Chapter 5. Real-World Applications and Opportunities
One of the questions that I am asked most often is how AI can be used in real-world applications. This chapter is a high-level overview of real-world applications and examples of AI. In particular, the goal of this chapter is to show how AI can create real-world value and help inspire visions for AI innovation.
It’s worth noting that this topic could be an entire book in and of itself, so the goal here is for you to understand how the application types work at a high level and to provide one or more examples of how we can apply each one. Before getting into specific real-world applications and examples, let’s review the current state of AI and the opportunities available.
AI Opportunities
A 2018 McKinsey AI adoption report noted that AI has gained the most traction in business areas that generate the most value within a given industry, which in order of greatest to lowest adoption includes service operations, product and/or service development, marketing and sales, supply-chain management, manufacturing, risk, human resources, strategy, and corporate finance. Further, it showed that industries adopting AI in the greatest numbers from highest to lowest include telecom, high tech, financial services, professional services, electric power and natural gas, health care systems and services, automotive and assembly, travel/transport/logistics, retail, and pharma/medical products.
PWC estimates that AI may contribute up to $15.7 trillion to the global economy by 2030, and McKinsey estimates that certain AI techniques “have the potential to create between $3.5 trillion and $5.8 trillion in value annually across nine business functions in 19 industries.”
Teradata estimates that 80% of enterprise companies worldwide have already incorporated some form of production AI into their organization, and Forrester estimates that “truly insights-driven businesses will steal $1.2 trillion per annum from their less-informed peers by 2020.”
As these industries and figures indicate, AI represents huge opportunities and is starting to be widely adopted across industries and business functions. These numbers are likely to increase significantly given the current rise of IoT. IDC predicts global spending on IoT will total nearly $1.4 trillion by 2021, and the global IoT market will grow to $457 billion by 2020.
How Can I Apply AI to Real-World Applications?
Another question that I am often asked (usually by executives and managers) is: “How can I apply AI to make decisions and solve problems?” Few people truly understand what AI is, what it can do, or specifically how they can apply it in real-world applications. Ideally a business executive, manager, or practitioner with AI expertise and business acumen can help answer this, but I’ve included this section for those who either do not have the luxury of AI expertise at the executive level or who would like to be able to figure this out on their own.
Everything involved with AI, machine learning, and data science, including potential applications, can be far from obvious. In fact, it can be downright daunting and overwhelming. How do you know which techniques apply to what use cases? How do you know what AI applications and outcomes are most common for your industry or business function? How do you know what level of granularity you should be thinking at? As an executive or manager, the key is to simply understand the top-level approaches and let the data scientists and machine learning engineers figure out what specific techniques to try. The key word being “try”—it’s an experimental and scientific process!
Translation between the business and technical sides of AI is one of the primary challenges in my experience. This is partly because AI is very technical and difficult for many people to understand in general. It’s also because the sky is almost the limit with AI and harnessing data to create value.
Let me explain further. Most AI and machine learning techniques can be applied to all industries and business functions in one way or another. Every company has data regardless of whether it is an early-stage startup or enterprise company, or whether it’s a health care, manufacturing, or retail company. Likewise, every business function (i.e., department) has data regardless of whether it’s marketing, sales, or operations.
Insurance companies want to predict customer churn just like retail companies do, and both can use the same techniques. We can use image recognition to replace key cards for getting into office buildings just like we can use it to diagnose cancer in radiographic images. In this case, the technique used and goals of recognizing or identifying certain objects in images is more or less the same. The only real difference is the data being used and the industry application. This can often be a difficult thing for those who are less familiar with AI to understand, and also for those more familiar to explain.
A combination of business folks, domain experts, and AI practitioners must work collaboratively to determine what opportunities are available, select and prioritize the ones to pursue, and determine which approaches, as outlined in this chapter, will work best. Most of the following approaches aren’t specific to an industry; rather, they’re customizable to specific data and goals. Also, you should strategically identify and prioritize AI opportunities and applications based on the potential value (and/or ROI) to the industry or business function being considered.
