In this chapter, we look at some of the more advanced issues related to data synchronization—specifically, timing issues related to data synchronization. When you write a Java program that makes use of several threads, issues related to data synchronization are those most likely to create difficulties in the design of the program, and errors in data synchronization are often the most difficult to detect since they depend on events happening in a specific order. Often an error in data synchronization can be masked in the code by timing dependencies. You may notice some sort of data corruption in a normal run of your program, but when you run the program in a debugger or add some debugging statements to the code, the timing of the program is completely changed, and the data synchronization error no longer occurs.
These issues can’t be simply solved. Instead, developers need to design their programs with these issues in mind. Developers need to understand what the different threading issues are: what are the causes, what they should look for, and the techniques they should use to avoid and mitigate them. Developers should also consider using higher-level synchronization tools—tools that provide the type of synchronization needed by the program and that are known to be threadsafe. We examine both of these ideas in this chapter.
Programmers with a background in a particular threading system generally tend to use terms specific to that system to refer to some of the concepts we discuss in this chapter, and programmers without a background in certain threading systems may not necessarily understand the terms we use. So here’s a comparison of particular terms you may be familiar with and how they relate to the terms in this chapter:
- Barrier
A barrier is a rendezvous point for multiple threads: all threads must arrive at the barrier before any of them are permitted to proceed past the barrier. J2SE 5.0 supplies a barrier class, and a barrier class for previous versions of Java can be found in the Appendix A.
- Condition variable
A condition variable is not actually a lock; it is a variable associated with a lock. Condition variables are often used in the context of data synchronization. Condition variables generally have an API that achieves the same functionality as Java’s wait-and-notify mechanism; in that mechanism, the condition variable is actually the object lock it is protecting. J2SE 5.0 also supplies explicit condition variables, and a condition variable implementation for previous versions of Java can be found in the Appendix A. Both kinds of condition variables are discussed in Chapter 4.
- Critical section
A critical section is a synchronized method or block. Critical sections do not nest like synchronized methods or blocks.
- Event variable
- Lock
This term refers to the access granted to a particular thread that has entered a synchronized method or block. We say that a thread that has entered such a method or block has acquired the lock. As we discussed in Chapter 3, a lock is associated with either a particular instance of an object or a particular class.
- Monitor
A generic synchronization term used inconsistently between threading systems. In some systems, a monitor is simply a lock; in others, a monitor is similar to the wait-and-notify mechanism.
- Mutex
Another term for a lock. Mutexes do not nest like synchronization methods or blocks and generally can be used across processes at the operating system level.
- Reader/writer locks
A lock that can be acquired by multiple threads simultaneously as long as the threads agree to only read from the shared data or that can be acquired by a single thread that wants to write to the shared data. J2SE 5.0 supplies a reader-writer lock class, and a similar class for previous versions of Java can be found in the Appendix A.
- Semaphores
Semaphores are used inconsistently in computer systems. Many developers use semaphores to lock objects in the same way Java locks are used; this usage makes them equivalent to mutexes. A more sophisticated use of semaphores is to take advantage of a counter associated with them to nest acquisitions to the critical sections of code; Java locks are exactly equivalent to semaphores in this usage. Semaphores are also used to gain access to resources other than code. Semaphore classes that implement most of these features are available in J2SE 5.0.
You probably noticed a strong pattern while reading this list of terms: beginning with J2SE 5.0, almost all these things are included in the core Java libraries. We’ll take a brief look into these J2SE 5.0 classes.
In Java, a semaphore is basically a lock with an attached
counter. It is similar to the Lock
interface as it can also be used to prevent access if the lock is
granted; the difference is the counter. In those terms, a semaphore
with a counter of one is the same thing as a lock (except that the
semaphore would not nest, whereas the lock—depending on its
implementation—might).
The Semaphore class keeps
tracks of the number of permits it can issue. It allows
multiple threads to grab one or more permits; the actual usage of the
permits is up to the developer. Therefore, a semaphore can be used to
represent the number of locks that can be granted. It could also be
used to throttle the number of threads working in parallel, due to
resource limitations such as network connections or disk space.
Let’s take a look at the Semaphore interface:
public class Semaphore {
public Semaphore(long permits);
public Semaphore(long permits, boolean fair);
public void acquire( ) throws InterruptedException;
public void acquireUninterruptibly( );
public void acquire(long permits) throws InterruptedException;
public void acquireUninterruptibly(long permits);
public boolean tryAcquire( );
public boolean tryAcquire(long timeout, TimeUnit unit);
public boolean tryAcquire(long permits);
public boolean tryAcquire(long permits,
long timeout, TimeUnit unit);
public void release(long permits);
public void release( );
public long availablePermits( );
}The Semaphore interface is
very similar to the Lock interface.
The acquire() and release() methods are similar to the
lock() and unlock() methods of the Lock interface—they are used to grab and
release permits, respectively. The tryAcquire( ) methods are similar to the
tryLock() methods in that they
allow the developer to try to grab the lock or permits. These methods
also allow the developer to specify the time to wait if the permits
are not immediately available and the number of permits to acquire or
release (the default number of permits is one).
Semaphores have a few differences from locks. First, the
constructor requires the specification of the number of permits to be
granted. There are also methods that return the number of total and
free permits. This class implements only a grant and release
algorithm; unlike the Lock
interface, no attached condition variables are available with
semaphores. There is no concept of nesting; multiple acquisitions by
the same thread acquire multiple permits from the semaphore.
If a semaphore is constructed with its fair flag set to true, the semaphore tries to allocate the
permits in the order that the requests are made—as close to
first-come-first-serve as possible. The downside to this option is
speed: it takes more time for the virtual machine to order the
acquisition of the permits than to allow an arbitrary thread to
acquire a permit.
Of all the different types of thread synchronization tools, the barrier is probably the easiest to understand and the least used. When we think of synchronization, our first thought is of a group of threads executing part of an overall task followed by a point at which they must synchronize their results. The barrier is simply a waiting point where all the threads can sync up either to merge results or to safely move on to the next part of the task. This is generally used when an application operates in phases. For example, many compilers make multiple passes between loading the source and generating the executable, with many interim files. A barrier, when used in this regard, can make sure that all of the threads are in the same phase.
Given its simplicity, why is the barrier not more
commonly used? The functionality is simple enough that it
can be accomplished with the low-level tools provided by Java. We can
solve the coordination problem in two ways, without using a barrier.
First, we can simply have the threads wait on a condition variable.
The last thread releases the barrier by notifying all of the other
threads. A second option is to simply await termination of the threads
by using the join() method. Once
all threads have been joined, we can start new threads for the next
phase of the program.
However, in some cases it is preferable to use barriers. When
using the join() method, threads
are exiting and we’re starting new ones. Therefore, the threads lose
any state that they have stored in their previous thread object; they
need to store that state prior to terminating. Furthermore, if we must
always create new threads, logical operations cannot be placed
together; since new threads have to be created for each subtask, the
code for each subtask must be placed in separate run() methods. It may be easier to code all
of the logic as one method, particularly if the subtasks are very
small.
Let’s examine the interface to the barrier class:
public class CyclicBarrier {
public CyclicBarrier(int parties);
public CyclicBarrier(int parties, Runnable barrierAction);
public int await( ) throws InterruptedException, BrokenBarrierException;
public int await(long timeout, TimeUnit unit) throws InterruptedException,
BrokenBarrierException, TimeoutException;
public void reset( );
public boolean isBroken( );
public int getParties( );
public int getNumberWaiting( );
}The core of the barrier is the await() method. This
method basically behaves like the conditional variable’s await() method. There is an option to either
wait until the barrier releases the thread or for a timeout condition.
There is no need to have a signal()
method because notification is accomplished by the barrier when the
correct number of parties are waiting.
