Chapter 13. Building Knowledge Bases
This application is about organizing information and making it easy to access by humans and computers alike. This is known as a knowledge base. The popularity of knowledge bases in the field of NLP has waned in recent decades as the focus has moved away from “expert systems” to statistical machine learning approaches.
An expert system is a system that attempts to use knowledge to make decisions. This knowledge is about entities, relationships between entities, and rules. Generally, expert systems had inference engines that allowed the software to utilize the knowledge base to make a decision. These are sometimes described as collections of if-then rules. However, these systems were much more complicated than this. The knowledge bases and rule sets could be quite large for the technology of the time, so the inference engines needed to be able to efficiently evaluate many logical statements.
Generally, an expert system has a number of actions it can take. There are rules for which action it should take. When the time to take an action comes, the system has a collection of statements and must use these to identify the best action. For example, let’s say we have an expert system for controlling the temperature in a house. We need to be able to make decisions based on temperature and time. Whenever the system makes a decision to toggle the heater, or air conditioner, or to do nothing it must take the current temperature (or perhaps a collection of temperature measurements) and the current time, combined with the rule set to determine what action to take. This system has a small number of entities—the temperatures and the time. Imagine if a system had thousands of entities, with multiple kinds of relationships, and a growing ruleset. Resolving the statements available at decision time in a knowledge base this large can be expensive.
In this chapter we will be building a knowledge base. We want a tool for building a knowledge base from a wiki and a tool for querying the knowledge base. This system should fit on a single machine now. We also want to be able to update the knowledge base with new kinds of entities and relationships. Such a system could be used by a domain expert in exploring a topic, or it could be integrated with an expert system. This means that it should have a human usable interface and a responsive API.
Our fictional scenario is a company that is building a machine learning platform. This company primarily sells to other businesses. The sales engineers sometimes fall out of sync with the current state of the system. The engineers are good and update the wiki where appropriate, but the sales engineers are having a hard time keeping up to date. The sales engineers create help tickets for engineers to help them update sales demos. The engineers do not like this. So this application will be used to create a knowledge base that will make it easier for the sales engineers to check out what may have changed.
Problem Statement and Constraints
What is the problem we are trying to solve?
We want to take a wiki and produce a knowledge base. There should also be ways for humans and other software to query the knowledge base. We can assume that the knowledge base will fit on a single machine.
What constraints are there?
The knowledge-base builder should be easily updatable. It should be easy to configure new types of relationships.
- The storage solution should allow us to easily add new entities and relationships.
- Answering queries will require less than 50GB disk space and less than 16 GB memory.
- There should be a query for getting related entities. For example, at the end of a wiki article there are often links to related pages. The “get related” query should get these entities.
The “get related” query should take less than 500ms.
How do we solve the problem with the constraints?
The knowledge-base builder can be a script that takes a wiki dump and processes the XML and the text. This is where we can use Spark NLP in a larger Spark pipeline.
- Our building script should monitor resources, to warn if we are nearing the prescribed limits.
- We will need a database to store our knowledge base. There are many options. We will use Neo4j, a graph database. Neo4j is also relatively well known. There are other solutions possible, but graph databases inherently structure data in the way that facilitates knowledge bases.
- Another benefit to Neo4j is that it comes with a GUI for humans to query and a REST API for programmatic queries.
Plan the Project
Let’s define the acceptance criteria. We want a script that does the following:
- Takes a wiki dump, generally a compressed XML file
- Extracts entities, such as article titles
- Extracts relationships, such as links between articles
- Stores the entities and relationships in Neo4J
- Warns if we are producing too much data
We want a service that does the following:
- Allows a “get related” query for a given entity—results must be at least the articles linked in the entity’s article
- Performs a “get related” query in under 500ms
- Has a human-usable frontend
- Has a REST API
- Requires less than 16GB memory to run
This is somewhat similar to the application in Chapter 12. However, unlike in that chapter, the model is not a machine learning model—it is instead a data model. We have a script that will build a model, but now we also want a way to serve the model. An additional, and important, difference is that the knowledge base does not come with a simple score (e.g., an F1-score). This means that we will have to put more thought into metrics.
Design the Solution
So we will need to start up Neo4J. Once you have it installed, you should be able to go to localhost:7474 for the UI.
Since we are using an off-the-shelf solution, we will not be going very much into graph databases. Here are the important facts.
