Capítulo IV.
Diseño de análisis OLAP
Es bien sabido que el concepto de Business Intelligence engloba múltiples conceptos. Uno de los más importantes es el concepto OLAP (On-Line Analytical Processing), acuñado por Edgar F. Codd.
Una manera sencilla de explicar este concepto es decir que es una tecnología que permite un análisis multidimensional[13] a través de tablas matriciales o pivotantes.
Si bien el término OLAP se introduce por primera vez en 1993, los conceptos base del mismo, como por ejemplo el análisis multidimensional, son mucho más antiguos.
A pesar de ser una tecnología que ya tiene más de cuatro décadas, sus características y su evolución han provocado que la gran mayoría de soluciones del mercado incluya un motor OLAP.
Es necesario comentar:
• Las herramientas OLAP de los diferentes fabricantes, si bien son similares, no son completamente iguales dado que presentan diferentes especificaciones del modelo teórico.
• La última tendencia en OLAP es la tecnología in-memory.
• Las soluciones open source OLAP han sido las últimas a añadirse a la lista y, por ahora, no tienen tanta variedad como su contrapartida propietaria.
• En el mercado open source OLAP sólo hay dos soluciones actualmente: el motor ROLAP Mondrian y el motor MOLAP PALO.
Este capítulo se centrará en presentar el concepto OLAP y sus diferentes opciones.
1. OLAP como herramienta de análisis
OLAP forma parte de lo que se conoce como sistemas analíticos, que permiten responder preguntas como: ¿por qué paso? Estos sistemas pueden encontrarse tanto integrados en suites de Business Intelligence o ser simplemente una aplicación independiente.
Es necesario, antes de continuar, introducir una definición formal de OLAP:
Se entiende por OLAP, o proceso analítico en línea, al método ágil y flexible para organizar datos, especialmente metadatos, sobre un objeto o jerarquía de objetos como en un sistema u organización multidimensional, y cuyo objetivo es recuperar y manipular datos y combinaciones de los mismos a través de consultas o incluso informes.
Una herramienta OLAP está formada por un motor y un visor. El motor es, en realidad, justo el concepto que acabamos de definir. El visor OLAP es una interfaz que permite consultar, manipular, reordenar y filtrar datos existentes en una estructura OLAP mediante una interfaz gráfica de usuario que dispone funciones de consulta MDX[14] y otras.
Las estructuras OLAP permiten realizar preguntas que serían sumamente complejas mediante SQL.
Consideremos un ejemplo gráfico que nos permitirá entender la potencia de este tipo de herramientas.
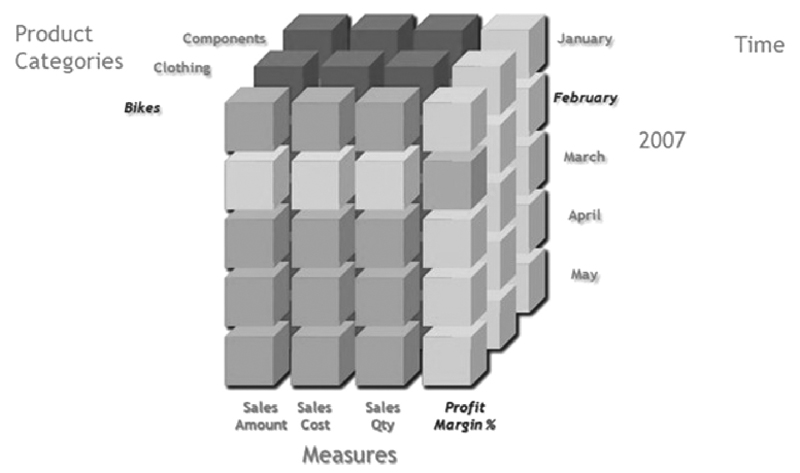
Imaginemos que queremos responder a la siguiente pregunta: ¿cuál es el margen de beneficios de la venta de bicicletas para febrero de 2007?
Si tenemos un cubo, como el de ejemplo, formado por el tiempo, los productos y las medidas, la respuesta es la intersección entre los diferentes elementos.
Cabe observar que una estructura de esta forma permite consultas mucho más completas, como por ejemplo comparar el margen de beneficios de febrero y mayo, entre diferentes productos, etc.
Además, el visor OLAP proporciona libertad a los usuarios finales para realizar dichas consultas de forma independiente al departamento de IT.
1.1. Tipos de OLAP
Existen diferentes tipos de OLAP, que principalmente difieren en cómo se guardan los datos:
• MOLAP (Multidimensional OLAP): es la forma clásica de OLAP y frecuentemente es referida con dicho acrónimo. MOLAP utiliza estructuras de bases de datos generalmente optimizadas para la recuperación de los mismos. Es lo que se conoce como bases de datos multidimensionales (o, más coloquialmente, cubos). En definitiva, se crea un fichero que contiene todas las posibles consultas precalculadas. A diferencia de las bases de datos relacionales, estas formas de almacenaje están optimizadas para la velocidad de cálculo. También se optimizan a menudo para la recuperación a lo largo de patrones jerárquicos de acceso. Las dimensiones de cada cubo son típicamente atributos tales como periodo, localización, producto o código de la cuenta. La forma en la que cada dimensión será agregada se define por adelantado.
• ROLAP (Relational OLAP): trabaja directamente con las bases de datos relacionales, que almacenan los datos base y las tablas dimensionales como tablas relacionales mientras se crean nuevas tablas para guardar la información agregada.
• HOLAP (Hybrid OLAP): no hay acuerdo claro en la industria en cuanto a qué constituye el OLAP híbrido, exceptuando el hecho de que es una base de datos en la que los datos se dividen en almacenaje relacional y multidimensional. Por ejemplo, para algunos vendedores, HOLAP consiste en utilizar las tablas relacionales para guardar las cantidades más grandes de datos detallados, y utiliza el almacenaje multidimensional para algunos aspectos de cantidades más pequeñas de datos menos detallados o agregados.
• DOLAP (Desktop OLAP): es un caso particular de OLAP ya que está orientado a equipos de escritorio. Consiste en obtener la información necesaria desde la base de datos relacional y guardarla en el escritorio. Las consultas y los análisis son realizados contra los datos guardados en el escritorio.
• In-memory OLAP: es un enfoque por el que muchos nuevos fabricantes están optando. Consiste en que la estructura dimensional se genera sólo a nivel de memoria y se guarda el dato original en algún formato que potencia su despliegue de esta forma (por ejemplo, comprimido o mediante una base de datos de lógica asociativa). En este último punto es donde cada fabricante pone su énfasis.
Cada tipo tiene ciertas ventajas, aunque hay desacuerdo sobre las ventajas específicas de los diferentes proveedores.
• MOLAP es mejor en sistemas más pequeños de datos, es más rápido para calcular agregaciones y retornar respuestas y necesita menos espacio de almacenaje. Últimamente, in-memory OLAP está apuntalándose como una opción muy válida al MOLAP.
• ROLAP se considera más escalable. Sin embargo, el preproceso de grandes volúmenes es difícil de implementar eficientemente, así que se desecha con frecuencia. De otro modo, el funcionamiento de las consultas puede ser no óptimo.
• HOLAP está entre los dos en todas las áreas, pero puede preprocesar rápidamente y escalar bien.
Todos los tipos son, sin embargo, propensos a la explosión de la base de datos. Éste es un fenómeno que causa la cantidad extensa de espacio de almacenaje que es utilizado por las bases de datos OLAP cuando se resuelven ciertas, pero frecuentes, condiciones: alto número de dimensiones, de resultados calculados de antemano y de datos multidimensionales escasos.
La dificultad en la implementación OLAP deviene en la formación de las consultas, elegir los datos base y desarrollar el esquema. Como resultado, la mayoría de los productos modernos vienen con bibliotecas enormes de consultas preconfiguradas. Otro problema está en la baja calidad de los datos, que deben ser completos y constantes.
1.2. Elementos OLAP
OLAP permite el análisis multidimensional. Ello significa que la información está estructurada en ejes (puntos de vista de análisis) y celdas (valores que se están analizando).
En el contexto OLAP existen diferentes elementos comunes a las diferentes tipologías OLAP (que en definitiva se diferencian a nivel práctico en que en MOLAP se precalculan los datos, en ROLAP no, y en in-memory se generan al iniciar el sistema):
• Esquema: un esquema es una colección de cubos, dimensiones, tablas de hecho y roles.
• Cubo: es una colección de dimensiones asociadas a una tabla de hecho. Un cubo virtual permite cruzar la información entre tablas de hecho a partir de sus dimensiones comunes.
• Tabla de hecho, dimensión y métrica.
• Jerarquía: es un conjunto de miembros organizados en niveles. En cuanto a bases de datos, se puede entender como una ordenación de los atributos de una dimensión.
• Nivel: es un grupo de miembros en una jerarquía que tienen los mismos atributos y nivel de profundidad en la jerarquía.
• Miembro: es un punto en la dimensión de un cubo que pertenece a un determinado nivel de una jerarquía. Las métricas (medidas) en OLAP se consideran un tipo especial de miembro que pertenece a su propio tipo de dimensión. Un miembro puede tener propiedades asociadas.
• Roles: permisos asociados a un grupo de usuarios.
• MDX: es un acrónimo de Multidimensional eXpressions (aunque también es conocido como Multidimensional Query eXpression). Es el lenguaje de consulta de estructuras OLAP, fue creado en 1997 por Microsoft y, si bien no es un lenguaje estándar, la gran mayoría de fabricantes de herramientas OLAP lo han adoptado como estándar de hecho.
1.3. 12 reglas OLAP de E. F. Codd
La definición de OLAP presentada anteriormente se basa en las 12 leyes que acuñó Edgar F. Codd en 1993. Estas reglas son las que, en mayor o menor medida, intentan cumplir todos los fabricantes de software:
• Vista conceptual multidimensional: se trabaja a partir de métricas de negocio y sus dimensiones.
• Transparencia: el sistema OLAP debe formar parte de un sistema abierto que soporta fuentes de datos heterogéneas (lo que llamamos actualmente arquitectura orientada a servicios).
• Accesibilidad: se debe presentar el servicio OLAP al usuario con un único esquema lógico de datos (lo que, en definitiva, nos indica que debe presentarse respecto una capa de abstracción directa con el modelo de negocio).
• Rendimiento de informes consistente: el rendimiento de los informes no debería degradarse cuando el número de dimensiones del modelo se incrementa.
• Arquitectura cliente/servidor: basado en sistemas modulares y abiertos que permitan la interacción y la colaboración.
• Dimensionalidad genérica: capacidad de crear todo tipo de dimensiones y con funcionalidades aplicables de una dimensión a otra.
• Dynamic sparse-matrix handling: la manipulación de datos en los sistemas OLAP debe poder diferenciar valores vacíos de valores nulos y además poder ignorar las celdas sin datos.
• Operaciones cruzadas entre dimensiones sin restricciones: todas las dimensiones son creadas igual y las operaciones entre dimensiones no deben restringir las relaciones entre celdas.
• Manipulación de datos intuitiva: dado que los usuarios a los que se destinan este tipo de sistemas son frecuentemente analistas y altos ejecutivos, la interacción debe considerarse desde el prisma de la máxima usabilidad de los usuarios.
• Reporting flexible: los usuarios deben ser capaces de manipular los resultados que se ajusten a sus necesidades conformando informes. Además, los cambios en el modelo de datos deben reflejarse automáticamente en esos informes.
• Niveles de dimensiones y de agregación ilimitados: no deben existir restricciones para construir cubos OLAP con dimensiones y con niveles de agregación ilimitados.
2. OLAP en el contexto de Pentaho
Mondrian es el motor OLAP integrado en Pentaho y ha sido renombrado como Pentaho Analysis Services. Este motor se combina con un visor OLAP –que es diferente si consideramos la versión Community o Enterprise– y con dos herramientas de desarrollo.
Resumiendo:
| Community | Enterprise | |
|---|---|---|
| Motor OLAP | Mondrian | |
| Visor OLAP | Jpivot, PAT | Pentaho Analyser (anteriormente Clearview) |
| Herramientas de desarrollo | Pentaho Schema Workbench, Pentaho Agreggation Designer | |
Trataremos cada uno de esos puntos en este apartado.
2.1. Mondrian
Mondrian es un servidor/motor OLAP escrito en java que está licenciado bajo la Eclipse Public License (EPL). Existe como proyecto desde 2003 y fue adquirido por Pentaho en 2005.
Mondrian se caracteriza por ser un motor ROLAP con caché, lo cual lo sitúa cerca del concepto de HOLAP. ROLAP significa que en Mondrian no residen datos (salvo en la caché) sino que éstos están en una base de datos en la que existen las tablas que conforman la información multidimensional con la que el motor trabaja. El lenguaje de consulta es MDX.
Mondrian se encarga de recibir consultas dimensionales a un cubo mediante MDX y de devolver los datos. El cubo es, en este caso, un conjunto de metadatos que definen cómo se ha de mapear la consulta por sentencias SQL al repositorio que contiene realmente los datos.
Esta forma de trabajar tiene ciertas ventajas:
• No se generan cubos/estructuras OLAP estáticas y por lo tanto se ahorra en tiempo de generación y en espacio.
• Se trabaja con datos actualizados siempre al utilizar la información residente en la base de datos.
• Mediante el uso del caché y de tablas agregadas, se pretende simular el mejor rendimiento de los sistemas MOLAP.
El siguiente diagrama presenta la arquitectura de Mondrian:
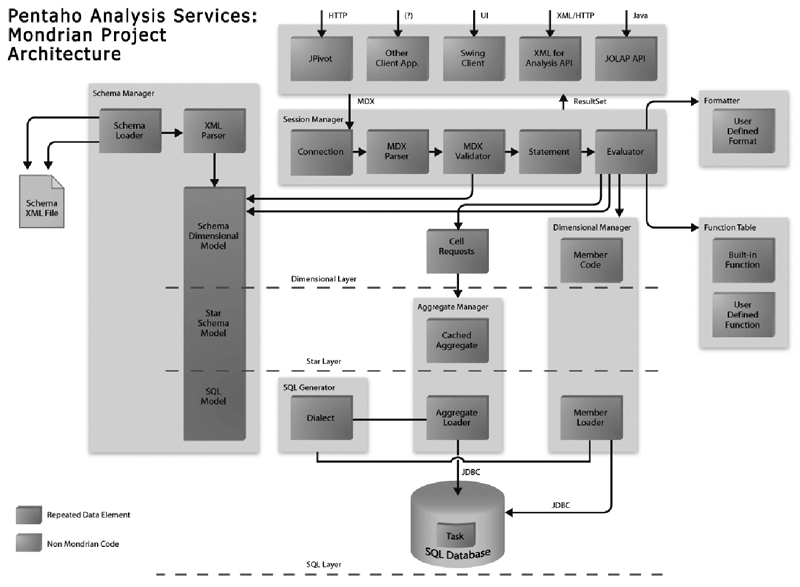
Mondrian funciona sobre las bases de datos estándar del mercado: Oracle, DB2, SQL Server, MySQL, PostgreSQL, LucidDB, Teradata..., lo que habilita y facilita el desarrollo de negocio.
Los últimos desarrollos de Mondrian se caracterizan por incluir olap4j.[15] Es una iniciativa del mismo desarrollador de Mondrian: Julian Hyde.
Mondrian es un caso atípico en el contexto OSBI. Para la gran mayoría de herramientas de inteligencia de negocio existen una o varias opciones. En el caso de soluciones ROLAP, Mondrian es el único producto.
Varios fabricantes han incluido Mondrian en sus soluciones (JasperSoft, Openi, OpenReports, SpagoBI, SQLPower e incluso la defenestada Lucidera). El hecho de existir una única solución y de existir toda una comunidad de fabricantes y usuarios a su alrededor, hace que el equipo de desarrollo de Mondrian (dirigido por Julian Hyde) tenga ciclos de desarrollo mucho menores que otras soluciones.
2.2. Visores OLAP
Como ya se ha comentado anteriormente, en el contexto de Pentaho, existen tres visores OLAP: JPivot, PAT y Pentaho Analyser.
JPivot
JPivot es un cliente OLAP basado en JSP que empezó en 2003. Puede considerarse un proyecto hermano de Mondrian dado que combinado con él permite realizar consultas tanto MDX como a partir de elementos gráficos que se renderizan en un navegador web. Durante largo tiempo ha sido el único visor existente para Mondrian. Pentaho ha adaptado su estilo para diferenciarlo de la interfaz original.
Las características principales de este visor analítico son:
• Capacidades de análisis interactivo a través de un acceso web basado en Excel, lo que le proporciona una alta funcionalidad.
• Está basado en estándares de la industria (JBDC, JNDI, SQL, XML/A y MDX).
• Posibilidad de extenderse mediante desarrollo.