When the barrier is constructed, the developer must specify the
number of parties (threads) using the barrier. This number is used to
trigger the barrier: the threads are all released when the number of
threads waiting on the barrier is equal to the number of parties
specified. There is also an option to specify an action—an object that
implements the run() method. When
the trigger occurs, the run()
method on the barrierAction object
is called prior to releasing the threads. This allows code that is not
threadsafe to execute; generally, it calls the cleanup code for the
previous phase and/or setup code for the next phase. The last thread
that reaches the barrier—the triggering thread—is the thread that
executes the action.
Each thread that calls the await() method gets back a unique return
value. This value is related to the arrival order of the thread at the
barrier. This value is needed for cases when the individual threads
need to negotiate how to divide up work during the next phase of the
process. The first thread to arrive is one less than the number of
parties; the last thread to arrive will have a value of zero.
In normal usage, the barrier is very simple. All the threads
wait until the number of required parties arrive. Upon arrival of the
last thread, the action is executed, the threads are released, and the
barrier can be reused. However, exception conditions can occur and
cause the barrier to fail. When the barrier fails, the CyclicBarrier class breaks the barrier and
releases all of the threads waiting on the await( ) method with a BrokenBarrierException. The barrier can be
broken for a number of reasons. The waiting threads can be
interrupted, a thread may break through the barrier due to a timeout
condition, or an exception could be thrown by the barrier
action.
In every exception condition, the barrier simply breaks, thus
requiring that the individual threads resolve the matter. Furthermore,
the barrier can no longer be reused until it is reinitialized. That
is, part of the complex (and application-specific) algorithm to
resolve the situation includes the need to reinitialize the barrier.
To reinitialize the barrier, you use the reset() method. However, if there are
threads already waiting on the barrier, the barrier will not
initialize; in fact, it will break. Reinitialization of the barrier is complex enough that
it may be safer to create a new barrier.
Finally, the CyclicBarrier class
provides a few operational support methods. These methods provide
informational data on the number of threads already waiting on the
barrier, or whether the barrier is already broken.
The countdown latch implements a synchronization tool that is very similar to a barrier. In fact, it can be used instead of a barrier. It also can be used to implement a functionality that some threading systems (but not Java) support with semaphores. Like the barrier class, methods are provided that allow threads to wait for a condition. The difference is that the release condition is not the number of threads that are waiting. Instead, the threads are released when the specified count reaches zero.
The CountDownLatch class provides a method to decrement the count. It can
be called many times by the same thread. It can also be called by a
thread that is not waiting. When the count reaches zero, all waiting
threads are released. It may be that no threads are waiting. It may be
that more threads than the specified count are waiting. And any thread
that attempts to wait after the latch has triggered is immediately
released. The latch does not reset. Furthermore, later attempts to
lower the count will not work.
Here’s the interface of the countdown latch:
public class CountDownLatch {
public CountDownLatch(int count);
public void await( ) throws InterruptedException;
public boolean await(long timeout, TimeUnit unit)
throws InterruptedException;
public void countDown( );
public long getCount( );
}This interface is pretty simple. The initial count is specified
in the constructor. A couple of overloaded methods are provided for
threads to wait for the count to reach zero. And a couple of methods
are provided to control the count—one to decrement and one to retrieve
the count. The boolean return value for the timeout variant of the
await() method indicates whether the latch
was triggered—it returns true if it is returning because the latch was
released.
The exchanger implements a synchronization tool that does not really have equivalents in any other threading system. The easiest description of this tool is that it is a combination of a barrier with data passing. It is a barrier in that it allows pairs of threads to rendezvous with each other; upon meeting in pairs, it then allow the pairs to exchange one set of data with each other before separating.
This class is closer to a collection class than a synchronization tool—it is mainly used to pass data between threads. It is also very specific in that threads have to be paired up, and a specific data type must be exchanged. But this class does have its advantages. Here is its interface:
public class Exchanger<V> {
public Exchanger( );
public V exchange(V x) throws InterruptedException;
public V exchange(V x, long timeout, TimeUnit unit)
throws InterruptedException, TimeoutException;
}The exchange() method is called with the data object to be exchanged
with another thread. If another thread is already waiting, the
exchange() method returns with the
other thread’s data. If no other thread is waiting, the exchange() method waits for one. A timeout
option can control how long the calling thread waits.
Unlike the barrier class, this class is very safe to use: it
will not break. It does not matter how many parties are using this
class; they are paired up as the threads come in. Timeouts and
interrupts also do not break the exchanger as they do in the barrier class; they simply generate an
exception condition. The exchanger continues to pair threads around
the exception condition.
Sometimes you need to read information from an object in an operation that may take a fairly long time. You need to lock the object so that the information you read is consistent, but you don’t necessarily need to prevent another thread from also reading data from the object at the same time. As long as all the threads are only reading the data, there’s no reason why they shouldn’t read the data in parallel since this doesn’t affect the data each thread is reading.
In fact, the only time we need data locking is when data is being changed, that is, when it is being written. Changing the data introduces the possibility that a thread reading the data sees the data in an inconsistent state. Until now, we’ve been content to have a lock that allows only a single thread to access the data whether the thread is reading or writing, based on the theory that the lock is held for a short time.
If the lock needs to be held for a long time, it makes sense to consider allowing multiple threads to read the data simultaneously so that these threads don’t need to compete against each other to acquire the lock. Of course, we must still allow only a single thread to write the data, and we must make sure that none of the threads that were reading the data are still active while our single writer thread is changing the internal state of the data.
Here are the classes and interfaces in J2SE 5.0 that implement this type of locking:
public interface ReadWriteLock {
Lock readLock( );
Lock writeLock( );
}
public class ReentrantReadWriteLock implements ReadWriteLock {
public ReentrantReadWriteLock( );
public ReentrantReadWriteLock(boolean fair);
public Lock writeLock( );
public Lock readLock( );
}You create a reader-writer lock by instantiating an object using
the ReentrantReadWriteLock
class. Like the ReentrantLock class, an option allows the locks to be distributed in
a fair fashion. By “fair,” this class means that the lock is granted
on very close to a first-come-first-serve basis. When the lock is
released, the next set of readers/writer is granted the lock based on
arrival time.
Usage of the lock is predictable. Readers should obtain the read
lock while writers should obtain the write lock. Both of these locks
are objects of the Lock class—their
interface is discussed in Chapter
3. There is one major difference, however: reader-writer locks
have different support for condition variables. You can obtain a
condition variable related to the write lock by calling the newCondition() method; calling that method on a read lock generates an
UnsupportedOperationException
.
These locks also nest, which means that owners of the lock can repeatedly acquire the locks as necessary. This allows for callbacks or other complex algorithms to execute safely. Furthermore, threads that own the write lock can also acquire the read lock. The reverse is not true. Threads that own the read lock cannot acquire the write lock; upgrading the lock is not allowed. However, downgrading the lock is allowed. This is accomplished by acquiring the read lock before releasing the write lock.
Later in this chapter, we examine the topic of lock starvation in depth. Reader-writer locks have special issues in this regard.
In this section, we’ve examined higher-level synchronization tools provided by J2SE 5.0. These tools all provide functionality that in the past could have been implemented by the base tools provided by Java—either through an implementation by the developer or by the use of third-party libraries. These classes don’t provide new functionality that couldn’t be accomplished in the past; these tools are written totally in Java. In a sense, they can be considered convenience classes; that is, they are designed to make development easier and to allow application development at a higher level.
There is also a lot of overlap between these classes. A Semaphore can be used to partially simulate
a Lock simply by declaring a
semaphore with one permit. The write lock of a reader-writer lock is
practically the same as a mutually exclusive lock. A semaphore can be
used to simulate a reader-writer lock, with a limited set of readers,
simply by having the reader thread acquire one permit while the writer
thread acquires all the permits. A countdown latch can be used as a
barrier simply by having each thread decrement the count prior to
waiting.
