The biggest promise of this method lies in relating diseases to the ways of living of different groups, and by doing so to unravel ‘causes’ of disease about which it is possible to do something.
—Jeremy N. Morris, 1955
Epidemiology appears forbidding and unapproachable to many people, starting with its association with “epidemic” and its erroneous association in some people’s minds with “epidermis” and “entomology.” The term derives from the Greek “epi” connoting “on” and “demos” meaning “people,” thus conveying the notion of “on, or pertaining to, populations.” There are many definitions, but they all have in common the basic idea that epidemiology is the study of the occurrence of health and disease in populations, with a view to illuminating the causes of disease and, ultimately, its control or prevention. Beyond its unwieldy name, epidemiology’s technical terminology and statistical apparatus undoubtedly help to make it unapproachable to a lay audience. Add to this the fact that concepts like “risk,” “association,” and “causation” are notoriously slippery, and their technical meaning is often different from what gets communicated to the public. Finally, the many conflicting media reports of findings from epidemiologic studies create confusion as to what are truly important hazards that are worth paying attention to, and this state of affairs has affected perceptions of the discipline.1
All of this is unfortunate because the results of epidemiologic studies are potentially of enormous relevance to the general public and because the basic principles of epidemiology can be understood and appreciated by those lacking specialized training. It has been said that, when stripped of its technical and statistical apparatus, much of epidemiology is basically common sense—but an “uncommon common sense.”2
It is not possible to give a comprehensive overview of epidemiology for the lay reader within the scope of a brief chapter.3 My goal is more modest, that is, to explain a number of key concepts and principles of epidemiology and to give examples of risk factors that have been firmly established in contrast to potential hazards that have received a great deal of publicity but for which clear evidence of harm is lacking. This outline provides a framework for understanding the detailed case studies that form the core of this book, but it should also help more generally in interpreting reports of “hazards”—as well as claims of health benefits—in the media. By “interpreting,” I do not mean evaluating the technical aspects of studies or reports but rather developing a “feel” for what epidemiology can achieve, as well as what its limitations are. Above all, I hope to give the reader a sense of perspective when confronted with dramatic claims concerning health effects.
THE BASIC SCIENCE OF PUBLIC HEALTH
Epidemiology is commonly referred to by its practitioners as “the basic science of public health.” What it has to offer is, above all, a unique and powerful approach to questions having to do with health and disease. Based on groups and salient differences between groups, it involves a different way of thinking from the mindset of clinical medicine centered on diagnosis and treatment of the individual patient. Epidemiology takes a broad phenomenological view of illness and health in their existing context, incorporating relevant findings from a wide range of other disciplines, including microbiology, toxicology, genetics, industrial hygiene, sociology, pathology, nutrition, ecology, statistics, etc. Epidemiology occupies a privileged position in assessing health hazards, since, unlike experimental studies involving animals and cell culture, it focuses on the actual exposures of people as they are experienced in everyday life. Thus, agencies charged with evaluating the health effects of environmental agents give priority to epidemiologic data, when these are available. Both the strengths and the limitations of epidemiology stem from the same source—that is, from the fact that it uses observational data to attempt to unravel the complex causes of multifactorial, multistage chronic diseases in free-living populations.
Often, epidemiology takes as its point of departure a striking contrast, such as the fact, noted in the 1970s, that rates of hepatocellular carcinoma, the most common type of liver cancer, showed a striking worldwide variation, with the highest rates in East Asia and southern Africa and the lowest in the Americas, northern Europe, and Australia. This observation eventually led to the development of a vaccine against hepatitis B virus that confers protection against this major cause of liver cancer. Or the fact, noticed over three hundred years ago, that nuns had elevated rates of breast cancer. This observation led eventually to an understanding of the role of reproductive and hormonal factors in the development of breast cancer, with dramatic implications for its treatment and prevention. From such fertile starting points, and the collation of many other relevant facts, a picture is developed that points to specific hypotheses and lines of inquiry. The work of pursuing these hypotheses, often carried out over decades, has led to stunning triumphs in public health affecting potentially millions of lives worldwide. Some of the major achievements of epidemiology are given in box 2.1.
Box 2.1 A Partial List of Major Achievements of Epidemiology
Cholera and use of contaminated water supplies
Vitamin B (niacin) deficiency and pellagra
Smoking and cancers of the lung, mouth, larynx, esophagus, bladder, kidney, pancreas, and liver
Alcohol consumption and cancers of the mouth, larynx, esophagus, liver, and breast
Multiple risk factors for coronary heart disease: cholesterol, smoking, obesity, high blood pressure, and diabetes
Reproductive factors and cancers of the breast, endometrium, and ovary
Estrogen and endometrial cancer
Estrogen and progesterone and breast cancer
DES (diethylstilbestrol) and clear cell adenocarcinoma of the vulva
Exposure to coke oven emissions (in the steel industry) and lung cancer
Exposure to asbestos and lung cancer and mesothelioma
Folic acid deficiency and neural tube defects
Aspirin and Reye’s disease
Lead and cognition
Hepatitis B virus (HBV) and primary cancer of the liver
Human papillomavirus (HPV) and cervical cancer
Aspirin and prevention of colorectal cancer
Oral contraceptives and prevention of ovarian cancer
Solar radiation and skin cancer
Fluoridation of water supplies and prevention of dental caries
Sleep position and sudden infant death syndrome
One of the strengths of epidemiology is worth pointing out at the outset. This is that knowledge of an association permitting the identification of high-risk groups can, in some situations, make it possible to curtail the incidence of disease, even in the absence of an understanding of the mechanism of causation. In the legendary example of the London cholera epidemic of 1854, John Snow did not have to know that the organism that caused cholera was vibrio cholerae. He merely had to remove the handle of the Broad Street pump, thereby preventing the local residents from using a contaminated water source. Similarly, we do not know precisely which of the thousands of constituents of tobacco smoke are responsible for inducing lung cancer; nevertheless, knowledge of the association of smoking with lung cancer makes it theoretically possible to eliminate roughly 90 percent of lung cancers. Finally, the data are persuasive that if Americans reduced the prevalence of obesity, the overall death rate, as well as deaths from heart disease, diabetes, and certain cancers would be reduced.4
Epidemiology deals with probabilities that apply to individuals as members of a group rather than to individuals themselves. Its ability to predict events on the individual level is often quite limited. Even when we are dealing with what is agreed to be a strong association, like that of cigarette smoking and lung cancer, only a minority of smokers will develop lung cancer. Furthermore, among smokers who develop lung cancer, one cannot be certain that, in the case of an individual smoker, smoking was “the cause” since some people who have never smoked also develop the disease. Nevertheless, “on a population basis,” the association between smoking and lung cancer is both strong and robust. The low predictive ability at the individual level of even strong epidemiologic findings is one source of misunderstanding of the value and use of such findings.
