Anhang
Lösungen der Aufgaben
Kapitel 1
-
Windows 3.1 war ein klassisches Desktop-Betriebssystem, das zum Betrieb MS-DOS benötigte (man spricht von einem Betriebssystemaufsatz). Als Hardwareplattform wurden die Intel-Prozessoren 80286, 80386 (und dazu kompatible) unterstützt. Es handelt sich um ein Einnutzerbetriebssystem, das mehrere unabhängige Aktivitäten unterstützte, also ein Multitasking-Betriebssystem. Des Weiteren handelt es sich um ein interaktives Betriebssystem; der Nutzer interagierte mittels Maus und Tastatur.
Das eben erwähnte MS-DOS kann ganz ähnlich klassifiziert werden: Es ist ebenfalls ein Desktop-Betriebssystem, es wird ebenfalls interaktiv bedient (aber nicht grafisch, sondern mittels einer Kommandozeile). Es unterstützt ebenso die Intel-Prozessoren, jedoch auch weitere Modelle bis hin zum »Urvater«, dem Intel 8086. Weder gibt es mehrere Nutzer noch irgendeine Form nebenläufiger Aktivitäten: Es ist ein Single-User-Single-Tasking-Betriebssystem.
Im Gegensatz dazu ist FreeRTOS ein Betriebssystem für eingebettete und Echtzeitsysteme. Das Akronym »RTOS« weist darauf hin, es steht für »Real Time Operating System«. Alle unterstützten Hardwareplattformen aufzuführen, wäre aufwendig; es sind ganze Familien von Microcontrollern, wie die ARM-Cortex-Prozessoren oder die der Atmel-Familie. Außerdem kommen häufig neue hinzu. Verschiedene Nutzeraccounts kann FreeRTOS nicht unterscheiden, jedoch sind mehrere Aktivitäten gleichzeitig möglich. Wir haben es also mit einem weiteren Single-User- und Multitaskingbetriebssystem zu tun. Bezüglich der Nutzerinteraktion wird es zumeist für autonome Systeme eingesetzt; eine direkte Nutzerinteraktion ist nicht vorgesehen.
Android 12 und iOS weisen sehr ähnliche Klassifizierungsmerkmale auf. Die unterstützte Hardwareplattform und der Einsatzzweck sind Mobiltelefone und Tablet-Computer. Beide unterstützen mehrere Nutzer, jedoch nicht gleichzeitig, was kein Wunder ist, schließlich können zwei Nutzer nicht gleichzeitig mit ein und demselben Mobiltelefon telefonieren (oder andere Arbeiten ausführen). Multitasking wird unterstützt, und im Allgemeinen wird interaktiv mit dem System kommuniziert. Android kommt auf Geräten verschiedener Hersteller zum Einsatz und ist ein Open-Source-Betriebssystem, während iOS ausschließlich Apple-Geräten vorbehalten und proprietär ist.
Als bislang noch nicht in diesem Buch erwähntes Betriebssystem soll das des in den 1980er-Jahren außerordentlich populären Heimcomputers »Commodore 64« fungieren. Es handelt sich dabei um eine Sammlung von Ein-/Ausgaberoutinen, beispielsweise zum Auslesen der Tastatur oder zum Zugriff auf ein Diskettenlaufwerk. Es ist ein sehr einfaches Desktop-Betriebssystem, das für den interaktiven Betrieb konzipiert wurde. Die Hardwareplattform sind die auf dem 8-Bit-Prozessor 6502 aufbauenden Computer der Firma Commodore (C64, C128). Weder sind mehrere Nutzer zulässig, noch ist es möglich, mehr als ein Programm gleichzeitig laufen zu lassen. Erwähnenswert ist, dass dieser sogenannte Kernal zusammen mit einem Interpreter für die damals sehr populäre Programmiersprache BASIC in einem ROM von etwa 16 KiB Größe residierte. Speicherplatz war ein knappes Gut, denn der Adressbus mit einer Breite von 16 Bit konnte maximal 64 KiB Speicher adressieren.
-
Der Hauptunterschied zwischen GPL und den beiden anderen Lizenzen liegt im sogenannten Copyleft. Code, der unter GPL steht, darf nur mit Code, der ebenfalls der GPL unterliegt, kombiniert werden. Jegliche von GPL-Software abgeleitete Software muss ebenfalls wieder unter der GPL stehen. Insbesondere ist es verboten, GPL-Software und abgeleitete Software unter proprietäre Lizenzen zu stellen. Damit wird einerseits sichergestellt, dass freie Software frei bleibt, sich also gewissermaßen niemand GPL-Software »unter den Nagel reißen« kann. Andererseits erschwert die GPL generell die Kommerzialisierung von Software und behindert damit beispielsweise Ausgründungen von Softwareunternehmen aus universitären Forschungsprojekten.
Sowohl die MIT- als auch die BSD-Lizenz sind entsprechend viel liberaler gefasst. Im Grunde genommen erlauben sie dem Nutzer der Software fast alles, wenn er sich an einige Grundregeln hält (beispielsweise nicht die Namen der Urheber der Software entfernt). Wenn bei der Entwicklung von Software also eine spätere Kommerzialisierung geplant ist, dann ist es günstiger, erarbeiteten Quellcode unter die MIT- oder BSD-Lizenz zu stellen. Des Weiteren enthalten beide Lizenzen einen Haftungsausschluss. Sie können also bei Benutzung dieser Software die Programmierer nicht für Schäden haftbar machen.
Die Unterschiede zwischen MIT- und BSD-Lizenz sind demgegenüber marginal. Von der BSD-Lizenz gibt es wiederum vier Versionen. Die freieste ist die »zero clause«-BSD-Lizenz, welche lautet:
»Permission to use, copy, modify, and/or distribute this software for any purpose with or without fee is hereby granted.«
Sie wird manchmal »Do-what-you-want-with-it-Lizenz« genannt, denn sie gestattet eigentlich alles. Die sogenannte »Two-clause«-BSD-Lizenz ähnelt am meisten der MIT-Lizenz. Beide erlauben das Weiterverteilen der originalen und daraus abgeleiteter Software in Quellcode- und/oder Binärform, und zwar kostenlos oder kostenpflichtig. Nur die Lizenz selbst und die Namen der Urheber dürfen nicht geändert werden.
Kapitel 2
- Die Aufgabe ist schwieriger als auf den ersten Blick erkennbar. Der Feuersalamander gehört zur Gattung der Eigentlichen Salamander (Salamandra), während der Kammolch zur Gattung Triturus gehört. Beide gehören in die Familie der sogenannten Echten Salamander; andere nahe verwandte Familien sind die Querzahnmolche, zu denen das bekannte Axolotl gehört, und die Riesenquerzahnmolche. Die zuständige Ordnung sind die Schwanzlurche (außerdem gibt es noch Froschlurche und Schleichenlurche). Diese drei Ordnungen wiederum konstituieren die Klasse der Amphibien (weitere Klassen sind die Reptilien, die Vögel und die Säugetiere), alle zusammen bilden das Taxon der Landwirbeltiere, auf die wir uns beschränken wollen. Abbildung A.1 zeigt einen kleinen Ausschnitt des resultierenden Verzeichnisbaumes.
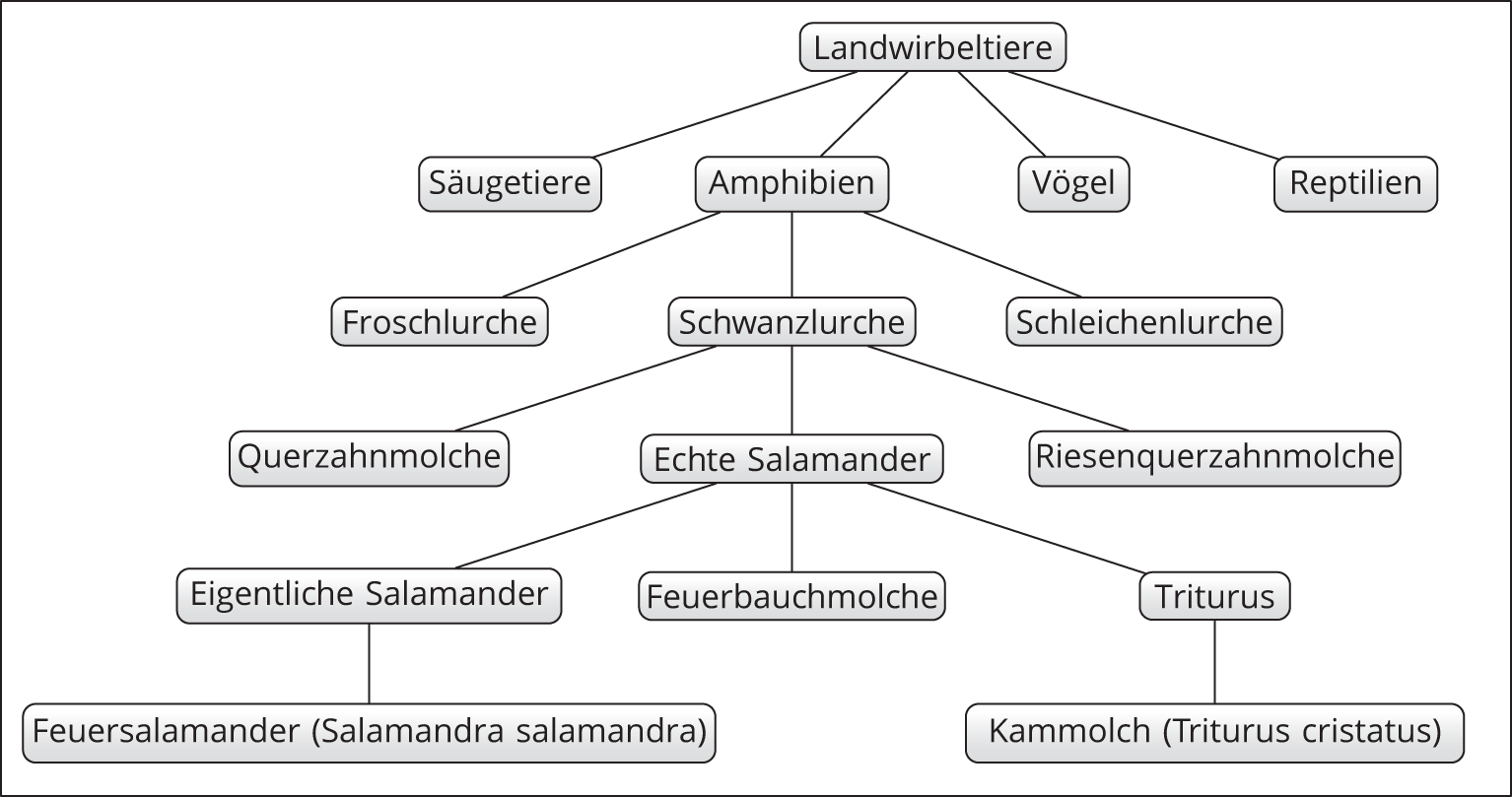
Abbildung A.1: Der Verzeichnisbaum zur taxonomischen Einordnung von Feuersalamander und Kammmolch
Kapitel 3

