing and analysis platform, Puma. Through the differentiation and optimisation of multiple data processing links, the data analysis cycle is reduced from 2 days to less than 10 seconds, tens of thousands of times more efficient, and large-scale commercial applications based on it have been blooming since then (Wei-Pang & Ntafos, 1992).
In March 2012, the Obama administration announced the ‘Big Data Research and Development Initiative’, which aims to improve people’s ability to acquire knowledge from massive and complex data and develop the core technologies needed for collecting, storing, retaining, managing, analysing, and sharing massive data. Big data has become the focus of information technology after an integrated circuit and the Internet.
People have never stopped to analyse data mining, but the rise of the concept of big data has happened in recent decades. The reason for its formation is the result of the joint action of various factors. If any of the factors is not developed enough, it will not form the hot and extensive application of big data.
1.3 Technical Support of Big Data
Information technology needs to solve the three core problems of information storage, information transmission, and information processing, and the continuous progress of human society in the field of information technology provides technical support for the advent of the big data era.
1.3.1 Storage Device Capacity Is Increasing
In recent years, computer hardware technology has developed rapidly, but on the other hand, information and data are also growing. To meet the requirements of information storage, hardware storage devices have been constantly improved. Nowadays, storage cards of the size of fingernails have several gigabytes or even tens of gigabytes of information capacity, which was unthinkable in the past. Hardware storage devices include hard disk, optical disk, U disk, mobile storage device, and so on. This kind of storage devices is collectively referred to as solid-state storage devices. At present, solid-state storage devices are used to store data and information in the world. This is mainly because of its low-carbon manufacturing nature. Besides, it is made of solid-state electronic storage chips through matrix arrangement, which has many advantages. Traditional devices do not have the advantages, so solid-state storage devices become the mainstream storage devices.
In 1956, IBM produced the world’s first commercial hard disk with a capacity of only 5 MB. It was not only expensive but also the size of a refrigerator. In 1971, Seagate founder Alan Shugart launched an 8-inch floppy disk storage device, which was no longer so huge. However, at the earliest time, its capacity was only 81 kb. A long document may need several floppy disks to copy. Then, there were 5.25-inch and 3.5-inch floppy disks, and the capacity was no more than 2 MB. In 1973, American Jim Russell built the first compact disc recording prototype. Since then, CD storage has entered the stage of history. Different storage technologies such as CD, MD, VCD, DVD, and HD-DVD have been developed. The storage capacity has also entered the G era from the M era. From storage cost, HP’s tape can store up to 15 TB in a single disk, and the price is only about 900 yuan ($139.88 USD), only 60 yuan ($9.33 USD) per TB. The cheap and high-performance hard disk storage device not only provides a large amount of storage space but also greatly reduces the cost of data storage.
Data volume and storage device capacity complement and promote each other. On the one hand, with the continuous generation of data, the amount of data to be stored is increasing, which puts forward higher requirements for the capacity of storage devices, which urges storage device manufacturers to manufacture products with a larger capacity to meet the market demand; on the other hand, storage devices with larger capacity further speed up the growth of data volume. In the era of high storage equipment prices, due to the consideration of cost issues, some unnecessary devices that cannot clearly reflect the value of data are often discarded. However, with the continuous reduction of the price of unit storage space, people tend to save more data in order to use more advanced data analysis tools to excavate value from it at some time in the future.
1.3.2 Increasing Network Bandwidth
In the 1950s, communication researchers recognised the need to allow conventional communication between different computer users and communication networks. This leads to the study of decentralised networks, queuing theory, and packet switching. In 1960, ARPANET, created by the Advanced Research Projects Agency (ARPA) of the U.S. Department of Defense, triggered technological progress and made it the centre of Internet development. In 1986, NSFNET, a backbone network based on TCP/IP technology, was established by the National Science Foundation of the United States to interconnect the Supercomputer Centre and academic institutions. The speed of NSFNET increased from 56 kbit/s to T1 (1.5 mbit/s) and finally to T3 (45 mbit/s).
The development of Internet access technology is very rapid. The bandwidth has developed from the initial 14.4 kbps to the current 100 Mbps or even 1 Gbps bandwidth. The access mode has also developed from the single telephone dial-up mode in the past to the diversified wired and wireless access methods. The access terminal also begins to develop towards mobile devices.
In the era of big data, information transmission is no longer encountering bottlenecks and constraints in the early stage of network development.