El menú de JPivot ofrece diversas opciones al usuario final:
• Navegador OLAP: permite determinar las dimensiones que aparecen en las filas y/o columnas así como los filtros aplicados y las métricas por aparecer.
• Consulta MDX: permite visualizar y editar la consulta MDX que genera el informe OLAP.
• Configurar tabla OLAP: permite configurar aspectos por defecto de la tabla OLAP como el orden ascendente o descendente de los elementos.
• Mostrar miembros padre: permite mostrar u ocultar el padre del miembro de una jerarquía.
• Ocultar cabeceras: muestra u oculta las cabeceras repetidas para facilitar la compresión del contenido.
• Mostrar propiedades: muestra o oculta las propiedades de los miembros de una jerarquía.
• Borrar filas o columnas vacías: muestra u oculta los valores sin contenido (conveniente para ciertos informes).
• Intercambiar ejes: intercambia filas por columnas.
• Drill buttons: member, position y replace:
– Member: permite expandir todas las instancias de un miembro.
– Position: permite expandir la instancia seleccionada de un miembro.
– Replace: permite sustituir un miembro por sus hijos.
• Drill through: permite profundizar en el detalle de información a partir de un nivel de información agregado superior.
• Mostrar gráfico: muestra un gráfico asociado a los datos. No todos los datos son susceptibles de generar gráficos consistentes.
• Configuración del gráfico: permite configurar las propiedades del gráfico. Desde el tipo del mismo hasta propiedades de estilo como tipo de letra, tamaño o color.
• Configuración de las propiedades de impresión/exportación: permite configurar las propiedades de la impresión como el título, disposición del papel, tamaño...
• Exportar a PDF: permite generar un PDF con el contenido del informe.
• Exportar a Excel: permite generar un Excel con el contenido del informe.
En el caso de la integración con Pentaho se añade la capacidad de crear y guardar nuevas vistas analíticas. Cabe comentar que la creación no ofrece muchas capacidades de configuración.
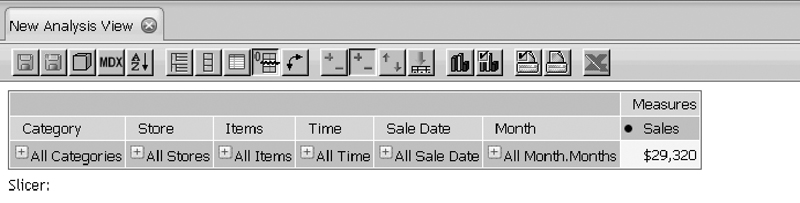
Cabe comentar que JPivot no es una herramienta muy orientada al usuario. No dispone de funcionalidades drag & drop ni tampoco otras funcionalidades como la creación de nuevas métricas o jerarquías.
Pentaho Analyser
Con el objetivo de ofrecer un servicio de alto valor añadido en la versión Enterprise, Pentaho ha adquirido el producto Clearview de Lucidera y lo ha renombrado como Pentaho Analyser sustituyendo JPivot.