Because epidemiology deals with groups, the frequency of occurrence of a given disease has an important bearing on the ability to study it. This is especially the case when one is studying a factor which may make only a relatively subtle contribution to causing a given disease or when there are multiple factors which play a role in its causation, as is almost always the case. The more common the disease, the easier it is to obtain an adequate study population, or sample size, and sample size is one of the determinants of the statistical power to detect an effect of a hypothesized factor. As a general rule, the subtler the role a given factor plays in the causation of a disease and the poorer the accuracy with which one can measure that factor, the greater the sample size required. We have been able to learn a great deal about factors that contribute to heart disease, in part because heart disease is the leading cause of death in the United States and other Western countries. In contrast, studies of relatively rarer diseases, such as scleroderma and ALS (amyotrophic lateral sclerosis), are hampered by, among other things, the difficulty of accruing an adequate sample size.
Epidemiologists focus on rates of occurrence of disease because absolute numbers of cases are uninformative with regard to etiology unless they are related to the appropriate denominator, i.e., the population from which they arose. A rate is the frequency of some health event per population over a certain unit of time (usually one year). Rates can be presented for an entire population. Examples are the infant mortality rate (expressed in terms of the number of deaths in children less than one year old per 1,000 live births) or the breast cancer incidence rate (expressed as the number of new cases of breast cancer per 100,000 women). These figures are referred to as “crude” rates in that they are the average for an entire population. While useful for certain purposes, crude rates can mask large differences within specific subgroups that make up the population. Once one begins to look at the rates for specific subgroups (by age, sex, and race) within a population, one may begin to see striking contrasts, and these may point to hypotheses about the causes of a disease. Epidemiology deals with differences in the rates of disease according to the myriad factors—starting with age, sex, ethnicity, socioeconomic level, occupation, religion, smoking status, country of birth, etc.—which may lead to an understanding of etiology.
Fundamental to epidemiology, at the most basic level, is a comparison. Comparison is implicit in the definition of “epidemic,” which is a sudden elevation in the number of cases of a disease relative to the background, or baseline, level. If comparison between two or more groups is fundamental to epidemiology, one needs to be sure that the comparison is a fair one. For this reason, the issues of confounding and bias are central concerns in epidemiology. Confounding refers to a muddying or obscuring of the association of the factor of interest with a disease by other factors that are correlated both with the factor of interest and with the disease. Confounding can lead either to a diminution of the observed effect of the factor of interest or to its inflation. A commonly used example of confounding involves comparing the health of residents of Alaska with that of residents of the lower states of the United States. If one were to compare the overall incidence of heart attacks among Alaskans to that among Americans in the lower forty-eight states, it would appear that Alaskans had much lower rates. However, the comparison would be misleading because it is confounded by a large difference in the age structure of the two populations being compared. The Alaskan population is considerably younger, and age is a risk factor for heart attack. When one makes the comparison taking age into account (i.e., when one compares “age-adjusted” rates), the difference in heart attack rates disappears.
To give another example, in assessing the possibility that coffee drinking increases the risk of bladder cancer, one would need to take smoking habits into account. This is because smoking is a known risk factor for bladder cancer and because coffee consumption and smoking are correlated. If one failed to take smoking habits into account in one’s analysis, it is likely that coffee drinking would appear to be a risk factor simply due to its correlation with smoking.
A final, and more topical, example of confounding comes from studies of the effect of a woman’s use of estrogen replacement therapy on her subsequent risk of coronary heart disease. For many years, observational studies were interpreted as indicating that women who had taken postmenopausal estrogens had lower rates of heart disease, and this finding figured prominently in the widespread promotion of estrogen replacement therapy by physicians in the 1980s and 1990s. However, it turned out that the finding was due to confounding, i.e., women who took estrogen replacement therapy (ERT) tended to be different, in a variety of ways, from women who did not. Specifically, ERT users tended to have a healthier lifestyle compared to nonusers. They tended to have lower body weight, were more likely to engage in physical activity, and were more likely to be nonsmokers and in general to be more health conscious—differences that would place them at lower risk of heart disease.5 By the late 1990s and particularly in 2002, randomized controlled trials, which were less susceptible to confounding compared to observational studies (as will be discussed below), showed that, rather than protecting against heart disease, use of ERT actually increased its risk by a modest amount.
It should be noted that you can only adjust for a potential confounding factor if you have thought to measure it, i.e., include it in your study. Also, adjustment for a poorly measured confounder does not eliminate the possibility of residual confounding, since measurement of the confounder may not be adequate to fully capture its effect.
At the most basic level, epidemiology involves evaluating the association between a given characteristic, exposure, or “risk factor,” on the one hand, and a state of health or disease, on the other. To give a few examples, using epidemiologic methods, researchers have studied the association between “handedness” (being left-handed versus being right-handed) and breast cancer; between seat belt use and injuries and deaths resulting from motor vehicle collisions; between the degree of elaboration of one’s writing style, as disclosed by diaries kept by young nuns, and the subsequent likelihood of developing Alzheimer’s disease; between exposure to television violence and rates of violent crime; between alcohol and illicit drug use and homicide; and between having a specific genetic makeup and the risk of virtually any disease. As these examples convey, the epidemiologic method can be used to study the influence of a wide range of social, behavioral, environmental, and genetic factors on health and disease. Many things that epidemiologists study are potential clues to the etiology of a disease, factors that it is hoped will lead to the primary contributors. In many cases, a risk factor is an indicator or marker of a phenomenon that may turn out, upon further study, to be important rather than the cause itself. This is another frequent source of misunderstanding.
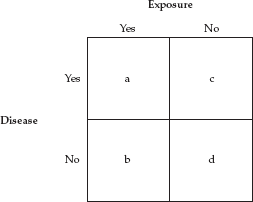
The basic relation between an exposure and a disease can be represented schematically by the “two-by-two table” favored by epidemiologists. At the simplest level, both an exposure and a disease can be expressed in dichotomous terms (yes/no or present/absent). Either one has (or has had) the exposure or one has not, and either one has the disease (or one develops it within a specified period of time) or one does not. In the two-by-two table the letters a, b, c, and d represent the number of people in each of the four quadrants.
To be sure, this is a simplified and idealized schema. In some situations, it may be difficult to find a group that is truly unexposed, and one often wants to look at different levels of exposure.6 Nevertheless, this schema is extremely useful in describing the essentials of epidemiologic studies.
In a case-control study (described in the next section), the measure of association obtained from this table is called the odds ratio—because it is the ratio of two sets of odds: the odds of having the exposure if one has the disease divided by the odds of having the exposure if one does not have the disease. The odds ratio can be obtained by the formula a × d/b × c, which is referred to as the “cross-product ratio.”
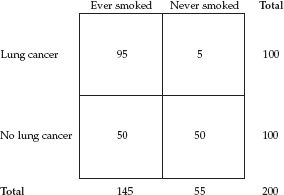
To give an example using actual data, let’s fill in the results from a typical study relating cigarette smoking to lung cancer. Say we conducted a study in several hospitals that entailed interviewing all patients with a diagnosis of lung cancer and, as a comparison group, an equal number of patients with diseases unrelated to smoking (e.g., fractures, hernias, enlarged prostates). The resulting two-by-two table would look like this:
We see from the table that 95 percent of lung cancer patients were smokers, whereas only 50 percent of the comparison group were smokers. Using the cross-product ratio, the odds ratio = 95 × 50/5 × 50, which yields 19. In this study, a patient with a diagnosis of lung cancer was 19 times more likely to be a smoker than a patient with a diagnosis other than lung cancer. I will come back to the odds ratio and other measures of association shortly.