1.3.3 CPU Processing Capacity Increased Significantly
In 1971, Intel released its first 4-bit microprocessor, the 4004 microprocessor, which had a maximum frequency of only 108 kHz. Soon after, Intel introduced 8008 microprocessors, and in 1974, 8008 developed into 8080 microprocessors, thus CPU entered the second generation of microprocessors. The second-generation microprocessors all adopt NMOS technology. Only four years later, 8086 microprocessor was born. It is the first 16-bit microprocessor in the world and the starting point of the third generation microprocessor. In 2000, Pentium 4 was born, when the CPU frequency has reached the GHz level, in 2004 Intel built the 3.4 GHz processor. But the process of CPU is only 90 nm, the consequence of ultra-high frequency is huge heat generation and power consumption, the power of 3.4 GHz CPU can exceed 100 W, and the power consumption of 4 GHz CPU which Intel was developing at that time is unimaginable. The new generation of Pentium 4 chips has not been well received in the market. Intel decided to change from ‘high frequency’ to ‘multi-core’ and started the research and development of dual-core, 4-core and 6-core, through multi-core ‘human-sea tactics’ to improve the efficiency of CPU. More than 10 years later, the manufacturing technology of CPU is also improving, and the main frequency is gradually increasing again. For example, the Core i7 processor of the eighth generation 14 nm achieves the main frequency of 3.7 GHz (turbo frequency 4.7 GHz) and also adopts a 6-core architecture.
The continuous improvement of CPU processing speed is also an important factor in increasing the amount of data. The continuous improvement of the performance of the CPU greatly improves the ability to process data, so that we can deal with the continuous accumulation of massive data faster.
1.3.4 The Deepening of Machine Learning
In the 1980s, the semiotics school was popular, and the dominant method was knowledge engineering. Experts in a certain field made a machine that could play a certain role in decision-making in a specific field, that is, the so-called ‘expert machine’.
Since the 1990s, the Bayesian school developed probability theory which became the mainstream thought at that time, because this method with extended attributes can be applied to more scenarios.
Since the end of the last century, the connection school has set off an upsurge, and the methods of neuroscience and probability theory have been widely used. Neural networks can recognise images and speech more accurately and do well in machine translation and emotional analysis. At the same time, because neural networks require a lot of computing, the infrastructure has been a large-scale data centre or cloud since the 1980s.
In the first decade of the 21st century, the most significant combination is that of the connecting school and the semiotics school, resulting in the formation of memory neural networks and agents capable of simple reasoning based on knowledge. Infrastructure is also moving towards large-scale cloud computing.
The in-depth study of machine learning algorithm improves people’s ability to process data and can mine rich valuable information from the data.
1.4 The Value of Big Data
The main value system of big data is that it can discover new things beyond our cognition through a large amount of data, which can be embodied in the following aspects.
1.4.1 Big Data Decision-Making Has Become a New Decision-Making Method
Making decisions based on data is not unique to the era of big data. Since the 1990s, data warehouse and business intelligence tools have been widely used in enterprise decision-making. Today, data warehouse has been an integrated information storage warehouse, which not only has the capacity of batch and periodic data loading but also has the ability of real-time detection, dissemination, and loading of data changes. It can also realise query analysis and automatic rule triggering combined with historical data and real-time data, so as to provide strategic decisions (such as macro decision-making and long-term planning) and tactical decision-making (such as real-time marketing and personalised service). However, data warehouse is based on relational database, so there are great limitations in data type and data volume (Maniar & Khatri, 2014). Now, big data decision-making can face a wide range of types of unstructured massive data for decision-making analysis, which has become a new popular decision-making method (Yan, Chen, & Huang, 2016). For example, government departments can integrate big data technology into ‘public opinion analysis’. Through the comprehensive analysis of various sources of data such as forum, microblog, WeChat, and community, we can clarify or test the essential facts and trends in the information, reveal the hidden information content contained in the information, make intelligence prediction for the development of things, help realise government decision-making, and effectively respond to various emergencies.