Es una solución que ofrece:
• Capacidades de drag & drop.
• Creación de nuevas medidas calculadas.
• Soporte para soluciones BI SaaS.
• Buscador de objetos.
• Funcionalidades encapsuladas (como, por ejemplo, consultas por jerarquía temporal).
Esta solución está completamente orientada al usuario facilitando su trabajo con la misma.
PAT
PAT es el acrónimo de Pentaho Analysis Tool. Es una herramienta desarrollada con GWT por parte de la comunidad de Pentaho para sustituir JPivot. La versión actual aún no está disponible para su uso en producción, sin embargo se espera que para el año 2010 salga la primera versión.
El siguiente diagrama muestra la arquitectura de PAT:
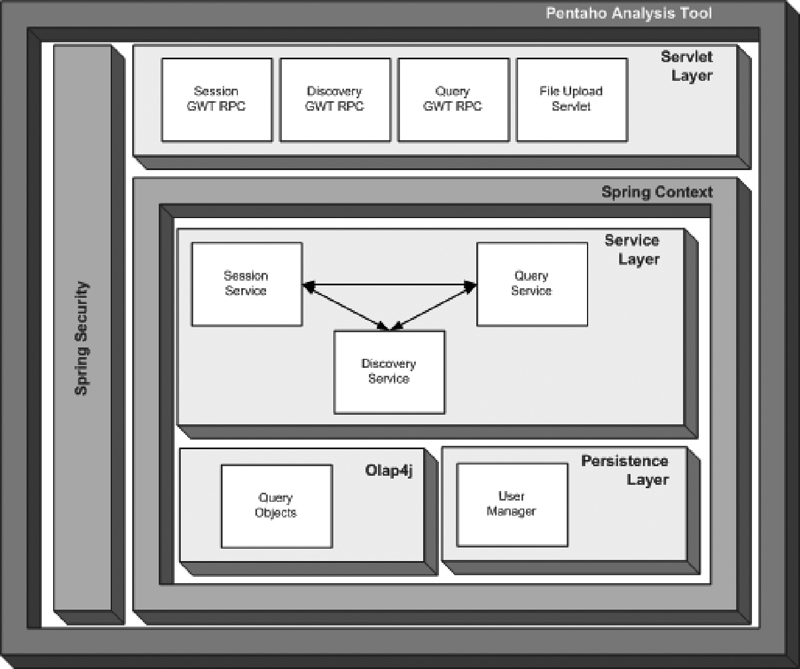
Las características que se contemplan en el roadmap para la versión 1.0 son:
• Capacidades de drag & drop.
• Uso de temas.
• Uso de olap4j para ser usado como visor OLAP de múltiples motores (Mondrian, Microsoft Analysis Services u otros).
• Duplicación de todas las funcionalidades de JPivot.
• Extensión de dichas capacidades, como por ejemplo soporte de gráficos en formato flash.