Table 5-1 should answer some of your questions, particularly around ways that you can apply AI. These techniques are applicable in one way or another to mostly every type of industry and business function. Because there are far too many different industries and business functions for it to be practical to include in this discussion, I’ve taken the approach of providing a specific type of goal and then listing one or more techniques to help accomplish it. This list and the contents of this chapter in general are not exhaustive.
| Goal | Technique |
|---|---|
Predict a continuous numeric value (e.g., stock price) |
Supervised learning (regression) |
Predict (or assign) a class, category, or label (e.g., spam or not-spam) |
Supervised learning (classification) |
Create groupings of similar data (to understand each group’s profile; e.g., market segments) |
Unsupervised learning (clustering) |
Identify highly unusual and/or dangerous outliers (e.g., network security, fraud) |
Unsupervised learning (anomaly detection) |
Personalize your product, services, features, and/or content to customers |
Recommendations (e.g., media, products, services); Ranking/scoring; Personalization (e.g., content, offers, messaging, interactions, layout) |
Detect, classify, and/or identify specific spatial (space), temporal (time), or spatiotemporal (both; e.g., audio, video) patterns; Detect and classify human sentiment (from voice, text, images, and video) |
Recognition (image, audio, speech, video, handwriting, text); Computer vision (e.g., detection: motion, gesture, expression, sentiment); Natural language processing (NLP) |
Have AI self-learn to optimize a process over time (e.g., game playing, automation) |
Reinforcement learning |
Allow people and processes to find highly relevant information quickly and easily (e.g., articles, images, videos, documents) |
Search (text, speech, visual); Ranking/scoring |
Turning unstructured text/speech (e.g., subjective feedback, comments, documents) into quantifiable, objective, and actionable analytics, insights, and predictions |
Natural language processing (NLP) |
Create a personal or virtual assistant, chatbot, or language-driven agent (e.g., Amazon Alexa, Apple Siri) |
Natural language processing (NLP); Natural language understanding (NLU); Examples: question answering and conversations |
Create better forecasts |
Time–series methods |
Generate data from one kind to another (e.g., text, audio, image, video, speech) |
Generative AI (including natural language generation [NLG]) |
Automate aspects of the data science and machine learning process |
AutoML |
Build hybrid applications involving software, hardware, and firmware (e.g., autonomous vehicles, robots, IoT) |
All techniques may be applicable either individually or in combination |
Predict or translate a sequence (e.g., language translation; predict characters, words, or sentences) |
Deep learning; Sequence-to-sequence learning |
Augmented intelligence or automate processes (e.g., repetitive tedious tasks, decision making, insights) |
All techniques might be applicable either individually or in combination |
It’s worth mentioning that you can combine many of these techniques into a single AI application—an application that leverages multiple approaches. Remember that pretty much all AI today is narrow and a bit of a one-trick pony. This means that we don’t yet have algorithms that can do more than one of these at the same time. Again, the trick is to have business folks, domain experts, and AI practitioners working together to choose the best approaches and combinations as needed.
Real-World Applications and Examples
Now let’s dive into an overview of real-world AI applications by approach category and with examples. The examples given are far from exhaustive and are predominantly business-focused (we will go over people-focused examples in Chapter 9). Also, I could have grouped applications by industry or business function, but instead I’ve chosen to group by type of approach given what we talked about earlier regarding how each approach can most likely be applied in some way across any industry or business function.
The idea is that you gain a solid understanding of the different types of techniques and applications without becoming bogged down in the technical details, thus the focus on explainability. We’ll use the word “algorithm” in an over-simplified way to describe either a single algorithm, model, or software program that uses multiple algorithms. In each category, I discuss the types of data inputs, the algorithm as a black box (for simplicity purposes, and even when the real algorithms aren’t black boxes), and the output(s).
Because this is meant to be a high-level overview, you are encouraged to further research any specific applications of interest, and how they are being applied in your industry or business function of choice. There are also many resources available to learn more about the technical details and specific algorithms used, as well.
Predictive Analytics
Prediction, aka predictive analytics or predictive modeling, is the process of predicting an output based on labeled, and sometimes unlabeled, input data. Predictive analytics in the context of machine learning and AI can be further categorized as either regression or classification.
The following two subsections on prediction cover making predictions from labeled (supervised) data. Predictive analytics involving time–series and sequential data is covered in a later section.
Regression
Figure 5-1 demonstrates how regression is the process of taking labeled input data, passing the data through a predictive model (we assume black boxes throughout for simplicity), and generating a numeric value from a continuous number range (e.g., a stock closing price).
