CHAPTER 3
Evolution of Two Technologies
3.1 Development Trend of Big Data Technology
In the era of big data, traditional software has been unable to process and mine information in large amounts of data. The most important change is Google’s ‘three carriages’. Google has successively released Google’s distributed file system (GFS), big data distributed computing framework MapReduce, and big data NoSQL database BigTable around 2004. These three papers have laid the cornerstone of big data technology. As we know, search engines mainly do two things, one is web page fetching, and the other is index building. In this process, there is a large amount of data to be stored and calculated. These three technologies are actually designed to solve this problem. We can also tell by the name, a file system, a computing framework, and a database system. Changes are always dominated by big companies like Google. At that time, when most companies were still working on improving single-machine performance, Google had begun to envision the distribution of data storage and calculations to a large number of cheap computers to execute. Because of that time period, most companies actually focused on a single machine, thinking about how to improve the performance of a single machine and looking for more expensive and better servers. Google’s idea is to deploy a large-scale server cluster, store massive amounts of data on this cluster in a distributed manner, and then use all machines on the cluster for data calculations. In this way, Google doesn’t actually need to buy a lot of expensive servers. It only needs to organise these ordinary machines together, which is very powerful.
Inspired by Google’s paper, in July 2004, Doug Cutting and Mike Cafarella implemented GFS-like functions in Nutch, the predecessor of later Hadoop Distributed File System (HDFS). Later in February 2005, Mike Cafarella implemented the original version of MapReduce in Nutch. By 2006, Hadoop was separated from Nutch and started an independent project. The open-source of Hadoop promoted the vigorous development of the big data industry and brought a profound technological revolution. If you have time, you can simply browse the Hadoop code, the pure software written in Java has no advanced technical difficulties and use also some of the most basic programming skills; there is nothing surprising, but it can bring huge influence to the society, even to drive a profound revolution of science and technology, and promote the development and progress of artificial intelligence.
Next, big data-related technologies continue to develop, and the open-source approach has gradually formed a big data ecosystem. Because MapReduce programming is cumbersome, Facebook contributes Hive, and SQL syntax provides great help for data analysis and data mining. Cloudera, the first commercial company to operate Hadoop, was also established in 2008.
Since memory hardware had broken through cost constraints, Spark gradually replaced MapReduce’s status in 2014 and was sought after by the industry. The operation speed of Spark running programs in memory can be 100 times faster than that of Hadoop MapReduce, and its operation mode is suitable for machine learning tasks. Spark was born in UC Berkeley AMPLab in 2009, open-sourced in 2010, and contributed to the Apache Foundation in 2013.
Both Spark and MapReduce are focused on offline calculations, usually, tens of minutes or longer, and are batch programs. Due to the demand for real-time computing, streaming computing engines have begun to appear, including Storm, Flink, and Spark Streaming.
The development of big data storage and processing technology has also spurred the vigorous development of data analysis and machine learning and has also prompted the emergence of emerging industries. Big data technology is the cornerstone, and the landing of artificial intelligence is the next outlet. Being in the Internet industry and feeling that the technology is progressing quickly, we should ignore the impetuousness and grasp the change.
Big data needs to cope with quantified and fast-growing storage, which requires the underlying hardware architecture and file system to be significantly higher than traditional technologies in terms of cost performance and able to elastically expand storage capacity. One challenge that big data poses to storage technology is the ability to adapt to multiple data formats. Therefore, the storage layer of big data is not only HDFS of Hadoop but also storage architectures such as HBase and Kudu.
3.2 Key Technologies of Big Data
From the perspective of the life cycle of data, big data needs to go through several links from the analysis and mining of data sources to finally generate value, including data generation, data storage, data analysis, and data utilisation, as shown in Figure 3.1.
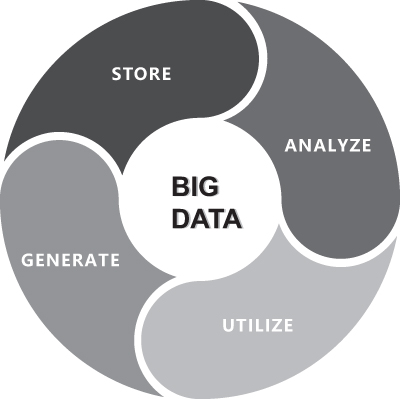
FIGURE 3.1 Big data lifecycle.
Big data needs to cope with quantified and fast-growing storage, which requires the underlying hardware architecture and file system to be much higher in cost performance than traditional technologies and able to elastically expand storage capacity. Google’s GFS and Hadoop’s HDFS laid the foundation for big data storage technology. In addition, another challenge that big data poses to storage technologies is the ability to adapt to multiple data formats. Therefore, the underlying storage layer of big data is not only HDFS but also storage architectures such as HBase and Kudu.
Blockchain is essentially a distributed database system. As a kind of chained access data technology, blockchain technology participates in the calculation and recording of data through multiple nodes participating in the calculation in the network and verifies the validity of its information with each other. From this point, the blockchain technology is also a specific database technology. Due to the characteristics of decentralised databases in terms of security and convenience, many people in the industry are optimistic about the development of blockchain and believe that blockchain is an upgrade and supplement to the existing Internet technology.
3.2.1 Hadoop
Hadoop is an open-source distributed computing platform provided by the Apache Software Foundation. It can provide users with a distributed infrastructure with transparent system details and make full use of the cluster method for storage and high-speed calculations.
Applications working in the Hadoop framework can work in an environment that provides distributed storage and computing across computer clusters. Hadoop is designed to scale from a single server to thousands of machines, and each machine provides local computing and storage.
The Hadoop framework includes the following four modules:
Hadoop Common: These are the Java libraries and utilities required by other Hadoop modules. These libraries provide the file system and operating system-level abstractions and contain the necessary Java files and scripts needed to start Hadoop.
Hadoop YARN: This is a framework for job scheduling and cluster resource management.
HDFS: A distributed file system that provides high-throughput access to application data.
Hadoop MapReduce: This is a parallel processing system for large data sets based on YARN.
We can use the following diagram to describe the four components available in the Hadoop framework, as shown in Figure 3.2.
