C++ Usage
This chapter dives into the question of what qualities make a good API in C++. The generic API qualities covered in Chapter 2 could be applied to any programming language: the concepts of hiding private details, ease of use, loose coupling, and minimal completeness transcend the use of any particular programming language. While I presented C++-specific details for each of these topics, the concepts themselves are not language specific.
However, many specific C++ style decisions can affect the quality of an API, such as the use of namespaces, operators, friends, and const correctness. I will discuss these issues, and more, in this chapter.
Note that I will defer some performance-related C++ topics, such as inlining and const references, until the next chapter on performance.
6.1 Namespaces
A namespace is a logical grouping of unique symbols. It provides a way to avoid naming collisions so that two APIs don’t try to define symbols with the same name. For example, if two APIs both define a class called String, then you cannot use the two APIs in the same program because only one definition can exist at any time. You should always use some form of namespacing in your APIs to ensure that they can interoperate with any other APIs that your clients may decide to use.
There are two popular ways that you can add a namespace to your API. The first is to use a unique prefix for all of your public API symbols. This is a very common approach and has the benefit that it can be used for vanilla C APIs as well. There are many examples of this type of namespacing, including
• The OpenGL API uses “gl” as a prefix for all public symbols, for example, glBegin(), glVertex3f(), and GL_BLEND_COLOR (Shreiner, 2004).
• The Qt API uses the “Q” prefix for all public names, for example, QWidget, QApplication, and Q_FLAGS.
• The libpng library uses the “png” prefix for all identifiers, for example, png_read_row(), png_create_write_struct(), and png_set_invalid().
• The GNU GTK+ API uses the “gtk” prefix, for example, gtk_init(), gtk_style_new(), and GtkArrowType.
• The Second Life source code uses the “LL” prefix (short for Linden Lab) for various classes, enums, constants, for example, LLEvent, LLUUID, and LL_ACK_FLAG.
• The Netscape Portable Runtime names all exported types with a “PR” prefix, for example, PR_WaitCondVar(), PR_fprintf(), and PRFileDesc.
The second approach is to use the C++ namespace keyword. This essentially defines a scope where any names within that scope are given an additional prefix identifier. For example,
The String class in this case must now be referenced as MyAPI::String. The benefit of this style is that you don’t need to meticulously ensure that every class, function, enum, or constant has a consistent prefix: the compiler does it for you. This method is used by the STL, where all container classes, iterators, and algorithms are contained within the “std” namespace. You can also create nested namespaces, forming a namespace tree. For example, Intel’s Threading Build Blocks (TBB) API use the “tbb” namespace for all its public symbols and “tbb::strict_ppl” for internal code. The Boost libraries also make use of nested namespaces, inside of the root “boost” namespace, for example, boost::variant contains the public symbols for the Boost Variant API and boost::detail::variant contains the internal details for that API.
Using the namespace feature can produce verbose symbol names, particularly for symbols contained within several nested namespaces. However, C++ provides a way to make it more convenient to use symbols within a namespace with the using keyword:
or, more preferably (because it limits the extent of symbols imported into the global namespace),
However, you should never use the using keyword in the global scope of your public API headers! Doing so would cause all the symbols in the referenced namespace to become visible in the global namespace. This would subvert the entire point of using namespaces in the first place (Stroustrup, 2000). If you wish to reference symbols in another namespace in your header files, then always use the fully qualified name, for example, std::string.
6.2 Constructors and Assignment
If you are creating objects that contain state and that may be copied or assigned by client programs (sometimes called value objects), you need to consider the correct design of your constructors and assignment operator. Your compiler will generate default versions of these methods for you if you don’t define them yourself. However, if your class has any dynamically allocated objects, then you must explicitly define these methods yourself to ensure that the objects are copied correctly. Specifically, your compiler can generate default versions for the following four special methods.
• Default constructor. A constructor is used to initialize an object after it has been allocated by the new call. You can define multiple constructors with different arguments. The default constructor is defined as the constructor that can be called with no arguments (this could be a constructor with no argument or with arguments that all specify default values). Your C++ compiler will automatically generate a default constructor if you do not explicitly define one.
• Destructor. The destructor is called in response to a delete call in order to release any resources that the object is holding. There can be only one destructor for a class. If you do not specify a destructor, your C++ compiler will generate one automatically. The compiler will also generate code to automatically call the destructors for all of your member variables, in the reverse order they appear in the class declaration.
• Copy constructor. A copy constructor is a special constructor that creates a new object from an existing object. If you do not define a copy constructor, the compiler will generate one for you that performs a shallow copy of the existing object’s member variables. So if your object allocates any resources, you most likely need a copy constructor so that you can perform a deep copy. The copy constructor gets called in the following situations:
• An object is passed to a method by value or returned by value
• An object is initialized using the syntax, MyClass a = b;
• An object is placed in a brace-enclosed initializer list
• An object is thrown or caught in an exception
• Assignment operator. The assignment operator is used to assign the value of one object to another object, for example, a = b. It differs from the copy constructor in that the object being assigned to already exists. Some guidelines for implementing the assignment operator include:
1. Use a const reference for the right-hand operand.
2. Return *this as a reference to allow operator chaining.
3. Destroy any existing state before setting the new state.
4. Check for self-assignment (a = a) by comparing this to the right-hand operator.
As a corollary to these points, if you wish to create objects that should never be copied by your clients (also known as reference objects), then you should declare the copy constructor and assignment operator as private class members or use boost::noncopyable.
Many novice C++ developers get into trouble because they have a class that allocates resources, and hence requires a destructor, but they define neither a copy constructor nor an assignment operator. For example, consider the following simple integer array class, where I show the implementation of the constructor and destructor inline to clarify the behavior.
This class allocates memory, but does not define either a copy constructor or an assignment operator. As a result, the following code will crash when the two variables go out of scope because the destructor of each will try to free the same memory.