Graph databases are built to store data as nodes and edges between nodes. The meaning of node in this case is usually some kind of entity, and the meaning of an edge is some kind of relationship. There can be different types of nodes and different types of relationships. Outside of a database, graph data can be easily stored in CSVs. There will be CSVs for the nodes. This CSV will have an ID column, some sort of name, and properties—depending on the type. Edges are similar, except that the row for an edge will also have the IDs of the two nodes the edge connects. We will not be storing properties.
Let’s consider a simple scenario in which we want to store information about books. In this scenario we have three kinds of entities: authors, books, and genres. There are three kinds of relationships: an author writes a book, an author is a genre author, a book is in a genre. For Neo4j, this data could be stored in six CSVs. The entities are the nodes of the graph, and the relationships are the edges, as shown in Figure 13-1.
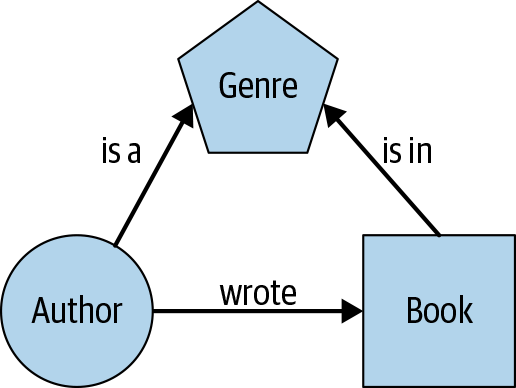
Figure 13-1. Simple graph example
Since we don’t have access to a company’s internal wiki, we will be using an actual Wikipedia dump. But rather than getting the full English language dump, which would be enormous, we will use the Simple English wikidump.
Simple English is a subset of the English language. It uses about 1,500 words, not counting proper nouns and some technical terms. This is useful for us because this will help us simplify the code we need to write. If this were a real company wiki, there would likely need to be a few iterations of data cleaning. Take a look at a dump of the Simple English Wikipedia.
Here is our plan:
- Get the data
- Explore the data
- Parse the wiki for entities and relationships
- Save the entities and relationships in CSVs
- Load the CSVs into Neo4J
Implement the Solution
First, let’s load the data. Most wikidumps are available as bzip2 compressed XML files. Fortunately, Spark has the ability to deal with this kind of data. Let’s load it.
import json import re import pandas as pd import sparknlp from pyspark.ml import Pipeline from pyspark.sql import SparkSession, Row from pyspark.sql.functions import lit, col import sparknlp from sparknlp import DocumentAssembler, Finisher from sparknlp.annotator import *
packages = [
'JohnSnowLabs:spark-nlp:2.2.2',
'com.databricks:spark-xml_2.11:0.6.0'
]
spark = SparkSession.builder \
.master("local[*]") \
.appName("Knowledge Graph") \
.config("spark.driver.memory", "12g") \
.config("spark.jars.packages", ','.join(packages)) \
.getOrCreate()
To give Spark a hint for parsing the XML, we need to configure what the rootTag is—the name of the element that contains all of our “rows.” We also need to configure the rowTag—the name of the elements that represent our rows.
df = spark.read\
.format('xml')\
.option("rootTag", "mediawiki")\
.option("rowTag", "page")\
.load("simplewiki-20191020-pages-articles-multistream.xml.bz2")\
.persist()
Now, let’s see what the schema looks like.
df.printSchema()
root |-- id: long (nullable = true) |-- ns: long (nullable = true) |-- redirect: struct (nullable = true) | |-- _VALUE: string (nullable = true) | |-- _title: string (nullable = true) |-- restrictions: string (nullable = true) |-- revision: struct (nullable = true) | |-- comment: struct (nullable = true) | | |-- _VALUE: string (nullable = true) | | |-- _deleted: string (nullable = true) | |-- contributor: struct (nullable = true) | | |-- _VALUE: string (nullable = true) | | |-- _deleted: string (nullable = true) | | |-- id: long (nullable = true) | | |-- ip: string (nullable = true) | | |-- username: string (nullable = true) | |-- format: string (nullable = true) | |-- id: long (nullable = true) | |-- minor: string (nullable = true) | |-- model: string (nullable = true) | |-- parentid: long (nullable = true) | |-- sha1: string (nullable = true) | |-- text: struct (nullable = true) | | |-- _VALUE: string (nullable = true) | | |-- _space: string (nullable = true) | |-- timestamp: string (nullable = true) |-- title: string (nullable = true)
That is somewhat complicated, so we should try and simplify. Let’s see how many documents we have.
df.count()
284812
Let’s look at the page for “Paper,” so we can get a handle on how to simplify the data.
row = df.filter('title = "Paper"').first()
print('ID', row['id'])
print('Title', row['title'])
print()
print('redirect', row['redirect'])
print()
print('text')
print(row['revision']['text']['_VALUE'])
ID 3319
Title Paper
redirect None
text
[[File:...
