9
What corpora are available?
David Y. W. Lee
1. Corpora, text collections, archives and corpus distribution sites
Given how rapidly new electronic corpora come into existence, a chapter such as this may, on the face of it, seem to run the risk of going out of date quite quickly. However, there is a case to be made for having a general survey of currently available corpora: it will help give newcomers to the field a quick overview of what is available (the corpus universe) as well as an understanding of the differences that can be found between one corpus and another (the different stars and constellations within the universe and their distinguishing characteristics). Many types of corpora for a huge variety of languages have sprung up all over the world (particularly in the last decade, in the case of languages other than English), and the trend looks set to continue apace largely because research within the corpus paradigm has proven so fruitful. The bird’s-eye view of currently available corpora in this chapter will provide a launching pad for those seeking out resources for research or pedagogical applications, but it is not intended to be exhaustive. This chapter is restricted to the description of ‘ready-made’ corpora – i.e. specially organised collections of text that are called corpora by their creators. There are many text-collection or text-library sites such Gutenberg or American Rhetoric where you may download individual books, plays, speeches, interviews, and so forth, to create your own personal corpus. Such electronic text libraries are certainly worth visiting, but are not the focus of this chapter.
2. Accessing and categorising corpora
One of the first problems a newcomer to the field faces is: Where do I go? How do I get access to a ready-made corpus? These are actually two different questions. Where you go to, first of all, is usually a website, where the copyright, user agreement and/or purchase form for the corpus may be downloaded. Many corpora are distributed through one of the international corpus distribution agencies or archive sites, such as the International Computer Archive of Modern and Medieval English (ICAME), the Linguistic Data Consortium (LDC) or the Oxford Text Archive (OTA). ICAME is a repository for many contemporary and historical English language corpora and also distributes many of the major English language corpora that linguists use for research. The LDC, in contrast, is very much multilingual in nature, as well as more ‘applied’ or ‘industrial’ in focus, being geared more towards the needs of computational linguists and people in natural language processing. The LDC includes a much wider range of ‘data sets’, including some that may be only marginally recognised as ‘corpora’ by some linguists. For example, the LDC has many collections of individual words, isolated numbers or phrases read aloud, as well as human-computer ‘conversations’, speech recorded in noisy environments, and so forth. Such data are mainly for the purposes of research in speech recognition, speech synthesis or machine translation rather than language description. However, the LDC also holds many specialised corpora of genres such as news reportage, telephone conversations, meetings, parallel translated texts, etc., that linguists would definitely find of interest. The third major distributor, the Oxford Text Archive, also has a multilingual collection (ranging from Latin and ancient Greek to modern languages), although its holdings are mostly of English. If you are confused about where to go because of these different sites, help is at hand: a new initiative called the Open Language Archives Community (OLAC) has a search engine that is a good one-stop shop for getting information on catalogued, major corpora, since its database of resources spans across the different sites.
The second issue mentioned above concerns the accessibility or the actual use of corpora. In an ideal world, all corpora would be easily accessible and freely searchable on-line. In reality, however, the majority of corpora are not accessible with a single click. There are a few notable exceptions, but even in these cases copyright, privacy and distribution issues usually restrict access to no more than a small window of context (a few words to the left and right of the search term you type in). Practically all published texts are the copyright of someone, so it is fair to say that most corpora cannot be free or cannot be fully and publicly accessible. Many corpora (e.g. the British National Corpus) have restrictions because they were collected with private funding, mainly from dictionary publishing houses, or because they contain whole or partial texts that are not copyrightcleared for distribution. Short snippets can, however, usually be accessed without problem, and web interfaces to some copyrighted corpora are on-line and without passwords because the built-in limitations ensure that there is no way to read any text in its entirety. For some classroom activities and research purposes, the limited web-accessible versions may well be sufficient. For deeper and more extensive analyses, however, you will probably need to obtain the actual text files, and will thus need to obtain or purchase a licence.
In view of the fact that the majority of corpora are of the English language, along with corresponding research on corpora, this survey will concentrate on English language resources. However, corpora of other languages are certainly increasing in number variety, and quality; and, in the case of endangered languages, such corpora may, regrettably, even be the last repositories of knowledge about those languages in the future.
This chapter will take a simple approach, first focusing on monolingual English language corpora, categorising them broadly into general, speech, parsed, historical and specialised, and then touching briefly on multimedia corpora and the concept of the web as a corpus. Within each of these categories there are, of course, possibilities for further subdivisions (e.g. spoken versus written), and some categories overlap, but the categories used here are in general use and perhaps the most helpful. The next major section is on ‘non-expert corpora’, those containing native-speaker developmental language, non-native or learner language, and lingua franca speech. These represent growing areas of interest in corpus-based research. The last major section covers monolingual corpora for languages other than English, as well as multilingual corpora in all their flavours: translation, comparable and parallel corpora.