When creating a value object, it is therefore essential that you follow the rule of “The Big Three.” This term was introduced by Marshall Cline in the early nineties and essentially states that there are three member functions that always go together: the destructor, the copy constructor, and the assignment operator (Cline et al., 1998). If you define one of these, you normally need to define the other two as well (declaring an empty virtual destructor is one exception, as it does not perform any actual deallocation). James Coplien referred to this same concept as the orthodox canonical class form (Coplien, 1991).
6.2.1 Controlling Compiler-Generated Functions
In the C++98 standard, you have little control over the compiler’s behavior of automatically generating these special functions. For example, as already noted earlier, if you do not declare a copy constructor, the compiler will always generate one for you. However, in the new C++11 specification, you have explicit control over whether the compiler generates, or does not generate, these functions. For instance, the following example specifically tells the compiler to create a private default constructor and a virtual destructor, using the compiler-generated version of these in both cases.
You can also tell the compiler to disable certain functions that would otherwise be generated for you. For example, this can be used as another way to make a class be non-copyable as an alternative to the technique described earlier of declaring a private copy constructor and assignment operator.
Of course, these are C++11-only features. However, some compilers already provide experimental support for this functionality, such as the GNU C++ 4.4 compiler.
6.2.2 Defining Constructors and Assignment
Because writing constructors and operators can be a tricky business, here’s an example that demonstrates the various combinations. It builds on the previous array example and presents a class for storing an array of strings. Because the array is allocated dynamically, you must define a copy constructor and assignment operator, otherwise the memory will be freed twice on destruction if you copy the array. Here’s the declaration of the Array class in the header file:
Array &operator = (const Array &in_array);
std::string Get(int index) const;
and here are sample definitions for the constructors and assignment operator:
Array::Array(const Array &in_array) :
mArray(new std::string[in_array.mSize])
std::copy(in_array.mArray, in_array.mArray + mSize, mArray);
Array &Array::operator = (const Array &in_array)
if (this != &in_array) // check for self assignment
delete [] mArray; // delete current array first
mArray = new std::string[in_array.mSize];
std::copy(in_array.mArray, in_array.mArray + mSize, mArray);
Given the aforementioned Array class, the following code demonstrates when the various methods will be called.
Array a; // default constructor
Array a(10); // non-default constructor
Array b(a); // copy constructor
Array c = a; // copy constructor (because c does not exist yet)
Note that there are certain cases where your compiler may elide the call to your copy constructor, for example, if it performs some form of Return Value Optimization (Meyers, 1998).
6.2.3 The Explicit Keyword
You may have noticed use of the explicit keyword before the declaration of the non-default constructor in the Array example I just presented. Adding explicit is a good general practice for any constructor that accepts a single argument. It is used to prevent a specific constructor from being called implicitly when constructing an object. For example, without the explicit keyword, the following code is valid C++:
This will call the Array single-argument constructor with the integer argument of 10. However, this type of implicit behavior can be confusing, unintuitive, and, in most cases, unintended. As a further example of this kind of undesired implicit conversion, consider the following function signature:
Without declaring the single-argument constructor of Array as explicit, you could call this function as
This weakens the type safety of your API because now the compiler will not enforce the type of the first argument to be an explicit Array object. As a result, there’s the potential for the user to forget the correct order of arguments and pass them in the wrong order. This is why you should always use the explicit keyword for any single-argument constructors unless you know that you want to support implicit conversion.
You can also declare your copy constructor to be explicit too. This will prevent implicit invocations of the copy constructor, such as passing an object to a function by value or returning an object by value. However, you will still be able to explicitly call the copy constructor using the “Array a = b” or “Array a(b)” syntax.
As a side note, the new C++11 specification lets you use the explicit keyword in front of conversion operators as well as constructors. Doing so will prevent those conversion functions from being used for implicit conversions.
6.3 Const Correctness
Const correctness refers to use of the C++ const keyword to declare a variable or method as immutable. It is a compile-time construct that can be used to maintain the correctness of code that shouldn’t modify certain variables. In C++, you can define variables as const, to mean that they should not be modified, and you can also define methods as const, to mean that they should not modify any member variables of the class. Using const correctness is simply good programming practice. However, it can also provide documentation on the intent of your methods, and hence make them easier to use.
6.3.1 Method Const Correctness
A const method cannot modify any member variables of the class. In essence, all member variables are treated as const variables inside of a const method. This form of const correctness is indicated by appending the const keyword after the method’s parameter list. There are two principal benefits of declaring a method as const:
1. To advertise the fact that the method will not change the state of the object. As just discussed, this is helpful documentation for users of your API.
2. To allow the method to be used on const versions of an object. A non-const method cannot be called on a const version of an object.
Scott Meyers describes two camps of philosophy about what a const method represents. There’s the bitwise constness camp, which believes that a const method should not change any member variables of a class, and then there’s the logical constness camp, which says that a const method may change a member variable if that change cannot be detected by the user (Meyers, 2005). Your C++ compiler conforms to the bitwise approach. However, there are times when you really want it to behave in the logical constness manner. A classic example is if you want to cache some property of a class because it takes too long to compute. For example, consider a HashTable class that needs to return the number of elements in the hash table very efficiently. As a result, you decide to cache its size and compute this value lazily, on demand. Given the following class declaration:
void Insert(const std::string &str);
int Remove(const std::string &str);
you may want to implement the GetSize() const method as follows:
Unfortunately, this is not legal C++, as the GetSize() method does actually modify member variables (mSizeIsDirty and mCachedSize). However, these are not part of the public interface: they are internal state that lets us offer a more efficient API. This is the reason why there is the notion of logical constness. C++ does provide a way around this problem with the mutable keyword. Declaring the mCachedSize and mSizeIsDirty variables as mutable states that they can be modified within a const method. Using mutable is a great way to maintain the logical constness of your API instead of removing the const keyword on a member function that really should be declared const.
