This chapter describes the 49 built-in simple types that are included in XML Schema. These simple types represent common types that can be used directly in schemas. They are also the foundation for deriving other simple types, as described in Chapter 8. A complete reference to the built-in simple types and the facets that apply to them can be found in Appendix B.
There are 49 simple types built into XML Schema. They are specified in Part 2 of the XML Schema recommendation. This part of the recommendation makes a distinction between “datatypes” and “simple types.” Datatypes are abstract concepts of data, such as “integer.” Simple types are the concrete representations of these datatypes. Most of the built-in types are atomic types, although there are three list types as well.
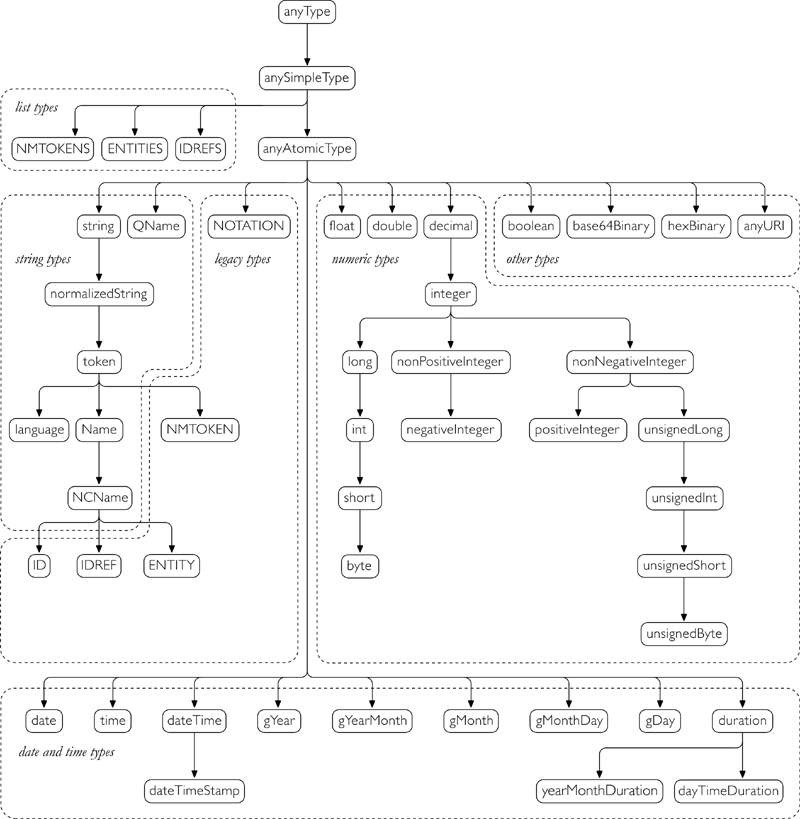
Types in the XML Schema type system form a hierarchy. Figure 11–1 depicts the hierarchy of the built-in types, showing that some built-in types are derived from other built-in types. The downward arrows represent derivation by restriction, so the types become more restrictive toward the bottom of the diagram. For example, nonPositiveInteger is more restrictive than integer, which is more restrictive than anyAtomicType.
Figure 11–1. The built-in type hierarchy
At the top of the hierarchy are three special types:
1. anyType is a generic complex type that allows anything: any attributes, any child elements, any text content.
2. anySimpleType, derived from anyType, is the base of all simple types, including atomic, list, and union types.
3. anyAtomicType, derived from anySimpleType, is a generic type from which all atomic types are derived.
anyType can be declared as the type of an element, in which case that element can have any content. It is also the default type for elements if none is specified. anyType can also be extended or restricted by complex type definitions. anySimpleType and anyAtomicType are special types that cannot be used as the base for user-defined types in a schema. However, they can be declared as the type of an element or attribute.
The types directly under anyAtomicType are known as primitive types, while the rest are derived built-in types. The primitive types represent basic type concepts, and all other built-in atomic types are restrictions of those types. When you define new simple types in your schema, they can never be primitive; they must be derived from a built-in primitive type.
Figure 11–1 shows that the three built-in list types (NMTOKENS, ENTITIES, and IDREFS) are derived from anySimpleType. Any user-defined list and union types are also derived from anySimpleType, although they have item types or member types that may be specific atomic types.

Starting in version 1.1, it is possible for implementations to support other primitive types, in addition to the built-in types described in this chapter. Consult the documentation of your XML Schema processor to determine whether you have access to any additional primitive types.
Every type in the XML Schema type system has a value space. This value space represents the set of possible values for a type. For example, for the int type, it is the set of integers from –2147483648 to 2147483647. Every type also has a lexical space, which includes all the possible representations of those values. For int, each value in the value space might have several lexical representations. For example, the value 12 could also be written as 012 or +12. All of these values are considered equal for this type (but not if their type were string).
Of the lexical representations, one is considered the canonical representation: It maps one-to-one to a value in the value space and can be used to determine whether two values are equal. For the int type, the rule is that the canonical representation has no plus sign and no leading zeros. If you turn each of the three values 12, +12, and 012 into their canonical representation using that rule, they would all be 12 and therefore equal to each other. Some primitive types, such as string, only have one lexical representation, which becomes, by default, the canonical representation. In this chapter, the canonical representation of a particular type is only mentioned if there can be more than one lexical representation per value in the value space.
As we saw in Chapter 8, simple types inherit the facets of their ancestors. For example, the integer type has a fractionDigits facet that is set to 0. This means that all of the twelve types derived (directly and indirectly) from integer also have a fractionDigits of 0.
However, it is not just the facet value that is inherited, but also the applicability of a facet. Each primitive type has certain facets that are applicable to it. For example, the string type has length as an applicable facet, but not totalDigits, because it does not make sense to apply totalDigits to a string. Therefore, the totalDigits facet cannot be applied to string or any of its derived types, whether they are built-in or user-defined.
It is not necessary to remember which types are primitive and which are derived. This chapter lists the applicable facets for all of the built-in types, not just the primitive types. When you derive new types from the built-in types, you may simply check which facets are applicable to the built-in type, regardless of whether it is primitive or derived.
The types string, normalizedString, and token represent a character string that may contain any Unicode characters allowed by XML. Certain characters, namely the “less than” symbol (<) and the ampersand (&), must be escaped (using the entities < and &, respectively) when used in strings in XML instances. The only difference between the three types is in the way whitespace is handled by a schema-aware processor, as shown in Table 11–1.
Table 11–1. Whitespace handling of string types