Listing A.1: Automatische Ermittlung der längsten Collatz-Sequenz (collatz2.c)
Listing A.1 zeigt eine mögliche Lösung. Die interaktive Eingabe des Startwertes wird durch eine Schleife ersetzt, die alle Startwerte im Intervall [2,10.000.000] in der Variablen
sdurchprobiert. Des Weiteren muss man die Iterationen zählen, was die Variableierledigt. Zum Dritten müssen wir das Iterationsmaximum (imax) und den zugehörigen Startwert (smax) abspeichern und bei Bedarf aktualisieren. Vergessen Sie nicht, beide Variablen zu initialisieren. Es ist auch sinnvoll, auf die Ausgabe der einzelnen Iterationswerte zu verzichten, weil diese ohnehin mit hoher Geschwindigkeit durch das Terminalfenster scrollen und die Abarbeitungsgeschwindigkeit ohne Ausgabe bedeutend höher liegt.Wenn Sie alles korrekt programmiert haben, müssten Sie innerhalb von wenigen Sekunden herausgefunden haben, dass die maximale Iterationsanzahl bei 686 liegt, und zwar für den Startwert
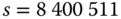 .
.
Kapitel 4
-
Die genaue Anzahl der Systemrufe eines Betriebssystems ist manchmal schwierig zu ermitteln, da häufig verschiedene Versionen des Betriebssystems existieren und ab und zu neue Systemrufe ergänzt werden. Zum Zeitpunkt der Drucklegung dieses Manuskripts besaß Linux 328 verschiedene Systemrufe.
Windows 10 verfügt im Gegensatz dazu über ungefähr 2000 Systemrufe. Ein Grund dafür ist, dass die Funktionen zur grafischen Ausgabe im Windows direkt zum Betriebssystem gehören, im Linux hingegen nicht.
Da Microkernel nur die für ein System essenziell notwendige Funktionalität im Kernelmode zur Verfügung stellen, kommt L4 mit ganzen sieben (!) Systemrufen aus.
-
- entziehbar, exklusiv nutzbar, physisch
- Das Fenster einer Applikation ist einfach ein bestimmter Bereich im Hauptspeicher, der als Bildschirmgrafik interpretiert wird. Speicherbereiche kann man prima auslesen und beschreiben, folglich handelt es sich um eine entziehbare Ressource. Ein Fenster ist normalerweise einer einzigen Aktivität zugeordnet. Beschreiben mehrere Aktivitäten diesen Speicherbereich, kann es zu Konflikten kommen. Daher handelt es sich um eine exklusive Ressource. Da das Fenster keine physische Repräsentation hat, handelt es sich um eine logische Ressource.
-
Unter einer Partition versteht man einen Teil eines Massenspeichers, der für sich genommen wiederum für das Betriebssystem so aussieht, als würde er ein komplettes Massenspeichermedium umfassen. Diese Organisationseinheit stammt aus der Zeit, in der man mehrere Betriebssysteme auf einem Massenspeicher koexistieren lassen wollte: Man partitionierte, also unterteilte, den Massenspeicher, und jede dieser Partitionen nahm ein separates Betriebssystem auf.
Insofern ist es eigentlich unsinnig, die Partition als zuteilbare Ressource zu betrachten. Tun wir es trotzdem einmal. Entziehbarkeit bedeutet, dass man den inneren Zustand der Ressource sichern und später bitgetreu restaurieren kann. Der innere Zustand der Partition besteht einfach aus den in den einzelnen Blöcken abgelegten Bytes. Da man diese problemlos auslesen und beschreiben kann (vorausgesetzt, man verfügt über genügend Speicherplatz), handelt es sich um eine entziehbare Ressource. Mehrere Prozesse können auch gleichzeitig auf die Partition zugreifen, solange nicht mehr als einer den gleichen Block beschreibt. Somit ist eine Partition gemeinsam nutzbar. Zu guter Letzt handelt es sich um eine virtuelle oder logische Ressource, denn sie wird aus einem Teil einer physischen Ressource (beispielsweise einer Festplatte) konstruiert.
Kapitel 5
-
Der Code kann ganz schnell aus Listing 5.1 entwickelt werden:

Listing A.2: Zwei Prozesse geben konkurrierend ihre PID auf dem Terminal aus (2processes.c)
Nach der Unterscheidung zwischen Vater und Sohn betreten beide eine unendliche Schleife, in der sie ihre PID ausgeben und danach mittels
sleep()eine Sekunde blockieren. Wenn Sie dieses Programm mehrmals aufrufen, erhalten Sie mit hoher Wahrscheinlichkeit unterschiedliche Ausgabesequenzen von Vater und Sohn. - Ähnlich wie beim Kommando »quit« wird zunächst verglichen, ob die eingegebene Zeichenkette »ls« lautet. Ist dies der Fall, dann wird das aktuelle Verzeichnis geöffnet (Zeile 36), enumeriert, also Eintrag für Eintrag eingelesen, die relevanten Daten (hier: Dateiname und Dateigröße) werden ausgegeben (37–40), und das Verzeichnis wird wieder geschlossen. Der zusätzliche Einschluss der Headerdatei
dirent.hist dafür nötig. Eine komfortablere Implementation würde natürlich nicht nur das aktuelle Verzeichnis ausgeben, sondern eine Pfadangabe als Parameter akeptieren, deren Inhalt ausgegeben wird.

Listing A.3: Die kleine Shell mit zusätzlichem ls-Kommando (minishell2.c)
- Im Gegensatz zu zwei Threads, die eine gemeinsame Variable inkrementieren, arbeiten zwei Prozesse in jeweils einem eigenen Adressraum. Es ist also zunächst unmöglich, dass diese eine gemeinsame Variable referenzieren. Im Kapitel 8 »Kommunikation« erlernen Sie, wie man das Problem lösen kann: Die Variable muss in einem sogenannten Shared-Memory-Segment angelegt werden, das beide Prozesse in ihrem jeweiligen Adressraum einblenden.
-
Die Anzahl der Threads wird nun als Parameter an der Kommandozeile übergeben und landet in der globalen Variablen
n. In den Zeilen 30–43 wird geprüft, ob der Nutzer den Parameter sinnvoll gewählt hat, also beispielsweise keine negative Zahl und keine Zeichenkette, die keine Zahl repräsentiert. Zur Ablage der TID, für die Zwischenergebnisse und für die Threadparameter (der jeweilige Startwert) ist nun jeweils ein Feld zuständig, nämlichtid,sumundstart. Die Erzeugung der Threads, das Warten auf deren Ende sowie die Summation der Zwischenergebnisse erfolgen jeweils in einer Schleife, da erst zur Laufzeit feststeht, wievielmal dies erfolgen muss. Die Threadfunktion selbst muss im Vergleich zu Listing 5.6 kaum geändert werden; nur die Schrittweite bei der Addition und die Ergebnisvariable werden angepasst.Beachten Sie, dass das Erschaffen der Threads und das Join nicht in einer Schleife vereinigt werden können, denn sonst werden die Threads seriell abgearbeitet!


Listing A.4: Eine variable Anzahl von Threads addiert die Zahlen von 1 bis
LIMIT(nthreads.c) -
Das Programm in Listing A.5 erzeugt zunächst einen (zusätzlichen) Thread, der im Sekundenabstand seine Thread-ID ausgibt. Danach ruft der Hauptthread
fork(). Sowohl der resultierende Sohnprozess als auch der Vaterprozess geben danach ebenfalls im Sekundentakt ihre Thread-ID aus.
Listing A.5: Ein Prozess, der aus zwei Threads besteht, ruft
fork()(2threads+fork.c)Aus den Ausgaben kann man schlussfolgern, dass beim
fork()nicht der gesamte Prozess bestehend aus beiden Threads kopiert wird, sondern nur der (fork()rufende) Hauptthread. Dies wird erhärtet durch die Ausgabe despstree-Kommandos (Abbildung A.2), das die Verwandschaftsbeziehungen der einzelnen Prozesse und Threads illustriert. Man erkennt, dass der Vaterprozess einen Sohnprozess besitzt und zusätzlich einen weiteren Thread, der in geschweiften Klammern notiert wird.

Abbildung A.2: Ausschnitt der Ausgabe von pstree bei der Abarbeitung von 2threads+fork
Kapitel 6
-
- Abbildung A.3 zeigt den resultierenden Plan. Es lohnt sich eigentlich kaum, einen dritten Prozessor hinzuzunehmen, denn nur ein einziger Teilprozess (
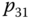 ) wird auf dem zusätzlichen Prozessor abgearbeitet (der ebenfalls auf CPU3 abgearbeitete
) wird auf dem zusätzlichen Prozessor abgearbeitet (der ebenfalls auf CPU3 abgearbeitete 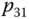 könnte genauso gut auf einem der anderen beiden Prozessoren laufen). Der Grund sind die zahlreichen Präzedenzen; die Hinzunahme eines vierten Prozessors würde gar keinen Vorteil bringen. Im Vergleich zum Plan für zwei Prozessoren verkürzt sich die Gesamtbearbeitungszeit hier immerhin von 21 auf 16 Zeiteinheiten, also um fast 25 %.
könnte genauso gut auf einem der anderen beiden Prozessoren laufen). Der Grund sind die zahlreichen Präzedenzen; die Hinzunahme eines vierten Prozessors würde gar keinen Vorteil bringen. Im Vergleich zum Plan für zwei Prozessoren verkürzt sich die Gesamtbearbeitungszeit hier immerhin von 21 auf 16 Zeiteinheiten, also um fast 25 %.

Abbildung A.3: Offline generierter Plan für die Taskmenge unter »Offline-Planung« für drei Prozessoren
- Ohne explizite Präzedenzen besteht noch ein wenig mehr Beschleunigungspotenzial (Abbildung A.4). Die Gesamtbearbeitungszeit fällt auf zwölf Zeiteinheiten (übrigens im Vergleich zu 31 auf einem Uniprozessorsystem, erinnern Sie sich?), und die Auslastung der drei Prozessoren ist ebenfalls ziemlich hoch.