Since the objective of epidemiology is to detect and understand associations between a factor and a disease, the better the job of measuring the exposure of interest and the better the job of defining the disease entity in question, the better the chances of detecting a meaningful association. If measurement of the exposure is poor, this introduces “noise” and decreases the researcher’s ability to detect an association. Similarly, if the disease in question cannot be precisely and objectively defined, it is unlikely that any associations are going to be biologically meaningful. Poor measurement of the exposure and the outcome is referred to as misclassification. This means that, due to poor measurement, some subjects who are actually exposed to the risk factor are mistakenly classified as “not exposed,” and to the same extent those who are not exposed are classified as “exposed.” In the same way, the absence of hard criteria for judging whether someone has the disease or not leads to classifying some people with the disease as “free of the disease,” and conversely classifying some who are free of the disease as having the disease.
In contrast to random measurement error, which reduces one’s ability to detect an association, bias refers to systematic errors or imbalances in the design or conduct of a study that can lead to distorted results. Common biases are described in the following section.
TYPES OF STUDY DESIGN
The different types of study design utilized in epidemiology are usually grouped under descriptive studies and analytic studies. Generally, descriptive studies appear early in the study of a disease and are followed by analytic studies, usually case-control and cohort studies. In the hierarchy presented here, there is progression toward a greater ability to identify causal factors. However, each type of study has its strengths and weaknesses and each can provide valuable evidence.
Descriptive Studies
Descriptive studies provide basic information about the occurrence of a disease in time and space, according to factors such as age, sex, ethnicity, social class, occupation, etc. Cases of a disease presenting at one or more hospitals or within a defined area or population are characterized as to demographic factors, lifestyle, behavioral factors, and environmental exposures. Such information is essential in gauging the magnitude of a public health problem and can suggest hypotheses that can be pursued using other study designs. But, because descriptive studies lack a control group, they cannot be used to assess causality directly. For example, studies describing the occurrence of a rare form of pneumonia and a rare form of cancer in young gay men in Los Angeles and New York City in 1981 provided the first clues to the etiology of what was later identified as AIDS. These studies revealed that men with these conditions had engaged in anal sex with many sexual partners and had also used amyl nitrite and other recreational drugs. At first, attention focused on amyl nitrite and its adverse effects on the immune system as an explanation for the disease, but further research implicated anal intercourse in the transmission of HIV.
Ecological Studies
Ecological studies, or correlational studies, correlate existing data on populations with existing data on disease rates. What distinguishes ecological studies from other types of studies is that they make use of data on exposure and disease pertaining to groups rather than individuals. An example of an ecologic study is the striking correlation on an international level, first noted in the 1970s, between per capita consumption of fat in the diet and death rates from breast cancer in women. Women in advanced “Western” countries, like the United Kingdom, Denmark, and the United States had both a high intake of fat and high rates of breast cancer, whereas countries like Japan and Thailand had a low intake of fat and low rates of breast cancer. Plotting fat intake against the breast cancer death rate for different countries yielded an impressive graph showing a more or less ascending trend in the breast cancer death rate with increasing fat intake, as shown in fig. 2.1.
Note that not every woman in the United States consumes the same level of fat in her diet nor has the same risk of developing breast cancer. Nevertheless, in an ecologic study, one uses only the average intake for the group and contrasts this with the average for other groups. Because they make use of aggregate data on population groups and because many other factors are likely to differ among the populations one is comparing, confounding is a major problem affecting ecologic studies, and these are useful mainly in providing clues that require more detailed investigation with other approaches. In the 1950s, when the first studies appeared showing an association between cigarette smoking and lung cancer, some commentators pointed out that, while there was a strong correlation internationally between per capita sales of cigarettes and lung cancer death rates in different countries, there was also a strong correlation between sales of silk stockings and lung cancer rates. Did this mean that silk stockings were a cause of lung cancer? Of course not. Rather, in more affluent countries, consumers could purchase both cigarettes and silk stockings. Both items reflect a certain level of economic development. So, the existence of a strong ecologic correlation between an exposure and a disease is not a sufficient condition for any judgment regarding causality. Without additional and finer-grained evidence linking cigarette smoking with lung cancer, the association could simply be due to confounding by economic differences. When overly strong claims are made based on ecologic data, scientists refer to the “ecological fallacy,” namely the unwarranted assumption that, just because a given factor is correlated with a disease based on aggregate data, this suggests (1) that the same correlation will hold at the individual level or (2) that the association is indicative of a causal relationship.
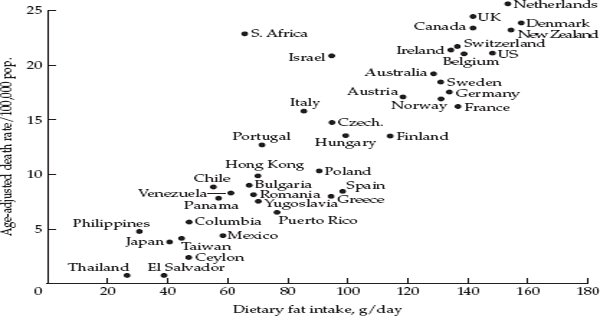
FIGURE 2.1 Correlation between per capita consumption of dietary fat and age-adjusted breast cancer mortality in forty-one countries. Source: Carroll and Khor, 1975.
In spite of the pitfalls of ecologic data, it should be remembered that major triumphs in epidemiology and public health have started with observations based on ecologic data, such as the observation that prevalence rates of hepatitis B virus infection worldwide showed a striking correlation with rates of primary liver cancer.7
Case-Control Studies
The study of lung cancer using hospitalized patients referred to earlier is an example of a case-control study. In this type of analytic study, cases of a specific disease are identified through hospital records or disease registries, and a comparison group—controls—is selected by one of several methods. Controls should be drawn from the base popluation from which the cases arose and should be at risk of the disease under study. Most commonly, either hospital controls or population controls are used. The former could be patients hospitalized for conditions other than the disease of interest. Population controls can be selected from the community using random digit dialing, Medicare rosters, motor vehicle registry lists, or other sources. Information on exposure can include information recorded in the hospital record (when hospital controls are used), information collected in personal interviews, usually using a structured questionnaire, or analyses carried out on biological specimens obtained from cases and controls. Typically, in case-control studies involving a personal interview, participants are asked detailed questions about a range of relevant factors, including sociodemographic characteristics, occupation, lifestyle factors (smoking, alcohol consumption, diet), menstrual and reproductive factors (in women), medical history and use of medications, physical activity, and environmental exposures. In addition to interview data and biological specimens obtained from participants, measurements can be made in the current and previously occupied homes, as was done in studies of radon and electromagnetic fields.