The string type has a whiteSpace facet of preserve, which means that all whitespace characters (spaces, tabs, carriage returns, and line feeds) are preserved by the processor.
The normalizedString type has a whiteSpace facet of replace, which means that the processor replaces each carriage return, line feed, and tab by a single space. There is no collapsing of multiple consecutive spaces into a single space.
The token type represents a tokenized string. The name token may be slightly confusing because it implies that there may be only one token with no whitespace. In fact, there can be whitespace in a token value. The token type has a whiteSpace facet of collapse, which means that the processor replaces each carriage return, line feed, and tab by a single space. After this replacement, each group of consecutive spaces is collapsed into one space character, and all leading and trailing spaces are removed.
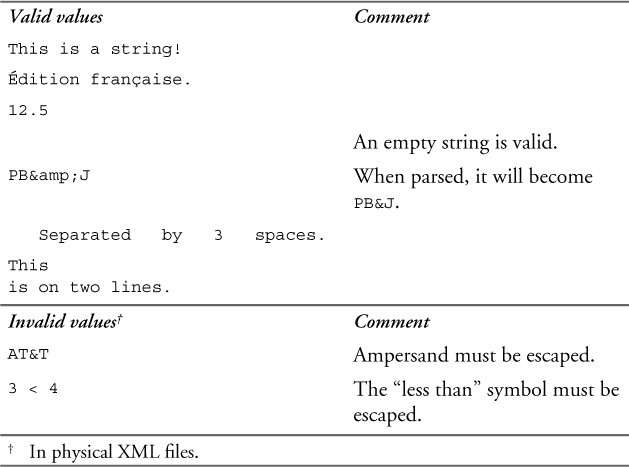
Table 11–2 shows some valid and invalid values of the string types.
Table 11–2. Values of the string types
The facets indicated in Table 11–3 can restrict string, normalizedString, and token, and their derived types.1
Table 11–3. Facets applicable to string, normalizedString, and token types

First, consider whether to use a string-based simple type at all. If it is a long string of general text, such as a letter or a long description of an item, this may not be wise. This is because simple types are not extensible. Later, you may want to allow XHTML markup in the letter, or break the item description down into more structured components. It will be impossible to do this without altering the schema in a way that is not backwards compatible.
Additionally, simple types cannot support internationalization requirements such as Ruby annotations and BIDI (bidirectionality) elements.
In these cases, you should instead declare a complex type with mixed content, and include a wildcard to allow for future extensions. The complex type definition shown in Example 11–1 accomplishes this purpose. The character data content of an element of this type will have its whitespace preserved.
Example 11–1. Extensible mixed content
<xs:complexType name="TextType" mixed="true">
<xs:sequence>
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="xml:lang"/>
</xs:complexType>
For short, atomic items, such as a postal code or a gender, it does make sense to use string, normalizedString, or token. But which one? Here are some general guidelines:
• string should be used for text where formatting, such as tabs and line breaks, is significant. However, as mentioned above, it may be better to use mixed complex type in this case.
• normalizedString is used when formatting is not significant but consecutive whitespace characters are significant. This can be used when the information in the string is positional.
• token should be used for most short, atomic strings, especially ones that have an enumerated set of values. Basing your enumerated types on token means that <gender> M </gender> will be valid as well as <gender>M</gender>.
The type Name represents an XML name, which can be used as an element name or attribute name, among other things. Values of this type must start with a letter, underscore (_), or colon (:), and may contain only letters, digits, underscores (_), colons (:), hyphens (-), and periods (.). Colons should only be used to separate namespace prefixes from local names.
Table 11–4 shows some valid and invalid values of the Name type.
Table 11–4. Values of the Name type

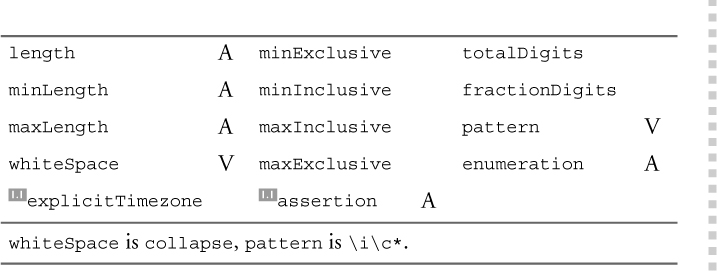
The facets indicated in Table 11–5 can restrict Name and its derived types.
Table 11–5. Facets applicable to Name type
The type NCName represents an XML non-colonized name, which is simply a name that does not contain colons. An NCName must start with either a letter or underscore (_) and may contain only letters, digits, underscores (_), hyphens (-), and periods (.). This is identical to the Name type, except that colons are not permitted.
Table 11–6 shows some valid and invalid values of the NCName type.
Table 11–6. Values of the NCName type

The facets indicated in Table 11–7 can restrict NCName and its derived types.
Table 11–7. Facets applicable to NCName type

The type language represents a natural language identifier, generally used to indicate the language of a document or a part of a document. Before creating a new attribute of type language, consider using the xml:lang attribute that is intended to indicate the natural language of the element and its content.
Values of the language type conform to RFC 3066, Tags for the Identification of Languages, in version 1.0 and to RFC 4646, Tags for Identifying Languages, and RFC 4647, Matching of Language Tags, in version 1.1. The three most common formats are:
• For ISO-recognized languages, the format is a two- or three-letter (usually lowercase) language code that conforms to ISO 639, optionally followed by a hyphen and a two-letter, usually uppercase, country code that conforms to ISO 3166. For example, en or en-US.
• For languages registered by the Internet Assigned Numbers Authority (IANA), the format is i-langname, where langname is the registered name. For example, i-navajo.
• For unofficial languages, the format is x-langname, where langname is a name of up to eight characters agreed upon by the two parties sharing the document. For example, x-Newspeak.
Any of these three formats may have additional parts, each preceded by a hyphen, which identify more countries or dialects. Schema processors will not verify that values of the language type conform to the above rules. They will simply validate them based on the pattern specified for this type, which says that it must consist of one or more parts of up to eight characters each, separated by hyphens.
Table 11–8 shows some valid and invalid values of the language type.
Table 11–8. Values of the language type

The facets indicated in Table 11–9 can restrict language and its derived types.
Table 11–9. Facets applicable to language type

The type float represents an IEEE single-precision 32-bit floating-point number, and double represents an IEEE double-precision 64-bit floating-point number. The lexical representation of both float and double values is a mantissa (a number which conforms to the type decimal described in the next section) followed, optionally, by the character “E” or “e” followed by an exponent. The exponent must be an integer. For example, 3E2 represents 3 times 10 to the 2nd power, or 300.