Abbildung A.4: Offline generierter Plan für die Taskmenge unter »Offline-Planung« für drei Prozessoren ohne explizite Präzedenzen
Das Beispiel verdeutlicht, dass es für effiziente Parallelisierung notwendig ist, die expliziten Anhängigkeiten zwischen den Aktivitäten zu minimieren.
- Abbildung A.3 zeigt den resultierenden Plan. Es lohnt sich eigentlich kaum, einen dritten Prozessor hinzuzunehmen, denn nur ein einziger Teilprozess (
- Der entstehende Plan ist identisch mit dem, den das Verfahren SRT generiert hat (Abbildung 6.7). Die mittlere Verweilzeit der Prozesse beträgt in beiden Fällen
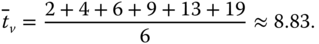
-
- Wenn man die Prozessanzahl mit
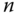 repräsentiert, die Größe des Quantums mit
repräsentiert, die Größe des Quantums mit 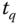 und die Reaktionszeit eines Prozesses mit
und die Reaktionszeit eines Prozesses mit 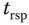 , dann gilt:
, dann gilt:
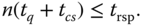
Jeder der
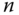 Prozesse muss ein Quantum, erhalten und danach muss jeweils zum nächsten Prozess umgeschaltet werden, bevor der erste Prozess sein zweites Quantum bekommt. Dies stellt man nach
Prozesse muss ein Quantum, erhalten und danach muss jeweils zum nächsten Prozess umgeschaltet werden, bevor der erste Prozess sein zweites Quantum bekommt. Dies stellt man nach 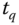 um, setzt die entsprechenden Werte ein und rechnet aus:
um, setzt die entsprechenden Werte ein und rechnet aus: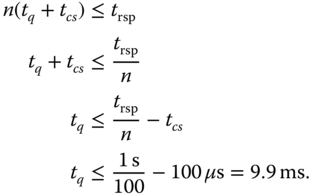
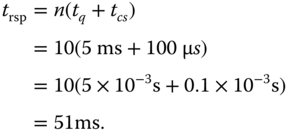
- Wenn man die Prozessanzahl mit
Kapitel 7
- Die Zeilen 15 und 16 bilden einen kritischen Abschnitt bezüglich der gemeinsam genutzten Ressource
guthaben. Der Ehemann könnte beispielsweise versuchen, 5000 Dublonen abzuheben. Dies wird nicht gestattet, und das existierende Guthaben landet in der Variablentmp. Nun wird der Prozess an dieser Stelle unterbrochen. Die Frau versucht beispielsweise, 4000 Dublonen abzuheben, sodass in ihrer (lokalen) Variablentmpebenfalls das komplette gerade noch existierende Guthaben landet. Danach setzt sieguthabenauf 0 und bekommt die 3000 Dublonen austmpausbezahlt. Schließlich wird der Prozess des Ehemanns fortgesetzt. Er setzt (erneut)guthabenauf 0 und bekommt ebenfalls 3000 Dublonen aus seiner Variablentmpausbezahlt. Das Vermögen des Paares hat sich verdoppelt. Dies kann verhindert werden, indem die Zeilen 15 und 16 nur atomar durchlaufen werden. -
Es handelt sich um eine einigermaßen verzwickte Aufgabe. Das Problem hängt damit zusammen, dass die verschiedenen Cores die Schreiboperation zu den Variablen nicht gleichzeitig »sehen«. Sehen Sie sich dazu bitte das Listing A.6 an.
Da sich der Code beider Threads unterscheidet, sind der Einfachheit halber zwei (unterschiedliche) Threadfunktionen implementiert. Für den Moment ignorieren Sie bitte die ominösen Funktionsaufrufe
_mm_mfence()in den Zeilen 18 und 32; kommentieren Sie sie am besten aus. Bitte überzeugen Sie sich zunächst, dass das Programm den Peterson-Algorithmus von Abbildung 7.7 implementiert. Die Threads konkurrieren um den Zugriff auf die Variablex. Diese Zugriffsoperation (konkret dasx++in den Zeilen 21 und 35) bildet den kritischen Abschnitt.Der »Hauptthread« in
main()erzeugt beide Threads und wartet danach mittelspthread_join()auf deren Beendigung. Beide Threads inkrementieren unabhängig voneinander die mit 0 initialisierte globale Variablexgenau eine Million mal. Somit müsste am Ende inxder Wert 2.000.000 stehen, was der Hauptthread entsprechend überprüft.Dies ist jedoch nicht der Fall; der Wert ist um etwa 10–20 zu klein, was auf einige wenige Lost Updates hindeutet. Der Grund hierfür ist die eingangs erwähnte Tatsache, dass zwischen der Komplettierung der Schreiboperation des einen Threads auf
turnund der Sichtbarkeit dieser Werteveränderung im anderen Thread, der auf einem anderen Core abgearbeitet wird, eine kleine Zeitspanne liegt; der zweite Thread liest somit manchmal einen veralteten Wert. Dies geschieht verhältnismäßig selten; wenn manITERATIONSein oder zwei Zehnerpotenzen kleiner macht, dann kann es sein, dass sich der Fehler gar nicht manifestiert (probieren Sie es am besten aus!).Abhilfe dagegen bieten sogenannte Barrieren oder Fences, also Zäune. Das sind Mechanismen, die den aufrufenden Thread (kurz) blockieren, bis die Änderung an der gerade manipulierten Variable sicher für alle anderen Threads sichtbar ist, ungeachtet davon, ob diese auf dem gleichen oder anderen Cores oder Prozessoren abgearbeitet werden. Die Intel-Architektur bietet zu diesem Zweck spezielle Maschineninstruktionen wie beispielsweise
mfencean. Diese Instruktion wird im Programm durch ein sogenanntes Compiler-Intrinsic, die Funktion_mm_mfence(), realisiert. Da diese Funktion aber architekturspezifisch ist, verliert man an dieser Stelle die Portabilität der Programmiersprache C. Das Programm ist nur noch auf Intel- und AMD-Prozessoren lauffähig, diemfencebesitzen.Bleibt noch die Frage zu klären, warum Gary Peterson in seinem Artikel [17] dieses Problem nicht erwähnt hat. Ganz einfach: Es existierte zur damaligen Zeit schlichtweg noch nicht. Die damaligen Systeme wiesen strikte Speicherkonsistenz auf.
Wenn Sie mehr über diesen schon recht fortgeschrittenen Aspekt erfahren wollen, müssen Sie sich über Konsistenzmodelle informieren. Das liegt aber wieder ganz klar außerhalb dieses Büchleins.


Listing A.6: Eine korrekte Implementierung des Peterson-Algorithmus mittels pthreads und einem Fence (peterson-pthreads-fence.c)
- Einen Lösungsversuch in IA-32-Assembler ohne Nutzung von
xchgfür die Implementierung vonenter_cs()zeigt Listing A.7.
Listing A.7: Eine inkorrekte Implementierung von
enter_cs()eines SpinlocksZunächst wird der Wert der Variablen
lockin das EAX-Register geschrieben. Danach wird der Wert von EAX mit der Konstantenlocked, also 0, verglichen. Im Gleichheitsfall wird zum Anfang gesprungen und der Vorgang erneut versucht. Schlägt der Vergleich fehl, war das Spinlock also geöffnet. Dann wird es in der nächsten Instruktion geschlossen, indem der Wert 0 hineingeschrieben wird. Außerdem erreicht der Prozess den kritischen Abschnitt.Stellen Sie sich nun vor, dass zwei Prozesse den Code von
enter_cs()gleichzeitig ausführen und das Spinlock ursprünglich geöffnet ist. Beide holen sich den Wert in ihr jeweiliges Register EAX, beide stellen fest, dass der Spinlock (vermeintlich) frei ist, beide schreiben den Wert 0 in das Spinlock, und beide betreten den kritischen Abschnitt. Es handelt sich beim betrachteten Code um eine Race Condition bezüglich des Zustands des Spinlocks. - Aus Umfangsgründen soll an dieser Stelle auf die Angabe des vollständigen Listings verzichtet werden.
Kapitel 8
- Den zugehörigen Quellcode einer funktionsfähigen Lösung enthält Listing A.8.