The analysis of a case-control study entails a comparison of the level of exposure to the factor of interest among cases to that among controls. As we saw above, the association is expressed by calculating the odds ratio summarizing the two-by-two table or a more elaborate table classifying subjects as to their level of exposure. In addition, one needs to determine whether cases and controls differ on other factors, which might account for any observed difference in the study factor. If a third factor is related both to the exposure of interest and to the disease, it is a potential confounder and needs to be taken into account. This means that one attempts to collect information on a variety of factors that are known or potential confounders.
Case-control studies have a number of advantages. They enable the researcher to enroll large numbers of what may be a rare disease by including multiple hospitals, and they are relatively inexpensive to conduct. Additionally, they can yield results in a relatively short time. However, case-control studies are susceptible to two types of systematic bias that can distort the results. First, selection bias can occur if either cases or controls are not representative of the population from which they are drawn with respect to the exposure of interest. This could arise due to a low response rate among cases or controls or due to the use of a different mechanism for enrolling cases and controls. For example, in a study of electromagnetic fields and childhood cancer, cases were identified through a cancer registry, whereas controls were identified through random digit dialing. Thus, only households with telephones were eligible for control selection. It was pointed out that this difference may have introduced selection bias due to a higher socioeconomic status of controls compared to cases. The second type of bias is referred to as information bias (or reporting bias) and stems from the fact that one is obtaining information about exposure after the disease has been diagnosed. Cases may answer questions differently from controls because people who have recently been diagnosed with a serious illness tend to ruminate about what could have caused their condition. For example, if one is interested in collecting information about exposure to use of hair dyes in a case-control study of breast cancer, cases may tend to go back over their history more carefully and report greater exposure simply due to their motivation to explain their condition. Controls do not have the same motivation. Furthermore, collecting information by interview relies on memory, and in a case-control study one may be interested in information relating to events in the distant past.
Cohort Studies
Cohort studies can be viewed as the inverse of case-control studies. That is to say, rather than starting with the disease of interest, one starts with the exposure of interest. Thus, unlike the case-control study, in which one is looking backward in order to identify the cause of the disease, the cohort study follows the actual temporal sequence, starting with exposure and leading to the occurrence of disease. Cohort studies are also commonly referred to as “prospective” or “longitudinal” studies. Typically, one assembles a cohort of healthy individuals at the outset and assesses their exposure to factors of interest and then follows these individuals for a number of years in order to monitor their health status and the occurrence of “outcomes” of interest. For example, in 1959 the American Cancer Society enrolled over one million men and women by means of volunteers who contacted neighbors and friends with whom they expected to maintain contact over the coming years. In order to be eligible, a household had to have a person between the ages of 40 and 79. Participants completed and returned a four-page questionnaire including questions on smoking habits, alcohol consumption, exposure to dusts and chemicals, height and weight, how many hours of sleep they averaged per night, and their current state of health. The cohort was followed until 1972 and cause of death among its members was determined from death certificates. This early cohort study was a source of many important findings, including those documenting the link between smoking and heart disease and lung cancer.
The measure of association derived from a cohort study is the relative risk, which is simply the rate of occurrence of the disease of interest in those with the exposure divided by its rate of occurrence in those without the exposure. This corresponds to the odds ratio in a case-control study.
Compared to the case-control study, the principle strength of the cohort study is that it avoids selection bias and information bias. As long as follow-up of the cohort is largely complete, selection bias is not a threat, and since information on exposure is collected prior to the onset of disease, information bias is not a problem. The principle limitations of the cohort design are that cohort studies are expensive and can require a considerable amount of time to produce results. However, once established, cohort studies tend to become extremely valuable resources. A number of cohort studies have been in progress for 40–50 years and have provided a wealth of information as the participants have aged. Biological specimens that were stored can be used to test new hypotheses that come along.
Cohort studies can be carried out in the general population (American Cancer Society, the Framingham Study), occupational groups (uranium miners, steelworkers, agricultural workers, etc.), religious groups (Mormons, Seventh Day Adventists), and professional groups (doctors, nurses, teachers) or by enrolling the members of other organizations (Kaiser-Permanente health maintenance organization and the AARP).
Completeness of follow-up of the original cohort is the most crucial factor affecting the validity of cohort studies. If a sizeable proportion of the participants is “lost to follow-up” and the reason for loss to follow-up is related to the exposure under study, this could bias the results.
Randomized Controlled Trials
Case-control and cohort studies are observational in nature in that information is collected on free-living individuals, and one attempts to measure exposure to the factor of interest as best one can. In contrast, a randomized controlled trial is an experimental design. This type of study does not lend itself to assessing the association of environmental exposures with disease, which concerns us here. However, an understanding of the randomized controlled trial will help us understand some of the limitations of observational studies. In a randomized controlled trial, individuals who meet certain criteria and agree to participate are randomly assigned to different exposure groups. The design is similar to that of the standard animal experiment in which genetically identical animals are divided into two groups, differing only in the fact that the “experimental group” is exposed to the agent or substance under study, while the “control group” is not. (In practice, there can be more than two groups, depending on the number of dosage levels or different agents being studied.)
Suppose that one wanted to test the hypothesis that eating a high-fiber diet was protective against developing polyps of the colon, which can go on to develop into colon cancer. One would likely enroll a cohort of men and women of an age where these polyps occur fairly frequently, say, in their fifties and sixties. One would then randomly assign participants to one of two groups, referred to as the “intervention group” and the “control group.” The intervention group would be instructed to eat a high-fiber diet, and the controls would be instructed to eat their usual diet. Both groups would undergo screening for polyps at regular intervals. Due to their having been randomly allocated, individuals in the two groups should be similar in all other respects except for their assignment either to a high-fiber diet or to their usual diet. Because the two groups are balanced in terms of a wide range of factors that could affect their risk of developing polyps in the colon (age, smoking, alcohol consumption, weight, physical activity, past diet, etc.), this experimental design enables one to isolate the effect of the exposure of interest, in this case, fiber. Because of their experimental design, randomized controlled trials are referred to as the “gold standard” in medicine and epidemiology. Note that by balancing the two or more groups in terms of extraneous factors by randomization, the randomized controlled trial avoids the problem of confounding, which is so fundamental in observational studies.
Randomized controlled trials can only be used in certain situations. Since it would be unethical to subject human subjects to an exposure known or likely to be harmful, one can only test exposures (or treatments) that are thought to have potential benefits or relative benefits. Thus, one could not conduct a randomized controlled trial in which one assigned nonsmokers to smoke cigarettes of widely different tar levels in order to learn about their long-term health impact. One could, however, conduct a randomized trial among smokers to compare the effects of different methods of smoking cessation. In spite of the increased rigor of the experimental design, randomized controlled trials do not always provide a definitive answer to a question. In the example given above of allocating healthy men and women to be on either a high-fiber diet or to continue eating their usual diet, if the study finds no effect on the likelihood of developing polyps, this may be because the level of fiber prescribed to the intervention group was inadequate; the study period was too short; one might have to consume a high-fiber diet starting much earlier in life for fiber to protect against polyps; or other reasons. In other words, in a given study one can only test specific aspects of a question. Thus, it is important to realize that depending on the specific question under study, different types of studies can provide valuable evidence for or against an association. Each type of study design has its strengths and limitations. This is why when there is a convergence of supporting evidence from different types of studies, this greatly strengthens the case for a given factor playing a causal role.