3. Major English language corpora
‘General language’ corpora (spoken, written and both)
Much of the research in the early years was based on the first generation of ‘standard’ corpora – so-called because they set the standard for future corpora and also because they were compiled along roughly the same sampling lines: the Brown Corpus of written American English, the Lancaster Oslo-Bergen (LOB) corpus of written British English, the Wellington Corpus of Written New Zealand English, the Australian Corpus of English (ACE) and the Kolhapur Corpus of Indian English are all approximately one million words in size, and designed to be more or less comparable with each other. They all contain 500 texts, of about 2,000 words each, sampled across a wide variety of written genres. In terms of time period, the texts were from the 1960s in the case of Brown and LOB, the 1970s in the case of the Kolhapur, and the 1980s in the case of ACE and the Wellington corpus. Recently, more contemporary analogues to the Brown and LOB have been compiled, and are similarly named to show the connection: FROWN (Freiburg– Brown Corpus of American English) and FLOB (Freiburg–LOB Corpus of British English) contain texts from the 1990s but in other respects follow the same sampling criteria and text domain proportions as Brown and LOB. In addition, a corpus covering the early 1930s, the period before the LOB sampling frame, has also been compiled, and another one-million-word comparable corpus, the BE06 Corpus, has been compiled to represent the texts of the mid-2000s, as a further update. This multiple copying of the original Brown/LOB design is not because the sampling criteria and genre proportions therein are considered ideal (indeed, they are not). It is rather because the compilers wanted maximal comparability for regional and diachronic research.
Among the many one-million-word corpora in existence are the various national components of the International Corpus of English (ICE). This ambitious and wideranging project was launched in 1990 with the aim of collecting material for comparative studies of English worldwide. At the time of writing, eighteen research teams around the world have finished or are currently preparing corpora of their own national or regional variety of English, all following a common corpus design as well as a common scheme for grammatical annotation in order to allow cross-corpus comparisons. While ICE follows the Brown/LOB format of 500 texts of approximately 2,000 words each, it differs in that spoken texts are included (making up 60 per cent of the one-million-word total).
The second generation of corpora are products of the internet age, and are therefore mostly very large. The first mega-corpus that should be mentioned is the Bank of English, which was launched in 1991 covering both spoken and written English, and different regional varieties (British English, 70 per cent; American, 20 per cent; and other varieties of English, 10 per cent). This corpus was a continuation of the COBUILD corpus at the University of Birmingham which had started earlier, in 1980. In the same year that the Bank of English was launched, the ambitious British National Corpus (BNC) project was also initiated, and by 1994 had completed its mission of creating a broad-coverage mega-corpus of 100 million words, of which a tenth was composed of transcribed speech. The BNC has so far proved to be one of the most heavily used and researched corpora, and therefore will be described in some detail. While the Bank of English may be bigger, uptake of the BNC by universities and researchers appears to have been greater, perhaps because it was promoted more actively, but also because it has been more freely accessible to the general public (at the time of writing, there are at least three public web interfaces to the BNC, whereas only a fifty-six-million-word subset of the Bank of English is freely searchable through a web interface that gives very restricted access to the texts). The ten-million-word spoken component of the BNC has both a demographically sampled (mostly ‘casual conversation’) component and a ‘contextgoverned’ (mostly ‘task-oriented’) component, in the ratio of 6:4. The task-oriented component contains the more formal speech varieties, typically those with one speaker but many listeners, such as broadcast news, radio interviews, formal speeches and lectures. The written component of the BNC (ninety million words) was drawn mainly from published sources, although small amounts of unpublished, miscellaneous texts were also sampled. The huge variety of types of text included in the BNC has made it very valuable for research, and accounts for its continued popularity of use (see Lee 2001 for a detailed breakdown of the genres in the corpus).
The success of the BNC in stimulating linguistic research on British English soon resulted in a push for a North American counterpart, and also inspired numerous national corpora for other languages (see the section on ‘Non-English corpora’ below). In 1999, the American National Corpus (ANC) consortium was set up, and in 2003 the first component (about ten million words) was released, followed by a second release (about twenty-two million words) a few years later. When completed, the ANC is expected to have a core corpus of at least 100 million words, comparable in variety to the BNC, except that new genres of the internet that were only nascent or nonexistent when the BNC was being compiled, such as personal e-mails, internet chat and web pages, are included in the ANC. Corpus of Contemporary American English (COCA) is a megacorpus that attempts to capture a snapshot of English as it is used in the United States. Its texts are mostly culled from the web or other electronic sources under a ‘fair use’ understanding of copyright law, and the corpus is thus not available to download, but can be searched online, with limited concordance contexts given for search results. The corpus contains more than 385 million words at the time of writing, and is equally sampled for the broad genre categories of speech, fiction, popular magazines, newspapers and academic texts. The spoken texts are transcripts from broadcast interviews, talk shows and so forth, however, rather than demographically sampled conversations, so ‘informal conversation’ is one area that is lacking. COCA is designed to have new data added every six to nine months, and can therefore serve as a record of linguistic changes in American English.