Listing A.8: Zählen der über eine Pipe empfangenen Bytes (wc-with-pipes.c)
Der Ursprungsprozess baut zunächst die Infrastruktur auf. Eine Pipe wird angelegt (Zeile 65), danach werden zwei Söhne erzeugt, die die Funktionen
son1()beziehungsweiseson2()ausführen. Beide Söhne erben die Deskriptoren der Pipe. Der Vater schließt danach diese Deskriptoren (Zeilen 85/86), da er selbst nicht an der Kommunikation teilnimmt. Er wartet nacheinander auf die Beendigung beider Sohnprozesse (Zeilen 87 und 90) und endet danach selbst.Sohn Nummer 1 liest die Pfadangabe mittels
fgets()vonstdin(Zeile 21). Danach schließt er sein Leseende der Pipe. Nun öffnet er die durch die Pfadangabe spezifizierte Datei (Zeile 25). In der darauffolgenden Schleife (Zeile 32–36) liest er die Datei und schreibt die empfangenen Daten in das Schreibende der Pipe, wobei blockweise gearbeitet wird. Nachdem EOF erreicht wurde, werden das Schreibende der Pipe sowie der Dateideskriptor geschlossen, und der Prozess endet.Sohn Nummer 2 schließt das Schreibende der Pipe und liest danach in einer Schleife blockweise aus der Pipe. Die durch
read()zurückgelieferte Anzahl tatsächlich gelesener Bytes akkumuliert der Prozess in der Variablenbytes, die nach erreichtem EOF nachstdoutgeschrieben wird. Zu guter Letzt schließt er das Schreibende (die Pipe wird damit vernichtet) und endet. -
Listing A.9 zeigt eine mögliche Lösung. Zur Synchronisation werden zwei POSIX-Semaphore (
blockson,blockdad) genutzt.Die Schleife in den Zeilen 73–77 ist der interessanteste Teil. Der Vater wartet zunächst auf die Freigabe der Semaphore
blockdaddurch einen Sohn (die erste Iteration startet sofort, da die Semaphore offen initialisiert ist). Danach kopiert der Vater eine der vier Nachrichten in das Mapping (Zeile 75). Danach wird einer der Sohnprozesse, die alle am Semaphorblocksonwarten, deblockiert. Dieser schreibt die Nachricht nachstdoutund gibt dann mittelssem_post()dem Vater das Signal, die nächste Nachricht in das Mapping zu schreiben.

Listing A.9: Ein Prozess übermittelt seinen Kindprozessen Nachrichten mittels eines anonymen Mappings (mmap-anonym.c)
Überzeugen Sie sich, dass wirklich zwei Semaphore zur korrekten Synchronisation benötigt werden! Die Fehlerbehandlung wurde in diesem Beispiel aus Gründen der Übersichtlichkeit vernachlässigt.
-
-
Der Server vereinbart zunächst zwei Signalhandler:
- für SIGINT, um ihn aus dem Speicher zu entfernen,
- für SIGCHLD, um den Statuswert des beendeten Kindprozesses abzuholen.
Danach wird die Nachrichtenwarteschlange angelegt. Die Verarbeitungsschleife startet in Zeile 57. Der Server schläft vor jeder Receive-Operation für 100 Millisekunden; er wird gewissermaßen künstlich gebremst. Dann führt er Receive aus und blockiert, bis die erste Nachricht eintrifft (oder er ein Signal empfängt).
Nach dem Empfang einer Nachricht wird ein Kindprozess gestartet (Zeile 69), der die Behandlung derselben übernimmt, während der Vater sofort wieder an der Nachrichtenwarteschlange lauscht. Das Kind konstruiert im Puffer
cmdbufdas persystem()aufzurufendecp-Kommando und schreibt dieses zur Kontrolle nachstdout. In Zeile 81 wird es schließlich ausgeführt.


Listing A.10: Ein Server übernimmt via Nachrichtenwarteschlange Dateinamen, die zu archivieren sind (mq-archive-server.c)
Client und Server benötigen ein gemeinsames Headerfile
mq-archive.h, damit beispielsweise beide den Key der Nachrichtenwarteschlange erhalten.
-
Der Client ist im Gegensatz zum Server sehr einfach strukturiert. Er holt sich zunächst Zugriff zur Nachrichtenwarteschlange (Zeile 16) und betritt dann die Schleife, in der er
- zeilenweise von
stdinliest (die Pfadangaben der zu archivierenden Dateien), - das am Ende stehende
'\n'abschneidet, - die eingelesene Zeile in die Nachricht kopiert (Zeile 35),
- die Nachricht per
msgsnd()an die Nachrichtenwarteschlange schickt (Zeile 37).
Die Schleife wird verlassen, wenn EOF von
stdingelesen wird.Beachten Sie, dass eine Nachricht einen Kopf und einen Körper hat. Der Kopf muss eine Ganzzahl größer null enthalten; er wird aber weder vom Client noch vom Server weiter verwendet.

- zeilenweise von
-
Listing A.12: Ein Client, der Dateinamen von stdin entgegennimmt und diese per Nachrichtenwarteschlange an den Server (Listing A.10) überträgt (mq-archive-client.c)
Kapitel 9
- Da der Adressbus eine Breite von 16 Bit besitzt, ist die größtmögliche Adresse
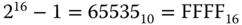 . Da nicht Bytes, sondern Worte à 24 Bit (3 Byte) adressiert werden, können maximal
. Da nicht Bytes, sondern Worte à 24 Bit (3 Byte) adressiert werden, können maximal 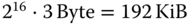 in das System eingebaut werden. Gegenwärtig ist genau die Hälfte davon, nämlich 96 KiB, im System verbaut. Somit ist die größte Adresse
in das System eingebaut werden. Gegenwärtig ist genau die Hälfte davon, nämlich 96 KiB, im System verbaut. Somit ist die größte Adresse 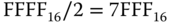 .
. - An dieser Implementierungsaufgabe sollen Sie sich ohne Muster versuchen.
-
- First Fit:
Anforderung
Dauer [
 s]
s]Teilung
Resultatsegment
12 KiB
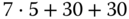
7
 7a (12 KiB, belegt)
7a (12 KiB, belegt) 7b (6 KiB, frei)
7b (6 KiB, frei)7a
10 KiB
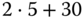
-
2
9 KiB
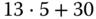
-
12
Beachten Sie, dass die dritte Anforderung 13 Segmente durchmustern muss, da Segment 7 in Schritt 1 in die Teilsegmente 7a und 7b zerlegt wurde. Die Gesamtdauer beträgt
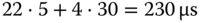 .
. - Next Fit:
Anforderung
Dauer [
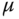 s]
s]Teilung
Resultatsegment
12 KiB
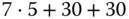
7
 7a (12 KiB, belegt)
7a (12 KiB, belegt) 7b (6 KiB, frei)
7b (6 KiB, frei)7a
10 KiB
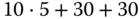
16
 16a (10 KiB, belegt)
16a (10 KiB, belegt) 16b (2 KiB, frei)
16b (2 KiB, frei)16a
9 KiB
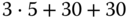
18
 18a (9 KiB, belegt)
18a (9 KiB, belegt) 18b (2 KiB, frei)
18b (2 KiB, frei)18a
Es wird ungünstigerweise jedes Mal ein Segment geteilt. Gesamtdauer:
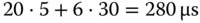 .
. - Best Fit:
Anforderung
Dauer [
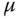 s]
s]Teilung
Resultatsegment
12 KiB
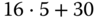
-
16
10 KiB
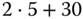
-
2
9 KiB
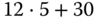
-
12
Da genügend exakt passende Segmente existieren, wird kein Segment geteilt. Der reine Suchaufwand ist erwartungsgemäß höher als bei den beiden vorangegangenen Strategien. Gesamtdauer:
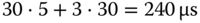 .
. - Worst Fit:
Anforderung
Dauer [
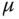 s]
s]Teilung
Resultatsegment
12 KiB
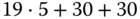
7
 7a (12 KiB, belegt)
7a (12 KiB, belegt) 7b (6 KiB, frei)
7b (6 KiB, frei)7a
10 KiB
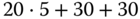
16
 16a (10 KiB, belegt)
16a (10 KiB, belegt) 16b (2 KiB, frei)
16b (2 KiB, frei)16a
9 KiB
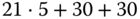
18
 18a (9 KiB, belegt)
18a (9 KiB, belegt) 18b (2 KiB, frei)
18b (2 KiB, frei)18a
Zufälligerweise werden genau die gleichen Segmente ausgewählt und geteilt wie bei Next Fit; der Suchaufwand ist aber höher, da jedes Mal die gesamte Liste durchsucht werden muss. Gesamtdauer:
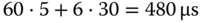 .
.
- First Fit:
-
- Für Prozess A wird ein Segment der Größe 256 KiB benötigt, Prozess B erhält 1 MiB, Prozess C erhält genau die geforderten 64 KiB, und Prozess D erhält ebenfalls 1 MiB. Abbildung A.5 zeigt das resultierende Speicherabbild.