In addition, the following values are valid: INF (infinity), +INF (positive infinity, version 1.1 only), -INF (negative infinity), 0 (positive 0), -0 (negative 0), and NaN (Not a Number). 0 and -0 are considered equal. INF and +INF are equal and are considered to be greater than all other values, while -INF is less than all other values. The value NaN cannot be compared to any other values.
The canonical representation for float and double always contains an uppercase letter E and a decimal point in the mantissa. No leading or trailing zeros are present, except that there is always at least one digit before and after the decimal point in the mantissa, and at least one digit in the exponent. No positive signs are included. For example, the canonical representation of the float value +12 is 12.0E0.
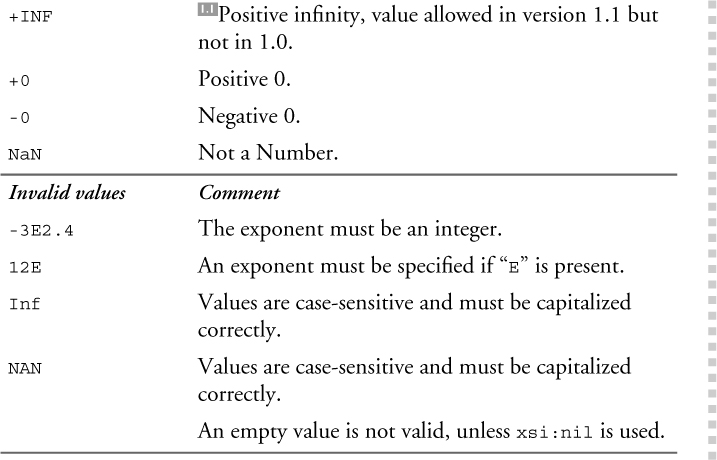
Table 11–10 shows some valid and invalid values of the float and double types.
Table 11–10. Values of the float and double types

The facets indicated in Table 11–11 can restrict float, double, and their derived types.
Table 11–11. Facets applicable to float and double types

The type decimal represents a decimal number of arbitrary precision. Schema processors vary in the number of significant digits they support, but a minimally conforming processor must support at least 16 significant digits. The lexical representation of decimal is a sequence of digits optionally preceded by a sign (“+” or “-”) and optionally containing a period. If the fractional part is 0 then the period and trailing zeros may be omitted. Leading and trailing zeros are permitted but not considered significant. That is, the decimal values 3.0 and 3.0000 are considered equal.
The canonical representation of decimal always contains a decimal point. No leading or trailing zeros are present, except that there is always at least one digit before and after the decimal point. No positive signs are included.
Table 11–12 shows some valid and invalid values of the decimal type.
Table 11–12. Values of the decimal type
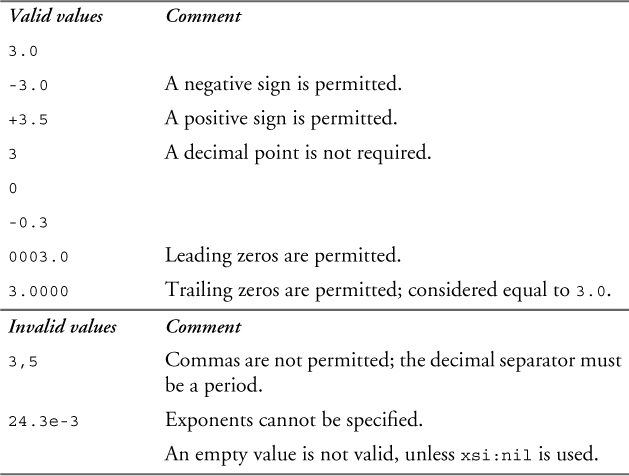
The facets indicated in Table 11–13 can restrict decimal and its derived types.
Table 11–13. Facets applicable to decimal type

The type integer represents an arbitrarily large integer; from it, 12 other built-in integer types are derived (directly or indirectly). The lexical representation of the integer types is a sequence of digits. Some of the integer types allow or require a sign (“+” or “-”) to precede the numbers, others prohibit it. Leading zeros are permitted, but decimal points are not.
The canonical representations of integer types do not contain leading zeros or positive signs. Table 11–14 lists all of the integer types, with their bounds and the rules for preceding signs.


Table 11–15 shows some valid and invalid values of the integer types.
The facets indicated in Table 11–16 can restrict the integer types and their derived types.
Table 11–15. Values of the integer types