Speech corpora
If you are interested in studying spoken English, then in addition to the spoken English transcripts that form part of ‘general language’ corpora such as the BNC and ANC, there are some spoken corpora that may meet your needs more precisely, particularly if you are interested in studying the actual speech signal and not just text transcripts. Some researchers use the term ‘speech corpus’ to refer to such multimedia corpora, to distinguish them from others that are available in transcript form only or that contain poor sound recordings that are unsuitable for phonetic studies. The BNC, for example, does not qualify as a ‘speech corpus’, as the original sound recordings can currently only be accessed at the National Sound Archive of the British Library, apart from the subset of recordings that are shared with the Bergen Corpus of London Teenage Language (COLT), which is available on CD-ROM.
For general studies of British Received Pronunciation (RP), the Spoken English Corpus (SEC; 53,000 words), consisting mainly of radio broadcasts between 1984 and 1991, is still a good choice in spite of the slightly dated material. This is because the SEC is accompanied by not only orthographic transcripts and sound recordings, but also phonemic and prosodic mark-up, along with part-of-speech tags and grammatical parse trees. The associated Machine Readable Spoken English Corpus (MARSEC) is an updated version of the SEC, containing digitised versions of the original tape recordings, time-aligned with the transcripts. The original prosodic mark-up in the SEC was also converted to ASCII characters for easier processing. The Aix-MARSEC database is a further extension, adding annotations for syllables, stress feet, rhythm units and other phenomena.
Another spoken corpus that is prosodically marked up, but a bit older in provenance (recordings were made in the 1960s and 1970s), is the London–Lund Corpus of Spoken English (LLC). This 500,000-word corpus consists of about 100 texts of 5,000 words each. The highly detailed prosodic and other annotations in the LLC indicate stress, tones, tone units, pauses and other prosodic and paralinguistic phenomena, and are therefore useful for speech researchers.
If you think that the SEC and LLC represent a rather conservative brand of spoken British English, you may now choose from a range of speech corpora that go beyond the standard dialects. For the speech of native speakers from across the British Isles, there is the IViE (Intonational Variation in English) Corpus, containing nine urban varieties of English (read-aloud speech as well as free conversation), and FRED (the Freiburg Corpus of English Dialects), which contains oral history interviews. More specialised dialectal speech corpora include the following: the Newcastle Electronic Corpus of Tyneside English (NECTE), which contains dialect speech from Tyneside in Northeast England; the Limerick corpus of Irish English (L-CIE), which contains speech from all parts of Ireland; and the Scottish Corpus of Texts and Speech (SCOTS), representing speech from across Scotland, including Scots Gaelic.
Mention should be made of CANCODE, the Cambridge and Nottingham Corpus of Discourse in English, which is a five-million-word collection of spoken British English (copyright Cambridge University Press), transcribed from recordings made between 1995 and 2000 across a wide variety of situations: casual conversation, people working together, shopping, finding out information, having discussions, and so forth. The files encode information about the relationships between the speakers: whether they were intimates, casual acquaintances, work colleagues or strangers. This corpus has been the basis of a large number of publications. Unfortunately, CANCODE is currently not accessible to the general public.
For spoken American English, there is the Switchboard Corpus (three million words, 240 hours of speech), which consists of spontaneous telephone conversations, averaging six minutes in length, recorded in the early 1990s using speakers from every major dialect of American English. For better quality and face-to-face speech, there is the Santa Barbara Corpus of Spoken American English (SBCSAE; 249,000 words), which consists of recordings of (non-surreptitious) spontaneous speech across different regions of the United States and from speakers of all ethnic backgrounds, sex, age, and so forth, though it was not designed to support demographically accurate sociolinguistic studies of accent. SBCSAE includes speech events such as casual conversations, family chats, visits to a veterinarian’soffice, lectures, sermons, and so forth. The transcripts are time-aligned with the sound recordings, and contain detailed prosodic mark-ups that mirror those of the LLC. Some parts of the Saarbrücken Corpus of Spoken English (SCoSE) contain speech by native speakers of English (stories, jokes and interviews), and the Monroe Corpus contains dialogue recorded in a simulated situation in a laboratory (task-oriented speech). Both have transcripts aligned with sound files and constitute useful additions to the stable of American speech corpora. The publishers Pearson Longman also have a large corpus of American speech as part of their Longman Corpus Network. Finally, special mention should be made of the Michigan Corpus of Academic Spoken English (MICASE), which has sound recordings available, though these are not aligned with the transcripts. MICASE is discussed below in the section on specialised corpora.
Parsed corpora
A brief mention should be made here of several corpora that have been parsed (syntactically analysed at the phrasal or functional level). If you are interested in quantitative studies of grammatical structures that cannot be easily found by searching word strings alone, a parsed corpus allows you to search ‘parse trees’ or structural syntactic tags. As might be expected, parsed corpora are typically smaller than normal/unparsed corpora because most of them are hand-checked for accuracy. The Lancaster–Leeds Treebank, probably the first syntactically parsed corpus, is a manually analysed small subset (45,000 words) of the LOB Corpus that was used to train the computer programs that were later used to produce the Lancaster Parsed Corpus (LPC), which is a larger analysed subset (about 144,000 words) of LOB. The various Penn Treebank releases (containing news reports, Brown Corpus texts, manuals, radio transcripts, Switchboard Corpus transcripts, etc.) may also be of interest. They employ tags for different types of phrases and clauses that mirror the Lancaster scheme.