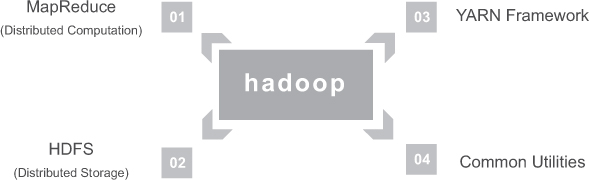
FIGURE 3.2 Hadoop architecture.
Hadoop implements the distributed file system HDFS. HBase is a NoSQL database based on HDFS that has been listed as the centre. It is used to quickly read and write large amounts of data and is managed by Zookeeper. HDFS not only simplifies the requirements of POSIX but also allows streaming access to the related data in the file system.
The original goal of Hadoop design is high reliability, high scalability, high fault tolerance, and high efficiency. The unique advantage of the design is that with the emergence of Hadoop, many large companies will fall into trouble. At the same time, it has also aroused widespread interest in the research community. Due to the unique advantages of data extraction, conversion, and loading, Hadoop can be widely used in big data processing applications. The distributed architecture of Hadoop makes the big data processing engine as close to the storage as possible. The batch results of these processes can be moved directly to storage, making them relatively suitable for batch processing tasks.
The advantages of the Hadoop platform:
High scalability: Theoretically, it can be unlimited. Because in the Hadoop test framework, performance and capacity can be improved by simply adding some hardware.
Low cost: You don’t need to rely on high-end hardware. As long as ordinary PCs, the entire system is stacked by cheap machines, and the reliability of the system is ensured through software fault tolerance.
Mature ecosystem: Open-source, with many tools (HIVE), which lowers the threshold for using Hadoop and improves the applicability of Hadoop.
3.2.2 MapReduce
Hadoop MapReduce is a software framework for easily writing applications. It processes large amounts of data on large clusters (thousands of nodes) in a reliable and fault-tolerant manner and processes commodity hardware in parallel.
The term MapReduce actually refers to the following two different tasks performed by the Hadoop program:
Map Task: This is the first task, which receives input data and converts it into a set of data, where individual elements are decomposed into tuples (key/value).
Reduce Task: This task takes the output of the map task as input and combines these data elements into a smaller set of tuples. The reduce task is always executed after the map task.
Usually, the input and output are stored in the file system. The framework is responsible for scheduling tasks, monitoring them and re-executing failed tasks.
The MapReduce framework consists of a single master JobTracker and a slave TaskTracker for each cluster node. The supervisor is responsible for resource management, tracking resource consumption/availability, scheduling job component tasks on the slave station, and monitoring and re-executing fault tasks. The slave TaskTracker performs tasks according to the instructions of the host and periodically provides task status information to the master device. JobTracker is a single point of failure for the Hadoop MapReduce service, which means that if JobTracker is shut down, all running jobs will stop.
Hadoop’s MapReduce function recognises the interruption of a single job, sends the scattered jobs to multiple nodes, and then reduces them to the data warehouse in the form of a single data set. By using the MapReduce framework, people can easily develop distributed systems and only write their own Map and Reduce functions to perform big data measurement and processing. In order for the client to write files into HDFS, they must be cached in local temporary storage. If the cached data is larger than the required HDFS block size, the file creation request will be sent to the NameNode. The NameNode responds to the client with the DataNode ID and target block. When the client starts sending temporary files to the first DataNode, it will immediately pipe the contents of the block to the DataNode replica.
All of the above are theoretical explanations of MapReduce, so let’s understand the problem in terms of the process and code generated by MapReduce. If you want to count the most words that have appeared in computer papers over the past 10 years and see what everyone has been working on, what should you do once you have collected your papers?
Method 1: You can write a small program that goes through all the papers in order, counts the number of occurrences of each encountered word, and finally you will know which words are the most popular. This method is very effective and the simplest to implement when the data set is small, and is appropriate for solving this problem.
Method 2: Write a multi-threaded program that traverses the papers concurrently. This problem can theoretically be highly concurrent since counting one file does not affect counting another file. When our machine is multi-core or multi-processor, method two are definitely more efficient than method one. But writing a multi-threaded program is much more difficult than method one, we have to synchronise and share the data ourselves, for example, to prevent two threads from double counting the file.
Method 3: Give the assignment to multiple computers to complete. We can use the program from method one, deploy it to N machines, and then split the proceedings into N copies, with one machine running one job. This method runs fast enough, but it’s a pain to deploy, we have to manually copy the program to another machine, we have to manually separate the proceedings, and most painful of all, we have to integrate the results of the N runs (we can write another program, of course).
Method 4: Let MapReduce help us out. MapReduce is essentially method three, but how to split a fileset, how to copy the program, how to integrate the results are all defined by the framework. We just define this task (the user program) and leave the rest to MapReduce.
The map function: accepts a key-value pair (key-value pair), resulting in a set of intermediate key-value pairs. The MapReduce framework will map function generated by the intermediate key-value pairs of the same key value is passed to a reduce function.
The reduce function: accepts a key, and a set of related values (value list), the set of values will be merged to produce a smaller set of values (usually only one or zero values).
The core code of the statistical word frequency MapReduce function is very short, mainly to implement these two functions.
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
In the example of the word count, the map function accepts the key as the file name and the value as the file’s contents. Map traverses the words one by one, generating an intermediate key-value pair <w, ‘1’> for each word it encounters (indicating that we have found another word w); MapReduce passes the same key-value pair (both words w) to reduce. function, so that the reduce function accepts the key as the word w, the value is a series of ‘1’ (the most basic implementation is like this, but can be optimised), the number of keys equal to the number of key-value pairs with the key w, and then accumulate these ‘1’ to get the number of occurrences of the word w. Finally, the number of occurrences of the word w is written to the underlying distributed storage system (GFS or HDFS), and is stored in the user-defined location. These occurrences are written to a user-defined location and stored in the underlying distributed storage system (GFS or HDFS).
3.2.3 Spark
Spark, as Apache’s top open-source project, is a fast and versatile large-scale data processing engine. It is similar to Hadoop’s MapReduce computing framework. However, compared to MapReduce, Spark has its scalability, in-memory computing, and other features. The advantages of data in any format on Hadoop are more efficient when batch processing, and have lower latency. Relative to the goal of ‘one stack to rule all’, in fact, Spark has become a unified platform for rapid processing of lightweight big data. Various applications, such as real-time stream processing, machine learning, interactive query, etc. It can be built on different storage and running systems through Spark.