Table 11–16. Facets applicable to integer types

When defining types for values that are sequences of digits, it may be difficult to determine whether the type should be based on an integer or a string. For example, a quantity is an example of a value that is better treated as an integer than a string. 5-digit U.S. zip codes, on the other hand, are valid integers, but they are probably better interpreted as strings. Here are some general guidelines:
Use integer (or, more likely, nonNegativeInteger) if:
• You will ever compare two values of that type numerically. For example, if you compare the quantity 100 to the quantity 99, you obviously want 100 to be greater. But if you define them as strings, they will be compared as strings in languages such as XSLT 2.0 and XQuery, and 100 will be considered less than 99.
• You will ever perform mathematical operations on values of that type. You might want to double a quantity, but you are unlikely to want to double a zip code.
• You want to restrict their values’ bounds. For example, you may require that quantity must be between 0 and 100. While it can be possible to restrict a string in this way, by applying a pattern, it is more cumbersome.
Use string (or, more likely, token) if:
• You want to restrict your values’ lexical length. For example, zip codes must be five digits long; 8540 is not a valid zip code, but 08540 is valid. While it is technically possible to restrict an integer to five digits by applying a pattern, it is more cumbersome.
• You will ever take a substring. For example, you may want to extract the central processing facility as the first three digits of a zip code.
• You plan to derive nonnumeric types from this type, or use it in a substitution group with nonnumeric types. For example, if you plan to also define types for international postal codes, which may contain letters or other characters, it is safer to base your U.S. zip code elements on a string type, so that they can be used in a substitution group with other postal code elements.
XML Schema provides a number of built-in date and time types, whose formats are based on ISO 8601. This section explains each of the date and time types and provides general information that applies to all date and time types.
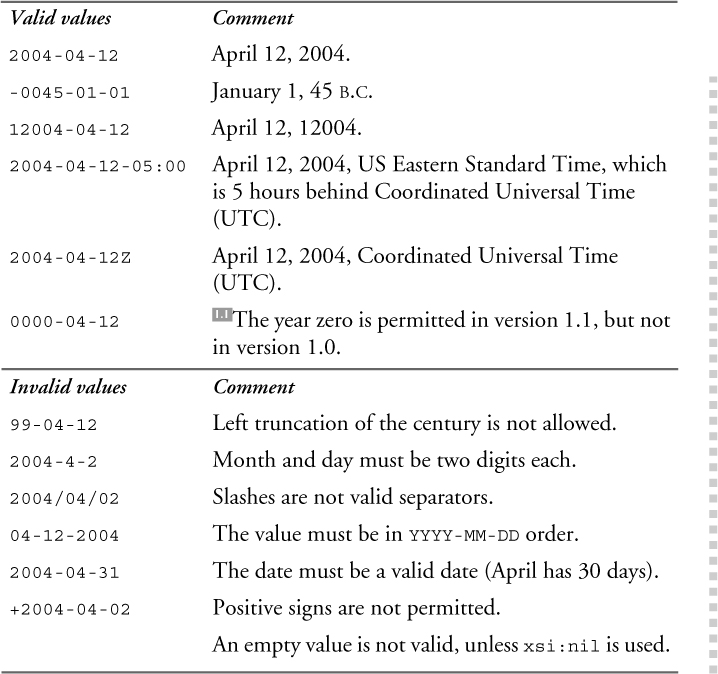
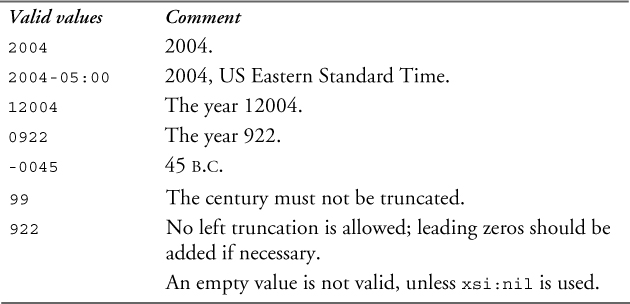
The type date represents a Gregorian calendar date. The lexical representation of date is YYYY-MM-DD where YY represents the year, MM the month and DD the day. No left truncation is allowed for any part of the date. To represent years later than 9999, additional digits can be added to the left of the year value, but extra leading zeros are not permitted. To represent years before 0000, a preceding minus sign (“-”) is allowed. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–17 shows some valid and invalid values of the date type.
Table 11–17. Values of the date type
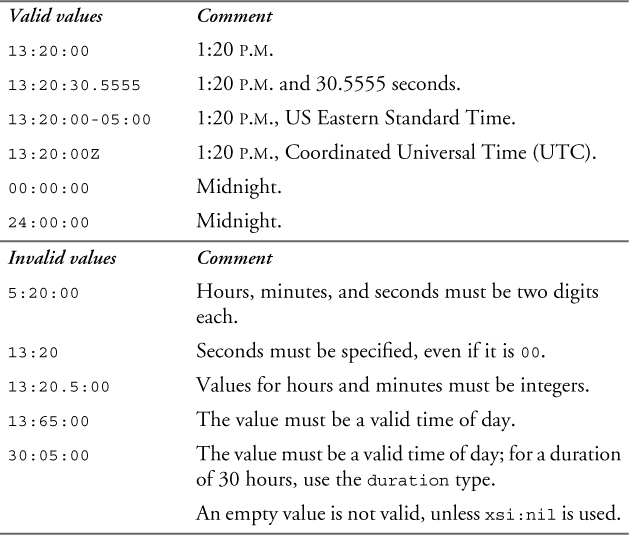
The type time represents a time of day. The lexical representation of time is hh:mm:ss.sss where hh represents the hour, mm the minutes, and ss.sss the seconds. An unlimited number of additional digits can be used to increase the precision of fractional seconds if desired. The time is based on a 24-hour time period, so hours should be represented as 00 through 24. Either of the values 00:00:00 or 24:00:00 can be used to represent midnight. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–18 shows some valid and invalid values of the time type.
Table 11–18. Values of the time type
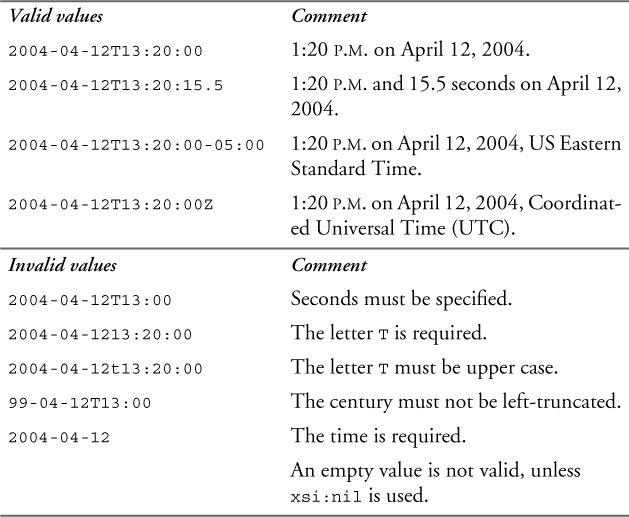
The type dateTime represents a specific date and time. The lexical representation of dateTime is YYYY-MM-DDThh:mm:ss.sss, which is a concatenation of the date and time forms, separated by a literal letter T. All of the same rules that apply to the date and time types are applicable to dateTime as well. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–19 shows some valid and invalid values of the dateTime type.
Table 11–19. Values of the dateTime type
The type dateTimeStamp represents a specific date and time, but with a time zone required. It is derived from dateTime and has the same lexical representation and rules. The only difference is that a value is required to end in a time zone, as described in Section 11.4.13 on p. 233.
Table 11–20 shows some valid and invalid values of the dateTimeStamp type.
Table 11–20. Values of the dateTimeStamp type
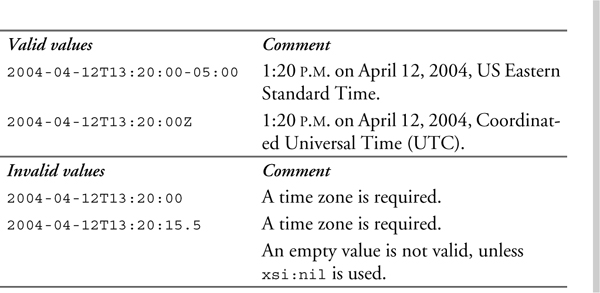
The type gYear represents a specific Gregorian calendar year. The letter g at the beginning of most date and time types signifies “Gregorian.” The lexical representation of gYear is YYYY. No left truncation is allowed. To represent years later than 9999, additional digits can be added to the left of the year value. To represent years before 0000, a preceding minus sign (“-”) is allowed. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–21 shows some valid and invalid values of the gYear type.
Table 11–21. Values of the gYear type
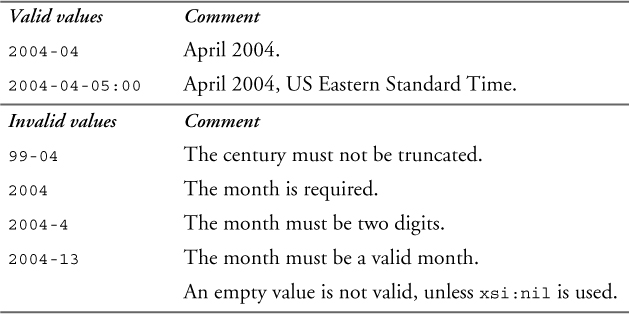
The type gYearMonth represents a specific month of a specific year. The lexical representation of gYearMonth is YYYY-MM. No left truncation is allowed on either part. To represent years later than 9999, additional digits can be added to the left of the year value. To represent years before 0000, a preceding minus sign (“-”) is permitted. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–22 shows some valid and invalid values of the gYearMonth type.
Table 11–22. Values of the gYearMonth type
The type gMonth represents a specific month that recurs every year. It can be used to indicate, for example, that fiscal year-end processing occurs in September of every year. To represent a duration in months, use the duration type instead. The lexical representation of gMonth is --MM. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233. No preceding sign is allowed.
Table 11–23 shows some valid and invalid values of the gMonth type.
Table 11–23. Values of the gMonth type