Abbildung A.5: Speicherabbild nach vier Forderungen
- Es werden insgesamt
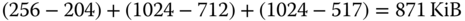 verschwendet.
verschwendet. - Wenn man annimmt, dass für den gesamten Speicher von 4 MiB keine extra Liste angelegt wird, dann benötigt man zehn Listen, nämlich für die Blockgrößen (in KiB) 2048, 1024, 512, 256, 128, 64, 32, 16, 8 und 4.
- Der größte freie Block hat eine Länge von 1 MiB.
- Für Prozess A wird ein Segment der Größe 256 KiB benötigt, Prozess B erhält 1 MiB, Prozess C erhält genau die geforderten 64 KiB, und Prozess D erhält ebenfalls 1 MiB. Abbildung A.5 zeigt das resultierende Speicherabbild.
-
- Wenn man jedes Byte einer virtuellen Seite ansprechen möchte, benötigt man 12 Bit, denn
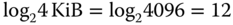 .
. 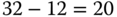 (Bit)
(Bit)- Die Seitentabelle kann
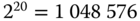 Einträge aufweisen.
Einträge aufweisen. - Da jeder Eintrag in der Seitentabelle eine Kachel mit Größe 4 KiB referenziert, kann ein Prozess maximal 1 048 576 Kacheln à 4 KiB umfassen. Das sind
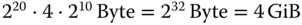 .
.
- Wenn man jedes Byte einer virtuellen Seite ansprechen möchte, benötigt man 12 Bit, denn
- Das Seitentabellenverzeichnis enthält genau 4096 Byte / 4 Byte = 1024 Einträge. Jeder dieser Einträge referenziert eine Seitentabelle von 4 KiB Größe. Somit beansprucht eine voll ausgebaute Tabellenstruktur
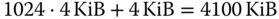 , also reichlich 4 MiB.
, also reichlich 4 MiB. -
- Bei FIFO entscheidet der Einlagerungszeitpunkt einer Seite; es wird stets die älteste Seite ausgelagert. Die folgende Tabelle gibt für jeden relevanten Systemzeitpunkt wieder, welche Seiten sich im Hauptspeicher eingeblendet finden (Arbeitsmenge AM) und wann ein Pagefault (PF) auftritt. Innerhalb eines Zeitpunktes sind die eingeblendeten Seiten nach dem Einlagerungszeitpunkt geordnet, die älteste Seite steht oben.
t
0
1
2
3
4
5
6
7
8
9
10
11
12
-
A
A
A
B
B
B
C
D
D
D
A
B
AM
-
-
B
B
C
C
C
D
A
A
A
B
C
-
-
-
C
D
D
D
A
B
B
B
C
D
PF
(x)
(x)
(x)
x
x
x
x
x
Initial wird zunächst der Speicher gefüllt (
 ). Zu
). Zu  wird erstmalig verdrängt – dies ist bei allen Verfahren identisch. B verdrängt die älteste Seite A. Insgesamt kommt es zu fünf echten Page Faults – ein Hinweis, dass das Verfahren nicht allzu gut ist.
wird erstmalig verdrängt – dies ist bei allen Verfahren identisch. B verdrängt die älteste Seite A. Insgesamt kommt es zu fünf echten Page Faults – ein Hinweis, dass das Verfahren nicht allzu gut ist. - LRU arbeitet so ähnlich wie FIFO, nur wird jetzt nicht die älteste Seite entfernt, sondern die Seite, die am längsten nicht referenziert wurde. Die Arbeitsmenge in der folgenden Tabelle ist daher nach den Referenzzeitpunkten geordnet. Die am längsten nicht referenzierte Seite steht oben (und ist damit der Auslagerungskandidat).
t
0
1
2
3
4
5
6
7
8
9
10
11
12
-
A
A
A
B
C
C
B
D
D
A
B
B
AM
-
-
B
B
C
D
D
D
A
A
B
D
C
-
-
-
C
D
B
B
A
B
B
D
C
D
PF
(x)
(x)
(x)
x
x
x
Im Vergleich zu FIFO arbeitet dieses Verfahren hier deutlich besser; nur drei Page Faults sind nach der Initialisierung notwendig. Wie Sie gleich sehen werden, liegt dies ziemlich nahe am theoretischen Optimum.
- Das optimale Verfahren verfügt über einen unbeschränkten Blick in die Zukunft und lagert folgerichtig immer diejenige Seite aus, die zukünftig am längsten nicht benötigt wird.
t
0
1
2
3
4
5
6
7
8
9
10
11
12
-
A
A
A
A
A
A
A
A
A
A
B
B
AM
-
-
B
B
B
B
B
B
B
B
B
D
D
-
-
-
C
D
D
D
D
D
D
D
C
C
PF
(x)
(x)
(x)
x
x
Zu
 ist ein solcher Blick in die Zukunft erstmals erforderlich. A wird zu
ist ein solcher Blick in die Zukunft erstmals erforderlich. A wird zu 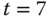 wieder benötigt, B zu
wieder benötigt, B zu 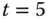 und C zu
und C zu 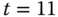 . Es wird also C ausgelagert. Diese Entscheidung rentiert sich: Bis zu
. Es wird also C ausgelagert. Diese Entscheidung rentiert sich: Bis zu 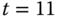 können alle Referenzen mit den eingeblendeten Seiten erfüllt werden. Zu
können alle Referenzen mit den eingeblendeten Seiten erfüllt werden. Zu 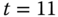 wird C wieder benötigt. Es wird entweder A oder B ausgelagert, da wir nicht genug Wissen über Seitenreferenzierungen nach
wird C wieder benötigt. Es wird entweder A oder B ausgelagert, da wir nicht genug Wissen über Seitenreferenzierungen nach 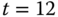 haben. D verbleibt auf alle Fälle in der Arbeitsmenge, da es im nächsten Schritt benötigt wird. Für diese Referenzkette ist also ein Minimum von zwei Seitenfehlern unvermeidbar.
haben. D verbleibt auf alle Fälle in der Arbeitsmenge, da es im nächsten Schritt benötigt wird. Für diese Referenzkette ist also ein Minimum von zwei Seitenfehlern unvermeidbar. - Die Tabelle gibt die Arbeitsmenge (AM) an, der Wert des R-Bits jeder eingelagerten Seite wird nach dem Doppelpunkt notiert. Die Zeile AK enthält den aktuellen Auslagerungskandidaten, also die Position des Zeigers.
t
0
1
2
3
4
5
6
7
8
9
10
11
12
-
A:1
A:1
A:1
D:1
D:1
D:1
D:1
D:1
D:1
D:1
C:1
C:1
AM
-
-
B:1
B:1
B:0
B:1
B:1
B:0
B:1
B:1
B:1
B:0
D:1
-
-
-
C:1
C:0
C:0
C:0
A:1
A:1
A:1
A:1
A:0
A:0
AK
-
-
-
A
B
B
B
D
D
D
D
B
A
PF
(x)
(x)
(x)
x
x
x
x
Zu
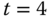 wird A ausgelagert. Da alle Seiten frisch eingelagert sind, werden alle Seiten geprüft, alle R-Bits zurückgesetzt, und dann wird die älteste Seite ausgelagert. Danach werden B und D referenziert und die entsprechenden Referenzbits gesetzt (
wird A ausgelagert. Da alle Seiten frisch eingelagert sind, werden alle Seiten geprüft, alle R-Bits zurückgesetzt, und dann wird die älteste Seite ausgelagert. Danach werden B und D referenziert und die entsprechenden Referenzbits gesetzt (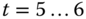 ). Auslagerungskandidat bleibt B. Zu
). Auslagerungskandidat bleibt B. Zu 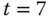 erfolgt die nächste Verdrängung. Das R-Bit von B ist jedoch gesetzt, folglich wird es gelöscht (B erhält seine zweite Chance), und C wird neuer Auslagerungskandidat. Sein R-Bit ist 0, damit erhält C keine zweite Chance und wird ausgelagert. Zu
erfolgt die nächste Verdrängung. Das R-Bit von B ist jedoch gesetzt, folglich wird es gelöscht (B erhält seine zweite Chance), und C wird neuer Auslagerungskandidat. Sein R-Bit ist 0, damit erhält C keine zweite Chance und wird ausgelagert. Zu 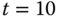 sind noch einmal alle Referenzbits gesetzt, also ist ein weiterer kompletter Zyklus durch die Ringliste notwendig. Dieser komplette Umlauf ist in der Praxis extrem unwahrscheinlich, da ein Prozess viel mehr Seiten eingeblendet hat.
sind noch einmal alle Referenzbits gesetzt, also ist ein weiterer kompletter Zyklus durch die Ringliste notwendig. Dieser komplette Umlauf ist in der Praxis extrem unwahrscheinlich, da ein Prozess viel mehr Seiten eingeblendet hat.Bedingt durch eine etwas unglückliche Referenzierungsfolge summiert sich die Anzahl der Seitenfehler in diesem Beispiel auf vier.
- Bei NFU wird stets die Seite mit der geringsten Anzahl an Referenzen ausgelagert. Der entsprechende Zähler ist für die eingelagerten Seiten nach dem Doppelpunkt angegeben.
t
0
1
2
3
4
5
6
7
8
9
10
11
12
-
A:1
A:1
A:1
B:1
B:2
B:2
B:2
B:3
B:4
B:4
B:4
B:4
AM
-
-
B:1
B:1
C:1
C:1
C:1
D:2
D:2
D:2
D:3
D:3
D:4
-
-
-
C:1
D:1
D:1
D:2
A:1
A:1
A:1
A:1
C:1
C:1
PF
(x)
(x)
(x)
x
x
x
Zu
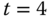 sind die Zähler identisch 1, daher wird in diesem Fall die lexikografisch kleinste Seite (A) ausgelagert. Zu
sind die Zähler identisch 1, daher wird in diesem Fall die lexikografisch kleinste Seite (A) ausgelagert. Zu 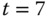 wird C ausgelagert, da sein Zählerstand der kleinste ist. Zu
wird C ausgelagert, da sein Zählerstand der kleinste ist. Zu 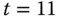 wird A ausgelagert. Sehr schön demonstriert wird der Nachteil, den neu ins System eingelagerte Seiten gegenüber »alteingesessenen« haben. Die neuen Seiten werden schnell wieder ausgelagert, sie haben keine Chance, ihre Zählerstände genügend weit zu erhöhen.
wird A ausgelagert. Sehr schön demonstriert wird der Nachteil, den neu ins System eingelagerte Seiten gegenüber »alteingesessenen« haben. Die neuen Seiten werden schnell wieder ausgelagert, sie haben keine Chance, ihre Zählerstände genügend weit zu erhöhen. - Die Tabelle muss nun gedanklich um 90 Grad gedreht werden, weil die Seitenbreite zur Notation der Zählerstände nicht ausreicht.
t
AM
PF
0
-
-
1
A:1000
(x)
2
A:1000 B:1000
(x)
3
A:1000 B:1000 C:1000
(x)
4
B:0100 C:1000 D:1000
x
5
B:0100 C:1000 D:1000
6
B:1010 C:0100 D:1100
7
A:1000 B:1010 D:1100
x
8
A:1000 B:1101 D:0110
9
A:1000 B:1101 D:0110
10
A:0100 B:1110 D:1011
11
B:1110 C:1000 D:1011
x
12
B:0111 C:1000 D:1101
Seiten, die eingelagert werden, erhalten sofort den Zählerstand 1000, auch wenn die Einlagerung nicht mit dem Aktualisieren der Zähler zusammenfällt. Zu
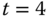 sind die Zählerstände aller Seiten identisch, daher muss wiederum eine beliebige Seite (hier: A) ausgewählt werden. Das Verfahren generiert eine identisch gute Auslagerungsfolge wie LRU (nur drei Page Faults), jedoch ist es im Gegensatz zu diesem praktikabel.
sind die Zählerstände aller Seiten identisch, daher muss wiederum eine beliebige Seite (hier: A) ausgewählt werden. Das Verfahren generiert eine identisch gute Auslagerungsfolge wie LRU (nur drei Page Faults), jedoch ist es im Gegensatz zu diesem praktikabel.
- Bei FIFO entscheidet der Einlagerungszeitpunkt einer Seite; es wird stets die älteste Seite ausgelagert. Die folgende Tabelle gibt für jeden relevanten Systemzeitpunkt wieder, welche Seiten sich im Hauptspeicher eingeblendet finden (Arbeitsmenge AM) und wann ein Pagefault (PF) auftritt. Innerhalb eines Zeitpunktes sind die eingeblendeten Seiten nach dem Einlagerungszeitpunkt geordnet, die älteste Seite steht oben.
Kapitel 10
-
- Es werden natürlich
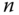 Operationen benötigt, es müssen einfach alle Blöcke hintereinanderweg gelesen werden.
Operationen benötigt, es müssen einfach alle Blöcke hintereinanderweg gelesen werden. - Um den letzten Block zu lesen, sind
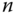 Leseoperationen vonnöten. Danach ist der vorletzte Block zu lesen, dieser benötigt
Leseoperationen vonnöten. Danach ist der vorletzte Block zu lesen, dieser benötigt 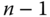 Operationen, da man sich wiederum von vorn beginnend durch die Blockliste hangeln muss. Der drittletzte Block benötigt
Operationen, da man sich wiederum von vorn beginnend durch die Blockliste hangeln muss. Der drittletzte Block benötigt 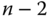 und so weiter bis zum letzten zu lesenden Block, der der erste der Datei ist. Er benötigt genau eine Operation. Insgesamt sind somit
und so weiter bis zum letzten zu lesenden Block, der der erste der Datei ist. Er benötigt genau eine Operation. Insgesamt sind somit
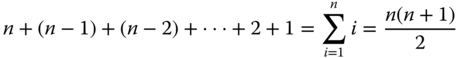
Operationen notwendig. Das Beispiel unterstreicht die Bedeutung einer guten Cacheingstrategie. Wenn das System beispielsweise immer die letzten
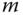 gelesenen Blöcke aufhöbe, dann würde sich die Anzahl notwendiger Leseoperationen auf
gelesenen Blöcke aufhöbe, dann würde sich die Anzahl notwendiger Leseoperationen auf 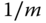 reduzieren.
reduzieren.
- Es werden natürlich
-
- Eine Datei von 128 MiB benötigt offenbar
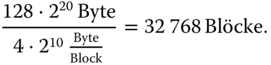
Bei einer 32 Bit großen Blocknummer muss jeder Eintrag in der Indextabelle damit eine Größe von
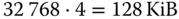 besitzen, was nicht allzu realistisch erscheint.
besitzen, was nicht allzu realistisch erscheint. - Mit einer Blocknummerngröße von 32 Bit kann es maximal
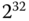 verschiedene Blöcke geben. Jeder dieser Blöcke umfasst 4 KiB. Somit hat das Dateisystem eine maximale Größe von
verschiedene Blöcke geben. Jeder dieser Blöcke umfasst 4 KiB. Somit hat das Dateisystem eine maximale Größe von 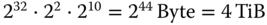 .
. - 9000 Dateien sind kleiner als 4 KiB. Jede dieser Dateien würde nur eine einzige Blocknummer in der Indextabelle benötigen. Sie besitzt jedoch laut Ergebnis von a) 32 768 Blocknummern, von denen somit 32 767 nutzlos sind. Somit werden in der Indextabelle insgesamt
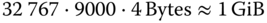 verschwendet.
verschwendet. - Die Indextabelle hat eine Gesamtgröße von 10 000 Dateien à 128 KiB, das sind etwa 1.2 GiB.
- Eine Datei von 128 MiB benötigt offenbar
-
Es ist günstig, diese Aufgabe rekursiv zu lösen. Die gesamte Arbeit steckt in der Funktion
rd_dir(), die eine Pfadangabe als Zeichenkette entgegennimmt.Zunächst wird mittels des Systemrufs
getcwd()das aktuelle Arbeitsverzeichnis des Prozesses ermittelt (Zeile 19), um am Ende der Funktion wieder in dieses hineinzuwechseln (Zeile 56). Danach wird in das als Parameter übergebene Verzeichnis hineingewechselt (Funktionchdir(), Zeile 25). Nun wird das Verzeichnis mittelsopendir()eröffnet (Zeile 31) und dann in einer Schleife Eintrag für Eintrag mittelsreaddir()gelesen (Zeile 36). Mittelslstat()werden die Attribute des Eintrags ermittelt.Nun muss anhand des Typs des Verzeichniseintrags entschieden werden, was getan werden muss. Dazu stellt das Betriebssystem Makros wie
S_ISDIR(das »wahr« zurückliefert, wenn es sich um ein Verzeichnis handelt) oderS_ISREG(zur Erkennung einer regulären Datei) zur Verfügung. Handelt es sich um ein Verzeichnis, jedoch weder um das aktuelle noch um das übergeordnete, dann muss dieses genauso behandelt werden wie das gegenwärtig bearbeitete Verzeichnis;rd_dir()ruft sich mit dem Verzeichnisnamen als Parameter rekursiv. Zuvor wird der Name des Verzeichnisses ausgegeben. Handelt es sich hingegen beim Eintrag um eine reguläre Datei, dann wird deren Name und Größe ausgegeben, und es geht zur nächsten Iteration. Ist das Verzeichnis komplett iteriert, muss es mittelsclosedir()geschlossen werden (Zeile 53).