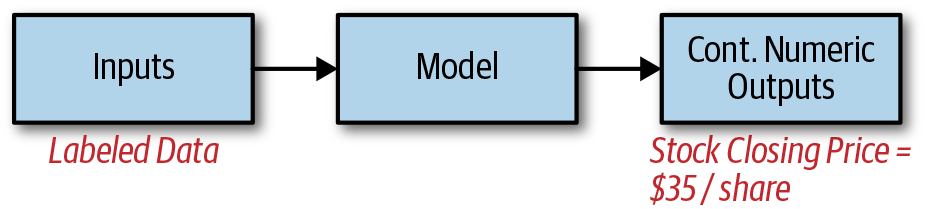
Figure 5-1. Regression
Applications include customer lifetime value and net profit, revenue and growth forecasting, dynamic pricing, credit and loan default risk, and algorithmic stock trading.
Classification
Classification is the process of taking labeled input data, passing the data through a model (classifier), and assigning one or more classes (categories/labels) to the input, as depicted in Figure 5-2.
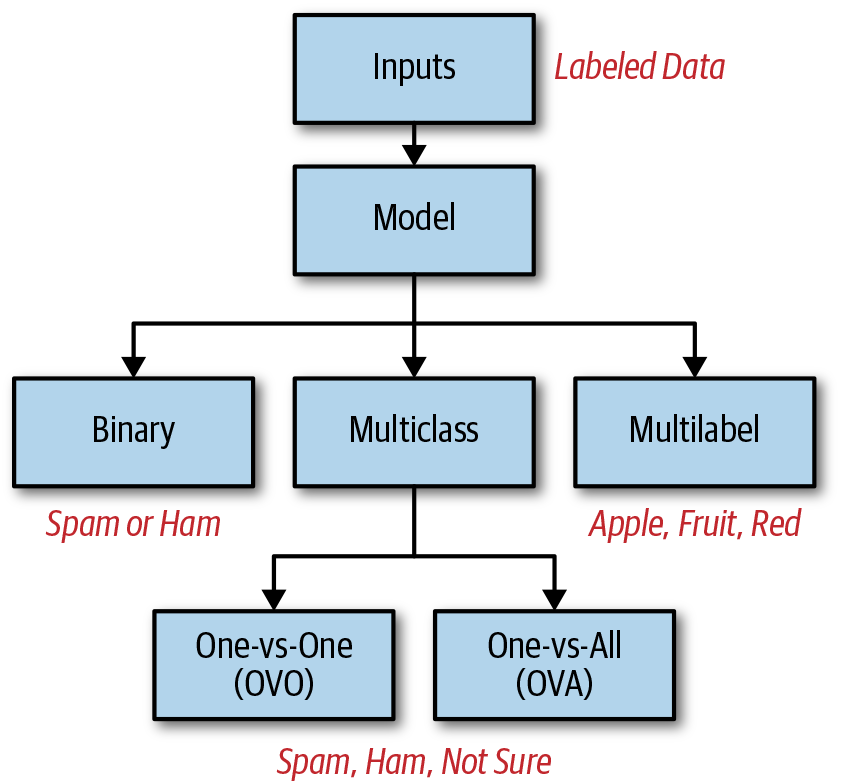
Figure 5-2. Classification
A standard example of a binary classifier is an email spam filter. An email represents the input data that is passed through a classifier model, which then determines whether the email is spam or not-spam, not-spam being a phrase used in this case to refer to a good, non-spam email. Spam emails are sent to the spam folder, and not-spam emails are sent to the inbox.
Suppose a third class was included and labeled as “unsure.” Now the classifier can assign three possible classes to a given email input: spam, not-spam, and unsure. This is an example of multiclass classification because there are more than two possible classes. In this case, the email client could have a “Possibly Spam” folder for the user to review and verify each email, thus teaching the classifier how to better distinguish between spam and not-spam.
When there are three or more possible classes to assign to an input, the algorithm can either select a single class to assign to the input or it can assign probabilities for each of the possible classes for the given input. In the latter case, the class with the highest probability can be used as the assigned class, or the probabilities for all classes can be used in whatever customized way you want. In this example, suppose that a new incoming email is determined to be 85% likely to be spam, 10% likely to be not-spam, and 5% likely to be unsure. You could either just say the email is spam since the probability is highest or use the different probabilities in another way.