The type gMonthDay represents a specific day that recurs every year. It can be used to say, for example, that your birthday is on the 12th of April every year. The lexical representation of gMonthDay is --MM-DD. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–24 shows some valid and invalid values of the gMonthDay type.
Table 11–24. Values of the gMonthDay type

The type gDay represents a day that recurs every month. It can be used to say, for example, that checks are paid on the 5th of each month. To represent a duration in days, use the duration type instead. The lexical representation of gDay is ---DD. An optional time zone expression may be added at the end, as described in Section 11.4.13 on p. 233.
Table 11–25 shows some valid and invalid values of the gDay type.
Table 11–25. Values of the gDay type

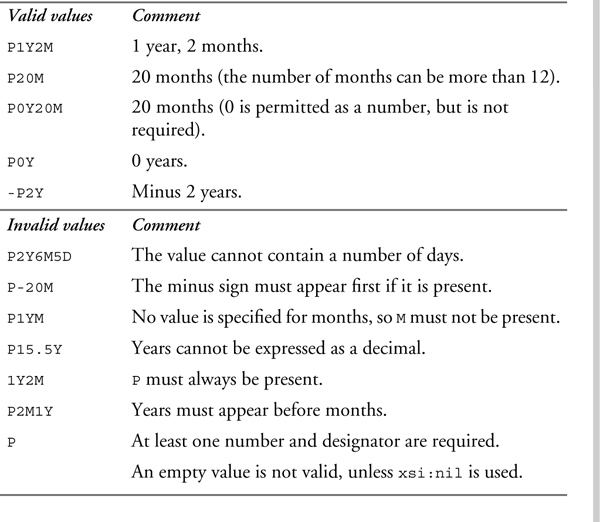
The type duration represents a duration of time expressed as a number of years, months, days, hours, minutes, and seconds. The lexical representation of duration is PnYnMnDTnHnMnS, where P is a literal value that starts the expression, nY is the number of years followed by a literal Y, nM is the number of months followed by a literal M, nD is the number of days followed by a literal D, T is a literal value that separates the date and time, nH is the number of hours followed by a literal H, nM is the number of minutes followed by a literal M, and nS is the number of seconds followed by a literal S. The following rules apply to duration values:
• Any of these numbers and corresponding designators may be absent if they are equal to 0, but at least one number and designator must appear.
• The numbers may be any unsigned integer, with the exception of the number of seconds, which may be an unsigned decimal number.
• If a decimal point appears in the number of seconds, there must be at least one digit after the decimal point.
• A minus sign may appear before the P to specify a negative duration.
• If no time items (hours, minutes, seconds) are present, the letter T must not appear.
In the canonical representation of duration, the months value must be less than 12, the hours value less than 24, and the minutes and seconds values less than 60. This means that P15M and P1Y3M are both valid (and equal) lexical representations that map to the same canonical value P1Y3M.
Table 11–26 shows some valid and invalid values of the duration type.
Table 11–26. Values of the duration type


When deriving types from duration, applying the bounds facets (minExclusive, minInclusive, maxInclusive, and maxExclusive) can have unexpected results. For example, if the maxInclusive value for a duration-based type is P1M, and an instance value contains P30D, it is ambiguous. Months may have 28, 29, 30, or 31 days, so is 30 days less than a month or not?
It is best to avoid the ambiguity by always specifying bounds for durations in the same unit in which the instance values will appear, in this case setting maxExclusive to P32D instead of P1M. You can use the pattern facet to force a particular unit of duration. For example, the pattern P\d+D applied to the duration type would force the duration to be expressed in days only.
Alternatively, if you are using version 1.1, you can use one of the two totally ordered duration types, yearMonthDuration or dayTimeDuration, described in the next two sections.
The type yearMonthDuration, new in version 1.1, represents a duration of time expressed as a number of years and months. The lexical representation of duration is PnYnM, where P is a literal value that starts the expression, nY is the number of years followed by a literal Y, and nM is the number of months followed by a literal M.
yearMonthDuration is derived from duration, and all of the same lexical rules apply.
Table 11–27 shows some valid and invalid values of the yearMonthDuration type.
Table 11–27. Values of the yearMonthDuration type
The type dayTimeDuration, new in version 1.1, represents a duration of time expressed as a number of days, hours, minutes, and seconds. The lexical representation of duration is PnDTnHnMnS, where P is a literal value that starts the expression, nD is the number of days followed by a literal D, T is a literal value that separates the date and time, nH is the number of hours followed by a literal H, nM is the number of minutes followed by a literal M, and nS is the number of seconds followed by a literal S.
dayTimeDuration is derived from duration, and all of the same lexical rules apply.
Table 11–28 shows some valid and invalid values of the dayTimeDuration type.
Table 11–28. Values of the dayTimeDuration type

All of the date and time types, with the exception of the duration types, allow a time zone indicator at the end. The letter Z is used to indicate Coordinated Universal Time (UTC). All other time zones are represented by their difference from Coordinated Universal Time in the format +hh:mm or -hh:mm. These values may range from -14:00 to 14:00.
For example, US Eastern Standard Time, which is 5 hours behind UTC, is represented as -05:00. If no time zone value is present, it is considered unknown; it is not assumed to be UTC.
For most built-in types, a time zone is optional. However, for the dateTimeStamp type, it is required. This is because that type has its explicitTimezone facet set to required. In user-defined types derived from the date and time types, you can choose to leave the time zone optional, or require or prohibit a time zone using the explicitTimezone facet, as described in Section 8.4.7 on p. 150.
Table 11–29 shows some valid and invalid values of time zones.

The facets indicated in Table 11–30 can restrict the date and time types as well as their derived types.
Table 11–30. Facets applicable to date and time types