2.3. Herramientas de desarrollo
Pentaho Schema Workbench
Pentaho Schema Workbench (PSW) es una herramienta de desarrollo que permite crear, modificar y publicar un esquema de Mondrian. Es un programa java multiplataforma.
Es una herramienta muy orientada al desarrollador conocedor de la estructura de un esquema de Mondrian. Permite crear todos los objetos que soporta Mondrian: esquema, cubo, dimensiones, métricas...
Tiene dos áreas: la zona en la que se muestra la estructura jerárquica del esquema OLAP y la zona de edición de las propiedades de cada elemento.
Presenta un menú superior para crear cubos, dimensiones, dimensiones conformadas, métricas, miembros calculados, subconjuntos (named set) y roles, así como operaciones estándar como cortar, copiar y pegar.

Además, entre sus características incluye:
• Realizar consultas MDX contra el esquema creado (requiere conocer la sintaxis del lenguaje).
• Consultar la base de datos que sirve de origen para el esquema de Mondrian.
• Publicar directamente el esquema en el servidor de Pentaho.
Pentaho Aggregation Designer
Un método para optimizar Mondrian, aparte de configurar la caché del mismo adecuadamente, es la creación de tablas agregadas.
Desde hace pocos meses, Pentaho ofrece una herramienta de diseño orientada a dicha función: Pentaho Aggregation Designer.
Esta herramienta java permite analizar la estructura del esquema de Mondrian contra la cantidad de datos que recuperar y, a partir de dicho análisis, recomendar la creación de tablas agregadas.
En nuestro caso particular no haremos uso de esta herramienta. Aunque se incluye para que pueda ser conocida.
3. Caso práctico
3.1. Diseño de OLAP con Schema Workbench
El diseño de estructuras OLAP es común en Pentaho y otras soluciones open source del mercado dado que las herramientas que proporcionan sólo difieren en pequeños puntos de rediseño de la interfaz GUI. El punto realmente diferente es cómo se publican en una u otra plataforma.
En el proceso de creación de una estructura OLAP debemos tener presente que lo que haremos es mapear el diseño de la base de datos (tablas de hecho y dimensiones) con nuestro diseño, de forma que:
• Es posible crear un esquema con menos elementos que los existentes en la base de datos (no interesa contemplar todos los puntos de vista de análisis, por ejemplo).
• Es posible crear un esquema con la misma cantidad de elementos. Se consideran todas las tablas de hecho y las dimensiones.
• Es posible crear un esquema con más elementos que los existentes en la base de datos. Por ejemplo, es posible crear dimensiones u otros objetos que sólo existen en el esquema OLAP y que se generan en memoria.
Para este primer ejemplo, vamos a considerar un mapeo uno a uno (todos los elementos del data warehouse tendrán su correspondencia en la estructura OLAP).
Esta herramienta permite crear elementos o bien a través del despliegue de los elementos disponibles en cada elemento de la arquitectura

o bien a través del menú superior que incluye la creación de cubos, dimensiones, jerarquías, niveles, medidas, medidas calculadas, elementos virtuales (cubos, dimensiones y métricas), roles y operaciones estándar como copiar, cortar, pegar, e incluso la edición del XML de forma directa.