Lastly, certain algorithms can assign multiple labels to the same input. An example related to image recognition could be an image of a red apple as input data, with multiple classes assigned to the image such as red, apple, and fruit. Assigning all three classes to the image would be appropriate in this example.
Applications include credit risk and loan approval and customer churn. Classification can be combined with recognition applications as discussed in a later section of this chapter.
Personalization and Recommender Systems
Recommender systems are a form of personalization that use existing information to make suggestions and results that are more relevant to individual users. You can use this to increase customer conversions and sales, delight, and retention], for example. In fact, Amazon increased its revenue by 35% with the addition of these engines, and 75% of the content watched on Netflix is generated by its recommendations.
Recommender systems are a specific type of information filtering system. You can also use search, ranking, and scoring techniques for personalization, which we discuss later in the chapter. Recommender systems make recommendations by taking inputs such as items (e.g., products, articles, music, movies) or user data and passing the data through a recommender model, or engine, as shown in Figure 5-3.
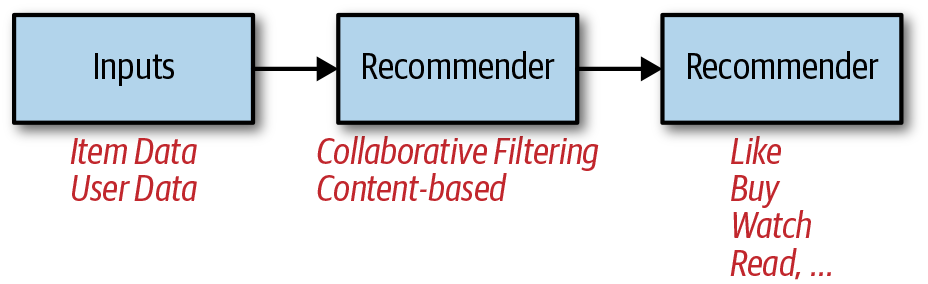
Figure 5-3. Recommender systems
It’s worth mentioning the “cold-start problem” associated with recommender systems. The cold-start problem refers to situations in which an intelligent application does not yet have enough information to make highly personalized and relevant recommendations to a specific user or group. An example includes users who have not yet generated information about their preferences, interests, or purchase history. Another example is when items (e.g., clothes, products, videos, songs) are first introduced to the public. There are multiple techniques that you can use to help address this problem, but because of space restrictions, we won’t discuss those here.
Recommender system applications include generating recommendations for products, movies, music and playlists, books, and TV shows (e.g., Amazon, Netflix, Spotify). In addition to recommendations, personalized content can also include news, feeds, emails, and targeted advertising (e.g., Twitter). Other examples include personalized medicine and medical treatment plans, personalized images and thumbnails (e.g., YouTube, Netflix, Yelp), wine recommendations, personalized shopping such as perfect jacket matching, fashion matching (e.g., StitchFix), and automated complete outfit recommendations.
Computer Vision
Computer vision is a broad field that includes pattern recognition (another approach discussed in the next section) when it involves visual information such as images and video. Computer vision represents the process of taking inputs such as photo images, video still images, and a sequence of images (video), passing the data through a model, and producing an output, as illustrated in Figure 5-4.
The output can be recognition, detection, and identification of specific objects, features, or activities. Vision-related applications imply a degree of automation, particularly when automating vision, typically requiring a human in applications (e.g., inspection). Machine vision is a term used to describe similar and somewhat overlapping techniques used in industrial applications such as inspection, process control, measurement, and robotics.

Figure 5-4. Computer vision
There are many very interesting and powerful applications of computer vision, and the use cases are growing rapidly. For example, we can use computer vision for:
-
Giving “sight” to autonomous vehicles (e.g., cars, drones)
-
Human interaction prediction such as hugs and handshakes
-
People counting (e.g., lines, infrastructure planning, retail)
Unmanned aerial vehicles (UAVs) are vehicles usually referred to as drones. By applying computer vision, drones are able to perform inspections (e.g., oil pipelines, cell towers), explore areas and buildings, help with mapping tasks, and deliver purchased goods. Computer vision is also becoming widely used for public safety, security, and surveillance. Of course, care should be taken so that applications are ethical and for the benefit of people.