[[File:...
[[File:...
[[File:...
[[File:...
[[File:...
Modern '''paper''' is a thin [[material]] of (mostly)
[[wood fibre]]s pressed together. People write on paper, and
[[book]]s are made of paper. Paper can absorb [[liquid]]s such as
[[water]], so people can clean things with paper.
The '''pulp and paper industry''' comprises companies that use wood as
raw material and produce [[Pulp (paper)|pulp]], paper, board and other
cellulose-based products.
== Paper making ==
Modern paper is normally ...
==Related pages==
* [[Paper size]]
* [[Cardboard]]
== References ==
{{Reflist}}
[[Category:Basic English 850 words]]
[[Category:Paper| ]]
[[Category:Writing tools]]
It looks like the text is stored in revision.text._VALUE. There seem to be a few special entries, namely categories and redirects. In most wikis, pages are organized into different categories. Pages are often in multiple categories. These categories have their own pages that link back to the articles. Redirects are pointers from an alternate name for an article to the actual entry.
Let’s look at some categories.
df.filter('title RLIKE "Category.*"').select('title')\
.show(10, False, True)
-RECORD 0-------------------------- title | Category:Computer science -RECORD 1-------------------------- title | Category:Sports -RECORD 2-------------------------- title | Category:Athletics -RECORD 3-------------------------- title | Category:Body parts -RECORD 4-------------------------- title | Category:Tools -RECORD 5-------------------------- title | Category:Movies -RECORD 6-------------------------- title | Category:Grammar -RECORD 7-------------------------- title | Category:Mathematics -RECORD 8-------------------------- title | Category:Alphabet -RECORD 9-------------------------- title | Category:Countries only showing top 10 rows
Now let’s look at a redirect. It looks like the redirect target, where the redirect points, is stored under redirect._title.
df.filter('redirect IS NOT NULL')\
.select('redirect._title', 'title')\
.show(1, False, True)
-RECORD 0------------- _title | Catharism title | Albigensian only showing top 1 row
This essentially gives us a synonymy relationship. So, our entities will be titles of articles. Our relationships will be redirects, and links will be in the related section of the page. First let’s get our entities.
entities = df.select('title').collect()
entities = [r['title'] for r in entities]
entities = set(entities)
print(len(entities))
284812
We may want to introduce a same-category relationship, so we extract the categories, too.
categories = [e for e in entities if e.startswith('Category:')]
entities = [e for e in entities if not e.startswith('Category:')]
Now, let’s get the redirects.
redirects = df.filter('redirect IS NOT NULL')\
.select('redirect._title', 'title').collect()
redirects = [(r['_title'], r['title']) for r in redirects]
print(len(redirects))
63941
Now we can get the articles from revision.text._VALUE.
data = df.filter('redirect IS NULL').selectExpr(
'revision.text._VALUE AS text',
'title'
).filter('text IS NOT NULL')
To get the related links, we need to know what section we are in. So let’s split the texts into sections. We can then use the RegexMatcher annotator to identify links. Viewing the data, it looks like sections look like == Paper making == as we saw in the previous example. Let’s define a regex for this, adding in the possibility for extra whitespace.
section_ptn = re.compile(r'^ *==[^=]+ *== *$')
Now, we will define a function that will take a partition of the data and generate new rows for the sections. We will need to keep track of the article title, the section, and the text of the section.
def sectionize(rows):
for row in rows:
title = row['title']
text = row['text']
lines = text.split('\n')
buffer = []
section = 'START'
for line in lines:
if section_ptn.match(line):
yield (title, section, '\n'.join(buffer))
section = line.strip('=').strip().upper()
buffer = []
continue
buffer.append(line)
Now we will call mapPartitions to create a new RDD and convert that to a DataFrame.
sections = data.rdd.mapPartitions(sectionize)
sections = spark.createDataFrame(sections, \
['title', 'section', 'text'])
Let’s look at the most common sections.
sections.select('section').groupBy('section')\
.count().orderBy(col('count').desc()).take(10)
[Row(section='START', count=115586), Row(section='REFERENCES', count=32993), Row(section='RELATED PAGES', count=8603), Row(section='HISTORY', count=6227), Row(section='CLUB CAREER STATISTICS', count=3897), Row(section='INTERNATIONAL CAREER STATISTICS', count=2493), Row(section='GEOGRAPHY', count=2188), Row(section='EARLY LIFE', count=1935), Row(section='CAREER', count=1726), Row(section='NOTES', count=1724)]
Plainly, START is the most common because it captures the text between the start of the article and the first section, so almost all articles will have this. This is from Wikipedia, so REFERENCES is the next most common. It looks like RELATED PAGES occurs on only 8,603 articles. Now, we will use Spark-NLP to extract all the links from the texts.