6.3.2 Parameter Const Correctness
Use of the const keyword can also be used to indicate whether you intend for a parameter to be an input or an output parameter, that is, a parameter used to pass some value into a method or a parameter used to receive some result. For example, consider a method such as
It’s not clear from this function signature whether this method will modify the string that you pass in. Clearly it returns a string result, but perhaps it also changes the parameter string. It certainly could do so if it wanted to. If the purpose of this method is to take the parameter and return a lowercase version without affecting the input string, then the simple addition of const can make this unequivocally clear.
Now the compiler will enforce the fact that the function StringToLower() will not modify the string that the user passes in. As a result, it’s clear and unambiguous what the intended use of this function is just by looking at the function signature.
Often you’ll find that if you have a const method, then any reference or pointer parameters can also be declared const. While this is not a hard and fast rule, it follows logically from the general promise that the const method does not modify any state. For example, in the following function the root_node parameter can be declared const because it’s not necessary to modify this object in order to compute the result of the const method:
6.3.3 Return Value Const Correctness
When returning the result of a function, the main reason to declare that result to be const is if it references internal state of the object. For example, if you are returning a result by value, then it makes little sense to specify it as const because the returned object will be a copy and hence changing it will not affect any of your class’s internal state.
Alternatively, if you return a pointer or reference to a private data member, then you should declare the result to be const, as otherwise users will be able to modify your internal state without going through your public API. In this case, you must also think about whether the returned pointer or reference will survive longer than your class. If this is possible, you should consider returning a reference-counted pointer, such as a std::shared_ptr, as discussed earlier in Chapter 2.
Therefore, the most common decision you will have with respect to return value const correctness is whether to return the result by value or const reference, that is,
In general, I recommend that you return the result by value as it is safer. However, you may prefer the const reference method in a few cases where performance is critical. Returning by value is safer because you don’t have to worry about clients holding onto references after your object has been destroyed, but also because returning a const reference can break encapsulation.
On the face of it, our const reference GetName() method given earlier seems acceptable: the method is declared to be const to indicate that it doesn’t modify the state of the object, and the returned reference to the object’s internal state is also declared to be const so that clients can’t modify it. However, a determined client can always cast away the constness of the reference and then modify the underlying private data member directly, such as in the following example:
6.4 Templates
Templates provide a versatile and powerful ability to generate code at compile time. They are particularly useful for generating lots of code that looks similar but differs only by type. However, if you decide to provide class templates as part of your public API, several issues should be considered to ensure that you provide a well-insulated, efficient, and cross-platform interface. The following sections address several of these factors.
Note that I will not cover all aspects of template programming, only those features that impact good API design. For a more thorough and in-depth treatment of templates, there are several good books on the market (Alexandrescu, 2001; Josuttis, 1999; Vandevoorde and Josuttis, 2002).
6.4.1 Template Terminology
Templates are an often poorly understood part of the C++ specification, so let’s begin by defining some terms so that we can proceed from a common base. I will use the following template declaration as a reference for the definitions:
This class template describes a generic stack class where you can specify the type of the elements in the stack, T.
• Template Parameters: These names are listed after the template keyword in a template declaration. For example, T is the single template parameter specified in our Stack example given earlier.
• Template Arguments: These entities are substituted for template parameters during specialization. For example, given a specialization Stack<int>, “int” is a template argument.
• Instantiation: This is when the compiler generates a regular class, method, or function by substituting each of the template’s parameters with a concrete type. This can happen implicitly when you create an object based on a template or explicitly if you want to control when the code generation happens. For example, the following lines of code create two specific stack instances and will normally cause the compiler to generate code for these two different types.
Stack<std::string> myStringStack;
• Implicit Instantiation: This is when the compiler decides when to generate code for your template instances. Leaving the decision to the compiler means that it must find an appropriate place to insert the code, and it must also make sure that only one instance of the code exists to avoid duplicate symbol link errors. This is a non-trivial problem and can cause extra bloat in your object files or longer compile and link times to solve. Most importantly for API design, implicit instantiation means that you have to include the template definitions in your header files so that the compiler has access to the definitions whenever it needs to generate the instantiation code.
• Explicit Instantiation: This is when the programmer determines when the compiler should generate the code for a specific specialization. This can make for much more efficient compilation and link times because the compiler no longer needs to maintain bookkeeping information for all of its implicit instantiations. However, the onus is then placed on the programmer to ensure that a particular specialization is explicitly instantiated once and only once. From an API perspective, explicit instantiation allows us to move the template implementation into the .cpp file, and so hide it from the user.
• Lazy Instantiation: This describes the standard implicit instantiation behavior of a C++ compiler wherein it will only generate code for the parts of a template that are actually used. For example, given the previous two instantiations, if you never called IsEmpty() on the myStringStack object, then the compiler would not generate code for the std::string specialization of that method. This means that you can instantiate a template with a type that can be used by some, but not all, methods of a class template. For example, say one method uses the >= operator, but the type you want to instantiate does not define this operator. This is fine as long as you don’t call the particular method that attempts to use the >= operator.
• Specialization: When a template is instantiated, the resulting class, method, or function is called a specialization. More specifically, this is an instantiated (or generated) specialization. However, the term specialization can also be used when you provide a custom implementation for a function by specifying concrete types for all the template parameters. I gave an example of this earlier in the API Styles chapter, where I presented the following implementation of the Stack::Push() method, specialized for integer types. This is called an explicit specialization.
void Stack<int>::Push(int val)
// integer specific push implementation
• Partial Specialization: This is when you provide a specialization of the template for a subset of all possible cases. That is, you specialize one feature of the template but still allow the user to specify other features. For example, if your template accepts multiple parameters, you could partially specialize it by defining a case where you specify a concrete type for only one of the parameters. In our Stack example with a single template parameter, you could partially specialize this template to specifically handle pointers to any type T. This still lets users create a stack of any type, but it also lets you write specific logic to handle the case where users create a stack of pointers. This partially specialized class declaration might look like:
6.4.2 Implicit Instantiation API Design
If you want to allow your clients to instantiate your class templates with their own types, then you need to use implicit template instantiation. For example, if you provide a smart pointer class template, smart_pointer<T>, you do not know ahead of time what types your clients will want to instantiate it with. As a result, the compiler needs to be able to access the definition of the template when it is used. This essentially means that you must expose the template definition in your header files. This is the biggest disadvantage of the implicit instantiation approach in terms of robust API design. However, even if you can’t necessarily hide the implementation details in this situation, you can at least make an effort to isolate them.