The major advantage in using these classes is that they offload threading and data synchronization issues. Developers should design their programs at as high a level as possible and not have to worry about low-level threading issues. The possibility of deadlock, lock and CPU starvation, and other very complex issues is mitigated somewhat. Using these libraries, however, does not remove the responsibility for these problems from the developer.
Deadlock between threads competing for the same set of locks is the hardest problem to solve in any threaded program. It’s a hard enough problem, in fact, that it cannot be solved in the general case. Instead, we try to offer a good understanding of deadlock and some guidelines on how to prevent it. Preventing deadlock is completely the responsibility of the developer—the Java virtual machine does not do deadlock prevention or deadlock detection on your behalf.
Let’s revisit the simple deadlock example from Chapter 3.
package javathreads.examples.ch03.example8;
...
public class ScoreLabel extends JLabel implements CharacterListener {
...
private Lock adminLock = new ReentrantLock( );
private Lock charLock = new ReentrantLock( );
private Lock scoreLock = new ReentrantLock( );
...
public void resetScore( ) {
try {
charLock.lock( );
scoreLock.lock( );
score = 0;
char2type = -1;
setScore( );
} finally {
charLock.unlock( );
scoreLock.unlock( );
}
}
public void newCharacter(CharacterEvent ce) {
try {
scoreLock.lock( );
charLock.lock( );
// Previous character not typed correctly: 1-point penalty
if (ce.source == generator) {
if (char2type != -1) {
score--;
setScore( );
}
char2type = ce.character;
}
// If character is extraneous: 1-point penalty
// If character does not match: 1-point penalty
else {
if (char2type != ce.character) {
score--;
} else {
score++;
char2type = -1;
}
setScore( );
}
} finally {
scoreLock.unlock( );
charLock.unlock( );
}
}
}To review, deadlock occurs if two threads execute the newCharacter() and resetScore() methods in a fashion that each
can grab only one lock. If the newCharacter() method grabs the score lock
while the resetScore() method grabs
the character lock, they both eventually wait for each other to release
the locks. The locks, of course, are not released until they can finish
execution of the methods. And neither thread can continue because each
is waiting for the other thread’s lock. This deadlock condition cannot
be resolved automatically.
As we mentioned at the time, this example is simple, but more complicated conditions of deadlock follow the same principles outlined here: they’re harder to detect, but nothing more is involved than two or more threads attempting to acquire each other’s locks (or, more correctly, waiting for conflicting conditions).
Deadlock is difficult to detect because it can involve many classes that call each other’s
synchronized sections (that is, synchronized methods or synchronized
blocks) in an order that isn’t apparently obvious. Suppose we have 26
classes, A to Z, and that the synchronized methods of class A call those
of class B, those of class B call those of class C, and so on, until
those of class Z call those of class A. If two threads call any of these
classes, this could lead us into the same sort of deadlock situation
that we had between the newCharacter() and resetScore() methods, but it’s unlikely that a
programmer examining the source code would detect that deadlock.
Nonetheless, a close examination of the source code is the only option presently available to determine whether deadlock is a possibility. Java virtual machines do not detect deadlock at runtime, and while it is possible to develop tools that examine source code to detect potential deadlock situations, no such tools exist yet for Java.
The simplest way to avoid deadlock is to follow this rule. When a lock is held, never call any methods that need other locks—i.e., never call a synchronized method of another class from a synchronized method. This is a good rule that is often advocated, but it’s not the ideal rule for two reasons:
It’s impractical: many useful Java methods are synchronized, and you’ll want to call them from your synchronized method. As an example, many of the collection classes discussed in Chapter 8 have synchronized methods. To avoid the usage of collection classes from synchronized methods would prevent data from being moved or results from being saved.
It’s overkill: if the synchronized method you’re going to call does not in turn call another synchronized method, there’s no way that deadlock can occur. Furthermore, if the class or library is accessed only through its class interface—with no cross-calling—placing extra restrictions on using the library is silly.
Nonetheless, if you can manage to obey this rule, there will be no deadlocks in your program.
Another frequently used technique to avoid deadlock is to lock some higher-order object that is related to the many lower-order objects we need to use. In our example, that means removing the efficiency that causes this deadlock: to use only one lock to protect the score and the character assignments.
Of course, this is only a simple example: we don’t need to lock everything. If we can isolate the location of the deadlock, we can use a slightly higher order lock only to protect the methods that are having problems. Or we can make a rule that adds the requirement that an additional lock be held prior to acquiring the problem locks. All these variations of locking multiple objects suffer from the same lock granularity problem that we’re about to discuss.
The problem with this technique is that it often leads to situations where the lock granularity is not ideal. By synchronizing with only one lock, we are preventing access to variables we may not be changing or even using. The purpose of threaded programming is to accomplish tasks simultaneously—not to have these threads waiting on some global lock. Furthermore, if we’ve done our program design correctly, there was probably a reason why we attempted to acquire multiple locks rather than a single global lock. Solving deadlock issues by violating this design becomes somewhat counterproductive.
The most practical rule to avoid deadlock is to make sure that the locks are always acquired in the same order. In our example, it means that either the score or character lock must be acquired first—it doesn’t matter which as long as we are consistent. This implies the need for a lock hierarchy—meaning that locks are not only protecting their individual items but are also keeping an order to the items. The score lock protects not only the values of the score, but the character lock as well. This is the technique that we used to fix the deadlock in Chapter 3:
package javathreads.examples.ch03.example9;
...
public class ScoreLabel extends JLabel implements CharacterListener {
...
public void resetScore( ) {
try {
scoreLock.lock( );
charLock.lock( );
score = 0;
char2type = -1;
setScore( );
} finally {
charLock.unlock( );
scoreLock.unlock( );
}
}
...
}Since the resetScore() method
now also grabs the score lock first, it is not possible for any thread
to be waiting for the score lock while holding the character lock. This
means that the character lock may eventually be grabbed and released,
followed by the eventual release of the score lock. A deadlock does not
occur.
Again, this is a very simple example. For much more complex situations, we may have to do all of the following:
Use only locking objects—things that implement the
Lockinterface—and avoid use of thesynchronizedkeyword. This allows the separation of the locks from the objects in the application. We do this even with our simple example.Understand which locks are assigned to which subsystems and understand the relationships between the subsystems. We define a subsystem as a class, group of classes, or library that performs a relatively independent service. The subsystem must have a documented interface that we can test or debug in our search for deadlocks. This allows us to form groups of locks and map out potential deadlocks.
Form a locking hierarchy within each subsystem. Unlike the other two steps, this can actually hurt the efficiency of the application. The subsystem needs to be studied. The relationship of the locks must be understood in order to be able to form a hierarchy that will have minimal impact on the efficiency of the application.
If you are developing a very complex Java program, it’s a good idea to develop a lock hierarchy when the application is being designed. It may be very difficult to enforce a lock hierarchy after much of the program has been developed. Finally, since there is no mechanism to enforce a lock hierarchy, it is up to your good programming practices to make sure that the lock hierarchy is followed. Following a lock acquisition hierarchy is the best way to guarantee that deadlock does not occur in your Java program due to synchronization.
