7
Graphs, Patterns and Rewriting
In the previous chapters, we took an operational and intuitive approach to the notion of graph rewriting. In this chapter, we shall take a closer look at its mathematical dimension. First, we shall provide the conceptual framework for a formal definition of graph rewriting. Unlike other forms of rewriting (terms, words, etc.), there is no common agreement on the definition of graph rewriting. We have chosen to present the definition that underpins the GREW system. Next, we shall consider the application of these mathematical elements; more precisely, we shall demonstrate certain consequences associated with the characteristics of rewriting as presented in the GREW system, including termination and confluence.
In this chapter, we shall define the key features underlying our notion of rewriting. First, note that we make no assumptions concerning graph structure: graphs may be cyclic or acyclic, there are no limitations to tree width, etc. In this, our approach differs from second order monadic logic [COU 12] and “term-graph”-type forms of rewriting [PLU 99].
Second, rewriting is considered without node creation. The GREW system does include an add_node command, but this is only applied in exceptional cases, such as when transforming "du" into "de le" in French. As there is a strong correlation between nodes and input words, we can anticipate the need to produce new nodes, creating a “stock” before computation and drawing on this reserve instead of creating nodes during the computation process itself. The reason for this can be seen in the effect of node creation on computation efficiency. Let us suppose that two computation branches G → G1 → G2 and G → G′1 → G′2 produce the same graph, with the exception of names: these graphs are said to be isomorphic. We would like to continue computation using only one of the two. To do this, however, we would need to establish a correspondence between names, and this operation is difficult: there is no known polynomial time algorithm to solve the problem. In practice, the problem of isomorphism essentially arises for new nodes (as existing nodes are “anchored” by their subjacent word). If we prevent the creation of new nodes, we observe that equality offers a close approximation of the isomorphism relation, and is easy to compute, making it relatively economical with respect to the benefits of shared computation. In practice, we obtain a considerable increase in efficiency.
As we shall see, prohibiting the addition of nodes means that certain computations are no longer possible. However, this property means that we can predict and avoid loops in a program. Furthermore, as the presence of a loop often indicates a design fault, this is a useful indication to the programmer that there is an error in the program requiring attention.
Moreover, by working with given naming, we can also predict whether a system will produce a single solution for each input. This notion is known as confluence. When a system always produces exactly one solution, computation becomes much more efficient – technically, the difference is an exponential factor. It can also be an element in confirming correctness, as in the case of termination.
The third property is the hypothesis of injective recognition: two distinct nodes in the pattern will be distinct in the image. This hypothesis does not impose constraints, in that any system which does not conform can be simulated by a model which does. The inverse property is not guaranteed (not all “injective” systems can be simulated by non-injective systems), hence our choice.
Finally, we have introduced edge shifting commands (specifically shift_in, shift_out), which are not generally used. For example, these commands do not fit the context of SPO or DPO-type algebraic approaches. In passing, note that node deletion, as used in our approach, is also incompatible with DPO.
Feature structures are treated in an abstract manner in the mathematical model, which considers them as an unstructured finite set. This abstraction can be justified as follows. Consider, for instance, the way of representing a clause V[cat=v] in a pattern. We may use the hypothesis that the number of features is finite (say cat and lem) and that each feature has a finite number of values (for example v, n and adj for cat and porte and ferme for lem). We therefore have a finite number of feature structures (six, in our example: (cat=v, lem=porte), (cat=v, lem=ferme), … , (cat=adj, lem=ferme)). The pattern containing the clause V[cat=v] may be replaced by two patterns, containing the clauses V[cat=v, lem=ferme] and V[cat=v, lem=porte], respectively. As the feature set is finite, this operation is always possible. GREW notation may be seen as a way of summarizing a (finite) set of rules in a single form.
First and foremost, let us begin by introducing the mathematical model. After defining the concepts outlined above, we shall present a number of proof principles, giving access to the formal dimension of graph rewriting. Our presentation only uses elementary mathematical concepts in order to make it accessible to non-mathematicians.
Most of the results presented below are already widely known, and we have simply replaced them in their context. Rozenberg’s compilation [ROZ 97] gives a much more detailed presentation. A reminder of the notations and definitions is provided in the Appendix.
7.1. Graphs
The most elementary mathematical definition in graph theory presents graphs as pairs 〈V, E〉, in which V is a set of nodes and E is a subset E ⊆ V × V, the edges (or arcs).
In the context of natural language processing, this definition is not sufficient, as it does not allow us to assign content, such as a feature structure, to nodes. The same is true of edges, which cannot be labeled. Furthermore, a priori, nodes are not ordered. Typically, in graphs with nodes representing the words in a sentence, nodes have a subjacent order. A richer definition is therefore required in order to take account of these phenomena.
In what follows, we shall assume that we have access to a (countable) set of identifiers, known as the universe and denoted as U. We shall also assume that the set U is equipped with a strict partial order, denoted as ≺, and its corresponding large order ≼. Note that x ≼ y if, and only if, x = y or x ≺ y. The universe is used to identify nodes in a graph.
If we wish to work on syntax to semantic transformations, for example, we may choose to use U = {W, S} × ℕ, i.e. the pairs (W, n) or (S, n) with n ∈ ℕ. The former are used for words, while the latter are used for concepts. The order may thus be (a, n) ≺ (b, m) ⇔ a = b = W ∧ n < m. In other words, the order applies to words, not to concepts.
With an empty order (i.e. x ⊀ y for all x, y ∈ U), we return to the general situation encountered in graph theory.
Throughout this chapter, we shall also suppose that we have access to two finite sets. The first, denoted as ΣN, is the set of node labels. The second, denoted as ΣE, is the set of edge labels. For example, when treating syntax, ΣN may be the set of dictionary words or the set of feature structures, and ΣE the set of syntactic functions {suj, obj, mod, …}.
Using U, ΣN, ΣE, we are able to define a graph:
DEFINITION 7.1.– A graph is created by a triplet 〈N, ε, ℓ, 〉 where N ⊂ U is the set of nodes, the set of edges ε is a subset ε ⊆ N × ΣE × N and ℓ is a function N → ΣN, known as a labeling function.
In the cases covered here, the set N will always be considered to be finite. Let  be the set of all graphs, of which the nodes are in the universe U, with nodes labeled as ΣN and edges as ΣE. As a general rule, we shall use the letters m, n, p, q and their derivatives n′, n0, etc. to denote graph nodes. For edges, we shall use the notation
be the set of all graphs, of which the nodes are in the universe U, with nodes labeled as ΣN and edges as ΣE. As a general rule, we shall use the letters m, n, p, q and their derivatives n′, n0, etc. to denote graph nodes. For edges, we shall use the notation  rather than (m, e, n).
rather than (m, e, n).
Finally, for a given graph G, NG denotes the set of nodes, EG the set of edges and ℓG the node labeling function. The size of a graph G denotes the number of nodes NG and is denoted as |G|.
The surface syntax of the sentence “John eats with John” can be represented by the following graph:

made up of nodes N = { W1, W2, W3, W4 }, edges ε = {(W2, SUJ, W1), (W2, MOD, W3), (W3, MOD, W4) } and the labeling function ℓ = [W1 ↦ ‘John’, W2 ↦ ‘eats’, W3 ↦ ‘with’, W4 ↦ ‘John’].
A double arrow is used to mark the subjacent order taken from the U universe. For example, to show the word order in the previous sentence, we note:

If no further conventions are used, the number of double arrows on the graph rapidly becomes excessive. We therefore use the following notation:
- –
 indicates that there is a relation u ≼ v between nodes u and v.
indicates that there is a relation u ≼ v between nodes u and v. - –
 indicates that there is no relation of this type, i.e. u ⊀ v.
indicates that there is no relation of this type, i.e. u ⊀ v. - –
 tells us nothing about nodes u and v, either u ≼ v, or u ⊀ v.
tells us nothing about nodes u and v, either u ≼ v, or u ⊀ v.
The previous graph can then be illustrated as follows:

As ≼ is an order relation, from W1 ≼ W2 and W2 ≼ W3, we can deduce W1 ≼ W3, and so this relation does not need to be indicated. In this way, we can delete all of the curved arrows from the previous diagram.
EXAMPLE 7.1.– Given a word w = a1a2 · · · ak ∈ Σ* for an alphabet Σ, the flat graph of w, denoted as flat(w), is the graph  which may be illustrated as:
which may be illustrated as:

7.2. Graph morphism
The notion of graph morphism is used to describe pattern matching. We shall apply the following idea: given a morphism μ : P → G, P acts as the pattern, G is the graph in which the pattern is to be found and the morphism μ indicates how the pattern P is to be read as a subgraph of G.
DEFINITION 7.2 (Subgraph).– A graph G is a subgraph of G′ if NG ⊆ NG′, εG ⊆ εG′ and ℓG = ℓG′|NG, i.e. for all n ∈ NG, ℓG(n) = ℓG′ (n).
The subgraph is full when  . Take the following examples: G1 is a subgraph of G2 (not full, as an edge B from 1 to 2 would be required), and G3 is a full subgraph of G2.
. Take the following examples: G1 is a subgraph of G2 (not full, as an edge B from 1 to 2 would be required), and G3 is a full subgraph of G2.

For a graph G and a sub-set N ⊆ NG of its nodes, the subgraph of G induced by N is the graph  . This is the subgraph of G with nodes N, containing all of the edges of G between two nodes in N. It is, by construction, a full subgraph of G.
. This is the subgraph of G with nodes N, containing all of the edges of G between two nodes in N. It is, by construction, a full subgraph of G.
DEFINITION 7.3 (Graph morphism).– A graph morphism μ from a source graph G to a target graph G′ is a function from NG to NG′ which verifies:
- – for any node n ⊆ NG, ℓG′ (μ(n)) = ℓG(n);
- – for any edge
 ;
; - – for any pair of nodes
 .
.
A graph morphism μ from G to G′ is denoted as a function, μ: G → G′.
To present a morphism, in this case μ0, we use dotted lines, as shown on the left-hand side below, or colors, as in the case on the right1. Formally, μ0 = [1 ↦ 4, 2 ↦ 5, 3 ↦ 6].

Note that there is one edge between nodes 1 and 3, but two edges between their respective images 4 and 6.
Given a graph G, the identity function 1NG: n ∈ NG ↦ n ∈ NG defines a morphism G → G. By definition, we set  , and when we know from the context which graph G is concerned, we used the simplified notation 1: G → G.
, and when we know from the context which graph G is concerned, we used the simplified notation 1: G → G.
A subgraph G′ of a graph G induces a morphism defined by the function 1G′, G: n ∈ NG′ ↦ n ∈ NG. Conversely, a graph morphism induces a subgraph following the definition below.
DEFINITION 7.4 (Image of a morphism).– Given two graphs G and G′ and a morphism μ: G → G′, the image of G through the morphism μ is defined as the graph μ(G) with  and
and 
By definition, a morphism μ: G → G′ is a function NG → NG′. The set μ(NG) thus denotes a set of nodes in G′. The corresponding induced subgraph is G′|μ(NG), and we see that μ(G) is a subgraph of G′|μ(NG), which is itself a subgraph of G′. Indeed, the two graphs μ(G) and G′|μ(NG) share the same nodes μ(NG) and the same labeling function, and the edges of μ(G) are the edges of 
This is an inclusion, and not an equality, as we see in the case of the morphism μ0: G0 → G1 defined above. The image of the morphism μ0(G0) is shown in bold on the left, and the subgraph G1|μ0(NG0) induced by the function μ0 is shown in bold on the right:

Graph μ0(G0) does not contain the edge labeled E between nodes 4 and 6, but this edge is present in G1|μ0(NG0). This edge is said to be glued to the image of the morphism.
Morphisms may be composed. Taking μ: G → G′ as a first morphism and μ′: G′ → G″ as a second, the function μ′ º μ: NG → NG″ defines a morphism G → G′. The three conditions are all fulfilled. First, we have ℓG″ (μ′ º μ(n)) = ℓG″ (μ′ (μ(n))) = ℓG′ (μ(n)) = ℓG(n). Readers may wish to verify the deduction of the other two properties in a similar manner.
Let us return to the main subject of this section, the use of morphisms for pattern matching. The notion, in the form seen so far, does not correspond to that presented in Chapter 1. For example, consider the following morphism μ1:

The graph on the left does not “match” the graph on the right. This is due to the fact that the two nodes 2 and 3 are associated with the same node 5. To avoid identifications of this kind, the notion of injective morphism is used.
DEFINITION 7.5.– The morphism of graph μ: G → G′ is injective if, for all nodes n ≠ m ∈ NG, we have μ(n) ≠ μ(m). Injectivity is indicated by using a curved arrow instead of a straight arrow: μ: G → G′.
In other terms, for an injective morphism, two distinct nodes cannot be mapped to the same node, as in the example above. In more formal terms, the morphism is the function μ1 = [1 ↦ 4, 2 ↦ 5, 3 ↦ 5]. In our case, 2 ≠ 3, but μ1(2) = μ1(3) = 5. The morphism is therefore not injective.
DEFINITION 7.6.– A morphism μ: G → G′ is said to be an isomorphism when a morphism ν: G′ → G exists such that μ º ν = 1G′ and ν º μ = 1G.
Intuitively, an isomorphism is simply a renaming of nodes. One example which is particularly useful for our purposes, involves the fact that the image of a graph G obtained using an injective morphism is isomorphic to G. In more technical terms, an injective morphism μ: G → G′ induces an isomorphism  defined as follows: n ∈ NG ↦ μ(n) ∈ μ(NG). We can show that this is an isomorphism. According to the definition of μ(NG), for all p ∈ μ(NG), we have n ∈ NG such that μ(n) = p. An n of this type is unique, since we would have m ≠ n such that μ(n) = μ(m) = p, disproving the injectivity hypothesis. We can thus define the function ν: p ∈ μ(NG) ↦ n ∈ NG, where n is the only element in NG such that μ(n) = p. This function is, in fact, a morphism: taking p = μ(n), we have ℓG(ν(p)) = ℓG(n) = ℓG′ (μ(n)) = ℓμ(G)(p). The same type of verification shows that the other two properties are morphisms. Furthermore, we see that
defined as follows: n ∈ NG ↦ μ(n) ∈ μ(NG). We can show that this is an isomorphism. According to the definition of μ(NG), for all p ∈ μ(NG), we have n ∈ NG such that μ(n) = p. An n of this type is unique, since we would have m ≠ n such that μ(n) = μ(m) = p, disproving the injectivity hypothesis. We can thus define the function ν: p ∈ μ(NG) ↦ n ∈ NG, where n is the only element in NG such that μ(n) = p. This function is, in fact, a morphism: taking p = μ(n), we have ℓG(ν(p)) = ℓG(n) = ℓG′ (μ(n)) = ℓμ(G)(p). The same type of verification shows that the other two properties are morphisms. Furthermore, we see that  and ν(μ(n)) = ν(p) = n. We therefore have an isomorphism.
and ν(μ(n)) = ν(p) = n. We therefore have an isomorphism.
In definition 7.6, the condition μºν = 1G′ and νºμ = 1G could actually be replaced either by μ º ν = 1G′ or by ν º μ = 1G. This is a direct consequence of the Cantor–Bernstein theorem.
7.3. Patterns
Injective morphisms are the key to pattern matching. The source graph is the pattern which we wish to find, and the target graph is the graph in that we are searching for the pattern. The image of the morphism is the part of the graph which corresponds precisely to the pattern. Injectivity indicates that all of the nodes in a pattern are distinct in the target graph.
DEFINITION 7.7 (Positive pattern).– A positive pattern B is a graph. A positive matching μ of a positive pattern B onto the graph G is an injective morphism μ: B ↪ G.
The morphism μ0 is a positive matching of B0 onto G0:

The notion of positive matching concerns that which should be present in a graph, not that which must be absent, the latter corresponding to negative clauses in GREW. To do this, we need to use the notion of negative conditions.
DEFINITION 7.8 (Pattern).– A pattern is a couple  made up of a positive pattern B and a list of injective morphisms
made up of a positive pattern B and a list of injective morphisms  . The morphisms νi of
. The morphisms νi of  are negative conditions.
are negative conditions.
DEFINITION 7.9 (Matching).– Given a pattern  as described above and a graph G, a matching of P onto G is a positive matching μ: B ↪ G such that no integer 1 ≤ i ≤ k exists for which there is an injective morphism ξi such that ξi o νi = μ:
as described above and a graph G, a matching of P onto G is a positive matching μ: B ↪ G such that no integer 1 ≤ i ≤ k exists for which there is an injective morphism ξi such that ξi o νi = μ:

Matching of this type will be denoted as μ: P ↪ G.
Negative conditions are used to eliminate “wrong matchings”. To illustrate the use of these conditions, let us return to the matching μ0: B0 ↪ G0. In actual fact, a second matching exists, μ1: B0 ↪ G0:

The two morphisms μ0 and μ1 are matchings of the pattern 〈B0, ()〉. Now, consider the morphism  defined by
defined by