Geoff Sampson’s SUSANNE Corpus (Surface and Underlying Structural Analyses of Naturalistic English; 130,000 words) is a freely downloadable parsed corpus based on a subset of the Brown corpus of American English that has not only phrasal and clausal tags but also surface function tags for roles such as ‘logical subject’ and ‘agent of passive’. Sampson’s LUCY Corpus (165,000 words) contains mostly modern texts from the 1990s: some from the BNC, and some from A-level secondary school exams and university-level coursework and essays. (LUCY also contains children’s writing taken from a 1960s project.) The parsing scheme used for LUCY was an adaptation of the SUSANNE scheme, as it had to deal with non-standard structures not found in the more polished writing that machine parsers are trained on (see Sampson 1995).
For parsed speech, there is CHRISTINE (80,500 words), also by Sampson, which is based on a subset of the BNC, the London–Lund Corpus, and the Reading Emotional Speech Corpus. Again, the parse scheme is slightly different, this time adapted to deal with spoken phenomena such as pauses, discourse items and speech repairs.
As noted earlier, ICE-GB, the British component of the International Corpus of English, is fully parsed and manually checked, and is a very good choice if you are looking for a syntactically analysed corpus of both spoken and written English. One advantage it has over the other parsed corpora is that it can be explored interactively using the dedicated tool ICECUP that not only allows sophisticated ‘fuzzy’ queries to be made through a visual interface, but also provides synchronised audio playback of the text fragments returned by the word or syntactic searches.
Finally, note that many of the corpora of historical varieties of English (see next section) have been parsed. The Penn–Helsinki Parsed Corpus of Middle English version 2 (PPCME2) and the York–Helsinki Parsed Corpus of Old English Poetry, for example, share a common annotation scheme, and can be searched using a Java software tool called CorpusSearch. There is also the Parsed Corpus of Early English Correspondence, which covers the period 1410–1681.
Historical corpora
There is a wealth of corpora covering the English of earlier periods, and much empirical research has already been conducted on these corpora to describe and track changes in the language. There are three main collections of historical English that cover a wide span of time and genres: the diachronic part of the Helsinki Corpus of English, ARCHER (A Representative Corpus of Historical English Registers), and COHA (Corpus of Historical American English). The Helsinki Corpus (1.6 million words) covers the period from around 750 to 1700, and thus spans Old English (413,300 words), Middle English (608,600 words) and early modern (British) English (551,000 words). ARCHER is a multi-genre corpus (currently 1.8 million words) covering the early modern English period right up to the present (1650–1990) for both British and American English. It is divided into fifty-year blocks to facilitate comparisons (though not all periods are available for American English). ARCHER is, at the time of writing, undergoing correction, expansion and tagging. The corpus is not publicly available, but the several universities involved in the project are willing to host visits by interested scholars. COHA’s aim is to create a 300-million-word corpus of historical American English covering the early 1800s to the present time, and is ‘balanced’ in each decade for the genres of fiction, popular magazines, newspapers and academic prose.
Other historical corpora focus on a specific historical period, or on a specific genre. The Lampeter Corpus (about one million words) is a collection of non-literary prose tracts covering the 100-year period from 1640 to 1740. For letters and newsletters, there are quite a number of corpora: the Newdigate Newsletters Corpus (one million words), containing manuscript newsletters dated 1674–92; the Corpus of Early English Correspondence (CEEC; 2.7 million words) covering 1417 to 1681; the Corpus of Late EighteenthCentury Prose (300,000 words) containing letters on practical subjects from the period 1761–90; and the Corpus of late Modern English Prose (100,000 words) consisting of informal private letters by British writers from the period 1861 to 1919. There are also some letters (182,000 words) in ICAMET (Innsbruck Computer Archive of MachineReadable English Texts), which also contains a Middle English prose component of six million words. For historical newspapers, the Zurich English Newspaper Corpus (ZEN; 1.2 million words) covers the period 1661 to 1791. For obvious reasons, historical corpora are almost all written data. However, for a window into how people used to speak, the Old Bailey Corpus and the Corpus of English Dialogues (CED) offer speech-related genres such as trial proceedings, witness depositions, drama and fictional dialogues.
Finally, for early literary texts, there are now many electronic text libraries from which you can download your own selections: for example, Early English Books On-line (EEBO; mainly 1500s–1600s), Literature Online (LION; mainly 1700s–1800s), and Bartleby and Project Gutenberg (many periods and genres). Even the Oxford English Dictionary’s quotations database may now be searched just like a corpus, to get samples of earlier usages of English words.
