The pipe() system call creates a new pipe.
#include <unistd.h>
int pipe(int filedes[2]);Note
Returns 0 on success, or -1 on error
A successful call to pipe() returns two open file descriptors in the array filedes: one for the read end of the pipe (filedes[0]) and one for the write end (filedes[1]).
As with any file descriptor, we can use the read() and write() system calls to perform I/O on the pipe. Once written to the write end of a pipe, data is immediately available to be read from the read end. A read() from a pipe obtains the lesser of the number of bytes requested and the number of bytes currently available in the pipe (but blocks if the pipe is empty).
We can also use the stdio functions (printf(), scanf(), and so on) with pipes by first using fdopen() to obtain a file stream corresponding to one of the descriptors in filedes (Mixing Library Functions and System Calls for File I/O). However, when doing this, we must be aware of the stdio buffering issues described in Section 44.6.
Note
The call ioctl(fd, FIONREAD, &cnt) returns the number of unread bytes in the pipe or FIFO referred to by the file descriptor fd. This feature is also available on some other implementations, but is not specified in SUSv3.
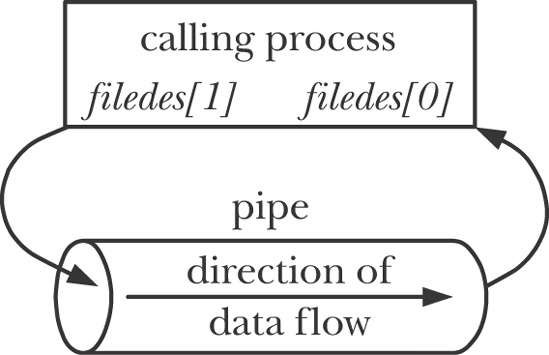
Figure 44-2 shows the situation after a pipe has been created by pipe(), with the calling process having file descriptors referring to each end.
A pipe has few uses within a single process (we consider one in The Self-Pipe Trick). Normally, we use a pipe to allow communication between two processes. To connect two processes using a pipe, we follow the pipe() call with a call to fork(). During a fork(), the child process inherits copies of its parent’s file descriptors (File Sharing Between Parent and Child), bringing about the situation shown on the left side of Figure 44-3.
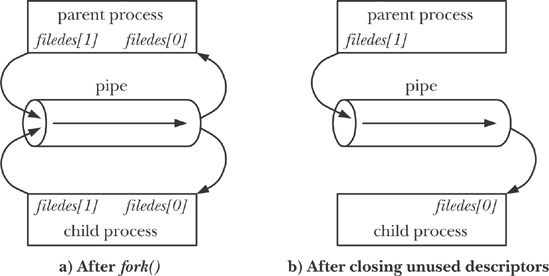
While it is possible for the parent and child to both read from and write to the pipe, this is not usual. Therefore, immediately after the fork(), one process closes its descriptor for the write end of the pipe, and the other closes its descriptor for the read end. For example, if the parent is to send data to the child, then it would close its read descriptor for the pipe, filedes[0], while the child would close its write descriptor for the pipe, filedes[1], bringing about the situation shown on the right side of Figure 44-3. The code to create this setup is shown in Example 44-1.
Example 44-1. Steps in creating a pipe to transfer data from a parent to a child
int filedes[2];
if (pipe(filedes) == -1) /* Create the pipe */
errExit("pipe");
switch (fork()) { /* Create a child process */
case -1:
errExit("fork");
case 0: /* Child */
if (close(filedes[1]) == -1) /* Close unused write end */
errExit("close");
/* Child now reads from pipe */
break;
default: /* Parent */
if (close(filedes[0]) == -1) /* Close unused read end */
errExit("close");
/* Parent now writes to pipe */
break;
}One reason that it is not usual to have both the parent and child reading from a single pipe is that if two processes try to simultaneously read from a pipe, we can’t be sure which process will be the first to succeed—the two processes race for data. Preventing such races would require the use of some synchronization mechanism. However, if we require bidirectional communication, there is a simpler way: just create two pipes, one for sending data in each direction between the two processes. (If employing this technique, then we need to be wary of deadlocks that may occur if both processes block while trying to read from empty pipes or while trying to write to pipes that are already full.)
While it is possible to have multiple processes writing to a pipe, it is typical to have only a single writer. (We show one example of where it is useful to have multiple writers to a pipe in Section 44.3.) By contrast, there are situations where it can be useful to have multiple writers on a FIFO, and we see an example of this in Section 44.8.
Note
Starting with kernel 2.6.27, Linux supports a new, nonstandard system call, pipe2(). This system call performs the same task as pipe(), but supports an additional argument, flags, that can be used to modify the behavior of the system call. Two flags are supported. The O_CLOEXEC flag causes the kernel to enable the close-on-exec flag (FD_CLOEXEC) for the two new file descriptors. This flag is useful for the same reasons as the open() O_CLOEXEC flag described in . The O_NONBLOCK flag causes the kernel to mark both underlying open file descriptions as nonblocking, so that future I/O operations will be nonblocking. This saves additional calls to fcntl() to achieve the same result.