There are a few more concerns about deadlock when using the Lock interface (or any locking mechanism that is not the
Java synchronized keyword). The
first is illustrated by how we have used the Lock class in every example up to this
point. Our resetScore() method can
be easier written (and understood) as follows:
public void resetScore( ) {
scoreLock.lock( );
charLock.lock( );
score = 0;
char2type = -1;
setScore( );
charLock.unlock( );
scoreLock.unlock( );
}However, what happens if the thread that calls the resetScore() method encounters a runtime
exception and terminates? Under many threading systems, this leads to
a type of deadlock because the thread that terminates does not
automatically release the locks it held. Under those systems, another
thread could wait forever when it tries to change the score. In Java,
however, locks associated with the synchronized keyword are always released
when the thread leaves the scope of the synchronized block, even if it
leaves that scope due to an exception. So in Java when using the
synchronized keyword, this type
of deadlock never occurs.
But we are using the Lock
interface instead of the synchronized keyword. It is not possible for
Java to figure out the scope of the explicit lock—the developer’s
intent may be to hold the lock even on an exception condition.
Consequently, in this new version of the resetScore() method, if the setScore() method throws a runtime
exception, the lock is never freed since the unlock() methods are never called.
There is a simple way around this: we can use Java’s finally clause to make sure that the locks
are freed upon completion, regardless of how the method exits. This is
what we’ve done in all our examples.
By the way, this antideadlock behavior of the synchronized keyword is not necessarily a
good thing. When a thread encounters a runtime exception while it is
holding a lock, there’s the possibility—indeed, the expectation—that
it will leave the data it was manipulating in an inconsistent state.
If another thread is then able to acquire the lock, it may encounter
this inconsistent data and proceed erroneously.
When using explicit locks, you should not only use the finally clause to free the lock, but you
should also test for, and clean up after, the runtime exception
condition. Unfortunately, given Java’s semantics, this problem is
impossible to solve completely when using the synchronized keyword or by using the
finally clause. In fact, it’s
exactly this problem that led to the deprecation of the stop() method: the stop() method works by throwing an
exception, which has the potential to leave key resources in the Java
virtual machine in an inconsistent state.
Since we cannot solve this problem completely, it may sometimes be better to use explicit locks and risk deadlock if a thread exits unexpectedly. It may be better to have a deadlocked system than to have a corrupted system.
Since the Lock interface
provides options for when a lock can’t be grabbed; can
we use those options to prevent deadlock? Absolutely. Another way to
prevent deadlock is not to wait for the lock—or at least, to place
restrictions on the waiting period. By using the tryLock() method to provide alternatives in the algorithm, the
chances of deadlock can be greatly mitigated. For example, if we need
a resource but have an alternate (maybe slower) resource available,
using the alternate resource allows us to complete the operation and
ultimately free any other locks we may be holding. Alternatively, if
we are unable to obtain the lock within a time limit, perhaps we can
clean up our state—including releasing the locks we are currently
holding—and allow other conflicting threads to finish up and free
their locks.
Unfortunately, using explicit locks in this fashion is more complex than using a lock hierarchy. To develop a lock hierarchy, we simply have to figure out the order in which the locks must be obtained. To use timeouts, we need to design the application to allow alternative paths to completion, or the capability to “undo” operations for a later “redo.” The advantage to timeouts is that there can be a greater degree of parallelism. We are actually designing multiple pathways to completion to avoid deadlock instead of placing restrictions on the algorithm in order to avoid deadlock.
You must decide whether these types of benefits outweigh the added complexity of the code when you design your Java program. If you start by creating a lock hierarchy, you’ll have simpler code at the possible expense of the loss of some parallelism. We think it is easier to write the simpler code first and then address the parallelism problems if they become a performance bottleneck.
The problem with deadlock is that it causes the program to hang indefinitely. Obviously, if a program hangs, deadlock may be the cause. But is deadlock always the cause? In programs that wait for users, wait for external systems, or have complex interactions, it can be very difficult to tell a deadlock situation from the normal operation of the program. Furthermore, what if the deadlock is localized? A small group of threads in the program may deadlock with each other while other threads continue running, masking the deadlock from the user (or the program itself). While it is very difficult to prevent deadlock, can we at least detect it? To understand how to detect deadlock, we must first understand its cause.
Figure 6-1 shows two cases of threads and locks waiting for each other. The first case is of locks waiting for the owner thread to free them. The locks are owned by the thread so they can’t be used by any other thread. Any thread that tries to obtain these locks is placed into a wait state. This also means that if the thread deadlocks, it can make many locks unavailable to other threads.

The second case is of threads waiting to obtain a lock. If the lock is owned by another thread, the thread must wait for it to be free. Technically, the lock does not own the thread, but the effect is the same—the thread can’t accomplish any other task until the lock is freed. Furthermore, a lock can have many threads waiting for it to be free. This means that if a lock deadlocks, it can block many waiting threads.
We have introduced many new terms here—we’ll explain them before we move on. We define a deadlocked lock as a lock that is owned by a thread that has deadlocked. We define a deadlocked thread as a thread that is waiting for a deadlocked lock. These two definitions are admittedly circular, but that is how deadlocks are caused. A thread owns a lock that has waiting threads that own a lock that has waiting threads that own a lock, and so on. A deadlock occurs if the original thread needs to wait for any of these locks. In effect, a loop has been created. We have locks waiting for threads to free them, and threads waiting for locks to be freed. Neither can happen because indirectly they are waiting for each other.
We define a hard wait as a thread trying to acquire a lock by
waiting indefinitely. We call it a soft wait if a timeout is assigned to
the lock acquisition. The timeout is the exit strategy if a deadlock
occurs. Therefore, for deadlock detection situations, we need only be
concerned with hard waits. Interrupted waits are interesting in this
regard. If the wait can be interrupted, is it a hard wait or a soft
wait? The answer is not simple because there is no way to tell if the
thread that is implemented to call the interrupt() method at a later time is also
involved in the deadlock. For now, we will simply not allow the wait for
the lock to be interrupted. We will revisit the issue of the delineation
between soft and hard waits later in this chapter. However, in our
opinion, interruptible waits should be considered hard waits since using
interrupts is not common in most programs.
Assuming that we can keep track of all of the locks that are owned by a thread and keep track of all the threads that are performing a hard wait on a lock, is detecting a potential deadlock possible? Yes. Figure 6-2 shows a potential tree that is formed by locks that are owned and formed by hard waiting threads. Given a thread, this figure shows all the locks that are owned by it, all the threads that are hard waiting on those locks in turn, and so on. In effect, each lock in the diagram is already waiting, whether directly or indirectly, for the root thread to eventually allow it to be free. If this thread needs to perform a hard wait on a lock, it can’t be one that is in this tree. Doing so creates a loop, which is an indication of a deadlock situation. In summary, we can detect a deadlock by simply traversing this tree. If the lock is already in this tree, a loop is formed, and a deadlock condition occurs.