One final thing to note about computer vision. I used the term “sight” earlier. Humans are able to sense the environment and world around them through the five common senses, which are sight, smell, hearing, touch, and taste. Information is “sensed” through sensing organs and then passed to our nervous system to translate the information and also decide what action or reaction should occur, if any. Computer vision is the analogous mechanism for giving AI applications the sense of sight.
Pattern Recognition
Pattern recognition involves taking unstructured input data, passing the data through a model, and detecting the presence of a particular pattern (detection), assigning a class to a recognized pattern (classification), or actually identifying the subject of the recognized pattern (identification), as illustrated in Figure 5-5.
Inputs in these applications can include images (including video—a sequence of still images), audio (e.g., speech, music, sounds), and text. Text can be further characterized as digital, handwritten, or printed (e.g., paper, checks, license plates).

Figure 5-5. Pattern recognition
For cases in which images are the inputs, the goal might be object detection, recognition, identification, or all three. A good example is facial recognition. Training a model to detect a face in an image and classify the detected object as a face is an example of object recognition where the object is an unidentified face. “Detection” is a term used to indicate that something is detected that differs from the background. It can also include object location measurements and specification of a bounding box around the object detected. Recognition is the process of actually assigning a class or label (face in this example) to the detected object, and identification takes this a step further and assigns an identity to the face detected (e.g., Alex’s face). Figure 5-6 presents some image recognition examples.

Figure 5-6. Image recognition and detection
Biometric identification such as facial recognition can be used to automatically tag people in images. Recognizing specific people by their fingerprints is another form of biometric identification.
Other applications include:
Audio recognition applications include:
-
Flaw detection (e.g., due to manufacturing defects or part failure)
Lastly, handwritten or printed text can be converted to digital text through the process of optical character recognition (OCR) and handwriting recognition. Text can also be converted to speech, but that can be considered more of a generative application as opposed to a recognition application. We discuss generative applications later in this chapter.
Clustering and Anomaly Detection
Clustering and anomaly detection, shown in Figure 5-7 are the two most common unsupervised machine learning techniques. They are also considered pattern recognition techniques.
Both processes take input data, which is unlabeled, pass it through the appropriate algorithm (clustering or anomaly detection), and then produces groups in the clustering case, or a determination if something is anomalous in the case of anomaly detection. Let’s discuss clustering first.
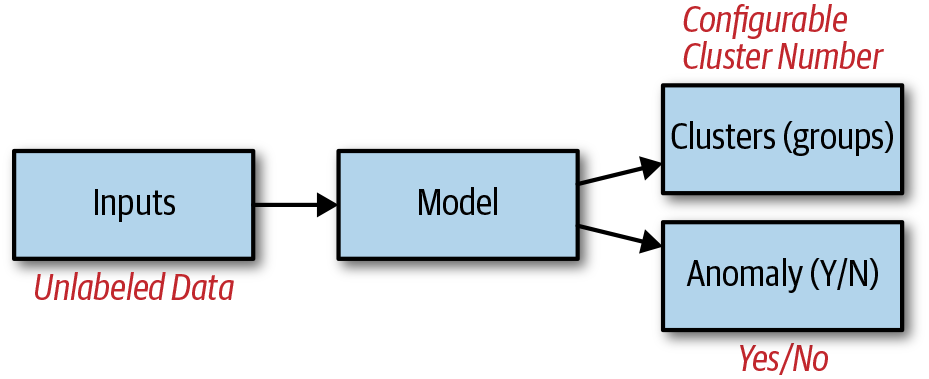
Figure 5-7. Clustering and anomaly detection (different models)
Clustering turns unlabeled data into groupings of similar data. The number of groups is determined by the person performing the clustering task, usually a data scientist. There isn’t really a right or wrong number of clusters, but often a number is selected through trial and error and/or is considered an ideal number for a given application.
Because the data is unlabeled, the practitioner must assign some sort of meaning or label to each group that best describes it (e.g., sports enthusiasts). The model then can be used to assign new data to one of the groups and thus assume the label or description of that group. This can be thought of as a form of predictive classification; that is, assigning a class (via a labeled group) to a new data point. Assigning new data points (e.g., customers) to clusters (aka segments) provides a way to better target, personalize, and strategically position products and sell to each group in an appropriate way.