When deriving types from date and time types (other than the duration types), it is important to note that applying the bounds facets (minExclusive, minInclusive, maxInclusive, and maxExclusive) can have unexpected results. If the values of the bounds facets specify time zones and the instance values do not, or vice versa, it may be impossible to compare the two. For example, if maxInclusive for a time-based type is 14:30:00Z, this means that the maximum value is 2:30 P.M. in UTC. If the value 13:30:00 appears in an instance, which is 1:30 P.M. with no time zone specified, it is impossible to tell if this value is valid. It could be 1:30 P.M. in UTC, which would be valid, or 1:30 P.M. US Eastern Standard Time, which would be 6:30 P.M. UTC, and therefore invalid. Since this is indeterminate, the schema processor will consider it an invalid value.
To avoid this problem, either use time zones in both bounds facet values and instance values, or do not use time zones at all. If both the bounds and the instance values have a time zone, the two values can be compared. Likewise, if neither has a time zone, the two values are assumed to be in the same time zone and compared as such.
The XML DTD types described in this section are attribute types that are specified in the XML recommendation. It is recommended that these types are only used for attributes, in order to maintain compatibility with XML DTDs. However, it is not an error to use these types in element declarations.
The type ID is used for an attribute that uniquely identifies an element in an XML document. An ID value must conform to the rules for an NCName, as described in Section 11.2.3 on p. 210. This means that it must start with a letter or underscore, and can only contain letters, digits, underscores, hyphens, and periods.
ID values must be unique within an XML instance, regardless of the attribute’s name or its element name. Example 11–2 is invalid if attributes custID and orderID are both declared to be of type ID.
Example 11–2. Invalid nonunique IDs
<order orderID="A123">
<customer custID="A123">...</customer>
</order>
In version 1.0, ID carries two additional constraints, both of which have been eliminated in version 1.1:
1. A complex type cannot include more than one attribute of type ID or of any type derived from ID. The type definition in Example 11–3 is illegal.
2. ID attributes cannot have default or fixed values specified. The attribute declarations in Example 11–4 are illegal.
Example 11–3. Illegal duplication of ID attributes (version 1.0)
<xs:complexType name="CustType">
<xs:attribute name="id" type="xs:ID"/>
<xs:attribute name="custID" type="xs:ID"/>
</xs:complexType>
Example 11–4. Illegal attribute declarations (version 1.0)
<xs:attribute name="id" type="xs:ID" fixed="A123"/>
<xs:attribute name="custID" type="xs:ID" default="C00000"/>
The facets indicated in Table 11–31 can restrict ID and its derived types.
Table 11–31. Facets applicable to ID type
The type IDREF is used for an attribute that references an ID. A common use case for IDREF is to create a cross-reference to a particular section of a document. Like ID, an IDREF value must be an NCName, as described in Section 11.2.3 on p. 210.
All attributes of type IDREF must reference an ID in the same XML document. In Example 11–5, the ref attribute of quote is of type IDREF, and the id attribute of footnote is of type ID. The instance contains a reference between them.
Schema:
<xs:element name="quote">
<xs:complexType>
<!--content model-->
<xs:attribute name="ref" type="xs:IDREF"/>
</xs:complexType>
</xs:element>
<xs:element name="footnote">
<xs:complexType>
<!--content model-->
<xs:attribute name="id" type="xs:ID" use="required"/>
</xs:complexType>
</xs:element>
Instance:
<quote ref="fn1">...</quote>
<footnote id="fn1">...</footnote>
ID and IDREF are best used for referencing unique locations in document-oriented XML. To enforce complex uniqueness of data values, and primary and foreign key references, consider using identity constraints, which are described in Chapter 17.
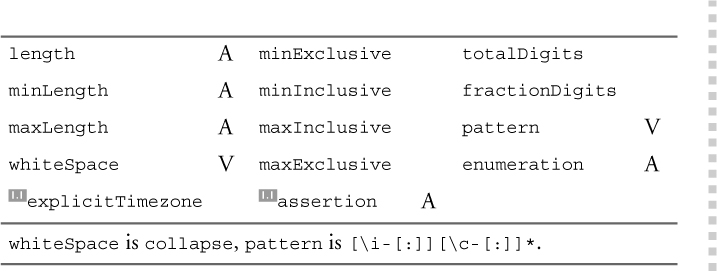
The facets indicated in Table 11–32 can restrict IDREF and its derived types.
Table 11–32. Facets applicable to IDREF type

The type IDREFS represents a list of IDREF values separated by whitespace. There must be at least one IDREF in the list.
Each of the values in an attribute of type IDREFS must reference an ID in the same XML document. In Example 11–6, the refs attribute of quote is of type IDREFS, and the id attribute of footnote is of type ID. The instance contains a reference from the quote element to two footnote elements, with their IDs (fn1 and fn2) separated by whitespace.
Schema:
<xs:element name="quote">
<xs:complexType>
<!--content model-->
<xs:attribute name="refs" type="xs:IDREFS"/>
</xs:complexType>
</xs:element>
<xs:element name="footnote">
<xs:complexType>
<!--content model-->
<xs:attribute name="id" type="xs:ID" use="required"/>
</xs:complexType>
</xs:element>
Instance:
<quote refs="fn1 fn2">...</quote>
<footnote id="fn1">...</footnote>
<footnote id="fn2">...</footnote>
The facets indicated in Table 11–33 can restrict IDREFS and its derived types.
Table 11–33. Facets applicable to IDREFS type

Since IDREFS is a list type, restricting an IDREFS value with these facets may not behave as you expect. The facets length, minLength, and maxLength apply to the number of items in the IDREFS list, not the length of each item. The enumeration facet applies to the whole list, not the individual items in the list. For more information, see Section 10.3.3 on p. 190.
The type ENTITY represents a reference to an unparsed entity. The ENTITY type is most often used to include information from another location that is not in XML format, such as graphics. An ENTITY value must be an NCName, as described in Section 11.2.3 on p. 210. An ENTITY value carries the additional constraint that it must match the name of an unparsed entity in a document type definition (DTD) for the instance.
Example 11–7 shows an XML document that links product numbers to pictures of the products. In the schema, the picture element declaration declares an attribute location that has the type ENTITY. In the instance, each value of the location attribute (in this case, prod557 and prod563) matches the name of an entity declared in the internal DTD subset of the instance.
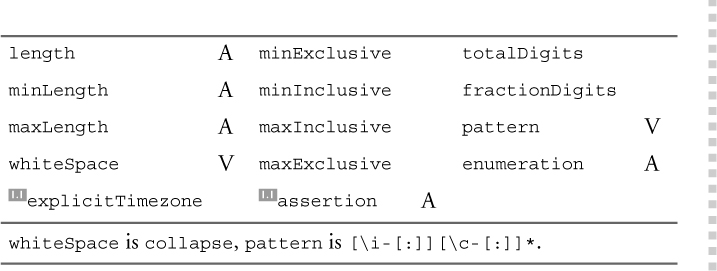
The facets indicated in Table 11–34 can restrict ENTITY and its derived types.
Table 11–34. Facets applicable to ENTITY type
Example 11–7. Using an unparsed entity
Schema:
<xs:element name="picture">
<xs:complexType>
<xs:attribute name="location" type="xs:ENTITY"/>
</xs:complexType>
</xs:element>
<!--...-->
Instance:
<!DOCTYPE catalog SYSTEM "catalog.dtd" [
<!NOTATION jpeg SYSTEM "JPG">
<!ENTITY prod557 SYSTEM "prod557.jpg" NDATA jpeg>
<!ENTITY prod563 SYSTEM "prod563.jpg" NDATA jpeg>
]>
<catalog>
<product>
<number>557</number>
<picture location="prod557"/>
</product>
<product>
<number>563</number>
<picture location="prod563"/>
</product>
</catalog>
The type ENTITIES represents a list of ENTITY values separated by whitespace. There must be at least one ENTITY in the list. Each of the ENTITY values must match the name of an unparsed entity that has been declared in a document type definition (DTD) for the instance.
Expanding on the example from the previous section, Example 11–8 shows the declaration of an attribute named location that is of type ENTITIES. In the instance, the location attribute can include a list of entity names. Each value (in this case there are two: prod557a and prod557b) matches the name of an entity that is declared in the internal DTD subset for the instance.
Schema:
<xs:element name="pictures">
<xs:complexType>
<xs:attribute name="location" type="xs:ENTITIES"/>
</xs:complexType>
</xs:element>
Instance:
<!DOCTYPE catalog SYSTEM "catalog.dtd" [
<!NOTATION jpeg SYSTEM "JPG">
<!ENTITY prod557a SYSTEM "prod557a.jpg" NDATA jpeg>
<!ENTITY prod557b SYSTEM "prod557b.jpg" NDATA jpeg>
]>
<catalog>
<product>
<number>557</number>
<pictures location="prod557a prod557b"/>
</product>
</catalog>
The facets indicated in Table 11–35 can restrict ENTITIES and its derived types.
Table 11–35. Facets applicable to ENTITIES type