Using this algorithm, here is an implementation of a deadlock-detecting lock:
package javathreads.examples.ch06;
public class DeadlockDetectedException extends RuntimeException {
public DeadlockDetectedException(String s) {
super(s);
}
}
package javathreads.examples.ch06;
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
public class DeadlockDetectingLock extends ReentrantLock {
private static List deadlockLocksRegistry = new ArrayList( );
private static synchronized void registerLock(DeadlockDetectingLock ddl) {
if (!deadlockLocksRegistry.contains(ddl))
deadlockLocksRegistry.add(ddl);
}
private static synchronized void unregisterLock(DeadlockDetectingLock ddl) {
if (deadlockLocksRegistry.contains(ddl))
deadlockLocksRegistry.remove(ddl);
}
private List hardwaitingThreads = new ArrayList( );
private static synchronized void markAsHardwait(List l, Thread t) {
if (!l.contains(t)) l.add(t);
}
private static synchronized void freeIfHardwait(List l, Thread t) {
if (l.contains(t)) l.remove(t);
}
private static Iterator getAllLocksOwned(Thread t) {
DeadlockDetectingLock current;
ArrayList results = new ArrayList( );
Iterator itr = deadlockLocksRegistry.iterator( );
while (itr.hasNext( )) {
current = (DeadlockDetectingLock) itr.next( );
if (current.getOwner( ) == t) results.add(current);
}
return results.iterator( );
}
private static Iterator getAllThreadsHardwaiting(DeadlockDetectingLock l) {
return l.hardwaitingThreads.iterator( );
}
private static synchronized
boolean canThreadWaitOnLock(Thread t, DeadlockDetectingLock l) {
Iterator locksOwned = getAllLocksOwned(t);
while (locksOwned.hasNext( )) {
DeadlockDetectingLock current =
(DeadlockDetectingLock) locksOwned.next( );
if (current == l) return false;
Iterator waitingThreads = getAllThreadsHardwaiting(current);
while (waitingThreads.hasNext( )) {
Thread otherthread = (Thread) waitingThreads.next( );
if (!canThreadWaitOnLock(otherthread, l)) {
return false;
}
}
}
return true;
}
public DeadlockDetectingLock( ) {
this(false, false);
}
public DeadlockDetectingLock(boolean fair) {
this(fair, false);
}
private boolean debugging;
public DeadlockDetectingLock(boolean fair, boolean debug) {
super(fair);
debugging = debug;
registerLock(this);
}
public void lock( ) {
if (isHeldByCurrentThread( )) {
if (debugging) System.out.println("Already Own Lock");
super.lock( );
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
return;
}
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
if (canThreadWaitOnLock(Thread.currentThread( ), this)) {
if (debugging) System.out.println("Waiting For Lock");
super.lock( );
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
if (debugging) System.out.println("Got New Lock");
} else {
throw new DeadlockDetectedException("DEADLOCK");
}
}
public void lockInterruptibly( ) throws InterruptedException {
lock( );
}
public class DeadlockDetectingCondition implements Condition {
Condition embedded;
protected DeadlockDetectingCondition(ReentrantLock lock, Condition e) {
embedded = e;
}
public void await( ) throws InterruptedException {
try {
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
embedded.await( );
} finally {
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
}
}
public void awaitUninterruptibly( ) {
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
embedded.awaitUninterruptibly( );
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
}
public long awaitNanos(long nanosTimeout) throws InterruptedException {
try {
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
return embedded.awaitNanos(nanosTimeout);
} finally {
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
}
}
public boolean await(long time, TimeUnit unit)
throws InterruptedException {
try {
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
return embedded.await(time, unit);
} finally {
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
}
}
public boolean awaitUntil(Date deadline) throws InterruptedException {
try {
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
return embedded.awaitUntil(deadline);
} finally {
freeIfHardwait(hardwaitingThreads, Thread.currentThread( ));
}
}
public void signal( ) {
embedded.signal( );
}
public void signalAll( ) {
embedded.signalAll( );
}
}
public Condition newCondition( ) {
return new DeadlockDetectingCondition(this);
}
}Before we go into detail on this deadlock-detecting lock, it must be noted that this listing has been cut down for this book. For the latest, fully commented version, including testing tools, please see the online examples, which include (as example 1) a class that can be used to test this implementation.
In terms of implementation, this class inherits from the Lock interface, so it may be used anywhere
that a Lock object is required.
Furthermore, deadlock detection requires the registration of all locks
involved in the deadlock. Therefore, to detect a deadlock, replace all
the locks with this class, even the locks provided by the synchronized keyword. It may not be possible to detect a loop if any
of the locks are unregistered.
To use this class, replace all instances of ReentrantLock with DeadlockDetectingLock. This slows down your
program, but when a deadlock is detected, a DeadlockDetectedException is immediately thrown. Because of the performance
implications of this class, we do not recommend using it in a production
environment: use it only to diagnose occurrences of deadlock. The
advantage of using this class is that it detects the deadlock
immediately when it occurs instead of waiting for a symptom of the
deadlock to occur and diagnosing the problem then.
The DeadlockDetectingLock
class maintains two lists—a deadlockLocksRegistry and a hardwaitingThreads list. Both of these lists
are stored in thread-unsafe lists because external synchronization will
be used to access them. In this case, the external synchronization is
the class lock; all accesses to these lists come from synchronized
static methods. A single deadlockLocksRegistry list holds all
deadlock-detecting locks that have been created. One hardwaitingThreads list exists for each
deadlock-detecting lock. This list is not static; it holds all the
thread objects that are performing a hard wait on the particular
lock.
The deadlock locks are added and removed from the registry by
using the registerLock() and unregisterLock()
methods. Threads are added and removed from the hard waiting list using the markAsHardwait() and freeIfHardwait()
methods respectively. Since these methods are
static—while the list is not—the list must be passed as one of the
parameters to these methods. In terms of implementation, they are
simple; the objects are added and removed from a list container.
The getAllLocksOwned()
and getAllThreadsHardwaiting() methods are used to get the two types of waiting subtrees
we mentioned earlier. Using these subtrees, we can build the complete
wait tree that needs to be traversed. The getAllThreadsHardwaiting() method simply
returns the list of hard waiting threads already maintained by the
deadlock-detecting lock. The list of owned locks is slightly more
difficult. The getAllLocksOwned()
method has to traverse all registered deadlock-detecting locks, looking
for locks that are owned by the target thread. In terms of
synchronization, both of these methods are called from a method that
owns the class lock; as a result, there is no need for these private
methods to be synchronized.
The canThreadWaitOnLock()
method is used to traverse the wait tree, looking to see
if a particular lock is already in the tree. This is the primary method
that is used to detect potential deadlocks. When a thread is about to
perform a hard wait on a lock, it calls this method. A deadlock is
detected if the lock is already in the wait tree. Note that the
implementation is recursive. The method examines all of the locks owned
to see if the lock is in the first level of the tree. It also traverses
each owned lock to get the hard waiting threads; each hard waiting
thread is further examined recursively. This method uses the class lock
for synchronization.
With the ability to detect deadlocks, we can now override the
lock() method of the ReentrantLock class. This new implementation is actually not that
simple. The ReentrantLock class is
incredibly optimized—meaning it uses minimal synchronization. In that
regard, our new lock() method is also
minimally synchronized.
The first part of the lock()
method is for nested locks. If the lock is already owned
by this thread, there is no reason to check for deadlocks. Instead, we
can just call the original lock()
method. There is no race condition for this case: only the owner thread
can succeed in the test for nested locks and call the original lock() method. And since there is no chance
that the owner of the lock will change if the owner is the currently
executing thread, there is no need to worry about the potential race
condition between the isHeldByCurrentThread() and super.lock() method calls.
The second part of the lock()
method is used to obtain new locks. It first checks for deadlocks by
calling the canThreadWaitOnLock()
method. If a deadlock is detected, a runtime exception is thrown.
Otherwise, the thread is placed on the hard wait list for the lock, and
the original lock() method is called.
Obviously, a race condition exists here since the lock() method is not synchronized. To solve
this, the thread is placed on the hard wait list before the deadlock
check is done. By simply reversing the tasks, it is no longer possible
for a deadlock to go undetected. In fact, a deadlock may be actually
detected before it happens due to the race condition.
There is no reason to override the lock methods that accept a
timeout since these are soft locks. The interruptible lock request is
disabled by routing it to the uninterruptible version of the lock() method.
Unfortunately, we are not done yet. Condition variables can also
free and reacquire the lock and do so in a fashion that makes our
deadlock-detecting class much more complex. The reacquisition of the
lock is a hard wait since the await() method can’t
return until the lock is acquired. This means that the await() method needs to release the lock, wait
for the notification from the signal() method to arrive, check for a
potential deadlock, perform a hard wait for the lock, and eventually
reacquire the lock.