MEASURES OF ASSOCIATION
If there is no association between an exposure and a disease, in the two-by-two table the proportions of those with the exposure would not differ between those with the disease and those without the disease, and the relative risk would be equal to 1.0. This is referred to as the “null value.” If a study has an adequate sample size and the relative risk is above 1.0, and especially if it is well above 1.0, then the exposure of interest shows a positive association with the disease, and it may be a risk factor for the disease. If the relative risk is below 1.0, say 0.5, for example, then the factor under study shows an “inverse association” with the disease and may be “protective.” In order to account for the possibility that the observed association could be due to chance, one conventionally provides a 95 percent confidence interval bracketing the calculated odds ratio or relative risk. If the confidence interval does not include the null value (1.0), then the odds ratio or relative risk is said to be statistically significant. What this means is that the result is unlikely to be due to chance. More precisely, if one repeated the same study one hundred times, in ninety-five of those repetitions one would obtain a value for the odds ratio lying between the upper and lower bound of the confidence interval. Conventionally, one accepts a 5 percent possibility that the observed association could be due to chance. In the two-by-two table based on the hypothetical study of lung cancer, described earlier, the 95 percent confidence interval associated with the odds ratio of 19.0 was 8.0–43.0. Although, one can never completely rule out chance as a factor in any particular study, an association like that of smoking in this hypothetical study is unlikely to be due to chance.
A word about “statistical significance” is in order. Statistical significance is easily abused, and some journals discourage undue emphasis on it. Not every finding that is statistically significant is biologically significant, but too often the fact that a given result is statistically significant is used to imply precisely this. More relevant to gauging the importance of a finding is the consistency with existing evidence from other sources and the impact on a population basis. Most important discoveries in the area of epidemiology do not depend primarily on tests of statistical significance to demonstrate their importance.
EXAMPLES OF ESTABLISHED ASSOCIATIONS
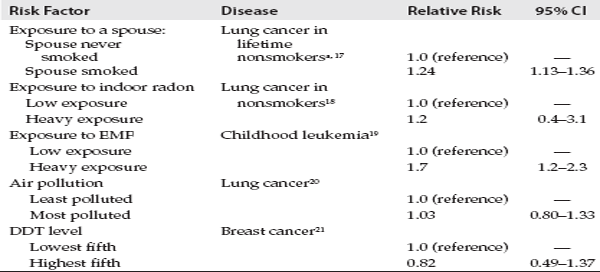
We are now in a position to look at some examples of findings from different types of studies in order to understand the difference between established associations and associations where the evidence is weak, inconsistent, and inconclusive. Table 2.1 shows the findings from epidemiologic studies in which the presumptive factor has been firmly established to play a role in the disease based on research conducted over many years. (The relative risks in tables 2.1–2.3 are selected from individual studies or, in some cases, meta-analyses, on a given topic. They should not be viewed as definitive but, rather, as an indication of the strength of the association. The magnitude of the relative risk for smoking and lung cancer, for example, will vary from one study to another.) Note that these examples were selected for illustrative purposes, and there are many other examples that could be cited. In the first two entries in table 2.1, exposure was assessed by means of a clinical assay performed on blood to measure levels of the human papillomavirus (HPV) or the hepatitis B virus (HBV) antigen. In the subsequent entries, exposure information was obtained by asking the subjects questions about smoking, alcohol consumption, hormone replacement therapy, etc. The relative risks are shown in decreasing order, ranging from 90 to about 1.2. (For the sake of comparison, the bottom line of table 2.1 shows the results of a large study of silicone breast implants and connective tissue disorders, where there is no association, i.e., the relative risk equals 1.0.)
TABLE 2.1 Relative Risks for Different Diseases Associated with Exposure to Different Risk Factors
aCI, confi dence interval; na, not available.
bSuperscript numbers indicate note reference.
cReference risk category (1.0) for a person with no or minimal exposure.
When one is dealing with a relative risk of 90 or 100 in a well-designed study, it is unlikely that the result is due to confounding or bias. In the case of smoking and drinking, the magnitude of the association is still substantial and has been consistently reported in many studies. Even though the value of the relative risk is much smaller when it comes to the association of a number of breast cancer risk factors, these characteristics have been consistently shown to be risk factors for the disease.
Table 2.2 shows representative results from studies investigating a number of environmental exposures, including secondhand tobacco smoke, air pollution, electromagnetic fields, DDT exposure, and residential radon exposure, some of which will be discussed in the extended case studies in the following chapters. Here one is dealing with excess risks of a small magnitude, below 2.0. But, in addition to the small magnitude of the apparent increase, another crucial aspect of these studies is the difficulty of assessing the exposure in question. In the examples in table 2.1, information on exposure status of the study subjects was either highly accurate (a highly specific clinical assay) or reasonably accurate, even if obtained by self-report. For example, even though people may not remember the details precisely or may underreport certain exposures, information regarding smoking habits, alcohol consumption, estrogen replacement therapy, family history of breast cancer in first degree relatives, and age at first live birth and number of full-term pregnancies is reasonably accurate. While imperfect, the data permit one to contrast those with relatively heavy to those with low, or no, exposure. In the case of silicone breast implants, exposure information based on surgical records achieves a high degree of accuracy.
TABLE 2.2 Findings from Epidemiological Studies of Selected Environmental Exposures
aSuperscript numbers indicate note reference.
In contrast, for the exposures shown in table 2.2, exposure assessment is much more problematic and much weaker. In the case of secondhand tobacco smoke exposure, typically, one can obtain information about whether the subject’s spouse smoked, how long the subject was married, how much the spouse smokes (smoked), whether other members of the household smoke, and whether, how often, and how long he/she was exposed to smoke at work and in other venues. However, this is far from having a quantitative measure of the amount of smoke a nonsmoker has been exposed to over the years. For residential radon exposure, typically, one can obtain a residential history and take year-long measurements in several rooms of the current and previous homes occupied for a substantial number of years. But here, again, the results are very far from providing a quantitative estimate of lifetime exposure as one can obtain—even if in an admittedly crude way—for lifetime cigarette consumption, as approximated by “pack-years” of smoking (obtained by multiplying the average number of packs of cigarettes smoked per day by a smoker by the total number of years he or she smoked). Similar qualifications apply to estimating a person’s lifetime exposure to DDT, electromagnetic fields, or air pollution.
Thus, a crucial aspect of epidemiologic studies providing information on human risks is the quality of the exposure information that can be obtained. It may be that if one could do a better job of measuring the exposure, one might see a much stronger association, or, alternatively, that one might see no effect. But, in the absence of a technical breakthrough—in the form of the development of a biological marker that provides a reliable indicator of lifetime exposure, as does pack-years of smoking or serologic evidence of infection—things are likely to remain frustratingly uncertain due to the inadequacy of the assessment of exposure and the extremely weak nature of the observed associations.