Spark is a big data-parallel computing framework based on in-memory computing. Spark is based on in-memory computing, which improves the real-time performance of data processing in a big data environment, and at the same time guarantees high fault tolerance and high scalability, allowing users to deploy Spark on a large number of cheap hardware to form a cluster.
Compared to most big data processing frameworks, Spark is becoming one of the new and most influential big data frameworks after Hadoop’s MapReduce with its excellent low-latency performance. The entire ecosystem with Spark as the core, the bottom layer is the distributed storage system HDFS, Amazon S3, Mesos, or other format storage systems (such as HBase); resource management adopts cluster resource management models such as Mesos, YARN, or Spark comes with independent operating mode, as well as local operating mode. In the Spark big data processing framework, Spark provides services for a variety of upper-layer applications. For example, Spark SQL provides SQL query services, performance is 3– 50 times faster than Hive; MLlib provides machine learning services; GraphX provides graph computing services; Spark Streaming decomposes streaming computing into a series of short batch calculations, and provides high reliability and throughput service. It is worth noting that whether it is Spark SQL, Spark Streaming, GraphX or MLlib, you can use the Spark core API to deal with problems. Their methods are almost universal, and the processed data can also be shared, which not only reduces the learning cost but also its data Seamless integration greatly improves flexibility.
Spark has the following key features.
Running fast: Spark uses an advanced DAG (Directed Acyclic Graph) execution engine to support cyclic data flows and in-memory computations, with memory-based execution up to a hundred times faster than Hadoop MapReduce and up to ten times faster than disk-based execution.
Ease of use: Spark supports programming in Scala, Java, Python, and R. The simple API design helps users easily build parallel programs and allows for interactive programming through the Spark Shell.
Versatility: Spark provides a complete and powerful technology stack, including SQL queries, streaming computing, machine learning, and graph algorithm components that can be seamlessly integrated into the same application and are robust enough to handle complex computations.
Various operating modes: Spark can run in a standalone clustered mode, or in Hadoop, or in cloud environments such as Amazon EC2, and can access a variety of data sources such as HDFS, Cassandra, HBase, Hive, and more.
Figure 3.3 shows the architectural design of The Spark. The Spark runtime architecture includes a Cluster Manager, a Worker Node to run job tasks, a Driver for each application, and an Executor for specific tasks on each Worker Node. The Cluster Manager can be Spark’s own resource manager or a resource management framework such as YARN or Mesos.
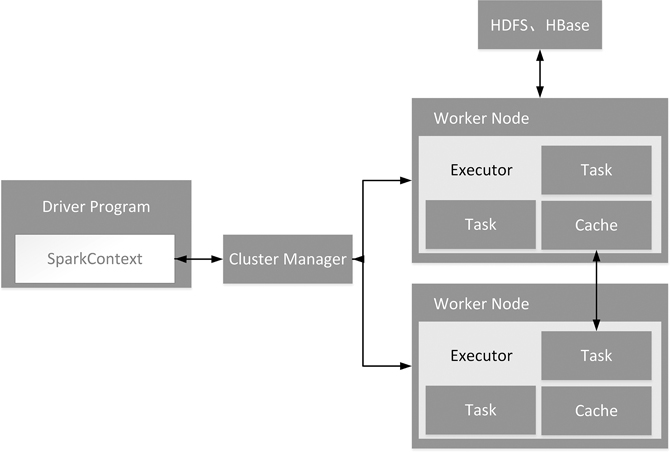
FIGURE 3.3 Spark architecture design.
3.3 Development of Blockchain Technology
Blockchain is essentially a distributed database system. As a kind of chain access data technology, blockchain technology participates in the calculation and recording of data through multiple nodes participating in the calculation in the network and verifies the validity of its information with each other. From this point of view, blockchain technology is also a specific database technology, which has played a great role in upgrading and supplementing existing Internet technologies.
In 1976, two masters of cryptography, Bailey W. Diffie and Martin E. Hellman published a paper ‘New Directions in Cryptography’, which covered all the new development areas of cryptography in the coming decades, including asymmetric encryption, Elliptic curve algorithms, hashing and other means have laid the development direction of the entire cryptography so far, and also played a decisive role in the development of blockchain technology and the birth of Bitcoin.
Immediately after in 1977, the famous RSA algorithm was born. It was not surprising that the three inventors won the Turing Award in 2002. However, the patents they applied for RSA, in the world generally recognised that the algorithm cannot apply for patents, really no one admits, and it expired in 2000 in advance. In 1980, Merkle Ralf proposed the Merkle-Tree data structure and the corresponding algorithm. One of the main uses later was to verify the correctness of data synchronisation in distributed networks. It was worth noting that in 1980, the really popular hash algorithm and distributed network have not yet appeared, for example: the well-known SHA-1, MD5 and other things were born in the 1990s. In that era, Merkle released such a data structure, which later played an important role in the field of cryptography and distributed computing, which is somewhat surprising. However, if you understand the background of Merkle, you know that this is no accident: He is a doctoral student of Hellman, one of the two authors of ‘New Directions in Cryptography’ (the other author, Diffie is a research assistant of Hellman). ‘New Directions in Cryptography’ is the research direction of Merkle Ralf’s doctoral students. It is said that Merkle is actually one of the main authors of ‘New Directions in Cryptography’. It was only because he was a doctoral student at the time that he did not receive the invitation to the academic conference to publish this paper. Turing Award missed.
In 1982, Lamport raised the question of General Byzantium, marking that the reliability theory and practice of distributed computing have entered a substantial stage. In the same year, David Chom proposed the cryptographic payment system ECash. It can be seen that with the progress of cryptography, keen people have begun to try to apply it to the fields of currency and payment. It should be said that ECash is a cryptography One of the earliest pioneers in encryption currency.
In 1985, Koblitz and Miller independently proposed the famous elliptic curve encryption (ECC) algorithm. Because the RSA algorithm previously invented is too large to calculate, it is difficult to be practical. The proposal of ECC really makes the asymmetric encryption system practical. Therefore, it could be said that in 1985, about 10 years after the publication of ‘New Directions in Cryptography’, the theoretical and technical foundation of modern cryptography had been fully established.