%%writefile wiki_regexes.csv
\[\[[^\]]+\]\]~link
\{\{[^\}]+\}\}~anchor
Overwriting wiki_regexes.csv
assembler = DocumentAssembler()\
.setInputCol('text')\
.setOutputCol('document')
matcher = RegexMatcher()\
.setInputCols(['document'])\
.setOutputCol('matches')\
.setStrategy("MATCH_ALL")\
.setExternalRules('wiki_regexes.csv', '~')
finisher = Finisher()\
.setInputCols(['matches'])\
.setOutputCols(['links'])
pipeline = Pipeline()\
.setStages([assembler, matcher, finisher])\
.fit(sections)
extracted = pipeline.transform(sections)
Now, we could define a relationship based on just links occurring anywhere. For now, we will stick to the related links only.
links = extracted.select('title', 'section','links').collect()
links = [(r['title'], r['section'], link) for r in links for link in r['links']]
links = list(set(links))
print(len(links))
4012895
related = [(l[0], l[2]) for l in links if l[1] == 'RELATED PAGES']
related = [(e1, e2.strip('[').strip(']').split('|')[-1]) for e1, e2 in related]
related = list(set([(e1, e2) for e1, e2 in related]))
print(len(related))
20726
Now, we have extracted our entities, redirects, and related links. Let’s create CSVs for them.
entities_df = pd.Series(entities, name='entity').to_frame()
entities_df.index.name = 'id'
entities_df.to_csv('wiki-entities.csv', index=True, header=True)
e2id = entities_df.reset_index().set_index('entity')['id'].to_dict()
redirect_df = []
for e1, e2 in redirects:
if e1 in e2id and e2 in e2id:
redirect_df.append((e2id[e1], e2id[e2]))
redirect_df = pd.DataFrame(redirect_df, columns=['id1', 'id2'])
redirect_df.to_csv('wiki-redirects.csv', index=False, header=True)
related_df = []
for e1, e2 in related:
if e1 in e2id and e2 in e2id:
related_df.append((e2id[e1], e2id[e2]))
related_df = pd.DataFrame(related_df, columns=['id1', 'id2'])
related_df.to_csv('wiki-related.csv', index=False, header=True)
Now that we have our CSVs, we can copy them to /var/lib/neo4j/import/ and import them using the following:
-
Load entities
LOAD CSV WITH HEADERS FROM "file:/wiki-entities.csv" AS csvLine CREATE (e:Entity {id: toInteger(csvLine.id), entity: csvLine.entity}) -
Load “REDIRECTED” relationship
USING PERIODIC COMMIT 500 LOAD CSV WITH HEADERS FROM "file:///wiki-redirected.csv" AS csvLine MATCH (entity1:Entity {id: toInteger(csvLine.id1)}),(entity2:Entity {id: toInteger(csvLine.id2)}) CREATE (entity1)-[:REDIRECTED {conxn: "redirected"}]->(entity2) -
Load “RELATED” relationship
USING PERIODIC COMMIT 500 LOAD CSV WITH HEADERS FROM "file:///wiki-related.csv" AS csvLine MATCH (entity1:Entity {id: toInteger(csvLine.id1)}),(entity2:Entity {id: toInteger(csvLine.id2)}) CREATE (entity1)-[:RELATED {conxn: "related"}]->(entity2)Let's go see what we can query. We will get all entities related to "Language" and related to entities that are related to Language (i.e., second-order relations).