If you’ve already examined the code, you’ll notice that the
implementation of the await() method
is simpler than we just discussed. It doesn’t even check for the
deadlock. Instead, it simply performs a hard wait prior to waiting for
the signal. By performing a hard wait before releasing the lock, we keep
the thread and lock connected. This means that if a later lock attempt
is made, a loop can still be detected, albeit by a different route.
Furthermore, since it is not possible to cause a deadlock simply by
using condition variables, there is no need to check for deadlock on the
condition variable side. The condition variable just needs to allow the
deadlock to be detected from the lock() method side. The condition variable
also must place the thread on the hard wait list prior to releasing the
lock due to a race condition with the lock() method—it is possible to miss detection
of the deadlock if the lock is released first.
At this point, we are sure many readers have huge diagrams on their desk—or maybe on the floor—with thread and lock scenarios drawn in pencil. Deadlock detection is a very complex subject. We have tried to present it as simply as possible, but we are sure many readers will not be convinced that this class actually works without a few hours of playing out different scenarios. To help with this, the latest online copy of this class contains many simple test case scenarios (which can easily be extended).
To help further, here are answers to some possible questions. If you are not concerned with these questions, feel free to skip or skim the next section as desired. As a warning, some of these questions are very obscure, so obscure that some questions may not even be understood without a few hours of paper and pencil work. The goal is to work out the scenarios to understand the questions, which can hopefully be answered here.
We have stated that a deadlock condition is detected when a loop in the wait tree is detected. Is it really a loop? The answer is yes. This means that we have to be careful in our search or we can recursively search forever. Let’s examine how the loop is formed from another point of view. Any waiting thread node can have only one parent lock node. That’s because a thread can’t perform a hard wait on more than one lock at a time. Any owned lock node can have only one parent thread node. That’s because a lock can’t be owned by more than one thread at a time. In this direction, only nodes connected to the top node can form the loop. As long as none of the owned lock nodes are connected to the top thread node, we don’t have a loop. It is slightly more complicated than this, but we will address it with the next question.
Why are we using only the thread tree? What about the lock tree? These questions introduce a couple of definitions, so let’s back up a few steps. To begin, we are trying to determine whether a thread can perform a hard wait on a particular lock. We then build a wait tree using this thread object as the top node; that’s what we mean by the thread tree. However, the lock isn’t independent. It is also possible to build a wait tree using the lock object as the top node, which we define as the lock tree. There may be other locks in the lock tree that could be in the thread tree, possibly forming a deadlock condition.
Fortunately, we don’t have to traverse the lock tree because the thread tree is guaranteed to contain a root node as the top node. The top node of the thread tree is the currently running thread. It is not possible for this thread to be currently waiting on a lock since it wouldn’t be executing the lock request. The top node of the lock tree is only the root node if the lock is not owned. For a loop to form, either the lock tree or the thread tree must be a subtree of the other. Since we know that the thread tree definitely contains the root node, only the lock node can be the subtree. To test for a subtree, we just need to test the top node.
Isn’t marking the hard wait prior to checking for the deadlock condition a problem? Can it cause spurious deadlock exceptions? The answer is no. The deadlock condition will definitely occur since the thread will eventually perform the hard wait. It is just being detected slightly before it actually happens. On the other hand, our class may throw more than one deadlock exception once the deadlock has been detected. It must be noted that the purpose of this class is not to recover from the deadlock. In fact, once a deadlock exception is thrown, the class does not clean up after it. A retry attempt throws the same exception.
Can marking the hard wait first interfere with the deadlock check? By marking first, we are making a connection between the thread and the lock. In theory, this connection should be detected as a deadlock condition by the deadlock check. To determine if we’re interfering with the deadlock check, we have to examine where the connection is made. We are connecting the lock node to the top thread node—the connection is actually above the top thread node. Since the search starts from the top thread node, it isn’t able to detect the deadlock unless the lock node can be reached first. This connection is seen from the lock tree but is not a problem because that tree is not traversed. Traversals by other threads will be detected early as a deadlock condition since the hard wait will eventually be performed.
Can marking the hard wait first cause an error condition in other threads? Will it cause a loop in the trees? We need to avoid a loop in the wait trees for two reasons. First, and obviously, is because it is an indication of a deadlock condition. The second reason is because we will be searching through the wait trees. Recursively searching through a tree that has a loop causes an infinite search (if the lock being sought is not within the loop).
The answer to this question is no, it can’t cause an error condition. First, there is no way to enter the loop from a thread node that is not within the loop. All thread nodes within the loop are performing a hard wait on locks within the loop. And all lock nodes within the loop are owned by thread nodes within the loop. Second, it is not possible to start from a thread node that is within the loop. With the exception of the top thread node, all the thread nodes are performing a hard wait. To be able to perform the deadlock check, a thread cannot be in a wait state and therefore can’t be in the wait tree. If a loop is formed, only the thread represented by the top thread node can detect the deadlock.
This answer assumes that a deadlock-detected exception has never been thrown; this class is not designed to work once such an exception is thrown. For that functionality, consider using the alternate deadlock-detecting class that is available online.
How can the simple solution of switching the “thread
owns the lock” to the “thread hard waiting for lock” work for condition
variables? Admittedly, we did a bit of hand waving in the
explanation. A better way to envision it is to treat the operations as
being separate entities—as if the condition variable is releasing and reacquiring the lock. Since the
reacquisition is mandatory (i.e., it will eventually occur), we mark the
thread for reacquisition before we release the lock. We can argue that
switching the ownership state to a hard wait state removes the
connection from the thread tree, making detection impossible. This is
just an artifact of examining the wait tree from the condition
variable’s perspective. When the lock() method is called at a later time, we
will be using a different thread object as the top node, forming a
different wait tree. From that perspective, we can use either the
ownership state or hard wait state for the detection of the
deadlock.
Why don’t we have to check for potential deadlocks on
the condition variable side? It is not necessary. Marking for
the wait operation prior to unlocking works in a pseudo atomic manner,
meaning that it is not possible for another thread to miss the detection
of the deadlock when using the lock()
method. Since it is not possible to create a new deadlock just by using
condition variables, we don’t need to check on this end. Another
explanation is that there is no need to check because we already know
the answer: the thread is capable of performing a hard wait because it
has previously owned the lock and has not had a chance to request
additional locks.
Isn’t marking for the hard wait prior to performing
the await()
operation a problem? Can it cause spurious deadlock
exceptions? Can it cause an error condition in other threads?
Two of these questions are very similar to the questions for the
lock() method side. The extra
question here addresses the issue of interfering with the deadlock
check. That question doesn’t apply on the lock() method
side because we do not perform a deadlock check on the condition
variable side.
However, the answers to the other questions are not exactly the same as before. In this case, the thread is performing a hard wait on the lock before the thread releases ownership of the lock. We are creating a temporary loop—a loop that is created even though the deadlock condition does not exist. This is not a case of detecting the deadlock early—if the loop were detected, the deadlock detected would be incorrect.
These three questions can be answered together. As with the error
question on the lock() method side,
it is not possible to enter the loop from a thread node outside of the
loop. Second, the one thread node that is within this small loop is not
performing a deadlock check. And finally, any deadlock check does not
traverse the lock tree. This means that an error condition can’t occur
in another thread and that detecting a false deadlock condition also
can’t occur in another thread. Of course, eventually it would be
possible to get to the lock node externally, but by then, the loop would
have been broken. It is not possible for another thread to own the lock
unless the condition variable thread releases it first.
To review, we are traversing the thread tree to check whether the lock tree is a subtree. Instead of recursively traversing from the thread tree, isn’t it easier to traverse upward from the lock tree? Our answer is maybe. We simply list the pluses and minuses and let the reader decide. Two good points can be made for traversing from the lock tree. First, the search is not recursive. Each node of the lock tree has only one parent, so going upward can be done iteratively. Second, moving upward from lock node to parent thread node does not need any iterations—the owner thread object is already referenced by the lock object. On the other hand, moving downward from the thread node to the lock node requires iteration through the registered locks list.