Specialised corpora
The category of ‘specialised corpora’ is where we place corpora that are not ‘general’ (or ‘national’) corpora’–those that do not aim to comprehensively represent a language as a whole, but only specialised segments of it (e.g. domains or genres). Specialised corpora are usually smaller in scale than general language corpora precisely because of their narrower focus. This is not a problem, however, as the greater homogeneity among texts in a specialised area confers the advantage of fewer texts being required for the corpus to be representative of that language variety. One important specialised area is that of academic English, and quite a few corpora have been created to serve the needs of practitioners of English for Academic Purposes (EAP). MICASE (the Michigan Corpus of Academic Spoken English; 1.8 million words) is a corpus of spoken English transcribed from about 190 hours of recordings of various speech events in a North American university (Simpson et al. 2003). It has spawned various national equivalents, including BASE (the British Academic Spoken English corpus; 1.6 million words), LIBEL CASE (LimerickBelfast Corpus of Academic Spoken English), and CUCASE (City University Corpus of Academic Spoken English, in Hong Kong). These corpora allow researchers to examine differences across national contexts. For written academic English, in addition to the LOB category J texts (‘learned and scientific writings’) and the academic component of the BNC (see Lee 2001), the following two purpose-built corpora may be useful: the Chemnitz Corpus of Specialised and Popular Academic English (SPACE), consisting of comparable academic texts taken from scholarly papers (specialised expert-to-expert communication) and derived popular versions (broader journalist-to-layperson communication); and the Reading Academic Text corpus (RAT), consisting of research articles and PhD theses from the fields of Agriculture, Agricultural Botany and Agricultural and Food Economics (with plans for expansion to other disciplines in the future).
An international organisation called the Professional English Research Consortium (PERC) is also, at the time of writing, creating a 100-million-word corpus of professional English, by which is meant journal texts used by professionals in science, engineering, technology, law, medicine, finance and other fields. This PERC Corpus (formerly called ‘Corpus of Professional English’) will aid research and generate educational applications in the area of ESP/Professional English, feeding into the development of educational resources such as specialised dictionaries, handbooks, language tests and other materials.
For general business English, there is the Wolverhampton Business English Corpus: this is a collection of over ten million words from the general domain of business, taken from twenty-three different websites around the world between 1999 and 2000. There is also a Business Letters Corpus (BLC; one million words) composed of samples of US and UK business letters (mostly model letters from textbooks rather than real-life letters). The BLC is accessible through an on-line concordancer.
Multimedia corpora, multimodal texts
A growing number of corpora are now fully multimedia in the sense of having transcripts that are aligned or synchronised with the original audio or video recordings. This allows researchers and ordinary users of a corpus to go beyond the written word to embrace the audio and visual elements of situated discourse: the use of prosody, gestures, gaze, space, and so forth. We now have audio/video-to-transcript aligned corpora that can be played and viewed through any web browser. At the TalkBank website, the audio/video files of the Santa Barbara Corpus of Spoken American English (SBCSAE) can be easily played, with the transcripts scrolling in sync. A similar multimedia browsing facility is offered with the spoken texts of the multimedia Scottish Corpus of Texts and Speech (SCOTS), a fourmillion-word written and spoken corpus that captures the languages of Scotland, from Broad Scots to Scottish English. As an example of a pedagogical application of multimedia corpora, ELISA (English Language Interview Corpus as a Second-Language Application) is pioneering: it is a small corpus of interviews with people from different professional careers, and offers a multimedia facility along with exercises and other teaching materials. As Braun (2005) argues, such an integration of text and video is much needed in order to help learners more easily authenticate decontextualised corpus materials, and thus get the most out of them.
This ability to see or hear recordings and follow along with the transcript represents an important and significant advance for both research and pedagogy, and the SACODEYL project (Peréz-Paredes and Alcaraz-Calero 2009) now provides a suite of tools that will assist in the compilation and distribution of time-aligned transcripts (SACODEYL also includes ready-to-use multimedia corpora of European teenager talk). Perhaps the most ambitious example of a multimodal corpus is the Singapore Corpus of Research in Education (SCoRE), which is a multilevel annotated multimedia corpus of spoken and written material collected from primary and secondary schools in Singapore. It contains video- and audio-recorded classroom interactions, along with teaching materials and students’ assignments, and is annotated not only for part of speech, but also discourse-level phenomena such as Initiation, Response and Feedback.
The web as a corpus
In the era of the internet, with the innumerable electronic documents that continually grow in number and diversity, many corpus linguists question the need to cling to the old paradigm of corpus research: design a corpus, collect the texts, tag them with bibliographical or source information, format them to conform to an international standard, add linguistic annotations, then release the finished product. Some people now feel that a much simpler way is to intelligently harvest the web for texts that we want, either dynamically (‘on the fly’, with no way to duplicate the exact same collection of texts later) or statically (texts are trawled from the web, possibly cleaned up in some way, and then compiled into a finished corpus).
The most important question is: can the web be considered a corpus in the first place? Here, Kilgarriff and Greffenstette (2003: 334) offer their point of view:
[many linguists] mix the question ‘What is a corpus?’ with ‘What is a good corpus (for certain kinds of linguistic study)?’, muddying the simple question ‘Is corpus x good for task y?’ with the semantic question, ‘Is x a corpus at all?’…We define a corpus simply as ‘a collection of texts’. If that seems too broad, the one qualification we allow relates to the domains and contexts in which the word is used rather than its denotation: A corpus is a collection of texts when considered as an object of language or literary study. The answer to the question ‘is the web a corpus?’ is yes.
