Chapter 2. Building a Hypothesis Backlog
The aim of chaos engineering is to help you build trust and confidence in how your whole sociotechnical system will perform during turbulent conditions. One way to get rolling might be to jump straight in and start introducing those turbulent conditions—break networks, introduce latency, and see what collapses1
But wait! Before you unleash Chaos Monkey unchained in production, remember that you want to learn from your chaos, which means that you need much more than just to have caused chaos. You need to follow the scientific method.
Start with Experiments?
If chaos engineering follows the scientific method, then starting with an experiment seems like the right choice. The challenge then quickly becomes, “Which experiment?” Experiments are often complex and detailed, and, more importantly, require a lot of work to plan and execute. That’s a big expenditure of wasted effort should you ultimately decide not to conduct the experiment.
A better approach is to take a step back to figure out what experiments you might find valuable before you go ahead and invest your time and effort.
What Experiments Would Build Trust and Confidence?
Chaos engineering does not start with the question, “Where shall we create chaos?”, but rather with, “Where would it be most valuable to create an experiment that helps us build trust and confidence in our system under turbulent conditions?”
Instead of starting by injecting failure and chaos, or even by designing full-blown experiments, start by asking “What idea do we want to gather some evidence to support or refute?” or more simply, “What could possibly go wrong?” These questions are the essence of a hypothesis, and so the key to figuring out what experiments to invest in starts with building up a backlog of such questions for your own systems. This collection of questions is called the Hypothesis Backlog.
Gathering Hypotheses
There are many sources of hypotheses when it comes to how a system might deviate from the norm, such as:
-
Conducting past incident analysis
-
Asking “What could happen if…?” or “What worries us?” ideally using a common, detailed sketch of the system
We’ll look at incident analysis and sketching the system next.
Incident Analysis
Incident analysis is a whole body of work, even a field in itself, that touches on many aspects of safety and how humans think and operate in challenging situations. It deserves a book in its own right! From the perspective of chaos engineering, identifying contributing causes through incident analysis is fertile ground for starting to think about hypotheses for chaos experiments.
But in many respects, it’s like the age-old saying of “locking the stable door after the horse has bolted.” Learning from past incidents is an essential job for any team that is investing in resilience, and chaos engineering can help with that learning by providing additional evidence of weaknesses as the system is improved. However, learning only from past incidents is a “postmortem” approach and is frequently expensive and painful. Using only this learning approach, you are naturally reactive, making decisions based on evidence sourced from the harshest of situations and conditions.
Instead of relying solely on incident analysis, chaos engineering offers us a much more proactive approach; think of it as pre-mortem.
Sketching Your System
Start by sketching your system. Get your team together and come up with a picture of your system, including all the people, practices, and processes involved, that describes in detail what the system looks like.2
You want your system sketch, or sketches, to be detailed enough that you can start to ask specific questions about what could be explored. The sketch is your first step toward building a sensitivity to failure in your system. This sensitivity is by no means special to chaos engineering, but it is something that you will develop as a skill over time as you gain more experience with the practice.
Examples, Sketches and Source
A set of sketches and source code for an example application is provided and is being developed and contributed to by the Chaos Toolkit community in its Community Playground project on GitHub for you to grab, run, and even contribute to. See Appendix B for information on this project.
We recommend getting your own copy of the project, even if only so you can peruse the code as you learn chaos engineering throughout this book.
You will very likely end up with more than one sketch, and it’s common to have at least one for each of the different areas where dark debt may be present in your system. Here are some examples of questions to ask with regard to each potential area of dark debt:
- People, practices, and processes
-
Who works with the system? What continuous integration and delivery (CI/CD) pipeline do you have, and with what stages? What monitoring systems do you have, and who is responsible for them?
- Application
-
What are the timeouts configured at the application level? Are there any persistence systems you are integrating with?
- Platform
-
What platform services is your system relying on or providing? Is a container orchestration layer such as Kubernetes being used?
- Infrastructure
-
What virtual machines, actual machines, networks, racks, servers, etc., are in place?
The secret here is to go as deep and be as detailed as you can, while making sure your system sketches are something that everyone recognizes so that you can achieve an accurate baseline picture before asking the all-important question, “What do we want to explore?”