Unfortunately, there are two bad points to traversing upward from the lock tree. First, moving upward from the thread node to the lock node on which it is performing the hard wait is incredibly time-consuming. We need to iterate through the registered locks list to find the hard wait lists, which we must, in turn, iterate through to find the lock node. In comparison, moving downward from the lock node to the thread node is done by iterating through one hard wait list. And it gets worse. We need to iterate through all of the hard wait lists. By comparison, we need to iterate only through the hard wait lists in the wait tree in our existing implementation. This one point alone may outweigh the good points.
The second bad point stems from the techniques that we use to solve the race conditions in the lock class. The class allows loops to occur—even temporarily creating them when a deadlock condition does not exist. Searching from a lock node that is within a loop—whether recursively downward or iteratively upward—does not terminate if the top thread node is not within the loop. Fortunately, this problem can be easily solved. We just need to terminate the search if the top lock node is found. Also note that finding the top lock node is not an indication of a deadlock condition since some temporary loops are formed even without a deadlock condition.
To review, we are traversing the thread tree instead of the lock tree because the top thread node is definitely the root node. The top lock node may not be the root node. However, what if the top lock node is also the root node? Isn’t this a shortcut in the search for a deadlock? Yes. It is not possible for the lock tree to be a subtree of the thread tree if the top lock node is a root node. This means we can remove some calls to the deadlock check by first checking to see if the lock is already owned. This is an important improvement since the deadlock check is very time-consuming.
However, a race condition exists when a lock has no owner. If the lock is unowned, there is no guarantee that the lock will remain unowned during the deadlock check. This race condition is not a problem since it is not possible for any lock in the wait tree to be unowned at any time during the deadlock check; the deadlock check may be skipped whether or not the lock remains unowned.
This shortcut is mostly for locks that are infrequently used. For frequently used locks, this shortcut is highly dependent on the thread finding the lock to be free, which is based on the timing of the application.
The modification with some deadlock checking removed is available online in our alternate deadlock-detecting lock.
The deadlock-detecting lock disallows interruptible
locking requests. What if we do not agree with this
compromise? There are only a few options. Disallowing the interrupt
was the easiest compromise that works for the majority of the cases. For
those readers who believe an interruptible lock should be considered a
soft lock, the change is simple—just don’t override the lockInterruptibly() method. And for those
readers who believe that an interruptible lock should be considered a
hard lock while still not compromising interrupt capability, here is a
modified version of the method:
public void lockInterruptibly( ) throws InterruptedException {
if (isHeldByCurrentThread( )) {
if (debugging) System.out.println("Already Own Lock");
try {
super.lockInterruptibly( );
} finally {
freeIfHardwait(hardwaitingThreads,
Thread.currentThread( ));
}
return;
}
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
if (canThreadWaitOnLock(Thread.currentThread( ), this)) {
if (debugging) System.out.println("Waiting For Lock");
try {
super.lockInterruptibly( );
} finally {
freeIfHardwait(hardwaitingThreads,
Thread.currentThread( ));
}
if (debugging) System.out.println("Got New Lock");
} else {
throw new DeadlockDetectedException("DEADLOCK");
}
}This change is also provided online in our alternate
deadlock-detecting lock class. In terms of implementation, it is
practically identical to that of the lock() method. The difference is that we now
place all lock requests within a try-finally clause. This allows the method to
clean up after the request, regardless of whether it exits normally or
by exception.
The deadlock-detecting lock regards all lock requests with a timeout as soft locks. What if we do not agree with this premise? This topic is open to debate. While an application that uses timeouts should have an exit strategy when the timeout occurs, what if the exit strategy is to inform the user and then simply retry? In this case, deadlock could occur. Furthermore, at what point is retrying no longer tolerable? When the timeout period is more than an hour? A day? A month? Obviously, these issues are design-specific.
Here is an implementation of the tryLock() method that treats the request as a
soft wait—but only if it is less than a minute:
public boolean tryLock(long time, TimeUnit unit)
throws InterruptedException {
// Perform operation as a soft wait
if (unit.toSeconds(time) < 60) {
return super.tryLock(time, unit);
}
if (isHeldByCurrentThread( )) {
if (debugging) System.out.println("Already Own Lock");
try {
return super.tryLock(time, unit);
} finally {
freeIfHardwait(hardwaitingThreads,
Thread.currentThread( ));
}
}
markAsHardwait(hardwaitingThreads, Thread.currentThread( ));
if (canThreadWaitOnLock(Thread.currentThread( ), this)) {
if (debugging) System.out.println("Waiting For Lock");
try {
return super.tryLock(time, unit);
} finally {
freeIfHardwait(hardwaitingThreads,
Thread.currentThread( ));
if (debugging) System.out.println("Got New Lock");
}
} else {
throw new DeadlockDetectedException("DEADLOCK");
}
}This change is also provided in the online examples as an
alternative to the deadlock-detecting lock class (including a testing
program, which is example 2 in this chapter). Its implementation is
practically identical to that of the lock() method. Again, the difference is that
we now place all lock requests within a try-finally clause. This allows the method to
clean up after the request, regardless if it exits normally or by
exception. This example treats the operation as a soft wait for requests
that are under a minute. The request is treated as a hard wait
otherwise. We leave it up to you to modify the code to suit your needs.
One alternate solution could be to use a different time period to
separate soft and hard wait lock operations; this time period could also
be calculated depending on conditions in the program. Another alternate
solution could be for the trylock()
method to return false instead of throwing the deadlock-detected
exception.
While the deadlock-detecting lock is well-designed for detecting the deadlock condition, the design for reporting the condition is pretty weak. Are there better options? This is actually intentional. This class is not designed to be used in a production environment. Searching for deadlocks can be very inefficient—this class should be used only during development. In fact, most readers will probably not use this class at all. The main purpose of this class is so that we can understand deadlocks—how to detect them and, eventually, how to prevent them.
For those who insist on using the deadlock-detecting lock in a production environment, there are a few options. The class can be designed to fail fast—meaning that if a deadlock is detected, the class could throw the exception for every invocation, regardless of whether the request is involved in the deadlock or not. Another option is for the class to report the condition in a manner that allows the program to shut down properly. A third, and not recommended, option is to allow the class to continue functioning. The first and third options are provided as conditional code in the alternate online example.
This topic of deadlock detection seems to be incredibly
complex. In fact, the discussion on the theory and implementation is
more than twice as long as the code itself. Is this topic really that
complex? The concept of deadlock detection is complex, but
there is another reason why this class is even more complex. The
implementation of this class is accomplished by minimal synchronization.
This is mainly because the ReentrantLock class is implemented with
minimal
synchronization, making the class implementation more complex.
Whenever multiple threads compete for a scarce resource, there is the danger of starvation, a situation in which the thread never gets the resource. In Chapter 9, we discuss the concept in the context of CPU starvation: with a bad choice of scheduling options, some threads never have the opportunity to become the currently running thread and suffer from CPU starvation.
Lock starvation is similar to CPU starvation in that the thread is unable to execute. It is different from CPU starvation in that the thread is given the opportunity to execute; it is just not able to because it is unable to obtain the lock. Lock starvation is similar to a deadlock in that the thread waits indefinitely for a lock. It is different in that it is not caused by a loop in the wait tree. Its occurrence is somewhat rare and is caused by a very complex set of circumstances.