Whether or not you agree with this definition, if you want to concordance the web dynamically, you can use a so-called web concordancer such as WebCorp, WebKWiC, or KWiCFinder. It is also possible to do a more sophisticated search based on syntactic structure by using the Linguist’s Search Engine, a tool that makes it possible to retrieve sentences from the web on the basis of a parse tree. If ‘live’ concordancing is too dynamic and unreplicable, you can concordance a static, ready-made web-culled corpus using Birmingham University’s WebCorpLSE, which will query a large collection of web-sourced texts (currently around seventy million words). Another example of a ready-made web-derived corpus is ‘ukWaC’, a two-billion-word corpus of British English (part-of-speech tagged and lemmatised) taken from web pages in the ‘.uk’ internet domain (Ferraresi et al. 2008). This corpus has been analysed and appears to stand up well when compared with traditionally compiled corpora such as the BNC, with differences well accounted for by divergences in time period and subject domains. Similar web-derived corpora exist for other languages such as German and Italian.
4. Developmental, learner and lingua franca corpora
Developmental language corpora
Since the term ‘learner’ usually connotes ‘foreign learner’, it is better to use the terms ‘non-expert’ or ‘developmental’ to describe the various data contained in the CHILDES database and the Polytechnic of Wales (POW) Corpus, which are collections of nativespeaker language produced by children at various developmental stages. Another developmental corpus is LUCY (mentioned earlier), as part of it consists of essays written in the 1960s by nine- to twelve-year-old British children. LUCY has real utility as a suitable reference corpus against which the writing of non-native writers of the same age can be compared.
There are also some corpora containing the output of non-expert teenage and young adult native speakers who are not necessarily as proficient or polished as the published writers that typically dominate native-speaker corpora. One example is the Louvain Corpus of Native English Essays (LOCNESS; 324,000 words), which contains essays (mostly argumentative) written by British and American students, post-secondary to university level. This corpus is often used for direct comparisons with the ICLE Corpus of non-native speaker writing (see next section) because they represent the same genre and topics. In terms of actual disciplinary writing by native-speaker university students (i.e. not argumentative essays written for proficiency or composition classes), there are two main corpora: the British Academic Written English Corpus (BAWE; 6.5 million words) and its American counterpart, the Michigan Corpus of Upper-level Student Papers (MICUSP; two million words). Both corpora include the writing of both native and non-native speakers, but native speakers predominate.
ESL/EFL learner corpora
Two major learner corpus projects that are international in scope are ICLE (International Corpus of Learner English; 3.7 million words so far) for written language and LINDSEI (Louvain International Database of Spoken English Interlanguage; 1.1 million words, at the time of writing) for spoken. ICLE consists of mainly argumentative essays from undergraduate and graduate students of English from twenty-one different language backgrounds, while LINDSEI contains transcripts of two types of speech by speakers from eleven different L1 backgrounds: informal interviews (based on a given topic) and picture-prompted speech (based on a standard set of pictures that illustrate a story). There are two other ongoing projects that are collecting writing samples from university students: LANCAWE (Lancaster Corpus of Academic Written English), based in the UK, and MELD (Montclair Electronic Language Learners’ Database; 98,000 words) in the US. They differ from ICLE in that the participants are in an English-immersion environment.
The types of writing contained in the above corpora represent the general linguistic proficiency of university-level learners of English, but in terms of research writing, where the writing is done for the communication of disciplinary content or research rather than for the sake of a language proficiency class or test, there are few existing learner corpora. Two possible sources are BAWE and MICUSP, which, as mentioned earlier, have some non-native speaker contributions, but the genres of text in these corpora are very varied, and not all are research-based. A dedicated corpus of learner research writing is the CAWE corpus (Chinese Academic Written English; 408,000 words, at the time of writing, and growing), consisting of undergraduate dissertations written by English majors in mainland China. These texts represent extended pieces of research writing that may be compared to either native-speaker dissertations or published journal articles in the same field to reveal the extent to which learners are successful in writing ‘like the experts’.
While the various learner corpora above represent the writing of advanced or upperlevel students, there is much less data on the writing of younger learners of English, especially those who are producing their first essays or paragraphs in a foreign language. The International Corpus of Crosslinguistic Interlanguage (ICCI) aims to fills this gap, and is underway in Austria, Hong Kong, Israel, Poland, Spain and Taiwan. When completed, it will contain the writing of primary school to pre-university learners of English across various proficiency levels and L1 backgrounds. The overall design and essay topics in ICCI will closely mirror the already completed JEFLL Corpus (Japanese EFL Learner Corpus; 700,000 words), which is a collection of compositions written by more than 10,000 Japanese learners of English, mostly from junior to senior high school levels.
There are also some specialised corpora of learner English. For research on business letters, you can conduct on-line searches on the Learner Business Letters Corpus (Learner BLC), which contains over 200,000 words taken from samples of business letters written by Japanese business people (with errors intact). For phonetic research on learner speech, the LeaP Corpus (Learning Prosody in a Foreign Language) provides over twelve hours of speech (read speech, prepared speech, free speech and nonsense words) from 131 different learners of German and English as a foreign language, across thirty-two different native language backgrounds (it also has some recordings of native speakers for comparison).