Interestingly, during the period from 1985 to 1997, there were no particularly significant developments in cryptography, distributed networks, and relations with payment/currency. In the author’s opinion, this phenomenon is easy to understand: when new ideas, concepts, and technologies are created, there must always be a considerable amount of time for everyone to learn, explore, and practice, and then there may be breakthrough results. The first 10 years are often the development of theory, and the latter 10 years have entered the stage of practical exploration. The period of about 1985–1997 should be the stage of the rapid development of related fields in practice. Finally, starting from 1976, after about 20 years, the field of cryptography and distributed computing finally entered an explosive period.
In 1997, the HashCash method, which was the first generation of POW (Proof of Work) algorithm, appeared at that time and was mainly used for anti-spam. In various papers published later, the specific algorithm design and implementation have completely covered the POW mechanism used by Bitcoin later.
By 1998, the complete idea of cryptocurrency finally came out, and Wei Dai and Nick Sabo simultaneously proposed the concept of cryptocurrency. Among them, Dai Wei’s B-Money was called the spiritual pioneer of Bitcoin, and Nick Sabo’s Bitgold outline was very close to the characteristics listed in Satoshi’s Bitcoin paper, so that some people once suspected that Sabo was Satoshi. Interestingly, it was another 10 years since the birth of Bitcoin.
With the advent of the 21st century, there have been several major developments in the blockchain-related field: First, the peer-to-peer distributed network. During the three years from 1999 to 2001, Napster, Edonkey 2000, and BitTorrent emerged one after another. The basis of P2P network computing.
Another important thing in 2001 was that the NSA released the SHA-2 series of algorithms, including the currently most widely used SHA-256 algorithm, which was the hash algorithm finally adopted by Bitcoin. It should be said that in 2001, all the technical foundations of the birth of Bitcoin or blockchain technology were solved in theory and practice, and Bitcoin was ready to come out. This phenomenon was often seen in human history. It takes about 30 years from the time when an idea or technology is proposed to its true development.
This phenomenon is not uncommon not only in the field of technology but also in other fields such as philosophy, natural sciences, and mathematics. The emergence and development of blockchain also follow this model. This model is also easy to understand, because after the birth of an idea, an algorithm, and a technology, it must be digested, explored, and practiced, and it takes roughly a generation of time.
Satoshi Nakamoto published the famous paper ‘Bitcoin: A Peer-to-Peer Electronic Cash System’ in November 2008. In January 2009, the founding block was excavated with his first version of the software, containing this sentence: ‘The Times 03/Jan/2009 Chancellor on brink of second bailout for banks’. Opened the era of Bitcoin like a curse. For the development process of Bitcoin, there are several time nodes that I think are important.
In September 2010, the first mining site Slush invented the method of multiple nodes cooperative mining, which became the beginning of the industry of Bitcoin mining. You should know that before May 2010, 10,000 bitcoins were only worth $25. If calculated at this price, all bitcoins (21 million) would also be worth $50,000. Concentrating on mining is obviously meaningless. Therefore, the decision to establish a mining pool means that someone believes that Bitcoin will become a virtual currency that can be exchanged with real-world currencies and has unlimited growth space in the future. This is undoubtedly a vision.
In April 2011, the first version officially recorded by Bitcoin official: 0.3.21 was released. This version was very junior, but of great significance. First of all, because he supports uPNP and realises the ability of the P2P software we use every day, Bitcoin could really enter the room and enter the home of ordinary people so that anyone could participate in the transaction. Secondly, before this, the smallest unit of bitcoin node only supported 0.01 bitcoin, which was equivalent to ‘point’, and this version really supports ‘satoshi’. It could be said that since this version, Bitcoin had become what it was now, and it had really formed the market. Before this, it was basically a plaything for technicians.
In 2013, Bitcoin released version 0.8, which was the most important version in the history of Bitcoin. It had completely improved the internal management of the Bitcoin node itself and the optimisation of network communication. It was after this point in time that Bitcoin really supported large-scale transactions across the entire network, becoming the electronic cash envisioned by Satoshi Nakamoto, and truly having global influence.
Things have not always been smooth. In the most important version 0.8, Bitcoin encountered a big bug, so after this version is released, Bitcoin had a hard fork in a short time, resulting in the entire Bitcoin finally having to fall back to the old version, this also led to a sharp drop in the price of Bitcoin.
The development after Bitcoin is well known by more and more people. For example, the attitudes of countries around the world, the growth of computing power-reached 1EH/S in January 2016, and more than 10,000 related open-source projects prove that the Bitcoin ecosystem was fully mature.
Everyone is familiar with Ethereum, and the second-largest digital currency in circulation is second only to Bitcoin. Known as Blockchain 2.0. Ethereum was invented by Vitalik Buterin. This Russian guy did development and news reports in the field of Bitcoin very early and finally developed Ethereum on his own. At the end of 2013, Vitalik Buterin described Ethereum for the first time as a result of his research on the Bitcoin community. Soon after, Vitalik published an Ethereum white paper ‘The structure of smart contracts’. In January 2014, Vitalik officially announced Ethereum at the North American Bitcoin Conference in Miami, Florida.
Ethereum is divided into four stages, Frontier, Homestead, Metropolis, Serenity, the transition between stages needs to be achieved through a hard fork. The first three phases use a proof of work (POW) system, and the last phase uses a proof of stake (POS) system.
At the same time, Vitalik started working with Dr. Gavin Wood to create Ethereum. In April 2014, Gavin published the Ethereum Yellow Book as a technical description of the Ethereum virtual machine. According to the specific instructions in the Yellow Book, the Ethereum client has been implemented in seven programming languages (C++, Go, Python, Java, JavaScript, Haskell, Rust), making the software more optimised overall. It improves the compatibility of Ethereum development and provides a solid foundation for the later development of Ethereum. Multiple development teams located in many countries can implement the same Ethereum protocol in different programming languages, so that Ethereum can be integrated into other systems as widely as possible, providing long-term flexibility and being suitable for the future.
The consortium blockchain is called Blockchain 3.0. Blockchain is towards more complex intelligent contracts, hyperledger in the future can record anything that can be expressed in the form of code, expand the application to the government, health, science, art, etc.
It can be said that blockchain has already built a potential value interconnection layer beyond information interconnection based on the bottom layer of the Internet. Hyperledger, led by IBM, is arguably the current leader.