Let’s go see what we can query. We will get all entities related to “Language”, and related to entities that are related to “Language” (i.e., second-order relations).
import requests
query = '''
MATCH (e:Entity {entity: 'Language'})
RETURN e
UNION ALL
MATCH (:Entity {entity: 'Language'})--(e:Entity)
RETURN e
UNION ALL
MATCH (:Entity {entity: 'Language'})--(e1:Entity)--(e:Entity)
RETURN e
'''
payload = {'query': query, 'params': {}}
endpoint = 'http://localhost:7474/db/data/cypher'
response = requests.post(endpoint, json=payload)
response.status_code
200
related = json.loads(response.content)
related = [entity[0]['data']['entity']
for entity in related['data']]
related = sorted(related)
related
1989 in movies Alphabet Alphabet (computer science) Alphabet (computer science) American English ... Template:Jctint/core Testing English as a foreign language Vowel Wikipedia:How to write Simple English pages Writing
We have processed a wikidump and have created a basic graph in Neo4j. The next steps in this project would be to extract some more node types and relationships. It would also be good to find a way to attach a weight to the edges. This would allow us to return better results from our query.
Test and Measure the Solution
We now have an initial implementation, so let’s go through metrics.
Business Metrics
This will depend on the specific use case of this application. If this knowledge base is used for organizing a company’s internal information, then we can look at usage rates. This is not a great metric, since it does not tell us that the system is actually helping the business—only that it is getting used. Let’s consider a hypothetical scenario.
Using our example, the sales engineer can query for a feature they want to demo and get related features. Hopefully, this will decrease the help tickets. This is a business-level metric we can monitor.
If we implement this system and do not see sufficient change in the business metrics, we still need metrics to help us understand if the problem is with the basic idea of the application or if it is with the quality of the knowledge base.
Model-Centric Metrics
Measuring the quality of a collection is not as straightforward as measuring a classifier. Let’s consider what intuitions we have about what should be in the knowledge base and turn these intuitions into metrics.
- Sparsity versus density: if too many entities have no relationship to any other entity, they decrease the usefulness of the knowledge base; similarly, relationships that are ubiquitous cost resources and provide little benefit. Following are some simple metrics that can be used to measure connectivity.
- Average number of relationships per entity
- Proportion of entities with no relationships
- Ratio of occurrences of a relationship to a fully connected graph
- The entities and relationships that people query are ones we must focus on. Similarly, relationships that are almost never used may be superfluous. Once the system is deployed and queries are logged, we can monitor the following to learn about usage.
- Number of queries where an entity was not found
- Number of relationships that are not queried in a time period (day, week, month)
The benefit of having an intermediate step of outputting CSVs is that we don’t need to do a large extraction from the database—we can calculate these graph metrics using the CSV data.
Now that we have some idea of how to measure the quality of the knowledge base, let’s talk about measuring the infrastructure.
Infrastructure Metrics
We will want to make sure that our single-server approach is sufficient. For a company that is small- to medium-sized, this should be fine. If the company were large, or if the application were intended for much broader use, we would want to consider replication. That is, we would have multiple servers with database, and the users would be redirected through a load balancer.
With Neo4j you can look at system info by querying :sysinfo. This will give you information about the amount of data being used.
For an application like this, you would want to monitor response time when queried and update time when adding new entities or relationships.
Process Metrics
On top of the generic process metrics, for this project you want to monitor how long it takes for someone to be able to update the graph. There are a few ways that this graph is likely to be updated.
- Periodic updates to capture wiki updates
- Adding a new type of relationship
- Adding properties to entities or relationships
The first of these is the most important to monitor. The whole point of this application is to keep sales engineers up to date, so this data has to keep up to date. Ideally, this process should be monitored. The next two are important to monitor because the hope of this project is to decrease the workload on developers and data scientists. We don’t want to replace the work needed to support sales efforts with effort maintaining this application.
Review
Many of the review steps from Chapter 12 will apply to this application too. You will still want to do the architecture review and the code review. The model review will look different in this situation. Instead of reviewing a machine learning model, you will be reviewing the data model. In building a knowledge graph, you need to balance the needs of performance while structuring the data in a way that makes sense for the domain. This is not a new problem; in fact, traditional relational databases have many ways of balancing these needs.
There are some common structural problems that you can watch out for. First, there is a node type that has only one or two properties; you may want to consider making it a property of the nodes it connects to. For example, we could define a name-type node and have it connect to entities, but this would needlessly complicate the graph.
Deployment will be easier with this kind of application, unless it is customer facing. Your backup plan should be more concerned with communicating with users than with substituting a “simpler” version.
Conclusion
In this chapter, we explored creating an application that is not machine learning based. One of the most valuable things we can do with NLP is make it easier for people to access the information inside. This can, of course, be done by building models, but it can also be done by organizing the information. In Chapter 14, we will look into building an application that uses search to help people organize and access information in text.