As mentioned at the start of this chapter, corpora can belong to more than one category. The Hong Kong Corpus of Conversational English (HKCCE; 500,000 words) could conceivably be classified under ‘Speech corpora’ above, or put together with the various components of ‘world Englishes’ that are part of the ICE project. However, since the typical focus of research using the HKCCE is on the learner-like features of Hong Kong speakers of English in contexts where they are speaking to (mostly) native speakers of English, the corpus fits better in this section. HKCCE comprises about fifty hours of recordings of conversations, as well as academic, business and public discourses.
Lingua franca corpora
While the so-called New Englishes of the former British colonies are represented in the ICE project, along with a few other World English varieties, few corpora deal specifically with intercultural encounters where English is used as a lingua franca among speakers who do not share an L1 or a similar cultural or national background. Two corpora have filled the gap: the VOICE Corpus (Vienna–Oxford International Corpus of English; one million words; 120 hours) and the ELFA Corpus (English as a Lingua Franca in Academic Settings; one million words, 131 hours). VOICE comprises naturally occurring, non-scripted face-to-face interactions in English between speakers from different firstlanguage backgrounds (e.g. a Korean sales representative negotiating a contract with a German client in Luxembourg). ELFA is a similar, complementary corpus, where the contexts of speech are academic rather than business or general. Perhaps as research into lingua franca English increases, more such corpora will be compiled in the future.
5. Non-English corpora and multilingual corpora
The above corpora have all been about English, and this reflects the imbalance in the field. Nevertheless, numerous non-English corpora have arisen in the past few decades, and some of the major ones will be introduced here. They will be divided into the broad categories of monolingual, parallel and comparable corpora.
Monolingual non-English corpora
The British National Corpus model has inspired and spawned a host of other national corpora based on a similar design, among which we can include the following: CORIS/ CODIS (Italian), Czech National Corpus (C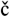 esk Národní Korpus), Hungarian National Corpus, Hellenic National Corpus (also known as the ILSP Corpus), German National Corpus, Modern Chinese Language Corpus (MCLC), Polish National Corpus, Russian Reference Corpus (BOKR), Slovak National Corpus and the Korean National Corpus (or Sejong Balanced Corpus). Many of these, being products of the internet age, are mega corpora that exceed the 100-million-word size of the BNC.
esk Národní Korpus), Hungarian National Corpus, Hellenic National Corpus (also known as the ILSP Corpus), German National Corpus, Modern Chinese Language Corpus (MCLC), Polish National Corpus, Russian Reference Corpus (BOKR), Slovak National Corpus and the Korean National Corpus (or Sejong Balanced Corpus). Many of these, being products of the internet age, are mega corpora that exceed the 100-million-word size of the BNC.
For the European languages, there is also the PAROLE (Preparatory Action for Linguistic Resources Organisation for Language Engineering) project that has resulted in a set of common-design corpora and lexicons for fourteen European languages (fifteen, if you include English). About twenty million words have been collected for each of the following languages: Belgian French, Catalan, Danish, Dutch, French, Finnish, German, Greek, Irish, Italian, Norwegian, Portuguese and Swedish. The harmonised standards and specifications used in these resources allow cross-linguistic comparisons to be made.
Not all countries/languages are equal in resources, however: German has one of the largest collections of text, COSMAS, with two billion words; Portuguese has a 180million-word corpus of newspaper text (CETEMPúblico), a mixed corpus of forty-five million words (Corpus do Português), and several other written and spoken corpora (the Linguateca site has listings); Spanish has the Corpus del Español (100 million words and growing); Dutch has a large ten-million-word spoken corpus (Corpus Gesproken Nederlands) and many large written corpora (search the Institute for Dutch Lexicology, INL, for their listings).
In Asia, the Balanced Corpus of Contemporary Written Japanese (BCCWJ) is a 100million-word corpus. For Chinese, there now are practically too many corpora to mention, but some of the well-known ones include: Academia Sinica Balanced Corpus (five million words of Taiwanese Mandarin); the Peking University corpora (hundreds of millions of Chinese characters); Modern Chinese Language Corpus (MCLC; 700 million characters); PH corpus (3.7 million characters); and a large fifty-million-word general corpus compiled for the making of a frequency dictionary (Xiao et al. 2009). There are also several one-million-word corpora that allow various types of comparison: Lancaster Corpus of Mandarin Chinese (LCMC; texts from 1990s); UCLA Chinese Corpus (UCLACC; texts from the period 2000–5); Lancaster–Los Angeles Spoken Chinese Corpus (LLSCC); ZJU Corpus of Translational Chinese (ZCTC).
Corpora are not restricted to the major languages, however. Some minority-language corpora include the following: the New Corpus for Ireland (NCI; thirty million words of Irish, and twenty-five million words of Irish English); Cronfa Electroneg o Gymraeg (one million words of Welsh); Scottish Corpus of Texts and Speech (SCOTS; target of four million words); Oslo Corpus of Bosnian Texts (1.5 million); and the ‘Brown’ Corpus of Bulgarian (one million words). Some smaller corpora include those representing fourteen South Asian languages that are in the EMILLE (Enabling Minority Language Engineering) Corpus (ninety-two million words). The data here is mainly written, with only around 2.6 million words of spoken data for Bengali, Gujarati, Hindi, Punjabi and Urdu.