1.4.2 Big Data Application Promotes Deep Integration of Information Technology and Various Industries
Some experts pointed out that big data will change the business functions of almost every industry in the next 10 years. In the Internet, banking, insurance, transportation, materials, energy, services and other industries, the accumulation of big data will accelerate the deep integration of these industries and information technology and open up new directions for industry development. For example, big data can help express delivery companies choose the best travel route with the lowest freight cost, assist investors to choose the stock portfolio with maximum revenue, assist retailers to effectively locate target customer groups, help Internet companies achieve accurate advertising (Mohanty, Jagadeesh, & Srivatsa, 2013), and enable power companies to make distribution plans to ensure grid security. In short, big data has touched every corner, which will lead to great and profound changes in our lives.
1.4.3 Big Data Development Promotes the Continuous Emergence of New Technologies and Applications
The application demand for big data is the source of big data new technology development. Driven by various application requirements, various breakthrough big data technologies will be proposed and widely used, and the energy of data will also be released. In the near future, applications that rely on human judgement will gradually be replaced by applications based on big data. For example, today’s auto insurance companies can only rely on a small amount of owner information to classify customers into simple categories, and give corresponding premium preferential schemes according to the number of car accidents. There is no big difference in which insurance company customers choose. With the emergence of the Internet of Vehicles, ‘big data of automobiles’ will profoundly change the business model of the automobile insurance industry (Liang, Susilo, & Liu, 2015). If a commercial insurance company can obtain the relevant details of customers’ vehicles, and use the mathematical model built in advance to make a more detailed judgement on the customer’s accident level, and give a more personalised ‘one-to-one’ preferential scheme, then there is no doubt that this insurance company will have an obvious market competitive advantage and win the favour of more customers.
1.4.4 Big Data as a Strategic Resource
For the government, big data is considered to be an important source of improving the comprehensive national strength and enhancing the competitiveness of the country.
Therefore, the introduction of various policies and guidelines at the national level to guide enterprises and organisations to develop in accordance with the trend has become a way for governments of various countries to compete (Wang, Yang, Feng, Mi, & Meng, 2014).
The U.S. government released the world’s first national big data strategy on March 29, 2012 and the federal big data research and development strategic plan on May 23, 2016, to accelerate the process of big data R & D Action proposed by the U.S. government in 2012. In addition, the ‘data pulse’ plan of the United Nations, the ‘data rights’ movement of the United Kingdom, the ‘ICT comprehensive strategy for 2020’ of Japan, and the big data centre strategy of South Korea are all the planning and deployment of the government at the national level from the strategic level.
All sectors of society have great enthusiasm for big data and believe that the introduction of big data can improve their competitiveness. One of the basic motivations for people to have such value expectations is that people think that through big data processing and analysis, we can have insight into the information intelligence and knowledge insight of customers, friends, products, and channels in all dimensions, so as to provide research clues and technical basis for the design of innovative application mode and business model.
1.5 Key Technologies of Big Data
No matter how complex the structure of big data processing system is, the technology used is very different, but on the whole, it can be divided into the following several important parts. The structure of big data system is shown in Figure 1.1.
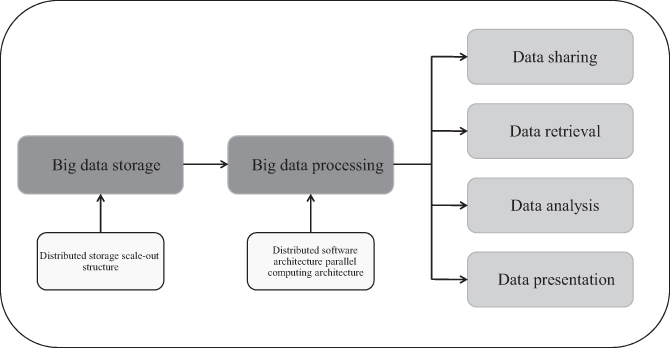
FIGURE 1.1 The structure of big data system.
From the general process of data processing, we can see that the key technologies needed in the big data environment are mainly for the storage and operation of massive data. After nearly 40 years of development, the traditional relational database has become mature and still evolving data management and analysis technology. As the language of accessing a relational database, SQL has been standardised, and its function and expression ability have been continuously enhanced. However, it cannot be competent for the analysis of large data under the unprecedented environment of the Internet. The relational data management model pursues a high degree of consistency and correctness of the vertical expansion system. By adding or replacing CPU, memory and hard disk to expand the ability of a single point, it will eventually encounter a ‘bottleneck’.