When concerns arose in the early 1990s that silicone breast implants were causing a variety of diseases in women, numerous studies were carried out using different designs to assess the claims of adverse health effects ranging from ill-defined connective tissue disorders and rheumatoid arthritis to breast cancer. Because “the exposure,” i.e., having had silicone breast implants, was clearly defined and well documented in medical records, the resulting studies were of a high caliber. These studies uniformly showed no evidence that women who had had breast augmentation had any higher incidence of the suspected conditions than women who had not had the procedure.22 As a result, millions of women who had had silicone breast implants had their anxiety about their health allayed. Thus, when one is dealing with a well-defined and well-documented exposure, epidemiologic research can achieve quite clear-cut results.
If the estimate of the relative risk of disease due to an exposure is uncertain, any estimate of the impact of the exposure on the general population is going to be uncertain, because calculation of the proportion of disease attributable to an exposure incorporates the relative risk. This is why some observers have questioned estimates of the numbers of lung cancer and heart disease deaths in never smokers (3,000 and 35,000–53,000, respectively) attributed to secondhand tobacco smoke exposure and the number of lung cancer deaths attributed to residential radon exposure (up to 20,000).23
JUDGING WHETHER AN ASSOCIATION IS CAUSAL
To say that exposure x is “associated” with disease y is simply to say that the two variables are correlated. Although the existence of an association between two phenomena is a necessary condition for the existence of a causal association, it is axiomatic that association does not prove causation. When the first studies reporting an association between cigarette smoking and lung cancer appeared in the early 1950s, the science of epidemiology, particularly with regard to chronic diseases with long latency periods, was still in its infancy. Some eminent statisticians were skeptical that case-control and cohort studies could provide an unbiased assessment of the association since these types of studies did not conform to the ideal of experimental design in which subjects are randomly assigned to the intervention or control group. Furthermore, when dealing with chronic diseases, such as heart disease or cancer, one cannot expect the same kind of rigorous proof as that provided by Koch’s postulates for acute infectious diseases. This is because chronic diseases have long latency periods and complex, multifactorial etiologies.
Judgments about the causality of complex, multifactorial diseases are more problematic than our notions derived from our early life experience allow for.24 Some observers have pointed out that all diseases have a number of “component causes,” all of which are necessary, as opposed to a single sufficient cause.25 This reminds us that our knowledge of the causation of these diseases is always incomplete and that other contributing factors remain to be identified. Further, it has been argued that there is no clear set of criteria that can be used for judging whether a given association is causal.26,27 Nevertheless, findings like those summarized in table 2.1 represent knowledge that has been repeatedly confirmed and buttressed by new research findings and has been the basis for interventions that have proven to reduce the incidence of specific diseases. Thus, in practical terms, table 2.1 shows causal associations.
In the mid-1960s the British statistician Austin Bradford Hill proposed a set of considerations for judging the causality of an association,28 and these were included in the first Report of the U.S. Surgeon General on Smoking and Health.29 Although Hill identified nine criteria, four are generally considered the most important: the magnitude of the association, consistency, temporal relationship, and coherence of explanation. Hill argued that the greater the magnitude of an observed association, the more likely it is to be causal. One reason for this is that the greater the magnitude of an association, the less likely it is to be due to confounding by some extraneous factor or the play of chance. Consistency refers to the fact that the association should be observable in different studies carried out in different populations. Temporality refers to the logical necessity that the exposure (cause) must precede the disease (effect). Finally, coherence of explanation alludes to the requirement that all relevant information concerning exposure and occurrence of the disease in question should be mutually reinforcing. This is often referred to as “biological plausibility.” One additional criterion that is frequently added to Hill’s original criteria is that of a dose-response relationship. That is, the greater the exposure (dose), the greater the probability of developing the disease (response). The demonstration of a dose-response relationship between a risk factor and a disease adds a crucial element to the evidence for a causal association. Table 2.3 shows the dose-response relationships between the number of cigarettes smoked per day and the risk for lung cancer and heart disease, between alcohol intake and cancer of the mouth, and between number of years of using hormone replacement therapy and risk of endometrial cancer.
As a number of critics have recently pointed out, there are exceptions to all of Hill’s criteria.30,31 For example, as shown in table 2.1, the relative risk does not have to be large when one is dealing with a causal association, and the requirement of a dose-response relationship is not always met. Beyond any fixed set of criteria or guidelines, it can be agreed that for any given question the relevant evidence needs to be evaluated critically on its own terms. Nevertheless, although they may not be uniformly applicable in all cases, Hill’s criteria are still considered to have great value in assessing the evidence on a given question.32,33
Let’s briefly summarize what is known about cigarette smoking as a cause of lung cancer using Hill’s criteria for judging causality. First, the magnitude of the association is substantial: current smokers (typically those who have smoked for three or four decades) have about a 20-fold increased risk of lung cancer in men and a somewhat lower relative risk in women. Second, regarding consistency, hundreds of studies carried out in different countries and different groups within countries and in both sexes show similar results. Third, typically smokers begin smoking in their teenage years and, unless they quit, smoke for many decades before the average onset of lung cancer (about age 62)—thus, the exposure/cause clearly precedes the disease/effect. Fourth, as shown in table 2.3, smoking shows a classic dose-response relationship with lung cancer. In the example given, as the average number of cigarettes smoked increases, the relative risk of developing lung cancer increases correspondingly, reaching a relative risk of about nineteen in male smokers of forty or more cigarettes per day. In addition, an early age of starting smoking age and greater number of years of smoking also make independent contributions to increasing risk. There are other pieces of information that further strengthen the case for a causal role of smoking in the development of lung cancer. These include the fact that when the exposure is removed, i.e., when a smoker gives up smoking and remains abstinent, the risk decreases over time approaching (but not necessarily ever reaching) that of someone who never smoked. Additionally, known carcinogens—such as benzo-a-pyrene—have been isolated from tobacco smoke, and smokers have evidence of genetic damage that puts them at increased risk of lung cancer. Finally, mice whose skin was painted with tobacco smoke condensate developed tumors at the site of application. Taken together, these findings amount to a varied and robust case for smoking playing a causal role in the development of lung cancer. Smoking is the most studied cause of cancer. Even the tobacco industry, which long claimed that the evidence was “only statistical” in nature, has come to accept it.
TABLE 2.3 Relative Risks for Different Diseases by Level of Exposure to Different Risk Factors
aSuperscript numbers indicate note reference.
bcpd, number of cigarettes smoked per day.
c na, not available.
d Relative risks are adjusted for smoking and other risk factors.
Even though the association of hormone replacement therapy (early formulations used only estrogen) with breast cancer shows only a modest relative risk, this has been confirmed in many studies, and this finding is supported by many other types of evidence.38 These include the association of reproductive and menstrual factors with risk of breast cancer, which suggest that the greater a woman’s exposure to endogenous estrogen, the greater her risk of breast cancer. Most recently, strong support for a role of estrogen in breast cancer has come from treatment of breast cancer with aromatase inhibitors, which block the formation of estrogen in adipose tissue, the major source of estrogen in postmenopausal women. Thus, even though the relative risk associated with hormone replacement therapy is quite small—on the order of 1.3—based on the consistency in the results of many epidemiological studies and the coherence with what is known from clinical studies, the association of estrogen with breast cancer is reasonably firmly established.