Given that you need to include the template definition in your header file, it’s easy, and therefore tempting, to simply inline the definitions directly within the class definition. This is a practice that I have already classified as poor design, and that assertion is still true in the case of templates. Instead, I recommend that all template implementation details be contained within a separate implementation header, which is then included by the main public header. Using the example of our Stack class template, you could provide the main public header:
Then the implementation header, stack_priv.h, would look as follows:
This technique is used by many high-quality template-based APIs, such as various Boost headers. It has the benefit of keeping the main public header uncluttered by implementation details while isolating the necessary exposure of internal details to a separate header that is clearly designated as containing private details. (The same technique can be used to isolate consciously inlined function details from their declarations.)
The technique of including template definitions in header files is referred to as the Inclusion Model (Vandevoorde and Josuttis, 2002). It’s worth noting that there is an alternative to this style called the Separation Model. This allows the declaration of a class template in a .h file to be preceded with the export keyword. Then the implementation of the template methods can appear in a .cpp file. From an API design perspective, this is a far more preferable model, as it would allow us to remove all implementation details from public headers. However, this part of the C++ specification is very poorly supported by most compilers. In particular, neither GNU C++ 4.3 nor Microsoft Visual C++ 9.0 compilers support the export keyword. You should therefore avoid this technique in your APIs to maximize the portability of your API.
6.4.3 Explicit Instantiation API Design
If you want to provide only a predetermined set of template specializations for your API and disallow your users from creating further ones, then you do in fact have the option of completely hiding your private code. For example, if you have created a 3D vector class template, Vector3D<T>, you may only want to provide specializations of this template for int, short, float, and double, and you may feel that it’s not necessary to let your users create further specializations.
In this case, you can put your template definitions into a .cpp file and use explicit template instantiation to instantiate those specializations that you wish to export as part of your API. The template keyword can be used to create an explicit instantiation. For instance, using our Stack template example given previously, you could create explicit instantiations for the type int with the statement:
This will cause the compiler to generate the code for the int specialization at this point in the code. As a result, it will subsequently no longer attempt to implicitly instantiate this specialization elsewhere in the code. Consequently, using explicit instantiation can also help increase build times.
Let’s take a look at how you can organize your code to take advantage of this feature. Our stack.h header file looks almost exactly the same as before, just without the #include "stack_priv.h" line:
Now you can contain all of the implementation details for this template in an associated .cpp file:
The important lines here are the last three, which create explicit instantiations of the Stack class template for the types int, double, and std::string. The user will not be able to create further specializations (and the compiler will not be able to create implicit instantiations for the user either) because the implementation details are hidden in our .cpp file. However, our implementation details are now hidden successfully in our .cpp file.
To indicate to your users which template specializations they can use (i.e., which ones you have explicitly instantiated for them), you could add a few typedefs to the end of your public header, such as
It’s worth noting that by adopting this template style, not only do you (and your clients) get faster builds due to the removal of the overhead of implicit instantiation, but also, by removing the template definitions from your header, you reduce the #include coupling of your API and reduce the amount of extra code that your clients’ programs must compile every time they #include your API headers.
It’s also worth noting that most compilers provide an option to turn off implicit instantiation completely, which may be a useful optimization if you only plan to use explicit instantiation in your code. This option is called -fno-implicit-templates in the GNU C++ and Intel ICC compilers.
In the new C++11 specification, support has been added for extern templates. That is, you will be able to use the extern keyword to prevent the compiler from instantiating a template in the current translation unit. In fact, support for this feature is already in some current compilers, such as the GNU C++ compiler. With the addition of extern templates, you have the ability to force the compiler to instantiate a template at a certain point and to tell it not to instantiate the template at other points. For example,
6.5 Operator Overloading
In addition to overloading functions, C++ allows you to overload many of the operators for your classes, such as +, *=, or []. This can be very useful to make your classes look and behave more like built-in types and also to provide a more compact and intuitive syntax for certain methods. For example, instead of having to use syntax such as
you could write classes that support the following syntax:
Of course, you should only use operator overloading in cases where it makes sense, that is, where doing so would be considered natural to the user of your API and not violate the rule of least surprise. This generally means that you should preserve the natural semantics for operators, such as using the + operator to implement an operation analogous to addition or concatenation. You should also avoid overloading the operators &&, ||, & (unary ampersand), and , (comma) as these exhibit behaviors that may surprise your users, such as short-circuited evaluation and undefined evaluation order (Meyers 1998; Sutter and Alexandrescu, 2004).
As covered earlier in this chapter, a C++ compiler will generate a default assignment operator (=) for your class if you don’t define one explicitly. However, if you wish to use any other operators with your objects, then you must explicitly define them, otherwise you’ll end up with link errors.