In December 2015, led by the Linux Foundation, IBM, Intel, Cisco, and others jointly announced the establishment of the Hyperledger joint project. The hyperledger project provides an open-source reference implementation for transparent, open, decentralised enterprise distributed ledger technology. The hyperledger introduced the blockchain technology into the application scenario of distributed alliance ledger for the first time, laying a foundation for building a highly efficient commercial network based on the blockchain technology in the future. Currently, the hyperledger consists of eight top sub-projects for different purposes and scenarios:
Fabric: the target is the basic core platform of blockchain, which supports permission management and is realised based on Go language;
Sawtooth: support the brand new hardware chip-based consensus mechanism, Proof of Elapsed Time (PoET);
Iroha: ledger platform project, based on C++ implementation, with Web and mobile-oriented features;
Blockchain Explorer: provides a Web interface to view the status (block number, transaction history) information of the query binding Blockchain;
Cello: provide the deployment and runtime management functions of the blockchain platform. Application developers need not care how to build and maintain the blockchain
Indy: provides a digital identity management mechanism based on distributed ledger technology;
Composer: provides high-level language support for the development of chaincode, automatically generates chaincode, etc.;
Burrow: provides support for Ethereum virtual machines to implement a privileged blockchain platform for efficient trading.
The logical architecture of Fabric is the technical component. From the application, including the SDK, API, events, and through the SDK, API, events on the underlying blockchain operation: including identity management, ledger management, contract management, intelligent deployment, and call. From the point of the underlying blockchain, this end provides the following services: member management service, consensus, chaincode, security, and password services. Fabric provides pluggability and flexibility by separating parts into modules. The basic framework of Fabric is as showed in Figure 3.4.
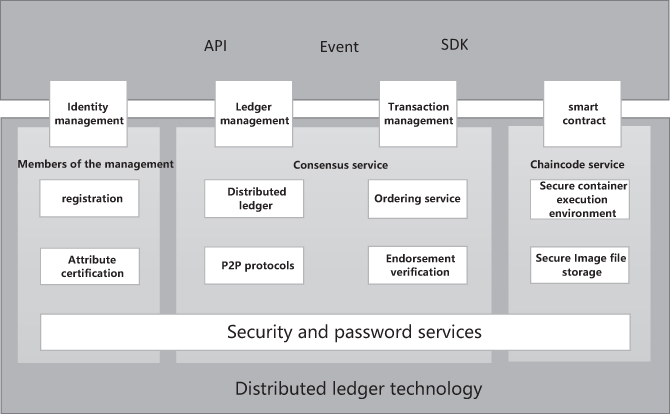
FIGURE 3.4 The basic framework of fabric.
3.4 Taxonomy of Blockchain Systems
Current blockchain systems can be roughly categorised into three types: public blockchain, private blockchain and consortium blockchain (Buterin, 2014). We compare these three types of blockchain from different perspectives (Zheng, Xie, Dai, Chen, & Wang, 2018). The comparison is listed in Table 3.1.
Property |
Public Blockchain |
Consortium Blockchain |
Private Blockchain |
|---|---|---|---|
Consensus determination |
All miners |
Selected set of nodes |
One organisation |
Read permission |
Public |
Could be public or restricted |
Could be public or restricted |
Immutability |
Nearly impossible to tamper |
Could be tampered |
Tampered |
Efficiency |
Low |
High |
High |
Centralised |
No |
Partial |
Yes |
Consensus process |
Permissionless |
Permissioned |
Permissioned |
Consensus determination. In public blockchain, each node could take part in the consensus process. And only a selected set of nodes are responsible for validating the block in consortium blockchain. As for private chain, it is fully controlled by one organisation who could determine the final consensus.
Read permission. Transactions in a public blockchain are visible to the public while the read permission depends on a private blockchain or a consortium blockchain. The consortium or the organisation could decide whether the stored information is public or restricted.
Immutability. Since transactions are stored in different nodes in the distributed network, so it is nearly impossible to tamper the public blockchain. However, if the majority of the consortium or the dominant organisation wants to tamper the blockchain, the consortium blockchain or private blockchain could be reversed or tampered.
Efficiency. It takes plenty of time to propagate transactions and blocks as there are a large number of nodes on public blockchain network. Taking network safety into consideration, restrictions on public blockchain would be much more strict. As a result, transaction throughput is limited and the latency is high. With fewer validators, consortium blockchain and private blockchain could be more efficient.
Centralised. The main difference among the three types of blockchains is that public blockchain is decentralised, consortium blockchain is partially centralised and private blockchain is fully centralised as it is controlled by a single group.
Consensus process. Everyone in the world could join the consensus process of the public blockchain. Different from public blockchain, both consortium blockchain and private blockchain are permissioned. One node needs to be certificated to join the consensus process in consortium or private blockchain.
Since public blockchain is open to the world, it can attract many users. Communities are also very active. Many public blockchains emerge day by day. As for consortium blockchain, it could be applied to many business applications. Currently, Hyperledger (Androulaki et al., 2018) is developing business consortium blockchain frameworks. Ethereum also has provided tools for building consortium blockchains. As for private blockchain, there are still many companies implementing it for efficiency and auditability.
3.5 Scalability of Blockchain Technology
Currently, the blockchain scalability bottleneck is mainly in three aspects: performance inefficiency, high confirmation delay, and function extension. For example, Bitcoin can only deal with seven transactions per second on average. Obviously, it cannot meet the requirement of current digital payment scenarios, nor can it be carried in other applications such as distributed storage and credit service. Here are four mainstream solutions to improve the performance of blockchain system, including the sharding mechanism, DAG-based, off-chain payment network, and cross-chain technology.
3.5.1 Sharding Mechanism
In 2016, Luu et al. published a paper, which proposed the concept of Sharding in the field of blockchain for the first time. Its general design idea is: Turn each block in the blockchain network into a sub-blockchain, and sub-blockchain can accommodate several (currently 100) collation packaged with transaction data. These collations finally constitute a block on the main chain; because this collation exists as a whole in a block, its data must be packaged and generated by a specific miner, essentially the same as the blocks in the existing protocol, so no additional network confirmation is required. That would increase the trading capacity of each block by about 100 times.
Elastico and Zilliqa are two typical projects using the sharding mechanism. They both adopt PoW to prove as Sharding algorithm, and the scheme during the consensus adopted PBFT algorithm. In order to resist the Sybil attack, at the beginning of a consensus, nodes need to conduct simple work to prove to get involved in PBFT identity. The criteria for dividing nodes into different sets are based on the result of PoW. By establishing a probability model, it can be obtained that when the sharding size reaches 600, the probability that the attacker can control a sharding (i.e. having more than 1/3 nodes in any shard) is negligible, even if the attacker has 1/3 computing power. The specific process can be abstracted as follows:
The node obtains its identity through PoW and divides it into different sets.