Por otra parte, esta herramienta incluye un explorador de la base de datos que, una vez creada la conexión a la base de datos, nos permite explorar la estructura de las tablas para recordar cuál es nombre de los campos y atributos a usar.

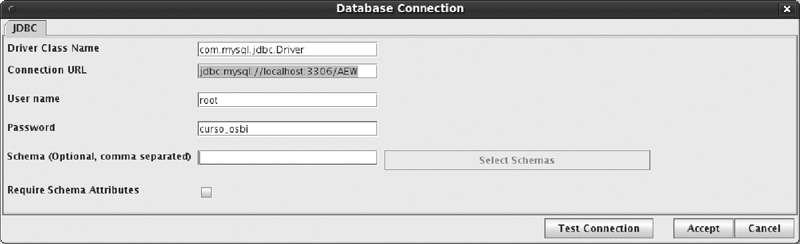
Los pasos en el proceso de creación son los siguientes:
• Creación de una conexión al data warehouse. La herramienta de diseño necesita conocer cuál es la fuente de origen de tablas y datos. Por ello, antes de empezar cualquier diseño es necesario dicha conexión. Una vez creada se guarda en memoria y queda grabada para futuras sesiones. En nuestro caso particular los parámetros de conexión son:
– Driver Class Name: com.mysql.jdbc.
– Driver Connection URL: jdbc:mysql://localhost:3306/AEW.
– User Name: root.
– Password: curso_osbi.
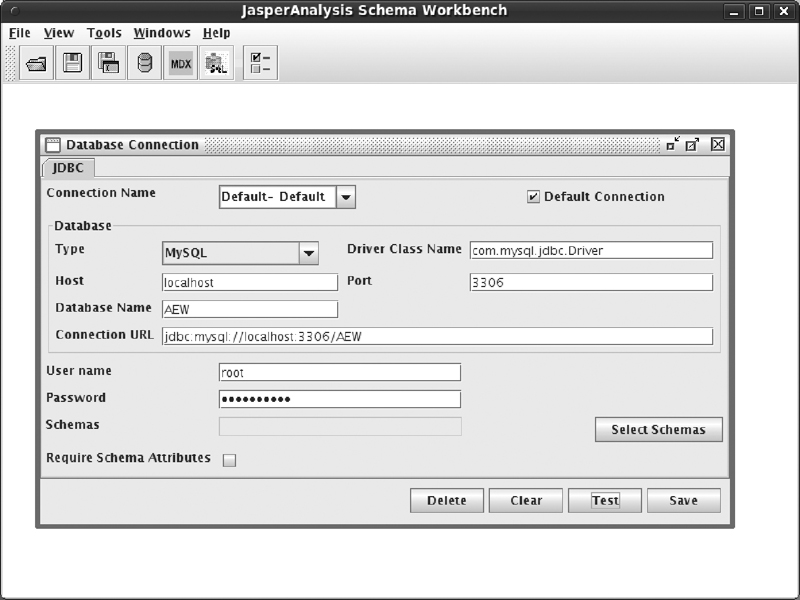
Es necesario recordar que en caso de que la base de datos fuera diferente, estos parámetros serían diferentes. En tal caso también sería necesario comprobar la inclusión del plugin jdbc en la herramienta.
En el caso de la herramienta de JasperSoft, este menú es ligeramente diferente, si bien las opciones a cumplimentar son las mismas.
• Una vez creada la conexión podemos crear nuestro primer esquema. Los pasos son: crear un esquema, uno o varios cubos, una o varias tablas de hecho, una o varias dimensiones y una o varias métricas.
Para entender el proceso analizaremos un esquema creado completamente.
• Primero completamos el esquema introduciendo el nombre del esquema. En nuestro caso, por ejemplo, visitas. En caso de que se vaya creado un esquema que contiene diversos cubos, la recomendación sería nombrarlo con el nombre del proyecto, AEW.

• Creamos un cubo. Debemos definir el nombre y activar las opciones de enabled y caché. Esta última opción es importante dado que indica al motor Mondrian que las consultas que se hagan deben guardarse en la caché.

• Todo cubo necesita de una tabla de hecho. En nuestro caso, la de visitas. En el campo name, elegimos la tabla del data warehouse que tiene el rol de tabla de hecho.

• Un cubo necesita de al menos una dimensión. Analizamos el caso de creación de la dimensión resultado. Definimos su nombre y la correspondiente clave foránea (foreignKey).
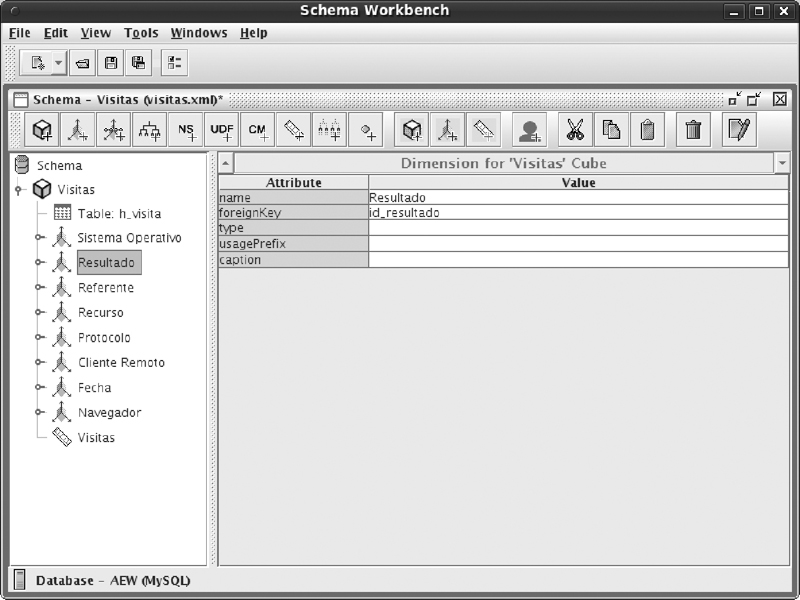
• Es necesario definir la tabla que contiene la información de la dimensión. En nuestro caso, d_resultado.