6.5.1 Overloadable Operators
Certain operators cannot be overloaded in C++, such as ., .*, ?:, and ::, the preprocessor symbols # and ##, and the sizeof operator. Of the remaining operators that you can overload for your own classes, there are two main categories:
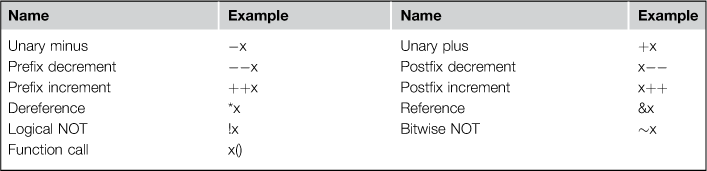
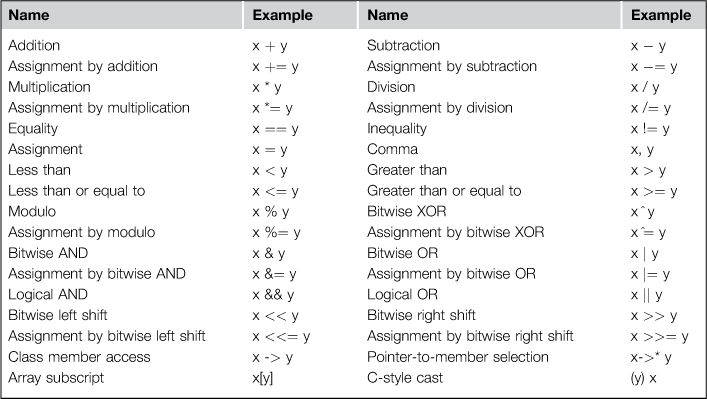
6.5.2 Free Operators versus Member Operators
Operators can be defined either as members of your class or as free functions. Some operators have to be defined as class members, but others can be defined either way. For example, the following code illustrates the += operator defined as a class member:
explicit Currency(unsigned int value);
Currency &operator +=(const Currency &other);
The following code shows an equivalent API using a free function version of the operator:
explicit Currency(unsigned int value);
unsigned int GetValue() const;
This section covers some best practices for whether you should make your operators free functions or methods.
To begin with, the C++ standard requires that the following operators be declared as member methods to ensure that they receive an lvalue (an expression that refers to an object) as their first operand:
The remaining overloadable operators can be defined as either free functions or class methods. From the perspective of good API design, I recommend that you favor the free function version over the class method version of defining an operator. There are two specific reasons for this.
1. Operator symmetry. If a binary operator is defined as a class method, it must have an object to be applied to as the left-hand operand. Taking the * operator as an example, this means that your users would be able to write expressions such as “currency * 2” (assuming that you’ve defined a non-explicit constructor or a specific * operator for the int type) but not “2 * currency” because 2.operator*(currency) does not make sense. This breaks the commutative property of the operator that your users will expect, that is, that x * y should be the same as y * x. Note also that declaring the * operator as a free function lets you benefit from implicit type conversions for both left- and right-hand operands if you do not declare your constructors as explicit.
2. Reduced coupling. A free function cannot access the private details of a class. It is therefore less coupled to the class because it can only access the public methods. This is a general API design statement that was covered in Chapter 2: turn a class method that does not need to access private or protected members into a free function to reduce the degree of coupling in your API (Meyers, 2000; Tulach, 2008).
Having stated this general preference toward free function operators, I now present the exception to this rule: If your operator must access private or protected members of your class, then you should define the operator as a method of the class. I make this exception because otherwise you would have to declare the free function operator to be a friend of your class. As discussed later in this chapter, adding friends to your classes is a greater evil. One specific reason I’ll mention here is that your clients cannot change the friendship list of your classes, so they could not add new operators in this same way.
6.5.3 Adding Operators to a Class
Let’s develop the Currency class a little further to make the aforementioned points more concrete. The += operator modifies the contents of an object, and because we know that all member variables should be private, you will most likely need to make the += operator be a member method. However, the + operator does not modify the left-hand operand. As such, it shouldn’t need access to private members and can be made a free function. You also need to make it a free function to ensure that it benefits from symmetry behavior, as described earlier. In fact, the + operator can be implemented in terms of the += operator, which allows us to reuse code and provide more consistent behavior. It also reduces the number of methods that might need to be overloaded in derived classes.
Obviously, the same technique applies to the other arithmetic operators, such as -, -=, *, *=, /, and /=. For example, *= can be implemented as a member function, whereas * can be implemented as a free function that uses the *= operator.
As for the relational operators ==, !=, <, <=, >, and >=, these must also be implemented as free functions to ensure symmetrical behavior. In the case of our Currency class, you can implement these using the public GetValue() method. However, if these operators should need access to the private state of the object, there is a way to resolve this apparent dilemma. In this case, you can provide public methods that test for the equality and less than conditions such as IsEqualTo() and IsLessThan(). All relational operators could then be implemented in terms of these two primitive functions (Astrachan, 2000).
bool operator ==(const Currency &lhs, const Currency &rhs)
bool operator !=(const Currency &lhs, const Currency &rhs)
bool operator <(const Currency &lhs, const Currency &rhs)
bool operator <=(const Currency &lhs, const Currency &rhs)
bool operator >(const Currency &lhs, const Currency &rhs)
The last operator I will consider here is <<, which I will use for stream output (as opposed to bit shifting). Stream operators have to be declared as free functions because the first parameter is a stream object. Again, you can use the public GetValue() method to make this possible. However, if the stream operator did need to access private members of your class, then you could create a public ToString() method for the << operator to call as a way to avoid using friends.