Conduct transaction consensus within each sharding through PBFT algorithm.
The transaction set after the consensus segmentation and the signature in the consensus process are broadcast to a certain shard. The shard verifies the signature, conducts the consensus segmentation, and packages the consensus into blocks and broadcasts the whole network.
Elastico’s solution is based on the UTXO model. By making transactions on the main chain and creating a receipt (with receiptID), the user can store the data in a specified sharding. And the user on the Sharding chain can create a receipt-consuming transaction to spend the receipt given receiptID. Elastico can therefore effectively resist double-spend attack during transaction processing so that when processing a trade, it maps to different Sharding processes via the input to the trade as a baseline.
Zilliqa is a solution model based on the account model. When the transaction processing, it maps to different shards by the identity of the sender. In the consensus process, different sender trading could be mapped to different subdivisions (different validations), but the same sender transactions will be handled by the same sharding, so the trusted nodes in the sharding are determined to the state of a particular sender. Therefore, it can resist a double-spend attack model based on the account.
3.5.2 DAG-based
Using a DAG as a distributed ledger is not about removing proof-of-work mining, blocks, or transaction fees. It is about leveraging the structural properties of DAGs to potentially solve blockchain’s orphan rate problem. The ability of a DAG to withstand this problem and thus improve on scalability is contingent on the additional rules implemented to deal with transaction consistency, and any other design choices made.
The DAG blockchain mainly improves the data layer and consensus layer of bitcoin blockchain, as shown in Figure 3.5. It follows the P2P network structure of bitcoin blockchain to organise the nodes of the whole network. On the bitcoin blockchain, newly released blocks will be added to the original longest chain, which will be extended indefinitely according to the longest chain considered by all nodes.
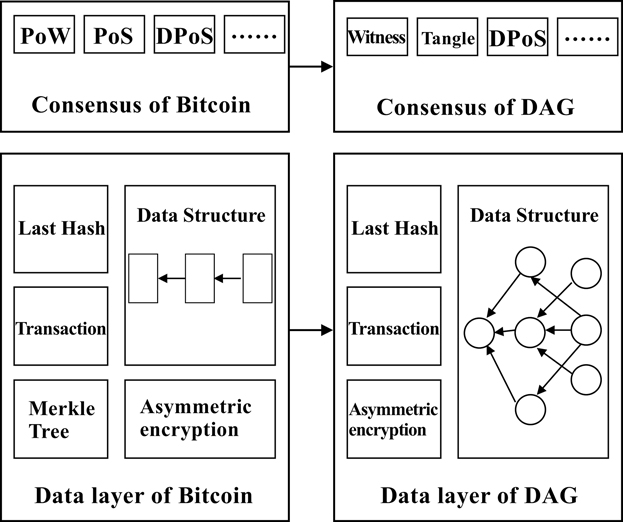
FIGURE 3.5 The difference between DAG and Bitcoin.
3.5.3 Off-Chain Payment Network
Such solutions are generally proposed on the original public chain, such as Bitcoin’s Lightning Network and Ethereum’s Raiden Network, which mainly solve the payment problem.
The two strategies are to keep the underlying blockchain protocol unchanged, put transactions under the chain for execution, and solve scalability problems by changing the way the protocol is used. The part of the off-chain can be implemented with the traditional centralised distributed system, and the performance is scalable. Under this strategy, only coarse-grained ledgers are recorded on the distributed ledger, while truly fine-grained details of bilateral or limited multilateral transactions are not recorded as transactions on the distributed ledger. The disadvantage is that there is a centralised system.
3.5.3.1 Lightning Network
The lightning network is the earliest scheme to form a payment network through the payment channel under the chain and improve the transaction throughput of the blockchain. It consists of a blockchain-based downlink transport network that works at the P2P level, and its availability depends on the creation of a two-way payment channel through which users can conduct seamless cryptocurrency transactions. To create a payment channel, both parties need to set up a multi-signature wallet and store some funds that can only be accessed if both parties provide private keys. After the two sides decide to open a payment channel, they can transfer money back and forth in their wallets. Although the process of establishing a payment channel involves transactions on the chain, all transactions that take place within the channel are on the chain and therefore do not require a global consensus. As a result, these trades can be executed quickly through smart contracts, allowing for higher TPS while paying lower fees.
However, there are some limitations of Lightning networks. If the receiver of both parties are not online, Lightning online payment cannot be made. In order to ensure the security of funds, it is necessary to monitor the payment channel regularly. Lightning networks are not suitable for large payments, because they rely on a large number of multi-signature wallets (basically Shared wallets), so they probably do not have enough balance to act as intermediaries for large payments. Creating and closing payment channels involves on-chain transactions that require manual operation and may incur high transaction costs.
3.5.3.2 Raiden Network
Model based on Ethernet, Raiden network reference the structure of the Lightning network. Since Raiden Network is a complementary network, it users a channel to deal with a number of deals, some of the encryption algorithm is then used to record and verify the actual transaction data under the chain. Finally, when the Channel is shut down, the transaction data is shut down. Actual cryptocurrency transactions and authentication are carried into the blockchain. In this way, the actual number of transactions on the blockchain will be reduced and transaction costs will be reduced and accelerated.
It works like the bar tab, because you only pay the total amount to the bar at the end of the day, instead of going through the entire payment process every time you buy a drink. Each bar tab is called a channel.
Any particular channel is one-to-one (for example, Alice to Bob) and the channels can be linked together to form a network so that users can pay anyone in the network. Figure 3.6 shows that even if F has only channel A, anyone in the network can pay F through the channel interaction associated with A.