Clustering applications include market/customer segmentation and targeting, 3D medical image segmentation, product groupings for shopping, and social network analysis.1
Anomaly detection is a technique used to detect data patterns that are anomalous; that is, highly unusual, outside the norm, or abnormal. Anomaly detection applications include audio-based flaw and crack detection, cybersecurity, network security, quality control (e.g., manufacturing defect detection), and computer and network system health (e.g., NASA, fault and error detection).
In the case of anomaly detection applications in cybersecurity and network security, common threats include malware, ransomware, computer viruses, system and memory attacks, denial of service (DoS) attacks, phishing, unwanted program execution, credential theft, data transfer and theft, and more. Needless to say that there’s no shortage of use cases for anomaly detection.
Natural Language
Natural language is a very interesting and exciting area of AI development and use. It is usually broken into three subcategories: natural language processing (NLP), natural language generation (NLG), and natural language understanding (NLU). Let’s cover each of these individually.
NLP
NLP is the process of taking language input in the form of text, speech, or handwriting, passing it through an NLP algorithm, and then generating structured data as output, as shown in Figure 5-8. There are many potential NLP use cases and outputs.
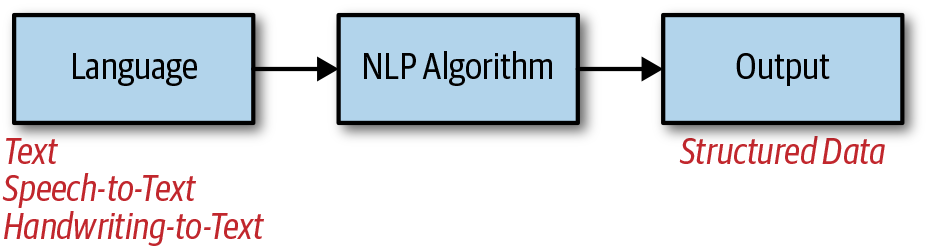
Figure 5-8. NLP
It’s worth mentioning that NLP is sometimes considered a superset of NLG and NLU, and therefore natural language applications in AI can be considered a form of NLP in general. Others think of it as a specific set of natural language applications, some of which we discuss now.
Specific tasks and techniques associated with NLP include quantified and objective text analytics, speech recognition (speech to text), topic modeling (e.g., topics and the prominence of each discovered in a document), text classification (e.g., Game of Thrones), sentiment analysis (e.g., positive, negative, neutral), entity detection (e.g., person, place), named recognition (e.g., Grand Canyon, Miles Davis), semantic similarity (e.g., similarity in meaning between individual words and text in general), part-of-speech tagging (e.g., noun, verb) and machine translation (e.g., English-to-French translation).
One specific NLP application involves recording business meetings, transcribing them, and then providing a meeting summary with analytics around topics discussed and meeting performance (https://www.chorus.ai). Another application uses NLP to analyze job descriptions and assign an overall score based on factors such as gender neutrality, tone, wording, phrasing, and more. It also provides recommendations for changes that would improve the score and overall job description.
Other applications include:
Many cloud-based service providers are now offering NLP services and APIs that provide some of this functionality.
NLG
NLG is the process of taking language in the form of structured data as input, passing it through an NLG algorithm, and then generating language as output, as depicted in Figure 5-9. The language output can be in the form of text or text-to-speech, for example. Examples of structured input data are sports statistics from a game, advertising performance data, or company financial data.

Figure 5-9. NLG
Applications include:
-
Automatically generating text summaries based on sentences and documents (https://arxiv.org/abs/1602.06023, https://arxiv.org/abs/1603.07252)
-
Recaps (e.g., news and sports)
Andrej Karpathy created models that automatically generate Wikipedia articles, baby names, math papers, computer code, and Shakespeare. Other applications include generating handwritten text and even jokes.
NLU
Lastly, NLU is the process of taking language input (text, speech, or handwriting), passing the input through an NLU algorithm, and then generating “understanding” of the language as an output, as shown in Figure 5-10. The understanding generated can be used to take an action, generate a response, answer a question, have a conversation, and more.