Putting all of these recommendations together, here’s what the operators of our Currency class might look like:
explicit Currency(unsigned int value);
Currency(const Currency &obj);
Currency &operator =(const Currency &rhs);
Currency &operator +=(const Currency &rhs);
Currency &operator -=(const Currency &rhs);
Currency &operator *=(const Currency &rhs);
Currency &operator /=(const Currency &rhs);
Currency operator +(const Currency &lhs, const Currency &rhs);
Currency operator -(const Currency &lhs, const Currency &rhs);
Currency operator *(const Currency &lhs, const Currency &rhs);
Currency operator /(const Currency &lhs, const Currency &rhs);
bool operator ==(const Currency &lhs, const Currency &rhs);
bool operator !=(const Currency &lhs, const Currency &rhs);
bool operator <(const Currency &lhs, const Currency &rhs);
bool operator >(const Currency &lhs, const Currency &rhs);
bool operator <=(const Currency &lhs, const Currency &rhs);
bool operator >=(const Currency &lhs, const Currency &rhs);
std::ostream& operator <<(std::ostream &os, const Currency &obj);
6.5.4 Operator Syntax
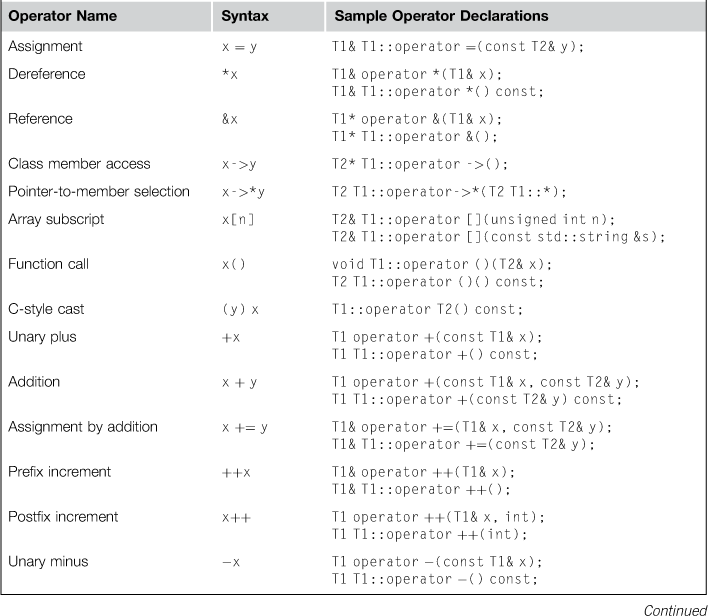
Table 6.1 provides (i) a list of operators that you can overload in your classes and (ii) the recommended syntax for declaring each operator so that they have the same semantics as their built-in counterparts. Table 6.1 omits operators that you cannot overload, as well as those stated previously that you should not overload, such as && and ||. Where an operator can be defined as either a free function or a class method, I present both forms, but I list the free function form first as you should generally prefer this form, unless the operator needs access to protected or private members.
Table 6.1
List of operators and syntax for declaring these in your APIs
6.5.5 Conversion Operators
A conversion operator provides a way for you to define how an object can be converted automatically to a different type. A classic example is to define a custom string class that can be passed to functions that accept a const char * pointer, such as the standard C library functions strcmp() or strlen().
// convert MyString to a C-style string
operator const char *() { return mBuffer; }
// MyString objects get automatically converted to const char *
Note that the conversion operator does not specify a return value type. That’s because the type is inferred by the compiler based on the operator’s name. Also, note that conversion operators take no arguments. In the C++11 standard, it’s also possible to prefix a conversion operator with the explicit keyword to prevent its use in implicit conversions.
6.6 Function Parameters
The following sections address a couple of C++ best practices relating to the use of function parameters. This includes when you should use pointers instead of references to pass objects into a function and when you should use default arguments.
6.6.1 Pointer versus Reference Parameters
When specifying parameters for your functions you can choose between passing them as value parameters, pointers, or references. For example,
bool GetColor(int r, int g, int b); // pass by value
You pass a parameter as a reference or pointer when you want to receive a handle for the actual object rather than a copy of the object. This is done either for performance reasons (as discussed in Chapter 7) or so that you can modify the client’s object. C++ compilers normally implement references using pointers so they are often the same thing under the hood. However, there are several practical differences, such as
• References are used as if they were a value, for example, object.Function() instead of object->Function().
• A reference must be initialized to point to an object and does not support changing the referent object after initialization.
• You cannot take the address of a reference as you can with pointers. Using the & operator on a reference returns the address of the referent object.
The question of whether to use a pointer or a reference for a parameter is really a matter of personal taste. However, I will suggest that in general you should prefer the use of references over pointers for any input parameters. This is because the calling syntax for your clients is simpler and you do not need to worry about checking for NULL values (because references cannot be NULL). However, if you need to support passing NULL or if you’re writing a plain C API, then you must obviously use a pointer.
In terms of output parameters (parameters that your function may modify), some engineers dislike the fact that the use of references does not indicate to your clients the fact that a parameter may be changed. For example, the reference and pointer versions of the GetColor() function given earlier can be called by clients as follows:
In both of these cases, the GetColor() function can modify the value of the red, green, and blue variables. However, the pointer version makes this fact explicit due to the required use of the & operator. For this reason, APIs like the Qt framework prefer to represent output parameters using pointers instead of references. If you decide to follow this convention too—which I recommend—then by implication all of your reference parameters should be const references.
6.6.2 Default Arguments
Default arguments are a very useful tool to reduce the number of methods in your API and to provide implicit documentation on their use. They can also be used to extend an API call in a backward-compatible fashion so that older client code will still compile, but newer code can optionally provide additional arguments (although it should be noted that this will break binary compatibility, as the mangled symbol name for the method will necessarily change). As an example, consider the following code fragment for a Circle class:
In this case, the user is able to construct a new Circle object in a number of different ways, supplying as much detail as needed. For example,
However, there are two issues to be aware of with this example. First, it supports combinations of arguments that don’t make logical sense, such as supplying an x argument but no y argument. Also, the default values will be compiled into your client’s programs. This means that your clients must recompile their code if you release a new version of the API with a different default radius. In essence, you are exposing the behavior of the API when you do not explicitly specify a radius value.
To illustrate why this might be bad, consider the possibility that you later add support for the notion of different default units, letting the user switch between values specified in meters, centimeters, or millimeters. In this case, a constant default radius of 10.0 would be inappropriate for all units.
An alternative approach is to provide multiple overloaded methods instead of using default arguments. For example,
Using this approach, the implementation of the first two constructors can use a default value for the attributes that are not specified. But importantly, these default values are specified in the .cpp file and are not exposed in the .h file. As a result, a later version of the API could change these values without any impact on the public interface.
Not all instances of default arguments need to be converted to overloaded methods. In particular, if the default argument represents an invalid or empty value, such as defining NULL as the default value for a pointer or "" for a string argument, then this usage is unlikely to change between API versions. However, if you have cases where you are hardcoding specific constant values into your API that might change in future releases, then you should convert these cases to use the overloaded method technique instead.
As a performance note, you should also try to avoid defining default arguments that involve constructing a temporary object because these will be passed into the method by value and can therefore be expensive.