Refining Mental Models
The value of this process of collectively sketching out your entire sociotechnical system cannot be underestimated. It’s often best to do it in a way that can be maintained over time. You are capturing and clarifying everyone’s mental models of the system; this is valuable because sharing and refining mental models is one reason some teams can move quickly and with confidence when working with, and even developing and evolving, their software-based systems.3
Capturing “What Could Possibly Go Wrong?”
With your system sketches now in hand you can ask these questions:
-
“Could this fail?”
-
“Has this caused problems before?”
-
“If this fails, what else could be impacted?”
Any question that helps you explore the possibilities for failure in your system is a good one at this stage. You won’t be able to spot them all, and that’s OK. At this point what’s important is just to build up a big collection of possible failures.
Write down each failure you and the team highlight, making sure to describe it in as much detail as you can. Figure 2-1 shows an example of a failure card.

Figure 2-1. Failure card
Collectively, you and your team will come up with many, many possible failures through this exercise alone, especially when you consider all the different levels of attack and their compound effects. Take your time with this important step. It is an opportunity not only to find failures but to really build that sensitivity to failure that is crucial to a chaos engineer.
Introducing Likelihood and Impact
At some point you will begin to exhaust your team’s ideas, or perhaps your list will start to feel endless. A big list of failures is a scary thing and is not very helpful on its own, but with a little more work you can turn it into what you need.
To turn your collection of failures into something more useful you are going to apply a technique called Failure Mode and Effects Analysis Lite. Failure Mode and Effects Analysis is a powerful technique that has long been part of a reliability engineer’s toolbox.4 You are going to use a faster version of the technique purely for the refinement of your set of failures, to help you decide which failures should be turned into chaos engineering hypotheses for your backlog.
So far you’ve completed the first two steps of building a Hypothesis Backlog:
-
Build a detailed sketch of your system.
-
Brainstorm and collect a set of detailed possible system failures across your real system and from the perspective of different attack vectors.
The next step is:
Building a Likelihood-Impact Map
Your collection of potential failures needs a little spice to make it really useful. The spice you’ll add in now includes:
-
The likelihood that a failure may occur5
-
The potential impact your system will experience if it does
You can factor in this information to build a likelihood-impact map.
Isn’t Likelihood Just Guesswork?
In many respects, the level of probability that you’ll consider for your likelihood-impact map is just guesswork, and that’s as far as it needs to go at this point. You don’t actually know the real impact of even posited failures such as the ones in your big list; that’s something that chaos engineering experiments will help you find evidence for once you’ve decided which ones are worth the effort of making them into experiments.
First, if you haven’t already done so, put each detailed failure on its own card or sticky note. Then create a large grid with the labels “Impact” and “Likelihood” on it, as shown in Figure 2-2.6
Figure 2-2. Empty impact and likelihood grid
Now take each of your specific failure cards or sticky notes and collectively, as a team, discuss where on the map it should be placed. If it’s a high-likelihood failure—perhaps one you’ve seen frequently—with a large impact on customer or user experience, then it should go toward the top right corner of the map. If it’s something you hardly ever expect to see—and something that would likely have little impact on the user experience of your system if it did arise—then the bottom left corner would be the right place for it.
Continue placing your failures onto the map until you and your team have something like the grid shown in Figure 2-3.
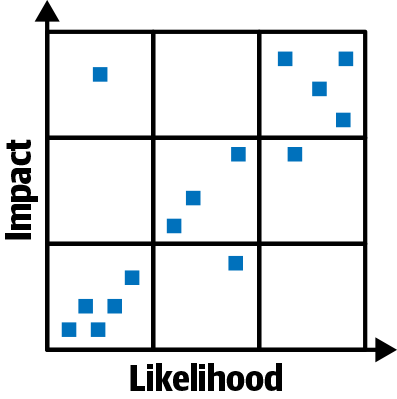
Figure 2-3. Failure cards arranged on impact and likelihood grid
You now have a picture of what failures are guessed to be most likely, and an estimate of their potential impact on the user experience. You might feel at this point that you have enough to start building a plan for applying chaos to explore some of your potential failure cases—but wait! There is one final step that will make this map even more useful to you in figuring out what failures to work into chaos experiment hypotheses. It’s time to figure out which failures might actually affect what you care about the most.