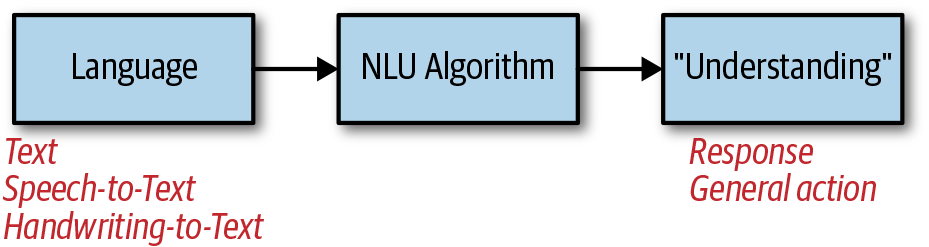
Figure 5-10. NLU
It’s very important to note that the term understanding can be very deep and philosophical and also involves concepts like comprehension. Comprehension loosely refers to the ability to not only understand information (as opposed to just rote memorization), but also to incorporate that understanding into existing knowledge and use it as part of one’s ever-growing knowledge base. Lack of human-like language understanding and comprehension is one of the major shortcomings of natural language–based AI applications today, and the shortcoming stems from the extraordinary difficulty associated with machines achieving human-like language understanding. Remember our discussion of AI-complete/AI-hard problems? This is definitely one example.
Without getting into a full-blown philosophical discussion, let’s just use the term understanding to mean that the algorithm (again, hugely oversimplified) is able to do more with the input language than just parse it and perform simpler tasks like text analytics. NLU is a significantly more difficult problem to solve than NLP and NLG (and for AI problems in general) and is a major foundational component to achieving artificial general intelligence (AGI).
Given the current state-of-the-art for NLU, applications include personal and virtual assistants, chatbots, customer success (support and service) agents, and sales agents. These applications usually include some form of written or spoken conversation, often centered around information gathering, question answering or some sort of assistance.
Specific examples include personal assistants such as Amazon’s Alexa, Apple Siri, Google’s Assistant, and Nuance’s Nina. Chatbot examples include an oil and lube expert, job interviews, student loan money mentorship, and a business insurance expert agent. This is a very active area of research and potential advancement in AI, so it’s definitely worth keeping an eye on it.
Time-Series and Sequence-Based Data
In many cases, data is captured in sequences in which the data order is important and is determined by a specific index. One of the most common data sequence indexes is time, and data sequenced by time is called time–series data. Daily stock price fluctuation during market hours, DNA sequences, IoT sensor data, and scientific phenomena such as wind patterns are good examples of time–series data. Time–series analysis and modeling can be used for learning, predicting, and forecasting time dependencies, including those due to trends, seasonality, cycles, and noise.
Sequences of letters and words are also valid types of sequential data for certain applications, and these sequences are given labels such as n-grams, skip-grams, sentences, paragraphs, and even language itself, where language is either spoken, written, or digitally represented. Audio and video data is sequential, as well.
Applications include:
-
Prediction (regression and classification)
-
sequence-to-sequence prediction, such as machine translation
Search, Information Extraction, Ranking, and Scoring
Many powerful AI applications are centered around finding, extracting, and ranking (or scoring) information. This applies mainly to unstructured and semi-structured data in particular, with examples including text documents, web pages, images, and videos. We can use this type of data, along with structured data in some cases, for information extraction, providing search results or prioritized recommendations, and ranking or scoring items in terms of relevance, importance, or priority. This group of techniques is associated with personalization in many cases because search results and other items can be ordered or ranked by most-to-least relevant to the particular user or group.
Currently, many search tasks are conducted by typing or speaking into a search engine such as Google, which is powered by Google’s proprietary AI-based search algorithm. Ecommerce applications also have their own search engines to search for products. Search can be driven by text, sound (voice), and visual inputs. Text-based search applications include Google Search (I bet you saw that one coming!), Microsoft Bing, and a decentralized, transparent, and community-driven search.
Sound- and image-based search applications include:
Visual search is conducted based on the contents of the image. There are already shopping applications that work this way. The user takes a picture and submits it to the visual search engine. The image is then used to generate relevant results such as clothing. Some of these image-based engines can also present visually similar items and recommendations, as well.
Ranking and scoring methods are alternatives to classification techniques, and applications include:
Reinforcement Learning
Reinforcement learning (RL) is a completely different AI technique than those described thus far (recall that we mentioned it briefly when discussing the ways that humans learn). The general idea is that there is a virtual agent taking actions in a virtual environment with the goal of getting positive rewards. Each action can cause a change in the state of the environment, and each action taken is determined by a model called a policy. The policy tries to determine the optimal action to take when in a given state. Don’t worry if this doesn’t make much sense; I give an example that will hopefully make this more clear. Figure 5-11 shows a visual representation of RL.