6.7 Avoid #define for Constants
The #define preprocessor directive is essentially used to substitute one string with another string in your source code. However, its use is generally frowned upon in the C++ community for a number of good reasons (Cline et al., 1998; DeLoura, 2001; Meyers, 2005). Many of these reasons are related to the subtle problems that can happen if you use #define to specify code macros that you wish to insert into multiple places, such as
However, you should never be using #define in this way for your public API headers because of course it leaks implementation details. If you want to use this technique in your .cpp files, and you understand all of the idiosyncrasies of #define, then go ahead, but never do this in your public headers.
That just leaves the use of #define to specify constants for your API, such as
You should avoid even this usage of #define (unless you are writing a pure C API of course) because of the following reasons.
1. No typing. A #define does not involve any type checking for the constant you are defining. You must therefore make sure that you explicitly specify the type of the constant you are defining to avoid any ambiguities, such as the use of the “f” suffix on single-precision floating-point constants. If you defined a floating-point constant as simply “10,” then it may be assumed to be an integer in certain cases and cause undesired math rounding errors.
2. No scoping. A #define statement is global and is not limited to a particular scope, such as within a single class. You can use the #undef preprocessor directive to undefine a previous #define, but this makes little sense for declaring a constant that you want your clients to be able to use.
3. No access control. You cannot mark a #define as public, protected, or private. It is essentially always public. You therefore cannot use #define to specify a constant that should only be accessed by derived classes of a base class that you define.
4. No symbols. In the example given earlier, symbolic names such as MORPH_IN_TIME may be stripped from your code by the preprocessor, and as such the compiler never sees this name and cannot enter it into the symbol table (Meyers, 2005). This can hide valuable information from your clients when they try to debug code using your API because they will simply see the constant value used in the debugger, without any descriptive name.
The preferred alternative to using #define to declare API constants is to declare a const variable. I will discuss some of the best practices of declaring constants in the later chapter on performance, as it’s possible to declare const variables in a way that adds bloat to your clients programs. For now, I will simply present a good conversion of the earlier #define example to be
where the actual values of these constants are specified in the associated .cpp file. (If you really want your users to know what the values of these constants are, then you can tell them this information in the API documentation for the Morph class.) Note that this representation does not suffer from any of the problems listed previously: the constants are typed as floats, scoped to the Morph class, marked explicitly as publicly accessible, and will generate entries in the symbol table.
A further use of #define is to provide a list of possible values for a given variable. For example,
This is better expressed using enumerated types via the enum keyword. Using enums gives you better type safety because the compiler will now ensure that you set any enum values with the symbolic name and not directly as an integer (unless you explicitly cast an int to your enum type of course). This also makes it more difficult to pass illegal values, such as –1 or 23 in the example given earlier. You can turn the aforementioned #define lines into an enumerated type as follows:
6.8 Avoid Using Friends
In C++, friendship is a way for your class to grant full access privileges to another class or function. The friend class or function can then access all protected and private members of your class. This can be useful when you need to split up your class into two or more parts but you still need each part to access private members of the other part. It’s also useful when you need to use an internal visitor or callback technique. That is, when some other internal class in your implementation code needs to call a private method in your class.
One alternative would be to expose data members and functions that need to be shared, converting them from private to public so that the other class can access them. However, this would mean that you are exposing implementation details to your clients; details that would not otherwise be part of your logical interface. From this point of view, friends are a good thing because they let you open up access to your class to only specific clients. However, friendship can be abused by your users, allowing them to gain full access to your class’s internal details.
For example, consider the following class that specifies a single Node as part of a Graph hierarchy. The Graph may need to perform various iterations over all nodes and therefore needs to keep track of whether a node has been visited already (to handle graph cycles). One way to implement this would be to have the Node object hold the state for whether it has been visited already, with accessors for this state. Because this is purely an implementation detail, you don’t want to expose this functionality in the public interface. Instead, you declare it as private, but explicitly give the Graph object access to the Node object by declaring it as a friend.
This seems okay on the face of it: you have kept the various *Visited() methods as private and only permitted the Graph class to access our internal details. However, the problem with this is that the friendship offer is based on the name of the other class only. It would therefore be possible for clients to create their own class called Graph, which would then be able to access all protected and private members of Node (Lakos, 1996). The following client program demonstrates how easy it is to perform this kind of access control violation.
// define your own Graph class
void ViolateAccess(Node *node)
// call a private method in Node
So, by using friends you are leaving a gaping hole in your API that could be used to circumvent your public API boundary and break encapsulation.
In the example just given, a better solution that obviates the need to use friends would be for the Graph object to maintain its own list of nodes that it has already visited, for example, by maintaining a std::set<Node *> container, rather than storing the visited state in the individual nodes themselves. This is also a better conceptual design because the information about whether another class has processed a Node is not inherently an attribute of the Node itself.
6.9 Exporting Symbols
In addition to language-level access control features (public, private, and protected), there are two related concepts that allow you to expose symbols in your API at the physical file level. These are:
The term external linkage means that a symbol in one translation unit can be accessed from other translation units, whereas exporting refers to a symbol that is visible from a library file such as a DLL. Only external linkage symbols can be exported.
Let’s look at external linkage first. This is the first stage that determines whether your clients can access symbols in your shared libraries. Specifically, global (file scope) free functions and variables in your .cpp file will have external linkage unless you take steps to prevent this. For example, consider the following code that might appear in one of your .cpp files:
const int INTERNAL_CONSTANT = 42;
std::string Filename = "file.txt";
Even though you have contained the use of these functions and variables inside a .cpp file, a resourceful client could easily gain access to these symbols from their own programs (ignoring symbol exporting issues for the moment). They could then call your global functions directly and modify your global state without going through your public API, thus breaking encapsulation. The following program fragment demonstrates how to achieve this:
extern const int INTERNAL_CONSTANT;
// call an internal function within your module
// access a constant defined within your module
std::cout << "Constant = " << INTERNAL_CONSTANT << std::endl;
There are a couple of solutions to this kind of external linkage leakage problem.