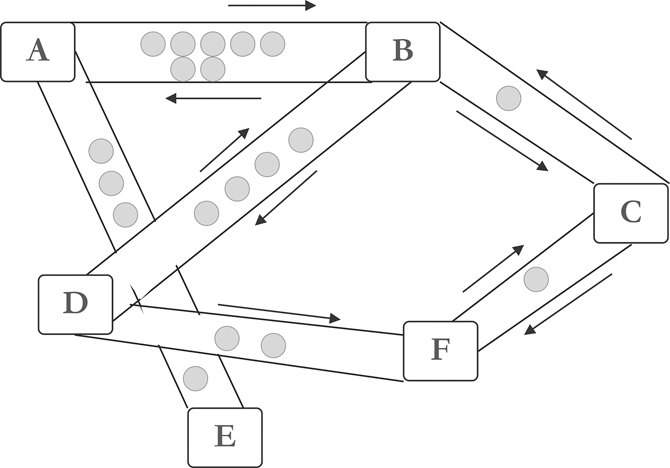
FIGURE 3.6 Process of Raiden Network.
Since only two participants can receive deposits in the payment channel’s smart contracts, payment channel transfers are not affected by double-spend attacks, making them as secure as transactions on the chain.
3.5.4 Cross-Chain Technology
Cross-chain is the technology to solve the problem of the interaction between the chain and chain. The process can be divided into two stages: assets on A chain of locking phase and the corresponding assets on the chain B unlock stage. The main challenges are how to ensure that the asset on chain A is locked, how to determine the asset on chain B is unlocked, and how to guarantee the atomicity of asset locking and unlocking between chain A and B, that is, the corresponding asset between two chains either locks and unlocks successfully or locks and unlocks fail. For the above challenges, different cross-chain technologies were proposed, mainly including four categories.
3.5.4.1 Multi-Centre Witness
The Witness mechanism uses witness to guarantee the locking and unlocking of assets in different chains. The multi-signature script in the blockchain script is mainly used to realise the two-way exchange between the chains. The specific process is as follows: the user transfers the asset of chain A to the multi-signature script address of several witnesses for locking, and the witnesses release the corresponding asset to the address of the user in chain B after confirmation. This technology is applied in Byteball and DagCoin.
3.5.4.2 Side Chain/Relay Technology
The side chain is based on anchoring some kind of general certificate on the original chain, just like the dollar anchoring to gold. Sidechains are connected to various chains, while other blockchains can exist independently.
The representative of side chain technology is BTC Relay. It is considered the first side chain on the blockchain. BTC Relay connected the Ethereum network to the bitcoin network by using Ethereum’s smart contracts, allowing users to verify bitcoin transactions on Ethereum. It creates a smaller version of the bitcoin blockchain through Ethereum’s smart contracts, which require access to bitcoins’ network data, making decentralisation difficult. The specific process is as follows:
Alice and Bob use the smart contract to conduct transactions. Alice users BTC coin to exchange Bob’s ETH coin, and Bob sends his ETH coin to the smart contract;
Alice sends BTC coins to Bob’s address.
Alice generates the SPV certificate through the transaction information of bitcoin and inputs the certificate into the contract in the ETH system;
After the contract is triggered, confirm the SPV certificate, and then release Bob’s ETH coin to Alice’s address before.
In addition, another typical implementation is Cosmos. It is a heterogeneous network developed by the Tendermint team that supports cross-chain interaction. Cosmos adopts the Tendermint consensus algorithm, which is similar to the practical Byzantine fault-tolerant consensus engine with high performance, consistency, and under its strict bifurcated liability system, can prevent malicious participants from making improper operations.
The central and individual Spaces of the Cosmos network can be communicated through the blockchain communication (IBC) protocol, which is specific to the blockchain network, similar to the UDP or TCP network protocols, as shown in Figure 3.7. Tokens can be transferred safely and quickly from one space to another without the need for exchange liquidity. Instead, all transfers of tokens within the space go through the Cosmos centre, which records the total number of tokens held per space. This centre separates each space from the other fault Spaces. Because everyone can connect the new space to the Cosmos centre, Cosmos is also compatible with future blockchains.
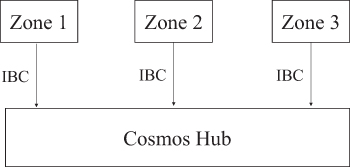
FIGURE 3.7 Structure on cosmos relay network.
3.5.4.3 Hash Locking
Hash locking works in the same way as HTLC in Lightning networks. By using Hash preimage as secret and conditional payment, the atomicity of different transactions can be guaranteed without the participation of trusted third parties, so as to realise fair cross-chain exchange.
As shown in Figure 3.8, the process of cross-chain atom exchange is as follows:
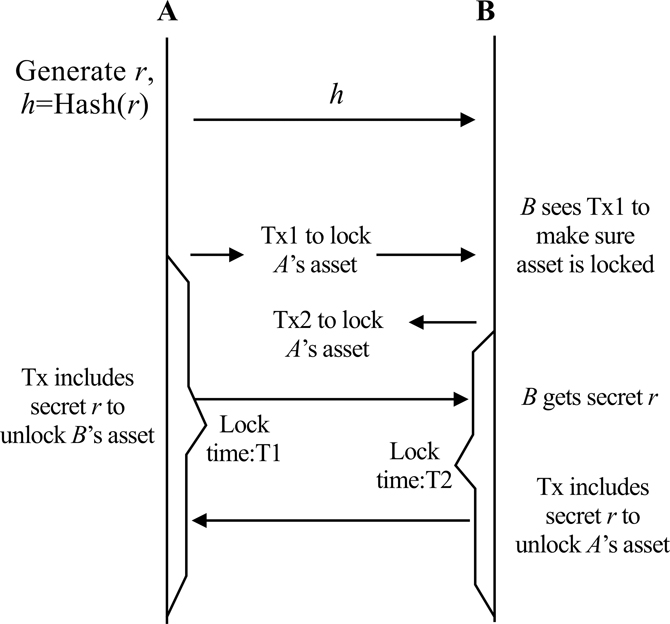
FIGURE 3.8 Process of cross-chain atomic swap.
A generates random number r and calculates its Hash value h, then send h to B.
A and Block up the assets for exchange successively by using HTLC. The locking time of A shall be longer than that of B, that is, T1 < T2. From the perspective of A, in time T1, B can obtain the asset locked by A through public image r, otherwise, A can redeem its asset. From the perspective of B, in time T2, A can obtain the asset locked by B through public image r, otherwise, B can redeem its asset.
A obtains the locked assets of B by publishing the preimage r. Meanwhile, B obtains secret r and obtains the locked assets of A on another chain by publishing r.
