In this and the next few chapters, we describe POSIX threads, often known as Pthreads. We won’t attempt to cover the entire Pthreads API, since it is rather large. Various sources of further information about threads are listed at the end of this chapter.
These chapters mainly describe the standard behavior specified for the Pthreads API. In Linux Implementations of POSIX Threads, we discuss those points where the two main Linux threading implementations—LinuxThreads and Native POSIX Threads Library (NPTL)—deviate from the standard.
In this chapter, we provide an overview of the operation of threads, and then look at how threads are created and how they terminate. We conclude with a discussion of some factors that may influence the choice of a multithreaded approach versus a multiprocess approach when designing an application.
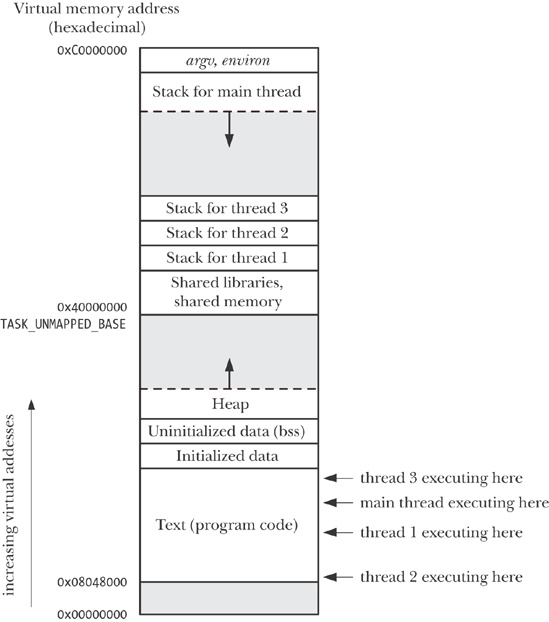
Like processes, threads are a mechanism that permits an application to perform multiple tasks concurrently. A single process can contain multiple threads, as illustrated in Figure 29-1. All of these threads are independently executing the same program, and they all share the same global memory, including the initialized data, uninitialized data, and heap segments. (A traditional UNIX process is simply a special case of a multithreaded processes; it is a process that contains just one thread.)
Note
We have simplified things somewhat in Figure 29-1. In particular, the location of the per-thread stacks may be intermingled with shared libraries and shared memory regions, depending on the order in which threads are created, shared libraries loaded, and shared memory regions attached. Furthermore, the location of the per-thread stacks can vary depending on the Linux distribution.
The threads in a process can execute concurrently. On a multiprocessor system, multiple threads can execute in parallel. If one thread is blocked on I/O, other threads are still eligible to execute. (Although it sometimes useful to create a separate thread purely for the purpose of performing I/O, it is often preferable to employ one of the alternative I/O models that we describe in Chapter 63.)
Threads offer advantages over processes in certain applications. Consider the traditional UNIX approach to achieving concurrency by creating multiple processes. An example of this is a network server design in which a parent process accepts incoming connections from clients, and then uses fork() to create a separate child process to handle communication with each client (refer to A Concurrent TCP echo Server). Such a design makes it possible to serve multiple clients simultaneously. While this approach works well for many scenarios, it does have the following limitations in some applications:
It is difficult to share information between processes. Since the parent and child don’t share memory (other than the read-only text segment), we must use some form of interprocess communication in order to exchange information between processes.
Process creation with fork() is relatively expensive. Even with the copy-on-write technique described in Memory Semantics of fork(), the need to duplicate various process attributes such as page tables and file descriptor tables means that a fork() call is still time-consuming.
Threads address both of these problems:
Sharing information between threads is easy and fast. It is just a matter of copying data into shared (global or heap) variables. However, in order to avoid the problems that can occur when multiple threads try to update the same information, we must employ the synchronization techniques described in Chapter 30.
Thread creation is faster than process creation—typically, ten times faster or better. (On Linux, threads are implemented using the clone() system call, and Table 28-3, in Speed of Process Creation, shows the differences in speed between fork() and clone().) Thread creation is faster because many of the attributes that must be duplicated in a child created by fork() are instead shared between threads. In particular, copy-on-write duplication of pages of memory is not required, nor is duplication of page tables.
Besides global memory, threads also share a number of other attributes (i.e., these attributes are global to a process, rather than specific to a thread). These attributes include the following:
process ID and parent process ID;
process group ID and session ID;
controlling terminal;
process credentials (user and group IDs);
open file descriptors;
record locks created using fcntl();
signal dispositions;
file system-related information: umask, current working directory, and root directory;
interval timers (setitimer()) and POSIX timers (timer_create());
System V semaphore undo (semadj) values (Semaphore Undo Values);
resource limits;
nice value (set by setpriority() and nice()).
Among the attributes that are distinct for each thread are the following:
thread ID (Thread IDs);
signal mask;
thread-specific data (Thread-Specific Data);
alternate signal stack (sigaltstack());
realtime scheduling policy and priority (Overview of Realtime Process Scheduling and Realtime Process Scheduling API);
CPU affinity (Linux-specific, described in CPU Affinity);
capabilities (Linux-specific, described in Chapter 39); and
stack (local variables and function call linkage information).
Note
As can be seen from Figure 29-1, all of the per-thread stacks reside within the same virtual address space. This means that, given a suitable pointer, it is possible for threads to share data on each other’s stacks. This is occasionally useful, but it requires careful programming to handle the dependency that results from the fact that a local variable remains valid only for the lifetime of the stack frame in which it resides. (If a function returns, the memory region used by its stack frame may be reused by a later function call. If the thread terminates, a new thread may reuse the memory region used for the terminated thread’s stack.) Failing to correctly handle this dependency can create bugs that are hard to track down.