Since ENTITIES is a list type, restricting an ENTITIES value with these facets may not behave as you expect. The facets length, minLength, and maxLength apply to the number of items in the ENTITIES list, not the length of each item. The enumeration facet applies to the whole list, not the individual items in the list. For more information, see Section 10.3.3 on p. 190.
The type NMTOKEN represents a single string token. NMTOKEN values may consist of letters, digits, periods (.), hyphens (-), underscores (_), and colons (:). They may start with any of these characters. NMTOKEN has a whiteSpace facet value of collapse, so any leading or trailing whitespace will be removed. However, no whitespace may appear within the value itself. Table 11–36 shows some valid and invalid values of the NMTOKEN type.
Table 11–36. Values of the NMTOKEN type

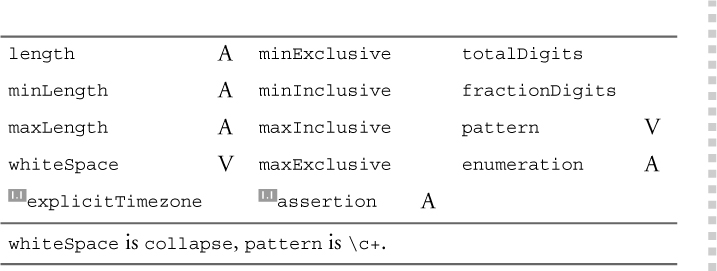
The facets indicated in Table 11–37 can restrict NMTOKEN and its derived types.
Table 11–37. Facets applicable to NMTOKEN type
The type NMTOKENS represents a list of NMTOKEN values separated by whitespace. There must be at least one NMTOKEN in the list. Table 11–38 shows some valid and invalid values of the NMTOKENS type.
Table 11–38. Values of the NMTOKENS type

The facets indicated in Table 11–39 can restrict NMTOKENS and its derived types.
Table 11–39. Facets applicable to NMTOKENS type

Since NMTOKENS is a list type, restricting an NMTOKENS value with these facets may not behave as you expect. The facets length, minLength, and maxLength apply to the number of items in the NMTOKENS list, not the length of each item. The enumeration facet applies to the whole list, not the individual items in the list. For more information, see Section 10.3.3 on p. 190.
The type NOTATION represents a reference to a notation. A notation is a method of interpreting XML and non-XML content. For example, if an element in an XML document contains binary graphics data in JPEG format, a notation can be declared to indicate that this is JPEG data. An attribute of type NOTATION can then be used to indicate which notation applies to the element’s content. A NOTATION value must be a QName as described in Section 11.6.1 on p. 246.
NOTATION is the only built-in type that cannot be the type of attributes or elements. Instead, you must define a new type that restricts NOTATION, applying one or more enumeration facets. Each of these enumeration values must match the name of a declared notation. For more information on declaring notations and NOTATION-based types, see Section 19.7 on p. 493.
The facets indicated in Table 11–40 can restrict NOTATION and its derived types.
Table 11–40. Facets applicable to NOTATION type

The type QName represents an XML namespace-qualified name that consists of a namespace name and a local part.
When appearing in XML documents, the lexical representation of a QName consists of a prefix and a local part, separated by a colon, both of which are NCNames. The prefix and colon are optional.
The lexical structure is mapped onto the QName value in the context of namespace declarations, as described in Chapter 3. If the QName value is prefixed, the namespace name is that which is in scope for that prefix. If it is not prefixed, the default namespace declaration in scope (if any) becomes the QName’s namespace.
QName is not based on string like the other name-related types, because it has this special two-part value with additional constraints that cannot be expressed with XML Schema facets. Table 11–41 shows some valid and invalid values of the QName type.
Table 11–41. Values of the QName type

The facets indicated in Table 11–42 can restrict QName and its derived types.
Table 11–42. Facets applicable to QName type

The type boolean represents logical yes/no values. The valid values for boolean are true, false, 0, and 1. Values that are capitalized (e.g., TRUE) or abbreviated (e.g., T) are not valid. Table 11–43 shows some valid and invalid values of the boolean type.
Table 11–43. Values of the boolean type

The facets indicated in Table 11–44 can restrict boolean and its derived types.
Table 11–44. Facets applicable to boolean type
The types hexBinary and base64Binary represent binary data. Their lexical representation is a sequence of binary octets.
The type hexBinary uses hexadecimal encoding, where each binary octet is a two-character hexadecimal number. Lowercase and uppercase letters A through F are permitted. For example, 0FB8 and 0fb8 are two equal hexBinary representations consisting of two octets. The canonical representation of hexBinary uses only uppercase letters.
The type base64Binary, typically used for embedding images and other binary content, uses base64 encoding, as described in RFC 3548. The following rules apply to base64Binary values:
• The following characters are allowed: the letters A to Z (upper and lower case), digits 0 through 9, the plus sign (+), the slash (/), the equals sign (=), and XML whitespace characters.
• XML whitespace characters may appear anywhere in the value.
• The number of nonwhitespace characters must be divisible by 4.
• Equals signs may only appear at the end of the value, and there may be zero, one, or two of them. If there are two equals signs, they must be preceded by one of the following characters: AQgw. If there is only one equals sign, it must be preceded by one of the following characters: AEIMQUYcgkosw048. In either case, there may be whitespace between the necessary characters and the equals sign(s).
The canonical representation of base64Binary removes all whitespace characters. For more information on base64 encoding, see RFC 3548, The Base16, Base32, and Base64 Data Encodings.
Table 11–45 shows some valid and invalid values of the binary types.
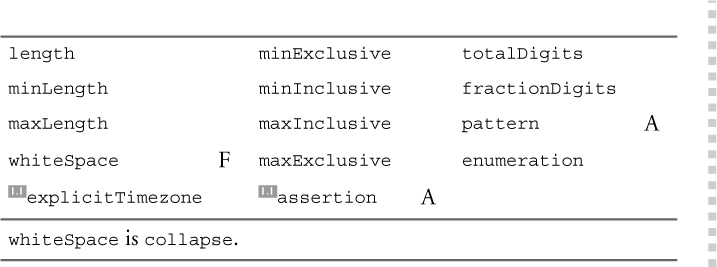
The facets indicated in Table 11–46 can restrict hexBinary, base64Binary, and their derived types.
Table 11–45. Values of the binary types
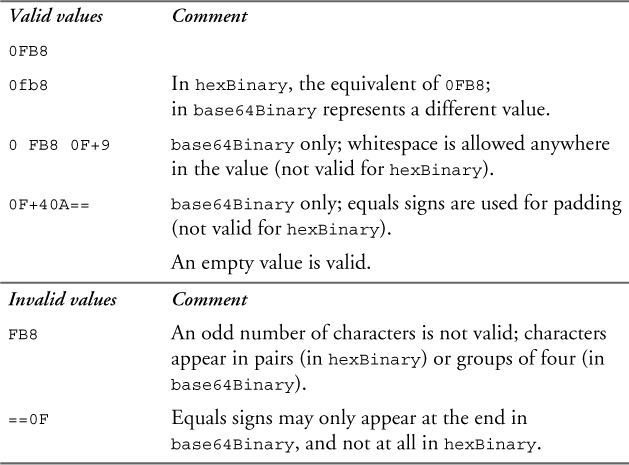
The length facet for the binary types represents the number of binary octets (groups of 8 bits each). For example, the length of the hexBinary value 0FB8 is equal to 2. Since base64 characters represent 6 bits each, the length of the base64Binary value 0FB8 is equal to 3. Whitespace and equals signs are ignored when calculating the length of a base64Binary value.
Table 11–46. Facets applicable to binary types