3.5.4.4 Distributed Private Key Control Technology
Private assets are mapped to the blockchain of built-in asset templates based on protocols through distributed private key generation and control technology, and new assets are created based on the deployment of new smart contracts which based on cross-chain transaction information. When a registered asset is transferred from the original chain to the cross-chain, the cross-chain node will issue corresponding tokens of equivalent value to the user in the existing contract. In order to ensure that the original chain assets can still trade with each other across the chain, the operation of realising and unlocking distributed control management is called lock-in and lock-out. Lock-in is the process of implementing distributed control management and asset mapping for all digital assets controlled by keys. The decentralised network needs to be entrusted with the user’s private key, and the user holds the private key of the agent asset across the chain. When unlocked, control of the digital asset is returned to the owner.
3.6 Similarities between Big Data and Blockchain Technology
Big data and blockchain technologies are constantly developing. There is a common keyword between big data and blockchain: distributed, representing a shift from the monopoly of technology authority to decentralisation. Some may think the two technologies are mutually exclusive. In fact, they are two complementary technologies. Like other emerging technologies, big data and blockchain are gradually changing the way some industries operate. What will happen when these two technologies are applied simultaneously? To answer this question, it is necessary to better understand the differences and connections between blockchain and big data.
The main similarities between big data and blockchain technology are as follows:
Distributed database: Due to the massive and fast-growing storage needs of big data to deal with, more and more distributed storage technologies have emerged. Hadoop (White, 2012), Spark (Zaharia, Chowdhury, Franklin, Shenker, & Stoica, 2010), MapReduce (Dean & Ghemawat, 2008), SAS, and Rapid Miner offer flexibility, and scalability performance to improve the storage capacity and the analytic process (Oussous, Benjelloun, Lahcen, & Belfkih, 2018; Tsai, Lai, Chao, & Vasilakos, 2015). Blockchain technology calculates and records data together through multiple nodes participating in the calculation in the network. From this point of view, blockchain technology is also a specific database technology.
Distributed Computing: The analysis of big data needs huge distributed computing power. Fault-tolerance, security, and access control are the critical requirements of big data technology (Dean & Ghemawat, 2008). The consensus mechanism of blockchain is to generate and update data through an algorithm. These three requirements are also needed by blockchain technology.
Serving the economy and society: Behind big data and blockchain technologies are urgent economic and social needs. The more centralised the application technology, the more complex the system will be, and the more difficult the implementation will be. The cost of communication and management is also getting higher and higher. The emergence of such distributed systems is from the needs of economic society.
3.7 Differences between Big Data and Blockchain Technologies
There are also many differences between big data and blockchain technology. As early as 1980, Alvin Toffler, a famous futurist, praised ‘big data’ as ‘the colorful movement of the third wave’ in his book The Third Wave. In October 2008, Satoshi Nakamoto described an electronic cash system called Bitcoin based on blockchain technology in his paper Bitcoin: a peer-to-peer electronic cash system (Nakamoto, 2008). As shown in Table 3.2, in big data, most of the data is unstructured, while data of blockchain is structured due to its special structure. What’s more, big data sets are large and complex enough while the data that blockchain can carry now is limited, far from the big data standard. The blockchain system itself is a database, and the main purpose of big data is to deeply analyse and mine data. In terms of security and anonymity, big data is not as good as blockchain technology.
Big Data |
Blockchain |
|
|---|---|---|
Appear time |
1980 |
2008 |
Data structure |
Mostly unstructured |
Structured |
Data size |
Huge |
Restricted |
Purpose of data collection |
Analysis and mining |
Database |
Security |
Vulnerable to attack |
Difficult to tamper with |
Anonymity |
Weak |
Strong |
3.8 Chapter Summary
Blockchain technology can be used in big data, and the technology ecology of big data flourishes. No software can solve all the problems. It can solve the problems only in a range, even Spark, Flink, etc. In the context of emphasising transparency and security, blockchain has its place. The use of blockchain technology on big data systems can prevent data from being added, modified, and deleted at will. Of course, the time and data magnitude are limited.
Taking time and data volume as the axis, the current big data engine is generally good at processing data. Blockchain can be a good supplement. For example, the centralization of big data is not secure enough. By adding blockchain, historical data cannot be tampered with. Yes, we can Hash the big data, add a timestamp, and store it on the blockchain. At some point in the future, when we need to verify the authenticity of the original data, we can do the same Hash processing on the corresponding data. If the answer is the same, it means that the data has not been tampered with. Or, only the aggregated data and results are processed. In this way, only incremental data processing needs to be processed, and the corresponding data magnitude and throughput level may be processed by today’s blockchain or improved systems.
This chapter describes some of the key technologies of big data, the history of blockchain technology, and more. The types of blockchain types include public, private and consortium chains. Finally, some sections on the scalability of the blockchain are introduced. By combining big data and blockchain, the data in the blockchain can be made more valuable, and the predictive analysis of big data can be implemented into actions. They will all be the cornerstones of the digital economy.
References
Androulaki, E., Barger, A., Bortnikov, V., Cachin, C., Christidis, K., De Caro, A., . . ., Manevich, Y. (2018). Hyperledger fabric: a distributed operating system for permissioned blockchains. Proceedings of the Thirteenth EuroSys Conference, ACM.
Buterin, V. (2014). Ethereum: A next-generation smart contract and decentralized application platform. Retrieved from https://github.com/ethereum/wiki/wiki/%5BEnglish%5D-White-Paper 7.
Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1), 107–113.
Nakamoto, S. (2008). Bitcoin: A peer-to-peer electronic cash system.
Oussous, A., Benjelloun, F.-Z., Lahcen, A. A., & Belfkih, S. (2018). Big Data technologies: A survey. Journal of King Saud University-Computer and Information Sciences, 30(4): 431–448.
Tsai, C.-W., Lai, C.-F., Chao, H.-C., & Vasilakos, A. V. (2015). Big data analytics: a survey. Journal of Big Data, 2(1), 21.
White, T. (2012). Hadoop: The definitive guide. O'Reilly Media, Inc. Sevastopol, California.
Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., & Stoica, I. (2010). Spark: Cluster computing with working sets. HotCloud, 10(10–10), 95.
Zheng, Z., Xie, S., Dai, H.-N., Chen, X., & Wang, H. (2018). Blockchain challenges and opportunities: A survey. International Journal of Web and Grid Services, 14(4), 352–375.