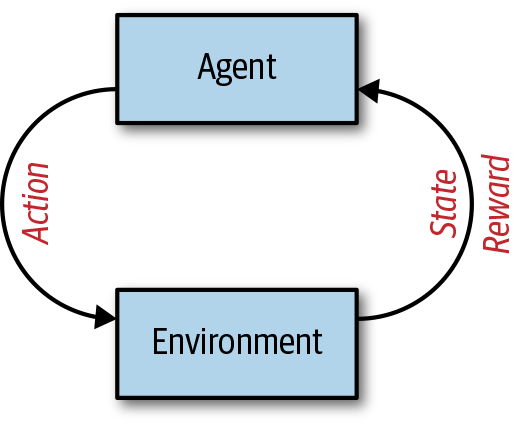
Figure 5-11. Reinforcement learning
You can consider Ms. Pac-Man (why not call her Ms. Pac-Woman?) as an example. On any given screen, Ms. Pac-Man has the goal of eating all the dots, but in a bigger picture sense has the goal of scoring the maximum amount of points possible. Why is scoring the maximum amount of points the true goal, or why of the game? First, the more points you score, the more free lives you get and therefore the longer you’re able to play and continue to accrue more points. Second, you get serious bragging rights if you can complete the game or set the world record, and who doesn’t want that?
In this case, the points are the reward, Ms. Pac-Man is the agent, the environment is the screen, and the human in the loop (the player) is the policy that determines the actions to take through a joystick. The environment has states, as well. There’s the regular noninvincible Ms. Pac-Man that has to dodge ghosts that are chasing her while eating dots and fruit, and then there’s the invincible Ms. Pac-Man that ate the pill of invincibility (I have no clue what it’s actually called) and can eat ghosts for a lot of extra points. The change between invincible and not invincible is a change of state of the environment, and also of the agent’s abilities within the environment.
It’s worth noting that people playing Ms. Pac-Man are sometimes driven by the goal of finishing screens and getting as far as possible rather than maximizing points. In that case, people will just use the invincible state to hurry up and eat as many dots as possible unimpeded and might not maximize points by eating ghosts. Suppose that you have an RL application for which the goals is to maximize points, though. In this case the application will try to learn how to do that and that will involve eating as many ghosts and fruits as possible.
There is one more thing to mention here. Scoring points is a positive reward. Touching a ghost and losing a life is a negative reward. Over time, the RL application should try to maximize getting points and minimize losing lives. Although this example is framed in the context of a game, we can use RL in many other ways.
Applications include:
Hybrid, Automation, and Miscellaneous
In this last section on real-world applications, I point out some applications that I have categorized as hybrid or miscellaneous because they involve multiple, combined approaches or do not fit into any of the categories already discussed.
Example applications include:
-
Autonomous self-driving cars and fleets and Self-driving shuttles
-
Real-time flight route prediction and air traffic flow optimization
-
Intelligent systems such as those associated with the IoT
Another really interesting field of AI development is generative applications, which basically refers to AI that is able to generate something from an input of a certain type for a given application. Some examples include:
Other applications include transformations such as style transfer (e.g., transforming a normal image to a “fine art” rendition in the style of Van Gough or Picasso). Another technique is called super-resolution imaging, where a 2D image is converted to a 3D image by generating the missing 3D image data. Finally, automatic colorization of images is another interesting AI application.
Summary
Hopefully this chapter has helped answer questions, or at least given you ideas about how you can take advantage of different AI approaches to solve problems and achieve goals. As we’ve discussed, there’s no shortage of different techniques. The key is to understand the available options at an appropriate level and then choose and prioritize high-value use cases and applications as part of your overall AI vision and strategy. This is an important part of AIPB, and we now turn our attention to developing an AI vision.
1 Hu, H. (2015). Graph-Based Models for Unsupervised High Dimensional Data Clustering and Network Analysis. UCLA. ProQuest ID: Hu_ucla_0031D_13496. Merritt ID: ark:/13030/m50z9b68. Retrieved from eScholarship.