• Toda dimensión tiene una o varias jerarquías. Para definir cada jerarquía es necesario definir su nombre, indicar si acumula los valores (hasAll), el nombre de dicha acumulación y, finalmente, su clave primaria.
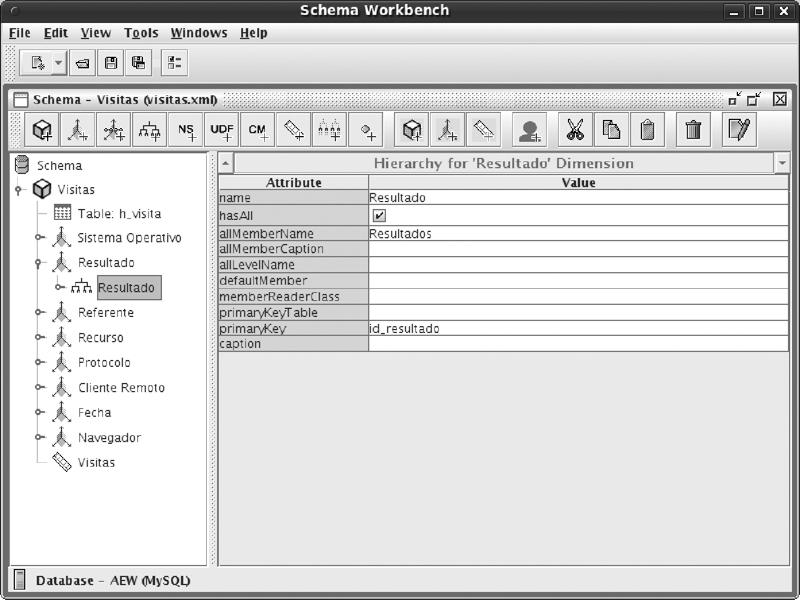
• Toda jerarquía necesita de como mínimo un nivel que la componga. Para definir correctamente el nivel debemos especificar el nombre del nivel, la tabla donde está la información, la columna que contiene dicha información, cómo se ordenan los resultados, la tipología del valor, la tipología de nivel, si los valores son únicos y si es necesario ocultar el nivel en algún caso.

• Algunos miembros contienen información adicional que podemos mostrar como propiedades. En este caso, para resultado podemos mostrar la descripción del valor. Añadimos una propiedad y definimos el nombre, la columna que contiene la información y la tipología del valor.

• El resto de dimensiones se definen de la misma forma.
• Una vez definidas las dimensiones, es necesario definir las métricas. En este caso, sólo definimos las visitas.
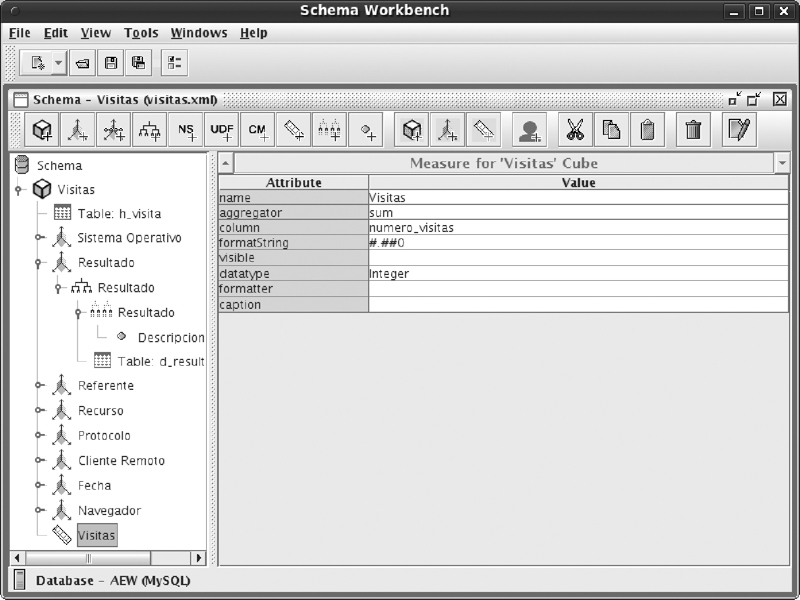
• Finalmente guardamos el esquema creado.

• La herramienta de desarrollo comprueba que el esquema que vamos creando está bien definido (en caso negativo, en la parte inferior aparece un mensaje en rojo).

• Podemos comprobar que el diseño que hemos realizado funciona correctamente y responde a nuestras preguntas. Para ello usamos el MDX query. Si la conexión a base de datos se ha definido correctamente y el esquema OLAP está bien definido, se conectará con éxito. Para poder comprobar el funcionamiento es necesario escribir una consulta MDX. El lenguaje MDX es similar a SQL pero mucho más complejo. Vamos a considerar una consulta sencilla en la que ponemos las medidas en la columna y la dimensión sistema operativo en las filas.

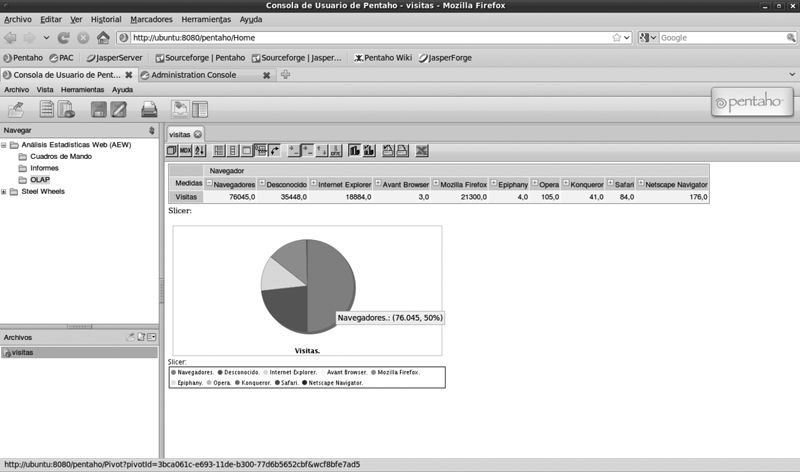
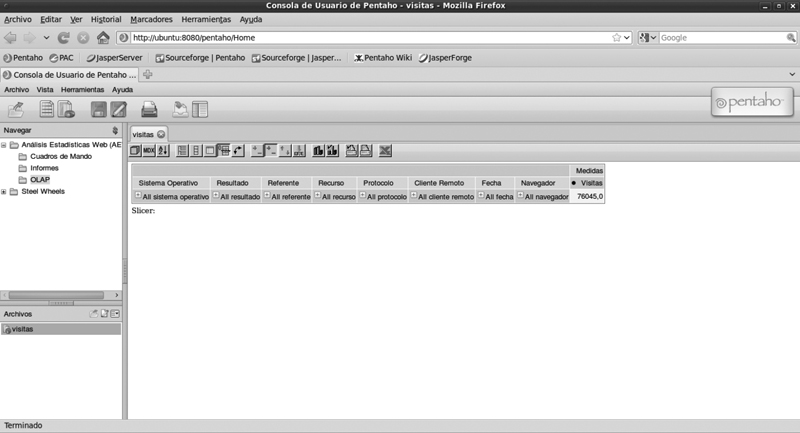
El resultado son 76.045 visitas.
3.2. Publicación de un esquema OLAP en Pentaho Server
La publicación del esquema OLAP en Pentaho Server se puede hacer directamente en Pentaho Schema Workbench. Seguimos el siguiente proceso:
• Nos conectamos al repositorio. Previamente tenemos que haber definido una contraseña de publicación.