The research on big data mainly comes from big companies that rely on data to obtain business interests. As the world’s largest information retrieval company, Google company is at the forefront of big data research. In the face of the explosive increase of Internet information, only improving the server performance cannot meet the needs of business. If we compare various big data applications to ‘cars’, the ‘highway’ supporting the operation of these ‘cars’ is cloud computing. It is the support of cloud computing technology in data storage, management, and analysis that makes big data useful. Google company expanded from the horizontal, through the use of cheap computer nodes set sample, rewriting software, so that it can be executed in parallel on the cluster, to solve the storage and retrieval function of massive data. In 2006, Google first proposed the concept of cloud computing. The key to support Google’s various big data applications is the series of cloud computing technologies and tools developed by Google. Google’s three key technologies for big data processing are Google File System (GFS), MapReduce, and BigTable. Google’s technical solutions provide a good reference for other companies, and major companies have put forward their own big data processing platform, and the technologies adopted are similar. The key technologies of big data systems will be introduced from the following aspects: distributed file system (DFS), distributed data processing technology, distributed database system, and open-source big data system Hadoop.
1.5.1 Big Data Acquisition Technology
Data collection refers to various types of structured, semi-structured (or weakly structured), and unstructured massive data obtained through RFID radio frequency data, sensor data, social network interaction data, and mobile Internet data. It is the foundation of the big data knowledge service model. The key points are to breakthrough big data collection technologies such as distributed high-speed and high-reliability data crawling or collection and high-speed data full image; to break through big data integration technologies such as high-speed data analysis, conversion, and loading; to design quality evaluation model and develop data quality technology.
Big data acquisition is generally divided into big data intelligent perception layer: it mainly includes data sensing system, network communication system, sensor adaptation system, intelligent identification system, and software and hardware resource access system, which can realise intelligent identification, positioning, tracking, access, transmission, signal conversion, monitoring, preliminary processing, and management of massive structured, semi-structured, and unstructured massive data. We must focus on the technologies of intelligent identification, perception, adaptation, transmission, and access for big data sources. Basic support layer: provide the virtual server required by big data service platform, the database of structured, semi-structured, and unstructured data and Internet of things resources. The key technologies include distributed virtual storage technology, visualisation interface technology for big data acquisition, storage, organisation, analysis and decision-making operation, network transmission and compression technology of big data, and privacy protection technology of big data (Chang et al., 2008).
1.5.2 Big Data Preprocessing Technology
It mainly completes the analysis, extraction, and cleaning of received data.
Extraction: since the acquired data may have multiple structures and types, the data extraction process can help us transform these complex data into a single or easy to process configuration, so as to achieve the purpose of rapid analysis and processing (Chang & Wills 2016).
Cleaning: for big data, not all of them are valuable. Some data are not what we care about, while others are completely wrong interference items. Therefore, we should filter and ‘denoise’ the data to extract effective data.
1.5.3 Big Data Storage and Management Technology
Big data storage and management should use memory to store the collected data, establish the corresponding database, and manage and call. Focus on complex structured, semi-structured, and unstructured big data management and processing techniques (Chen, Lv, & Song, 2019). It mainly solves several key problems of big data, such as storability, representability, processability, reliability, and effective transmission. Develop reliable DFS, energy efficiency optimised storage, computing into storage, big data’s de-redundancy (Dean & Ghemawat, 2004), and efficient and low-cost big data storage technology; breakthrough distributed non-relational big data management and processing technology (Li et al., 2015), heterogeneous data fusion technology, data organisation technology, research big data modelling technology; breakthrough big data index technology; breakthrough big data mobile, backup, replication, and other technologies. Develop big data visualisation technology (Ghemawat, Gobioff, & Leung, 2003).
The database is divided into the relational database, non-relational database, and database cache system. Among them, non-relational database mainly refers to the NoSQL database, which can be divided into key-value database, column storage database, graph database, and document database. Relational database includes traditional relational database system and NewSQL database.
Develop big data security technology. Improve data destruction, transparent encryption and decryption, distributed access control, data audit and other technologies; breakthrough privacy protection and reasoning control (Copeland & Khoshafian, 1985), data authenticity identification and forensics, data holding integrity verification, and other technologies.
1.5.4 Big Data Analysis and Mining Technology
For the development of big data analysis technology, improve the existing data mining and machine learning technology; develop new data mining technologies such as data network mining, special group mining and graph mining; breakthrough big data fusion technologies such as object-based data connection and similarity connection; breakthrough domain-oriented big data mining technologies such as user interest analysis (Dean & Ghemawat, 2004), network behaviour analysis, and emotional semantic analysis.