In the discussion so far, we have talked about using pipes for communication between a parent and a child process. However, pipes can be used for communication between any two (or more) related processes, as long as the pipe was created by a common ancestor before the series of fork() calls that led to the existence of the processes. (This is what we meant when we referred to related processes at the beginning of this chapter.) For example, a pipe could be used for communication between a process and its grandchild. The first process creates the pipe, and then forks a child that in turn forks to yield the grandchild. A common scenario is that a pipe is used for communication between two siblings—their parent creates the pipe, and then creates the two children. This is what the shell does when building a pipeline.
Note
There is an exception to the statement that pipes can be used to communicate only between related processes. Passing a file descriptor over a UNIX domain socket (a technique that we briefly describe in Passing File Descriptors) makes it possible to pass a file descriptor for a pipe to an unrelated process.
Closing unused pipe file descriptors is more than a matter of ensuring that a process doesn’t exhaust its limited set of file descriptors—it is essential to the correct use of pipes. We now consider why the unused file descriptors for both the read and write ends of the pipe must be closed.
The process reading from the pipe closes its write descriptor for the pipe, so that, when the other process completes its output and closes its write descriptor, the reader sees end-of-file (once it has read any outstanding data in the pipe).
If the reading process doesn’t close the write end of the pipe, then, after the other process closes its write descriptor, the reader won’t see end-of-file, even after it has read all data from the pipe. Instead, a read() would block waiting for data, because the kernel knows that there is still at least one write descriptor open for the pipe. That this descriptor is held open by the reading process itself is irrelevant; in theory, that process could still write to the pipe, even if it is blocked trying to read. For example, the read() might be interrupted by a signal handler that writes data to the pipe. (This is a realistic scenario, as we’ll see in The Self-Pipe Trick.)
The writing process closes its read descriptor for the pipe for a different reason. When a process tries to write to a pipe for which no process has an open read descriptor, the kernel sends the SIGPIPE signal to the writing process. By default, this signal kills a process. A process can instead arrange to catch or ignore this signal, in which case the write() on the pipe fails with the error EPIPE (broken pipe). Receiving the SIGPIPE signal or getting the EPIPE error is a useful indication about the status of the pipe, and this is why unused read descriptors for the pipe should be closed.
Note
Note that the treatment of a write() that is interrupted by a SIGPIPE handler is special. Normally, when a write() (or other “slow” system call) is interrupted by a signal handler, the call is either automatically restarted or fails with the error EINTR, depending on whether the handler was installed with the sigaction() SA_RESTART flag (Interruption and Restarting of System Calls). The behavior in the case of SIGPIPE is different because it makes no sense either to automatically restart the write() or to simply indicate that the write() was interrupted by a handler (thus implying that the write() could usefully be manually restarted). In neither case can a subsequent write() attempt succeed, because the pipe will still be broken.
If the writing process doesn’t close the read end of the pipe, then, even after the other process closes the read end of the pipe, the writing process will still be able to write to the pipe. Eventually, the writing process will fill the pipe, and a further attempt to write will block indefinitely.
One final reason for closing unused file descriptors is that it is only after all file descriptors in all processes that refer to a pipe are closed that the pipe is destroyed and its resources released for reuse by other processes. At this point, any unread data in the pipe is lost.
The program in Example 44-2 demonstrates the use of a pipe for communication between parent and child processes. This example demonstrates the byte-stream nature of pipes referred to earlier—the parent writes its data in a single operation, while the child reads data from the pipe in small blocks.
The main program calls pipe() to create a pipe  , and then calls fork() to create a child
, and then calls fork() to create a child  . After the fork(), the parent process closes its file descriptor for the read end of the pipe
. After the fork(), the parent process closes its file descriptor for the read end of the pipe  , and writes the string given as the program’s command-line argument to the write end of the pipe
, and writes the string given as the program’s command-line argument to the write end of the pipe  . The parent then closes the read end of the pipe
. The parent then closes the read end of the pipe  , and calls wait() to wait for the child to terminate
, and calls wait() to wait for the child to terminate  . After closing its file descriptor for the write end of the pipe
. After closing its file descriptor for the write end of the pipe  , the child process enters a loop where it reads
, the child process enters a loop where it reads  blocks of data (of up to
blocks of data (of up to BUF_SIZE bytes) from the pipe and writes  them to standard output. When the child encounters end-of-file on the pipe
them to standard output. When the child encounters end-of-file on the pipe  , it exits the loop
, it exits the loop  , writes a trailing newline character, closes its descriptor for the read end of the pipe, and terminates.
, writes a trailing newline character, closes its descriptor for the read end of the pipe, and terminates.
Here’s an example of what we might see when running the program in Example 44-2:
$./simple_pipe 'It was a bright cold day in April, '\'and the clocks were striking thirteen.'It was a bright cold day in April, and the clocks were striking thirteen.
Example 44-2. Using a pipe to communicate between a parent and child process
pipes/simple_pipe.c#include <sys/wait.h> #include "tlpi_hdr.h" #define BUF_SIZE 10 int main(int argc, char *argv[]) { int pfd[2]; /* Pipe file descriptors */ char buf[BUF_SIZE]; ssize_t numRead; if (argc != 2 || strcmp(argv[1], "--help") == 0) usageErr("%s string\n", argv[0]);pipes/simple_pipe.c