Parallel and comparable multilingual corpora
Johansson (2007: 9–11) gives the following definitions: translation corpora contain ‘original texts and their translations into one or more other languages’; comparable corpora contain ‘original texts in two or more languages matched by criteria such as genre, time of publication, etc.’, while the term parallel corpus is reserved for ‘bidirectional translation corpora’, a combination of translation corpora and comparable corpora that use the same framework (i.e. comparable originals in at least two languages plus their translations into the other language(s)). Johansson’s equation of parallel with bidirectional is not observed by everyone, and for the purposes of this chapter, the terms and definitions given by Aston (1999) will be used instead, summarised in Table 9.1 (see also chapters by Kenning, and Kübler and Aston, this volume).
In parallel corpora, the two components are aligned on a paragraph-to-paragraph or sentence-to-sentence basis. The English–Norwegian Parallel Corpus (ENPC) and English–Swedish Parallel Corpus (ESPC) are good examples of a parallel bidirectional corpus: each corpus has four related components, allowing for various types of comparison to be carried out. This design is also the basis for the Oslo Multilingual Corpus (OMC), which has German, French and Finnish source texts and translations in various combinations. Other examples of bidirectional parallel corpora are the IJS–ELAN Slovene–English Parallel Corpus and COMPARA (English and Portuguese). Examples of bidirectional parallel corpora for an Asian language would be the BFSU Chinese–English Parallel Corpus (by Beijing Foreign Studies University), and the Babel Chinese–English Parallel Corpus. Some multilingual corpora, however, are only unidirectional. Examples include Kacenka (English to Czech), MULTEXT-East (English to nine different languages) and the HKIEd English–Chinese Parallel Corpus, which has both English- and Chineseorigin texts and their translations, but the source texts do not follow the same sampling frame and are thus not comparable.
This chapter has given a very broad survey of available corpora, and is intended to help readers orient themselves to particular areas of interest. The taxonomy and the categorisation of corpora used here are only one of many possibilities, and many corpora fit under more than category. Nevertheless, it is hoped that the descriptions here have given readers a good sense of the scope of corpora that are available, and helped facilitate research endeavours.
Further reading
Granger, S. (ed.) (1998) Learner English on Computer. Essex: Addison Wesley Longman. (Chapter 1 describes the design of the ICLE corpus, while the rest of the book exemplifies the kinds of research and pedagogical application that can come out of learner corpus research.)
Kennedy, G. (1998) An Introduction to Corpus Linguistics. London: Longman. (Chapter 2 of this book gives a very good and detailed history of the development of corpora, especially the earlier ones.)
References
Aston, G. (1999) ‘Corpus Use and Learning to Translate’, Textus 12: 289–314.
Biber, D. (1990) ‘Methodological Issues Regarding Corpus-based Analyses of Linguistic Variation’, Literary and Linguistic Computing 5: 257–69.
——(1993) ‘Representativeness in Corpus Design’, Literary and Linguistic Computing 8(4): 243–57.
Braun, S. (2005) ‘From Pedagogically Relevant Corpora to Authentic Language Learning Contents’, ReCALL 17(1): 47–64.
Ferraresi, A., Zanchetta, E., Baroni, M. and Bernardini, S. (2008) ‘Introducing and Evaluating ukWaC, a Very Large Web-Derived Corpus of English,’ in S. Evert, A. Kilgarriff and S. Sharoff (eds) Proceedings of the 4th Web as Corpus Workshop (WAC-4) Can We Beat Google? Marrakech, Morocco, 1 June 2008, available at http://webascorpus.sourceforge.net/
Johansson, S. (2007) Seeing through Multilingual Corpora: On the Use of Corpora in Contrastive Studies. Amsterdam: John Benjamins.
Kilgarriff, A. and Greffenstette, G. (2003) ‘Introduction’ to ‘The Web as Corpus’, special issue of Computational Linguistics 29(3): 333–47.
Lee, D. Y. W. (2001) ‘Genres, Registers, Text Types, Domains, and Styles: Clarifying the Concepts and Navigating a Path through the BNC Jungle’, Language Learning and Technology 5(3): 37–72.
Park, B. (2001) ‘Introducing the Korean National Corpus’, paper presented at Corpus Research Group, Lancaster University, 19 November (see also http://www.sejong.or.kr/).
Peréz-Paredes, P. and Alcaraz-Calero, J. M. (2009) ‘Developing Annotation Solutions for Online Data Driven Learning’, ReCALL 21(1): 55–75.
Sampson, G. (1995) English for the Computer: The SUSANNE Corpus and Analytic Scheme. Oxford: Clarendon Press.
Simpson, R. C., Lee, D. Y. W. and Leicher, S. (2003) MICASE Manual. Ann Arbor, MI: English Language Institute, University of Michigan.
Xiao, R., Rayson, P. and McEnery, T. (2009) A Frequency Dictionary of Mandarin Chinese: Core Vocabulary for Learners. London: Routledge.