Data mining is a process of extracting potentially useful information and knowledge from a large number of, incomplete, noisy, fuzzy, and random practical application data. There are many technical methods involved in data mining, including many classification methods (Kumar & Goyal, 2016).
According to the mining task, it can be divided into classification or prediction model discovery, data summary, clustering, association rule discovery, sequential pattern discovery, dependency or dependency model discovery, anomaly, and trend discovery.
According to the mining objects, it can be divided into a relational database, object-oriented database, spatial database, temporal database, text data source, multimedia database, heterogeneous database, heritage database, and global web.
According to the mining method, it can be roughly divided into: machine learning method, statistical method, neural network method, and database method. In machine learning, it can be divided into inductive learning method (decision tree, rule induction, etc.), case-based learning, genetic algorithm, etc. Statistical methods can be subdivided into: regression analysis (multiple regression, autoregression, etc.), discriminant analysis (Bayesian discrimination, Fisher discrimination, nonparametric discrimination, etc.), cluster analysis (systematic clustering, dynamic clustering, etc.), and exploratory analysis (principal component analysis, correlation analysis, etc.). In the neural network method, it can be subdivided into forward neural network (BP algorithm, etc.) and self-organising neural network (self-organising feature mapping, competitive learning, etc.). Database methods are mainly multidimensional data analysis or OLAP and attribute oriented induction (Jun, Yoo, & Choi, 2018).
From the perspective of mining tasks and mining methods, we focus on the breakthrough:
Visual analysis. The most basic function for users is to analyse data. Data visualisation can let the data speak by itself and let users feel the results intuitively.
Data mining algorithm. Visualisation is to translate machine language to people, and data mining is the mother tongue of the machine. Segmentation, clustering, outlier analysis, and a variety of algorithms allow us to refine data and mine value. These algorithms must be able to cope with the amount of big data but also have a high processing speed.
Predictive analysis. Predictive analysis allows analysts to make some forward-looking judgements based on the results of image analysis and data mining.
Semantic engine. A semantic engine needs to be designed to have enough artificial intelligence to extract information from data. Language processing technology includes machine translation, sentiment analysis, public opinion analysis, intelligent input, question answering system, and so on.
Data quality and data management. Data quality and management is the best practice of management. Data processing through standardised processes and machines can ensure a predetermined quality of analysis results.
1.5.5 Big Data Presentation Technology
Visualisation is one of the most effective ways to explore and understand large data sets. Data are usually boring, relatively speaking, people are more interested in size, graphics, colour, etc. By using the data visualisation platform, the number is placed in the visual space, and the boring data is transformed into rich and vivid visual effects. It will therefore be easier for people to find the hidden patterns, which not only helps to simplify people’s analysis process but also greatly improves the efficiency of data analysis.
Data visualisation refers to the process of representing the data in large data sets in the form of graphics and images and discovering the unknown information by using data analysis and development tools. The basic idea of data visualisation technology is to represent each data item in the database as a single graph element, and a large number of data sets constitute the data image. At the same time, each attribute value of the data is expressed in the form of multidimensional data, so that the data can be observed and analysed from different dimensions. Although visualisation is not the most challenging part in the field of data analysis, it is the most important link in the whole data analysis process.
Whether we draw illustrations for demonstration, conduct data analysis, or use data to report news, we are in fact seeking the truth. In some cases, statistics can give false impressions, but it is not the numbers themselves that cause the illusion, but the people who use them. Sometimes it is intentional, but more often it is due to carelessness. If we don’t know how to create the right graph, or how to look at the data objectively, we can make a fallacy. However, as long as we master the appropriate visualisation skills and processing methods, we can be more confident in presenting opinions and feel good about our findings (Karafiloski & Mishev, 2017).
1.6 Chapter Summary
Big data, as another disruptive technology in the IT industry after cloud computing and Internet of things, attracts people’s attention. Big data is everywhere. All walks of life in society, including finance, automobile, retail, catering, telecommunications, energy, government affairs, medical care, sports, and entertainment, are integrated into the imprint of big data. Big data will have a significant and far-reaching impact on human social production and life.
Modern people have many different definitions of big data, among which the four characteristics of big data are very important, namely volume, velocity, variety, and value. From these characteristics, we can see the difference between big data and traditional data mode, so as to grasp big data as a whole and better understand what needs to be paid attention to when big data and blockchain are combined.
