The principal topics of this and the next few chapters are the system calls fork(), exit(), wait(), and execve(). Each of these system calls has variants, which we’ll also look at. For now, we provide an overview of these four system calls and how they are typically used together.
The fork() system call allows one process, the parent, to create a new process, the child. This is done by making the new child process an (almost) exact duplicate of the parent: the child obtains copies of the parent’s stack, data, heap, and text segments (Memory Layout of a Process). The term fork derives from the fact that we can envisage the parent process as dividing to yield two copies of itself.
The exit(status) library function terminates a process, making all resources (memory, open file descriptors, and so on) used by the process available for subsequent reallocation by the kernel. The status argument is an integer that determines the termination status for the process. Using the wait() system call, the parent can retrieve this status.
Note
The exit() library function is layered on top of the _exit() system call. In Chapter 25, we explain the difference between the two interfaces. In the meantime, we’ll just note that, after a fork(), generally only one of the parent and child terminate by calling exit(); the other process should terminate using _exit().
The wait(&status) system call has two purposes. First, if a child of this process has not yet terminated by calling exit(), then wait() suspends execution of the process until one of its children has terminated. Second, the termination status of the child is returned in the status argument of wait().
The execve(pathname, argv, envp) system call loads a new program (pathname, with argument list argv, and environment list envp) into a process’s memory. The existing program text is discarded, and the stack, data, and heap segments are freshly created for the new program. This operation is often referred to as execing a new program. Later, we’ll see that several library functions are layered on top of execve(), each of which provides a useful variation in the programming interface. Where we don’t care about these interface variations, we follow the common convention of referring to these calls generically as exec(), but be aware that there is no system call or library function with this name.
Some other operating systems combine the functionality of fork() and exec() into a single operation—a so-called spawn—that creates a new process that then executes a specified program. By comparison, the UNIX approach is usually simpler and more elegant. Separating these two steps makes the APIs simpler (the fork() system call takes no arguments) and allows a program a great degree of flexibility in the actions it performs between the two steps. Moreover, it is often useful to perform a fork() without a following exec().
Note
SUSv3 specifies the optional posix_spawn() function, which combines the effect of fork() and exec(). This function, and several related APIs specified by SUSv3, are implemented on Linux in glibc. SUSv3 specifies posix_spawn() to permit portable applications to be written for hardware architectures that don’t provide swap facilities or memory-management units (this is typical of many embedded systems). On such architectures, a traditional fork() is difficult or impossible to implement.
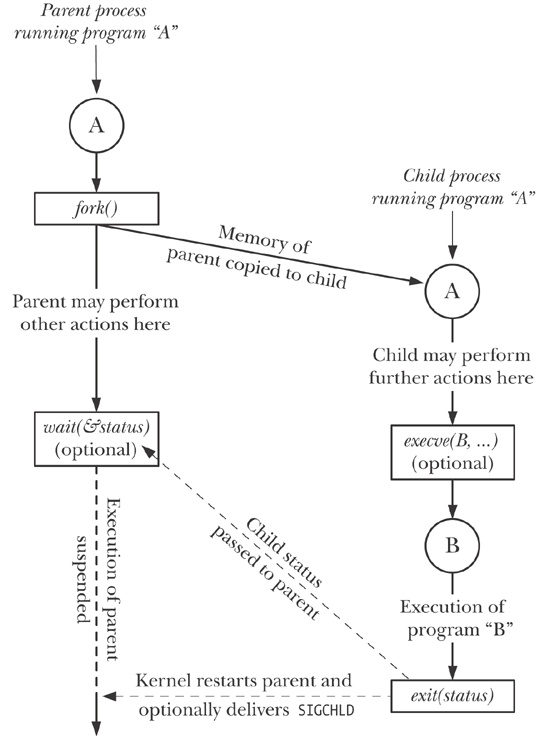
Figure 24-1 provides an overview of how fork(), exit(), wait(), and execve() are commonly used together. (This diagram outlines the steps taken by the shell in executing a command: the shell continuously executes a loop that reads a command, performs various processing on it, and then forks a child process to exec the command.)
The use of execve() shown in this diagram is optional. Sometimes, it is instead useful to have the child carry on executing the same program as the parent. In either case, the execution of the child is ultimately terminated by a call to exit() (or by delivery of a signal), yielding a termination status that the parent can obtain via wait().
The call to wait() is likewise optional. The parent can simply ignore its child and continue executing. However, we’ll see later that the use of wait() is usually desirable, and is often employed within a handler for the SIGCHLD signal, which the kernel generates for a parent process when one of its children terminates. (By default, SIGCHLD is ignored, which is why we label it as being optionally delivered in the diagram.)