INTERACTION
The effect of a given exposure may not be uniform across an entire population but may be greater in some subgroup, such as the elderly, smokers, or those with certain medical conditions. Another way to describe this phenomenon is that the exposure of interest may be either enhanced by or dependent on a second exposure or characteristic. This is commonly referred to as interaction. A classic example of interaction is the fact that individuals who both smoke and consume alcohol are at increased risk of cancers of the mouth compared to those who only smoke or only drink. Table 2.4 shows the interaction between smoking and alcohol consumption in the development of cancer of the mouth and pharynx. Here one sees an increase in risk with increased smoking among those who do not drink (top row), as well as an increase in risk with increasing alcohol consumption among nonsmokers (first column). In fact, within each level of one risk factor, there is an increase in risk with increasing level of the other factor. But the greatest increase in risk occurs among those who are both heavy smokers and heavy drinkers. This group has a 15-fold increased risk compared to those who neither smoked nor drank. Other examples of interaction are the fact that exposure to either asbestos or radon have a much greater effect in smokers than in nonsmokers. The issue of interaction will be central when we consider the effects of radon exposure (chapter 5). Evidence that the effect of a given exposure is greatest in, or limited to, a particular group can have important implications for identifying those at highest risk, designing an appropriate intervention strategy, and formulating policy.
TABLE 2.4 Relative Risk of Oral Cancer According to Level of Exposure to Smoking and Alcohol
Risks are expressed relative to a risk of 1.00 for persons who neither smoked nor drank. Source: Rothman and Keller, 1972.
Since we are always dealing with multiple causes, attention to interaction between two different factors in producing a disease will receive increasing attention in the future. Thus, an understanding of why some smokers develop lung cancer and other diseases, while others do not, entails an understanding of the interaction between smoking and genetic makeup in terms of the enzymes that play a role in the activation or detoxification of the carcinogens and other toxins in tobacco smoke. In the era of the Human Genome Project, the question of the interplay between environmental exposures and lifestyle factors, on the one hand, and genetic makeup, on the other, has emerged as a major area of study.
META-ANALYSIS
Often there are a number of small studies addressing a question and providing inconsistent results. In this situation, epidemiologists have resorted to the technique of meta-analysis to combine the results from the individual studies in order to obtain a summary estimate that is more stable due to the larger sample size. Meta-analysis can be thought of as a process of taking a weighted average of the results of a number of individual studies. The technique was originally developed to combine data from a number of randomized controlled trials to achieve a more precise measure of the effect of a treatment. In this case, the combining of studies can be justified on the basis that each trial provided an unbiased estimate of the effect of treatment, owing to the experimental design.39 When it comes to observational studies, the results of different studies can be affected in different ways by biases and confounding, and the assumption that their results can be arithmetically averaged is questionable.40,41 Also, often the individual studies were not designed using common definitions and criteria. For all of these reasons, one may be combining results that are not comparable. Furthermore, combining studies that all suffer from the same biases does nothing to improve the validity of results.42 Another potential problem is that meta-analysis depends on the published literature, and, if certain studies have not been published, this could skew the results of the meta-analysis. Some have suggested that, rather than conducting a meta-analysis of observational studies, more can be learned from examining the reasons that different studies yield different results. In other words, meta-analysis is no substitute for careful examination of the design and results of the individual studies in an attempt to determine whether individually and collectively they supply convincing evidence for an association. Thus, the uncritical use of a meta-analysis to summarize the results from observational studies of difficult to measure exposures can be misleading.
POOLING OF STUDIES
In contrast to meta-analysis, which is carried out by extracting the key results from published papers, pooling of data from a number of independent studies involves the collaboration of researchers who undertake to reanalyze the data from individual studies using a common strategy. While this permits greater uniformity and comparability to be achieved, there may still be aspects of the different studies that are not comparable. For example, different studies may have used different definitions of who qualifies as a never smoker (as is true of pooled radon studies) or may have used different measurement techniques. There may also be other differences between the studies being combined. For example, the effect of radon in a study carried out in northern China, where indoor air pollution from cooking and heating is a problem, may be different from its effect in Western countries.
Pooling of comparable studies to enable a more precise estimate of the effect of a given exposure, as well as exploring the robustness of the data, is a valuable tool, especially when one is dealing with a weak or subtle effect or attempting to detect an effect in a particular subgroup. However, when more and more studies are pooled and a clear signal does not emerge, this conveys important information that needs to be acknowledged.
ABSOLUTE RISK VERSUS RELATIVE RISK
Until now we have focused on the relative risk (or the odds ratio) and its use in evaluating the causality of an association. The relative risk is the most commonly used measure of association in epidemiologic studies, and this is what gets reported most often to the public. This is understandable, given that the relative risk has a straightforward interpretation: the risk in those exposed to a given agent is, say, two or three times greater (or less) than the risk in those who are not exposed. However, while useful in assessing etiology, the relative risk conveys no information about the impact of a given risk factor on the general population. This is because the relative risk is independent of the prevalence (i.e., the frequency) of the risk factor and the incidence of the disease in the population. A relative risk of 10.0 can result from differing ratios 10:1, 1,000:100, or 1,000,000:100,000.43
Unlike the relative risk, the absolute risk describes the population impact of a given risk factor and indicates how many cases of a disease would be eliminated if the risk factor were removed. Thus, the absolute risk, or risk difference, is the incidence of the disease of interest among the exposed minus its incidence among the nonexposed. The absolute risks corresponding to the above relative risks are: 9, 900, and 900,000 cases of disease in the population (10 – 1 = 9, etc.). Thus, a large relative risk may apply to very few people, and, conversely, a small relative risk can apply to a very large population. The contrast in the association of smoking with lung cancer and heart disease points up the difference between relative and absolute risks. Compared to those who have never smoked, current smokers have a relative risk for lung cancer of roughly 20 but a relative risk for heart disease of roughly 2.0. However, in spite of the much larger relative risk for lung cancer, smoking is actually responsible for causing more illness through its effect on heart disease than through its effect on lung cancer. This is due to the fact that heart disease is a much more common disease than lung cancer.
The importance of putting information regarding relative risks in perspective by presenting complementary information on the absolute risk and population impact has recently received attention both in medical and public health journals and in the lay press.44–46 A recent review of the use of relative risks and absolute risks in medical publications concluded that, “Effects presented in relative terms alone have been repeatedly shown to seem more impressive than the same effects presented in absolute terms in studies of physicians, policy makers, and patients. . . . The lack of accessibility of these fundamental data [i.e., absolute risks—G.K] may well lead journal readers (doctors, policy makers, journalists, and patients) to have exaggerated perceptions of the reported effect sizes.”47 As one commentator has remarked, there is an “essential tension” between the perspective of relative risk and that of absolute risk.48 Each provides crucial information in gauging the importance of a particular cause or risk factor within the context of the overall health of a population.