Listing A.13: Ein ls-Kommando, das rekursiv Verzeichnisinhalte auflistet (mylsrek.c)
Das Hauptprogramm besteht nur noch aus der Prüfung der erhaltenen Parameteranzahl und dem initialen Aufruf von
rd_dir()mit dem aufzulistenden Verzeichnis (argv[1], Zeile 70). - Für eine ganze Umdrehung benötigt die Platte 1/7200 min, also 1/120 s das sind ungefähr 8.3 ms. Unter der Voraussetzung, dass die Blöcke unmittelbar aneinandergrenzen, werden für das Lesen eines Blocks der äußeren Spur
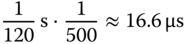
und für das Lesen eines Sektors auf der innersten Spur
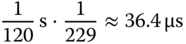
benötigt. Im Vergleich zu Rotationslatenz und Seek-Zeit, die beide im Millisekundenbereich liegen, ist dies zu vernachlässigen.
Die rohe Leserate beträgt außen 4096 Bytes/16.6 µs, das sind etwa 246 MiB s−1, und innen ungefähr 113 MiB s−1.
Kapitel 11
- Die Variable
passwort[]wird nicht mehr überschrieben, sondern der Pufferüberlauf wird erkannt (»stack smashing detected«) und der Prozess daraufhin abgebrochen:robge@sorpen:∼/src$ gcc -o bo -fstack-protector bo.crobge@sorpen:∼/src$./bo `perl -e 'print "a"x134,'`Passwort!Puffer: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaPasswort!Passwort: 12345678*** stack smashing detected ***: <unknown> terminatedAbgebrochen -
Das Programm gibt jeweils eine Adresse aus dem Text-, dem Daten- und dem Stacksegment aus, jedoch nicht den Anfang dieser Segmente.