The morphism μ0 is not a matching for the pattern 〈B0, (ν0)〉. Indeed, the morphism ξ0 = [b0 ↦ g0, b1 ↦ g1] verifies ξ0 0 ν0 = μ0. Now, consider the case of the morphism ν1 defined as follows:

Morphism μ1 is not a matching for pattern 〈B0, (ν1)〉. The morphism ξ1 = [b0 ↦ g2, b1 ↦ g1, b2 ↦ g0] is such that ξ1 0 ν1 = μ1.
To describe a negative condition ν: B ↪ B′, we use the following convention. Graph B′ is shown with the parts that should not appear in the image of ν(B) “crossed out”. For the morphism ν0, this gives us:  For pattern ν1, we have:
For pattern ν1, we have: 
In a pattern  , the positive pattern B plays a central role. For this reason, we shall use the notation NP for NB, εP for εB, etc. We shall treat the pattern as if it were a graph, i.e. its subjacent positive pattern. In the rare cases where this may result in ambiguity, we shall use the usual notation.
, the positive pattern B plays a central role. For this reason, we shall use the notation NP for NB, εP for εB, etc. We shall treat the pattern as if it were a graph, i.e. its subjacent positive pattern. In the rare cases where this may result in ambiguity, we shall use the usual notation.
One final remark remains to be made here. Given a pattern , let us suppose that there is an isomorphism among the negative conditions ν: in this case, there will be no matches for P. Now, suppose that we have a positive matching μ: B ↪ G. Let νi: B ↪ B′ be the isomorphism in question. Therefore, there is a morphism ηi such that ηiºνi = 1B. Take ξi = μºηi, which is injective (as a composition of two injective morphisms). However, ξi º νi = μ º ηi º νi = μ º 1B = μ, hence μ is not a match. In other terms, if we have an isomorphism in the negative conditions, matching ceases to be possible. This type of negative condition makes the corresponding pattern useless, and we shall consider our patterns to be exempt.
7.3.1. Pattern decomposition in a graph
In this section, we shall consider a morphism μ: P → G. We will show how the nodes of graph G may be decomposed into distinct subsets. This will be useful later in describing the effects of rewriting.
DEFINITION 7.10 (Decompositions: image, crown and context).– The nodes in G can be grouped into three distinct subsets: NG = Pμ + Kμ + Cμ:
- – the image of the morphism is the set Pμ = μ(NP);
- – the crown denotes the set of nodes that are directly attached to the image of the morphism. In formal terms,
 :
: - – the context denotes the other nodes: Cμ = NG \ (Pμ ∪ Kμ).
The edges are grouped into four distinct sets: εG = Pμ + Hμ + Kμ + Cμ:
 , the edges in the image of μ
, the edges in the image of μ
 , the edges glued to the image μ
, the edges glued to the image μ
 , the edges between the crown and the image;
, the edges between the crown and the image;
 edges crown edges context edges pattern glued edges
edges crown edges context edges pattern glued edges

7.4. Graph transformations
The principle of computation by rewriting is as follows. We match a pattern, then locally modify the pattern image graph, and repeat the process. An imperative-type elementary command language is used to describe local transformations of the image graph. Before this is possible, however, a number of definitions are required to describe the effects of commands.
7.4.1. Operations on graphs
Given two graphs G and G′, we define G + G′ = 〈NG + NG′, εG + εG′,ℓ〉 where

This is the juxtaposition of the two graphs G and G′ ; note that G and G′ are two full subgraphs of G + G′.
Taking G′ to be a subgraph of G, we note  , i.e. the graph G with all nodes from G′ and all of the associated edges removed.
, i.e. the graph G with all nodes from G′ and all of the associated edges removed.
Given a list of edges  , we use G ∪ E = 〈 NG, εG ∪ E, ℓG〉 to denote the graph G to which the edges E are added. When E ∩ εG = Ø, we use this notation with the sum G + E. The counterpart to this addition is a subtraction: G – E = 〈 NG, εG \ E, ℓG〉. Note that the symbols + and ? apply both to graphs and to edges, and ambiguity here can be resolved by reference to the context.
, we use G ∪ E = 〈 NG, εG ∪ E, ℓG〉 to denote the graph G to which the edges E are added. When E ∩ εG = Ø, we use this notation with the sum G + E. The counterpart to this addition is a subtraction: G – E = 〈 NG, εG \ E, ℓG〉. Note that the symbols + and ? apply both to graphs and to edges, and ambiguity here can be resolved by reference to the context.
Henceforth, several equations will be used on a regular basis:
LEMMA 7.1.– Given a morphism ξ: G → H such that ξ(G) is a full subgraph of H, we have the equation:

where Kξ denotes the crown edges.
LEMMA 7.2.– Given a full subgraph G of H, if for all  either p ∈ NG or q ∈ NG, then:
either p ∈ NG or q ∈ NG, then:

7.4.2. Command language
A command language is used to describe graph transformations. There are six categories of command described below, where p, q ∈ U, α ∈ ΣN and e ∈ ΣE:
- –
label(p, α); - –
del_edge(p, e, q); - –
add_edge(p, e, q); - –
del_node(p); - –
shift_in(p, e, q); - –
shift_out(p, e, q).
The operational semantics of commands is simple enough that it can be presented in an explicit and formal manner. In passing, note that there are several different notions of semantics with different levels of abstraction. We shall present an operational form of semantics, providing a step-by-step description of the means of transforming graphs.
DEFINITION 7.11 (Operational command semantics).– Given a morphism μ: P ↦ H, a graph G = 〈N, E, ℓ〉, possibly distinct from H, and a command c, we define the graph G ·μ c in the following cases:
- – Label: if c =
label(p, α) and μ(p) ∈ N. The command assigns the label α to the node μ(p) in the graph, if such a node exists. Formally, G ·μ c = 〈N, ε, ℓ[μ(p) ↦ α]〉; - – Delete: if c =
del_edge(p, e, q) and μ(p), μ(q) ∈ N. The command deletes the edge in G. Formally,
in G. Formally, 
- – Add: if c =
add_edge(p, e, q) and μ(p), μ(q) ∈ N. The command adds an edge in G. In other words:
in G. In other words: 
- – Delete node: if c =
del_node(p) and μ(p) ∈ N. Thedel_node(p) command deletes the node μ(p) from graph G along with all of its associated edges: G ·μ c = G|N\{μ(p)}; - – Shift in-edges: if c =
shift_in(p, e, q) and μ(p), μ(q) ∈ N. The command replaces all edges originating from a crown node r of the form with an edge
with an edge  , and all other edges are retained. Formally,
, and all other edges are retained. Formally, 
- – Shift out-edges: if c =
shift_out(p, e, q) and μ(p), μ(q) ∈ N. This operation is symmetrical to that described above.
The definition is extended to a sequence of commands  as follows. If
as follows. If  , we define:
, we define:  . Otherwise,
. Otherwise,  . We note
. We note  , and we define:
, and we define: 
In the previous definition, the graph 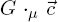 is only defined if the nodes used in the commands have an image in G via the morphism μ. To ensure that a command list can be applied correctly to a match, we use the notion of adequation of a command list to a pattern. Proposition 8.1 proves that, in this case, rewriting is always correctly defined.
is only defined if the nodes used in the commands have an image in G via the morphism μ. To ensure that a command list can be applied correctly to a match, we use the notion of adequation of a command list to a pattern. Proposition 8.1 proves that, in this case, rewriting is always correctly defined.
DEFINITION 7.12.– A command list (c1, …, ck) is said to be in adequation with the pattern  if it verifies the following conditions:
if it verifies the following conditions:
- – each node appearing in a command is a node in B;
- – for any command ci, 1 ≤ i ≤ k; if ci =
del_node(p) with p → NB, then the name p does not appear in any command cj with i < j ≤ k.
In other words, the names used in the commands are taken from the positive pattern and not from the negative conditions, and it is not possible to refer to a deleted node.
Consider the commands c1 = del_edge(p, A, q), c2 = shift_out(p, D, q), c3 = label(q,  ) and c4 =
) and c4 = add_edge(p, B, q) and the morphism μ1 from B0 to G:

The successive application of commands (c1, c2, c3, c4) to G produces the following results:

We see that the final command has no effect: it is impossible to add an edge that already exists. This type of phenomenon may be avoided by introducing a negative condition into the pattern. For example, the negative pattern  ensures that there is no edge labeled B in the image. In this case, the desired edge will be added.
ensures that there is no edge labeled B in the image. In this case, the desired edge will be added.
EXERCISE 7.1.– Apply the command list (shift_in(p, D, q), del_node(p), shift_in(q, D, r)) with respect to the matching:

7.5. Graph rewriting system
DEFINITION 7.13 (Rewriting rule).– A graph rewriting rule R is a couple  made up of a pattern P and a command sequence
made up of a pattern P and a command sequence  in adequation with P.
in adequation with P.
Rule 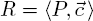 , built up from a given pattern P and command list , may be illustrated as follows:
, built up from a given pattern P and command list , may be illustrated as follows:

DEFINITION 7.14 (Rewriting relation).– Given a graph G, a rule  and a matching μ: P → G, the graph
and a matching μ: P → G, the graph  is the graph rewritten from G using the rule R and matching μ. This transformation is denoted as
is the graph rewritten from G using the rule R and matching μ. This transformation is denoted as  .
.
EXAMPLE 7.2.– Rule R above may be applied to graph G via the morphism μ:

The result of this application is G′:

Rule R may be reapplied to G′ via the morphism μ′:

The resulting graph is G″:

This is written as G → R,μ G′ → R,μ′ G″. In short, by applying the rule several times, all  are turned into
are turned into  .
.
Given a rule  , the morphism 1B: B ↪ B is injective. This is a match. Suppose, using absurd reasoning, that we have a negative condition νi and a morphism with ξiºνi = 1B. In this case, νi would be an isomorphism, which is not authorized for negative conditions.
, the morphism 1B: B ↪ B is injective. This is a match. Suppose, using absurd reasoning, that we have a negative condition νi and a morphism with ξiºνi = 1B. In this case, νi would be an isomorphism, which is not authorized for negative conditions.
Hence, we see that we can always apply the rule commands to the subjacent positive pattern: this is auto-application  , or in simplified notation,
, or in simplified notation,  .
.
DEFINITION 7.15 (Graph rewriting system).– A graph rewriting system R is a finite set of rules. Such a system induces a binary relation over graphs: G →R G′ if, and only if, we have a rule R ∈ R and a matching μ such that G →R,μ G′. The notation G →R G′ may be simplified to G → G′ if the system R can be deduced from the context.
Given a rewriting system R, we shall use the following definitions. A finite sequence G0 → G1 → G2 → · · · → Gn is known as a derivation. Its length is n. The transitive reflexive closure of the relation → is written →*. Remember that G →* G′ if (and only if) a derivation G → · · · → G′ exists. The degenerated case of a derivation of length 0 is G →* G. In some cases, more precision is needed regarding the number of steps in a computation: G →n G′ shows that there is a derivation of length n between G and G′.
When there is no graph G′ ≠ G such that G → G′, G′ is said to be a normal form2. This is the case of graph G″ above. The normal forms are the results of computations. Henceforth, let G →! G′ be the relation containing all graphs G and G′ such that G →* G and G′ is a normal form. In other terms, G →! G′ if G′ has been obtained by rewriting from G, and no further progress is possible.
EXERCISE 7.2.– Given node labels  and edge labels ΣE = {A, B, C}, create a rewriting system to replace all node labels with
and edge labels ΣE = {A, B, C}, create a rewriting system to replace all node labels with  .
.
EXERCISE 7.3.– Given node labels  and edge labels ΣE = {A, B, C}, create a rewriting system to replace all edge labels A with B. Calculate the result for the graph
and edge labels ΣE = {A, B, C}, create a rewriting system to replace all edge labels A with B. Calculate the result for the graph

7.5.1. Semantics of rewriting
DEFINITION 7.16.– A graph rewriting system R induces a relation 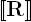 over the graphs of
over the graphs of  , defined as follows:
, defined as follows:

As such, this leads to a computation procedure. Given a graph rewriting system R, and starting from an input graph G, the computation principle involves rewriting the graph for all imaginable possibilities, and then extracting all of the normal forms.
Conversely, a relation R over graphs is computed by a rewriting system R if (and only if)  .
.
In cases where a rewriting system R is such that for any graph G, there is at most one graph H such that  , the relation computed by the rewriting system is actually a function. In this case, the equation above is denoted as
, the relation computed by the rewriting system is actually a function. In this case, the equation above is denoted as  . Given a function f, we say that a rewriting system R computes f if, for any graph G,
. Given a function f, we say that a rewriting system R computes f if, for any graph G,  .
.
EXERCISE 7.4.– Given node labels  and edge labels ΣE = {A, B, C}, create a rewriting system to compute the function f such that for any graph G = 〈N, ε, ℓ〉, f(G) = 〈N′, ε′, ℓ′〉 verifies:
and edge labels ΣE = {A, B, C}, create a rewriting system to compute the function f such that for any graph G = 〈N, ε, ℓ〉, f(G) = 〈N′, ε′, ℓ′〉 verifies:
- – N = N′;
- – ε = ε′;
- – for all nodes p and q connected by a maximum link chain A, ℓ′ (p) = ℓ′ (q) = ;
- – for all other nodes p, ℓ′ (p) = ℓ(p).
A maximal chain A from p to q is a sequence of nodes p1, …, pn linked by edges A without a link A toward p or a link A originating from q:

Any labels X0, …, Xn+1 may be used for nodes p, p1, …, pn, q.
7.5.2. Rule uniformity
We have seen that certain commands such as add_edge, del_edge may not always operate. This phenomenon makes subsequent mathematical analysis harder, and is easily avoided by using uniform rules.
DEFINITION 7.17.– A rewriting system is said to be uniform if each of the rules it contains is uniform. A rule  is uniform if:
is uniform if:
- 1) for every triplet (p, e, q), there is at most one command
del_edge(p, e, q) oradd_edge(p, e, q) in; - 2) if there is an index i such that ci =
add_edge(p, e, q), then
- 3) if there is an index i such that ci =
del_edge(p, e, q), then
As we shall see in Chapter 7, any rule can be replaced by a (finite) set of uniform rules that operate in the same way as the initial rule.
7.6. Strategies
Now, let us formalize the notion of strategies as used in GREW. This notion is defined by the following grammar (where R denotes a rule, and S, S1 and S2 denote a strategy):

The notion of strategy is a refinement of the notion of semantics presented above. For a strategy S, we define the function  over the graphs as follows:
over the graphs as follows:
- – for a rule
 , i.e. the set of graphs such that
, i.e. the set of graphs such that  for a certain morphism μ;
for a certain morphism μ; - –
 ;
; - –
 ;
; - –
 , the union of the graphs resulting from the application of S1 and S2;
, the union of the graphs resulting from the application of S1 and S2; - –
 , the set of graphs obtained after application of S1 then S2;
, the set of graphs obtained after application of S1 then S2; - – supposing that
 , then
, then  is a singleton composed of one of these graphs
is a singleton composed of one of these graphs  . The choice of graph G is not specified. In practice, the first computed graph is chosen;
. The choice of graph G is not specified. In practice, the first computed graph is chosen; - –
 otherwise;
otherwise; - – for all
 and any strategy S, Si is defined as follows: S0 = Id, S1 = S and Si+1 = Seq(S, Si). Noting
and any strategy S, Si is defined as follows: S0 = Id, S1 = S and Si+1 = Seq(S, Si). Noting  , we define
, we define  ;
;
The definition for the iteration takes account of the fact that a looping rule  is considered in the same way as if it had not been applied. Using only uniform systems, the definition can be rewritten in the form
is considered in the same way as if it had not been applied. Using only uniform systems, the definition can be rewritten in the form 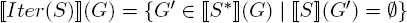 .
.
There are a number of notable relations between strategies. We shall mention those underlying the extension of the definition of the sequence and of the alternative to any given number of arguments. The proofs are the direct consequences of their definitions.
- – Empty is absorbant for Seq, i.e. Seq(Empty, S) = Seq(S, Empty) = Empty;
- – Id is neutral for the sequence, Seq(Id, S) = Seq(S, Id) = S;
- – Empty is neutral for the alternative: Alt(Empty, S) = Alt(S, Empty) = S;
- – the alternative is commutative: Alt(S1, S2) = Alt(S2, S1).
Strategy equalities should be understood in the extensional sense, i.e. S1 = S2 if, and only if, for any graph  .
.
When a strategy S only produces a single normal form (this property is known as confluence, and will be discussed in detail later), in general, it is better to use the strategy Iter(Pick(S)) in computations as it is more efficient than Iter(S). This strategy makes use of the equivalence given in lemma 7.4.
LEMMA 7.4.– Generally speaking, Iter(Pick(S)) ⊆ Pick(Iter(S)) and for systems which terminate3, we have an equality.
Readers may wish to look for an example without an equality.