• Definimos la carpeta en pentaho-solutions donde se guardará el esquema que JDNI usará (debe estar previamente definida a través de la consola de administración de Pentaho).
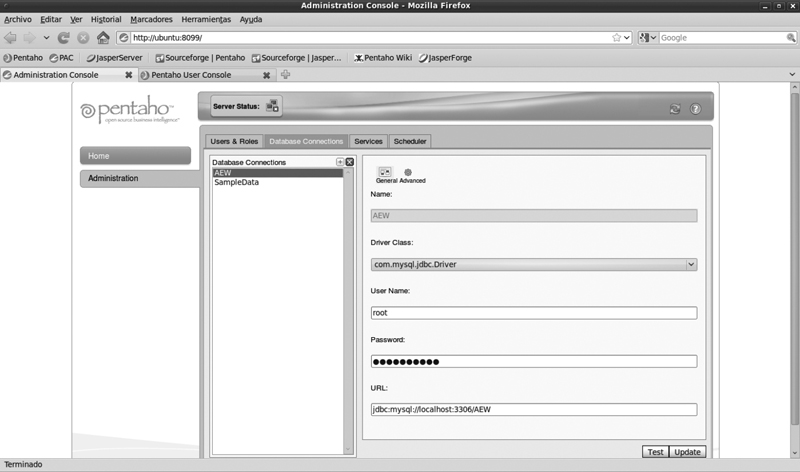
• En la PAC (Pentaho Administration Console) podemos editar las conexiones a base de datos.
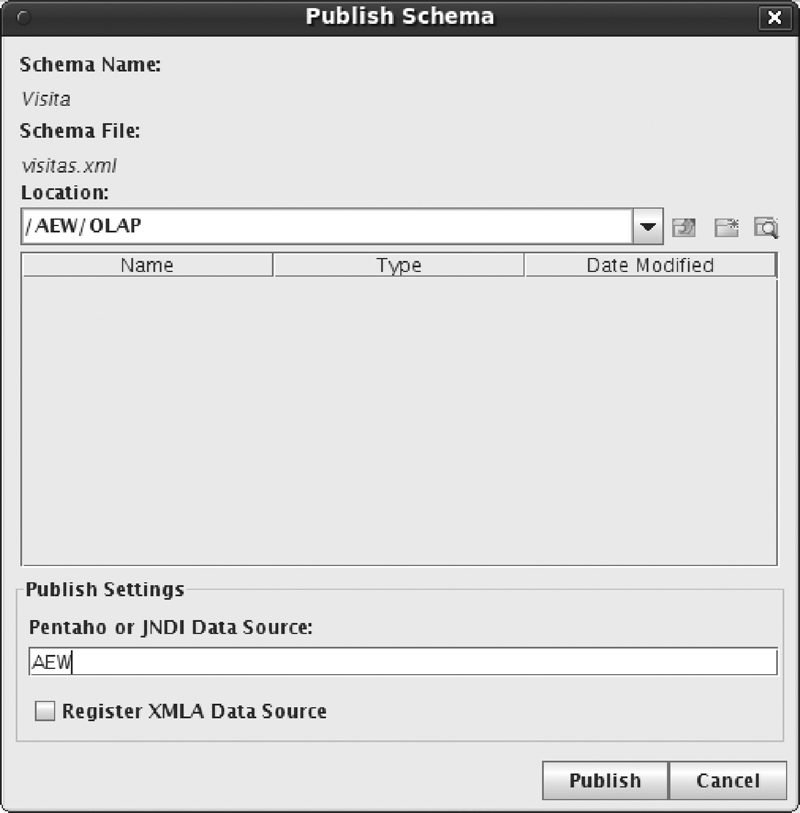
• Si todo está definido de forma correcta, la publicación finalizará con éxito.