Adding What You Care About
You have a map full of potentially worrying failures, organized by your own guesses as to their likelihood and potential impact. You need one more bit of information to turn them into a collection you can navigate and pick from when building your Hypothesis Backlog: an estimate of what the value would be to you and your team, and even your organization, if you were to build trust and confidence in how the system reacts to a particular failure.
This might sound like a complicated thing to add, but it’s usually simpler than you think, though it does require thought and discussion. You need to build another list of the things you, your team, and your company care about. Call it a “taxonomy of -ilities.”7 Ask “What do we care about?” and you’ll likely come up with a list that includes the following:
-
Reliability
-
Safety
-
Security
-
Durability
-
Availability
Some of these may require discussion within the team about what everyone thinks the term might mean for your context, but as long as you all agree, then your list is fine regardless of what it contains. It is your list of things you care about.
Now take another look at each of the failures on your map and mark what “-ilities” you think might be affected if that failure happened. Once again, these are guesses, and it’s not wrong to conclude that every failure will affect all of the things you care about. When you’re done, each failure will look like the example shown in Figure 2-6.

Figure 2-6. Failure card with contribution added
You now have a collective understanding of:
-
What failures you can guess might happen
-
What impact you can guess a particular failure might have
-
What likelihood you guess a failure might have of occurring
-
What things you care about might be affected if a given failure occurs
This means that you now have everything you need to take the final step: creating your Hypothesis Backlog!
Creating Your Hypothesis Backlog
A chaos experiment starts with a hypothesis, and with everything you’ve already prepared, the next steps should be easy—not just converting a failure into a hypothesis in a backlog, but also prioritizing which hypotheses might be worth taking to the next level by turning them into a full chaos experiment for a Game Day (see Chapter 3) or even a fully automated chaos experiment (see Chapters Chapter 4 and Chapter 5).
Discuss with your team which failures are worth making into hypotheses. You should have all you need to make that decision, based on combinations such as:
-
Selecting the high-impact, high-likelihood failures that map most closely to the most important “ilities”
-
Selecting the lowest-impact failures so that you can explore chaos engineering as safely as possible
-
Selecting the failures that have the most “-ilities,” and therefore perhaps the greatest value, to be explored further
Your map of failures supplies the raw data. It is now up to you and your team to decide what criteria for selection to apply. Eventually you will have a subset of failures to focus on, and converting them into hypotheses simply requires you to shift the terminology of the failure from “what happens and its impact” to “when it happens it will not have the impact.”
For example, take the failure card from Figure 2-6. You can convert that into a hypothesis card by switching the emphasis as demonstrated in Figure 2-7.

Figure 2-7. Hypothesis card
Now your newly minted hypothesis card reads: “The system will meet its SLOs if database cluster (DB1) becomes unavailable,” where SLO stands for Service Level Objective. This hypothesis is worth considering for prioritizing as an experiment because of where the card is placed on the likelihood-impact map (a high-impact failure), and because of its importance in contributing to building trust and confidence in your system in terms of the “-ilities:” durability and availability.
Summary
Grab a beverage—you’ve come a long way! In this chapter you’ve learned how to build a catalog of potential failures and—adding impact, likelihood, and value (“-ilities”)—turn those failures into a set of prioritized hypotheses in a backlog that are ready for consideration as chaos engineering experiments.
Once you’ve recharged, it will be time to take one of those hypotheses and explore it in the simplest (and cheapest, in terms of tooling) way possible, through planning and running a Game Day.
1 You could do this in production, if you’re feeling especially masochistic…
2 I suggest using the guidelines for sketching the technical facets of systems that Simon Brown describes in his excellent “C4: Context, Containers, Components and Code” approach.
3 Jessica Kerr talks and writes often about the value of understanding and developing shared mental models and how this contributes to high-performing teams.
4 Thanks to Jenny Martin for all the insights about how this process could be tailored to chaos engineering.
5 I use “likelihood” here rather than “probability” as what we are discussing is far from formal, mathematical probability.
6 Using as big a whiteboard as you can possibly find, or maybe even an available wall, is great for this exercise. It will ideally be something you can keep permanently as your “Wall of Failure Sensitivity.”
7 Mainly because a lot of the things you care about will end with “-ility.”