Lock starvation occurs when a particular thread attempts to acquire a lock and never succeeds because another thread is already holding the lock. Clearly, this can occur on a simple basis if one thread acquires the lock and never releases it: all other threads that attempt to acquire the lock never succeed and starve. Lock starvation can also be more subtle; if six threads are competing for the same lock, it’s possible that five threads will hold the lock for 20% of the time, thus starving the sixth thread.
Lock starvation is not something most threaded Java programs need to consider. If our Java program is producing a result in a finite period of time, eventually all threads in the program will acquire the lock, if only because all the other threads in the program have exited. Lock starvation also involves the question of fairness: at certain times we want to make sure that threads acquire the locks in a reasonable order so that one thread won’t have to wait for all other threads to exit before it has its chance to acquire the lock.
Consider the case of two threads competing for a lock. Assume that thread A acquires the object lock on a fairly periodic basis, as shown in Figure 6-3.
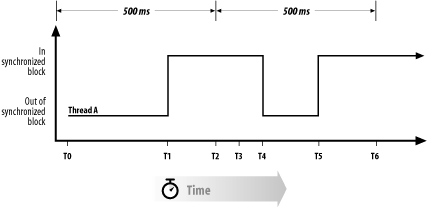
Here’s what happens at various points on the graph:
- T0
At time T0, both thread A and thread B are able to run, and thread A is the currently running thread.
- T1
Thread A is still the currently running thread, and it acquires the object lock when it enters the synchronized block.
- T2
A timeslice occurs; this causes thread B to become the currently running thread.
- T3
Very soon after becoming the currently running thread, thread B attempts to enter the synchronized block. This causes thread B to block. That allows thread A to continue to run; thread A continues executing in the synchronized block.
- T4
Thread A exits the synchronized block. Thread B could obtain the lock now, but it is still not running on any CPU.
- T5
Thread A once again enters the synchronized block and acquires the lock.
- T6
Thread B once again is assigned to a CPU. It immediately tries to enter the synchronized block, but the lock for the synchronized block is once again held by thread A. So, thread B blocks again. Thread A then gets the CPU, and we’re now in the same state as we were at time T3.
It’s possible for this cycle to continue forever such that thread B can never acquire the lock and actually do useful work.
Clearly, this example is a pathological case: CPU scheduling must occur only during those time periods when thread A holds the lock for the synchronized block. With two threads, that’s extremely unlikely and generally indicates that thread A is holding the lock almost continuously. With several threads, however, it’s not out of the question that one thread may find that every time it is scheduled, another thread holds the lock it wants.
Synchronized blocks within loops often have this problem:
while (true) {
synchronized (this) {
// execute some code
}
}At first glance, we might expect this not to be a problem; other threads can’t starve because the lock is freed often, with each iteration of the loop. But as we’ve seen, this is not the case: unless another thread runs during the short interval between the end of the synchronized block (when the lock is released) and the beginning of the next iteration of the loop (when the lock is reacquired), no other thread will be able to acquire the lock.
There are two points to take away from this:
Acquisition of locks does not queue
When a thread attempts to acquire a lock, it does not check to see if another thread is already attempting to acquire the lock (or, more precisely, if another thread has tried to acquire the lock and blocked because it was already held). In pseudocode, the process looks like this:
while (lock is held) wait for a while acquire lockFor threads of equal priority, there’s nothing in this process that prevents a lock from being granted to one thread even if another thread is waiting.
Releasing a lock does not affect thread scheduling
When a lock is released, any threads that were blocked waiting for that lock could run. However, no actual scheduling occurs, so none of the threads that have just moved into the runnable state are assigned to the CPU; the thread that has just released the lock keeps access to the CPU. This can be different if the threads have different priorities or are on a multiprocessor machine (where a different CPU might be idle).
Nonetheless, lock starvation remains, as might be guessed from our example, something that occurs only in rare circumstances. In fact, each of the following circumstances must be present for lock starvation to occur:
Multiple threads are competing for the same lock
This lock becomes the scarce resource for which some threads may starve.
The results that occur during this period of contention must be interesting to us
If, for example, we’re calculating a big matrix, there’s probably a point in time at the beginning of our calculation during which multiple threads are competing for the same lock and CPU. Since all we care about is the final result of this calculation, it doesn’t matter to us that some threads are temporarily starved for the lock: we still get the final answer in the same amount of time.We’re concerned about lock starvation only if there’s a period of time during which it matters whether the lock is allocated fairly.
All of the properties of lock starvation stem from the fact that a thread attempting to acquire a lock checks only to see if another thread is holding the lock—the thread knows nothing about other threads that are also waiting for the lock. This behavior in conjunction with properties of the program such as the number of threads, their priorities, and how they are scheduled manifests itself as a case of lock starvation.
Fortunately, this problem has already been solved by the ReentrantLock class. If we’re in one of the rare situations where lock
starvation can occur, we just need to construct a ReentrantLock object where the fairness flag
is set to true. Since the ReentrantLock class with its fairness flag set
grants the lock on very close to a first-come, first-served basis, it is
not possible for any thread to be starved for a lock regardless of the
number of threads or how they’re written.
Unfortunately, the downside to using the ReentrantLock class in this manner is that we
are affecting the scheduling. We discuss how threads are scheduled in
Chapter 9, but in general,
threads have a priority, and the higher-priority threads are given the
CPU more often than low-priority threads. However, the ReentrantLock class does not take that into
account when issuing locks: locks are issued first-come, first-served
regardless of the thread’s priority.
Programs that set thread priorities do so for a reason. The reason
could be because the developer wanted to have the scheduler behave in a
certain manner. While using the fair flag in the ReentrantLock class may prevent lock
starvation, it may also change the desired scheduling behavior.
Lock starvation is a rare problem; it happens only under very
distinct circumstances. While it can be easily fixed with the ReentrantLock class, it may also change some
of these desired circumstances. On the other hand, if priorities and
scheduling are not a concern, the ReentrantLock class provides a very simple and
quick fix.
Generally, reader/writer locks are used when there are many more readers than writers; readers also tend to hold onto the lock for a longer period of time than they would a simple lock. This is why the reader/writer lock is needed—to share data access during the long periods of time when only reading is needed. Unfortunately, readers can’t just grab the lock if the lock is held for reading by another thread. If many readers were holding the lock, it would be possible for many more readers to grab the lock before the first set of readers finished. Many more readers could then obtain the lock before the second set of readers finished. This would prevent the writer from ever obtaining the lock.
To solve this, the reader/writer lock does not grant the read
lock to a new thread if there is a writer waiting for the lock.
Instead it places the reader into a wait state until the first set of
readers frees the lock. Once the first set of readers have completed,
the first writer is given exclusive access to the lock. When that
writer completes, the ReentrantReadWriteLock class consults its
fairness flag to see what to do next. If the fairness flag is true,
the thread waiting longest—whether a reader or a writer—is granted the
lock (and multiple readers can get the lock in this case). If
the fairness flag is
false, locks are granted arbitrarily.
The strong integration of locks into the Java language and API is very useful for programming with Java threads. Java also provides very strong tools to allow thread programming at a higher level. With these tools, Java provides a comprehensive library to use for your multithreaded programs.
Even with this library, threaded programming is not easy. The developer needs to understand the issues of deadlock and starvation, in order to design applications in a concurrent fashion. While it is not possible to have a program threaded automatically—with a combination of using the more advanced tools and development practices, it can be very easy to design and debug threaded programs.
Here are the class names and Ant targets for the examples in this chapter:
Description | Main Java class | Ant target |
|---|---|---|
Deadlock-detecting Lock | | ch6-ex1 |
Alternate Deadlock-detecting Lock | | ch6-ex2 |
Three tests are available for each example. The first test uses two threads and two competing locks. The second test uses three threads and three competing locks. The third test uses condition variables to cause the deadlock. Test numbers are selected with this property:
<property name="DeadlockTestNumber" value="2"/>