It has been several decades since the concept of big data was proposed. There are many excellent technology applications and implementations. The subversive promotion of big data technology to traditional industries has accelerated the development of big data technology. Many enterprises have found that using big data technology can solve the problems that have not been solved in their business field. At the same time, many enterprises have already owned with a large amount of data, we want to realise the value-added of data through big data technology.
The development of big data technology to today’s level is closely related to some infrastructure. The capacity of storage equipment is not expanded and the price is decreasing, which makes a large amount of data storage feasible. After accumulating a large amount of data, the demand for big data processing will be generated. The continuous increase of network bandwidth makes information transmission no longer encounter the bottleneck and restriction in the early stage of network development. Enterprises can quickly share a large amount of data, thus increasing the data dimension. Using higher dimensional data can get more information, and at the same time, it also has higher requirements for big data processing capacity. The improvement of processor performance greatly improves the ability of computer to process data, which makes us deal with the massive data accumulated more quickly. Finally, the in-depth study of machine learning algorithm improves people’s ability to process data and can mine rich valuable information from the data.
The application of big data corresponds to a series of technologies, including big data acquisition technology, big data preprocessing technology, big data storage and management technology, big data analysis and mining technology, and big data display technology.
References
Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., . . . Gruber, R. E. (2008). Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems, 26(2), 1–26.
Chang, V., & Wills, G. (2016). A model to compare cloud and non-cloud storage of big data. Future Generation Computer Systems, 57, 56–76.
Chen, J., Lv, Z., & Song, H. (2019). Design of personnel big data management system based on blockchain. Future Generation Computer Systems, 101(Dec.), 1122–1129.
Copeland, G. P., & Khoshafian, S. N. (1985). A decomposition storage model. ACM Sigmod International Conference on Management of Data. https://dl.acm.org/doi/proceedings/. ACM.
Dean, J., & Ghemawat, S. (2004). MapReduce: Simplified data processing on large clusters. Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation - Volume 6. https://dl.acm.org/conferences. USENIX Association.
Ghemawat, S., Gobioff, H., & Leung, S. T. (2003). The google file system. ACM Sigops Operating Systems Review, 37(5), 29–43.
Jun, S. P., Yoo, H. S., & Choi, S. (2018). Ten years of research change using google trends: from the perspective of big data utilizations and applications. Technological Forecasting and Social Change, 130(MAY), 69–87.
Karafiloski, E., & Mishev, A. (2017). Blockchain solutions for big data challenges: A literature review. IEEE EUROCON 2017-17th International Conference on Smart Technologies. https://ieeexplore.ieee.org/. IEEE.
Kumar, O., & Goyal, A. (2016). Visualization: A novel approach for big data analytics. Second International Conference on Computational Intelligence & Communication Technology (pp. 121–124). http://www.proceedings.com/. IEEE.
Li, B., Wang, M., Zhao, Y., Pu, G., Zhu, H., & Song, F. (2015). Modeling and verifying Google file system. IEEE International Symposium on High Assurance Systems Engineering. IEEE.
Maniar, K. B., & Khatri, C. B. (2014). Data science: Bigtable, mapreduce and Google file system. International Journal of Computer Trends and Technology, 16(3), 115–118.
Mohanty, S., Jagadeesh, M., & Srivatsa, H. (2013). “Big Data” in the Enterprise. Big Data Imperatives, 8(2), 23–33.
Liang, K., Susilo, W., & Liu, J (2015). Privacy-preserving ciphertext multi-sharing control for big data storage. IEEE transactions on information forensics and security, 10(2), 103–107.
Wang, N., Yang, Y., Feng, L., Mi, Z., & Meng, K. (2014). SVM-based incremental learning algorithm for large-scale data stream in cloud computing. KSII Transactions on Internet and Information Systems, 8(10), 3378–3393.
Ward, J. S., & Barker, A. (2013). Undefined by data: A survey of big data definitions. Computer Science, 3(8), 220–228.
Wei-Pang, C., & Ntafos, S. (1992). The zookeeper route problem. Information Sciences, 63(3), 245–259.
Yan, Y., Chen, C., & Huang, L. (2016). A productive cloud computing platform research for big data analytics. IEEE International Conference on Cloud Computing Technology & Science, 42(12), 499–502. https://2020.cloudcom.org/.