• Finalmente podemos comprobar que ha sido publicado correctamente entrando en el servidor de Pentaho.
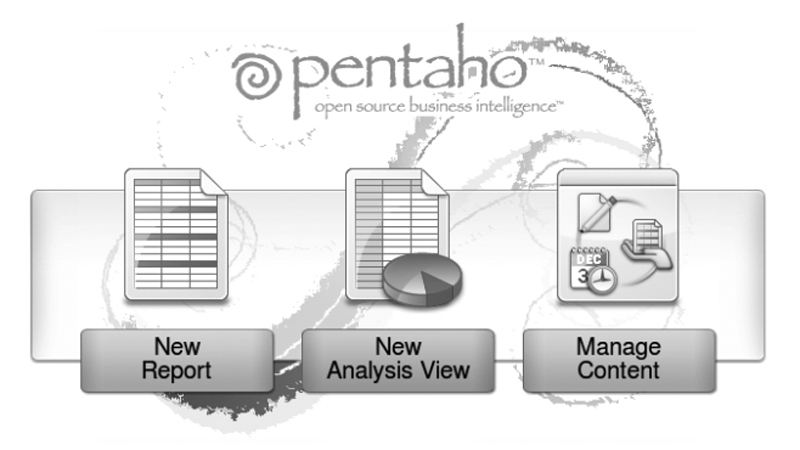
• Podemos crear una nueva consulta a través de la interfaz web de Pentaho. En la pantalla inicial seleccionamos new analysis view.
• Escogemos nuestro esquema y nuestro cubo visitas.
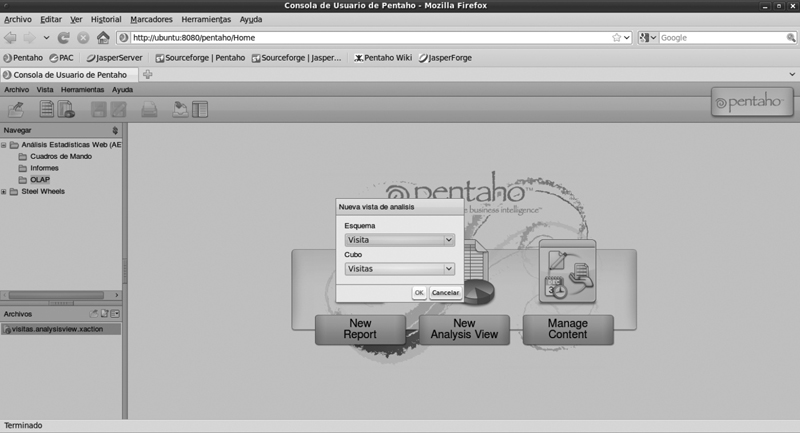
• Aparecerá la navegación por defecto que a partir del menú superior podremos refinar la información mostrada. Una vez terminemos, guardamos la consulta con el menú superior, y escogemos dónde se guarda nuestra vista OLAP.
4. Anexo 1: MDX
MDX es un lenguaje de consultas OLAP creado en 1997 por Microsoft. No es un estándar pero diversos fabricantes lo han adoptado como el estándar de hecho.
Tiene similitudes con el lenguaje SQL, si bien incluye funciones y fórmulas especiales orientadas al análisis de estructuras jerarquizadas que presentan relaciones entre los diferentes miembros de las dimensiones.
Sintaxis de MDX
La sintaxis de MDX es compleja; la mejor manera de ejemplificarla es a través de un caso determinado. Imaginemos un cubo de ventas con las siguientes dimensiones:
• Temporal de las ventas con niveles de año y mes.
• Productos vendidos con niveles de familia de productos y productos.
• Medidas: importe de las ventas y unidades vendidas.
Para obtener, por ejemplo, el importe de las ventas para el año 2008 para la familia de productos lácteos, la consulta seria:
SELECT
{[medidas].[importe ventas]}
on columns,
{[tiempo].[2008]}
on rows FROM [cubo ventas] WHERE ([Familia].[lácteos])
Es posible observar que la estructura general de la consulta es de la forma SELECT... FROM... WHERE...:
• En el select se especifica el conjunto de elementos que queremos visualizar que debe especificarse si se devuelve en columnas o filas.
• En el from, el cubo de donde se extrae la información.
• En el where, las condiciones de filtrado.
• { } permite crear listas de elementos en las selecciones.
• [ ] encapsulan elementos de las dimensiones y niveles.
Funciones de MDX
MDX incluye múltiples funciones para realizar consultas a través de la jerarquía existente en el esquema OLAP. Podemos destacar entre ellas:
• CurrentMember: permite acceder al miembro actual.
• Children: permite acceder a todos los hijos de una jerarquía.
• prevMember: permite acceder al miembro anterior de la dimensión.
• CrossJoin(conjunto_a,conjunto_b): obtiene el producto cartesiano de dos conjuntos de datos.
• BottomCount(conjunto_datos,N): obtiene un número determinado de elementos de un conjunto, empezando por abajo, opcionalmente ordenado.
• BottomSum(conjunto_datos,N,S): obtiene de un conjunto ordenado los N elementos cuyo total es como mínimo el especificado (S).
• Except(conjunto_a,conjunto_b): obtiene la diferencia entre dos conjuntos.
• AVG COUNT VARIANCE VARIANCE y todas las funciones trigonométricas (seno, coseno, tangente, etc.).
• PeriodsToDate: devuelve un conjunto de miembros del mismo nivel que un miembro determinado, empezando por el primer miembro del mismo nivel y acabando con el miembro en cuestión, de acuerdo con la restricción del nivel especificado en la dimensión de tiempo.
• WTD(<Miembro>): devuelve los miembros de la misma semana del miembro especificado.
• MTD(<Miembro>): devuelve los miembros del mismo mes del miembro especificado.
• QTY(<Miembro>): devuelve los miembros del mismo trimestre del miembro especificado.
• YTD(<Miembro>): devuelve los miembros del mismo año del miembro especificado.
• ParallelPeriod: devuelve un miembro de un periodo anterior en la misma posición relativa que el miembro especificado.
Miembros calculados en MDX
Una de las funcionalidades más potentes que ofrece el lenguaje MDX es la posibilidad de realizar cálculos complejos tanto dinámicos (en función de los datos que se están analizando en ese momento) como estáticos. Los cubos multidimensionales trabajan con medidas (del inglés measures) y con miembros calculados (calculated members).
Las medidas son las métricas de la tabla de hechos a las que se aplica una función de agregación (count, distinct count, sum, max, avg, etc.).
Un miembro calculado es una métrica que tiene como valor el resultado de la aplicación de una fórmula que puede utilizar todos los elementos disponibles en un cubo, así como otras funciones de MDX disponibles. Estas fórmulas admiten desde operaciones matemáticas hasta condiciones semafóricas pasando por operadores de condiciones.
5. Glosario
DOLAP Desktop On-Line Analytical Processing
EPL Eclipse Public License
HOLAP Hybrid On-Line Analytical Processing
JDBC Java Database Connection
JNDI Java Naming and Directory Interface
JSP Java Server Page
MDX Multidimensional eXpressions
MOLAP Multidimensional On-Line Analytical Processing
MTD Month To Day
OLAP On-Line Analytical Processing
OSBI Open Source Business Intelligence
PAT Pentaho Analysis Tool
PSW Pentaho Schema Workbench
QTY Quarter To Day
ROLAP Relational On-Line Analytical Processing
SaaS Software as a Service
SQL Structured Query Language
XML/A XML for Analysis
WTD Week To Day
YTD Year To Day
6. Bibliografía
BOUMAN, R., y VAN DONGEN, J. (2009). Pentaho® Solutions: Business Intelligence and Data Warehousing with Pentaho® and MySQL. Indianapolis: Wiley Publishing.
MENDACK, S. (2008). OLAP without Cubes: Data Analysis in non-cube Systems. Hoboken: VDM Verlag.
SCHRADER, M., y otros (2009). Oracle Essbase & Oracle OLAP: The Guide to Oracle’s Multidimensional Solutions. Nueva York: McGraw-Hill.
THOMSEN, E. (2002). OLAP Solutions: Building Multidimensional Information Systems. Hoboken: John Wiley & Sons.
WEBB, C., y otros (2006). MDX Solutions: With Microsoft SQL Server Analysis Services 2005 and Hyperion Essbase. Hoboken: John Wiley & Sons.
WREMBEL, R. (2006). Datawarehouses and OLAP: Concepts, Architectures and Solutions. Hersbey: IGI Globals.