In addition to its role in identifying specific risk factors with the ultimate goal of preventing specific diseases, epidemiology provides another valuable function—that of monitoring the health of populations and monitoring the prevalence of risk factors. From this perspective, based on existing knowledge, we can project, for example, that the increase in the prevalence of overweight and obesity in the United States and elsewhere is likely to have substantial consequences in terms of the disease burden due to diabetes and other chronic diseases related to overweight. Monitoring of this sort can help inform intervention strategies designed to reduce the prevalence of risk factors in order to reduce the disease burden in the future. Epidemiology has also been able to allay fears concerning many suspected hazards which have arisen over the past thirty years, including—to mention just a few—possible adverse effects of coffee drinking, chocolate, silicone breast implants, oral contraceptives, cell phones, and electromagnetic fields.
Although the tendency of epidemiology to focus on individual risk factors has been extremely successful and has yielded vital new knowledge, the limitations of what has come to be referred to as “risk factor epidemiology” have prompted some epidemiologists to delineate a broader and more encompassing perspective. This alternative view emphasizes the complex “web of causation” and the multidimensionality of the social and material environment. It is, of course, important to document the many health effects of a behavior like smoking, but it is also important to recognize that smoking habits are often correlated with many other behaviors and exposures that affect health. For example, smokers tend to consume more alcohol and coffee, to eat less healthy diets, to engage less in physical activity, to have more sexual partners, and to be less likely to use seatbelts than nonsmokers. In the United States, smoking also has increasingly become a marker for lower socioeconomic status. And socioeconomic status has been shown to have a surprisingly strong effect on mortality, which is independent of risk factors like smoking and obesity.49
This broader, more encompassing perspective, which has been referred to as “eco-epidemiology,” emphasizes the importance of viewing human health as multidimensional in terms of a whole array of behaviors and exposures in their social and material context, and, at the same time, considering overall health and longevity, instead of just a particular “outcome” of interest. This approach can do much to put the knowledge of specific risk factors and suspected hazards in perspective and can thereby have a beneficial effect on what public health messages are given to the public.
One value of this more comprehensive approach to health and society is that, when it comes to a new potential hazard, emerging evidence is seen against the background of what is known about risk factors for specific diseases and their population impact. We have to keep in mind the essential tension between the information conveyed by the relative risk and that conveyed by the absolute risk. A risk factor with only a modest relative risk can have a large population impact if its prevalence in the population is high and the disease is a common one. This is the rationale for paying attention to subtle and hard to detect environmental exposures, such as exposure to DDT, electromagnetic fields, radon, air pollution, and passive smoking. Because these are difficult to measure exposures, it is all the more imperative to critically evaluate the evidence from all relevant research, to acknowledge the limitations of the existing evidence, and, above all, to put any tentative conclusions in the context of what is known about other causes of the disease. In addition, these more difficult to measure exposures may turn out to affect specific subgroups and to interact with other exposures in ways that will only be revealed by continued research.
But another essential tension, which is equally important, is that conveyed by the contrasting associations displayed in tables 2.1 and 2.2, between risk factors that are firmly established and those that are topics of legitimate study but where the evidence is weak, inconsistent, or inconclusive. Here it is the responsibility of researchers, regulators, editors, and journalists to provide a sober and critical assessment of the limitations of the evidence. Reasonable interim conclusions based on the available evidence may take a number of different forms. For example, the conclusion may be that, in spite of extensive work, studies to date show no consistent or credible evidence of health effects (EMF), while recognizing that this lack of evidence of adverse long-term effects may be due to methodological limitations affecting all studies of a given question (DDT). Or one may conclude that a given risk factor is indeed a proven hazard but that its proven effects are limited to those with exposures above a certain level or among smokers (residential radon). Finally, one may conclude that a given risk factor appears weak and that the existing studies should not be overinterpreted, that the increase in risk associated with exposure may be at the limit of what epidemiologic studies can detect but that nevertheless a weak effect is plausible and that, as a result, exposure should be avoided (secondhand tobacco smoke). These kinds of distinctions can go a long way toward reducing the confusion generated by results that get publicized based on a finding of a “30 percent” increased risk, which is not only small but also uncertain due to the uncertainties of the underlying science. This kind of qualification would help people to focus on firmly established and large population effects—things that will make a difference. The uncertain 30 percent increased risk for lung cancer and heart disease attributed to secondhand tobacco smoke needs to be compared with the firmly established 2,000 percent increase in risk of lung cancer and the 100 percent increased risk of heart disease due to active smoking. Furthermore, a 30 percent increased risk attributed to secondhand smoke is different from a 30 percent increased risk for breast cancer attributed to hormone replacement therapy since the latter association is based on more reliable exposure information.
As part of a more global perspective on health and society, it needs to be realized that in addition to the measures derived from epidemiologic studies—relative risk and absolute risk—there is a very real risk and very real consequences associated with overstating the findings and implied health implications of a suspected health hazard. These entail confusing the public as to what are truly important health risks, leading to needless anxiety and fatalism (“everything causes cancer”; “we are surrounded by environmental hazards”) and a diversion of funds away from less sensational (because better established and less novel and anxiety-provoking) causes of disease, entailing a very real cost to society and the public’s health. This risk, which has to do with how information from scientific studies is communicated to the public, qualified, and put into perspective, could be called “misinformation risk,” and is the topic of the succeeding chapters. By setting findings regarding potential environmental hazards against the background of the solid and far-reaching achievements of epidemiology and its value in monitoring the overall health and exposure status of the population, we will be in a better position to understand how specific environmental threats were overblown and wrenched from their appropriate context.
Box 2.2 Major Take-Home Points
Epidemiology has a rich record of achievements that have the potential to affect the lives of millions of people.
However, epidemiology is an observational science and, for this reason, is subject to the pitfalls of confounding and bias.
Epidemiology deals with populations. Even strong findings that apply to a population as a whole usually cannot be used to accurately predict individual risk.
Findings from epidemiologic studies are often tentative and serve as clues to be pursued by researchers rather than as knowledge that has immediate practical applications.
One needs to distinguish between findings that are well established and that actually matter, in terms of relevance to health, from those that are weak and inconclusive or are simply topics for further study.
Findings that are well established are usually findings pertaining to an exposure that can be measured with reasonable accuracy and that have been confirmed by studies carried out in different populations, as well as by clinical and experimental findings.
Findings regarding a given risk factor for a disease need to be placed in the context of what is known about other risk factors for that disease.
In presenting the results of epidemiologic studies, it is important to provide the absolute risk, a measure of the population impact, as well as the relative risk.
It is important to think about health in a global way, as opposed to focusing only on isolated risk factors for specific diseases. Some exposures are risk factors for one disease but are protective against another disease (estrogen increases the risk of cancers of the breast and endometrium but is protective against osteoporosis. Light/moderate alcohol consumption is a risk factor for breast cancer but appears to be protective against heart disease). Thus, it is the overall pattern of one’s lifestyle and environmental exposures that is most important.