1. Static declaration. Prepend the declaration of your functions and variables with the static keyword. This specifies that the function or variable should have internal linkage and hence will not be accessible outside of the translation unit it appears in.
2. Anonymous namespace. A more idiomatic C++ solution is to enclose your file-scope functions and variables inside an anonymous namespace. This is a better solution because it avoids polluting the global namespace. This can be done as follows:
const int INTERNAL_CONSTANT = 42;
std::string Filename = "file.txt";
For symbols that have external linkage, there is the further concept of exporting symbols, which determines whether a symbol is visible from a shared library. Most compilers provide decorations for classes and functions that let you explicitly specify whether a symbol will appear in the exported symbol table for a library file. However, this tends to be compiler-specific behavior. For example:
1. Microsoft Visual Studio. Symbols in a DLL are not accessible by default. You must explicitly export functions, classes, and variables in a DLL to allow your clients to access them. You do this using the __declspec decorator before a symbol. For example, you specify __declspec(dllexport) to export a symbol when you are building a DLL. Clients must then specify __declspec(dllimport) in order to access the same symbol in their own programs.
2. GNU C++ compiler. Symbols with external linkage in a dynamic library are visible by default. However, you can use the visibility __attribute__ decorator to explicitly hide a symbol. As an alternative to hiding individual symbols, the GNU C++ 4.0 compiler introduced the -fvisibility=hidden flag to force all declarations to hidden visibility by default. Individual symbols can then be explicitly exported using __attribute__ ((visibility("default"))). This is more like the Windows behavior, where all symbols are considered internal unless you explicitly export them. Using the -fvisibility=hidden flag can also cause a dramatic improvement in load time performance of your dynamic library and produce smaller library files.
You can define various preprocessor macros to deal with these compiler differences in a cross-platform way. Here’s an example of defining a DLL_PUBLIC macro to export symbols explicitly and a DLL_HIDDEN macro to hide symbols when using the GNU C++ compiler. Note that you must specify an _EXPORTING define when you build the library file on Windows, that is, /D "_EXPORTING". This is an arbitrary define name—you can call it whatever you like (as long as you also update the code that follows).
#if defined _WIN32 || defined __CYGWIN__
#ifdef _EXPORTING // define this when generating DLL
#define DLL_PUBLIC __attribute__((dllexport)) #define DLL_PUBLIC __declspec(dllexport) #define DLL_PUBLIC __attribute__((dllimport)) #define DLL_PUBLIC __declspec(dllimport)#define DLL_PUBLIC __attribute__ ((visibility("default")))
For example, to export a class or function of your API you can do the following:
Many compilers also allow you to provide a simple ASCII file that defines the list of symbols that should be exported by a dynamic library so that you don’t need to decorate your code with macros such as DLL_PUBLIC. Symbols that do not appear in this file will be hidden from client programs. For example, the Windows Visual Studio compiler supports .def files, whereas the GNU compiler supports export map files. See Appendix A for more details on these export files.
6.10 Coding Conventions
C++ is a very complex language with many powerful features. The use of good coding conventions can partially help manage this complexity by ensuring that all code follows certain style guidelines and avoids common pitfalls. It also contributes toward consistent code, which I identified as one of the important qualities of a good API in Chapter 2.
Producing a coding standard document can be a lengthy and factious process, not only because of the complexity of the language but also because of the amount of personal taste and style that it aims to stipulate. Different engineers have different preferences for where to place brackets and spaces, what style of comments to adopt, or whether to use lower or upper camelCase for function names. For example, in this book I have consistently formatted source code snippets with pointer or reference symbols next to variable names, not type names, that is,
instead of
I favor the former style because from a language perspective the pointer is actually associated with the variable, not the type (in both of these cases, a and b are both of type pointer to char). However, other software engineers prefer the latter style.
In this book, I do not advocate that you should adopt any particular style for your projects, but I do urge you to adopt some conventions for your API, whatever they are. The important point is to be consistent. Indeed, it’s generally accepted among engineers that when editing a source file you should adopt the conventions that are already in force in that file instead of adding your own style into the mix and producing a file with a mixture of inconsistent styles (or you might be more antisocial and reformat the entire file to your own style).
Because a number of large companies have already gone through the process of creating and publishing coding style documents, you could always simply adopt one of these standards to make the decision easier. Doing a Web search for “C++ coding conventions” should return a large number of hits for your consideration. In particular, the Google C++ style guide is a very extensive document used by many other groups (http://google-styleguide.googlecode.com/). There are also some great books that provide even more depth and detail on numerous code constructs that should be used or avoided (Sutter and Alexandrescu, 2004).
Without making specific suggestions, I will enumerate some of the areas that a good coding standard should cover.
• Naming conventions. Whether to use .cc, .c++, or .cpp; capitalization of filenames; use of prefixes in filenames; capitalization of classes, functions, variables, differentiating private members, constants, typedefs, enums, macros, namespaces; use of namespaces; etc.
• Header files. How to #include headers; ordering #include statements; using #define guards; use of forward declarations; inlining code policy; etc.
• Comments. Comment style; templates for commenting files, classes, functions, and so on; documentation requirements; commenting code with to do notes or highlighting known hacks; etc.
• Formatting. Line length limit; spaces versus tabs; placement of braces; spacing between statements; how to break long lines; layout of constructor initialization lists; etc.
• Classes. Use of constructors; factories; inheritance; multiple inheritance; interfaces; composition, structs versus classes; access control; etc.
• Best practices. Use of templates; use of exceptions; use of enums; const correctness; use of pointers for output parameters; use of pimpl; initialization of all member variables; casting; operator overloading rules; virtual destructors; use of globals; etc.
• Portablity. Writing architecture-specific code; preprocessor macros for platforms; class member alignment; etc.
• Process. Compiling with warnings as errors; unit tests requirements; use of code reviews; use of use cases; SCM style check hooks; compile with extra checks such as -Wextra and -Weffc++; etc.