The type anyURI represents a Uniform Resource Identifier (URI) reference. URIs are used to identify resources, and they may be absolute or relative. Absolute URIs provide the entire context for locating a resource, such as http://datypic.com/prod.html. Relative URIs are specified as the difference from a base URI, for example ../prod.html. It is also possible to specify a fragment identifier using the # character, for example ../prod.html#shirt.
The three previous examples happen to be HTTP URLs (Uniform Resource Locators), but URIs also encompass URLs of other schemes (e.g., FTP, gopher, telnet), as well as URNs (Uniform Resource Names). URIs are not required to be dereferenceable; that is, it is not necessary for there to be a web page at http://datypic.com/prod.html in order for this to be a valid URI.
URIs require that some characters be escaped with their hexadecimal Unicode code point preceded by the % character. This includes non-ASCII characters and some ASCII characters including control characters, space, and certain punctuation characters. For example, ../édition.html must be represented instead as ../%C3%A9dition.html, with the é escaped as %C3%A9. However, the anyURI type will accept these characters either escaped or unescaped. With the exception of the characters % and #, it will assume that unescaped characters are intended to be escaped when used in an actual URI, although the schema processor will do nothing to alter them. It is valid for an anyURI value to contain a space, but this practice is strongly discouraged. Spaces should instead be escaped using %20. For more information on URIs, see RFC 2396, Uniform Resource Identifiers (URI): Generic Syntax.
Version 1.1 expands the definition of anyURI to include IRfIs, or Internationalized Resource Identifiers. Compared to URIs, IRIs allow a much broader range of characters without requiring them to be escaped. Since the anyURI type does not require escaping anyway, this has little practical impact on your schemas. For more information about IRIs, see RFC 3987, Internationalized Resource Identifiers (IRIs).
Note that when relative URI references such as ../prod are used as values of anyURI, no attempt is made by the schema processor to determine or keep track of the base URI to which they may be applied. For example, it will not attempt to resolve the value relative to the URL of the containing document, or any xml:base attributes that may appear in it.
Table 11–47 shows some examples of valid and invalid anyURI values. The schema processor is not required to parse the contents of an anyURI value to determine whether it is valid according to any particular URI scheme. Since the bare minimum rules for valid URI references are fairly generic, the schema processor will accept most character strings, including an empty value. The only values that are not accepted are ones that make inappropriate use of reserved characters, such as those containing multiple # characters or % characters not followed by two hexadecimal digits.
Table 11–47. Valid values of anyURI type

The facets indicated in Table 11–48 can restrict anyURI and its derived types.
Table 11–48. Facets applicable to anyURI type

When a schema processor is comparing two values, it does more than compare lexical values as if they were strings. It takes into account the types of the values. This comes into play during validation of an instance in several places:
• Validating fixed values
• Validating enumerated values
• Validating values against bounds facets
• Determining uniqueness of identity constraint fields
• Validating key references
• Comparisons in assertions
This is also important to consider when using schema-aware languages, such as XSLT 2.0 and XQuery, which allow a processor to use type information from the schema when comparing values.
One of the factors used in determining the equality of two values is the relationship of their types in the derivation hierarchy. Types that are related to each other by restriction, list, or union can have values that are equal. For example, the value 2 of type integer and the value 2 of type positiveInteger are considered equal, since positiveInteger is derived from integer. Types that are not related in the hierarchy can never have values that are equal. This means that an integer value will never equal a string value, even if they are both 2. This is true of both the built-in and user-derived types. Example 11–9 illustrates this point.1
Example 11–9. Equality based on type definition hierarchy
<integer>2</integer> does not equal <string>2</string>
<integer>2</integer> equals <positiveInteger>2</positiveInteger>
<string>abc</string> equals <NCName>abc</NCName>
<string>abc</string> does not equal <QName>abc</QName>
<IDREFS>abc</IDREFS> equals <IDREF>abc</IDREF>
Some of the built-in types have multiple lexical representations that are equivalent. For example, an integer may be represented as 2, 02, +2, or +00002. These values are all considered equal if they have the type integer, because they all represent the same canonical value. However, these same lexical values are unequal if they have the type string. Example 11–10 illustrates this point.
Another factor to take into account is whitespace normalization. Whitespace is normalized before any validation takes place. Therefore, it plays a role in determining whether two values are equal. For example, the string type has a whiteSpace facet value of preserve, while the token type’s is collapse. The value “ a ” that has the type string will not equal “ a ” that has the type token, because the leading and trailing spaces will be stripped for the token value. Example 11–11 illustrates this point.
Example 11–10. Equality based on equivalent lexical representations
<integer>2</integer> equals <integer>02</integer>
<integer>2</integer> equals <positiveInteger>02</positiveInteger>
<string>2</string> does not equal <string>02</string>
<boolean>true</boolean> equals <boolean>1</boolean>
<hexBinary>0fb8</hexBinary> equals <hexBinary>0FB8</hexBinary>
<time>13:20:00-05:00</time> equals <time>12:20:00-06:00</time>
Example 11–11. Equality based on whitespace normalization
<string> a </string> does not equal <token> a </token>
<string>a</string> equals <token> a </token>
<token>a</token> equals <token> a </token>