Listing A.14: Ein Programm, das sich permanent selbst aufruft (aslr-stat.c)
Wenn man das Programm eine Weile laufen lässt, sieht man an den Ausgaben sehr schön, mit welcher Granularität die Address Space Layout Randomization erfolgt. Der
sleep()-Aufruf in Zeile 13 ist eine Art Bremse. Die Geschwindigkeit der Prozesserzeugung wird damit auf eine pro Sekunde begrenzt, und Sie haben eine realistische Chance, den jeweils aktuellen Prozess mittelskillall aslr-statzu eliminieren. -
Die Quelltextdatei
getpass.centhält die Funktionmy_getpass()zum Einlesen einer Passphrase. Den Rest der Implementation finden Sie im Quelltextauth.cdes Listings 11.6. Zusätzlich wird noch die Headerdateimycrypt.hbenötigt, die Listing 11.8 enthält.Das Binary erzeugen Sie mittels des Aufrufs
$ gcc -Wall -Wextra --pedantic -o auth auth.c getpass.c -lcryptZum Ausprobieren benötigen Sie aber zunächst noch die Lösung der nächsten Aufgabe.
-
Das Programm übernimmt genau einen Parameter, nämlich das gewünschte Nutzerkennzeichen. Die Datei
PWFILE, die die Hashes enthält, wird geöffnet und nach dem Nutzerkennzeichen durchsucht (Zeilen 41–48). Im Falle, dass es schon vergeben wurde, bricht das Programm mit einer Fehlermeldung ab. Nun wird durch den Aufruf vonmy_getpass()die Passphrase eingelesen (Zeile 52). Unterschreitet diese eine gewisse Mindestlänge, dann wird sie zurückgewiesen, und der Prozess endet (Zeile 58–63). Nun muss die Passphrase ein zweites Mal eingelesen werden, um versehentliche Tippfehler zu eliminieren (Zeile 66). Zuvor muss sie in einen extra Puffer (passbuf) kopiert werden, weilmy_getpass()stets denselben Pufferspeicher zurückliefert; damit würde die erste Phrase überschrieben werden! In Zeile 71 schließlich werden beide Phrasen verglichen. Differieren Sie, so endet das Programm (in einer ordentlichen Applikation würde man stattdessen zur erneuten Eingabe beider Phrasen auffordern). Nun wird das sogenannte Salz in Funktiongenerate_salt()erzeugt, dessen genaue Erläuterung an dieser Stelle unterbleiben soll. Passphrase und Salz werden konkateniert und mittels des Verfahrens SHA-512 gehasht (Funktioncrypt(), Zeile 78). Danach wird die Passphrase überschrieben (Zeile 79), und Nutzerkennzeichen und Hash werden in die Datei geschrieben (Zeile 83). Damit endet das Programm.


Listing A.15: Programm zum Anlegen von Nutzerzugängen (myadduser.c)
Falls Sie sich fragen, was es mit dem Salz auf sich hat oder wieso gerade mittels des Verfahrens SHA-512 gehasht wird, dann setzen Sie Ihre Lektüre vielleicht mit einem guten Buch zum Thema Informationssicherheit fort, vielleicht [3]. »Betriebssysteme für Dummies« endet hier, aber das kann natürlich auch ein neuer Anfang sein!